Anthropic Academy 课程全集(中文版)
本文档包含 Anthropic Skilljar 平台上 13 门课程的完整中文翻译。 翻译来源:Anthropic 官方课程平台 anthropic.skilljar.com
目录
入门与素养
- Claude 101 入门指南 — 从零开始学习使用 Claude(13 节)
- AI 素养:框架与基础 — 学会高效、安全、负责任地与 AI 系统协作(15 节)
- 教育者 AI 素养 — 面向教育工作者的 AI 协作技能培训(5 节)
- 学生 AI 素养 — 面向学生的 AI 协作技能培训(6 节)
- 非营利组织 AI 素养 — 面向非营利组织的 AI 素养与实践指南(10 节)
- 教授 AI 素养 — 面向教师的 AI 素养教学方法论(8 节)
开发者工具
- Agent Skills 入门 — 学习创建和管理 Claude Code 技能(6 节)
- 使用 Anthropic API 构建应用 — Claude API 开发完整教程:从基础到高级(96 节)
- Claude 与 Google Vertex AI — 在 Google Cloud 平台上使用 Claude(93 节)
- Claude Code 实战 — Claude Code 编程助手完整实战教程(21 节)
- Claude 与 Amazon Bedrock — 在 AWS Bedrock 上使用 Claude(83 节)
- 模型上下文协议(MCP)入门 — MCP 开发完整教程(14 节)
- MCP 高级主题 — 模型上下文协议进阶开发(15 节)
第 1 课:Claude 101 入门指南
从零开始学习使用 Claude 课程链接:Claude 101 入门指南 | 共 13 节课
Claude 模型概览
Claude 共有三个模型系列,分别针对不同的优先级进行了优化:
Opus = 智能程度最高的模型,适用于需要深度推理和规划的复杂、多步骤任务。其权衡之处在于成本和延迟(latency)较高。
Sonnet = 一款均衡型模型,在智能、速度和成本效益方面表现良好。具备强大的编码能力和精确的代码编辑功能。是大多数实际应用场景的最佳选择。
Haiku = 速度最快的模型,为速度和成本效益而优化。不具备 Opus/Sonnet 那样的推理能力。最适合实时用户交互和高吞吐量处理。
选择框架:若智能优先 → Opus。若速度优先 → Haiku。若需求均衡 → Sonnet。
通用方法 = 在同一应用中根据具体任务需求使用多个模型,而非选择单一模型。
所有模型共享核心能力:文本生成、编码、图像分析。主要区别在于优化重点不同。
访问 API
API Access Flow (API 访问流程) = 从用户输入到显示响应的 5 步流程。
第 1 步:客户端将用户文本发送至开发者的服务器(切勿直接从客户端应用访问 Anthropic API,以保护 API 密钥的私密性)。
第 2 步:服务器使用 SDK(Python、TypeScript、JavaScript、Go、Ruby)或纯 HTTP 请求向 Anthropic API 发出请求。必需参数 = API 密钥 + 模型名称 + 消息列表 + max_tokens(最大生成词元数)限制。
第 3 步:文本生成过程有 4 个阶段:
- Tokenization (分词) = 将输入拆分为词元(单词/单词的一部分/符号/空格)。
- Embedding (嵌入) = 将词元转换为代表所有可能词义的数字列表。
- Contextualization (上下文关联) = 根据相邻词元调整嵌入,以确定精确含义。
- Generation (生成) = 输出层为下一个词生成概率,模型根据概率 + 随机性进行选择,添加所选词,然后重复此过程。
第 4 步:当达到 max_tokens 或生成特殊的 end_of_sequence token (序列结束标志) 时,模型停止。
第 5 步:API 将包含生成文本 + 使用量计数 + 停止原因的响应返回给服务器,服务器再将其发送给客户端以供显示。
Token (词元) = 文本块(单词/部分/符号)。 Embedding (嵌入) = 词义的数值表示。 Contextualization (上下文关联) = 使用相邻词语进行意义提炼。 Max_tokens (最大生成词元数) = 生成长度的限制。 Stop_reason (停止原因) = 模型停止生成的原因。
发起请求
向 Anthropic 发起 API 请求 = 该过程涉及 4 个设置步骤并需理解消息结构。
设置步骤:
- 安装包 = 在 Jupyter notebook 中运行
pip install anthropic python-dotenv。 - 存储 API 密钥 = 创建一个包含
ANTHROPIC_API_KEY="your_key"的.env文件(并在版本控制中忽略它)。 - 加载环境变量 = 使用
python-dotenv安全地加载 API 密钥。 - 创建客户端 = 初始化 Anthropic 客户端并定义模型变量(
claude-3-sonnet)。
API 请求结构:
- 函数 =
client.messages.create() - 必需参数 =
model、max_tokens、messages - Model (模型) = 要使用的 Claude 模型名称。
- Max_tokens (最大生成词元数) = 用于生成长度的安全限制(不是目标长度)。
- Messages (消息) = 包含对话交流的列表。
消息类型:
- 用户消息 =
{"role": "user", "content": "your text"}(人类创作的内容)。 - 助手消息 = 包含模型生成的响应。
响应访问:
- 完整响应 = 包含元数据和嵌套结构。
- 纯文本 =
message.content[0].text仅提取生成的文本。
请求示例结构:client.messages.create(model=model, max_tokens=1000, messages=[{"role": "user", "content": "What is quantum computing?"}])
多轮对话
Multi-Turn Conversations (多轮对话) = 包含多次来回交流并保持上下文的对话。
关键限制:Anthropic API 不存储任何消息。每个请求都是独立的,没有先前交流的记忆。
解决方案需要两步:
- 在代码中手动维护消息列表。
- 在每次后续请求中发送完整的对话历史。
消息结构 = 一个由字典组成的列表,每个字典包含 role (角色,user/assistant) 和 content (内容) 字段。
对话流程:
- 发送初始用户消息。
- 接收助手响应。
- 将助手响应附加到消息历史中。
- 将新的用户消息添加到历史中。
- 发送完整的历史记录以进行有上下文感知的后续交流。
需要辅助函数:
add_user_message(messages, text)= 将用户消息附加到历史记录中。add_assistant_message(messages, text)= 将助手响应附加到历史记录中。chat(messages)= 将消息历史发送到 API 并返回响应。
没有消息历史 = 响应缺乏上下文和连续性。拥有完整的历史记录 = Claude 能维持对话上下文并提供相关的后续答复。
系统提示词
System Prompts (系统提示词) = 一种通过为 Claude 分配特定角色或行为模式来定制其响应风格和语气的技术。
实现方式 = 使用 system 关键字参数,将系统提示词作为纯字符串传递给 create 函数。
目的 = 控制 Claude 如何响应,而不是响应什么。例如:数学导师的角色会让 Claude 给出提示而非直接答案。
结构 = 首行通常分配角色(“你是一位耐心的数学导师”),随后是具体的行为指令。
关键原则 = 系统提示词指导响应的方法,而非内容。同一个问题会根据分配的角色得到不同的处理方式。
技术实现 = 创建一个 params 字典,如果提供了提示词,则有条件地添加 system 键,然后使用 ** 解包将 params 传递给 create 函数。通过完全排除 system 参数来处理 None 的情况。
用例示例 = 一个数学导师,它提供指导/提示而不是完整的解决方案,鼓励学生思考而非直接给出答案。
温度(Temperature)
Temperature (温度) = 一个介于 0 到 1 之间的参数,通过影响词元选择的概率来控制 Claude 文本生成中的随机性。
文本生成过程:输入文本 → 分词 → 为可能的下一个词元分配概率 → 基于概率选择词元 → 重复。
温度效应:
- 温度为 0 = 确定性输出,总是选择概率最高的词元。
- 温度较高 = 增加选择较低概率词元的几率,产生更有创意/意想不到的输出。
使用指南:
- 低温(接近 0) = 用于数据提取、需要一致性的事实性任务。
- 高温(接近 1) = 用于创意任务,如头脑风暴、写作、讲笑话、市场营销。
实现方式:在模型 API 调用中添加 temperature 参数。较高的值不保证输出不同,只是增加了变化的概率。
核心洞见:温度直接操纵下一个词元选择的概率分布,使得高概率词元在选择过程中的主导地位增强或减弱。
响应流
Response Streaming (响应流) = 一种技术,它在 AI 响应生成时逐块显示,而不是等待完整响应。
解决的问题:AI 响应可能需要 10-30 秒。用户期望即时反馈,而不仅仅是加载动画。
工作原理:
- 服务器将用户消息发送给 Claude。
- Claude 立即发送初始响应(无文本,仅为确认)。
- 随后是一系列事件流,每个事件包含文本块。
- 服务器将这些文本块转发到前端进行实时显示。
事件类型:
message_start= 初始确认。content_block_start= 文本生成开始。content_block_delta= 包含实际的文本块(最重要)。content_block_stop/message_stop= 生成完成。
实现方式: 基础版:client.messages.create(stream=True) 返回一个事件迭代器。 简化版:client.messages.stream() 及其 text_stream 属性仅提取文本。 最终消息:stream.get_final_message() 将所有文本块组装起来以便存储。
主要优点:通过即时响应可见性改善用户体验(UX),并能捕获完整的消息以供数据库存储。
控制模型输出
控制模型输出 = 除了修改提示词之外的两种关键技术
Pre-filling Assistant Messages (预填充助手消息) = 在对话末尾手动添加一条助手消息,以引导响应方向
工作原理:
- 组装包含用户提示词 + 手动添加的助手消息的消息列表。
- Claude 将这条助手消息视为已创作的内容。
- Claude 从预填充文本的末尾精确地继续响应。
- 响应被引导至预填充的方向。
关键点:Claude 从预填充的精确末尾继续,而不是从完整的句子开始。必须将预填充部分与生成的响应拼接在一起。
示例:预填充“咖啡更好,因为” → Claude 会继续给出支持咖啡的理由。
Stop Sequences (停止序列) = 当特定字符串出现时,强制 Claude 停止生成
工作原理:
- 在聊天函数中提供一个停止序列字符串。
- 当 Claude 生成该确切字符串时,响应立即停止。
- 生成的停止序列文本不包含在最终输出中。
示例:提示词“从 1 数到 10” + 停止序列“五” → 输出在“四,”处停止(“五”不被包含)。
优化:停止序列设为“, 五” → 得到干净的输出“一, 二, 三, 四”。
这两种技术都提供了对响应方向和长度的精确控制,而无需更改核心提示词。
结构化数据
Structured Data Generation (结构化数据生成) = 一种结合使用助手消息预填充和停止序列的技术,以获得没有 Claude 自然添加的解释性页眉/页脚的原始输出。
问题 = Claude 在生成 JSON/代码/结构化内容时,会自动添加 markdown 格式、标题和注释。用户通常只想要原始数据以便于复制粘贴。
解决方案模式:
- 用户消息 = 请求结构化数据。
- 助手消息预填充 = 使用起始分隔符(例如,"```json")。
- 停止序列 = 使用结束分隔符(例如,"```")。
工作原理 = Claude 看到预填充的消息,假定它已经开始了响应,于是只生成所请求的内容,并在遇到分隔符时停止。
结果 = 获得没有任何额外格式或注释的原始结构化数据输出。
应用 = 适用于任何结构化数据类型(JSON、Python 代码、列表等),不仅限于 JSON。当你需要无需解释性文本的、干净且可解析的输出时,都可以使用。
主要优点 = 输出可以直接使用/复制,无需手动选择或解析不需要的文本。
提示词评估
Prompt Engineering (提示词工程) = 编写/编辑提示词以帮助 Claude 理解请求和期望响应的技术。
Prompt Evaluation (提示词评估) = 使用客观指标自动测试提示词以衡量其有效性。
编写提示词后的三种路径:
- 测试一两次,然后部署到生产环境(陷阱)。
- 使用自定义输入进行测试,针对边界情况进行微调(陷阱)。
- 通过评估流水线运行以获得客观评分(推荐)。
核心要点:工程师普遍对提示词测试不足。应使用评估流水线在迭代和部署提示词之前获得客观的性能分数。
典型的评估工作流
典型的评估工作流 = 一个用于改进提示词的 6 步迭代过程。
第 1 步:编写初始提示词草稿 - 创建一个用于优化的基线提示词。
第 2 步:创建评估数据集 - 一组测试输入(可以是 3 个例子,也可以是数千个,手写或由大语言模型生成)。
第 3 步:生成提示词变体 - 将每个数据集输入插入到提示词模板中。
第 4 步:获取大语言模型响应 - 将每个提示词变体输入给 Claude,并收集输出。
第 5 步:评分响应 - 使用评分系统为每个响应打分(例如,1-10 分制),并计算平均分以评估整体提示词性能。
第 6 步:迭代 - 根据分数修改提示词,重复整个过程,并比较不同版本。
关键点:目前尚无标准方法。有许多开源/付费工具可用。可以从简单的自定义实现开始。评分的复杂性各不相同。客观评分通过 A/B 比较实现了系统性的提示词改进。
生成测试数据集
自定义提示词评估工作流 = 构建提示词 + 生成测试数据集 + 评估性能。
目标 = 一个 AWS 代码辅助提示词,它只输出 Python、JSON 配置或正则表达式,不带任何解释。
数据集生成方法 = 手动组装或使用 Claude 自动生成(使用像 Haiku 这样的快速模型进行生成)。
数据集结构 = 一个 JSON 对象数组,每个对象包含一个描述用户请求的 task 属性。
生成过程 = 提示 Claude 创建测试用例 → 使用助手消息预填充 "```json" → 设置停止序列 "```" → 将响应解析为 JSON → 保存到文件。
关键实现 = generate_dataset() 函数,它向 Claude 发送提示词,获取结构化的 JSON 响应(包含测试任务),并将其保存到 dataset.json 文件中,以供后续评估使用。
测试数据集通过在多种输入场景下运行提示词来衡量性能一致性,从而实现系统性评估。
运行评估
评估执行过程 = 将测试用例与提示词合并,通过大语言模型运行,并对输出进行评分。
测试用例 = 数据集中的单个记录(JSON 对象)。
三个核心函数:
run_prompt= 将测试用例与提示词合并,发送给 Claude,并返回输出。run_test_case= 调用run_prompt,对结果进行评分,并返回一个摘要字典。run_eval= 遍历数据集,为每个数据集调用run_test_case,并汇总结果。
基础提示词结构 = "Please solve the following task: [test_case_task]"(v1 起始点)。
当前局限 = 没有输出格式指令,硬编码评分(score=10),Claude 的响应冗长。
运行时间 = 使用 Haiku 模型对整个数据集执行,大约需要 31 秒。
输出格式 = 一个对象数组,每个对象包含 Claude 的输出、原始测试用例和分数。
下一步 = 实现一个合适的评分系统来取代硬编码的分数。
评估流水线核心 = 数据集 + 提示词 + 大语言模型 + 评分器,代码复杂度最低。
基于模型的评分
Model Based Grading (基于模型的评分) = 一种评估系统,它接收模型输出并分配客观分数(通常为 1-10 分,10 分表示最高质量)。
三种评分器类型:
- 代码评分器 = 程序化检查(长度、词语存在性、语法验证、可读性分数)。
- 模型评分器 = 额外的 API 调用来评估原始模型输出,在评估质量/指令遵循度方面非常灵活。
- 人工评分器 = 由人来评估响应,最灵活但耗时且乏味。
关键要求:必须返回客观信号(通常是数值分数)。预先定义评估标准。
模型评分器的实现模式:
- 创建一个详细的提示词,要求提供优点/缺点/推理/分数(不仅仅是分数,以避免默认的中间分数)。
- 使用带有预填充助手消息和停止序列的 JSON 响应格式。
- 从返回的 JSON 中解析出分数和推理。
- 计算所有测试用例的平均分作为最终指标。
模型评分器提供了高度的灵活性,但可能不一致。尽管如此,它仍为提示词优化提供了客观的基线。
基于代码的评分
Code Based Grading (基于代码的评分) = 一种针对包含代码、JSON 或正则表达式的大语言模型输出的自动验证系统。
核心实现:
validate_json()= 尝试解析 JSON,如果有效则返回 10,如果出错则返回 0。validate_python()= 尝试进行AST parsing(抽象语法树解析),如果有效则返回 10,如果出错则返回 0。validate_regex()= 尝试编译正则表达式,如果有效则返回 10,如果出错则返回 0。
数据集要求:
- 必须包含一个 "format" 键,指定预期的输出类型(JSON/Python/RegEx)。
- 通过修改提示词模板进行更新,以实现自动化数据集生成。
提示词工程:
- 指示模型仅以原始代码/JSON/正则表达式响应。
- 无注释、解释或评论。
- 使用预填充的助手消息和 ```code``` 代码块。
- 添加停止序列以提取干净的输出。
评分系统:
- 最终分数 = (模型分数 + 语法分数) / 2。
- 结合了语义评估和语法验证。
- 能够衡量正确性和技术有效性。
关键局限 = 需要已知预期的格式才能正确选择验证器。
提示词工程
Prompt Engineering (提示词工程) = 改进提示词以从语言模型获得更可靠、更高质量输出的技术。
模块结构:从一个初始的差提示词开始 → 逐步应用提示词工程技术 → 在每种技术应用后评估改进效果 → 观察性能随时间的提升。
示例目标:根据身高、体重、身体目标和饮食限制,为运动员生成一日膳食计划。
技术设置:
- 更新了评估流水线,采用了灵活的提示词评估器类。
- 支持
concurrency(并发)(根据速率限制调整max_concurrent_tasks)。 generate_dataset()方法根据指定的输入创建测试用例。run_prompt()函数单独处理每个测试用例。
关键组件:
prompt_input_spec= 定义所需提示词输入的字典。extra_criteria= 用于模型评分的额外验证要求。output.html= 显示测试用例结果和分数的格式化评估报告。
过程:编写初始提示词 → 插入测试用例输入 → 运行评估 → 应用工程技术 → 重新评估 → 重复直至性能满意。
初始结果:对于基础提示词,预计得分会较差(例如:2.32),尤其是在使用能力较弱的模型时。随着技术的应用,分数会提高。
清晰直接
清晰直接 = 在提示词的第一行使用简单、直接的语言和动词来明确指定任务。
第一行的重要性 = 提示词中最关键的部分,为 AI 响应奠定基础。
结构 = 动词 + 清晰的任务描述 + 输出规格。
示例:
- “写三段关于太阳能电池板工作原理的文字。”
- “找出三个使用地热能的国家,并为每个国家附上发电统计数据。”
- “为一名运动员生成符合其饮食限制的一日膳食计划。”
关键组成部分 = 开头使用动词 +直接的任务陈述 + 预期的输出细节。
结果 = 提升了提示词性能(示例显示分数从 2.32 提高到 3.92)。
具体化
具体化 = 添加指导方针或步骤来引导模型输出朝特定方向发展。
两种指导方针: A 型(属性) = 列出期望输出具有的品质/属性(长度、结构、格式)。 B 型(步骤) = 为模型提供在推理过程中应遵循的具体步骤。
A 型控制输出特征。B 型控制模型如何得出答案。
这两种技术在专业的提示词中经常结合使用。
何时使用:
- A 型(属性):推荐用于几乎所有提示词。
- B 型(步骤):用于复杂问题,当你希望模型考虑其可能不会自然考虑的更广阔视角或其他观点时。
改进示例:在添加了指导方针后,膳食计划提示词的分数从 3.92 跃升至 7.86,表明通过具体化可以显著提高质量。
使用 XML 标签构建结构
使用 XML Tags (XML 标签) 构建提示词结构 = 使用 XML 标签来组织和界定提示词内的不同内容部分,以提高 AI 的理解能力。
目的 = 当在提示词中插入大量内容时,XML 标签有助于 AI 模型区分不同类型的信息并理解文本分组。
实现方式 = 将内容部分包裹在描述性的 XML 标签中,如 <document> 或 <example>,而不是直接堆砌非结构化文本。
标签命名 = 使用描述性、具体的标签名称(例如,"sales_records" 比 "data" 更好),以提供关于内容性质的上下文。
用例示例 = 一个包含混合代码和文档的调试提示词,当使用 <source_code> 和 <documentation> 标签将其分开时,会变得更加清晰。
优点 = 使提示词结构对 AI 显而易见,减少了关于内容边界的混淆,即使对于较小的内容块也能提高输出质量。
应用 = 可以将任何插入的内容包裹起来,如 <user_input>,即使内容很短,也能明确其为需要考虑的外部输入。
提供示例
One-shot/Multi-shot prompting (单样本/多样本提示) = 在提示词中提供示例来引导模型行为。单样本 = 单个示例,多样本 = 多个示例。
实现方式:使用包含样本输入和理想输出的 XML 标签来构建示例。务必清晰地包裹示例,以区别于实际的提示词内容。
主要应用:
- 边界情况处理(讽刺检测、边缘场景)。
- 复杂的输出格式化(JSON 结构、特定格式)。
- 阐明预期的响应质量/风格。
最佳实践:
- 为边界情况添加上下文(“要特别注意讽刺”)。
- 包含解释为什么输出是理想的推理过程。
- 使用提示词评估中得分最高的示例作为模板。
- 将示例放在主要指令/指导方针之后。
效果提升:将示例与解释其为何理想的说明相结合,以强化期望的输出特性。
工具调用(Tool Use)简介
Tool use (工具调用) = 一种让 Claude 能够访问其训练数据之外的外部信息的方法。
默认限制:Claude 只知道其训练数据中的信息,缺乏当前/实时的信息。
工具调用流程:
- 向 Claude 发送初始请求 + 访问外部数据的指令。
- Claude 评估是否需要外部数据,并请求特定信息。
- 服务器运行代码从外部源获取所请求的数据。
- 向 Claude 发送包含检索到数据的后续请求。
- Claude 使用原始提示词 + 外部数据生成最终响应。
天气示例:用户询问当前天气 → Claude 请求天气数据 → 服务器调用天气 API → Claude 接收天气数据 → Claude 提供有信息依据的天气响应。
核心概念:工具使 Claude 能够通过在 Claude 的请求之间协调外部数据检索,用实时/当前信息来增强其响应。
项目概览
项目概览
目标 = 在 Jupyter notebook 中通过工具实现,教 Claude 设置基于时间的提醒。
目标交互 = 用户:“设置一个下周四的医生预约提醒” → Claude:“我会在那个时间点提醒你”。
需要工具解决的三个核心问题:
- 时间知识差距 = Claude 知道当前日期但不知道确切时间。
- 时间计算错误 = Claude 有时会算错基于时间的加法(例如,从 1973 年 1 月 13 日起的 379 天)。
- 无提醒机制 = Claude 理解提醒的概念但缺乏实现能力。
需要构建的三个相应工具:
- 当前日期时间工具 = 获取当前日期 + 时间。
- 时长增加工具 = 将时长添加到日期时间上(例如,当前日期 + 20 天)。
- 提醒设置工具 = 实际设置提醒。
实现方法 = 一次构建一个工具,逐步实现多工具协调。
工具函数
Tool Functions (工具函数) = 当 Claude 需要额外信息来帮助用户时,会自动执行的 Python 函数。
主要特点:
- 当 Claude 判断需要额外数据时,它会调用的普通 Python 函数。
- 必须使用描述性的函数名和参数名。
- 应验证输入并对无效输入抛出带有有意义信息的错误。
- 错误消息对 Claude 可见,使其能够用修正后的参数重试。
最佳实践:
- 命名良好的函数和参数。
- 对无效输入进行验证并立即抛出错误。
- 有意义的错误消息,能指导修正。
实现模式示例:
def get_current_datetime(date_format="%Y%m%d %H:%M:%S"):
if not date_format:
raise ValueError("date format cannot be empty")
return datetime.now().strftime(date_format)
工具函数工作流:Claude 识别到信息需求 → 调用工具函数 → 接收结果或错误 → 如果发生错误,可能会用修正后的参数重试。
目的:通过提供对实时信息(如当前日期时间、天气等)的访问,扩展 Claude 的能力至其训练数据之外。
工具模式(Tool Schemas)
Tool Schemas (工具模式) = 描述工具函数及其参数的 JSON 模式规范,供语言模型使用。
JSON Schema (JSON 模式) = 一种数据验证规范(非机器学习专用),用于验证 JSON 数据,已被机器学习社区采纳用于工具调用。
工具模式结构:
name:工具标识符。description:3-4 句解释工具的作用、何时使用以及它返回什么数据。input_schema:描述函数参数的实际 JSON 模式,包括类型和描述。
模式生成技巧:
- 将工具函数提供给 Claude.ai。
- 提示:“为这个函数编写一个用于工具调用的有效 JSON 模式规范,并遵循附加文档中的最佳实践”。
- 附上 Anthropic API 文档的工具使用页面。
- 复制生成的模式。
实现模式:
- 描述性地命名函数。
- 将模式命名为 [function_name]_schema。
- 从
anthropic.types导入ToolParam。 - 用
ToolParam()包装模式字典以防止类型错误。
目的 = 通过标准化的 JSON 验证格式,告知 Claude 可用工具、必需参数和使用上下文。
处理消息块
支持工具的 Claude 请求
第 3 步:使用工具向 Claude 发出请求 = 在请求中除了用户消息外,还需使用 tools 关键字参数包含工具模式,其中含有 JSON 模式规范。
Multi-Block Messages (多块消息)
内容结构变化 = 消息现在包含多个块,而不仅仅是文本块。
工具响应格式 = 助手消息包含:
- 文本块 = 面向用户的解释。
- 工具使用块 = 包含工具执行的函数名 + 参数。
消息历史管理
关键要求 = 手动维护对话历史,因为 Claude 不存储任何内容。
多块处理 = 将整个 response.content(所有块)附加到消息列表中,而不仅仅是文本。
需要更新辅助函数 = add_user_message 和 add_assistant_message 函数必须支持多个块,而不仅仅是单个文本块。
对话流程 = 用户消息 → 带有工具使用块的助手响应 → 执行工具 → 以完整的历史记录向 Claude 回应。
发送工具结果
Tool Results (工具结果) = 从已执行的工具函数中获得的结果,在后续请求中发送回 Claude。
过程:执行 Claude 请求的工具函数 → 创建一个 Tool Result Block (工具结果块) → 发送包含完整对话历史的后续请求。
工具结果块结构:
tool_use_id= 与原始工具使用块中的 ID 匹配,以将请求与结果配对。content= 工具函数输出,转换为字符串(通常是 JSON)。is_error= 用于标记函数执行错误的布尔标志(默认为 false)。
tool_use_id 的目的 = 当 Claude 同时进行多个工具调用时,将多个工具请求链接到正确的结果。每个工具使用都会获得一个唯一的 ID,工具结果必须引用匹配的 ID。
后续请求要求:
- 包含完整的消息历史(原始用户消息 + 助手的工具使用消息 + 带有工具结果的新用户消息)。
- 即使不再使用工具,也必须包含原始的工具模式。
- 工具结果块放在用户消息中,而不是助手消息中。
对话流程:用户请求 → Claude 助手响应(文本 + 工具使用块) → 服务器执行工具 → 带有工具结果块的用户消息 → Claude 的最终响应(集成了结果)。
使用工具进行多轮对话
使用工具的多轮对话 = 对话中 Claude 为回答单个用户查询而顺序使用多个工具。
Tool Chaining (工具链) 过程 = 用户提问 → Claude 请求第一个工具 → 工具执行 → 返回结果 → Claude 请求第二个工具 → 工具执行 → 返回结果 → Claude 提供最终答案。
示例流程 = 用户问“从今天起 103 天后是哪一天” → Claude 调用 get_current_datetime → Claude 调用 add_duration_to_datetime → Claude 提供答案。
实现模式 = 使用 while 循环,持续调用 Claude 直到不再有工具请求,检查每个响应中是否有 tool_use 块。
run_conversation 函数 = 接收初始消息,循环调用 Claude,执行请求的工具,将结果添加到对话中,直到得到最终响应。
必需的重构:
add_user_message/add_assistant_message= 更新以处理多个消息块,而不仅仅是纯文本。chat函数 = 接受tools参数,返回整个消息而不仅仅是第一个文本块。text_from_message辅助函数 = 从具有多个内容块的消息中提取所有文本块。
核心洞见 = 无法预测用户查询需要多少个工具,因此系统必须能自动处理任意长度的工具调用链。
实现多轮交互
多轮交互的实现 = 持续调用 Claude 直到它停止请求工具
stop_reason 字段 = 表明 Claude 为何停止生成文本
stop_reason= "tool_use" 表示 Claude 想要调用一个工具。- 存在其他值,但
tool_use是最常检查的。
run_conversation 函数 = 主循环,其功能如下:
- 用消息 + 可用工具调用 Claude。
- 将助手响应添加到对话历史中。
- 检查
stop_reason- 如果不是 "tool_use",则跳出循环。 - 如果是 "tool_use",则调用
run_tools函数。 - 将工具结果作为用户消息添加。
- 重复此过程,直到没有更多的工具请求。
run_tools 函数 = 处理多个工具使用块:
- 从
message.content中筛选出类型为 "tool_use" 的块。 - 遍历每个工具请求。
- 通过
run_tool辅助函数运行相应的工具函数。 - 创建
tool_result块,包含:type="tool_result",tool_use_id=original_id,content=JSON_encoded_output,is_error=boolean。 - 返回所有工具结果块的列表。
run_tool 函数 = 一个分发器,其功能如下:
- 接收
tool_name和tool_input。 - 使用
if语句将工具名称与函数匹配。 - 执行相应的工具函数。
- 可扩展以添加多个工具。
错误处理 = 在工具执行周围使用 try/except 块:
- 成功:
is_error=false,content=tool_output。 - 失败:
is_error=true,content=error_message。
关键架构要点:
- 助手消息可以包含多个块(文本 + 多个
tool_use)。 - 每个
tool_use块都得到一个单独的tool_result响应。 - 工具结果作为包含所有结果的用户消息发回。
- 该过程重复进行,直到 Claude 提供最终的纯文本响应。
使用多个工具
实现多个工具 = 在初始框架建立后,向现有工具系统添加额外的工具。
过程 = 3 个步骤:(1) 将工具模式添加到 RunConversation 函数的 tools 列表中,(2) 在 RunTool 函数中添加条件分支来处理新的工具名称,(3) 实现实际的工具函数。
关键组件:
RunConversation函数 = 包含tools列表,使 Claude 了解可用的工具。RunTool函数 = 根据工具名称将工具调用路由到相应的函数。- 工具模式 = 为 AI 模型定义工具结构。
- 工具函数 = 实际的实现代码。
添加的示例工具:
AddDurationToDateTime= 计算带有时长偏移的日期/时间。SetReminder= 创建提醒(一个打印确认信息的模拟实现)。
工具链 = AI 可以在单次对话中按顺序使用多个工具(例如,先计算日期,然后用结果设置提醒)。
消息结构 = 助手响应可以包含多个块:同一消息中可同时包含文本块和工具使用块。
可扩展性 = 初始框架建立后,添加新工具就变成了简单的模式:模式 + 路由 + 实现。
批量工具(Batch Tool)
Batch Tool (批量工具) = 一种工具,它使 Claude 能够在单个助手消息中并行运行多个工具,而不是发出多个顺序请求。
问题:理论上 Claude 可以在一条消息中发送多个工具使用块,但在实践中很少这样做,导致不必要的顺序工具调用。
解决方案:创建一个批量工具模式,该模式接受一个 invocations(调用)列表,每个调用包含工具名称 + 参数。Claude 不再直接调用工具,而是调用这个批量工具,并附带一个期望执行的工具数组。
实现方式:
- 在模式中添加批量工具,并带有
invocations参数。 - 创建
run_batch函数,遍历invocations列表。 - 从每个调用中提取工具名称和经 JSON 解析的参数。
- 为每个请求的工具调用
run_tool函数。 - 返回一个包含所有工具执行结果的
batch_output列表。
机制:通过提供一个更高级别的抽象,手动处理多个工具使用块本应自动完成的工作,从而“欺骗” Claude 进行并行工具执行。
结果:对于可并行执行的任务,只需一次请求-响应周期,而不是多个顺序的轮次。
用于结构化数据的工具
用于结构化数据的工具 = 一种从数据源中提取结构化 JSON 的替代方法,它使用 Claude 的工具系统,而不是消息预填充和停止序列。
与基于提示词的提取方法的主要区别:
- 输出更可靠。
- 设置更复杂。
- 需要 JSON 模式规范。
核心流程:
- 为工具定义 JSON 模式,其中输入 = 期望的数据结构。
- 将提示词 + 模式发送给 Claude。
- Claude 使用与模式匹配的结构化参数调用工具。
- 从工具使用块中提取 JSON(不需要工具结果)。
关键要求 = 使用 tool_choice 参数强制进行工具调用:
tool_choice = {"type": "tool", "name": "your_tool_name"}- 确保 Claude 总是调用指定的工具。
实现步骤:
- 为提取工具创建模式定义。
- 更新
chat函数以接受tool_choice参数。 - 将
tool_choice传递给client.messages.create()。 - 从
response.content[0].input访问结构化数据。
使用场景 = 当可靠性比简单性更重要时。基于提示词的方法更适合快速/简单的提取,而工具更适合复杂/可靠的提取。
文本编辑器工具
Text Editor Tool (文本编辑器工具) = Claude 内置的用于文件/文本操作的工具(读取、写入、创建、替换、撤销文件/目录)。
主要特点:
- 只有 JSON 模式是内置于 Claude 中的,实现必须自定义编码。
- 发送给 Claude 的模式存根会自动扩展为完整的模式。
- 模式类型字符串因 Claude 模型版本而异(3.5 和 3.7 版本有不同的日期)。
- 使 Claude 能够开箱即用地扮演软件工程师的角色。
必需的实现:
- 用于处理 Claude 工具使用请求的自定义类/函数。
- 用于查看文件、字符串替换、创建文件等的函数。
- Claude 不提供实际的文件系统操作。
工作流程:
- 向 Claude 发送最小的模式存根(名称 + 带有特定版本日期的类型)。
- Claude 在内部将其扩展为完整模式。
- Claude 发送工具使用请求。
- 自定义实现执行实际的文件操作。
- 结果被发送回 Claude。
使用场景:
- 复制 AI 代码编辑器的功能。
- 在无法使用原生编辑器的情况下进行文件系统操作。
- 自动代码生成/重构。
- 多文件项目操作。
优点 = 通过 API 调用而非图形用户界面(GUI)交互,近似实现了高级代码编辑器的功能。
网络搜索工具
Web Search Tool (网络搜索工具) = Claude 的一个内置工具,用于在网络上搜索最新/专业信息以回答用户问题。
实现 = 无需自定义代码,Claude 自动处理搜索执行。
模式要求:
type: "web_search_20250305"name: "web_search"max_uses: number (限制总搜索次数,默认为 5)allowed_domains: 可选列表,用于将搜索限制在特定域名。
响应结构:
- 文本块 = Claude 的解释性文本。
- 工具使用块 = Claude 执行的搜索查询。
- 网络搜索结果块 = 找到的页面(标题、URL)。
Citations(引用) 块 = 支持 Claude 陈述的特定文本。
主要特点:
- 每个请求可进行多次搜索(最多
max_uses次)。 - 可通过域名限制进行质量控制。
- 引用系统将陈述链接到源材料。
UI 渲染模式:
- 将文本块显示为普通文本。
- 将搜索结果显示为参考列表。
- 用来源归属(域名、标题、URL、引用的文本)高亮显示引用。
用例示例:将搜索限制在 NIH.gov 以获取医疗/运动建议,确保信息有科学依据,而不是来自泛泛的网络内容。
检索增强生成(RAG)简介
RAG = Retrieval Augmented Generation (检索增强生成),一种使用语言模型查询大型文档的技术。
问题:如何在不超出上下文限制的情况下,使用 Claude 从大型文档(100-1000+ 页)中提取特定信息。
选项 1(直接方法):将整个文档文本直接放入提示词中。
- 局限性:存在硬性的词元限制,长提示词效果下降,成本更高,处理更慢。
选项 2(RAG 方法):两步过程。
- 第 1 步:将文档分成小块。
- 第 2 步:对于用户问题,找到最相关的块,并仅将这些块包含在提示词中。
RAG 的好处:模型专注于相关内容,可扩展至大型/多个文档,提示词更小,成本更低,处理更快。
RAG 的缺点:更复杂,需要预处理,需要搜索机制来查找相关块,不保证块中包含完整上下文,可能存在多种分块策略(等分 vs. 基于标题)。
关键挑战:为特定用例定义相关性和最佳分块策略。
RAG 以简单性换取了可扩展性和效率,但需要仔细的实现和评估。
文本分块策略
Text Chunking Strategies (文本分块策略) = 为 RAG 流水线将文档分割成更小部分的过程。
核心问题:分块质量直接影响 RAG 性能。糟糕的分块会导致检索到不相关的上下文(例如,为一个关于软件工程 bug 的查询检索到医学上的“bug”文本)。
三种主要策略:
- 基于大小的分块 = 将文本分割成等长的字符串。
- 优点:易于实现,在生产环境中最常见。
- 缺点:可能切断单词,缺乏上下文。
- 解决方案:重叠策略 = 包含相邻块的字符以保留上下文。
- 权衡:会产生文本重复,但能改善块的意义。
- 基于结构的分块 = 根据文档结构(标题、段落、章节)进行分割。
- 最适合结构化文档(markdown, HTML)。
- 局限性:需要文档格式有保证。
- 示例:按 markdown 标题(##)分割以创建基于章节的块。
- 基于语义的分块 = 使用自然语言处理(NLP)对相关句子/章节进行分组。
- 最先进的技术。
- 根据语义相似性对连续的句子进行分组。
- 实现复杂。
关键实现说明:
- 按字符分块 = 最可靠的后备方案,适用于任何文档类型。
- 按句子分块 = 如果句子检测可靠,这是一个很好的折中方案。
- 按章节分块 = 结果最佳,但需要结构化输入。
- 策略选择取决于文档类型是否有保证以及用例需求。
规则:没有通用的最佳分块方法——取决于文档结构的保证和具体用例。
文本嵌入
Text Embeddings (文本嵌入) = 由 Embedding Model (嵌入模型) 生成的文本含义的数值表示。
嵌入模型 = 接收文本输入,输出一长串数字(范围从 -1 到 +1)。
嵌入数字 = 代表输入文本未知品质/特征的分数。理论上每个数字都对不同方面(快乐程度、主题相关性等)进行评分,但用户并不知道其实际含义。
Semantic Search (语义搜索) = 使用文本嵌入在 RAG 流水线中查找与用户问题相关的文本块。它解决了将用户查询与相关文档块匹配的搜索问题。
RAG 流水线过程 = 提取文本块 → 用户提交查询 → 使用语义搜索找到相关块 → 将相关块作为上下文添加到提示词中。
实现 = Anthropic 推荐使用 Voyage AI 进行嵌入生成。需要单独的账户/API 密钥。上手免费,通过 SDK 易于集成。
核心洞见 = 嵌入实现了语义相似性匹配而非关键字匹配,从而能更好地理解文本关系以用于检索任务。
完整的 RAG 流程
RAG Flow (RAG 流程) = 一个 7 步过程,结合了文本分块、嵌入和向量搜索,为大语言模型查询检索相关上下文。
第 1 步:文本分块 = 将源文档分割成独立的文本片段。 第 2 步:生成嵌入 = 使用嵌入模型将文本块转换为数值向量。 第 3 步:归一化 = 将向量的模长缩放到 1.0(由嵌入 API 自动处理)。 第 4 步:Vector Database (向量数据库) 存储 = 将嵌入存储在专门为数值向量操作优化的数据库中。 第 5 步:查询处理 = 使用相同的模型将用户问题转换为嵌入。 第 6 步:相似性搜索 = 使用 Cosine Similarity (余弦相似度) 计算找到最相似的存储嵌入。 第 7 步:提示词组装 = 将用户问题与检索到的相关文本块结合,发送给大语言模型。
关键数学概念:
- 余弦相似度 = 向量之间夹角的余弦值,返回值在 -1 到 1 之间,越接近 1 表示越相似。
Cosine Distance(余弦距离) = 1 减去余弦相似度,值越接近 0 表示相似度越高。- 向量数据库 = 执行相似性计算以找到最匹配的嵌入。
流程:预处理(步骤 1-4) → 用户查询 → 实时检索(步骤 5-7) → 大语言模型响应。
实现 RAG 流程
RAG 流程实现 = 检索增强生成过程的 5 步实践演练。
第 1 步:文本分块 = 使用 chunk_by_section 函数在 report.MD 文件上按章节分割文档。
第 2 步:嵌入生成 = 使用 generate_embedding 函数为每个块创建向量表示(支持单个字符串或字符串列表输入)。
第 3 步:向量存储填充 = 创建一个向量索引实例,使用 zip() 遍历块-嵌入对,并使用 store.add_vector(embedding, {content: chunk}) 存储每一对。将原始文本与嵌入一起存储,以便检索到有意义的结果。
第 4 步:查询处理 = 用户提问“软件工程部门去年做了什么”,为用户查询生成嵌入。
第 5 步:相似性搜索 = 使用 store.search(user_embedding, 2) 找到 2 个最相关的块,返回结果及余弦距离(第二部分为 0.71,方法论部分为 0.72)。
关键组件:
- 向量索引类 = 自定义的向量数据库实现。
- 余弦距离 = 查询与存储嵌入之间的相似性度量。
- 元数据存储 = 将原始文本内容与嵌入一同存储,可实现有意义的检索。
工作流程已完成,但存在局限,需要进一步改进。
BM25 词法搜索
BM25 = Best Match 25,一种 lexical search (词法搜索) 算法,常用于 RAG 流水线中以补充语义搜索。
仅使用语义搜索的问题 = 可能会漏掉精确的术语匹配,即使特定术语在某些文档中频繁出现,也可能返回不相关的结果。
Hybrid search (混合搜索) 方法 = 并行地将语义搜索(嵌入/向量数据库)与词法搜索(BM25)相结合,然后合并结果以获得更好的平衡。
BM25 算法步骤:
- 将用户查询分词为独立的术语(去除标点,按空格分割)。
- 统计每个术语在所有文本块/文档中的出现频率。
- 根据使用频率为术语分配相对重要性(稀有术语 = 重要性更高,常见词如 "a" = 重要性更低)。
- 根据文本块包含高权重术语的频率对其进行排序。
核心洞见 = 在整个语料库中频繁使用的术语,对于搜索相关性的重要性低于稀有、特定的术语。
BM25 的优势 = 更擅长查找精确的术语匹配,优先考虑包含稀有/特定搜索词的文档,补充了语义搜索的弱点。
实现 = 语义搜索和词法搜索系统都使用相似的 API(add_document, search 函数),使其易于结合。
下一步 = 合并两种搜索系统的结果,以同时获得语义理解和精确术语匹配的好处。
多索引 RAG 流水线
Multi-Index RAG Pipeline (多索引 RAG 流水线) = 一个结合了语义搜索(向量索引)和词法搜索(BM25 索引)的系统,以提高检索准确性。
关键组件:
- 向量索引 = 使用嵌入进行语义相似性搜索。
- BM25 索引 = 基于词法/关键字的搜索。
- 检索器类 = 一个包装器,它将查询转发给两个索引并合并结果。
Reciprocal Rank Fusion (倒数排序融合) = 一种用于合并来自不同索引的搜索结果的技术。公式:RRF_score = 对于每个文档,在所有搜索方法中求和 (1/(rank + 1))。文档按最高的组合分数排序。
示例:向量搜索返回 [doc2, doc7, doc6],BM25 返回 [doc6, doc2, doc7]。经过 RRF 计算后,最终排名变为 [doc2, doc6, doc7],因为 doc2 在两种方法中都排名靠前。
优点:
- 通过结合不同的搜索范式提高了搜索准确性。
- 采用模块化设计和标准化的 API(
search()和add_document()方法)。 - 易于扩展,可添加额外的搜索索引。
- 更好地处理单一方法失败的边缘情况。
实现模式允许多种搜索方法协同工作,同时保持索引类的独立和隔离。
结果重排序
Reranking (重排序) = 一个后处理步骤,在初次检索后使用大语言模型根据相关性对搜索结果进行重新排序。
过程:运行向量 + BM25 搜索 → 合并结果 → 将结果传递给大语言模型,并附上提示词要求按相关性对文档进行排序 → 获取重新排序后的结果。
实现细节:为提高效率,使用文档 ID 而非全文。大语言模型接收用户查询 + 候选文档 + 指示其按递减顺序列出最相关文档的指令。使用助手消息预填充 + 停止序列确保结构化的 JSON 输出。
权衡:通过利用大语言模型对语义相关性的理解,提高了搜索准确性。但由于额外的 LLM 调用,增加了延迟。当初始检索方法未能捕捉到微妙的查询意图时(例如,“ENG team” vs “engineering team”),此方法尤其有效。
改进示例:查询“工程团队在 2023 年事故中做了什么?”在重排序后,正确地将软件工程部分置于网络安全部分之上,尽管混合搜索最初给它的排名较低。
上下文检索
Contextual Retrieval (上下文检索) = 一种在嵌入文档块之前为其添加上下文,以提高 RAG 流水线准确性的技术。
问题:当文档被分割成块时,单个块会失去原始文档的上下文,从而降低检索准确性。
解决方案:一个预处理步骤,在将每个块插入检索器数据库之前,为其添加上下文信息。
过程:
- 取单个块 + 原始源文档。
- 发送给大语言模型(Claude),并附上提示词要求生成定位上下文。
- 大语言模型生成简短的上下文,解释该块与整个文档的关系。
- 将生成的上下文与原始块连接 = “带上下文的块”。
- 使用带上下文的块作为向量/BM25 索引的输入。
大型文档处理:如果源文档太大,无法放入单个提示词中,则使用选择性上下文策略:
- 包含文档开头的起始块(1-3个)以获取摘要/概要。
- 包含目标块之前的块以获取局部上下文。
- 跳过提供相关性较低上下文的中间块。
实现:add_context 函数接收一个文本块 + 源文本,通过大语言模型生成上下文,将上下文与原始块连接,并返回带上下文的版本。
好处:块保留了与更宏观的文档结构和交叉引用的联系,提高了对具有相互关联章节的复杂文档的检索准确性。
扩展思考
Extended Thinking (扩展思考) = Claude 的一项功能,允许在生成最终响应前进行推理。
关键机制:
- 显示一个用户可见的独立思考过程。
- 提高了复杂任务的准确性,但增加了成本(为思考的词元付费)和延迟。
thinking budget(思考预算) = 为思考阶段分配的最少 1024 个词元。max_tokens必须超过思考预算(例如,预算为 1024,则max_tokens≥ 1025)。
何时使用:
- 在提示词优化未能达到预期准确性后启用。
- 使用提示词评估来判断其必要性。
响应结构:
thinking块 = 包含推理文本 + 加密签名。text块 = 最终响应。- 签名 = 防止思考文本被篡改(安全措施)。
特殊情况:
- 经过编辑的思考块 = 被安全系统标记的加密思考文本。
- 为保持对话连续性而提供,不丢失上下文。
- 可以使用测试字符串强制生成编辑块:“entropic magic string triggered redacted thinking [special characters]”。
实现:
- 设置
thinking=true和thinking_budget参数。 - 确保
max_tokens>thinking_budget以保证足够的响应生成能力。
图像支持
Claude 视觉能力 = 在用户消息中处理图像,用于分析、比较、计数和描述任务。
图像限制:
- 每个请求最多 100 张图像。
- 存在尺寸/维度限制。
- 图像消耗词元(根据像素高度/宽度计算收费)。
图像块结构 = 用户消息中的一种特殊块类型,持有原始图像数据(base64)或在线图像的 URL 引用。每条消息允许有多个图像块。
成功的关键因素 = 需要强有力的提示词技术才能获得准确结果。简单的提示词通常会失败。
针对图像的提示词技术:
- 循序渐进的分析指令。
- 单样本/多样本示例(交替的图像和文本对)。
- 清晰的指导方针和验证步骤。
- 结构化的分析框架。
用例示例 = 从卫星图像中自动评估火灾风险,分析树木密度、财产通道、屋顶悬挑,并分配数值风险评分。
实现 = 对图像数据进行 base64 编码,创建包含图像块(type: image, source: base64, media_type, data)的消息,后跟包含详细提示指令的文本块。
核心要点 = 图像的准确性完全取决于提示词的复杂程度,而不仅仅是图像质量。
PDF 支持
Claude 中的 PDF 支持:
Claude 可以使用与图像处理类似的代码直接读取 PDF 文件。
关键实现变更:
- 文件类型 = "document" 而不是 "image"。
- 媒体类型 = "application/pdf" 而不是 "image/png"。
- 变量命名 =
file_bytes而不是image_bytes。
Claude PDF 能力 = 读取文本 + 图像 + 图表 + 表格 + 混合内容提取。
PDF 处理 = 全面文档分析的一站式解决方案。
使用模式 = 与图像输入相同,但使用特定于文档的参数。
引用
Citations (引用) = 一项功能,允许 Claude 引用源文档并显示信息来源。
引用类型:
citation_page_location= 用于 PDF 文档,显示文档索引/标题/起始页/结束页/引用的文本。citation_char_location= 用于纯文本,显示文本块中的字符位置。
实现:
- 在请求中添加
"citations": {"enabled": true}。 - 添加 "title" 字段以标识源文档。
- 适用于 PDF 文件和纯文本源。
响应结构 = content 变为一个文本块列表,其中一些包含带有位置数据的 citations 数组。
目的 = 为用户提供透明度,以验证 Claude 的信息来源并检查其解释的准确性。
UI 优势 = 当用户悬停在引用内容上时,可以实现引用弹出窗口/覆盖层,显示源文档、页码和确切的引用文本。
关键用例 = 确保用户可以调查 Claude 是如何根据源材料构建响应的,而不是看起来像凭空记忆说话。
提示词缓存
Prompt Caching (提示词缓存) = 一项通过重用先前请求的计算工作来加快 Claude 响应速度并降低文本生成成本的功能。
正常请求流程:用户发送消息 → Claude 处理输入(创建内部数据结构,执行计算)→ Claude 生成输出 → Claude 丢弃所有处理工作 → 准备好下一个请求。
问题:当后续请求包含相同的输入消息时,Claude 必须重复它刚刚丢弃的所有计算工作,这造成了效率低下。
解决方案:提示词缓存将输入消息处理的结果存储在临时缓存中,而不是丢弃。当后续请求中出现相同的输入时,Claude 会检索缓存的工作,而不是重新处理,从而显著加快响应生成速度。
主要优点:重用以前的计算工作,以避免对重复内容进行冗余处理。
提示词缓存规则
Prompt Caching (提示词缓存) = 一个保存初始请求处理工作的系统,以便在内容相同的后续请求中重用。
核心机制:初始请求 → Claude 处理 + 将工作保存到缓存 → 后续请求内容相同 → Claude 从缓存中检索工作,而不是重新处理。
缓存持续时间 = 最长 1 小时。
缓存激活需要手动在消息块中添加 cache breakpoint (缓存断点)。
文本块格式:
- 简写:
content = "text string"(无法添加缓存控制)。 - 完整写法:
content = [{"type": "text", "text": "content", "cache_control": {...}}](缓存所需)。
缓存范围 = 所有内容,直到并包括断点,都会被缓存。
缓存失效 = 断点前内容的任何更改都会使整个缓存失效。
内容处理顺序 = 工具 → 系统提示词 → 消息(拼接在一起)。
缓存断点放置选项:
- 工具模式。
- 系统提示词。
- 消息块(文本、图像、工具使用、工具结果)。
每个请求最多 4 个断点。
多个断点 = 创建多个缓存层,如果只有后面的内容发生变化,可能实现部分缓存命中。
最小缓存阈值 = 内容需要达到 1024 个词元才能被缓存。
最佳用例 = 请求间内容完全相同(系统提示词、工具定义、静态消息前缀)。
提示词缓存实战
提示词缓存实现 = 自动缓存工具模式和系统提示词以减少词元使用。
设置 = 修改 chat 函数,默认对工具和系统提示词启用缓存。
工具模式缓存 = 将 cache_control 字段(类型为 "ephemeral")添加到列表中的最后一个工具。最佳实践:创建工具列表的副本,克隆最后一个工具模式,添加缓存控制,然后覆盖,以避免修改原始模式。
系统提示词缓存 = 将系统提示词包装在带有 cache_control 类型 "ephemeral" 的文本块字典中。
多个缓存断点 = 可以在单个请求中为工具和系统提示词都设置缓存点。
缓存顺序 = 工具 → 系统提示词 → 消息。
词元使用模式:
cache_creation_input_tokens= 首次使用时写入缓存的词元。cache_read_input_tokens= 在后续相同请求中从缓存中读取的词元。- 当部分内容与缓存数据匹配时,可能发生部分缓存读取。
缓存失效 = 缓存内容(工具或系统提示词)的任何更改都会使缓存失效,强制创建新缓存。
使用场景 = 跨请求内容相同 - 相同的工具模式、系统提示词或消息序列。
代码执行与文件 API
Files API (文件 API) = 允许提前上传文件,并在之后通过文件 ID 引用它们,而不是在每个请求中包含原始文件数据。上传文件 → 获取带有 ID 的文件元数据对象 → 在未来请求中使用该 ID。
Code Execution (代码执行) = 一个基于服务器的工具,Claude 在隔离的 Docker 容器中执行 Python 代码。无需实现,只需包含预定义的工具模式。Claude 可以多次运行代码,解释结果,并生成最终响应。
关键限制:Docker 容器没有网络访问权限。数据输入/输出依赖于与 Files API 的集成。
组合工作流程:通过 Files API 上传文件 → 获取文件 ID → 在容器上传块中包含该 ID → 要求 Claude 进行分析 → Claude 编写/执行可访问上传文件的代码 → 返回分析和结果。
Claude 可以在容器内生成文件(如图表、报告),这些文件可以通过响应中返回的文件 ID 进行下载。
使用场景:数据分析、文件处理、复杂任务的自动代码生成。响应包含代码块、执行结果和最终分析。
实现:使用带有文件 ID 的容器上传块,包含分析提示词,Claude 会自动处理代码执行。
MCP 简介
MCP = Model Context Protocol (模型上下文协议),一个通信层,为 Claude 提供上下文和工具,而无需开发者编写繁琐的代码。
架构:MCP client (MCP 客户端) 连接到 MCP server (MCP 服务器)。服务器内部包含工具、资源和提示词作为组件。
解决的问题:消除了为服务集成编写/维护大量工具模式和函数的负担。例如:一个 GitHub 聊天机器人将需要实现用于仓库、拉取请求、问题、项目的工具——这需要大量的开发者工作。
解决方案:由 MCP 服务器处理工具的定义和执行,而不是你的应用程序服务器。MCP 服务器 = 外部服务的接口,将功能包装成即用型工具。
主要优点:开发者无需亲自编写工具模式和函数实现。
常见问题:
- 谁创建
MCP服务器?任何人都可以,通常服务提供商会提供官方实现(如 AWS 等)。 - 与直接 API 调用相比?
MCP免去了你亲自编写工具模式/函数的需要。 - 与工具调用相比?
MCP和工具调用是互补的——MCP处理由谁来完成工作(服务器 vs 开发者),但两者都涉及工具。
核心价值:将集成负担从应用程序开发者转移到 MCP 服务器维护者。
MCP 客户端
MCP Client = MCP 客户端,是你的服务器与 MCP 服务器之间的通信接口,提供了对服务器工具的访问。
传输无关 = 客户端/服务器可以通过多种协议(stdio、HTTP、WebSockets)进行通信。
常见设置 = 客户端和服务器在同一台机器上,使用标准输入/输出。
通信 = 由 MCP 规范定义的消息交换。
关键消息类型:
list tools请求 = 客户端向服务器请求可用工具。list tools结果 = 服务器以工具列表作为响应。call tool请求 = 客户端请求服务器使用参数运行工具。call tool结果 = 服务器以工具执行结果作为响应。
典型流程:
- 用户查询服务器。
- 服务器向
MCP客户端请求工具列表。 MCP客户端向MCP服务器发送list tools请求。MCP服务器以list tools结果作为响应。- 服务器将查询 + 工具发送给 Claude。
- Claude 请求执行工具。
- 服务器要求
MCP客户端运行工具。 MCP客户端向MCP服务器发送call tool请求。MCP服务器执行工具(例如,GitHub API 调用)。- 结果通过链条回传:
MCP服务器 →MCP客户端 → 服务器 → Claude → 用户。
目的 = 使服务器能够将工具执行委托给专门的 MCP 服务器,同时保持与 Claude 的集成。
项目设置
基于 CLI 的聊天机器人项目 = 通过动手实践来教授 MCP 客户端-服务器交互。
项目组件:
MCP客户端 = 连接到自定义的MCP服务器。MCP服务器 = 提供 2 个工具(读取文档、更新文档)。- 文档集合 = 仅存储在内存中的虚拟文档。
关键区别:普通项目要么实现客户端,要么实现服务器,而不是两者都实现。本项目为了教学目的,两者都将实现。
设置过程:
- 下载
CLI_project.zip入门代码。 - 解压并在代码编辑器中打开。
- 遵循
readme.md中的设置说明。 - 将 API 密钥添加到
.env文件中。 - 安装依赖项(使用/不使用 UV)。
- 运行项目:
uv run main.py或python main.py。 - 使用聊天提示词进行测试。
预期结果 = 一个能响应基本查询的工作聊天界面,为添加 MCP 功能做好准备。
使用 MCP 定义工具
使用 Python SDK 实现 MCP 服务器时,通过装饰器创建工具,而非手动编写 JSON 模式。
MCP Python SDK = 一个官方包,它使用 @mcp.tool 装饰器从 Python 函数定义中自动生成工具的 JSON 模式。
工具定义语法 = @mcp.tool(name="tool_name", description="description") + 带有类型化参数的函数,使用 Field() 来描述参数。
实现的两个工具:
read_doc_contents= 接收一个doc_id字符串,从内存中的docs字典返回文档内容。edit_document= 接收doc_id、old_string、new_string参数,对文档内容执行查找/替换操作。
错误处理 = 检查 doc_id 是否存在于 docs 字典中,如果未找到则引发 ValueError。
主要优势 = SDK 消除了手动编写 JSON 模式的工作,自动从 Python 函数签名和装饰器生成模式。
必需的导入 = 用于参数描述的 pydantic 中的 Field,以及用于服务器和工具装饰器的 mcp 包。
实现模式 = 装饰器定义工具元数据,函数参数定义带有类型和描述的工具参数,函数体包含工具逻辑。
服务器检查器
MCP Inspector (MCP 检查器) = 一个用于测试 MCP 服务器的浏览器内调试器,无需连接到应用程序。
访问方式:在终端运行 mcp dev [server_file.py] → 在端口上启动服务器 → 在浏览器中导航到提供的 URL。
界面:左侧边栏有连接按钮 → 顶部菜单显示资源/提示词/工具部分 → 工具部分列出可用工具 → 点击工具以在右侧面板中打开手动测试界面。
测试工作流程:连接到服务器 → 导航到工具 → 选择特定工具 → 输入所需参数 → 点击运行工具 → 验证输出。
主要功能:实时开发测试、手动工具调用、参数输入表单、成功/失败反馈,无需完整的应用程序集成。
注意:UI 在开发过程中正在积极变化,但核心功能保持相似。
使用示例:通过输入文档 ID 测试文档工具,验证读取操作,测试编辑操作,链接操作以验证更改。
主要好处:在开发阶段高效地调试 MCP 服务器实现。
实现客户端
MCP 客户端实现:
MCP 客户端 = MCP 客户端是客户端会话的包装类,用于资源清理和与 MCP 服务器的连接管理。
客户端会话 = 来自 MCP Python SDK 的与 MCP 服务器的实际连接,关闭时需要进行资源清理。
客户端目的 = 将 MCP 服务器的功能暴露给代码库的其余部分,使其能够向服务器请求工具列表和执行工具。
关键函数:
list_tools()=await self.session.list_tools(),返回result.tools。call_tool()=await self.session.call_tool(tool_name, tool_input)。
使用流程 = 客户端获取要发送给 Claude 的工具定义,然后在 Claude 请求时执行这些工具。
常见模式 = 将客户端会话包装在更大的类中进行资源管理,而不是直接使用会话。
测试 = 可以直接运行客户端文件,使用测试工具来验证服务器连接和工具检索。
集成 = 项目中的其他代码调用客户端函数与 MCP 服务器交互,使 Claude 能够通过定义的工具检查/编辑文档。
定义资源
MCP Resources (MCP 资源) = 一种允许 MCP 服务器向客户端暴露数据以供读取操作的机制。
资源类型 = 两种类型:直接型(静态 URI (统一资源标识符),如 "docs://documents")和模板型(参数化 URI,如 "docs://documents/{doc_id}")。
URI = 用于访问特定资源的地址/标识符,在创建资源时定义。
资源流程 = 客户端发送带有 URI 的读取资源请求 → 服务器将 URI 匹配到函数 → 服务器执行函数 → 在读取资源结果中返回数据。
实现 = 使用带有 URI 和 MIME Types 参数的 @mcp.resource 装饰器。
MIME Types = 向客户端提示返回数据格式的线索(application/json 用于结构化数据,text/plain 用于纯文本)。
模板化资源 = URI 参数由 SDK 自动解析,并作为关键字参数传递给处理函数。
资源 vs 工具 = 资源主动提供数据(当被@提及时获取文档内容),而工具被动执行动作(当 Claude 决定调用它们时)。
数据返回 = SDK 自动将返回的数据序列化为字符串,客户端负责反序列化。
测试 = MCP 检查器可以分别列出直接资源和模板化资源,并允许测试单个资源调用。
访问资源
MCP 资源访问实现:
资源读取函数 = 用于从 MCP 服务器请求和解析资源的客户端函数。
函数参数 = URI (资源标识符)。
实现步骤:
- 从
pydantic导入json模块 +AnyURL。 - 调用
await self.session.read_resource(AnyURL(uri))。 - 从
result.contents[0]中提取第一个元素。 - 检查
resource.mime_type以确定解析策略。
内容解析逻辑:
- 如果
mime_type == "application/json"→ 返回json.loads(resource.text)。 - 否则 → 返回
resource.text(纯文本)。
服务器响应结构 = result.contents 列表,其第一个元素包含 type/mime_type 元数据。
资源集成 = MCP 客户端函数由其他应用程序组件调用,以获取文档内容用于提示词。
最终结果 = 文档内容自动包含在 Claude 提示词中,无需调用工具。
关键点 = 资源通过结构化的请求/响应模式直接向客户端暴露服务器信息。
定义提示词
MCP Prompts (MCP 提示词) = MCP 服务器向客户端应用程序暴露的、用于特定任务的预定义、经过测试的提示词模板。
目的 = 服务器作者创建针对其服务器领域量身定制的高质量、经过评估的提示词,而不是让用户编写临时提示词。
实现 = 使用 @mcpserver.prompt 装饰器,并附带名称/描述,定义一个返回消息列表的函数(可以直接发送给 Claude 的用户/助手消息)。
用例示例 = 一个文档格式化提示词,它接收文档 ID,指示 Claude 使用工具读取文档,将其重新格式化为 markdown,并保存更改。
主要优点 = 特定于服务器的专业知识,预先测试的质量,可在客户端应用程序间重用,比用户生成的提示词效果更好。
消息结构 = 返回包含格式化提示词文本(已插入参数)的 base.UserMessage 对象。
客户端集成 = 提示词在客户端应用程序中作为自动完成选项(斜杠命令)出现,提示用户输入所需参数,然后执行预构建的提示词工作流。
客户端中的提示词
MCP 客户端提示词实现:
列出提示词 = await self.session.list_prompts(),返回 result.prompts。 获取提示词 = await self.session.get_prompt(prompt_name, arguments),返回 result.messages。
提示词工作流程:
- 在
MCP服务器中定义提示词及其预期参数(例如,document_id)。 - 客户端使用提示词名称 + 参数字典调用
get_prompt。 - 参数作为关键字参数传递给提示词函数。
- 函数将参数插入到提示词文本中。
- 返回一个消息数组,可直接提供给大语言模型。
核心概念:提示词是服务器定义的模板,客户端可以用特定参数调用这些模板,为大语言模型生成带有上下文的指令。参数从客户端调用 → 提示词函数 → 插入参数的提示词文本 → 大语言模型消费。
Anthropic 应用
Anthropic 应用 = Anthropic 部署的两个应用程序:Claude Code 和 Computer Use。
Claude Code = 一个基于终端的编码助手,是智能体架构的一个示例。
Computer Use = 一个扩展 Claude 能力超出文本生成范围的工具集。
主要目的 = 这些应用展示了 agents (智能体) 的概念,并为理解智能体设计和实现提供了实际示例。
设置过程 = 涉及为在示例项目上使用 Claude Code 进行终端配置。
与智能体的联系 = 这两个应用都体现了智能体的工作方式,可作为构建高效智能体的学习模型。
Claude Code 设置
Claude Code = 一个基于终端的编码助手程序,帮助完成与代码相关的任务。
核心能力 = 搜索/读取/编辑文件 + 高级工具(网络抓取、终端访问)+ MCP 客户端支持,以通过 MCP 服务器扩展功能。
设置过程:
- 安装
Node.js(用npm help命令检查)。 - 运行
npm install安装 Claude Code。 - 在终端执行
claude命令以登录到 Anthropic 账户。
完整设置指南 = docs.anthropic.com。
MCP 客户端功能 = 可以消费来自 MCP 服务器的工具,以扩展其超出基本文件操作的能力。
Claude Code 实战
Claude Code = 一个 AI 编码助手,它在项目上扮演合作工程师的角色,而不仅仅是一个代码生成器。
主要能力:项目设置、功能设计、代码编写、测试、部署、生产环境错误修复。
设置工作流:
- 下载项目,在编辑器中打开。
- 运行
claude命令启动。 - 要求 Claude 阅读 README 并执行设置说明。
- 运行
init命令 = Claude 扫描代码库以了解其架构/编码风格,并创建一个claude.md文件。 claude.md= 自动包含在未来请求中的上下文。
内存类型:项目(共享)、本地、用户内存文件。
上下文管理:
- 使用 # 符号向内存中添加特定笔记。
- 可以手动编辑
claude.md或重新运行init来更新。 - Claude 可以处理
Git操作(暂存、提交)。
有效的提示策略:
方法 1 - 三步工作流:
- 识别相关文件,要求 Claude 分析它们。
- 描述功能,要求 Claude 规划解决方案(暂不编写代码)。
- 要求 Claude 实施该计划。
方法 2 - 测试驱动开发:
- 提供相关上下文。
- 要求 Claude 为该功能建议测试。
- 选择并实施选定的测试。
- 要求 Claude 编写代码直到测试通过。
核心原则:Claude Code = 效率倍增器。更详细的指令 = 显著更好的结果。将其视为合作工程师,而不仅仅是代码生成器。
使用 MCP 服务器增强功能
Claude Code = 一个内置了 MCP (模型上下文协议) 客户端的 AI 助手,可以连接到 MCP 服务器以扩展功能。
MCP 服务器集成 = 通过命令将外部工具/服务连接到 Claude Code:claude mcp add [server-name] [startup-command]。
实现示例 = 一个暴露了“文档路径转 Markdown”工具的文档处理服务器,允许 Claude Code 通过运行 uv run main.py 来读取 PDF/Word 文档。
动态能力扩展 = MCP 服务器可以实时为 Claude Code 添加新功能,无需修改其核心。
常见用例 = 生产监控 (Sentry)、项目管理 (Jira)、通信 (Slack)、自定义开发工作流工具。
主要优点 = 通过模块化的服务器连接,极大地提高了开发工作流的灵活性。
设置过程 = 1) 创建带有工具的 MCP 服务器,2) 使用名称和启动命令将服务器添加到 Claude Code,3) 重启 Claude Code 以访问新功能。
并行化 Claude Code
并行化 Claude Code = 同时运行多个 Claude 实例以并行完成不同任务。
核心问题 = 多个 Claude 实例同时修改相同文件会产生冲突和无效代码。
解决方案 = 使用 Git 工作树为每个 Claude 实例提供隔离的工作区。
Git 工作树 = 一种功能,它在单独的目录中创建完整的项目副本,每个副本对应不同的 Git 分支。
工作流程 = 创建工作树 → 将任务分配给 Claude 实例 → 在隔离环境中工作 → 提交更改 → 合并回主分支。
自定义命令 = 通过在 .claude/commands 目录中使用包含 $ARGUMENTS 占位符以支持动态值的 markdown 文件,来自动化工作树的创建/管理。
并行执行的好处 = 单个开发者指挥一个虚拟的软件工程师团队,生产力可大幅扩展,仅受工程师管理能力的限制。
合并冲突 = Claude 在分支合并过程中自动解决冲突。
清理 = Claude 在功能完成后处理工作树的移除。
主要优势 = 可根据开发者管理同步任务的能力,扩展至无限个并行实例。
自动调试
自动调试 = 使用 AI (Claude) 自动检测、分析和修复生产环境中的错误,无需人工干预。
核心工作流:
GitHub Action每日运行以检查生产环境。- 获取过去 24 小时的
CloudWatch日志。 - Claude 识别错误并进行去重。
- Claude 分析每个错误并生成修复方案。
- 创建一个包含建议解决方案的拉取请求。
关键组件:
- 用于调度/自动化的
GitHub Actions。 - 用于日志检索的
AWS CLI。 - 用于错误分析和代码修复的 Claude Code。
- 用于生产错误监控的
CloudWatch。
优点:
- 捕获仅在生产环境中出现的错误(开发环境中不存在的问题)。
- 减少手动查找日志和调试的时间。
- 提供带有解释的、有上下文感知的修复方案。
- 创建可供审查的、包含更改的拉取请求。
常见用例:环境之间的配置错误(无效的模型 ID、API 密钥等,这些在本地有效但在生产环境中失败)。
实现要求:仓库访问权限、云日志服务、AI 编码助手、CI/CD pipeline 集成。
计算机使用
Computer Use = Claude 通过视觉观察和控制操作与计算机界面进行交互的能力。
主要能力:
- 对应用程序/浏览器进行截图。
- 点击按钮、输入文本、导航界面。
- 自主遵循多步指令。
- 执行 QA 测试和自动化任务。
工作原理:
- 在隔离的
Docker容器环境中运行。 - 用户通过聊天界面提供指令。
- Claude 视觉观察屏幕并执行操作。
- 生成关于任务完成情况/结果的报告。
主要用例:
- Web 应用程序的自动化 QA 测试。
- 跨不同场景的 UI 交互测试。
- 为重复性的计算机任务节省时间。
- 通过系统性测试识别 bug。
设置要求 = 提供参考实现以供本地测试。
示例工作流程:用户描述测试要求 → Claude 导航到应用程序 → 执行测试用例 → 报告通过/失败结果并附带详细发现。
计算机使用如何工作
Computer use = 一种工具系统实现,允许 Claude 与计算环境进行交互。
工具使用流程:用户发送消息 + 工具模式 → Claude 以工具使用请求(ID、名称、输入)响应 → 服务器执行代码 → 结果作为工具结果发送回 Claude。
计算机使用遵循相同的流程:
- 向 Claude 发送特殊的工具模式(一个小的模式在幕后会扩展为更大的结构)。
- 扩展后的模式包括一个带有参数的
action函数:鼠标移动、左键点击、截图等。 - Claude 发送工具使用请求。
- 开发者必须通过计算环境(通常是
Docker容器)来满足请求。 - 容器执行程序化的按键/鼠标移动。
- 响应被发送回 Claude。
关键点:
- Claude 不直接操纵计算机。
- 计算机使用 = 工具系统 + 开发者提供的计算环境。
- Anthropic 提供参考实现(一个带有预构建鼠标/键盘执行代码的
Docker容器)。 - 设置需要
Docker+ 简单的命令执行。 - 可以通过直接的聊天界面来测试 Claude 的计算机使用功能。
计算机使用 = 一个抽象层,其中工具系统处理 Claude 的通信,而 Docker 容器处理实际的计算机交互。
智能体与工作流
Workflows and agents (工作流与智能体) = 用于处理 Claude 无法在单个请求中完成的用户任务的策略。
决策规则:当您对任务有精确的理解并知道确切的步骤顺序时,使用工作流。当任务细节不明确时,使用智能体。
Workflow (工作流) = 针对已知步骤顺序的特定问题,对 Claude 进行的一系列调用。
示例工作流:图像到 3D 模型的转换器。
- 第 1 步:Claude 详细描述上传的图像。
- 第 2 步:Claude 使用
CADQueryPython库根据描述建模对象。 - 第 3 步:创建模型的渲染图。
- 第 4 步:Claude 将渲染图与原始图像进行比较。
- 第 5 步:如果不准确,从第 2 步开始重复并提供反馈。
这遵循了评估者-优化者模式:
- 生产者 = 生成输出(Claude +
CADQuery建模)。 - 评估者 = 评估输出质量(比较步骤)。
- 循环持续直到评估者接受输出。
关键点:工作流是其他工程师成功使用过的实现模式。识别工作流模式并不会自动实现它们——你仍然需要编写实际的代码。
并行化工作流
Parallelization Workflows (并行化工作流) = 将一个复杂任务分解为多个同步的子任务,然后汇总结果。
示例:零件的材料选择。
- 替代方案:不是用一个大的提示词让 Claude 在金属/聚合物/陶瓷/复合材料之间根据所有标准进行选择。
- 使用方案:分别进行并行的请求,每个请求评估一种材料的适用性,然后在最后的汇总步骤中比较结果。
结构:输入 → 多个并行的子任务 → 聚合器 → 最终输出。
优点:
- 专注 = 每个子任务处理一个特定的分析,而不是同时处理多个考虑因素。
- 模块化 = 单个提示词可以独立改进/评估。
- 可扩展性 = 易于添加新的子任务而不影响现有的。
- 质量 = 减少了由过于复杂的单个提示词引起的混淆。
核心原则:将复杂的决策分解为专门的并行分析,然后综合结果。
链式工作流
Chaining Workflows (链式工作流) = 将大型任务分解为一系列明确的顺序步骤,而不是一个复杂的单一提示词。
核心概念:与其用一个包含多项要求的大型提示词,不如将其拆分为多个独立的调用,每个调用专注于一个特定的子任务。
示例工作流:用户输入主题 → 搜索热门话题 → Claude 选择最有趣的 → Claude 研究该主题 → Claude 编写脚本 → 生成视频 → 发布到社交媒体。
主要优点:允许 AI 专注于单个任务,而不是同时处理多个约束。
主要用例:当 Claude 在复杂的提示词中,尽管重复强调,仍持续忽略某些约束时。这在包含许多“不要做 X”要求的长提示词中很常见。
问题场景:一个包含约束(不提 AI、无表情符号、专业语气)的长提示词 → Claude 无论重复多少次都会违反某些约束。
解决方案:第 1 步 - 发送初始提示词,接受不完美的输出。第 2 步 - 发送一个后续提示词,要求 Claude 根据发现的具体违规情况重写。
关键洞见:即使是看起来简单的工作流,在处理 AI 难以在单次处理中完全遵循的、充满约束的提示词时,也变得至关重要。
路由工作流
Routing Workflows (路由工作流) = 一种工作流模式,它对用户输入进行分类,以确定合适的处理流水线。
关键机制:向 Claude 发送一个初始请求,将用户输入分类到预定义的类型/类别中。根据分类响应,系统将请求路由到具有定制提示词/工具的专门处理流水线。
示例流程:
- 用户输入主题(例如,“Python functions”)。
- Claude 对主题进行分类(例如,“教育类”)。
- 系统使用特定于教育的提示词模板。
- Claude 以教育的语气/结构生成脚本。
优点:确保输出与主题性质相符。编程主题会得到带有定义/解释的教育性处理。娱乐主题会得到时髦的语言/引人入胜的开场。
结构:一个路由步骤 → 多个专门的处理流水线 → 每个流水线都有针对特定类别的定制提示词/工具。
用例:社交媒体视频脚本生成,其中不同主题需要不同的语气和方法。
智能体与工具
Agents (智能体) = AI 系统,它们制定计划以使用提供的工具完成任务,在确切步骤未知时非常有效。Workflows (工作流) = 在已知精确步骤时是更好的选择。
主要区别:工作流需要预定的步骤,而智能体则使用可用工具动态规划。
智能体的优势:能够用同一套工具解决各种任务,可以以意想不到的方式组合工具。
工具抽象原则:提供通用/抽象的工具,而不是高度专业化的工具。例如 - Claude Code 使用 bash、web_fetch、file_write(抽象)而不是 refactor_tool、install_dependencies(专业化)。
工具组合示例:get_current_datetime + add_duration + set_reminder 可以通过不同的组合解决各种与时间相关的任务。
智能体行为:在需要时可以请求额外信息,创造性地组合工具以实现目标,最适合与一小组灵活的工具一起工作。
设计方法:给予智能体可以拼接在一起的抽象工具,而不是单一用途的专业化工具。这使得动态问题解决和意想不到的用例成为可能。
环境检查
Environment Inspection (环境检查) = 智能体评估其环境和行动结果,以了解进展并处理错误。
核心概念:每次行动后,智能体需要超越基本工具返回值的反馈机制,来理解新的环境状态。
计算机使用示例:Claude 在每次行动(打字、点击)后都会截图,以查看环境如何变化,因为它无法预测像按钮点击这样的行动的确切结果。
代码编辑示例:在修改文件之前,智能体必须读取当前文件内容以了解现有状态。
社交媒体视频智能体应用:
- 通过
bash使用Whisper CPP生成带时间戳的字幕,验证对话位置。 - 使用
FFmpeg按时间间隔提取视频截图,检查视觉效果。 - 在发布前验证视频创作是否符合预期。
主要优点:环境检查使智能体能够衡量任务进展、检测错误并适应意外结果,而不是盲目操作。
工作流 vs 智能体
Workflows (工作流) = 预先定义的一系列对 Claude 的调用,步骤已知。Agents (智能体) = 一种灵活的方法,使用 Claude 组合基本工具来完成未知任务。
主要区别:
任务划分:工作流将大任务分解为更小、更具体的子任务,从而实现更高的专注度和准确性。智能体则创造性地处理各种挑战,无需预定步骤。
测试/评估:由于执行顺序已知,工作流更容易测试。由于执行路径不可预测,智能体更难测试。
用户体验:工作流需要特定的输入。智能体根据用户查询自己创建输入,并在需要时可以请求额外输入。
成功率:由于结构化方法,工作流的任务完成率更高。由于复杂性被委托,智能体的完成率较低。
建议:为保证可靠性,优先选择工作流。仅在确实需要灵活性时才使用智能体。用户想要的是 100% 可用的产品,而不是花哨的智能体。
核心原则:可靠地解决问题是第一位的,创新是第二位的。
第 2 课:AI 素养:框架与基础
学会高效、安全、负责任地与 AI 系统协作 课程链接:AI 素养:框架与基础 | 共 15 节课
人工智能流畅度导论
本模块预计用时:10-15 分钟
在本课程结束时,您将能够:
- 理解本课程的目的和结构
- 认识到 AI Fluency (人工智能流畅度) 在当今世界的重要性
- 识别未来学习旅程中的关键组成部分
- 为本课程的收获设定明确的期望
AI Fluency (人工智能流畅度) 导论
(4 分钟)
欢迎!本视频将介绍本课程的重点:与人工智能 (AI) 发展有意义的协作,而不仅仅是学习 AI 技术。我们将解释本课程如何探讨构建一个与 AI 系统合作的持久框架,该框架超越了简单和暂时的技巧。我们将解释我们所说的 AI Fluency 是什么:它指的是以有效、高效、合乎道德和安全的方式与 AI 协作的能力。我们还将概述课程结构,涵盖 AI Fluency 的每个核心能力 (4D) 以及关键的技术和实践概念。课程结束时,您将拥有一个深思熟虑的 AI 互动框架,有信心选择何时以及如何有效地与 AI 合作,掌握实用的协作技能,并能够负责任地评估和传播 AI 辅助的工作。
关键要点
- 本课程侧重于人机协作,而不仅仅是将 AI 理解为一种技术
- AI Fluency 意味着以有效、高效、合乎道德和安全的方式与 AI 系统互动
- AI Fluency 框架以“4D”能力为中心:Delegation (委托)、Description (描述)、Discernment (辨别) 和 Diligence (勤勉)
- 目标是培养持久的技能,随着 AI 技术的发展而保持其相关性
- 有效的 AI 协作既需要实践技能,也需要我们对与 AI 合作的思维方式进行根本性转变
练习
付诸实践
您需要访问一个语言模型 (5-10 分钟)
在整个课程中,您将通过直接与语言模型合作来练习所学知识。虽然我们的示例以 Claude (Anthropic 的 AI 助手) 为特色,但欢迎您使用任何您喜欢的语言模型。我们将探讨的原则和技能适用于不同的 AI 系统。
入门简单且免费:
- Claude: 访问 claude.ai 创建一个免费账户
- 完成课程活动无需付费订阅
- 您也可以根据喜好使用其他 AI 聊天机器人
对 Claude 不熟悉?别担心!我们将在每个练习中提供明确的指导,帮助您入门。
反思
在继续之前,请花点时间思考一下您自己使用 AI 的经历:
- 在使用 AI 实现特定结果时,您遇到了哪些挑战?
- AI 协作的哪些可能性最让您兴奋?
- 您希望从本课程中获得什么?
下一步
在下一课中,我们将探讨为什么 AI Fluency 在当今快速发展的技术环境中至关重要。我们将介绍人们与 AI 协作的三种关键方式 (Automation (自动化)、Augmentation (增强) 和 Agency (代理)) 以及 AI Fluency 框架的核心能力:“4D”,即 Delegation (委托)、Description (描述)、Discernment (辨别) 和 Diligence (勤勉)。
对本课程的反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
我们为什么需要 AI Fluency?
您将学到什么
在本课程结束时,您将能够:
- 理解 AI Fluency 的含义及其在当今快速发展的技术环境中的重要性
- 认识到我们与 AI 协作的三种新兴方式:Automation (自动化)、Augmentation (增强) 和 Agency (代理)
我们为什么需要 AI Fluency?
本视频探讨了对 AI “流畅”的真正含义及其重要性。我们讨论了 AI Fluency 如何涉及培养实践技能、知识、见解和价值观,帮助您以有效、高效、合乎道德和安全的方式与 AI 系统互动。我们还介绍了人们与 AI 互动的三个方式:
- Automation (自动化): AI 根据您的指示完成特定任务。
- Augmentation (增强): 您与 AI 作为创造性思维和任务执行的伙伴进行协作。
- Agency (代理): 您配置 AI 代表您独立工作,建立其知识和行为模式,而不仅仅是给它特定的任务。
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。
在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
4D 框架
您将学到什么
在本课程结束时,您将能够:
- 解释基本的 AI Fluency 框架及其核心“4D”:Delegation (委托)、Description (描述)、Discernment (辨别) 和 Diligence (勤勉)
4D 框架
(5 分钟)
本视频介绍了 AI Fluency 的四个核心能力,即“4D”:Delegation (委托)、Description (描述)、Discernment (辨别) 和 Diligence (勤勉)。
- Delegation (委托): 深思熟虑地决定哪些工作与 AI 合作,哪些自己完成
- Description (描述): 与 AI 系统进行清晰的沟通
- Discernment (辨别): 以批判性的眼光评估 AI 的输出和行为
- Diligence (勤勉): 确保您与 AI 的互动是负责任的
我们探讨了这些能力如何在不同的 AI 互动方式中协同工作,以及为什么培养这些技能能为您应对 AI 的未来发展做好准备。
关键要点
- AI Fluency 意味着以有效、高效、合乎道德和安全的方式与 AI 互动
- 我们与 AI 互动有三种主要方式:
- Automation (自动化): AI 根据您的指示执行特定任务
- Augmentation (增强): 您与 AI 作为创造性思维和任务执行的伙伴进行协作
- Agency (代理): 您引导 AI 代表您独立工作,塑造其知识和行为,而非具体行动
- AI Fluency 框架由四个核心能力 (4D) 组成:
- Delegation (委托): 决定哪些工作与 AI 合作,哪些自己完成
- Description (描述): 与 AI 系统进行有效沟通
- Discernment (辨别): 批判性地评估 AI 的输出
- Diligence (勤勉): 确保负责任的 AI 协作
- 这些能力适用于所有三种与 AI 合作的方式
- 培养这些能力为您应对不断发展的 AI 功能做好准备
练习
练习 1: 应用 4D
预计用时:5 分钟
选择以下一个协作场景,并思考您将如何应用 4D 框架:
沟通项目
您正在与一个 AI 助手合作,为营销活动起草一系列电子邮件。
- Delegation (委托): 这个项目的哪些方面您会自己处理,哪些会与 AI 协作?
- Description (描述): 您将如何向 AI 传达您对活动基调、目的和成功标准的设想?
- Discernment (辨别): 什么标准能帮助您评估 AI 起草的邮件是否满足您的需求?
- Diligence (勤勉): 在透明度和责任方面,哪些考虑是重要的?
研究项目
您正在使用 AI 帮助分析一篇研究论文的大型数据集。
- Delegation (委托): 您将如何在自己和 AI 之间分配分析工作?
- Description (描述): AI 需要了解哪些关于您研究问题的背景信息,才能很好地完成其任务?
- Discernment (辨别): 您将如何验证 AI 分析的准确性?
- D diligence (勤勉): 发表 AI 辅助的研究时,可能会出现哪些伦理问题?
创意项目
您正在与 AI 合作,为一个故事开发角色概念。
- Delegation (委托): 您希望通过 AI 协作探索哪些创意元素,哪些希望独立发展?
- Description (描述): 您会如何引导 AI 生成符合您故事世界的角色?
- Discernment (辨别): 您将如何决定保留、修改或丢弃 AI 建议的哪些元素?
- Diligence (勤勉): 您将如何承认 AI 对您创意工作的贡献?
练习 2: 探索您热爱的事物
预计用时:5-10 分钟
花 5-10 分钟与 Claude 聊一个您充满热情且非常了解的话题。我们将在本课程的其余练习中使用 Claude,但您也可以用其他 AI 完成这些练习。事实上,您不妨尝试在多个 AI 助手中完成本课程的练习,以感受它们的不同之处。
说明:
- 选择一个您非常了解并喜欢讨论的话题,比如一个爱好、专业兴趣、喜欢的系列书籍等。
- 与 Claude 就这个话题进行自然对话,就像与有共同兴趣的人聊天一样。
- 尝试注意以下时刻:
- Claude 增强了您的思维
- 您需要澄清或纠正 Claude 的理解
- 您的专业知识引导您评估 Claude 的回应
练习 3: 学习新知识
预计用时:5-10 分钟
花 5-10 分钟请 Claude 教您一个您不熟悉但有兴趣探索的话题。看看这次经历与您谈论热爱且熟悉的事物有何不同。
说明:
- 选择一个您想了解更多的话题。
- 与 Claude 进行对话,帮助您理解这个话题的基础知识。不要担心提示的方式是“错误”还是“正确”,就请 Claude 教您。
- 尝试注意以下时刻:
- Claude 提供了有帮助的解释
- 提供了使抽象概念具体化的例子
- 自然地回应您提出的问题
- 解释了您想要仔细核实其解释的地方
反思
在继续之前,请花点时间思考:
- 在 4D (Delegation, Description, Discernment, Diligence) 中,您对哪一个已经最有信心?哪一个可能需要更多发展?
- 您能回想起最近一次 AI 互动中,这个框架可能会有所帮助的例子吗?
- 4D 框架中的哪些具体技能最能增强您的工作或个人项目?
下一步
下一课,深度解析 1:“什么是生成式 AI?” 是一个分为两部分的技术课程,解释了现代 AI 的基本工作原理,它与以前技术的不同之处,以及其当前的能力和局限性。这些知识将为 4D 提供宝贵的背景,尤其能加强您的 Delegation (委托) 能力。
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。
部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
生成式 AI 基础
您将学到什么
在本课程结束时,您将能够:
- 定义 generative AI (生成式人工智能) 及其与其他 AI 类型的区别
- 认识到生成式 AI 的关键特征和技术基础
生成式 AI 基础
(6 分钟)
本视频介绍了 generative AI (生成式人工智能) 的概念,重点是其创造新内容的能力,而不仅仅是分析已存在的内容。我们详细介绍了像 Claude 这样的 large language models (LLMs, 大型语言模型) 的实际工作原理,以及使其成为可能的技术历程,从像 transformer architecture (Transformer架构) 这样的算法突破到海量的训练数据集和强大的计算能力。我们还解释了这些系统如何通过 pre-training (预训练) 和 fine-tuning (微调) 进行学习,并讨论了像 context windows (上下文窗口) 和 emergent capabilities (涌现能力) 这样的概念。
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
能力与局限
您将学到什么
在本课程结束时,您将能够:
- 识别当前生成式 AI 的主要能力和局限性
能力与局限
(7 分钟)
本视频探讨了目前生成式 AI 能做什么和不能有效做什么。我们强调了生成式 AI 在语言任务上的多功能性、保持对话流程的能力以及在没有额外训练的情况下切换不同任务的能力。我们还讨论了其局限性,包括知识截止日期、hallucinations (幻觉,即事实不正确的输出)、上下文窗口限制和推理挑战。我们强调该领域正在迅速发展,并解释说,最有效的应用是将人类和 AI 的互补优势结合在一起。
关键要点
- 生成式 AI 创造新内容 (文本、图像、代码),而不仅仅是分析现有数据
- 像 LLMs 这样的现代系统之所以成为可能,得益于三个关键发展:
- 算法和架构的突破 (特别是 Transformer 架构)
- 海量的数字训练数据
- 计算能力的急剧增加
- 生成式 AI 通过两个阶段学习:预训练 (分析数十亿个示例中的模式) 和微调 (学习遵循指令并提供有用的回应)
- 当前的能力包括跨任务的多功能性、对话感知能力以及与外部工具连接的能力
- 当前的局限性包括知识截止日期、可能产生幻觉、上下文窗口限制以及复杂推理方面的挑战
- 最有效的应用结合了人类和 AI 的优势,人类提供批判性思维、判断力、创造力和道德监督
练习
反思
在继续之前,请花点时间思考:
- 了解生成式 AI 的技术基础 (如训练数据和预训练/微调) 如何改变您对与这些系统合作的看法?
- 在了解了这些系统的工作原理及其当前局限性之后,您想到了哪些伦理问题?
下一步
在下一课中,我们将更深入地了解 4D 能力中的第一个:Delegation (委托)。您将学习如何根据对目标和 AI 能力的理解,做出关于在自己和 AI 之间分配工作的战略决策。这个基础将帮助您深思熟虑地决定何时以及如何将 AI 引入您的创意和解决问题的过程中。
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
深入了解 Delegation (委托)
您将学到什么
在本课程结束时,您将能够:
- 理解 Delegation (委托) 能力及其三个组成部分:Problem Awareness (问题感知)、Platform Awareness (平台感知) 和 Task Delegation (任务委托)
- 认识到何时以及如何有效地将任务委托给 AI
- 在与 AI 合作时,培养对任务、平台和模式的意识
深入了解 Delegation (委托)
(6 分钟)
本视频探讨了 AI Fluency 的第一个核心能力:Delegation (委托)。我们解释说,Delegation (委托) 专注于决定哪些工作自己做,哪些与 AI 合作,以及如何有效地分配任务。我们介绍了 Delegation (委托) 的三个关键组成部分:
- Problem Awareness (问题感知): 在开始之前,理解您的目标和实现它所涉及的工作
- Platform Awareness (平台感知): 了解不同 AI 系统的能力
- Task Delegation (任务委托): 战略性地在您和 AI 之间分配工作
我们还强调了为什么有效的 Delegation (委托) 需要您所在领域的专业知识和对 AI 能力的理解——以及为什么这对于与 AI 系统有效、高效地合作至关重要。
关键要点
- Delegation (委托) 是关于深思熟虑地决定哪些工作由自己完成,哪些与 AI 共同完成,或者让 AI 独立处理,以及如何分配这些任务。
- Problem Awareness (问题感知) 意味着在引入 AI 之前,清晰地理解您的目标和工作的性质。
- Platform Awareness (平台感知) 涉及了解不同 AI 系统的能力和局限性。
- Task Delegation (任务委托) 是在人与 AI 之间深思熟虑地分配工作以利用各自优势的过程。
- 有效的委托需要领域专业知识和对 AI 能力的理解。
- 目标不是自动化一切,而是为任何给定的任务或目标创建最有效的人机合作关系。
练习
与 AI 助手一起分析任务
说明:
- 从您的工作或个人生活中挑选一个简单的任务 (比如起草一封邮件、规划一个演示文稿、或者计划一次会议或活动)。
- 与 Claude 开始对话。
- 与 Claude 分享您正在考虑做的任务。
- 例如:“嗨,Claude,我正在准备如何 [插入任务],想和你讨论一下,制定一个委托计划,弄清楚哪些部分我应该委托给像你这样的 AI,哪些不应该。你能帮我吗?”
- 一起探讨以下问题:
- 任务的总体愿景是什么?一个好的结果是什么样的?
- 要达到这个目标,需要哪些不同的工作?
- 这些工作中哪些需要人类的专业知识、创造力或判断力?
- 注意: 在讨论这些问题时,进行一次真正的对话!不要只是陈述或列出答案。真正地来回交流——你们各自都可能看到对方没有看到的东西!
- 共同创建一个简单的委托计划,利用你们双方和 AI 的优势。
反思
在继续之前,请花点时间思考:
- 回想一个最近你与 AI 合作的项目。如果当时有这个 Delegation (委托) 框架,你的方法可能会有什么不同?
- 你认为在你的工作或学习中,哪类任务最能从 AI 协作中受益?
下一步
在下一课中,您将把学到的关于 Delegation (委托) 的知识应用到一个多步骤项目中,这个项目将在本课程的剩余部分贯穿始终。您将选择一个您感兴趣的项目,明确其愿景,将其分解为任务,并创建一个战略性地在您和 AI 之间分配工作的委托计划 (就像您在本课中练习的那样)。这个项目将成为您在课程进展中应用所有 AI Fluency 能力的实践画布。
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
项目规划与委托
您将学到什么
在本课程结束时,您将能够:
- 将您对 Delegation (委托) 的理解应用到一个贯穿本课程剩余部分的实际多步骤项目中
项目规划与委托
预计用时:20 分钟
第一步:选择您的项目
选择一个中等规模、多步骤的项目,您可以在本课程的剩余时间里持续进行。您的项目应具备以下特点:
- 足够充实,包含多种类型的任务
- 易于管理,能在大约 1 小时的工作时间内完成
- 是您真正感兴趣于创建或完成的事情
以下是一些建议,供您参考:
沟通项目:
- 就您熟悉的某个主题,制作一个引人入胜的演示文稿
- 写一篇或一系列文章,向普通大众解释一个复杂的主题
- 为您想追求的一个想法,制定一份提案或推介
- 创建一份个人或专业简介及配套材料
研究项目:
- 研究并总结某项新兴技术或趋势的现状
- 分析一个数据集,以识别模式并提出建议
- 比较多种产品、服务或方法,并提出建议
- 调查一个历史事件,并以引人入胜的方式呈现您的发现
创意项目:
- 构思一个短篇故事,包含丰满的角色和情节
- 设计一个简单的网站结构,并为关键页面准备内容
- 为一个产品、服务或体验,开发一个概念
学习项目:
- 为您想培养的一项技能,创建一个结构化的学习计划
- 围绕您正在学习的一个主题,建立一个资源集合
- 为您熟悉的一个流程,制作一份教程或指南
- 为您想掌握的一个主题,创建一套学习资料
第二步:项目愿景与目标
与 Claude 开始对话。分享您的项目想法,并邀请 Claude 向您提问,直到您感觉对最终结果有了清晰的愿景。共同努力,直到您对以下内容有了清晰的画面:
- 您的项目成功的样子
- 是什么让这个项目对您特别有价值或有意义
第三步:任务分解与委托分析
与您在上一课中所做的类似,通过 Delegation (委托) 的视角与 Claude 一起探索您的项目:
- 共同确定完成项目所需的主要任务。
- 对每个任务,逐一讨论:
- 需要哪些具体的技能、知识或 AI 能力?
- 哪些部分会从独特的人类优势中受益?
- 哪些部分可以很好地利用 AI 的能力?
- 在哪里协作可能会产生最大的影响?
- 注意: 同样,就这些问题进行真诚的对话,而不仅仅是交换陈述。挑战假设,请求澄清,并对讨论中出现的意外见解保持开放。
- 创建一个包含您主要任务和委托决策的项目计划。
- 保存您的项目计划——您将在本课程的后面部分回到这个项目,以练习您的 Description (描述)、Discernment (辨别) 和 Diligence (勤勉) 技能。
反思
在继续之前,请花点时间思考:
- 在您与 Claude 的规划对话中,出现了哪些见解?
- 您预计您的委托计划中最具挑战性的方面会是什么?
- 还有哪些额外的信息或技能可能帮助您更有效地委托给 AI?
下一步
在下一课中,我们将探讨第二个核心能力:Description (描述)。您将学习与 AI 系统有效沟通的方法,这将帮助您执行刚刚创建的计划。这包括定义您想要什么、指导 AI 如何处理任务以及指定您希望 AI 在整个过程中如何与您互动的技巧。
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
深入了解 Description (描述)
您将学到什么
在本课程结束时,您将能够:
- 理解如何有效地向 AI 系统传达您的意图
- 认识到清晰、有目的的沟通的重要性
- 培养三种 Description (描述) 类型的技能:Product (产品)、Process (过程) 和 Performance (性能)
深入了解 Description (描述)
(4 分钟)
本视频探讨了 AI Fluency 的 Description (描述) 能力——与 AI 系统有效沟通的艺术。我们解释说,Description (描述) 不仅仅是编写提示;它涉及到创建一个协作环境,让您和 AI 都能有效地协同工作。我们介绍了 Description (描述) 的三个关键组成部分:
- Product Description (产品描述): 清晰地定义您希望 AI 创建什么
- Process Description (过程描述): 指导 AI 如何处理您的请求
- Performance Description (性能描述): 定义您希望 AI 在协作过程中的行为方式。
我们还强调,AI 无法读懂您的心思,您的结果质量往往取决于您如何清晰地阐明您的需求、偏好的方法和期望的互动风格。
关键要点
- Description (描述) 是指以创造高效协作环境的方式与 AI 沟通
- Product Description (产品描述) 涉及清晰地定义您在输出、格式、受众和风格方面的要求
- Process Description (过程描述) 指导 AI 如何处理您的请求,这与指定最终目标同样重要
- Performance Description (性能描述) 定义了行为方面,比如 AI 应该是简洁还是详细,是挑战性的还是支持性的
- AI 系统是互动伙伴,而不是数据库或自动售货机
- 前期清晰的沟通可以节省时间并带来更好的结果
练习
糟糕提示大改造
预计用时:10 分钟
说明:
- 请 Claude 向您挑战一些写得不好的提示,让您来改进。
- 运用您的 Description (描述) 思维来改进每一个提示,考虑:
- 清晰的 Product Description (产品描述) (您具体想要什么)
- Process (过程) 指导 (您希望 Claude 如何处理它)
- Performance (性能) 规格 (您希望 Claude 在协作期间如何表现)
- 与 Claude 讨论“改造前”和“改造后”的版本,并就您改进后的描述如何帮助它提供更好的回应征求反馈。
- 大约 5 分钟后,交换角色,由您提供糟糕的提示让 Claude 来修正。注意 Claude 倾向于添加哪些信息,以及它如何组织这些信息。
反思
在继续之前,请花点时间思考:
- 您认为在当前的 AI 互动中,您可能忽略了 Description (描述) 的哪个组成部分 (product, process, or performance)?
- 回想一下最近一次不尽如人意的 AI 互动。更好的描述技巧可能会如何改善结果?
下一步
在下一课中,我们将更深入地探讨 4D 能力中的第一个:Delegation (委托)。您将学习如何根据对目标和 AI 能力的理解,做出关于在自己和 AI 之间分配工作的战略决策。这个基础将帮助您深思熟虑地决定何时以及如何将 AI 引入您的创意和解决问题的过程中。
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
高效的提示技巧
您将学到什么
在本课程结束时,您将能够:
- 理解什么是 prompt engineering (提示工程) 及其对高效 AI 协作的重要性
- 应用六种基础提示技巧来改善您的 AI 互动
- 识别导致成功 AI 互动的常见模式
- 在 AI 响应不符合您的需求时,进行故障排除和优化提示
高效的提示技巧
本视频探讨了与像 Claude 这样的 AI 助手合作时,制作有效提示的实用技巧。我们解释说,prompt engineering (提示工程) 只是为 AI 系统设计有效指令的实践,它将熟悉的人类沟通原则与 AI 特有的考虑因素相结合。我们介绍了六种基础技巧:提供背景、展示期望输出的示例、指定约束、将复杂任务分解为步骤、要求 AI 先思考,以及定义 AI 的角色或语气。我们还分享了当响应不完全正确时的故障排除策略,并强调了导致成功互动的常见模式。
关键要点
- 有效的提示结合了清晰的沟通原则和 AI 特有的技巧
- 六种基础提示技巧:
- 提供背景: 具体说明你想要什么,为什么想要,以及相关的背景信息
- 展示示例: 演示你想要的输出风格或格式
- 指定约束: 清晰定义格式、长度和其他输出要求
- 将复杂任务分解为步骤: 引导 AI 完成多步推理
- 要求 AI 先思考: 给 AI 留出空间来处理其过程
- 定义 AI 的角色或语气: 指定你希望 AI 如何沟通
- “秘密武器”:请 AI 本身帮助改进你的提示
- 成功的提示是迭代的(也可能需要与 AI 协作!)。期望根据结果不断优化你的方法
- 常见的成功模式包括提供清晰的任务概述、格式规范、明确的约束和相关的背景信息
练习
反思
在继续之前,请花点时间思考:
- 您认为六种提示技巧中的哪一种最能增强您当前的 AI 互动?
- 想一想最近一次不符合您需求的 AI 互动。哪些技巧可能会改善结果?
- 理解这些提示技巧与 AI Fluency 框架中的 Description (描述) 能力有何联系?
如果您愿意,可以重温上一课的“糟糕提示大改造”练习,来实践这些提示原则。
下一步
在下一课中,我们将探讨第三个核心 AI Fluency 能力:Discernment (辨别)。这次的深度解析和前一课都侧重于如何有效地与 AI 沟通以及如何实践良好的 Description (描述)。Discernment (辨别) 则解决了同样重要的挑战:深思熟虑地评估 AI 的响应产出——这是对话的另一半!
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
深入了解 Discernment (辨别)
您将学到什么
在本课程结束时,您将能够:
- 理解如何深思熟虑地评估 AI 的输出和过程
- 为您的 AI 互动培养批判性思维技能
- 学会在您的 AI 互动中识别和解决质量问题
深入了解 Discernment (辨别)
(5 分钟)
本视频探讨了 Discernment (辨别),这是 AI Fluency 中专注于深思熟虑地评估 AI 输出、过程和行为的能力。我们解释说,Discernment (辨别) 是 Description (描述) 的另一面。Description (描述) 帮助您清晰地传达您的意图,而 Discernment (辨别) 则帮助您评估收到的内容是否满足您的需求。视频介绍了三种类型的 Discernment (辨别):
- Product Discernment (产品辨别): 评估 AI 输出的质量
- Process Discernment (过程辨别): 评估 AI 完成任务的方法
- Performance Discernment (性能辨别): 评估 AI 在互动过程中的行为
这些技能共同帮助确保您的 AI 协作始终以深思熟虑的人类判断为指导。
关键要点
- Discernment (辨别) 是你审慎评估 AI 产出什么、如何产出以及其行为方式的能力
- Product Discernment (产品辨别) 侧重于评估实际输出的质量(准确性、适当性、连贯性、相关性)
- Process Discernment (过程辨别) 涉及评估 AI 是如何得出其输出的,寻找逻辑错误、注意力差距或不当的推理
- Performance Discernment (性能辨别) 评估 AI 在协作过程中的行为,考虑其沟通风格对你的需求是否有效
- Discernment (辨别) 与 Description (描述) 在一个持续的反馈循环中携手并进
- 即使是最先进的 AI 系统也受益于人类的判断和监督
练习
专家辨别:在您的领域评估 AI 响应
活动目标
通过在您拥有专业知识的领域评估 AI 生成的内容,练习 Product (产品)、Process (过程) 和 Performance (性能) 的辨别能力,认识到您的知识如何增强您批判性评估 AI 输出的能力。
说明
第一步:回到您的专业领域
回想您在早期练习中与 Claude 讨论过的话题(第二课,练习二:“探索您热爱的事物”)。那是一个您有深厚知识和热情的话题。
第二步:请求多种解释
与 Claude 开始新的对话,并要求它就您专业领域的某个特定方面生成三种不同的解释或分析。例如:
- 如果您的话题是摄影,您可以要求对景深进行三种不同的解释
- 如果您的话题是烹饪,您可以要求对发酵技术进行三种不同的分析
- 如果您的话题是历史,您可以要求对某个特定历史事件提供三种不同的视角
第三步:运用您的专家辨别能力
凭借您的专业知识,仔细评估 Claude 提供的每一种解释:
Product Discernment (产品辨别):
- 哪种解释包含最准确的信息?
- 是否有任何事实错误或误解?
- 对于学习该主题的人来说,细节的层次是否恰当?
Process Discernment (过程辨别):
- Claude 在每种解释中是否遵循逻辑推理?
- 它的分析或思维过程中是否存在漏洞?
- Claude 是否在概念之间建立了恰当的联系?
Performance Discernment (性能辨别):
- Claude 是否关注了您的具体问题并对反馈和指导做出了响应?
- 术语的使用是否适合该主题?
- 语气和风格如何影响解释的清晰度?
第四步:提供反馈和优化
根据您的评估:
- 确定最强的解释,并具体告诉 Claude 它有效的原因
- 确定最弱的解释,并就其问题所在提供具体反馈
- 与 Claude 合作,创建一个解决您所发现问题的改进版本
第五步:反思
与 Claude (在同一次聊天中) 讨论:
- 您拥有的哪些具体知识使您能够识别优点或缺点?
- 没有您专业知识的人在辨别这些解释的质量时可能会遇到什么困难?
- 这次经历告诉您,领域知识和有效的 Discernment (辨别) 之间有什么关系?
想要进行更有趣的 Discernment (辨别) 练习,您不妨尝试最后一课(“附加活动”)中的一些“游戏之夜”建议。
反思
在继续之前,请花点时间思考:
- 您觉得哪种 Discernment (辨别) (产品、过程或性能) 最难应用,为什么?
- Discernment (辨别) 如何补充 Description (描述)?它们是如何协同工作的?
- 哪些信号或模式可能表明 AI 的输出需要更仔细的审查?
下一步
在下一课中,您将有机会将 Description (描述) 和 Discernment (辨别) 的技能应用到您的整个课程项目中。您将实践所学的关于如何有效地与 AI 沟通以及如何批判性地评估其输出,以产生能够充分利用人类和 AI 能力的成果。
反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license.
本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
Description-Discernment (描述-辨别) 循环
预计用时:30 - 60 分钟
在本课程结束时,您将能够:
- 将 Description (描述) 和 Discernment (辨别) 技能应用于实际项目
- 进行富有成效的 Description-Discernment (描述-辨别) 反馈循环
- 通过人机协作创造出超越任何一方单独所能达到的成果
练习
练习:使用 Description-Discernment (描述-辨别) 循环执行项目
现在是时候将您学到的一切付诸实践,利用您一直在培养的 Description (描述) 和 Discernment (辨别) 技能,来完成您在第五课中计划的项目。
第一步:回顾您的项目计划
- 找出您在第五课中创建的项目计划
- 快速回顾您关于哪些任务将受益于人类专业知识、AI 能力或协作的委托决策
- 随时根据您此后学到的知识来完善您的计划
第二步:准备您的描述方法
与 Claude 开始对话,并解释您们将要共同完成的项目。在开始执行之前,规划您将如何运用 Description (描述):
- Product Description (产品描述): 您需要 Claude 为每个任务提供哪些具体输出?您期望的格式、风格、长度和细节水平是什么?
- Process Description (过程描述): Claude 应该如何处理每个任务?您希望它遵循哪些特定的方法、框架或步骤?
- Performance Description (性能描述): 在这个项目中,您希望 Claude 表现出什么样的协作行为?它应该是简洁还是详细,是挑战性的还是支持性的,是专注于想法还是分析?
与 Claude 讨论这些问题,为你们的协作建立清晰的期望。
第三步:使用 Description-Discernment (描述-辨-别) 循环执行您的项目
现在,与 Claude 一起完成您计划的项目任务。对于每个任务:
- 清晰地描述您的需求,使用您学到的 Description (描述) 技能:
- 具体说明您想要什么 (Product (产品))
- 指导 Claude 应该如何处理或思考任务 (Process (过程))
- 指定您希望 Claude 在过程中如何与您互动 (Performance (性能))
- 辨别您收到的内容质量:
- 评估输出本身 (Product Discernment (产品辨别))
- 评估 Claude 是如何完成任务的 (Process Discernment (过程辨别))
- 考虑 Claude 的行为是否最有助于您所需 (Performance Discernment (性能辨别))
- 根据您的辨别进行优化:
- 对有效和无效之处提供反馈
- 根据需要澄清或调整您的描述
- 请求迭代,直到您对结果满意为止
- 融入您自己的专业知识和判断:
- 添加您独特的视角、创造力或领域知识
- 做出关于保留、修改或丢弃哪些内容的最终决定
- 对最终输出负责
对项目中的每个任务持续进行这个 Description-Discernment (描述-辨别) 循环,直到完成。
反思
在继续之前,请花点时间思考:
- 您注意到了哪些类型的描述能带来最佳结果的模式?
- 对您来说,哪个需要更多努力:Description (描述) 还是 Discernment (辨别)?您认为原因是什么?
- 您实际的项目执行与您在第五课的初步计划相比如何?您在此过程中做了哪些调整?
下一步
在下一课中,我们将探讨 AI Fluency 框架中的最后一个能力:Diligence (勤勉)。虽然 Delegation (委托)、Description (描述) 和 Discernment (辨别) 主要关注有效性和效率,但 Diligence (勤勉) 则涉及与 AI 合作的伦理和安全方面。您将学习如何确保您的 AI 协作是负责任、透明和可问责的。
对本课程的反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。
在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license. 本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
深入了解 Diligence (勤勉)
预计用时:20 分钟
在本课程结束时,您将能够:
- 理解 AI 协作的伦理含义
- 理解 AI 工作中透明度的重要性
- 认识到您在 AI 互动和输出中的责任
视频:深入了解 Diligence (勤勉)
(7 分钟)
本视频探讨了 Diligence (勤勉),这是 AI Fluency 中专注于负责任和合乎道德的 AI 协作的能力。我们解释说,虽然其他能力主要关注有效性和效率,但 Diligence (勤勉) 则处理同样至关重要的伦理和安全方面。我们介绍了三个组成部分:
- Creation Diligence (创建勤勉): 审慎地选择您使用的 AI 系统以及您如何与它们合作
- Transparency Diligence (透明度勤勉): 在您的工作中坦诚 AI 的角色
- Deployment Diligence (部署勤勉): 为您与他人分享的 AI 辅助输出承担责任
我们强调,不同的情境可能有不同的期望,但我们每个人都有责任去理解和满足这些期望。
关键要点
- Diligence (勤勉) 意味着为我们的 AI 协作承担责任
- Creation Diligence (创建勤勉) 涉及深思熟虑地选择我们使用的 AI 系统以及我们如何与它们互动
- Transparency Diligence (透明度勤勉) 意味着对所有需要了解的人诚实地说明 AI 在我们工作中的作用
- Deployment Diligence (部署勤勉) 要求我们为验证和担保我们使用或分享的输出承担责任
- 不同的情境(个人、学术、专业)可能对披露和验证有不同的期望
- 深思熟虑的 Diligence (勤勉) 有助于确保我们的 AI 协作不仅有效和高效,而且合乎道德和安全
练习
练习:创建一份勤勉声明
预计用时:14 分钟
在这个练习中,您将为您一直从事的项目起草一份勤勉声明。这是本课程本身的勤勉声明。
第一步:理解勤勉声明
预计用_时:3 分钟_
勤勉声明是对您工作中 AI 角色的透明承认,以及您对最终输出负责的承诺。以下是一个示例:
“在创建这份 [文件/项目/内容] 的过程中,我与 [AI 助手名称] 合作,协助完成了 [具体任务:起草、研究、编辑等]。我确认,所有 AI 生成和共同创建的内容都经过了彻底的审查和评估。最终的输出准确地反映了我的理解、专业知识和意图。虽然 AI 的协助在过程中起到了重要作用,但我对内容、其准确性和呈现方式负全部责任。此披露本着透明的精神,并承认 AI 在创作过程中的作用。”
第二步:反思您的 AI 协作
预计用时:5 分钟
回顾您在课程项目上的工作,并考虑:
Creation Diligence (创建勤勉):
- 您选择与哪些 AI 系统合作,为什么?
- 您与 AI 分享了哪些数据或信息?
- 在您的选择中,是否有任何隐私、安全或伦理方面的考虑?
Transparency Diligence (透明度勤勉):
- 您的项目输出的受众是谁?
- 他们对 AI 披露可能有何期望?
- AI 具体在您工作的哪些方面做出了贡献?
Deployment Diligence (部署勤勉):
- 您采取了哪些步骤来验证 AI 贡献的准确性和适当性?
- 您如何确保最终输出符合您的标准和要求?
- 您对最终产品承担什么责任?
第三步:起草您的勤勉声明
预计用时:6 分钟
与 Claude 开启一段对话,然后:
- 分享您在第二步中的反思,也可以选择性分享您过去与 Claude 就此项目进行的对话
- 与 Claude 协作,为您的项目起草一份具体的勤勉声明
- 确保您的声明涵盖:
- 您使用了哪些 AI 系统
- AI 如何为您的项目做出贡献
- 您采用的审查流程
- 您对最终输出承担责任的声明
- 任何特定情境的考虑因素(学术、专业等)
第四步:将您的声明添加到您的项目中
当您完成项目时,将您的勤勉声明添加到适当的位置(例如,页脚、附录或元数据中)。
反思
在继续之前,请花点时间思考:
- 您觉得 Diligence (勤勉) 的哪个方面(创建、透明度或部署)最具挑战性,为什么?
- 您处理 Diligence (勤勉) 的方法会如何根据情境(个人、学术、专业)而变化?
- 承认 AI 在您工作中的角色会如何影响他人对它的看法?
- 在您的项目中出现了哪些您未曾预料到的伦理问题?
- 您可能会为负责任的 AI 协作制定哪些个人准则?
下一步
在本课程的最后一课中,我们将反思我们学到的关于 AI Fluency 的知识,以及这些能力如何协同工作。我们将重新审视整个框架,并讨论随着 AI 能力的发展,您如何继续发展这些技能。结论将帮助您综合所获得的知识和实践,并将其应用于未来的 AI 协作。
对本课程的反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license.
本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
结论
预计用时:15 分钟
在本课程结束时,您将能够:
- 巩固课程的关键学习内容
- 将 AI Fluency 与您的持续发展联系起来
视频:结论
(6 分钟)
这个总结视频回顾了 AI Fluency 框架,并将整个课程中探讨的关键概念整合在一起。我们重述了四个核心能力(4D):Delegation (委托)(决定哪些工作与 AI 合作,哪些独立完成)、Description (描述)(与 AI 有效沟通)、Discernment (辨别)(评估 AI 的输出和行为)以及 Diligence (勤勉)(确保负责任的 AI 协作)。我们强调,这些能力适用于与 AI 互动的所有三种主要方式(Automation (自动化)、Augmentation (增强) 和 Agency (代理)),并且流畅度是通过实践发展的,而非一蹴而就。我们最后提醒大家,AI 系统功能强大但并非神奇的解决方案;它们的用处和安全性取决于我们如何通过深思熟虑的参与来启用它们。
关键要点
- AI Fluency 是通过有意识地练习四个核心能力来发展的
- Delegation (委托) 强调我们的专业知识和判断力仍然是有效 AI 协作的基础
- Description (描述) 涉及清晰的沟通,以连接我们的意图和 AI 的能力
- Discernment (辨别) 需要对输出进行深思熟虑和批判性的评估,以便在系统约束内工作
- Diligence (勤勉) 确保我们 AI 工作中的问责制、透明度和责任感
- 当人类和 AI 互相取长补短时,最强大的成果才会出现
- 该框架旨在随着 AI 系统的不断发展而保持其相关性
练习
练习:与 Claude 讨论 AI Fluency 课程
与 Claude 就本课程和 AI Fluency 框架进行一次有意义的对话(可从 https://ringling.libguides.com/ai/framework 上传一份框架副本)
建议的对话开场白:
- “我刚刚完成了一门关于 AI Fluency 的课程,涵盖了 Delegation (委托)、Description (描述)、Discernment (辨别) 和 Diligence (勤勉)。我们来讨论一下这些能力如何应用于 [我的学位课程或我的工作或其他]。”
- “我们来探讨一下随着 AI 能力的进步,AI Fluency 框架可能会如何演变。未来哪些新的能力可能会变得重要?”(如果您这样做,请联系我们,告诉我们您的发现!)
- “根据我们的对话,帮我确定一下我似乎已经很好理解了 4D 能力中的哪些,以及我可能需要进一步发展的哪些。”
- “这是 [你在这门课上做的某个练习]。我们来分析一下,以提高我的能力。”
练习:制定个人 AI 政策
在 Claude 的帮助下,为您在个人和专业情境中负责任且合乎道德的 AI 协作创建您自己的指导方针:
- 为您在不同情境下何时以及如何与 AI 合作制定明确的标准
- 为敏感或机密信息设定界限
- 明确您将如何对 AI 辅助的工作进行质量控制
- 确定与您的领域或活动最相关的伦理问题
- 制定解决伦理困境的决策标准
- 考虑可能受到您 AI 互动影响的不同人的观点
- 确定您将如何在不同情境下披露 AI 协作
- 创建署名和透明度声明的模板
- 建立何时需要更详细披露的标准
在这个过程中,将 Claude 作为思考伙伴,从多个角度探讨伦理问题。
反思
以上练习是本课的反思部分。通过这些练习,您将有机会巩固您的学习成果,并将其与您的持续发展联系起来。
下一步
恭喜您完成 AI Fluency: 框架与基础课程!这只是您 AI Fluency 旅程的开始。随着 AI 技术的不断发展,您在 Delegation (委托)、Description (描述)、Discernment (辨别) 和 Diligence (勤勉) 方面培养的能力,将为您与这些系统的工作提供一个持久的指导框架。
请记住,流畅度是通过实践发展的。与 AI 的每一次互动都是完善您的技能和加深理解的机会。通过将 AI 视为一个思考伙伴而不仅仅是一个工具,并坚持对有效性、效率、道德和安全的承诺,您已为驾驭人机协作的未来做好了充分准备。
我们鼓励您继续探索、实验和反思您的 AI 互动。第 12 课中有许多很好的附加练习,可以继续您的旅程。
我们鼓励您与他人(以及我们!)分享您所学到的知识,寻求不同的观点,并为我们如何以能够增强人类潜力,同时尊重我们的价值观和对彼此的责任的方式与 AI 合作这一持续的对话做出贡献。感谢您在本课程中的参与和投入!
对本课程的反馈
在您学习本课程的过程中,我们很乐意听取您关于如何在生活、工作或课堂中使用课程概念的意见以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license.
本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
结业证书
[无内容]
附加活动
预计用时:自定进度
以下活动专为在完成 AI Fluency: 框架与基础课程后进行自主学习而设计。
选择那些与您的兴趣和需求产生共鸣的活动——或者将它们作为灵感,创造您自己的活动!
制定个人 AI Fluency 计划
在 AI 助手的帮助下,创建一个结构化的计划,随着时间的推移发展您的 AI Fluency:
当前能力评估
- 对于 4D 中的每一个能力,评估您目前的熟练程度(新手、发展中、自信)
- 记录每个能力中的具体优势和需要成长的领域
- 确定您目前最常使用和最不有效地使用哪种 AI 互动方式(Automation (自动化)、Augmentation (增强)、Agency (代理))
发展重点识别
- 选择 1-2 个能力作为首要发展重点
- 确定这些能力中在您的情境下最有价值的具体方面
- 考虑您希望在哪种 AI 互动方式上变得更加熟练
具体行动规划
- 创建具体的活动来发展每个重点能力
- 设定练习的时间表和频率
- 确定支持您发展的资源和工具
- 定义您将如何识别进展和成功
在这个过程中,将 Claude 作为思考伙伴,分享您的自我评估,并就您的计划获得反馈。
建立个人提示与模式库
在 Claude 的帮助下,为您经常进行的 AI 互动创建一个个性化的有效提示和模式集合:
常见任务模板创建
- 确定您经常使用 AI 执行的 5-10 个任务
- 为每个任务开发一个能持续产生良好结果的模板提示
- 包括您每次需要添加的可变信息的占位符或注释
有效策略文档化
- 记录对不同类型任务有效的具体 Description (描述) 技巧
- 记录能帮助您更有效地评估输出的 Discernment (辨别) 模式
- 注意哪些方法对不同的互动模式最有效
个人参考资源构建
- 以易于搜索和访问的方式组织您的模板和策略
- 包括成功输出的示例以供参考
- 创建一个系统,以便在发现新的有效方法时更新您的库
您可以与 Claude 合作,分析您过去成功的互动,并识别使它们有效的模式。
游戏之夜!
这些为您和 Claude 设计的有趣练习,通过文字谜题帮助您练习精确的 Description (描述) 并磨练您的 Discernment (辨别) 技能。由于谜题有具体的说明(不像“起草一封感谢信”这样的开放式任务),它们是练习清晰沟通的绝佳方式。而且因为它们故意设置得有些棘手,所以它们是很好的 Discernment (辨别) 锻炼!仅仅通过玩几个游戏,您就可以学到很多关于仔细评估和引导 AI 思维过程的知识。尝试以下任何或所有游戏。
交换谜语
创建一个谜语(或者试试这个:“一百零几个鼓点,我敲击着,描绘出一曲光的交响乐。我在做什么?”)。
(答案:我正在电脑键盘上打字(通常是 104 个键),以在显示器上创建像素。)
让 Claude 猜测,并且,重要的是,解释它的推理。
不仅要注意 Claude 猜了什么,还要注意它为什么这么猜。
然后不要给它答案,而是温和地引导 Claude 走向正确的思维链和情境,以得出答案。
然后交换角色,让它给您出一个谜语。让 Claude 像您刚才那样引导您。
合作填字游戏
一起解决填字游戏的线索(神秘填字游戏的线索可能特别有趣)。
重点不在于您或 Claude 在填字游戏方面的表现如何。而在于学习如何引导和完善思维:“记住,它只有 5 个字母”“不,不可能是那个,因为它以 B 开头”“也许他们说的‘swallow’不是喝的意思,而是燕子这种鸟。”
这些引导技巧在“真实”项目中将被证明出奇地有用。
词语联想
与 Claude(或您选择的模型)玩词语联想游戏非常令人满意且富有启发性。网上有很多免费的游戏,搜一下就行了!
即使只是挑选 12 - 20 个随机词语,与 Claude 合作寻找它们之间的关系,也是很好的 Discernment (辨别) 练习。当您注意到 Claude 建立了可疑的联系或忽略了有希望的模式时,指出来并引导它进行更好的推理。同样,也要对 Claude 发现您可能错过的联系持开放态度!
在协作过程中,练习所有三种类型的 Discernment (辨别):
- Product Discernment (产品辨别): 答案是否合乎逻辑,并且真正符合一个连贯的主题?
- Process Discernment (过程辨别): Claude 是如何解决这个谜题的?它是否考虑了多种可能性?它是否过于狭隘地关注某一种解释?
- Performance Discernment (性能辨别): Claude 是如何传达其思考过程的?是否清晰?它是否提出了好的问题?它是否有效地在您的建议基础上进行构建?
更多游戏建议
通过以下活动继续发展您的 Description (描述) 和 Discernment (辨别) 技能:
- 二十个问题: 让 Claude 想一个物体、人物或概念,然后您通过问是/否问题来猜测。然后交换角色。注意你们各自是如何构建问题和提供线索的。
- 协作讲故事: 用一句话开始一个故事,让 Claude 接下一句,然后来回交替。观察你们双方如何保持叙事连贯性并互相借鉴对方的想法。
- 一位巫师在酒馆里走向你: 如果您喜欢玩角色扮演游戏,可以尝试与语言模型一起玩一两个游戏,扮演玩家或游戏主持人。
- 概念与约束: 选择一个复杂的概念和非常严格的约束,比如“只用烹饪的比喻来解释”。然后让 Claude 给您一个挑战,自己尝试一下,并比较方法。
- 高级解谜: 创建您自己的逻辑或文字谜题,然后挑战 Claude 来解决。或者,让 Claude 为您创建谜题来解决。(如果您是程序员,可以把谜题换成棘手的问题,比如和 Claude 一起挑战 https://projecteuler.net/)。
对本课程的反馈
我们很乐意听取您关于如何在生活、工作或课堂中使用本课程概念的意见,以及您的任何反馈。在此处分享您的反馈。
致谢和许可
Copyright 2025 Rick Dakan, Joseph Feller, and Anthropic. Released under the CC BY-NC-SA 4.0 license.
本课程基于 Dakan 和 Feller 的 AI Fluency 框架。部分支持来自爱尔兰高等教育局,通过国家教学与学习促进论坛提供。
第 3 课:教育者 AI 素养
面向教育工作者的 AI 协作技能培训 课程链接:教育者 AI 素养 | 共 5 节课
第2课:将 AI 素养应用于课程设计和学习成果
第2课:将 AI 素养应用于课程设计和学习成果
核心概念 AI 素养通过构建丰富、共享的情境来变革课程设计,将 AI 从一个通用的助手转变为一个能理解特定教学情境、约束和教学愿景的协作者。
三项基础课程设计任务
- 确定对学生至关重要的内容和概念
- 规划学习路径——即各项主题之间如何相互衔接
- 阐明具体的学习目标
4D 框架在课程设计中的应用
课程设计中的 Delegation (委派)
- 根据学科专业知识和目标做出明智的委派决策
- 确定需要完成的工作(内容选择、排序、目标设定)
- 决定由谁来做(人、AI 或两者兼有)以及如何做
- 在确定“谁做”和“如何做”之前,先回答“做什么”和“为什么做”
课程设计中的 Description (描述)
- 创建一个植根于实际教学挑战的思考空间
- 示例:“我正在为新闻专业的学生构建一门统计学课程,他们需要数据素养,但通常对数学感到焦虑,或对统计学在职业生涯中的重要性持怀疑态度”
- 分享具体的挑战、学生需求、先修课程要求和预期成果
- 解释对成功的愿景和所受的约束
- 同时使用产品描述(你希望 AI 做什么)和过程描述(如何做)
课程设计中的 Product Discernment (成果辨别)
- 依据自身的专业知识评估 AI 的建议
- 提问:这个概念真的对目标学生有帮助吗?
- 不仅仅是接受/拒绝——要解释为什么某个建议在特定情境下有效或无效
- 利用专业知识来塑造更好的未来建议
- 识别意想不到的见解和新的思维方式
课程设计中的 Diligence (尽责)
- 不要外包决策——对最终呈现给学生的内容负责
- 记录与 AI 协作过程中的关键决策
- 与学生分享你的思考过程,以示范负责任的 AI 使用方式
- 质量保证和透明度
- 在展示 AI 如何增强教学专业知识的同时,保持问责制
AI 角色扮演技巧 要求 AI “扮演我的一名学生”来评估课程流程:
- 在不同阶段,学生会有何反应?
- 哪里可能会产生困惑?
- 每个阶段需要什么样的背景知识?
- 在主题转换时需要提供哪些支持?
学习目标的增强
- 利用先前协作中建立的既有情境
- 上传包含更丰富情境描述的课程大纲
- 制定准确、有意义、能激励人心、忠于教学理念并符合机构要求的学习目标
- 将课程成果与简历技能对应起来,以激励学生
- 由于流程加快,可以尝试不同的方法
超越节省时间的益处
- 发现隐藏的假设和盲点
- 探索概念之间富有创造性的联系
- 在探索新想法的同时保持连贯性
- 培养个人能力,并通过实践得到加强
关键原则
- 4Ds 是一个真正的认知伙伴关系框架,而非一张核对清单
- 教学和学科专业知识指导着协作探索
- 构建情境的方法适用于:新课程开发、课程更新、课程系列设计、学习路径规划
- 从宏观入手,通过细节构建并维护情ö境
- 目标是增强而不仅仅是效率——实现更好的教与学,而不仅仅是更快的规划
练习结构(50分钟) 阶段1:规划方法(明确课程、所需工作、自身专业知识与 AI 辅助的界限) 阶段2:启动协作(分享教学情境、解释挑战、设定伙伴关系) 阶段3:通过 Description (描述) 和 Discernment (辨别) 构建对话(内容识别、学习路径规划、学习目标设定) 阶段4:文档记录与反思(验证准确性、记录决策、标注被拒绝的建议、创建 AI 角色声明)
成果 创建一种真正的认知伙伴关系,其中人类的判断、价值观和师生关系仍然是核心,而 AI 则增强了教学实践。
第1课:教育者 AI 素养导论
教育者 AI 素养 = 一个旨在将 AI 有效、高效、合乎道德且安全地融入教学实践的框架
课程目的 = 将 4D 框架(Delegation (委派)、Description (描述)、Discernment (辨别)、Diligence (尽责))专门应用于教育情境
为何 AI 素养在教育领域至关重要:
- 学生已经在用 AI
- 雇主期望毕业生具备 AI 素养
- 院校需要负责任的 AI 整合策略
- 教育者塑造着下一代与 AI 的互动方式
课程成果:
- 将 4D 框架应用于教学实践
- 使用 AI 进行课程设计和教案规划
- 在保持教学愿景和学术诚信的前提下创建教学材料
- 引领机构内的 AI 对话
- 为学生示范负责任的 AI 互动方式
先修课程要求 = 完成《AI 素养:框架与基础》课程
4D 框架总结:
AI 素养 = 负责任的 Human in the loop (人在环路中),是 Augmentation (增强) 而非自动化
Delegation (委派) = 决定由谁来做什么工作(人 vs AI vs 协作) 三种类型:
- 问题认知 = 在与 AI 互动前,明确目标和成功标准
- 平台认知 = 理解不同 AI 的能力和局限性
- 任务委派 = 分配工作以利用人类的创造力/判断力 + AI 的速度/处理能力
Description (描述) = 如何与 AI 沟通(是对话而非命令) 三个维度:
- 产品描述 = 对最终输出的详细说明(长度、受众、风格、格式)
- 过程描述 = 指导 AI 的方法(分步思考、多视角分析)
- 表现描述 = 定义 AI 在互动中的行为(扮演批判性编辑、支持性头脑风暴伙伴)
Discernment (辨别) = 评估 AI 的输出并相应调整 三个层次:
- 成果辨别 = 对 AI 创作成果的质量评估(准确性、实用性、新视角)
- 过程辨别 = 审视 AI 的推理过程和假设
- 表现辨别 = 评估 AI 在互动中的行为
Description (描述) + Discernment (辨别) = 一个持续的反馈循环,将 AI 从工具转变为思维伙伴
Diligence (尽责) = 在整个协作过程中负责任地使用 AI 三个方面:
- 创造尽责 = 审慎选择 AI 系统,考虑隐私、安全和适宜性
- 透明尽责 = 诚实披露 AI 的辅助作用
- 部署尽责 = 对经 AI 辅助的输出成果承担所有权和责任
关键原则:
- Augmentation (增强) > Automation (自动化) (尤其在学习情境中)
- 教学价值观始终是核心
- 4Ds 作为相互关联的能力协同工作
- 随着 AI 技术的发展,这些技能依然适用
教学情境文档 = 一种可复用的工件,用于与 AI 建立共享的理解,以备未来协作之用
核心情境领域:
- 学科领域、级别、具体课程
- 学生背景、挑战、目标
- 机构限制
- 教学理念和方法
- 常见的教学痛点
- AI 集成目标
- 独特的教学情境方面
情境文档的好处:
- 提高与 AI 协作的效率
- 在未来的互动中节省时间
- 在不同的 AI 对话中保持一致性
- 帮助 AI 理解教育者的特定需求和限制
第3课:将 AI 素养应用于学习材料和作业
第3课:将 AI 素养应用于学习材料和作业
核心学习目标
- 使用 4D 框架借助 AI 构建教学材料
- 利用已建立的情境进行连贯的材料开发
- 通过 Discernment (辨别) 应用系统的质量控制
- 创建整合式的学习体验
AI 的学科影响框架
关于学科的三个关键问题:
- 什么会被自动化 = 在未来职业生涯中,AI 可能会自动化的常规任务
- 合作潜力 = 在哪些领域,人与 AI 的协作最具影响力
- 谁来负责 = 人类如何管理 AI 工作并对其负责
三种现有的专业知识:
- Disciplinary Expertise (学科专业知识) = 领域内容、价值观、方法、思维模式
- Pedagogical Expertise (教学专业知识) = 学生的困惑点、顿悟时刻、掌握技能的培养过程
- Assessment Expertise (评估专业知识) = 识别真正的理解,设计评估方法
AI 在三个领域的颠覆性影响
对课程的影响:
- 基础知识依然重要,但学生会质疑其必要性
- 需要针对“既然 AI 能做,为什么还要学”给出令人信服的、特定于学科的答案
- 任务:识别 AI 可自动化的内容,判断哪些概念变得更重要/次要,评估 AI 如何改变最佳实践
对教学的影响:
- AI 可以实现个性化辅导、交互式模拟、即时反馈
- 挑战:区分是增强学习还是走了捷径
- 任务:定义 AI 如何增强/抑制学习,识别最佳的师生-AI 协作模式,确定有效的教学方法
对评估的影响:
- 最紧迫的颠覆 = 当学生能在几秒钟内生成内容时,我们评估的是什么
- 需要对 AI 辅助和纯人工完成的作品进行真实性评估
- 任务:识别 AI 辅助学习的真实表现,创建能防止“走捷径”的作业,重视过程而非结果,适应学生不可避免的 AI 使用
4Ds 在学科专业知识中的应用
Discernment (辨别) = Quality Evaluation (质量评估)
- 建立质量标准 = 详细的评分标准,超越模糊的术语,明确卓越的标志
- 收集杰出作品 = 与学生一起进行系统性分析,让专家的思维过程可见
- 诊断失败案例 = 对有缺陷的例子进行法医式检查,理解失败的模式
Description (描述) = Communication Mastery (沟通精通)
- 绘制学科成果图谱 = 精确记录关键产出,揭示其底层逻辑
- 揭示专家思维 = 让解决问题的过程可见,追踪微观决策
- 明确规范 = 揭示领域特定的行为,用具体术语定义“像 X 一样思考”
Delegation (委派) = Work Decomposition (工作分解)
- 揭示问题结构 = 将挑战分解为不同组成部分,探索 AI 的可能性
- 探索 AI 的可能性 = 什么可以被自动化/增强/委派给 AI 代理
- 设计决策树 = 基于案例研究,建立何时以及如何让 AI 参与的框架
Diligence (尽责) = Ethical Standards (道德标准)
- 编纂道德框架 = 领域特定的“不作恶”原则,创建决策矩阵
- 明确透明度规范 = 披露期望,为 AI 辅助提供引文模板
- 共同创建问责政策 = 与学生共同建立标准,发展同行评审协议
使用 AI 创建材料
情境利用:
- 已建立的情境 = 每个新工作流都比从零开始更好
- 引用之前的对话和课程设计工作
- 与 AI 分享视频文字记录和课程情境
4Ds 在材料创作中的应用:
- Delegation (委派) = 了解需要什么材料以及为什么需要
- Description (描述) = 利用已建立的情境 + 具体要求
- Description-Discernment (描述-辨别) 循环 = 一个精炼工具,解释建议为何有效或无效
- Diligence (尽责) = 保护敏感数据,验证准确性,检查偏见,创建透明度
四种材料创作选项:
选项1:讲座幻灯片
- 准备:分享课程情境、演示风格、课堂动态、视觉偏好
- 过程:初步大纲 → 评估流程/复杂性 → 开发关键幻灯片 → 制作完整幻灯片
- 最终检查:验证准确性,标注图片/引用需求,记录 AI 的贡献
选项2:学习/复习指南
- 准备:引用讲座主题,描述学生学习习惯,解释有效的辅助工具
- 过程:确定关键概念 → 设计自查问题 → 预判易错点 → 建立知识联系
- 最终检查:验证答案准确性,检查与评估的一致性,确保无障碍性
选项3:互动式课堂练习
- 准备:描述课堂设置、时间限制、学生互动模式、学习目标
- 过程:协作设计活动 → 思考后勤安排 → 预判学生反应 → 创建引导笔记
- 最终检查:测试指令清晰度,考虑无障碍性,规划应急方案
选项4:知识点测验
- 准备:引用学习目标、评估水平、学术诚信方法
- 过程:设计 5-10 个不同类型的问题 → 混合问题类型 → 连接到学习目标 → 创建答案解释
- 最终检查:验证答案正确性,检查偏见/混淆,确保难度适中
关键原则
- AI 素养 = 放大而非取代人类的专业知识
- 学科知识 = 实现前所未有成就的基础
- 人类能力 = 领域专业知识、判断力、创造力、道德和人际关系
- 培养学生成为不可替代的人,而不是被替代的人
- 关注连贯性和质量,而不仅仅是效率
- Description-Discernment (描述-辨别) 循环 = 通过有意义的迭代进行强大的精炼
第 4 课:学生 AI 素养
面向学生的 AI 协作技能培训 课程链接:学生 AI 素养 | 共 6 节课
第1课:AI 素养导论与 4D 框架
AI Fluency (AI 素养) = 通过持久的原则,而非临时的技巧或工具,有效、高效、合乎道德且安全地使用 AI
4D 框架 = 四个相互关联的能力,共同构成 AI 素养:Delegation (委派)、Description (描述)、Discernment (辨别)和 Diligence (勤勉)
Augmentation (增强) vs Automation (自动化):
- 增强 = AI 帮助你更好地完成工作(学习中的首选方式)
- 自动化 = AI 为你完成工作,无需深入思考(对学习有害)
Human in the Loop (人机回圈) = 在保持所有权的同时,做出负责任的决策并深思熟虑地使用 AI
DELEGATION (委派) = 决定哪些工作应由人类、AI 或两者共同完成
三种委派意识:
- 问题意识 = 在使用 AI 前,明确实际目标
- 平台意识 = 了解不同 AI 的能力与局限,以选择合适的工具
- 任务委派 = 分配工作以发挥人类的长处(创造力、判断力、情境理解)和 AI 的长处(速度、一致性、信息处理)
DESCRIPTION (描述) = 如何与 AI 进行协作式对话,而不仅仅是提问
描述的三个维度:
- 产品描述 = 明确最终成果的细节(长度、关键信息、受众、风格、格式)
- 过程描述 = 指导 AI 的处理方法(“一步一步思考”、“考虑多种视角”)
- 性能描述 = 定义 AI 在互动中的行为(扮演批判性编辑、支持性头脑风暴伙伴)
DISCERNMENT (辨别) = 通过批判性评估,识别好坏结果并相应调整
辨别的三个层次:
- 产品辨别 = 评估 AI 输出的准确性、实用性及是否提供新视角
- 过程辨别 = 审视 AI 的推理过程、假设和逻辑步骤
- 性能辨别 = 评估 AI 是否在其被请求的角色中表现出助益
描述-辨别循环 = 一个持续的反馈循环,你描述需求、评估结果,然后迭代优化描述
DILIGENCE (勤勉) = 通过合乎道德、透明和负责任的实践,为 AI 的使用承担责任
三种勤勉:
- 创造勤勉 = 审慎选择 AI 系统,考虑隐私、安全和适用性
- 透明度勤勉 = 诚实地向教授、团队成员和雇主报告与 AI 的协作
- 部署勤勉 = 对 AI 辅助的输出负责,验证其准确性并确保其适当性
学习背景文件 = 一份个性化的参考文件,用于为未来的 AI 会话建立学术背景、学习目标、AI 边界和协作偏好
学习背景的关键要素:
- 学术背景(专业、课程、优劣势、目标)
- 学习风格与挑战
- AI 经验与使用边界
- 偏好的支持类型(寻求指导 vs 完成任务)
- 学术诚信考量
基本原则 = AI 素养技能与技术演进无关,因为它们关注的是战略思维、沟通、评估和道德责任,而非特定工具
第3课:AI 在职业规划中的应用
AI 在职业规划中的应用 = 使用 AI 作为思维伙伴,进行职业探索、技能构建和求职,同时保持真实性
核心原则 = AI 处理信息收集和指导,人类驱动战略、决策和价值观
职业探索过程:
- AI 的优势 = 行业研究、趋势分析、技能差距识别、薪资洞察、职业轨迹规划、头脑风暴职位角色
- 人类的责任 = 自我认知、价值观、权衡取舍、人生目标、直觉
- 两步过程 = 信息收集 (AI) + 个人反思 (人类)
AI 职业探索任务:
- 行业研究 = “在可持续技术领域,有哪些结合了环境科学和数据分析的新兴职位?”
- 技能差距分析 = “雇主期望的 UX 设计师技能与训练营所教授的技能有何不同?”
- 市场洞察 = “按城市划分,入门级顾问的真实薪资发展路径是怎样的?”
- 职业轨迹 = “从教学岗位转型到企业培训的路径有哪些?”
- 职位头脑风暴 = “有哪些能运用新闻技能且更稳定的职业?”
- 价值观澄清 = AI 提出问题以帮助明确职业目标和价值观
利用 AI 进行技能发展:
- 明确学习需求 = 不要说“帮我学习数据分析”,而应说“作为一名市场经理,我需要学习客户调查分析技能,从 Excel 数据透视表开始”
- AI 作为教练 = 创建练习场景,对样本提供反馈,进行情景角色扮演
- 主动学习检查 = 定期评估自己是在真正进步,还是仅仅在走过场
求职应用:
- 经验法则 = AI 负责头脑风暴、指导和起草,人类负责呈现真实的自我
- AI 任务 = 识别可迁移技能、练习面试问题、寻找独特的求职信切入点
- 人类的责任 = 专业知识、职业目标、真实的个人身份、最终的材料
通用 AI 内容的问题 = 招聘人员能立即识别出由 AI 生成的简历和求职信,并认为其无效
职业发展工作流: 第一部分 - 职业探索 (15分钟):
- 与 AI 分享你的背景
- 研究使用相似技能的职业、新兴职位、薪资发展、日常工作内容
- 在 AI 引导下进行自我反思,思考你的精力来源、权衡取舍、价值观和成功定义
- 创建一个包含 2-3 个目标职位和技能差距的职业地图
第二部分 - 简历改进 (15分钟):
- 第1步:AI 根据具体职位描述,批判性地审视你当前的简历
- 第2步:AI 收集信息以解决需要改进的方面
- 第3步:结合实际经历,用更有力的语言修改简历
第三部分 - 面试准备 (15分钟):
- AI 分析职位角色,提出 5 个切合实际的问题
- 每次一个问题,并进行追问
- 用具体例子进行练习
- AI 就内容、清晰度和相关性提供反馈
关键指南:
- AI 帮助练习和准备,但在实际情境中,人类必须保持真实
- 不要背诵脚本,要理解自己的经历,以便灵活讨论
- 雇主想雇用的是你,而不是 AI 版本的你
- AI 素养本身就是一项宝贵的职业技能,值得强调
- 记录与 AI 的互动,在适当时对 AI 的辅助保持透明
真实性原则 = AI 可以帮助你更好地讲述你的故事,但故事的起点和终点都是你的专业知识
第4课:成为人机回圈中的人类
第4课:成为人机回圈中的人类
核心概念 Human in the Loop (人机回圈) = 在所有与 AI 的互动中,人类保持决策控制权。你决定要问什么,评估 AI 输出的准确性和合理性,并判断输出是否可用。在每一次互动中都带入你的判断力、创造力和道德考量。
关键原则
- AI 素养 = 安全、高效、有效、负责地与 AI 协作
- 未来的领导者 = 那些能深思熟虑地与 AI 系统合作的人
- 你的人性 = 是独一无二且宝贵的(才能、经历、知识、视角)
- AI 增强人类的能力,但无法取代人类的洞察力、判断力和关怀
AI 素养的基本组成部分
- 深思熟虑地委派
- 清晰地描述需求
- 批判性地思考输出
- 谨慎地跟进执行
个人 AI 协作策略结构
第1部分:使用边界
- 定义何时适合使用 AI(练习、探索、建立理解)
- 定义何时应独立工作(考试、展示掌握程度、原创性思考)
- 识别 AI 能增值的专业情境
- 设立“红线”= 你绝对不会使用 AI 的情况
第2部分:学习应用
- 将 AI 作为导师/教练,而不是作业完成器
- 保持解释你提交的任何内容的能力
- 使用 AI 增进理解,而不是绕过理解
- 记录有效的具体策略
第3部分:透明度标准
- 何时主动披露 AI 的辅助
- 如何记录 AI 的贡献
- 提供细节的程度
- 处理模棱两可的情况
第4部分:技能维护
- 需要在没有 AI 的情况下练习的核心技能
- 定期安排“无 AI”的工作间隔
- 验证持续学习的方法
- 对过度依赖(和利用不足)的警示信号
第5部分:道德准则
- 准确性和事实核查的责任
- 尊重他人的工作和思想
- 隐私和数据方面的考虑
- AI/计算机使用的更广泛影响
第6部分:持续成长
- 持续了解 AI 的能力
- 定期反思的时间间隔
- 策略调整过程
- 与他人分享知识
关键反思问题
- 与 AI 的互动是否帮助我成长?
- 我是在发展未来所需的技能,还是仅仅在完成任务?
- 我是否诚实地对待 AI 在我工作中的角色?
- 我使用 AI 的方式是否符合我的价值观?
实施指南
- 考虑到具体情境和限制,保持策略的现实性
- 策略应足够简洁,以便实际参考
- 包括创建日期和更新计划
- 保存在多个易于访问的地方
- 在真实场景中练习应用
- 与他人分享和讨论以建立问责制
课程完成要素
- 用于深思熟虑的 AI 互动的 4D 框架
- 一种 AI 增强的学习方法,旨在增强而非取代才能
- 一种保持真实性的 AI 增强的职业思维
- 反映个人价值观的个人 AI 策略
- 成为 AI 领导角色的基础
下一步
- 立即实施你的策略
- 与同伴分享学习心得
- 将“AI 素养”连同证据一起添加到你的简历中
- 对 AI 的发展保持好奇心
- 帮助在社区中塑造积极的 AI 使用方式
第2课:AI 作为学习伙伴
AI 学习伙伴框架
核心区别 = 使用 AI 完成工作 vs 使用 AI 学习
- AI 完成工作 = 借来的智能,削弱批判性思维
- AI 作为学习伙伴 = 构建知识,增强能力
AI 依赖的后果
- 没有 AI 支持,考试不及格
- 求职面试时难以解释自己的思路
- 无法评估 AI 建议的质量
- 现实世界中解决问题的能力不足
学习背景下的 4D 框架
Delegation (委派) (学习重点) 问题意识 = 在使用 AI 之前先问:我想学什么?我的学习目标是什么? 任务分配 = 保留对学习至关重要的任务(如撰写论点),委派支持性任务(如扮演辩论伙伴) 平台选择 = 选择为学习而非快速给出答案而设计的 AI 系统
Description (描述) (学习配置) 默认 AI 行为 = 设计为直接给出答案(对学习无益) 学习提示 = 将 AI 配置为导师/教练,而非答案提供者 有效的描述:
- “请向我提问,而不是直接解释”
- “请引导我接近解决方案,但不要直接解决”
- “帮我更深入地挖掘我的理解”
有用的 AI 学习输出:
- 针对难题的提示/线索
- 测试理解能力的提问
- 从不同角度提出的批判性反馈
- 用新例子重新解释概念
- 渐进式的练习题
- 扮演学生,让你来教它
Discernment (辨别) (学习评估) 学习检查问题:
- 我能向别人解释这个概念吗?
- 没有 AI,我能解决类似的问题吗?
- 我是否理解了“为什么”,而不仅仅是“它有效”?
真正的理解 vs 只是跟上 = 相信自己对理解的内在感觉 信息验证 = 将 AI 的学习内容与非 AI 来源交叉核对
Diligence (勤勉) (学术诚信) 创造勤勉 = 遵守学校的 AI 政策,使用经批准的系统 透明度勤勉 = 记录与 AI 的互动,培养披露技能 部署勤勉 = 必须能解释提交作业的每一部分,并将概念应用于新情况
练习结构
第一部分:AI 学习伙伴设置 (15-30分钟) 配置步骤:
- 分享第1课中的学习背景
- 分享视频文字记录以帮助 AI 理解
- 明确学习目标 vs 完成作业的目标
- 定义提问式 vs 直接回答式的方法
按需制定的学习协议:
- 问题解决 = 仅提供提示/问题
- 概念复习 = 渐进式难度测试
- 备考 = 进行测验,并解释错误答案
- 写作 = 通过提问来发展论点
- 阅读 = 用自己的话解释概念
- 作业规划 = 测试对要求的理解
第二部分:动态学习日志 (15-30分钟) 日志结构:
- 每周概念学习总结
- 理解清晰度评估
- AI 学习使用情况记录
- 有效学习策略的识别
- 练习需求的识别
- 具体技能发展笔记
追踪系统:
- 建议每周记录一次
- 每月进行综合分析,寻找模式
- 标注 AI 辅助工作 vs 独立完成工作
- 记录“顿悟时刻”
- 通过反思提示建立问责制
关键成果 长期益处 = 真正的理解、解决问题的能力、面试自信、评估 AI 建议的能力、职场价值 投资心态 = 培养超越完成学业的思考、学习和适应能力 竞争优势 = 在 AI 触手可及的世界中,拥有人类的智能、创造力和判断力技能
第 5 课:非营利组织 AI 素养
面向非营利组织的 AI 素养与实践指南 课程链接:非营利组织 AI 素养 | 共 10 节课
欢迎学习非营利组织的 AI 素养
你将学到什么
预计用时:20 分钟
在本课程结束后,你将能够:
- 定义 AI 素养 (AI Fluency) 的含义
- 阐明你的价值观和约束,以便更有效地与 AI 协作
- 确定你在工作中集成 AI 工具和能力的目标
欢迎学习非营利组织的 AI 素养
(3 分钟)
该视频介绍了我们的“非营利组织的 AI 素养”课程。它承认了该领域中对 AI 的热情与有意义的实施之间的差距,并引入了 AI 素养的概念,即以有效、高效、合乎道德和安全的方式与 AI 系统合作的能力。视频介绍了作为课程基础的 4D 框架 (4D Framework)——委派 (Delegation)、描述 (Description)、辨别 (Discernment) 和尽责 (Diligence),并强调以使命为中心的思维应指导非营利组织的所有 AI 应用。
关键要点
- AI 素养是以高效、有效、合乎道德和安全的方式使用 AI 的能力。它结合了实用技能、知识、见解和价值观,帮助你适应不断发展的 AI 技术,同时忠于你非营利组织的使命。
- 4D 框架包含四个相互关联的能力:委派 (Delegation)、描述 (Description)、辨别 (Discernment) 和尽责 (Diligence)。
- 委派-尽责 (Delegation-Diligence) 循环支持在何时以及如何使用 AI 方面做出深思熟虑、负责任的选择。
- 描述-辨别 (Description-Discernment) 循环通过来回协作帮助你从 AI 互动中获得更多。
- 对于非营利组织而言,每一次 AI 效率的提升最终都应转化为为你所服务的社区带来更大的影响。
练习 定义你的组织价值观、使命以及使用 AI 的目标
这个练习将帮助你塑造与 AI 协作用于工作的目的。这个基础将帮助你通过使命的视角来评估 AI 的机会。
第一部分:自我反思(独立完成)
回答以下问题:
- 你所在组织的使命和愿景是什么?
- 描述你的工作环境和具体角色——约束、优势、机会等。
- 塑造你工作的核心价值观和理念是什么?
- “如果 AI 能帮我 _______,我就能花更多时间 _______。” 专注于 AI 效率如何能让你解放出来,从事更具影响力、以人为中心的活动。
第二部分:协作(与 AI)
与 Claude(或你选择的任何其他 AI 助手)开始对话:
开启对话:
- 解释你是一名非营利组织的专业人士,希望为自己的组织和工作创建一个可复用的摘要。
- 告诉 AI 这份文件将有助于为未来的协作建立共同的理解。
- 表示你希望 AI 帮助你思考工作中所有相关的方面。
- 你可以要求 AI 就你的工作对你进行访谈,或者
- 你可以直接开始分享信息,并询问 AI 还需要了解哪些有用的信息。
慢慢来。目标是一场能够浮现重要背景信息的来回对话。
需要涵盖的关键领域(AI 应帮助你探索这些):
- 你组织的使命、愿景和价值观
- 你角色中通常的工作范围
- 你组织面临的典型挑战
- 机构背景和约束
- 改进的机会
- 工作中的常见痛点
- 将 AI 融入工作的目标
- 你角色或组织的任何独特之处
让对话更轻松:
- 不必一次性分享所有内容。
- 鼓励 AI 提出后续问题。
- 在有助于说明你的背景时,分享具体例子(注意隐私和敏感数据)。
- 在对话过程中边想边说、逐步完善你的想法是完全可以的。
创建一份可复用的文件:
- 要求 AI 将对话内容整合成一份结构化的背景文件,你可以在未来的 AI 对话中分享。
- 与 AI 一起审查它,并补充任何缺失的内容和/或进行修正。
- 要求一个易于复制和复用的格式。
课程反思
- 你对自我反思问题的回答如何影响了你与 AI 的对话?是否出现了新的优先事项或担忧?
- 查看你的背景文件,你认为你非营利工作的哪些方面将从 AI 协作中获益最多?
下一步
在下一课中,我们将更深入地探讨 4D 框架,为本课程的其余部分奠定基础。
反馈
随着你学习的深入,我们很乐意听到你如何将课程中的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
4D 框架
你将学到什么
预计用时:30 分钟
在本课程结束后,你将能够:
- 解释 AI 素养框架 (4D) 如何应用于非营利工作
- 定义 4D 中的每一个 D——委派 (Delegation)、描述 (Description)、辨别 (Discernment) 和尽责 (Diligence)
4D 框架
(6 分钟)
该视频介绍了构成 AI 素养基础的四个相互关联的能力——4D 框架。你将学习两种互动模式:用于决定何时以及是否使用 AI 的委派-尽责 (Delegation-Diligence) 循环,以及用于日常有效使用 AI 的描述-辨别 (Description-Discernment) 循环。每个能力都被分解为三个子部分,并附有针对非营利组织的具体示例。
关键要点
- 委派-尽责 (Delegation-Diligence) 循环指导关于何时使用 AI 的更高级别决策。
- 委派 (Delegation) 涉及决定哪些工作应由人类完成,哪些应由 AI 完成。它包括问题意识 (Problem Awareness)(了解你的目标)、平台意识 (Platform Awareness)(了解你工具的能力和局限性)以及任务委派 (Task Delegation)(深思熟虑地分配工作)。
- 尽责 (Diligence) 意味着对你如何使用 AI 负责。它包括创建尽责 (Creation Diligence)(有意识地选择使用哪些工具)、透明尽责 (Transparency Diligence)(诚实地说明 AI 的作用)以及部署尽责 (Deployment Diligence)(验证并为产出负责)。
- 描述-辨别 (Description-Discernment) 循环指导日常有效的互动。
- 描述 (Description) 是你如何与 AI 系统有效沟通。它包括产出描述 (Product Description)(定义输出)、过程描述 (Process Description)(指导方法)以及表现描述 (Performance Description)(在协作期间塑造 AI 行为)。
- 辨别 (Discernment) 意味着批判性地评估 AI 的工作。它包括产出辨别 (Product Discernment)(评估质量)、过程辨别 (Process Discernment)(评估 AI 如何得出输出)以及表现辨别 (Performance Discernment)(评估 AI 行为)。
练习
练习 #1:规划你的 AI 需求
为什么?这个练习揭示了你已经在思考哪些 AI 能力,以及哪些需要关注,这样你就可以有策略地将精力投入到最重要的地方。
- 自我反思:写下你对使用 AI 的问题和担忧清单。
- 协作:与 AI 开启对话。问 AI:“你能帮我理解这些问题和担忧在 AI 素养 4D 框架中各自属于哪个部分吗?”
- 反思:你的大部分问题和担忧属于 4 个能力中的哪一个?
- 这个模式揭示了你目前关注的焦点。这是你最需要发展的领域,还是你在回避一个更难但能解锁更多进展的能力?
- 根据你确定首先要优先考虑的能力,下一次使用 AI 时,你会采取哪一件具体的不同做法?
练习 #2:识别一个跨能力的挑战(延伸目标)
延伸目标 = 理解每次你与 AI 互动时,你正在(或应该)以一种相互关联的方式与这些能力中的每一个进行互动。
在将你的问题映射到 4D 之后,确定一个你需要同时发展多种能力才能有效前进的领域。
例如:
- “我意识到我既需要委派 (Delegation) 技能(决定 AI 是否应帮助处理志愿者沟通),又需要尽责 (Diligence) 技能(确保我们保护志愿者隐私),然后才能继续前进。”
- “在我首先发展描述 (Description) 技能以获得更好的输出之前,我对准确性的辨别 (Discernment) 担忧并不重要。”
课程反思
- 查看你映射的问题和担忧,你是否对哪个能力领域占主导地位感到惊讶?这可能告诉你目前你与 AI 的关系是怎样的?
- 两个循环(委派-尽责和描述-辨别)可能会如何改变你最近与 AI 的一次互动?
下一步
在下一课中,我们将把描述 (Description) 和辨别 (Discernment) 付诸实践,你将学习如何与 AI 一起有效地进行研究和写作——这些技能直接适用于拨款提案、捐赠者沟通和项目材料。
反馈
随着你学习的深入,我们很乐意听到你如何将课程中的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
与 AI 一起研究
你将学到什么
预计用时:50 分钟
在本课程结束后,你将能够:
- 使用描述 (Description) 技能来制作有效的提示,指导 AI 收集和整合与你非营利工作相关的信息。
- 使用辨别 (Discernment) 技能来评估 AI 生成的研究的准确性、相关性以及是否适合你的非营利组织背景。
与 AI 一起研究
(7 分钟)
该视频通过一个研究场景展示了描述-辨别 (Description-Discernment) 循环的实际应用。你将跟随一位名叫 Maria 的执行董事,她正在将她的住房非营利组织从波特兰扩展到西雅图,她使用 AI 来研究政策环境、资金机会和合规要求。视频展示了如何制作内容丰富的提示,批判性地评估 AI 的输出,并迭代以获得有用的结果。
关键要点
- 有效的描述 (Description) 提供背景信息:不要只问宽泛的问题——解释你是谁,你为谁服务,以及你具体需要知道什么。这些背景信息有助于 AI 提供相关、可操作的信息。
- 辨别 (Discernment) 不是可有可无的:你必须批判性地评估 AI 的输出,尤其是在准确性至关重要时。标记需要验证的具体声明,注意信息缺口,并质疑信息的时效性。
- 描述-辨别循环是迭代的:你的第一个提示很少能提供你需要的一切。利用你从评估每个回应中学到的东西,来制作更好、更有针对性的后续问题。
- AI 加速研究但不能取代专业知识:AI 可以帮助你快速入门,但你仍然是决策者,必须对你负责的每一项交付成果运用专业判断。
练习 1:政策和立法追踪
这个练习帮助你练习使用描述 (Description) 和辨别 (Discernment) 来研究与你非营利工作相关的政策领域。
第一部分:自我反思
选择一个与你工作相关的政策领域(住房政策、教育资金、医疗保健准入、环境法规等)。制作一个研究提示,其中包括:
- 你想了解的具体政策或立法
- 你非营利组织的背景(你为谁服务,为什么这对你的使命很重要)
- 你需要知道什么(对受益人的影响、资金影响、合规要求、倡导机会)
- 时间范围或地理范围
第二部分:协作
与 AI 分享你的提示并审查回应。运用辨别 (Discernment):
- 识别至少 2 个需要验证的声明。
- 指出任何与你社区相关的缺失视角。
- 标记任何看起来过时或过于笼统的信息。
第三部分:反思
- 你最初的提示是否给了 AI 足够有用的背景信息?
- 在第二次尝试时,你会对你的提示做哪些修改?
- 在工作中使用这些信息之前,你会采取哪些验证步骤?
延伸目标:要求 AI 追溯其摘要中一个关键声明的原始来源,并比较其表述的准确性。
练习 2:捐赠者或拨款前景研究
这个练习将描述 (Description) 和辨别 (Discernment) 应用于筹款研究——一个准确性至关重要的高风险领域。
第一部分:自我反思
选择你的研究重点(例如:特定项目的拨款机会、你所在地区有相关捐赠优先事项的企业捐赠者,或资助像你这样组织的基金会前景)。制作一个研究提示,其中包括:
- 你组织的使命和寻求资金的具体项目/需求
- 你非营利组织的特点(预算规模、地理区域、服务人群)
- 资金参数(拨款金额范围、合格费用、申请时间)
- 除了主题一致性之外,什么构成“良好匹配”(价值观、捐赠历史、可及性)
第二部分:协作
与 AI 分享你的提示并审查回应。运用辨别 (Discernment):
- 检查建议的资助者是否真的资助你这种规模/类型的组织。
- 验证当前的申请截止日期和资格要求。
- 识别任何过时的信息(已关闭的项目、改变的优先事项)。
- 注意哪些前景与你的价值观相符,而不仅仅是你的预算需求。
第三部分:反思
- AI 是否理解了什么使一个资助者与你的使命“一致”,而不仅仅是主题相关?
- 在投入时间申请之前,你需要验证哪些关键细节?
- 这项研究中缺少了哪些只有你(或你的网络)才知道的信息?
延伸目标:选择一个建议的资助者,并请 AI 帮助你研究他们最近的拨款,以了解他们实际的捐赠模式与声明的优先事项。
课程反思
- 与更通用的提示相比,提供关于你非营利组织的背景信息如何改变了 AI 研究输出的质量?
- 在使用 AI 进行研究时,你将在工作流程中建立哪些验证习惯?
下一步
在下一课中,我们将在一个不同的背景下探索同样的描述 (Description) 和辨别 (Discernment) 技能:与 AI 一起写作。你将看到当你在创作内容而不是收集信息时,这个循环是如何工作的。
反馈
随着你学习的深入,我们很乐意听到你如何将课程中的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
与 AI 一起写作
你将学到什么
预计用时:50 分钟
在本课程结束后,你将能够:
- 应用描述 (Description) 技能,制作清晰、内容丰富的提示,引导 AI 创作或改进符合你非营利组织使命和受众需求的文字材料。
- 应用辨别 (Discernment) 技能,评估 AI 生成的文字材料的准确性、适宜性,以及是否符合你的组织价值观和沟通标准。
与 AI 一起写作
(7 分钟)
该视频演示了应用于写作的描述-辨别 (Description-Discernment) 循环,重点是保持真实性和人际联系。你将跟随 James,他经营着一个小型环境正义组织,在 48 小时的最后期限内使用 AI 撰写一份紧急拨款提案。视频展示了如何通过上传文件提供丰富的背景信息,如何用具体指令指导 AI 的方法,以及如何通过辨别 (Discernment) 进行迭代,最终创作出一份他能引以为傲的提案。
关键要点
- 上传过去成功的作品,以帮助 AI 理解你组织的声音和方法——这能节省时间并提高真实性。
- 注入 AI 不知道的细节:你的过往记录、合作伙伴关系、员工专业知识以及真实的社区关系。
- 在修改时要具体:不要说“让这个更有说服力”,而要说“添加关于我们社区关系的这些具体细节”。
- 让你的专业知识指导每一次修改:AI 帮助你写得更快,但内容的实质由你塑造。
- 建立一个认知环境 (cognitive environment):人与 AI 之间的来回互动有助于工具随着时间的推移与你的特定需求保持一致。
- 为最终结果负责:当你提交由 AI 辅助创作的作品时,你应该能够为每一个字负责,因为你在整个过程中都运用了辨别力 (Discernment)。
练习 1:拨款提案
这个练习帮助你练习使用描述 (Description) 和辨别 (Discernment) 来创作能真实代表你组织的高风险筹款内容。
第一部分:自我反思
选择一个你需要资金的项目或倡议。制作一个写作提示,其中包括:
- 拨款机会以及资助者关心什么
- 你的项目关键细节(谁、什么、哪里、成果)
- 你组织的风格和价值观
- 具体要求(字数限制、必需元素、语气)
- 是什么让你的方法独特或有效
第二部分:协作
与 AI 分享你的提示并审查草稿。运用辨别 (Discernment):
- 验证所有声称的数据点和成果是否准确。
- 检查语言是否反映了你组织的真实风格,还是听起来很通用。
- 识别任何关于受益人的基于缺陷的框架或有问题的语言。
- 评估它是否解决了资助者的优先事项,还是仅仅描述了你的项目。
- 指出只有你了解的关于你工作所缺失的内容。
第三部分:反思
- 你最初忘记包含哪些可以改进草稿的背景信息?
- 为了更好地捕捉你组织的独特方法,你会对你的提示做哪些修改?
- AI 草稿的哪些部分可用,哪些需要完全重写?
延伸目标:针对你识别出的语气或框架问题,用具体的反馈迭代你的提示,然后比较两个版本,看看描述 (Description) 的改进如何影响输出质量。
练习 2:社交媒体帖子
这个练习将描述 (Description) 和辨别 (Discernment) 应用于需要为公众捕捉你组织真实声音的内容。
第一部分:自我反思
选择你的内容目标:
- 突出一个项目影响或成功故事
- 推广一个即将举行的活动或宣传活动
- 分享与你使命相关的教育内容
- 感谢捐赠者或志愿者
制作一个写作提示,其中包括:
- 平台和格式(Instagram 轮播图、LinkedIn 帖子、Facebook 故事等)
- 你的受众以及什么能激励他们
- 关键信息和号召性用语
- 你组织的社交媒体风格(专业、有趣、激进等)
- 任何需要的视觉元素(信息图数据、引言图、照片描述)
- 限制条件(字符限制、标签策略、无障碍要求)
第二部分:协作
与 AI 分享你的提示并审查内容。运用辨别 (Discernment):
- 检查语气是否与你组织实际的沟通方式相匹配。
- 验证任何统计数据或声明是否准确和最新。
- 评估语言是否尊重你所服务人群的尊严。
- 评估视觉建议的无障碍性(如适用,alt 文本、颜色对比度)。
- 考虑此内容是否会与你的实际关注者产生共鸣,还是感觉很通用。
第三部分:反思
- 你的提示是否捕捉到了让你组织社交媒体声音与众不同的地方?
- 你会保留草稿的哪些元素,又会完全重写哪些?
- 如果你请求了可视化内容,它是否为你的受众讲述了正确的故事?
延伸目标:要求 AI 为不同平台(Instagram、LinkedIn、Twitter/X)创建 3 个变体,并评估它将核心信息适应每个平台受众和规范的能力如何。
课程反思
- 上传过去的作品或提供详细的背景信息如何改变了 AI 写作输出的质量?
- 在与 AI 写作时,你将使用哪些策略来保持你组织的真实声音?
下一步
在下一课中,我们将探讨 AI 隐私,试图更好地理解你与 AI 共享的数据会发生什么。
反馈
随着你学习的深入,我们很乐意听到你如何将课程中的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
理解隐私和数据
你将学到什么
预计用时:30 分钟
在本课程结束后,你将能够:
- 阐明隐私顾虑,并根据其数据处理政策评估 AI 工具
- 实践数据卫生策略,以安全地处理敏感信息
理解隐私和数据
(10 分钟)
该视频解决了非营利组织专业人士对 AI 最常见的担忧之一:数据隐私。你将了解与 AI 工具共享的数据究竟会发生什么,如何评估不同平台和计划的隐私保护措施,以及如何为安全的 AI 使用准备敏感数据。
关键要点
- AI 引入了新的隐私考量——尤其是在训练方面:一些 AI 使用你的输入来训练未来的模型,这意味着你数据中的模式可能会影响未来的输出。
- 不同的工具有不同的规则:你用来头脑风暴活动主题的免费 AI 与具有严格数据保留政策的付费账户不同。根据你的任务选择你的工具——保护更强的工具可以更安全地共享敏感数据。
- 安全的 AI 使用不是要避免它——而是要负责任地使用它:在开始一个新项目之前,运用问题意识 (Problem Awareness) 和平台意识 (Platform Awareness)。通常,你可以通过将任务分解为多个部分来从 AI 中获得全部好处,而无需共享敏感信息。
- 你通常可以完全删除识别信息:对于模式分析,你很可能不需要姓名、联系方式或其他个人可识别信息 (PII)。从你的实际目标出发,反向确定哪些数据是真正必要的。
- 如果出现问题,你有多种选择:删除对话,通过平台的隐私流程请求数据删除,并遵循你组织的协议。
关于 Claude 隐私设置的说明
具体到 Claude,你可以在 privacy.anthropic.com 和 trust.anthropic.com 找到详细的数据政策信息。你可以直接在 Claude 应用中调整你的隐私设置,包括选择不让你的对话被用于训练。其他 AI 提供商应该有类似的资源——如果他们没有,这可能是一个危险信号。
练习 1:评估数据敏感性
这个练习帮助你培养关于哪些数据可以安全地与 AI 工具共享的判断力。
第一部分:审查样本数据
选择以下与你工作最相关的场景之一:
- 一份包含姓名、金额和联系信息的捐赠者捐赠历史电子表格
- 包含人口统计细节的项目参与者的调查回复
- 一份包含受益人故事和成果数据的拨款报告草稿
第二部分:标注敏感性
对于你选择的场景,确定:
- 哪些字段或部分包含个人可识别信息 (PII)?
- 哪些信息对于你想要进行的分析是必不可少的?
- 哪些信息可以在不损失分析价值的情况下被删除或匿名化?
- 如果这些数据被泄露,最坏的情况是什么?
第三部分:规划你的方法
- 在与 AI 共享之前,你会删除或修改什么?
- 哪种工具/计划级别适合这种敏感度?
- 收到 AI 的分析后,你会采取哪些验证步骤?
练习 2:实践数据卫生
这个练习将带你实际操作,为安全的 AI 使用准备敏感数据。
第一部分:选择你的文件
从你的工作中选择一个包含一些敏感信息的真实文件(或创建一个真实的样本)。这可以是:
- 一份包含客户细节的项目报告
- 一份提及具体捐赠金额的捐赠者沟通草稿
- 提及员工或志愿者姓名的会议记录
第二部分:清理文件
通读文件并:
- 用通用标识符(如“个人A”、“捐赠者1”等)替换姓名。
- 如果不重要,删除或泛化位置细节。
- 完全删除联系信息。
- 考虑具体的金额是否需要精确,或者可以是范围。
第三部分:用 AI 测试
与 AI 分享你清理后的文件,并提出一个与你工作相关的问题。反思:
- 删除识别信息是否限制了 AI 帮助你的能力?
- 你需要提供哪些额外的背景信息来弥补?
- 你对你共享的信息级别感到满意吗?
课程反思
- 思考 AI 隐私与你已经思考其他软件工具(电子邮件、云存储、CRM)的方式相比如何?
- 基于本课,你在与 AI 共享数据的方法上会做出哪一项改变?
下一步
在下一课中,我们将把这些隐私实践付诸行动,探索与 AI 进行数据分析——学习如何发现模式、产生见解,并在保护敏感信息的同时加强你的项目。
反馈
随着你学习的深入,我们很乐意听到你如何将课程中的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
与 AI 进行数据分析
你将学到什么
预计用时:50 分钟
在本课程结束后,你将能够:
- 使用委派-尽责 (Delegation-Diligence) 循环,系统地验证 AI 对你具体工作的分析能力。
- 应用描述 (Description) 和辨别 (Discernment),在识别数据模式的同时,认识到 AI 的局限性。
- 通过测试你已经理解的数据,建立对 AI 辅助分析的信心。
与 AI 进行数据分析
(7 分钟)
该视频解决了一个非营利组织专业人士在使用 AI 进行数据分析时面临的关键问题:我如何知道我能信任结果?你将跟随 Valley Veterans Services 的项目总监 Rio,他使用委派-尽责 (Delegation-Diligence) 循环,系统地利用他已经知道答案的过往数据来验证 AI 的分析能力。视频演示了如何通过测试建立信心,识别能力差距,并形成一种你可以自信地应用于新数据的方法。
关键要点
- 用你已经理解的数据来测试 AI:在信任 AI 进行新分析之前,用你已经知道正确结果的过往数据来验证它。如果 AI 在正确的指导下能匹配你已知的结果,你就可以自信地将它用于未来类似的任务。
- 使用辨别 (Discernment) 来识别 AI 推理中的差距:在测试时,注意 AI 错过了哪些重要背景,以及你需要提供哪些额外的描述 (Description)。
- 建立经过验证的方法,而不是盲目信任:每一轮测试都会告诉你 AI 擅长什么,以及它需要指导的地方。记录下有效的方法,以便你可以复制它。
- 即使你不擅长数据分析,AI 也能提供帮助:如果你自己对数据分析不熟悉,AI 可以帮助你头脑风暴解决方案,编写 Excel 公式,以及重新格式化混乱的数据——只需不断要求澄清,以便你理解整个过程。
- 验证能建立信心,但不能消除责任:你仍然有责任检查结果是否合理,并对 AI 的作用保持透明。
练习 1:消息分析
这个练习使用风险较低的数据(你自己的公开沟通内容)来练习用于数据分析的描述-辨别 (Description-Discernment) 循环。
第一部分:收集你的数据
收集 10-20 个你组织的沟通案例——社交媒体帖子、邮件主题行、时事通讯标题或活动公告。包括一些你认为表现好的和表现差的内容。
第二部分:用 AI 分析
与 AI 分享你的数据集,并要求它识别模式:
- 你的高表现内容中出现了哪些主题或话题?
- 出现了哪些语言、语气或格式模式?
- 你沟通的内容与引起共鸣的内容之间是否存在差距?
第三部分:运用辨别 (Discernment)
评估 AI 的分析:
- 识别出的模式是否与你对什么有效的感觉相符?
- AI 错过了关于你的受众或目标的哪些背景信息?
- AI 识别出的模式中是否有让你感到惊讶的?
反思:
- 你想从你的数据集中学到什么?
- 高表现内容如何与你真实的风格和组织价值观保持一致?
- 你是否触达了正确的受众?
延伸目标:使用 AI 审查你的消息传递如何与你组织声明的使命和价值观相比较,找出差异,并根据分析创建一个消息传递指南。
练习 2:分析捐赠者捐赠模式
这个练习将数据分析技能应用于高风险的筹款数据,并建立在第 5 课的数据卫生实践之上。
第一部分:准备你的数据
使用第 5 课中清理过的捐赠者数据集,或者通过删除个人可识别信息来准备一个新的数据集。确保你有跨越多个时间段的历史捐赠数据。
第二部分:用 AI 分析
要求 AI 识别以下模式:
- 随时间变化的捐赠者保留率
- 重复捐赠与一次性捐赠的模式
- 宣传活动效果比较
- 按金额范围划分的捐赠趋势
第三部分:运用辨别 (Discernment)
批判性地评估 AI 的发现:
- 这些趋势是否与你对捐赠者群体的了解相符?
- AI 是否只关注货币价值,而忽略了关系因素?
- 哪些模式有助于加强捐赠者关系,而不仅仅是最大化收入?
反思:
- 实施效率建议的成本可能是什么?(例如,如果发现表明应重点关注主要捐赠者而牺牲小额捐赠者,这对社区认知或长期可持续性有何影响?)
- 除了捐赠金额外,哪些模式有助于加强与捐赠者的关系?
练习 3:趋势分析以预测社区需求(延伸目标)
这个高级练习结合了多个数据源,以练习预测分析——一个备受追捧的能力。
第一部分:收集多样化的来源
收集你已经用来了解社区需求的信息:
- 你自己的项目数据和服务请求
- 关于你社区的外部报告或数据集
- 影响你服务对象的新闻或政策发展
第二部分:分析新兴模式
要求 AI 帮助你识别:
- 人们请求支持类型的趋势
- 可能增加或改变需求的外部因素
- 当前服务与新兴需求之间的差距
第三部分:运用严格的辨别 (Discernment)
这种分析需要最高水平的批判性评估:
- AI 的预测与你的直接社区经验相比如何?
- AI 可能忽略了哪些系统性因素或本地背景?
- 在以尊严和尊重预测社区需求时,你需要牢记哪些价值观?
反思:
- 你如何负责任地处理这个过程?
- 哪些因素和系统性问题可以解释或情境化 AI 无法做到的事情?
课程反思
- 用你已经理解的数据测试 AI 如何改变了你使用它进行新分析的信心?
- 你识别出了哪些差距或局限性,这将影响你未来如何委派数据分析任务?
下一步
在下一课中,我们将探讨工作流程增强——当 AI 代表你处理常规任务时,如何应用这些相同的原则,从而解放你的时间用于更高影响力的工作。
反馈
随着你学习的深入,我们很乐意听到你如何将课程中的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
工作流程增强
你将学到什么
预计用时:40 分钟
在本课程结束后,你将能够:
- 将 4D 框架的所有四个维度结合起来,与 AI 一起构建一个可重复的流程。
工作流程自动化
(6 分钟)
该视频将 4D 框架的所有四个维度汇集在一起,构建一个实用的工作流程自动化。你将跟随一位名叫 Emily 的发展协调员,她正在为组织的年度晚会做准备,并建立一个 AI 辅助的电子邮件响应系统。视频演示了如何根据 AI 应处理的内容与需要人工关注的内容对任务进行分类,如何精确地描述系统的行为,以及如何通过测试和透明度来保持尽责 (Diligence)。
关键要点
- 从问题意识 (Problem Awareness) 开始:在接触任何 AI 工具之前,先分析你实际的工作量。人们在问什么?出现了什么模式?在决定要自动化什么之前,先列一个具体清单。
- 任务委派 (Task Delegation) 意味着问“AI 应该做这个吗?”而不仅仅是“AI 能做这个吗?”:一些任务(如回答有记录的问题)是自动化的好选择。而另一些(如处理投诉或高风险请求)则应由人类处理。
- 用真实案例迭代测试:使用你收到的实际邮件来测试系统。你会发现描述中的差距需要完善——这是正常且必要的。
- 实践所有三种类型的尽责 (Diligence):创建尽责 (Creation Diligence) 意味着有意识地决定自动化什么。部署尽责 (Deployment Diligence) 意味着在输出发布前进行审查(尤其是在早期)。透明尽责 (Transparency Diligence) 意味着诚实地说明 AI 的作用,尤其是在出现问题时。
练习 1:规划你的自动化机会
这个练习帮助你识别工作中哪些重复性任务是 AI 自动化的好选择。
第一部分:审计你的重复性任务
回顾你过去一周的工作。列出 5-10 个让你觉得重复或耗时的任务。对于每个任务,请注意:
- 这发生的频率如何?(每天、每周、每月)
- 每次需要多长时间?
- 响应/流程是基本标准化的,还是差异很大?
第二部分:按 AI 适宜性分类
将你的任务分为三类:
- AI 可以处理:标准化的响应、有记录的信息、清晰的流程
- AI 可以辅助,人类决定:AI 可以起草或准备,但你在行动前审查的任务
- 人类应该处理:高风险决策、情绪化情境、复杂的判断
第三部分:确定优先级
从你的“AI 可以处理”或“AI 可以辅助”类别中选择一个能为你节省最多时间的任务。这将是你的自动化候选任务。
反思:
- 什么标准帮助你决定每个任务属于哪个类别?
- 你是否对适合自动化的任务数量之多(或之少)感到惊讶?
练习 2:构建你的自动化描述
这个练习将带你使用三种类型的描述 (Description) 来描述一个自动化系统。
第一部分:定义你的产出
对于你在练习 1 中确定的任务,写一个清晰的产出描述 (Product Description):
- 你想要的最终结果是什么?
- 系统将接收什么输入?
- 它应该产生什么输出?
第二部分:定义你的流程
写一个过程描述 (Process Description),概述步骤:
- 系统首先应该做什么?
- 存在哪些决策点?
- 什么时候应该升级给人类处理?
- 它需要访问哪些信息?
第三部分:定义表现
写一个表现描述 (Performance Description),定义行为:
- 它应该使用什么语气?
- 它应该如何处理不确定性?
- 它绝对不应该做什么?
- 它应该如何回应请求者的请求?
第四部分:用真实案例测试
与 AI 分享你的描述以及 3-5 个你工作中的真实案例。评估输出:
- 它是否正确分类了?
- 响应是否准确和恰当?
- 你的描述需要做哪些调整?
练习 3:规划尽责 (Diligence)(延伸目标)
这个练习帮助你思考自动化的责任方面。
第一部分:创建尽责 (Creation Diligence)
回答关于你计划的自动化的问题:
- 为什么这个任务适合由 AI 处理?
- 可能会出什么问题,你将如何发现?
- 如果 AI 犯错,影响是什么?
第二部分:部署尽责 (Deployment Diligence)
规划你的审查流程:
- 你会审查每一个输出,还是定期抽样?
- 你将如何随时间监控问题?
- 哪些触发因素会导致你暂停自动化?
第三部分:透明尽责 (Transparency Diligence)
决定你的透明度方法:
- 谁需要知道 AI 参与其中?
- 你将如何披露 AI 的作用?
- 如果有人想要人工服务,你将提供哪些后续选项?
课程反思
- 将 4D 框架的所有四个维度结合起来使用,如何改变了你处理这个自动化任务的方式?
- 在精确地描述一个足以让 AI 执行的自动化系统过程中,有什么让你感到惊讶的?
下一步
在下一课中,我们将讨论如何深思熟虑且可持续地将 AI 整合到你的组织中——从解决对 AI 依赖的担忧到建立一个反映你价值观的 AI 政策。
反馈
随着你学习的深入,我们很乐意听到你如何将课程中的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
整合
你将学到什么
预计用时:45 分钟
在本课程结束后,你将能够:
- 以加强人类能力和推进使命的方式将 AI 整合到你的组织中
- 解决对 AI 依赖和保持人际联系的担忧
- 创建一个反映你价值观并确保可持续使用 AI 的组织 AI 政策
整合
(5 分钟)
该视频解决了非营利组织专业人士对组织 AI 采纳最常见的两个担忧:我如何避免变得过于依赖 AI?以及我们如何平衡效率与人情味?视频介绍了成为“人类在环 (human in the loop)”的概念,以及这对于使命驱动的组织具体意味着什么。然后,它详细介绍了一个组织 AI 政策的关键要素,这可以帮助你在团队中推广 AI 素养。
关键要点
- 成为“人类在环”不仅仅是监督:在非营利组织的背景下,它意味着确保 AI 服务于你的使命——你决定 AI 应该帮助解决什么问题,你评估解决方案是否符合你的价值观,并且你维护定义非营利工作的关系和现实世界的影响。
- 通过理解而非回避来避免依赖:定期反思你的流程并问“我们能解释 AI 在做什么吗?”如果可以,那就是健康的增强。如果不可以,就重新设计你的流程,直到你可以为止。
- AI 应该让你有更多时间从事人类工作,而不是更少:在最好的情况下,AI 减少噪音,让你能专注于手写的卡片、个性化的外联,以及与社区中个体相处的时间。在最坏的情况下,它将这种人情味自动化了。
- 尽早建立关于生产力的文化规范:当你将 AI 引入你的组织时,讨论关于节省下来的时间该如何使用的期望,以确保每个人都对 AI 支持的工作感到满意。
- AI 政策有助于推广你的理解:政策记录了你关于平台、任务委派、质量监督、透明度和价值观一致性的决定,以便整个组织可以一致地工作。
练习:起草你的组织 AI 政策
这个练习汇集了你在本课程中学到的一切,以创建一个可以指导你整个组织使用 AI 的实用文件。
第一部分:平台意识 (Platform Awareness)
回答这些问题以建立你的技术指南:
- 你的组织将使用哪些 AI 工具?哪些是禁止的?
- 对于不同类型的工作,哪些数据保留和训练政策是可以接受的?
- 不同的敏感度级别需要哪些不同的工具或保护措施?
- 你将如何随着工具和政策的变化保持信息更新?
第二部分:任务委派 (Task Delegation)
定义 AI 使用的边界:
- 哪些类型的工作适合 AI 辅助?
- 哪些工作应该完全由人类完成?为什么?
- 谁来决定一个新的用例是否合适?
- 你如何处理灰色地带?
第三部分:期望和能力
解决 AI 整合的人文方面:
- 通过 AI 效率节省的时间将如何重新分配?
- 对不同角色的现实期望是什么?
- 你将如何在团队中建立 AI 能力(而不仅仅是一个“AI 专家”)?
- 当基于 AI 的工作流程失败时会发生什么?
第四部分:质量和监督
建立问责制:
- 在 AI 输出被使用或分享之前,谁来审查?
- 对于不同类型的内容,需要哪些验证步骤?
- 当 AI 犯错时会发生什么?
- 你将如何随时间监控问题?
第五部分:透明度
决定你将如何沟通 AI 的使用:
- 利益相关者、资助者以及你所服务的人需要了解你使用 AI 的哪些情况?
- 你将如何在具体的输出中披露 AI 的参与?
- 在拨款、报告和沟通中,你对 AI 署名的态度是什么?
第六部分:价值观一致性
将 AI 的使用与你的使命联系起来:
- 你如何确保 AI 服务于你的使命,而不是反过来?
- 哪些价值观和道德原则指导你的 AI 决策?
- 在与弱势群体进行 AI 辅助工作时,你将如何保持尊严和尊重?
- 什么时候你应该选择不使用 AI,即使它会更有效率?
第七部分:汇编和审查
与 AI 合作,将你的答案整合成一份政策文件草稿:
- 分享你的回答,并请 AI 帮助将它们组织成一份清晰、可用的政策。
- 审查草稿的完整性以及是否符合你组织的风格。
- 确定需要与你的团队进一步讨论的任何差距或领域。
- 规划随着你组织 AI 使用的发展,你将如何引入和重新审视这项政策。
课程反思
- 从本课程开始到现在,你对 AI 整合的看法有何变化?
- 基于你所学的知识,你在与 AI 合作时会采取哪一项不同的做法?
反馈
我们很乐意听到你如何将本课程的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
下一步
你将学到什么
预计用时:15 分钟
在本课程结束后,你将能够:
- 访问蓝图和资源,继续建立你的 AI 素养
- 与你组织中的同事分享你所学的知识
- 了解在哪里领取你的结业证书
下一步
(5 分钟)
该视频汇集了你所学的一切,并挑战你立即将其付诸实践。你将获得关于如何从你的工作中选择一个真实任务,应用 4D 框架的所有四个能力,并通过亲身实践来建立 AI 素养的指导。视频还介绍了支持你继续学习的蓝图和资源。
关键要点
- 本周从一个真实任务开始:选择一个等着你去做的任务——一份拨款申请、一份捐赠者报告、需要分析的项目数据——并利用你所学的知识,在 AI 的支持下完成它。
- 应用完整的 4D 框架:从委派 (Delegation) 开始(哪些需要 AI 支持 vs. 人类判断?),转到描述 (Description)(分享你组织的背景、任务要求和期望的结果),使用辨别 (Discernment)(评估并通过迭代进行改进),并实践尽责 (Diligence)(为最终结果负责)。
- 记住这是一个循环,不是一条直线:你可能会从委派流向描述,再回到辨别,然后意识到你想以不同的方式进行委派。这就是你的 AI 素养通过实践在增长。
- 使用蓝图指导你的初次尝试:访问针对常见非营利任务的逐步指南,以支持你最初的 AI 互动。
- 与你的社区分享:使用你的结业证书在你组织中开启关于 AI 素养的对话。
你的最终作业
在完成本课程之前,请从你的工作中选择一个真实任务,本周在 AI 的支持下完成它。
第一步:选择你的任务
选择一个具体的、等着你去做的任务:
- 即将到期的拨款申请或报告
- 你一直拖延的捐赠者沟通
- 需要分析的项目数据
- 需要更新的政策或程序
- 活动策划或宣传内容
第二步:应用 4D 框架
逐一实践每个能力:
- 委派 (Delegation):哪些部分能从 AI 支持中受益?哪些需要你的人类判断?
- 描述 (Description):分享你组织的背景、任务要求,以及你希望 AI 如何处理它。
- 辨别 (Discernment):评估你得到的结果,找出差距,并完善你的方法。
- 尽责 (Diligence):为最终结果负责,验证准确性,并在适当的地方保持透明。
第三步:反思你的经验
完成任务后,思考:
- 哪些地方做得好?你会做哪些不同的事情?
- 哪些能力感觉很自然?哪些需要更多练习?
- 你将如何将这种方法应用于未来的任务?
继续你的学习 蓝图
在 https://claude.com/resources/use-cases/category/nonprofits 访问针对常见非营利任务的逐步指南。这些蓝图涵盖:
- 拨款写作和报告
- 捐赠者沟通和前景研究
- 数据分析和可视化
- 以及更多
资源
你可以访问:
- 4D 框架指南
- 关键术语备忘单
- 课程练习和反思提示
加深你的理解
如果你还没有学习,Anthropic 的《AI 素养:框架与基础》课程对 4D 框架及其应用提供了更深入的探索。
课程反思
- 你承诺本周在 AI 支持下完成的一个任务是什么?
- 从本课程开始到现在,你与 AI 的关系有何变化?
- 你组织或网络中的谁会从学习这门课程中受益?
恭喜!
恭喜你完成“非营利组织的 AI 素养”!你已经在 4D 框架中建立了基础,实践了将其应用于研究、写作、数据分析和工作流程自动化,并为负责任的组织整合制定了策略。
请记住:AI 素养不是一个终点——它是一个持续的实践。工具将继续发展,但你所学的框架将帮助你深思熟虑地适应,将你的使命和价值观置于每一个决定的中心。
在回答几个快速问题后,你将在下一课中获得结业证书。
反馈
我们很乐意听到你如何将本课程的概念应用到工作中,以及你的任何反馈。在此处分享你的反馈。
致谢与许可
版权所有 2025 Anthropic and Giving Tuesday。基于 Rick Dakan 教授(瑞林艺术与设计学院)和 Joseph Feller 教授(科克大学学院)开发的 AI 素养框架。根据 CC BY-NC-SA 4.0 许可发布。
课程测验
[无内容]
第 6 课:教授 AI 素养
面向教师的 AI 素养教学方法论 课程链接:教授 AI 素养 | 共 8 节课
AI 素养教学简介与方法
AI FLUENCY FRAMEWORK (AI 素养框架) = 一个双重用途的工具,既描述了人们与 AI 协作时发生的情况,又引导他们采用更好的实践方法
课程结构 = 3 节课,分别阐述:1) 如何向学生介绍该框架 (教学法),2) 如何评估学生是否理解 (评估),3) 如何与现有课程整合
教学方法 = 4 种不同的切入点,用于向学生介绍 AI 素养框架
方法 1:循序渐进 (线性)
- 框架作为一个顺序过程:Delegation (委派) → Description (描述) → Discernment (辨别) → Diligence (审慎)
- 最适合:需要结构化和可管理进度的 AI 初学者
- 实施:由四部分组成的作业,循序渐进 (例如,第 1 部分 = 委派/项目规划,第 2 部分 = 描述/动手工作坊,第 3 部分 = 辨别/评估,第 4 部分 = 审慎/伦理)
- 优点:自然、直观,创造结构化的学习旅程
方法 2:从任何地方开始 (非线性)
- 框架作为一个相互关联的系统,任何能力都可以是起点
- 最适合:能够应对真实世界复杂性的有经验的 AI 用户
- 核心洞见:各项能力相互影响 (辨别问题 → 新的委派决策;审慎要求 → 不同的描述策略;描述挑战 → 委派差距)
- 实施:小组项目,基于真实 AI 协作场景的案例学习
- 优点:反映了实际 AI 协作的复杂现实,培养适应性思维
方法 3:一次只关注一个 D (聚焦)
- 一次深入探索单一能力
- 最适合:特定目的、技能培养课程、工作坊
- 实施:整个工作坊专注于一项能力 (例如,三个辨别课程,分别涵盖产品/过程/表现评估)
- 优点:在没有认知过载的情况下掌握特定领域,允许对技术和边缘案例进行细致入微的探索
方法 4:两个循环
- 最具概念性的方法,将 AI 素养视为嵌套的过程
- 最适合:已掌握基础知识并需要更深入理解的学生
- 结构:委派-审慎循环 (战略/伦理决策) + 描述-辨别循环 (战术/迭代工作)
- 优点:揭示了各项能力在实践中如何不断相互影响
委派-审慎循环 = 负责任的 AI 协作的战略和伦理决策框架
循环组件: Delegation (委派) = 问题意识 + 平台意识 + 任务委派 Diligence (审慎) = 创作审慎 + 透明度审慎 + 部署审慎
双向流动: 正向 (委派 → 审慎):战略决策引发伦理问题 反向 (审慎 → 委派):伦理约束澄清并改进战略选择
教学策略:
- 应用场景使联系清晰可见
- 为两个方向提供分步指南
- 认识到约束能增强而非限制创造力
- 专注于为选择提供清晰的理由
描述-辨别循环 = 为人机协作构建 cognitive environment (认知环境) 的即时技巧
核心概念:是对话而非命令 - 建立共享的背景和理解,而不是单一的提示词交换
认知环境 = 协作背景,包括:
- 随时间演变的共享词汇和参考
- 定义明确的目标、价值观、流程、方法
- 已建立的实现最佳表现的交互模式
- 在先前互动基础上发展的机制
三个视角: 产品 = 我们共同创造的东西 (对目标和质量不断演变的理解) 过程 = 共享的思考和解决问题的方法 表现 = 人与 AI 之间的关系动态
教学策略:
- 需要积累背景知识的多重互动作业
- 分享教师自己的 AI 协作过程
- 记录协作的演变,而不仅仅是输出
- 从自动化转向 augmentation (增强)
成功指标:
- 共享语言:对早期对话中复杂思想的简写引用
- 探索心态:从刻板的命令演变为灵活、互动的approche
嵌套系统 = 两个循环如何协同工作: 委派-审慎循环 = 设定方向和边界的战略容器 描述-辨别循环 = 用丰富的互动填充容器的战术内容 结果 = 负责任、成熟的 AI 协作,超越任何一方单独能达到的成就
课程时长 = 2 小时 (30 分钟视频,90 分钟练习)
练习结构 = 3 个渐进式练习,培养教学能力:
- 建立教学背景并探索方法 (30 分钟)
- 设计委派-审慎循环课程 (30 分钟)
- 设计描述-辨别循环课程 (30 分钟)
评估与设计 AI 素养
评估与设计 AI 素养笔记
核心评估框架
AI 素养评估 = Outcome-based assessment (成果导向评估) + Process-based assessment (过程导向评估) + Reflection-based assessment (反思导向评估) 的结合
成果导向评估 = 关注学生通过 AI 协作产出的内容。评估学生是否通过人机合作实现了既定目标。
过程导向评估 = 考察学生如何随时间与 AI 协作。捕捉迭代模式、从失败中恢复的能力、方法的成熟度。
反思导向评估 = 关注元认知意识。学生分析策略成功/失败的原因、学到了什么以及未来的应用。
评估 4D
委派 (Delegation) 评估
- 成果:委派计划是否合理?目标是否现实?工具选择是否正确?
- 过程:审查带有注释的 chat logs (聊天记录),显示对选项的探索和决策过程
- 反思:学生解释他们的选择、考虑过的替代方案,以及委派如何影响最终成果
描述 (Description) 评估
- 成果:提示词和 AI 回应的质量。指令是否清晰?背景是否充分?从初版到终版的演变
- 过程:对话记录显示迭代优化、失败的尝试、建立共享背景的过程
- 反思:分析哪些描述技巧最有效,针对特定任务的沟通方法,描述质量与输出质量的关系
辨别 (Discernment) 评估
- 成果:学生注释 AI 输出,标记优点/缺点。决策日志解释了保留/修改/丢弃了什么
- 过程:行内评估评论,捕捉/纠正错误,跨交互的模式识别
- 反思:分析评估标准的变化、最初错过的问题、不同任务类型间的比较
审慎 (Diligence) 评估
- 成果:审慎声明的质量、署名/透明度文档、事实核查证据
- 过程:聊天记录中的数据处理、伦理决策、敏感信息处理、约束检查
- 反思:讨论伦理困境、对责任的理解、意外的挑战、未来的改进
作业设计原则
真实性 (Authenticity) = 创建模拟真实世界 AI 协作的作业,解决 AI 合作能增值的真实问题
迭代 (Iteration) = 内置优化机会,展示随时间的成长
教学透明度 (Pedagogical Transparency) = 明确评估协作过程和反思,而不仅仅是最终输出
作业类型
成果导向作业
- 改进 AI 输出:将平庸的 AI 输出转变为优秀的作品
- 产品比较:使用多个 AI 系统完成相同任务,分析差异
- 基于约束的挑战:满足特定要求 (格式、长度、风格、受众)
- 同伴产品评审:学生设定目标,与 AI 共同创作,然后交换并互相评论
过程导向作业
- 带注释的聊天记录:学生标出转折点、突破、失败恢复的关键时刻
- 录屏解说:在 AI 工作期间实时解释决策过程
- 过程手册:针对不同任务类型的个人 AI 策略指南
- AI 辅助/同伴复盘:与 AI 或同伴讨论聊天记录
反思导向作业
- 引导式探究:针对特定作业提出具体问题
- 学习日志:通过整个课程的证据自我评估 4D 的发展
- 情景/案例研究:将所学应用于假设或真实世界情景
- 个人策略声明:制定自己的 AI 协价值观/策略
管理作业量
详细的交付成果评分标准 = 清晰、细化的 deliverable (交付成果),便于快速核对
强调自我和同伴评审 = 在适当指导下,学生最能观察到自身发展
闪电式会议 = 简短的会议取代书面反馈 (5 分钟讨论)
选择性抽样 = 不用阅读每个字;学生标记出关键时刻以供关注
关键评估产物
聊天记录 = 主要的过程文档 审慎声明 = 透明度和署名文档 学习日志 = 反思和元认知发展 决策日志 = 记录保留/修改/丢弃了哪些 AI 输出 过程手册 = 个人策略文档
评估重点领域
关注可观察的行动和具体的产物,而不是对理解程度的假设
不同的能力适合不同的评估方法
评估应是学习机会,而不仅仅是衡量
学生需要明白你关心的是他们如何学习与 AI 协作,而不仅仅是他们产出了什么
基本原则:通过文档和反思让无形的决策过程变得可见
AI 素养作业组件指南
AI 素养作业组件
成果导向组件
改进 AI 输出 = 学生通过批判和迭代将平庸的 AI 输出转变为优秀作品
- 评估重点:辨别 (Discernment)、描述 (Description)
- 交付成果:带注释的原始版本 + 改进版
- 有效原因:强制建立明确的质量标准,需要应用领域知识,培养 AI 指导技能
- 变体:不同类型的缺陷,同伴改进交换
产品比较 = 学生使用多个 AI 系统完成相同任务,分析差异
- 评估重点:委派 (Delegation)、辨别 (Discernment)
- 交付成果:多个输出 + 比较矩阵 + 推荐报告
- 有效原因:建立平台意识,培养基于证据的选择技能,揭示权衡
- 过程:使用标准的 AI 助手 + 具备推理能力的系统 + 专业系统
基于约束的挑战 = 在限制内通过 AI 协作达成特定要求
- 评估重点:描述 (Description)、委派 (Delegation)
- 交付成果:满足所有约束的最终产品
- 有效原因:发展精确的 AI 沟通能力,揭示规范的重要性,培养在限制下解决问题的能力
- 变体:伦理约束,相互冲突的约束,时间压力
同伴产品评审 = 根据目标和伦理评估同伴的 AI 辅助作品
- 评估重点:辨别 (Discernment)、审慎 (Diligence)
- 交付成果:评审反馈表
- 标准:目标达成度,AI 使用的适当性,人类监督质量,AI 署名充分性
- 变体:盲审,小组会议
过程导向组件
带注释的聊天记录 = 提交完整的聊天记录并附有详细注释
- 评估重点:描述 (Description)、辨别 (Discernment)
- 注释标记:转折点,见解/突破,失败/恢复,沟通演变,共享背景的建立
- 有效原因:使思维过程可见,捕捉真实的解决问题过程,揭示沟通的演变
- 变体:以能力为重点的注释,模式比较
录屏解说 = 屏幕录制并实时口述 AI 工作过程
- 评估重点:所有 4D
- 解说内容:选择的理由,对回应的评估,考虑过的替代方案,伦理考量
- 有效原因:捕捉真实的决策过程,揭示隐性知识,显示实际工作与报告工作的差异
- 变体:配对评论,前后对比
过程手册 = 个人 AI 协作策略参考指南
- 评估重点:所有 4D
- 包括:对话指南,决策树,质量清单,陷阱恢复,伦理准则
- 有效原因:鼓励系统性文档记录,创建有用的资源,建立元认知意识
- 变体:协作手册,特定学科的要求
AI 辅助/同伴辅助复盘 = 从外部视角对 AI 协作进行结构化分析
- 评估重点:所有 4D
- 分析内容:积极模式,错失的机会,优势,改进领域
- 有效原因:提供外部视角,揭示盲点,鼓励同伴学习
反思导向组件
引导式探究 = 回答促进深度反思的特定问题
- 评估重点:因问题而异
- 问题类型:惊喜时刻,失败的策略,沟通的演变,伦理决策
- 有效原因:针对特定的 AI 素养方面,要求基于证据的反思
- 变体:学科定制,渐进式问题
学习日志 = 持续记录 AI 素养的发展
- 评估重点:所有 4D 的长期发展
- 每周条目:尝试,成功,挑战,技能提升,未来目标
- 每月总结:模式识别,目标设定
- 变体:多媒体日志,协作日志,AI 对话日志
情景和案例研究 = 将 AI 素养学习应用于现实情景
- 评估重点:审慎 (Diligence)、委派 (Delegation)
- 分析包括:委派决策,伦理考量,行动计划,风险缓解
- 有效原因:培养战略思维,建立伦理推理能力,连接理论与实践
- 变体:真实案例,特定学科情景,利益相关者角色扮演
个人策略声明 = 将学习综合成个人 AI 协作框架
- 评估重点:审慎 (Diligence),整体性评估所有 4D
- 组件:伦理原则,决策标准,质量标准,透明度承诺,界限,学习策略
- 有效原因:需要深度综合,建立职业认同,创建问责制
- 变体:小组工作的协作策略
评估矩阵
委派 (Delegation) 评估矩阵:
- 强劲表现 = 对何时/为何/如何与 AI 协作进行战略性思考
- 成果重点:任务划分质量,工具选择适当性,目标达成度
- 过程重点:决策文档,平台探索,适应证据
- 反思重点:选择分析,替代方案考量,影响评估
描述 (Description) 评估矩阵:
- 强劲表现 = 就输出/过程/行为与 AI 进行有效沟通
- 成果重点:提示词演变,背景建立,沟通清晰度
- 过程重点:迭代优化,恢复模式,共享词汇发展
- 反思重点:策略分析,技术识别,背景洞察
辨别 (Discernment) 评估矩阵:
- 强劲表现 = 使用特定领域、细致入微的标准进行批判性评估
- 成果重点:注释质量,评估深度,基于证据的判断
- 过程重点:错误捕捉,一致性,随时间提升的质量
- 反思重点:标准演变,错过问题分析,元评估技能
审慎 (Diligence) 评估矩阵:
- 强劲表现 = 在整个协作过程中整合伦理推理
- 成果重点:署名质量,透明度文档,验证证据
- 过程重点:数据处理,许可文档,约束检查
- 反思重点:伦理困境讨论,责任理解,价值观阐述
矩阵使用:
- 评分标准制定:选择相关的 D,选择评估类型,调整指标,定义表现水平
- 提供反馈:使用指标指导评审,参考强劲表现的标志
- 学生评估:事先分享标准,鼓励自我识别能力证据
AI 对您学科的影响
课程概览
- 时长 = 50+ 分钟 (20 分钟视频 + 30 分钟练习 + 线下讨论)
- 重点 = AI 对特定学科在课程/教学/评估方面的影响
- 目标 = 使用 4D 框架创建特定学科的 AI 素养应用
核心原则 AI 素养 = 放大人类专业知识,而非取代它 学科知识 = 通过 AI 合作取得前所未有成就的基础
给毕业生的三个关键问题
- 什么会被自动化? = AI 会处理哪些常规职业任务
- 合作潜力在哪? = 人机协作在哪些领域影响最大
- 谁来负责? = 如何管理独立的 AI 工作并对其负责
AI 颠覆模式 颠覆在不同学科中并非一成不变
- 课程可能保持稳定,而评估方式发生转变
- 教学法可能演变,而核心内容保持不变
- 一些颠覆是机遇,可以加以利用
- 另一些则是问题,需要解决
- 你的专业知识决定了它是哪一种
应对 AI 的三种专业知识类型
- 学科专业知识 = 领域内容、价值观、方法、思维模式
- 教学专业知识 = 学生挣扎/突破的模式,学习的情感旅程
- 评估专业知识 = 识别真正的理解,设计深度学习评估
课程影响分析 学科评估任务:
- 识别领域内 AI 的自动化能力
- 确定基础概念的重要性如何随 AI 变化
- 将 AI 增强改进映射到最佳实践
- 准备回答“既然 AI 能做 X,为什么还要学?”这类问题
- 定义如何有效指导 AI 智能体
教学法转型 增强机会:
- 规模化的个性化辅导
- 交互式模拟
- 即时反馈系统
- AI 作为教育助手/互动学习伙伴
风险评估:
- 区分增强学习与削弱学习的 AI
- 识别能发挥潜力的师生 AI 协作模式
- 确定应采纳与应避免的教学方法
- 应对学生无论如何都会使用 AI 的现实
评估革命 核心挑战:
- 当学生几秒钟就能生成文章时,我们评估的是什么?
- 创建尊重个人成长/创造力/解决问题能力的评估
- 评估 AI 辅助和纯人工两种表现
基本任务:
- 在 AI 辅助工作中识别真实学习的体现
- 创建学生无法用 AI 走捷径的作业
- 重视过程/成长,而不仅仅是产品
- 确定 AI 协作在何处增强与何处削弱目标
- 适应学生使用 AI 的现实
不可替代的人类能力
- 领域专业知识
- 对真实世界背景的理解
- 在模糊情况下的判断力
- 创造性解决问题
- 伦理推理
- 建立关系
将 4D 应用于学科
辨别 (DISCERNMENT) = 质量评估能力 建立质量标准:
- 超越模糊术语,清晰阐述卓越
- 创建捕捉深层质量标志的详细评分标准
- 记录学生可以内化/应用的标准
收集优秀作品:
- 与学生系统地分析范例
- 通过注释指南使专家思维过程可见
诊断失败:
- 深入研究有缺陷的例子
- 理解单独工作或与 AI 协作时的失败模式
描述 (DESCRIPTION) = 掌握领域沟通 绘制学科产品图谱:
- 精确记录关键领域产出
- 创建揭示底层逻辑的模板
- 让学生对专业产出进行逆向工程
揭示专家思维:
- 使专家解决问题的方法过程可见
- 记录微观决策和迭代
- 创建专家思维流程图
命名领域规范:
- 浮现定义你领域的行为
- 与学生一起构建行为表现模式
委派 (DELEGATION) = 理解工作分解 揭示问题结构:
- 将挑战分解为组成部分
- 创建问题结构图
- 绘制 AI 自动化/增强/智能体可能性的图谱
设计决策树:
- 创建何时/如何让 AI 参与的框架
- 通过案例研究构建,使委派决策明确化
审慎 (DILIGENCE) = 体现领域价值观 编纂伦理框架:
- 定义特定领域的“不伤害”原则
- 构建探索伦理边缘的案例研究
- 创建伦理决策矩阵
明确透明度规范:
- 按领域记录披露期望
- 创建 AI 辅助披露模板
共同创建问责政策:
- 与学生共同建立标准,而非强加于人
- 一起起草政策
- 制定同伴评审协议
反馈循环的好处 能阐明质量的学生 → 能更好地评估任何输出 理解方法的学生 → 能有效地指导任何过程 内化伦理的学生 → 能负责任地驾驭任何协作
练习
练习 1:AI 影响立场文件 (40 分钟) 第 1 步:用 AI 探索课程 (10 分钟) 第 2 步:教学转型分析 (10 分钟) 第 3 步:评估策略重构 (10 分钟) 第 4 步:立场综合 (10 分钟)
练习 2:与同事进行 4D 讨论 辨别讨论 = “质量是什么样的?” 描述讨论 = “我们如何沟通?” 委派讨论 = “我们要做什么工作?” 审慎讨论 = “我们的价值观/标准是什么?”
最终信息 目标 ≠ 培养学生被 AI 取代 目标 = 培养学生变得不可替代 未来需要能够批判性思考、清晰沟通、明智协作、负责任行动的人
人类专业知识 + AI 素养 = 在 AI 增强的未来中茁壮成长的基础
第 7 课:Agent Skills 入门
学习创建和管理 Claude Code 技能 课程链接:Agent Skills 入门 | 共 6 节课
什么是 skills (技能)?
你将学到什么
预计用时:15 分钟
在本课程结束后,你将能够:
- 定义什么是 Claude Code skills (技能) 以及它们如何工作
- 解释 skills (技能) 的存放位置(个人目录与项目目录)
- 区分 skills (技能)、
CLAUDE.md和 slash commands (斜杠命令) - 识别哪些场景适合使用 skills (技能) 这一自定义工具
什么是 skills (技能)?
(3 分钟)
本视频介绍 skills (技能)——一种可重用的 markdown 文件,它能教会 Claude Code 如何自动处理特定任务。你无需在每次要求 Claude 审查 PR 或撰写提交信息时重复指令,只需编写一次 skill,Claude 就会在任务出现时应用它。视频内容包括:什么是 skills (技能)、它们存放在哪里,以及它们与 Claude Code 其他自定义选项的比较。
核心要点
- Skills (技能) 是包含指令的文件夹,Claude Code 可以发现并使用它们来更准确地处理任务。每个 skill 都存在于一个
SKILL.md文件中,其frontmatter (前言)部分包含名称和描述。- Claude 使用描述来将 skills (技能) 与请求进行匹配。当你要求 Claude 做某件事时,它会将你的请求与可用的 skill 描述进行比较,并激活匹配的 skills (技能)。
- 个人 skills (技能) 存放于
~/.claude/skills,并跟随你在所有项目中。项目 skills (技能) 存放于仓库内的.claude/skills目录中,并与克隆该仓库的任何人共享。- Skills (技能) 按需加载——与加载到每个对话中的
CLAUDE.md或需要显式调用的 slash commands (斜杠命令) 不同,skills (技能) 在 Claude 识别到相应情境时会自动激活。- 如果你发现自己总是在向 Claude 重复解释同样的事情,那么这就是一个有待编写的 skill。
每次你向 Claude 解释团队的编码标准时,你都在重复自己。每次进行 PR 审查时,你都要重新描述你希望反馈的结构。每次撰写提交信息时,你都要提醒 Claude 你偏好的格式。Skills (技能) 解决了这个问题。
一个 skill 是一个 markdown 文件,它一次性地教会 Claude 如何做某件事。然后,Claude 会在相关时自动应用该知识。
Skills (技能) 是什么
Skills (技能) 是包含指令和资源的文件夹,Claude Code 可以发现并使用它们来更准确地处理任务。每个 skill 都存在于一个 SKILL.md 文件中,其 frontmatter (前言) 包含名称和描述。
描述是 Claude 决定是否使用该 skill 的依据。当你要求 Claude 审查一个 PR 时,它会将你的请求与可用的 skill 描述进行匹配,并找到相关的那个。Claude 读取你的请求,将其与所有可用的 skill 描述进行比较,并激活匹配的那些。
以下是一个 skill 的 frontmatter (前言) 示例:
---
name: pr-review
description: Reviews pull requests for code quality. Use when reviewing PRs or checking code changes.
---
在 frontmatter (前言) 下方,你编写实际的指令——你的审查清单、格式偏好,或 Claude 在该任务中需要知道的任何信息。
Skills (技能) 的存放位置
你可以根据需要将 skills (技能) 存放在不同的地方:
- 个人 skills (技能) 存放于
~/.claude/skills(你的主目录)。它们会跟随你到所有项目中——你的提交信息风格、你的文档格式、你喜欢代码被解释的方式。 - 项目 skills (技能) 存放于仓库根目录下的
.claude/skills。任何克隆该仓库的人都会自动获得这些 skills (技能)。这里存放的是团队标准,比如公司的品牌指南、偏好的字体以及网页设计的颜色。
在 Windows 上,个人 skills (技能) 存放于 C:/Users/<your-user>/.claude/skills。
项目 skills (技能) 会与你的代码一起提交到版本控制中,因此整个团队都可以共享它们。
Skills (技能) vs. CLAUDE.md vs. Slash Commands (斜杠命令)
Claude Code 有多种自定义行为的方式。Skills (技能) 的独特性在于它们的自动化和任务特定性。以下是它们的比较:
CLAUDE.md文件会加载到每个对话中。如果你希望 Claude 总是使用 TypeScript 的严格模式,那就把它写在CLAUDE.md里。- Skills (技能) 在匹配到你的请求时按需加载。Claude 最初只加载名称和描述,所以它们不会占满你的整个上下文窗口。你的 PR 审查清单在你调试代码时不需要出现在上下文中——它只在你真正要求审查时才会加载。
- Slash commands (斜杠命令) 需要你显式输入。Skills (技能) 则不需要。Claude 在识别到情境时会自动应用它们。
当 Claude 将一个 skill 匹配到你的请求时,你会在终端看到它被加载:
何时使用 Skills (技能)
Skills (技能) 最适用于那些应用于特定任务的专业知识:
- 你的团队遵循的代码审查标准
- 你偏好的提交信息格式
- 你的组织的品牌指南
- 特定类型文档的模板
- 针对特定框架的调试清单
经验法则是:如果你发现自己总是在向 Claude 重复解释同样的事情,那么这就是一个有待编写的 skill。
课程反思
- 回想一下你最近与 Claude Code 的互动。你发现自己在重复哪些指令?一个 skill (技能) 可能会如何为你节省时间?
- 考虑一下你团队的工作流程。哪些标准或流程最能从编码为 skills (技能) 中受益?
下一步
在下一课中,你将从头开始创建你的第一个 skill,并了解 Claude Code 是如何在幕后发现、匹配和加载 skills (技能) 的。
反馈
随着你学习本课程,我们很想听听你在工作中是如何使用 skills (技能) 的,以及你的任何反馈。请在此处分享你的反馈。
创建你的第一个 skill
你将学到什么
预计用时:20 分钟
在本课程结束后,你将能够:
- 从头开始创建一个具有正确
frontmatter (前言)结构的 skill - 测试并验证一个 skill 在 Claude Code 中能被正确加载
- 解释 Claude Code 如何将传入的请求与可用的 skills (技能) 进行匹配
- 描述 skill 的优先级层次结构(企业、个人、项目、插件)
创建你的第一个 skill
(4 分钟)
本视频将引导你从头开始构建一个 skill——一个适用于你所有项目的个人 PR 描述 skill。你将清楚地看到如何构建 SKILL.md 文件、如何测试它,并理解 Claude Code 是如何发现和匹配 skills (技能) 到你的请求的。视频还将介绍在名称冲突时决定哪个 skill 胜出的优先级层次结构。
核心要点
- 一个 skill 是一个包含
SKILL.md文件的目录,该文件在frontmatter (前言)中包含元数据(名称、描述),其下方是具体指令。- Claude 在启动时只加载 skill 的名称和描述,然后使用
semantic matching (语义匹配)将传入的请求与这些描述进行匹配。- 在 Claude 将完整的 skill 内容加载到上下文之前,你会收到一个确认提示。
- 名称冲突的优先级:企业 → 个人 → 项目 →
Plugins (插件)。- 要更新一个 skill,请编辑其
SKILL.md。要移除一个,请删除其目录。更改后务必重启 Claude Code 才能生效。
让我们从头开始创建一个 skill,然后看看 Claude Code 实际上是如何在幕后加载和匹配 skills (技能) 的。
创建一个 Skill
我们将构建一个个人 skill,教会 Claude 如何以一致的格式编写 PR 描述。由于这是一个个人 skill,它存放在你的主目录中,并在你所有的项目中都有效。
首先,在 skills 文件夹内为你的 skill 创建一个目录。目录名应与你的 skill 名称相匹配:
mkdir -p ~/.claude/skills/pr-description
然后,在该目录内创建一个 SKILL.md 文件。该文件有两部分,由 frontmatter (前言) 的破折号分隔:
---
name: pr-description
description: Writes pull request descriptions. Use when creating a PR, writing a PR, or when the user asks to summarize changes for a pull request.
---
When writing a PR description:
1. Run `git diff main...HEAD` to see all changes on this branch
2. Write a description following this format:
## What
One sentence explaining what this PR does.
## Why
Brief context on why this change is needed
## Changes
- Bullet points of specific changes made
- Group related changes together
- Mention any files deleted or renamed
name 标识你的 skill。description 告诉 Claude 何时使用它——这是匹配的标准。第二组破折号之后的所有内容都是 Claude 在 skill 被激活时遵循的指令。
测试你的 Skill
Claude Code 在启动时加载 skills (技能),因此在创建 skill 后请重启你的会话。你可以通过检查可用 skills (技能) 列表来验证它是否可用。
你应该能看到你创建的 skill。要测试它,可以在一个分支上做一些更改,然后说类似“为我的更改写一个 PR 描述”这样的话。Claude 会提示它正在使用 PR 描述 skill,检查你的 diff,并按照你的模板编写一个描述——每次都是相同的格式。
Skill 匹配如何工作
当 Claude Code 启动时,它会扫描四个位置以查找 skills (技能),但只加载名称和描述——而不是全部内容。这是一个重要的细节。
当你发送一个请求时,Claude 会将你的消息与所有可用 skills (技能) 的描述进行比较。例如,“解释这个函数是做什么的”会匹配一个描述为“用可视化图表解释代码”的 skill,因为意图有重叠。
一旦找到匹配项,Claude 会请求你确认加载该 skill。这个确认步骤让你清楚 Claude 正在引入什么上下文。在你确认后,Claude 会读取完整的 SKILL.md 文件并遵循其指令。
Skill 优先级
如果你克隆了一个仓库,其中有一个 skill 的名称与你的某个个人 skill 相同,哪一个会胜出?有一个明确的优先级顺序:
- 企业 (Enterprise) — 托管设置,最高优先级
- 个人 (Personal) — 你的主目录 (
~/.claude/skills) - 项目 (Project) — 仓库内的
.claude/skills目录 Plugins (插件)— 已安装的插件,最低优先级
这使得组织可以通过企业 skills (技能) 来强制执行标准,同时仍允许个人进行定制。如果你的公司有一个企业级的“code-review” skill,而你创建了一个同名的个人“code-review” skill,那么企业版本将优先。
为避免冲突,请使用描述性的名称。不要只用“review”,而应使用像“frontend-review”或“backend-review”这样的名称。
更新和移除 Skills (技能)
要更新一个 skill,请编辑其 SKILL.md 文件。要移除一个,请删除其目录。任何更改后都需重启 Claude Code 才能生效。
课程反思
- 你日常工作流程中有什么任务可以立即转化为一个 skill?它的描述会是什么样的?
- 优先级层次结构可能会如何影响你团队的 skill 管理策略?你会更依赖个人级别的还是项目级别的 skills (技能)?
下一步
在下一课中,你将学习高级配置选项,包括元数据字段、使用 allowed-tools 进行工具限制,以及如何使用 progressive disclosure (渐进式披露) 和多文件组织来构建更大型的 skills (技能)。
反馈
随着你学习本课程,我们很想听听你在工作中是如何使用 skills (技能) 的,以及你的任何反馈。请在此处分享你的反馈。
配置和多文件 skills (技能)
你将学到什么
预计用时:20 分钟
在本课程结束后,你将能够:
- 配置高级 skill 元数据字段,包括
allowed-tools和model - 编写能可靠地在正确请求上触发的有效 skill 描述
- 使用
allowed-tools限制 Claude 在 skill 激活时可以执行的操作 - 使用
progressive disclosure (渐进式披露)和多文件结构来组织复杂的 skills (技能)
配置和多文件 skills (技能)
(4 分钟)
本视频涵盖了使 skills (技能) 更强大的高级技术:完整的元数据字段集、如何编写能可靠触发的描述、为安全敏感的工作流程限制工具访问,以及使用 progressive disclosure (渐进式披露) 将大型 skills (技能) 组织到多个文件中。你将学习如何保持 skills (技能) 的高效性,同时支持复杂的用例。
核心要点
name和description是必需的——allowed-tools和model是可选但功能强大的补充。- 一个好的描述回答两个问题:这个 skill 做什么?Claude 应该何时使用它?
allowed-tools限制了 Claude 在 skill 激活时可以使用的工具——这对于只读或安全敏感的工作流程很有用。Progressive disclosure (渐进式披露):保持SKILL.md在 500 行以内,并链接到支持文件(参考文献、脚本、资产),Claude 只在需要时才读取这些文件。- 脚本在执行时不会将其内容加载到上下文中——只有输出会消耗 tokens (令牌),从而保持上下文的高效性。
一个基本的 skill 只需要一个名称和描述就能工作,但有几种高级技术可以让你的 skills (技能) 在 Claude Code 中变得更有效。让我们来了解一下关键字段、描述的最佳实践、工具限制以及如何构建更大型的 skills (技能)。
Skill 元数据字段
Agent skills (代理技能) 开放标准在 SKILL.md 的 frontmatter (前言) 中支持多个字段。其中两个是必需的,其余是可选的:
name(必需) — 标识你的 skill。仅使用小写字母、数字和连字符。最多 64 个字符。应与你的目录名相匹配。description(必需) — 告诉 Claude 何时使用该 skill。最多 1,024 个字符。这是最重要的字段,因为 Claude 用它来进行匹配。allowed-tools(可选) — 限制 Claude 在 skill 激活时可以使用的工具。model(可选) — 指定该 skill 使用哪个 Claude 模型。
编写有效的描述
你的指令要明确。如果有人告诉你“你的工作是帮助处理文档”,你不会知道该做什么——Claude 也是这么想的。
一个好的描述回答两个问题:
- 这个 skill 做什么?
- Claude 应该何时使用它?
如果你的 skill 没有在你期望的时候触发,尝试添加更多与你实际提问方式相匹配的关键词。描述是 Claude 用来判断一个 skill 是否相关的依据,所以语言很重要。
使用 allowed-tools 限制工具
有时你希望一个 skill 只能读取文件,而不能修改它们。这对于安全敏感的工作流程、只读任务或任何需要防护栏的情境都很有用。
在这个例子中,allowed-tools 字段被设置为 Read, Grep, Glob, Bash。当这个 skill 激活时,Claude 只能在不请求许可的情况下使用这些工具——不能编辑,不能写入。
---
name: codebase-onboarding
description: Helps new developers understand the system works.
allowed-tools: Read, Grep, Glob, Bash
model: sonnet
---
如果你完全省略 allowed-tools,该 skill 不会限制任何东西。Claude 会使用其正常的权限模型。
Progressive Disclosure (渐进式披露)
Skills (技能) 与你的对话共享 Claude 的上下文窗口。当 Claude 激活一个 skill 时,它会将该 SKILL.md 的内容加载到上下文中。但有时你需要 skill 所依赖的参考文献、示例或实用脚本。
把所有东西都塞进一个 2000 行的文件里有两个问题:它占用了大量的上下文窗口空间,而且维护起来也不方便。
Progressive disclosure (渐进式披露) 解决了这个问题。将核心指令保留在 SKILL.md 中,并将详细的参考资料放在单独的文件里,Claude 只在需要时才读取它们。
开放标准建议将你的 skill 目录组织为:
scripts/— 可执行代码references/— 附加文档assets/— 图片、模板或其他数据文件
然后在 SKILL.md 中,用明确的指令链接到这些支持文件,告诉 Claude 何时加载它们:
在这个例子中,只有当有人询问系统设计时,Claude 才会读取 architecture-guide.md。如果他们问在哪里添加一个组件,它就永远不会加载那个文件。这就像在上下文窗口中有一个目录,而不是整篇文档。
一个好的经验法则是:保持 SKILL.md 在 500 行以内。如果你超过了这个长度,考虑一下内容是否应该被分割到单独的参考文件中。
高效使用脚本
你 skill 目录中的脚本可以在不加载其内容到上下文的情况下运行。脚本执行后,只有其输出会消耗 tokens (令牌)。在你的 SKILL.md 中需要包含的关键指令是告诉 Claude 运行脚本,而不是读取它。
这在以下情况中特别有用:
- 环境验证
- 需要保持一致的数据转换
- 作为经过测试的代码比生成代码更可靠的操作
课程反思
- 想想一个你想构建的、涉及多个文件的 skill。你会如何组织
SKILL.md与支持的参考文件?- 在你的团队中,是否有工作流程可以通过使用
allowed-tools限制工具访问来增加一个重要的安全层?
下一步
在下一课中,我们将比较 skills (技能) 与其他自定义 Claude Code 的方式——CLAUDE.md、subagents (子代理)、hooks (钩子) 和 MCP 服务器——这样你就能为每种情况选择正确的工具。
反馈
随着你学习本课程,我们很想听听你在工作中是如何使用 skills (技能) 的,以及你的任何反馈。请在此处分享你的反馈。
Skills (技能) vs. 其他 Claude Code 功能
你将学到什么
预计用时:15 分钟
在本课程结束后,你将能够:
- 比较 skills (技能) 与
CLAUDE.md、subagents (子代理)、hooks (钩子)和 MCP 服务器 - 为给定的用例选择正确的 Claude Code 自定义功能
- 设计一个有效结合多种功能的互补设置
Skills (技能) vs. 其他 Claude Code 功能
(3 分钟)
Claude Code 提供了多种自定义选项,选择错误的选项可能会导致不必要的复杂性。本视频将详细分析何时使用 skills (技能) 而不是 CLAUDE.md、subagents (子代理)、hooks (钩子) 和 MCP 服务器。你将了解每个选项之间的关键区别,以及它们在典型开发设置中如何互补。
核心要点
CLAUDE.md会加载到每个对话中,最适合始终开启的项目标准。Skills (技能) 按需加载,最适合任务特定的专业知识。Subagents (子代理)在隔离的执行上下文中运行——用它们来处理委托的工作。Skills (技能) 为你当前的对话添加知识。Hooks (钩子)是事件驱动的(在文件保存、Tool Use (工具调用)时触发)。Skills (技能) 是请求驱动的(根据你的提问激活)。- MCP 服务器提供外部工具和集成——这与 skills (技能) 完全是不同类别。
- 每个功能都有自己的专长——将它们结合起来,而不是强行将所有东西都塞进一种方法中。
Claude Code 提供了多种自定义选项:Skills (技能)、CLAUDE.md、subagents (子代理)、hooks (钩子) 和 MCP 服务器。它们解决不同的问题,了解何时使用哪个可以避免你构建错误的东西。让我们来逐一分析。
CLAUDE.md vs. Skills (技能)
CLAUDE.md 会加载到每个对话中,始终如此。如果你希望 Claude 在你的项目中使用 TypeScript 的严格模式,就把它放在你的 CLAUDE.md 文件里。
Skills (技能) 按需加载。当 Claude 将一个请求匹配到一个 skill 时,该 skill 的指令就会加入到对话中。你的 PR 审查清单在你编写新代码时不需要在上下文中——它只在你请求审查时才激活。
使用 CLAUDE.md 来处理:
- 始终适用的项目范围标准
- 诸如“绝不修改数据库 schema”之类的约束
- 框架偏好和编码风格
使用 Skills (技能) 来处理:
- 任务特定的专业知识
- 仅在某些时候才相关的知识
- 会让每个对话都变得混乱的详细流程
Skills (技能) vs. Subagents (子代理)
Skills (技能) 为你当前的对话添加知识。当一个 skill 激活时,它的指令会加入到现有的上下文中。
Subagents (子代理) 在一个独立的上下文中运行。它们接收一个任务,独立完成,然后返回结果。它们与主对话是隔离的。
使用 Subagents (子代理) 的时机:
- 你想将一个任务委托给一个独立的执行上下文
- 你需要与主对话不同的工具访问权限
- 你希望在委托的工作和你的主上下文之间实现隔离
使用 Skills (技能) 的时机:
- 你想增强 Claude 在当前任务中的知识
- 该专业知识在整个对话中都适用
Skills (技能) vs. Hooks (钩子)
Hooks (钩子) 在事件发生时触发。一个 hook (钩子) 可能会在 Claude 每次保存文件时运行一个 linter (代码检查器),或者在某些 Tool Use (工具调用) 前验证输入。它们是事件驱动的。
Skills (技能) 是请求驱动的。它们根据你的提问来激活。
使用 Hooks (钩子) 来处理:
- 应在每次文件保存时运行的操作
- 特定
Tool Use (工具调用)前的验证 - Claude 行为的自动化副作用
使用 Skills (技能) 来处理:
- 为 Claude 处理请求的方式提供信息的知识
- 影响 Claude 推理过程的指南
综合运用
一个典型的设置可能包括:
CLAUDE.md— 始终开启的项目标准- Skills (技能) — 按需加载的任务特定专业知识
Hooks (钩子)— 由事件触发的自动化操作Subagents (子代理)— 用于委托工作的隔离执行上下文- MCP 服务器 — 外部工具和集成
每个功能都有自己的专长。当另一个选项更合适时,不要强行把所有东西都塞进 skills (技能) 里——你可以同时使用多个。Skills (技能) 提供自动化的任务特定专业知识,CLAUDE.md 用于始终开启的指令,subagents (子代理) 在隔离的上下文中运行,hooks (钩子) 在事件上触发,而 MCP 提供外部工具。
当你有希望 Claude 在相关主题出现时自动应用的知识时,请使用 skills (技能),并将它们与其他功能结合起来,以实现全面的定制。
课程反思
- 查看你当前的
CLAUDE.md文件。里面是否有任何内容作为 skill (仅在相关时加载) 会更好?- 想想你团队的开发工作流程。哪种 Claude Code 功能组合 (skills, hooks, subagents, MCP) 能解决你们最常见的痛点?
下一步
在下一课中,你将学习如何与你的团队和组织共享 skills (技能)——从将它们提交到仓库,到通过 plugins (插件) 分发,再到通过企业托管设置进行全企业范围的部署。
反馈
随着你学习本课程,我们很想听听你在工作中是如何使用 skills (技能) 的,以及你的任何反馈。请在此处分享你的反馈。
共享 skills (技能)
你将学到什么
预计用时:20 分钟
在本课程结束后,你将能够:
- 通过将 skills (技能) 提交到 Git 仓库与团队共享
- 通过
plugins (插件)和市场在多个项目间分发 skills (技能) - 使用企业托管设置在整个组织范围内统一部署 skills (技能)
- 配置自定义
subagents (子代理)以使用特定的 skills (技能)
共享 skills (技能)
(4 分钟)
当 skills (技能) 在团队或组织内共享时,它们的价值会大大增加。本视频涵盖了三种主要的分发方法——仓库提交、plugins (插件) 和企业托管设置——并解释了如何配置自定义 subagents (子代理) 来使用 skills (技能)。你将了解哪种方法适合哪种场景,以及如何处理一个重要的陷阱:subagents (子代理) 不会自动继承 skills (技能)。
核心要点
- 存放于
.claude/skills的项目 skills (技能) 通过 Git 自动共享——任何克隆仓库的人都会得到它们。Plugins (插件)让你通过市场在多个仓库间分发 skills (技能),以供更广泛的社区使用。- 企业托管设置 (Enterprise managed settings) 可在整个组织范围内以最高优先级部署 skills (技能),非常适合强制性标准和合规性要求。
Subagents (子代理)不会自动看到你的 skills (技能)——你必须在自定义 agent 的frontmatter (前言)的skills字段中明确列出它们。- 内置 agents (代理)(如 Explorer, Plan, Verify)完全无法访问 skills (技能)——只有在
.claude/agents中定义的自定义subagents (子代理)才能。
当 skills (技能) 被共享时,它们的价值会大大增加。一个只有你使用的 PR 审查 skill 很有用,但同一个 skill 在整个团队中共享,可以标准化代码审查,并在你的组织内创建一致的体验。让我们看看分发 skills (技能) 的不同方式。
将 Skills (技能) 提交到你的仓库
最简单的共享方法是直接将 skills (技能) 提交到你的仓库。将它们放在 .claude/skills 中,任何克隆该仓库的人都会自动获得这些 skills (技能)——无需额外安装。
当你推送更新时,每个人在下一次拉取时都会得到更新。这种方法非常适合:
- 团队编码标准
- 项目特定的工作流程
- 引用你代码库结构的 skills (技能)
.claude 目录包含你的 agents (代理)、hooks (钩子)、skills (技能) 和设置——所有这些都通过常规的 Git 工作流程进行版本控制并与团队共享。
通过 Plugins (插件) 分发 Skills (技能)
Plugins (插件) 是一种扩展 Claude Code 的方式,其定制功能旨在跨团队和项目共享。在你的插件项目中,创建一个 skills 目录,其文件结构与 .claude 目录类似——每个 skill 都有自己的文件夹,里面有一个 SKILL.md 文件。
在你将插件分发到市场后,其他用户可以发现并将其安装到自己的 Claude Code 中。
当你的 skills (技能) 不是非常特定于项目,并且对你的直属团队之外的社区成员也有用时,这种方法是最佳选择。
通过托管设置进行企业部署
管理员可以通过托管设置在整个组织范围内部署 skills (技能)。企业 skills (技能) 拥有最高优先级——它们会覆盖同名的个人、项目和插件 skills (技能)。
托管设置文件支持诸如 strictKnownMarketplaces 之类的功能,以控制可以从何处安装 plugins (插件):
"strictKnownMarketplaces": [
{
"source": "github",
"repo": "acme-corp/approved-plugins"
},
{
"source": "npm",
"package": "@acme-corp/compliance-plugins"
}
]
这对于强制性标准、安全要求、合规性工作流程以及必须在整个组织内保持一致的编码实践来说是正确的选择。这里的关键词是“必须”。
Skills (技能) 和 Subagents (子代理)
这里有一个让人惊讶的地方:subagents (子代理) 不会自动看到你的 skills (技能)。当你将一个任务委托给一个 subagent (子代理) 时,它会以一个全新的、干净的上下文开始。
需要理解的重要区别是:
- 内置 agents (代理)(如 Explorer, Plan, 和 Verify)完全无法访问 skills (技能)。
- 你定义的自定义
subagents (子代理)可以使用 skills (技能),但前提是你明确列出它们。 - Skills (技能) 在
subagent (子代理)启动时加载,而不是像在主对话中那样按需加载。
要创建一个带有 skills (技能) 的自定义 subagent (子代理),请在 .claude/agents 中添加一个 agent markdown 文件。你可以在 Claude Code 中使用 /agents 命令以交互方式创建一个:
生成的 agent 文件包含一个 skills 字段,列出了要加载的 skills (技能)。以下是 frontmatter (前言) 的样子:
---
name: frontend-security-accessibility-reviewer
description: "Use this agent when you need to review frontend code for accessibility..."
tools: Bash, Glob, Grep, Read, WebFetch, WebSearch, Skill...
model: sonnet
color: blue
skills: accessibility-audit, performance-check
---
当你委托给这个 subagent (子代理) 时,它会同时加载两个 skills (技能) 并将它们应用于每次审查。首先确保这些 skills (技能) 存在于你的 .claude/skills 目录中,然后创建一个新的 subagent (子代理) 或将 skills 字段添加到现有 agent 的 markdown 文件中。
这种模式在以下情况下非常有效:
- 你想要具有特定专业知识的隔离任务委托。
- 不同的
subagents (子代理)需要不同的 skills (技能)(前端审查员 vs. 后端审查员)。 - 你想在不依赖提示的情况下在委托的工作中强制执行标准。
课程反思
- 对于你一直在考虑构建的 skills (技能),哪种共享方法(仓库、插件、企业)最有意义?
- 你是否有工作流程中,带有特定 skills (技能) 的自定义
subagents (子代理)可以提高委托工作的连贯性?
下一步
在最后一课中,你将学习如何排查常见的 skill 问题——从不触发的 skills (技能),到优先级冲突,再到运行时错误——并提供一个你可以随时参考的实用清单。
反馈
随着你学习本课程,我们很想听听你在工作中是如何使用 skills (技能) 的,以及你的任何反馈。请在此处分享你的反馈。
排查 skills (技能) 问题
你将学到什么
预计用时:15 分钟
在本课程结束后,你将能够:
- 使用 skills (技能) 验证器在调试前捕获结构性问题
- 诊断并修复常见的 skill 触发和加载问题
- 解决企业、个人、项目和插件 skills (技能) 之间的优先级冲突
- 调试运行时错误,包括依赖缺失、权限和路径问题
排查 skills (技能) 问题
(4 分钟)
当 skills (技能) 不按预期工作时,问题通常可以归为几个可预测的类别。本视频将逐一讲解这些问题——从不触发的 skills (技能) 到优先级冲突,再到运行时故障——并为你提供一个系统性的故障排查方法。你还将了解 skills (技能) 验证器工具以及如何使用 claude --debug 来诊断加载问题。
核心要点
- 从 skills (技能) 验证器工具开始——它能在你花时间调试其他问题之前捕获结构性问题。
- 如果一个 skill 不触发,原因几乎总是描述问题——添加与你实际提问方式相匹配的触发短语。
- 如果一个 skill 不加载,检查
SKILL.md是否在一个命名的目录内(而不是在skills根目录),并且文件名是否完全是SKILL.md。- 如果使用了错误的 skill,说明你的描述太相似了——让它们更有区分度。
- 对于运行时错误,检查依赖项、文件权限 (
chmod +x) 和路径分隔符(在所有地方都使用正斜杠)。
当 skills (技能) 不工作时,问题通常属于以下几类之一:skill 不触发、不加载、有冲突或在运行时失败。好消息是,大多数修复都相当直接。
使用 Skills (技能) 验证器
首先要尝试的是 agent skills (代理技能) 验证器命令。安装步骤因操作系统而异,但使用 uv 是最快设置它的方法。
安装后,可以导航到你的 skill 目录或从任何地方运行该命令。验证器会在你花时间调试其他问题之前捕获结构性问题。
Skill 不触发
你的 skill 存在并通过了验证,但 Claude 在你期望的时候没有使用它。原因几乎总是描述。
Claude 使用 semantic matching (语义匹配),所以你的请求需要与描述的含义有重叠。如果重叠不够,就不会匹配。以下是该怎么做:
- 对照你实际的提问方式检查你的描述。
- 添加用户实际会说的触发短语。
- 用不同的变体进行测试,比如“帮我分析这个的性能”、“这个为什么慢?”、“让这个快一点”。
- 如果任何变体未能触发,就把这些关键词添加到你的描述中。
Skill 不加载
如果你问 Claude “有哪些可用的 skills (技能)?” 时,你的 skill 没有出现,请检查以下结构要求:
SKILL.md文件必须在一个命名的目录内,而不是在skills根目录。- 文件名必须完全是
SKILL.md——“SKILL”全大写,“md”小写。
运行 claude --debug 查看加载错误。查找提及你 skill 名称的消息。有时仅此一项就能直接指出问题所在。
使用了错误的 Skill
如果 Claude 使用了错误的 skill,或者在几个 skills (技能) 之间显得困惑,那可能是你的描述太相似了。让它们更有区分度。尽可能具体不仅有助于 Claude 决定何时使用你的 skill,还能防止与其他听起来相似的 skills (技能) 发生冲突。
Skill 优先级冲突
如果你的个人 skill 被忽略了,可能是一个企业级或更高优先级的 skill 有相同的名称。
例如,如果有一个企业级的“code-review” skill,而你也有一个个人的“code-review” skill,那么企业级的那个总是会胜出。你的选择是:
- 将你的 skill 重命名为更有区分度的名称(这通常是更容易的途径)。
- 与你的管理员讨论企业 skill 的问题。
插件 Skills (技能) 未出现
安装了插件但看不到它的 skills (技能)?清除缓存,重启 Claude Code,然后重新安装。
如果之后 skills (技能) 仍然没有出现,插件的结构可能有问题。这时候验证器工具就真的派上用场了。
运行时错误
Skill 加载了,但在执行期间失败。一些常见原因:
- 依赖缺失:如果你的 skill 使用外部包,它们必须被安装。在你的 skill 描述中添加依赖信息,这样 Claude 才知道需要什么。
- 权限问题:脚本需要执行权限。在你的 skill 引用的任何脚本上运行
chmod +x。 - 路径分隔符:在所有地方都使用正斜杠,即使在 Windows 上也是。
快速故障排查清单
- 不触发? 改进你的描述并添加触发短语。
- 不加载? 检查你的路径、文件名和 YAML 语法。
- 用了错误的 skill? 让描述之间更有区分度。
- 被覆盖了? 检查优先级层次结构,并在需要时重命名。
- 插件 skills (技能) 缺失? 清除缓存并重新安装。
- 运行时失败? 检查依赖、权限和路径。
课程反思
- 你在自己的工作中遇到过这些故障排查场景吗?哪个修复方法能为你节省最多的时间?
- 你会如何建立一个流程,在与团队共享 skills (技能) 之前对它们进行验证?
课程总结
恭喜你完成《Agent Skills (代理技能) 入门》课程!你已经学会了如何在 Claude Code 中创建、配置、共享和排查 skills (技能)。当你开始为自己的工作流程构建 skills (技能) 时,请记住,最好的 skills (技能) 来自于真实的痛点——从你发现自己最常重复的指令开始。
反馈
我们很想听听你在工作中是如何使用 skills (技能) 的,以及关于本课程的任何反馈。请在此处分享你的反馈。
你是一个专业的技术文档翻译专家。请将以下英文技术课程内容翻译成地道的、专业的中文。
翻译规则:
- 技术术语保留英文原文并在首次出现时附加中文说明,如 "Tool Use(工具调用)"
- 代码块、代码片段、命令行内容不翻译,保持原样
- 图片的 markdown 语法保持不变(
) - 标题层级和 markdown 格式保持不变
- 专有名词如 Claude, Anthropic, MCP, RAG, API 等保持英文
- URL 链接保持不变
- 翻译要自然流畅,不要逐字翻译,而是传达原意
- ">" 开头的引用块内容也要翻译
- 列表项的格式保持不变(-、1. 等)
- 已经是中文的内容保持不变
请直接输出翻译后的完整 markdown 内容,不要添加任何额外说明或包装。
第 8 课:使用 Anthropic API 构建应用
Claude API 开发完整教程:从基础到高级 课程链接:使用 Anthropic API 构建应用 | 共 96 节课
第1部分:Introduction
1. Welcome to the course
此课时为课程介绍/总结页面,请访问在线平台查看。
2. Overview of Claude models
类型:视频 | 时长:3:56 | 视频:02 - 001 - Overview of Claude Models.mp4
视频文字稿
在本视频中,我们将探讨 Claude 的三个模型家族 (model families),并了解哪一个适合您的特定用例 (use case)。为了帮助您理解这些模型的不同之处,我将逐一介绍每个模型的关键特性,然后展示一个用于选择正确模型的简单框架。在深入探讨具体细节之前,请允许我说明一点。这三个模型都具备 Claude 的核心能力,因此它们都能处理文本生成、编码、图像分析以及许多其他任务。
它们之间真正的区别在于优化方向。一个专注于智能 (intelligence),一个专注于速度和成本效益 (cost efficiency),还有一个则在智能和速度之间寻求平衡。首先是 Opus。Opus 是 Claude 最强大的模型。
当我说“强大”时,我指的是这个模型能提供您从 Claude 中获得的最高水平的智能。在实践中,这意味着 Opus 专为那些需要高水平智能和规划才能完成的复杂需求场景而设计。它可以长时间独立处理复杂的项目,比如一个可能持续数小时的任务,模型需要管理多步骤流程并自行处理大量不同的需求,而无需太多人工干预。Opus 支持我们所谓的推理 (reasoning),这意味着它可以为简单任务提供快速响应,也可以花一些时间为更复杂的任务进行思考。
缺点是 Opus 的延迟 (latency) 中等,成本较高,这确实是您需要做出的权衡。虽然您获得了非常高的智能,但您发出的每个请求也需要稍多的时间和成本。接下来是 Sonnet。Sonnet 在 Claude 的产品线中处于一个“甜点”位置。
它在智能、速度和成本之间取得了很好的平衡,这使得它在大多数实际用例中都非常有用。Sonnet 的出色之处在于其强大的编码能力和快速的文本生成。许多开发者喜欢它能够精确编辑复杂代码库的能力,这意味着它可以在不破坏大量现有功能的情况下对项目进行更改。最后,我们有 Haiku。
Haiku 是 Claude 速度最快的模型,专为响应时间非常重要的应用而设计。关于 Haiku 有一点需要注意,那就是它不支持 Opus 和 Sonnet 所具备的推理能力。相反,Haiku 针对速度和成本效益进行了优化。这使得 Haiku 成为需要实时交互的面向用户的应用的绝佳选择。
现在让我们来谈谈如何为您的特定应用决定使用这三个模型中的哪一个。思考模型选择的方式,归根结底在于理解这些不同模型之间的权衡。一方面,您拥有非常高的智能;另一方面,您需要考虑更高的成本和更长的响应时间。Opus 位于智能这一端。
它非常智能,但更昂贵,延迟也更高。Haiku 位于成本和速度这一端。它的智能程度中等,成本低,速度最快。而 Sonnet 正好处于中间位置,在这些不同品质之间取得了很好的平衡。
所以,您可以这样决定使用哪个模型。您真正需要确定或弄清楚的是,对于您的特定用 例,什么最重要。如果智能是您的首要任务,意味着您有一个需要非常强推理能力的复杂任务,那么您可能应该使用 Opus。您选择了质量,而非速度和成本。
如果速度是您的首要任务,意味着您有实时用户交互,或者有大量需要尽快获得响应的高吞吐量处理,那么您应该选择 Haiku。如果您需要在智能、速度和成本之间取得更好的平衡,这在大多数应用中通常都是如此,那么 Sonnet 可能是您的最佳选择。这里需要注意的一点是,许多团队并不仅仅选择一个模型并一直使用它。相反,您可能会在同一个应用中使用多个不同的模型。
您可能会在面向用户的交互中使用 Haiku,因为速度非常重要;或许使用 Sonnet 来处理主要的业务逻辑;而对于那些需要更深层次推理的真正复杂的任务,则使用 Opus。以上就是关于 Claude 的三个模型家族以及如何选择它们的内容。顺便说一下,在本课程中,我们将最常使用 Claude Sonnet,因为它为我们提供了这三种品质的绝佳平衡。
第3部分:Accessing Claude with the API
3. Accessing the API
类型:视频 | 时长:5:18 | 视频:03 - 001 - Accessing the API.mp4
在使用 Claude 构建应用时,理解完整的请求生命周期 (request lifecycle) 有助于您做出更好的架构决策并更有效地调试问题。让我们一起来看看,从用户在您的聊天界面点击“发送”那一刻起,到 Claude 的响应出现在屏幕上,这整个过程都发生了什么。
五步请求流程
与 Claude 的每一次交互都遵循一个可预测的模式,包含五个不同阶段:请求到服务器、请求到 Anthropic API、模型处理、响应到服务器以及响应到客户端。
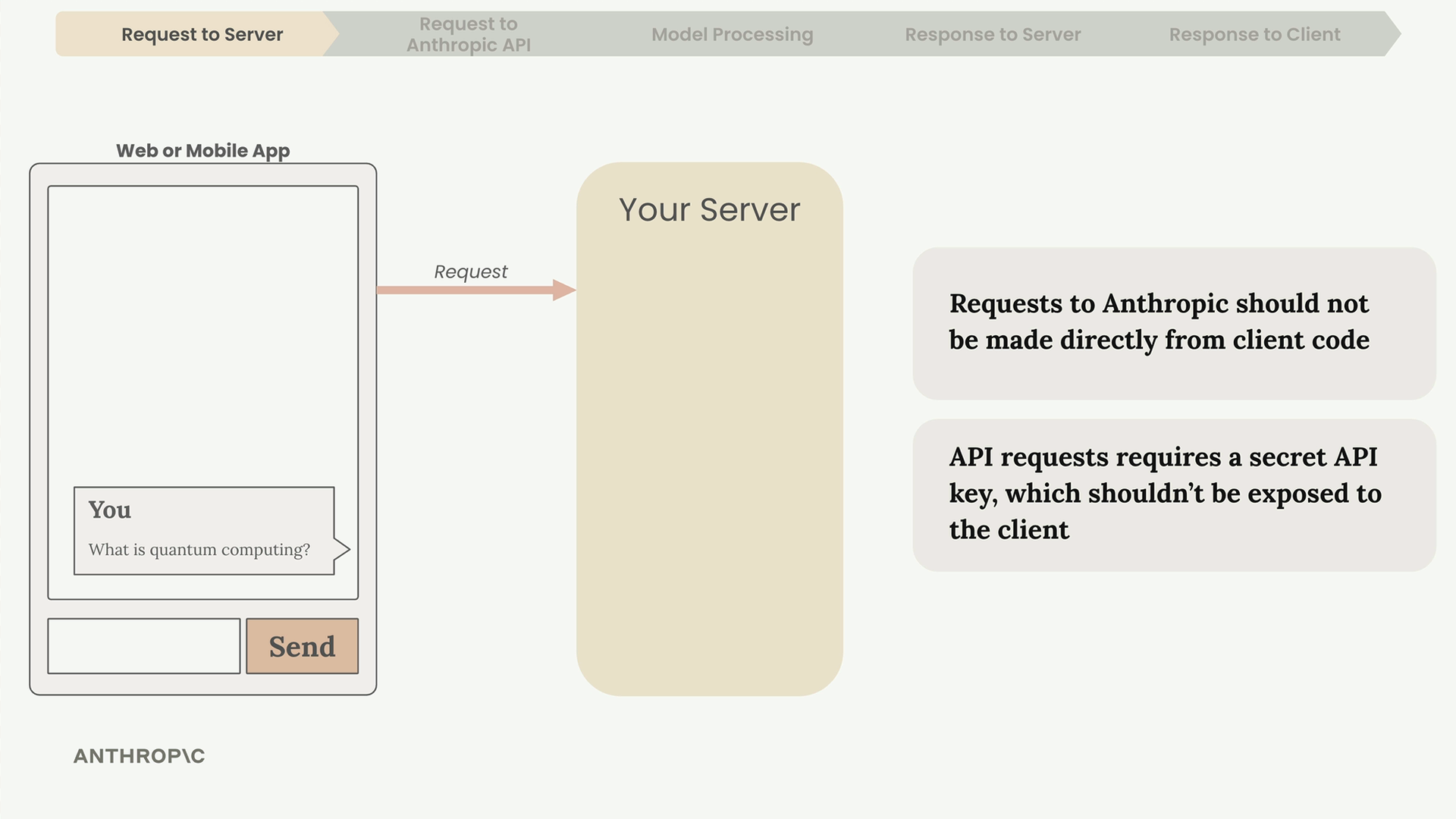
为什么您需要一个服务器
您绝不应该直接从客户端代码向 Anthropic API 发出请求。原因如下:
- API 请求需要一个秘密的 API 密钥 (API key) 进行认证
- 在客户端代码中暴露此密钥会造成严重的安全漏洞
- 任何人都可以提取该密钥并发出未经授权的请求
相反,您的 Web 或移动应用应将请求发送到您自己的服务器,然后由该服务器使用安全存储的密钥与 Anthropic API 通信。
发起 API 请求
当您的服务器联系 Anthropic API 时,您可以使用官方 SDK 或发起普通的 HTTP 请求。Anthropic 为 Python、TypeScript、JavaScript、Go 和 Ruby 提供了 SDK。
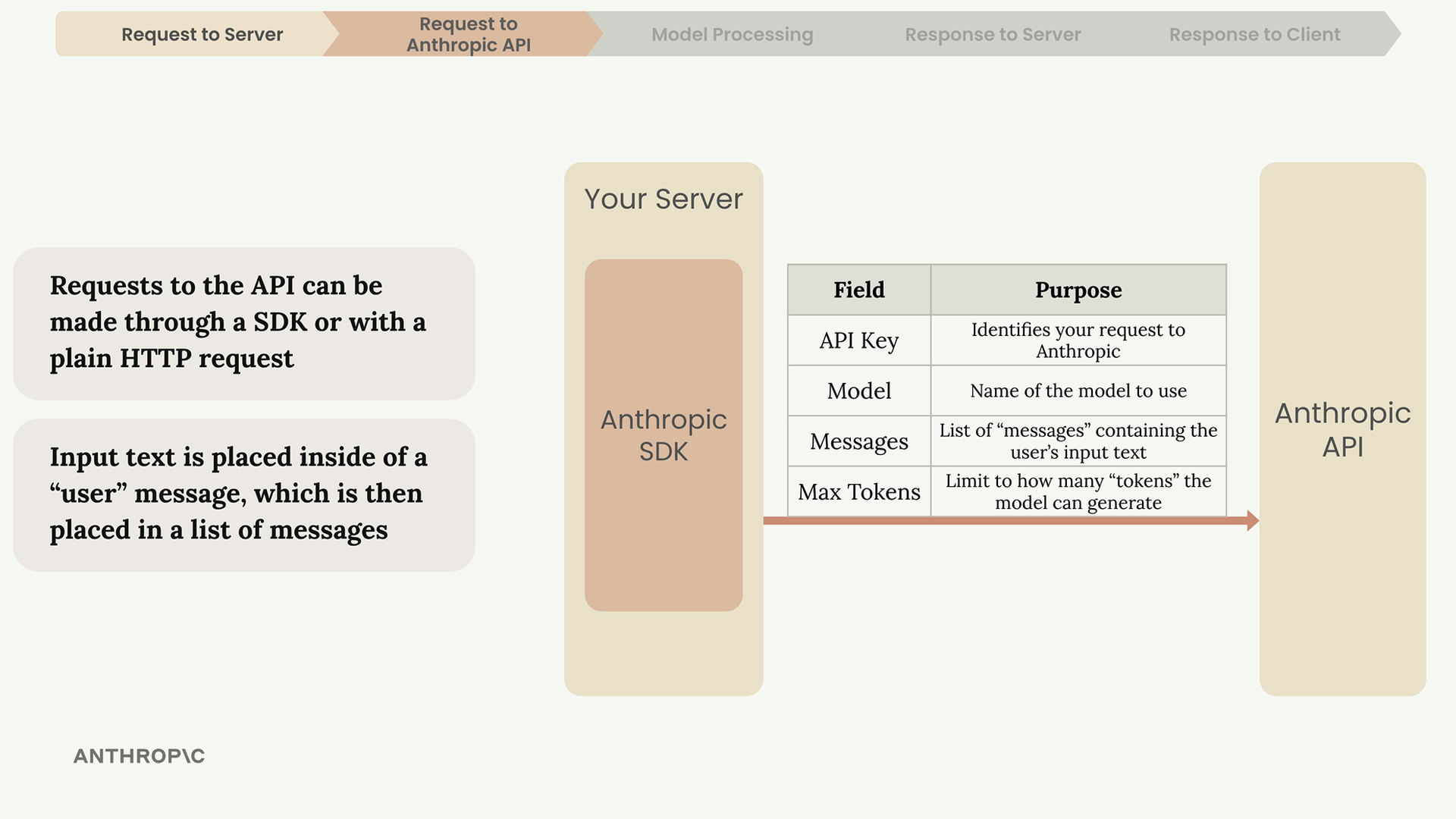
每个请求都必须包含以下基本字段:
- API Key - 用于向 Anthropic 标识您的请求
- Model - 要使用的模型名称(如 "claude-3-sonnet")
- Messages - 包含用户输入文本的列表
- Max Tokens - Claude 可以生成的令牌数量上限
Claude 内部处理流程
一旦 Anthropic 收到您的请求,Claude 会通过四个主要阶段来处理它:分词 (tokenization)、嵌入 (embedding)、情境化 (contextualization) 和生成 (generation)。
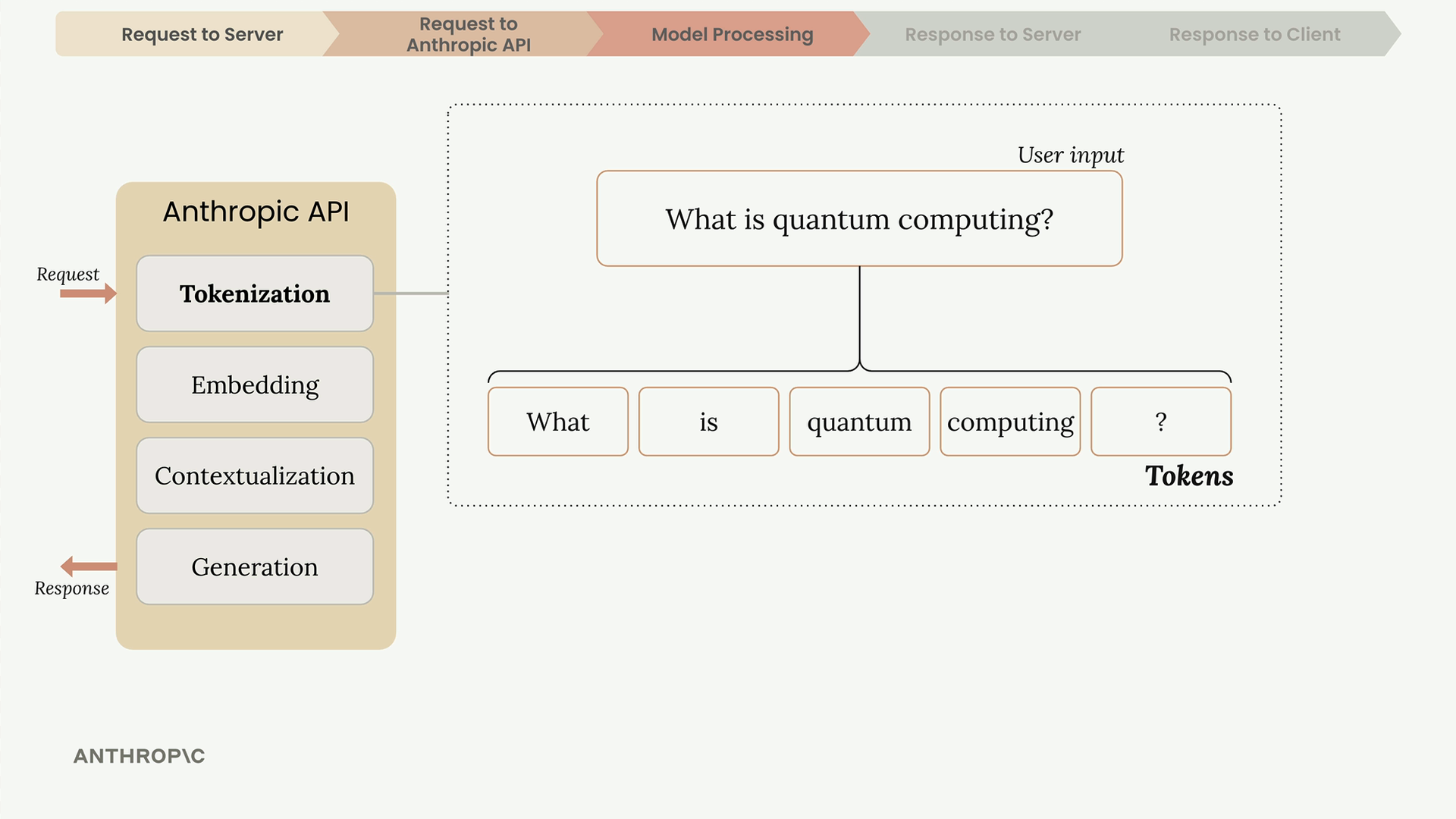
分词 (Tokenization)
Claude 首先将您的输入文本分解成称为令牌 (token) 的小块。这些可以是完整的单词、单词的一部分、空格或符号。为简单起见,您可以将每个单词视为一个令牌。
嵌入 (Embedding)
每个令牌都被转换成一个嵌入——一个长长的数字列表,代表了该词所有可能的含义。您可以将嵌入看作是捕捉语义关系的数字定义。
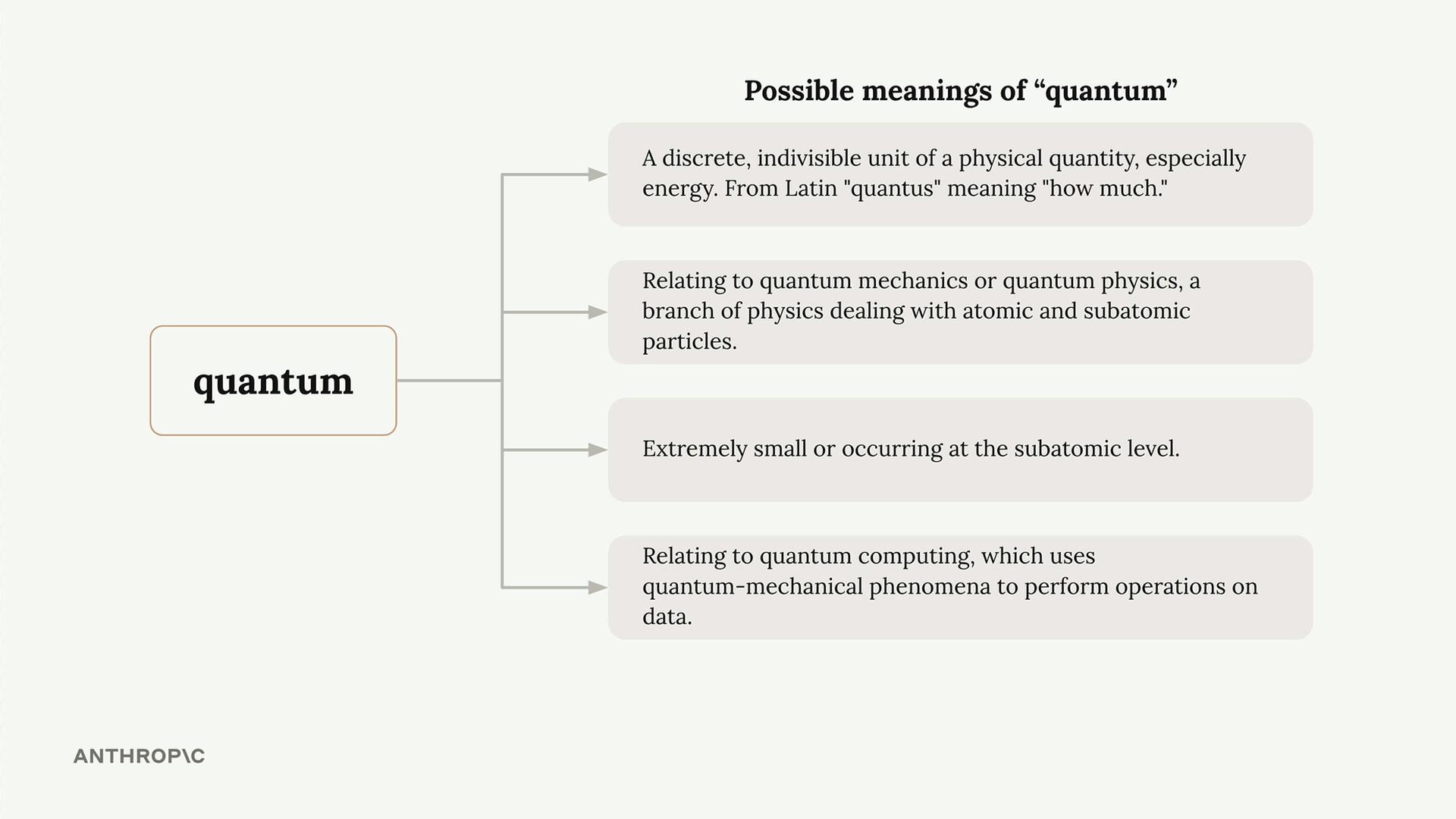
词语通常有多种含义。例如,“quantum” 可能指:
- 物理量的离散单位(物理学)
- 量子力学或量子物理学概念
- 极其微小或亚原子级别的事物
- 量子计算应用
情境化 (Contextualization)
Claude 根据周围的词语来提炼每个嵌入,以确定在上下文中可能性最大的含义。这个过程会调整数字表示,以凸显出适当的定义。
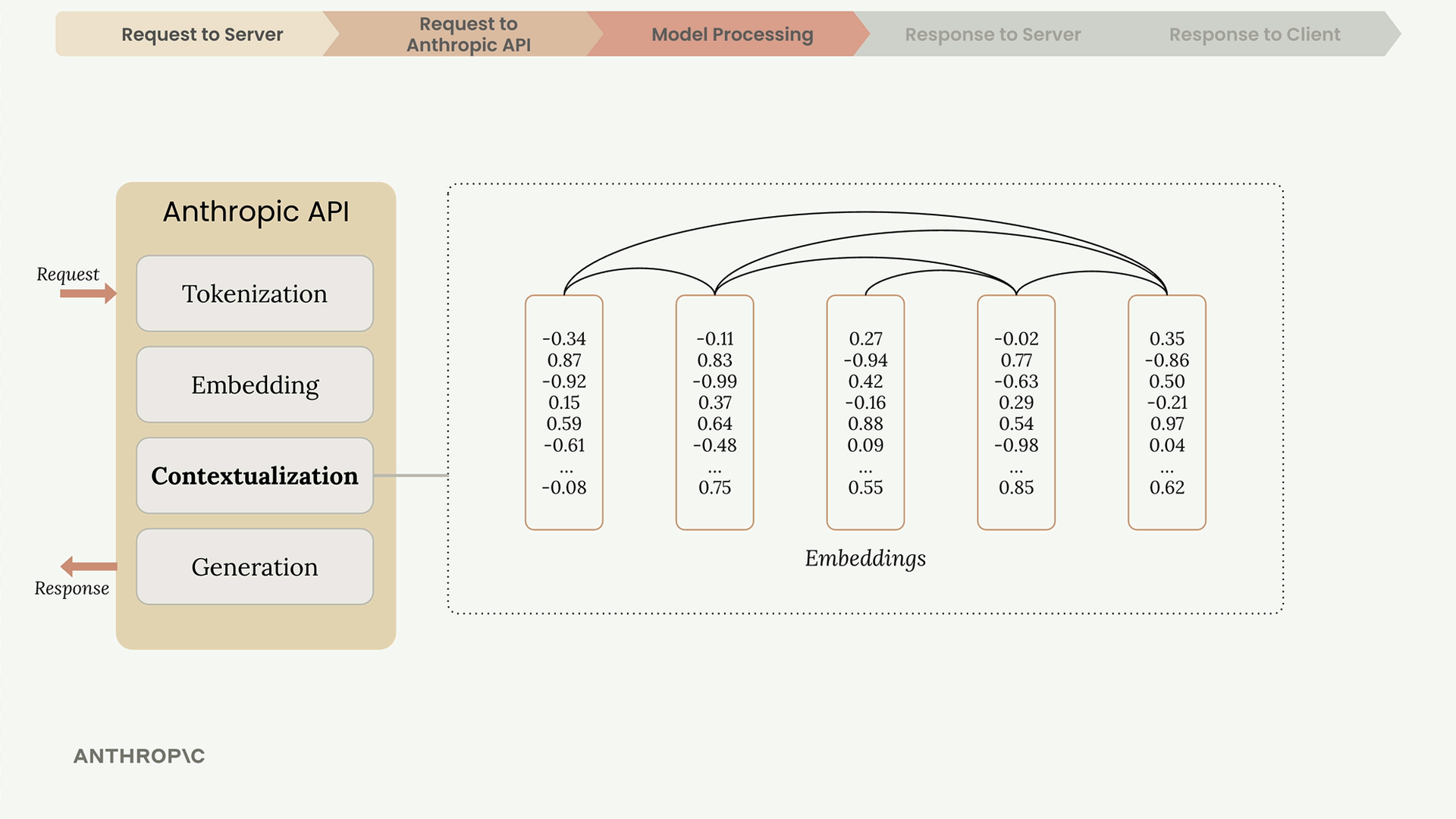
生成 (Generation)
经过情境化的嵌入会通过一个输出层,该层计算每个可能的下一个词的概率。Claude 并非总是选择概率最高的词——它会结合概率和受控的随机性来创建自然、多样的响应。
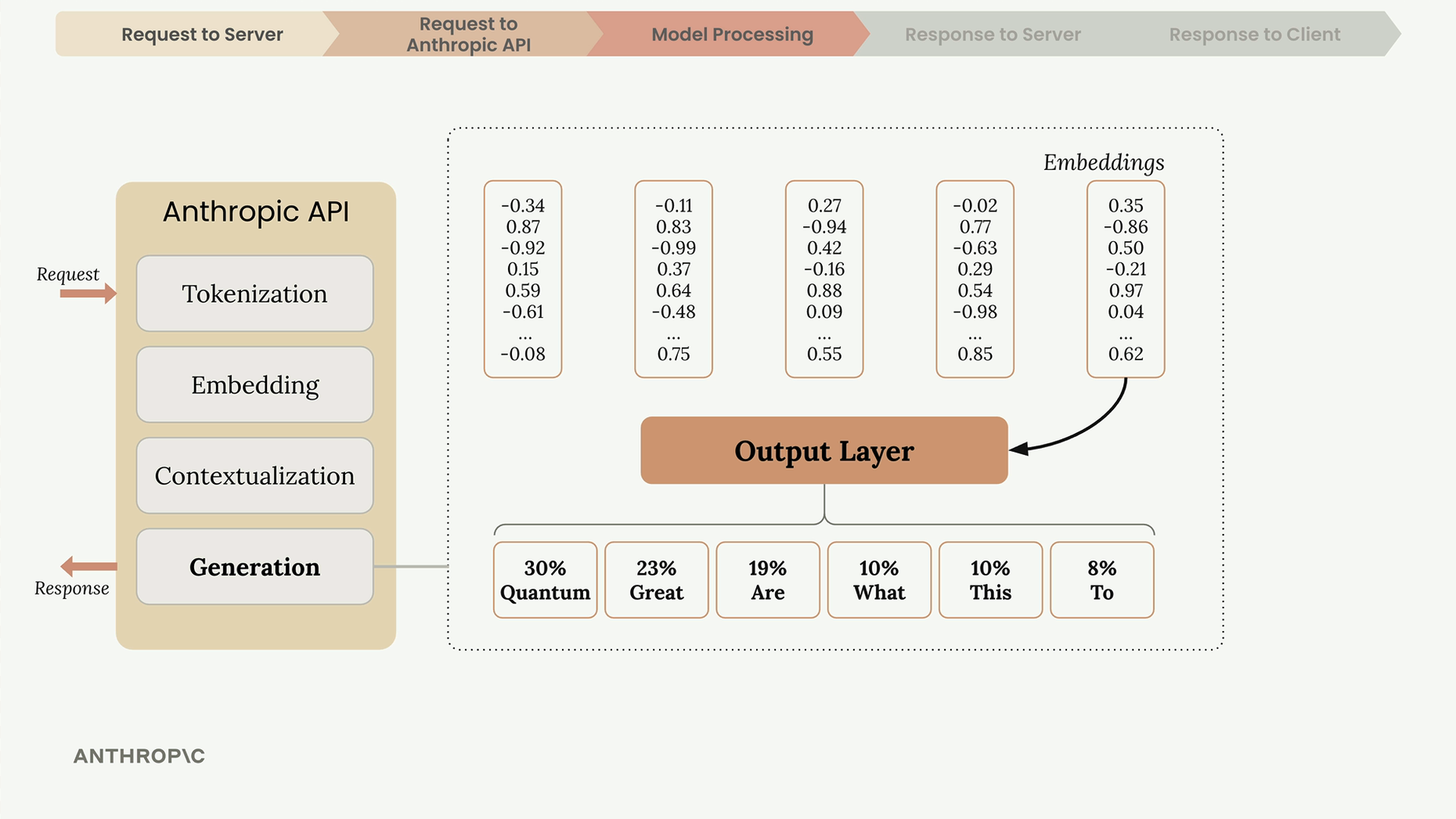
选择每个词后,Claude 将其添加到序列中,并为下一个词重复整个过程。
Claude 何时停止生成
在生成每个令牌后,Claude 会检查几个条件来决定是否继续:
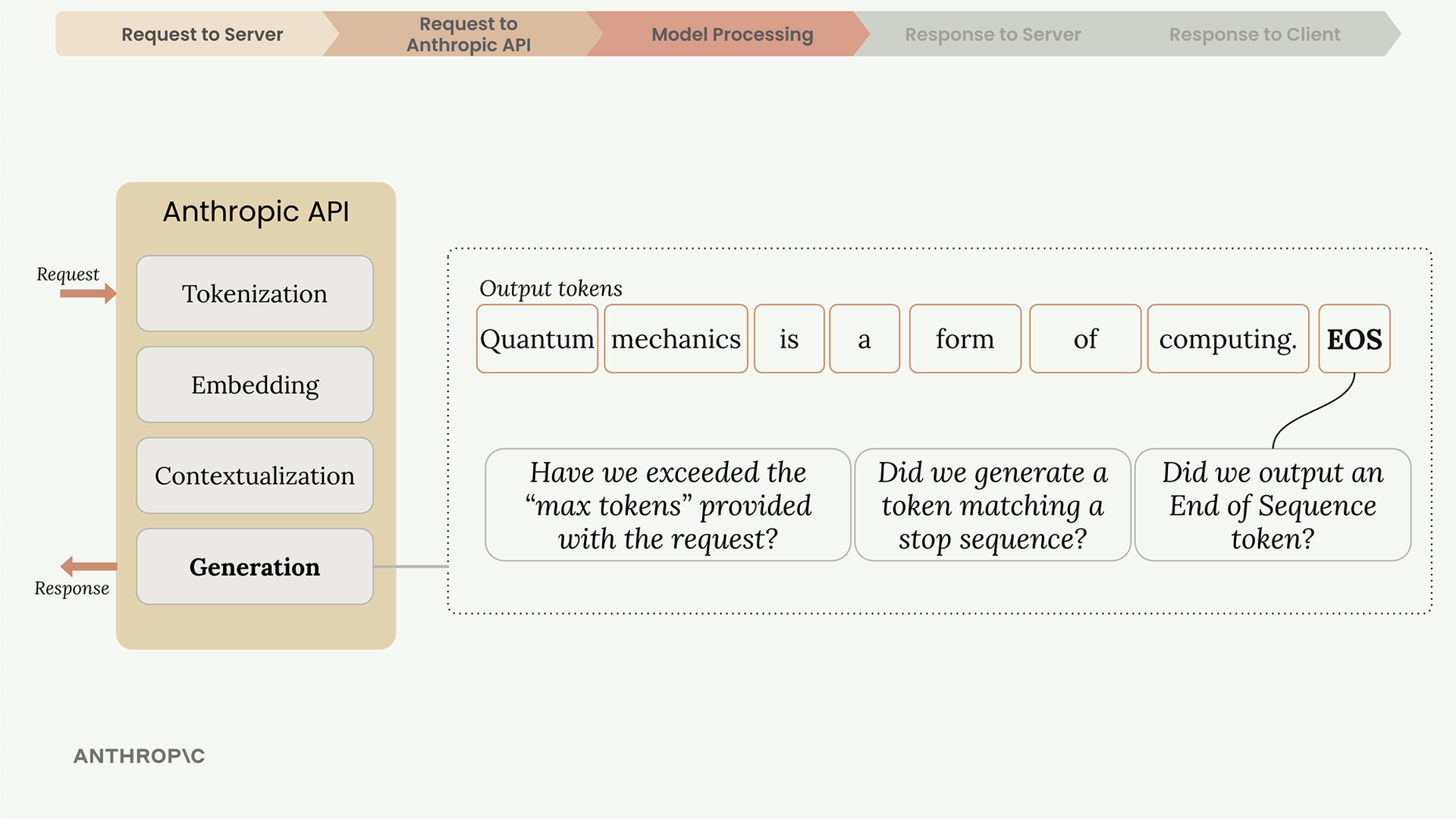
- 达到最大令牌数 - 是否已达到您指定的限制?
- 自然结束 - 是否生成了序列结束令牌?
- 停止序列 (stop sequence) - 是否遇到了预定义的停止短语?
API 响应
生成完成后,API 会返回一个结构化的响应,其中包含:
- Message - 生成的文本
- Usage - 输入和输出令牌的数量
- Stop Reason - 生成结束的原因
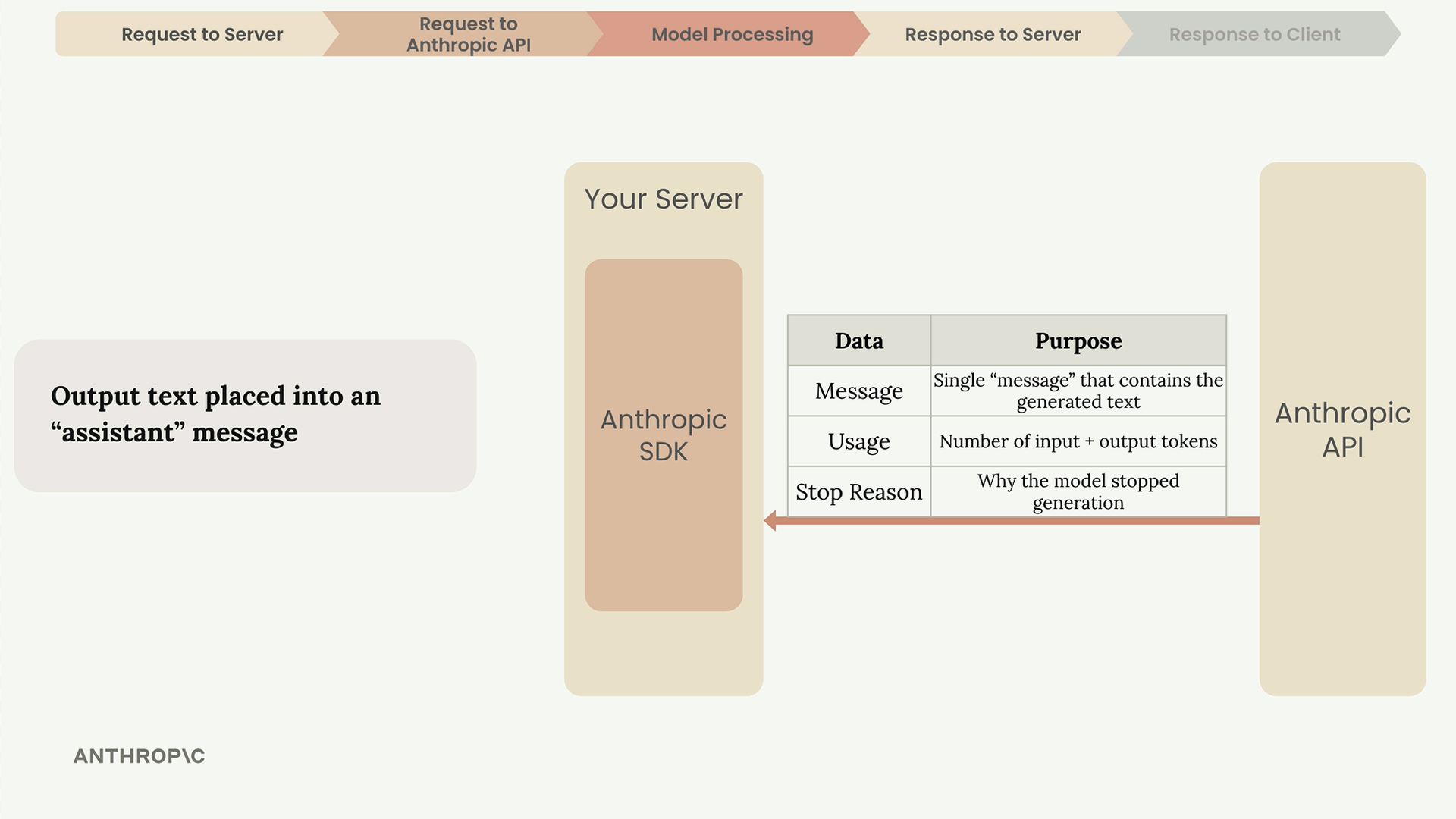
您的服务器接收此响应,并将生成的文本转发回您的客户端应用程序,显示在用户界面中。
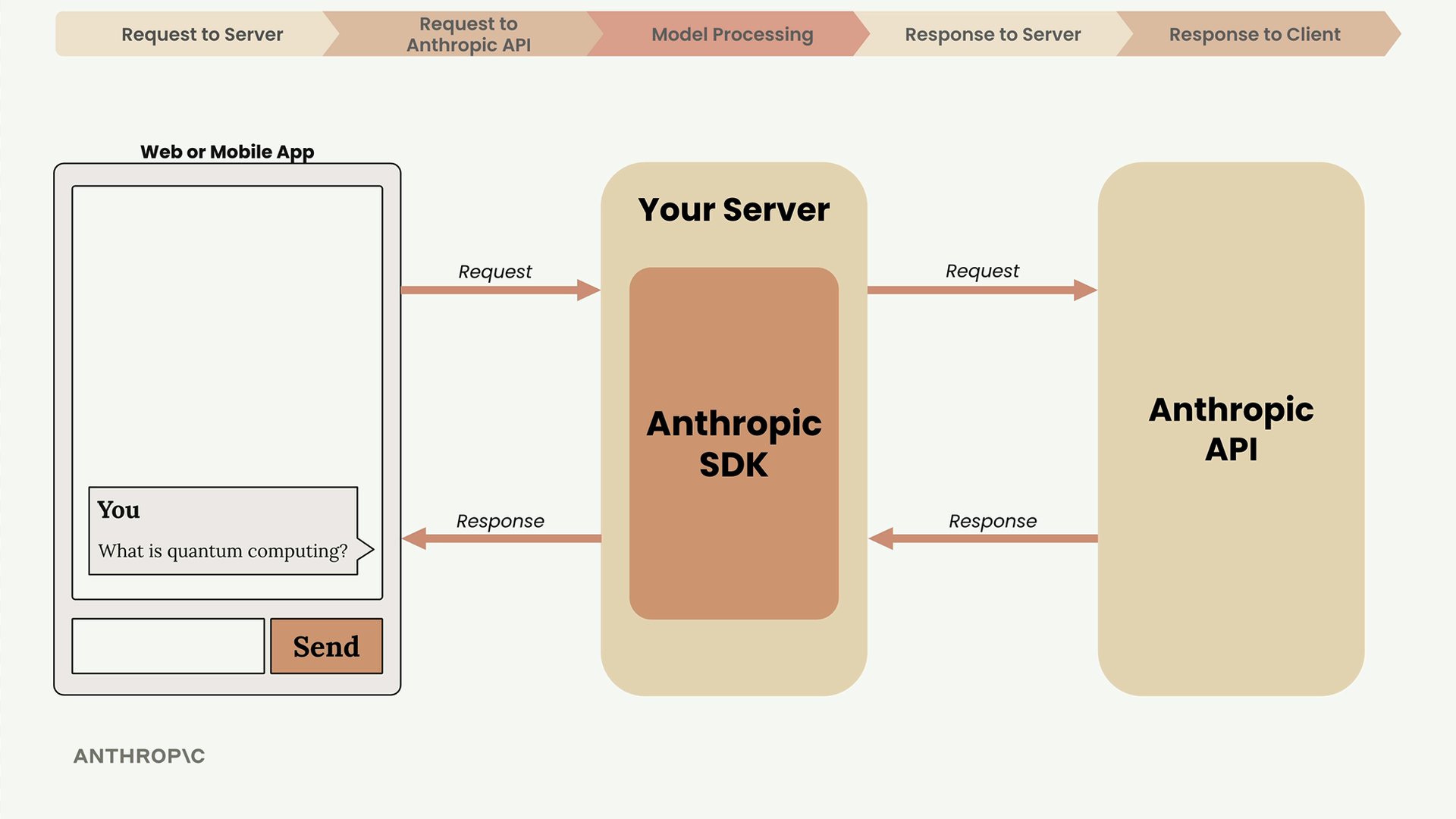
关键要点
理解这个流程有助于您:
- 设计保护 API 密钥的安全架构
- 为您的用例设置适当的令牌限制
- 在您的应用程序逻辑中处理不同的停止原因
- 通过理解问题可能发生在流程中的哪个环节来调试问题
不必记住每个细节——目标是熟悉您在使用 Claude API 时会遇到的术语和总体流程。
视频文字稿
在本模块中,我们将探讨如何访问 Claude 并用它来生成一些文本。为了帮助您理解其工作原理,我将带您了解向 Anthropic API 发出请求的完整生命周期。我们还将简要了解 Claude 内部的幕后工作。为了开始这次演练,我们将以一个简单、标准的聊天机器人应用为例。
假设您正在构建一个 Web 应用,并希望在 Web 浏览器中向用户显示一个聊天窗口。当用户输入消息并点击发送时,他们期望一些响应会奇迹般地出现。如我所说,我想探究这里幕后发生了什么,以生成这段文本并将其显示在屏幕上。我们将把它分解为五个独立的步骤。
我已在此图的顶部概述了这五个步骤。我们将逐一讲解。当用户输入一些文本并点击发送时,该文本将被发送到您(开发者)实现的服务器。我提到这一步只是为了明确一点。
您不应该尝试直接从 Web 或移动应用访问 Anthropic API。每当您向 API 发出请求时,您都需要包含一个秘密的 API 密钥(API key)。确保此密钥保密的最佳方法是永远不要将其包含在您的客户端应用中,而只通过您实现的服务器向 API 发出请求。进入第二步。
一旦您的服务器从客户端收到请求,服务器将直接向 Anthropic API 发出请求。通常,您会通过 Anthropic 发布的其中一个 SDK 来发出此请求。有针对 Python、TypeScript、JavaScript、Go 和 Ruby 的官方 SDK 实现。现在,如果您不想使用 SDK,也完全可以不使用。
您也可以根据需要发起一个普通的 HTTP 请求。当您发出此请求时,您需要传递几条数据。特别是,您需要包含一个 API 密钥、您希望运行的模型的名称、一个消息列表(其中将包含用户提交的文本),以及一个 max_tokens 值,该值限制了 Claude 将生成的文本长度。接下来是 Anthropic API,这里才是我们文本实际生成的地方。
在这里,我们将稍微详细地介绍语言模型内的文本生成过程。这个过程很复杂,所以我将给您一个简化的高级概述。我们将把文本生成过程分解为四个独立的阶段。在第一阶段,用户的输入将被分解成更小的字符串。
这些文本块中的每一个都被称为一个令牌(token)。这些令牌可以是完整的单词,也可以是单词的一部分,甚至是空格或符号。为了清楚起见,我们将假设每个单词构成一个单独的令牌。然后,每个令牌都被转换成一个嵌入(embedding)。
一个嵌入是一个长长的数字列表,您可以将这些列表看作是给定单词的基于数字的定义。现在,书面语言的一个有趣方面是,一个单词可以有许多可能的含义,只有该单词在句子中的位置以及周围其他单词的存在才能将定义缩小到特定的含义。例如,“quantum”(量子)是一个有许多不同定义的词,当我们看到这个词时,我们并不知道它的真正含义,直到我们看到它周围的其他词。同样,每个嵌入可以被认为是包含了每个单词所有可能的含义。
为了将每个嵌入提炼成一个单一精确的定义,我们使用一个称为情境化(contextualization)的过程。在情境化中,每个嵌入都会根据其周围的其他嵌入进行调整。这个过程有助于凸显每个嵌入在其邻居语境下最有意义的含义。最后一步是生成(generation),这是文本实际被写出的地方。
到这时,每个嵌入都已从其邻居那里吸收了大量信息。最终处理过的嵌入被传递到一个输出层,该层为每个可能的下一个词产生概率。现在,模型并不会自动选择概率最高的那个词。相反,它会结合概率和随机性来选择词语,这有助于创建更自然和更多样化的响应。
然后,所选的词被添加到我们的嵌入列表的末尾,整个过程再次重复。在生成每个输出令牌后,模型将暂停并问自己几个问题,以决定是否已完成文本生成。首先,它会计算已生成的令牌数量,并查看是否大于输入请求中提供的 max_tokens 参数。这个 max_tokens 参数将限制模型将生成的总令牌数。
模型还可以生成一个特殊的序列结束令牌。这不是一个常规词。这是模型用来表示它认为已达到其生成的自然终点并且应该停止的特殊信号。一旦生成完成,API 将向您的服务器发送响应。
响应将包含一条消息,其中有生成的文本,以及使用情况 (usage) 和停止原因 (stop reason)。使用情况是您输入到模型中的令牌数和生成的令牌数的计数。停止原因将准确告诉您模型为什么决定停止生成文本,无论是它达到了一个自然的序列结束令牌,还是可能超出了分配的令牌数。一旦您的服务器收到此响应,它会将生成的文本发送回您的 Web 或移动应用,您将在屏幕上显示它。
这就是整个流程。现在,我们在这个视频中涵盖了许多主题。我并不期望您现在就记住所有这些。唯一的目标是开始让您熟悉一些围绕通过 API 访问 Claude 的常用术语。
4. Getting an API key
此课时为环境配置/安装指南,请访问在线课程平台按步骤操作。
5. Making a request
类型:视频 | 时长:6:02 | 视频:03 - 003 - Making a Request.mp4
一旦您了解了基本设置和结构,向 Anthropic API 发出您的第一个请求就会变得很简单。本指南将引导您完成使用 Python 让 Claude 响应您的提示所需的基本步骤。
设置您的环境
在进行任何 API 调用之前,您需要安装所需的包并安全地配置您的 API 密钥。
首先,在您的 Jupyter notebook 中安装必要的依赖项:
%pip install anthropic python-dotenv
接下来,在您的 notebook 所在的同一目录中创建一个 .env 文件,以安全地存储您的 API 密钥:
ANTHROPIC_API_KEY="your-api-key-here"
这种方法可以将您的 API 密钥与代码分开,并防止意外地将其提交到版本控制中。请务必将 .env 添加到您的 .gitignore 文件中。
加载环境变量并创建您的 API 客户端:
from dotenv import load_dotenv
load_dotenv()
from anthropic import Anthropic
client = Anthropic()
model = "claude-sonnet-4-0"
create 函数
进行 API 请求的核心是 client.messages.create() 函数。此函数需要三个关键参数:
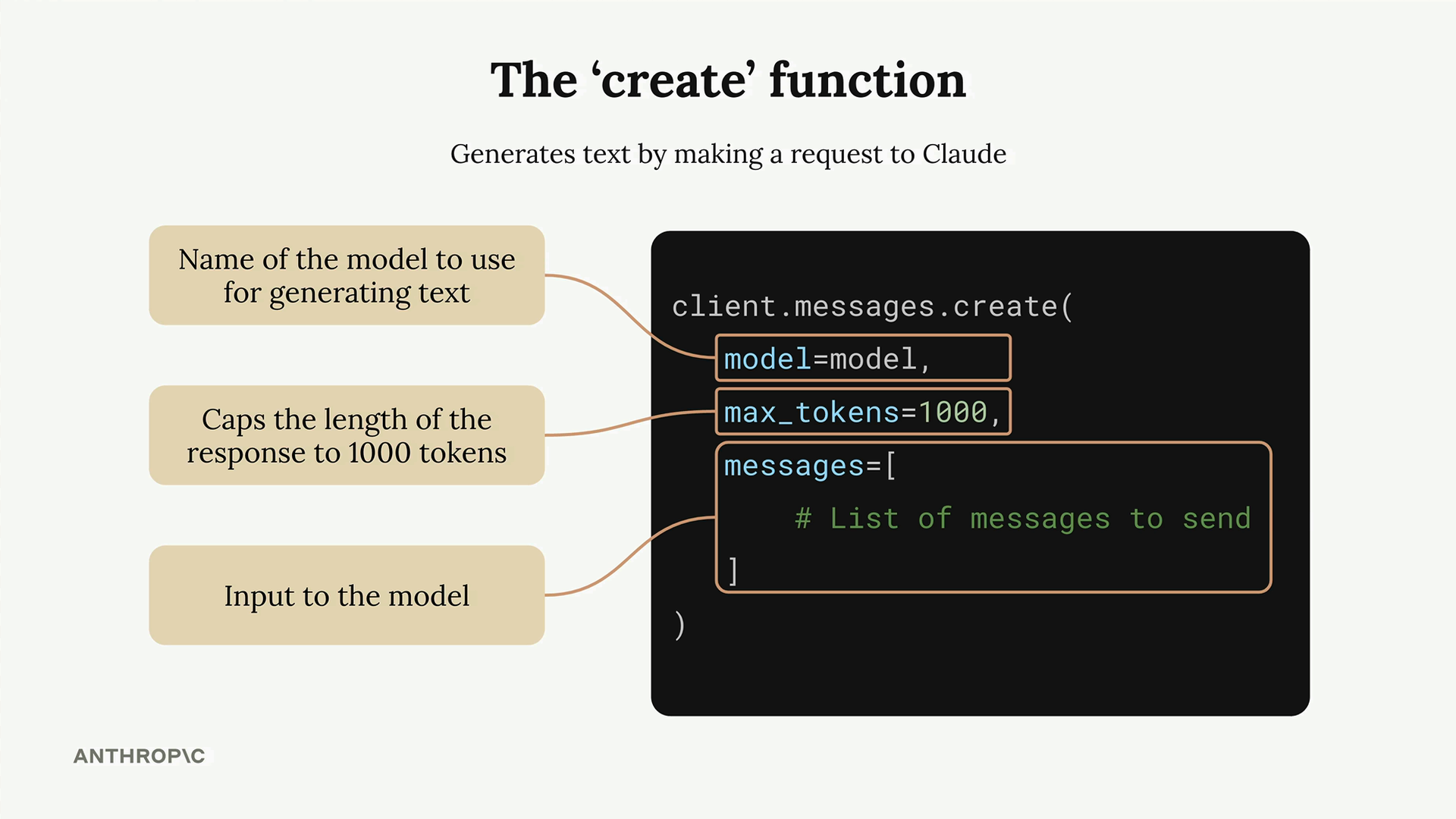
- model - 您要使用的 Claude 模型名称
- max_tokens - 响应长度的安全限制(不是目标长度)
- messages - 您要发送给 Claude 的对话历史
max_tokens(最大令牌数)参数起到安全机制的作用。如果您将其设置为 1000,Claude 将在生成 1000 个令牌后停止,即使它还有更多话要说。Claude 不会试图达到这个限制——它只是写出它认为合适的内容,并在达到最大值时停止。
理解 messages
Messages(消息)代表您与 Claude 之间的对话,类似于聊天应用程序。有两种类型的消息:
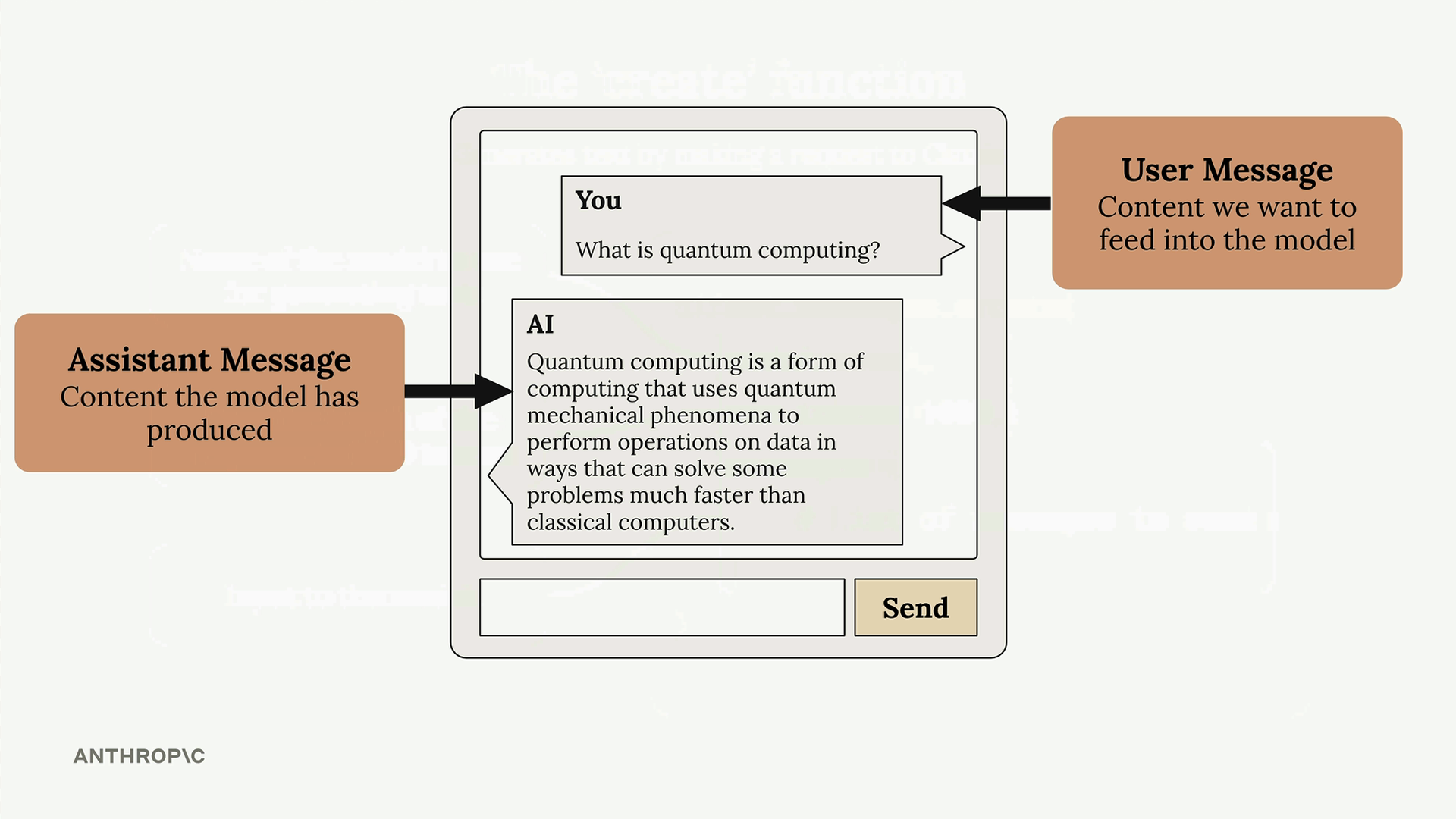
- 用户消息 - 您想发送给 Claude 的内容(由人类编写)
- 助手消息 - Claude 生成的响应
每条消息都是一个字典,包含一个 role(角色,"user" 或 "assistant")和一个 content(内容,即实际文本)。
发出您的第一个请求
以下是向 Claude 发出请求的完整示例:
message = client.messages.create(
model=model,
max_tokens=1000,
messages=[
{
"role": "user",
"content": "What is quantum computing? Answer in one sentence"
}
]
)
当您运行此代码时,Claude 将处理您的请求并返回一个响应对象,其中包含生成的文本以及有关请求的元数据。
提取响应
响应对象包含大量信息,但通常您只需要生成的文本。使用以下方式访问它:
message.content[0].text
这将为您提供干净、可读的输出,例如:“量子计算是一种利用量子力学原理(如叠加和纠缠)来使用量子比特(qubits)处理信息的计算类型,它有可能以指数级速度解决某些经典计算机无法解决的复杂问题。”
掌握了这些基础知识,您就可以开始尝试不同的提示,并与 Claude 构建更复杂的交互了。
视频文字稿
我们已经讲了很多,所以在这个视频中,我们将改变一下方式,亲自动手写一些代码。我们将学习如何向 Anthropic API 发出一个简单和基础的请求。我将带您完成四个设置步骤。第一步,我们将打开一个 Jupyter Notebook 并安装 Anthropic Python SDK,以及一个名为 python-dotenv 的包。
首先,我自己打开一个 notebook。我已经在我的 notebook 中添加了一些注释,以便引导自己完成这个过程。在第一步这里,我将添加一个魔法安装命令,即百分号、pip、install、anthropic、python-dotenv。如果您像我一样在 Visual Studio Code 中编写 notebook,您可能会注意到百分号这里出现了一个红色的语法错误。
如果您看到那个语法错误,完全没问题。您可以忽略它。写完这个命令后,我将运行它来安装这些包。然后我会清除输出,这样您就能更容易地看到我屏幕上的内容。
接下来,我们将使用那个 python-dotenv 包来存储和加载我们的 API 密钥。提醒一下,我在上一讲中给出了创建 API 密钥的说明。所以如果您还没有创建 API 密钥,我建议您回到上一讲去查找那些说明。为了在我的编辑器中存储这个密钥,我将在我的 notebook 所在的同一目录下创建一个具有非常特殊名称的文件。
我将把这个文件命名为 .env。然后,我将在这里面放入我刚才生成的 API 密钥。我会准确地写出 ANTHROPIC_API_KEY,然后是一个等号。之后,在双引号内,我将放入那个密钥。
快速说明一下,我们创建这个文件并将密钥放入其中的全部原因,是为了在我们使用版本控制时可以忽略这个文件。这样我们就不会意外地将这个文件,比如说,提交到 git,然后意外地将其推送到某个公共仓库,让任何人都能看到这个文件。所以再次强调,如果您正在使用 Git 或类似的版本控制系统,我建议您在提交工作时确保忽略这个文件。现在,回到我的 notebook 中,我可以安全地加载那个环境变量。
然后,进入第三步,我们将使用 Anthropic 包创建我们的 API 客户端。在这个单元格中,我还会声明一个名为 model 的变量。这将是一个字符串。它将包含我们希望在 Anthropic API 中运行的模型的名称。
我们将使用 Claude 3.5 Sonnet。现在进入最后一步,我们将实际使用刚刚创建的那个客户端发出一个请求。不过,在编写任何代码之前,我想向您展示一些术语,这些东西会让后续工作变得更容易一些。所以首先要理解的是,我们将通过使用 Anthropic SDK 中的 create 函数来访问 Claude。
这个函数需要三个不同的关键字参数,一个 model,一个 max_tokens,和一个 messages。model 关键字参数只是我们要运行的模型的名称。我们已经在之前的单元格中提前定义了那个变量。第二个必需的关键字参数是 max_tokens。
它为 Claude 可以生成的令牌数量设置了一个最大预算。例如,如果我们传入一个 1000 的 max_tokens,如果 Claude 尝试生成任何超过这个长度的内容,那么生成将被自动停止,我们将收到前 1000 个生成的令牌。这里需要注意的一点是,Claude 不会试图达到您的 max_tokens 数量。换句话说,Claude 不会尝试写一个 1000 个令牌的响应,它只会写它认为合适的响应。
因此,您应该真正将 max_tokens 视为一种安全机制,以确保您不会生成过多的文本。最后是 messages。这是我真正想要关注的部分,因为 messages 将是我们接下来视频中的一个巨大焦点。为了理解 messages 是什么,我希望您回想一下我们刚才讨论的聊天应用。
所以用户可能会向 Claude 输入一些问题,然后期望得到一个答案。我们传递给这个 create 函数的 messages,就是为了表示这样的交流。messages 有两种类型,一种是用户消息 (user message),一种是助手消息 (assistant message)。用户消息包含我们想要输入给 Claude 的文本。
用户消息中的内容是由用户或我们作为开发者创作的文本。换句话说,用户消息将包含由某个人编写的文本。第二种消息类型是助手消息。这些消息包含由模型生成并发送给我们的文本。
现在,我认为我们已经有足够的知识来至少发出我们的第一个请求了。所以让我们这样做,然后再多讨论一下 messages。回到我的 notebook,在最后一个单元格中,我将声明一个 message 变量,它将来自 client.messages.create。我将传入我们刚才讨论的那些不同参数。
所以我将传入一个 model 为 model,一个 max_tokens,我这里用 1000,我认为这绝对是一个安全的限制,然后是一个输入消息的列表。所以在这里,我将放入一个单独的用户消息,它将包含我想要发送给 Claude 的问题或查询。要创建一个用户消息,我们将创建一个字典,它将有一个 user 的 role,然后是一个 content,其中包含我们想要发送给 Claude 的实际字符串。所以在这种情况下,我将要求 Claude 用一句话定义量子计算,比如“什么是量子计算?用一句话回答”。
然后我将运行它,这会花一两分钟的时间,因为我们实际上正在访问 Claude。之后,在下面的单元格中,我将尝试打印出 message 变量。我们看看会得到什么。好了,在里面,我们可以看到有很多东西输出来,但值得注意的是,我们在这里附近得到了一个关于量子计算是什么的定义。
所以,在我们得到的这个 message 变量中,我们的文本是相当深层嵌套的。我们通常只想获取 Claude 生成的文本,而通常不太关心这个东西里面包含的任何其他属性。所以要只访问生成的文本,我们会这样写 message.content[0].text。如果我再次运行那个单元格,现在我将只看到生成的文本,没有其他任何东西。
6. Multi-Turn conversations
类型:视频 | 时长:8:54 | 视频:03 - 004 - Multi-Turn Conversations.mp4
在使用 Anthropic API 和 Claude 时,您需要理解一个至关重要的概念:Claude 不会存储您的任何对话历史。您发出的每个请求都是完全独立的,不带有先前交流的任何记忆。
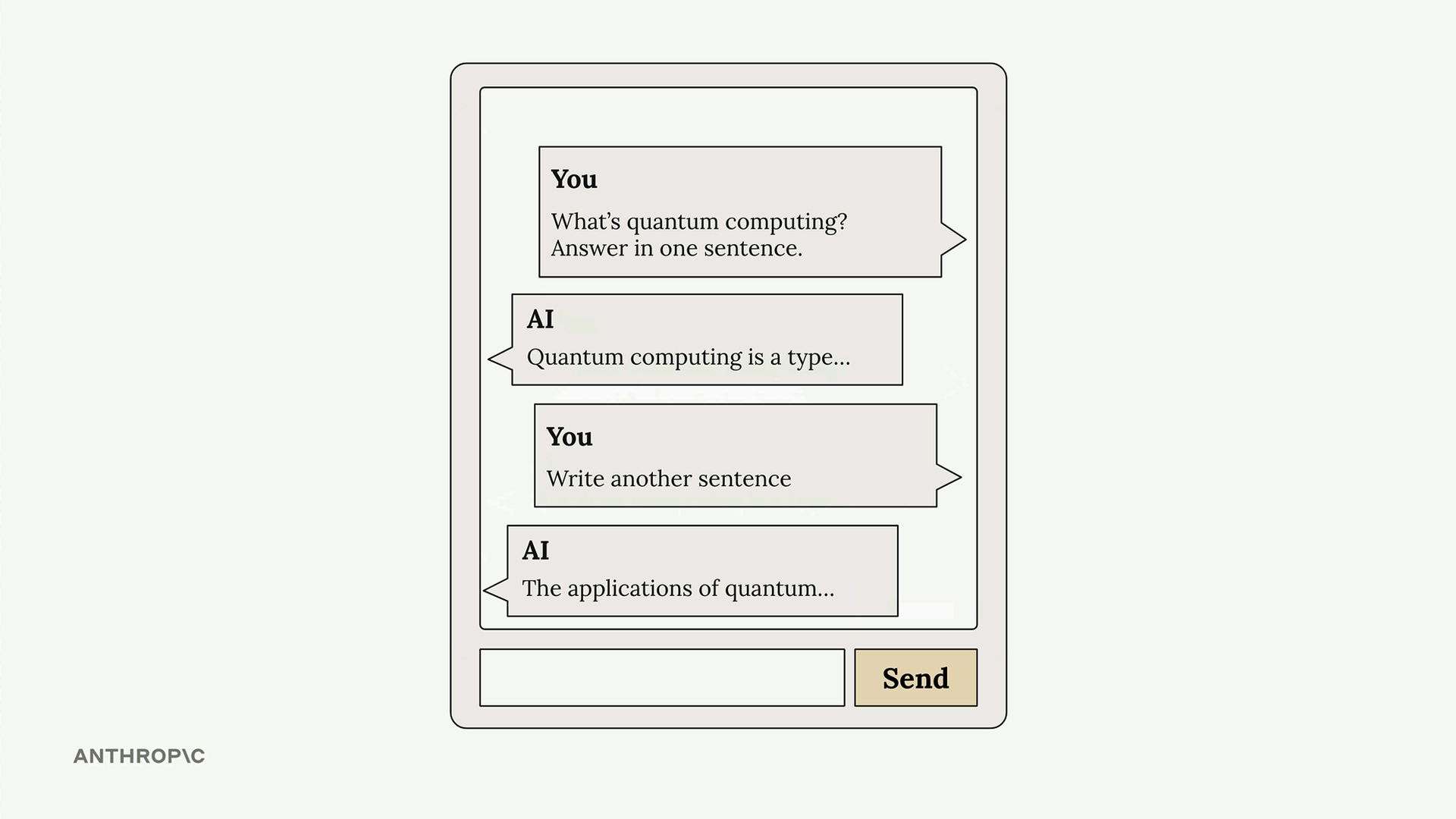
这意味着,如果您想进行多轮对话,让 Claude 记住先前消息的上下文,您需要自己来处理会话状态 (conversation state)。
无状态 (Stateless) 对话的问题
假设您问 Claude “什么是量子计算?” 并得到了一个很好的回答。然后您追问“再写一句话”——Claude 完全不知道您在指什么。它会写一句关于完全随机事情的句子,因为它没有关于量子计算讨论的任何记忆。

多轮对话如何工作
要维护对话上下文,您需要做两件事:
- 在您的代码中手动维护一个所有消息的列表
- 在每次请求时发送完整的消息历史
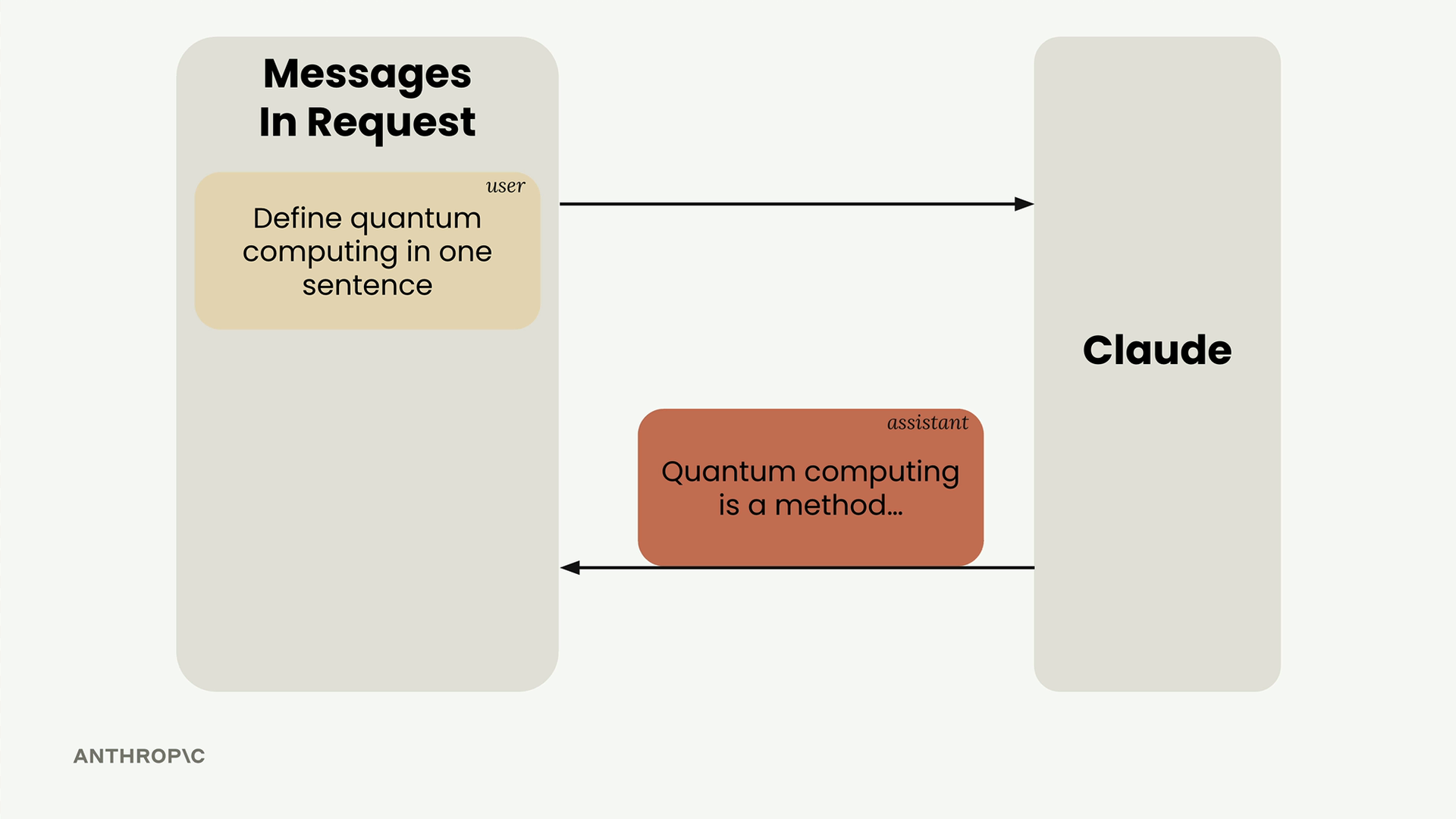
以下是实际可行的流程:
- 将您的初始用户消息发送给 Claude
- 获取 Claude 的响应,并将其作为助手消息添加到您的消息列表中
- 将您的追问作为另一个用户消息添加
- 将整个对话历史发送给 Claude
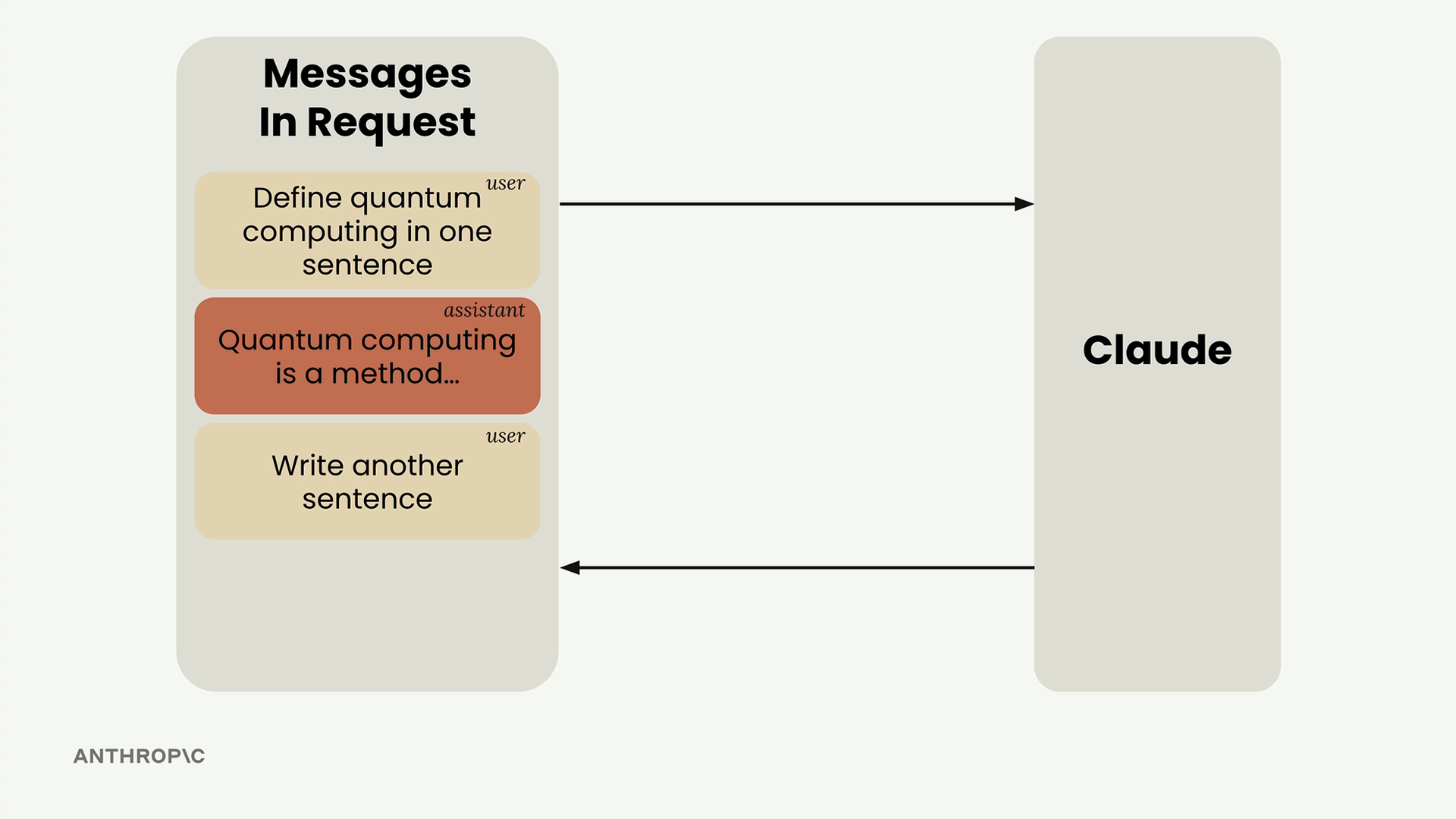
构建辅助函数
为了让对话管理更容易,您可以创建三个辅助函数:
def add_user_message(messages, text):
user_message = {"role": "user", "content": text}
messages.append(user_message)
def add_assistant_message(messages, text):
assistant_message = {"role": "assistant", "content": text}
messages.append(assistant_message)
def chat(messages):
message = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
)
return message.content[0].text
整合所有部分
以下是如何使用这些函数来维护一个对话:
# 从一个空的消息列表开始
messages = []
# 添加初始的用户问题
add_user_message(messages, "Define quantum computing in one sentence")
# 获取 Claude 的响应
answer = chat(messages)
# 将 Claude 的响应添加到对话历史中
add_assistant_message(messages, answer)
# 添加一个追问
add_user_message(messages, "Write another sentence")
# 在拥有完整上下文的情况下获取追问的响应
final_answer = chat(messages)
现在 Claude 会明白“再写一句话”指的是扩展关于量子计算的定义,因为您已经提供了完整的对话上下文。
这些辅助函数在您使用 Claude 的整个过程中都会非常有用,使构建能够跨多个交流回合维护有意义对话的应用程序变得更加容易。
视频文字稿
到目前为止,我们编写的代码模拟了与模型的一次非常简单的交流。我们可以像这样在一个聊天框中将这次对话可视化。我们发送了一个请求,问了类似“什么是量子计算,用一句话回答”的问题。然后我们得到了一个非常简单的单句回复。
很自然地,我们可能希望在某个时候继续这个对话。所以我们可能希望能够发送一个后续问题,比如“再写一句话”。然后我们会期望得到一个以某种方式扩展量子计算内容的回复。要进行这样的多消息对话,您需要了解关于 Anthropic API 和 Claude 本身的一个非常关键的事情。
那就是,Anthropic API 和 Claude 不会存储您发送给它的任何消息。您发送的任何消息都不会以任何方式被存储,您得到的任何回复也不会以任何方式被存储。所以,如果您想进行某种对话,其中有多条消息能够保持上下文或流程,那么您需要做两件事。您需要在您的代码中手动维护一个所有交流消息的列表。
第二,您需要确保在每次后续请求时都提供那个完整的消息列表。所以让我们详细地探讨一下这个想法,确保它非常清楚,并且您理解这里发生了什么。我想做的第一件事是写一些示例代码,只是为了向您证明 Claude 不会存储任何消息或类似的东西。我可以通过尝试模拟这种对话来证明这一点,我先问什么是量子计算,然后问“再写一句话”。
回到我的 notebook,我将转到我最初问“什么是量子计算”的那个单元格。我想把我预先写好的第二个请求粘贴到 Claude。所以在这个第二个请求中,我要求 Claude 写另一句话,我将打印出那个后续请求中的文本。所以现在我们有点模拟了这里发生的事情,我们先问那个问题,然后发送一个后续问题。
我们会发现我们得不到任何可读或可用的文本。所以我将运行它,看看会发生什么。回到这里,我现在将运行那个单元格,我们会看到我们得到的东西与量子计算完全无关。所以再次,为了确保非常清楚为什么我们会看到这个结果而不是关于量子计算的内容,让我们看几个图表。
好的,在这个图表中,我首先会向您展示我编写的查询代码究竟发生了什么,我们得到的响应与量子计算毫无关系。所以,最初,我向 Claude 发出了一个类似的请求,其中我有一条用户消息,我要求 Claude 用一句话定义量子计算。然后我得到了一个完全符合我预期的响应。Claude 给了我一个关于量子计算的单句定义。
然后我发出第二个请求,其中正文里只有一条消息。唯一的消息是要求 Claude 写另一句话。当我发送这个请求时,Claude 对任何过去的对话或我与它交换的任何先前消息都没有记忆。所以 Claude 只会尽力满足我的请求。
它会写出一句话,但很可能与量子计算无关。所以现在让我向您展示我们需要做什么来解决这个问题。我们将这样解决问题。首先,我们将再次只用一条用户消息发出那个初始请求。
然后,我们将把得到的那个助手消息追加到一个消息列表中。所以我们将在这里获取助手消息,我们可以想象我们将把它添加到左侧的列表中。然后,当我们想跟进这个对话或以某种方式继续它时,我们将在底部追加一条用户消息。所以现在我们可以把这看作是一次真实的对话。
我要求定义量子计算,我得到了一个回复,现在我正在添加另一个我想问 Claude 的问题或查询。在这种情况下,是“再写一句话”。现在,当我把这个消息列表发送给 Claude 时,它将拥有整个对话的完整上下文和历史。它看到了我们围绕这个问题线索交换的所有先前消息。
希望 Claude 能够给我们一个更合理的答案,希望是一个单句的后续回答,能够稍微扩展它之前的答案。为了看到这个完整流程的实际效果,我将回到我的 notebook,我们将尝试编写一些代码,让我们能够维护对话的完整上下文。回到我的 notebook,我将开始创建三个不同的辅助函数,它们将帮助我们维护对话的历史或上下文。在本课程的剩余部分,我们将经常使用这些辅助函数。
在这个单元格中,我将在顶部给自己留一些空间,然后定义我们的第一个辅助函数,它将帮助我们维护这个历史。我将把这个函数命名为 add_user_message。它将接收一个消息列表和一些文本。然后我将创建一个名为 user_message 的变量。
它将有一个 user 的 role 和我们传入的任何文本的 content。然后我将把这个新的用户消息追加到消息列表中。接下来,我将添加第二个辅助函数,它将专门用于向历史中添加助手消息。所以我将复制这个函数,只是为了节省一点时间。
我将它重命名为 add_assistant_message。然后我将遍历代码,凡是看到 user 这个词的地方,我都会把它换成 assistant。这里,这里,还有这里。好的,现在是我们的第三个辅助函数。
我将把这里的 messages.create 函数调用。我将把它重命名为 chat。每当我调用 chat 时,我都会传入一个消息列表。所以这就像我的消息历史。
然后我将缩进我们这里的调用。我将用 messages 参数替换 messages,然后从这个函数返回的将是 message.content[0].text。好了,这就是三个辅助函数。再次强调,我们将在本课程的剩余部分经常使用它们。
这些辅助函数将使我们能够更容易地进行一个随时间推移保持某些历史或上下文的对话。所以现在让我给您演示一下我们将如何使用它们。好的,在下面的单元格中,我将写下一些注释,她将引导我们完成维护一个有历史记录的对话的过程。我首先会创建一个空的消息列表。
所以这里的 messages 变量,我们可以想象它存储了我们整个对话的历史。随着时间的推移,我们将向其中添加一系列不同的用户和助手消息。接下来,我将添加我的初始用户消息。所以我会调用 add_user_message 函数。
我将传入我正在追加消息的消息列表,然后我的用户文本将是“用一句话定义量子计算”。现在,为了确保我们走在正确的道路上,我将打印出消息列表并运行该单元格。我们可以立即看到我们有一个正确的消息结构。所以我有一个列表。
它里面有一个字典,角色是 user,内容包含我想要输入给 Claude 的东西。所以现在我们可以通过使用我们刚刚组合的 chat 函数轻松地调用 Claude。我将调用 chat 并传入我的消息列表。然后,我们将得到某种答案。
我将打印出答案并再次运行该单元格。所以我们得到响应,我们应该在这里看到一个关于量子计算的句子。所以现在我们处于这种情况。我们已经向 Claude 发送了一条初始消息,并得到了一个助手消息作为回应。
现在我们需要把这个答案追加到我们的对话历史中。所以我们需要通过使用我们刚刚定义的 add_assistant_message 函数来添加或追加它。所以回到这里。我将调用 add_assistant_message。
我想添加到我们的消息列表中,我想特别添加我们刚刚得到的答案中的内容。所以现在让我们再做一次检查,确保我们的消息列表看起来是正确的。如果我打印出 messages,我应该看到我的用户消息,然后是带有我们从 Claude 那里得到的内容的后续助手消息。好的,那看起来不错。
所以现在进入最后一步。我们将追加最后一条用户消息,并再次将整个对话历史发送给 Claude。所以为此,我将用我的消息列表再做一个 add_user_message。然后我这里的后续问题或后续请求将是“再写一句话”。
我将再次用更新后的消息列表调用 chat。我将把结果赋给 answer,然后我将打印出 answer。所以现在让我们运行这个,看看我们做得怎么样。好的,在短暂的停顿之后,我们得到了一个绝对是后续消息的回复,而且绝对仍然是关于量子计算的。
所以看来我们已经正确地维护了我们整个对话的历史。好的,这看起来很不错。我们现在有三个可重用的辅助函数,我们将在本课程的剩余部分继续使用它们。
7. Chat exercise
类型:视频 | 时长:3:54 | 视频:03 - 005 - Chat Exercise.mp4
视频文字稿
让我们做一个快速练习,以确保到目前为止一切都讲清楚了。在这个练习中,我们将构建一个非常小的聊天机器人,它将在我们的 Jupyter Notebook 中运行。它的工作方式如下。每当我们运行一个单元格时,我们将使用内置的 input 函数提示用户输入一些文本。
然后,我们将把用户输入的任何内容添加到消息列表中。接着,我们将把这个消息列表通过我们刚刚组合的 chat 函数传递给 API。这将为我们提供一些来自 Claude 的反馈,即一些生成的文本。我们将把这些生成的文本添加到我们的消息列表中。
我们会打印出生成的文本,然后我们将循环回到第一步,以便我们一遍又一遍地重复整个过程。我将很快地向您展示这个东西打算如何工作。所以我已经准备好了一个解决方案。我把它隐藏在这个单元格里,我将再次运行这个单元格,这样您就可以看到我打算让它如何工作。
所以每当我运行这个单元格时,我都会立即使用内置的 input 函数提示用户输入。稍后我会告诉您如何使用它,以防您不熟悉。然后我将输入类似“一加一等于几”的内容。我应该立刻看到我的消息被打印出来,然后我应该使用 chat 函数从 Claude 获得一个响应,并也打印出来。
然后我应该再次被提示添加更多的文本。所以现在我可以说类似“在那个答案上加二”的话。然后我应该看到我正在维护我的对话历史或上下文。所以我现在应该得到一个回复,上面写着“在前一个答案二的基础上再加二,结果应该是四”。
同样,这个过程会一直进行下去,直到我最终点击这里的 interrupt(中断)按钮并按 escape 键来中断它。现在,正如我提到的,如果您不熟悉内置的 input 函数,没问题。我现在会给您一个小提示,并确保我们想要做的事情非常清楚。所以我会粘贴一些代码,您可以把它当作一个小模板。
好的,这就是我们想要使用的大致结构。我们将初始化一个起始的消息列表,它将完全是空的。然后我们将有一个 while True 循环,它将永远运行。在 while 循环内部,我们将要求用户输入一些文本,使用内置的 input 函数。
当用户在显示的输入框中输入内容时,它将被赋给这个 user_input 变量。然后我在这里放了一些注释,以引导您完成我们需要做的步骤。好的,请在这里暂停视频。我鼓励您尝试一下这个练习。
否则,请继续观看,我们马上会讲解解决方案。那么让我们开始吧。让我告诉您我们如何把它组合起来。所以要实现剩下的部分,我们只需要遵循我在这里放的不同注释。
我们要做的第一件事是把那个用户输入,使用我们刚才组合的 add_user_message 函数,添加到我们的消息列表中。所以我将调用 add_user_message。我将传入消息列表和我的 user_input。然后我将使用内置的 chat 函数调用 Claude,并传入我的消息列表。
这将给我返回一些答案。我将把那个答案作为一条助手消息添加到我的消息列表中。所以 add_assistant_message。就像这样。
然后我只需要打印出生成的文本。另外,我可以选择性地加入一些分隔符,用小破折号的形式。只是为了确保使用这个应用程序的人清楚这是由我们的 AI 生成的。所以我将打印一个破折号,破折号,破折号。
在其中两个之间,我将打印出我得到的答案。就是这样。所以现在为了测试它,我将运行这个单元格。然后在我开始与 Claude 聊天后,我应该在单元格下方看到一些输出。
所以我会问 Claude“一加一等于几”。然后我会得到我的回复,然后“再加二”。我应该看到“在一加一的基础上再加二,我们应该得到四”。好的,非常好。
所以这就是我们对一个循环聊天机器人的非常简单的实现。
8. System prompts
类型:视频 | 时长:6:20 | 视频:03 - 006 - System Prompts.mp4
系统提示 (System prompts) 是一种强大的方式,可以定制 Claude 响应用户输入的方式。您不再得到通用的答案,而是可以塑造 Claude 的语气、风格和方法,以匹配您的特定用例。

系统提示为何重要
考虑构建一个数学辅导聊天机器人。当学生问“如何解方程 5x + 2 = 3 中的 x?”时,您希望 Claude 表现得像一个真正的导师,而不仅仅是直接给出答案。一个好的数学导师应该:
- 最初给出提示而不是完整的解决方案
- 耐心地引导学生一步步解决问题
- 展示类似问题的解法作为例子
您绝对不希望 Claude:
- 立即给出直接答案
- 告诉学生直接使用计算器
系统提示如何工作

系统提示为 Claude 如何响应提供了指导。您将它们定义为纯字符串,并将其传递到 create 函数调用中。主要优点是:
- 系统提示为 Claude 如何响应提供了指导
- Claude 会尝试以指定角色的人会回应的方式来回应
- 有助于让 Claude 保持在任务上
以下是基本结构:
system_prompt = """
You are a patient math tutor.
Do not directly answer a student's questions.
Guide them to a solution step by step.
"""
client.messages.create(
model=model,
messages=messages,
max_tokens=1000,
system=system_prompt
)
看出区别
如果没有系统提示,Claude 会立即给出一个完整的、分步的解决方案。这可能很有帮助,但它并不鼓励学生自己思考问题。
有了数学导师的系统提示后,Claude 的响应发生了巨大变化。Claude 不再提供完整的解决方案,而是提出引导性问题,例如“您认为隔离 x 的第一步应该是什么?考虑一下我们可能需要在两边进行什么运算来开始移动项。”
构建一个灵活的聊天函数
你可以通过接受系统提示作为参数,而不是硬编码它们,来使你的聊天函数更具可复用性:
def chat(messages, system=None):
params = {
"model": model,
"max_tokens": 1000,
"messages": messages,
}
if system:
params["system"] = system
message = client.messages.create(**params)
return message.content[0].text
这种方法处理了一个重要的细节:Claude 的 API 不接受 system=None,所以你需要仅在提供了 system 参数时才条件性地包含它。
现在你可以带或不带系统提示来调用你的聊天函数:
# 不带系统提示
answer = chat(messages)
# 带系统提示
system = """
你是一位有耐心的数学导师。
不要直接回答学生的问题。
引导他们一步步找到解决方案。
"""
answer = chat(messages, system=system)
系统提示对于创建行为一致且符合其预期用途的 AI 应用至关重要。它们将通用的 AI 响应转化为专业的、角色合适的互动。
视频文字稿
在本视频中,我们将探讨如何自定义 Claude 生成响应的语气和风格。为了帮助你理解这为什么重要,我希望你想象一下我们正在制作一个数学导师聊天机器人。用户将使用这个聊天机器人来请求解决数学问题的帮助。例如,一个用户可能会请求帮助解决 5x + 2 = 3。
现在,我们希望我们的数学导师做一些事情,也绝对不希望它做另一些事情。例如,我们可能希望 Claude 最初只给学生一些提示。也许只是给他们一两个关于如何初步着手解决问题的小技巧。然后,如果学生仍然不太明白如何解决问题,只有在这时,才可能引导学生一步步完成解答。
我们可能还希望 Claude 展示一个类似问题的解法,给学生一些关于如何处理这个特定问题的启发。同样,有些事情我们绝对不希望 Claude去做。例如,我们不希望 Claude 只是立即用一个完整的答案来回应。我们也不希望 Claude 告诉学生直接去用计算器解决问题之类的话。
为了解决这个问题,我们将使用一种名为“系统提示 (system prompting)”的技术。系统提示用于自定义 Claude 回应的风格和语气。我们将系统提示定义为一个纯字符串,然后将其传递到 create 函数调用中。系统提示的第一行通常会给 Claude 分配一个角色,所以我们可能会直接告诉 Claude 它是一个有耐心的数学导师。
这将鼓励 Claude 以真实数学导师回应的方式来回应。它可能会变得有耐心,提供大量解释,但可能不会直接回答学生的问题。相反,它会引导他们找到解决方案。现在,为了看到实际效果,让我们回到我们的 notebook,看看 Claude 在有和没有系统提示的情况下是如何回应数学问题的。
回到我的 notebook 里,我新建了一个 notebook,并只引入了我们最初的客户端创建代码和那三个辅助函数。你不需要创建一个新的 notebook。我只是让你知道我这么做了,为了整理我的代码。然后在这里下面的单元格里,我将问 Claude 一个非常简单的问题。
我将让它解决一个简单的数学问题。我们会看到它最初是如何回应的。它很可能只会给我们一个直接的答案。然后我们会回来添加一个系统提示,鼓励它给我们更多一点的解释,一种导师式的教学方法。
那么,让我们看看在完全没有系统消息的情况下,Claude 会如何回应我们。我将创建一个消息列表。我会在我的消息列表中添加一个用户消息。我会让它解方程 5x + 3 = 2,求 x。
然后我会通过调用带有我的消息列表的 chat 函数来获取答案,并打印出答案。如果我运行这个单元格,我可能会看到一个关于如何解决这个问题的精确、分步的解决方案。现在,这对于学生来说可能很有用,因为它会向他们展示一个分步的解决方案,但这不完全是我们想要的。我们想让学生思考,我们希望他们自己得出解决方案。
我们只想给他们小步骤,并引导他们朝正确的方向前进。所以,我们将通过使用系统提示来自定义 Claude 的回应方式。让我来告诉你怎么做。在我的 chat 函数里,我将创建一个名为 system 的新变量。
我将给它赋一个多行字符串。在里面,我将放入我事先写好的一个系统提示。所以,我会告诉 Claude 它是一个有耐心的数学导师。它不应该直接回答学生的问题。
相反,给他们一些关于如何解决问题的指导。我将确保把系统提示作为 system 关键字参数传递给 create 函数。然后我将重新运行这个单元格。我会再回到下面,看看 Claude 现在是如何回应的。
好的,这个答案看起来好多了。Claude 不再是直接告诉学生如何解决问题,而是提示用户一步一步地完成解答。Claude 正在问学生,也许可以先把 x 单独放在等式的一边,然后问学生我们该怎么做。所以现在我们为学生提供了一个更具互动性的体验。
这希望能帮助他们比仅仅得到一个直接答案更好地学习这里发生了什么。好的,所以很明显,使用系统提示是一个强大的工具,可以在 Claude 如何回答给定的用户输入方面引导它朝着特定的方向发展。在我们继续之前,我想对我们的 chat 函数进行一点重构。我不想在函数内部硬编码一个系统提示,而是希望在调用 chat 函数时能够指定一个系统提示。
换句话说,我想把这部分剪切下来,放到下面的单元格里,然后我希望能像这样传入一个系统提示。所以现在我们有了一个更具可复用性的 chat 函数,我们可以在未来用于各种不同的问题,而不需要在函数内部硬编码系统提示。所以现在我们需要确保我们接收这个 system 参数并将其传递给 create 函数。现在,这样做需要比你想象的要多一点工作。
让我来告诉你为什么。我将很快地在 chat 函数中添加一个 system 关键字参数,并将其默认值设为 none。如果我现在运行这个单元格,然后运行下面的单元格,一切都会正常工作,完全符合预期。但是,如果我转到 chat 函数,并决定我完全不想在这里提供系统提示,那么如果我删除它然后运行该单元格,我最终会得到一个错误消息。
所以我们不允许传入一个为 none 的系统提示。所以我们需要更动态地组装我们将要传递给 create 函数的参数。如果我们有一个为 none 的 system,我们根本不希望包含这个参数。
所以让我用一个小重构来告诉你我们该怎么做。首先,我将在上面创建一个参数字典。我将剪切并粘贴 model、max_tokens 和 messages。我将把它转换成字典语法。
所以我用双引号、双引号、冒号,像这样。然后我会检查是否传入了系统提示。所以如果传入了,那么我想把它作为 system 键添加到 params 字典中,像这样。然后我将更新下面的 create 调用为 **parameters。
就这样。现在我将重新运行那个单元格。我会回到下一个。如果我调用 chat 时没有传入任何 system 关键字参数,没问题。
一切都会正常工作。如果我决定确实要提供一个系统提示,是的,那也会正常工作。好的,这看起来不错。所以我们现在在我们的 chat 函数中支持了系统提示。
9. 系统提示练习
类型:视频 | 时长:1:25 | 视频:03 - 007 - System Prompts Exercise.mp4
视频文字稿
我们来做一个关于系统提示的快速练习。我更新了我的 notebook,现在我让 Claude 写一个 Python 函数,用来检查一个字符串中是否有重复的字符。如果我运行这个并打印出答案,我会看到生成了大量的代码。其中一些是少量的代码,但也有大量的解释和大量的注释。
所以我想在这里做一个练习,我们尝试减少生成的代码量。我想尽可能地得到这个函数最简洁的实现。要做到这一点,我希望你写出一个系统提示并将其传递给聊天函数调用。你的系统提示应该为 Claude 分配一个角色,并鼓励它尽可能简洁地回应。
所以,再次强调,请在这里暂停视频,试一试,我们马上会讲解解决方案。为了解决这个问题,我将向 chat 函数调用传递一个系统提示。在其中,我将为 Claude 分配一个角色,这将鼓励它编写非常简洁的代码。我会说:You are a Python engineer who writes very concise code.(你是一位编写非常简洁代码的 Python 工程师。)
那么现在让我们运行这个单元格,看看我们现在能得到什么样的回应。好的,这绝对更符合我的期望。你会看到我们为实现这个唯一性检查而必须编写的实际代码非常非常短,比我们刚才看到的代码短得多。希望你在这个练习中取得了一些成功。
如果你没有,那也完全没关系。课程中还会有很多其他的练习,你可以测试你的技能。
10. Temperature
类型:视频 | 时长:6:07 | 视频:03 - 008 - Temperature.mp4
Temperature (温度) 是一个强大的参数,它控制着 Claude 响应的可预测性或创造性。理解如何有效使用它可以极大地改善你的 AI 应用。
Claude 如何生成文本
在深入探讨 temperature 之前,了解 Claude 的文本生成过程会很有帮助。当你向 Claude 发送一个像“你觉得呢?”这样的提示时,它会经过三个关键步骤:
- Tokenization (分词) - 将你的输入分解成更小的块
- Prediction (预测) - 计算可能的下一个词的概率
- Sampling (采样) - 根据这些概率选择一个 token
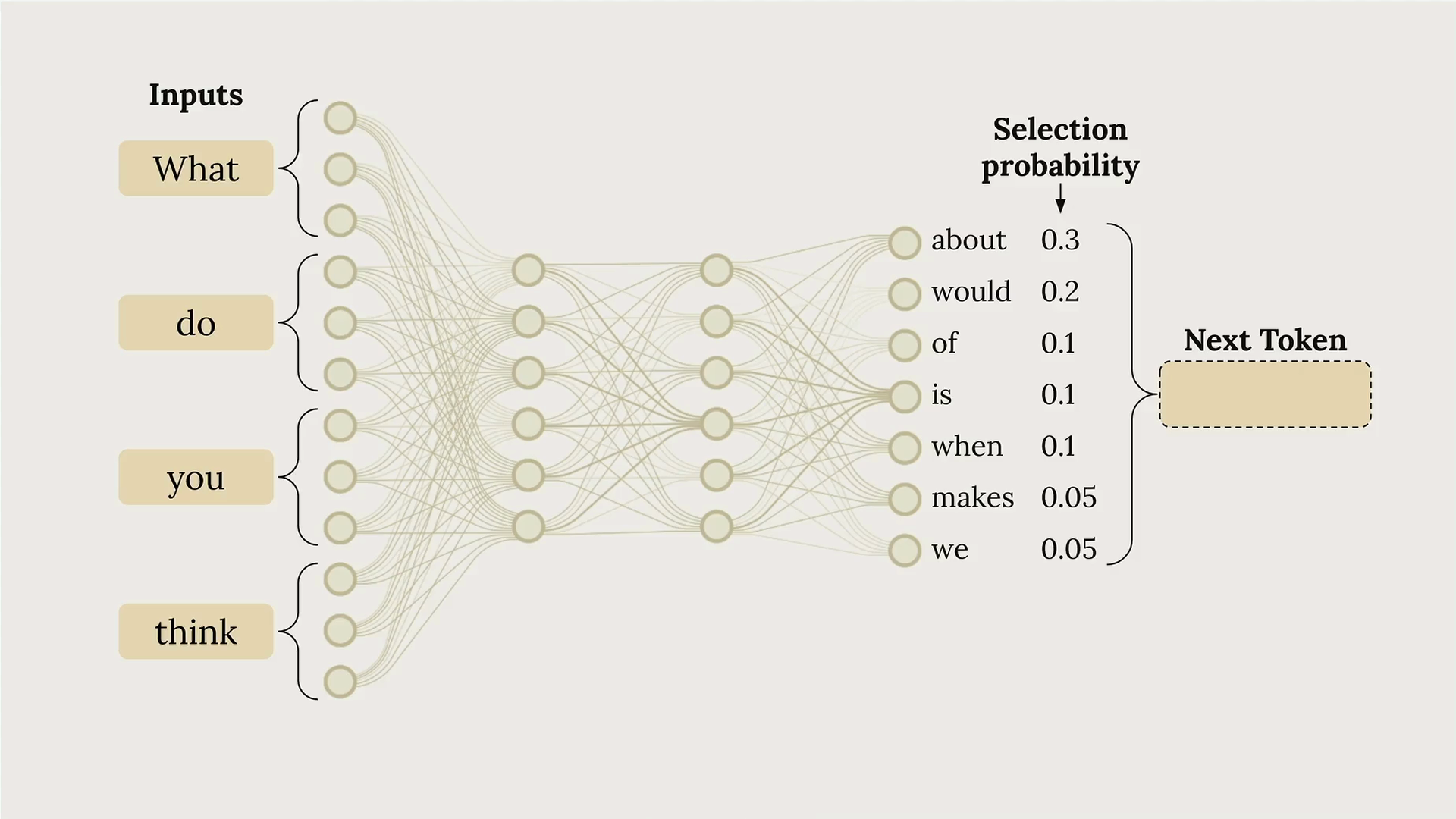
在这个例子中,Claude 可能会给 "about" 分配 30% 的概率,给 "would" 20%,给 "of" 10%,以此类推。然后模型选择一个 token 并重复整个过程来构建完整的句子。
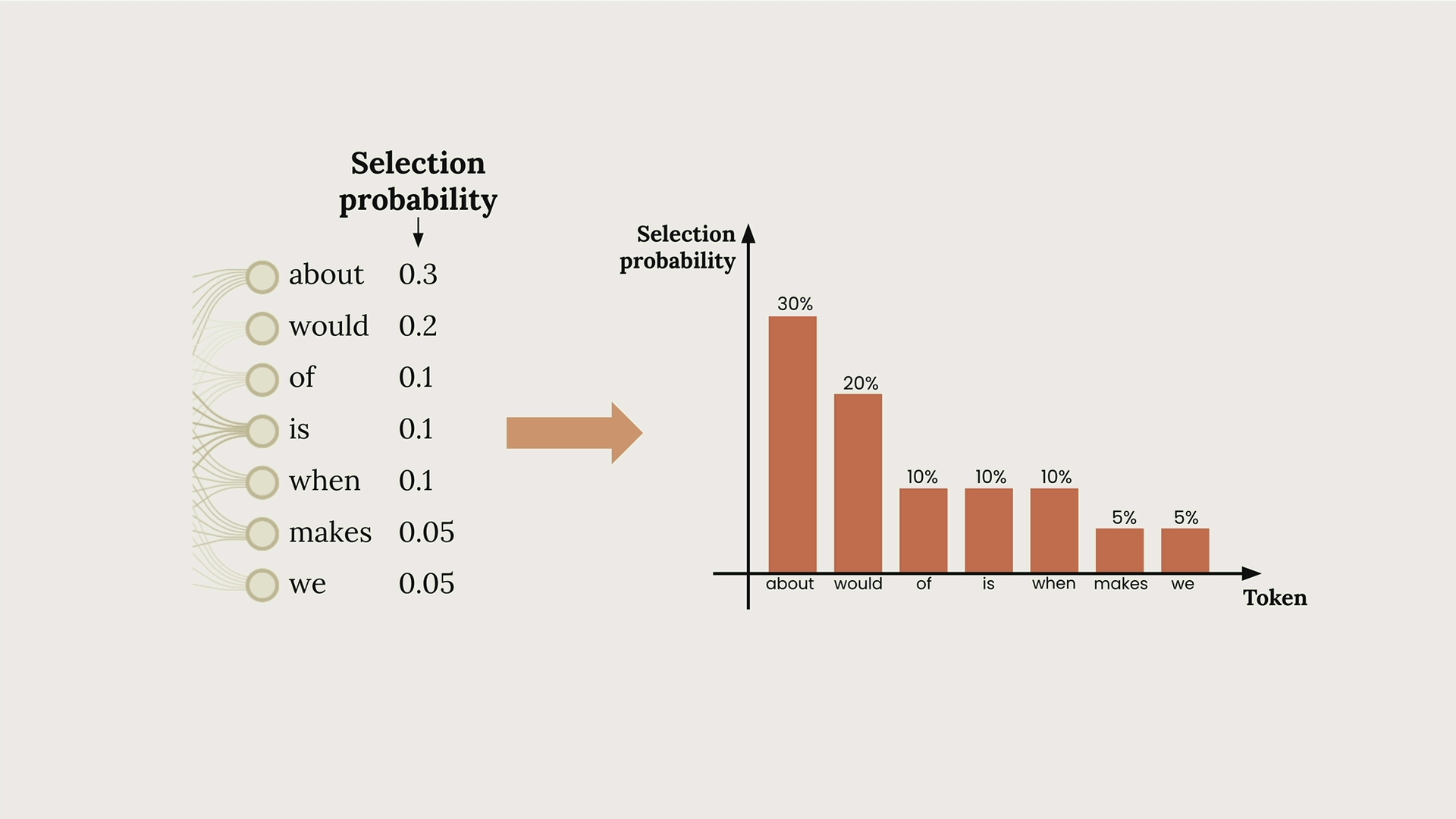
Temperature 的作用
Temperature 是一个介于 0 和 1 之间的小数值,它直接影响这些选择概率。它就像是调节 Claude 响应的“创造力旋钮”。
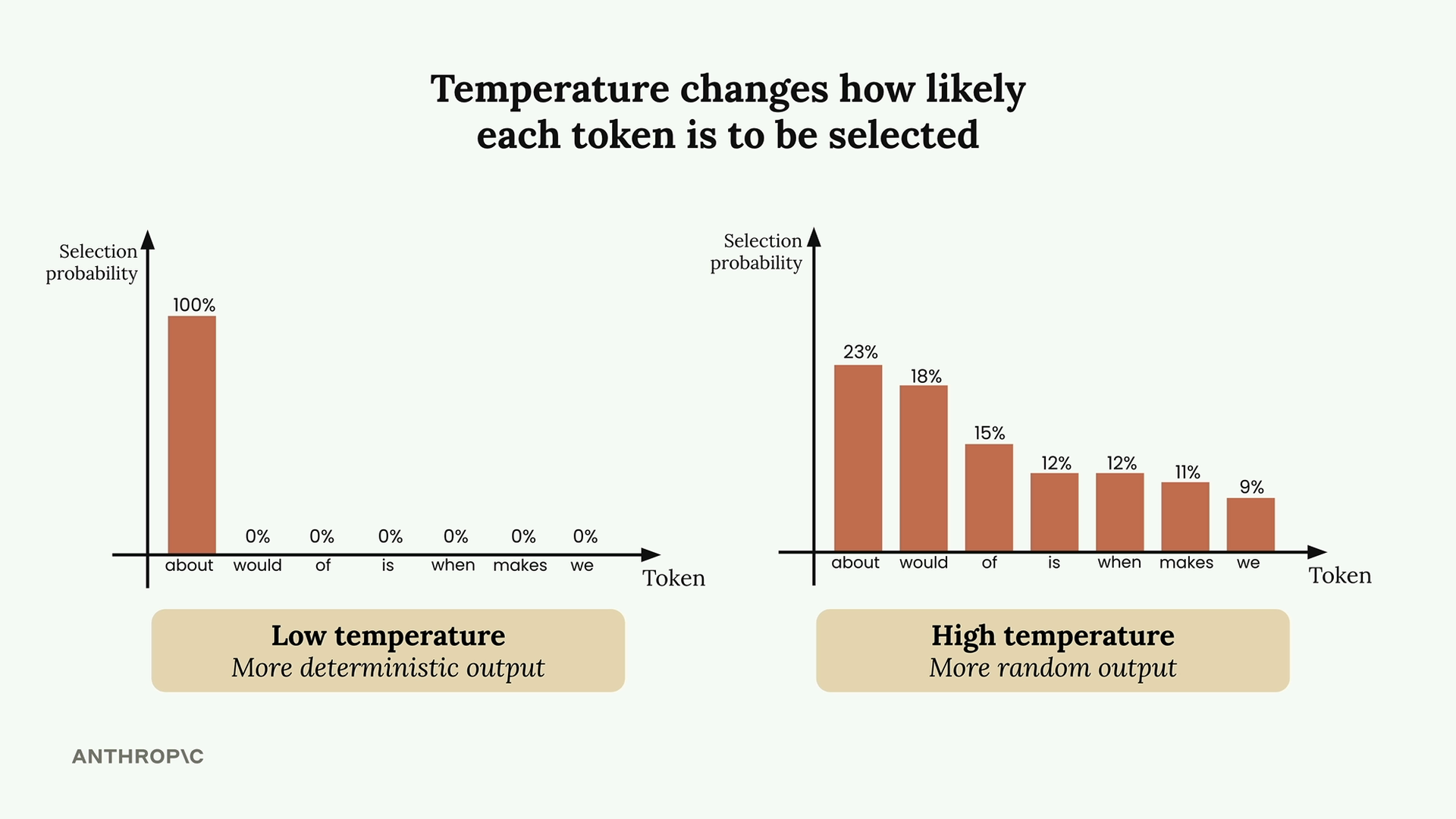
在低 temperature(接近 0)时,Claude 变得非常具有确定性 (deterministic)——它几乎总是选择概率最高的 token。在高 temperature(接近 1)时,Claude 会更均匀地在各种选项中分配概率,从而产生更多样化和更具创造性的输出。
交互式 Temperature 演示
你可以通过 Claude 的交互式演示看到 temperature 的实际作用。观察当你调整 temperature 滑块时,概率分布是如何变化的:
在 temperature 为 0.0 时,“about” 获得 100% 的概率——完全是确定性的。在 temperature 为 1.0 时,概率在所有可能的 token 中更均匀地分布,引入了随机性和创造力。
选择合适的 Temperature
不同的任务需要不同的 temperature 范围:
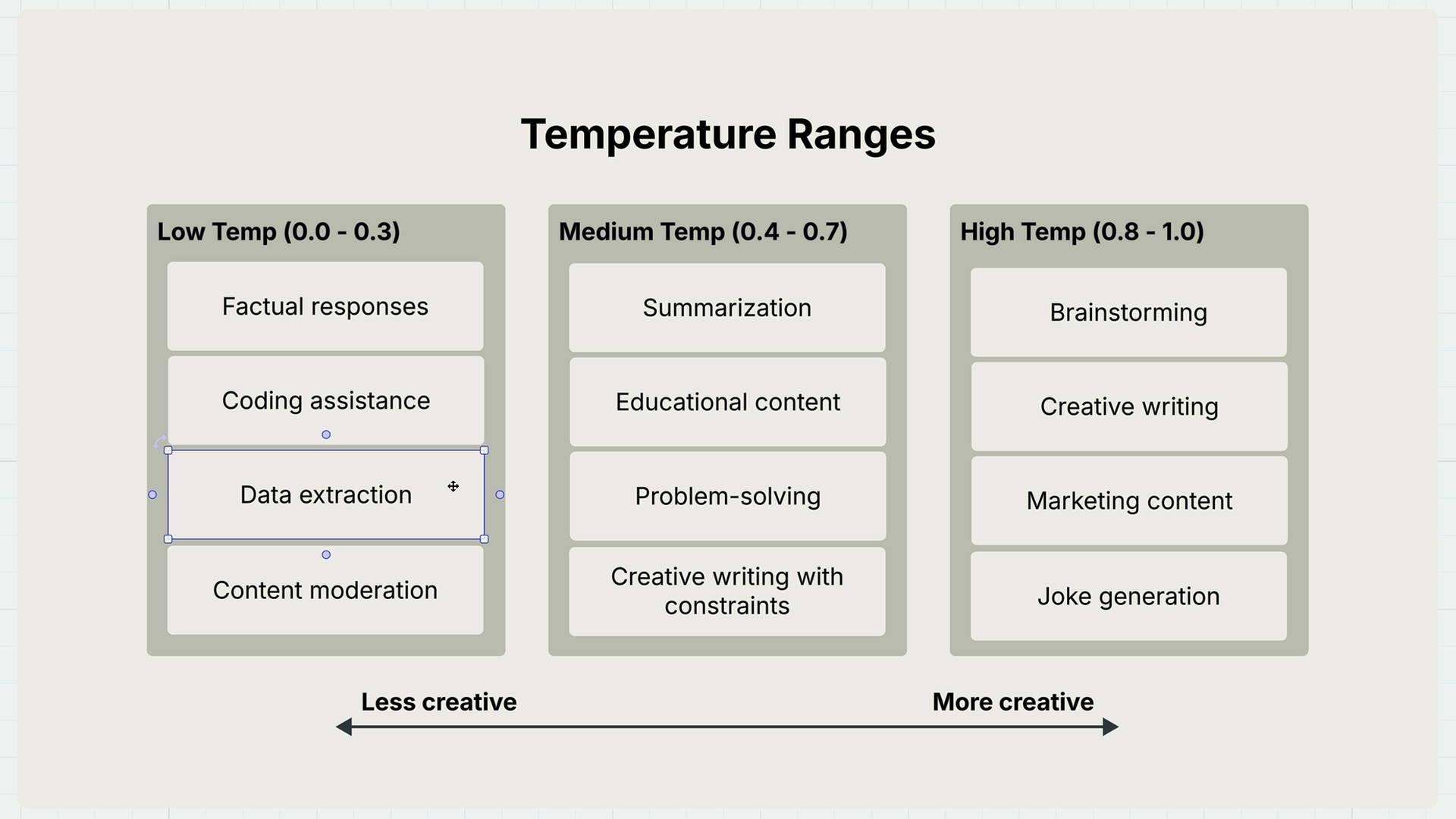
低 Temperature (0.0 - 0.3)
- 事实性回答
- 编码辅助
- 数据提取
- 内容审核
中 Temperature (0.4 - 0.7)
- 总结
- 教育内容
- 问题解决
- 有约束的创意写作
高 Temperature (0.8 - 1.0)
- 头脑风暴
- 创意写作
- 营销内容
- 笑话生成
在代码中实现 Temperature
为你的聊天函数添加 temperature 支持非常直接。以下是如何修改你现有的函数:
def chat(messages, system=None, temperature=1.0):
params = {
"model": model,
"max_tokens": 1000,
"messages": messages,
"temperature": temperature
}
if system:
params["system"] = system
message = client.messages.create(**params)
return message.content[0].text
关键的改动是添加 temperature=1.0 作为参数,并在 params 字典中包含 "temperature": temperature。
测试 Temperature 的效果
要看 temperature 的实际作用,可以尝试用不同的设置来生成电影创意:
# 低 temperature - 更可预测
answer = chat(messages, temperature=0.0)
# 高 temperature - 更具创造性
answer = chat(messages, temperature=1.0)
在 temperature 为 0.0 时,你可能会持续得到像“一个时间旅行的考古学家必须阻止古代文物被盗”这样的回答。在 temperature 为 1.0 时,你会在主题、角色和情节元素上看到更多的多样性。
核心要点
请记住,temperature 并不能保证每次都产生不同的输出——它只是改变了得到它们的概率。即使在很高的 temperature下,Claude 有时也可能产生相似的响应。关键在于将你的 temperature 选择与你的特定用例相匹配:
- 需要一致、事实性的回答?使用低 temperature
- 想要创意的头脑风暴?调高 temperature
- 介于两者之间?中等 temperature 对于大多数通用任务效果很好
Temperature 是你可以调整以微调 Claude 行为以满足你特定需求的最实用的参数之一。
视频文字稿
在本课程的早些时候,我们非常简短地谈到了 Claude 实际上是如何生成文本的。记住,我们向 Claude 输入一些文本,比如“what do you think”。Claude 然后会对这段文本进行分词,或者说将其分解成更小的块。接着,Claude会进入一个预测阶段,它会决定接下来可能出现哪些词,并为每个不同的选项分配一个概率。
最后,在采样阶段,系统会根据这些概率实际选择一个 token。所以在我屏幕上的这个图表中,给定输入“what do you think”,可能的下一个 token 可能是“about”、“wood”等等。你在这里右侧看到的所有内容。每一个都被赋予了一个概率。
然后,也许在这种情况下,Claude 决定“about”是最佳的下一个 token。所以我们最终会得到一个短语,“what do you think about?”。整个过程会重复进行,以完成句子或整个消息。现在,为了确保事情非常清楚,我这里显示的数字是概率,即每个 token 被选中的百分比机会。
为了让这些概率更清晰,我将在本视频的剩余部分将它们显示在一个图表中。所以概率仍然相同,只是格式更容易我们理解。你也会注意到我已经将它们从左到右排序。实际上并没有内部排序。
我只是按概率从大到小排序,为了让这个图表更容易理解。所以现在我们回顾了 Claude 是如何生成文本的,我想向你展示一种我们可以直接影响这些概率并控制 Claude 最终可能选择哪个 token 的方法。所以我们可以使用一个叫做“温度 (temperature)”的参数来控制这些概率。温度是一个介于 0 和 1 之间的小数值,我们在进行模型调用时提供它。
所以每当我们调用那个 converse 函数时,温度都会影响概率的精确分布。这有点难以理解。所以你可以看看我这里的图或者这些图表。或者,我用 plot 本身做了一个快速的小演示,让你更好地了解正在发生什么。
那么,让我来展示那个演示。好的,这就是我们刚才在图表中看到的同一个图表。每当我们提供一个趋近于零的温度值时,正如你所见,我这里有温度,最高概率的事件将更有可能发生。所以我们最高的概率是“about”,它会一直增加到 100%。
所以在温度为零时,我们开始得到我们所谓的确定性输出,即我们总是选择具有最高初始概率的 token。然后,随着我们开始增加温度,我们选择具有较低初始概率的 token 的机会也增加了。所以我们从可能 0% 的机会选择“we”作为下一个 token,一直到比如说 9%。所以这就是温度背后的理论,但这在现实世界中到底意味着什么呢?
嗯,我们开始根据我们试图完成的实际任务来使用不同的温度值。这些是一些示例范围和可能适合每个示例范围的任务。对于像数据提取这样的任务,我们真的不想要太多的随机性或创造性。如果我们给 Claude 一大段文本,并要求它提取非常具体的信息,那里就完全不需要任何创造力。
我们只需要 Claude 查看我们提供的确切文本,并提取出最相关的信息。然后在温度较高的那一端,我们开始变得更有创造力。我们开始看到更少见的 token 被使用。我们可能希望在进行任何真正注重创意的任务时使用较高的温度,比如头脑风暴、写作,也许是做一些非常有创意的营销,或者像笑话这样的东西,很多笑话的精髓就在于以不总是那么预期的方式使用词语。
现在我们理解了温度的全部内容,让我们回到我们的 notebook,了解如何动态调整温度。我想更新我们的 chat 函数,让它接收一个 temperature 参数,我们将把它传递给我们的 create 函数调用。所以在参数列表中,我将添加 temperature,并且我将默认我的温度为 1.0。所以我希望偏向于更有创意的一面。
然后我将接收该参数并将其作为 temperature 添加到 Params 对象中。这就是我们为了在我们的应用程序中添加调整温度支持所要做的全部工作。所以现在为了测试这个,我将重新运行这个单元格。然后我将转到下一个单元格,我将要求 Claude 生成一个一句话的电影创意。
最初,我将提供一个 0.0 的温度。所以现在理论上,我应该会得到一些本质上总是有点相似的电影创意。所以我将运行这个。第一次,我会得到一个时间旅行的考古学家。
你会发现这是一个非常常见的模式,至少对我来说是这样。当我的温度为零时,我经常得到关于时间旅行的某物的电影创意。所以如果我再运行一次,我可能会看到另一个时间旅行的东西。是的,同样的事情。
也许再来一次。是的,同样的想法,一个厌倦了的时间旅行历史学家。我们现在试着调整一下我们的温度,希望能鼓励 Claude 给我一些更原创或更有创意的想法。我将试着把我的温度调到 1.0。
现在如果我再运行一次,我希望不会再得到一个关于疲惫的时间旅行者之类的想法。你几乎可以立刻看到我确实得到了。所以这是需要注意的一点。仅仅因为你调高了温度并不意味着你总会得到截然不同的想法。
它只是增加了得到不同想法的机会。所以如果我再运行一次,我可能会看到一个更有创意的想法。好的,那绝对更有创意。这次没有关于时间旅行的内容,再来一次测试。
又一次,不是关于时间旅行者或类似的东西。好的,这就是温度。现在记住,这里有一些通用的指导。每当我们做的任务需要较少的创造力,或者我们希望有一个非常确定性的输出时,我们就想使用那个较低的温度值。
每当我们有一个需要更多一点创造力的任务时,那就是我们想开始考虑调高一点温度的时候。
12. Response streaming
类型:视频 | 时长:8:23 | 视频:03 - 009 - Response Streaming.mp4
在使用 Claude 构建聊天应用时,存在一个重大的用户体验挑战:响应生成可能需要 10-30 秒,让用户只能盯着一个加载动画。解决方案是“响应流 (response streaming)”,它让用户可以看到文本在 Claude 生成时逐块出现,从而创造出更具响应性的感觉。
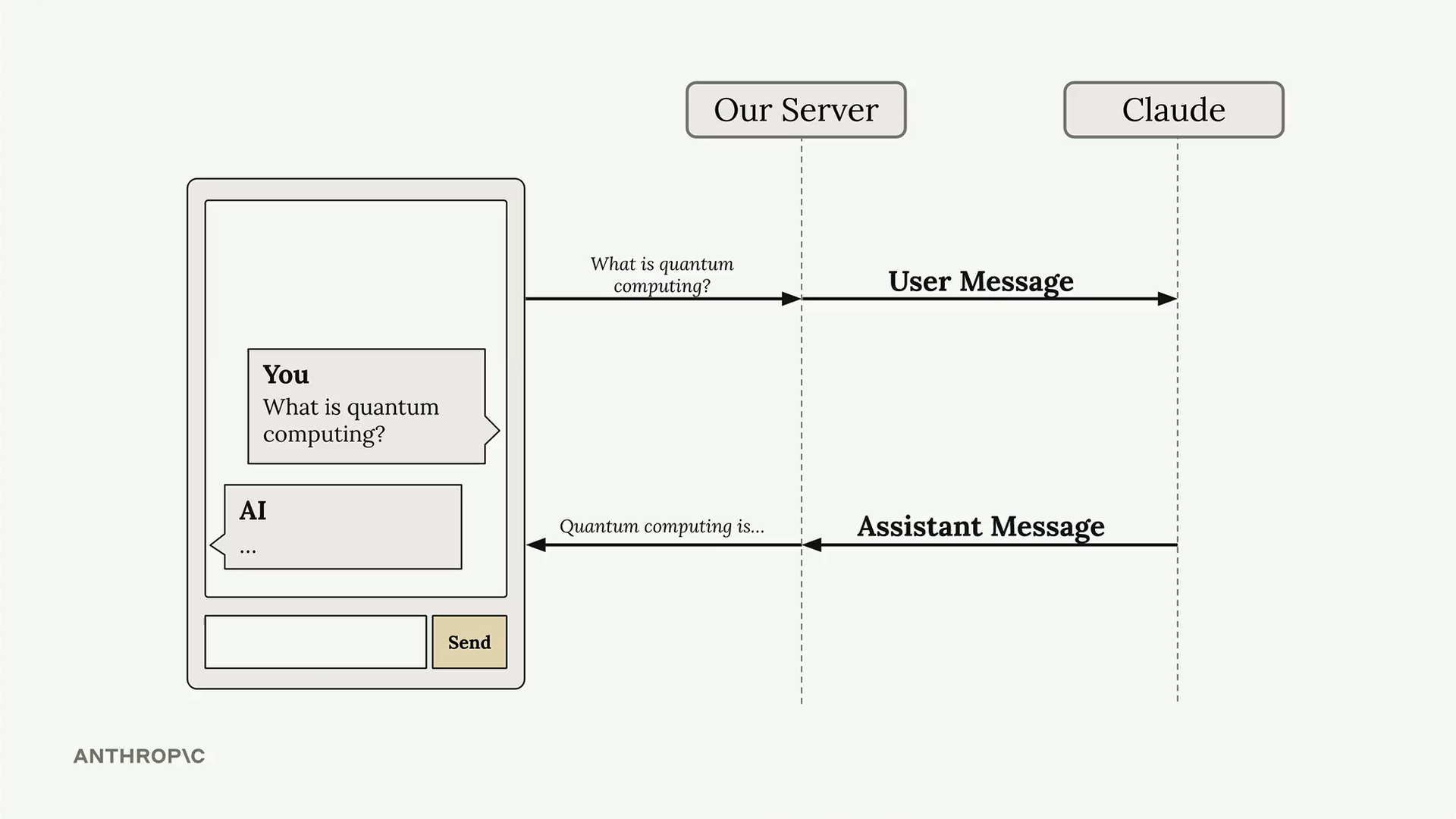
标准响应的问题
在典型的聊天设置中,你的服务器将用户消息发送给 Claude,并等待完整的响应,然后才将任何内容发送回客户端。这会造成一个尴尬的延迟,用户没有任何反馈表明有事情正在发生。
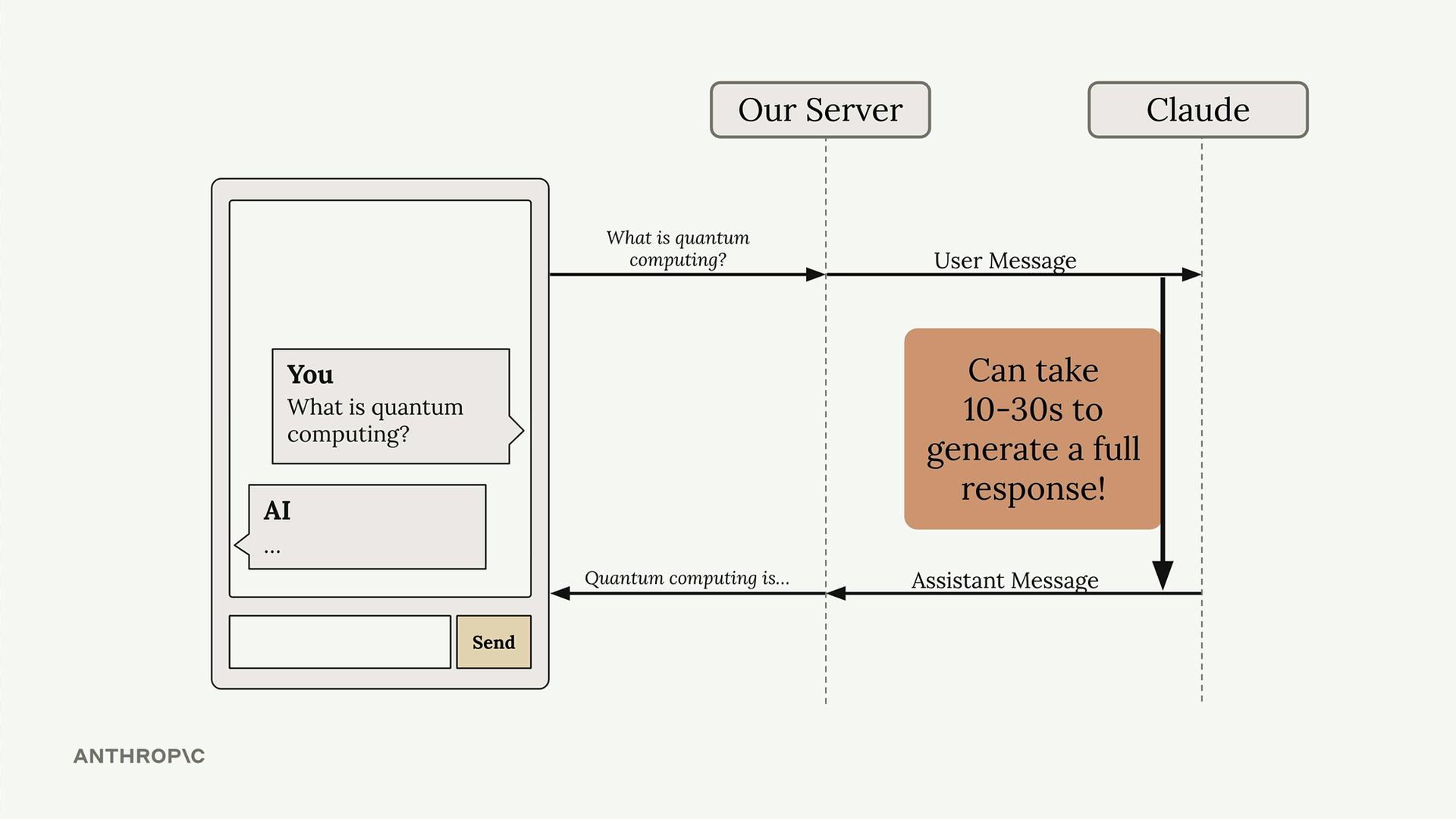
流式传输的工作原理
启用流式传输后,Claude 会立即发回一个初始响应,表明它已收到你的请求并正在开始生成文本。然后你会收到一系列事件,每个事件都包含整个响应的一小部分。
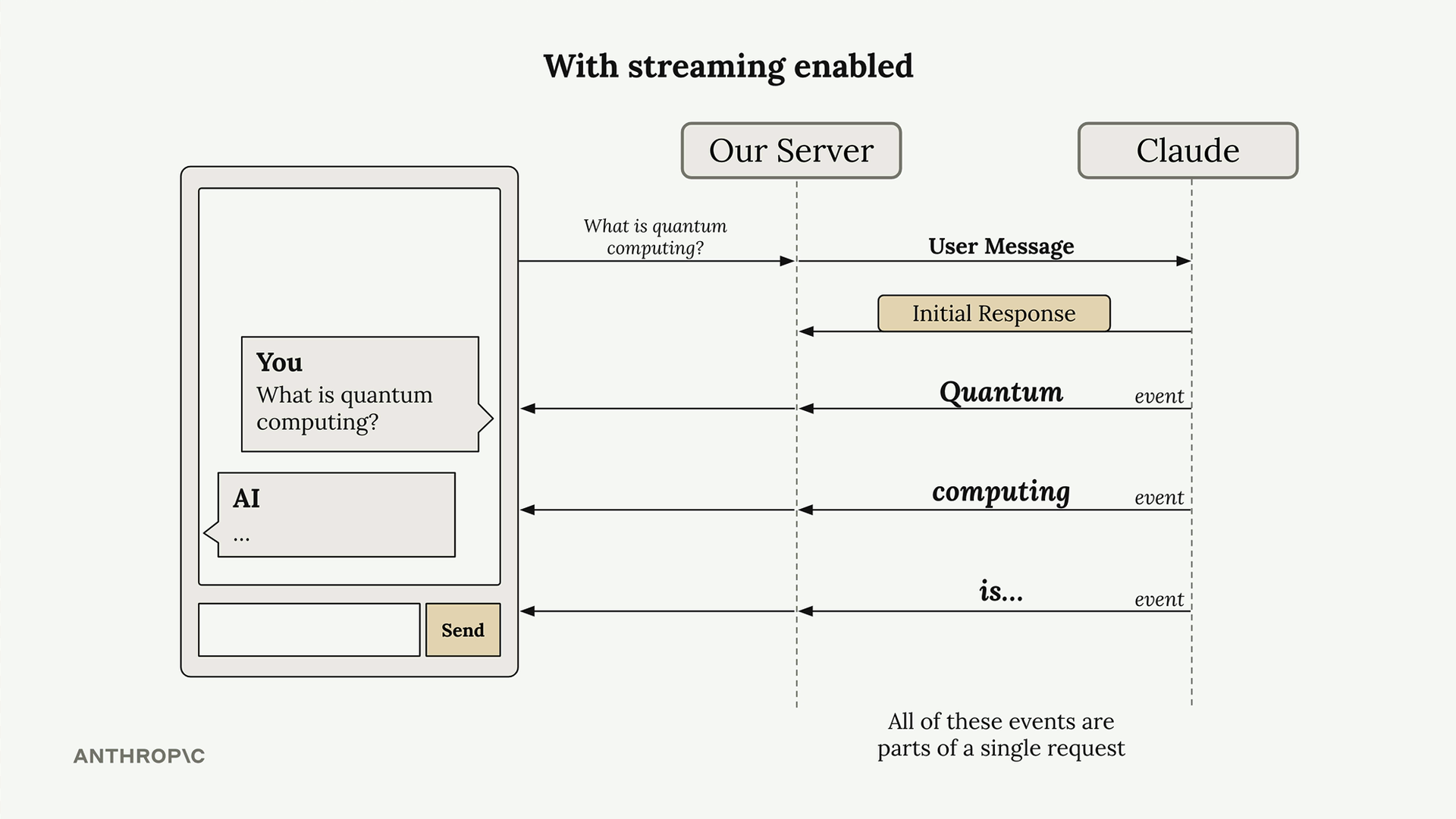
你的服务器可以在这些文本块到达时将它们转发给你的客户端应用程序,让用户可以看到响应逐字构建起来。所有这些事件都是对 Claude 的单次请求的一部分。
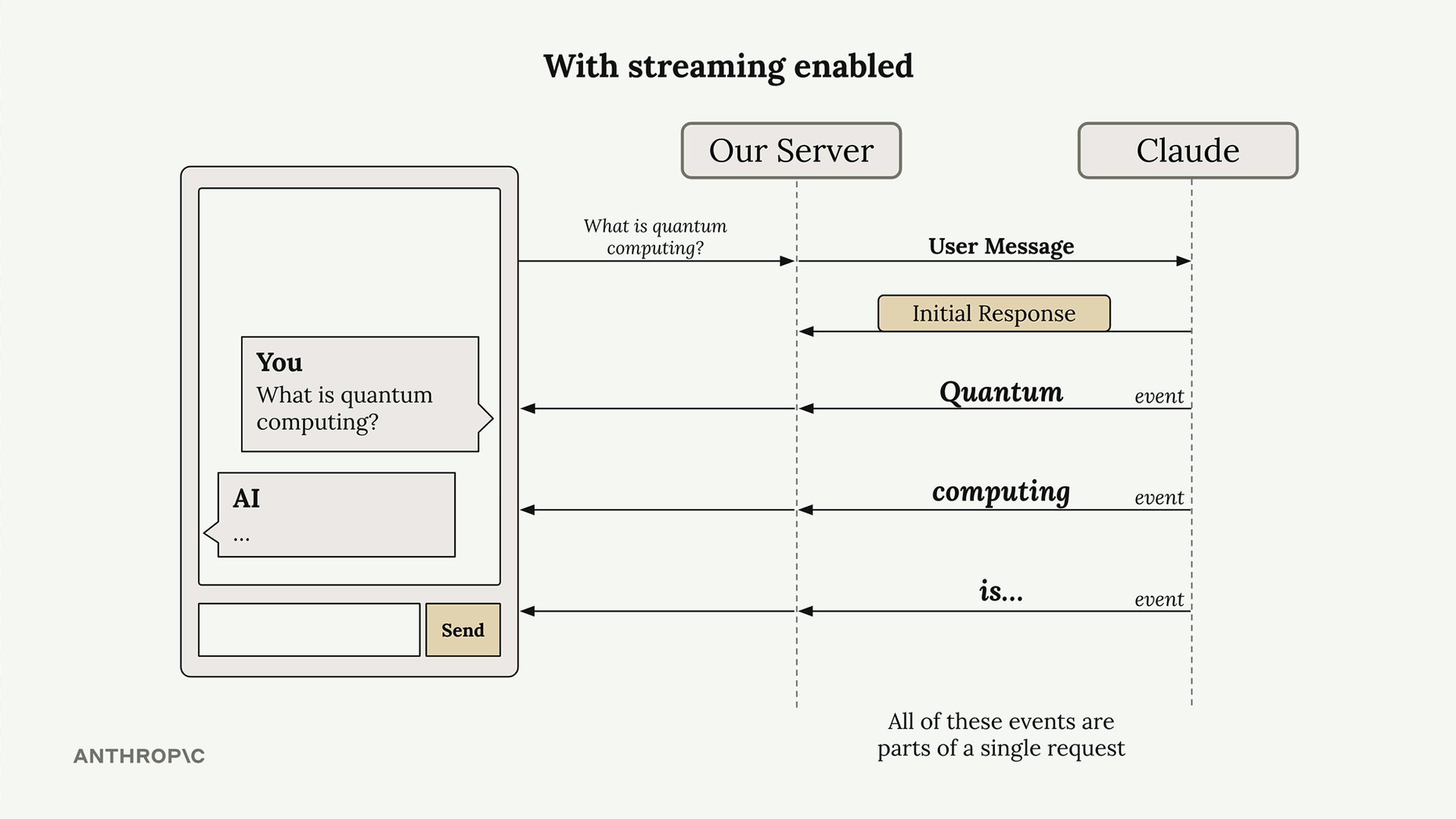
理解流事件
当你启用流式传输时,Claude 会发回几种类型的事件:
- MessageStart - 正在发送一条新消息
- ContentBlockStart - 包含文本、工具使用或其他内容的新块的开始
- ContentBlockDelta - 实际生成文本的块
- ContentBlockStop - 当前内容块已完成
- MessageDelta - 当前消息已完成
- MessageStop - 关于当前消息的信息结束
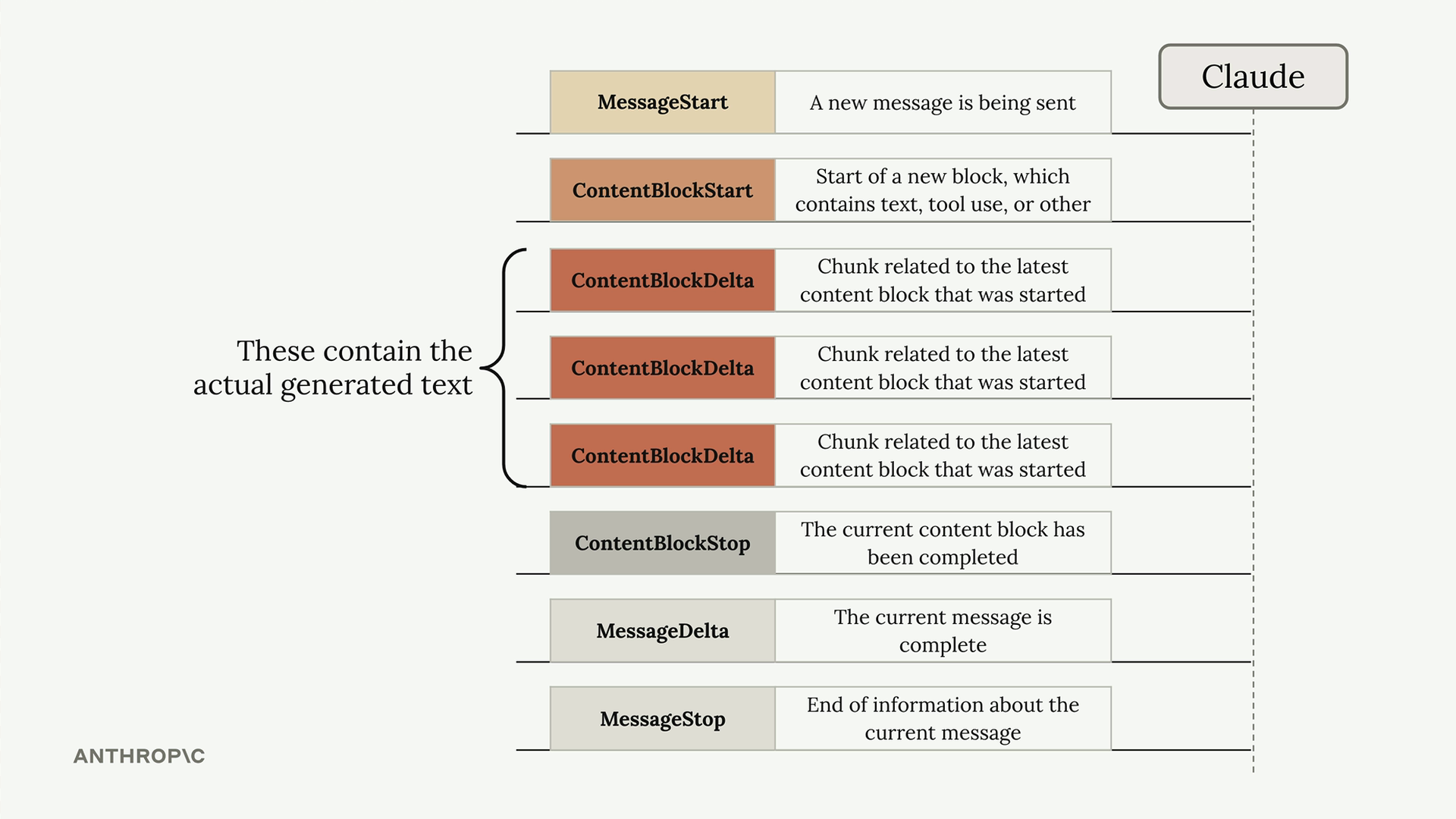
ContentBlockDelta 事件包含你想要显示给用户的实际生成文本。
基本流式实现
要启用流式传输,请在你的 messages.create 调用中添加 stream=True:
messages = []
add_user_message(messages, "Write a 1 sentence description of a fake database")
stream = client.messages.create(
model=model,
max_tokens=1000,
messages=messages,
stream=True
)
for event in stream:
print(event)
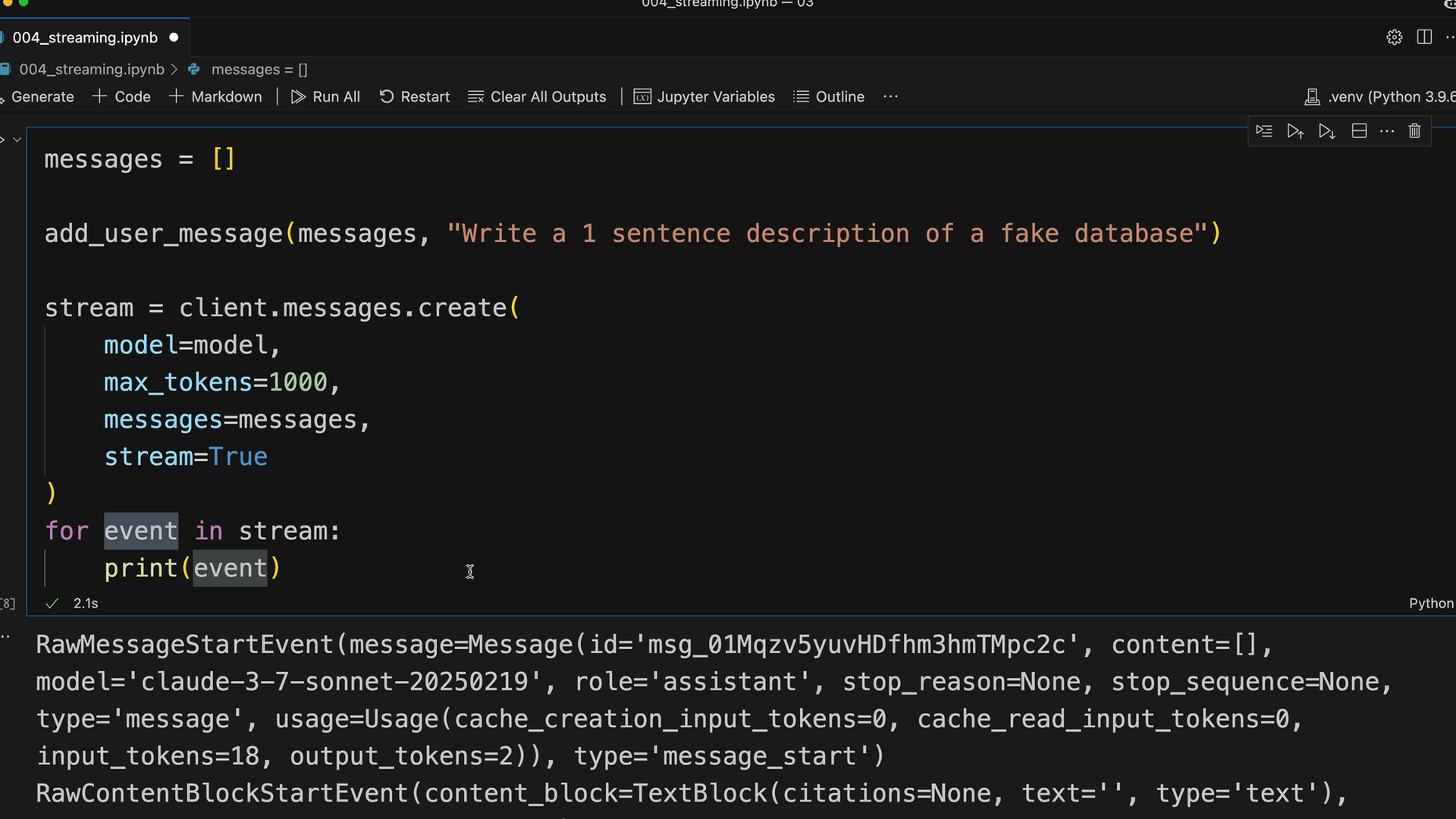
简化的文本流
与其手动解析事件,你可以使用 SDK 的简化流式接口,该接口只提取文本内容:
with client.messages.stream(
model=model,
max_tokens=1000,
messages=messages
) as stream:
for text in stream.text_stream:
print(text, end="")
这种方法会自动过滤掉除了实际文本内容之外的所有内容,这通常是你向用户显示响应时所需要的。
获取完整的消息
虽然流式传输单个块对于用户体验来说很棒,但你通常需要完整的消息来进行存储或进一步处理。在流式传输完成后,你可以获取组装好的最终消息:
with client.messages.stream(
model=model,
max_tokens=1000,
messages=messages
) as stream:
for text in stream.text_stream:
# Send each chunk to your client
pass
# Get the complete message for database storage
final_message = stream.get_final_message()
这让你两全其美:为用户提供实时流式传输,并为你的应用程序逻辑提供一个完整的消息对象。
视频文字稿
我想回顾一下本节前面我们看过的那个原始的聊天界面例子。所以,请记住,这里的思路是,我们有一个在 Web 应用或移动应用中运行的聊天窗口。用户将输入一个问题。这个问题将被提交到我们的服务器。
我们会把这些内容塞进一个用户消息里,然后发送给 Claude。Claude 接着会给我们返回一个助手消息。我们会从中提取文本,再把它发送回我们的移动应用或 Web 应用。并且,希望这些内容会出现在屏幕上。
现在,这在此时听起来相当直接和容易,但这里有一个我们尚未真正解决的小问题。你看,从将用户消息发送给 Claude 到最终收到助手消息回传之间的时间,很可能比我们预期的要长得多。在某些情况下,根据输入的用户消息和输出的助手消息的大小,可能需要 10 秒,甚至长达 30 秒。现在,在用户等待响应的整个期间,我们可以在屏幕上显示一个加载动画。
但这并不是一个很好的用户体验。大多数用户的期望是,当他们输入一些初始消息,比如“什么是量子计算”时,他们应该几乎立刻就能在屏幕上看到一些响应。为了获得更好的用户体验,我们将使用一种名为“流式传输 (streaming)”的技术。那么,让我来给你讲讲流式传输是如何工作的。
我们的服务器仍然会向 Claude 发送一个初始的用户消息,但随后 Claude 会几乎立即向我们发回一个初始响应。这个初始响应实际上不包含任何文本内容。相反,它更像是一个给我们的服务器的信号,表明 Claude 已经收到了我们的初始请求,并且 Claude 即将开始生成一些文本。然后,我们将开始接收一个事件流。
我们将深入探讨这些事件到底是什么,但现在,你只需要明白它们包含了我们想要发回并最终显示给用户的生成响应的片段。我们收到的事件数量取决于我们正在生成的文本量。每个事件将只包含整个生成消息的一小部分。所以,也许第一个事件只包含文本“quantum”,然后第二个说“computing”,第三个是“is”,依此类推。
现在,每个事件不仅仅包含一个词。它可能包含许多词,甚至是一整个句子。这真的取决于 Claude 生成每一小段文本需要多少时间。现在,正如我提到的,我们的服务器将接收这些事件,我们的服务器可以选择性地从每个事件中提取文本,并立即将其发送回我们的 Web 应用或移动应用,或者我们正在使用的任何其他地方,在那里我们可以将那一小块文本显示在屏幕上。
然后我们可以为我们服务器上收到的每个额外事件重复这个过程。所以最终的效果是,用户将开始看到一些文本,逐块地出现在聊天界面中。现在让我们回到我们的 notebook,我们将写一点代码来更好地理解流式传输是如何工作的。好的,回到我的 notebook,我仍然有这三个辅助函数。
现在,我们将在这个视频中忽略 chat 函数,因为当我们开始使用流式传输时,它与我们已经实现的 chat 函数配合得不是很好。所以我将在这里下面创建一个消息列表,然后手动调用 client.messages.create 函数。所以我将创建一个空的消息列表。我将向消息列表添加一个用户消息。
我将让 Claude 写一个关于虚构数据库的一句话描述。然后我将调用 client.messages.create。我将传入模型的名称。仍然需要提供一个 max_tokens。
提供我们的消息列表。然后最后,我们将在这里放入一个额外的关键字参数 stream=True。这将返回给我们的不是一个最终答案,而是一个不同事件的流。我们可以遍历这个东西,因为它是一个正常的迭代器。
所以我们可以说 for event in stream: 然后打印出 event。现在,如果我运行这个,我们将很快在屏幕上看到一系列不同的事件。所以这些中的每一个都代表了 Claude 发送回给我们的不同的小数据块。你会注意到我们以一个名为 raw message store event 的事件开始。
然后我们得到一个 raw content block start,一个 raw content block delta。实际上我们得到了好几个。然后,在底部,我们最终得到一个 content block stop 事件,一个 message delt 事件,和一个 message stop 事件。所以这些都是在单次请求的上下文中,全部来自 Claude 发送回给我们的事件。
这些不同的事件中的每一个,在我们从 Claude 得到的整个响应的上下文中,都有一些意义。然而,有一种事件类型我们通常比所有其他事件更关心,那就是原始的 content block delta 事件。这个事件包含了 Claude 正在生成并逐块发送回给我们的实际文本。实际上,我们通常会反复得到相同的事件序列。
所以当我们从 Claude 得到响应时,我们几乎总是以收到一个 message start 开始,然后是一个 content block start,然后我们将得到一系列的 content block deltas。再次强调,这些是包含实际文本的。所以我们通常想要收集所有这些不同的事件,并从中提取文本,然后将该文本发送回我们的 Web 应用或移动应用,或我们正在使用的任何其他东西。现在,回到我们的 notebook,在这个 for 循环里,我们可以添加一个检查,来判断我们正在处理的是哪种事件。
然后,如果它是那些原始内容块增量事件之一,我们可以深入其中并获取我们实际关心的文本。但这需要我们编写大量额外的代码。幸运的是,Anthropic SDK 提供了一种与我刚才展示的不同的创建流的方式。这种创建流的替代方法,我马上会向你展示,它使得仅从响应中获取文本变得容易得多。
再次强调,文本通常是我们真正关心的响应部分。所以让我给你展示一种流式响应的替代方法。我将转到下一个代码单元格。在这里,我将再次创建一个消息列表,添加一个用户消息,内容是“写一句关于虚构数据库的描述”。
然后我们将调用一个稍微不同的函数,并将其包装在一个 with 块中。所以说 with client.messages.stream。在里面,我们将再次放入我们的 model、max_tokens 和 messages。但我们不需要添加 stream=True 参数。
然后我们会说 as stream,冒号,然后缩进,在里面,我会说 for text in stream.text_stream,像这样。所以现在 text 就只是那些不同事件的文本部分了。所以只是我们实际关心的文本,再次强调,这几乎总是我们在从 Claude 流式传输响应时真正关心的东西。现在为了向你展示这实际上是如何工作的,我将添加一个 print 语句并记录下那个文本。
我将添加一个 end 为空字符串。end 为空字符串只是为了确保这些打印语句不会在打印语句的末尾添加换行符。所以我们会看到每个文本片段都并排记录下来。现在我将运行这个,它会发生得非常快,但你会看到我们现在正逐块地收到一个流式响应。
让我再做一次。所以再次运行。我会看到块、块、块。就是这样。
你会注意到每个块都包含多个不同的词。所以再次强调,我们不保证在每个事件中只得到一个单词。我们可能会得到好几个。这里还有最后一个特性我想向你展示。
现在,正如我所提到的,我们经常希望将响应流式传输回移动应用或 Web 应用,这样用户就可以尽快在屏幕上看到每个文本块的出现。但我们经常想做的另一件事是,在完成流式传输后,将整个消息取出来,或许存入数据库中。这样我们就有了与特定用户进行的整个对话的记录。让我告诉你我们如何收集所有这些不同的事件,并将它们全部组装成一个单独的最终消息。
我将用 pass 替换这个打印语句,这样我们就不会有任何打印了。然后,在它之后,我将执行 stream.getfinalmessage。现在,如果我再次运行这个,我们仍然在流式传输一个响应,如果我们想的话可以打印出来,但我们也会将我们收到的所有单个事件收集起来,并将它们组装成一个最终的消息,然后我们可以将其存储在数据库中,或者用它做任何我们需要做的事情。
13. 控制模型输出
类型:视频 | 时长:6:27 | 视频:03 - 010 - Controlling Model Output.mp4
除了精心制作更好的提示之外,还有两种强大的技术可以控制 Claude 的输出:预填充助手消息和停止序列。这些方法让你能够精确控制 Claude 如何响应以及何时停止生成文本。
预填充助手消息
消息预填充 (Prefilled Assistant Messages) 让你能够提供 Claude 响应的开头部分,然后它会从那个起点继续。这项技术对于引导 Claude 朝特定方向发展非常有用。
它的工作原理是这样的:你不仅仅是发送一条用户消息,而是在你的消息列表末尾添加一条助手消息。Claude 看到这条助手消息后会想:“我已经开始回答这个问题了,所以我应该从我停下的地方继续。”
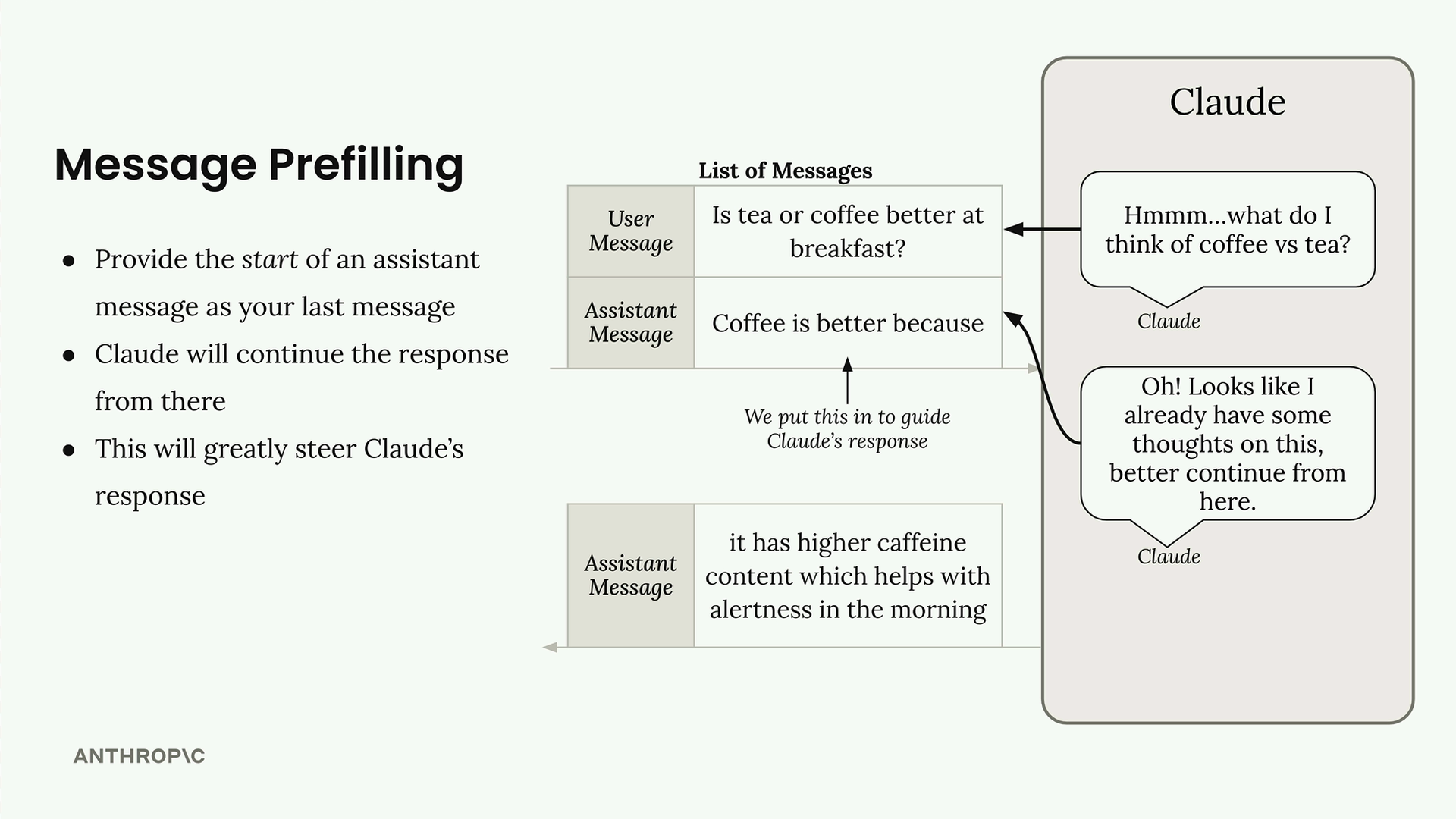
例如,如果你问“早餐喝茶好还是咖啡好?”而不进行预填充,Claude 通常会给出一个提及两种选择的平衡回答。但如果你添加一条助手消息说“咖啡更好,因为”,Claude 就会从那里继续,并为咖啡构建一个论据。
需要理解的关键是,Claude 会从你预填充文本结束的地方精确地继续。如果你写“咖啡更好,因为”,Claude 不会重复那段文字——它会紧接着“因为”之后,并完成这个想法。
以下是代码结构:
messages = []
add_user_message(messages, "Is tea or coffee better at breakfast?")
add_assistant_message(messages, "Coffee is better because")
answer = chat(messages)
你可以使用这项技术将 Claude 引导到任何方向:
- 偏向咖啡:“咖啡更好,因为”
- 偏向茶:“茶更好,因为”
- 采取相反立场:“两者都不太好,因为”
停止序列
停止序列 (Stop Sequences) 会在 Claude 生成特定的字符序列时,强制其立即结束响应。这对于控制响应的长度或终点非常完美。

这个概念很直接:你提供一个字符串列表,一旦 Claude 生成了其中任何一个字符串,它就会立即停止响应。停止序列本身不包含在最终响应中。
例如,如果你让 Claude “从 1 数到 10”,并设置停止序列为 "5",你会得到:
1, 2, 3, 4,
生成在 "5" 之前就停止了,因为那是你的停止序列。
要实现停止序列,你需要修改你的聊天函数以接受一个 stop_sequences 参数:
def chat(messages, stop_sequences=[]):
# Add stop_sequences to your API call parameters
然后像这样使用它:
messages = []
add_user_message(messages, "Count from 1 to 10")
answer = chat(messages, stop_sequences=["5"])
你可以精确调整停止发生的位置。如果你想避免尾随的标点符号,可以使用一个更具体的停止序列,比如 ", 5",而不仅仅是 "5"。
实际应用
这些技术在以下方面特别有用:
- 格式一致性: 使用预填充来确保响应总是以特定的结构开始
- 长度可控: 使用停止序列在自然的断点处截断响应
- 有偏向的响应: 当你需要 Claude 采取特定立场而不是保持中立时
- 结构化输出: 结合两种技术来生成符合特定模板的响应
预填充消息和停止序列都为你提供了对 Claude 行为的精细控制,使它们成为构建可靠 AI 应用的重要工具。
视频文字稿
除了仅仅改变我们发送给 Claude 的提示,还有另外两种方式可以强烈影响我们从中得到的输出。所以在这个视频中,我们将讨论两种技术。一种是预填充助手消息,第二种是停止序列。让我们首先看看预填充助手消息。
好的,让我们想象一下,我们向 Claude 发送了一个非常难以回答的问题。比如“早餐喝茶好还是咖啡好?”我完全不知道 Claude 会给我什么样的回应。事实上,让我们快速转到我们的 Jupyter notebook,看看我们首先会得到什么样的回应。
回到我的 notebook,我正在创建一个空的消息列表。然后我将添加一个用户消息,文本内容是“早餐喝茶好还是咖啡好”。然后我将这个消息列表输入到我们的聊天函数中,然后我将打印出我们得到的答案。我将运行这个。
然后,如果我们看一下响应,我们会发现 Claude 并没有采取强硬的立场。相反,Claude 采取了一种折中的方式,说有些人喜欢茶,有些人喜欢咖啡。总的来说,这个响应完全没问题,但在某些情况下,我们可能希望将 Claude 的响应引向一个或另一个方向。可能有一种情况,我们希望总是引导 Claude 偏向茶,或者另一种情况,我们希望引导它偏向咖啡。
所以,我们可以通过预填充一个助手响应来做到这一点。通过消息预填充,我们仍然会组装一个消息列表。我们会把我们的用户提示放在里面,但会有一个额外的小区别。你和我将手动在最后加上一个助手消息,并且你和我将编写那个助手消息的内容。
然后,在 Claude 中,我们可以想象这是幕后发生的事情。我们可以想象 Claude 会看到第一条消息,然后对自己说,好的,用户想知道我对咖啡和茶的看法。然后它会看第二条消息,这是一条助手消息。因为这是一条助手消息,Claude 会对自己说,哦,看起来我已经对这个情况有了一些想法。
所以我最好继续我的最终响应。我将用这个作为开头来回复。所以 Claude 会基本上用这个作为它响应的开始。因为 Claude 看到了句子,“咖啡更好,因为”,这将非常强烈地引导它支持咖啡在早餐时更好。
所以,很有可能,Claude 会给我们返回一个最终的助手消息,说一些像“它含有更高的咖啡因”,这意味着在谈论咖啡。现在这里需要特别注意的一点是,每当我们在这里放入这个最终的助手消息时,Claude 都会假设这是已经编写好的内容,并且它会从这个句子的末尾继续它的响应。所以你可能会期望 Claude 给你一个像这样的完整响应,上面写着“咖啡更好,因为它含有更高的咖啡因”,但事实并非如此。它会从你预填充内容的末尾继续响应。
换句话 话,这其实不是一个完整的句子。如果你想用这个,你可能需要回去把那段文字和这段文字拼接起来。好的,解释起来有点难懂。但在实践中,一旦你看了一两个演示,就会变得非常简单。
所以我们直接写些代码,看看这到底是怎么运作的。回到这里,如果你想引导 Claude 偏向于支持咖啡,在添加了用户消息之后,我们可以再添加一个助手消息。传入我们的消息列表,然后我们在这里放入我们的预填充内容。所以我可能会说,“咖啡更好,因为”,就这样。
我们现在向我们的初始消息列表中添加了两条不同的消息,并将它们发送给 Claude。同样,Claude 将会看到助手消息,并假定它编写了这些内容。所以我们接下来得到的响应的其余部分将会被引导向支持咖啡。现在让我们运行这个,看看我们会得到什么样的响应。
就是这样。所以现在 Claude 明确地采取了早餐偏爱咖啡的立场,并且它为我们之前写的文本提供了理由。它通过说咖啡能给你提供开始一天的能量来证明这一点。如果我们想改变 Claude 的方向,让它偏爱茶,我们可以把咖啡改成茶,像这样,重新运行,现在我们就会得到一些关于为什么茶更好的理由。
最后,我们也可以引导 Claude 朝着完全不同的方向发展。所以我们可以把助手消息改成类似“两者都不太好,因为”这样,现在 Claude 就会试图论证为什么早餐喝茶或咖啡都不太好。既然我们已经看过了消息预填充,让我们来看看本视频的另一个主题,那就是停止序列。停止序列会强制 Claude 在生成你提供的某个特定字符串时立即停止生成响应。
所以让我们想象一下,我们提供一个“从1数到10”的提示,自然我们的期望是得到1、2、3、4、5一直到10。我们可以通过提供一个字符串“5”作为停止序列来提前停止生成。然后在内部,每当 Claude 生成字符串“5”时,它会立即停止响应,并将已经生成的内容发回给我们。再次强调,让我们来看一个这个的快速示例。
回到我的 notebook,我将向上滚动找到我们的 chat 函数实现。我将向其中添加一个额外的参数 stop_sequences,并将其默认设置为空列表。然后我将更新我的 premiums 字典,以添加该 stop_sequences 参数。然后我将转到我的 notebook 的底部,在那里我将添加一个新的代码单元格。
我将再次创建一个空的消息列表。我将向列表中添加一个用户消息,并让 Claude 从 1 数到 10。然后我将该列表输入到 chat 函数中,并打印出答案。所以让我们运行这个,正如预期的那样,我们可能会得到 1 到 10。
现在让我们尝试将序列限制在5。换句话说,如果 Claude 生成了字符5,我希望立即停止响应,并且之后不再生成任何文本。要做到这一点,我可以在这里添加一个 stop_sequences 列表。在其中,我将放入一个包含“5”的字符串。
然后,如果我运行这个单元格,我应该会看到 1, 2, 3, 4, 逗号和空格,然后生成了 5,但因为我提供了它作为停止序列,整个生成将在此结束,并且 5 将不会被包括在内。如果我想去掉那个多余的空格和逗号,我可以在我的停止序列中加入逗号、空格、5,像这样。现在如果我再次运行这个,我将只得到 1, 2, 3, 4。
14. 结构化数据
类型:视频 | 时长:5:59 | 视频:03 - 011 - Structured Data.mp4
当你需要 Claude 生成像 JSON、Python 代码或项目符号列表这样的结构化数据 (structured data) 时,你经常会遇到一个常见问题:Claude 乐于助人,总想在你的内容周围添加解释性文本。虽然这通常很好,但有时你只需要原始数据,别无其他。
考虑构建一个生成 AWS EventBridge 规则的 Web 应用。用户输入描述,点击生成,并期望看到他们可以立即复制和使用的干净 JSON。如果 Claude 返回的 JSON 被包裹在 markdown 代码块和解释性文本中,用户就无法简单地复制整个响应——他们必须手动只选择 JSON 部分。
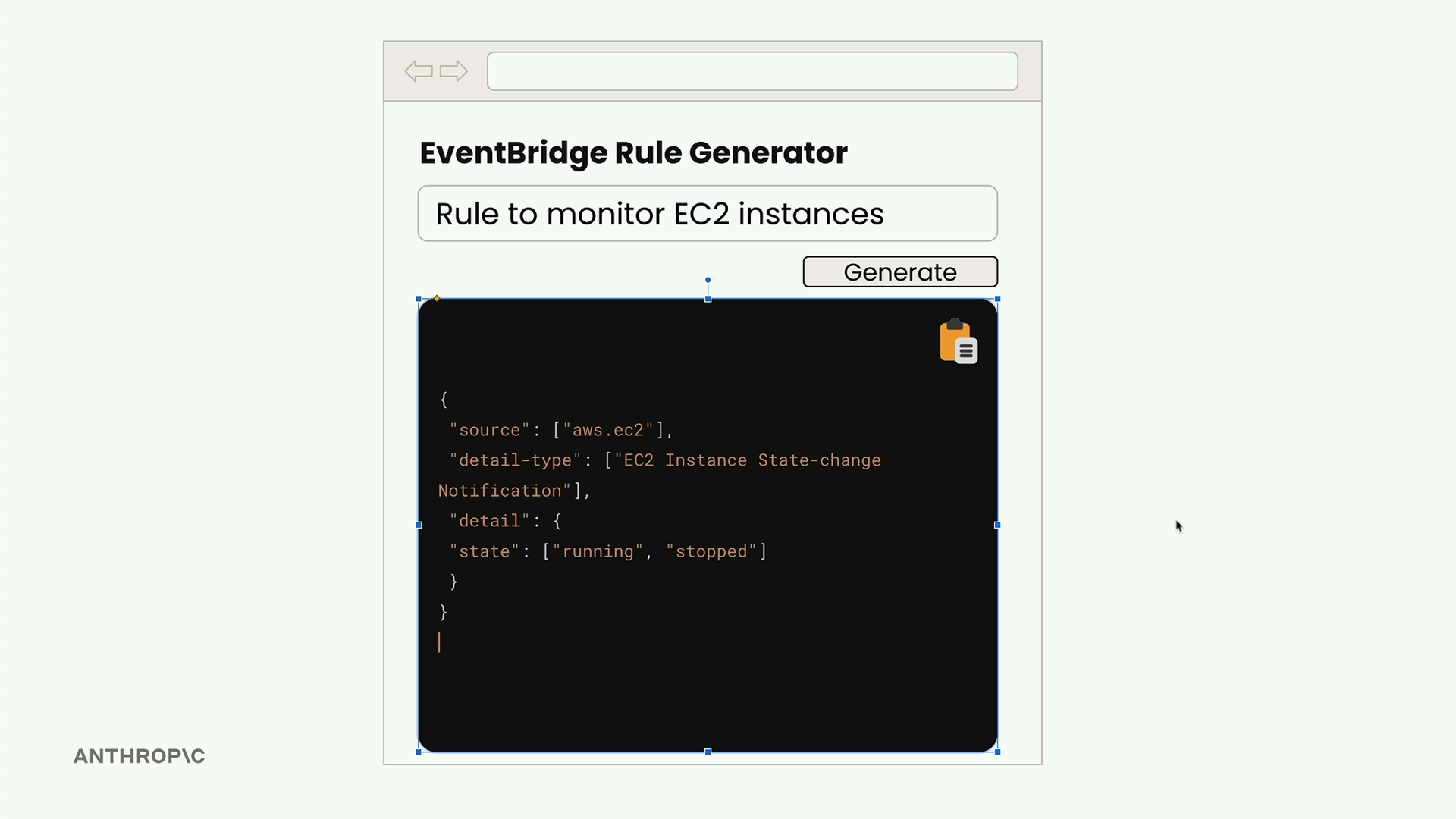
默认响应的问题
默认情况下,当你要求 Claude 生成 JSON 时,你可能会得到这样的东西:
```json
{
"source": ["aws.ec2"],
"detail-type": ["EC2 Instance State-change Notification"],
"detail": {
"state": ["running"]
}
}
This rule captures EC2 instance state changes when instances start running.
JSON 是正确的,但它被包裹在 markdown 格式中,并包含了说明性文字。对于一个需要用户复制原始 JSON 的 Web 应用来说,这给用户体验带来了不便。
## 解决方案:助手消息预填充 + 停止序列
你可以将助手消息预填充与停止序列结合起来,以获得你想要的确切内容。它的工作原理如下:
messages = []
add_user_message(messages, "Generate a very short event bridge rule as json") add_assistant_message(messages, "```json")
text = chat(messages, stop_sequences=["```"])
这种技术的工作原理是:
1. 用户消息告诉 Claude 要生成什么
2. 预填充的助手消息让 Claude 认为它已经开始了一个 markdown 代码块
3. Claude 继续只编写 JSON 内容
4. 当 Claude 试图用 ``` 关闭代码块时,停止序列立即结束生成
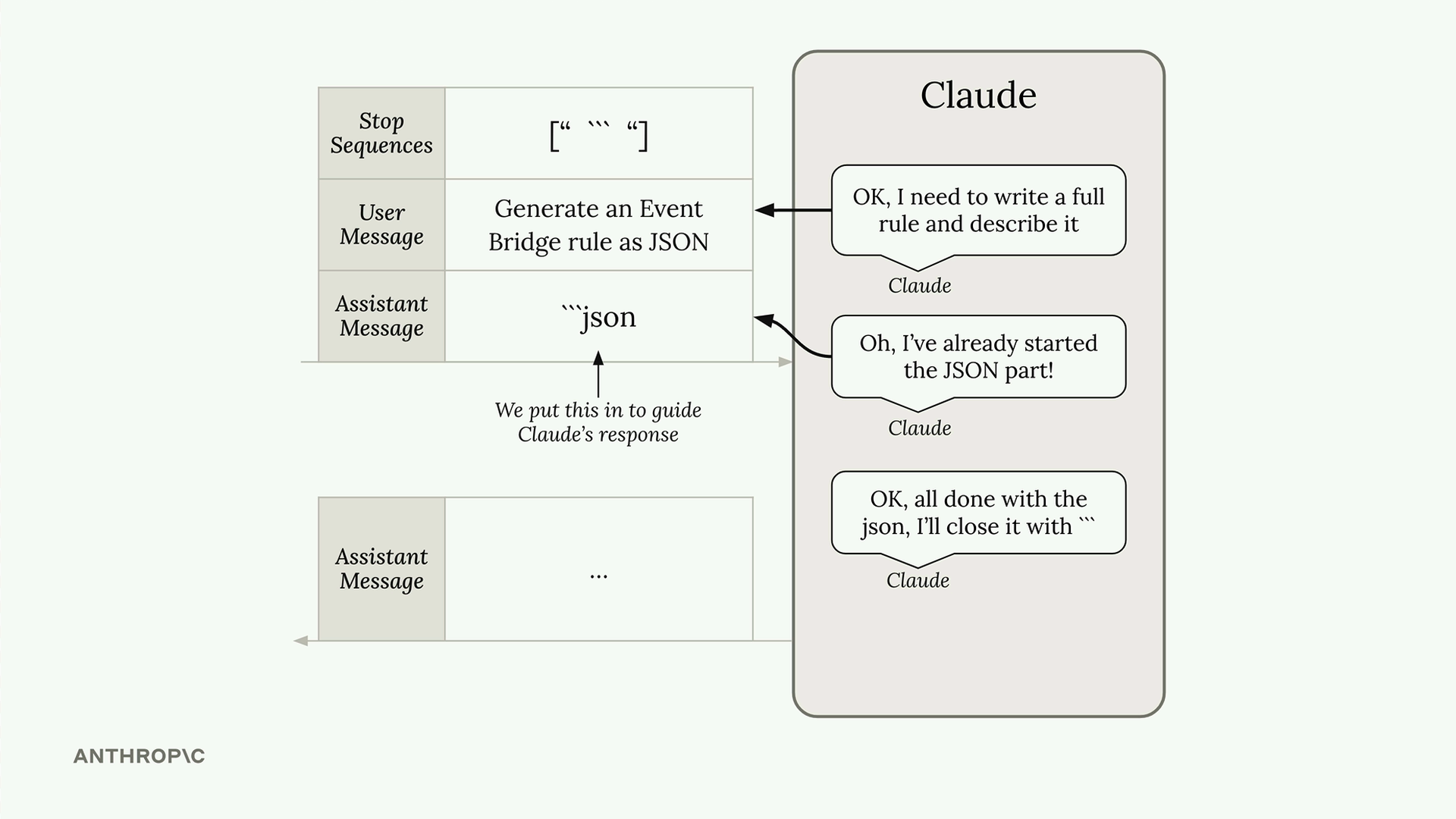
结果是干净的 JSON,没有任何额外的格式:
{ "source": ["aws.ec2"], "detail-type": ["EC2 Instance State-change Notification"], "detail": { "state": ["running"] } }
## 处理响应
你可能会注意到响应中有一些额外的换行符。这些很容易处理:
import json
Clean up and parse the JSON
clean_json = json.loads(text.strip())
超越 JSON
这项技术不仅限于 JSON 生成。当您需要不带任何评论的结构化数据时,都可以使用它:
- Python 代码片段
- 项目符号列表
- CSV 数据
- 任何您只想要内容而不需要解释的格式化内容
关键在于识别出 Claude 自然而然想要用来包装您的内容的结构,然后将其用作您的预填充 (prefill) 和停止序列 (stop sequence)。对于代码,这通常是 Markdown 代码块。对于列表,则可能是不同的格式标记。
这种方法让您能够精确控制 Claude 的输出格式,从而更容易地将 AI 生成的内容集成到需要干净、结构化数据的应用程序中。
视频文字稿
停止序列 (stop sequences) 和助手消息预填充 (assistant message prefilling) 可以以一种非常强大的方式结合在一起。在任何需要生成某种结构化数据的时候,您很可能会相当频繁地这样做。为了帮助您理解这些东西是如何协同工作的,我将带您快速浏览一个例子。让我们想象一下,我们正在构建一个像您在屏幕上看到的 Web 应用程序。
这是一个将根据用户输入生成 EventBridge 规则的 Web 应用。如果您不熟悉它们,EventBridge 规则在 AWS 中使用,它们本质上是小的 JSON 片段。所以,用户将输入一些像这样的提示,然后点击“生成”。用户很可能希望看到一个生成的规则立即出现在这里,他们可以非常容易地立即选择或点击这个小小的复制按钮并在其他地方使用。
这里的关键点在于,关键用户体验的一部分是我们只想显示生成规则的 JSON,而没有其他任何东西。所以如果我们显示一个看起来像这样的响应,对我们的用户来说肯定没有那么有帮助。我们仍然在生成规则,但现在它在顶部有一个标题,在底部有一个评论页脚。所以现在用户无法真正使用这个“全部复制”按钮。
他们将不得不进入并手动选择那里的 JSON。所以这是一个我们真的不希望 Claude 那么有帮助并解释其工作的例子。我们只想要一些非常特定的数据,没有别的。现在需要明确的是,这不仅仅是生成 JSON 时才有的问题。
事实证明,任何时候您使用 Claude 生成任何类型的结构化数据。所以它可能是 JSON,也可能是 Python,甚至只是一个项目的文本列表。Claude 经常会尝试插入一个页眉或页脚或一些额外的评论。而在许多这些场景中,您不想要那些额外的评论。
您只想要您要求 Claude 创建的原始内容。因此,为了帮助 Claude 保持在正轨上,只给我们我们要求提供的原始内容,而没有任何额外的页眉、页脚、评论或任何类似的东西,我们可以使用我们的停止序列 (stop sequence) 与预填充的助手消息相结合。让我来告诉您怎么做。我将回到我的 notebook。
我将在这里新建一个单元格继续。我将再次创建一个消息列表。我会加入一个用户消息。我会说一些类似“以 Jason 格式生成一个非常短的 event ridge 规则”的话。
然后我会像这样把它传递出去,然后让我们看看初步尝试会得到什么。所以马上,我们可以看到我们确实得到了一些 JSON,但不幸的是它有那个反引号、反引号、反引号、JSON 的部分,然后还有一个匹配的结束部分。为了确保非常清楚,这些反引号是为了将这一切格式化为 Markdown。所以如果您要将其渲染为 Markdown 文本,它会格式化得非常好。
但在我们的例子中,我们不想要任何那些额外的字符。我们只想要原始的 JSON 本身。为此,我们可以做两件事。我们将同时使用一条助手消息和一个停止序列 (stop sequence)。
现在,我们只是写出这样做的代码。然后我会给您看一个图表来解释这一切是如何工作的。首先,我将预填充一条助手消息。所以我们说添加助手消息。
我的预填充消息将是反引号、反引号、反引号、JSON。然后在我的聊天调用中,我将添加停止序列 (stop sequences)。任何时候我们看到反引号、反引号、反引号,我都想立即停止生成。那么现在我们运行这个单元格,看看我们得到什么。
好的,现在我们只得到了 JSON 本身。您会注意到这里有一些换行符,但这完全没问题。我们可以通过将响应解析为 JSON 或通过调用 strip 来非常容易地移除那些额外的换行符。所以我可以说 text 是 chat。
我将打印出 text,然后在下一个单元格中,我可能会导入 JSON 并对 text 使用 JSON loads 和 strip。如果我运行它,是的,我们确实得到了格式非常好的 JSON,我们可以以任何我们期望的方式访问它。好的,那么助手消息和停止序列到底是怎么回事呢?好吧,让我给您看一个图表来分解这一切,并确保它非常清楚。
所以再一次,我们正在做我们的用户消息。我们提供了一个预填充的助手和一个停止序列。Claude 将会查看这个请求的所有不同部分。它会首先查看那个用户消息内容然后说,好吧,很明显我需要写一个完整的规则。
而且我也许还应该描述一下它。所以也许放上一个页眉和一个页脚,因为这有点像 Claude 自然想做的事情。它想解释它正在做的工作。但然后它会遇到那条助手消息。
就像我们在上一个视频中学到的,Claude 会假设它已经在它的响应中写出了那些内容。所以它会说,哦,我已经开始了 JSON 部分。所以现在我所要做的就是写出实际的 JSON。它然后会在响应中写出所有这些 JSON。
然后当它到达最末尾时,它会自然地想要关闭它认为它早些时候创建的那个 Markdown 代码块。所以 Claude 会想要放入一个结束的反引号、反引号、反引号。然而,一旦它这样做,它就会遇到停止序列,这将完全停止生成并立即将响应发回给我们。所以您可以真正地想象这里真正发生的是我们有点像在说,从这个开始,到那个结束,只给我们中间的所有东西。
而这导致我们只得到我们真正关心的部分,也就是 JSON 本身。就像我提到的,这是一个我们将会非常频繁使用的非常强大的技术。任何时候我们想要生成某种结构化数据并且只得到那些数据,没有其他任何东西。并且记住,这项技术可以用于任何类型的结构化数据。
它不仅限于在 JSON 上使用。所以任何时候我们有任何非常具体的内容我们想要生成并且只得到那个内容而没有任何额外的评论,我们将考虑使用助手消息预填充 (assistant message prefilling) 和停止序列 (stop sequences)。
15. 结构化数据练习
类型:视频 | 时长:4:57 | 视频:03 - 012 - Structured Data Exercise.mp4
视频文字稿
让我们做一个非常快速的练习,只是为了确保停止序列和消息预填充的概念非常清楚。所以在这个练习中,我希望您写出我在屏幕上这里展示的确切代码。所有这些代码应该都非常熟悉。如果您看一下提示,它说“生成三个不同的示例 AWS CLI 命令”。
现在,当您运行此代码时,您可能会得到一些看起来大致像这样的输出。为了让它更容易阅读,我在这里将其渲染为 Markdown。这是我得到的示例起始输出。
您会注意到它确实给了我们三个不同的示例命令,但它们周围有很多评论。所以我有一个标题,然后是一些数字列出每个单独的命令。对于这个练习,我希望您使用这段代码,并且仅使用消息预填充 (message prefilling) 和停止序列 (stop sequences),我希望您在一个响应中获得所有三个不同的命令,彼此相邻,没有任何额外的注释或解释之类的。我希望您仅使用消息预填充和停止序列来完成此操作,所以完全不要调整这个提示。
所以请尝试一下。我在这里放了一个小提示,只是为了提醒您,使用消息预填充,它不仅限于使用像反引号这样的字符。您可以放入任何您想要的预填充响应。我现在鼓励您暂停这个视频,并尝试一下这个练习。
否则,我将立即给出一个解决方案。好的,我们开始。这是我们解决这个问题的方法。要解决这个问题,我建议您做的第一件事是看一下没有任何预填充或停止序列或任何类似东西的输出。
所以如果我们看一下我们这里有的,我们会注意到我们的三个命令中的每一个都被一系列三个反引号包裹着。所以一个好的开始可能是放入一个由三个反引号组成的预填充消息,以告诉 Claude,立即开始编写命令,跳过任何初始评论。然后我们可能还会决定也放入一个由三个反引号组成的停止序列。让我们看看这能带我们走多远。
所以我将放入一条助手消息。我将用三个反引号开始所有内容。我将放入一个由三个反引号组成的停止序列。让我们运行这个看看它能带我们走多远。
我最初的输出看起来还算合理,但还不是完美的。我确实得到了三个命令。这是一、二和三。但您会注意到,我还在最开始得到了 bash 这个词。
那么这个词究竟是从哪里来的呢?好吧,让我给您看看 Claude 真正想做什么。我们提供了三个反引号的初始助手消息。每当您放下三个反引号时,这有点表明您正在写一些 Markdown。
当您用反引号写一个 Markdown 代码块时,您可以选择在这里放入一个语言标识符。如果您选择放入一个,那么当您将此渲染为 Markdown 时,那些反引号内的内容将使用该语言的语法高亮进行渲染。所以在这种情况下,Claude 决定在这里放入 bash,只是为了说,嘿,当我们渲染这些东西时,我们应该使用 bash 风格的语法高亮。现在对我们来说,我们根本不想要那个。
所以我们解决这个问题的一个方法可能是调整我们这里的预填充消息,并自己包含 bash。所以这现在将使 Claude 非常清楚,是的,您在一个 Markdown 代码块内。在这个代码块内,您应该写出 bash 格式的命令。所以让我再试着运行一次,看看我现在做得怎么样。
好的,看起来好多了。现在我要告诉您,从这一点来看,可能还有另外两个错误您可能想要解决。第一个是,有时您会得到一个单一的命令,这有点表明 Claude 可能想要写出三个独立的 Markdown 代码块。您可能遇到的另一个问题是,因为我们现在正在使用一个 bash 代码块,Claude 可能会尝试在其中插入一些 bash 格式的注释。
所以它可能会是这样的,This command does XYZ,您可能会看到这个重复出现。所以我们绝对不想要那些注释,真的只是因为这是这个练习的要求之一。所以为了去掉那些注释,并且也为了确保我们更可靠地得到所有三个命令,我们可以使用我给您的那个提示。记住那个提示是消息预填充不仅仅限于指定像反引号或类似的东西那样的字符。
我们也可以使用消息预填充来极大地引导 Claude 如何回答我们。所以在这种情况下,我们可以加入一些类似“这里是单个代码块中的所有三个命令,没有任何注释”的内容。然后我会在那里放一个冒号,然后是一个新行,这样它就会在下一行开始所有的 Markdown 内容。所以我将尝试运行这个,我们现在应该会得到一些更可靠的输出。
好的,看起来不错。当然,我可以整天运行它,我们可能会看到我们想要的确切结果。好的,这看起来不错。
17. Prompt evaluation
类型:视频 | 时长:1:48 | 视频:04 - 001 - Prompt Evaluation.mp4
在使用 Claude 时,写一个好的提示词仅仅是开始。要构建可靠的 AI 应用程序,您需要理解两个关键概念:提示词工程 (prompt engineering) 和提示词评估 (prompt evaluation)。提示词工程为您提供编写更好提示词的技术,而提示词评估则帮助您衡量这些提示词的实际效果。

Prompt Engineering vs Prompt Evaluation
提示词工程是您打造有效提示词的工具箱。它包括以下技术:
- 多样本提示 (Multishot prompting)
- 使用 XML 标签构建结构
- 许多其他最佳实践
这些技术帮助 Claude 准确理解您的要求以及您希望它如何回应。
提示词评估采用不同的方法。它不关注如何编写提示词,而是通过自动化测试来衡量其有效性。您可以:
- 对照预期答案进行测试
- 比较同一提示词的不同版本
- 审查输出中的错误
编写提示词后的三种途径
起草完一个提示词后,您通常面临三种后续选择:
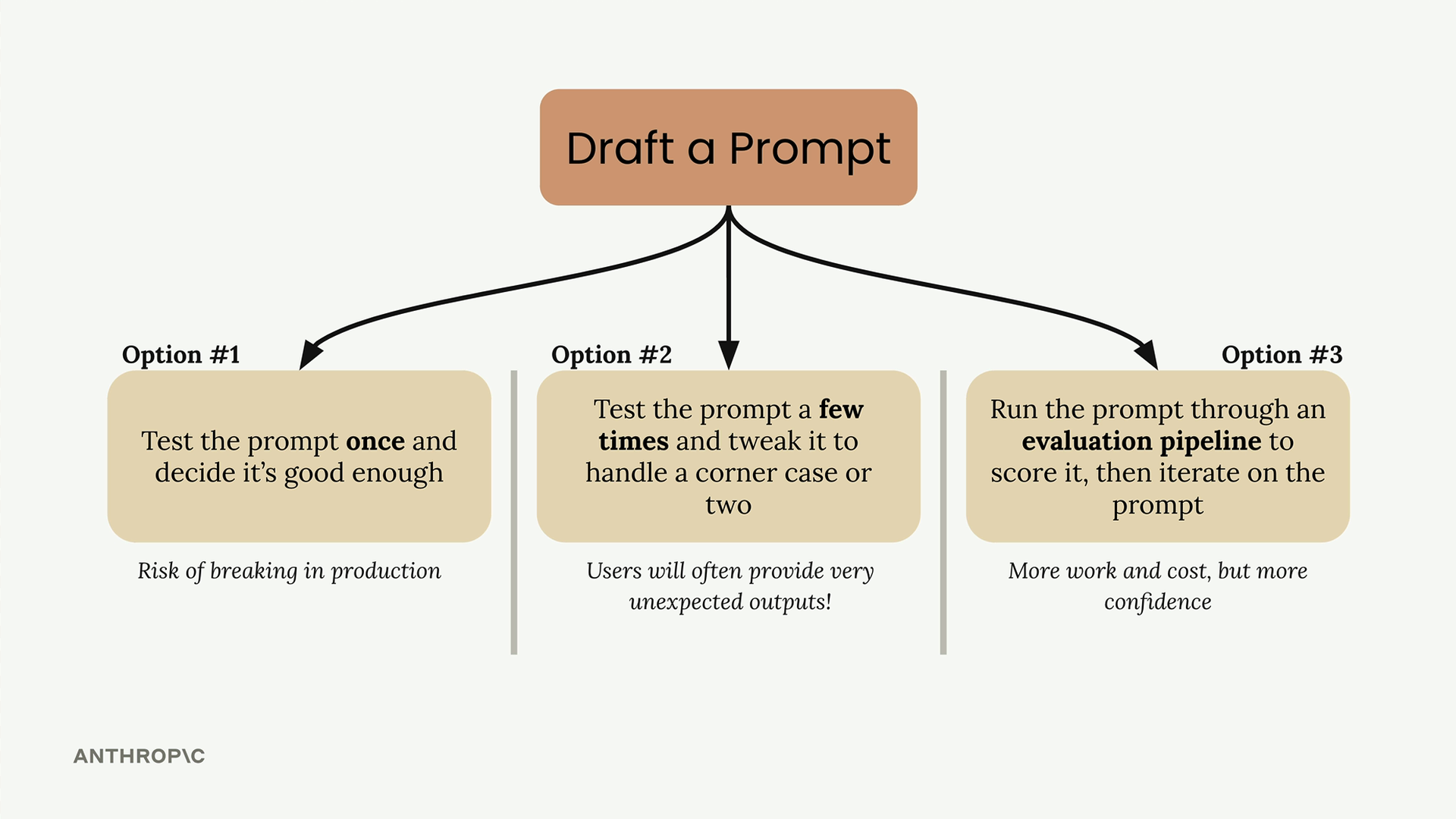
选项 1:测试一次提示词,然后认定它足够好。当用户提供意想不到的输入时,这在生产环境中存在巨大的崩溃风险。
选项 2:测试几次提示词,并对其进行微调以处理一两个极端情况。虽然比选项 1 好,但用户通常会提供您未曾考虑过的非常意外的输出。
选项 3:通过评估流程运行提示词以对其进行评分,然后根据客观指标对提示词进行迭代。这种方法需要更多的工作和成本,但能让您对提示词的可靠性有更大的信心。
为什么大多数工程师会掉入测试陷阱
选项 1 和 2 是所有工程师(包括我自己)都会掉入的常见陷阱。为一个严肃的应用程序编写提示词却没有进行足够彻底的测试,这是很自然的。我们往往低估了真实用户会遇到的边缘案例数量。
现实情况是,当您将提示词部署到生产环境时,用户会以您从未预料到的方式与之交互。在您有限的测试中看起来很可靠的提示词,在面对各种真实世界的输入时,很快就会崩溃。
评估优先的方法
选项 3 代表了一种更系统的提示词开发方法。通过评估流程运行您的提示词,您可以获得关于其在一系列更广泛的测试用例中性能的客观指标。这种数据驱动的方法让您能够:
- 在生产问题出现之前识别弱点
- 客观地比较不同版本的提示词
- 基于可衡量的改进充满信心地进行迭代
- 构建更可靠的 AI 应用程序
虽然这种方法需要在时间和测试基础设施上进行更多的前期投入,但它在最终应用程序的可靠性和健壮性方面会带来丰厚的回报。目标是在开发过程中而不是在用户遇到问题后发现问题。
视频文字稿
既然我们了解了如何访问 Claude,我们将稍微转移一下焦点,看看两个新主题:提示词工程 (prompt engineering) 和提示词评估 (prompt evaluation)。这两个主题都关乎于确保我们编写的提示词能从 Claude 那里获得最佳的输出。提示词工程是一系列我们想在编写或编辑提示词时使用的技术。这些技术将帮助 Claude 理解我们的要求以及我们希望它如何回应。
另一方面,提示词评估 (prompt evaluation) 是我们对一个提示词进行一些自动化测试,目的是获得某种客观的指标,告诉我们我们的提示词是否有效。在本节中,我们将主要关注提示词评估。在我们了解如何衡量一个提示词的有效性之后,我们再来看一些提示词工程技术。那么,让我们开始吧。
我想做的第一件事是帮助您理解提示词评估在整个提示词编写过程中的位置。每当您第一次编写提示词时,您通常有三种不同的前进路径。您可以从那里走三种不同的方式。对于选项一,您可能会拿着您组合的提示词,也许测试一两次,然后决定它在生产中使用已经足够好了。
对于选项二,您可能会用自己的自定义输入测试几次提示词,并可能对其进行一些微调,以处理您注意到的一两个边缘情况。我希望您立刻明白,选项一和选项二是所有工程师都会掉入的陷阱,包括我自己。这发生在每个人身上。我们都开始写那些最终将用于严肃应用程序的提示词,但我们并没有真正对它们进行足够的测试,以确保它们按预期工作。
所以每当您写一个提示词时,我强烈建议您选择选项三。通过一个评估流程来运行您的提示词,以获得一个客观的分数,这将告诉您您的提示词表现如何。然后您可以尝试对您的提示词进行一些迭代,并确保它的表现尽可能好。
18. 一个典型的评估工作流程
类型:视频 | 时长:4:36 | 视频:04 - 002 - A Typical Eval Workflow.mp4
一个典型的提示词评估工作流程遵循五个关键步骤,帮助您通过客观测量系统地改进您的提示词。虽然组装这些工作流程有许多不同的方式,并且有各种开源和付费工具可用,但了解核心过程可以帮助您从小处着手,并根据需要进行扩展。
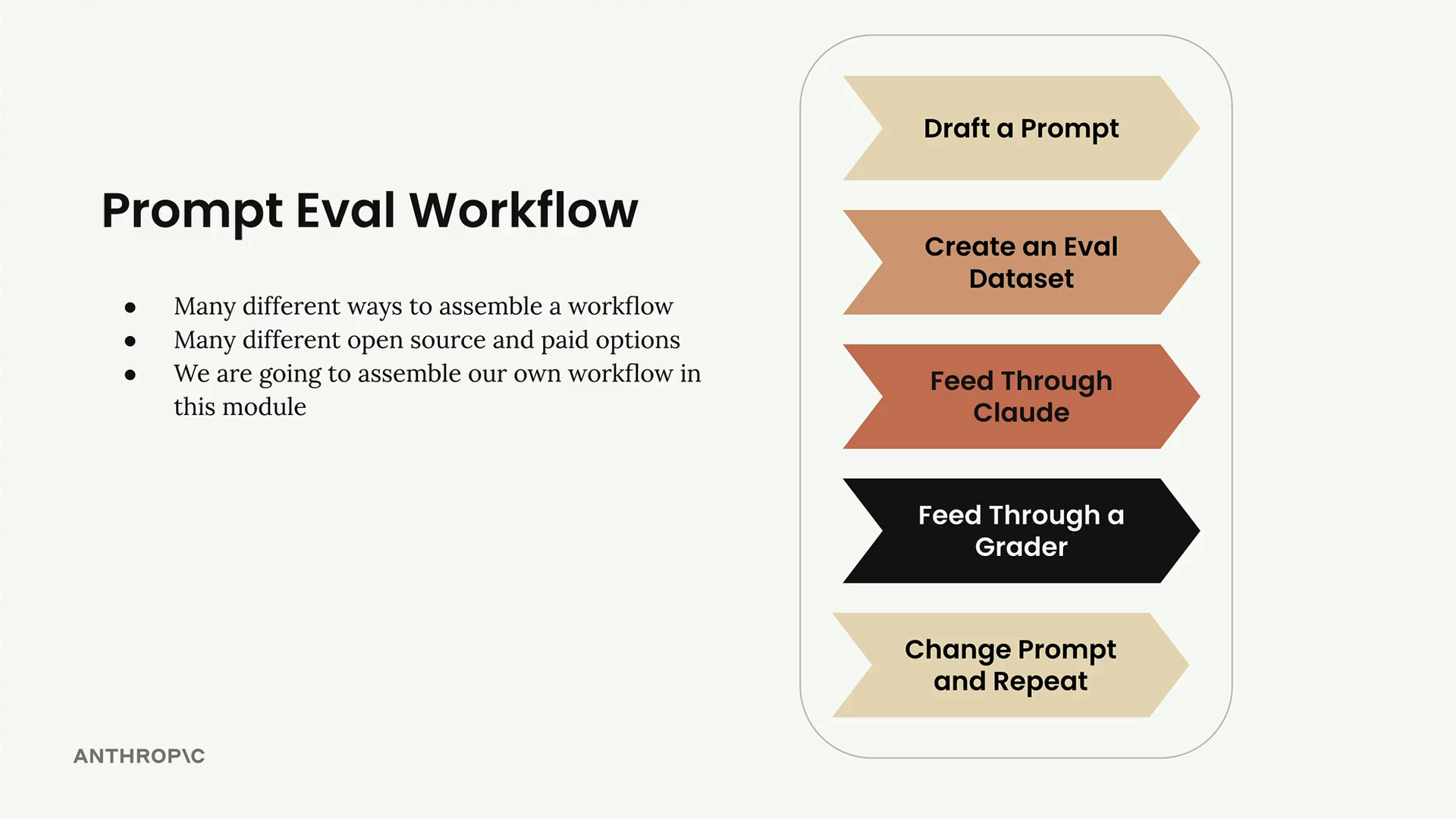
第 1 步:起草一个提示词
首先编写一个您想要改进的初始提示词。对于这个例子,我们将使用一个简单的提示词:
prompt = f"""
Please answer the user's question:
{question}
"""

这个基本的提示词将作为我们测试和改进的基线。
第 2 步:创建一个评估数据集
您的评估数据集 (eval dataset) 包含代表您的提示词在生产中将要处理的问题或请求类型的样本输入。数据集应包含将被插入到您的提示词模板中的问题。
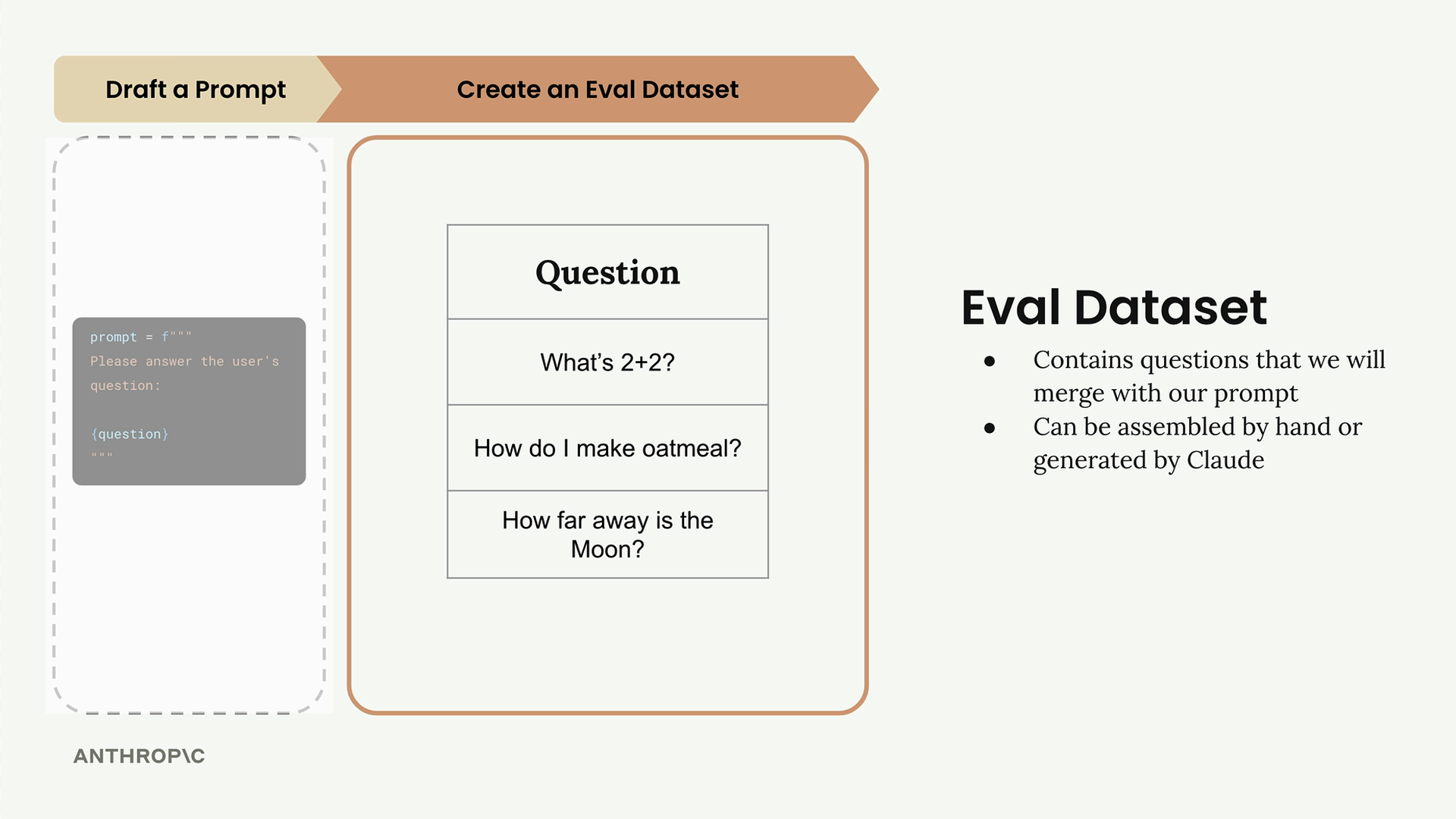
对于这个例子,我们的数据集包括三个问题:
- "2+2 是多少?"
- "我该如何做燕麦粥?"
- "月亮有多远?"
在真实的评估中,您可能会有数十、数百甚至数千条记录。您可以手动组装这些数据集,或者使用 Claude 为您生成。
第 3 步:输入给 Claude
从您的数据集中取出每个问题,并将其与您的提示词模板合并以创建完整的提示词。然后将每一个发送给 Claude 以获得响应。
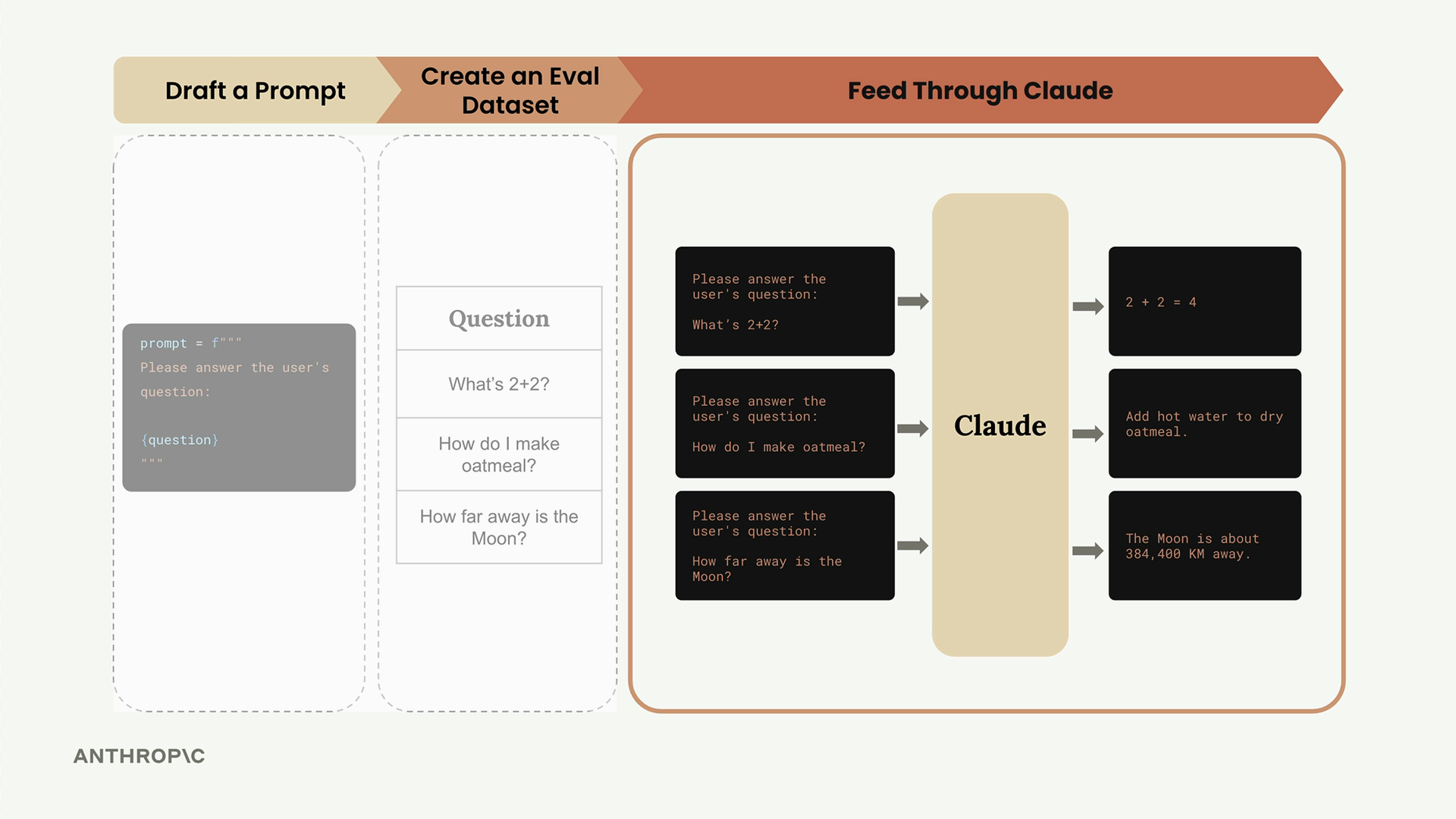
例如,第一个问题变成:
Please answer the user's question:
What's 2+2?
对于数学问题,Claude 可能会回答 "2 + 2 = 4",为第二个问题提供燕麦粥的烹饪说明,并为第三个问题给出到月亮的距离。
第 4 步:通过评分器进行评估
评分器 (grader) 通过检查原始问题和 Claude 的答案来评估 Claude 响应的质量。这一步提供客观评分,通常在 1 到 10 的范围内,其中 10 代表完美的答案,较低的分数表示有改进的空间。
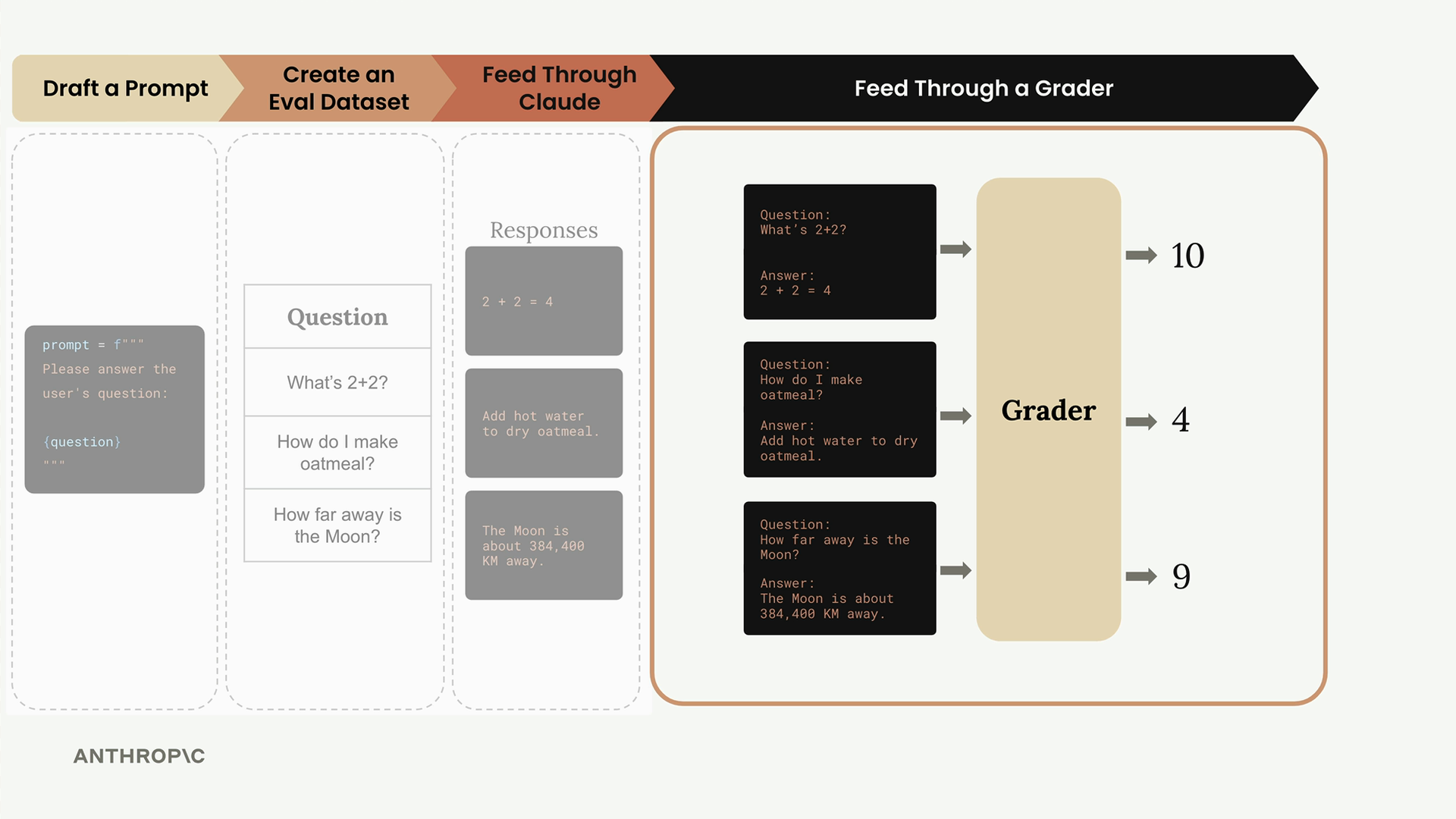
在我们的例子中,评分器可能会给出:
- 数学问题:10(完美答案)
- 燕麦粥问题:4(需要改进)
- 月亮问题:9(非常好的答案)
所有问题的平均分给您一个客观的测量值:(10 + 4 + 9) ÷ 3 = 7.66
第 5 步:更改提示词并重复
现在您有了一个基线分数,您可以修改您的提示词并再次运行整个过程,看看您的更改是否提高了性能。
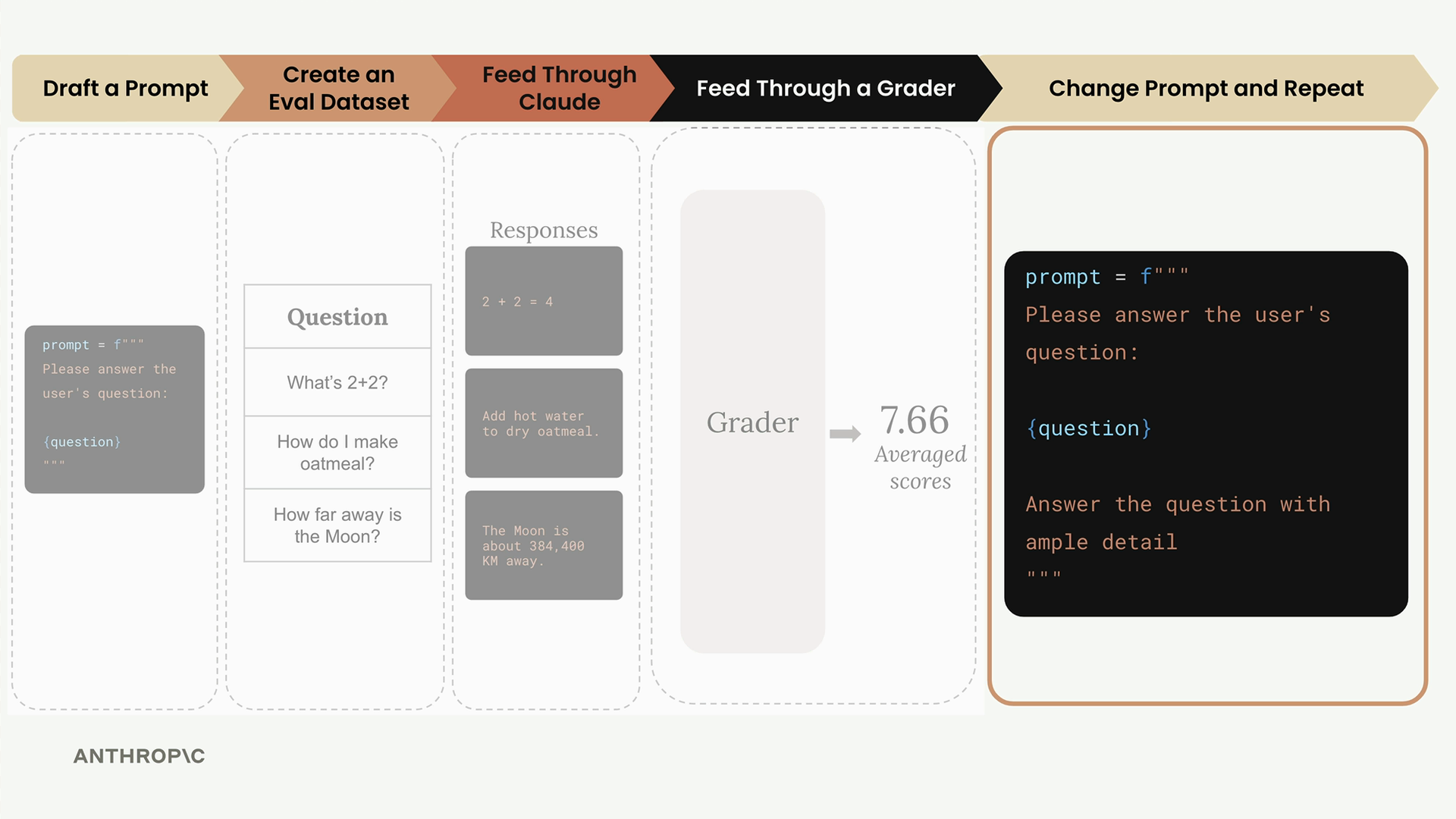
例如,您可能会在提示词中添加更多指导:
prompt = f"""
Please answer the user's question:
{question}
Answer the question with ample detail
"""
在通过相同的评估过程运行这个改进的提示词后,您可能会得到一个更高的平均分 8.7,这表明额外的指令帮助 Claude 提供了更好的响应。
提示词评分
这个工作流程的关键好处是获得提示词性能的客观测量。您可以:
- 用数字比较不同版本的提示词
- 使用得分最高的版本
- 继续迭代以找到更好的方法

这种系统化的方法消除了提示词工程中的猜测,并让您相信您的更改确实是改进,而不仅仅是不同的变体。
视频文字稿
在本视频中,我们将逐步介绍一个典型的提示词评估工作流程所实现的所有步骤。然而,在进行任何这些步骤之前,我只想让您明白两件重要的事情。首先,构建工作流程的方式有很多种。没有一套一成不变的方法论在行业内是标准化的。
第二件要理解的事情是,有许多不同的开源软件包,甚至在线付费选项,可以帮助您实现自己的工作流程。现在,在本视频和本模块中,我们将在 Jupyter notebook 中从头开始实现我们自己的自定义工作流程。我们这样做的原因,当然,只是为了帮助您理解这些工作流程的行为方式,但也是为了帮助您理解,您不必为了进行提示词评估而采用一个非常重量级的解决方案。您可以从小处着手,只是为了开始并了解一切是如何运作的,然后再进行扩展。
好的,那么我们开始吧。一个典型的提示词评估的第一步。第一步,我们将写出一个初始的提示词草稿。所以您和我将坐下来,只是写出一些我们想要以某种方式改进的提示词。
对于这个例子,我们将有一个非常简单的提示词,它只说,“请回答用户的问题”。然后我们将插入一些用户输入。即用户提供的一些问题。在第二步中,我们将创建一个评估数据集 (eval dataset)。
这个数据集将包含一些我们可能想要放入我们提示词中的可能输入。所以对我们来说,我们的提示词只有一个输入,一个用户提供的问题。所以对于我们的评估数据集,我们将有一个不同可能问题的列表,我们可能想要放入我们的提示词中。我的数据集只包含三个不同的问题。
但在真实的评估中,您的数据集中可能会有几十、几百甚至几千条不同的记录。现在,您可以手动组装这些数据集,或者您当然也可以使用 Claude 为您生成它们。一旦我们有了我们的评估数据集,我们就会将这些不同的问题中的每一个输入到我们的提示词中。这样我们就可以得到一个完整的提示词,然后我们可以将其输入到 Claude 中。
所以我们可能会在这里有第一个提示词,其中我们有,“请回答用户的问题”,然后是我们的数据集中的一个示例问题,比如“二加二等于几?”然后我们将对我们数据集中的所有其他记录重复此操作。所以这里是第二和第三个。然后我们将把这些中的每一个输入到 Claude 中,并从 Claude 中得到一个实际的响应。
所以对于第一个,我们可能会得到一个类似“2加2等于4”的响应,然后是一些关于如何做燕麦粥的东西,然后是一些关于到月亮的距离的东西。一旦我们从 Claude 中得到这些实际的答案,我们就会以某种方式对它们进行评分。在这个评分步骤中,我们将从我们的数据集中取出每个问题,以及我们从 Claude 中得到的答案。我们将它们全部配对,然后我们将它们一个接一个地输入到评分器 (grader) 中。
我们可以用很多不同的方式来实现这个评分器。我们稍后会看一些不同的方法。然后评分器会给我们一个分数,可能从1到10,基于 Claude 产生的答案的质量。所以10分意味着我们得到了一个完美的答案,真的没有任何可能的方法可以改进它。
也许像4分这样的分数表明那里肯定有改进的空间。现在,正如您可以猜到的,评分器这里有很多隐藏的复杂性,因为您可能很好奇或想知道,我们到底是如何得到这些分数的呢?再次,别担心。我们稍后会更详细地讨论这些评分器的事情。
在我们得到这些分数之后,我们就会把它们全部平均起来。所以在这种情况下,我会把分数加起来,除以三,得到一个平均分7.66。所以我现在有了一种客观的方式来描述我们最初的提示词表现如何。现在我们有了这个分数,我们就可以以某种方式改变我们的提示词,并迭代或重复整个过程。
所以如果我想提高我的分数,我可能会尝试在提示词中添加更多细节,以希望能更多地引导 Claude,并帮助它理解我们想要什么样的输出。所以我可能会在提示词的末尾加上一些类似“用充足的细节回答问题”的话。一旦我有了我的提示词的第二个版本,我就会再次通过整个流程运行它。然后我就会有提示词版本一和提示词版本二的分数。
然后我可以比较这两个分数,无论哪个分数更大或更高。这是一种客观的标志,总比没有好,它告诉我,在这种情况下,提示词 V2 可能是我们提示词的更好版本。所以既然我们对整个过程有了高层次的概述,正如我所提到的,我们将在 Jupyter notebook 中开始实现我们自己的自定义评估框架。那么,让我们在下一个视频中开始实现吧。
19. 生成测试数据集
类型:视频 | 时长:4:44 | 视频:04 - 003 - Generating Test Datasets.mp4
构建自定义提示词评估工作流程始于创建一个可靠的提示词,然后生成测试数据以查看其性能如何。让我们逐步建立一个评估系统,用于评估一个帮助用户编写 AWS 特定代码的提示词。
设定目标
我们的提示词需要帮助用户为 AWS 用例编写三种特定类型的输出:
- Python 代码
- JSON 配置文件
- 正则表达式
关键要求是,当用户请求帮助完成任务时,我们以这三种格式之一返回干净的输出,不带任何额外的解释、页眉或页脚。

这是我们的起始提示词(版本 1):
prompt = f"""
Please provide a solution to the following task:
{task}
"""
创建评估数据集
评估数据集包含我们将输入到提示词中的输入。对于提示词和输入的每种组合,我们将运行提示词并分析结果。
我们的数据集将是一个 JSON 对象数组,其中每个对象包含一个 "task" 属性,描述我们希望 Claude 完成的任务。我们可以手动创建此数据集,也可以使用 Claude 自动生成。

由于我们正在生成测试数据,这是使用像 Haiku 这样的更快模型而不是完整的 Claude 模型的绝佳机会。
使用代码生成测试数据
让我们创建一个自动生成测试数据集的函数。首先,我们需要与 Claude 一起工作的辅助函数:
def add_user_message(messages, text):
user_message = {"role": "user", "content": text}
messages.append(user_message)
def add_assistant_message(messages, text):
assistant_message = {"role": "assistant", "content": text}
messages.append(assistant_message)
def chat(messages, system=None, temperature=1.0, stop_sequences=[]):
params = {
"model": model,
"max_tokens": 1000,
"messages": messages,
"temperature": temperature
}
if system:
params["system"] = system
if stop_sequences:
params["stop_sequences"] = stop_sequences
response = client.messages.create(**params)
return response.content[0].text
现在我们将创建我们的数据集生成函数:
def generate_dataset():
prompt = """
Generate an evaluation dataset for a prompt evaluation. The dataset will be used to evaluate prompts that generate Python, JSON, or Regex specifically for AWS-related tasks. Generate an array of JSON objects, each representing task that requires Python, JSON, or a Regex to complete.
Example output:
```json
[
{
"task": "Description of task",
},
...additional
]
- Focus on tasks that can be solved by writing a single Python function, a single JSON object, or a single regex
- Focus on tasks that do not require writing much code
Please generate 3 objects. """
为了正确解析 JSON 响应,我们将使用预填充和停止序列:
messages = []
add_user_message(messages, prompt)
add_assistant_message(messages, "```json")
text = chat(messages, stop_sequences=["```"])
return json.loads(text)
## 测试数据集生成
让我们运行我们的函数,看看我们得到了什么样的测试用例:
dataset = generate_dataset() print(dataset)
这应该返回三个不同的测试用例,涵盖我们的目标输出——用于 AWS 特定任务的 Python 函数、JSON 配置和正则表达式。
## 保存数据集
一旦我们有了数据集,我们就会将其保存到文件中,以便稍后在评估期间轻松加载它:
with open('dataset.json', 'w') as f: json.dump(dataset, f, indent=2)
这会在与您的 notebook 相同的目录中创建一个 `dataset.json` 文件,其中包含您准备好进行提示词评估的任务列表。
有了这个基础,您现在就有了一种系统的方法来生成测试数据,以评估您的提示词在不同类型的 AWS 相关编码任务中的表现。
#### 视频文字稿
让我们开始构建我们自己的自定义提示词评估工作流程。我们将写出一个提示词,然后写出一些代码来评估它的表现。所以我们首先专注于制作一个提示词。我们提示词的目标是帮助用户编写一些针对 AWS 用例的特定代码。
所以我们将允许用户输入他们需要帮助的某种任务。然后我们将用三种输出类型中的一种来回应。我们要么输出 Python、JSON 配置,要么输出一个原始的、纯粹的正则表达式。这是我们三种可能的输出。
所以我们需要确保,当用户要求我们完成某种任务时,我们以这三种特定输出中的一种给他们一些输出,而没有任何其他类型的解释、页眉或页脚之类的东西。所以这是总的目标。现在,我们目标的第一步,当然,是写出一个提示词草稿。现在,我已经在这里的右侧为我们做好了。
我有了我们提示词的 V1 版本,它只说,“请为以下任务提供一个解决方案”,然后我们会把用户的任务放进去。第二步是组建一个数据集。记住,一个数据集将包含一些我们将要输入到我们提示词中的输入,然后我们将为提示词和输入的每一个组合运行我们的提示词。对于我们的特定情况,我们将有一个 JSON 对象数组,其中每个对象都有一个 task 属性。
这些任务将描述我们希望 Claude 完成的事情,所以我们将把这些任务中的每一个都放入我们的提示词中,然后将结果输入到 Claude 中。记住,当我们制作一个数据集时,我们可以手动组装它,或者我们可以用 Claude 自动生成它。现在,顺便说一下,如果您正在使用 Claude 做类似的事情,这将是一个非常好的机会来使用像 Haiku 这样更快的模型。这就是我们在这里要做的。
让我们回到 Jupyter,我们将打开我们的 notebook,然后我们将写出一点代码,它将生成一个像您在左侧看到的示例数据集,使用 Haiku。回到这里,我创建了一个新的 notebook,它有很多我们整个课程中一直在使用的相同代码。所以我在顶部单元格中创建了一个客户端,并且还加载了一些环境变量,我还创建了我们一直在开发的同样三个辅助函数。然后,在下面一点,我定义了一个名为 `generate_dataset` 的函数。
在里面,我准备了一个相当大的提示词来帮助我们开始。现在,我已经把这个 notebook 附在了这个讲座上。所以我鼓励您下载这个 notebook 并复制这里的提示词,或者直接使用这个 notebook 来为自己节省大量的打字时间。这个提示词将要求 Claude 继续并为我们生成一些不同的测试用例。
我们的测试用例将由一个 JSON 对象数组表示,每个对象都有一个 task 属性,描述要完成的任务。现在,我只是要求 Claude 生成三个这样的对象。这足以让我们开始,并确保我们实际上可以创建一个数据集。所以现在让我们向我们所在的这个 `generate_dataset` 函数添加一些代码。
它实际上会把这个提示词发送给 Claude,得到一个任务列表,然后将它们解析为 JSON。为了解析 JSON,我们将确保我们使用我们不久前谈到的同样的预填充和停止序列方法。那么,让我们开始吧。
在函数内部的下面,所以我要确保我缩进,我会声明一个消息列表。我会添加一个用户消息,即那个提示词,然后我会添加一个助手消息,我将输入反引号、反引号、反引号、JSON。然后我会用我们的消息列表和一些停止序列来调用 chat。在这种情况下,我们唯一的停止序列将是反引号、反引号、反引号。
然后最后,我将返回 JSON.loads, text。好的,所以我将运行这个单元格以确保该函数被定义,然后我们将在下面这里快速测试它。然后让我们打印出那个数据集,只是为了确保我们得到了一些看起来真实的数据。好的,就这样。
所以这是我们三个不同的测试用例。我们得到了一个我们将得到一个 Python 函数的情况,写一些 JSON 配置,然后写一个正则表达式。所以我们说这是一个好的开始。接下来,我想把这个数据集写入一个文件中。
所以当我们在评估我们的提示词时,我们可以非常容易地在以后加载它。为此,我们将以写入模式打开一个文件。我将把文件命名为 `dataset.json`。然后用两个缩进进行 `json.dump`。
所以我将再次运行这个。在那个单元格运行之后,在与我的 notebook 相同的目录中,我应该会找到一个 `dataset.json` 文件,里面应该是我们的任务列表。好的,这是一个好的开始。我们已经准备好了我们的评估数据集 (eval dataset)。
---
### 20. 运行评估
> 类型:视频 | 时长:6:42 | 视频:04 - 004 - Running the Eval.mp4
现在我们的评估数据集已经准备好了,是时候构建核心评估流程了。这包括获取每个测试用例,将其与我们的提示词合并,输入给 Claude,然后对结果进行评分。
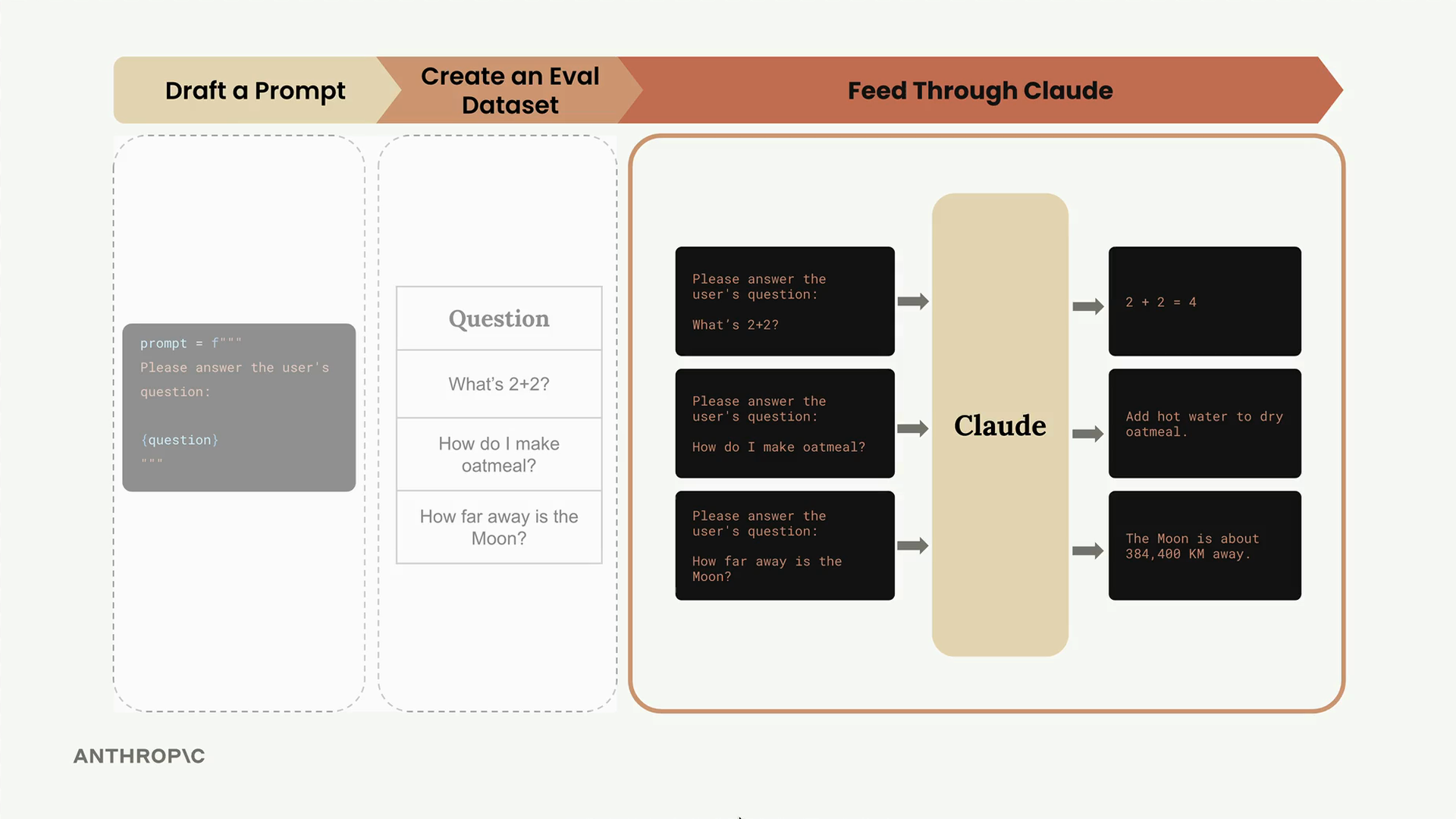
评估过程遵循一个清晰的工作流程:我们获取测试用例的数据集,将每个用例与我们的提示词模板结合,发送给 Claude 进行处理,然后使用评分器 (grader) 系统评估输出。
## 构建核心函数
评估流程由三个主要函数组成,每个函数都有特定的职责。让我们从最简单的一个开始——处理单个提示词的函数。
## `run_prompt` 函数
此函数获取一个测试用例并将其与我们的提示词模板合并:
def run_prompt(test_case): """Merges the prompt and test case input, then returns the result""" prompt = f""" Please solve the following task:
{test_case["task"]} """
messages = []
add_user_message(messages, prompt)
output = chat(messages)
return output
现在,我们保持提示词极其简单。我们没有包含任何格式化指令,所以 Claude 可能会返回比我们需要的更冗长的输出。我们稍后在迭代提示词设计时会对此进行优化。
## `run_test_case` 函数
此函数协调运行单个测试用例和对结果进行评分:
def run_test_case(test_case): """Calls run_prompt, then grades the result""" output = run_prompt(test_case)
# TODO - Grading
score = 10
return {
"output": output,
"test_case": test_case,
"score": score
}
目前,我们使用一个硬编码的分数 10。评分逻辑是我们将在接下来的部分花费大量时间的地方,但这个占位符让我们可以测试整个流程。
## `run_eval` 函数
此函数协调整个评估过程:
def run_eval(dataset): """Loads the dataset and calls run_test_case with each case""" results = []
for test_case in dataset:
result = run_test_case(test_case)
results.append(result)
return results
此函数处理我们数据集中的每个测试用例,并将所有结果收集到一个列表中。
## 运行评估
要执行我们的评估流程,我们加载数据集并通过我们的函数运行它:
with open("dataset.json", "r") as f: dataset = json.load(f)
results = run_eval(dataset)
第一次运行这个时,预计会花费一些时间——即使使用 Claude Haiku,处理一个完整的数据集也可能需要大约 30 秒。我们稍后会介绍优化技术。
## 检查结果
评估返回一个结构化的 JSON 数组,其中每个对象代表一个测试用例的结果:
print(json.dumps(results, indent=2))
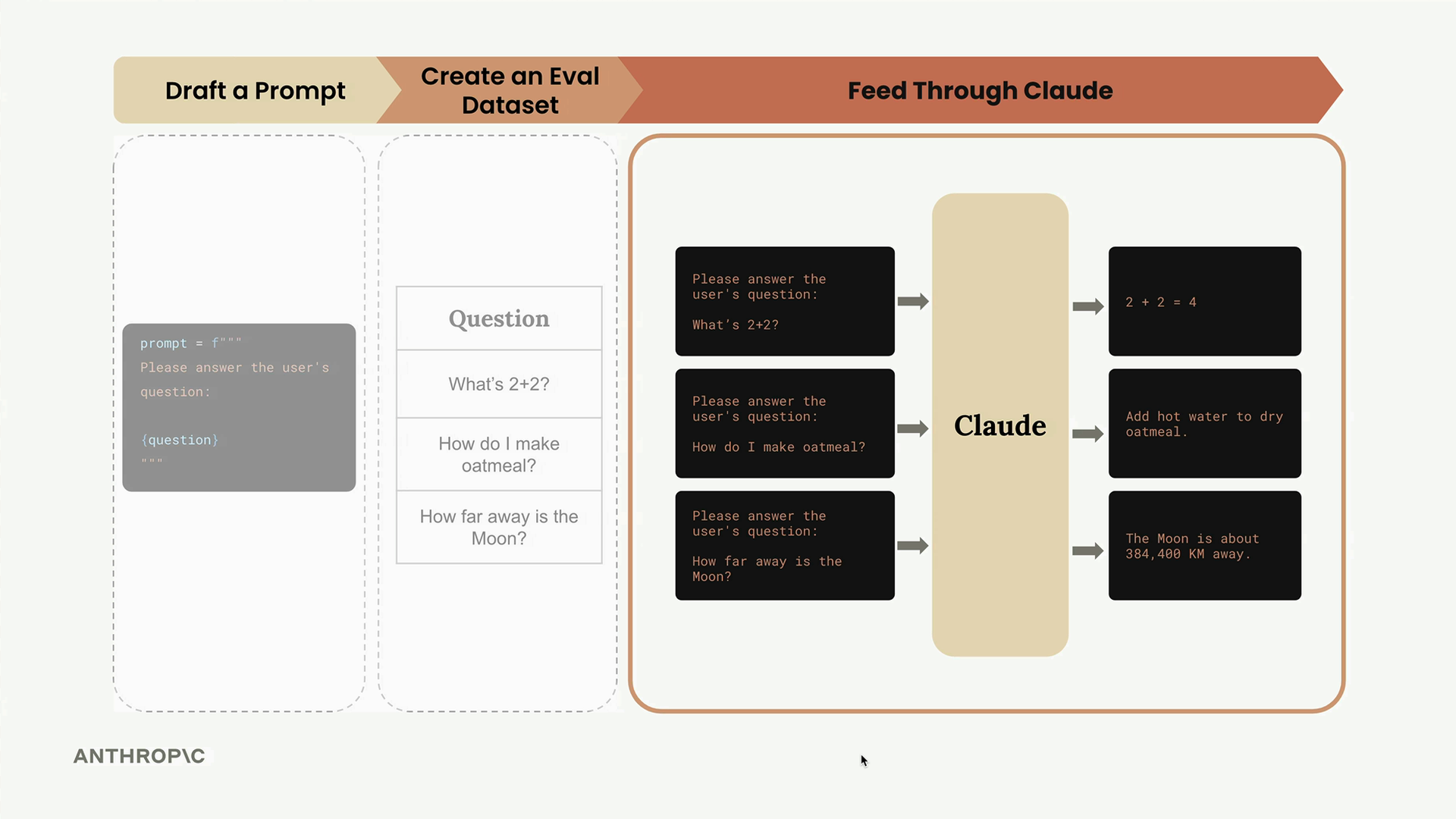
每个结果包含三个关键信息:
- **output**:来自 Claude 的完整响应
- **test_case**:被处理的原始测试用例
- **score**:评估分数(目前是硬编码的)
正如您在输出中看到的,由于我们尚未提供具体的格式化指令,Claude 生成了相当冗长的响应。这正是我们在优化提示词时要解决的问题。
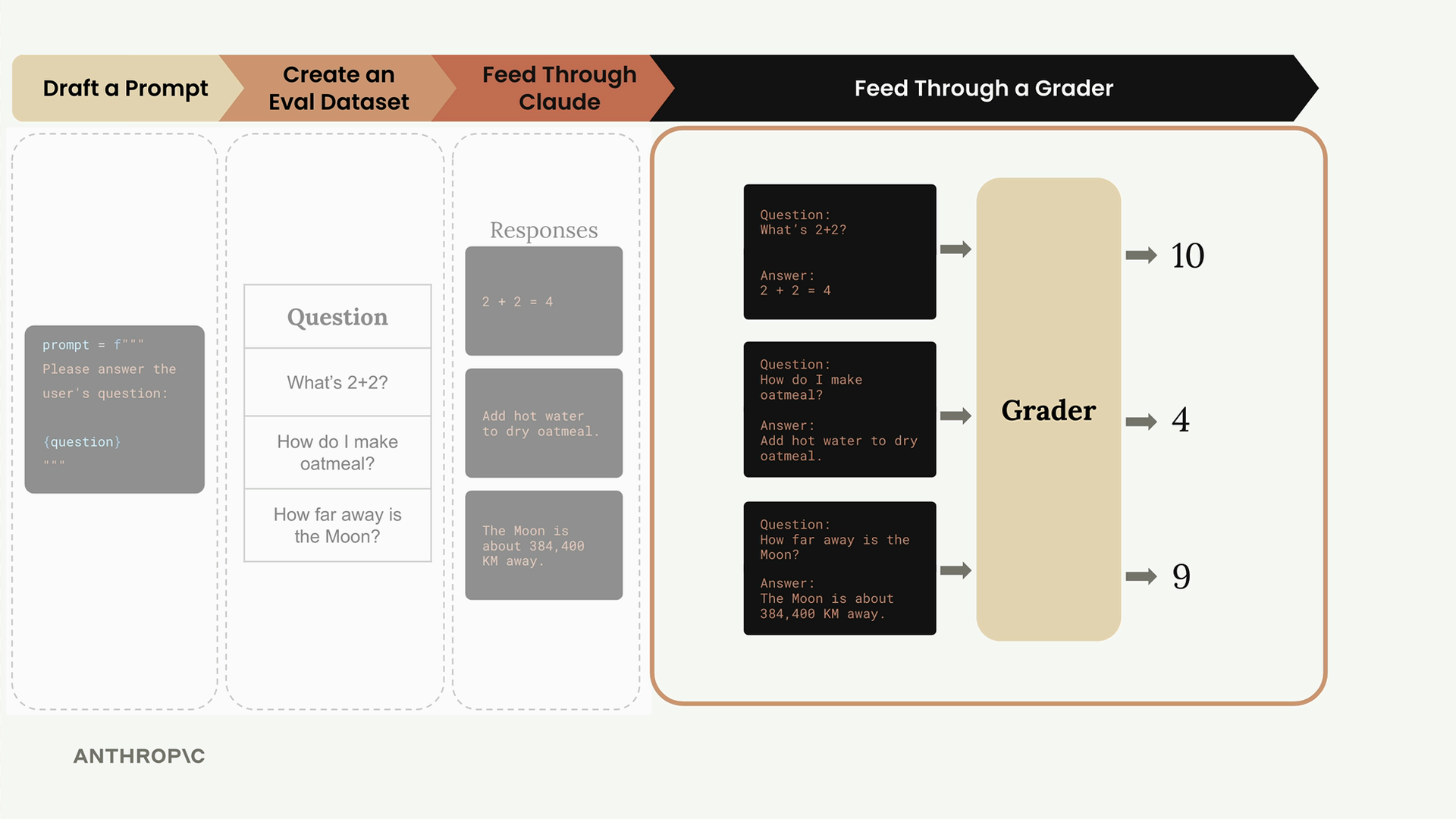
## 我们完成了什么
至此,我们已经成功构建了核心评估流程。我们可以获取数据集,通过 Claude 处理它,并收集结构化的结果。主要缺失的部分是评分系统——硬编码的分数 10 需要被实际的评估逻辑所取代。
这个流程代表了大多数 AI 评估系统的基础。虽然它可能看起来很简单,但您刚刚构建了评估流程实际所做的大部分工作。复杂性在于细节——更好的提示词、复杂的评分和性能优化。
接下来,我们将深入探讨评分器这个关键主题,它将把我们的硬编码分数转变为对 Claude 性能有意义的评估。
#### 视频文字稿
随着我们数据集的生成完成,我们现在需要处理该数据集中的每一条记录,我们称之为测试用例。所以我们要逐个处理每个测试用例,并将其与提示词合并。然后,我们将结果输入到 Claude 中。一旦我们获得了所有这些不同的输出,我们就会将它们通过我们的评分器 (grader)。
记住,我们还没有讨论过评分器。别担心,这很快就会讲到。再一次,为了节省一点时间,我在这里写了一些代码,以帮助指导我们工作流程的下一个阶段。我整理了三个独立的函数,并对每个函数的作用给出了非常清晰的注释。
第一个最容易理解的是 `run_prompt` 函数。它将通过一个测试用例被调用。我们刚才生成的那些 JSON 对象,每一个都是一个测试用例。所以您可以想象,这些对象将一个接一个地流入 `run_prompt` 函数。
所以在这里面,我们的目标是将我们生成的任务与我们的提示词合并,用 Claude 生成一些文本,然后返回结果。那么,让我们马上开始做吧。我将在这里放入我的 V1 提示词,它非常简单。记住,我们在这里从尽可能简单开始。
所以它只会说一些类似,“请解决以下任务”的话。我希望这是一个 F 字符串,我将放入 `test_case["task"]`。接下来,我们想把这个发送给 Claude。所以我将创建一个消息列表。我将添加一个用户消息。然后我将通过调用 `chat` 将其传递给 Claude。我们将得到一些结果文本,一些结果,或者这次我们称之为 `output`。然后,现在,我将只返回 `output`。
记住,我们现在没有任何格式化包含在内,也没有任何格式化指令在提示词中。所以我们很可能会得到比我们要求的更多的输出。我们提示词的真正目标是确保我们只得到 Python 或 JSON 或那个正则表达式。我们现在没有任何针对这个的东西。
所以我们几乎肯定需要回来做一些改进。但是现在,我们至少有了一个开始 `run_prompt` 的基础。我们接下来要做的是 `run_test_case`。这个函数的目标是接收一个单独的案例,调用我们刚刚组合的 `run_prompt` 函数,从 Claude 获得一些输出,然后对结果进行评分,并返回一个描述和所有发生的事情的字典。
这听起来很复杂,但实际上,它会出奇地简单。所以让我给您看我们在这里需要做的所有事情。我们将放入 `output`,它将来自调用我们刚才正在做的那个函数。所以这个 `run_prompt` 函数。
放入我们的测试用例,然后我们将在这里进行一些评分,这将是一个待办事项。现在,我只会说我们有一个硬编码的分数 10。所以我们肯定需要回来做很多繁重的工作。然后在底部,我们只会返回一些信息,总结运行这个测试用例的所有事情。
所以我将返回一个带有一些 `output` 的字典。给我从 Claude 那里得到的任何东西。我将包含 `test_case`。然后是我们的 `score`。
然后是最后一个步骤,我们必须实现 `RunEval`。所以这个函数将加载我们的数据集或作为参数接收它,任何一个都可以。然后我们将遍历那个数据集。对于每个测试用例,我们将调用 `run_test_case`,然后只是将所有结果组合在一起。
所以对于我们的实现,我会说 `results`。它将以一个空列表开始。对于数据集中的每个 `test_case`,我将从调用 `run_test_case` 中获得我们的 `result`,并传入 `test_case`。
然后将其添加到我们的 `results` 列表中。然后在这里的底部,我将只打印出我们所有的结果。实际上,让我们还是直接返回 `results` 吧。这样更好一些。
好的,这就是我们三个主要函数的概要。现在信不信由你,这就像一个评估流程的绝大部分。我们刚刚完成了绝大部分,除了明显的评分部分。所以正如您所见,这并没有很多代码。
现在我们来测试一下。所以在下一个单元格的下面,我将打开我们的 `dataset.json` 文件。并将其解析为 JSON。然后调用 `runEval` 函数。
就是我们刚才在这里用整个数据集组合的那个。最后,我将把结果赋给 `results`。我将重新运行上面的所有单元格,只是为了确保我执行了它们全部,然后我将运行这个单元格。我们看看会发生什么。
顺便说一句,第一次运行这个时,它会花费相当长的时间,即使您正在使用 Haiku。用 Haiku 完成这个大约需要 31 秒。我将向您展示一些加快我们评估运行时间的技术,但现在,我们就让它花费一点时间,但别担心,我们会加快它的。所以现在让我们看看 `results`,看看我们有什么。
`results` 将是一个相当大的 JSON 对象。所以我将用 `print`, `JSON dumps`,带上 `results` 和两个缩进,把它打印得很好看。就这样。所以现在我们得到一个对象数组。
每个对象代表我们单个测试用例之一的输出。我在这里有输出。那是来自 Claude 的输出。我们可以看到这里生成了很多东西。
如果我向下滚动一点,我会看到这个所基于的测试用例的定义。然后是分数,再次,现在只是硬编码为 10。然后这将一遍又一遍地重复。好的,所以在这一点上,我们已经成功地完成了这里的这个步骤。
我们将我们的数据集与我们的测试提示词合并在一起,我们从 Claude 得到了一些输出,我们把所有这些东西都整理在一起。所以现在我们真正要做的最后一件事是,把我们从 Claude 那里得到的输入和结果输入到这些不同的评分器中的一个。所以这终于到了我们开始学习评分器的时候了。我们将在下一个视频中开始讨论它们。
---
### 21. 基于模型的评分
> 类型:视频 | 时长:10:01 | 视频:04 - 005 - Model Based Grading.mp4
在构建提示词评估工作流程时,评分系统为输出质量提供了客观的信号。评分器 (grader) 接收模型输出并返回某种可衡量的反馈——通常是 1 到 10 之间的一个数字,其中 10 代表高质量,1 代表低质量。
## 评分器类型
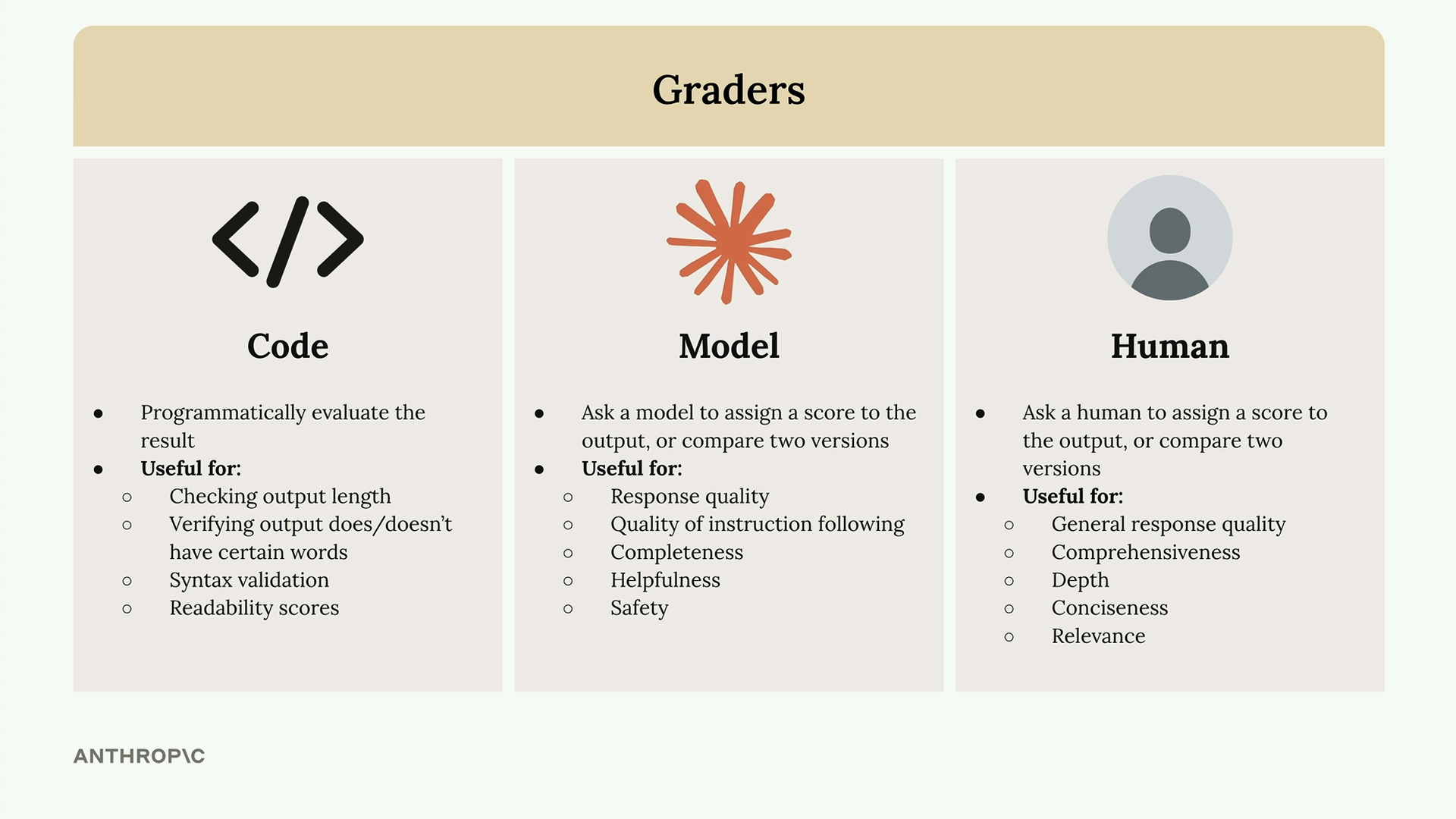
对模型输出进行评分主要有三种方法:
- **代码评分器 (Code graders)** - 使用自定义逻辑以编程方式评估输出
- **模型评分器 (Model graders)** - 使用另一个 AI 模型来评估质量
- **人工评分器 (Human graders)** - 让人们手动审查和评分输出
### 代码评分器
代码评分器让您可以实现任何可以想象的编程检查。常见用途包括:
- 检查输出长度
- 验证输出是否包含/不包含某些词语
- 对 JSON、Python 或正则表达式进行语法验证
- 可读性分数
唯一的要求是您的代码返回一些可用的信号——通常是 1 到 10 之间的一个数字。
### 模型评分器
模型评分器将您的原始输出输入到另一个 API 调用中进行评估。这种方法在评估以下方面提供了巨大的灵活性:
- 响应质量
- 指令遵循的质量
- 完整性
- 帮助性
- 安全性
### 人工评分器
人工评分器提供了最大的灵活性,但耗时且乏味。它们可用于评估:
- 总体响应质量
- 全面性
- 深度
- 简洁性
- 相关性
## 定义评估标准

在实施任何评分器之前,您需要明确的评估标准。对于一个代码生成提示词,您可能关注:
- **格式** - 应只返回 Python、JSON 或正则表达式,不带解释
- **有效语法** - 生成的代码应具有有效的语法
- **任务遵循** - 响应应直接用准确的代码解决用户的任务
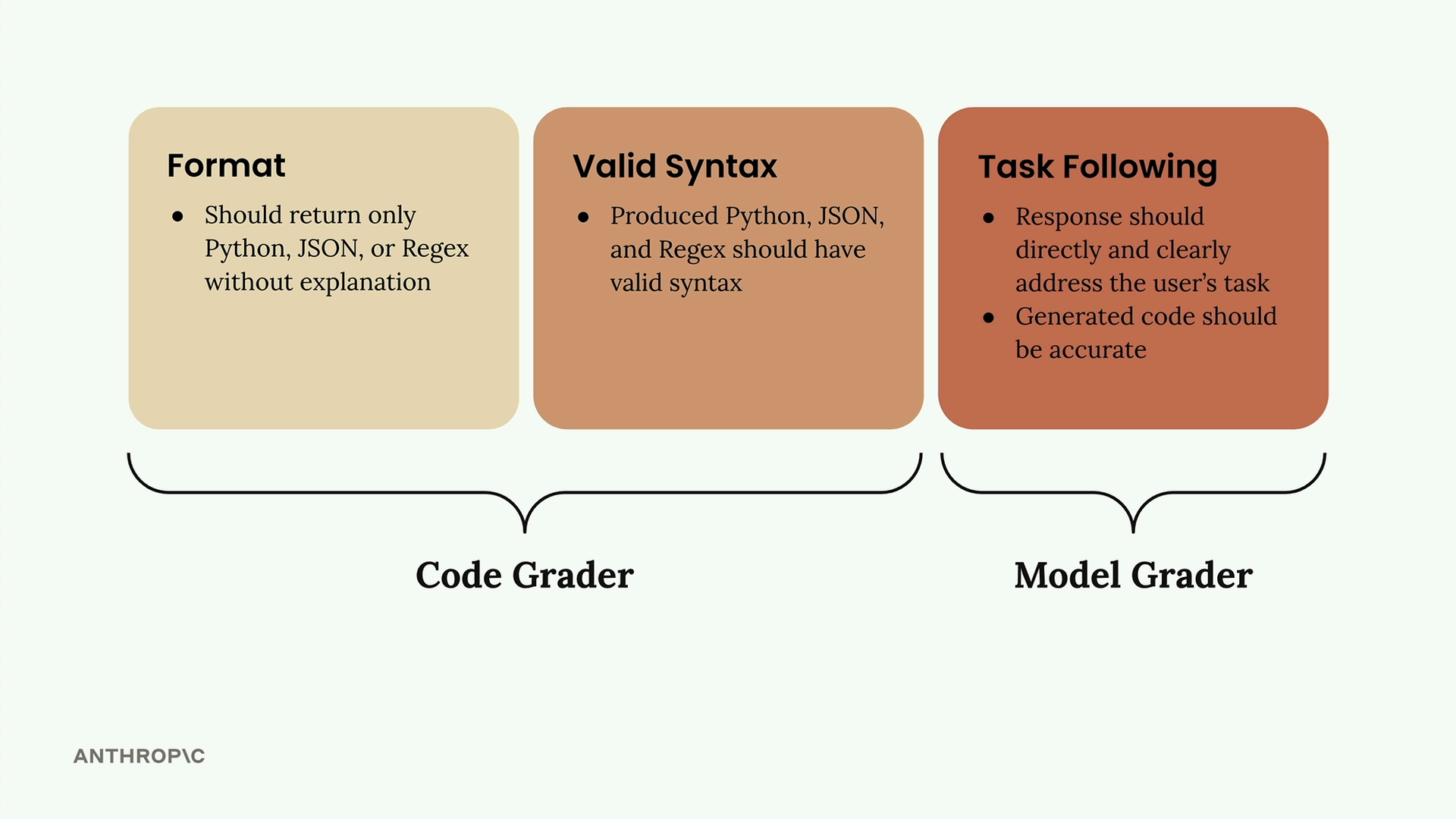
前两个标准很适合使用代码评分器,而任务遵循由于其灵活性更适合使用模型评分器。
## 实现一个模型评分器
以下是如何构建一个模型评分器函数:
def grade_by_model(test_case, output): # Create evaluation prompt eval_prompt = """ You are an expert code reviewer. Evaluate this AI-generated solution.
Task: {task}
Solution: {solution}
Provide your evaluation as a structured JSON object with:
- "strengths": An array of 1-3 key strengths
- "weaknesses": An array of 1-3 key areas for improvement
- "reasoning": A concise explanation of your assessment
- "score": A number between 1-10
"""
messages = []
add_user_message(messages, eval_prompt)
add_assistant_message(messages, "```json")
eval_text = chat(messages, stop_sequences=["```"])
return json.loads(eval_text)
关键的洞见是,除了分数之外,还要求提供优点、缺点和推理。没有这些上下文,模型往往会默认给出中等的分数,大约在 6 分左右。
## 将评分集成到您的工作流中
更新您的测试用例运行器以调用评分器:
def run_test_case(test_case): output = run_prompt(test_case)
# Grade the output
model_grade = grade_by_model(test_case, output)
score = model_grade["score"]
reasoning = model_grade["reasoning"]
return {
"output": output,
"test_case": test_case,
"score": score,
"reasoning": reasoning
}
最后,计算所有测试用例的平均分:
from statistics import mean
def run_eval(dataset): results = []
for test_case in dataset:
result = run_test_case(test_case)
results.append(result)
average_score = mean([result["score"] for result in results])
print(f"Average score: {average_score}")
return results
这样,您就有了一个客观的指标,可以在迭代 prompt 时进行跟踪。虽然基于模型的评分器可能有些反复无常,但它们为衡量改进提供了一个一致的基准。
#### 视频文字稿
接下来我们要在 prompt 评估工作流中实现的是一个评分系统。提醒一下,评分器 (grader) 会接收我们模型的输出。然后,我们希望评分器能给我们某种客观的信号。这个信号可能是一个数字,也可能是一个布尔值(true/false)。
它可以是任何东西,但你最常看到的是 1 到 10 之间的一个数字输出。其中 10 表示我们得到了一个非常高质量的输出,而 1 表示我们得到了一个非常低质量的输出。同样,这不是强制要求。我们不一定非要从这些评分器中得到数字,但这是一种你将经常看到的非常普遍的做法。
在本视频中,我们将讨论三种不同类型的评分器:基于代码的、基于模型的和人工的。我们首先来看看什么是基于代码的评分器。对于基于代码的评分器,我们会将模型的输出输入到我们编写的一段代码中。
在这段代码中,我们可以进行几乎所有你能想到的程序化检查。例如,我们可以验证模型的输出不会太长或太短。我们可以确保输出包含或不包含某些词语。如果返回的是 JSON 或代码,我们可以通过编程方式进行语法验证,甚至可以进行更复杂的检查,比如实现一个可读性分数,以确保生成的文本处于适合我们特定用例的阅读水平。
这里唯一的要求是,当我们运行这段代码时,它能返回某种我们可以使用的实际信号。同样,这通常是一个 1 到 10 之间的数字,但这并非强制要求。你将经常看到的下一种评分器是基于模型的评分器。在这种方式下,我们将原始模型调用(即我们已经发出的那次调用)的输出,输入到另一个模型中。
所以这是另一次 API 请求。当我们使用模型评分器时,我们获得了极大的灵活性。我们可以要求模型根据响应的总体质量、它遵循 prompt 指令的程度、响应的完整性等几乎任何你能想到的方面来评估一个响应。
再次强调,这里唯一真正的要求是模型能给我们返回某种明确的客观信号,通常是 1 到 10 之间的一个数字。
最后是人工评分。对于人工评分,我们会将模型的所有输出都呈现给一个真人。然后由这个人负责以某种特定的方式评估这些响应。你可以想象,人类非常灵活,所以我们可以要求他们以几乎任何你能想象的方式或针对任何指标来评估响应。
人工评分的一个主要缺点是它通常需要花费大量时间,而且无疑是一项非常繁琐的工作。现在,无论你使用哪种评分方式,你都需要预先决定你的评估标准是什么。换句话- 话说,你将重点关注响应的哪些方面?对于我们的特定用例,我确定了三个不同的评估标准。
首先,我认为我们应该评估响应,以确保我们只得到 Python、JSON 或正则表达式(regular expression),而没有 Claude 提供的任何额外解释。其次,每当我们得到 Python、JSON 或 regex 时,我们都应该确保它具有有效的语法,也就是说里面不应该有拼写错误或类似的东西。最后,我们可能应该做一些通用的任务遵循性检查,确保模型清楚地解决了用户的任务,并用基本准确、不包含任何重大错误或逻辑错误的代码来回答。
因此,对于这三个不同的评估标准,我认为我们可以用代码评分器来评估前两个。我们可以评估格式,确保我们得到的是实际的 Python、JSON 或 regex 代码。我们还可以用额外的代码来验证该代码的语法。最后,关于通用响应以及确保用户的问题得到明确解决,鉴于其灵活性,这更适合通过模型评分器来解决。
好的,让我们先开始实现模型评分器,因为信不信由你,这可能是最容易实现的一个。我将首先回到我的 notebook。找到我们之前在 `run_test_case` 函数中放置的那个待办事项(to do)。然后,在该单元格的上方,我将添加一个新单元格,其中包含一个我将命名为 `grade_by_model` 的函数。
我将假设我会传入我的测试用例字典。记住,测试用例字典本质上就是这些对象。每个数据集的值,都是我们的测试用例。我还会传入我们原始模型调用的输出。
然后,在这里面,我们基本上会调用一个模型,并要求它对输出进行评分。为此,我们通常会写一个相当长的 prompt。同样,为了节省一点时间,我将复制粘贴一个 prompt 进来。就是这个。
我把它粘贴进来。是的,它有点长,但这基本上是我们想要的最低要求。这个 prompt 将设定一个角色。然后它会非常明确地要求模型评估一个 AI 生成的解决方案。
然后我们会打印出任务。接着,我们会列出模型生成的解决方案。之后,我们会提供关于如何响应的具体指导。在这个特定的例子中,我要求模型给我一个 AI 生成解决方案的优缺点列表,以及背后的推理和一个实际分数。
现在,我们可以只要求一个分数,但如果你这样做,你会经常发现你倾向于只得到 6 分。所以,如果你不要求任何额外的优点、缺点或推理,你通常只会得到非常平庸的分数,因为模型会认为,嗯,可能更好,也可能更差,我们就给个 6 分吧。通过要求模型提供一些推理、优点和缺点,你实际上是让它更专注,并决定一个更具体的分数。
现在我们有了这个 prompt,我将调用我们的附加评分模型。就在它下面,我将再次创建一个 `messages` 列表。我会添加一个用户消息。然后,因为我们这里会得到一些 JSON,我们需要再次确保使用预填充的助手消息和一个停止序列来干净地提取它。所以我们将添加一个带有 `json` JSON 的助手消息,然后我会得到一些评估文本(eval text),然后我们将调用 `chat` 函数,传入 `messages` 和一个停止序列,这个停止序列同样是 `json` 的结束符号。
现在,这个评估文本应该是一个具有这种结构的 JSON 对象。所以我会解析它并直接返回。即 `return JSON.loads(eval_text)`。
好的,这就是我们的模型评分器。这基本上就是开始所需的全部内容。现在我们需要确保我们实际调用了这个评分器。要调用评分器,我将转到这里的待办事项。我将用 `model_grade` 替换 `score`。这将来自我们的 `grade_by_model` 函数。记住,我们必须传入测试用例,以及实际运行 prompt 的输出。
从中,我们将从 `model_grade` 中得到一个分数。我还会从返回的那个字典中提取分数背后的推理。在我们返回的这个 `model_grade` 字典内部,还有一个优缺点列表。你当然可以根据需要提取它们,但我只是为了让我们的例子更简洁一些。我将把分数和推理放入这个最终的输出字典中。
所以我会在这里添加一些额外的键,比如 `score`。哦,我那里已经有 `score` 了。我的错。我不需要那个,但我确实需要 `reasoning`。那将是 `reasoning`。好的,看起来不错。
我将确保运行这些单元格。我将运行那个,更新 `run_test_case`。然后我将重新运行我的实际评估。这需要一些时间来完成。对我来说,这次大约需要 22 秒。现在,如果我打印出那些结果,让我们看看我们得到了什么。
现在我得到了生成的输出。如果我向下滚动一点,我可以看到模型生成的分数以及该分数背后的一些推理。在这种情况下,我得到了 8 分。还不错。这就是我得到 8 分的原因。如果我继续往下看,下一个得到了 7 分。最后,我得到了 6 分。所以我们在这里可能要做的最后一件事是,把所有这些分数加起来,求一个平均值,然后打印出来。这样我们就得到了一个最终的、非常客观的分数,来告诉我们当前的 prompt 表现如何。
因此,为了对所有这些分数求平均并打印结果,我将找到这里的 `run_eval` 函数。我将使用列表推导式 `[result["score"] for result in results]` 来计算平均分。我将用 `mean` 函数调用来包装它。然后我将从 `statistics` 包中导入 `mean` 函数。
最后一步。让我们确保我们实际打印出了那个平均分。我们将执行一个 `print`。像这样打印 `average score`。好的,现在我将再次运行这段代码,以确保一切都按预期工作。运行后,我看到我确实得到了一个平均分 7.33。再一次,这最终给了我们一个实际的客观指标。
是的,它是由一个模型评分的,这个模型有时可能有点反复无常。也许我们可以提供更好的关于如何评分的指导,但至少我们有了一个可以开始关注并努力提高的分数。
---
### 22. 基于代码的评分
> 类型:视频 | 时长:7:26 | 视频:04 - 006 - Code Based Grading.mp4
在评估生成代码的 AI 模型时,你需要的不仅仅是检查响应是否有意义。你还需要验证生成的代码是否真的具有有效的语法并遵循正确的格式。这就是基于代码的评分发挥作用的地方。
## 代码评分如何工作
代码评分验证 AI 生成响应的两个关键方面:
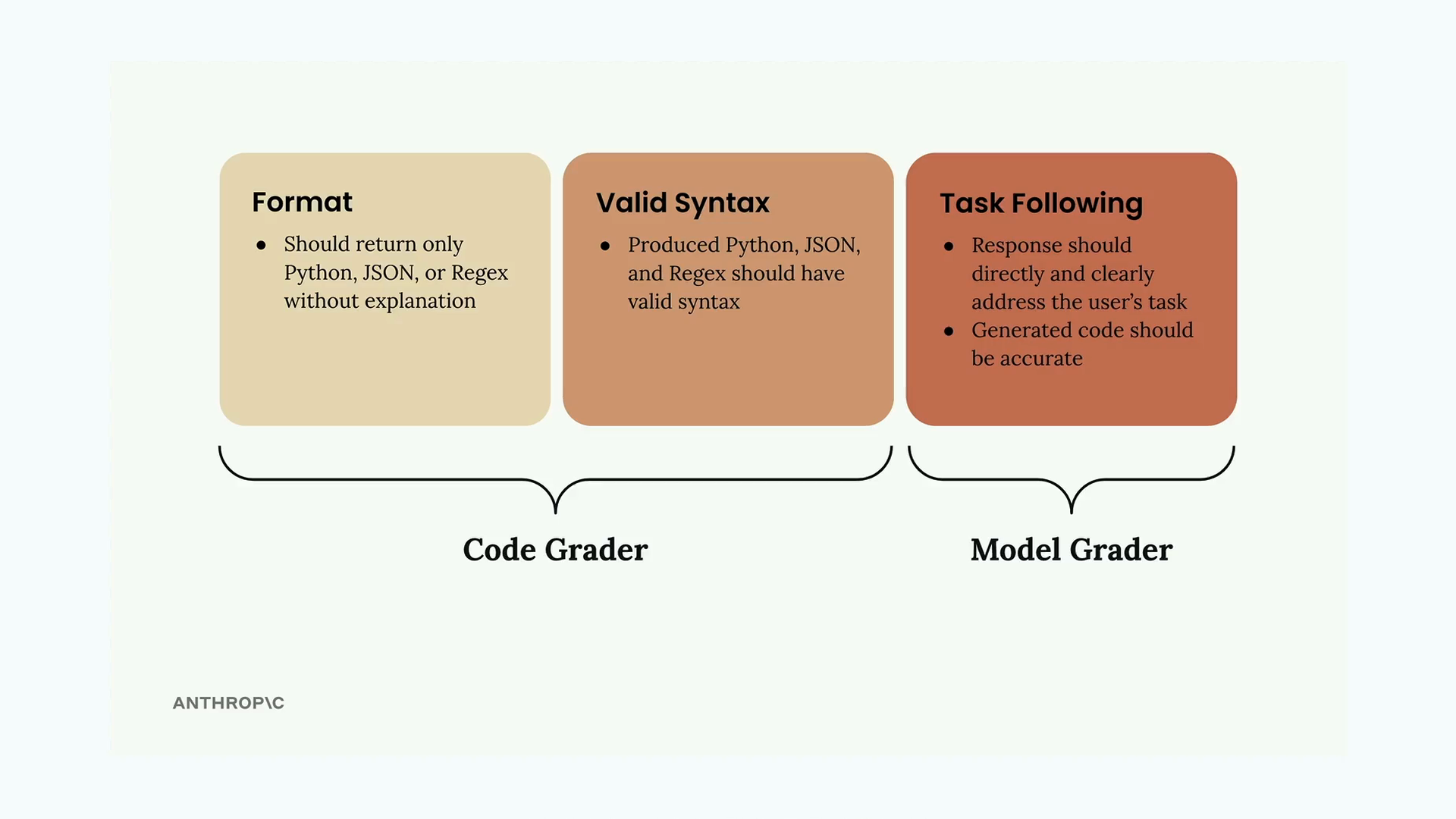
- **格式 (Format)** - 响应应只返回所请求的代码类型(Python、JSON 或 Regex),不带任何解释
- **有效语法 (Valid Syntax)** - 生成的代码应能作为预期的语言被正确解析
- **任务遵循 (Task Following)** - 响应应直接解决所提问题并且是准确的
前两个标准由代码评分器处理,而任务遵循由模型评分器评估。它们共同提供了一个全面的评估。
## 语法验证函数
要检查生成的代码是否具有有效语法,你可以创建三个辅助函数来尝试解析输出:

def validate_json(text): try: json.loads(text.strip()) return 10 except json.JSONDecodeError: return 0
def validate_python(text): try: ast.parse(text.strip()) return 10 except SyntaxError: return 0
def validate_regex(text): try: re.compile(text.strip()) return 10 except re.error: return 0
每个函数都尝试将其各自格式的文本进行解析。如果解析成功,它返回满分 10 分。如果解析失败并出现错误,则语法无效,返回 0 分。
## 数据集格式要求
为了让代码评分器知道使用哪个验证器,你的测试用例需要指定预期的输出格式:
{ "task": "Create a Python function to validate an AWS IAM username", "format": "python" }
你可以更新你的数据集生成 prompt,通过将其添加到示例输出结构中来自动包含此格式字段。
## 提高 Prompt 清晰度
为了从你的 AI 模型中获得更好的结果,请让你的 prompt 指令在预期输出格式方面更加具体:
- Respond only with Python, JSON, or a plain Regex
- Do not add any comments or commentary or explanation
你还可以使用带有代码块的预填充助手消息(pre-filled assistant message)来鼓励模型只返回原始代码:
add_assistant_message(messages, "```code")
这告诉 Claude 开始生成代码内容,而无需预先指定它是 Python、JSON 还是 Regex。
## 合并分数
最后一步是合并模型评分器的分数和代码评分器的分数。一个简单的方法是取平均值:
model_grade = grade_by_model(test_case, output) model_score = model_grade["score"] syntax_score = grade_syntax(output, test_case)
score = (model_score + syntax_score) / 2
这给予了内容质量和技术正确性同等的权重。你可以根据特定用例中更重要的因素来调整这些权重。
## 测试你的实现
一旦你实现了代码评分,运行你的评估以获得一个基准分数。分数本身并无好坏之分——重要的是你是否能通过优化你的 prompt 来提高它。这为你提供了一种量化衡量 prompt engineering 进展的方法,而不是依赖主观评估。
#### 视频文字稿
接下来,我们需要实现我们的代码评分器。我们的代码评分器将接收模型的输出,并确保我们只得到纯粹的 Python、JSON 或正则表达式,而没有任何形式的解释。此外,我们还应确保我们实际得到的任何类型的代码都具有有效的语法。你可能会好奇,我们到底要如何验证,比如说,Python 的语法呢?
嗯,我们用一个小技巧来解决这个问题。我们将定义三个辅助函数,一个叫 `ValidateJSON`,另一个叫 `ValidatePython`,还有一个叫 `ValidateRegX`。然后在每一个函数内部,我们将接收从模型得到的任何输出,并尝试将其解析为 JSON,或者解析为 Python 的抽象语法树(Abstract Syntax Tree, AST),或者尝试将其编译为正则表达式。对于这些操作中的任何一个,如果我们成功解析或加载,我们将返回满分 10 分。
否则,如果在此解析操作期间出现错误,我们将假定语法检查完全失败,并返回零分。这里还有另外一件事需要注意。为了知道要运行这些不同的验证器或评分函数中的哪一个,我们需要我们的测试用例数据集包含每次输出所期望的格式。换句话说,在我们的数据集中,对于我的第一个任务,我期望得到一个 Python 函数,然后是 JSON,然后是正则表达式。
所以我们需要更新我们的数据集,以包含像 `format` 这样的键,它会说,嘿,这个输出应该是 Python。这个应该是 JSON,而这个是正则表达式。当然,我可以手动编辑这个文件,但我们将更新生成我们数据集的 prompt,以便我们最终可以生成真正大的测试数据集。现在,要完成所有这些事情,我们需要经历几个不同的步骤。
因此,为了帮助你理解代码方面并保持一切井然有序,我整理了我们将要执行的项目的快速清单。所以我们的第一项是,添加用于验证 JSON、Python 和正则表达式的函数。为此,我将回到我的 notebook。找到 `run_test_case` 单元格。
我会在它上面添加一个新的单元格。然后在里面,我将添加你在那个图表中刚刚看到的三- 个函数。再一次,为了节省一点时间,我将把它们粘贴到这里。你随时可以从这个 notebook 的完成版本中复制完整的代码。
所以,在单元格的顶部,我导入了这两个辅助模块。然后是我刚刚看到的三个不同的验证器函数。在底部,我有一个通用的函数来决定使用哪个验证器。所以我这里有 `grade_syntax` 函数。它会查看测试用例。它会特别关注格式。所以我们需要确保我们的测试用例有我刚才提到的那个 `format` 属性。然后根据这个属性,我们将调用相应的格式化函数。
好的,这是第一步。现在第二步,我们需要更新我们的数据集,以确保我们包含那个 `format` 键。为此,我们将向上滚动一点,找到我们的数据集。就是这个。
所以生成数据集,我将在示例输出中添加内容。在任务上,我将在最后添加一个逗号,然后我将添加一个 `format` 键,在这里,我们将简单地说 JSON 或 Python 或 RegX。这基本上就是我们所要做的。所以现在如果我重新运行那个单元格,并重新运行它下面的单元格,即实际生成数据集的单元格,好了。
现在我们应该回到我们的数据集文件。我会看到,是的,我确实在里面得到了格式。而且看起来它与任务完全匹配。所以第一个任务是创建一个 JSON 配置,得到了 JSON,编写 Python,得到了 Python,然后编写一个正则表达式,我得到了 regx。
好的,进入第三步。现在,我们将更新我们的草稿 prompt 模板,只是为了确保它非常清楚地表明我们只想要 JSON、Python 或正则表达式。因为现在,我们的草稿 prompt 只是说,是的,尝试解决任务。所以不可避免地,我们会得到一些非 JSON 或非 Python 的内容,我们总是会无法通过实际的验证检查。
所以我们只是给我们的 prompt 一点帮助,给它一些我们知道它需要的工作。所以对于第三步,我们将回到我们的 `run_prompt`,那是我们草稿 prompt 的地方。我将稍微更新一下 prompt。我将添加一些注释,并要求它只用 Python、JSON 或纯正则表达式来响应。
并且不要添加任何评论、评注或解释。接下来,我将确保我们只得到我们真正关心的原始内容。再一次,为此,我们将使用一个预填充的助手消息和一个停止序列。所以我将在这里添加一个助手消息。
在我的助手消息中,在这种情况下,我可以放入三个反引号,然后通常,正如我们之前看到的,我们可能会在这里放入像 JSON 或 Bash 或 Python 之类的东西。但在这种特殊情况下,我们事先并不真正知道我们期望得到的具体格式。我们不知道我们将得到 Python、JSON 还是 RegX。所以这里有一个小技巧,一个小变通方法,我们可以只放入 `code`,这会预填充助手消息并告诉 Claude,嘿,你要在这里放入一些代码,而无需我们具体说明这将是 Python、JSON 还是 reg X。
然后我将像这样添加结尾的停止序列,用反引号。最后,我们需要将模型评分器和代码评分器的分数合并在一起。为此,回到这里,我将再次向下滚动,找到我们的 `run_test_case` 函数。这就是我们运行模型评分器的地方,就在它下面。
我将把语法评分器或者说代码评分器放在一起,随便你怎么称呼它。所以我会说我的语法分数是 `grade_syntax`。我们需要传入输出和我们的测试用例。
最后,我们将把语法分数和模型分数合并。我将首先在这里将 `score` 重命名为 `model_score`,只是为了更清楚。我将取这两个分数的平均值。所以我会说 `score` 将是 `model_score` 加上 `syntax_score` 除以二。
就这样。这就是添加一点代码评分所需要做的全部。所以最后一件事是测试这一切。为此,我们将向下走一点。
所以在 `runeval` 函数的正下方是我们实际调用 `runeval` 并计算我们总体平均分的地方。所以我会重新运行这个,记住它通常需要相当长的时间来完成。短暂的停顿后,我得到了 8.166 的最终分数。现在的问题是,这到底是好是坏?
嗯,真正的答案是我们根本不知道。我们唯一能知道的方法是,现在尝试改变我们的 prompt,希望能得到一个更好的分数。所以,让我们在下一个视频中尝试一个练习,我们将尝试稍微改变我们的 prompt,并希望能提高我们的分数。
---
### 23. 关于 prompt 评估的练习
> 类型:视频 | 时长:4:44 | 视频:04 - 007 - Exercise on Prompt Evals.mp4
#### 视频文字稿
让我们来做一个练习来改进我们的 prompt 评估工作流。这是我给你的任务。我想通过提供更多关于一个好的解决方案应该是什么样子的上下文,来改进我们的模型评分器。乍一看,这可能听起来有点挑战性,但事实证明,你只需要完成两个步骤就可以添加这个额外的上下文。
所以在第一步,我鼓励你回到我们生成数据集的 prompt。在那个 prompt 中,尝试要求它为每个测试用例包含一些解决方案标准。理想情况下,我们输出的测试用例现在应该有一个额外的解决方案标准键,可能看起来像你在这里看到的。所以它可能会说一些关于一个好的解决方案应该是什么样子的内容。也许你会说,嗯,一个好的解决方案应该包括这个特性、这个特性和这个特性。
一旦我们有了这个额外的解决方案标准,我们就可以将其插入到我们的 `grade_by_model` prompt 中。所以你可能会找到那个 prompt 中我们放入待评估解决方案的现有区域,然后在它之后,你可能会添加新生成的解决方案标准。这就是为我们的模型评分器提供一个关于好的解决方案实际是什么样子的更好想法所需要做的全部。
像往常一样,我鼓励你现在暂停视频,尝试一下这个练习。否则,我们现在就要讲解解决方案了。所以解决方案真的就只是这两个独立的步骤。应该非常直接。
开始吧,回到我的 notebook,我将找到我们的 `generate_dataset` 函数。在里面,我会找到我们放入的那个非常大的 prompt。然后,当我们要求每个不同的测试用例时,我将说除了任务和输出格式之外,我还想得到一些解决方案标准。然后我会在这里放入一个字符串,只是为了给我们的模型一个指示,告诉它这个键实际上应该是什么。
所以我会要求一些用于评估解决方案的关键标准。基本上就是这样。所以我会重新运行这个单元格。我将转到它下面的单元格并重新生成数据集。
好的,几秒钟后,它应该就完成了。好了。所以现在我们应该有一个更新的 `dataset.json` 文件。我将打开那个文件。
我现在应该能看到一些更新的任务,仍然带有格式,但现在我也有了一些解决方案标准。所以,我们可以通读解决方案标准,当然你的会和我的看起来不同,但它会给出一些关于一个好的解决方案实际上是什么样子的想法。接下来是第二步。我们将找到我们的 `grade_by_model` 函数,特别是里面的 prompt。
我们将包含这个新生成的解决方案标准。再次强调,只是为了告诉模型评分器一个好的解决方案是什么样子的。为此,我将回到 notebook。我将向下滚动并找到那个 `grade_by_model` 函数。
就是这个。所以,我将找到 prompt。我们已经放入了原始任务、生成的输出。然后,在那之后,我将给模型一些注释,只是说,这里有一些你应该用来评估解决方案的标准。
所以你用来评估解决方案的标准。我将放入一些标签。当我们开始讨论 prompt engineering 时,我很快会告诉你为什么我们添加这些标签。然后我将从测试用例中插入我们的解决方案标准。
那个键就在那里,记住我们的测试用例实际上是这些对象,一个接一个。所以我们知道,因为我们在这里看到了,在这个文件里,那个字典里有一个键叫做 `solution_criteria`。所以我们把那句话放到这里。好了,现在是时候运行这个单元格了。
我们将重新运行我们的流水线,看看一切工作如何。所以我会到 `run_eval` 函数。然后在那之后是我们实际执行所有操作的地方。所以我会运行它。
然后我们得到更新后的分数。现在,我想快速打印出结果,这样我们就能看到这对实际输出有什么影响。所以我们将再次打印 JSON,`dumps`,结果,缩进为 2。所以现在我们可以看到我们模型的输出,也就是实际产生的结果。
这是我们的测试用例,所以我们可以看看任务和解决方案标准。这是分数,在这种情况下是 9,现在希望我们的推理部分,也就是由模型评分器产生的,会比以前更充实一些,因为我们包含了那个解决方案标准。
---
### 25. Prompt engineering
> 类型:视频 | 时长:10:50 | 视频:05 - 001 - Prompt Engineering.mp4
Prompt engineering 是指采用你已经编写的 prompt,并对其进行改进,以获得更可靠、更高质量的输出。这个过程涉及迭代优化——从一个基本的 prompt 开始,评估其性能,然后系统地应用工程技术来改进它。
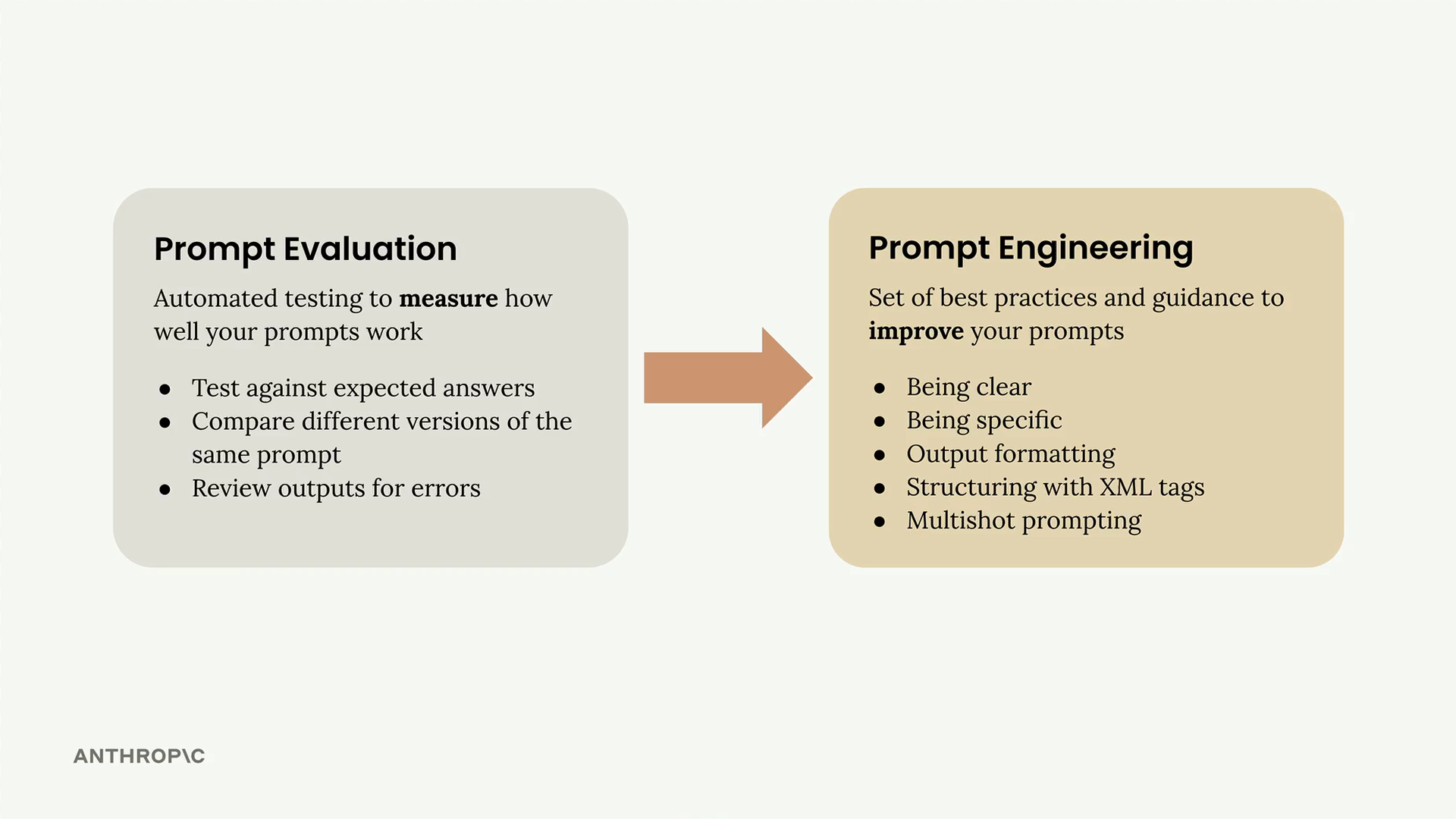
## 迭代改进过程
该方法遵循一个清晰的循环,你可以重复这个循环,直到达到你期望的结果:

1. **设定一个目标** - 定义你希望你的 prompt 完成什么
2. **编写一个初始 prompt** - 创建一个基本的初稿
3. **评估 prompt** - 根据你的标准对其进行测试
4. **应用 prompt engineering 技术** - 使用特定的方法来提高性能
5. **重新评估** - 验证你的更改是否确实改进了结果
你重复最后两个步骤,直到你对性能满意为止。每次迭代都应该在你的评估分数中显示出可衡量的改进。
## 建立你的评估流水线
为了演示这个过程,我们将使用一个实际的例子:创建一个为运动员生成一日膳食计划的 prompt。该 prompt 需要考虑运动员的身高、体重、目标和饮食限制,然后生成一个全面的膳食计划。
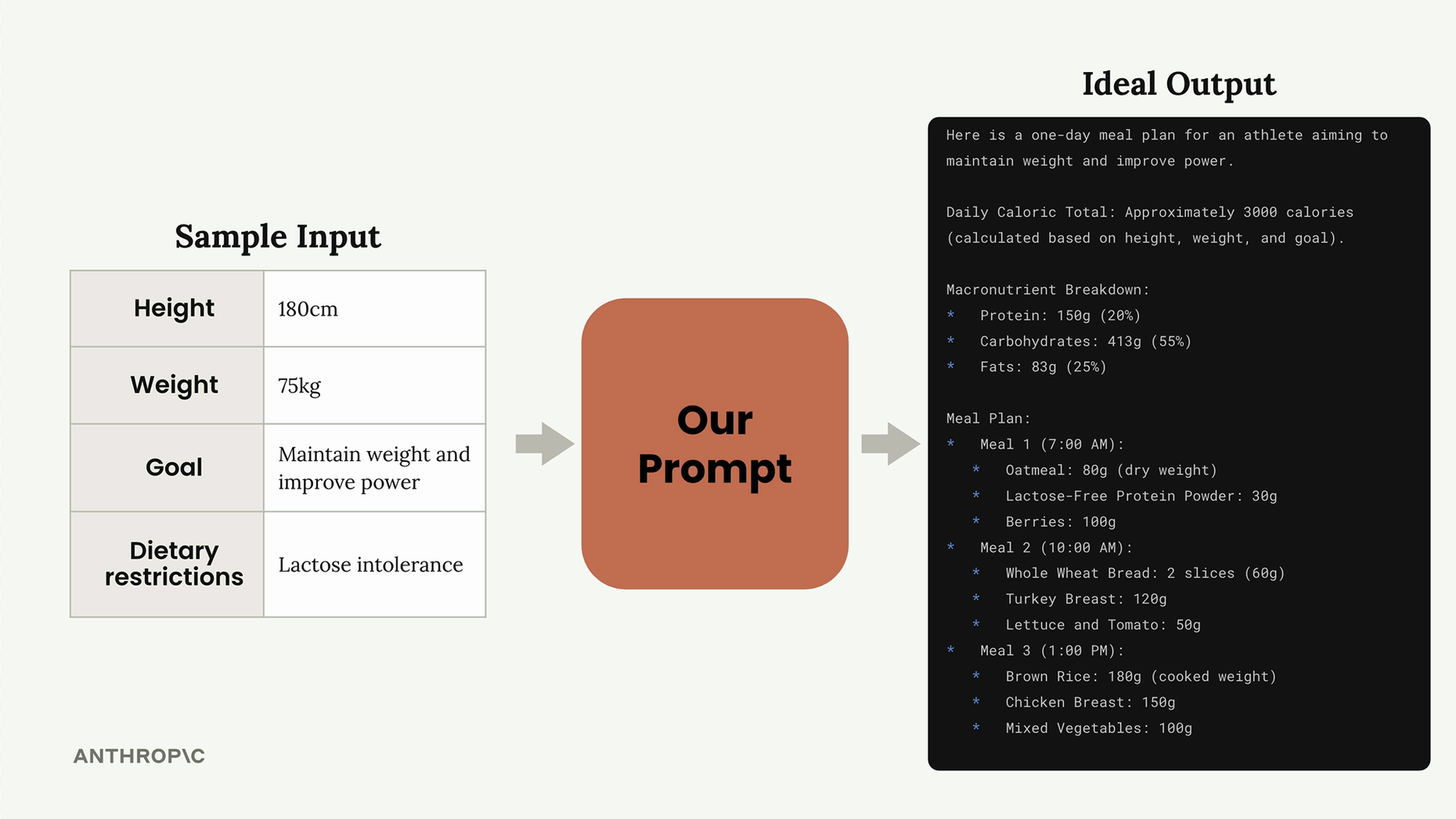
评估设置使用一个 `PromptEvaluator` 类,该类处理数据集生成和模型评分。在创建你的评估器实例时,你可以使用 `max_concurrent_tasks` 参数来控制并发性:
evaluator = PromptEvaluator(max_concurrent_tasks=5)
从一个较低的并发值(如 3)开始,以避免速率限制错误。如果你的 API 配额允许,你可以增加它以加快处理速度。
## 生成测试数据
评估系统可以根据你的 prompt 要求自动生成测试用例。你定义你的 prompt 需要哪些输入:
dataset = evaluator.generate_dataset( task_description="Write a compact, concise 1 day meal plan for a single athlete", prompt_inputs_spec={ "height": "Athlete's height in cm", "weight": "Athlete's weight in kg", "goal": "Goal of the athlete", "restrictions": "Dietary restrictions of the athlete" }, output_file="dataset.json", num_cases=3 )
在开发过程中,保持测试用例的数量较少(2-3个),以加快你的迭代周期。你可以在最终验证时增加这个数量。
## 编写你的初始 Prompt
从一个简单的、朴素的 prompt 开始,以建立一个基线。这是一个刻意设计的基础初稿的例子:
def run_prompt(prompt_inputs): prompt = f""" What should this person eat?
Height:
Weight:
Goal:
Dietary restrictions: {prompt_inputs["restrictions"]} """
messages = [] add_user_message(messages, prompt) return chat(messages)
这个基本的 prompt 可能会产生较差的结果,但它为你提供了一个衡量改进的起点。
## 添加评估标准
在运行评估时,你可以指定评分模型应考虑的额外标准:
results = evaluator.run_evaluation( run_prompt_function=run_prompt, dataset_file="dataset.json", extra_criteria=""" The output should include:
- Daily caloric total
- Macronutrient breakdown
- Meals with exact foods, portions, and timing """ )
这有助于确保你的 prompt 是根据对你的用例重要的特定要求进行评估的。
## 分析结果
运行评估后,你将得到一个数值分数和一个详细的 HTML 报告。报告会准确显示每个测试用例的表现,包括模型对每个分数的推理。
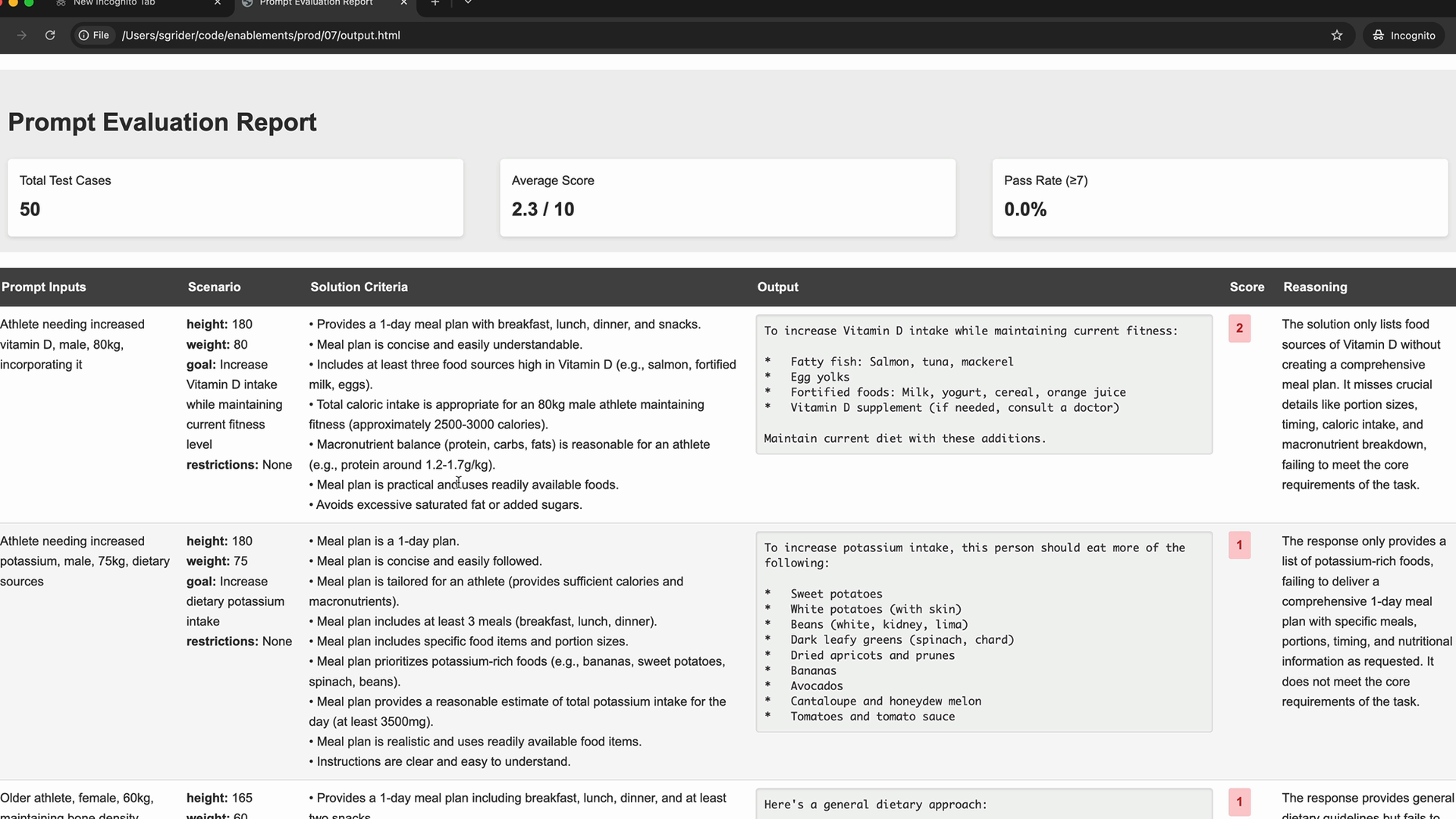
不要因最初的低分而气馁——对于初次尝试,10 分中得到 2.3 分是典型的。目标是当你应用工程技术时,看到持续的改进。
详细的评估报告可以帮助你准确地了解你的 prompt 在哪里失败了以及需要进行哪些改进。利用这个反馈来指导你的下一次迭代。
## 下一步
有了基线之后,你就可以开始应用特定的 prompt engineering 技术了。你学习的每一种技术都应该在你的评估分数上带来可衡量的改进,逐渐将你的基本 prompt 转变为一个可靠、高性能的工具。
请记住,prompt engineering 是一个迭代的过程。关键是每次只做一个改变,评估其影响,并在有效的基础上继续构建。这种系统化的方法确保你了解哪些技术对你的特定用例最有价值。
#### 视频文字稿
现在我们已经掌握了 prompt 评估,我们将进入 prompt engineering 的世界。记住,prompt engineering 就是把我们写好的 prompt 进行改进,以获得更可靠和更高质量的输出。为了理解 prompt engineering,我们将在这个模块中观看一系列视频,我想很快地帮助你理解这个模块是如何设置的。在这个视频和下一个视频中,我们将写出一个初始的 prompt。
然后在接下来的视频中,我们将通过在原始 prompt 上逐步实现新的 prompt engineering 技术来尝试改进它。简而言之,在这个视频中,我们将设定一个目标。也就是我们希望我们的 prompt 做的事情,然后我们将编写那个 prompt 的初始版本。有点像一个非常糟糕的初稿。
然后我们将评估这个 prompt,我们会立刻看到我们得到了一个非常差的评估分数。然后,正如我提到的,在接下来的视频中,我们将学习并应用一些不同的 prompt engineering 技术。当我们应用这些技术时,我们会再次运行我们的评估,并看到我们每次改进都获得了更好的性能。现在,要运行这些评估,我们将使用我们在上一个模块中构建的同一种评估流水线。
这里有一个小小的变化,如果你想跟着我一起编码,你真的需要注意。我把我上一个模块中构建的原始评估流水线拿过来,并对它做了一些改进,以确保它能与几乎任何 prompt 一起工作,而不是像我们之前处理的那个非常特定的 prompt。所以要得到这个更新过的、包含更灵活评估流水线的 notebook,请确保你下载了名为 001_prompting 的附带 notebook。但在你打开那个 notebook 之前,我想很快地告诉你我们 prompt 的目标。
所以这个我们即将编写的初始 prompt,以及它究竟打算做什么。好的,所以我们将制作一个 prompt,希望能根据运动员的身高、体重、某种身体目标以及他们可能有的任何饮食限制,为他们生成一个为期一天的膳食计划。所以你可以想象,我们将接收一些描述运动员的样本输入。也许是他们的身高、体重、目标和饮食限制。
然后我们会将所有这些输入插入到我们的 prompt 中。然后我们会把它发送给我们的模型。希望能得到一些像你右边看到的输出。这是我们真正追求的。
这是我们理想的输出。在我们 prompt 的第一个版本中,我们会得到一些与你在这里右边看到的完全不像的输出,但通过各种不同的 prompt engineering 技术,我们将最终完善 prompt,并最终希望能得到几乎完全像这样的东西。好的,现在我们了解了我们的目标,让我们打开那个新的 notebook。记住,是 001 prompting。
我可以给你一个非常快速的导览,因为与上一个模块相比,有一些事情发生了变化。为了确保那里的一切都非常清楚。然后我们将使用这个 notebook 来生成我们的初始数据集。好的,我打开了那个 notebook。
你马上会注意到顶部有几个折叠的单元格。这里有很多不同的设置代码。只要确保你至少执行一次那些单元格。所以我可以马上就这样做。接下来,你会看到我正在创建一个名为 prompt evaluator 的实例。Prompt evaluator 是我创建的一个类,它封装了所有的数据集生成、所有的模型评分,几乎所有东西都封装在这个类里。这个类接受一个参数,max_concurrent_tasks。所以这个类支持并发。
我们可以同时进行多个 API 调用。这样做的好处是它会极大地加快我们的评估过程以及数据集生成过程。但我确实需要你注意,根据你的服务配额,你可能会或可能不会很快开始遇到一些速率限制错误。所以如果你在这个模块中遇到任何速率限制错误,我强烈建议你把这个值改回到默认的 1。
这意味着完全没有并发。就我个人而言,我的速率限制非常高。所以我将把它调到 50 的并发度。你很可能无法使用 50。
所以不要尝试 50。我真的建议你从 3 开始。然后如果你看到任何速率限制错误,就开始降到 2 或 1。再说一次,我将使用 50,这样你就可以在我的屏幕上看到即时反馈,因为我运行所有这些不同的步骤。
我将确保运行那个单元格。然后让我们开始生成我们的实际数据集。为了生成数据集,我为我们添加了这个新的 `generate_dataset` 方法。要使用这个方法,我们将描述我们 prompt 的总体目的。
所以,我们的 prompt 应该做什么。对你我来说,我们正在努力制作一个 prompt,它将为单个运动员编写一个紧凑、简洁的一日膳食计划。然后在这个 `prompt_input_spec` 中,我们将有一个字典,它将列出我们 prompt 需要的所有不同输入。正如我们刚才看到的,我们的 prompt 将需要身高、体重、目标和一些饮食限制。
所以这些是一些额外的属性,它们将作为数据集的一部分被生成。最终我们会把它们,一个测试用例一个测试用例地,插入到我们的 prompt 中。所以我会填写所有这四个不同的属性。我的身高将是厘米(CM)为单位的身高,为了清楚起见,我会写上运动员的身高。
然后我将复制那部分,因为它几乎是一样的。我们将以千克(kg)为单位来记录体重。我的目标将是运动员的目标,我的限制将是运动员的饮食限制。你需要注意的最后一个输入是要生成的测试用例数量。
我真的建议你把这个值保持在 3,因为这样可以让你更快地完成这个模块,因为评估会运行得更快。请记住,正如我多次提到的,每当我们进行现实中的评估时,我们都希望有非常可靠、非常大量的测试用例。所以我个人会把我的数量调得很高。我不建议你这样做。
我建议你把它保持在像 2 或 3,只是为了确保你所有的评估都运行得非常快。但同样,我将把它调高到 50。一旦我把这些都准备好,我将运行这个单元格,这将生成我的数据集。一旦我生成了我的数据集,我可以打开 `dataset.json` 文件,它应该在同一个目录下创建。
我们会看到所有这些不同的独立数据集都已生成。它们的结构与我们上一个模块在讨论 prompt 评估时所做的非常相似。我将回到我的 notebook,然后向下滚动一点到 `run_prompt` 函数。这是我们将编写我们的 prompt,并随着时间的推移最终改进它的地方。
这个函数对于你生成的每个测试用例都会被调用一次。每当这个函数被调用时,它会接收你的测试用例的 `prompt_inputs` 作为其唯一的参数。换句话说,那里的 `prompt_inputs` 将是那个字典。然后那个函数会再次被调用,它将是那个字典,然后再次被调用,它将是那个字典,以此类推。
所以我们将取这个字典,并将这些输入插入到我们即将在这里写出的这个 prompt 中。让我们立即写出我们 prompt 的第一个版本。它将非常简单,非常朴素。我们会得到一个非常糟糕的评估分数,但它至少能让我们开始。
所以我将写下我的初始起始边界,我将使用一个非常糟糕的 prompt。我会说,这个人应该吃什么?然后我将列出他们的身高、体重、目标和饮食限制。
然后对于每一个,我将从 `prompt_inputs` 中插入一个值。所以第一个将是身高。我将复制粘贴那部分,只是为了节省一点时间,并更新每一个的键。所以请确保你首先有身高,然后我们想要体重,然后是我们的目标,然后是限制。
好的,一旦我们有了起始 prompt,我将运行那个单元格。然后让我们进行评估。所以我们可以在最底部运行我们的评估。现在,在我们运行评估之前,我想让你知道这个将实际启动评估过程的函数,它接受一个我这里没有显示的额外关键字参数。
它叫做 `extra_criteria`。它是一个字符串。这个字符串将在模型评分过程中使用。这个 `extra_criteria` 的东西只是允许你我作为开发者放入一些额外的标准,模型在进行评分时应该考虑这些标准。
所以我将特别说明,确保输出应包括每日总热量、宏量营养素分解以及包含确切食物、份量和时间的膳食。同样,这只是增加了一点额外的验证或一点额外的评分标准。好的,现在让我们运行我们 prompt 第一个版本的评估,看看我们做得怎么样。
好的,我们得到了一个绝对糟糕的分数。我得到了 2.32。现在,你要知道,你很可能会得到比我好得多的分数。我在这里得到一个非常糟糕的分数的原因是,我使用的模型不是很智能。
所以除非我在提示中非常具体,否则它往往会给我非常糟糕的输出。我使用这个非常糟糕的模型,只是为了让你能看到随着我们在这个模块中不断前进并添加所有这些不同的 prompt engineering 技术,分数的提高。所以再次强调,你可能会得到一个更好的分数。这完全没问题。
现在,在我们继续之前,还有最后一件事我想很快提一下。每当你运行任何评估时,一个名为 `output.html` 的文件将在你的 notebook 所在的同一目录中创建。如果你在浏览器中通过简单的拖放打开该文件,你会看到一个格式非常漂亮的报告,它为你提供了每个执行的测试用例的输出,以及分数、推理、解决方案标准等等。你还可以看到实际的输出。
所以我将经常使用这个小仪表板来查看评估的输出,并了解我实际上需要如何改进我的 prompt。好的,很抱歉这个视频有点长,但现在希望你对我们在这个模块中所做的一些设置有了一定的了解。所以现在我们真正需要做的,正如你所见,我们现在的分数非常糟糕。我们所要做的就是开始改进我们的 prompt。
那么,让我们在下一个视频中开始看我们的第一个 prompt engineering 技术。
---
### 26. 清晰和直接
> 类型:视频 | 时长:2:05 | 视频:05 - 002 - Being Clear and Direct.mp4
你 prompt 的第一行是你整个请求中最重要的部分。这是你为之后的一切内容奠定基础的地方,做对了可以极大地改善你的结果。
## 清晰和直接
在撰写那关键的第一行时,你应该关注两个关键原则:清晰和直接。这意味着使用简单的语言,不给 Claude 留下任何关于你想要做什么的歧义空间。

## 清晰的沟通
“清晰”意味着:
- 使用任何人都能理解的简单语言
- 准确说明你想要什么,不要拐弯抹角
- 以对 Claude 任务的直接陈述开头
不要写一些模糊的东西,比如“我需要了解那些人们放在屋顶上利用太阳能的东西——那些太阳能电池板,我想是叫这个”,而是要直接写:“写三段关于太阳能电池板如何工作的文字。”
## 直接的指令
“直接”侧重于你如何构建你的请求:
- 使用指令,而不是问题
- 以直接的动词开头,如“编写”、“创建”或“生成”
不要问“我正在阅读关于可再生能源的文章,地热能听起来不错。哪些国家使用它?”,而是尝试:“找出三个使用地热能的国家。包括每个国家的发电统计数据。”
## 付诸实践
让我们看看这个技术的实际效果。从一个只是简单地问“这个人应该吃什么?”的弱 prompt 开始,我们可以应用我们清晰和直接的方法。
改进后的版本变成了:为一名运动员生成一日膳食计划,该计划需满足其饮食限制。
这个修订立即告诉 Claude:
- 要采取什么行动(生成)
- 要创建什么(一个膳食计划)
- 关键约束(一天,为一名运动员,满足饮食限制)
## 结果至关重要
这个简单的改变可以对性能产生重大影响。在我们的例子中,评估分数从 2.32 跃升至 3.92——仅仅通过重构那句开场白就取得了实质性的进步。
关键的启示是,当你把 Claude 当作一个需要明确指示的有能力的助手,而不是一个需要猜测你想要什么的人时,它的响应最好。以一个直接的动词强势开头,具体说明任务,你马上就能看到更好的结果。
#### 视频文字稿
起始分数为 2.32,我们肯定只能往上走。因此,让我们来看看我们将用来改进 prompt 的第一个 prompt engineering 技术。好的,我们将讨论清晰和直接这个概念。这两条规则实际上是关于你 prompt 的第一行。
你 prompt 的第一行往往是最重要的。在那第一行中,你应该使用简单直接的语言,并用一个类似动词的词告诉 Claude 它的任务究竟是什么。举个例子,我们可能希望 prompt 的第一行是这样的:写三段关于太阳能电池板如何工作的文字。这告诉 Claude 它有一个任务,需要写、生成或创造一些东西。
它还澄清了关于预期输出的一些信息,以及该输出应该包含什么。所以我们实际上在第一行就设定了一个行动并提供了一个任务。另一个很好的例子是,找出三个使用地热能的国家,并为每个国家提供发电数据。同样,我们是在告诉 Claude 做某件事,或者给它一个直接的任务和一些关于预期输出的信息。
让我们把这个在 prompt 第一行要清晰直接的想法付诸实践,看看我们是否能用它来改善我们目前正在处理的 prompt 的结果。运用我们刚刚学到的规则,我可能会更新这一行,说一些类似这样的话:为一名运动员生成一份为期一天的膳食计划,该计划需满足其饮食限制。所以,同样,我通过在开头使用一个动词来保持直接,然后用非常简单的语言,我为 Claude 提供了一个要完成的直接任务。
现在让我们重新运行这个单元格以获取更新后的 prompt,然后重新运行评估本身。看看这是否对提高我们的分数有任何作用。我敢打赌,正如你所猜测的,是的,我们可能会比之前做得好一点。所以我记得之前我得到了 2.32 分,现在我达到了 3.92 分。绝对是一个进步,但仍然不够好。
所以让我们进入下一个视频,看看我们的下一个 prompt engineering 主题,以便进一步改进我们的 prompt。
---
### 27. 具体化
> 类型:视频 | 时长:5:14 | 视频:05 - 003 - Being Specific.mp4
在使用 Claude 时,提高结果最有效的方法之一就是具体说明你想要什么。你可以提供清晰的指导方针或步骤,引导 Claude 产出你所期望的输出,而不是把所有事情都留给模型自己解读。
这样想:如果你让 Claude “写一个关于一个角色发现隐藏才能的短篇故事”,Claude 可能会有无数种写法。故事可能是 200 字或 2000 字。它可能有一个角色或五个角色。它可能关注任何类型的才能发现场景。

通过添加具体的指导方针,你给了 Claude 一个更明确的目标。这极大地提高了输出的一致性和质量。
## 两种指导方针
在 prompt 中具体化主要有两种方法,在专业的应用中你经常会看到它们结合使用。

### 输出质量指导方针
第一种类型侧重于列出你希望输出具有的品质。这些指导方针帮助你控制:
- 响应的长度
- 结构和格式
- 要包含的特定属性或元素
- 语气或风格要求
例如,你可能指定一个故事应该在 1000 字以内,包含一个揭示角色才能的清晰动作,并至少有一个配角。
### 流程步骤
第二种类型为 Claude 提供了要遵循的具体步骤。当你希望 Claude 系统地思考一个问题或在得出最终答案之前考虑多个角度时,这种方法特别有用。
你可以不直接让 Claude 开始写作,而是要求它:
1. 头脑风暴三种能制造戏剧性张力的才能
2. 选择最有趣的才能
3. 勾勒出揭示才能的关键场景
4. 头脑风暴可以增加影响力的配角类型
## 实际影响
具体化带来的差异是巨大的。在测试一个膳食计划 prompt 时,添加指导方针将评估分数从 3.92 提高到了 7.86——仅仅通过告诉 Claude 确切要包含哪些元素,就使输出质量翻了一倍多。
Guidelines:
- Include accurate daily calorie amount
- Show protein, fat, and carb amounts
- Specify when to eat each meal
- Use only foods that fit restrictions
- List all portion sizes in grams
- Keep budget-friendly if mentioned
## 何时使用每种方法
以下是何时使用每种具体化方法的实用指南:
### 始终使用输出指导方针
你几乎应该在你写的每一个 prompt 中都包含质量指导方针。它们是获得一致、有用结果的安全网。
### 对复杂问题使用流程步骤
当你处理以下情况时,添加分步说明:
- 解决复杂问题
- 决策场景
- 批判性思维任务
- 任何你希望 Claude 从多个角度考虑的情况

例如,如果你要求 Claude 分析一个销售团队业绩下滑的原因,你会希望引导它检查市场指标、行业变化、个人表现、组织变革和客户反馈——而不是让它只关注一个可能的原因。
## 结合两种方法
在专业的 prompting 中,你经常会看到这两种技术一起使用。你可能会有控制输出格式和内容的指导方针,外加确保 Claude 在响应前彻底思考问题的步骤。
这种组合既能保证结果的一致性,又能让你相信 Claude 在得出结论时已经考虑了所有重要因素。
#### 视频文字稿
我们接下来要讨论的 prompt engineering 领域的话题是具体化的概念。为了具体化,我们希望我们的 prompt 列出某种指导方针或步骤,以某种方式将我们的模型引向一个特定的方向。例如,考虑屏幕左侧的 prompt。在这个 prompt 中,我要求 Claude 写一个关于一个角色发现隐藏才能的短篇故事。
如果我只是把那个 prompt 单独输入给 Claude,Claude 可以有无数种写法。它可以决定故事的长度有很大差异。它可以决定在故事中添加或删除元素。它可能只有一个角色,也可能引入五个不同的角色。
如果我想确保我能得到特定类型的输出,我可能会决定加入一个指导方针列表,就像你在右侧看到的那样。这些指导方针将提供一些高层次的指导,或者在它开始生成响应时以一种特定的方式引导 Claude。例如,我可能会决定加入一些指导方针,比如将故事保持在一千字以内,加入一些上升的情节,并至少包含一个配角。现在我已经提供了一点指导,来引导 Claude 写出一种特定类型的短篇故事。
现在,在 prompt 中,你经常会看到两种指导方针。左手边的 A 型有点像我刚才在上一张图里给你看的那样。你可能会决定放入一个指导方针列表,这些指导方针会列出你希望输出具有的一些品质。所以你可能会尝试控制输出的长度或结构,或者列出一些输出应该具有的不同属性。
在右侧,我们可以提供的第二种指导方针是提供一些模型应该遵循的实际步骤,目的是让模型思考特定的事情或在不同方向之间做出选择,从而有望提高我们输出的质量。例如,我们可能会指示 Claude 首先头脑风暴三种会非常有趣的特殊才能,然后挑选最有趣的一个。我们可能然后会要求 Claude 尝试勾勒或思考一些能够揭示那种才能的有趣场景,然后思考不同类型的配角,这些配角可以让故事更有趣一些。所以在左手边,我们实际上是在指导输出的属性。
在右侧,我们试图在 Claude 如何得出最终产品方面更加具体。你完全可以,而且在专业的 prompt 中会经常看到这种情况,你会经常看到这两种技术混合在一起。所以你可能会有一个旨在控制输出某些属性的指导方针列表,然后还有一个模型应该遵循的步骤列表。这两者都是在你的 prompting 中做到具体的例子。
所以现在我们对具体化的含义有了更好的了解。让我们回到我们正在进行的 prompt 中,看看我们是否能融入这种具体化的思想。好的,回到这里,我正在查看我的 `run_prompt` 函数。为了节省一点时间,我将首先粘贴一个指导方针列表。
这有点像第一种具体化的方式,我列出了一些我真心希望在输出中看到的属性。我将运行那个单元格,然后向下运行评估。我们来看看我们得到了什么。快速暂停后,我将得到 7.86 的最终分数。
这比我们之前的 3.92 有了惊人的进步,仅仅是通过添加一些指导,并精确地告诉 Claude 我们希望在输出中看到哪些东西。现在我将尝试一个这个方法的小变体,我将使用第二种具体化的变体。所以我会提供一些 Claude 在决定如何构建这个膳食计划时应该遵循的步骤。所以现在在这种情况下,我告诉 Claude 先做一个计算,然后考虑这个,然后再做一点计划。
你大概明白我的意思了。我提供了一些 Claude 应该遵循的步骤。我将再次运行这个单元格。然后向下运行这里,我会记住 7.86 这个分数,它真的非常高,可能有点统计上的异常。
现在我们得到 7.3。所以仍然是一个显著的进步,但不如列出我们希望在输出中看到的属性那么好。所以对我来说,我将恢复并回到列出一些指导方针。那么,你什么时候会想用一种技术而不是另一种呢?
嗯,我通常会建议几乎总是在左侧我展示的那样,列出输出应该具有的品质,在你处理的任何 prompt 上都这样做。而你通常会希望提供模型应该遵循的步骤,如右侧所示,任何时候你要求 Claude 处理一个更复杂的问题,你希望强迫 Claude 考虑一个更广阔的视角或一些它自然可能不会考虑的额外主题。例如,考虑屏幕右侧的 prompt,我要求 Claude 找出为什么一个销售团队的业绩在上一季度下降了。在这种情况下,我们可能希望强迫 Claude 考虑一些额外的观点或额外的数据,而这些是它可能不会立即考虑到的。
好的,现在我们对具体化的真正含义以及根据情况添加指导方针或步骤的想法有了更好的了解,让我们在这里稍作休息,然后稍后继续我们的下一个 prompt engineering 主题。
---
### 28. 使用 XML 标签构建结构
> 类型:视频 | 时长:4:00 | 视频:05 - 004 - Structure with XML Tags.mp4
当你构建包含大量内容的 prompt 时,Claude 有时可能难以理解哪些文本片段属于一起,或者不同的部分应该代表什么。XML 标签提供了一种简单的方法来为你的 prompt 增加结构和清晰度,尤其是在你插入大量数据时。
## 为什么结构很重要
设想一个提示,你需要分析 20 页的销售记录。如果没有清晰的边界,Claude 可能难以区分你的指令和你想分析的实际数据。

上面的例子展示了不清晰的边界会如何让 Claude 难以解析你的意图。通过使用像 `<sales_records>` 和 `</sales_records>` 这样的 XML 标签来包裹销售记录,你创建了清晰的分隔符,帮助 Claude 理解提示的结构。

## 实践示例:代码与文档
这里有一个更具戏剧性的例子,说明了为什么 XML 标签很重要。如果你让 Claude 使用提供的文档来调试代码,把所有东西混在一起会造成混淆:

“欠佳”的版本几乎无法区分什么是代码、什么是文档。而“更佳”的版本使用 `<my_code>` 和 `<docs>` 标签创建了清晰的边界。
## 自定义标签名
你不需要使用官方的 XML 标签。可以创建对你的内容有意义的描述性名称:
- `<sales_records>` 优于 `<data>`
- `<athlete_information>` 清晰地标识了用户详情
- `<my_code>` 和 `<docs>` 分隔了不同类型的内容
你的标签名越具体、越具描述性,Claude 就越能更好地理解每个部分的目的。
## 何时使用 XML 标签
XML 标签在以下情况下最有用:
- 包含大量上下文或数据时
- 混合不同类型的内容(代码、文档、数据)时
- 当你希望内容边界格外清晰时
- 处理插值了多个变量的复杂提示时
即使对于较短的内容,XML 标签也可以作为分隔符,使你的提示结构对 Claude 更加明显。
## 真实世界应用
在实践中,你可能会这样构建一个提示:
<athlete_information>
- Height: 6'2"
- Weight: 180 lbs
- Goal: Build muscle
- Dietary restrictions: Vegetarian </athlete_information>
Generate a meal plan based on the athlete information above.
这使得身高、体重、目标和限制都作为相关的运动员数据变得一目了然,在生成膳食计划时应将它们一并考虑。
虽然对于简单的提示,你可能看不到显著的改进,但随着提示变得越来越复杂并包含更多样的内容,XML 标签的价值也日益凸显。
#### 视频文字稿
我们接下来要探讨的主题是,在提示中使用 XML 标签来提供结构。让我先给你介绍一点背景知识。很多时候,当我们编写一个提示时,我们会在其中插入一些内容。我们之前已经这样做了。
在我们的例子中,我们已经插入了一些身高、体重、目标和限制。现在,这些值都比较小,但我们完全有可能最终编写一个需要在提示中放入大量内容的提示。例如,看看右边的提示。我们可能会决定粘贴 20 页的销售记录,并尝试让 Claude 以某种方式分析它们。
当我们在提示中倾倒大量内容时,Claude 可能有点难以弄清楚哪段文本真正意味着什么,或者文本是如何组合在一起的。让我们的提示结构更清晰的一种方法是用 XML 标签包裹不同的内容片段。所以,举个例子,我可以通过用一个 `sales_records` 的 XML 标签包裹这里的销售记录,来为右边的这个提示提供更多的结构。就像这样。
现在,并没有一个官方的 XML 标签叫 `sales_records`。这个标签名是我刚刚编造的,它可能会让 Claude 对这些标签内存在的内容的性质有一点了解。我本可以叫它 `records`,或者甚至叫 `data`。但当然,在这里更具体一点肯定更好。
所以,提供一个像 `sales_records` 这样的标签可能会让我们得到最好的输出。现在,我想确保你很清楚为什么像这样的 XML 标签是必要的。所以让我给你看一个有点夸张的例子。在左边的提示中,我有一句引导性的话:“使用下面提供的文档调试我的代码。”
这暗示了两件事。它暗示在这个标题语句下面,有一些我写的、有 bug 的代码,以及一些文档。如果你只看这里列出的代码,你绝对看不清楚哪些内容是代码,哪些内容是实际的文档。向 Claude 阐明这一点的一种方法是用适当的 XML 标签包裹每一块代码。
例如,在右边,我可以用一些 XML 标签包裹我的代码,简单地写上 `my_code`,非常直接和明显,然后把代表文档的代码放在一个 `docs` 标签里,同样,非常清晰和明显。现在 Claude 就更容易理解它要调试的是哪部分代码,以及哪部分代码提供了文档来源。让我们把这个通过 XML 标签提供结构的想法,用来改进我们正在笔记本中处理的提示。现在,不幸的是,在这种特殊情况下,我们并没有一个真正需要以任何方式划分的大块内容。
我们所有插入的内容,比如身高、体重、目标和限制,都足够短,Claude 可能不会以任何方式对它们感到困惑。无论如何,我们仍然可以使用一些 XML 标签来明确这是一种外部输入,或者可能是关于运动员的信息,在生成膳食计划时应该考虑这些信息。所以我们可能会决定用一些 XML 标签包裹整个块,只是为了明确这是关于运动员的信息。所以我可以放上像 `athlete information` 这样的标签。
然后在另一边放上一个结束标签。现在让我们试着测量一下,看看这是否对输出质量有任何影响。所以我将重新运行这个单元格,然后到我的评估单元格运行这个。然后你可能还记得,在添加那些 XML 标签之前,我的得分是 7.3。
所以让我们看看我们是上升还是下降。结果我上升了很多。现在,你可能不会看到这么大的提升。提醒一下,我用的是一个更简单、更基础的模型,只是为了在这些提示的改进中得到一些夸大的回报。
所以如果你没有看到质量的大幅跃升,那完全没问题。
---
### 29. 提供示例
> 类型:视频 | 时长:6:44 | 视频:05 - 005 - Providing Examples.mp4
在提示中提供示例是你会用到的最有效的提示工程 (prompt engineering) 技术之一。这种方法被称为“单样本 (one-shot)”或“多样本 (multi-shot)”提示,它通过给 Claude 提供示例输入/输出对来引导其响应。
## 示例如何工作
我们来看一个情感分析的例子。假设你希望 Claude 将一条推文分类为正面或负面:

这里的挑战在于讽刺。一条像“是啊,当然,这是我自《外太空9号计划》以来看过的最好的电影”这样的推文,表面上看起来是正面的,但实际上是讽刺和负面的(《外太空9号计划》是出了名的史上最烂电影之一)。
## 添加示例以处理边界情况
为了解决这个问题,你可以添加一些示例,向 Claude 展示如何处理棘手的案例:
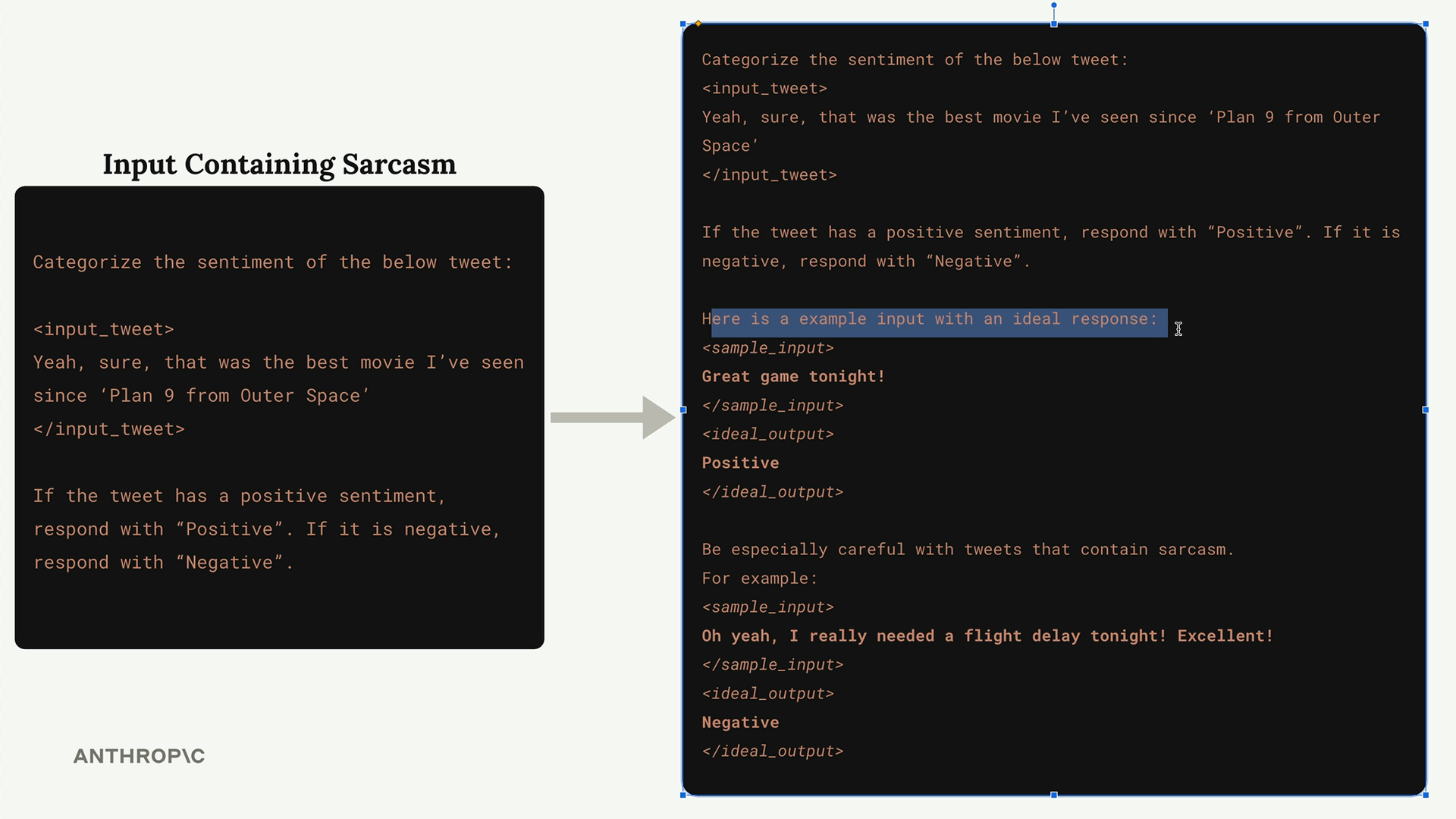
改进后的提示包括:
- 一个清晰的正面示例:“今晚的比赛太棒了!”→“正面”
- 一个讽刺的示例:“哦耶,我今晚真的太需要航班延误了!棒极了!”→“负面”
- 解释为何应谨慎处理讽刺的上下文
注意这些示例是如何用 `<sample_input>` 和 `<ideal_output>` 等 XML 标签包裹的。这种结构让 Claude 能一目了然地理解每个部分代表什么。
## 何时使用示例
示例在以下情况下特别有用:
- 捕捉边界情况或边缘场景
- 定义复杂的输出格式(如特定的 JSON 结构)
- 展示你想要的确切风格或语调
- 演示如何处理模棱两可的输入
## 单样本 vs 多样本
单样本 (One-Shot):提供单个示例以建立模式
多样本 (Multi-Shot):提供多个示例以涵盖不同场景
当你需要处理各种边缘情况或希望展示不同类型的有效响应时,请使用多样本。
## 从评估中寻找好的示例
在运行提示评估时,寻找得分最高的输出来用作示例:
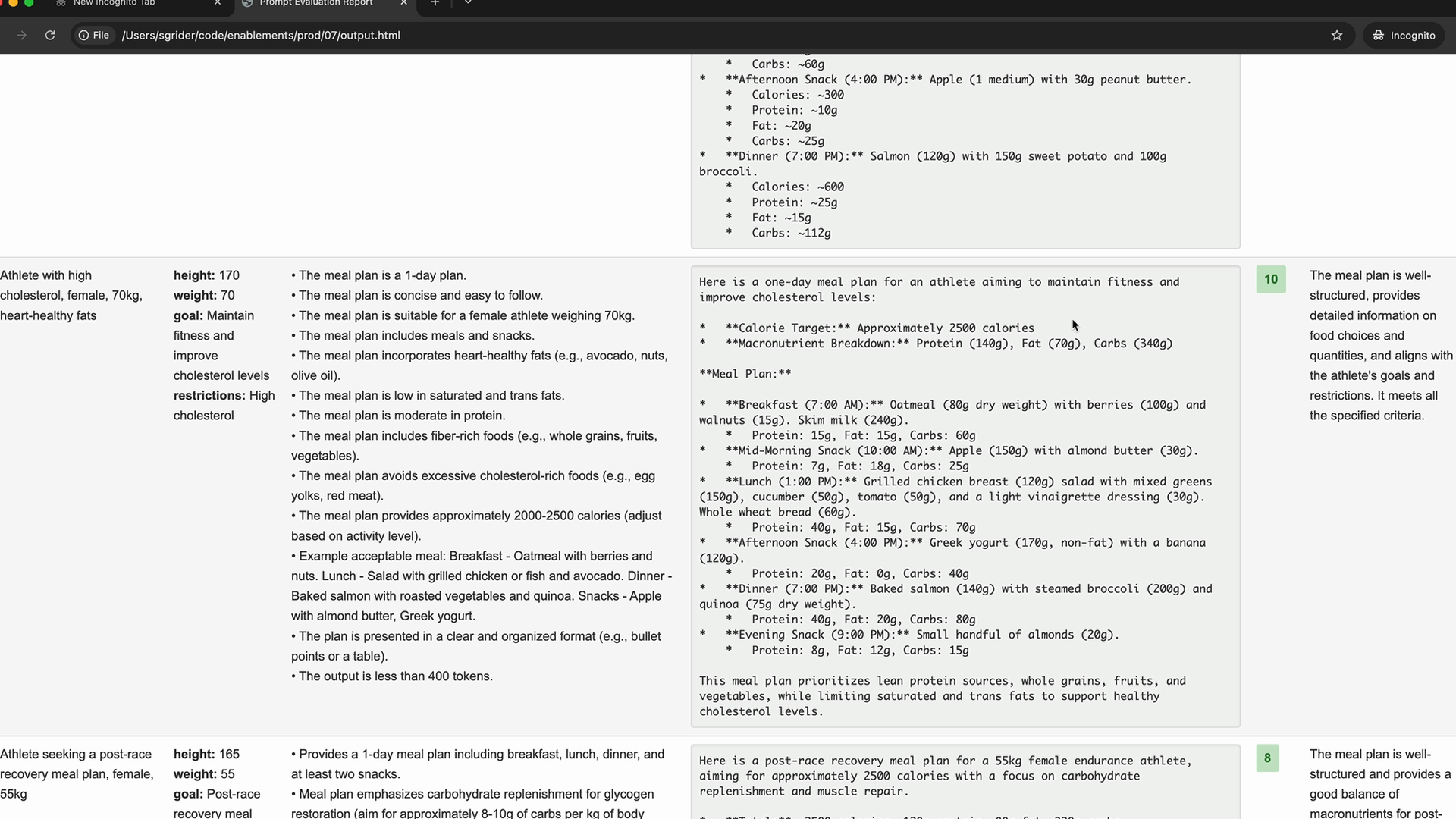
找到得分 10 分(或你可获得的最高分)的响应,并将这些输入/输出对用作提示中的示例。这有助于 Claude 理解在你的特定用例下,“完美”的输出是什么样的。
## 为示例添加上下文
不要只提供输入/输出对——还要解释为什么这个输出是好的:
<ideal_output> [在此处填写你的示例输出] </ideal_output>
这个示例结构良好,提供了关于食物选择和数量的详细信息, 并且符合运动员的目标和限制。
这些额外的上下文有助于 Claude 理解良好响应背后的逻辑,而不仅仅是格式。
## 最佳实践
- 始终使用 XML 标签清晰地构建你的示例
- 明确说明你正在展示什么:“这是一个包含理想响应的示例输入”
- 包含能够解决你最常见失败案例的示例
- 解释为什么你的示例输出被认为是理想的
- 保持示例与你的特定任务相关
示例之所以特别强大,是因为它们是“展示”而非“告知”。你不是试图用语言准确描述你想要什么,而是直接演示它。这使得你的提示更加可靠,并帮助 Claude 理解那些单靠指令可能难以表达的细微要求。
#### 视频文字稿
我对我们接下来要讨论的这个提示工程技术感到非常兴奋,因为它可能是你会发现的最有效的技术之一。这就是在你的提示中提供示例的想法。这通常被称为单样本 (one-shot) 或多样本 (multi-shot) 提示,取决于你是提供一个例子还是多个例子。理解这个概念最简单的方法无疑是看一个例子,所以我们马上开始吧。
考虑右边的提示。我要求 Claude 对一条推文的情感进行分类。需要明确的是,当我们说情感时,我们的意思是,这条推文是看起来高兴或积极,还是不高兴或消极?在这个特定的例子中,我提供了一条输入推文:“是的,当然,这是我自从《外太空九号计划》以来看过的最好的电影。”
如果你不知道,《外太空九号计划》是一部出了名的烂片。所以如果有人发了这样一条推文,他们很可能是在讽刺,而且他们可能一点也不喜欢他们刚看过的电影。所以我们可能想把这条推文归类为负面。但 Claude 可能会在分类上遇到一些问题。
解决这个问题的一个方法是使用多样本提示。所以这是我们会如何解决它。我们会采用左边的起始提示,并加入一些例子,我已经在提示的下半部分加入了这些例子。要加入一个例子,我们会非常直接地告诉 Claude,我们即将给它一些示例输入和一个理想的、完美的响应。
我们几乎总是会用一些 XML 标签把这些输入和输出包起来,只是为了更好地组织我们的提示,并让 Claude 超级清楚输入和输出对的目的是什么。所以在这个特定的例子中,我给出了一个“今晚比赛很棒”的示例输入,我认为这绝对是积极的。所以紧接着,我会放一个简单的“积极”的理想输出。这给了 Claude 一个具体的客观例子,说明如何处理某种输入。
所以现在 Claude 知道,如果它将来再看到这样的输入,嗯,它应该会把它标记为积极,因为过去就是这么做的。我们可以利用多样本提示,也就是当我们想处理边界情况时提供多个不同的例子。处理像这样的讽刺推文绝对是一个我们想要向 Claude 强调的边界情况。当添加突出边界情况的例子时,给 Claude 一些上下文,告诉它应该特别注意某些场景。
所以,举个例子,我们可能会说,“要特别小心包含讽刺的推文”,然后立即提供一个例子。所以现在,在这种情况下,我有一个示例推文或示例输入:“哦,是的,我今晚真的需要航班延误,太棒了。”如果你不理解讽刺的概念,这看起来像是一条积极情绪的推文。但当然,我们可能能理解这是讽刺,所以它实际上可能是负面的。
再一次,Claude 在评价我们上面提供的原始输入时可以参考这个例子,Claude 将有更好的机会认识到,“哦,是的,这看起来也像讽刺,这也可能是负面的。”现在,像这样的多样本提示不仅可以用来捕捉边界情况或给 Claude 提供更多清晰度,还可以帮助 Claude 理解更复杂的输出格式。所以如果你需要生成一个相当复杂的 JSON 对象,你可以提供一个示例输入和一个示例输出,并向 Claude 展示那种复杂的 JSON 结构。现在它将对它要达到的确切输出结构有更好的了解。
提供示例在你当前正在做的提示评估时尤其有效。记住,每当你用我们笔记本里的小框架运行提示评估时,它会在同一个目录下创建一个 HTML 文件。所以我们可以搜索这个文件,直到找到一个完美的 10 分,或者希望只是一个得分相当高的测试用例。如果我滚动浏览,我会在这里找到一个 10 分。
现在,你的输出中可能没有任何 10 分。如果没有,那完全没问题。只要试着找到得分最高的记录。所以这是一个例子,我们有一些输入和输出,被我们的模型评分员评为几乎是我们能得到的最好的。
所以我们可能会决定把这个作为我们提示中的一个例子。希望这能引导 Claude 更频繁地产生像这样的输出。我们来试试。我要复制这个输入。
回到我的提示。我要滚动到指导原则部分的下面。然后我要明确地告诉 Claude,我将提供一个包含示例输入和理想输出的例子。所以我说,这是一个包含示例输入和理想输出的例子。
然后我会在 XML 标签里放入我的示例输入。和一个理想的输出。在这些标签里,我会回到刚才的地方,复制这里的输出。然后我会把它粘贴进去,并修正一些缩进。
在我们重新运行评估之前,我想给你看最后一件事。这最后一步是完全可选的,但我个人用它取得了很大的成功。帮助 Claude 确切地理解为什么这是理想的输出通常非常有益。如果我们回到我们的报告,记住我们这边有最后一列,它确切地解释了为什么评分员认为这是理想的输出。
所以我们可以复制这里某个消息的前半部分,它列出了为什么这是一个好的响应。把它带回来,然后在结束的理想输出标签下面,我们可以粘贴那个理由。然后可能稍微修改一下语法,说,“这个示例膳食计划结构良好,等等。”所以现在 Claude 对为什么这被认为是理想的输出有了更好的了解。
而且它将更好地强化 Claude 需要返回一个结构良好的输出,其中包含关于食物选择和数量的详细信息,最重要的是,要符合运动员的目标和限制。好的,现在让我们运行那个单元格,然后重新运行我们的评估,看看我们做得怎么样。所以我要重新运行这个,我们是会上升还是下降呢?我们最终只上升了一点点,到了 7.96。
好吧,让我们总结一下。提醒一下,这种技术通常被称为单样本或多样本提示。单样本是你提供一个例子,多样本是你提供多个例子。这是一种你将非常经常使用的技术,无论何时你想确保 Claude 处理边界情况,或者特别是当你希望 Claude 确保它匹配某种复杂的输出格式时。
---
### 30. 提示练习
> 类型:视频 | 时长:5:22 | 视频:05 - 006 - Exercise on Prompting.mp4
#### 视频文字稿
让我们通过一个快速练习来测试你对提示工程的了解。现在,为了这个练习,我创建了一个名为 `003_exercise` 的新笔记本。你不必下载这个。我所做的只是替换了任务描述、提示输入规范,然后调整了下面的一些额外标准。
所以,如果你愿意,你可以手动更改你正在使用的笔记本中的所有内容,或者直接下载这个 `003_exercise` 并跟上我的进度。你在这个练习中的目标是,使用我们在这个模块中学到的所有提示工程主题来改进一个现有的提示。你将要处理的数据集会创建一系列来自一篇学术文章的文本段落。你的提示的目标是,接收那段文本,并将其中的所有主题提取到一个 JSON 字符串数组中。
当我说“主题”时,我的意思其实就是,这篇文章谈论了什么?所以如果这是一篇关于太阳能电池板的文章,我希望能得到一个包含“太阳能电池板”的 JSON 字符串数组,以及那段文本中提到的任何其他主题。提示的唯一输入是一个 `content` 属性。也就是一段文本。
现在,在我现在打开的笔记本中,我已经执行了单元格并生成了一个数据集。我已经为你准备了一个起始提示,现在它是一个非常差的提示,绝对可以改进很多。所以,请随意尝试这个提示,并使用我们学到的一些不同技术。为了评估你的进展,请运行下面的单元格。
我已经包含了一些额外的标准,以确保你基本达到了正确的结果。记住,无论何时运行评估,你总可以打开那个 `report.html` 文件,以更好地了解发生了什么。默认情况下,用那个非常简单的提示,我的平均分是 2.8。所以我希望我们至少能把平均分提高到 7 分左右。
像往常一样,我鼓励你在这里暂停视频,然后去尝试一下这个练习。否则,如果你想继续看,我马上就会讲解一个解决方案。好了,要解决这个问题,我们毫无疑问地知道,我们所有的工作都将集中在这个变量上。我们需要以某种方式改进这个提示,以获得更好的输出。
我们可能要做的第一件事是,确保你至少运行了一次评估,以生成那个 `output.html` 文件。然后,一旦你创建了那个文件,我鼓励你打开它,看看一些关于为什么输出评分如此之低的原因。你会注意到它们之间有一个共同的主题。我们能立刻看到的一个非常普遍的主题是,嗯,它不喜欢我们没有返回一个 JSON 字符串数组。
为了解决这个问题,让我们在提示中使用简单直接的技术。如果我们期望得到一个包含所有内容的 JSON 字符串数组,那么我们需要对 Claude 非常简单直接,并确切地告诉它我们想要什么。所以我要更新提示的第一行,我会说:“从一篇学术期刊的文本段落中提取关键主题,并放入一个 JSON 字符串数组中”,我尽可能用最简单的措辞,尽可能直接地表达。然后,如果我用评估重新运行提示,我会发现我几乎立刻就达到了一个惊人的 9.5 分。
所以我有点没想到会这么顺利,因为还有一些其他的技术我们可能想在这里尝试。但如果我们现在看看报告,我确实得到了这个包含所有不同主题的 JSON。而且看起来模型评分员对这个输出非常满意。现在,我不想就此打住。
显然,还有一些其他的技术我们可以加入,以确保我们得到正确类型的输出。所以我们可能要加入的下一个技术是通过使用一些 XML 标签来更好地构建我们的提示。在我们即将在这里插入的内容前后,我会添加一些 XML 标签,我将给它们取名为 `text`。现在,在这种情况下,我选择将这些标签称为 `text`,因为我之前在提示的第一行中提到了一些文本。
所以现在,我们在这里谈论一段文本和我们在这里提供文本之间有了一个更清晰的联系。我们可能要加入的另一个改进是,非常具体地说明我们希望 Claude 做什么。所以我可以列出一系列步骤让 Claude 遵循。让我们试试。
我可以说:“遵循这些步骤”,然后一步一步地列出我希望它做什么。所以我们可能会说:“仔细检查提供的文本。识别提到的每个主题,将每个主题添加到一个 JSON 数组中,然后最后用 JSON 数组回应。不要提供任何其他文本或评论。”
现在,如果你也想用单样本或多样本提示添加一个例子,完全可以。但我们已经有相当好的分数了,所以我认为这可能足够了。我要重新运行这个提示。然后我再运行一次评估,我又得到了 9.5 分。
所以,我会说这是一个相当强的提示,我绝对会相信它能从一篇文章中提取一个主题列表。
---
### 32. 工具使用简介
> 类型:视频 | 时长:2:54 | 视频:06 - 001 - Introducing Tool Use.mp4
工具 (Tools) 允许 Claude 访问外部世界的信息,将其能力扩展到训练数据之外。默认情况下,Claude 只知道其训练数据中的信息,无法访问时事、实时数据或外部系统。工具使用 (Tool use) 通过创建一种结构化的方式,让 Claude 请求和接收最新信息,从而解决了这个限制。
## 没有工具的问题
当用户向 Claude 询问当前信息时,它会遇到障碍。例如,如果有人问“加利福尼亚州旧金山的天气怎么样?” Claude 必须回应说“很抱歉,我无法访问最新的天气信息。”
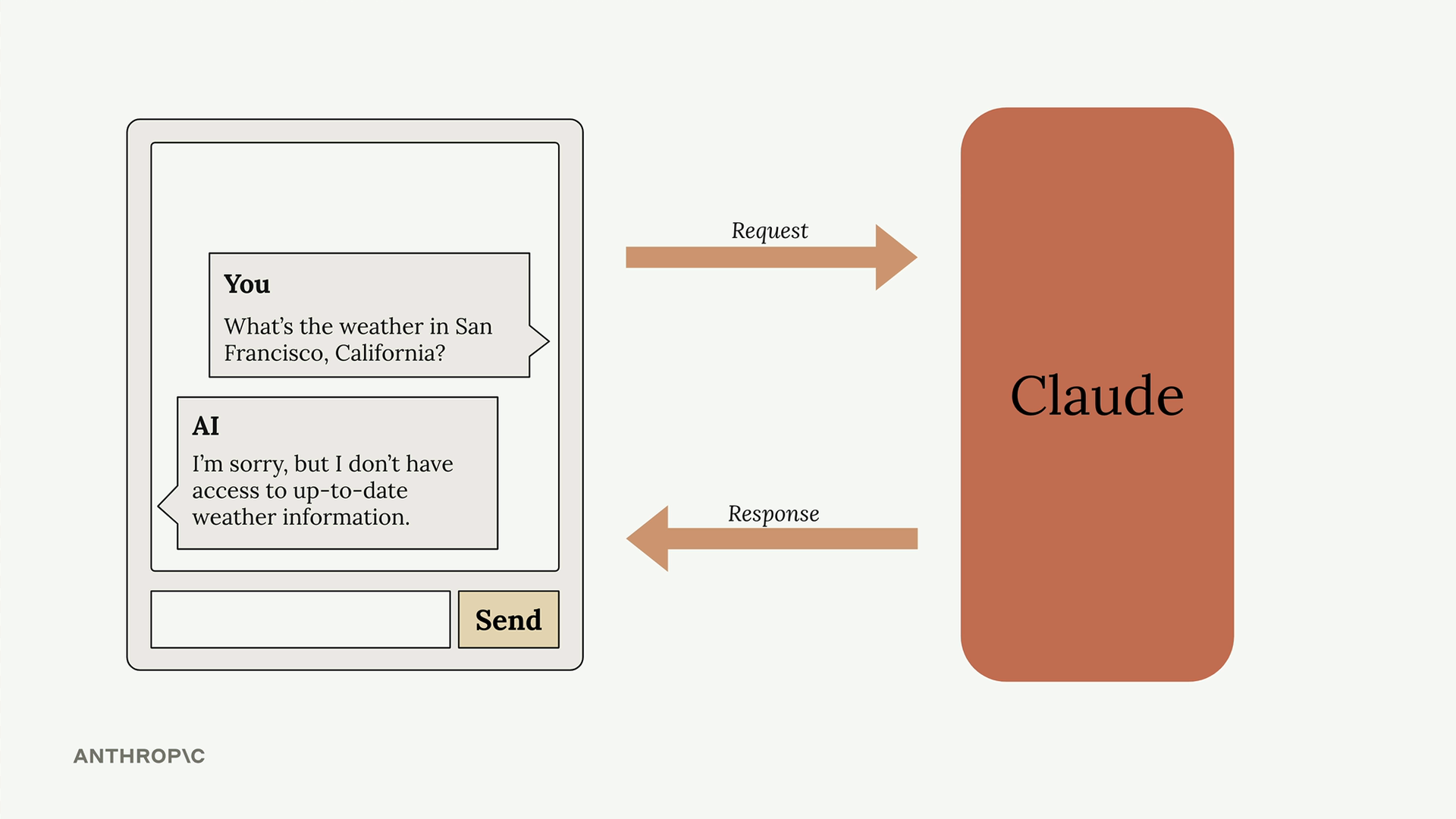
当人们需要实时数据,而理论上只要 Claude 能够访问当前信息就能提供帮助时,这会造成令人沮丧的用户体验。
## 工具使用如何工作
工具使用遵循你的应用程序和 Claude 之间特定的来回交互模式。以下是完整的流程:
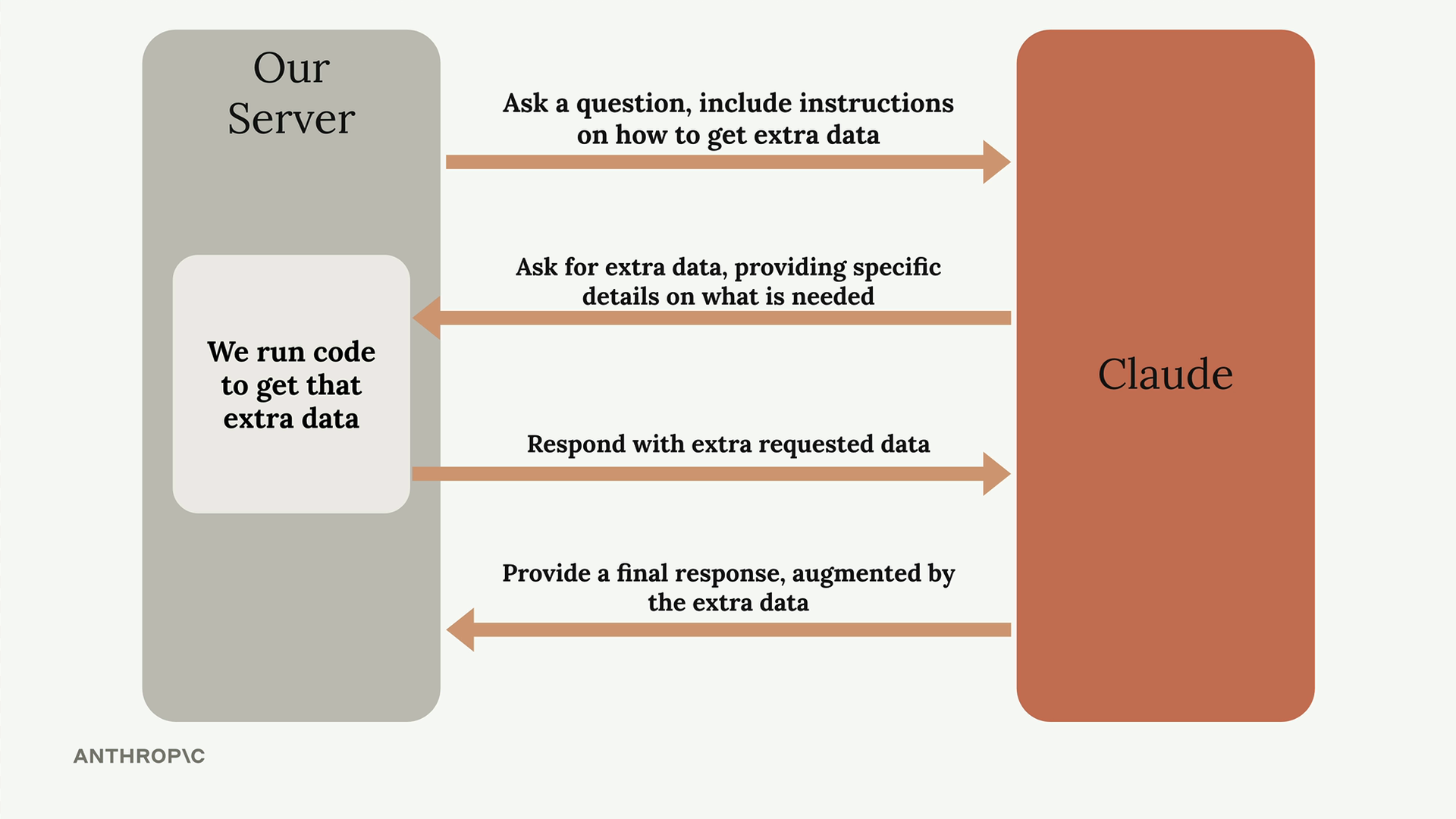
1. **初始请求:** 你向 Claude 发送一个问题,同时附上关于如何从外部源获取额外数据的说明
2. **工具请求:** Claude 分析问题后,决定需要额外信息,然后请求关于它需要什么数据的具体细节
3. **数据检索:** 你的服务器运行代码,从外部 API 或数据库中获取所请求的信息
4. **最终响应:** 你将检索到的数据发送回 Claude,然后它会结合原始问题和最新数据生成一个完整的响应
## 天气示例实践
让我们看看这在天气问题上是如何运作的。过程变得更加具体:
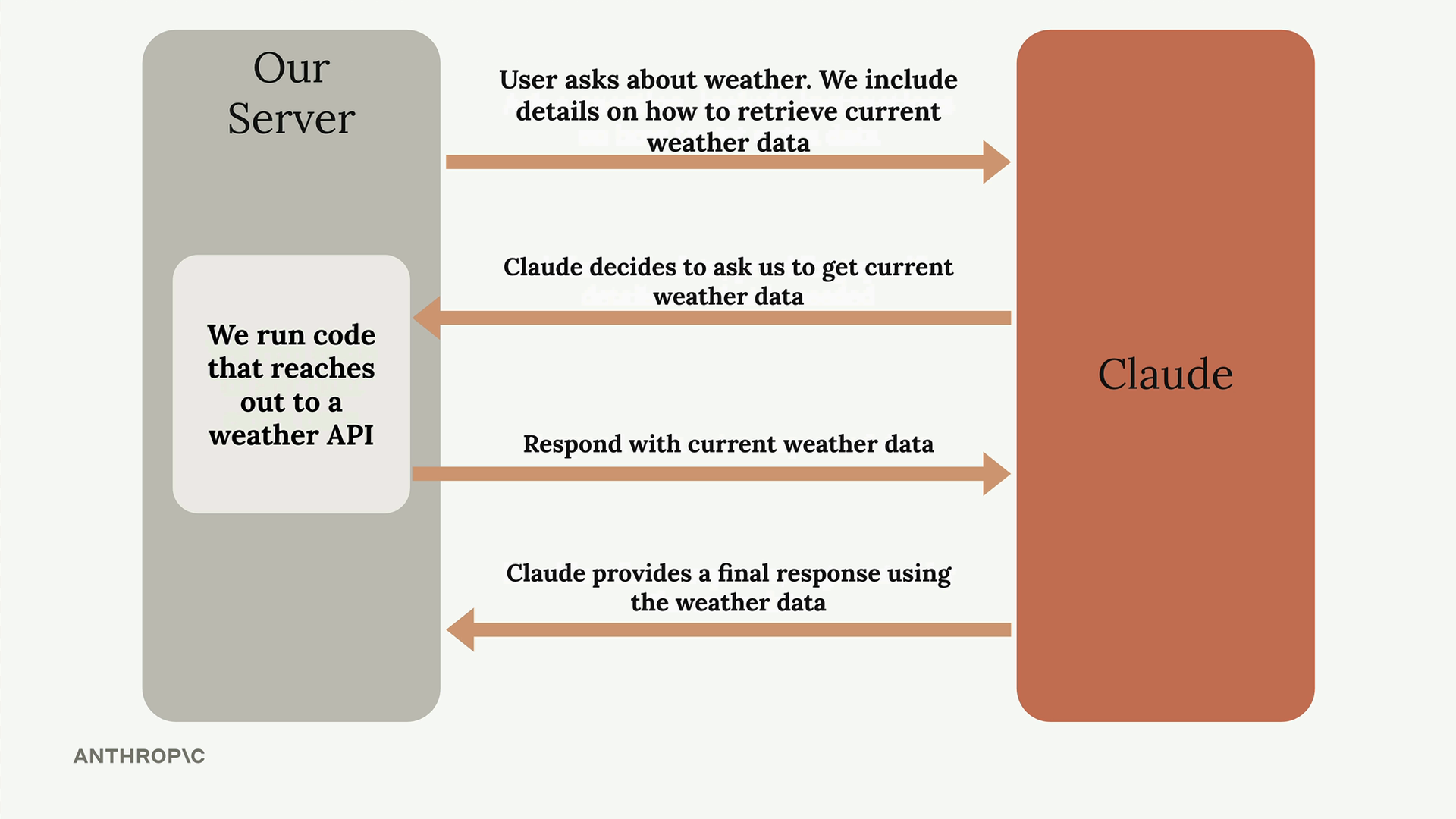
当用户询问当前天气时,你在提示中包含了关于如何检索天气数据的说明。Claude 识别出它需要当前信息,并请求特定位置的天气数据。你的服务器随后调用一个天气 API 来获取实时状况,并将该数据发送回 Claude。最后,Claude 结合最新的天气数据和用户的问题,提供一个准确的、当前的响应。
## 主要优势
- **实时信息:** 访问 Claude 训练期间无法获得的当前数据
- **外部系统集成:** 将 Claude 连接到数据库、API 和其他服务
- **动态响应:** 根据最新的可用信息提供答案
- **结构化交互:** Claude 确切地知道它需要什么信息以及如何请求
工具使用将 Claude 从一个静态的知识库转变为一个能够处理实时数据的动态助手。这为构建需要当前信息的应用程序开辟了可能性,无论是天气数据、股票价格、数据库查询,还是你的用户可能需要的任何其他实时信息。
#### 视频文字稿
在本模块中,我们将讨论工具的使用。工具允许 Claude 访问来自外部世界的信息。现在,理解工具的使用可能有点挑战性,所以在这段视频中,我将给你一个非常轻松的介绍。我们将逐步了解工具使用的整个流程,并理解它的全部内容。
我想首先给你举一个例子,说明 Claude 有时不幸会遇到它的局限性。记住,默认情况下,Claude 只能访问它实际训练过的信息。所以总的来说,它对最近发生的时事并没有太多信息。举个例子,如果我们有一个用户在使用我们的聊天机器人,问一个问题,比如,“现在加利福尼亚州旧金山的天气怎么样?”
如果把这个问题发给 Claude,我们可能会得到一个类似这样的回应:“对不起,但我无法访问像那样的最新天气信息。”为了解决这个问题并给用户一个更好的回应,我们可以使用工具。让我给你看一个图表,它会用非常简单的术语来分解工具。我还会给你看另一个图表,它会给你一个例子,说明我们将如何解决这个具体的天气问题。
好的,所以这就是我们最终在开始使用工具时要实现的整个流程。我们会向 Claude 发送一个初始请求。我们会问一个问题或者给 Claude 一个任务。与此同时,我们会包含关于 Claude 如何从外部世界获取一些额外数据的说明。
Claude 会查看被问到的问题或被给定的任务,然后可能会决定它需要请求一些额外的数据。所以它会向我们发送一个回应,请求一些额外的数据,并且它会给我们一些关于它究竟需要什么信息的细节。然后,在我们的服务器上,我们会运行一小段代码,去获取 Claude 请求的信息,然后在对 Claude 的后续请求中用它来回应。现在,理论上 Claude 拥有了给我们回应所需的所有信息。
所以它会生成一个最终的回应,希望这个回应能被那些额外的数据所增强或改进。现在我要给你看完全相同的流程,但我会为用户询问特定地点当前天气的情况定制每一个小步骤。所以情况是这样的。我们会向 Claude 发送一个初始查询,其中会包含一个用户询问天气的提示。
在那个初始请求中,我们会包含关于如何具体检索当前天气数据的细节。Claude 会查看提示并决定,“嘿,要回答这个问题,我需要获取一些当前的天气数据。”它会向我们发送回应,然后我们会运行一些代码,可能会联系某个第三方天气 API,并实际获取某个特定地点的当前天气情况的实时细节。一旦我们从那个外部 API 获得了那些细节,我们就会带着那些当前天气数据向 Claude 发出一个后续请求。
现在,Claude 拥有了它需要的所有信息。它有原始的提示和最新的天气数据,所以它可以生成一个最终的回应并发送给我们。
---
### 33. 项目概览
> 类型:视频 | 时长:2:23 | 视频:06 - 002 - Project Overview.mp4
我们将构建一个实践项目,教 Claude 如何为未来的日期设置提醒。这听起来可能很简单,但它揭示了几个有趣的挑战,我们将使用自定义工具来解决。

目标很直接:我们希望能够告诉 Claude “为我的医生预约设置一个提醒。时间是下周四算起的一周后”,然后让 Claude 回应说“好的,我会提醒你。”但要实现这一点,我们需要解决 Claude 在处理时间和提醒方面的一些限制。
## 为什么这具有挑战性
虽然 Claude 知道当前日期,但我们需要解决三个具体问题:
- **有限的时间意识:** Claude 可能知道当前日期,但不确切知道时间
- **日期计算问题:** Claude 并不总是能很好地处理基于时间的加法,尤其是在展望未来很多天的时候
- **没有提醒功能:** Claude 不知道如何设置提醒——它没有内置的提醒机制
这些限制中的每一个都代表了 Claude 自然能力与我们提醒系统所需功能之间的差距。工具就是我们弥合这些差距的方式。
## 我们需要的工具
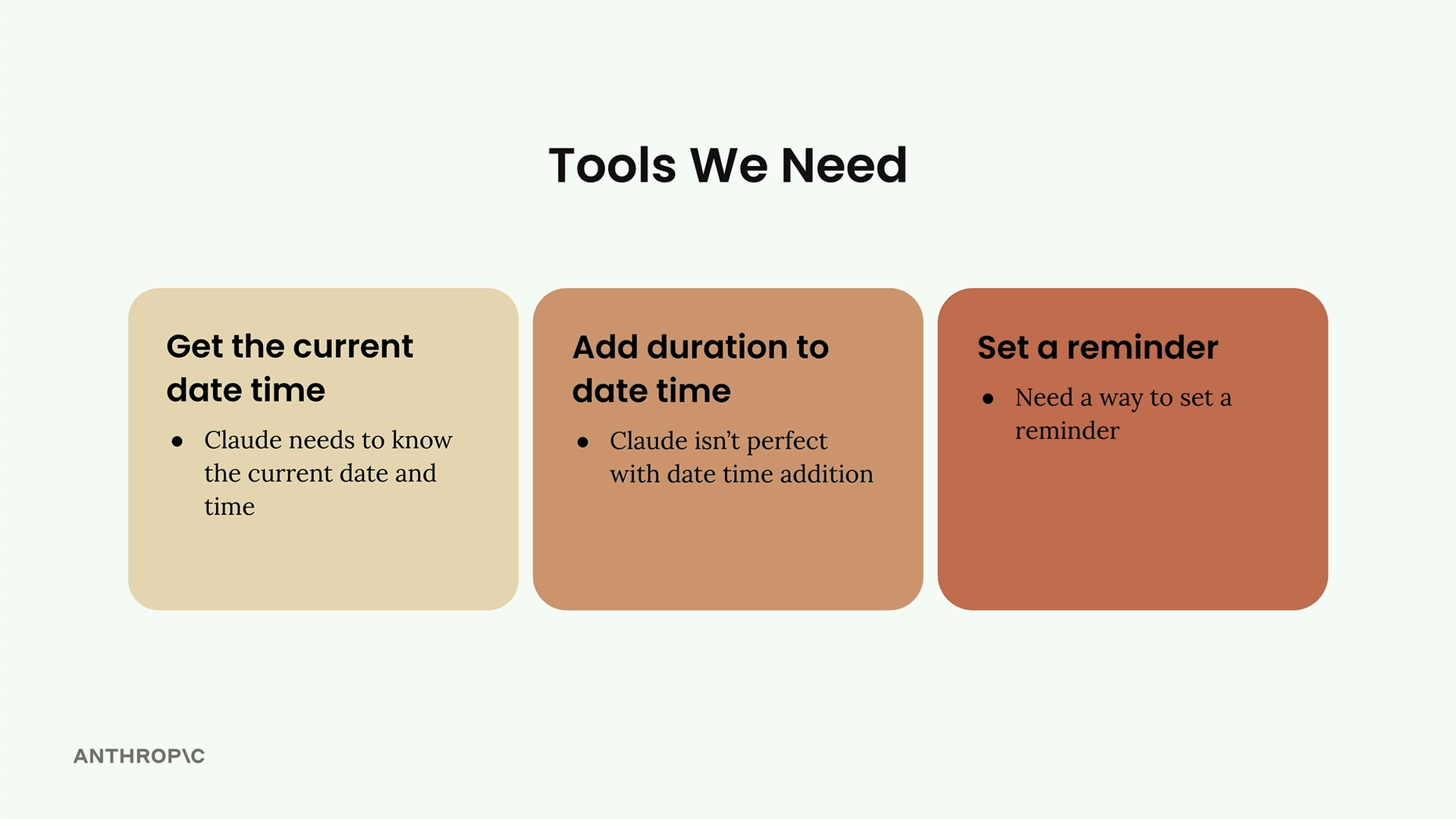
我们将创建三个独立的工具来应对每个挑战:
- **获取当前日期时间:** Claude 需要精确地知道当前日期和时间
- **为日期时间添加时长:** Claude 在日期时间加法上不完美,所以我们将给它一个可靠的工具来做这件事
- **设置提醒:** 我们需要一种方法来真正在系统中设置提醒
我们将逐一实现这些工具,从最简单的开始。这种方法让我们在构建更复杂的功能之前,先了解工具调用的工作原理。到最后,Claude 将能够通过组合这些工具来计算确切时间并设置提醒,从而处理像“一周后提醒我”这样的自然语言请求。
这个项目展示了与 AI 合作的一个关键原则:当模型存在局限性时,我们通过工具来扩展其能力,而不是试图在提示中绕过这些限制。
#### 视频文字稿
为了更多地了解工具,我们将为自己设定一个小目标。这将是我们在 Jupyter notebook 中实现的一个小项目。我们将尝试教 Claude 如何设置在未来某个时间点发生的提醒。这将要求我们实现几个不同的工具。
现在,我们只关注一个工具,但请知道我们最终将需要处理多个工具。所以我希望最终能向 Claude 发送类似这样的消息:“为我的医生预约设置一个提醒,时间是下周四起的一周后。”我希望 Claude 回答说:“好的,我会在那个时间点提醒你。”当你第一次看到这个任务时,你可能会觉得它看起来很简单,但事实证明,实际上有几个不同的挑战需要我们去解决,我们将通过使用工具来解决所有这些挑战。
具体来说,Claude 确实知道当前日期。换句话说,如果你现在打开一个提示,你可以问它当前日期是什么,它会给你一个完全正确的答案。然而,Claude 并不总是知道确切的时间。所以如果我们让 Claude 做类似“设置一个 24 小时后的提醒”这样的事情,并期望它正好是 24 小时,Claude 实际上并不知道 24 小时后是什么时候,因为它不知道当前时间。
其次,Claude 并不总是能完美处理基于时间的加法。所以如果我问它,“从 1973 年 1 月 13 日起 379 天后是哪一天?” Claude 很多时候会给你正确的答案,但有时它会算错。最后,Claude 根本不知道设置提醒是什么意思,它没有这个概念。
它在概念上知道设置提醒是什么,但在 Claude 内部完全没有任何机制可以在未来设置提醒。为了解决这些问题,我们将制作一个专门的工具。所以我们这里有三个问题。我们将一次制作三个独立的工具。
每个工具将做以下事情。我们将从一个非常简单的工具开始。它将帮助我们理解工具调用到底是什么。它的唯一工作就是获取当前的日期时间。
也就是当前的日期加上时间。我们将制作的第二个工具将为一个日期时间添加一个持续时间。这将允许我们说一些类似“取当前日期并加上 20 天,结果会是哪一天”这样的话。然后最后,我们也会制作一个提醒设置工具。
---
### 34. 工具函数
> 类型:视频 | 时长:5:22 | 视频:06 - 003 - Tool Functions.mp4
在使用 Claude 构建 AI 应用程序时,你通常需要让它能够访问实时信息或执行操作。这就是工具函数 (tool functions) 发挥作用的地方——它们是 Python 函数,当 Claude 需要额外数据来帮助用户时可以调用。
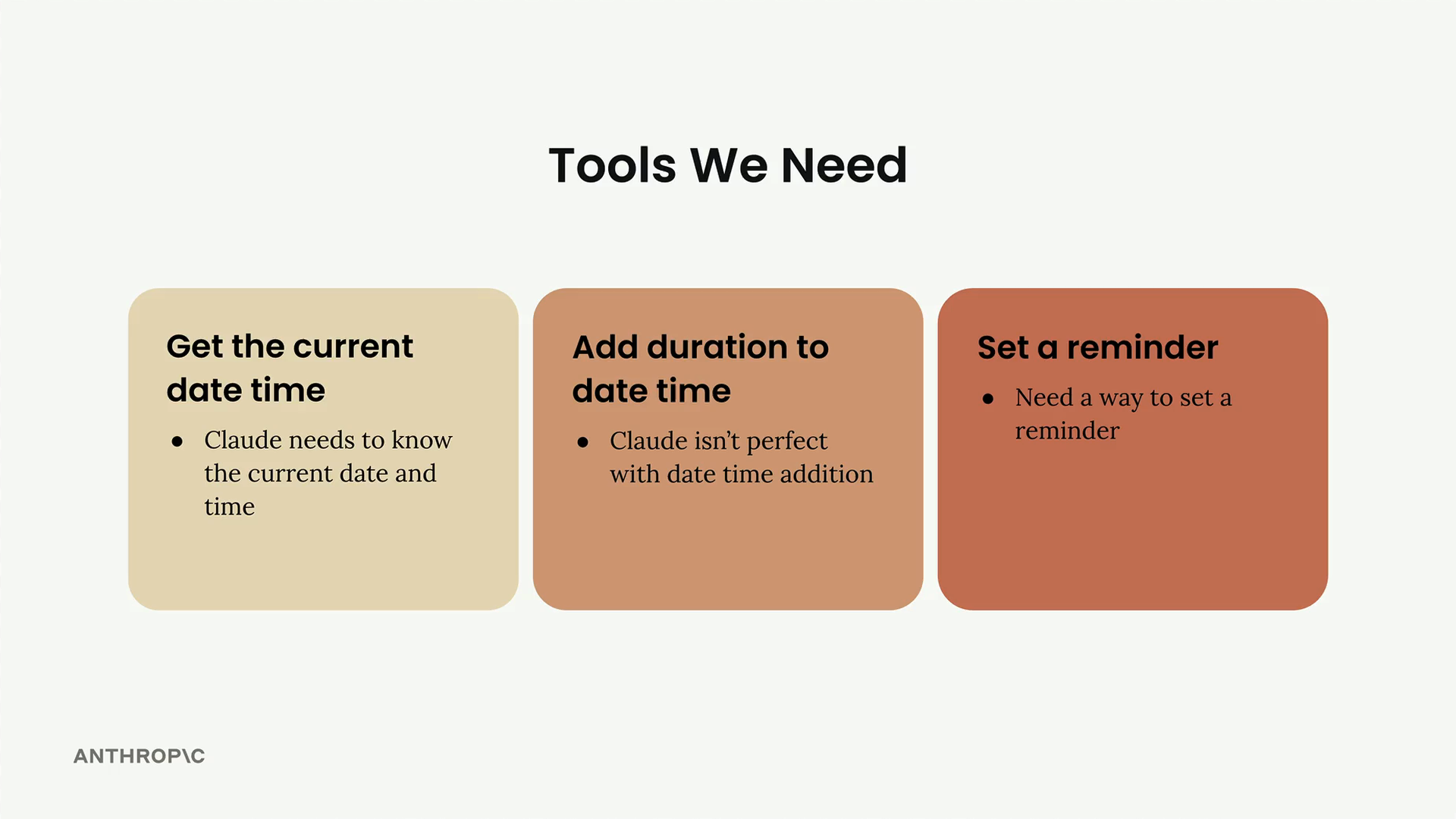
上图展示了我们将要实现的三个基本工具:获取当前日期/时间、为日期添加时长以及设置提醒。让我们从第一个开始。
## 什么是工具函数?
工具函数是一个普通的 Python 函数,当 Claude 决定需要额外信息来帮助用户时,它会被自动执行。例如,如果有人问“现在几点了?”,Claude 会调用你的日期/时间工具来获取当前时间。

这是一个天气工具函数的示例。请注意它如何验证输入并提供清晰的错误消息——这些都是重要的最佳实践。
## 工具函数的最佳实践
在编写工具函数时,请遵循以下准则:
- **使用描述性名称:** 你的函数名和参数名都应清晰地表明其用途
- **验证输入:** 检查必需的参数是否为空或无效,并在出现问题时引发错误
- **提供有意义的错误消息:** Claude 可以看到错误消息,并可能用修正后的参数重试函数调用
验证尤为重要,因为 Claude 会从错误中学习。如果你引发一个像“位置不能为空”这样清晰的错误,Claude 可能会尝试用一个合适的位置值再次调用该函数。
## 构建你的第一个工具函数
让我们创建一个函数来获取当前日期和时间。这个函数将接受一个日期格式参数,以便 Claude 可以请求不同格式的时间:
def get_current_datetime(date_format="%Y-%m-%d %H:%M:%S"): if not date_format: raise ValueError("date_format cannot be empty") return datetime.now().strftime(date_format)
这个函数使用 Python 的 `datetime` 模块来获取当前时间,并根据提供的格式字符串进行格式化。默认格式为我们提供年-月-日 时:分:秒。
你可以用不同的格式来测试它:
Default format: "2024-01-15 14:30:25"
get_current_datetime()
Just hour and minute: "14:30"
get_current_datetime("%H:%M")
验证检查确保 Claude 不能为日期格式传递一个空字符串。虽然这个特定错误不太可能发生,但它演示了验证输入并提供 Claude 可以学习的有益错误消息的模式。
## 后续步骤
创建函数只是第一步。接下来,你需要编写一个 JSON schema 来向 Claude 描述该函数,然后将其集成到你的聊天系统中。这种工具函数的方法为 Claude 提供了强大的功能,同时保持了代码的组织性和可维护性。
#### 视频文字稿
让我们开始着手我们的第一个工具,它将允许 Claude 检索当前的日期时间。在我们继续之前,我想让你知道我为你创建了一个新的笔记本。这个笔记本标题为 `001 Tools`,并附在本讲座中。在这个笔记本中,你会发现很多我们已经在本课程中编写过的相同代码。
然而,我也在下面添加了一个新单元格,标题为“工具和模式”。在这个单元格中,我放置了大量的样板代码,只是为了稍后为我们节省一点时间。特别是,你会找到 `add duration to date time` 函数,你稍后会用到它。所以,再次,我鼓励你下载附在本讲座中的这个笔记本,并将其作为起点。
好了。那么,再一次,我们将专注于实现第一个工具,即获取当前日期时间。我将一步一步地引导你完成整个过程。我们将在我们的笔记本中编写大量代码,并且我们不会使用我们在那里设置的任何辅助函数。
比如 `add user message` 和 `add assistant message` 等等。这样做的原因是,你会看到我们需要稍微重构那些函数以适应工具。所以,与其试图同时混合更新那些辅助函数和学习工具,那会非常混乱。所以,我们将转而只专注于尽可能不使用任何辅助函数来进行工具调用。
好的,那么让我们开始吧。我把整个过程分成了几个不同的步骤。第一步,当我们在我们的实现中添加一个工具时,就是编写一个工具函数。一个工具函数是一个普通的 Python 函数,当 Claude 决定它需要检索一些额外信息以便以某种方式帮助用户时,它将在某个时间点自动执行。
我在右边有一个可能的工具函数的例子,叫做 `get weather`。Claude 也许能够利用这个工具函数来检索世界上某个特定地点的当前天气。现在,关于工具函数有几个最佳实践。首先,我们总是希望使用命名良好且具有描述性的参数。
所以实际的函数本身和它接收的参数应该有相当好的命名,至少能给我们一个关于它们是什么的提示。其次,我们希望验证这些输入,并在输入本身有任何问题时引发一个错误。所以,例如,如果我们没有收到一个位置,或者位置是一个空字符串,我们会希望立即引发一个错误。最后,每当我们确实引发一个错误时,我们希望确保它包含某种有意义的错误消息。
在某些情况下,如果 Claude 尝试调用一个工具函数,并且导致了一个错误,Claude 会看到确切的错误消息。Claude 可能会决定再次尝试调用你的工具函数,并以一种稍微不同的方式调用它,试图纠正那个错误。所以,例如,你可以想象,如果 Claude 尝试调用这个 `get weather` 函数,并且它传入一个空字符串,最上面的验证检查会失败,我们会引发一个错误。Claude 会看到“位置不能为空”的错误消息。
Claude 可能会决定再次尝试调用这个工具函数,确保它传入的不再是空字符串。好了,让我们回到我们的笔记本,我们将组合我们的第一个工具函数。记住,我们正在组合的工具的目标是获取当前的日期时间。所以回到这里,我将在最底部添加一个新单元格,我将定义一个新函数,名为 `get current date time`。
这将接受一个我称之为 `date format` 的参数。我将给它一个默认值。这将是一个有点复杂的字符串。我将输入百分号大写 Y,百分号小写 m,百分号小写 d,然后一个空格,一个百分号 H 冒号,百分号 M 冒号,百分号 S。
现在这个字符串有点复杂,所以我鼓励你在这里暂停视频,仔细检查你输入的字符串,确保它与我的完全匹配。然后在这个函数内部,我将使用那个日期格式来获取当前的日期时间,并以匹配这个日期格式字符串的方式来格式化它。所以我将返回 `datetime.now.strftime`,我将传入那个 `date format`。所以现在,作为我们如何实际使用这个函数的一个快速例子,我们可以调用 `get current date time`。
如果我们就这样运行它,我们会得到一个年、月、日、时、分、秒格式的日期时间。或者,我可以输入一个自定义的日期格式字符串,比如百分号 H,冒号,百分号,大写 M。这将只打印出我当前时间的小时和分钟。对这个函数的一个好的改进是为 `date format` 参数添加一些验证。
不幸的是,我们不能很轻易地验证确切的结构。确保这个东西是一个有效的字符串格式化时间格式化器。但我们至少可以检查并确保我们没有传入一个空字符串。所以我可能会决定在这里添加一点验证,用一个 `if not date format`。
然后如果我们没有通过那个验证检查,我可能会引发一个 `value error` 并说一些类似“日期格式不能为空”的话。所以现在如果我尝试用一个空字符串调用 `get current date time`,我最终会得到一个错误消息,它会告诉我“日期格式不能为空”。现在老实说,Claude 犯这种传入空字符串的错误的可能性不大,但至少以防万一它这么做了,我们是在向 Claude 提供一些信号,我们是在告诉它如何修复错误。它可以再次尝试调用 `get current date time`,并确保它传入的日期格式不是空的。
---
### 35. 工具模式
> 类型:视频 | 时长:4:39 | 视频:06 - 004 - Tool Schemas.mp4
编写完工具函数后,下一步是创建一个 JSON schema,它会告诉 Claude 你的函数需要哪些参数以及如何使用它。这个 schema (模式) 就像一份文档,Claude 通过阅读它来理解何时以及如何调用你的工具。
## 理解 JSON Schema
JSON Schema 并非特定于 AI 或工具调用——它是一个广泛使用的数据验证规范,已经存在多年。AI 社区之所以采用它,是因为它是一种描述函数参数和验证数据的便捷方式。

完整的工具规范有三个主要部分:
- **name** - 一个清晰、描述性的工具名称(如 "get_weather")
- **description** - 工具的作用、何时使用以及返回什么
- **input_schema** - 描述函数参数的实际 JSON schema
## 编写有效的描述
你的工具描述对于帮助 Claude 理解何时使用你的函数至关重要。最佳实践包括:
- 力求用 3-4 句话解释工具的作用
- 描述 Claude 应该何时使用它
- 解释它返回什么样的数据
- 为每个参数提供详细的描述

## 生成 Schema 的简便方法
与其从头开始编写 JSON schema,你可以使用 Claude 本身来生成它们。过程如下:
1. 复制你的工具函数代码
2. 到 Claude 并让它为工具调用编写一个 JSON schema
3. 将 Anthropic 关于工具使用的文档作为上下文包含进去
4. 让 Claude 按照最佳实践生成一个格式正确的 schema
提示应该类似于:“为这个函数编写一个用于工具调用的有效 JSON schema 规范。遵循附加文档中列出的最佳实践。”
## 在代码中实现 Schema
一旦 Claude 生成了你的 schema,就把它复制到你的代码文件中。这里有一个很好的命名模式可以遵循:
def get_current_datetime(date_format="%Y-%m-%d %H:%M:%S"): if not date_format: raise ValueError("date_format cannot be empty") return datetime.now().strftime(date_format)
get_current_datetime_schema = { "name": "get_current_datetime", "description": "Returns the current date and time formatted according to the specified format", "input_schema": { "type": "object", "properties": { "date_format": { "type": "string", "description": "A string specifying the format of the returned datetime. Uses Python's strftime format codes.", "default": "%Y-%m-%d %H:%M:%S" } }, "required": [] } }
使用 `函数名` 后跟 `函数名_schema` 的模式,可以使你的 schema 保持组织性,并易于与它们对应的函数匹配。
## 增加类型安全
为了更好的类型检查,从 Anthropic 库中导入并使用 `ToolParam` 类型:
from anthropic.types import ToolParam
get_current_datetime_schema = ToolParam({ "name": "get_current_datetime", "description": "Returns the current date and time formatted according to the specified format", # ... rest of schema })
虽然这对功能来说并非严格必要,但它可以在你将 schema 与 Claude 的 API 一起使用时防止类型错误,并使你的代码更加健壮。
#### 视频文字稿
现在我们已经把工具函数整合好了,我们将进入第二步,也就是编写一个 JSON schema。我们最终会将所有这些配置发送给 Claude。Claude 将用它来理解可用的不同工具函数以及必须提供给这些工具函数的不同参数。我希望你首先理解的是 JSON schema 到底是什么。
所以你在右边看到的整个对象,严格来说,本身并不是一个 JSON schema。相反,在最顶端,有一个名称和一个描述。我稍后会告诉你它们是做什么的。在那下面,有一个 `input schema` 的键。
然后分配给它的是那个字典。我现在高亮的这部分,技术上才是 JSON schema。所以,让我再给你一些背景知识。JSON schema 的概念并不特定于语言模型或工具调用或任何类似的东西。
JSON schema 是一个数据验证规范。所以它是一套规则,可以用来验证任何类型的 JSON 数据。所以再说一遍,它并不特定于语言模型或工具或任何类似的东西。语言模型社区在某个时候决定,JSON schema 只是连接和处理工具调用的一种非常方便的方式。
这是一个被广泛理解的技术,已经存在了很多年。现在,到目前为止,我还没有真正解释 JSON schema 规范是关于什么的。所以,总的来说,这东西是用来告知 Claude 它有哪些可用的工具。我们将为工具提供一个名称,所以在这种情况下它可能是 GetWeather,然后是工具的描述。
这个描述旨在告诉 Claude 这个工具做什么,什么时候使用它,以及它将返回什么样的数据。最佳实践是确保你有一个大约三到四句话长的描述。所以尽管我在这里只显示了检索当前天气,实际上,我肯定希望有一个比这长得多的描述。然后,在这个 `input schema` 键下面将是实际的 JSON schema 规范。
这将描述应该传递给我们函数的不同参数。所以回到这个例子,如果我有一个接收一个位置的 git weather 函数,我会在这里输入 `input schema` 和位置,它需要是一个字符串,这里是那个参数用途的描述。同样,我们希望这个参数的描述也大约三到四句话长,并帮助 Claude 确切地理解这个参数控制什么以及它如何影响整个函数调用。现在,就像我提到的,你可能觉得必须自己写出所有这些配置有点吓人。
幸运的是,我有一个技巧,可以帮助你为每个你组合的工具写出一个几乎完美的 JSON schema 规范。让我给你演示一下这个技巧。首先,我将回到我的编辑器,找到我们的工具函数。对我们来说,它是 `get current date time` 函数。
然后我将把它带到一个 Claude 窗口。我在这里 Claude.ai。我将写一个非常简单的提示。我将要求 Claude 为这个函数编写一个用于工具调用的有效 JSON schema 规范。
然后我还会要求 Claude 遵循附加文档中列出的最佳实践。然后我将输入我的工具函数,像这样。然后,这里是真正的技巧。我将去 Anthropic API 文档。
在用户指南部分,有整整一页关于 Claude 工具使用的内容。整页有很多不同的最佳实践,以及好的工具描述和坏的工具描述的例子。所以我将复制这里所有的文本,回到我的 Claude 窗口,把它作为附件粘贴进去,然后运行。Claude 可能会回应一个非常强的 JSON schema 规范。
所以我现在要复制这个,把它带回我的编辑器,我将把它粘贴到我现有的 `get current date time` 函数的正下方。所以我说,`get current date time schema`,像这样。现在,作为我喜欢使用的一个小命名模式,我会给我的工具函数取任何我想要的名字,然后与之匹配的 schema 将是 `_schema`。所以同样的名字 `_schema`。
这样就更容易跟踪我的不同 schema 了。我还有最后一件事要做。在单元格的顶部,我将从 `anthropic.types` 添加一个导入。我将导入 `tool program`。
我将用这个 `tool param` 包裹整个字典。所以我将在这里输入 `tool param`,一个左括号,然后在底部的这里一个右括号。添加这个 `tool param` 并不是严格必要的。换句话说,我们的代码在没有它的情况下仍然可以工作,但它将防止稍后我们最终使用这个 schema 并利用它时出现类型错误。
---
### 36. 处理消息块
> 类型:视频 | 时长:5:44 | 视频:06 - 005 - Handling Message Blocks.mp4
在使用 Claude 的工具功能时,你会遇到一种新的响应结构,它不同于你之前见过的简单文本响应。Claude 现在可以返回包含文本和工具使用信息的多块消息 (multi-block messages),而不仅仅是单个文本块。
## 进行启用工具的 API 调用
要让 Claude 能够使用工具,你需要在 API 调用中包含一个 `tools` 参数。以下是构建请求的方法:
messages = [] messages.append({ "role": "user", "content": "What is the exact time, formatted as HH:MM:SS?" })
response = client.messages.create( model=model, max_tokens=1000, messages=messages, tools=[get_current_datetime_schema], )
`tools` 参数接受一个 JSON schema 列表,这些 schema 描述了 Claude 可以调用的可用函数。
## 理解多块消息
当 Claude 决定使用工具时,它会返回一个在 `content` 列表中包含多个块的助手消息。这与你之前处理的纯文本响应有很大不同。

多块消息通常包含:
- **文本块 (Text Block)** - 人类可读的文本,解释 Claude 正在做什么(例如“我可以帮你找出当前时间。让我为你查找该信息”)
- **工具使用块 (ToolUse Block)** - 给你的代码的指令,关于要调用哪个工具以及使用什么参数
ToolUse 块包括:
- 一个用于跟踪工具调用的 ID
- 要调用的函数名称(例如 "get_current_datetime")
- 格式化为字典的输入参数
- 类型指定 "tool_use"
## 使用多块消息管理对话历史
请记住,Claude 不会存储对话历史——你需要手动管理。在处理工具响应时,你必须保留整个内容结构,包括所有块。
以下是如何将多块助手消息正确地附加到你的对话历史中:
messages.append({ "role": "assistant", "content": response.content })
这既保留了文本块也保留了工具使用块,这对于在你进行后续 API 调用时维持对话上下文至关重要。
## 完整的工具使用流程
工具使用过程遵循以下模式:
1. 将带有工具 schema 的用户消息发送给 Claude
2. 接收带有文本块和工具使用块的助手消息
3. 提取工具信息并执行实际函数
4. 将工具结果连同完整的对话历史一起发送回 Claude
5. 从 Claude 接收最终响应
每个步骤都需要仔细处理消息结构,以确保 Claude 拥有提供准确响应所需的完整上下文。
## 更新辅助函数
如果你一直在使用像 `add_user_message()` 和 `add_assistant_message()` 这样的辅助函数,你需要更新它们以处理多块内容。当前版本可能只支持单个文本块,但现在它们需要适应包含工具使用块的更复杂内容结构。
这种多块消息处理对于构建能够无缝集成 Claude 工具能力同时保持正常对话流程的健壮应用程序至关重要。
#### 视频文字稿
第三步,我们将使用其 JSON schema 和一些用户消息来调用 Claude。因此,从我们的服务器上,我们将像以前一样向 Claude 发出请求,但现在我们还将包含此工具 schema。这有助于 Claude 理解它有一个可用的工具。让我们回到我们的 notebook,我们将尝试手动发出这个请求,而不使用我们之前构建的任何辅助函数,比如 `chat` 函数。
好的,回到这里,我将向下创建一个新单元格。我将创建一个空的消息列表。我将手动在其中附加一条新消息,`role` 为 `user`,`content` 为“what is the exact time formatted as our minute seconds”。然后,在其下方,我将调用 `client.messages.create` 函数。
所以我从 `client.messages.create` 获得一个响应,我将指定我的模型、我的 `max_tokens`、我的消息列表,现在我们还想包含这个 JSON schema,它告诉 Claude 它有一个可用的工具。为此,我们将包含一个 `tools` 关键字参数。这将是一个列表,其中包含我们创建的所有不同的 JSON schema 规范。到目前为止,你和我只创建了一个,它叫做 `get_current_datetime_schema`。
所以我们将把它放在这里。然后我将在最底部打印出 `response`,让我们运行它看看会发生什么。我们将在这里得到一个响应消息,它的结构我们以前从未见过。我们以前收到的所有消息都有一个 `content` 字段,其中有一个列表,列表里是一个文本块。
正如我之前多次提到的,在文本块内部是我们实际想要显示给用户的文本。但现在我们正在使用工具,这个 `content` 列表会有点不同。所以你可能会注意到,在 `content` 列表中,有第二个块叫做 `tool use block` (工具使用块)。所以这就是它的整个结构。
让我给你看一张图,以确保这件事非常清楚。好的,这是我们第一次接触 `multi-block message` (多块消息)。记住,一个消息要么是助手消息,要么是用户消息。我们通常会在消息中存储一些文本,这就是我们以前一直看到的。
但除了纯文本之外,还有其他类型的数据可以存储在消息中。当 Claude 决定使用一个工具时,它通常会向我们返回一个助手消息,其中既包含一个 `text block` (文本块),也包含一个 `tool use block` (工具使用块)。文本块旨在向用户显示一些文本,以帮助他们理解正在发生的事情。所以在这种情况下,文本块可能包含类似“我可以帮你查找当前时间。让我为你找到该信息”的内容。然后,除了这个文本块之外,还有工具使用块。这个工具使用块是给作为开发者的你我的一个信号,表明 Claude 想要使用一个工具。工具使用块将列出它想要调用的工具函数的名称。
所以在这种情况下,Claude 想要调用我们构建的 `get_current_datetime` 函数。然后它还提供了一些输入,或者说我们需要传递给该函数的参数。所以我们接下来要做的整个过程的一部分是找到合适的工具并实际运行它。但在此之前,有一件非常关键的事情我们需要处理,那就是关于 `content` 列表包含多个块的想法。
好的,这里给你一个快速提醒。此时,我们已经从我们的服务器向 Claude 发出了一个请求,在该请求中,我们有一个包含工具 schema 的单个用户消息。我们现在已经收到了一个响应。在这个响应中,有助手消息,并且它的 `content` 列表中有两个独立的块,一个文本块和一个工具使用块。
现在,我想提醒你一些关于 Claude 的事情。记住,Claude 不会存储任何消息历史或你正在进行的对话的任何信息。如果你想与 Claude 保持对话或历史记录,你必须手动管理它。这意味着当我们最终获取这个工具使用块并最终调用某个实际函数时,我们最终需要回应 Claude。
当我们这样做时,关键部分来了,我们需要确保我们包含了整个对话历史,就像我们在整个课程中所做的那样。所以我们已经知道如何做到这一点。唯一的区别是,这次我们需要确保我们处理可能包含多个块的消息。所以让我向你展示我们如何手动完成这个。
然后,稍后在本节中,我们将回到我们的辅助函数,特别是 `add_user_message` 和 `add_assistant_message`,并确保它们可以支持包含多个块的消息。因为现在它们只支持单个文本块。好的,为了管理这些消息,我将回到我们底部正在获取响应的代码单元格。我将获取我们的响应,并确保在我们的消息列表中附加一条新的助手消息。
所以我将删除那里的 `response`。我们会说 `messages.append`。我将放入一个新的 `role` 为 `assistant`。然后我们的 `content` 将是我们刚刚从响应中得到的 `content` 块的确切列表。
所以我们所要做的就是添加 `response.content`。就这样。所以现在如果我打印出 `messages` 并再次运行该单元格,我们应该看到我们最终得到了我们的用户消息。那是我们的原始消息。
我们现在有了我们的助手消息。其中有一个文本块和工具使用块。所以现在我们正在通过包含来自我们收集的所有这些不同消息的所有不同块来正确地构建我们的对话历史。所以再一次,我只想提醒你,我们最终将不得不回到 `add_user_message` 和 `add_assistant_message` 这两个辅助函数,并更新它们以处理像这样的多个块。
---
### 37. 发送工具结果
> 类型:视频 | 时长:9:22 | 视频:06 - 006 - Sending Tool Results.mp4
在 Claude 请求工具调用后,你需要执行该函数并将结果发回。这通过向 Claude 提供它所请求的信息来完成工具使用工作流。
## 运行工具函数
当 Claude 以一个 `tool use block` (工具使用块) 响应时,你提取输入参数并调用你的函数。以下是如何访问工具参数的方法:
response.content[1].input
这会给你一个 Claude 希望传递给你函数的参数字典。由于你的函数期望的是关键字参数而不是字典,你可以使用 Python 的解包语法:
get_current_datetime(**response.content[1].input)
## 工具结果块
运行工具函数后,你需要使用一个 `tool result block` (工具结果块) 将结果发回给 Claude。这个块位于一个用户消息内部,告诉 Claude 当你执行工具时发生了什么。

工具结果块有几个重要的属性:
- **tool_use_id** - 必须与此 `ToolResult` 对应的 `ToolUse` 块的 id 相匹配
- **content** - 运行你的工具的输出,序列化为字符串
- **is_error** - 如果发生错误则为 True
## 处理多个工具调用
Claude 可以在单个响应中请求多个工具调用。例如,如果用户问“10 + 10 是多少,30 + 30 是多少?”,Claude 可能会用两个独立的 `ToolUse` 块来响应。
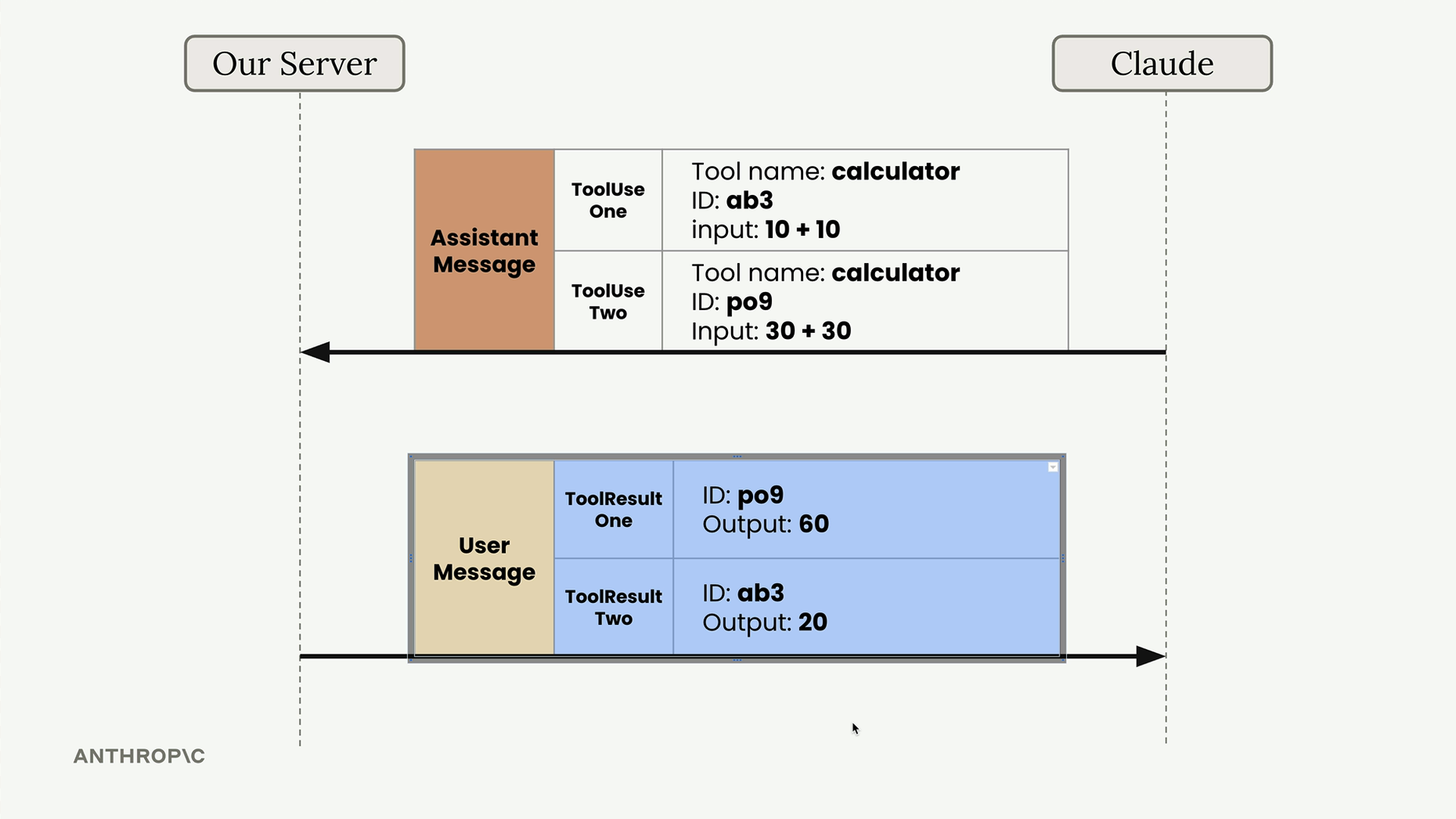
每个工具调用都有一个唯一的 ID,你必须在发回结果时匹配这些 ID。这确保了 Claude 知道哪个结果对应哪个请求,即使结果的到达顺序不同。
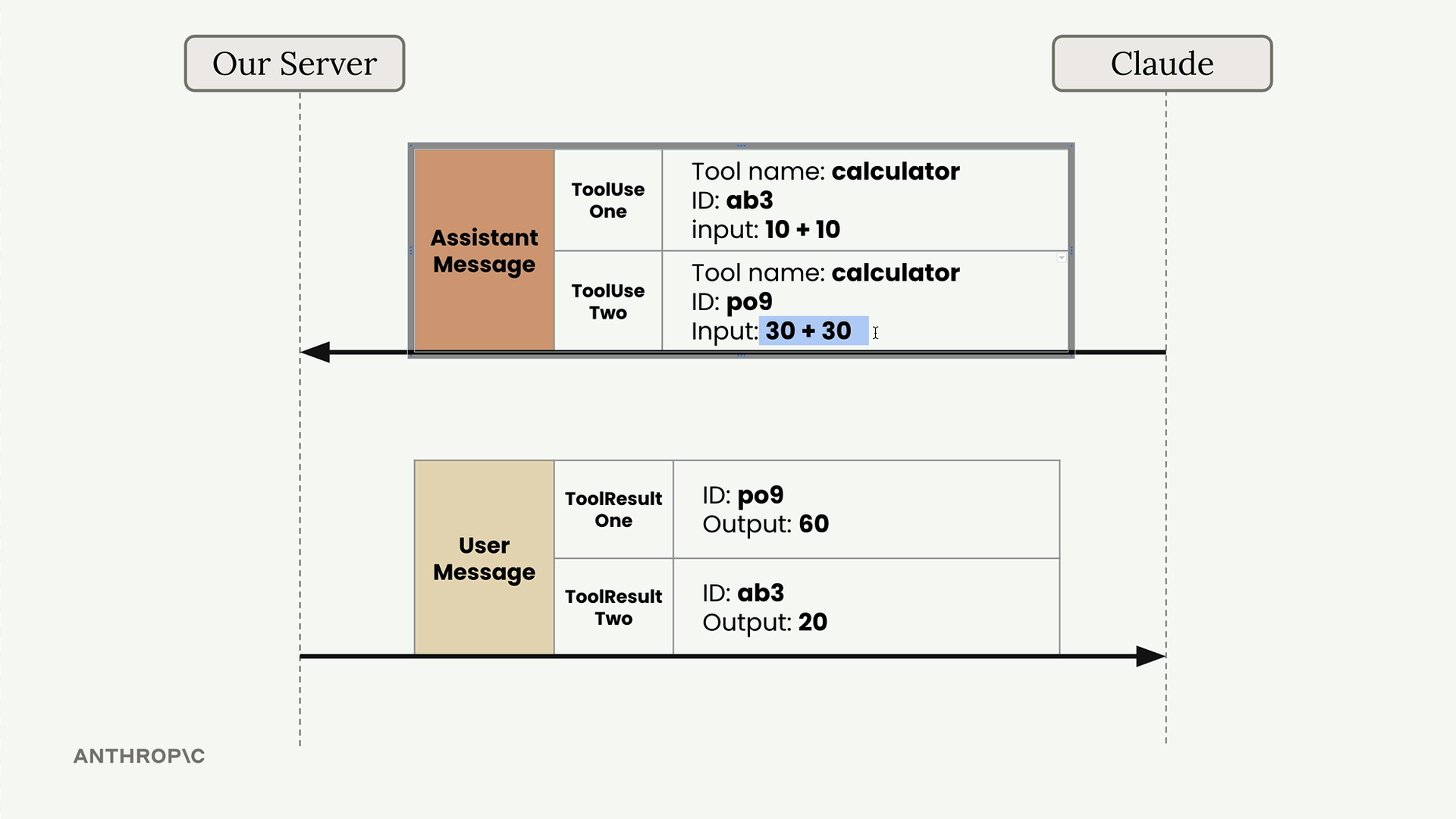
## 构建后续请求
你向 Claude 发出的后续请求必须包含完整的对话历史记录以及新的工具结果。结构如下:
messages.append({ "role": "user", "content": [{ "type": "tool_result", "tool_use_id": response.content[1].id, "content": "15:04:22", "is_error": False }] })
完整的消息历史现在包含:
- 原始用户消息
- 带有工具使用块的助手消息
- 带有工具结果块的用户消息
## 发出最终请求
在发送后续请求时,你仍然必须包含工具 schema,即使你并不期望 Claude 会再次调用工具。Claude 需要这个 schema 来理解你对话历史中的工具引用。
client.messages.create( model=model, max_tokens=1000, messages=messages, tools=[get_current_datetime_schema] )
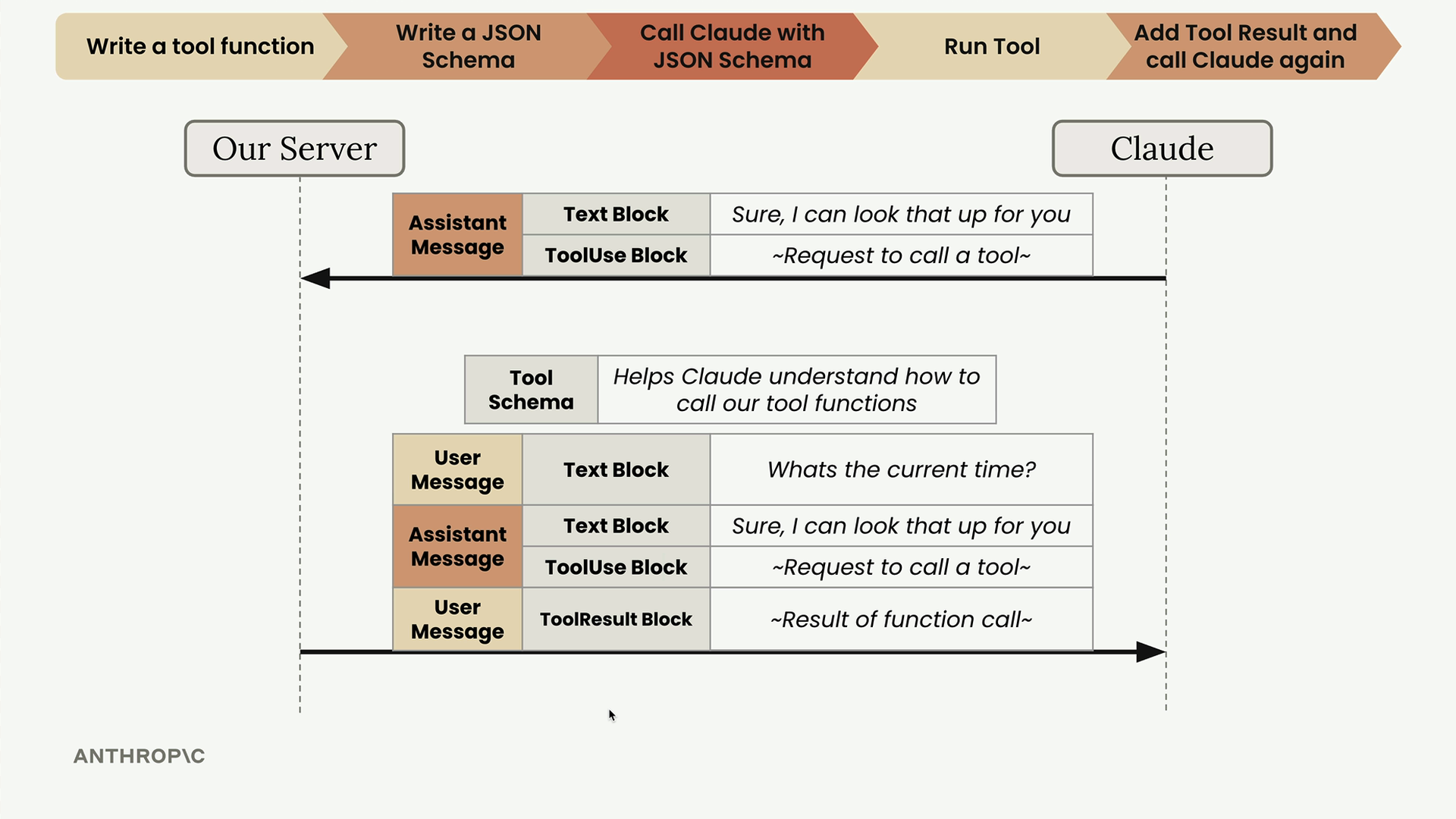
然后,Claude 将会以一个最终消息作为回应,该消息将工具结果整合到为用户提供的自然响应中。至此,工具使用工作流已完成——你已成功地使 Claude 能够通过你的自定义函数访问实时信息。
#### 视频文字稿
进入第四步,我们将运行 Claude 要求我们运行的工具函数。记住,在上一步中,我们从 Claude 那里得到了一个包含 `tool use block` (工具使用块) 的响应。让我们在我们的 notebook 里快速打印出来。回到这里,记住我们有这个 `response` 变量,我将向下创建一个新的单元格,然后打印出 `response`。
现在,在里面,我们得到一个带有 `content` 属性的消息,该列表中的第二个块是工具使用块。所以要访问它,我会用 `response.content[1]`。然后,在这里面,我们得到了一个 `input` 字段。这是 Claude 请求我们传递给 `get_current_datetime` 函数的输入或参数。
所以要得到那个字典,我们可以在后面链式调用 `.input`。现在,当我们加上 `.input` 时,你可能会在这里得到一个类型错误。在本视频中,我们将忽略类型错误,我们很快就会回来修复所有的类型错误。但只是让你知道,如果你在本视频中看到任何类型错误,完全没问题。
暂时忽略它们。所以现在我们的目标是获取这个字典,并将其提供给我们的 `get_current_datetime` 函数。这里需要注意一件事。记住我们的 `get_current_datetime` 函数。
在上面定义它时,它不接受字典。它接受一个名为 `date_format` 的关键字参数。所以要将该字典转换为关键字参数列表并将其应用于函数,我们可以这样做。我将调用 `get_current_datetime`,使用 `**` 和 `response.content[1].input`。
现在如果我运行它,我就会得到我真实世界的当前日期时间。对我来说,是 241 或 1441。除了我们需要修复的类型错误,这其实挺容易的。那么现在让我们进入第五步。
在第五步中,我们现在要向 Claude 发送一个后续请求。这个请求将包含我们完整的对话历史。所以我们会有一开始的用户消息。它会有我们刚刚处理的带有工具使用块的助手消息。
现在,我们将在最后附加另一条用户消息。这条用户消息将包含一种我们以前没见过的新类型的块,叫做 `tool result block` (工具结果块)。让我告诉你这个块是如何工作的。工具结果块将被放置在用户消息中。
工具结果将包含运行一个工具的结果。所以我们基本上是把我们刚从工具函数中得到的任何东西直接反馈给 Claude。工具结果块中会有几个不同的键。理解这些键的作用对你来说很重要。
第一个可能最难理解,`tool_use_id`。让我很快告诉你 `tool_use_id` 是怎么回事。我想让你想象一下,我们创建了一个名为 `calculator` 的新工具。这个工具用来计算一个数学表达式。
然后,也许一个用户发送了一条消息,比如“10 加 10 是多少?另外,30 加 30 是多少?”在这种情况下,Claude 可能想要两次调用 `calculator` 工具。一次调用来解决 10 加 10,第二次来解决 30 加 30。
为此,Claude 将会以一个包含多个工具使用块的助手消息来回应。所以我们可能会有第一个工具使用块,在这里我们需要计算的表达式是 10 加 10。然后在第二个块中,我们可能会有一个 30 加 30 的表达式。然后我们会执行我们的计算器工具两次,一次是为这个表达式,一次是为那个表达式。
然后我们会向 Claude 发送一个后续请求。在我们的后续请求中,我们会添加一个包含两个独立工具结果块的用户消息。所以我们会得到结果一和结果二。现在,当我们将这些结果发回给 Claude 时,Claude 需要能够弄清楚哪个结果属于哪个请求。
所以我们有请求一和请求二,然后是结果一和结果二。Claude 不想仅仅依赖于这些东西是否按相同的顺序排列。相反,它将使用 ID。所以在原始的工具使用块中,我们上面有一个 ID 是 AB3。
然后在第二个中,我们有 ID 是 PO9。在我们的后续请求中,我们发回给 Claude。我们需要确保我们放在这里的 ID 与输出相匹配。换句话说,PO9。
与 30 加 30 相关联,那么我们就要确保我们把 P09 与下面的 60 联系起来。同样,AB3 与 10 加 10,我们也要确保它与输出为 20 的 AB3 联系起来。所以这就是 `tool_use_id` 的作用。它帮助我们将工具使用请求与工具结果输出联系起来。
你需要知道的其他属性是 `content`,它会询问你从工具函数中得到的任何输出。即使你的工具函数返回的是像数字、字典或列表之类的东西,你也要把它转换成一个字符串,通常只要把它转换成纯 JSON 就可以了。然后,最后,我们还可以选择性地加入一个 `is-air` 字段。如果在运行你的工具函数时出了任何问题,你就要把这个设置为 true。
默认情况下,它总是 false。既然我们对这个工具结果块有了更好的了解,我想快速提醒你下一步需要做什么。我们刚从 Claude 那里得到一条助手消息,要求我们运行一个工具。我们知道它要求我们运行一个工具,因为它里面有一个工具使用块。
然后我们用提供的参数执行了我们的工具。所以既然我们有了工具函数的结果,我们需要向 Claude 发送一个后续请求。在这个请求中,我们将包含我们完整的消息历史。所以它将是我们原始的用户消息,带有工具使用块的助手消息。
现在我们将要追加一条额外的消息,一条用户消息,它包含一个工具结果块。这就是我们刚刚讨论的内容。就是这个东西。在这个工具结果块内部,它将包含实际函数调用的结果。
那么现在让我们回到我们的 notebook,获取我们的消息列表,并添加这个带有工具结果块的新用户消息。好的,回到我的 notebook 里,我将获取我的消息列表。我将追加一条新消息,其 `role` 是 `user`。然后是一个 `content` 列表,其中只包含一个块,它将是一个工具结果块。
所以我们给它一个 `tool_result` 类型。一个 `tool_use_id`,与这个工具使用块的 ID 相匹配。要访问那个 ID,我们将引用 `response.content[1].id`。当我输入它时,我会再次收到一个类型错误。
记住,我们现在对类型错误持开放态度。我们将忽略它,并且很快会修复它。然后我将添加一些内容。那将是调用我的函数的结果。
所以我将把调用 `get_current_datetime` 的结果赋给,比如说,`result`。你将重新运行它。然后我将引用 `content result`。最后,当我们运行这个函数时,没有错误。
所以我将输入 `is error false`,这并非绝对必要,因为这是默认值,但我还是会加上它。好的,现在我们已经更新了我们的消息列表,我将打印出这个列表。只是为了确保我们做的每一步都是正确的。所以现在我们有了完整的对话历史。
我们有原始的用户请求。我们有 Claude 要求我们使用一个工具的请求。现在我们追加了一条新的用户消息,其中包含一个工具结果块。所以现在你需要做的最后一件事就是把这个消息列表发回给 Claude。
我将在底部添加另一个代码单元。再次调用 Claude `messages.create`,附带我的模型 `max_tokens`。消息列表。然后,每当我们发出包含某些工具使用的后续请求时,我们还需要包含原始的工具 schema。
尽管我们可能不会在这里使用任何工具,我们仍然必须告诉 Claude 这个工具的存在,因为我们正在工具使用块和工具结果块中引用它。所以我们需要确保我们仍然包含我们的工具列表,这将是一个 `get_current_datetime_schema` 的列表。应该就是这样了。那么现在让我们运行这个。
我们应该能看到 Claude 的最终回应。就是这个了。这是我们的最终回应。我们有一个文本块,上面写着当前时间是 15:04。
嗯,这是一次成功的工具调用。我们已经完成了整个过程。让我们快速回顾一下。一切都从我们编写一个工具函数开始,然后编写一个工具 schema 来描述它。
工具 schema 的目标是帮助 Claude 理解可用的不同工具以及如何实际调用这些不同的工具。我们必须在之后我们发出的每个请求中都包含那个工具 schema。所以我在这里和下面都展示了它。当 Claude 回应我们时,它发回了一个包含两个独立块的助手消息。
所以这里是一个文本块,这里是一个工具使用块。文本块旨在向用户显示,以便用户了解正在发生的事情。而工具使用块包含一些关于 Claude 想要调用的工具的信息。所以它包含了它想要调用的工具的名称以及一些输入参数。
然后在我们的服务器上,我们执行了工具函数,然后我们向 Claude 发送了一个后续请求。这个后续请求包含了整个对话历史,以及工具 schema 的列表。我们请求中的最后一条消息是一条用户消息,它包含了一个工具结果块。工具结果块用于告知 Claude 运行某个工具函数的结果。
所以在这个块里,我们放入了当前时间,这正是 Claude 真正想要的。然后 Claude 给我们发回了一个最终结果,那只是一条只有文本块的助手消息。它利用了我们通过这个工具结果块输入给它的信息。
---
### 38. 使用工具进行多轮对话
> 类型:视频 | 时长:9:11 | 视频:06 - 007 - Multi-Turn Conversations with Tools.mp4
在构建具有多个工具的应用程序时,你需要处理 Claude 可能需要按顺序调用多个工具来回答单个用户问题的场景。例如,如果用户问“从今天起 103 天后是哪一天?”,Claude 需要先获取当前日期,然后再给它加上 103 天。
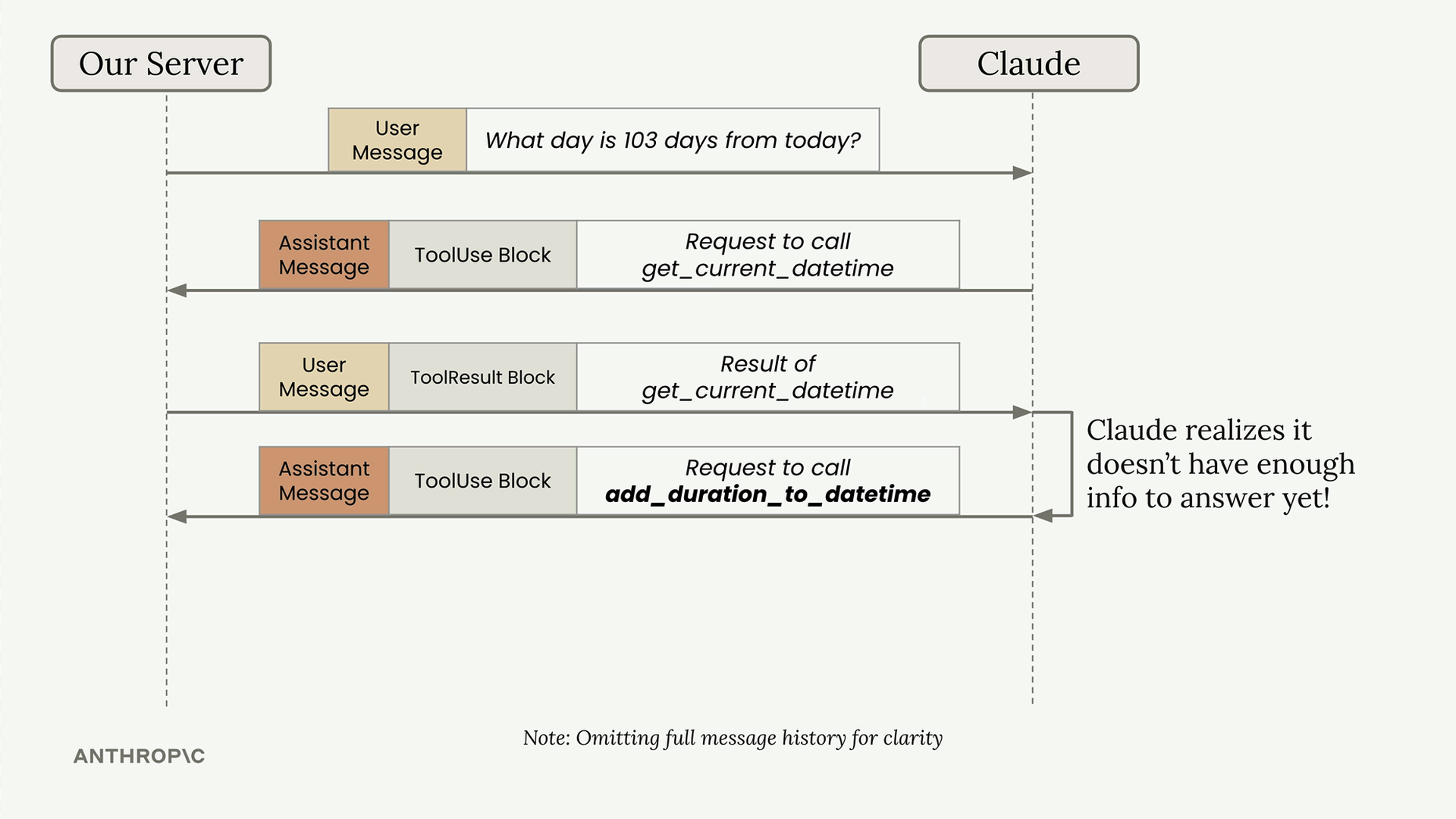
这就创建了一个 `multi-turn conversation pattern` (多轮对话模式),在这种模式下,Claude 在提供最终答案之前会发出多个工具请求。你的应用程序需要能自动处理这种情况。
## 多轮工具模式
当 Claude 需要多个工具时,幕后会发生以下情况:
1. 用户提问:“从今天起 103 天后是哪一天?”
2. Claude 以一个请求调用 `get_current_datetime` 的 `tool use block` (工具使用块) 作为回应
3. 你的服务器调用该函数并返回结果
4. Claude 意识到它需要更多信息,并请求 `add_duration_to_datetime`
5. 你的服务器调用该函数并返回结果
6. Claude 现在拥有足够的信息来提供最终答案
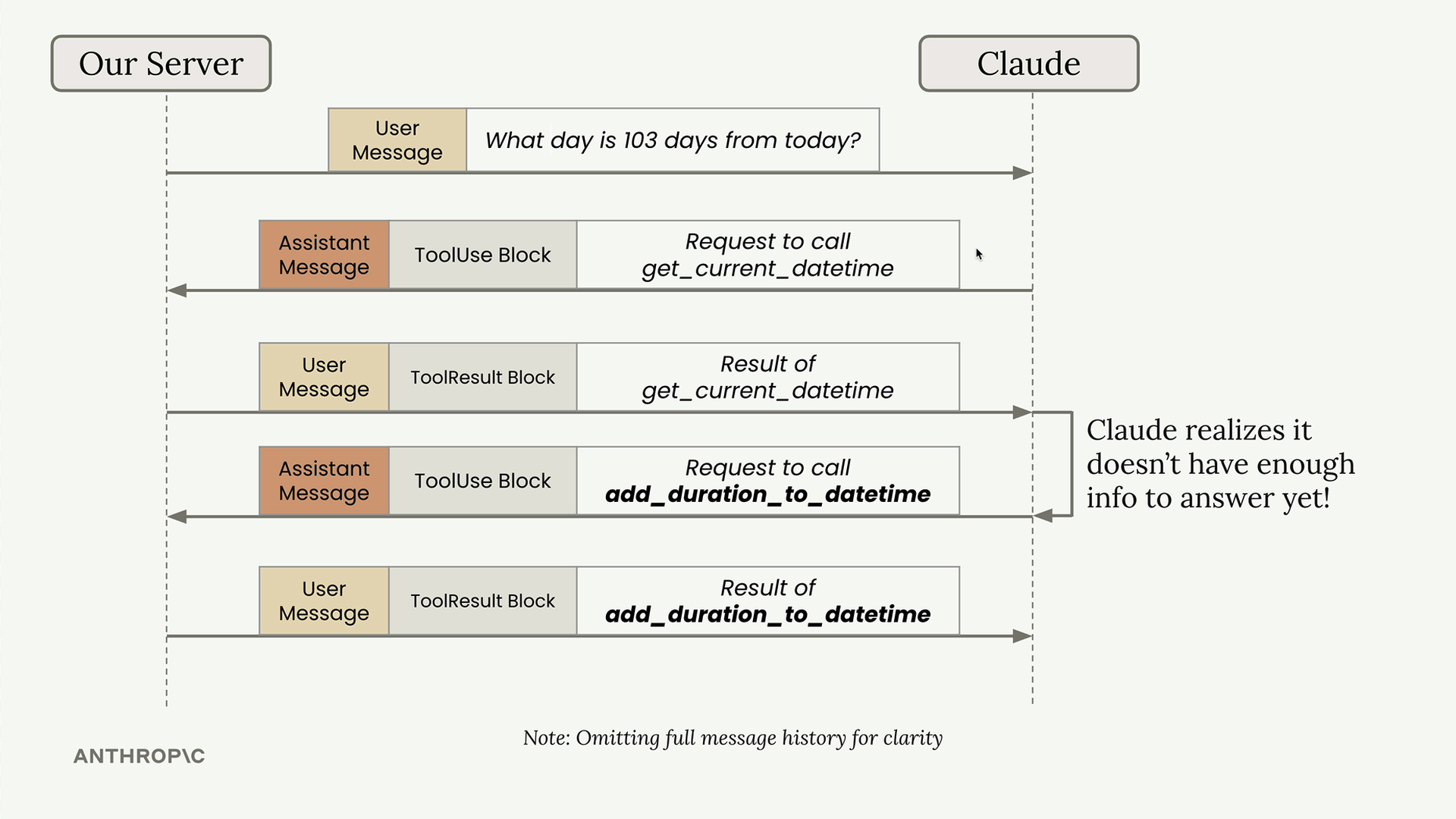
## 构建对话循环
为了处理这种模式,你需要一个对话循环,该循环会一直持续到 Claude 停止请求工具为止:
def run_conversation(messages): while True: response = chat(messages)
add_user_message(messages, response)
# Pseudo code
if response isn't asking for a tool:
break
tool_result_blocks = run_tools(response)
add_user_message(tool_result_blocks)
return messages

## 重构辅助函数
在实现对话循环之前,你需要更新你的辅助函数,以正确处理多个消息块。
### 更新消息处理器
你的 `add_user_message` 和 `add_assistant_message` 函数目前假设你总是在处理纯文本。更新它们以处理完整的消息对象:
from anthropic.types import Message
def add_user_message(messages, message): user_message = { "role": "user", "content": message.content if isinstance(message, Message) else message } messages.append(user_message)
这允许你传入一个字符串、一个块列表或一个完整的消息对象。
### 更新 Chat 函数
修改你的 `chat` 函数以接受一个工具列表,并返回完整的消息而不是仅仅是文本:
def chat(messages, system=None, temperature=1.0, stop_sequences=[], tools=None): params = { "model": model, "max_tokens": 1000, "messages": messages, "temperature": temperature, "stop_sequences": stop_sequences, }
if tools:
params["tools"] = tools
if system:
params["system"] = system
message = client.messages.create(**params)
return message
### 从消息中提取文本
由于你现在返回的是完整的消息对象,创建一个辅助函数以便在需要时提取文本:
def text_from_message(message): return "\n".join( [block.text for block in message.content if block.type == "text"] )
这个函数会查找消息中的所有文本块并将它们连接在一起,这在需要向用户显示最终响应时非常有用。
## 关键改进
这些重构步骤为你的代码处理健壮的工具做好了准备:
- **灵活的消息处理** - 你的辅助函数现在可以处理不同的消息格式
- **聊天中的工具支持** - `chat` 函数可以接收并传递工具 schema
- **完整的消息返回** - 你得到完整的消息对象而不仅仅是文本,保留了所有块
- **文本提取工具** - 从复杂消息中轻松获取可读文本的方法
有了这些基础,你就可以实现自动处理多个工具调用的对话循环了,从而创造出一种无缝的体验,让 Claude 可以根据需要使用任意数量的工具来回答用户的问题。
#### 视频文字稿
我们现在已经看了一个将单个工具连接到 Claude 的例子。但提醒一下,这个项目的目标是将多个不同的工具连接到 Claude。所以我们总共希望有三个不同的工具。我想思考一下,当我们将三个不同的工具连接到 Claude 时,我们的代码会发生什么。
那么让我们来看一个快速的例子。假设我们向 Claude 提交了一条用户消息,询问从今天起 103 天后是哪一天。现在要回答这个问题,Claude 需要使用两个独立的工具。首先,它需要使用 `Get Current Date Time` 来找出当前日期是什么,然后它需要使用 `Add duration to date time` 来给那个日期加上 103 天。
所以幕后会发生这样的事情。一开始,Claude 会立即用一个 `tool use block` (工具使用块) 回应我们,要求我们调用 `Get Current Date Time`。我们会调用那个函数,然后回应 Claude,告诉它当前日期是什么。之后,Claude 会意识到它没有足够的信息来回答用户最初的问题。
它现在需要获取当前日期并加上103天。所以Claude会用另一个单独的工具使用块回应我们,要求我们调用 `add_duration_to_datetime`。我们会调用它,然后将响应传回给Claude。现在Claude有足够的信息来回应我们实际的查询了。
现在我之所以特别给你看这个例子,是因为。如果我们从一个真实的用户,比如一个真实的人那里获得我们原始用户消息的输入,我们不能总是预测他们会向 Claude 提出什么样的问题。所以一个用户可能会问一些奇怪的问题,这需要多次不同的工具调用才能真正回答。所以当我们在我们的应用程序中添加工具调用时,我们真的需要允许这种情况的发生。
每当我们向 Claude 提交某个查询时,我们需要假设 Claude 可能想要连续使用多个工具。每当 Claude 回应我们时,我们需要查看响应,看看 Claude 是否在请求使用工具。如果不是,那么我们知道我们有一个最终的响应,可以最终发送回给我们的用户。这里有一个我们可能如何实现它的伪代码示例。
我们可以创建一个名为 `Run Conversation` 之类的函数,它会接收一个初始的消息列表。然后在 `while` 循环中,我们会联系 Claude,得到一个响应。然后我们会看一下那个响应。如果 Claude 没有请求使用工具,那么我们知道我们有一些响应可以发送回用户。
否则,如果 Claude 确实想使用一个工具,我们可以运行该工具,获取生成的工具结果块,将它们添加到一个用户消息中,然后再次运行 Claude,仍然在 `while` 循环内。在本视频的剩余部分,我们将花一些时间来重构我们的 notebook,以构建一个像这样的函数。所以我们将构建一个像 `run_conversation` 这样的函数,它将经历完全相同的操作系列。然而,为了把这个函数组合起来,我们将要做一点工作。
我们将需要对我们的 `add_user_message` 和 `add_assistant_message` 辅助函数以及 `chat` 函数做一点重构。我整理了一份我们将在 notebook 中做的所有事情的清单,为定义这个 `run_conversation` 函数做准备。在第一步中,我们将升级我们的 `add_user_message` 和 `add_assistant_message` 辅助函数,以便它们能更好地处理多个消息块。记住,每当我们开始使用工具时,我们都会从 Claude 那里得到可能包含多个不同块的响应。
目前,我们的 `add_user_message` 和 `add_assistant_message` 辅助函数完全是基于我们总是处理纯文本块而没有其他任何东西的假设来设置的。所以让我们马上在我们的 notebook 中处理这个问题。回到这里,我仍然在我们一直在使用的同一个 notebook 中。我只是删除了底部的一些包含一些示例工具调用的单元格,这样你就能更好地看到我在屏幕上做什么了。
好的,我将展开辅助函数单元格。我将找到 `add_user_message` 和 `add_assistant_message`。所以再次强调,现在我们假设我们总是得到一些文本,并且我们直接将其分配给 `content` 属性。所以现在我们想在这里允许更多的灵活性。
所以我们将这样做。在单元格的顶部,我将从 `Anthropic.types` 添加一个导入。我将导入 `Message`。然后我将重命名这里的第二个参数。
我将把它叫做 `message` 而不是 `text`。我将像这样展开这个字典。我将把 `text` 更新为 `message.content if isinstance(message, Message) else message`,同样也适用于 `assistant_message`。所以在这里,我将把它重命名为 `message`。
我将展开字典。然后为了节省时间,我将把那条语句复制到这里。好的,现在我将重新运行这个单元格,我将向你展示这次重构会做什么。所以回到这里。
我将像这样添加一个快速的示例调用。所以我只是让 Claude 以我们的分钟秒格式打印出当前时间。并且我提供了我们的 `get_current_datetime` 工具。然后我将打印出我们得到的消息或响应。
如果我运行它,我们会看到我们得到了像这样的常规消息。里面有一个 `content` 属性,它既有一个文本块,也有一个工具使用块。所以现在,为了非常容易地将它作为助手消息添加到我的消息历史中,我将使用 `Messages` 调用 `Add Assistant Message`,然后我现在可以放入我刚刚得到的整个响应,整个消息。所以我将调用它,然后在下一个单元格中打印出 `Messages`。
就这样。我的整个消息历史正在被建立起来。我运行这个的另一种方式是,像这样放入 `response.content`。这同样有效。
所以如果我这样做,然后打印出 `messages`,我仍然得到正确的东西。然后,当然,如果我愿意,我也可以在这里放一个纯字符串。然后打印出 `messages`。我们会看到,是的,仍然在建立那个响应历史。
所以现在我们在 `add_user_message` 和 `add_assistant_message` 中有了一个更灵活的辅助函数。我们可以放入一个纯字符串、一个块列表或整个消息,它会为我们解构这些东西。这将使处理包含某些工具使用块的消息在后续变得容易得多。进入我们重构的第二步。
我们将更新 `chat` 函数以接收一个工具 schema 列表。我们将把这个 schema 列表传递给 `client.messages.create` 函数调用。此外,从 `chat` 函数中,我们不再从助手消息内的第一个块返回纯文本。相反,我们将返回我们从 Claude 那里得到的整个消息。
再一次,这是因为我们现在预期会从 Claude 那里得到包含多个块的响应。而目前,我们的 `chat` 函数总是假设我们只得到一个块,只是一个文本块,没有别的。所以回到这里,这是 `chat` 函数。我将添加一个 `tools`。
它们将被默认设置为 `none`。然后我们将以与我们处理 `system` 相同的方式将其连接起来。所以我们会说,如果有任何工具被传入,我们会将其添加为 `tools` 参数。接下来,我将转到 `return` 语句。
就在这里。正如我刚才提到的,我们的 `chat` 函数目前的设置是假设我们总是从 Claude 那里得到一个单一的块,而且这个块总是一个文本块。这就是为什么我们有这段代码。我们做了一个非常大的假设,即我们总是得到那一个单一的块,而且它总是包含一些文本。
因为我们现在正在使用工具,情况不再是这样了。我们可能会得到一个包含多个块的消息,所以在这个 `content` 列表中有多个条目。其中一个可能是文本块,但我们不一定有保证。所以,与其总是做这个假设,我现在将返回整个消息。
这对我们来说会有点不方便,因为现在如果我们想获取文本,我们就得做更多的工作,但这绝对安全得多,因为,这确实反映了现实。好的,就是这样。所以现在,在同样的情况下,我们现在要添加一个小小的辅助函数。我们称它为 `text_from_message`。
这里的目标是查看一条消息,查看所有的块,找到所有的文本块,然后只从中提取文本。所以这有点像替换了我们刚才移除的功能。它将使从给定的消息中提取所有文本变得容易得多。所以我将在 `chat` 下面添加那个辅助函数。
我称之为 `text_from_message`。它将接收一条消息。在这里面,我将返回一个新的 `log new line`,它将连接一个 comprehension 和 `block.text.for block in message.content if block.type is equal to text`。所以这将查看一条消息中的所有不同块。
如果块是文本块,那么我们就只提取块的文本,然后将所有块的文本连接在一起并返回它。所以,这只是一个辅助函数,使从特定消息中获取所有文本变得更容易一些。好的,我们已经完成了大部分的重构。所以现在最后一步,我们马上就会处理,就是为单个对话中的多个工具调用添加支持。
所以,基本上,我们需要实现一个像这样的函数。我们需要创建一个函数,它会接收消息列表,然后继续调用 Claude,直到我们得到一个信号,表明 Claude 不再想调用工具了。
---
### 39. 实现多轮对话
> 类型:视频 | 时长:16:25 | 视频:06 - 008 - Implementing Multiple Turns.mp4
构建一个带工具的对话系统需要实现一个循环,该循环会持续调用 Claude,直到它停止请求工具使用。当 Claude 不再请求工具时,这标志着它已经为用户准备好了最终的响应。
## 检测工具请求
了解 Claude 是否想使用工具的关键在于响应消息的 `stop_reason` (停止原因) 字段。当 Claude 决定需要调用一个工具时,该字段会被设置为 "tool_use"。这为我们提供了一种清晰的方式来检查是否需要继续对话循环:
if response.stop_reason != "tool_use": break # Claude is done, no more tools needed
## 对话循环
主对话函数遵循一个简单的模式:
def run_conversation(messages): while True: response = chat(messages, tools=[get_current_datetime_schema]) add_assistant_message(messages, response) print(text_from_message(response))
if response.stop_reason != "tool_use":
break
tool_results = run_tools(response)
add_user_message(messages, tool_results)
return messages
这个循环会一直持续,直到 Claude 提供一个最终答案而不再请求任何工具。
## 处理多个工具调用
Claude 可以在一个响应中请求多个工具。消息内容包含一个块列表,我们需要分别处理每个 `tool use block` (工具使用块):
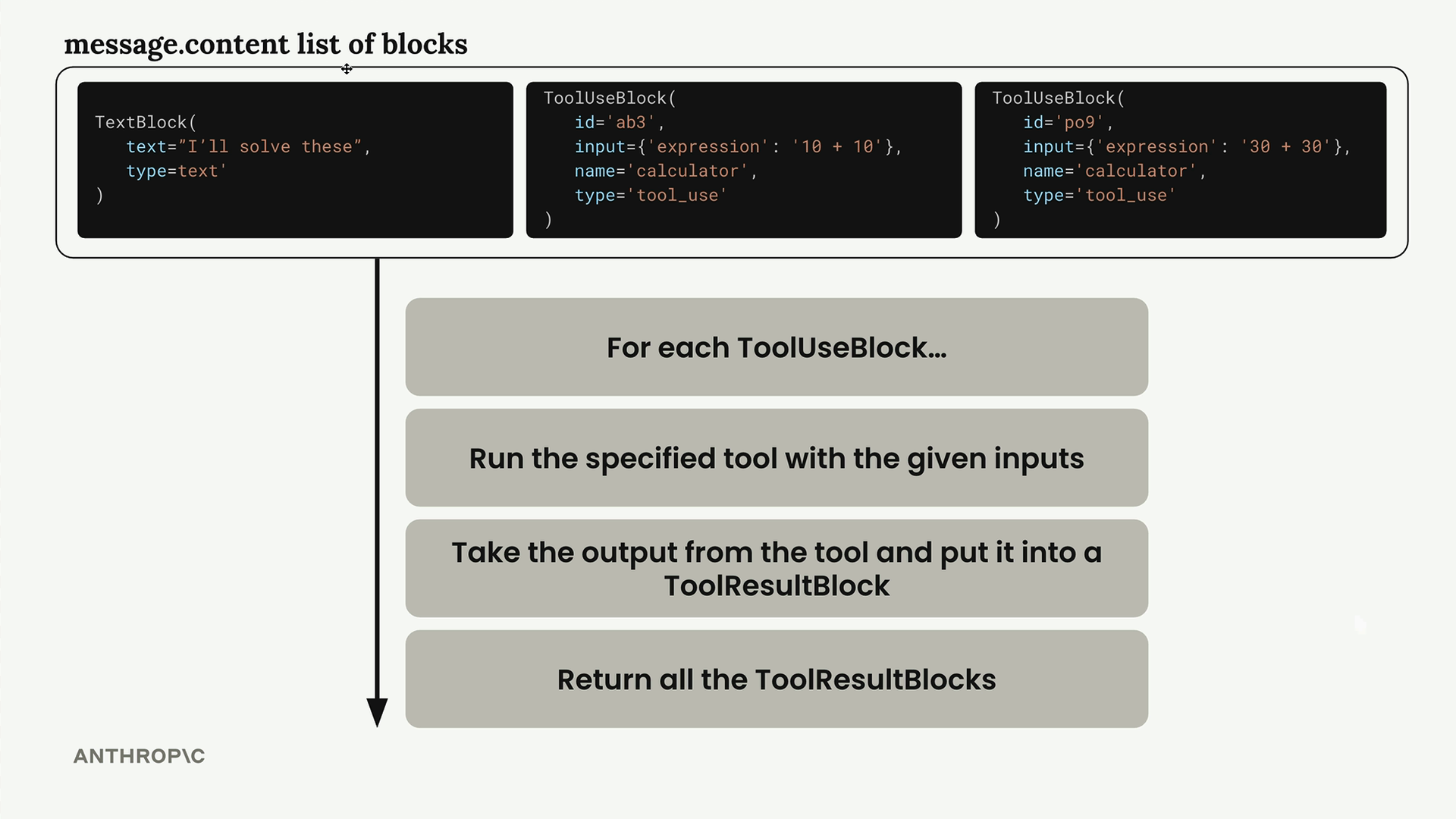
`run_tools` 函数通过筛选工具使用块并处理每一个来解决这个问题:
def run_tools(message): tool_requests = [ block for block in message.content if block.type == "tool_use" ] tool_result_blocks = []
for tool_request in tool_requests:
# Process each tool request...
## 工具结果块
每个工具使用块都必须用一个相应的 `tool result block` (工具结果块) 来回应。它们之间的连接通过匹配的 ID 来维持:
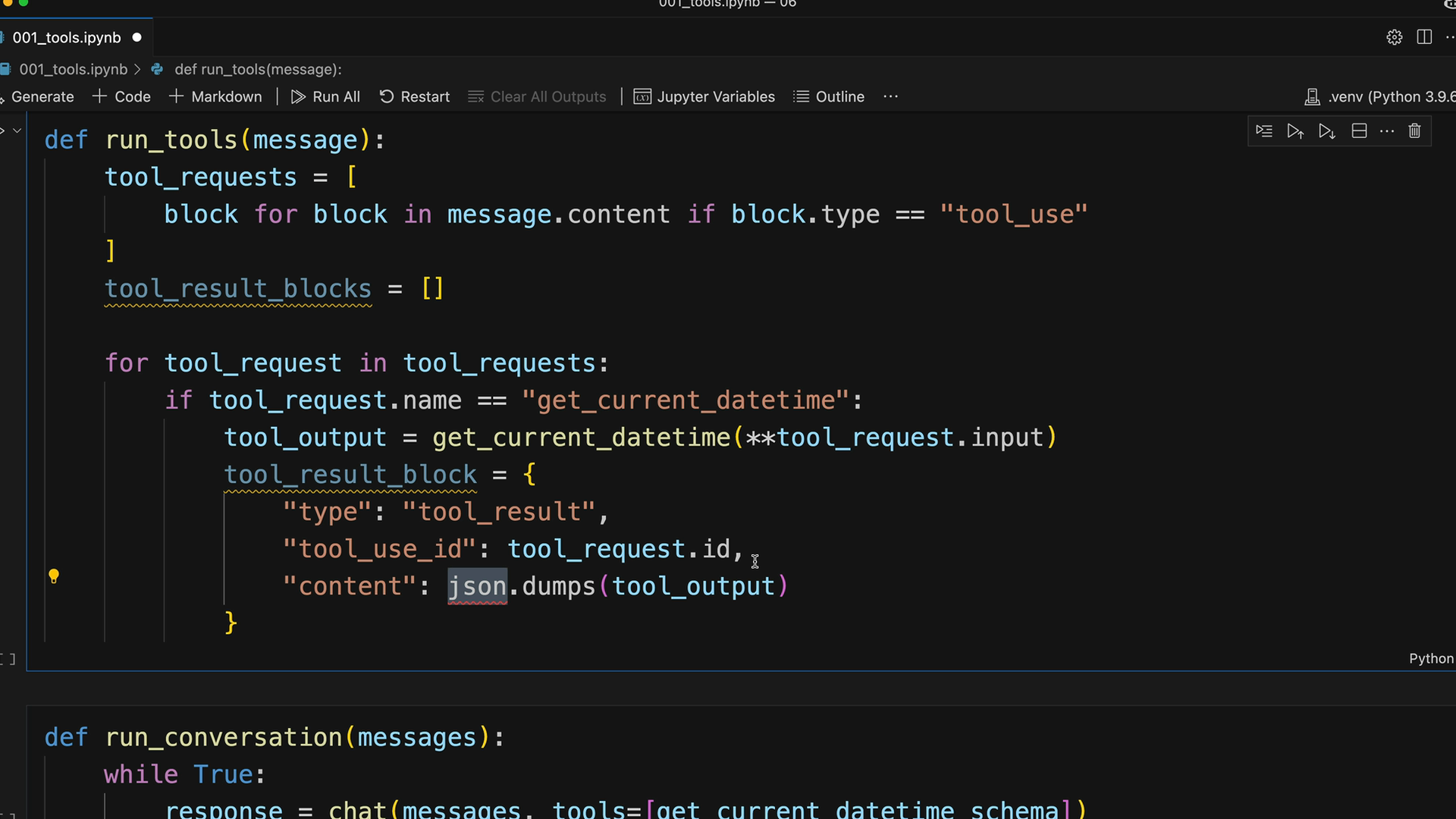
工具结果块的结构包括:
tool_result_block = { "type": "tool_result", "tool_use_id": tool_request.id, "content": json.dumps(tool_output), "is_error": False }
## 错误处理
健壮的工具执行需要处理潜在的错误。当一个工具失败时,我们仍然需要向 Claude 提供一个结果块:
try: tool_output = run_tool(tool_request.name, tool_request.input) tool_result_block = { "type": "tool_result", "tool_use_id": tool_request.id, "content": json.dumps(tool_output), "is_error": False } except Exception as e: tool_result_block = { "type": "tool_result", "tool_use_id": tool_request.id, "content": f"Error: {e}", "is_error": True }
## 可扩展的工具路由
为了支持多个工具,创建一个路由函数,将工具名称映射到它们的实现:
def run_tool(tool_name, tool_input): if tool_name == "get_current_datetime": return get_current_datetime(**tool_input) elif tool_name == "another_tool": return another_tool(**tool_input) # Add more tools as needed
这种方法使得在不修改核心对话逻辑的情况下添加新工具变得容易。
## 完整工作流
完整的多轮对话工作流程如下:
- 向 Claude 发送带有可用工具的用户消息
- Claude 以文本和/或工具请求作为回应
- 执行所有请求的工具并创建结果块
- 将工具结果作为用户消息发回
- 重复此过程,直到 Claude 提供最终答案
这就创造了一种无缝的体验,Claude 可以在多个回合中使用多个工具来完全回答复杂的用户请求。对话历史记录维护了完整的上下文,允许 Claude 在之前的工具结果基础上构建,以提供全面的响应。
#### 视频文字稿
既然我们完成了重构,我们将开始实现一个像 `run conversation` 这样的函数。实际上,我们真正的实现将与你在这里右侧看到的几乎完全相同。记住,这个函数的全部目标是不断调用 Claude,直到它不再请求使用工具。当它不再请求使用工具时,这对我们来说是一个信号,表明 Claude 有一个最终的响应,可以发送回我们的用户了。
我们首先要真正理解的是,我们如何知道 Claude 是否想使用一个工具。我们可以只看响应消息,看看里面是否有 `tool use block` (工具使用块)。但有一个更方便的方法。回到我的 notebook,我将再次运行那个小示例,这次我直接使用 `client messages, create`,而不是我们的 `chat` 函数。
我可以运行它,这是我的消息响应。现在,在里面,你会注意到有一个名为 `Stop Reason` 的字段,它被设置为一个字符串 "tool_underscore_use"。让我稍微给你讲讲那个字段。这个字段告诉我们 Claude 为什么决定停止生成任何更多的文本。
我们当前的 tool use 值对我们来说是一个信号,表明 Claude 已经决定它需要调用一个工具。所以如果我们的响应消息,我们从 Claude 那里得到的助手消息,有一个 tool use 的停止原因,那是一个非常清晰和直接的信号,表明 Claude 想要使用一个工具。还有一些其他可能的停止原因值。我们当然可以检查这些,但你最常检查的肯定会是 tool use。
所以这就是我们将如何实现那个小小的 if 语句。好的,让我们回到我们的 notebook。我们将开始实现这个 `run conversation` 函数。回到这里。
我将清除那个单元格。它只是为了演示目的。我将定义我的 `run conversation` 函数。它将接收一个消息列表,然后我们将设置我们的循环。
在这里面,我们将通过我们新升级的、现在支持工具的 `chat` 函数调用 Claude 来获得一个响应。所以我将传入我的消息列表,以及 Claude 可以调用的一些工具。在这种情况下,我们目前只有一个工具。所以我将在这里添加。
这是我们的 `get_current_datetime_schema`。然后我将获取我得到的那个响应,并使用新升级的 `add_assistant_message` 函数将其添加到我的消息对话历史中。然后我将使用我们刚刚组合的 `text_from_message` 函数打印出那个响应。我打印它只是为了让我们了解 Claude 当前在做什么。
所以我将用 `response` 打印出 `text_from_message`。好的,现在是我们使用 `stop_reason` 的部分。我们需要看一下我们刚从 Claude 那里得到的消息,并了解 Claude 是否想使用一个工具。如果它不想使用一个工具,那么我们想立即跳出这个 `while` 循环。
所以我们会说,如果 `response.stop_underscore_reason` 不等于 `tool_underscore_use`,那么这就表明 Claude 已经完成了,它不需要再使用任何工具了。所以我们会立即 `break`。如果我们通过了那个 `if` 语句,那么我们知道 Claude 想要调用一个工具。所以我们马上要组合一个新函数。
我们称它为 `Run Tools`。我们将传入我们刚从 Claude 那里得到的消息。`Run Tools` 的目标是查看这个消息中的所有 `tool use block` (工具使用块) 并为每个块运行相应的工具。我将在 `Run Conversation` 上方的一个新单元格中定义 `Run Tools` 函数。
所以在这里,我将组合一个名为 `Run Tools` 的新函数,它将接收一条消息。现在,这个函数组合起来会有点棘手,因为我们必须假设这里可能有多个工具调用。所以让我给你看一张图,以确保 `run tools` 内部需要发生的事情非常清楚。快速提醒一下,每当 Claude 给我们一个助手消息时,它可能包含不止一个工具使用块。
我们之前已经看过了。所以如果我们最初让 Claude 把 10 加 10 和 30 加 30 加起来,它可能会给我们返回两个独立的工具使用块。一个可能会要求我们运行一个计算器工具来计算 10 加 10。第二个工具使用块可能会要求我们计算 30 加 30。
所以我们需要设置这个 `run tools` 函数,假设我们可能有多个 `tool use block` (工具使用块)。所以这个函数将这样工作。我们将查看我们刚收到的那条消息,特别是它的 `content` 属性。记住 `content` 属性将是一个块的列表。
在里面,我们可能会有一个文本块,告诉我们 Claude 当前在想什么或做什么。我们不太关心那个文本块,所以我就从这张图中删掉它了。然后我们就只剩下两个独立的,或者可能更多,工具使用块了。所以在这个 `RunTools` 函数里,我们将遍历我们得到的所有不同的工具使用块。
对于每一个,我们将用给定的输入运行指定的工具。所以我们会看这个 `name` 字段。我们会找到要运行的合适的工具函数,然后用给定的输入运行它。然后我们会把每次工具运行的所有输出,组装成独立的 `tool result block` (工具结果块)。
记住,`tool result block` (工具结果块) 是我们向 Claude 传达运行工具结果的方式。一旦我们组装好所有这些不同的工具解析块,我们会把它们全部放进一个列表里,然后从 `Run Tools` 函数返回。好的,我们来试试实现这个。我知道这很令人困惑。
我知道这里有很多东西,但代码本身实际上没有最初看起来那么糟糕。所以回到这里,在 `Run Tools` 内部,我首先要做的是查看这个消息的 `content` 属性。那是一个块的列表。我将只提取工具使用块。
所以我将说 `tool request. is block for block in message.content if block.type is equal to tool use`。所以,这里有一点筛选操作。我们只获取 `tool use` 块,因为那些是我们唯一关心的。我特地称之为 `tool request`,因为我认为这比 `tool use` 更有意义。这些是 Claude 请求我们使用一个工具的请求。
然后我将创建一个名为 `tool_result_blocks` 的空列表。它最终将包含我们创建的所有不同的工具结果。然后我将遍历所有这些不同的工具请求。所以 `for tool_request in tool_request`。所以现在我们正在遍历每个单独的工具请求。
所以这里就是我们现在需要用给定的输入运行一个指定的工具。我们根据这个 `name` 属性知道我们想运行哪个工具。所以我们会说,如果 `toolrequest.name` 等于花括号,我们唯一的工具是 `get current date time`。那么我想用 `tool request` 中的 `star star inputs` 运行 `get current date time` 函数。所以 `tool request dot input`。
那会给我一些工具输出。我现在要用这个工具输出来组装一个全新的工具结果块。我们已经有一段时间没有使用工具结果块了,所以让我给你快速提醒一下这些东西是什么。好的,左手边是一个工具使用块。
这是我们目前正在处理的。这是 Claude 请求使用一个工具。右手边是一个 `tool result block` (工具结果块)。所以这是我们为响应 Claude 运行一个工具的请求而制定的。
记住,工具结果块有几个不同的属性,我们需要给它分配。首先,它会有一个 `tool use ID`。这需要与导致我们运行特定工具的工具使用块中的 ID 完全相等。注意这里左手边的 ID 字段,它叫做 ID,然后在工具结果块上,它是一个完全不同的属性。
它是一个 `tool use ID`,但它们需要完全相等。然后 `content` 将是我们工具运行的输出,也就是实际的工具函数。我们需要确保我们只是把它编码成一个字符串,没问题。如果运行工具时出现错误,我们还可以添加那个可选的 `is air` 属性。
然后最后,我们还需要添加一个 `tool_underscore_result` 类型。好的,回到这里,既然我们有了我们的工具输出,我们将组装我们的工具结果块。它将拥有我刚才指出的所有那些属性。它将有一个 `tool result` 类型,一个 `tool request.id` 的 `tool use ID`。
它会有一个 `content`,我将获取我从我的工具中得到的任何东西,并使用 `JSON dump string` 将其编码为 JSON。我需要确保我导入了 JSON,所以我将在这个单元格的顶部这样做。好了。然后最后,`is air`。
我现在将它设置为 `false`,我们马上会添加更健壮的错误处理。所以现在我们创建了我们的 `tool result block` (工具结果块),我们将把它添加到我们的 `two result blocks` 列表中。所以我将做一个 `tool result, blocks append in tool result block`。然后最后,在 `for` 循环之外,我将返回 `tool result blocks`。
好的,这就是我们 `run tools` 函数的开始。所以我们至少对它为我们做了什么有了一个概念。我们将筛选出所有不同的工具使用块,对于每一个,我们将运行某个给定的工具函数,然后将结果放入一个 `tool result block` (工具结果块),组装所有结果并返回那个列表。所以现在我们将对这个函数做两个快速的改进。首先,我们将添加更好的错误处理。
我们目前总是说没有错误。这绝对不准确。当我们运行我们的工具函数时,可能会出现某种错误。所以我将立即在这里做一个小改进,以捕获我们在运行工具时可能发生的任何错误。
为此,我将用一个 `try`。`Except` 语句来包装它。我将修复我的缩进,像这样。然后如果我进入下面的 `except` 语句,我仍然想组合一个 `tool result block` (工具结果块) 并将其添加到这个列表中。但现在我想有一个 `is error` 为 `true`。我可能想把错误消息放入这里的 `content` 字段,这样 Claude 就能更好地理解刚刚发生了什么错误。
所以我将复制这里的 `tool_result_block`,粘贴到 `accept` 语句里面。我将把 `is error` 改为 `true`。然后对于 `content`,我将放入一个 f-string,其中我放入带有 `E` 的 `air`。所以,我再次向 Claude 提供一些信息,帮助你理解为什么会发生错误。
记住,每当发生错误时,Claude 可能会尝试用一些更好的参数或格式更好的参数再次运行你的工具。好的,这是我们的第一个改进。现在,我想要做的第二个改进是,现在我们只考虑一种工具,`get current date time` 工具。记住,稍后,我们可能会有多个不同的工具。
所以除了 `get_current_datetime`,我们最终还会支持 `adoration to date time` 和 `set a reminder`。老实说,我们甚至会在此之后再添加一个。所以使用这里的这种模式,我们有一个 `if` 语句,只检查 `get_current_datetime`,扩展性不是很好。所以为了找出要运行哪个工具并实际运行它,我将在 `run tools` 上方再创建一个辅助函数。
我将称之为 `run_tool`。它将接收一个工具名称和该工具的输入。然后在这里面,我们将做一系列 `if` 语句或任何检查,来找出我们需要运行哪个工具函数,然后实际运行它并返回结果。所以如果 `tool_name` 是 `get_current_datetime`,那么我将返回 `get_current`,`date_time`,带有 `star star`,`tool`,`input`。
所以现在用这种方法,如果我们以后再添加额外的工具,我们可以在这里再添加额外的 `if` 检查。所以如果 `tool_name` 是我们有的其他任何工具,我们就可以运行那个特定的工具函数。所以我们很快就会回到 `run tool`,并在稍后添加一些额外的工具。好的,所以现在为了使用那个函数,我将回到这里。
我将把那个块缩进到 `try`,`accept` 和 `tool_results`。我将删除 `if` 语句,然后用 `run_tool` 替换这里的 `get current daytime`。我将把我们的 `tool request.name` 和 `tool request.input` 传递给它。就这样。
好的,这有点痛苦的重构,但这就是我们的 `run tools` 函数。不需要再做任何更改了。它会运行得很好。我们也把我们的 `run tool` 函数组合好了,也运行得很好。
所以现在我们需要做的最后一件事就是回到我们的 `conversation` 函数,并使用 `run tools`。这是我们调用 `run tools` 的地方。所以 `run tools` 现在将返回我们的 `tool result blocks` 列表。所以我得到 `tool results`。
我将把它添加到我的对话历史中。所以用 `messages` 和 `tool results` 添加 `user message`。然后在 `while` 循环之外,我将确保它们在 `while` 之外,我将返回消息列表。就这样。
好的,所以现在这个 `run_conversation` 函数包含了我们讨论的整个循环。所以每当我们进入 `run_conversation` 时,我们将调用 Claude,我们会得到一些助手消息。如果助手消息在请求任何工具,那么我们将继续通过 `if` 语句。我们将运行那些工具,得到结果,并将它们作为用户消息添加到我们的消息列表中。
然后我们将再次回到 `while` 循环的顶部,用那些消息中的工具结果列表再次调用 Claude。我们将一遍又一遍地重复这个过程,直到 Claude 不再请求使用工具为止。所以现在到了希望一切都能正常工作的地步了。我们将在下面做一个快速测试。
所以,我将创建一个消息列表。我将向其中添加一条用户消息。我将让 Claude 做一些可能需要两次独立工具调用的事情。所以我将让 Claude 以我们的时、分格式,以及秒格式,告诉我当前时间。
所以理论上,Claude 可能会把它分成两次独立的工具调用。然后我将调用 `run.conversation` 并传入消息列表。我将重新运行这个 notebook 中的所有单元格,因为我们现在已经改变了非常多的东西,所以我们将运行全部,然后我们将看一下我们得到的响应。
所以看起来这绝对是正确的答案,但我想看一下消息列表,真正理解发生了什么。所以,最初,我们有我们的用户消息。然后我们得到 Claude 的初始响应。它有一个文本块和一个工具使用块。
所以再一次,一条包含多个块的消息。这就是为什么现在确保我们所有的代码都能正确处理多个不同块如此关键。在这第一条消息中,我们有一个工具使用块,Claude 试图以我们的分钟格式获取当前时间。然后我们用一个工具结果来回应。
然后有趣的部分来了。Claude 决定向我们发起第二次工具调用。所以在第二次工具调用中,我们不再有文本部分了,再次强调了在单条消息中正确处理多个不同工具部分的重要性。在这第二条消息中,我们现在有了一个工具使用块。
Claude 现在将尝试以秒为单位调用 `get_current_datetime`。然后我们把结果发回给 Claude,然后我们得到 Claude 的最终响应,它只有一个文本块,上面写着“这是你最初查询的答案”。所以这是一个完美的结果,它明确地突出了我们刚刚经历的每一步。运行我们的对话直到我们有一个不要求使用工具的响应的整个过程。
在我们的 `run tools` 函数中,查看我们收到的所有不同块,只挑出工具使用块,然后为每个块运行一个工具,将响应格式化为一个工具结果,然后将所有不同的工具结果发回给 Claude 的重要性。这个视频很长,可能也相当令人困惑,但我们现在已经有了一个多轮工具调用的绝佳例子。所以现在我们在这个项目中要做的最后一件事是确保我们可以支持多个不同的工具。我们需要添加对 `adoration to daytime` 工具和 `set reminder` 工具的支持。
---
### 40. 使用多个工具
> 类型:视频 | 时长:3:38 | 视频:06 - 009 - Using Multiple Tools.mp4
一旦你拥有了核心的工具处理基础架构,向你的 Claude 实现中添加多个工具就变得很简单了。本教程展示了如何通过遵循一个简单的模式来集成额外的工具。
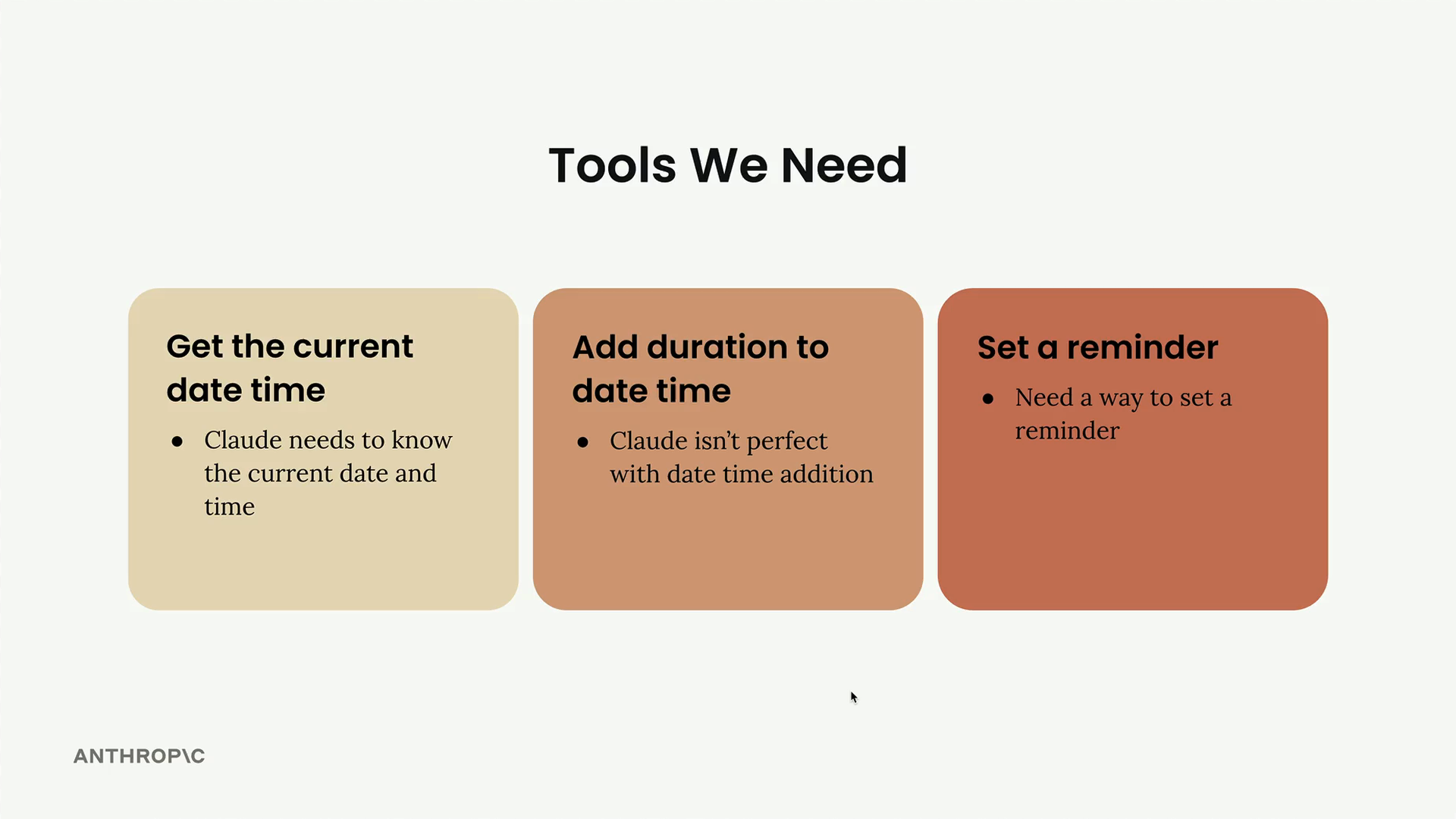
## 我们要添加的工具
我们的提醒系统需要三个主要功能:
- **获取当前日期时间** - Claude 需要知道当前的日期和时间
- **给日期时间添加时长** - Claude 在日期时间加法上并不完美
- **设置提醒** - 需要一种设置提醒的方法
好消息是,大部分实现工作已经完成了。提供了 `add_duration_to_datetime` 函数和 `set_reminder` 函数,以及它们对应的 schema。
## 向对话中添加工具
首先,更新 `run_conversation` 函数,在 `tools` 列表中包含新的工具 schema:
response = chat(messages, tools=[ get_current_datetime_schema, add_duration_to_datetime_schema, set_reminder_schema ])
这告诉 Claude 在对话期间它可以使用所有三个可用的工具。
## 更新工具路由器
接下来,修改 `run_tool` 函数以处理新的工具调用。为每个新工具添加 `elif` 分支:
def run_tool(tool_name, tool_input): if tool_name == "get_current_datetime": return get_current_datetime(**tool_input) elif tool_name == "add_duration_to_datetime": return add_duration_to_datetime(**tool_input) elif tool_name == "set_reminder": return set_reminder(**tool_input)
这个模式很简单:检查工具名称,用提供的输入调用相应的函数,然后返回结果。
## 测试多种工具的使用
为了测试系统,可以尝试一个需要多种工具的请求:“为我的医生预约设置一个提醒。时间是 2050 年 1 月 1 日之后的第 177 天。”
这个请求会强制 Claude:
1. 计算日期(使用 `add_duration_to_datetime`)
2. 设置提醒(使用 `set_reminder`)
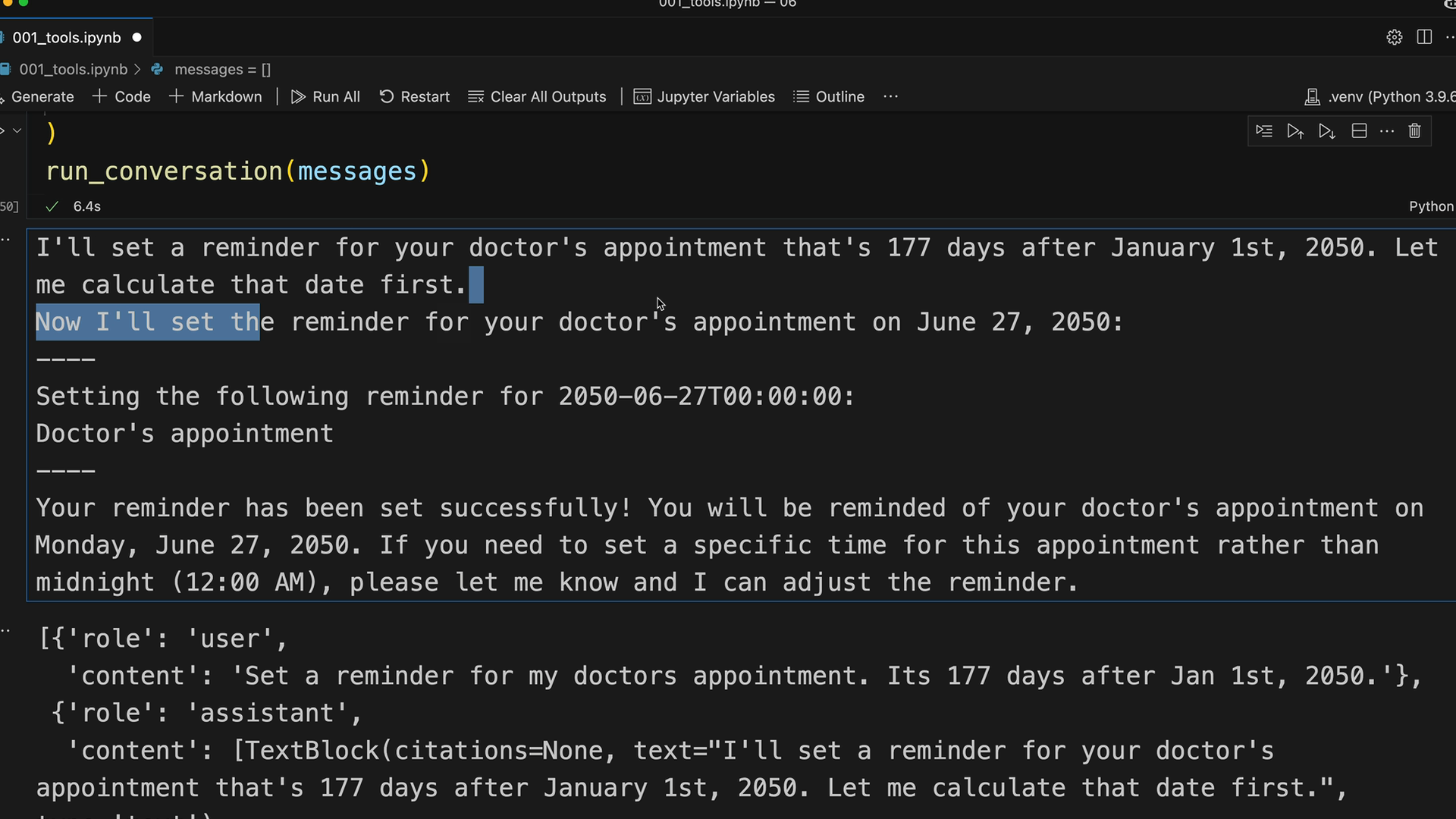
Claude 首先会解释它需要做什么,然后按顺序进行相应的 Tool Call (工具调用)。对话显示 Claude 计算出目标日期为 2050 年 6 月 27 日,然后为该日期设置了提醒。
## 理解消息流
当你检查对话历史时,你会看到完整的消息结构:
- 包含请求的用户消息
- 同时包含文本和工具使用块的 Assistant 消息
- 工具结果消息
- 后续的 Assistant 消息
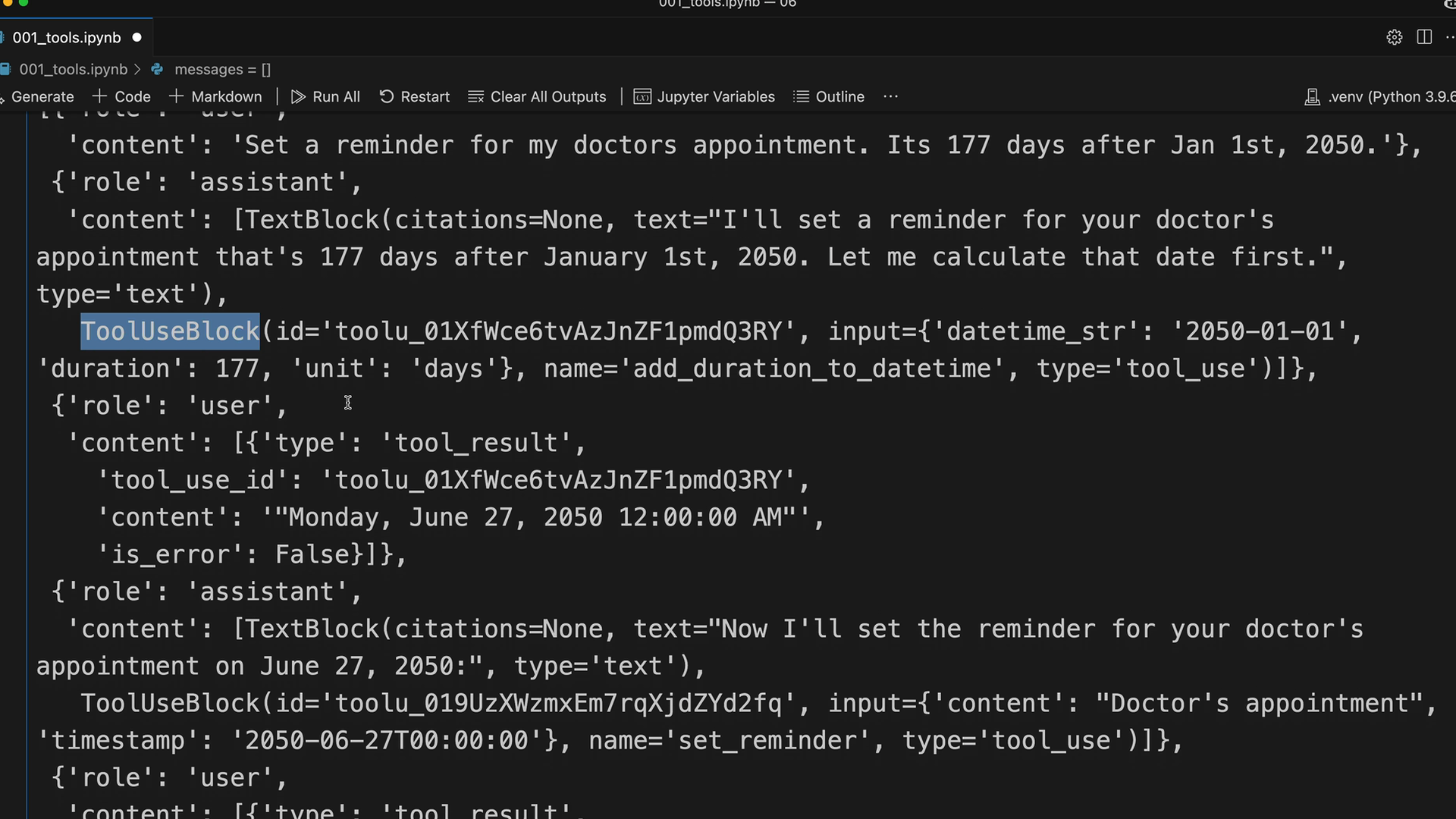
这演示了 Claude 如何在单条消息中包含多个块——将解释性文本与工具使用请求结合起来。
## 添加工具的简单模式
一旦你有了核心的工具基础架构,添加新工具就遵循以下模式:
1. 创建工具函数的实现
2. 定义工具的 schema (模式)
3. 在 `run_conversation` 中将 schema 添加到工具列表
4. 在 `run_tool` 中为该工具添加一个 case
这种模块化的方法使得扩展 AI Assistant 的能力变得容易,而无需重构现有代码。每个新工具都能无缝地与现有的对话流和工具处理逻辑集成。
#### 视频文字稿
我们最后要做的是加入 `Add Duration to DateTime` 工具和 `Set Reminder` 工具。这部分内容会有点反高潮,因为上一个视频相当有挑战性,而这个视频会非常简单、简短和直接。事实证明,我已经把我们需要的大部分代码都放在了 `Tools and Schemas` 单元格里。
你会发现我已经在这里实现了一个 `add_duration_to_datetime`。如果你向下滚动,你会看到我也已经准备好了 `set_reminder` 函数。`set_reminder` 实际上并不会设置提醒之类的东西,它只是会打印一条语句,说“嘿,我们在这个时间用给定的内容设置了一个提醒”。
我还为我们提供了 `add_duration_to_date time` schema 和 `set_reminder` schema。所以我们真正需要做的就是把这两个 schema 传给 Claude,并且我们还需要确保如果 Claude 要求使用任一工具,我们就调用相应的工具函数。那么,我们开始吧。这应该非常直接。
首先,我将找到 `run_conversation` 函数。在里面,我将找到工具列表,然后将 `add_duration_to_date time` schema 和 `set_reminder` schema 也添加进去。这样一来,Claude 就知道这两个其他工具的存在了。接下来,我只需要稍微往上一点,找到 `run_tool` 函数。
这个函数会接收一个工具名称和一些参数。我们所要做的就是找到相应的工具函数调用,调用它,然后返回结果。所以把东西加进去非常容易。我们来加一个 `if` 条件。
检查一下工具名是否是 `add_duration_to_date time`。如果是,我们就返回一个对 `add_duration_to_date time` 的调用,并传入 `**tool_input`。然后我将为另一个工具重复这个操作。如果工具名是 `set_reminder`,就返回 `set_reminder` 并传入 `**tool_input`。
就是这样。所以 `set_reminder` 传入 `tool_input`。就这样。一旦你把 `run_tool` 函数和 `run_conversation` 函数组合好,在最初的困难之后,所有关于工具使用的事情都变得非常简单和直接,因为添加额外的工具超级简单。
只需更新 `run_tool`,添加一个工具 schema,为实际的工具函数本身添加一个实现,然后就完成了。你已经全部搞定了。现在我们来测试一下。我要确保重新运行那个单元格。
我将重新运行 `run_conversation`。然后在最下面,我们来更新一下查询。我将要求 Claude 设置一个提醒。我会说提醒需要设置在 2050 年 1 月 1 日之后的 177 天。
这肯定会导致不止一次的工具调用。Claude 首先必须调用 `add_duration_to_datetime`,然后再设置提醒。我们来运行一下,看看效果如何。Claude 最初告诉我们它需要计算出 1 月 1 日之后的 177 天是哪天。
一旦计算出来,它就会尝试设置提醒。然后我们在这里看到了一个日志语句。这个日志语句来自 `set_reminder` 函数。记住,`set_reminder` 实际上什么也不做,它只是打印出给它的参数。
最后,我们从 Claude 那里得到一个回应,告诉我们我们的预约已经设置在 2050 年 6 月 27 日星期一这个正确的日期。我们也可以去看看消息对话历史。再次,我们有用户消息,这里的 Assistant 消息有一个文本块。除了文本块,再次地,还有一个工具使用块。
所以我们又一次看到了一个包含多个不同块的消息的例子。然后我们用工具结果来回应。我们得到一些后续信息。从这里开始,我想你明白这个过程了。
好了,就是这样。我们已经在我们的 notebook 中接入了多个不同的工具。进展非常棒。
---
### 41. batch tool (批量工具)
> 类型:视频 | 时长:8:26 | 视频:06 - 010 - The Batch Tool.mp4
在使用 Claude 的工具调用能力时,你可能会注意到 Claude 可以在单个 Assistant 消息中包含多个工具使用块。这使得 Claude 可以并行运行多个工具,而不是为每个工具都单独发出请求。然而,在实践中要让 Claude 始终这样做可能具有挑战性。

例如,如果你要求 Claude 为同一天设置两个提醒,理想情况下它会返回一个包含两个工具使用块的响应。但通常,Claude 会先进行第一次工具调用,等待你的响应,然后再在一次单独的往返中进行第二次工具调用。
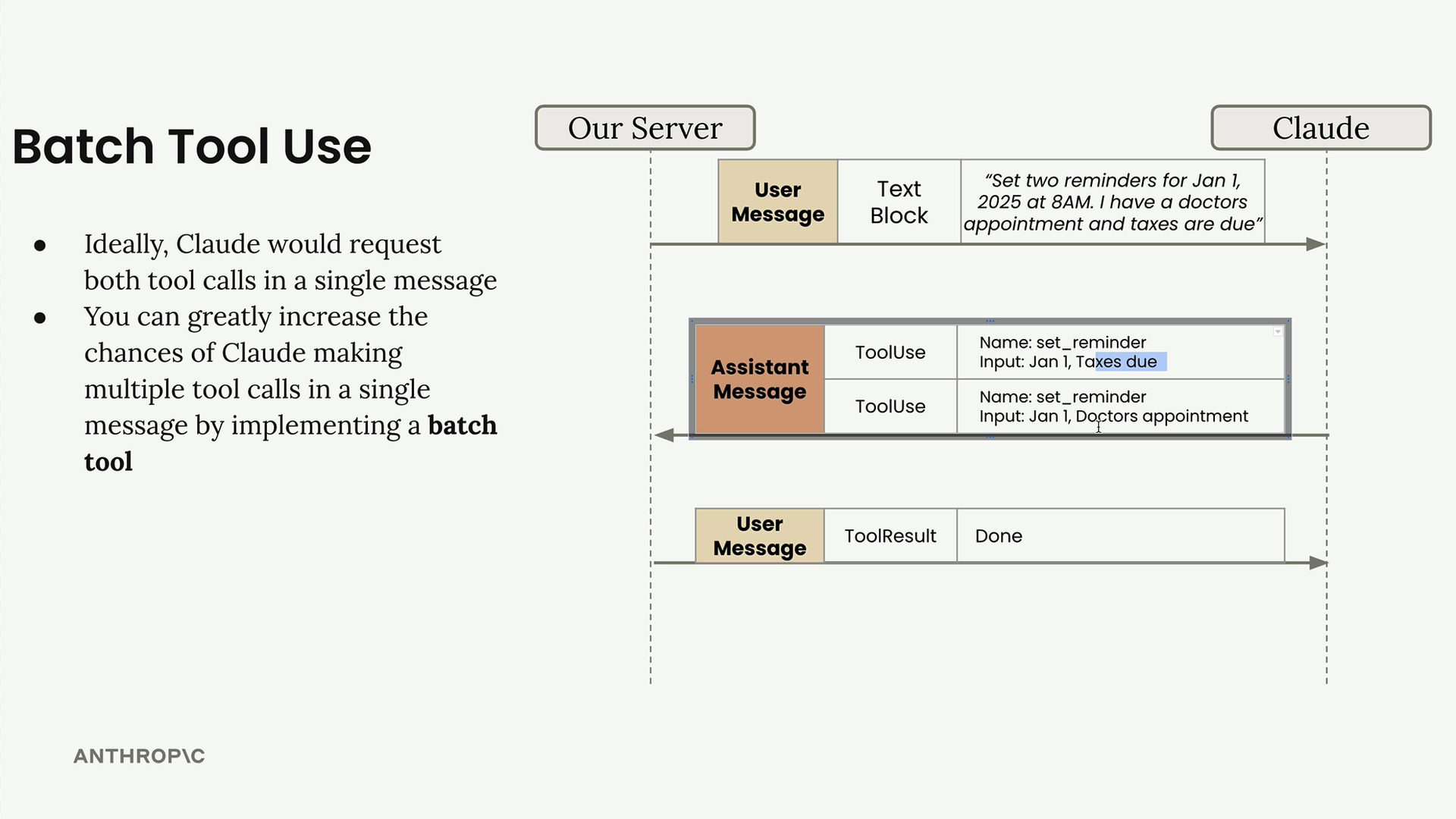
当这些操作可以同时执行时,这会产生不必要的来回通信。解决方案是实现一个 `batch tool (批量工具)`,以鼓励 Claude 一次性请求多个工具调用。
## 批量工具的工作原理
批量工具是一个额外的工具,它接受一个对其他工具的调用列表。Claude 不再直接调用多个工具,而是调用批量工具,并提供描述它想要运行哪些工具的参数。

批量工具接收一个 `invocations (调用)` 列表,其中每个调用都指定:
- 要调用的工具名称
- 传递给该工具的参数
当你收到一个批量工具调用时,你的代码会遍历调用列表并执行每个请求的工具调用。
## 实现批量工具的 Schema
首先,你需要为批量工具定义 schema。结构如下:
batch_tool_schema = { "name": "batch_tool", "description": "Invoke multiple other tool calls simultaneously", "input_schema": { "type": "object", "properties": { "invocations": { "type": "array", "description": "The tool calls to invoke", "items": { "type": "object", "properties": { "name": { "type": "string", "description": "The name of the tool to invoke" }, "arguments": { "type": "object", "description": "The arguments to pass to the tool" } } } } } } }
## 实现批量处理函数
接下来,你需要创建处理批量工具调用的函数:
def run_batch(invocations=[]): batch_output = []
for invocation in invocations:
name = invocation["name"]
args = json.loads(invocation["arguments"])
tool_output = run_tool(name, args)
batch_output.append({
"tool_name": name,
"output": tool_output
})
return batch_output
这个函数:
1. 遍历列表中的每个调用
2. 提取工具名称和参数
3. 使用你现有的 `run_tool` 函数调用相应的工具
4. 将所有结果收集到一个批量输出列表中
你还需要更新你的主工具路由函数来处理批量工具:
def run_tool(tool_name, tool_input): if tool_name == "get_current_datetime": return get_current_datetime(**tool_input) elif tool_name == "add_duration_to_datetime": return add_duration_to_datetime(**tool_input) elif tool_name == "set_reminder": return set_reminder(**tool_input) elif tool_name == "batch_tool": return run_batch(**tool_input)
## 结果
实现后,当 Claude 识别出多个操作可以并行执行时,它将更有可能使用批量工具。你将看到 Claude 调用批量工具并附带它想执行的所有操作的列表,而不是发出单独的请求。
批量工具本质上是一种变通方法,它为 Claude 提供了并行工具执行的更高层次抽象。虽然这看起来可能是一种不寻常的方法,但它是一种有效的技术,可以鼓励 Claude 将相关操作批量处理,从而减少 API 的往返次数并提高整体效率。
#### 视频文字稿
我已经重复好几次了,单个 Assistant 消息可以包含多个工具使用块。例如,如果我们要求 Claude 计算 10 加 10 和 30 加 30,Claude 可能会返回一个包含两个独立工具使用块的 Assistant 消息。Claude 已经意识到这两个操作可以并行运行。所以我们可以同时进行两次工具调用,然后向 Claude 发送一个包含两次评估结果的单一后续回复。
然而,我们会注意到,在实践中,让 Claude 这样做有时会有点挑战性。让我来告诉你为什么。回到我的 notebook,我已经更新了我的提示。我现在要求 Claude 并行执行两个任务。
我要求它在同一天设置两个独立的提醒。第一个提醒将有那段文本,第二个提醒在那里。现在,Claude 完全没有理由不能给我们返回一个包含两个工具使用块的单一响应。但如果我运行这个单元格,我们会很快看到实际情况并非如此。
如果我看一下输出的消息,我会注意到我收到的初始 Assistant 消息实际上只有一个工具使用块。然后我在这里又进行了一轮请求,我收到的第二个 Assistant 消息有另一个工具使用块。让我用图表的形式向你展示一下这里发生了什么。好的,情况是这样的。
我们向 Claude 发送了初始用户消息,要求设置两个独立的提醒。然后在我们收到的第一个响应中,只有一个工具使用块。我们然后用工具结果来回应它,接着我们又单独收到了另一个工具使用块。这里的这一额外请求轮次是完全没有必要的。
理想情况下,应该发生的是这样。我们发送初始用户消息,然后我们会收到一个包含两个独立工具使用块的 Assistant 消息。一个用于设置税务到期预约,另一个用于医生预约。虽然 Claude 有能力返回一个包含多个工具使用块的响应,但它这样做的频率并不像我们希望的那么高。
然而,有一个小技巧可以大大增加 Claude 在单条消息中返回多个工具使用的机会。这个技巧就是实现一个批量工具。让我来确切地告诉你什么是批量工具。批量工具出奇地简单。
这是另一个工具,就像 `get current date time` 或 `add duration to date time` 一样,是我们已经创建好的工具。你和我将为这个工具定义 schema 和一个函数。然后我们会像传入我们已经创建的所有其他工具一样,把它传入 Claude。
批量工具 schema 告诉 Claude 它可以并行运行多个其他工具。如果 Claude 决定确实要运行多个其他工具,它不会直接调用那些工具,而是会调用批量工具。并且它会提供一些参数,就像你在这里看到的这样。它将是一个对象列表,其中每个对象都代表 Claude 想要调用的某个其他工具。
所以我们可能会有一个对象代表为医生预约设置提醒,然后另一个对象代表为税务到期设置提醒。每当我们收到一个包含批量工具使用的响应时,你和我就要编写一些代码来处理这个对象数组。我们会遍历它,并调用这里列出的每一个工具。所以你可以把这看作是这些工具使用块之上的一个抽象。
这里的问题是,Claude 并不是真的想用多个工具使用块来回应,所以我们有点像给了它一个更高层次的抽象,这个抽象做的事情和有多个工具使用块完全一样。唯一的区别在于,你和我通过实现这个批量工具来手动处理它。这听起来可能很疯狂,我认为这确实有点疯狂,但就像我说的,这很大程度上是一个技巧。我们有点像在“欺骗” Claude 并行调用多个工具。
那么,让我们回到我们的 notebook,尝试实现这个批量工具。好的,回到这里,为了帮助我们,在 `Tools and Schema` 部分的底部,我已经为我们提供了一个批量工具的 schema。当 Claude 决定调用批量工具时,它会提供一个调用列表(invocations)。这个列表描述了 Claude 想要调用的所有其他工具。
在这个 `invocations` 列表内部,会有一个 Claude 想要调用的其他工具的名称,以及要提供给该工具的一些参数。我想给你快速演示一下这个东西是如何工作的。所以我将折叠那个单元格。我将转到我们的 `run conversation` 函数这里,然后我将加入那个批量工具的 schema。
然后我将确保我运行那个单元格。然后我将转到我下面的演示单元格,在那里我要求 Claude 做两件事,希望是并行的。现在我将再次运行这个。在我看结果之前,有一件非常重要的事情我想指出。
我们现在已经加入了批量工具的 schema,但我们还没有为它提供一个实现。换句话说,没有代码来实际处理 Claude 想要做的那个 `invocations` 列表并实际运行它们。所以这是我们仍然需要实现的东西。让我们看一下消息列表,看看 Claude 决定做什么。
好的,我们有初始的用户消息,然后是一个后续的 Assistant 消息。在那个消息里面,有一个文本块,然后是一个单一的工具使用块。如果你仔细看,Claude 确实决定使用批量工具。所以 Claude 想要运行两个独立的工具。
我们可以在 `invocations` 列表中看到它们被列出来了。所以我们将进行两次独立的调用,一次是调用 `set reminder`,内容是 `I have a doctor's appointment`,然后第二次调用,内容是 `taxes are due`。所以很明显,Claude 已经决定使用批量工具来并行化这两个独立的 `set reminder` 调用。所以现在我们所要做的就是为批量工具提供一个实际的实现。
让我来告诉你我们怎么做。首先,我将向上滚动到我们的 `run tool` 函数。就在这里。我将加入一个额外的 `else if` 条件。
所以如果 Claude 想要运行批量工具,我将返回一个对我们将要实现的新函数 `run batch` 的调用。并且我将再次使用 `star star tool input`。然后我将在这个函数正上方实现 `run batch` 函数。所以我们将加入一个 `run batch`。
它将接收一个 `invocations` 列表。我将把它默认设置为空列表。在函数内部,我们将编写一些与我们在 `run tools` 内部所做的非常相似的逻辑。所以我们将遍历 Claude 要求的所有不同调用。
我们将运行相应的工具。然后我们会构建某种响应,将所有这些不同的响应添加到一个列表中,然后在最后返回一个列表。所以这是我们如何做的。首先,我将创建一个列表,用于存放我们进行的所有这些不同工具调用的输出。
我将把它命名为 `batch output`。我将确保在函数底部返回它。在中间,我将遍历 Claude 请求的所有不同调用。所以对于 `invocation` in `invocations`,我将提取出 Claude 想要运行的工具的名称以及它的参数。
现在,这里传入的参数是以 JSON 格式编码的。所以我们需要使用我们已经导入的 JSON 模块来解析那个 JSON,就在那里。所以我可以用 `JSON load string` 来包装它。然后我们将通过使用这里的 `run tool` 函数来运行请求的工具。
`run tool` 已经接收一个工具名称和一些参数,并调用相应的工具。所以我们可以利用这一点来确保我们调用了相应的工具。我将通过调用带有 `name` 和 `arcs` 的 `run tool` 来获取一些工具输出。然后我将在我们的 `batch output` 列表中加入一条新记录,描述这次调用及其产生的结果。
所以我将加入 `batch output`,我将向它追加一个 `tool_name` 为 `name` 和一个 `output` 为 `tool_output`。现在我们来测试一下。我将确保我运行这个单元格。
然后我将转到我最底部的测试单元格。我将再次运行这个。现在我们已经为调用提供了实际的实现,我们应该会很快看到两个独立的提醒被完全并行地设置。非常好。
绝对成功了。如果我们看一下列出的消息,我们会再次得到我们的 Assistant 块。它有一个工具使用块,正在尝试用两个独立的调用来调用批量工具。然后我们用一个 `two result` 来回应。
在里面,我们可以看到我们两次独立调用 `set reminder` 的结果。输出是 `null`,这是预期的,因为现在 `set reminder` 工具实际上不返回任何东西。
---
### 42. 用于结构化数据的工具
> 类型:视频 | 时长:7:56 | 视频:06 - 011 - Tools for Structured Data.mp4
当你需要从 Claude 获取 `structured data (结构化数据)` 时,主要有两种方法:使用 `message prefills (消息预填充)` 和 `stop sequences (停止序列)` 的基于提示的技巧,或者使用一种更可靠的方法——工具。虽然基于提示的方法设置起来更简单,但工具提供了更可靠的输出,但代价是增加了额外的复杂性。
## 用于结构化数据的工具
基于工具的方法通过创建一个 JSON schema 来定义你想要提取的数据的确切结构。你不再是希望 Claude 能正确格式化其响应,而是实质上给了 Claude 一个函数去调用,该函数的特定参数与你期望的输出结构相匹配。

以下是该过程的工作原理:
- 编写一个描述你正在寻找的数据结构的 schema
- 使用 `tool_choice` 参数强制 Claude 使用一个工具
- 从工具使用响应中提取结构化数据
- 无需提供后续响应——一旦你获得数据,任务就完成了
例如,如果你想从一份财务报表中提取财务余额和关键见解,你的 schema 会将它们分别定义为一个整数和一个字符串数组。
## 控制工具使用
这项技术的关键部分是确保 Claude 确实调用了你的工具。你可以使用 `tool_choice` 参数来控制此行为:
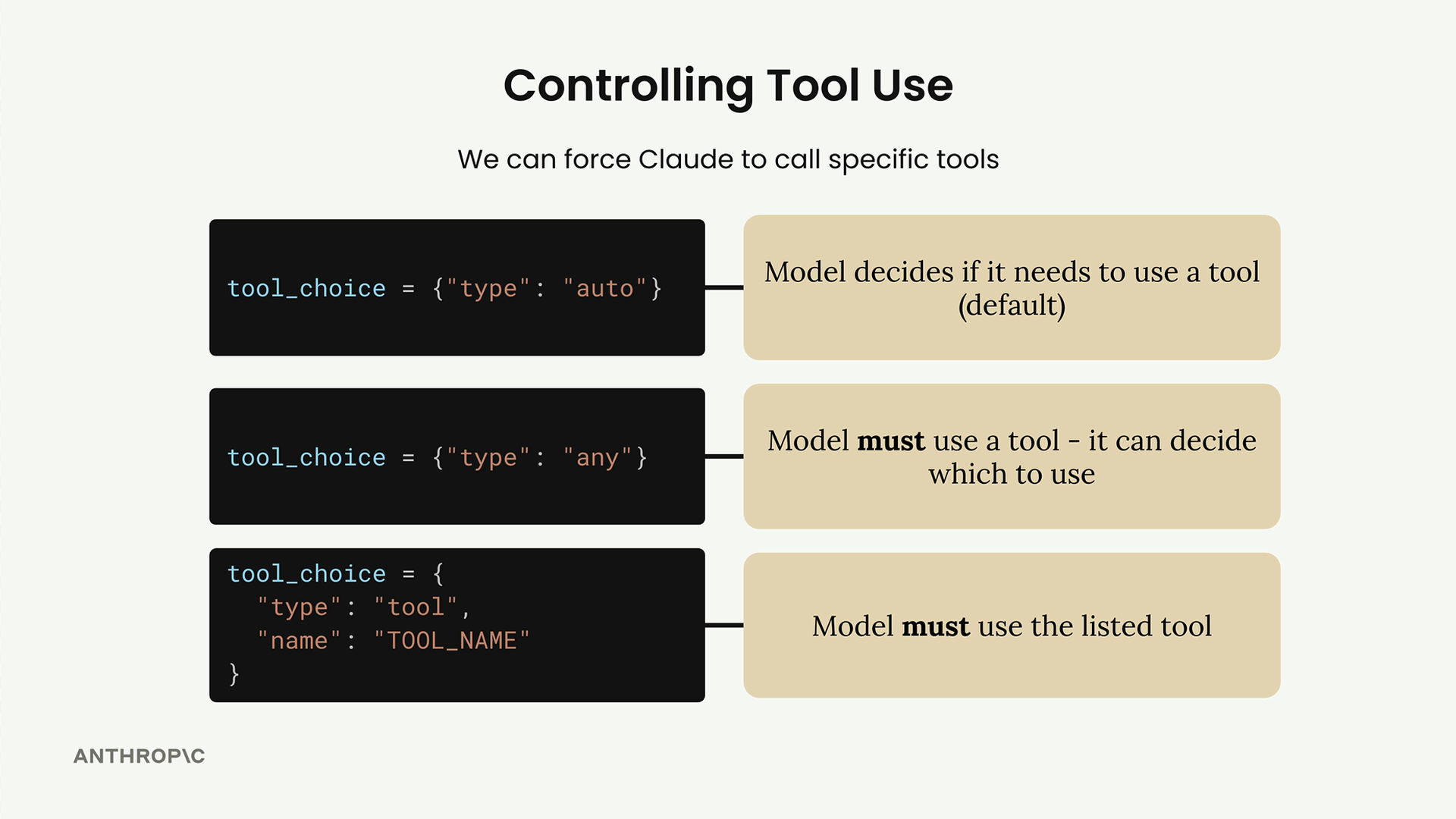
- `{"type": "auto"}` - 模型决定是否需要使用工具(默认)
- `{"type": "any"}` - 模型必须使用一个工具,但可以选择使用哪一个
- `{"type": "tool", "name": "TOOL_NAME"}` - 模型必须使用指定的工具
对于结构化数据提取,你通常会选择第三个选项,以保证 Claude 调用你特定的 schema 工具。
## 实现示例
假设你想从一篇文章中提取标题、作者和关键见解。首先,你会创建一个工具 schema:
article_summary_schema = { "name": "article_summary", "description": "Extracts structured data from articles", "input_schema": { "type": "object", "properties": { "title": {"type": "string"}, "author": {"type": "string"}, "key_insights": { "type": "array", "items": {"type": "string"} } } } }
然后你会调用 Claude,并强制它使用该工具:
response = chat( messages, tools=[article_summary_schema], tool_choice={"type": "tool", "name": "article_summary"} )
响应将包含一个工具使用块,其中 `input` 字段里有你的结构化数据。你可以直接访问它:
structured_data = response.content[0].input
## 何时使用哪种方法
当你需要快速简单地输出时,选择基于提示的结构化输出。当你需要保证可靠性并且能够处理额外的设置复杂性时,使用工具。这两种技术都很有价值,具体取决于你的特定用例和要求。
#### 视频文字稿
在本课程的前面部分,我们讨论了如何通过一些巧妙的技巧从 Claude 获取结构化输出。特别是,我们讨论了使用消息预填充(message pre-fill)和停止序列(stop sequences),以及一个精心设计的提示,以便从 Claude 那里获得一些 JSON。现在,这种方法确实效果很好,而且设置起来非常简单,但我们可以通过非常巧妙地使用工具来获得更可靠的输出。所以我们将看一下如何仅使用工具来实现结构化输出,而无需担心任何消息预填充或停止序列。
我预计你的第一个问题之一将会是,既然我们一直都可以使用工具,为什么还要学习这种结构化输出的方式呢?嗯,答案很简单。使用工具进行结构化输出需要更多的设置,复杂性也更高。
所以,同时掌握这两种获取结构化数据的能力是非常有价值的,因为在某些情况下,你可能只想使用这种基于提示的结构化输出。在其他情况下,你可能想使用工具。好了,让我们来看看如何利用工具来生成结构化数据。正如我刚才提到的,这是一种从某些数据源中提取结构化数据(主要是 JSON)的替代方法。
这比我们之前看过的技术更可靠,但同样,设置起来要复杂得多。这里的总体思路是,我们将为一个工具编写一个 JSON schema 规范,其输入将是我们正在寻找的数据结构。所以回到刚才,当我们看这个提示时,我们可以想象我们要求 Claude 查看一份财务报表,并提取一个整数类型的余额和一个字符串列表类型的关键见解。所以,如果我们想用基于工具的结构化输出来处理这个问题,我们会写出一个 JSON schema 规范,其中输入将是一个整数类型的余额和一个字符串列表类型的关键见解。
然后我们会将这个 JSON schema 规范连同我们可能想从中获取一些信息的财务数据一起提供给 Claude。现在,在这一点上,让我给你展示一个流程图,因为它在图表格式下更容易理解。好的,所以和以前一样,我们将为 Claude 写出一个合理的提示。所以我们可能会说,分析一份财务报表,然后调用某个提供的工具。
除了这个包含所有报表数据的提示外,我们还将提供那个 schema。所以这些将发送给 Claude。Claude 会查看提示。它会看到可用的工具,然后它会说,啊,太棒了。
我将调用这个财务分析工具,并确保我提供的参数与这个结构相匹配。所以 Claude 之后会用一个工具使用块来回应我们。在该块中,它会要求调用财务分析工具。其输入将是我们在这个财务分析 schema 中指定的确切输入。
所以我们会得到一个整数类型的余额和一个字符串列表类型的关键见解。一旦我们得到了这些数据,我们就完成了。所以不像通常的工具调用那样,我们通常会用一个工具结果块来回应,这里我们不需要这样做,因为我们唯一的目标就是获取这里提取的 JSON。就是这样。
所以一旦我们收到 Assistant 消息作为回应,我们差不多就是对 Claude 说,谢谢你的 JSON,我们完成了,我们不会再有任何后续请求。最后我想提的一件事是,这项技术的关键部分是确保 Claude 调用我们提供给它的工具。为了强制 Claude 调用特定工具,我们可以在调用 `client.messages.create` 函数时提供一个 `tool_choice` 参数。具体来说,我们可以提供一个 `tool_choice`,它是一个字典,类型为 `tool`,名称是我们想强制 Claude 调用的工具的名称。
所以在这种情况下,如果我们提供一个名为 `analyze_financial_statement` 的 schema,我们会把 `analyze_financial_statement` 放在这里,像这样。现在我们对这一切如何工作有了个概念,让我们回到我们的 notebook,进行一些实践操作。回到这里,我在一个名为 `002 Structured Data` 的新 notebook 里,它应该附在这节课上。它包含了我们之前使用的 notebook 中所有相同的代码。
唯一的区别是我在底部添加了这个额外的单元格。这个单元格将要求 Claude 写一篇关于计算机科学的一段式学术文章,并包含标题和作者名。我将快速运行这个,然后看看生成的文章。这篇文章有一个标题和作者名,然后是一些附带的文本。
所以我想尝试从这段文本中提取一些 JSON 数据。具体来说,我想提取标题作为字符串,作者作为字符串,然后我想从文章中提取一个包含一些关键见解的字符串列表。为此,我们将为一个新工具编写一个 schema 定义。我们的 schema 将向 Claude 明确指出,为了调用那个工具,它必须提供一个字符串类型的标题、一个字符串类型的作者,以及一个关键见解列表的参数。
这些也将是一个字符串列表。记住,创建新工具定义的最简单方法是利用 Claude 本身。所以我再次打开了我的浏览器。我在这里打开了关于工具使用的文档。
我将再次复制这个页面。我将要求 Claude 为一个名为 `Article Summary` 的函数写出一个工具 schema。这个函数应该被调用时带有标题(字符串类型)、作者(字符串类型)和一个关键见解列表。我将粘贴文档并运行它。
作为回应,我将得到我的 `article summary` 工具定义。所以现在我将复制这个,带回我的 notebook。我将转到包含我们所有其他工具和 schema 的单元格。我将把它粘贴到这里,并称之为 `article_summary_schema`。
就这样。我还要确保运行那个单元格。接下来我想做的是更新我们的 `chat` 函数实现。所以在 `helper_functions` 上方的单元格里,我将找到 `chat` 函数。
记住,这个 JSON 提取操作的一个关键方面是确保 Claude 总是调用你制作的特定工具。所以我们想确保我们的 `chat` 函数可以接收一个 `tool_choice` 参数,并且这个 `tool_choice` 将被传递给我们的实际 `client.messages .create` 函数调用。所以回到这里,我将再添加一个 `tool_choice` 参数。同样,我将把它默认设置为 `none`。
然后我们将像我们设置 `tools` 那样来设置它。所以如果提供了 `tool_choice`,那么 `params.tool_choice` 将会是 `tool_choice`。我还要确保运行这个单元格。我认为我们已经具备了进行一次小测试所需的一切。
在我的 notebook 最底部,我将添加一个新单元格。所以在这里,我将添加 `messages`。我将添加一个用户消息。我想加入我们刚刚从上一个单元格的响应中得到的文本。
所以,我将从 `response.message` 中添加一些文本。这将从该响应中提取所有文本,并将其添加为普通的用户消息。我将用 `messages` 列表来调用 `chat`。然后我们需要提供我们的 `tools` 列表,这里就只有 `article_summary_schema`。
最后,我们想强制 Claude 调用那个特定的工具。所以我们将放入一个 `tool_choice`,它将是一个字典,类型为 `tool`,名称为 `article_summary`。然后我将保存这个文件以重新格式化代码。好了。
这样看起来好多了。好了,现在我们来运行这个,看看我们得到了什么。在响应消息中,我们有一个 `tool_use` 块,像往常一样有 `inputs`。这里的 `inputs` 将是一个包含我们要求的所有数据的字典。
所以这里有标题、作者,然后是 `key_insights`,它将是一个不同字符串的列表。所以如果我们只想单独访问那些数据,我们可以把调用 `chat` 的结果赋给 `response`,然后打印出 `response .message[0].tool_calls[0].function.arguments`,像这样。让我再运行一次,现在我们就得到了我们的结构化数据。
---
### 43. fine-grained tool calling (细粒度工具调用)
> 类型:视频 | 时长:10:56 | 视频:011.1 - Fine Grained Tool Calling.mp4
当你将 Tool Use (工具使用) 与 Claude 中的 `streaming (流式传输)` 结合使用时,你会随着 AI 生成工具参数而获得实时更新。这创造了更具响应性的用户体验,但关于其幕后工作原理,有一些重要的细节需要了解。
## 基本的工具流式传输
启用流式传输后,Claude 在处理你的请求时会发回不同类型的事件。你已经熟悉像 `ContentBlockDelta` 这样的用于常规文本生成的事件。对于工具使用,你还需要处理一种新的事件类型,名为 `InputJsonEvent`。
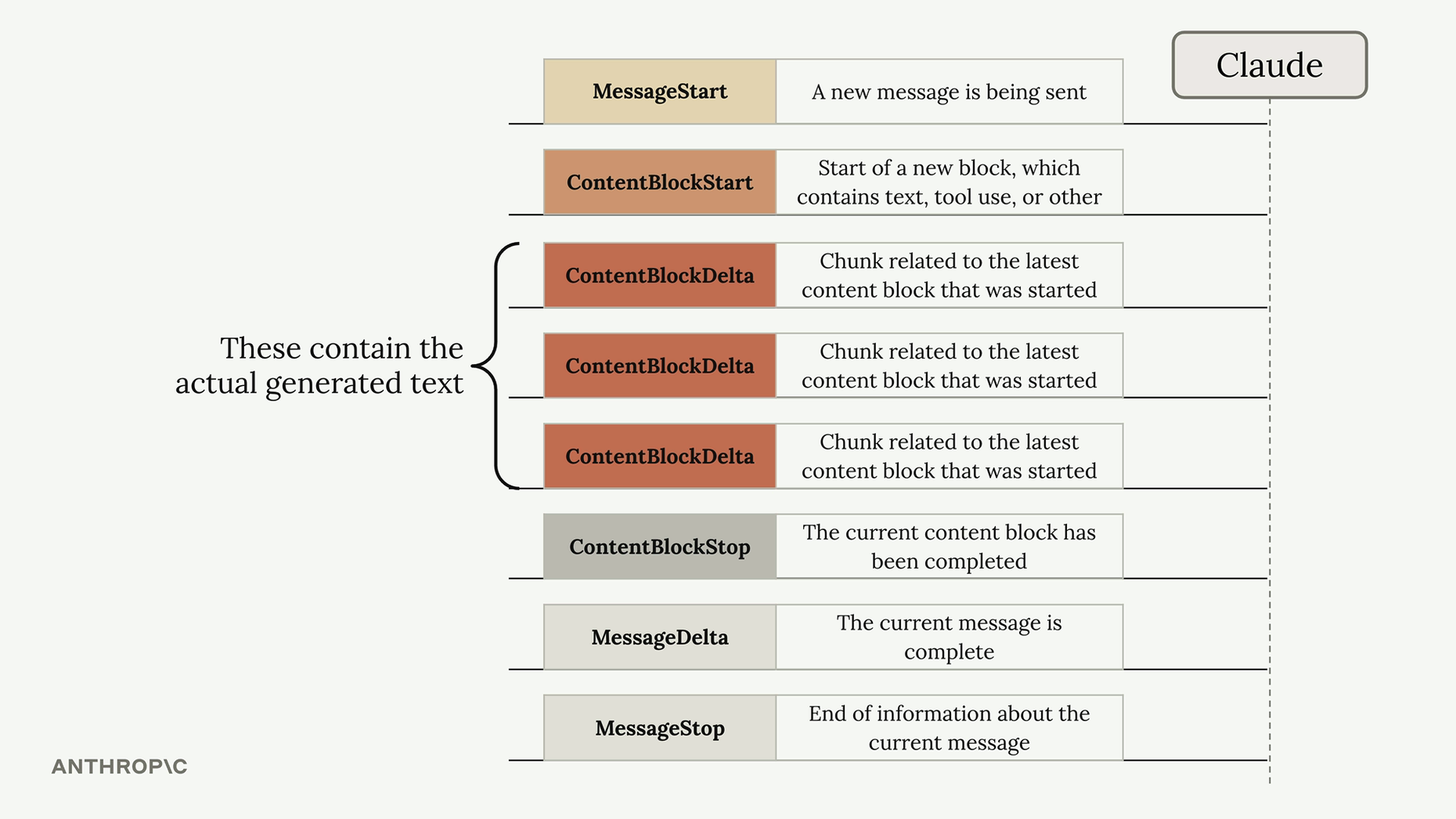
每个 `InputJsonEvent` 包含两个关键属性:
- **`partial_json`** - 一块代表工具参数一部分的 JSON
- **`snapshot`** - 从迄今为止收到的所有块累积构建的 JSON
以下是你在流式传输管道中处理这些事件的方式:
for chunk in stream: if chunk.type == "input_json": # Process the partial JSON chunk print(chunk.partial_json) # Or use the complete snapshot so far current_args = chunk.snapshot
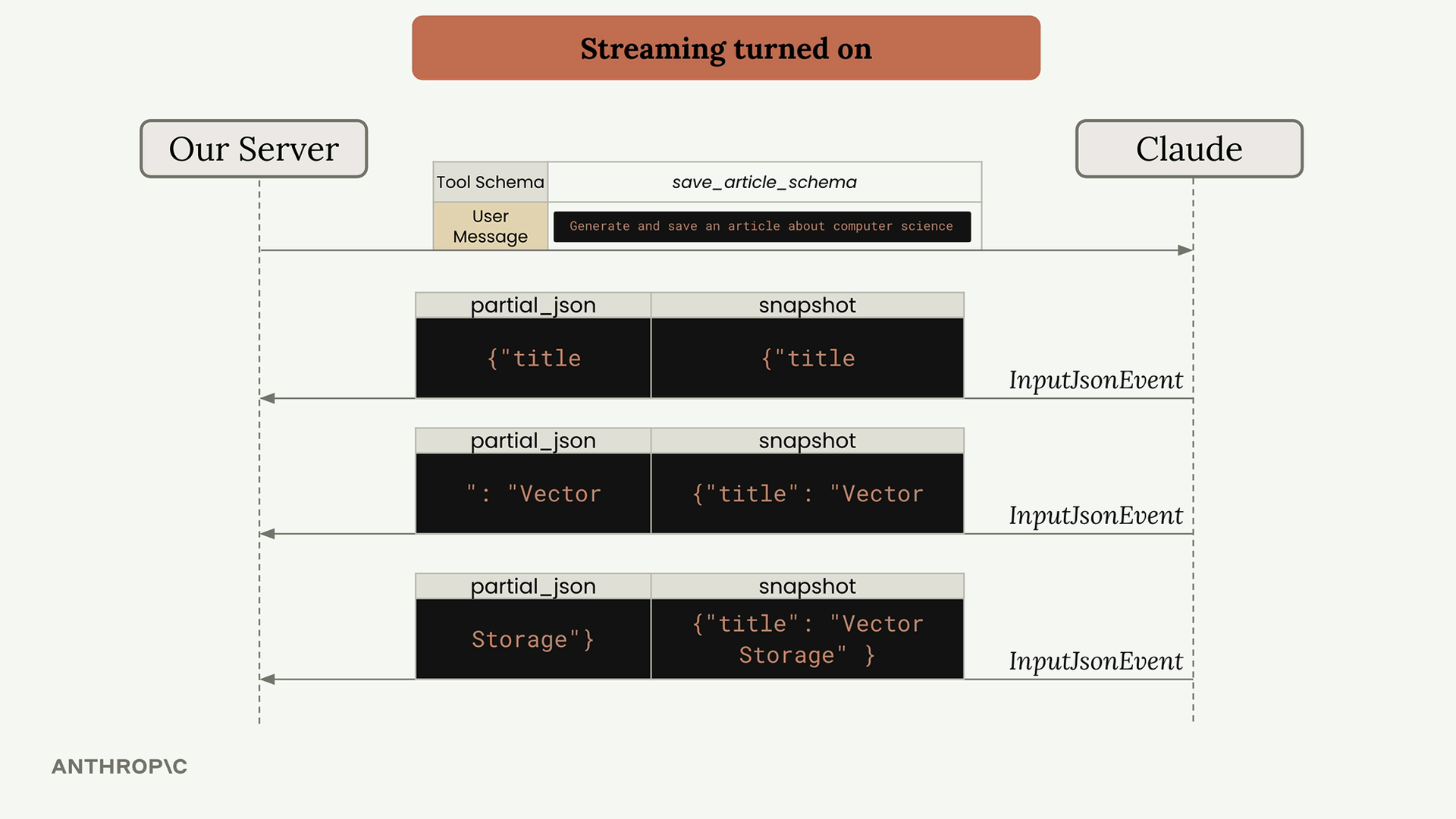
## JSON 验证如何工作
有趣的地方来了。Anthropic API 不会立即将 Claude 生成的每个块都发送给你。相反,它会先缓冲这些块并进行验证。

API 会等待完整的顶层键值对完成后再发送任何内容。例如,如果你的工具期望这个结构:
{ "abstract": "This paper presents a novel...", "meta": { "word_count": 847, "review": "This paper introduces QuanNet..." } }
API 将会:
1. 等到整个 `abstract` 值完成后
2. 根据你的 schema 验证该键值对
3. 一次性发送所有为 `abstract` 缓冲的块
4. 为 `meta` 对象重复此过程
这个验证过程解释了为什么即使启用了流式传输,你还是会看到延迟,然后是文本的爆发式出现。这些块被扣留,直到一个完整、有效的顶层键值对准备好。
## 细粒度工具调用
如果你需要更快、更精细的流式传输——也许是为了向用户显示即时更新或快速开始处理部分结果——你可以启用 `fine-grained tool calling (细粒度工具调用)`。

细粒度工具调用主要做一件事:它禁用了 API 端的 JSON 验证。这意味着:
- Claude 一生成块,你就会收到它们
- 顶层键之间没有缓冲延迟
- 更传统的流式传输行为
- **关键:** JSON 验证被禁用——你的代码必须处理无效的 JSON
通过在你的 API 调用中添加 `fine_grained=True` 来启用它:
run_conversation( messages, tools=[save_article_schema], fine_grained=True )
使用细粒度工具调用,你可能会在流的更早阶段收到一个 `word_count` 值,而无需等待整个 `meta` 对象完成。
## 处理无效的 JSON
使用细粒度工具调用时,Claude 可能会生成像 `"word_count": undefined` 这样的无效 JSON,而不是一个合适的数字。你的应用程序需要优雅地处理这些情况:
try: parsed_args = json.loads(chunk.snapshot) except json.JSONDecodeError: # Handle invalid JSON appropriately print("Received invalid JSON, continuing...")
如果不使用细粒度工具调用,API 的验证会捕捉到这个错误,并可能将有问题的值用字符串包装起来,这可能与你期望的 schema 不匹配。
## 何时使用细粒度工具调用
当出现以下情况时,考虑启用细粒度工具调用:
- 你需要向用户展示工具参数生成的实时进度
- 你想尽快开始处理部分工具结果
- 缓冲延迟对你的用户体验产生负面影响
- 你愿意实现健壮的 JSON 错误处理
对于大多数应用程序来说,带验证的默认行为是完全足够的。但是当你需要额外的响应性时,细粒度工具调用让你能够以 Claude 生成它们的速度来获取块。
#### 视频文字稿
在本视频中,我们将探讨如何将工具使用与流式传输(streaming)结合起来。你可能还记得,我们之前讨论过从 API 进行流式传输。流式传输可以让我们更好地向用户展示我们应用中正在发生的事情。所以,当我们启用了流式传输并向 Claude 发出请求时,我们会收到一些初步响应,然后会收到一系列不同的事件。
每个事件都会有一些我们可能想向用户展示的额外文本。你可能还记得,在我们的应用程序中,我们可能需要处理许多不同类型的事件,其中一个非常常见且需要我们留意的事件是 Content Block Delta。为了将工具与流式传输结合使用,我们将增加一种需要处理的额外事件类型,它叫做输入 JSON 事件(input JSON event)。
所以现在,如果我们打开流式传输并尝试使用工具,Claude 可能会向我们发送一种名为输入 JSON 事件的新型事件。这个对象将有两个重要的属性。首先,会有一个 partial JSON,它是一段代表 Claude 想发送到我们工具中的部分参数的 JSON。我们还会得到一个叫做 snapshot 的东西,它是我们迄今为止收到的所有不同 partial JSON 片段的累积总和。
为了让你更好地理解这是如何工作的,我准备了一个名为 003 tool streaming 的新 notebook。它附在本讲座中。这个 notebook 包含一个修改过的 `run conversation` 函数。它将使用一个名为 `chat stream` 的新函数来从 Anthropic API 打开一个响应流。
然后对于该流中的每个块(chunk),我们将根据块的类型来处理它。在接收到输入 JSON 块的情况下,我们现在要做的只是把它打印出来。所以我将到最底部,我已经准备好了一个提示以及一个名为 `save article schema` 的新工具。我将运行这个 notebook,让我们看看会发生什么。
很快,我们就会看到响应的每个块都进来了,包括工具调用的参数。你会注意到,这个 notebook 也在生成一篇学术文章,只是与我们之前的相比,属性略有不同。现在,老实说,工具流式传输除了这个之外并没有太多其他内容。我们真的只需要确保我们处理了那种额外的事件类型。
话虽如此,关于工具流式传输,我还有另一方面想告诉你,但这是关于一个你可能永远都不需要使用的非常非常特殊的功能。所以,让我给你一个非常简要的概述,然后你可以决定是否想了解这个非常专业的功能。如果我重新运行这个 notebook,你可能会注意到,我们似乎正在获得流式传输行为。文本是逐块出现的。
但特别是对于我们的工具调用参数,你会注意到我们必须坐等几秒钟。然后突然之间,一大块文本出现了。这个非常大的延迟,然后我们得到一大块文本的事实,对你来说可能根本不是什么大问题。然而,你可能正在开发一个应用程序,其中向用户展示非常精确的内容更新,并尽快显示出来,是非常重要的。
或者,也许你想尽快接收工具调用的部分内容,以便你能尽快开始做一些处理工作。所以在本视频的剩余部分,我将帮助你理解为什么会有那么大的延迟,然后一大块文本出现。我将向你展示 Anthropic API 中的一个功能来消除那个延迟。那么,我们开始吧。
我想做的第一件事是澄清我添加到这个 notebook 中的工具。所以我稍微调整了我们之前生成学术文章的工具。我们仍然在生成一篇文章,但现在它的输入结构略有不同。我在左下角有一个预期输入的例子。
所以我们期望收到一个 `abstract` 的键,它有点像学术论文的摘要,以及一个 `meta` 对象。`meta` 对象将有一个字数统计和一个评论。理论上,这个评论可以是关于所生成特定论文的任何长篇评论。现在,在这个例子输入中,有一些我只想非常快地检查一下或者说指出的东西。
在我们得到这个大对象中,我们将有两个顶层键。换句话说,整个大对象中的顶层键。有 `abstract` 和 `meta`。所以我们会称它们为顶层键。
`meta` 将指向一个对象,该对象内部有一些额外的键值对,但同样,顶层键是 `abstract` 和 `meta`。所以请把这一点记在脑子里一会儿。现在我想帮助你理解,当我们在流式模式下为工具调用生成一些参数时,Anthropic API 内部到底发生了什么。所以它的行为可能不像你预期的那样。
在这个图表的左上角,我把我们的调用发送给了 Anthropic API。一旦它收到我们的请求,Claude 将开始生成一些 JSON,这将是我们的工具调用的输入。JSON 不是一次性生成的。相反,它是逐块创建的。
现在,在这一点上发生了一些令人惊讶的事情。Anthropic API 不会立即将这些块立即发送回我们的服务器。相反,它会保留它们一段时间。保留这些块的原因是 Claude 有时会生成无效的 JSON。
所以,API 不会立即将每个块发送给我们,而是会尝试进行一个验证步骤,以确保它发送给我们的是有效的 JSON。让我向你展示验证步骤是如何工作的。首先,提醒一下,我们的工具调用有两个顶层键,`abstract` 和 `meta`。所以 API 不会等待整个对象生成完毕再进行验证。
相反,它会等待一个单一的顶层键值对生成完毕。所以在 `abstract` 键的情况下,Anthropic API 会等到它看到 `abstract` 值字符串的结束引号。一旦它在最右侧的第四个块上看到那个结束引号,API 就知道它至少已经生成了一个键值对。在这种情况下,是 `abstract` 键值对。
然后 API 将尝试单独验证那个键值对。它会将其与我们提供的 JSON schema 进行比较,并确保生成了有效的 JSON。如果有效,那么最初生成的每个块都将被发送回我们的服务器。请注意,我们确实收到了每个单独的块,而不是整个键值对作为一个单一的块。
如果你要打印出我们 notebook 中收到的所有不同块,你会发现我们确实收到了大量的不同单个块。它们只是恰好在几乎同一时间到达我们的服务器,因为这些块已经在 API 上被缓冲,以便它可以进行这个验证步骤。然后这个生成过程将继续处理 `meta` 顶层键。所以再一次,API 将等到整个 `meta` 顶层键值对生成完毕。
然后它会验证它,然后将每个单独的块发送回我们的服务器。所以这就是为什么,即使启用了流式传输,我们最终也会在 API 上缓冲块时出现这些非常大的停顿。然后突然之间,我们看到一大组块出现或一大块文本一下子出现。现在,再次强调,这种行为对你来说可能没问题。
你可能不介意这种缓冲和验证步骤。但如果你正在构建一个你想尽快向用户展示更新的 UI,或者如果你想尽快进行一些工具处理,那么这个大停顿可能会有点烦人。现在,如果是这样的话,我有个好消息。API 中有一个叫做细粒度工具调用(Fine-Grained Tool Calling)的功能。
从核心上讲,细粒度工具调用实际上只做一件事。它禁用了 JSON 验证步骤。所以如果你启用细粒度工具调用,API 将等待 Claude 生成几个块。它会将它们连接在一起,然后将那个大块发送到你的服务器。
所以使用这个功能,在生成工具输入时,你会看到一个更传统的流式输出。我确实想重复一遍,使用细粒度工具调用时,API 上的 JSON 验证是禁用的。所以你的服务器上运行的代码现在真的应该假设你可能会收到无效的 JSON,并且你应该实现一些适当的错误处理。我们正在使用的 notebook 已经为细粒度工具调用设置好了。
所以让我们看看当我们打开它时,我们的响应会发生什么。我将到 `run conversation` 调用这里,然后我将添加一个 `fine-grained tool`,像这样。我将运行这个。现在我们会看到,当我们最终到达工具调用时,我们将得到一个更经典的流式体验,我们会逐块地,一次只得到一点点文本。
所以再次,这将允许我们更快地处理工具调用的某些部分。比方说,这里的字数统计值对我们来说非常重要。如果没有细粒度工具调用,我们必须等待所有这些文本生成完毕,才能访问到字数统计。但如果我用细粒度工具调用再次运行这个,我们会看到现在我们可以更快地得到那个字数统计值。
我们不必等待所有这些额外的文本生成完毕。现在,你可能有点好奇,当我们得到一些无效的 JSON 时,究竟会发生什么。嗯,我准备了一个提示,几乎可以保证我们会得到一些无效的 JSON。我将很快把它复制粘贴进来。
然后我还会向 `run conversation` 函数添加一个额外的参数。只是为了确保我们确实能得到那个无效的 JSON。我在这里添加的额外参数只是一个强制工具调用。我强制模型总是调用我们已经创建的 `save article` 模型。
所以我将运行这个。我们会看到,最初一切都会顺利,但很快我们就会得到一个错误。我们得到错误的原因以及这个提示真正做什么,我们刚才看到了那个字数统计值。所以字数统计应该是一个数字。
这个提示将强制一个 `undefined` 的字数统计值。顺便说一下,`undefined` 在 JSON 中不是一个有效的值。等效的 JSON 值将是 `null`。所以如果我们得到一个 `undefined` 的 JSON 值,那将是无效的 JSON。
并且我们会导致一个解析错误。所以这正是我们在这里看到的。如果我再向下滚动一点,我会看到一个关于...是的,我们得到了一些无效的 JSON 的错误。具体来说是因为我们得到了一个 `undefined` 的字数统计。
你可能有点好奇,如果我们不使用细粒度工具调用,这里会发生什么。你可能只是有点好奇。所以如果我把它注释掉,然后再次运行这个。
那么现在验证步骤将会发生。所以让我们看看这会如何处理。所以 API 最终做的是,它仍然会放入那个 `meta` 对象。但它实际上不会是一个对象,而是会将整个东西用一个字符串包装起来。
所以现在从技术上讲,我们在这里的响应中真的没有遵循 JSON 规范。我们的 JSON schema,就是我们提供的那个,说 `meta` 必须是一个对象,它有一个数字类型的字数统计和一个字符串类型的评论。所以现在 `meta` 是一个字符串而不是一个对象。好了,让我们总结一下。
再次,工具流式传输本身并不太疯狂。我们可以轻松地将它添加到你可能已经创建的任何类型的流式传输管道中。使用默认的工具流式传输,如果你正在生成一个大的顶层键值对,那么在生成过程中会有延迟,因为 API 会进行一些验证步骤。如果这对你来说是个大问题,你总是可以打开细粒度工具流式传输,这将给你一个更经典的流式体验,但代价是失去了那个验证步骤。
---
### 44. The text edit tool (文本编辑器工具)
> 类型:视频 | 时长:8:41 | 视频:06 - 012 - The Text Edit Tool.mp4
重要提示:所有模型版本的工具版本字符串都可以在这里找到:https://docs.anthropic.com/en/docs/agents-and-tools/tool-use/text-editor-tool
Claude 有一个内置工具,你无需从头创建:`text editor tool (文本编辑器工具)`。这个工具赋予了 Claude 处理文件和目录的能力,就像你在标准文本编辑器中操作一样。
## 文本编辑器工具能做什么
文本编辑器工具为 Claude 提供了一套全面的文件操作能力:
- 查看文件或目录内容
- 查看文件中特定行范围的内容
- 替换文件中的文本
- 创建新文件
- 在文件的特定行插入文本
- 撤销最近对文件的编辑

这极大地扩展了 Claude 的能力,并实质上赋予了它开箱即用的软件工程师的能力。
## 理解实现要求
这里的情况有点令人困惑:虽然工具的 schema 是内置在 Claude 中的,但你仍然需要提供实际的实现。可以这样理解——Claude 知道如何请求文件操作,但你需要编写实际执行这些操作的代码。
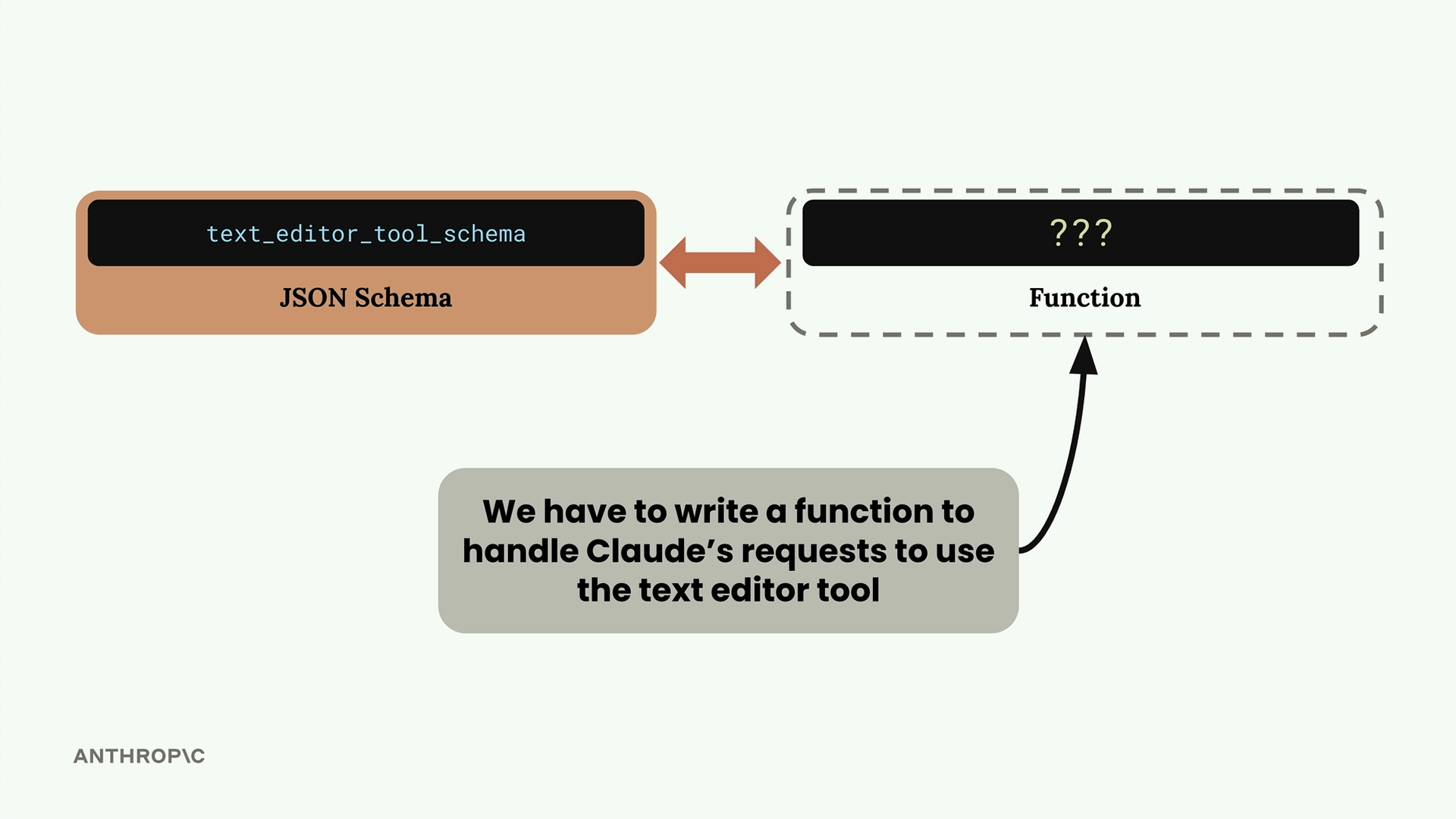
当你使用其他工具时,你既要编写 JSON schema,也要编写函数实现。对于文本编辑器工具,Claude 提供了 schema 的知识,但你必须编写函数来处理 Claude 创建文件、读取目录、替换文本等请求。
## Schema 版本
虽然主 schema 内置于 Claude 中,但在发出请求时,你确实需要包含一个小的 schema存根。确切的 schema 取决于你正在使用的 Claude 模型:
def get_text_edit_schema(model): if model.startswith("claude-3-7-sonnet"): return { "type": "text_editor_20250124", "name": "str_replace_editor", } elif model.startswith("claude-3-5-sonnet"): return { "type": "text_editor_20241022", "name": "str_replace_editor", }
Claude 看到这个小的 schema 后,会在幕后自动将其扩展为完整的文本编辑器工具规范。
## 实际示例
让我们看看文本编辑器工具的实际操作。当你要求 Claude 处理文件时,它将使用该工具来根据需要读取、修改和创建文件。
例如,如果你要求 Claude “打开 ./main.py 文件并总结其内容”,Claude 将会:
1. 使用文本编辑器工具查看该文件
2. 读取内容
3. 为你提供一个摘要
你可以更进一步,要求 Claude 修改文件。例如:“打开 ./main.py 文件并编写一个函数来计算 pi 到小数点后第 5 位。然后创建一个 ./test.py 文件来测试你的实现。”
Claude 将会:
1. 查看现有的 `main.py` 文件
2. 用包含 pi 计算函数的新实现替换其内容
3. 用适当的单元测试创建一个新的 `test.py` 文件
### 为什么要使用文本编辑器工具?
你可能会想,既然现代代码编辑器已经内置了 AI 助手,为什么还需要这个工具。在以下场景中,文本编辑器工具就显得很有价值:
- 你正在构建需要以编程方式编辑文件的应用程序
- 你在没有功能齐全的代码编辑器的环境中工作
- 你想将文件编辑功能直接集成到由 Claude 驱动的应用程序中
从本质上讲,文本编辑器工具让你可以在自己的应用程序中复制许多高级 AI 代码编辑器的功能,从而对 Claude 如何与你的文件系统交互进行精细控制。
#### 视频文字稿
正如我们在本模块前面看到的,通常情况下,作为开发人员,我们编写所有希望传递给 Claude 的不同工具。但有一个工具是 Claude 默认就可以访问的。这个工具叫做 Text Editor tool (文本编辑器工具),它直接内置在 Claude 中。这个工具赋予了 Claude 各种与标准文本编辑器中几乎所有操作相关的能力。
例如,这个工具让 Claude 能够打开文件或目录并读取其内容。它可以查看文件中的特定文本范围。它可以在文件中添加或替换文本。它可以创建新文件。
它可以执行撤销操作。基本上,你在普通文本编辑器中能做的所有事情,它都能做。因此,这极大地扩展了 Claude 的能力,几乎让 Claude 一开始就具备了作为一名软件工程师行动的能力。现在,理解文本编辑器工具有一点点复杂,所以我想通过几个图表来引导你,阐明这个工具为你做了什么,以及你我需要做什么才能在项目中实际使用它。
首先要理解的是,只有 JSON schema (JSON 模式) 部分是真正内置在 Claude 中的。让我澄清一下我的意思。请记住,当我们想要使用工具时,我们实际上需要编写两个独立的东西。首先,在左侧,我们必须写出那个 JSON schema 规范。
这会提供给 Claude,告诉 Claude 它可以使用的某个工具以及该工具所需的所有不同参数。然后在右侧,你和我必须编写一个工具函数实现来与那个 JSON schema 配对。这些是我们代码库中实现的实际函数,当 Claude 想要使用我们的工具时,这些函数会在某个时间点被调用。所以我们实际上需要编写两边的东西。
我们既要做 JSON schema,也要做工具函数实现。因此,当我们使用文本编辑器工具时,唯一真正为我们提供或内置在 Claude 中的东西是 JSON schema。那套指令告诉 Claude 如何使用这个工具。你必须提供一个实际的实现来处理 Claude 所有使用文本编辑器工具的请求。
那个实现是不存在的。它是你必须在我们代码库中编写的东西。换句话- -句话说,每当 Claude 决定说,比如创建一个新文件,它会向我们发回一个 `tool_use` (工具使用) 部分,说“我想创建一个新文件”,我们必须提供一个实际的函数,该函数会在我们硬盘的某个地方实际创建一个新文件。所以,使用文本编辑器工具不是“免费”的。
它需要我们这边付出一些努力,因为我们必须编写几个不同的函数。现在,让我们去一个 Jupyter notebook,我们将演示这个工具的用法,并看看如何编写这些不同的函数。回到这里,我正在一个名为 `005 Text Editor Tool` 的新 notebook 中。像往常一样,你可以在本讲座的附件中找到这个 notebook。
在这个 notebook 中,有很多我们到目前为止一直在使用的完全相同的辅助代码。但如果你看一下第三个单元格,它顶部有一条注释“implementation of the text editor tool (文本编辑器工具的实现)”,你会看到里面有大量的代码。这是我预先组合的一个类。它包含了使用文本编辑器工具所需的所有不同函数。
换句话说,这个类提供了谜题的这一块。记住,我刚才告诉过你,我们必须编写一些代码来处理 Claude 所有使用文本编辑器工具的请求。我为你在这个特定的类中写好了那些代码。在这个类中,你会注意到,如果你向下滚动一点,有一些方法,比如 `view`,可以用来查看文件或目录的内容。
还有一个 `string_replace` 函数,它将替换文件中的字符串。还有一个函数用来创建文件等等。所以所有东西都已在这个类中为你提供好了。我将折叠这个单元格。
接下来我想向你指出的是带有注释“make the text edit schema based upon the model version being used (根据使用的模型版本创建文本编辑 schema)”的单元格。现在,这里的事情变得有点复杂了。所以让我非常快速地给你看一个图表,帮助你理解这里发生了什么。现在,我已经重复了好几次,这个文本编辑器工具的 schema 已经内置在 Claude 中,我们不需要包含它。
这基本上是正确的,但这里也有一个小小的告诫,只是为了让事情稍微有点令人困惑。当我们向 Claude 发出请求,并且我们想使用这个文本编辑器工具时,我们确实需要包含一个非常非常小的 schema。所以我们需要发送一个看起来像这样的 schema。我们在这里放入的确切类型字符串,注意它有一个日期,会根据我们使用的 Claude 的确切版本而改变。
所以在这个函数中,我正在检查你是否正在使用 Claude 3.7 Sonnet。如果是,我将返回那个带有那个日期的 schema。如果你正在使用 Claude 3.5,它的日期会略有不同。所以根据确切的模型版本,你的日期会略有不同。
当我们把这个非常小的 schema 发送给 Claude 时,它会自动扩展成一个更大得多的 schema。它看起来有点像这样。所以 Claude 会看到我们包含了这个非常小的存根 schema,它的名称是 `string_replace_editor`。它还会注意到我们放在那里的确切类型。
然后在幕后,我们可以想象这个非常小的 schema 被替换成了这个大得多的 schema。它向 Claude 列出了大量关于如何使用文本编辑器工具的信息。既然我们对这里发生的事情有了稍微好一点的了解,我想给你一个快速的演示,看看文本编辑器工具能做什么。在我的 notebook 所在的同一目录下,我将创建一个名为 `main.py` 的新文件。
在里面,我将创建一个非常简单的函数叫做 `greeting`。它会打印出 `hi there`,像这样。然后我会确保我保存了那个文件。然后我将回到我的 notebook,在最底部,我添加了一个单元格,它将添加一个空的用户消息,然后将消息列表发送到 `run_conversation`。
我将请求 Claude 打开 `main.py` 文件,并告诉我这个文件里面有什么。所以我将请求 Claude 打开 `./main.py` 文件并总结其内容。然后我将运行它。然后在响应中,我们可以看到 Claude 确实获取了那个文件的内容。
它将是关于文件内部情况的摘要。如果我们看一下消息列表,我们会看到这里有一个 `tool_use` 块,Claude 请求查看 `main.py` 文件的内容。我刚才给你看的那个文本编辑器工具类中的代码将接收到那个命令。它会自动打开文件,然后将内容发送回 Claude。
我们实际上可以在这里看到内容。现在,在这一点上,你可能会有点好奇文本编辑工具到底为什么存在。换句话说,它到底为我们做了什么?除了它能以某种方式处理文件系统上的文件这个显而易见的事实之外,它真正提供了什么功能?
嗯,很可能你现在正在使用一个内置了非常高级的 AI 助手的代码编辑器。你可以要求那个助手重构文件、创建文件或做任何其他事情。事实证明,我们可以通过使用这个文本编辑工具,在很大程度上复制你那款高级代码编辑器的所有功能。所以,例如,我将更新我发送给 Claude 的提示。
我将请求 Claude 打开那个文件,并编写一个函数来计算圆周率到第五位小数。做完之后,我将请求 Claude 创建一个 `./test.py` 文件来测试你的实现。我将运行这个。
在请求完成后,我将向下滚动到交换的消息列表。所以在这里,我有我最初的用户消息,然后是我们的助手消息,在其中 Claude 决定使用文本编辑工具,具体来说,它想尝试查看一个文件。然后我们发回那个文件的内容。Claude 接着说,好的,太好了。
我知道这个文件里有什么了。我现在要尝试用一些新内容来替换它的内容。所以我们可以看到这里是计算圆周率的实际实现。然后如果我们再往下看一点,我们响应说我们成功地更新了文件。
Claude 接着会尝试创建 `test.py` 文件并在其中写入一些文本,具体是一些测试来检验它刚刚完成的实现。我们可以通过查看新更新的 `main.py` 文件来验证这一切都发生了。所以我们现在会看到一个计算圆周率的实现,以及一个附带的 `test.py` 文件,里面有一些测试。所以再次强调,使用这个工具,我们可以非常容易地模拟一个相当高级的代码编辑器。
你可能会想,好吧,为什么我不直接用我的代码编辑器呢?嗯,在你可能从事的一些不同应用程序的某些场景中,你可能想要在某个文件系统中编辑一些文件,或者类似的情况,而你并没有真正访问一个原生的、功能齐全的代码编辑器的权限。这将是一个你想要使用文本编辑工具的场景。
---
### 45. 网页搜索工具
> 类型:视频 | 时长:7:13 | 视频:06 - 013 - The Web Search Tool.mp4
重要提示:你的组织必须在设置控制台中启用 Web Search (网页搜索) 工具后才能使用它。你可以在这里找到此设置:https://console.anthropic.com/settings/privacy
Claude 内置了一个网页搜索工具,让它能够搜索互联网以获取最新的或专门的信息来回答用户的问题。与其他需要你提供实现的工具不同,Claude 会自动处理整个搜索过程——你只需要提供一个简单的 schema (模式) 来启用它。
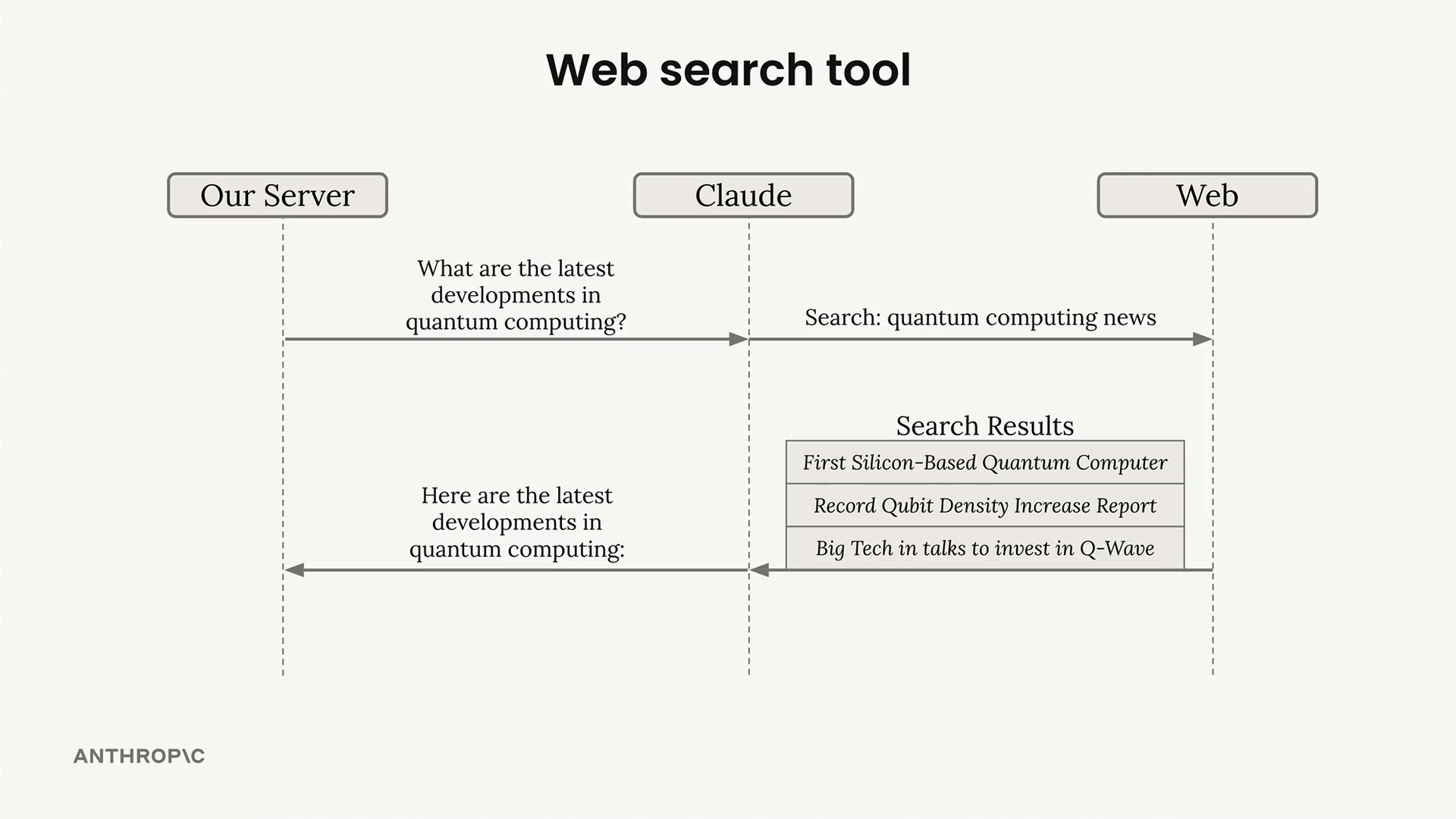
## 设置网页搜索工具
要使用网页搜索工具,你需要创建一个包含以下必需字段的 schema 对象:
web_search_schema = { "type": "web_search_20250305", "name": "web_search", "max_uses": 5 }
`max_uses` 字段限制了 Claude 可以执行的搜索次数。Claude 可能会根据初步结果进行后续搜索,所以这可以防止过多的 API 调用。单次搜索会返回多个结果,但 Claude 可能会决定需要进行额外的搜索。
## 响应如何工作
当 Claude 使用网页搜索工具时,响应包含几种类型的块:
- **Text blocks (文本块)** - Claude 对其正在做什么的解释
- **ServerToolUseBlock (服务端工具使用块)** - 显示 Claude 使用的确切搜索查询
- **WebSearchToolResultBlock (网页搜索工具结果块)** - 包含搜索结果
- **WebSearchResultBlock (网页搜索结果块)** - 带有标题和 URL 的单个搜索结果
- **Citation blocks (引用块)** - 支持 Claude 陈述的文本
响应结构让你能确切地看到 Claude 搜索了什么以及它找到了哪些来源。引用包括 Claude 用来支持其答案的具体文本,以及来源的 URL。
## 限制搜索域
你可以使用 `allowed_domains` 字段将搜索限制在特定域。当需要可靠、权威的来源时,这尤其有用:
web_search_schema = { "type": "web_search_20250305", "name": "web_search", "max_uses": 5, "allowed_domains": ["nih.gov"] }
例如,当询问关于医疗或运动建议时,限制在像 PubMed (nih.gov) 这样的域可以确保你获得的是基于证据的信息,而不是随机的博客内容。
## 渲染搜索结果
响应中不同类型的块是为特定的 UI 渲染而设计的:
- 将文本块渲染为常规内容
- 将网页搜索结果在顶部显示为来源列表
- 将引用与文本内联显示,包括来源域、页面标题、URL 和引用的文本
这种结构帮助用户理解 Claude 是如何得出答案的,并提供了关于所用来源的透明度。引用格式清楚地表明了哪些特定信息来自哪些来源,从而在 AI 的响应中建立了信任。
## 实际用法
网页搜索工具最适用于:
- 时事和最新发展
- Claude 训练数据中没有的专业信息
- 事实核查和寻找权威来源
- 需要最新信息的研究任务
只需在进行 API 调用时将 schema 包含在你的 `tools` 数组中,Claude 就会自动决定何时进行网页搜索有助于回答用户的问题。
#### 视频文字稿
Claude 中内置了另一个名为 web search tool (网页搜索工具) 的工具。顾名思义,这个工具允许 Claude 搜索网页以获取最新的或专门的信息来回答用户的问题。例如,如果我们询问有关量子计算的当前事件,Claude 可能会决定使用此工具查找一些与量子计算相关的最新文章,然后使用这些内容来构思答案。与文本编辑器工具不同,我们不必提供实现来实际运行搜索。
搜索完全由 Claude 完成,这使得这个工具非常容易运行和使用。让我们编写一些代码来理解这个工具的工作原理。我回到了一个 notebook 中。我创建了一个名为 `006 web search` 的新 notebook。
在底部我有一个单元格,里面有一些向 Claude 发出请求的典型代码。在上面的单元格中,我将创建一个名为 `web_search_schema` 的新变量。这将是我们编写的一个 schema,我们将在向 Claude 发出的请求中包含它,并将其列为一个工具。这个 schema 将启用网页搜索功能。
就像文本编辑器工具一样,我们必须提供这个非常小的 schema,它在幕后会被扩展成一个大得多的 schema。我们将在这里添加几个字段,特别是一个类型为 `web_search_2025-03-05`,然后一个名称为 `web_search`,一个 `max_uses` 为 5,目前就这些。现在,`max_uses` 是 Claude 可以运行搜索的次数。单次搜索可以返回多个不同的搜索结果,但根据这些搜索结果的内容,Claude 可能会决定进行后续研究。
这个过程可能会重复几次,所以我们将 Claude 可以搜索的总次数限制在五次。运行该单元格后,我将到下面。我将问 Claude 增加腿部肌肉的最佳锻炼方法是什么。我将添加我们刚刚组合的那个 schema。
像这样 `web_search_schema`。现在我将运行这个,它需要一些时间才能得到响应。我们得到的响应会非常大,所以我可以在这里滚动浏览它,我们会看到这里有大量的信息。为了帮助你理解我们得到的响应,我想给你看一个这个响应的简化版本,我拿了这个 `messages`, `content` 列表,并从中删除了大量内容,以便我们能更好地理解发生了什么。
所以这里是一个稍微删减过的形式。再次强调,这是响应消息中的 `content` 列表。`content` 列表将包含几个不同的块,其中一些是我们以前没有见过的。最初,我们得到一个文本块,它构成了 Claude 给我们的整个响应的框架。
Claude 说它将进行一次网络搜索,以更好地理解如何回答这个问题。然后我们将看到一个 `server_tool_use` 块。里面是搜索工具的输入。我们可以看到 Claude 将用来搜索网页的确切查询。
之后,我们将看到一个 `web_search_tool_result` 块的列表,里面会有许多不同的 `web_search_result` 块。这些是 Claude 从初始查询中收到的不同搜索结果。现在,一个实际的查询响应可能会有许多不同的搜索结果。在这种情况下,我删除了除了一个之外的所有结果,只是为了更好地理解这里发生了什么。
所以这是一个实际的网页搜索结果。我们可以看到 Claude 获取的页面标题和实际的 URL。这里还没有任何内容。这只是告诉我们 Claude 在进行这次搜索时确切找到了什么。
然后 Claude 将开始回答用户的问题。它会用各种不同的文本块来回答用户的问题,这些文本块可能包含一个 `citations` (引用) 列表。引用列表中的文本旨在以某种方式支持 Claude 的陈述。所以在这种情况下,Claude 引用了某个特定的网页。
它正在使用这段特定的文本来支持它试图提出的观点或论点。当我们定义网页搜索 schema 时,我们可以添加各种不同的字段。有一个字段我特别推荐你考虑使用,如果你对你的用户将要问什么有很好的理解的话。所以在我们的案例中,我们问的是增加腿部肌肉的最佳锻炼方法。
我不知道你是否曾在网上搜索过锻炼建议,但外面有大量的博客,可能只是 AI 生成的内容。你从那些博客中得到的建议可能并不完全准确,甚至不是关于如何真正增加腿部肌肉的最佳主意。另一方面,有一些网站收集不同的出版物,比如 PubMed。这是一个由美国政府维护的网站。
它包含了大量关于医学的学术文章。所以我们可以通过这里搜索,找到大量有证据支持的锻炼建议。所以如果我们能以某种方式告诉 Claude 只搜索这个网页及其中的内容,那将是非常棒的。这将使我们能够确保我们给用户提供的是最好的建议,而不仅仅是我们在网上找到的一些随机生成的东西。
为了让 Claude 只搜索这个页面,我们将找到域名,即 `nih.gov`。我将回到我的 notebook。我将找到我的网页搜索 schema,并在这里添加一个额外的字段 `allowed_domains`。我将放入一个包含 `NIH.gov` 的列表。
这将把 Claude 的搜索限制在那个域名,它不会尝试寻找任何其他东西。所以现在如果我再次运行这个单元格,然后再次向 Claude 发出请求,我将不得不等待响应返回。但是当我们确实得到响应时,我们应该能够滚动浏览它一点,并最终看到这里有一个 URL。而且我们应该只看到属于 `NIH.gov` 域名的 URL。
我们不应该看到任何其他东西。所以再次强调,这将使我们能够确保我们至少给用户提供一些有科学依据的建议。现在,我要做的最后一件事是向你展示我们真正打算如何使用这个庞大的、包含不同类型块的列表,这些块是我们在使用这个工具时得到的。这里的思路是,你将把所有的文本块渲染成纯文本,然后每当你得到一个 `web_search_result` 块或一个 `citation_web_search_result_location` 时,你可能会在 UI 中以某种方式将它们渲染出来,让用户明显地知道你正在试图以某种方式支持你的信息。
这里有一个如何做的例子。我写了一个小页面,它将获取我们在响应消息中看到的所有不同块并将它们渲染出来。在最顶端,我有一个我所有的 `web_search_tool_result` 块的列表。这些是 Claude 在进行网页搜索时找到的不同页面。
然后我将遍历整个块列表,并显示每个文本块中的文本。每当我发现一个带有 `citation_web_search_result_location` 的文本块时,我知道这是一个很长的术语,所以它是这里的一个。每当我发现其中一个时,我可能会像这样用一个小引用来渲染它,我会显示域名,显示我找到的页面标题,显示它的确切地址,以及确切的引用文本。再次强调,这只是让我们的用户能更好地理解 Claude 是如何实际获取其信息的。
---
### 47. 检索增强生成 (Retrieval Augmented Generation) 简介
> 类型:视频 | 时长:5:51 | 视频:07 - 001 - Introducing Retrieval Augmented Generation.mp4
Retrieval Augmented Generation (RAG) (检索增强生成) 是一种帮助你处理因太大而无法放入单个提示中的大型文档的技术。RAG 不是把所有东西都塞进一个巨大的提示里,而是将文档分解成块,并且在回答问题时只包含最相关的部分。
## 大型文档的问题
想象你有一份 800 页的财务文件,想问 Claude 关于它的具体问题,比如“这家公司有哪些风险因素?”你需要以某种方式将相关信息从文档中传递给 Claude,但是你能在提示中包含的文本量是有限的。

## 方案 1:在提示中包含所有内容
第一种方法很直接——从文档中提取所有文本,然后连同用户的问题一起塞进你的提示里。你的提示可能看起来像这样:
Answer the user's question about the financial document.
<user_question> {user_question} </user_question>
<financial_document> {financial_document} </financial_document>

这种方法有严重的局限性:
- 提示长度有硬性限制——你的文档可能太长了
- 对于非常长的提示,Claude 的效果会变差
- 更大的提示处理成本更高
- 更大的提示处理时间更长
## 方案 2:将文档分解成块
RAG 采用了一种更聪明的方法。首先,在预处理步骤中,你将文档分解成更小的块。然后,当用户提问时,你找到与他们问题最相关的块,并只在你的提示中包含那些块。
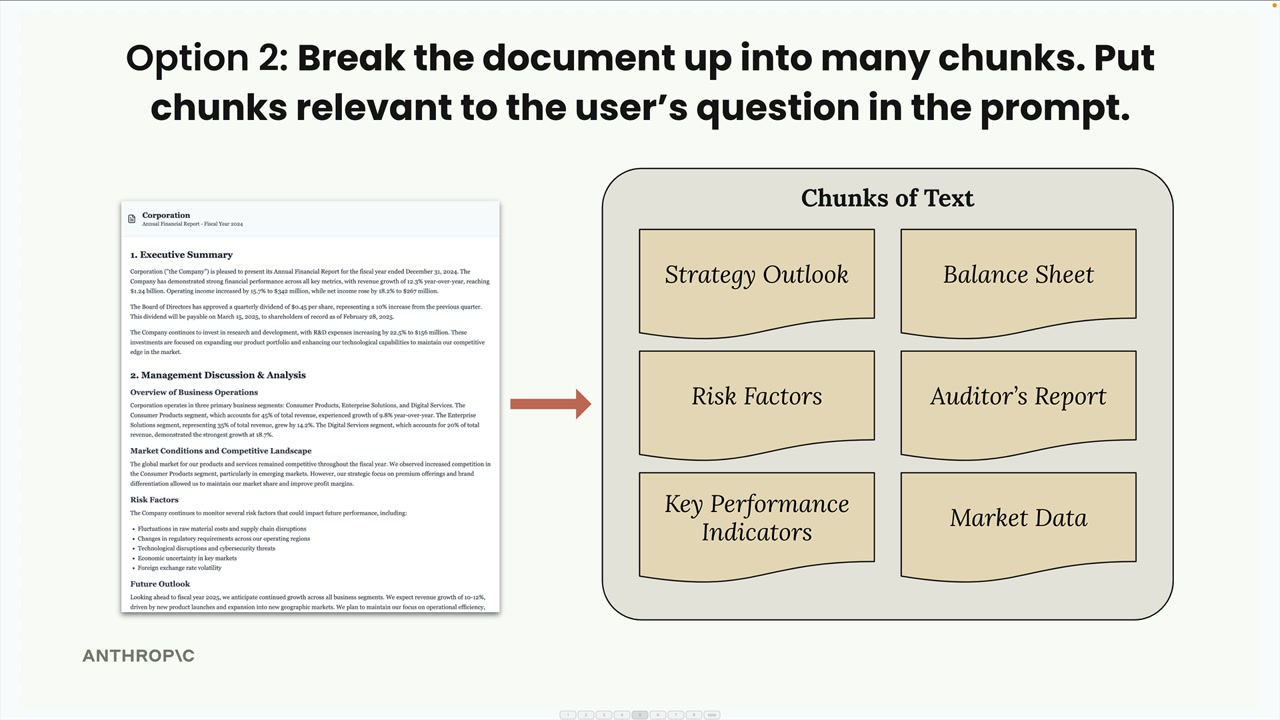
它是这样工作的:如果有人问“这家公司面临哪些风险?”你会搜索你的文本块,找到“风险因素”部分,然后只在你的提示中包含那个相关的块。
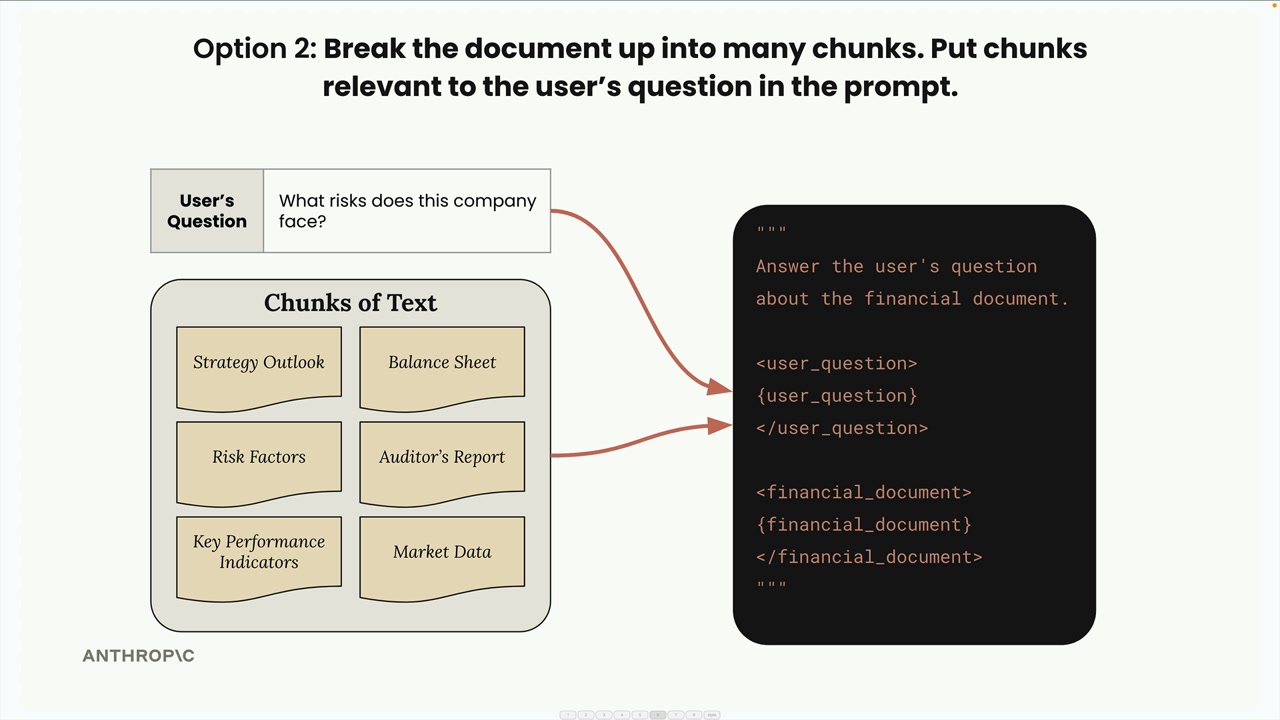
## RAG 的好处
- Claude 可以只关注最相关的内容
- 可扩展到非常大的文档
- 可处理多个文档
- 更小的提示成本更低,运行更快
## RAG 的挑战
- 需要一个预处理步骤来将文档分块
- 需要一个搜索机制来找到“相关”的块
- 包含的块可能不包含 Claude 需要的所有上下文
- 有多种分块文本的方式——哪种方法最好?
例如,你可以将文档分成大小相等的部分,或者你可以根据文档结构(如标题和章节)创建块。每种方法都有其权衡之处,你需要根据你的具体用例进行评估。
## 何时使用 RAG
RAG 涉及许多技术决策,并且比简单地在提示中包含所有内容需要更多的工作。你需要分析其好处是否大于你特定应用的复杂性。在处理非常大的文档、多个文档,或者当你需要优化成本和性能时,它尤其有价值。
关键的洞见在于,RAG 用简单性换取了可扩展性和效率。虽然它需要更多的前期工作来正确实施,但它使你能够处理用简单的提示填充方法无法处理的文档集合。
#### 视频文字稿
在本模块中,我们将大量讨论一种被称为 retrieval augmented generation (检索增强生成) 或简称 RAG 的技术。在本视频中,我特别想让你对 RAG 有一个非常扎实的了解。为了帮助你理解 RAG,我们将通过一个非常快速的例子来讲解。所以我想让你想象一下,你有一个非常大的财务文件,就像右边看到的那样。
这里面可能有大量的文本。它可能有从一百页到一千页不等的篇幅。我们可能想问 Claude 关于文件中非常具体领域的非常具体的问题。例如,我们可能想问一个问题,比如,这家公司有哪些风险因素?
现在,据推测,这份文件中可能有一些相关信息。所以我们需要解决一个非常基本的问题。我们如何从这份文件中获取一些信息并输入到 Claude 中,以便它能帮助我们回答问题?我想给你展示两种可能解决这个问题的方法。
所以,第一种选择,我们可以从这个文件中取出所有的文本,然后直接把它放进一个提示中,就像你在右边看到的那样。所以我们可能会要求 Claude 回答一个用户的问题,然后我们输入用户的问题,然后从文件中取出所有的文本,也把它放进提示中。现在,这可能不是最好的解决方案。它可能有效,也可能无效。
只是让你知道,我们能输入给 Claude 的文本量是有一个硬性限制的。所以如果这份文件非常非常长,我们把所有的文本都取出来,然后把所有的文本都输入给 Claude,我们可能马上就会得到一个错误,这意味着如果我们的文件非常非常长,这个解决方案一开始就不会奏效。这种方法的第二个问题是,随着你的提示越来越长,Claude 的效率会变得稍差。所以如果你开始在提示中放入大量的文本,Claude 将会更难准确地理解你想要什么并回答你的问题,因为提示中有大量的信息。
最后,更大的提示处理成本更高,处理时间也更长。所以这里也有财务上的负担和用户体验上的负担,因为他们必须等待更长的时间才能得到某种答案。所以第一种选择在某些情况下可能有效,在其他情况下,它可能完全失败。那么,到那时,让我们看看第二种选择。
第二种选择稍微复杂一些。所以第二种选择有两个独立的步骤。在第一步中,我们将从文档中取出所有文本并将其分解成小块。然后,每当用户提问时,我们将像以前一样,把他们的问题放进提示中。
但我们还将经历一个额外的小步骤。我们将非常仔细地检查用户的问题。然后我们将找到一段似乎与用户问题最相关的文本块。在这种情况下,如果一个用户问我们这家公司面临什么风险,而我们这里有一段似乎是关于风险因素的文本块,我们就会把那段文本块拿出来,并把它包含在提示中。
所以现在我们将 Claude 的所有注意力都集中在这份整体财务文件中非常小的一段上。希望 Claude 能比以前更好地回答用户的问题,以前我们只是把文件的所有文本都放进提示里。所以,第二种选择有一套明显的优点和缺点。优点是 Claude 可以只关注相关内容。
其次,这可以扩展到非常非常大的、有大量页面的文档。而且如果我们有多个文档,它也能工作。我们可以把所有这些不同的文档,把它们全部分成块,然后再次,只在提示中包含与用户问题相关的块。这种技术通常也会导致更小的提示,这意味着它运行的时间会更短,成本也会低得多。
但这种方法也有一些大的缺点。首先,自然地,复杂性要高得多。这需要一个预处理步骤,我们从文档中取出所有文本并将其分成块。我们还必须想出某种搜索所有这些块的方法,以找到与用户问题最相关的那些,我们甚至需要定义与用户问题相关的含义是什么。
当我们确实找到一些相关的块并将它们包含在提示中时,实际上并不能保证它们会包含 Claude 实际回答问题所需的所有上下文。如果用户问这家公司面临什么风险,并且只包含了风险因素部分,那可能会漏掉文件中其他一些重要的领域,比如战略展望,其中一些风险可能以某种方式得到了处理。最后,有很多不同的方法可以分割文本。所以我们可以 просто把文件的所有文本拿出来,然后把它分成相等的部分。
或者我们可以浏览文件,找到所有这些不同的标题,然后说对于每个标题,我们都要创建一个新的块。所以我们可能会有块一,然后块二,然后块三在下面的某个地方。有很多不同的方法可以定义一个块是什么。所以我们必须做一点评估,然后决定哪种技术最适合我们特定的应用。
所以,你可能猜到了,第二种选择就是 RAG。它是检索增强生成。正如我们刚刚讨论的,RAG 有很多大的优点,也有很多大的缺点。它周围有很多技术挑战。
它需要一个预处理步骤。我们还必须想出某种搜索机制来找到那些相关的块。我们必须对文档进行分块。总而言之,比第一种选择要做的工作要多得多。
所以每当我们考虑在一个应用中实现 RAG 时,我们真的必须分析所有这些不同的步骤,并弄清楚它是否适合我们特定的用例。好了,所以现在我们对 RAG 有了一个非常非常高层次的理解。让我们在稍后开始看看这个过程的实际实现。
---
### 48. 文本分块策略
> 类型:视频 | 时长:13:08 | 视频:07 - 002 - Text Chunking Strategies.mp4
文本分块是构建 RAG (Retrieval Augmented Generation) (检索增强生成) 管道中最关键的步骤之一。你如何分解文档直接影响到整个系统的质量。糟糕的分块策略可能导致不相关的上下文被插入到你的提示中,从而使你的 AI 给出完全错误的答案。

思考这个例子:你有一份文档,其中包含关于医学研究和软件工程的部分。如果你的分块很差,一个用户问“工程师今年修复了多少 bug?”时,可能会得到关于医学研究的信息,而不是软件工程的信息,仅仅因为医学部分碰巧在不同上下文中包含了“bug”这个词。
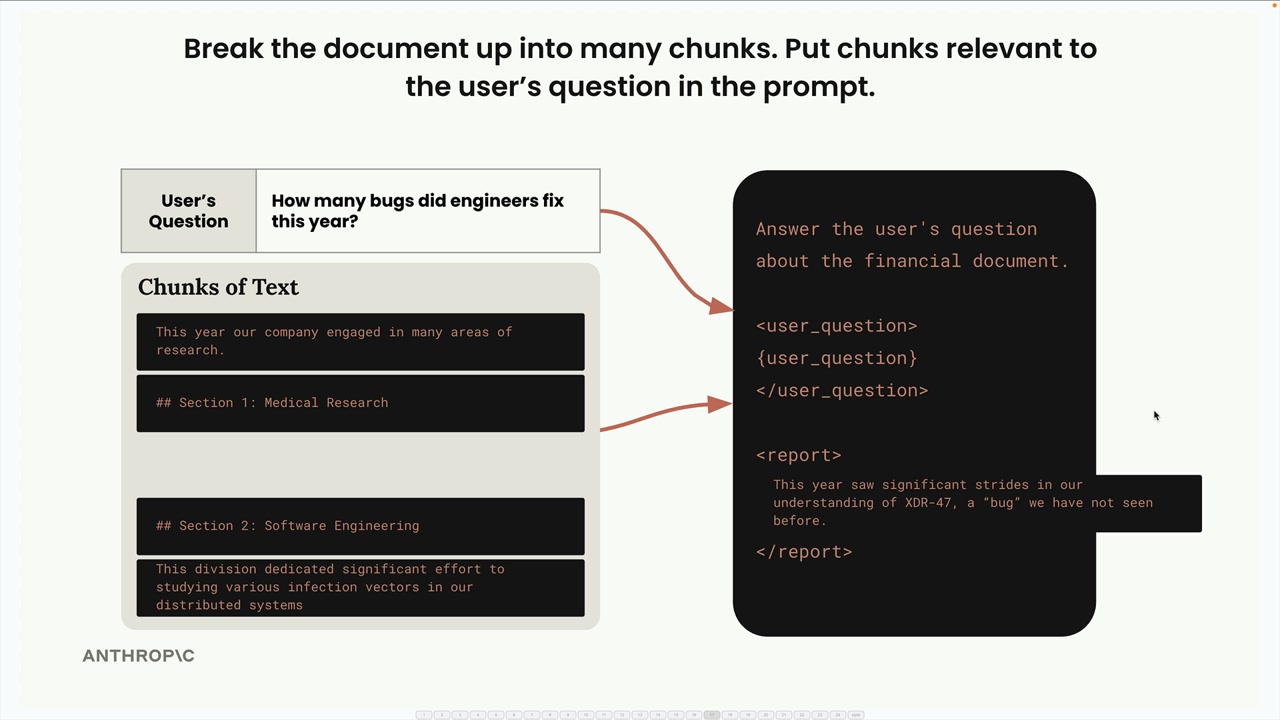
这就是为什么选择正确的分块策略如此重要。让我们探讨三种主要方法。
## 基于大小的分块
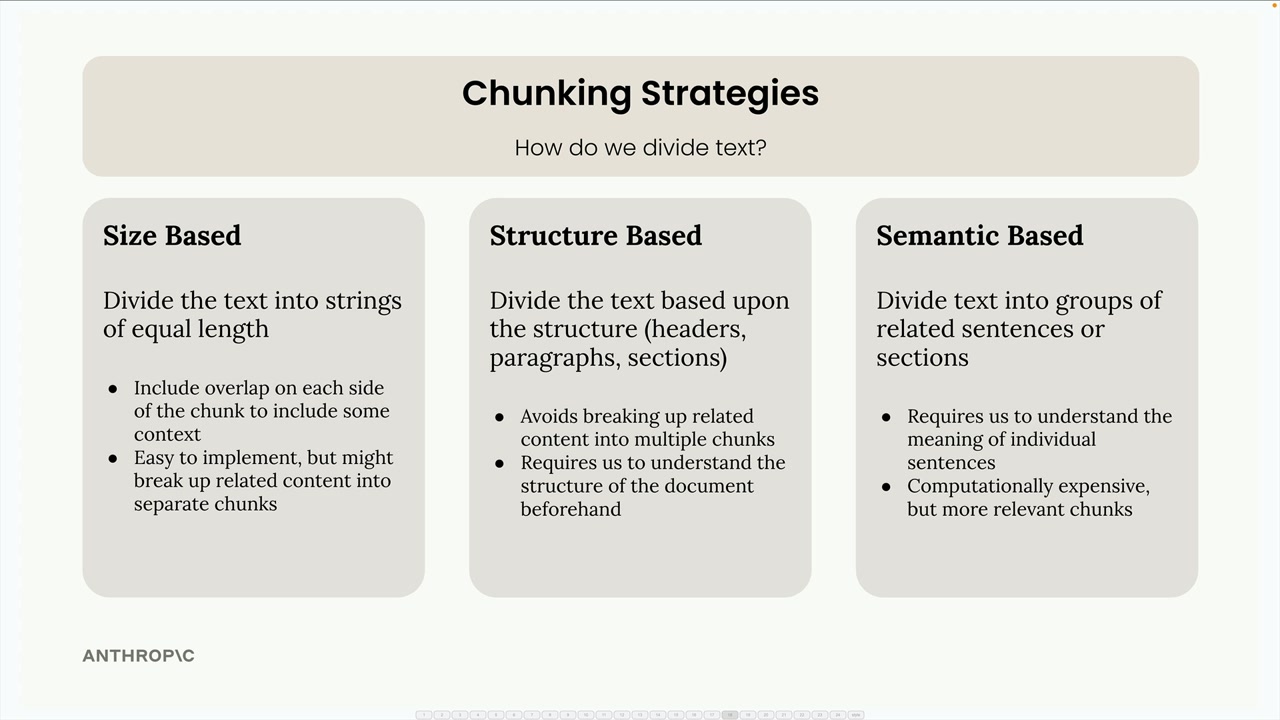
基于大小的分块是最简单的方法——你将文本分割成等长的字符串。如果你有一个 325 个字符的文档,你可能会将它分成三个大约 108 个字符的块。

这种方法易于实现,并且适用于任何类型的文档,但它有明显的缺点:
- 单词会在句子中间被切断
- 块会失去周围文本的重要上下文
- 章节标题可能与其内容分离

为了解决这些问题,你可以在块之间添加重叠。这意味着每个块都包含一些来自相邻块的字符,从而提供更好的上下文,并确保单词和句子的完整性。
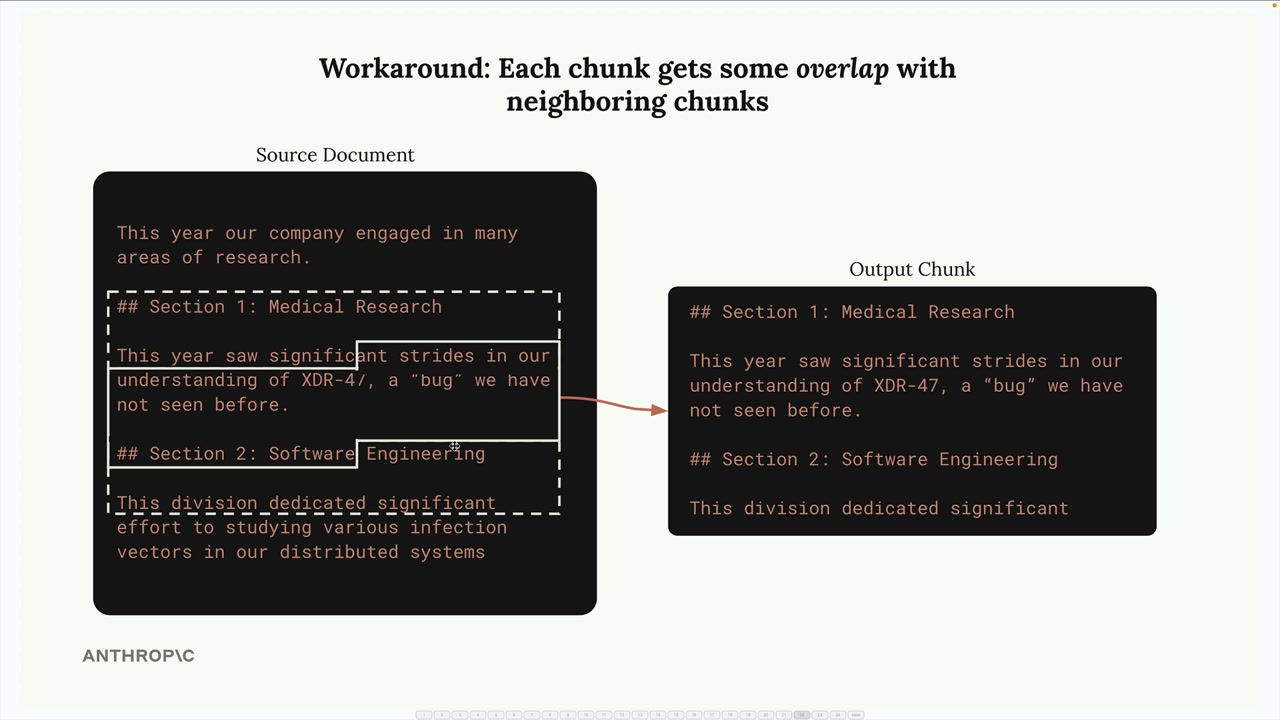
这里是一个基本的实现:
def chunk_by_char(text, chunk_size=150, chunk_overlap=20): chunks = [] start_idx = 0
while start_idx < len(text):
end_idx = min(start_idx + chunk_size, len(text))
chunk_text = text[start_idx:end_idx]
chunks.append(chunk_text)
start_idx = (
end_idx - chunk_overlap if end_idx < len(text) else len(text)
)
return chunks
## 基于结构的分块
基于结构的分块根据文档的自然结构——标题、段落和章节来划分文本。当你处理像 Markdown 文件这样格式良好的文档时,这种方法效果很好。
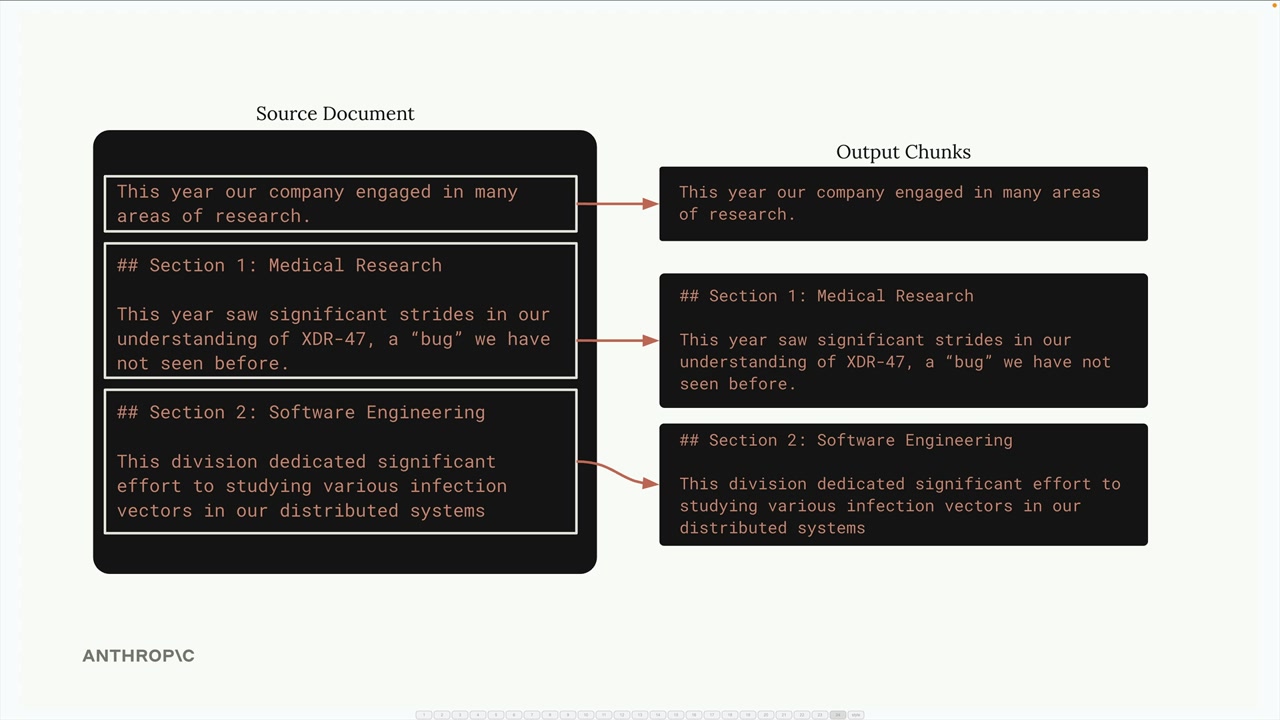
对于 Markdown 文档,你可以按标题标记进行分割:
def chunk_by_section(document_text): pattern = r"\n## " return re.split(pattern, document_text)
这种方法能为你提供最干净、最有意义的块,因为每个块都代表一个完整的部分。然而,它只有在你对文档结构有保证时才有效。许多现实世界中的文档是纯文本或 PDF,没有清晰的结构标记。
## 基于语义的分块
基于语义的分块是最复杂的方法。你将文本分成句子,然后使用自然语言处理来确定连续句子的相关程度。你从一组相关的句子中构建块。
这种方法计算成本高昂,但能产生最相关的块。它需要理解单个句子的含义,并且比其他策略更难实现。
## 基于句子的分块
一个实用的折中方案是按句子分块。你使用正则表达式将文本分割成单个句子,然后将它们分组到块中,并可选地添加重叠:
def chunk_by_sentence(text, max_sentences_per_chunk=5, overlap_sentences=1): sentences = re.split(r"(?<=[.!?])\s+", text)
chunks = []
start_idx = 0
while start_idx < len(sentences):
end_idx = min(start_idx + max_sentences_per_chunk, len(sentences))
current_chunk = sentences[start_idx:end_idx]
chunks.append(" ".join(current_chunk))
start_idx += max_sentences_per_chunk - overlap_sentences
if start_idx < 0:
start_idx = 0
return chunks
## 选择你的策略
你的选择完全取决于你的用例和文档保证:
- **基于结构**:当你可以控制文档格式(如公司内部报告)时,效果最佳
- **基于句子**:对于大多数文本文档来说,是一个很好的折中方案
- **基于大小**:最可靠的后备方案,适用于任何内容类型,包括代码
在生产环境中,带重叠的基于大小的分块通常是首选,因为它简单、可靠,并且适用于任何文档类型。虽然它可能不会给出完美的结果,但它能持续产生合理的块,不会破坏你的管道。
记住:没有单一的“最佳”分块策略。正确的方法取决于你的具体文档、用例,以及你愿意在实现复杂性和块质量之间做出的权衡。
#### 视频文字稿
在这段视频以及接下来的几段视频中,我们将开始在一系列不同的 notebook 中实现我们自己的自定义 RAG 工作流。我们将首先专注于制作我们能做的最简单、最基本的 RAG 设置,然后随着时间的推移,我们会添加一些额外的步骤。提醒一下,一个典型的 RAG 管道看起来有点像这样,为了简化事情。我们将拿一个源文档,把它分成文本块,然后每当用户问我们一个问题,我们就会找到一些相关的文本块,把它放进一个提示中,这差不多就是全部了。
所以整个流程的第一步是拿一个源文档,把它分成文本块。现在,信不信由你,把一个文档分成不同块的过程是整个 RAG 管道中比较复杂的步骤之一。仅仅因为我们如何分块我们的文档对我们的 RAG 管道的质量有巨大的影响。我想马上给你一个例子,帮助你理解为什么会这样。
所以,看一下这个源文档。它只有几行字,意在代表某种公司报告之类的东西。快速读一遍,我们可以看到它基本上有三个区域。我们有一个标题,一个关于医学研究的部分,还有一个关于软件工程的部分。
现在,有很多方法可以把这个东西分成不同的块,但我只建议一种方法。我会说,对于这个文档中每一个有点独特的行,我们都创建一个单独的块。所以我们最后大概会有五个独立的块,就像你在这里看到的这些。如果你现在考虑一下这些不同的块,你会发现一些非常有趣的事情。
这里的第三个文本块完全是关于医学研究的。这就是这段文本的内容。它在医学研究部分。但它包含了“bug”这个词。
所以从一个较高的层面来看,如果你只看这一段,它几乎就像是在谈论软件工程,仅仅因为它包含了“bug”这个词。同样地,下面,我们有软件工程部分,里面有“infection vectors”(感染向量)这个词。感染向量更像是一个医学术语。所以再一次,我们有一个关于软件工程的部分,但里面的语言有点像在谈论医学研究。
所以现在我想让你思考一下,如果我们把这些块加到我们的 RAG 管道中会发生什么。让我们想象一下,一个用户问了一个问题,比如,工程师今年修复了多少个 bug?所以现在我们作为 RAG 管道的一部分的工作就是找到我们拥有的与用户问题最相关的文本块。嗯,用户提到了 bug。
所以,乍一看,这里的这个文本块似乎是相关的,因为它包含了“bug”这个词。所以我们可能会决定把这个文本块作为上下文添加到整个提示中。正如你马上就能看出来的,这是一个巨大的错误。用户想从报告中了解一些关于软件工程的事情。
所以我们绝对想要这个部分,但我们错误地得到了关于医学研究的东西。所以这是一个分块策略可以轻易地在你的提示中引入巨大错误和非常糟糕的上下文插入的例子。为了解决这个问题,我们将花很多时间思考如何将我们的原始源文档分解成不同的文本块。在本视频中,我们将介绍三种不同的分块策略或方法来将我们的文档分割成不同的文本块,每种方法都有一些特性或技术旨在解决我们刚才看到的问题。
所以我们将讨论基于大小的分块、基于结构的分块和基于语义的分块。我们首先要讲的是基于大小的分块。这就是我们拿我们的大文档,也就是一大块文本,然后我们把它分成若干个等长的字符串。这是迄
-到目前为止最容易实现的技术,在某些方面,也可能是你在生产实现中最常看到的技术。
所以让我们看看基于大小的分块是如何完成的。通过基于大小的分块,我们将我们的原始文档分成若干个或多或少等长的字符串。在我们的特定情况下,我们有一个大约 325 个字符的源文档。所以我们可以完全任意地决定把它分成三个独立的块。
这意味着每个块大约有 108 个字符左右。所以我们可以取前 108 个字符,把它们放进块 1,接下来的 108 个放进块 2,然后对整个文档重复这个过程。现在,这是一个非常简单的技术,但它马上就有一个很大的缺点。那就是每个块很可能最终会包含一些被切断的单词。
你马上就能看到第一个块里的“significant”这个词被切断了。所以第一个块里只有“significan”,然后在下一个块里才结束这个词。此外,每个块都缺乏上下文。
例如,这里的第三个块很不幸地没有真正包含它上面的章节标题。而这个章节标题本可以为这里的文本提供很多关于它真正谈论的是什么的上下文。为了解决这个如果你使用基于大小的分块就会马上出现的问题,我们可以实施一个重叠策略。重叠策略是指我们仍然会做基于大小的分块,但我们还会包含一些来自相邻块的重叠部分。
所以,例如,我们这里有原始的块一,但我们可能会决定只包含来自下一个块的几个字符。所以在这种情况下,我们可能会包含“significant”这个词的其余部分以及整个句子的结尾。所以我们最终会得到一个像这样的块,它有更多的意义。然后对于块二,我们仍然会让主体是这个区域,但我们会包含一个来自块前和块后若干字符的重叠。
所以通过这个策略,我们最终会得到相当多的重复文本。例如,在这种情况下,我们在第二个块中有“section 1 medical research”,而这在第一个块中也包含了。所以文本有重复,但好处是每个文本块,总的来说,都提供了更多的上下文。你将看到的下一种策略是基于结构的分块。
这是我们根据文档的整体结构来划分文本的地方。所以我们可能会尝试找到标题、段落或一般章节,并用它们作为每个块的分割线。用我们的文档实现这种分块策略会非常容易,因为我们的文档是用 Markdown 语法编写的。我们知道这一点,因为它在每个章节都有磅符号,双井号。
所以我们可能会寻找这些小小的井号符号,然后说每次我们看到这种符号,就意味着我们必须开始一个全新的部分。所以我们可以很容易地编写一些代码来以编程方式在双井号字符上进行分割。我们最终会得到一些格式非常好的部分,就像你在这里看到的这样。现在这可能听起来是一个很棒的策略,但不幸的是,现实并不总是那么眷顾它。
在很多情况下,你将尝试处理的文档根本不是用 Markdown 语法格式化的。它们可能是只包含纯文本的普通 PDF 文档,在这种情况下,你将得不到这些非常清晰划分的部分。所以再次强调,尽管这看起来是一个很好的技术,但实现起来可能非常具有挑战性,特别是如果你对不同文档的结构没有任何保证的话。我们将讨论的最后一种分块策略是基于语义的分块。
这是指你可能会把所有的文本,把它分成句子或段落,然后使用某种自然语言处理技术来找出每个连续句子的相关性。然后你会从一组以某种方式相关的句子或段落中构建你的块。现在,仅从描述中你就可以看出,这绝对是一种更高级的技术,所以我们不会太深入地研究实际的实现。我之所以提到它,只是为了说明,分块策略的数量并没有一个固定的、有限的数字。
实际上有无数种方法可以决定如何划分我们的文本。所以决定使用哪种方法完全取决于你的具体用例以及你对你试图处理的文档有什么样的保证。现在在我们继续之前,我想和你一起看一个非常快速的例子。所以我准备了一个 Jupyter notebook,里面实现了三种不同的分块策略。
所以我鼓励你找到一个名为 `001 chunking` 的 notebook。也请确保你下载了附带的 `report.md` 文件,并将其放在与该 notebook 相同的目录中。这个 `report.md` 文件里有一个小小的虚构报告样本,我们将在学习如何实现 RAG 管道时用它来做测试。所以在这里面,你会找到几个不同的单元格。
第一个包含了一个 `chunk_by_character` 的示例实现。这是一个基于大小策略的实现,我们将把我们的文本分成等长的字符串,并且它们之间还有一定量的重叠。你会注意到参数将是文本、每个块的大小,以及一定量的块重叠。所以再次强调,这是我们希望在块的两侧拥有的字符数。
下一个单元格展示了我们如何按句子分块。非常相似的想法,但现在我使用正则表达式将文本分割成单个句子,然后每个块将由一定数量的句子组成,并且可以选择性地在每边有一些重叠。最后,如果我们对文档的结构及其确切内容有非常强的保证,我们可能会尝试使用 `chunk_by_section`,这将是基于结构分块的一个例子。所以在这个例子中,它会寻找一个换行符,然后是两个井号,然后是一个空格。
那将是我们的分割标准。所以我们会得到类似“executive summary”作为第一个块。嗯,技术上是第二个,这上面会是第一个块。但然后我们会得到“executive summary”里的所有东西,一直到“table of contents”,那将开始我们的第二个块。
然后下一个块将是“methodology”,然后是第一节等等。这将为我们提供每个块的最佳格式,因为每个块将恰好由一个部分组成,但这之所以可行,完全是因为我们对文档的结构有保证。我们知道它是 Markdown,而且我们知道我们只会在新部分开始的情况下看到那个换行符、井号、井号、空格。现在让我们快速测试一下每一个。
回到我的 notebook,我将到最底部的单元格,我将首先尝试 `chunk_by_character`。所以我打开文件,获取所有的文本。我将按字符分块,然后在每个块之间打印一个小分隔符。所以我将运行它。
我会看到我们得到了第一个块,第二个,依此类推。你马上就能看到默认设置并没有产生很好的块。默认设置是块长度为 150,重叠为 20。所以在这种情况下,每个块并没有提供太多的意义。
比如,这里的这个句子对我们来说到底有什么用?我们真的能用它来回答任何用户的问题吗?我不知道,也许不能。所以我们可能会决定大幅改变我们的默认设置。
也许我想要一个 500 的块长度,150 的重叠。让我们看看这是否会给我们带来一些更好的东西。好的,这比我们之前的要好一些。所以现在我开始能看到这里形成了实际的独立部分,它们给了我们一些信息。
你也会很快开始注意到重叠部分。我能看到“addressing complex challenges”。事实证明,这个确切的短语也包含在上面的那个块里。所以这就是我们得到的重叠的一个例子。
好了,接下来,让我们试试我们的第二种策略,那就是按句子分块。我还是会用默认参数。这个看起来其实挺强的。这应该默认会给我们每个块五个句子,并且有一个句子的重叠。
我们正在使用正则表达式来分割每个句子。所以可能会有它没有正确分割句子的情况。但乍一看,是的,我觉得这看起来挺不错的。每个块似乎都给了我们相当多的信息。
最后,我们可以试试按章节分块。运行它。现在我们可以看到第一个块不会包含很多有用的信息,但之后的所有东西都非常非常强,因为我们每次都恰好得到一个章节。我只得到执行摘要,然后是目录,然后是第一节、第二节、第三节,依此类推。
所以再次强调,你使用哪种策略完全取决于你的文档的性质以及你对其结构有什么保证。对我们来说,按章节分块看起来很棒。但是如果我们期望接收用户提供的文档,而这些文档的格式没有任何保证,那么使用按章节分块可能在长远来看是行不通的。在这种情况下,我们可能会退回到按句子分块。
但即使是这个也可能效果不太好。想象一下,例如,我们正在尝试对用户提供的代码进行分块。嗯,如果我们试图把代码分成单个的句子,我们很可能会得到很多意想不到的结果,因为代码倾向于在非常意想不到的地方有句点。所以这可能意味着我们只能退回到那个老旧可靠的标准,那就是按字符分块。
按字符分块并不能保证给你最好的结果,但它在绝大多数情况下都能工作,而且效果也相当不错。
---
### 49. 文本嵌入
> 类型:视频 | 时长:4:02 | 视频:07 - 003 - Text Embeddings.mp4
将文档分解成块后,RAG 管道的下一步是找到哪些块与用户的问题最相关。这本质上是一个搜索问题——你需要遍览所有文本块,并识别出与用户所问内容相关的那些。

## 语义搜索
寻找相关块最常用的方法是 semantic search (语义搜索)。与寻找精确词语匹配的基于关键词的搜索不同,语义搜索使用 text embeddings (文本嵌入) 来理解用户问题和每个文本块的意义和上下文。
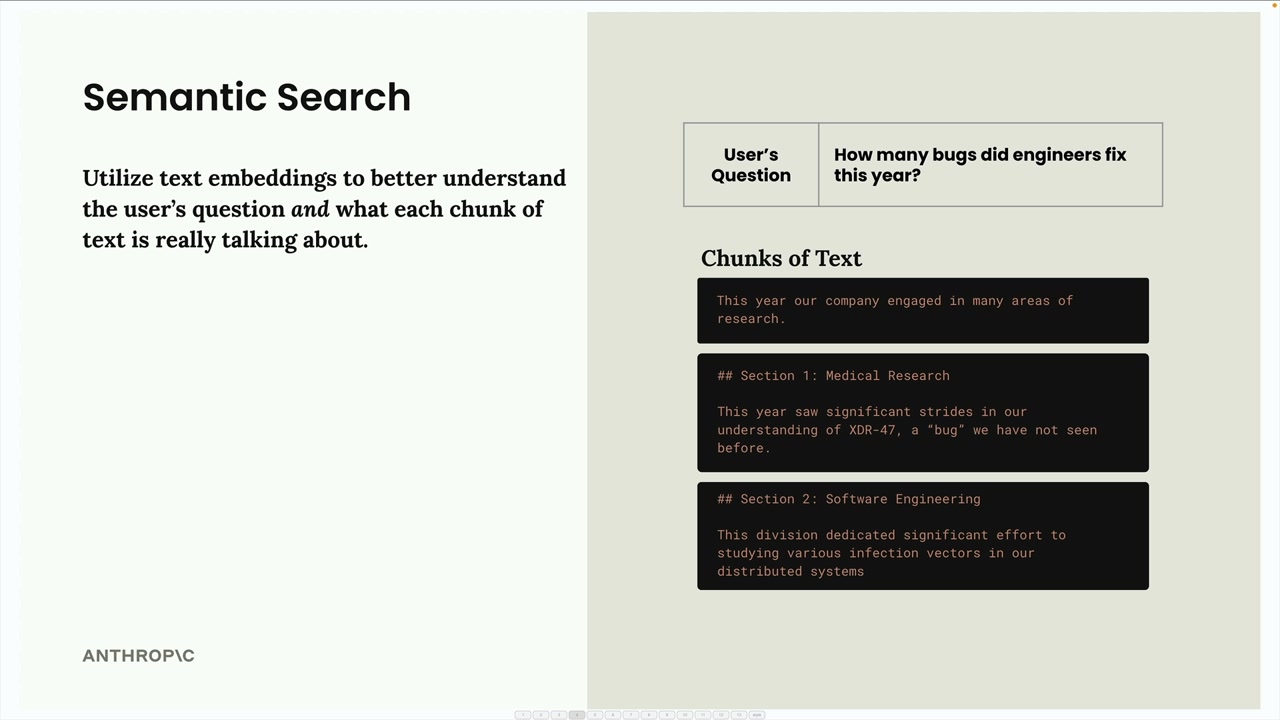
## 文本嵌入
文本嵌入是某些文本所含意义的数值表示。可以把它想象成将单词和句子转换成计算机可以用数学方式处理的格式。
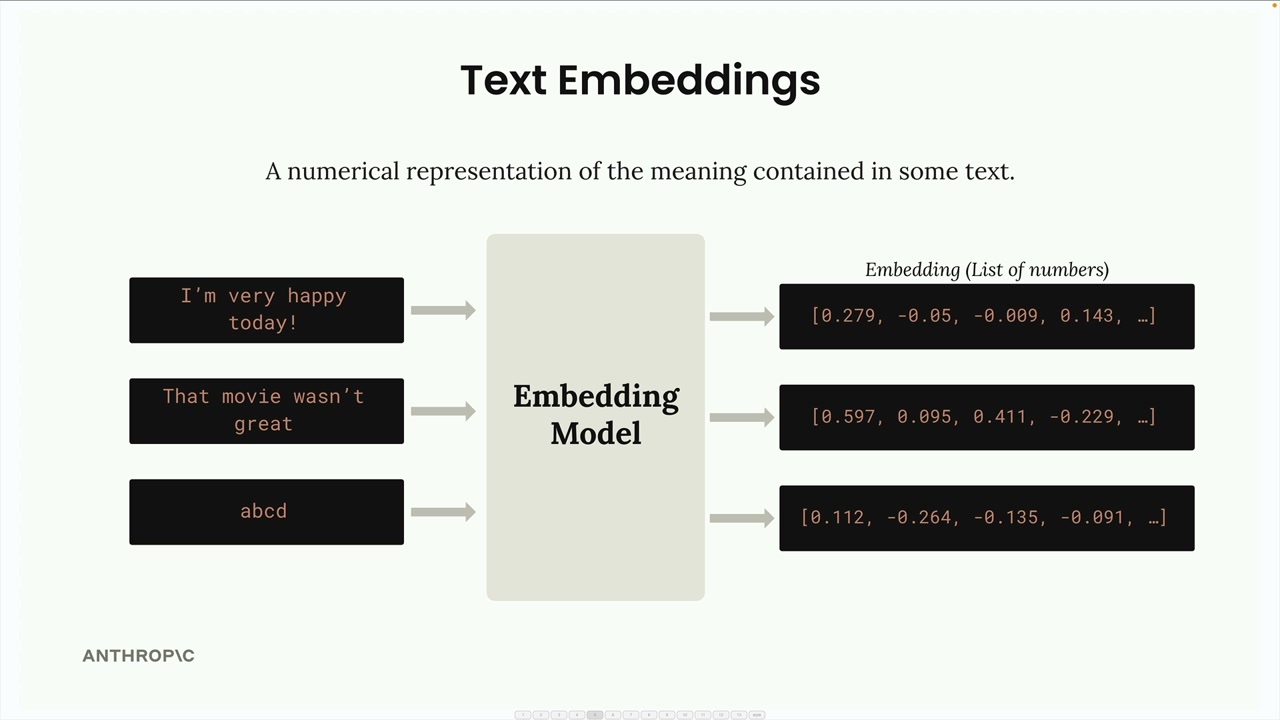
这个过程是这样工作的:
- 你将文本输入到一个嵌入模型中
- 模型输出一长串数字(即嵌入)
- 每个数字的范围从 -1 到 +1
- 这些数字代表输入文本的不同质量或特征
## 理解这些数字
嵌入中的每个数字本质上是输入文本某个质量的“得分”。然而,这里有一个重要的告诫:我们并不确切知道每个数字代表什么。
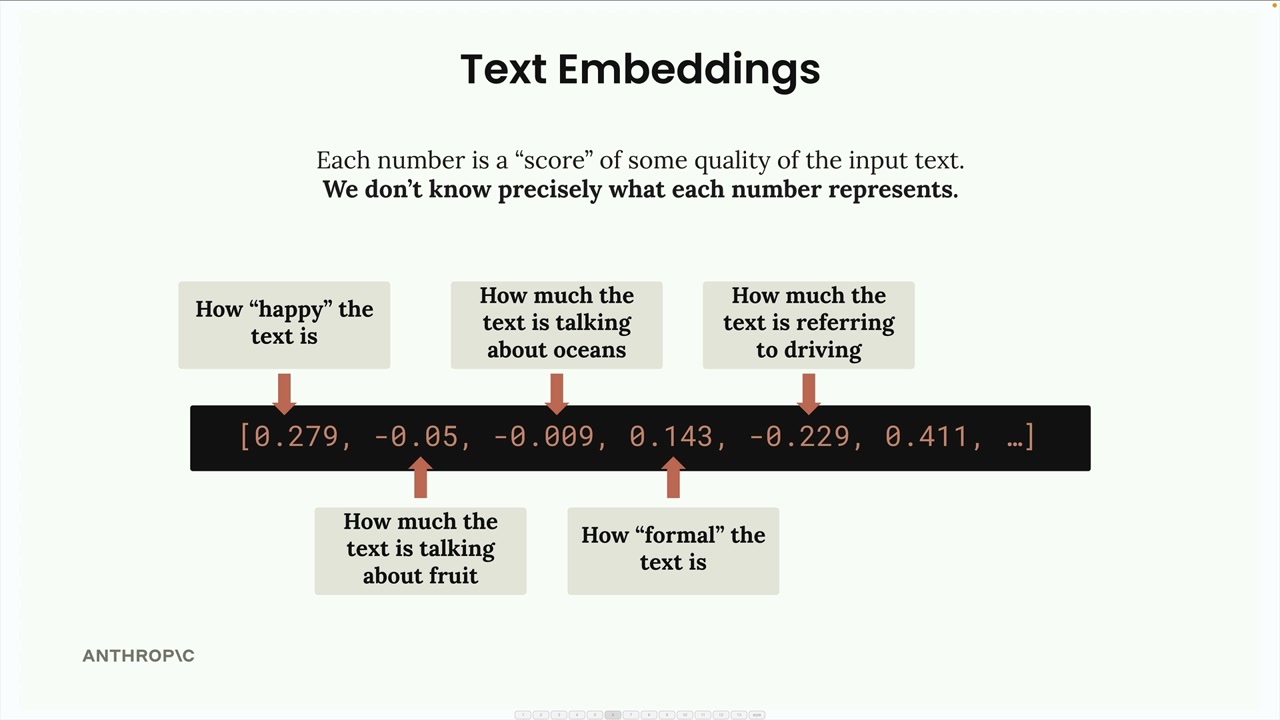
虽然可以想象一个数字可能代表“文本有多快乐”或“文本谈论海洋的程度”,但这只是概念上的例子。每个维度的实际意义是模型在训练期间学到的,并不能直接被人类解释。
## 使用 VoyageAI 进行嵌入
由于 Anthropic 目前不提供嵌入生成服务,推荐的提供商是 VoyageAI。你需要:
- 注册一个独立的 VoyageAI 账户
- 获取一个 API 密钥(免费开始)
- 将密钥添加到你的环境变量中
在你的 `.env` 文件中,添加:
VOYAGE_API_KEY="your_key_here"
实现
首先,安装 VoyageAI 库:
%pip install voyageai
然后设置客户端并创建一个函数来生成嵌入 (embeddings):
from dotenv import load_dotenv
import voyageai
load_dotenv()
client = voyageai.Client()
def generate_embedding(text, model="voyage-3-large", input_type="query"):
result = client.embed([text], model=model, input_type=input_type)
return result.embeddings[0]
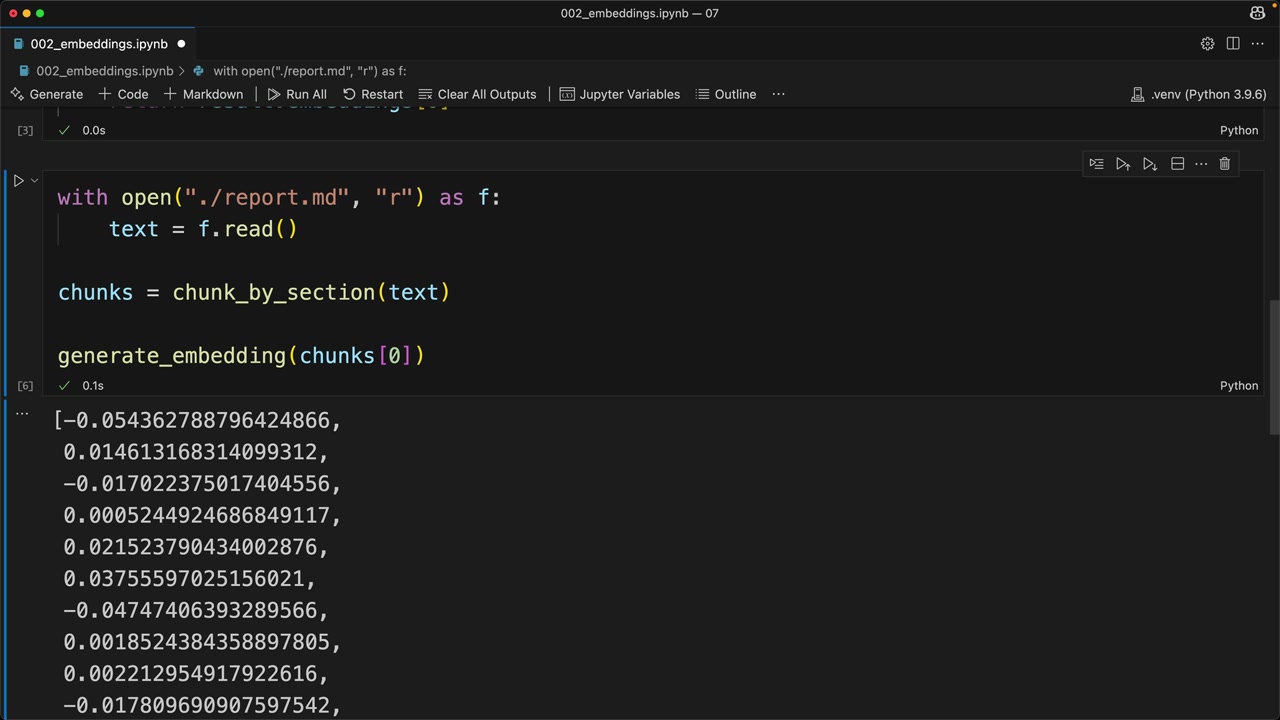
当您对一个文本块运行此函数时,您将得到一个浮点数列表,代表该文本的嵌入。这个过程快速而直接——真正的挑战在于理解如何在您的 RAG (检索增强生成) 管道中有效地使用这些嵌入来找到最相关的内容。
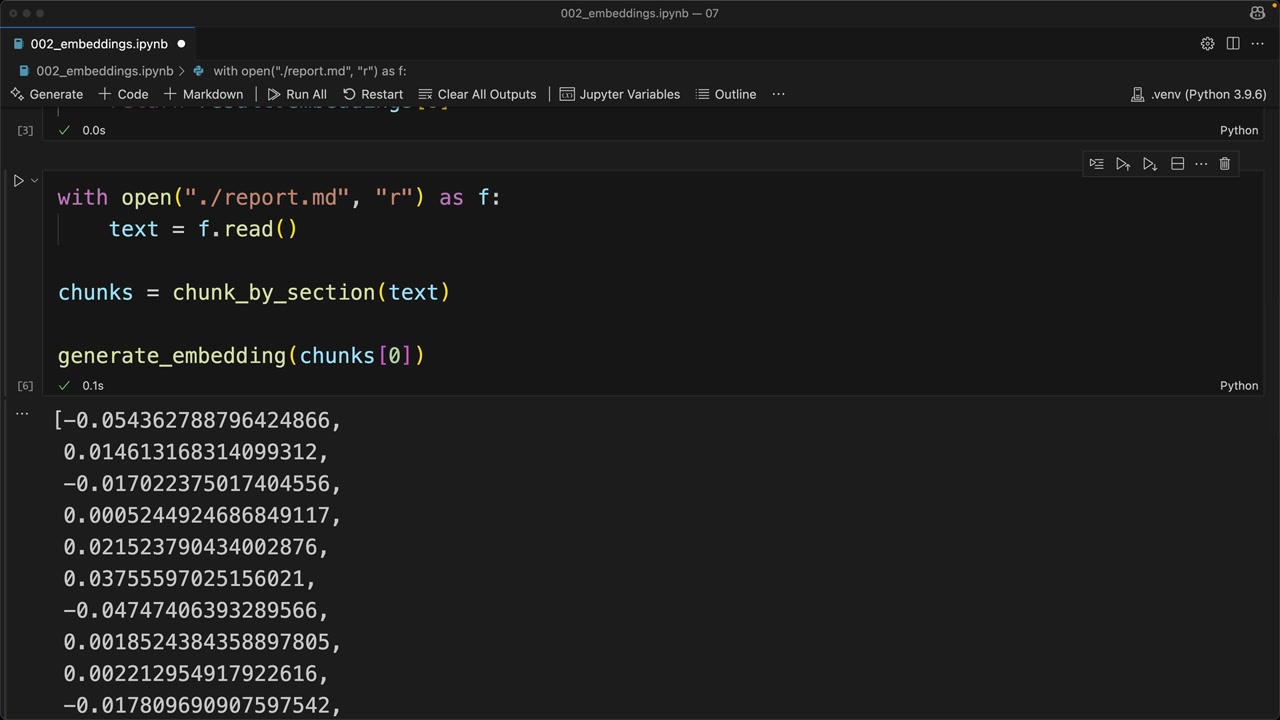
下一步是学习如何比较嵌入,以确定哪些文本块与用户的问题最相似,这是语义搜索 (semantic search) 过程的核心。
视频文字稿
从源文档中提取出一定数量的文本块后,我们 RAG 管道的下一步是等待用户提交问题、查询或类似内容。每当这种情况发生时,我们需要查看所有不同的文本块,并找到一些似乎与用户问题相关的文本块,以便将它们作为上下文添加到我们的提示 (prompt) 中。现在,这个寻找与用户问题相关的文本块的过程,哦,其中隐藏着很多复杂性。但当我们深入思考时,这确实是一个搜索问题。
我们希望接受用户的问题,并在我们所有的不同文本块中进行搜索,直到找到一些相关内容,然后以某种方式将它们呈现出来。在 RAG 管道中最常见的实现方式是实现一个被称为语义搜索的系统。语义搜索利用一种叫做文本嵌入的东西来更好地理解每个文本块的含义,并以某种方式找到与用户问题最相关的文本块。现在,我们将花相当多的时间来关注文本嵌入,并真正理解它们为我们做了什么。
那么,让我们来看几张图。文本嵌入是某些文本中所含意义的数值表示。这些文本嵌入是由所谓的嵌入模型 (embedding model) 生成的。我们将文本输入到一个嵌入模型中,比如“我今天非常开心”,然后嵌入模型会输出一个长长的数字列表。
这个长长的数字列表就是我们实际的嵌入。嵌入中的数字范围可以从-1到+1。那么现在的问题是,这些数字到底意味着什么?嵌入中的每个数字代表了输入文本某种质量的得分。
现在,这就是事情变得有点混乱的地方,因为我在这张图中展示了两个相互矛盾的想法。让我为您分解一下,说得非常清楚。实际上,我们并不知道嵌入中的每个数字到底与哪种质量相关联。所以当我标记第一个数字并说,“这是文本开心程度的得分”,这并不完全准确。
我们根本不知道第一个数字真正代表什么。尽管如此,以这种方式来思考这些数字是非常有帮助的。想象第一个数字可能是文本开心程度的一个得分,第二个是文本谈论水果的程度等等,这会很有帮助。
再次强调,这些标签完全是我编造的,我们实际上并不知道每个数字代表什么,但以这种方式思考嵌入非常有帮助。所以你真的应该这样想象这些数字。它们有点像输入文本不同质量的得分。你需要理解的最后一件事是如何实际生成这些嵌入。
Claude 目前不提供嵌入生成功能。相反,推荐的提供商是 Voyage AI。这是一家独立的公司,所以需要注册一个单独的账户和不同的 API 密钥。然而,上手是免费的,而且使用起来超级简单。
本讲座附有一个 PDF,它将引导您完成创建账户和获取 API 密钥的过程。一旦您生成了 API 密钥,您需要将它添加到您的 .env 文件中,就在您现有的 Anthropic API 密钥旁边。确保您将其分配给一个名为 Voyage_API_KEY 的变量。然后就在那里,您放入刚刚获得的生成密钥。
更新了 .EMV 文件后,我也鼓励您下载本讲座附带的一个名为 002_embeddings 的新 notebook 文件。在文件的最顶部,您会找到一个需要运行的命令,以安装 Voyage AI SDK。所以请确保运行该命令来安装这个库。在这个 notebook 的下方,我已经为大家准备好了一个名为 generate_embedding 的函数。
这个函数将接收一些文本,然后为其返回一个嵌入,基本上就这么简单。所以如果我运行这里面的所有单元格,然后运行底部的单元格,它目前正在打开报告,对报告进行分块,然后取第一个块并传入 generate_embedding。如果我然后运行这个单元格,我将得到我的嵌入列表。如您所见,生成嵌入相当快,也相当轻松。
所以真正的挑战不在于创建嵌入,而在于理解它们如何真正融入我们整个 RAG 管道。所以这将是我们接下来要探讨的主题。
50. 完整的 RAG 流程
类型:视频 | 时长:8:00 | 视频:07 - 004 - The Full RAG Flow.mp4
现在我们已经介绍了 RAG、文本分块 (text chunking) 和嵌入的基础知识,让我们一步步地完整了解整个 RAG 管道。这个例子将向您展示所有这些部分是如何协同工作以检索相关信息并生成响应的。
第 1 步:对源文本进行分块
首先,我们拿到源文档,并将其分解成易于管理的小块。在这个例子中,我们将使用两个简单的文本部分:
- 第 1 部分:医学研究 - “今年,我们在对 XDR-47 的理解上取得了重大进展,这是一种我们以前从未见过的‘bug’。”
- 第 2 部分:软件工程 - “该部门投入了大量精力研究我们分布式系统中的各种感染媒介 (infection vectors)。”
第 2 步:生成嵌入
接下来,我们使用嵌入模型将每个文本块转换成数值嵌入。为了让这个过程更容易理解,让我们想象我们有一个完美的嵌入模型,它总是返回两个数字,而且我们知道每个数字代表什么。
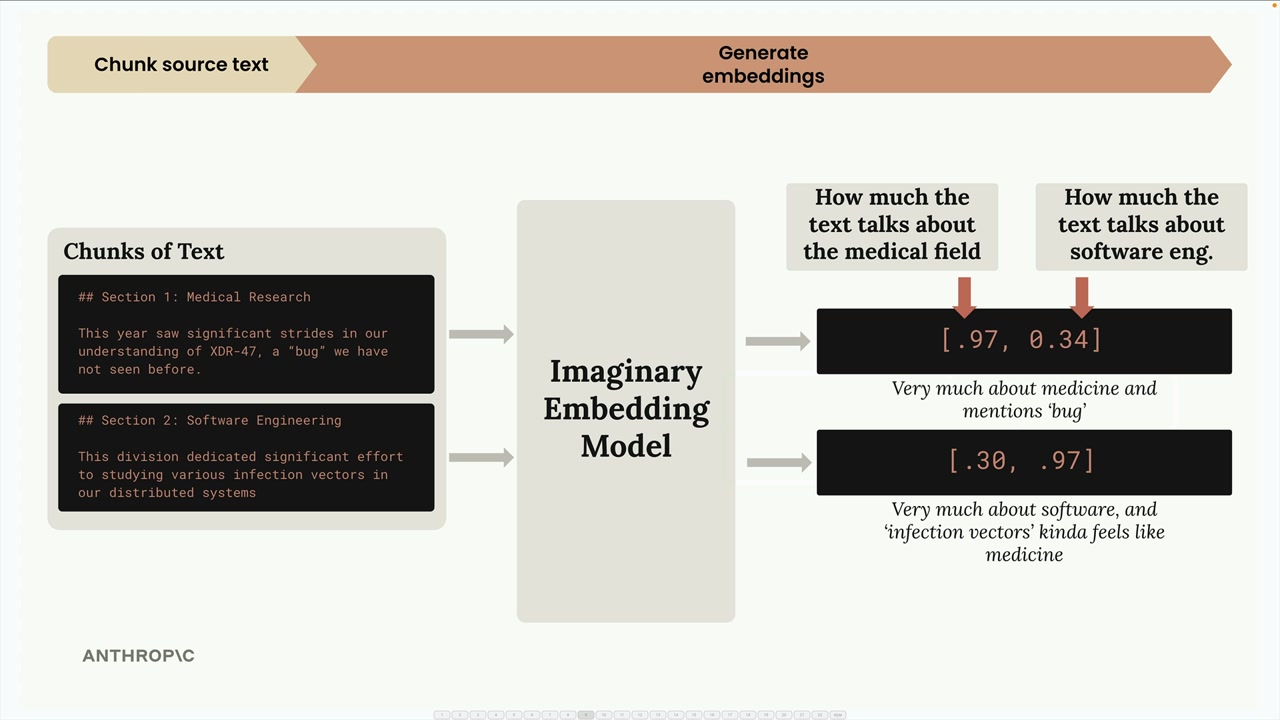
在我们想象的模型中:
- 第一个数字代表文本谈论医学领域的程度
- 第二个数字代表文本谈论软件工程的程度
对于医学研究部分,我们可能会得到 [0.97, 0.34]——非常侧重于医学,但由于“bug”这个词也带有一些软件元素。对于软件工程部分,我们得到 [0.30, 0.97]——非常侧重于软件,但由于“infection vectors”这个词也带有医学的意味。
归一化 (Normalization)
嵌入 API 通常会执行一个归一化步骤,它会缩放每个向量 (vector),使其长度为 1.0。您不需要担心这里的数学计算——这是自动处理的。这给了我们像 [0.944, 0.331] 和 [0.295, 0.955] 这样的归一化向量。
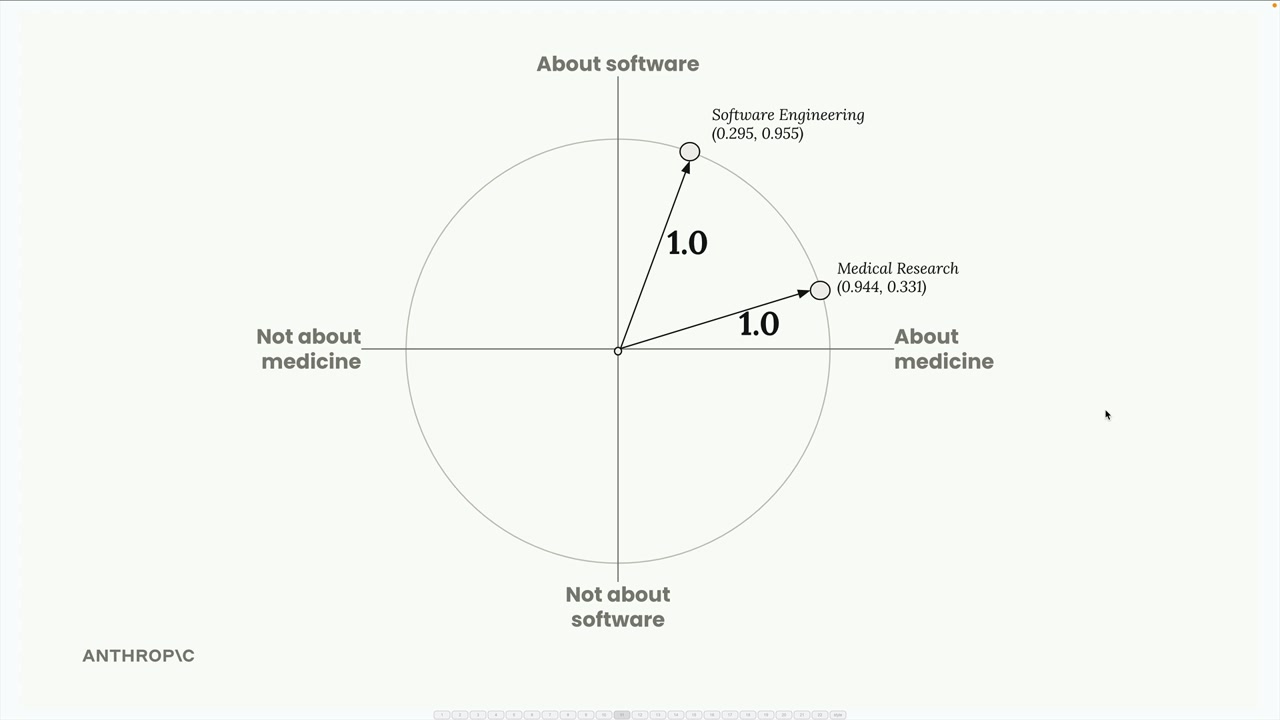
我们可以在一个单位圆 (unit circle) 上将这些嵌入可视化,其中每个点代表我们的一个文本块。
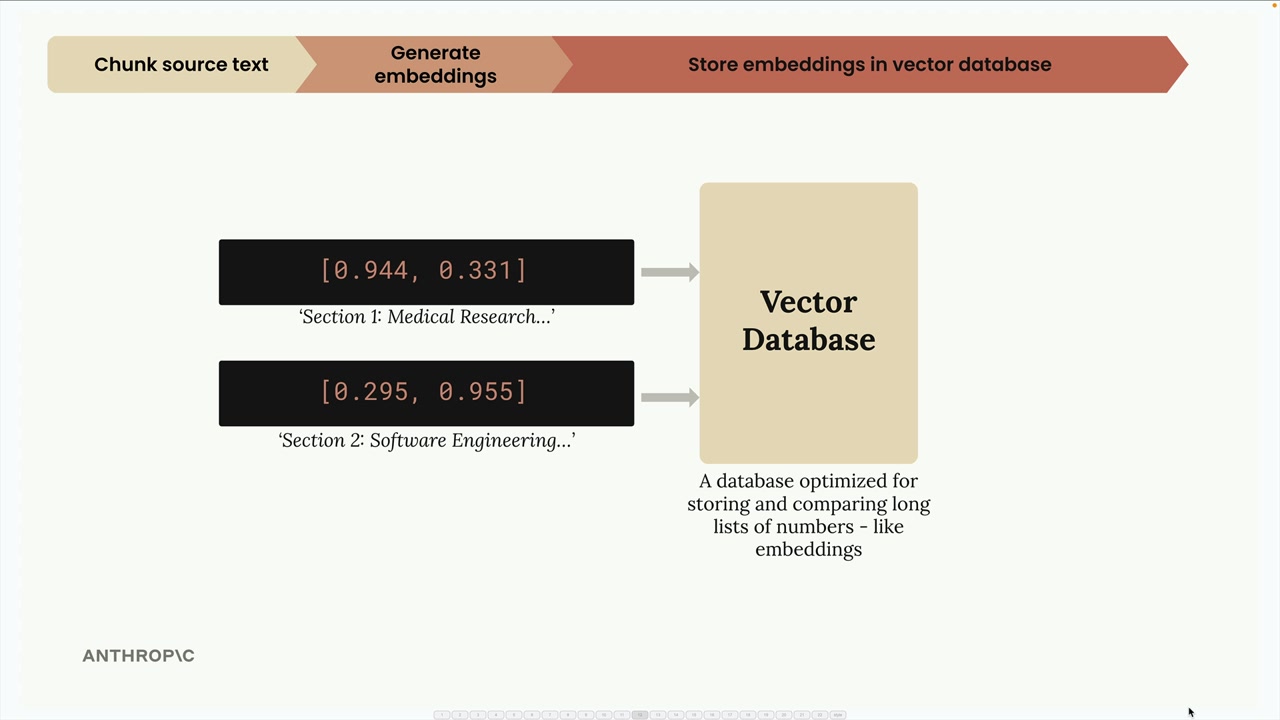
第 3 步:存储到向量数据库
我们将这些嵌入存储在向量数据库 (vector database) 中——这是一种专门用于存储、比较和搜索像我们嵌入这样的长数字列表的专用数据库。
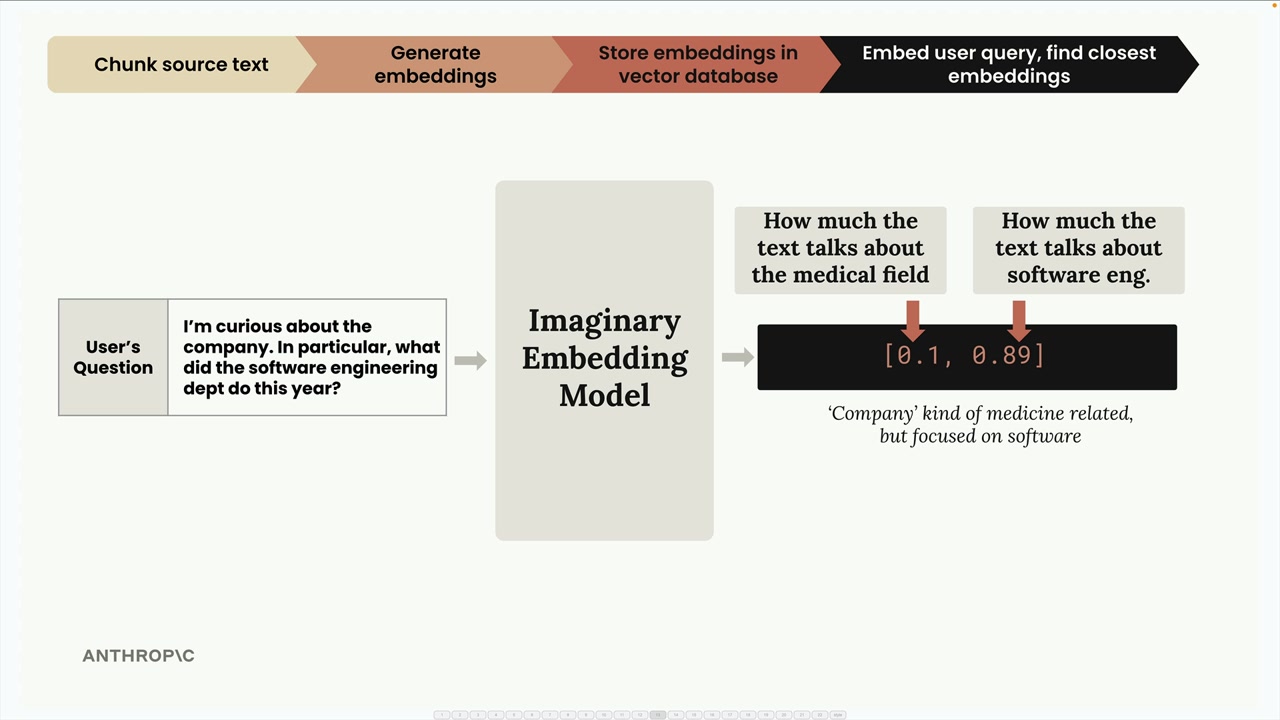
到此,我们暂停一下。到目前为止的所有工作都是预处理,是提前完成的。现在我们等待用户提交查询。
第 4 步:处理用户查询
当用户提问,比如“我对公司很好奇。特别是,软件工程部门今年做了什么?”,我们将他们的查询通过同一个嵌入模型处理。
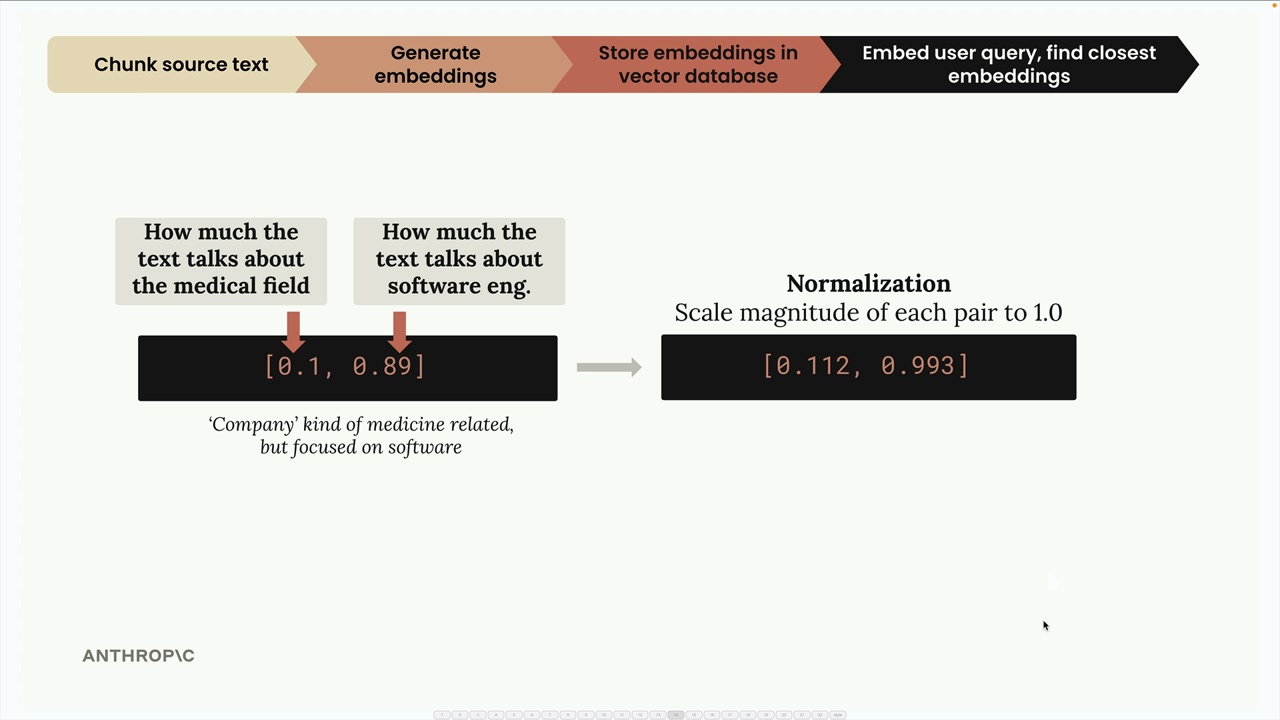
这个查询被嵌入为类似 [0.1, 0.89] 的形式——医学得分低,软件工程得分高。经过归一化后,我们得到 [0.112, 0.993]。
第 5 步:寻找相似的嵌入
我们将用户的查询嵌入发送到我们的向量数据库,并要求它找到最相似的已存储嵌入。
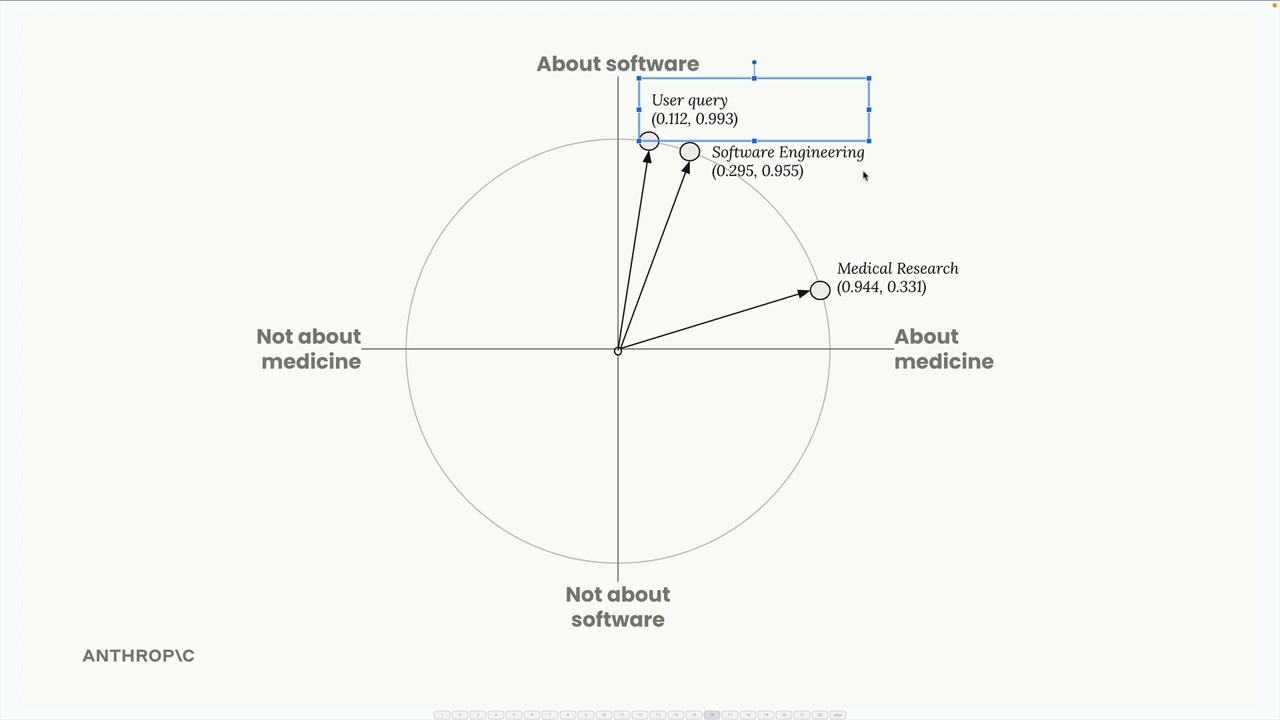
数据库返回了软件工程部分,因为它是与用户提问内容最接近的匹配。
相似度如何工作:余弦相似度 (Cosine Similarity)
向量数据库使用余弦相似度来确定哪些嵌入最相似。它测量的是两个向量之间夹角的余弦值。
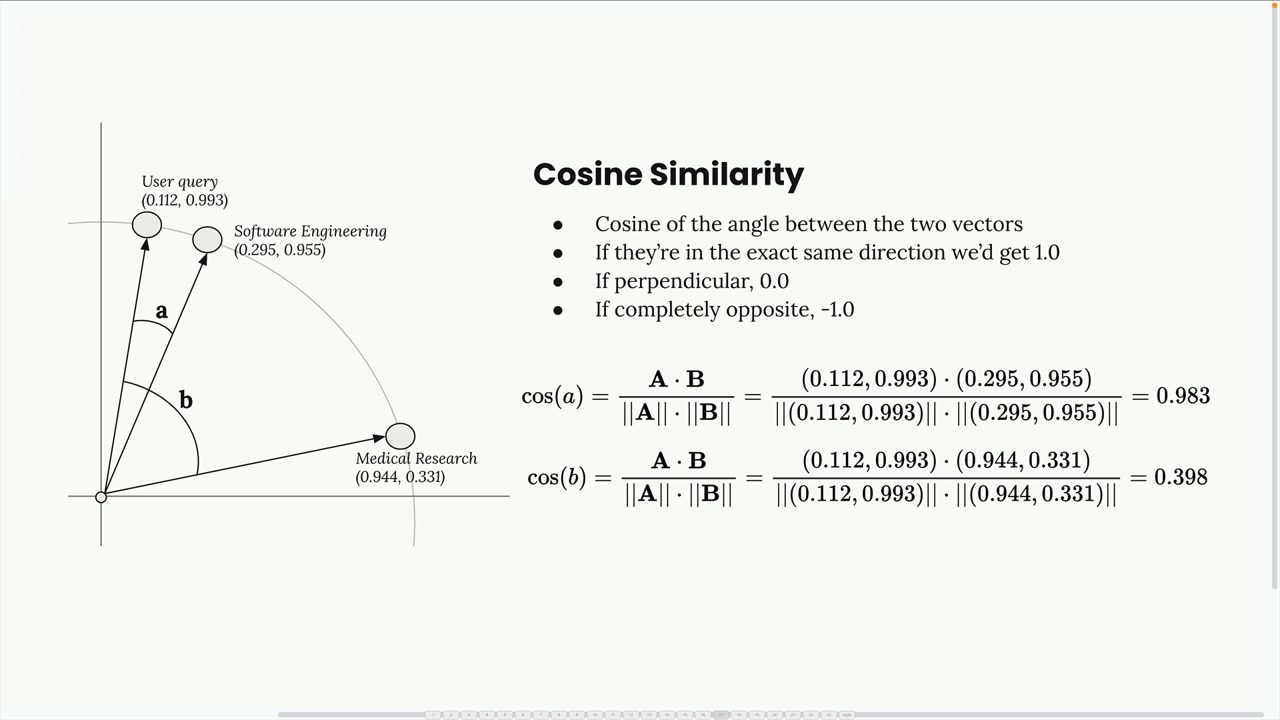
关于余弦相似度的关键点:
- 结果范围从 -1 到 1
- 值接近 1 意味着高度相似
- 值接近 -1 意味着非常不同
- 0 意味着垂直(没有关系)
在我们的例子中,用户查询和软件工程块之间的余弦相似度是 0.983——非常高的相似度。与医学研究块的相似度只有 0.398——低得多。
余弦距离 (Cosine Distance)
您经常会在向量数据库的文档中看到“余弦距离”。它就是简单地通过 (1 - 余弦相似度) 计算得出的。对于余弦距离:
- 值接近 0 意味着高度相似
- 值越大意味着相似度越低
这种调整使得数字在许多情况下更容易解释。
第 6 步:创建最终的提示
最后,我们把用户的问题和我们找到的最相关的文本块组合成一个提示,然后发送给 Claude 以获得响应。
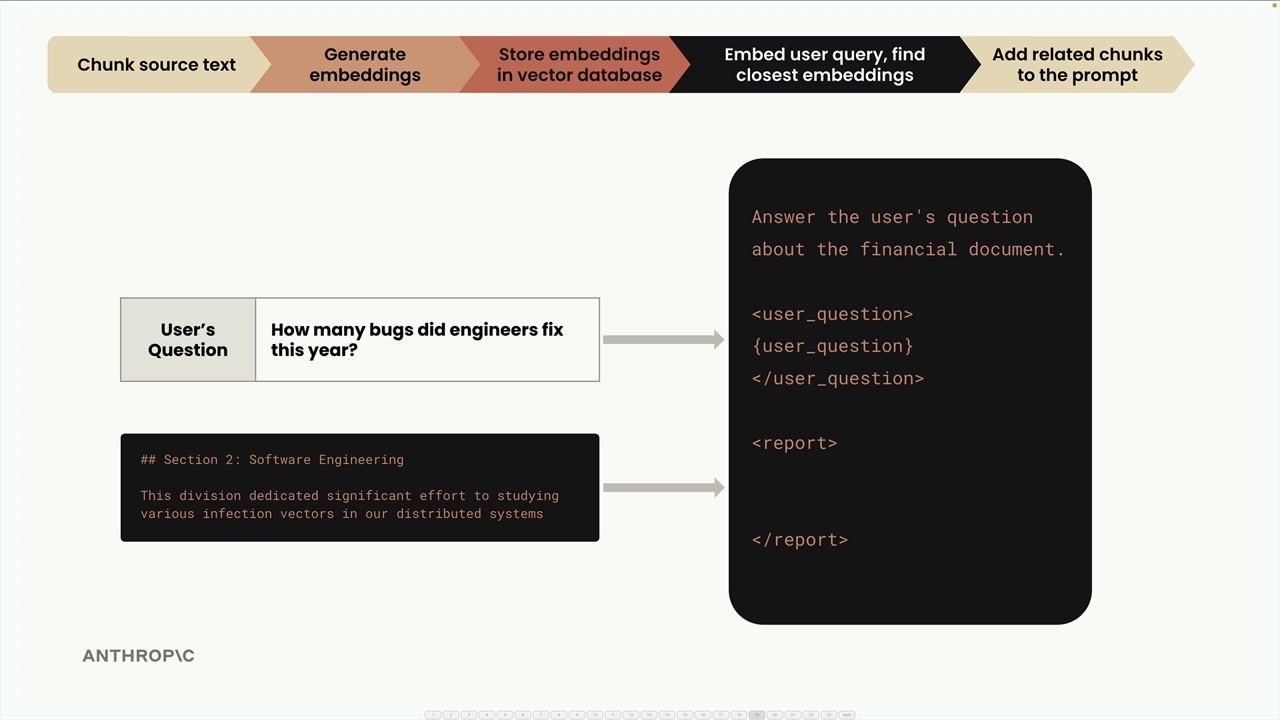
提示可能看起来像这样:
回答用户关于财务文档的问题。
<user_question>
工程师们今年修复了多少个 bug?
</user_question>
<report>
## 第 2 节:软件工程
该部门投入了大量精力研究我们分布式系统中的各种感染媒介。
</report>
这就是完整的 RAG 管道!系统成功地基于语义相似性检索到了最相关的信息,并将其作为上下文提供给模型,以生成准确的响应。
视频文字稿
在这个模块的这个阶段,我已经向您宏观地概述了 RAG 管道的工作原理。我们谈了一点文本分块,也初步接触了文本嵌入。所以现在我们将把这三个不同的话题,即我们对 RAG 过程的宏观概述、文本嵌入和文本分块,融合在一起,真正地理解整个 RAG 管道。所以我们将通过一个完整的 RAG 示例,深入很多细节,一步一步地真正理解所有内容。
那么,我们开始吧。第一步,和之前一样,我们将拿一些源文档,并将其分成独立的文本片段。所以在这个例子中,我将假设我只有两段文本,就是第一节,医学研究,和第二节,软件工程。第二步,我们将为这些不同的文本块生成嵌入。
现在在这个例子中,我们将假装我们有一个想象中的、超级完美的嵌入模型。这个嵌入模型有两个非常重要的特性。首先,我们假设它总是返回长度为二的嵌入,也就是只有两个独立的数字。我们还要假设我们确切地知道每个数字真正评价的是源文本的哪个方面。
记住,实际上并非如此。但在这种情况下,我们将想象我们确切地知道每个数字真正谈论的是什么。所以我们会说,第一个数字是文本谈论医学领域的程度,第二个是文本谈论软件工程的程度。所以对于第一个文本块,当我们嵌入它时,这东西肯定是在谈论医学研究。
所以我可能会给它打个 0.97 分,表示,是的,这绝对是在谈论医学领域。然后它还用了“bug”这个词,这个词略带软件工程的意味。此外,医学本身在软件工程方面也很有分量。所以我会给它打个 0.344 的软件工程分数。
然后是这里的第二段文本。嗯,它肯定是在谈论软件工程,所以我会给它打个 0.97 分。然后它还提到了“infection vectors”,这带有医学的意味。所以我也会给它一个稍高的医学分数,0.3。
现在我们已经生成了这些嵌入,我们将要进行一个额外的数学步骤,叫做归一化。现在,您其实不必太理解归一化。在绝大多数情况下,您使用的嵌入 API 已经为您完成了这一步。这个归一化步骤会将这些向量对的长度缩放到 1.0。
如果您不理解这个术语,完全没关系。别太担心。只要明白我们会对每个数字的实际大小做一个微小的调整。一旦我们生成了这些嵌入并对它们进行了归一化,我们就可以像这样在一张图上将它们可视化。
所以在这张图上,我画了一个单位圆,我们代表这两个嵌入的点将精确地落在圆上,因为我们已经将它们的长度归一化为一。所以我们把软件工程部分放在这里,医学研究部分放在这里。所以现在我们有了这些嵌入,我们将进入下一步。在这一步,我们将把这些嵌入存储到一个叫做向量数据库的东西里。
这是一个为存储、比较和查找长串数字(就像我们的嵌入一样)而优化的数据库。现在,在这个时间点上,我们暂停一下,休息一下,因为这都是我们提前做的预处理工作。所以在这个点上,我们只是坐等用户实际向我们的应用程序提交一个查询。所以我们会想象,在某个时间点,终于,一个用户会来到我们的应用,并可能在一个聊天机器人或类似的东西里输入他们的问题或查询。
也许在这种情况下,他们的问题会是,“我对公司很好奇,特别是,软件工程部门今年做了什么?”现在在这个时间点上,我们会拿用户的那个问题,然后通过完全相同的想象中的嵌入模型来处理它。在这种情况下,因为用户的问题是具体地问关于软件工程的,我会给它打 0.89 分。然后因为它也提到了公司,而且软件工程又和医学领域有些关联,我也会给它一个非常轻微的医学分数,0.1。
现在我们有了这个嵌入,我们将再次进行归一化步骤。然后最后,我们将利用我们的向量数据库。我们会拿用户的查询。我们会把它输入到向量数据库里,然后说,请搜索你存储的所有向量,并给我们与这个向量性质最接近的那个。
所以在我们的情况下,我有点期望能得到第二节软件工程,因为那大概就是用户在这里问的。但让我告诉您向量数据库内部到底发生了什么,它能够给我们这个非常紧密相关的结果。好的,这里有一点数学,别担心,不会太多。所以当我们把用户的查询添加到这张图上时,我们可以马上从视觉上看到用户的查询离软件工程非常近。
所以你我作为人类,可以看着这张图说,哦是的,很明显这两样东西非常接近。用户的查询与软件工程非常相似。所以显然,如果我们想在向量数据库里找到一些与用户查询相关的块,这就是我们想要的那个。但当然,我们这里用的是电脑。
我们的电脑实际上并不会像这样画一张图然后看它。背后有一些实际的计算在进行。所以让我们来研究一下那个计算到底是什么。您了解它有点重要,因为最终当您开始使用向量数据库时,它们会用很多与这种幕后数学相关的术语。
为了能很好地与向量数据库交互,您至少需要对这些数学有一个非常基本的了解。所以这就是我希望您了解它的原因。好的,这里是您的向量数据库内部正在进行的数学的宏观视角。为了找到哪些嵌入与用户的查询最相似,我们想要计算一个叫做余弦相似度的东西。
这是用户查询和数据库中存储的其他每个嵌入之间夹角的余弦值。所以我们想找到角度 A,就在这里,并取它的余弦值,以及角度 B,就在这里,并取它的余弦值。这个计算的数学公式显示在右边。这个计算的结果将是一个在 -1 和 1 之间的数字。
如果我们得到一个接近 1 的结果,就像我们这里得到的,那就意味着我们找到了一个与用户查询非常相似的嵌入。结果越接近 -1,意味着我们找到了一个与用户查询完全不相似的嵌入。在我们的例子中,我们的用户查询和软件工程块之间的余弦相似度是 0.983,这意味着这两个嵌入非常相似。所以这对我们来说是一个信号,我们应该把软件工程的文本块和用户的问题一起包含在我们的提示中。
现在,在我们继续之前,还有一件小事,现在可能会有点令人困惑,但当您稍后开始使用向量数据库时,了解它会非常有帮助。在很多向量数据库的文档中,您会看到一个被称为余弦距离的东西。这与余弦相似度不同。它的计算方法是一减去余弦相似度。
通常会做这样的调整,只是为了给我们一个更容易解释的数字。对于余弦距离,接近零的值意味着有很大的相似性。而比那更大的值意味着我们的相似性较小。再次,这是您在向量数据库文档中会经常看到的东西。
所以无论何时看到术语余弦距离和余弦相似度,都要注意它。所以现在我们对这些数学有了一个非常宏观的了解,让我们回到正轨。一旦我们找到了与用户问题高度相似的文本块,我们就会把用户的问题,把它添加到我们的提示中,以及我们找到的最相关的文本块,也把它放进我们的提示里。然后我们把那个提示发送给 Claude。
这就是整个过程,非常非常详细。所以现在我们从头到尾都理解了所有事情,包括幕后发生的所有技术,甚至一些数学,让我们在稍后的 notebook 中开始实现这一点。
51. 实现 RAG 流程
类型:视频 | 时长:5:12 | 视频:07 - 005 - Implementing the Rag Flow.mp4
既然我们从概念上理解了 RAG 流程,现在就让我们一步步地实现它。我们将通过一个完整的例子,演示如何对文本进行分块、生成嵌入、将它们存储在向量数据库中,并执行相似性搜索。
五步 RAG 实现
我们的实现遵循我们之前讨论过的相同的五个步骤:
- 按章节对文本进行分块
- 为每个块生成嵌入
- 创建一个向量存储并向其中添加每个嵌入
- 为用户的问题生成一个嵌入
- 搜索存储以找到最相关的块
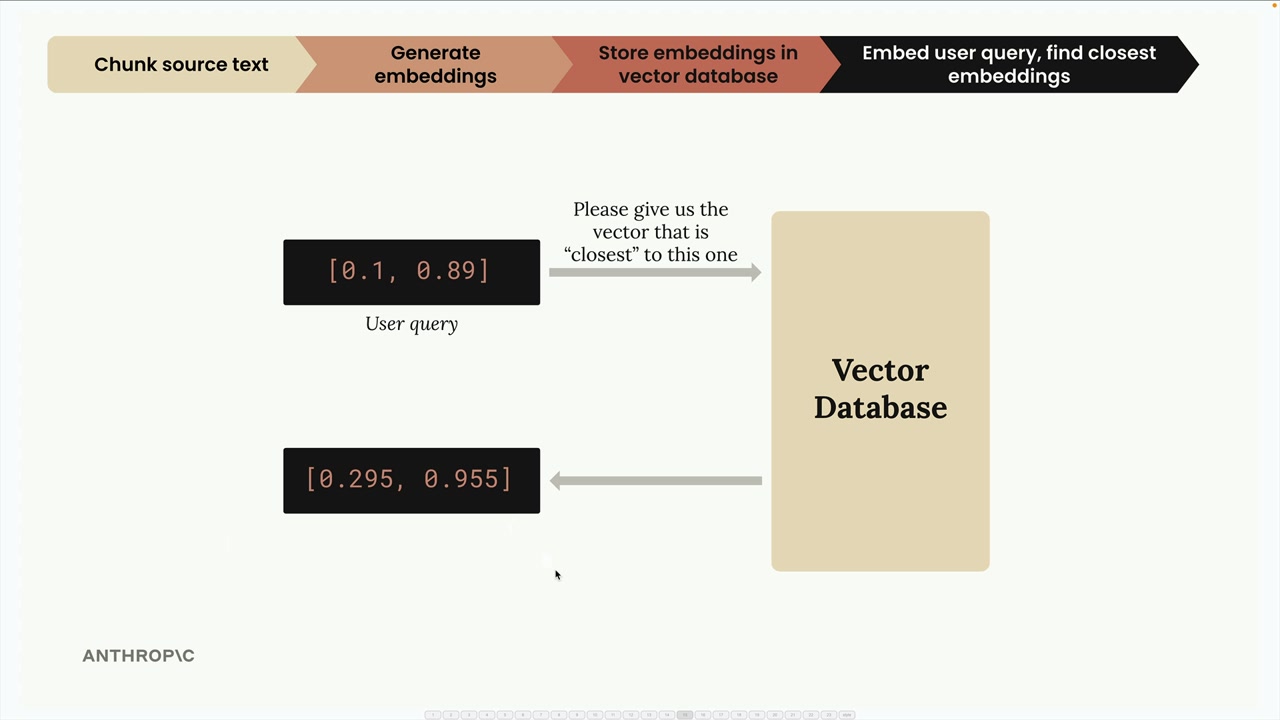
这张图显示了我们如何将用户查询转换为嵌入,并搜索我们的向量数据库以找到最相关的内容。
第 1 步:对文本进行分块
首先,我们加载文档并将其分割成易于管理的部分:
with open("./report.md", "r") as f:
text = f.read()
chunks = chunk_by_section(text)
chunks[2] # 测试查看目录
我们使用之前用过的 chunk_by_section 函数,将我们的文档分割成逻辑部分。
第 2 步:生成嵌入
接下来,我们一次性为我们所有的块创建嵌入:
embeddings = generate_embedding(chunks)
generate_embedding 函数已经更新,可以处理单个字符串和字符串列表,这使得批量处理更加高效。
第 3 步:存储在向量数据库中
现在我们创建向量存储,并用嵌入及其关联的文本填充它:
store = VectorIndex()
for embedding, chunk in zip(embeddings, chunks):
store.add_vector(embedding, {"content": chunk})
请注意,我们同时存储了嵌入和原始文本内容。这一点至关重要,因为当我们稍后进行搜索时,我们需要返回实际的文本,而不仅仅是数值嵌入值。
为什么要存储原始文本?
当我们查询向量数据库时,仅仅得到嵌入数字是没有用的。我们需要用来生成那些嵌入的实际文本。这就是为什么我们在数据库中为每个嵌入都包含了原始的文本块(或至少是对它的引用)。
第 4 步:处理用户查询
当用户提问时,我们为他们的查询生成一个嵌入:
user_embedding = generate_embedding("What did the software engineering dept do last year?")
第 5 步:寻找相关内容
最后,我们搜索我们的向量存储以找到最相似的块:
results = store.search(user_embedding, 2)
for doc, distance in results:
print(distance, "\n", doc["content"][0:200], "\n")
这次搜索返回了两个最相关的块以及它们的相似度得分(余弦距离)。
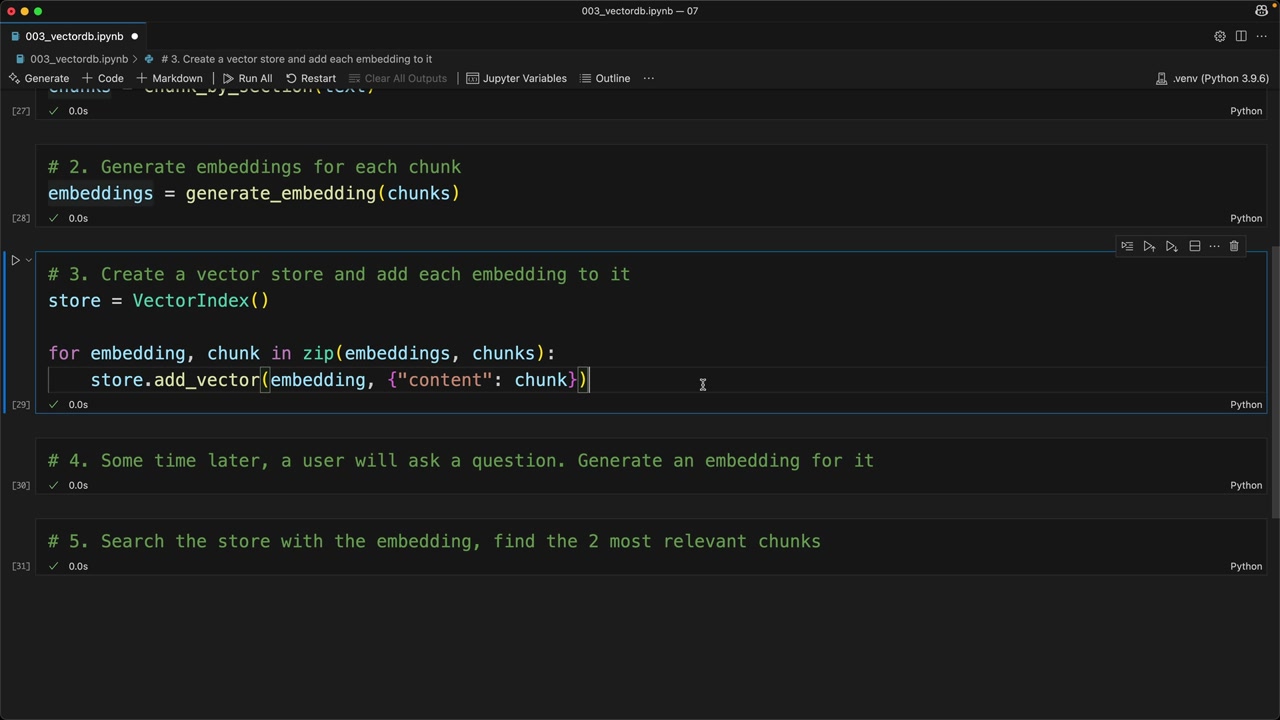
搜索结果向我们展示了文档的哪些部分与用户的问题最相关,以及相似度得分。
理解结果
当我们运行关于软件工程部门的示例查询时,我们得到:
- 第 2 节:软件工程,距离为 0.71(最接近的匹配)
- 方法论部分,距离为 0.72(第二接近的匹配)
距离值越低表示相似度越高,所以第 2 节与我们的查询最相关。
接下来呢?
这个实现在基本情况下运行良好,但在某些场景下,它的表现并不如预期。在接下来的部分中,我们将探讨改进方法,使我们的 RAG 系统更加健壮和准确。
关键要点是,RAG 的核心在于将文本转换为数字(嵌入),高效地存储这些数字,然后在用户提问时使用数学上的相似性来寻找相关内容。
视频文字稿
现在我们了解了整个 RAG 流程,我们将在另一个名为 003_VectorDB 的 notebook 中逐步完成一个示例。在这个 notebook 中,我提供了一个向量数据库的示例实现。我把它命名为 Claude_vector_index。如果你愿意,可以随时看一看,但我会带你了解所有你需要理解的内容。
在这个 notebook 中,我们将通过实现五个不同的步骤来走完整个 RAG 流程。这五个步骤和我们在上一个视频中讲的一样。那么,我们开始吧。第一步,我已经打开了文件并读取了其中的文本,具体来说是我们的 report.md 文件,它应该和 notebook 在同一个目录下。
所以在第一步中,我们将按章节对文本进行分块。我已经添加了一个函数来帮助完成这个任务。就是我们之前用过的那个 chunk_by_section 函数。所以为了进行分块处理,我会写 chunks = chunk_by_section(text)。
现在为了测试一下,确保一切都正常,我会尝试打印出 chunks 索引为 2 的内容。我应该能看到目录的打印输出。然后如果我去看索引 3,我应该能看到下一节的内容,然后是再下一节,依此类推。然后,进入第二步。
在第二步中,我们将为每个块创建一个嵌入。现在,我要告诉你,我稍微重写了嵌入函数,所以现在我们可以传入一个字符串或一个字符串列表。如果我们传入一个字符串列表,它会为每个字符串创建一个嵌入,然后以嵌入列表的形式返回。所以要实现第二步,我们将调用 generate_embedding 并传入所有的 chunks,然后将结果赋给 embeddings。
接下来,在第三步中,我们将创建一个向量存储的实例。一旦存储被创建,我们就会遍历所有不同的块和嵌入对。我们会把它们 zip 在一起,然后当我们拿到每一对时,我们会把它们插入到存储中。我们会用一个 for embedding, chunk in zip(embeddings, chunks) 循环来做这件事。
再次强调,对于每一个嵌入和块的对,我们会调用 store.add(vector=embedding, metadata={"content": chunk})。embedding 作为参数传入。然后作为第二个参数,我们会传入一个字典,内容是 chunk。现在,我很快地讲完了这一步。
所以让我们花点时间解释一下为什么我们要遍历所有这些东西,为什么我们要分块,以及为什么我们要添加这个带有 content of chunk 的额外字典。正如我们刚刚讨论的,最终在某个时间点,我们会联系我们的向量数据库,并返回一个与输入相关的所有不同嵌入的列表。现在,当我们得到这个列表时,仅仅得到数字本身,仅仅得到嵌入,对我们来说并没有什么用,因为嵌入对我们开发者来说并没有太多意义。我们真正关心的是与那个嵌入相关联的文本。
所以通常当你把这些不同的嵌入存储在你的向量数据库里时,你也会包含嵌入生成的那个块的文本,或者至少是那个块的 ID,一些至少能让你找回原始块文本的东西。所以在这种情况下,我会在每个嵌入旁边都包含原始的块文本。再次强调,只是为了当我们稍后进行查找时,我能得到最相似的块,我能得到我正在寻找的实际文本。现在进入第四步。
所以在第四步,未来的某个时间点,一个用户会向我们提问。我们需要拿那个问题并为它生成一个嵌入。所以我们会通过调用 generate_embedding 来创建一个 user_embedding。然后我这里的问题是,软件工程部门去年做了什么。
最后,在第五步,我们将尝试寻找一些相关的文档。所以我想用这个嵌入来搜索存储,并且我想找到两个最相关的块,而不仅仅是最相关的那个。我想得到与这个问题最相关的两个块。所以为此,我会写 results = store.search(。我将传入 user_embedding,并且我将在这里传入另一个参数 2,因为我想找到两个最相关的块。
然后我会打印出 for doc, distance in results: 我将打印出距离,一个换行符,然后是文档的内容。因为这里的每个块都非常非常大,我将只打印前 200 个字符。然后是另一个换行符,像这样。然后我运行它。
这就是我们的结果。所以我们得到第二节作为最好的结果。我们也看到了这里的余弦距离。所以它是 0.71。
而下一个最接近的块是 0.72,那是方法论部分。所以这是根据我们刚刚提交的用户查询找到的两个最相关的块。好的,这就是我们整个 RAG 的工作流程。现在这一切都行得通,但有一两种情况下,一切并不能如预期那样工作。
所以我们的工作流程中仍然有一些可以改进的地方,让我们马上开始讨论这些。
52. BM25 词法搜索
类型:视频 | 时长:10:00 | 视频:07 - 006 - BM25 Lexical Search.mp4
在构建 RAG 管道时,您会很快发现仅靠语义搜索并不总能返回最佳结果。有时您需要精确的术语匹配,而语义搜索可能会错过。解决方案是使用一种名为 BM25 的技术,将语义搜索与词法搜索 (lexical search) 结合起来。
单独使用语义搜索的问题
假设您正在一个文档中搜索一个特定的事件 ID,如 "INC-2023-Q4-011"。虽然语义搜索擅长理解上下文和意义,但它可能会返回一些语义上相关但实际上并不包含您要查找的确切术语的部分。
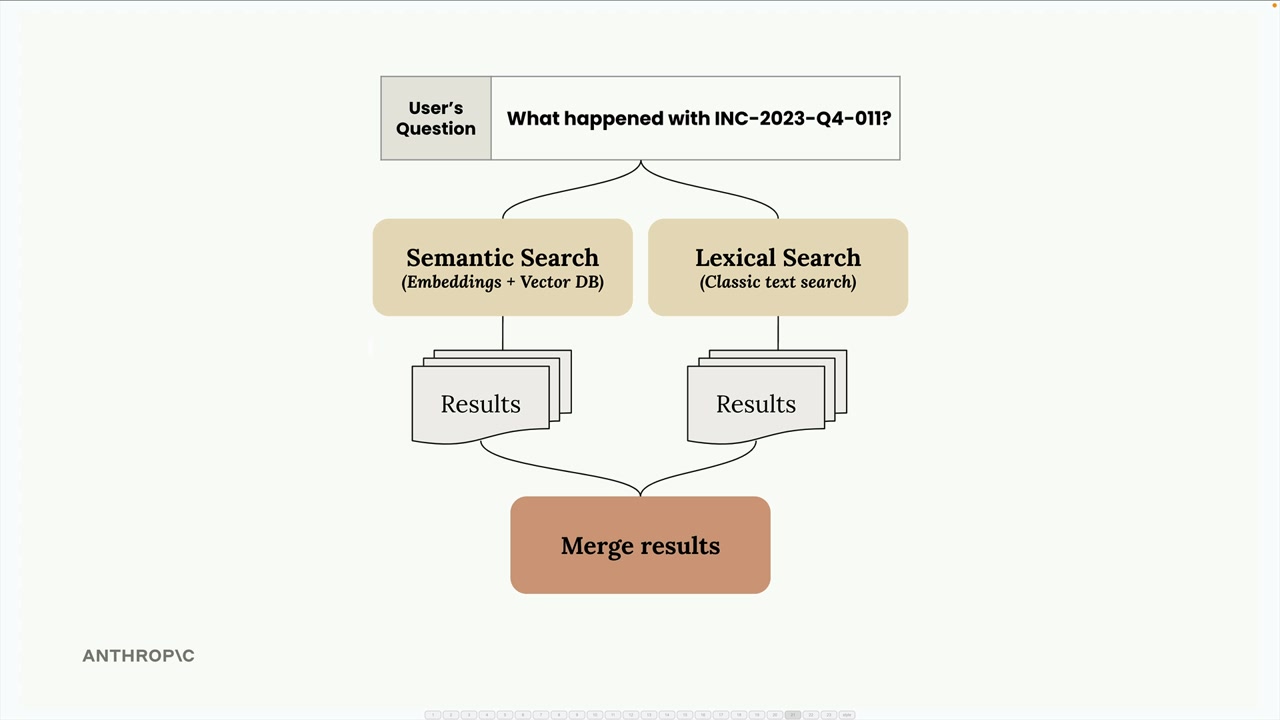
在上面的例子中,语义搜索返回了网络安全部分(其中确实包含该事件 ID),但也返回了一个完全没有提到该事件的财务分析部分。发生这种情况是因为语义搜索关注的是概念上的相似性,而不是确切的术语匹配。
混合搜索策略
解决方案是并行运行语义搜索和词法搜索,然后合并结果。这让您兼得两者的优点:
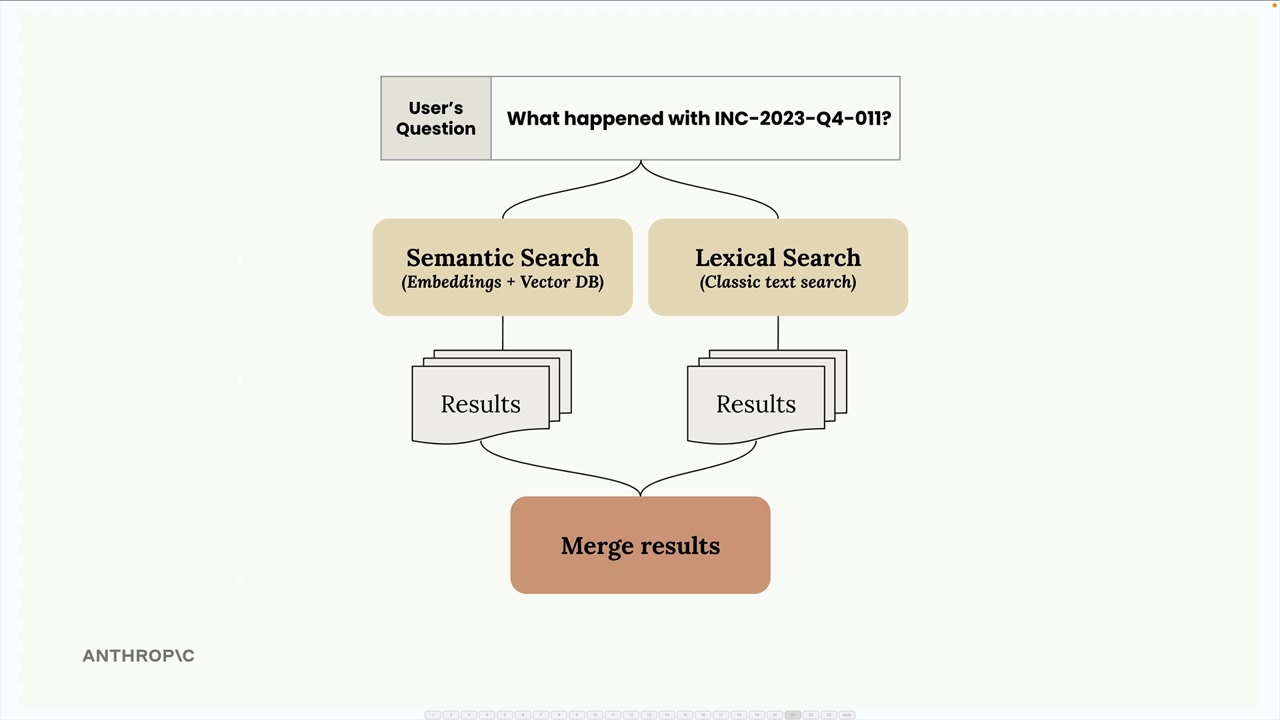
- 语义搜索 使用嵌入来寻找概念上相关的内容
- 词法搜索 使用经典的文本搜索来寻找确切的术语匹配
- 合并结果 结合两种方法以获得更高的准确性
BM25 如何工作
BM25 (Best Match 25) 是 RAG 系统中用于词法搜索的一种流行算法。以下是它处理搜索查询的方式:
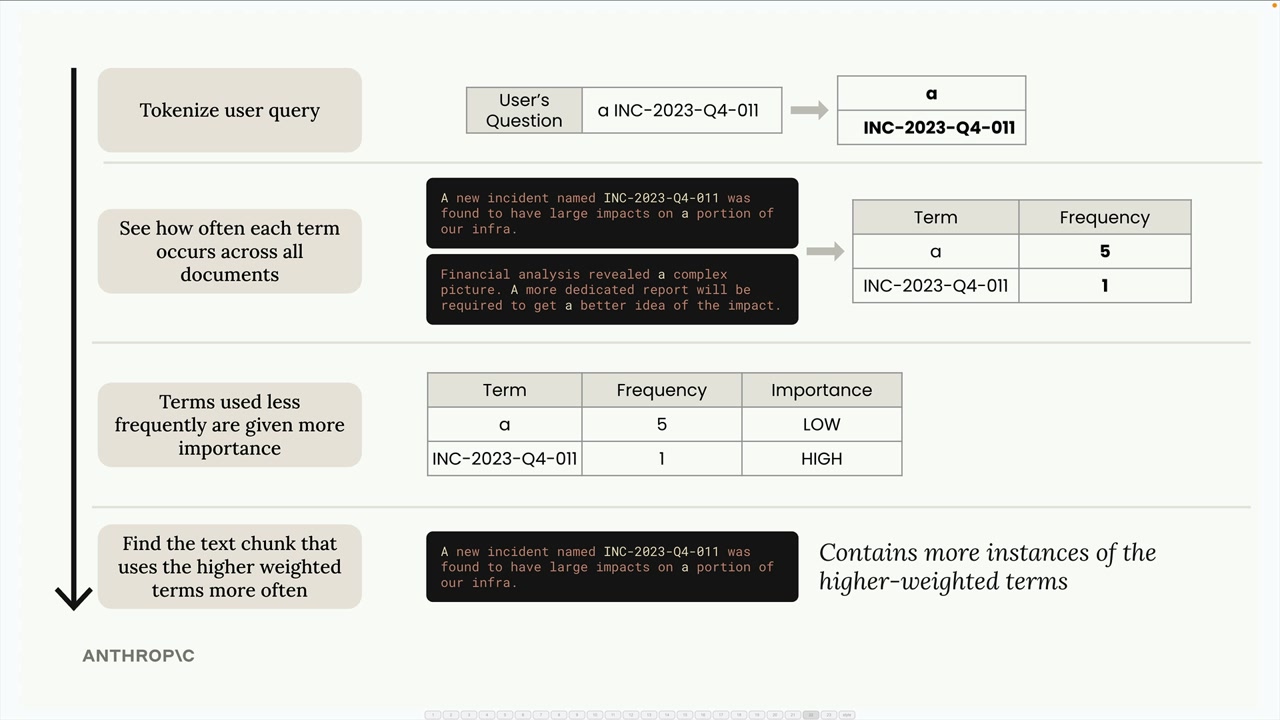
第 1 步:对查询进行分词 将用户的问题分解成单个术语。例如,"a INC-2023-Q4-011" 变成 ["a", "INC-2023-Q4-011"]。
第 2 步:统计术语频率 查看每个术语在您所有文档中出现的频率。像 "a" 这样的常用词可能出现 5 次,而像 "INC-2023-Q4-011" 这样的特定术语可能只出现一次。
第 3 步:根据重要性对术语加权 出现频率较低的术语获得更高的重要性得分。"a" 这个词的重要性得分很低,因为它很常见,而 "INC-2023-Q4-011" 的重要性得分很高,因为它很罕见。
第 4 步:寻找最佳匹配 返回包含更多高权重术语实例的文档。
实现 BM25 搜索
以下是如何设置一个基本的 BM25 搜索系统:
# 1. 按章节对您的文本进行分块
chunks = chunk_by_section(text)
# 2. 创建一个 BM25 存储并添加文档
store = BM25Index()
for chunk in chunks:
store.add_document({"content": chunk})
# 3. 搜索存储
results = store.search("What happened with INC-2023-Q4-011?", 3)
# 打印结果
for doc, distance in results:
print(distance, "\n", doc["content"][:200], "\n----\n")
当您运行此搜索时,您将得到比单独使用语义搜索好得多的结果。BM25 算法优先考虑那些实际包含您特定搜索术语的部分,特别是像事件 ID 这样的罕见术语。
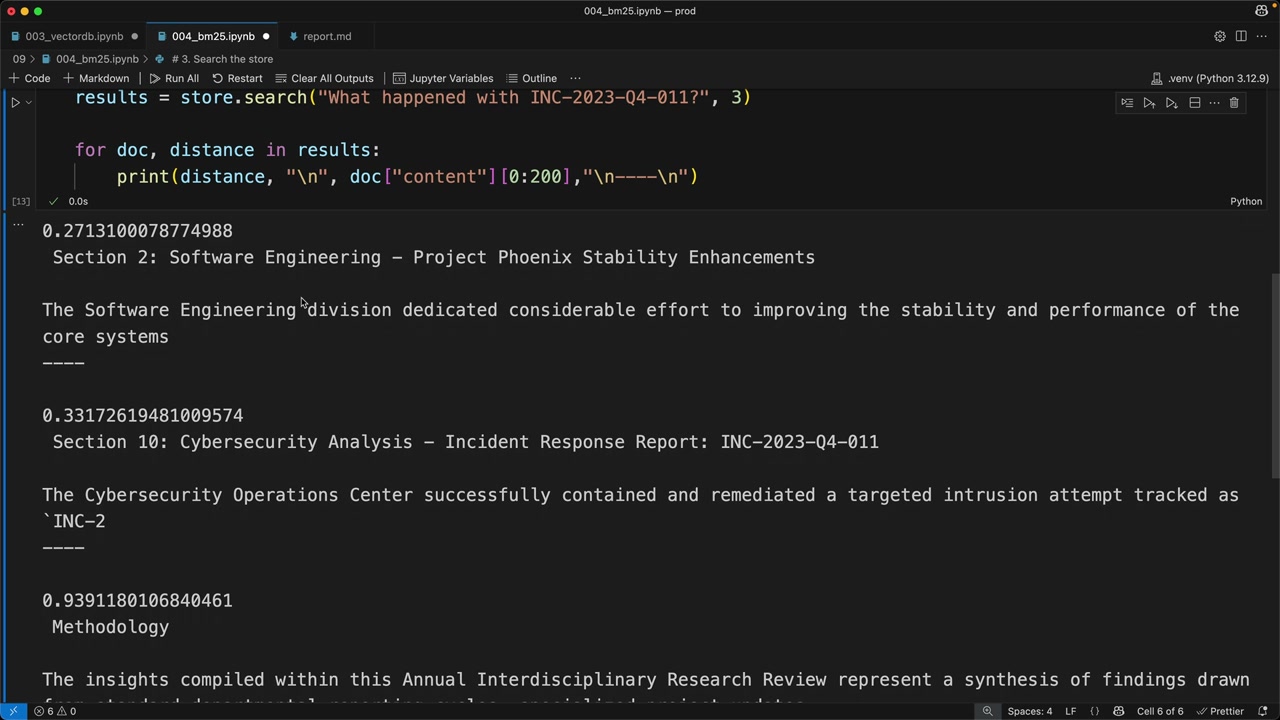
请注意,现在结果如何正确地优先考虑了软件工程部分和网络安全部分——这两部分都实际包含了您要搜索的事件 ID。
为什么这种方法效果更好
BM25 在寻找精确匹配方面表现出色,因为它:
- 给予罕见、特定的术语更高的权重
- 忽略那些不增加搜索价值的常用词
- 关注术语频率而不是语义含义
- 对于技术术语、ID 和特定短语尤其有效
关键的洞见是,两种搜索方法具有互补的优势。语义搜索理解上下文和意义,而词法搜索确保您不会错过确切的术语匹配。通过将它们结合起来,您可以创建一个更强大的搜索系统,有效地处理概念性查询和特定查找。
在下一步中,您将学习如何合并来自两种搜索系统的结果,以创建一个统一的混合搜索体验。
53. A Multi-Index RAG pipeline
此课时内容请访问在线课程平台查看完整内容。
54. Reranking results
此课时内容请访问在线课程平台查看完整内容。
55. Contextual retrieval
此课时内容请访问在线课程平台查看完整内容。
57. Extended thinking
类型:视频 | 时长:7:01 | 视频:08 - 001 - Extended Thinking.mp4
重要提示:扩展思考 (Extended Thinking) 与某些其他功能不兼容,特别是消息预填充 (message pre-filling) 和温度 (temperature) 参数。请在此处查看完整的限制列表:https://docs.anthropic.com/en/docs/build-with-claude/extended-thinking#feature-compatibility
扩展思考是 Claude 的一项高级推理功能,它让模型在生成最终响应之前有时间来处理复杂问题。可以把它看作是 Claude 的“草稿纸”——您可以看到得出答案的推理过程,这有助于提高透明度,并通常会带来更高质量的响应。
扩展思考如何工作
当启用扩展思考时,Claude 的响应从一个简单的文本块变成一个包含两部分的结构化响应:
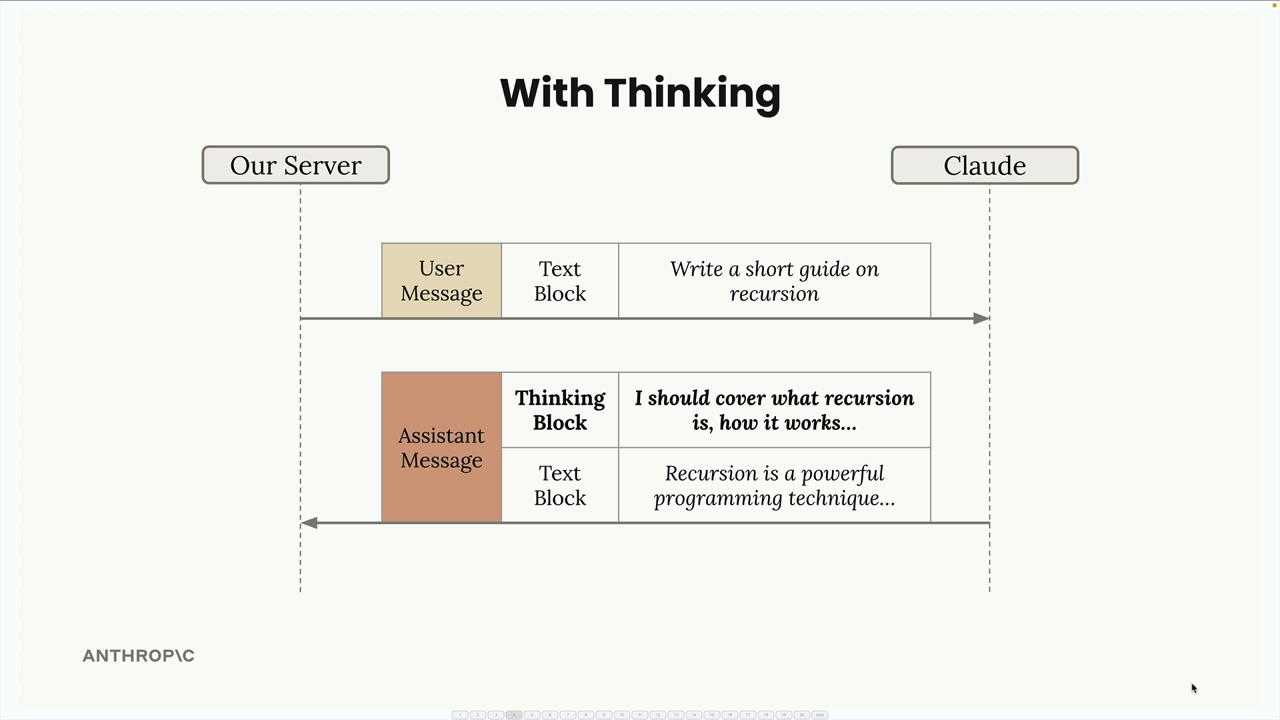
启用思考功能后,您既能得到推理过程,也能得到最终答案:

主要好处包括:
- 对复杂任务有更好的推理能力
- 在难题上准确性更高
- Claude 思考过程的透明度
然而,也有重要的权衡:
- 更高的成本(您需要为思考过程产生的 token 付费)
- 更长的延迟 (latency)(思考需要时间)
- 在您的代码中处理响应更复杂
何时使用扩展思考
决定很简单:使用您的提示评估 (prompt evaluations)。首先在不开启思考功能的情况下运行您的提示,如果您已经优化了提示但准确性仍未达到要求,那么再考虑启用扩展思考。当标准提示不足以解决问题时,这是一个可以使用的工具。
响应结构与安全性
扩展思考的响应包含一个特殊的签名系统以确保安全:

签名是一个加密令牌,确保您没有修改思考文本。这可以防止开发者篡改 Claude 的推理过程,因为这可能会将模型引向不安全的方向。
被编辑的思考 (Redacted Thinking)
有时您会收到一个被编辑过的思考块,而不是可读的推理文本:
当 Claude 的思考过程被内部安全系统标记时,就会发生这种情况。被编辑的内容以加密形式包含了实际的思考过程,允许您在未来的对话中将完整的消息传回给 Claude 而不会丢失上下文。
实现
要在您的代码中启用扩展思考,您需要向聊天函数添加两个参数:
def chat(
messages,
system=None,
temperature=1.0,
stop_sequences=[],
tools=None,
thinking=False,
thinking_budget=1024
):
thinking_budget 设置了 Claude 可以用于推理的最大 token 数。最小值为 1024 个 token,并且您的 max_tokens 参数必须大于您的 thinking_budget。
将思考配置添加到您的 API 参数中:
if thinking:
params["thinking"] = {
"type": "enabled",
"budget": thinking_budget
}
然后以启用思考的方式调用它:
chat(messages, thinking=True)
测试被编辑的响应
出于测试目的,您可以通过发送一个特殊的触发字符串来强制 Claude 返回一个被编辑的思考块。这有助于确保您的应用程序能够优雅地处理被编辑的响应而不会崩溃。
当您需要 Claude 处理复杂的推理任务时,扩展思考是一个强大的功能,但鉴于成本和延迟的影响,请谨慎使用。从标准提示开始,进行充分优化,然后在需要额外推理能力时再添加思考功能。
视频文字稿
让我们来研究一下 Claude 的一个更高级的功能,称为扩展思考。扩展思考让 Claude 在生成最终响应之前有时间对用户的查询进行推理。在许多聊天 UI 中,这将显示为一个独立的思考过程,用户可以选择性地查看,以更好地了解 Claude 是如何处理他们的问题的。现在总的来说,启用扩展思考将使 Claude 能够以更高的准确性处理更复杂的任务,但这其中有一些重大的权衡。
您需要为 Claude 在思考阶段生成的 token 付费,而且这个阶段本身也需要一些时间来完成。所以,智能的提升伴随着成本的增加,延迟也会增加。现在,一个关于扩展思考的常见问题是决定何时启用它。答案其实很简单。
您将依赖于您的提示评估。所以,您会写出一个提示,对它进行评估。如果准确性不符合您的要求,并且您已经花了相当多的精力来改进您的提示,那么这时候您就应该考虑启用扩展思考了。
扩展思考的使用相当直接。记住,当我们通常使用 Claude 时,我们发送一个可能包含文本块的用户消息。然后我们会收到一个也包含文本块的助手消息。当我们开始启用扩展思考时,我们得到的响应将包含一个我们以前没有见过的新块类型,叫做思考块 (thinking block)。
在这个思考块内部,将是 Claude 思考时生成的文本。关于这个思考块,有一件非常有趣的事情我想马上告诉您,因为一旦您开始写一些代码并开启扩展思考功能发出请求,您会很快看到它。在右侧,我有一个包含思考块和文本块的助手消息的例子。在思考块内部,您会注意到有一个叫做签名的东西。
签名是一个加密令牌,它的作用是这样的。如果您想把这个消息作为对话的一部分在未来发回给 Claude,Claude 希望确保您没有以任何方式修改思考块中的文本。签名是用来确保您没有改变文本的。Claude 完全不希望您改变那个文本,因为它在生成响应时被高度依赖。
如果允许开发者修改那个文本,他们可能会把 Claude 引向一个不安全的方向。关于思考,还有另一个与此相关的方面。在某些情况下,您可能会得到一个只有 redacted 内容字段而没有任何思考文本的思考块。这种情况发生在 Claude 生成的某些思考文本被某个内部安全系统标记时。
被编辑的内容是实际的思考文本,但处于完全加密的形式。它提供给您,这样您将来就可以把这个完整的消息作为对话的一部分还给 Claude,而 Claude 不会丢失任何关于他之前思考的上下文。要真正理解扩展思考,我们需要写一点代码。所以让我们回到我们的 Jupyter notebooks。
我创建了一个名为 001_thinking 的新 notebook。它再次拥有我们整个课程中一直在使用的许多类似代码,但我添加了一两个非常特别的东西。所以我鼓励您确保下载这个 notebook。它附在本讲座中。
为了启用思考,我们需要找到我们的 chat 函数。我们将向 chat 函数提供一些额外的参数,这些参数最终会添加到这个 params 对象中。所以我将添加 thinking,默认值为 false,然后是 thinking_budget,值为 1024。
thinking_budget 是我们希望允许 Claude 在生成响应的思考部分时使用的 token 数量。这里的最小值是 1024,所以我们的 thinking_budget 不能少于 1024。Claude 完全有可能不会在思考上花费 1024 个 token,但再次强调,这是我们能指定的最低预算。关于 thinking_budget,您还需要了解一个非常重要的事实。
那就是,max_tokens 必须大于您的 thinking_budget。所以,例如,如果我们的 thinking_budget 是 1024,max_tokens 必须至少是 1025。而这只会留下一个 token 来实际应用于生成一些文本。所以通常您会希望 max_tokens 的值比您的 thinking_budget 大得多。
所以就我而言,我将把这里的 max_tokens 增加到 4000。现在我有一个相当大的缓冲。这意味着我可以生成一个响应,其中有 1000 个 token 分配给思考,然后剩下的 3000 个 token 可以分配给实际生成一些文本。一旦我们添加了这两个关键字参数,我们就会向 params 字典添加一些额外的参数。
所以向下滚动一点,就在这里。我会说,如果 thinking 被启用,那么我想向我的 params 字典添加一个新键,具体来说是 thinking。这将是一个嵌套的字典,其 type 为 enabled,budget token 为我们作为 thinking_budget 传入的任何值,像这样。就这样。
所以我会运行这个单元格,然后我会滚动到底部,这样我们就可以测试一下。我将要求 Claude 写一篇关于递归的一段式指南。然后我会确保我在这里更新我的 chat 函数调用,通过传入 thinking=True 来启用思考。然后我运行它,让我们看看我们做得怎么样。
这是我们的响应。所以在响应中,我得到了两个独立的块。首先,我有我的思考块,然后稍微往下一点,就在那里,是我的文本块的开始。在思考块内部,我确实有一个签名。
伴随着它,我有我的思考文本。记住,签名的目的是确保我们不会篡改思考文本。当然,我们这里的文本块包含了我们要求 Claude 写的实际指南。现在我想给您看的最后一件事是,当您最初构建和测试您的应用程序时可能会用到的东西。
提醒一下,在某些情况下,Claude 可能会发回一个被编辑的思考块。在您构建应用程序时,您可能想确保您的代码在收到被编辑的思考块时能正常工作。所以我们实际上可以强制 Claude 给我们发回一个被编辑的思考块。我们所要做的就是发送一条包含一个非常非常特殊格式字符串的消息。
所以如果您滚动到这里的第二个单元格的最顶部,您会注意到我放入了 thinking_test_string。然后它的值是 Anthropic,magic string triggered redacted thinking,然后后面是一堆特殊的数字和字母。如果您把这个确切的字符串发送给 Claude,您保证会得到一个被编辑的思考块。再次强调,我们这样做只是为了测试目的,以确保我们能处理那种响应。
所以让我很快地给您展示一下。我将回到最底部的单元格。我将添加一个只包含那个 thinking_test_string 的用户消息。然后我发送这个。
现在我们应该会得到一个响应,里面会有一个被编辑的思考块。就是这样。所以我得到了我的被编辑的思考块,它除了一个数据和一个 redacted_thinking 的类型之外什么都没有。所以现在,就像我说的,我们就可以用这个来确保我们的应用程序在收到这种意想不到的思考块响应时不会崩溃。
58. Image support
类型:视频 | 时长:10:16 | 视频:08 - 002 - Image Support.mp4
Claude 的视觉 (vision) 能力让您可以在消息中包含图片,并要求 Claude 以无数种方式对它们进行分析。您可以要求 Claude 描述图片中的内容、比较多张图片、计算物体数量,或执行复杂的视觉分析任务。
图像处理基础

在处理图像时,有几个重要的限制需要牢记:
- 单次请求的所有消息中最多可包含 100 张图片
- 每张图片最大 5MB
- 发送单张图片时:最大高度/宽度为 8000px
- 发送多张图片时:最大高度/宽度为 2000px
- 图片可以作为 base64 编码或图片的 URL 包含进来
- 每张图片根据其尺寸计算 token 数量:
tokens = (width px × height px) / 750
要向 Claude 发送图片,您需要在用户消息中包含一个图像块 (image block) 和文本块 (text block)。结构如下:
with open("image.png", "rb") as f:
image_bytes = base64.standard_b64encode(f.read()).decode("utf-8")
add_user_message(messages, [
# Image Block
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/png",
"data": image_bytes,
}
},
# Text Block
{
"type": "text",
"text": "What do you see in this image?"
}
])
消息流
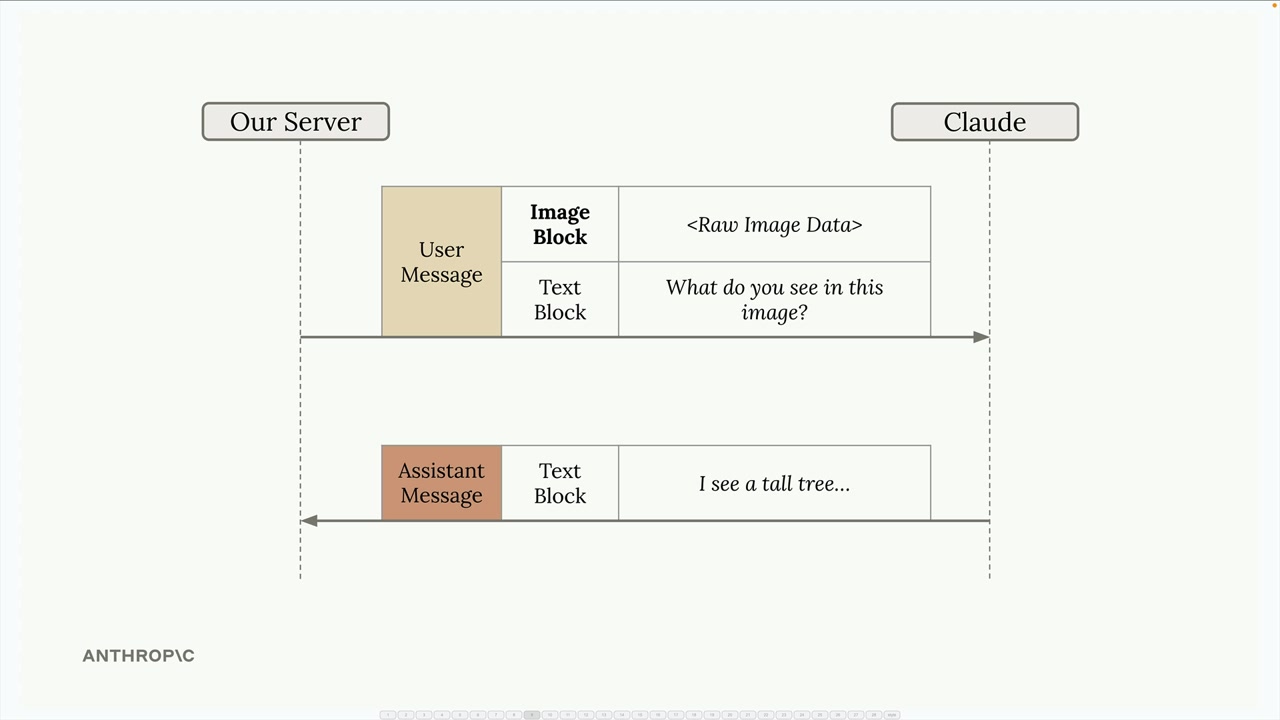
对话过程就像纯文本交互一样。您的服务器向 Claude 发送包含图像和文本块的用户消息,Claude 以包含其分析的文本块作为响应。
提示技巧
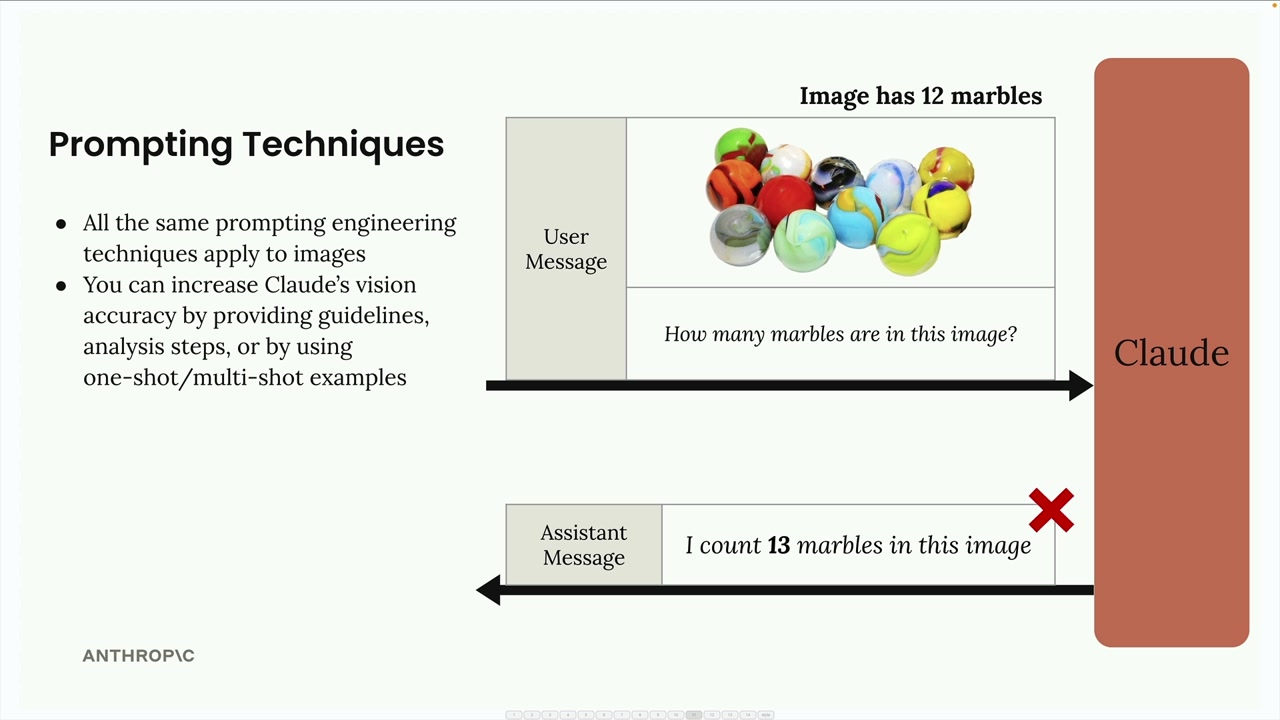
要从图像中获得好的结果,关键在于应用您在处理文本时会使用的相同的提示工程 (prompting engineering) 技巧。简单的提示通常会导致较差的结果。例如,问“这张图片里有多少个弹珠?”可能会返回一个不正确的计数。
您可以通过以下方式显著提高 Claude 的准确性:
- 提供详细的指导和分析步骤
- 使用单样本 (one-shot) 或多样本 (multi-shot) 示例
- 将复杂任务分解成更小的步骤
逐步分析

不要只提一个简单的问题,而是给 Claude 一个方法论:
请使用以下方法分析这张弹珠图片并确定确切数量:
1. 首先,一次识别一个独特的弹珠。在识别时为每个弹珠编号。
2. 通过使用不同的方法计数来验证您的结果。从左下角开始,逐行从左到右工作。
这张图片中确切、经过验证的弹珠数量是多少?
单样本示例
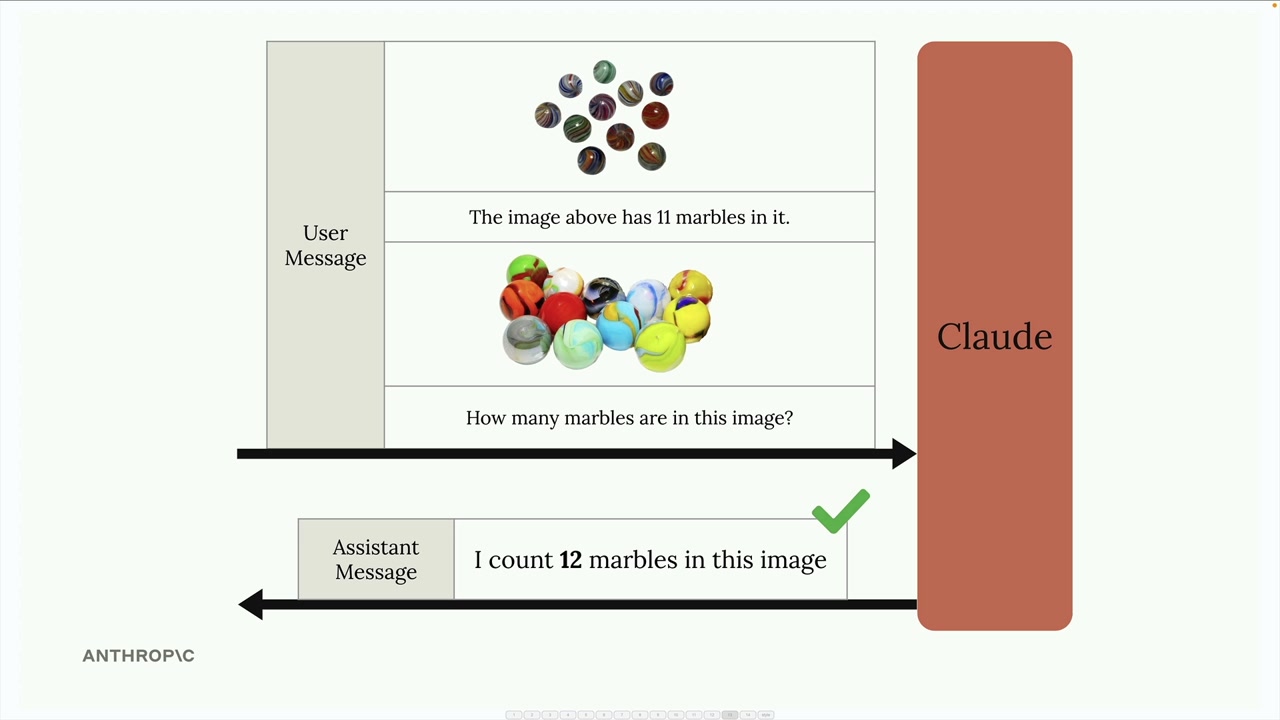
您也可以通过在消息中提供示例来提高准确性。包含一张已知数量的图片,说明正确答案,然后再询问您的目标图片。这为 Claude 提供了您想要的分析类型的参考点。
真实世界案例:火灾风险评估

这是一个实际应用:为房屋保险自动进行火灾风险评估。保险公司无需派遣检查员到每处房产,而是可以利用卫星图像和 Claude 的分析能力。
该系统分析卫星图像以识别:
- 住宅附近茂密、紧凑的树木
- 紧急服务车辆难以进入的路线
- 悬垂在住宅上方的树枝
相较于一个简单的提示如“提供一个火灾风险评分”,一个结构良好的提示会将分析分解为具体的步骤:
Analyze the attached satellite image of a property with these specific steps:
1. Residence identification: Locate the primary residence on the property by looking for:
- The largest roofed structure
- Typical residential features (driveway connection, regular geometry)
- Distinction from other structures (garages, sheds, pools)
2. Tree overhang analysis: Examine all trees near the primary residence:
- Identify any trees whose canopy extends directly over any portion of the roof
- Estimate the percentage of roof covered by overhanging branches (0-25%, 25-50%, 50-75%, 75%+)
- Note particularly dense areas of overhang
3. Fire risk assessment: For any overhanging trees, evaluate:
- Potential wildfire vulnerability (ember catch points, continuous fuel paths to structure)
- Proximity to chimneys, vents, or other roof openings if visible
- Areas where branches create a "bridge" between wildland vegetation and the structure
4. Defensible space identification: Assess the property's overall vegetative structure:
- Identify if trees connect to form a continuous canopy over or near the home
- Note any obvious fuel ladders (vegetation that can carry fire from ground to tree to roof)
5. Fire risk rating: Based on your analysis, assign a Fire Risk Rating from 1-4:
- Rating 1 (Low Risk): No tree branches overhanging the roof, good defensible space around the home
- Rating 2 (Moderate Risk): Minimal overhang (<25% of roof), some separation between tree canopies
- Rating 3 (High Risk): Significant overhang (25-50% of roof), connected tree canopies, multiple vulnerability points
- Rating 4 (Severe Risk): Extensive overhang (>50% of roof), dense vegetation against structure
For each item above (1-5), write one sentence summarizing your findings, with your final response being the numerical rating.
这个详细的提示指导 Claude 进行系统性分析,从而得到比简单请求更准确、更有用的评估结果。
请记住:适用于文本的提示技巧同样适用于图像。如果你想要可靠的结果,花时间精心设计详细、结构化的提示,而不是依赖简单的问题。
视频文字稿
我们将要研究的下一个 Claude 的高级功能是 Claude 的视觉能力。每当我们向 Claude 发送用户消息时,我们可以选择在消息中包含图像。然后,我们可以要求 Claude 对这些图像做任何你能想象到的事情。所以我们可以让 Claude 告诉我们图像里包含了什么。
我们可以要求 Claude 比较不同的图像。我们可以要求它数出不同的物体。真的,可能性非常多。关于图像处理,我希望你首先理解一些不同的限制或要求。
在单个请求的所有消息中,我们最多可以发送 100 张图像。每张图片的大小以及高度和宽度也存在一些限制。最后,你需要明白,每当你向 Claude 发送一张图片,它都会占用一定数量的 tokens(词元),而你将为此付费。有一个公式可以让你根据图像的像素高度和宽度,大致计算出你将被收取多少 tokens。
要向 Claude 发送图像,我们将在用户消息中包含另一种类型的块。这是一个 image block(图像块)。我们可以在一条用户消息中附加多个不同的 image block。每个 image block 将包含对单个图像的引用。
在这个 image block 内部,我们可以附加原始图像数据,就像我右侧这张图表中展示的那样,或者,我们也可以提供一个托管在网上某处的图像 URL。所以,现在我们了解了一些技术限制以及如何发送图像,有一个非常重要的事情我想立刻说明。每当工程师开始使用 Claude 处理图像时,我经常注意到他们会使用非常简单的提示,甚至有点像我这个例子里的提示。当使用图像时,从 Claude 那里获得好结果的首要方法是继续高度关注 prompting techniques(提示技巧)。
所以,如果你只是把一张图片扔给 Claude,然后输入一个非常简单的提示,你很可能得不到好的结果。例如,考虑右侧的对话。我放入了一张有 12 个弹珠的图片。顺便说一下,我实际测试过这个,我非常简单地问它这张图片里有多少个弹珠。
果然,我得到了一个错误的计数结果,13 个。通过使用我们之前在本课程中学到的同类提示技巧,我们可以显著提高 Claude 处理图像时的准确性。这些技巧包括提供指南、提供分析步骤,或者使用 one-shot(单样本)甚至 multi-shot(多样本)示例。让我向你展示两种可以轻松增强这个提示并实际获得正确结果的方法。
再次强调,我实际测试过并确保这些例子,至少对我来说,是按预期工作的。所以,我们可能做的第一件事是为 Claude 提供一系列分析图像的步骤。当然,这只有在我们已经对输入给 Claude 的图像内容有所了解的情况下才真正有效。所以,在这种情况下,我可能会要求 Claude 先看一遍,尝试识别每一个单独的弹珠,然后逐一计数。
然后要求它重新数一遍以验证初次计数,并为其提供一种不同的机制或策略来数弹珠。最后在底部,我要求,好了,现在我们来比较一下这两个不同的计数,并找出正确答案。通过提供一个更复杂的提示,我得到了包含 12 个弹珠的正确计数结果。我们在这里可能使用的另一种技巧是 one-shot 或 multi-shot prompting(多样本提示)。
下面是它的工作方式。在我的用户消息中,我可以交替出现图像部分和文本部分。所以,在这种情况下,我上面有一个图像部分,下面是一个文本部分,然后是另一张图像,再然后是一个文本部分。在最初的一对中,我提供了一张有 11 个弹珠的图像,然后非常直白地说,上面的图像里有 11 个弹珠。
提供这样一个例子可以轻松提高 Claude 在稍后处理你的图像时的准确性。像往常一样,我想在 Jupyter notebook 中测试这个功能。但这次,我们的例子会稍微复杂一些。我希望你通过一个简短的图示,提前了解我们将在 notebook 中演练的场景。
好的,这里有一个我们如何使用 Claude 图像支持功能的示例用例。如果你不知道的话,在美国很多地方,我们有非常严重的野火问题,野火一旦开始就会席卷一个地区,烧毁大量的房屋。因为这是一个非常普遍的风险,很多人都想购买火灾保险,以防他们的家被烧毁。但这些保险公司非常清楚,一栋房子完全可能在明天、明年或很快就被烧毁。
因此,这些保险公司通常会要求想要为房屋投保的房主修剪树木,甚至完全砍掉房子周围的树。现在,保险公司需要实际核实并确保房主适当地处理了树木。但要核实这一点,他们可能需要派人去检查每处房产,而且可能需要每年或每两年进行一次检查。这会很快变得非常昂贵。
所以,我们可以自动化这个过程的一种方法是获取高分辨率的最新卫星图像,然后将其输入 Claude,并要求 Claude 进行火灾风险评估。我们可能特别要求 Claude 尝试检测房产上的主要住宅。换句话说,在一张房产的卫星图像中,找到大概率被投保的主要住宅。然后寻找可能悬垂在住宅上方的树枝,这是一个非常常见的火灾风险。
也许可以尝试评估消防服务实际进入该住宅的难度。也就是说,确保有一条清晰的路径可以到达住宅。同时,也要看看住宅周围的树木,确保它们没有靠得太近或长得太密,这本身也可能是一种火灾风险。好的,那我们去 notebook 看看如何实现这个功能。我正在一个名为 002 images 的新 notebook 里。
在这里,我已经为我们准备好了一个起始提示。请注意,这个提示非常详细,并引导 Claude 思考我希望在图像中分析的不同要点或想法。我本可以写一个非常简单的提示,比如“根据此房产的卫星图像提供一个火灾评分”,然后就此打住。我几乎可以肯定,我不会得到一个好的结果。
所以,我应用了一些我们之前学到的不同 prompt engineering(提示工程)技巧,并提供了一系列不同的分析步骤供 Claude 执行。第一步。首先,在卫星照片中找到实际的主要住宅。第二步。
看看树木的密度。然后看看消防服务实际进入该房产的能力。看看有多少树木或特别是树枝悬垂在屋顶上,这是一个非常常见的火灾风险,最后根据所有这些不同的特性给出一个火灾风险评级。我提供了一些标准来帮助它决定应该是 1、2、3 还是 4。
最后在最底部,为每项写一个一句话的总结,并给出最终得分。这就是我们的提示。我会确保运行那个单元格。然后我们到最下面去。
我们将编写一些代码来读入一个示例图像,并将其与该提示一起输入 Claude,看看我们能得到什么样的结果。另外一个简短的事项。本讲座附带一个名为 images.zip 的 zip 压缩包。请确保解压该压缩包,并将 images 目录放置在与你的 notebook 相同的文件夹中。
这个文件夹包含了一些不同房屋的卫星图像,周围有一定数量的树木。例如,Image 1 有一座房子,周围肯定有大量的树木悬垂。Image 2 的树木肯定少得多,但这里仍然有一棵离房产很近的树。你可以浏览其余的图片,验证一下,是的,我们确实有一些卫星图像。
所以我们的目标是将这些不同的图像发送到 Claude,并为每个图像获得一个火灾风险评分。回到我的 notebook,我将首先打开一个图像文件并将其内容转换为 base 64。所以我会用 with open。在 images 目录中,我将专门寻找 image seven。
我之所以用这张图片,是因为它完全被树木包围。这是 prop7.PNG。正如你所见,这里肯定有很多火灾隐患。我会用 standard_b64encode 获取图像文件的 base64 编码。
我会传入 f.read() 并解码为 utf-8。然后我将添加一个空的消息列表。我会在里面添加一个用户消息。我添加的这条消息将有两个独立的块。
它首先会有一个 image block,结构与你在这里看到的完全一样,然后它会有一个文本块。文本块将包含我想要输入给 Claude 的实际指令。所以我会先添加一个代表 image block 的字典。类型为 image,嵌套一个分配给 source 的字典,其类型为 base64,media_type 为 image/png。
data 将是编码为 base 64 的图像字节。然后,在该字典之后,我将添加我的实际提示。所以我会给它一个 type 为 text。然后,我想发送的提示,我将其分配给了那里的 prompt 变量。
所以我会写 text of prompt。好的,最后,我会调用 chat 并传入我的消息列表。我将运行这个,让我们看看会得到什么。看一下响应,我将滚动到最底部,我应该会看到一个火灾风险评级。
在这种情况下,我得到了一个高风险评级,具体分数为 3。所以我认为 Claude 在评估主要房产周围所有树木方面做得相当不错,并判断出这里很可能会有问题。在我们继续之前,关于图像,还有最后一件事我想提醒你。当向 Claude 输入图像时,获得良好结果的关键完全在于你的提示技巧。
就像我们在使用纯文本时研究了很多改进提示的方法一样,这些相同的技巧也适用于图像世界。所以我真的鼓励你总是确保你准备一个经过深思熟虑和充分评估的提示。因为如果你依赖像我这里输入的这样简单的提示,它可能不会像你预期的那样工作得那么好。
59. PDF 支持
类型:视频 | 时长:1:29 | 视频:08 - 003 - PDF Support.mp4
Claude 可以直接阅读和分析 PDF 文件,这使其成为一个强大的文档处理工具。此功能的工作方式与图像处理类似,但在构建代码的方式上有一些关键区别。
设置 PDF 处理
要使用 Claude 处理 PDF 文件,你将使用与处理图像几乎完全相同的代码。主要区别在于文件类型规范和为清晰起见的变量名。
以下是如何修改现有图像处理代码以处理 PDF:
with open("earth.pdf", "rb") as f:
file_bytes = base64.standard_b64encode(f.read()).decode("utf-8")
messages = []
add_user_message(
messages,
[
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": file_bytes,
},
},
{"type": "text", "text": "Summarize the document in one sentence"},
],
)
chat(messages)
与图像处理的关键区别
在将图像处理代码调整为处理 PDF 时,你需要更新几个元素:
- 将文件扩展名从 .png 更改为 .pdf
- 为了清晰起见,将变量名从 image_bytes 更新为 file_bytes
- 将类型设置为 "document" 而不是 "image"
- 将媒体类型更改为 "application/pdf" 而不是 "image/png"
Claude 能从 PDF 中提取什么
Claude 的 PDF 处理能力超越了简单的文本提取。它可以分析和理解:
- 整个文档的文本内容
- PDF 中嵌入的图像和图表
- 表格及其数据关系
- 文档结构和格式
这使得 Claude 基本上成为一个一站式解决方案,可以从 PDF 文档中提取任何类型的信息,无论你需要摘要、数据分析还是特定的内容提取。
上图显示 Claude 成功处理了一篇保存为 PDF 的关于地球的维基百科文章,展示了它如何能用一句话理解和总结复杂的文档内容。
视频文字稿
除了图像,Claude 还可以直接从 PDF 文件中读取内容。我将在这段视频中向你展示如何操作。本视频附有一个名为 earth.pdf 的文档。如果你打开它,你会发现它只是维基百科关于地球文章的几页。
所以请确保你下载这个 PDF 文件,并将其放置在与你的 notebook 相同的目录中。要读取 PDF 文件,我们使用几乎与读取图像并将其输入 Claude 完全相同的代码。所以我将找到我们当前打开图像的地方,然后我将把它改成 earth.pdf。我会把这个变量名从 image bytes 改成 file bytes,因为我们不再是读取图像了。
我会确保也更新下面的变量名。我会把这里的类型从 image 改成 document,然后 media type 会从 image/png 变成 application/pdf。最后,我们向 Claude 提问关于这个文档的问题,我不再输入前一个单元格里那个长长的提示,而是要求 Claude 用一句话总结这个文档。让我们看看 Claude 会返回什么。
所以我要运行这个。这就是总结。看起来它成功地读取了那个 PDF 文件的内容。现在,Claude 不仅能从 PDF 中读取文本,它还能读取图像或图表、表格等等。
所以你应该把 Claude 看作一个一站式商店,可以从 PDF 文档中提取几乎任何类型的信息。
60. Citations (引用)
类型:视频 | 时长:5:19 | 视频:08 - 004 - Citations.mp4
当 Claude 根据你提供的文档回答问题时,用户可能会认为它只是利用其训练数据。但如果 Claude 能明确指出它从哪里找到了具体信息呢?这就是 citations(引用)功能的作用所在——一个强大的特性,让 Claude 能够引用你源文档的特定部分,并向用户精确展示每条信息的来源。
为什么引用很重要
想象一下,你问 Claude 地球大气层是如何形成的,并得到了一个详细的回答。没有引用,用户无法核实信息,也无法理解 Claude 实际上是在引用你提供的特定文档。引用通过在 Claude 的回应和你提供的源材料之间建立一条清晰的追溯路径,解决了这个透明度问题。
启用引用
要启用引用,你需要修改你的文档消息结构。在你的文档块中添加两个新字段:
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": file_bytes,
},
"title": "earth.pdf",
"citations": { "enabled": True }
}
title 字段为你的文档提供一个可读的名称,而 citations: {"enabled": True} 则告诉 Claude 追踪其找到信息的位置。
理解引用结构
启用引用后,Claude 的响应会变得更加复杂。你得到的不再是简单的文本,而是包含每个论断的引用信息的结构化数据。

每个引用包含几个关键信息:
- cited_text - 源文档中支持 Claude 陈述的精确文本
- document_index - Claude 引用的是哪个文档(当你提供多个文档时很有用)
- document_title - 你为文档指定的标题
- start_page_number - 引用文本开始的页码
- end_page_number - 引用文本结束的页码

使用引用构建用户界面
引用的真正威力在于构建能够让这些信息易于访问的用户界面。你可以创建交互式元素,用户将鼠标悬停在引用标记上,就能看到信息的具体来源。
这创造了一种透明的体验,用户可以:
- 看到 Claude 的回答是基于真实的源材料
- 通过检查原始文档来核实信息
- 理解每条引用信息周围的上下文
对纯文本使用引用
引用不仅限于 PDF 文档。你也可以对纯文本源使用它们。当处理文本时,像这样修改你的文档结构:
{
"type": "document",
"source": {
"type": "text",
"media_type": "text/plain",
"data": article_text,
},
"title": "earth_article",
"citations": { "enabled": True }
}
对于纯文本源,你将得到字符位置而不是页码,这些位置精确地指出了 Claude 在文本中找到每条信息的位置。
何时使用引用
引用在以下情况中尤其有价值:
- 用户需要核实信息的准确性
- 你正在处理权威性文档,希望用户能够参考
- 信息来源的透明度对你的应用至关重要
- 用户可能想探索特定事实的更广泛背景
通过实施引用,你将 Claude 从一个提供答案的“黑匣子”转变为一个展示其工作过程的透明研究助手。这能建立用户信任,并使他们能够在需要时更深入地研究你的源材料。
视频文字稿
在我们刚刚处理的 PDF 文件中,我将滚动到最后一页。在底部,你会注意到它提到了地球的大气层和海洋是由火山活动和排气形成的。现在,作为一个小练习,我想尝试问 Claude 一个非常简单的问题。我想问它地球的大气层和海洋是如何形成的。
我大概会期望看到类似“火山活动和排气”之类的答案。所以,我会复制这段文字,然后把它放进我的提示里,问 Claude。地球的大气层和海洋是如何形成的。现在,我将快速运行这个。
至少对我来说,我注意到在第一句话中,我得到了一个非常恰当的答案。我被告知这些是由火山活动和排气形成的。所以这正是我所期望的。但我希望你从用户的角度想象一下得到这个答案。
当用户看到这段生成的文本时,他们可能会认为这只是 Claude 直接从记忆中说出来的。用户可能并不真正理解我们实际上在引用某种来源。在这种情况下,来源并不完美。它是维基百科,但至少它是一些东西。
所以,如果能有某种方式告知用户或告诉他们我们是如何得到这些信息的,那就太棒了。幸运的是,Claude 可以使用一个叫做 Citations(引用)的功能。Citations 允许 Claude 直接引用一些外部信息来源,并说明它是通过查看某个其他文档或其他文本来源得到答案的。现在,让我给你演示一下 citations 是如何工作的,因为一旦你看到它的实际效果,我想你就会对它的作用有一个很好的了解。
我将向上滚动到我们的提示这里,然后对我们放入此消息的第一个块进行一些小修改。在 source 字段之后,我将添加一个 title 为 earth.pdf,因为这是我们正在打开的 PDF 文件的名称,以及一个 citations 字段,它将是一个包含 enabled: true 的字典,像这样。现在我将再次发送这个请求。让我们看看现在会得到什么。
现在我们会看到我们的响应比之前复杂得多。我们的 content 字段现在是一个列表,其中包含一些文本块,并且其中一些文本块有一个 citations 列表,里面有一个叫做 citation_page_location 的东西。那么,让我们先花点时间重点看一下 citation_page_location 到底是什么。让我给你看一张图。
citation_page_location 是 Claude 告诉我们它从哪里获得某个事实或某条信息的确切方式。在我们的例子中,我们得到了一个包含 cited_text、document_index、document_title、start_page 和 end_page 的结构。cited_text 是源文档中(在我们的例子中是 earth.pdf)以某种方式支持 Claude 陈述的文本。document_index 和 document_title 告诉我们这个陈述的确切出处,而 start_page 和 end_page 则告诉我们该陈述在该文档中的确切位置。
现在,给你这些引用的真正意图是让你能够根据 Claude 的回答构建一个像这样的用户界面。所以我拿了我们刚才从 Claude 那里得到的响应。我把它重新输入 Claude,并要求它以一个格式精美的文档形式呈现整个响应,并给我一些弹出窗口来代表所有不同的引用。但现在如果我把鼠标悬停在 1、2 或 3 上,我会看到一个格式精美的弹出窗口出现。
这个弹出窗口包含了那个 citation_page_location 对象中的所有信息。它旨在告知用户,Claude 的响应,特别是这个句子,实际上是受到了某个外部文档的启发。所以在这种情况下,这个句子来自 earth.pdf,特别是第 4 到 5 页的一些文字,而我们引用的实际文本是“地球的大气层是,等等等等”。所以这个整个 citations 功能允许你构建像这样的界面,用户可以确信 Claude 提供的信息来自某个实际的外部来源。
用户可以随后去参考那个来源,并确保 Claude 正确地解释了那个外部文档中的信息。这个 citations 功能并不仅限于与 PDF 文档一起使用。你也可以将它与纯文本一起使用。举个很简单的例子,在上面的单元格里,我手动从 PDF 文档中复制粘贴了一些文本,并将其分配给了一个名为 article_text 的变量。
现在我可以回到下面我发出请求的地方,然后我要对这个块做一个大的更新。我将保留 document 类型。我将保留 source,但我将把 type 改为 text。我将把 media_type 改为 text/plain,然后 data。
改为 article。这就是文本。哦,抱歉,是 article_text。好了。
这就是我分配给那个变量的文本。然后我将把标题改为类似 earth_article 之类的,因为它不再直接是一个 PDF 文件了。然后我可以保留 citations 中的 enabled: true。所以现在如果我再次运行这个,并看一下响应,我们会看到不再是 citation_page_location,而是 citation_chart_location。
所以这将给我们一个 Claude 正在引用的那一大块文本中的位置。我们现在可以用这个来构建一个与我刚才在浏览器中展示的非常相似的界面。所以再次强调,你可以从纯文本或 PDF 文档中引用。无论哪种方式,我真的建议你随时使用 citations 功能,只要确保用户能够以某种方式调查 Claude 是如何构建其响应,并确保 Claude 是从某些源文档(无论是 PDF 还是纯文本)中提取信息,这对你来说至关重要。
61. Prompt caching (提示缓存)
类型:视频 | 时长:3:35 | 视频:08 - 005 - Prompt Caching.mp4
Prompt caching(提示缓存)是一项功能,通过重用先前请求的计算工作来加快 Claude 的响应速度并降低文本生成成本。Claude 不会在每次请求后丢弃所有处理工作,而是在你再次发送相似内容时保存并重用它。
Claude 通常如何处理请求
要理解提示缓存,我们首先来看看在没有启用缓存的典型请求中会发生什么。
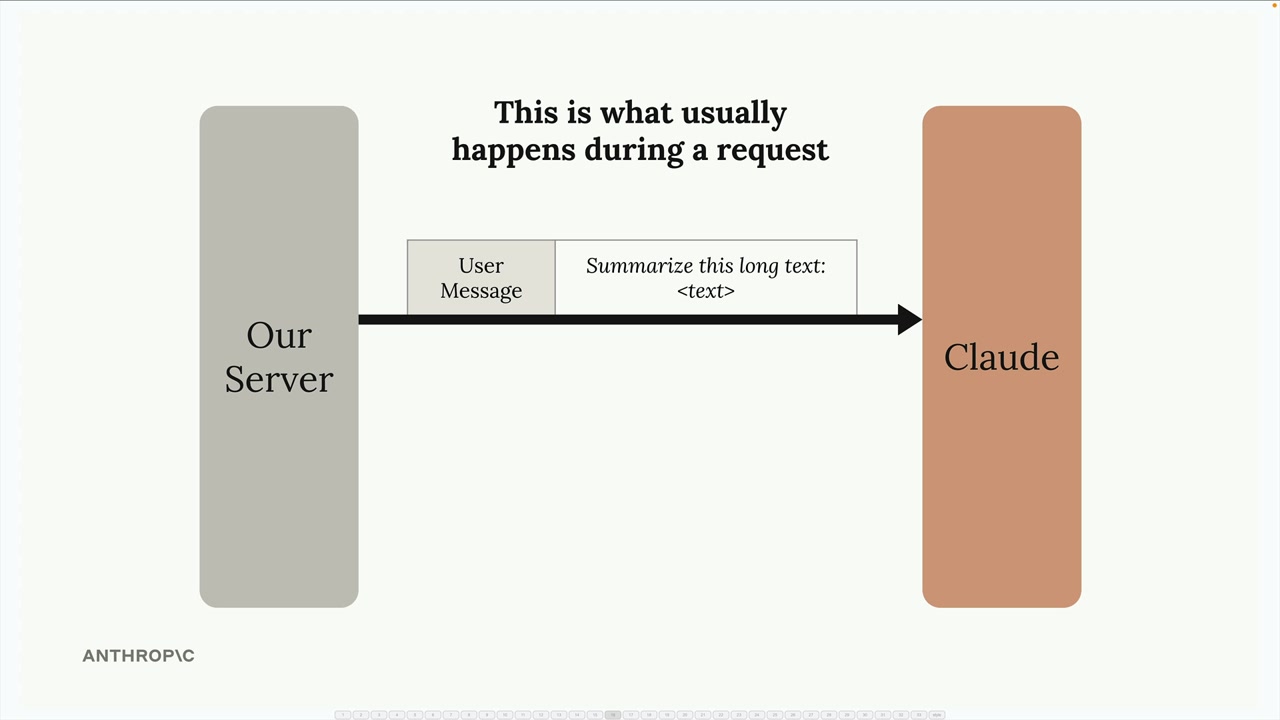
当你向 Claude 发送消息时,它不会立即开始生成响应。相反,Claude 会对你的输入进行大量的预处理工作:
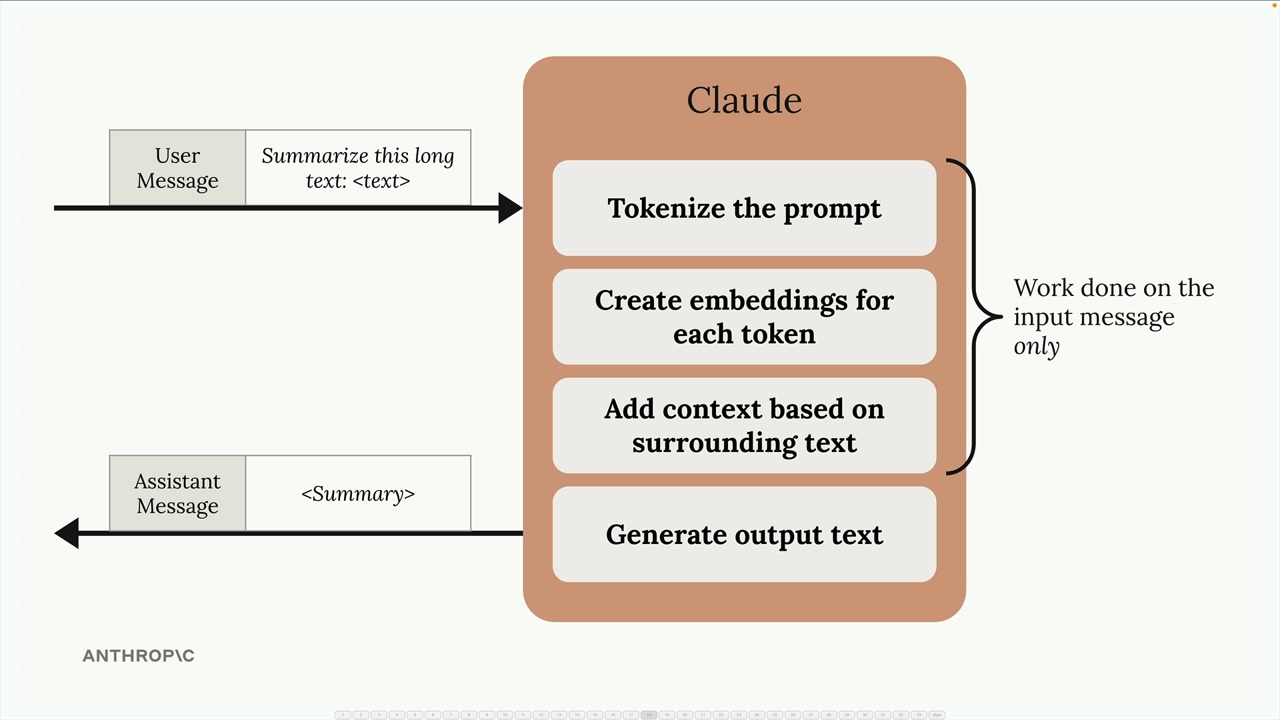
- 将提示分词为更小的片段
- 为每个词元创建嵌入(embeddings)
- 根据周围文本添加上下文
- 然后才生成实际的输出文本
在向你发送响应后,Claude 会丢弃所有这些计算工作——分词、嵌入和上下文分析都会被丢弃。
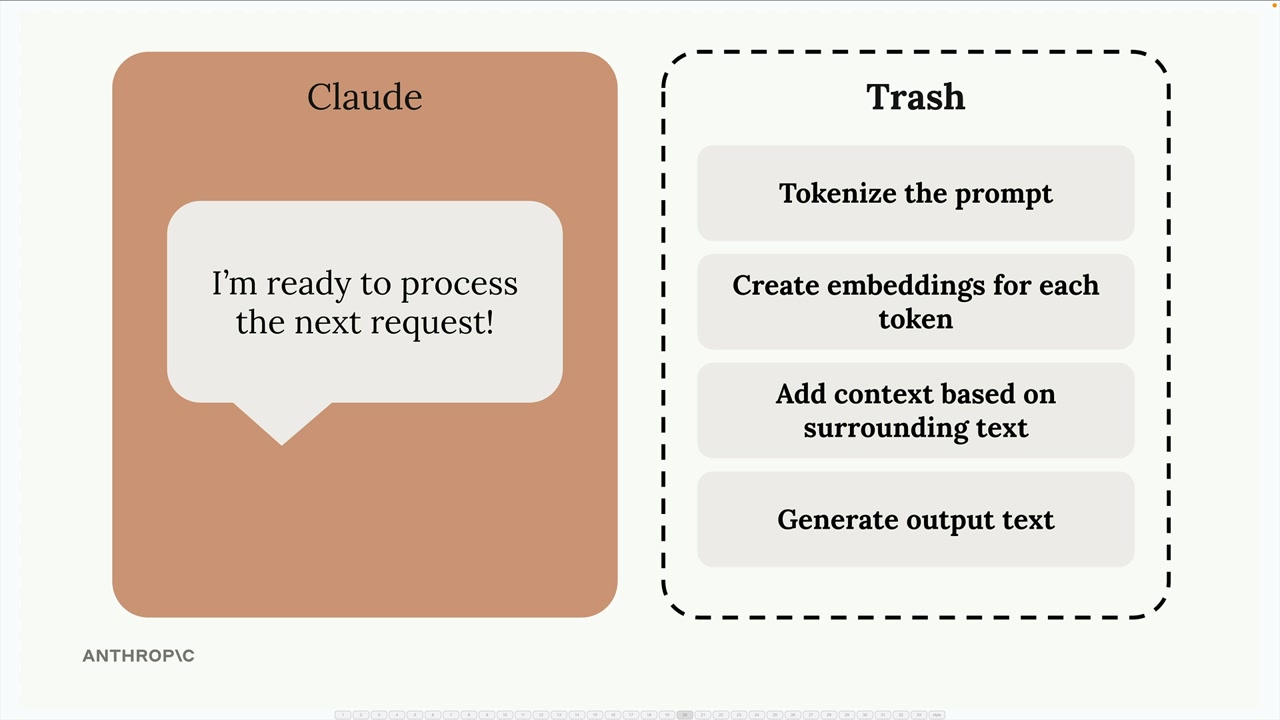
丢弃工作的问题
当你发出包含相同内容的后续请求时,这变得效率低下。例如,在一个对话中,你要求 Claude 优化对同一长文本的摘要:
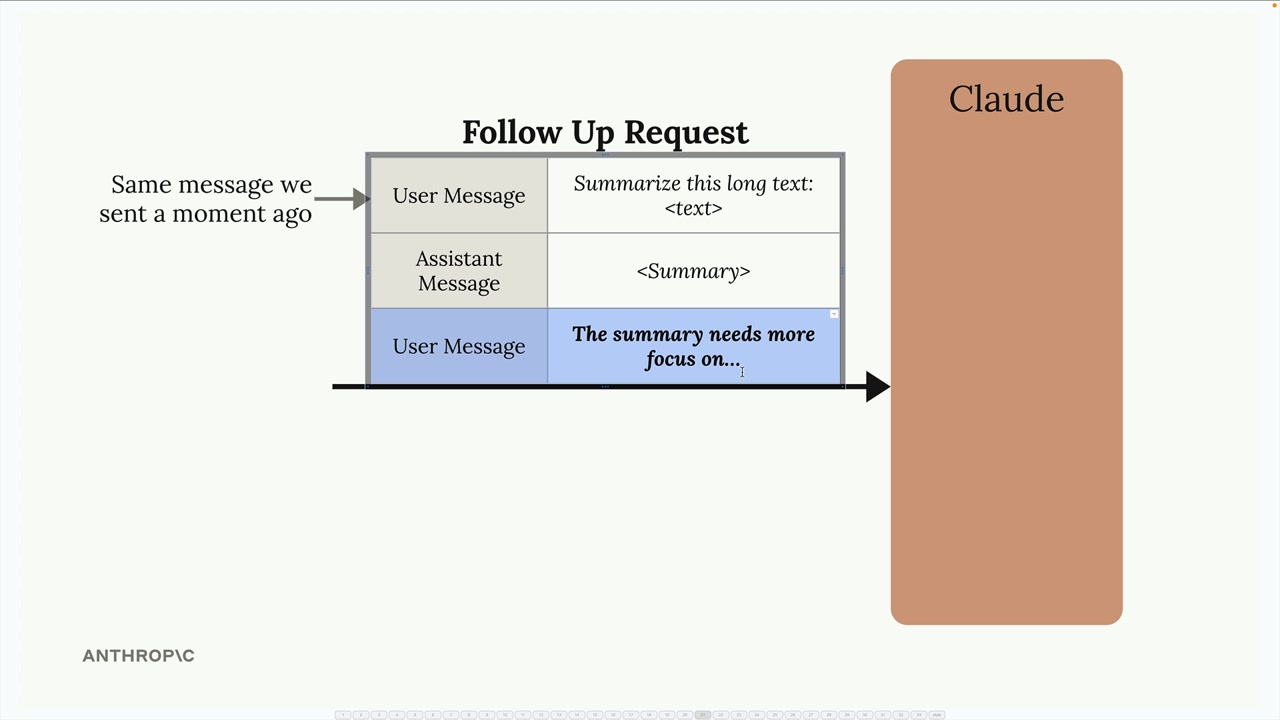
Claude 必须对它刚刚分析过的内容重复所有相同的预处理工作。正如 Claude 可能会对自己想:“我刚刚处理了那条消息,并把我做的所有工作都扔掉了——我本可以重用它的!”
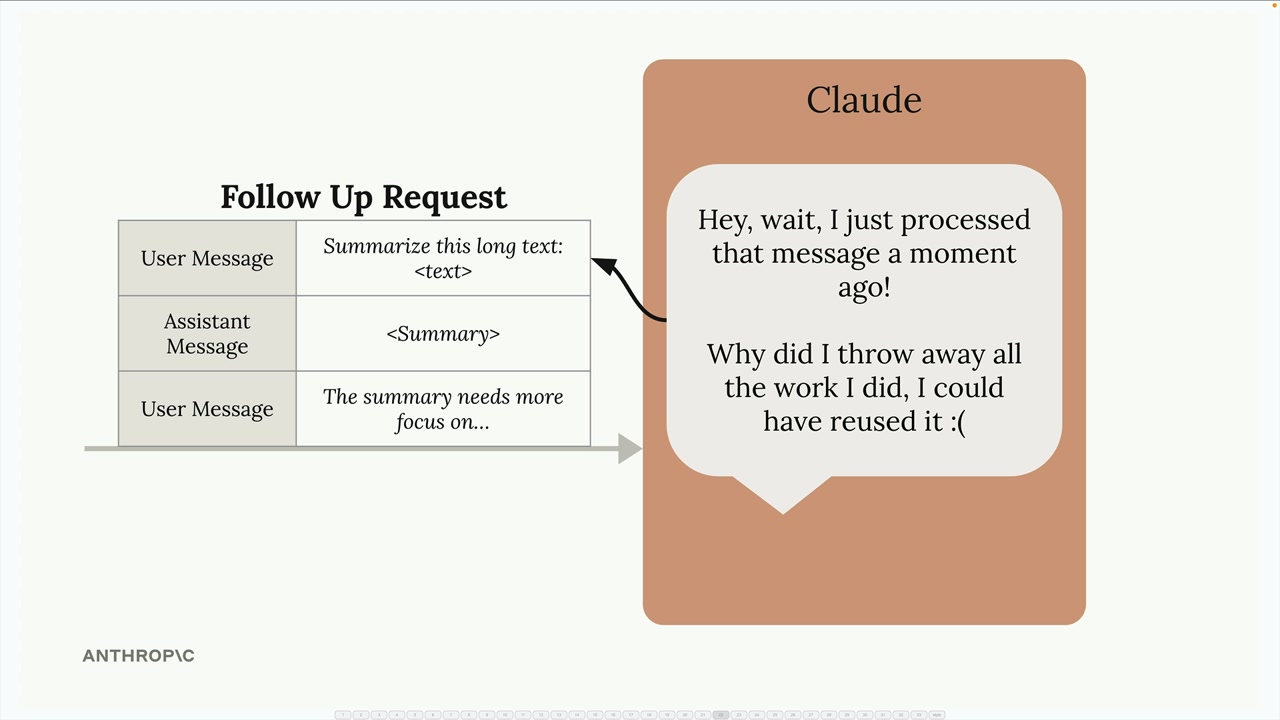
提示缓存如何解决这个问题
提示缓存通过保存预处理工作而不是丢弃它来改变这个工作流程:
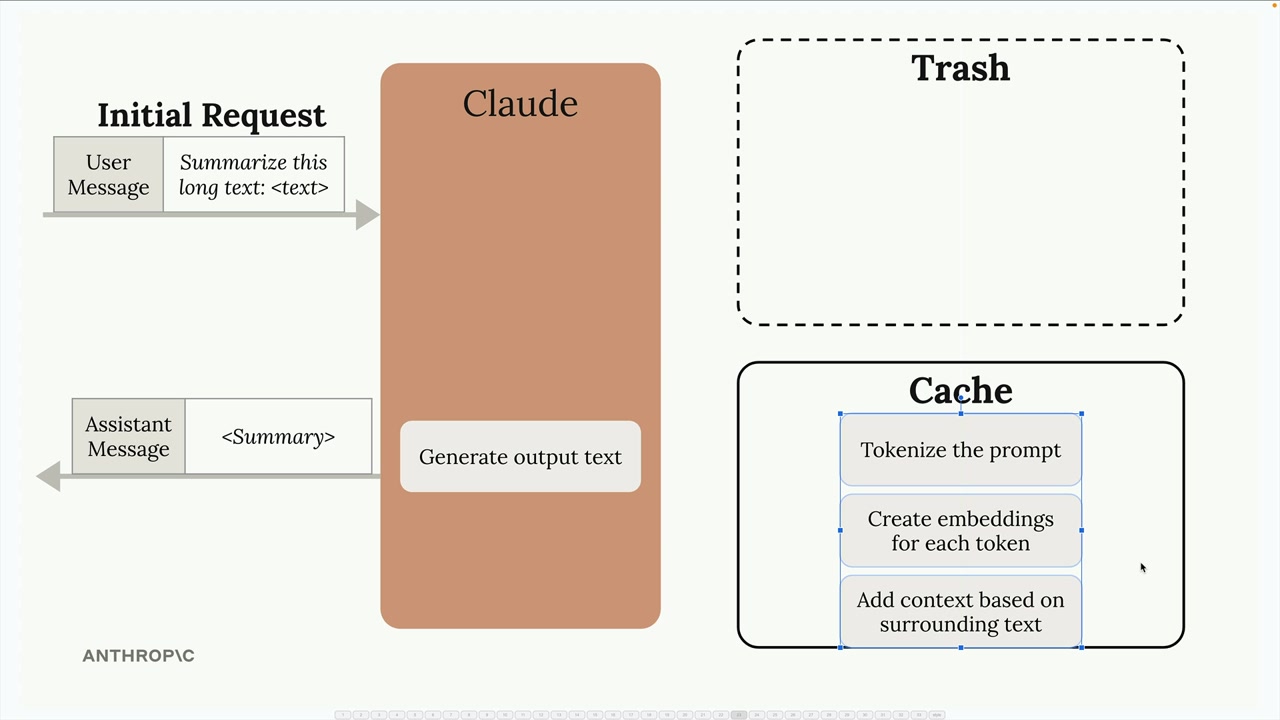
当你发出初始请求时,Claude 会执行所有常规的预处理,但会将结果存储在缓存中,而不是丢弃它们。缓存就像一个查找表,表示“如果我再看到这条消息,我将重用我已经做过的工作。”

主要优点和局限性
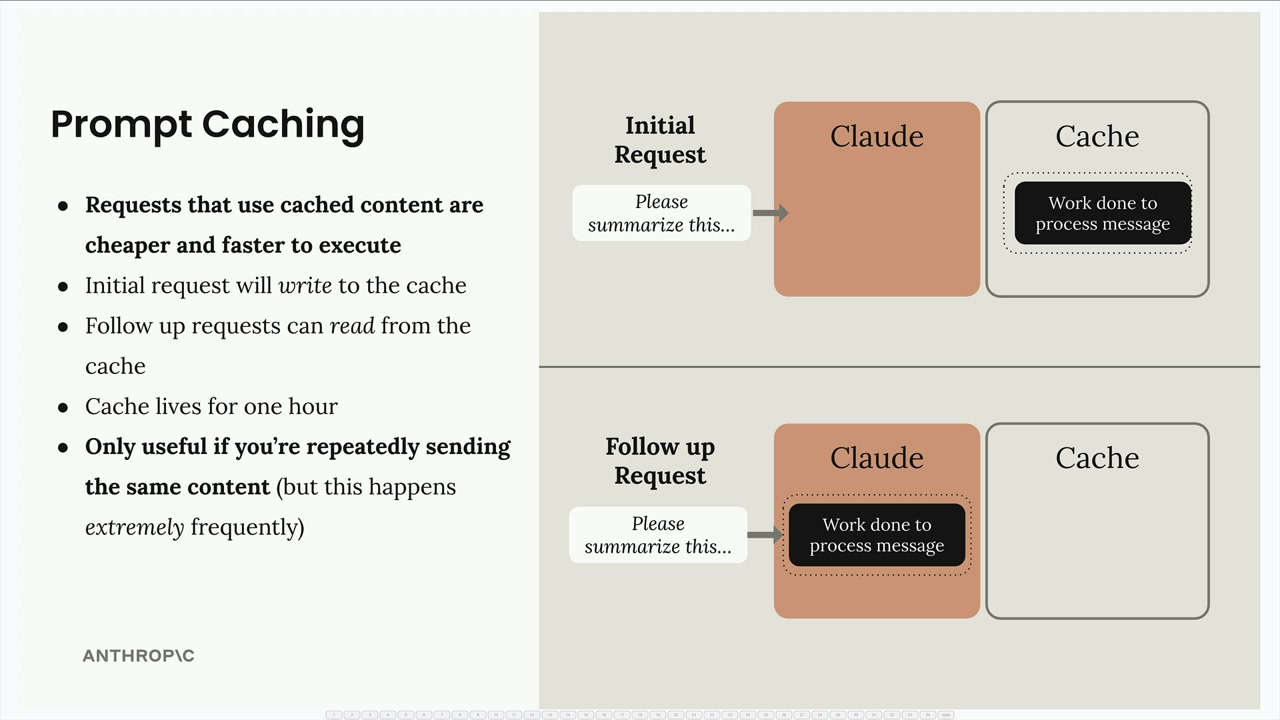
提示缓存提供了几个优势:
- 更快的响应: 使用缓存内容的请求执行得更快
- 更低的成本: 你为请求中被缓存的部分支付更少的费用
- 自动优化: 初始请求写入缓存,后续请求从中读取
但是,有一些重要的局限性需要记住:
- 缓存持续时间: 缓存内容仅存活一小时
- 有限的用例: 仅在你重复发送相同内容时才有效
- 高频率要求: 当相同内容在你的请求中极其频繁地出现时最有效
提示缓存最适用于文档分析工作流等场景,例如你对同一份大型文档提出多个问题,或者迭代编辑任务,其中基础内容保持不变,而你只是优化特定方面。
视频文字稿
我们将要关注的下一个功能是 prompt caching(提示缓存)。Prompt caching 用于加快 Claude 的响应速度并降低文本生成成本。为了帮助你理解 prompt caching 的工作原理,我们将演练一下在我们发出一个没有任何 prompt caching 功能的典型请求时,Claude 内部会发生什么。所以,这只是一个正常的请求。
我们已经稍微谈到过正常请求的整个流程。但别担心,这次我将详细介绍一下 Claude 内部发生的事情。像往常一样,一切都始于我们向 Claude 发送一条消息。当 Claude 收到这条消息时,在实际生成任何输出文本之前,它会对输入消息做大量的处理工作。
换句话说,Claude 会在内部创建大量的内部数据结构,并仅对输入文本进行大量的计算。然后,它最终会利用之前所做的所有工作来生成输出文本,然后以某种 assistant 消息的形式将响应发送回我们。响应发送给我们之后,Claude 会将输出文本和所有早期对输入消息所做计算的结果全部扔进垃圾桶。所有的一切都烟消云散了,我们看到所有那些工作都化为乌有。
一旦 Claude 完成了所有的清理工作,它就会向世界宣布:我准备好处理下一个请求了。现在,让我们设想一下,在发出这个初始请求之后,我们又发出了一个后续请求。在这个后续请求中,我们假设我们正在继续这个对话。所以,我们将附上一系列消息。
第一条将是我们刚才发送的完全相同的消息,然后是我们收到的 assistant 消息响应,然后是我们为了继续对话而附加的某个新用户消息。所以,我们将把所有这些消息发送到 Claude。在内部,当 Claude 看到第一条消息时,它可能会有点沮丧。因为 Claude 会看到那条消息并心想,当然,这并不是实际发生的情况。
我们可以想象这就是幕后发生的事情。Claude 会看到那条消息然后说,我刚看到这条消息。我刚为处理它做了那么多工作。然后我把所有的计算结果都扔掉了。
Claude 会想,我真希望我能重用我 10 秒钟前做的然后又扔掉的所有工作。如果 Claude 保存了它刚才扔掉的那些工作,它可能会更快地给我们返回响应,因为它不需要重复所有那些工作。所以,既然我们看到了这个问题,让我们想一些可能的解决方法。嗯,这里有一种可能的处理方式。
也许我们可以说,每当我们向 Claude 发出初始请求,并且 Claude 对我们发送的用户消息进行了所有初始处理工作之后,我们不是把所有分析的结果扔进垃圾桶,而是可以把所有那些工作缓存起来,或者放到某个临时数据存储中。然后,如果我们以后再发出后续请求,并且我们包含了完全相同的输入用户消息,Claude 就可以去它的缓存里说,嘿,我刚才看到过这条完全相同的消息,并且我保存了围绕那条特定消息的所有分析工作。所以,它不是再次重新分析那条消息,而是可以重用它之前做的所有工作。希望这能极大地加快生成一些文本输出的过程,因为我们正在重用一些我们已经做过的工作。
这种保存某些请求的工作以便将来使用的想法,正是 prompt caching 的核心所在。所以,稍后我们再回来,我们将演练一些 prompt caching 的实现细节,并真正理解 Claude 是如何实现它的。
62. 提示缓存的规则
类型:视频 | 时长:6:41 | 视频:08 - 006 - Rules of Prompt Caching.mp4
Claude 中的提示缓存通过存储对你消息所做的计算工作来运作,以便在后续请求中重用。这使得后续请求的执行速度更快、成本更低,但前提是你重复发送完全相同的内容。

这个过程很简单:你的初始请求将处理工作写入缓存,而后续请求可以从该缓存中读取,而不是重新处理相同的内容。缓存的生命周期为一小时,所以只有当你在该时间范围内重复发送相同内容时,此功能才有用。
缓存断点 (Cache Breakpoints)
缓存不是自动启用的——你需要手动向消息中的特定块添加缓存断点。它的工作原理如下:
- 对消息所做的工作不会自动缓存
- 你必须手动向一个块添加“缓存断点”
- 断点之前的所有工作都将被缓存
- 只有当后续请求中直到断点(含)的内容完全相同时,才会使用缓存

要添加缓存断点,你需要使用编写文本块的长格式(longhand form)而不是短格式(shorthand):

短格式没有地方可以添加 cache_control 字段,所以你必须使用扩展格式,并将 cache_control 字段设置为 {"type": "ephemeral"}。
缓存断点如何工作
当你在消息中放置一个缓存断点时,Claude 会缓存直到并包括该断点的所有处理工作。断点之后的内容会正常处理,不会被缓存。
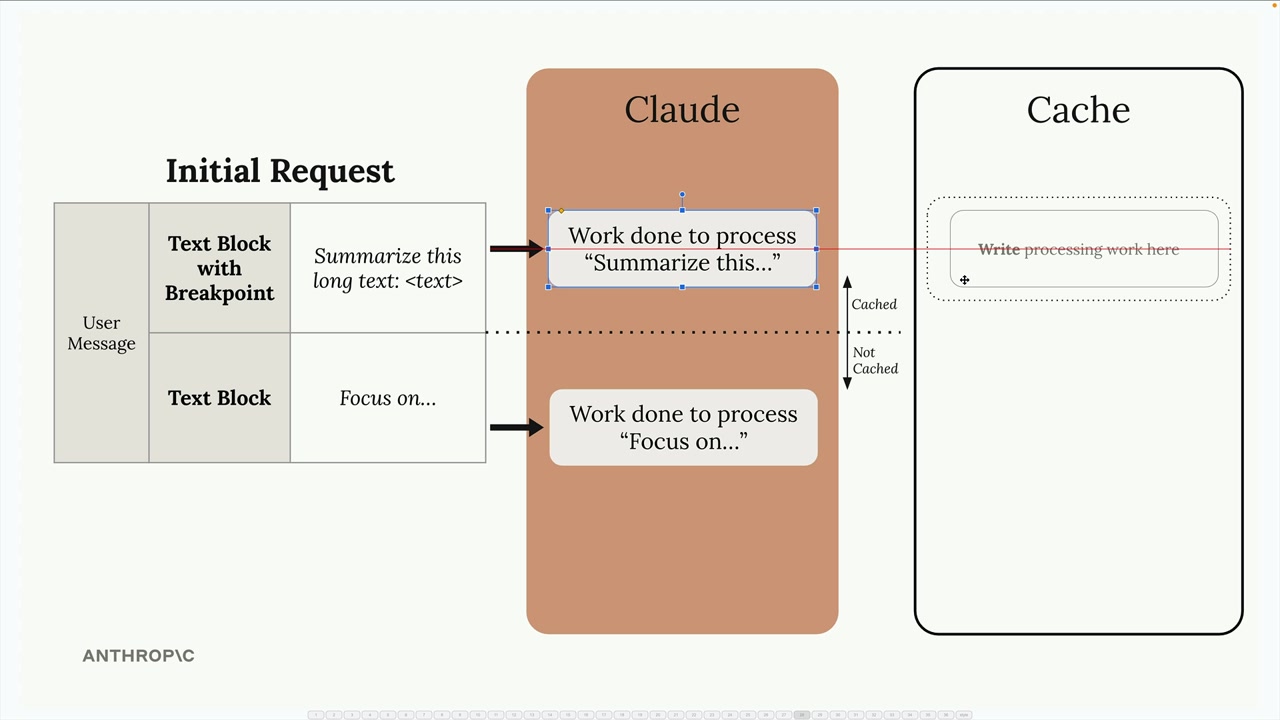
为了让缓存在后续请求中发挥作用,直到断点的内容必须完全相同。即使是微小的改动,比如添加“please”这个词,也会使缓存失效,并迫使 Claude 重新处理所有内容。
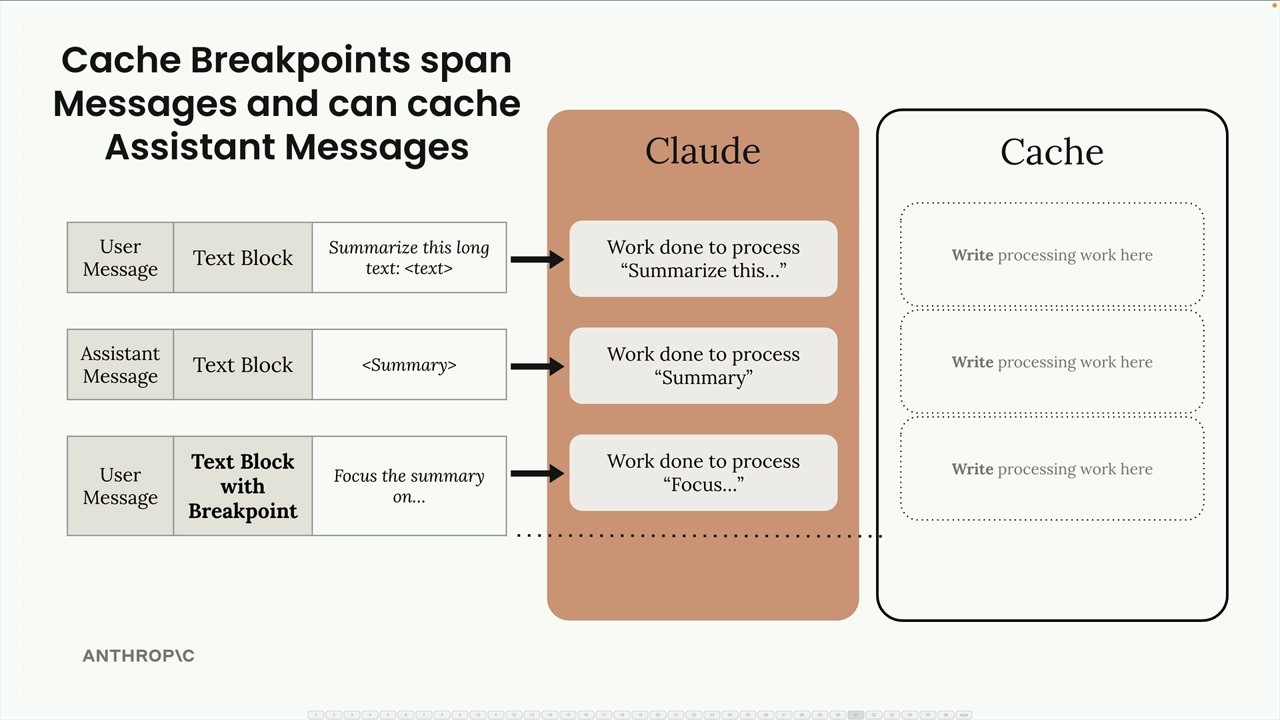
跨消息缓存
缓存断点可以跨越多个消息和消息类型。如果你在后面的消息中放置一个断点,所有之前的消息(用户、助手等)都将被包含在缓存内容中。
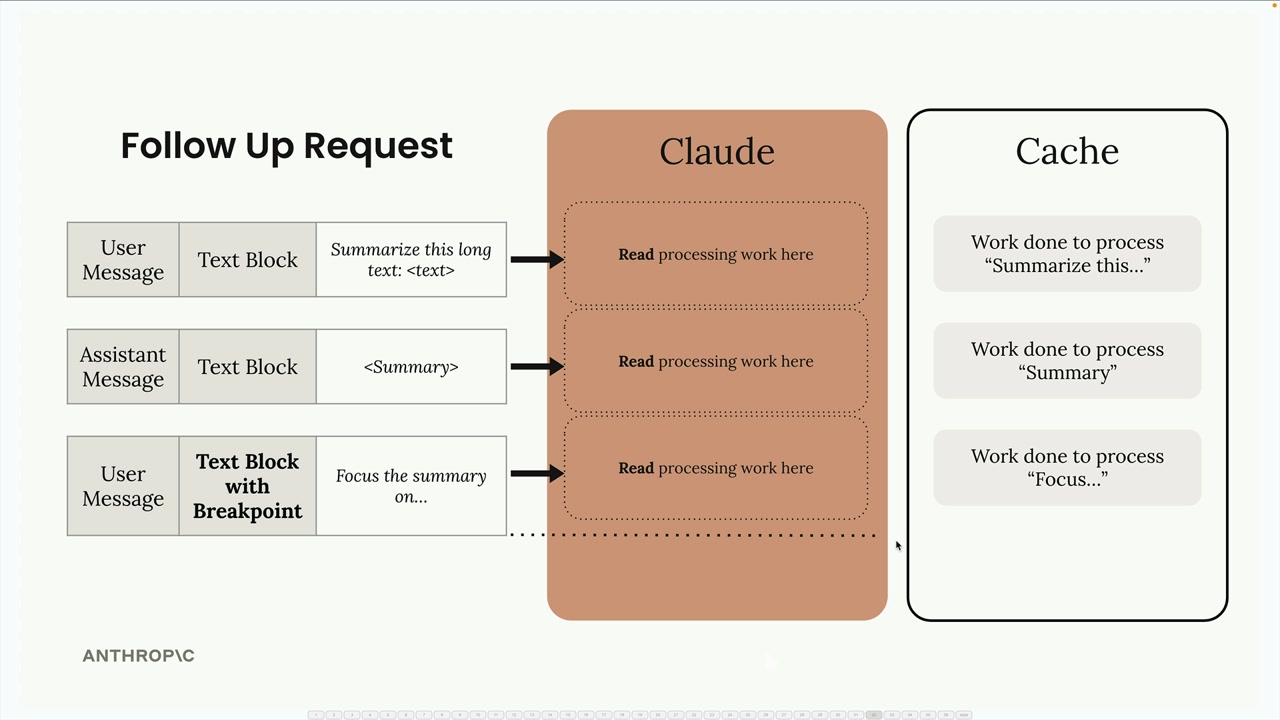
这对于你想要缓存整个对话上下文直到某个特定点的对话场景尤其有用。
系统提示和工具
你不仅限于文本块——缓存断点可以添加到:
- 系统提示
- 工具定义
- 图像块
- 工具使用和工具结果块

系统提示和工具定义是缓存的绝佳候选者,因为它们在请求之间很少改变。这通常是你从提示缓存中获得最大收益的地方。
缓存顺序
在幕后,Claude 以特定的顺序处理你的请求组件:首先是工具,然后是系统提示,最后是消息。理解这个顺序有助于你有效地放置断点。
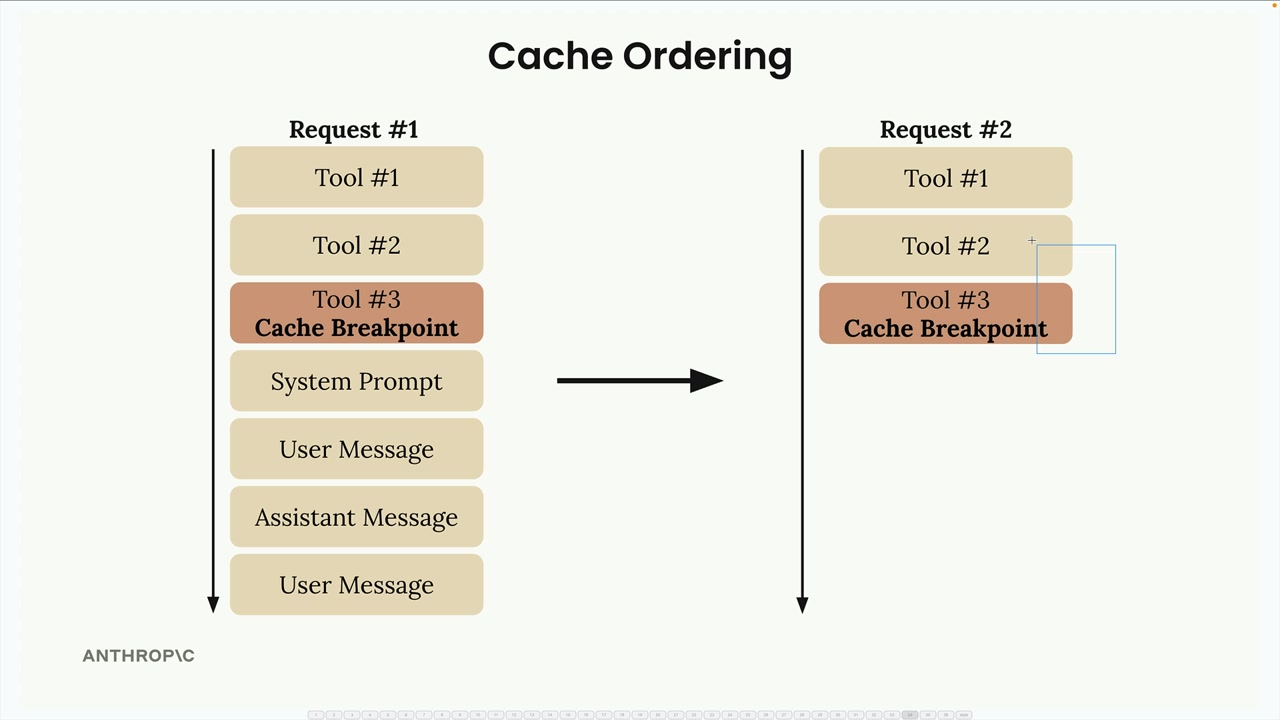
你总共可以添加最多四个缓存断点。例如,你可能会缓存你的工具,然后在对话历史的中间部分再添加一个断点。这让你在请求的不同部分发生变化时,可以灵活地决定缓存哪些内容。
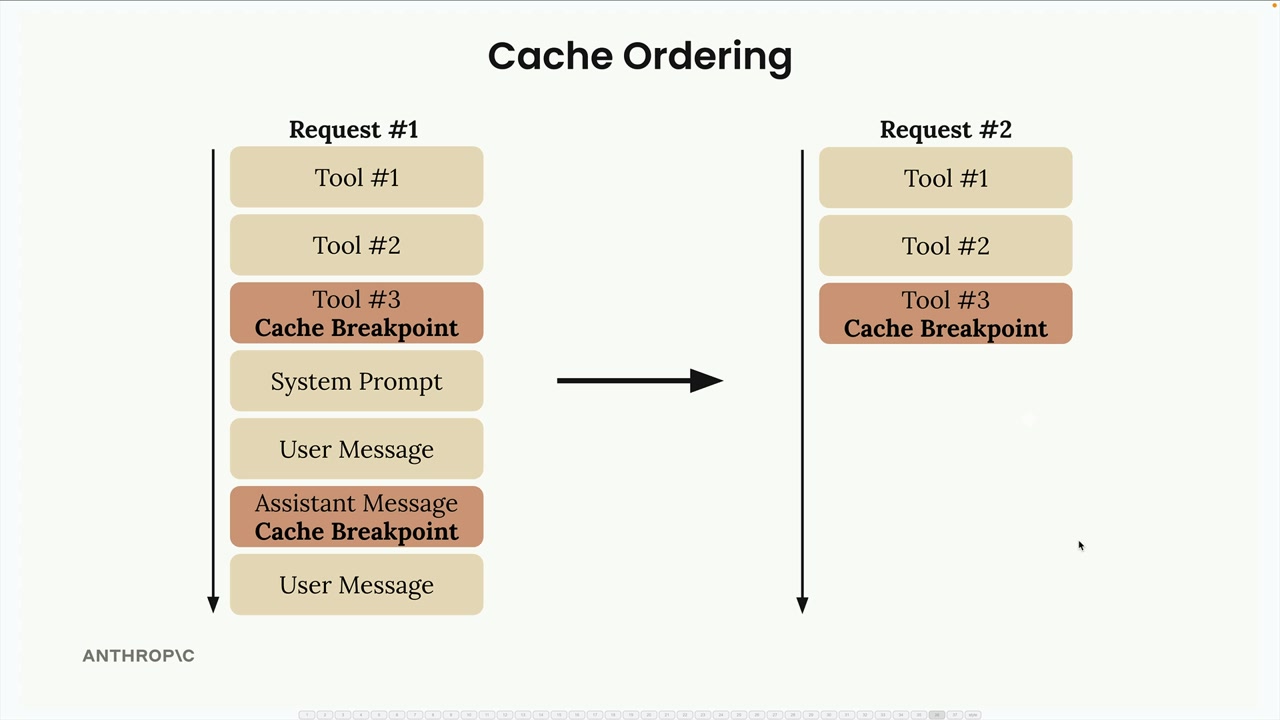
最小内容长度
缓存有一个最小阈值:内容必须至少有 1024 个 tokens 长才能被缓存。这是你试图缓存的所有消息和块的总和,而不是单个块。

一个简单的“Hi there!”消息不会达到这个阈值,但如果你将该内容复制 500 次(或者有一个真正很长的提示),它将超过 1024 个 tokens,并有资格被缓存。
有效使用提示缓存的关键在于识别出在多次调用中保持一致的请求部分,并策略性地放置断点,以最大化重用并最小化缓存失效。
视频文字稿
现在我们理解了理论,我们将探讨 prompt caching 在 Claude 中是如何实际工作的。Prompt caching 的核心思想与我们在上一个视频中讨论的完全相同。我们将向 Claude 发出初始请求。Claude 将对该初始消息进行一些处理,然后 Claude 会将所有这些工作保存到一个临时缓存中。
然后,如果我们在未来的某个时间点发出一个后续请求,并包含完全相同的消息,Claude 不会再次处理该消息,而是会查看缓存,找到它已经保存的工作,并加载它。需要明确的是,缓存中保存的工作不会永久存在。它只在那里存储一个小时。你会发现,每当你重复向 Claude 发送相同的内容时,prompt caching 最为有用,因为它确实是这样一个两阶段的过程。
我们必须发出那个初始请求来向缓存中写入一些数据,然后只有后续的请求才能利用那些预先完成的工作。这个缓存系统在 Claude 中不是默认启用的。相反,要打开缓存,我们必须手动向我们不同消息之一的块中添加一个 cache breakpoint(缓存断点)。我在右侧这个示例用户消息中展示了一个例子。
所以,我们只需要加入那个小小的 cache_control 字段就可以打开缓存。关于 cache_control 实际做什么,有很多规则。但在我们深入这些规则并真正解释发生了什么之前,我想给你一个小提示,这会让你的生活轻松一些。在本课程中,我们一直频繁地使用一种简写方式来写出文本块。
我在左手边展示了这一点。这是一个使用简写方式定义文本块的用户消息。如果我们的用户消息只有一个很短的文本,我们可以直接将一个字符串分配给 content 字段。还有另一种方式可以写出文本块,我在右手边展示了这种替代方式。
另一种方法是写出 content 字段,给它分配一个列表,然后在里面放一个字典,这个字典有一个 type 为 text,然后一个 text 字段包含你的实际文本。我们之前并没有真正使用过这种长格式,但如果你想使用 cache_control,你想打开这个 prompt caching 功能,你必须用长格式写出这些文本字段。这样你才能真正加上那个 cache_control 字段。换句话说,我们必须在某个地方写出 cache_control,而在右手边,我们有地方放它。
如果我们使用短格式,我们就没有地方放它。当我们在一个块中添加断点时,我们整个请求中的所有内容都将被缓存,直到并包括那个断点。所以,在这种情况下,如果我们发送一个像这样的请求,其中第一个块有一个断点,Claude 将会做一些工作来处理这里的这段文本。这将会产生一些工作量。
因为这个文本块有断点,所以这个工作将被存储在缓存中。但后面的工作是在断点之后,所以它不会被缓存。如果我们稍后发送一个后续请求,Claude 将会查看缓存并发现一些工作已经为处理这个第一个块完成了。所以它将检索那份工作并用它来节省一些力气。
需要记住的一件事是,我们的后续请求必须包含完全相同的内容,直到那个断点。所以,举个例子,如果我们最初的这个有断点的文本块,我们只在里面加上“please”这个词。那么这个内容就不再相同了,所以这份工作就不会从缓存中被使用。相反,Claude 会重新处理整个块以及它之前的所有内容。
缓存断点可以跨越多个不同的消息和多个不同的块。所以,举个例子,如果我们发送一个用户消息,然后一个助手消息,然后另一个用户消息,而这里的最后一条消息有一个带断点的块,所有内容都将被缓存,直到并包括这个块。所以我们可以想象,处理所有这三条消息所做的工作将被存储在缓存中。然后,当我们稍后发出后续请求时,只要直到并包括那个断点的一切都是相同的,工作就会从缓存中被检索出来。
再次强调,我们将节省一些力气。我们不仅限于在文本块上添加缓存点。我们也可以将它们添加到几乎任何其他类型的块上,比如图像块、工具使用或工具结果。我们也可以将它们添加到工具模式和系统提示中。
我在右手边展示了这两种情况的例子。你很可能会为你的工具和你的系统提示启用缓存。因为事实证明,对于大多数应用程序,不是全部,但对于许多应用程序来说,你的系统提示和你的工具列表最终不会改变。所以这些是放置缓存断点的绝佳位置。
总的来说,我们可以将断点应用于工具模式、系统提示和消息块。现在,这并不是三个独立的缓存系统。让我确切地告诉你我的意思。每当你加入工具、系统提示和消息时,在幕后,当它们被输入 Claude 时,它们都会被连接在一起,并且它们是以特定的顺序连接的。
首先是工具,然后是系统提示,然后是你的消息列表。所以,如果你在你最后一个工具上放置一个缓存断点,所有直到并包括那个最后工具的内容都将被缓存。但系统提示和你的消息列表将不会被缓存。所以,如果我们然后发出一个后续请求,并且我们改变了那里的助手消息,没关系。
我们仍然会节省一些工作,因为工具列表已经提前缓存了。最后我想很快提一下,我们可以添加多个不同的缓存断点,最多四个。所以我可能会决定在我传入的最后一个工具模式上添加一个缓存断点,然后也许我会在下面这个助手消息上添加一个缓存断点。如果我然后发出一个后续请求,并且我改变了下面的用户消息,没问题。
我们将节省掉重新处理整个工具列表、系统提示以及用户消息的工作。同样,如果我们改变了第一个用户消息,那么我们将使下面所有内容的缓存失效,但我们仍然有我们工具列表的缓存工作。所以,如果合适的话,我们很可能会添加多个不同的缓存断点。我们可能会决定缓存我们整个工具列表和系统提示,也许还有一些消息。
你具体把这些不同的断点放在哪里,真的只取决于你的特定应用程序。最后我想分享的一件事是,缓存有一个最小内容长度。所以,为了缓存一些内容,我们必须至少缓存 1024 个 tokens。所以在右上角的例子中,我在一条只有“high there”文本的消息上设置了一个缓存断点。
这肯定没有 1024 个 tokens 长,所以这个内容不会被写入缓存。但如果我把那个文本块复制 500 次,现在我可能就有了超过 1024 个 tokens,所以这整个不同块的列表就会被缓存。
63. 在实践中应用提示缓存
类型:视频 | 时长:7:21 | 视频:08 - 007 - Prompt Caching in Action.mp4
提示缓存是一个强大的优化功能,当你重复向 Claude 发送相同内容时,它能使你的 API 请求更快、更便宜。让我们来探讨如何在你的应用中有效地实现它。
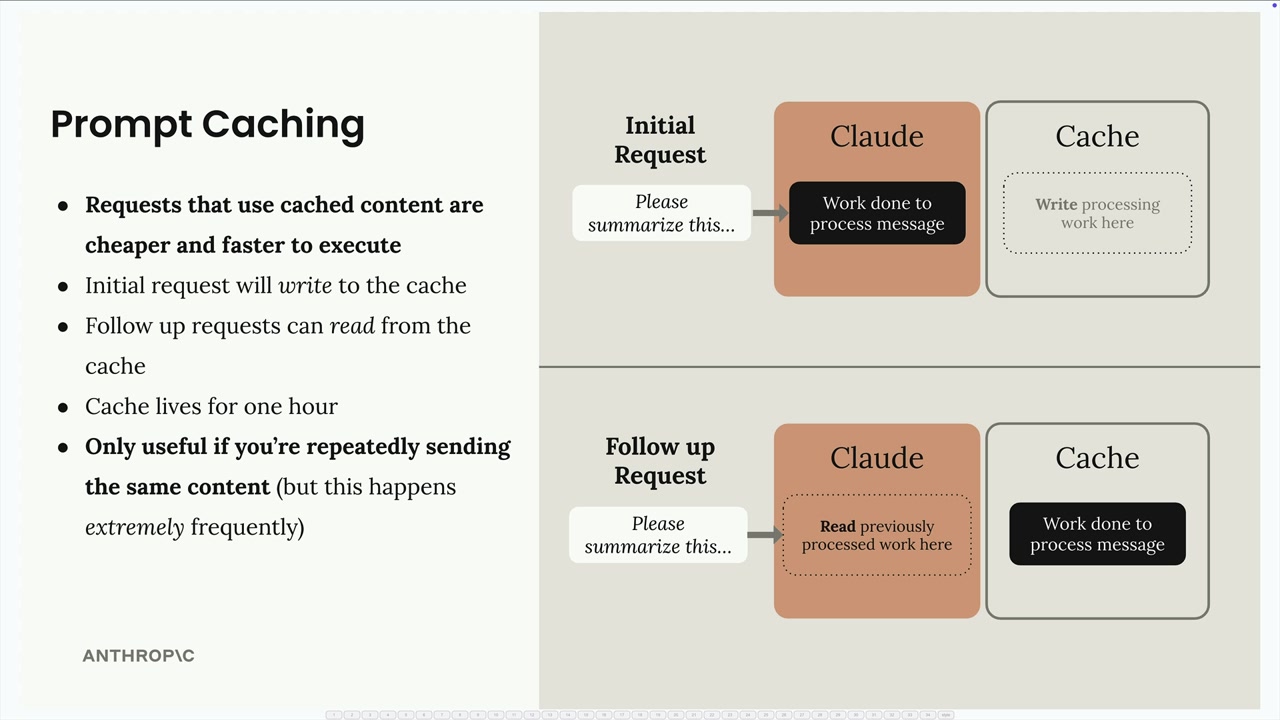
提示缓存的工作原理
当你启用提示缓存时,第一个请求会将内容写入一个存活一小时的缓存中。后续请求可以从这个缓存中读取,而不是再次处理相同的内容。这在你发送以下内容时特别有价值:
- 大型系统提示(比如一个 6K tokens 的编码助手提示)
- 复杂的 tool schemas (工具模式)(多个工具大约 1.7K tokens)
- 重复的消息内容
关键在于,缓存只有在你重复发送完全相同的内容时才有用——但在许多应用中,这种情况发生得非常频繁。
设置工具模式缓存
要缓存你的工具模式,你需要在列表中的最后一个工具上添加一个 cache_control 字段。以下是正确的做法,而无需修改你原始的工具定义:
if tools:
tools_clone = tools.copy()
last_tool = tools_clone[-1].copy()
last_tool["cache_control"] = {"type": "ephemeral"}
tools_clone[-1] = last_tool
params["tools"] = tools_clone
这种方法在添加 cache_control 字段之前,创建了 tools 列表和最后一个工具模式的副本。虽然你可以直接修改 tools[-1]["cache_control"],但复制的方法可以防止你以后重新排序工具时出现问题。
系统提示缓存
对于系统提示,你需要将它们结构化为一个带有缓存控制的文本块:
if system:
params["system"] = [
{
"type": "text",
"text": system,
"cache_control": {"type": "ephemeral"}
}
]
这将你的系统提示从一个简单的字符串转换为支持缓存的结构化格式。
理解缓存行为
当你运行启用了缓存的请求时,你会在响应中看到不同的使用模式:
- 第一次请求:
cache_creation_input_tokens=1772- Claude 写入缓存 - 后续请求:
cache_read_input_tokens=1772- Claude 从缓存中读取 - 内容改变: 出现新的缓存创建 tokens
缓存非常敏感——即使在你的工具或系统提示中改变一个字符,也会使该组件的整个缓存失效。
缓存顺序和断点
你可以在单个请求中设置多个缓存断点。顺序很重要:
- 工具(如果提供)
- 系统提示(如果提供)
- 消息
如果你改变了系统提示但保持工具不变,你会看到部分缓存读取(对于工具)和缓存写入(对于新的系统提示)。这种精细化的缓存意味着你只需为实际改变的部分付费处理。
实践考量
在以下情况下,Prompt caching (提示词缓存) 最为有效:
- 跨请求的 tool schemas (工具模式) 保持一致
- 稳定的 system prompts (系统提示词)
- 应用程序会发出多个具有相似上下文的请求
请记住,cache (缓存) 只会持续一小时,因此它适用于 API 使用相对频繁的应用程序,而不是长期存储。
视频文字稿
是时候亲手实践一下提示词缓存了。我创建了一个名为 003 caching 的新 notebook (笔记本)。你当然可以在本讲座的附件中找到它。在这里,你会找到一个名为“含有 6K tokens (令牌) 的提示词”的部分。
这可以作为一个系统提示词。我们稍后会用到它。此外,还有一个 tool schema (工具模式) 部分。其中定义了几个不同的工具模式。
所有这些不同的工具模式加起来大约有 1.7K 个令牌。我们将要更新我们的 chat function (聊天函数),它位于上面名为 helper functions 的单元格中。我们要确保我们的 chat 函数默认情况下总是为我们的工具模式和系统提示词启用提示词缓存。让我来演示一下如何操作。
在 helper function 单元格中,我将向下滚动到我们的 chat 函数。就是这里。我再向下滚动一点,你会注意到我添加了两个待办事项。首先,如果提供了工具列表,我希望总是缓存这个工具列表。
其次,如果我们提供了系统提示词,我也希望缓存它。记住,在单个请求中我们可以有多个不同的 cache breakpoints (缓存断点)。所以如果我们最终同时传递了系统提示词和工具列表,我们将设置两个不同的缓存断点。让我们首先处理缓存工具列表的问题。
要做到这一点,请记住,我们需要修改我们传递给 Claude 的最后一个工具模式。具体来说,我们需要添加 cache_control 字段。但我们可以这样做。我们可以直接写 tools[-1],然后给它设置一个 cache_control 字段,类型为 ephemeral。
就像这样。这肯定能行,但不是最佳的编码技巧。你看,这实际上会修改我们的工具模式,向其中添加 cache_control 字段。在我们的应用程序中,可能存在某种场景,我们稍后决定更改传入的工具模式的顺序。
如果我们这样做了,最终可能会在我们的工具模式中设置多个不同的缓存断点,这可能不是我们想要的结果。所以,一个更好的方法是首先创建我们工具列表的副本。然后我们将克隆其中的最后一个工具模式,并为其添加 cache_control 字段。让我看看该怎么做。
我将创建一个名为 tools_clone 的新变量,它通过调用 tools.copy() 得到。这将创建列表的完整副本。接下来,我将复制其中的最后一个工具。然后我将为最后一个工具模式添加 cache_control 字段。
所以类型将是 ephemeral。然后我将用我刚刚创建的 tool_schema_copy 覆盖 tools_clone 中的最后一个元素。tools_clone 的最后一个元素将是 tools.clone 在索引 -1 的位置。我将把我的 tools_clone 赋值给 tools 程序。
再次快速重复一下,这里面我所有的这些复制逻辑并非绝对必要。这只是一个好的实践,以防我们将来某个时候决定更改我们的工具列表。接下来,我们将处理第二个待办事项。所以如果我们传入一个系统提示词,我想确保我们总是在上面设置一个缓存断点。
要做到这一点,我将移除注释。我将用一个列表替换 system。我们将在这里面放入一个 text block (文本块)。所以它会是一个字典,包含一个 text 类型的 type,text 的内容是 system,最后是一个 cache_control,类型为 ephemeral。
就是这样。好了,现在我们来运行这个单元格。我们将到最底部去测试我们设置好的这个缓存功能。所以在最下面这里,我已经定义了一个工具列表。
这些是上面那个单元格里定义的工具模式。我们这里还有那个非常大的系统提示词,名为 code_prompt。那么,让我们先试试什么都不传。所以,没有工具列表,也没有任何提示词。
我们只想看看处理“1+1等于几”这条消息并生成回应需要用多少令牌。所以如果我运行这个,我会得到一个输出,我们可以注意到这里面有一个 usage 字段。看起来我们输入了 14 个令牌,输出了 11 个。现在我们试试加入我们的工具列表。
所以当我加入它并运行这个,我们现在会看到一个非常不同的 usage 字段。现在我们的用量里有一个 cache_creation_input_tokens,数值是 1700。这意味着 Claude 已经看到我们想要缓存我们的模式。所以它向缓存中写入了总共约 1700 个令牌。
所以现在如果我们立即发出一个后续请求,不改变任何东西,我们会看到我们现在将从缓存中读取一定数量的令牌。所以现在我们有了一个 1700 的 cache_read。这意味着我们已经成功地将我们的模式存储在缓存中,并在未来的某个时间点将它们检索出来。现在,如果我们以任何方式改变我们的用户消息,比如删除末尾的那个问号,然后重新运行,我们仍然会从缓存中读取,因为请记住,缓存的顺序是工具列表,然后是我们的系统提示词,然后是我们不同的消息。
所以我们仍然会像这样从缓存中读取。然而,如果我们以任何方式改变我们的任何一个工具,我们就会使缓存失效。所以如果我到我的工具列表里,我要改变第一个工具的描述。我要把 ads 这个词的 s 去掉。
所以现在只是 add a specified duration。现在如果我重新运行单元格,我已经改变了我的工具模式。这意味着我们应用于所有不同工具的缓存断点将不再适用。如果我再次运行最底部的单元格,我们会看到一个更新了的 usage 值。
所以现在我们将再次进行缓存写入。所以不再是读取。我们现在回到了写入,因为我们发送了一个在 Claude 看来是完全不同的工具列表。好了,现在我们来试试加入我们的系统提示词。
我将到我们的 chat 函数,然后加入 system=code_prompt。所以现在当我们发出这个请求时,请记住缓存的顺序,是工具,然后是系统提示词,然后是我们的消息列表。因为我们保持工具列表完全相同,但我们正在改变系统提示词,我预计会看到部分缓存读取和缓存写入同时发生。我们将看到的缓存读取是因为我们正在使用相同的工具列表。
而缓存写入则是因为我们通过发送这个新提示词来设置一个新的缓存断点。所以我将运行这个。现在我们应该会看到一个,有了,一个 1700 的缓存读取和一个 6.3K 的缓存写入。现在,就像我们的工具列表一样,如果我们去到我们的系统提示词并以任何方式改变这个提示词,也许只是删除最后这里的 builder 这个词,然后重新运行那个单元格。
现在,再一次,在 Claude 看来,如果我们再发送另一个请求,这将是一个完全不同的系统提示词。所以我们将丢失掉之前围绕系统提示词的所有缓存数据。所以现在我再发送一次,我们将再次看到一个大约 1.7K 的缓存读取,有了。然后我们再次写入这个全新的系统提示词,所以这又是 6.3K。
好了,我的朋友们,这就是提示词缓存。再次强调,任何时候当你发送相同的内容时,无论是相同的消息列表、相同的工具模式,还是相同的系统提示词,你都会非常频繁地使用提示词缓存。
64. 代码执行与 Files API
类型:视频 | 时长:11:07 | 视频:08 - 008 - Code Execution and the Files API.mp4
Anthropic API 提供了两个强大的功能,它们可以非常好地协同工作:Files API 和 Code Execution (代码执行)。虽然它们乍一看可能各自独立,但将它们结合起来,为委派复杂任务给 Claude 开启了一些非常有趣的可能性。
Files API
Files API 提供了处理文件上传的另一种方式。你可以预先上传文件,稍后再引用它们,而无需在消息中将图片或 PDF 直接编码为 base64 数据。
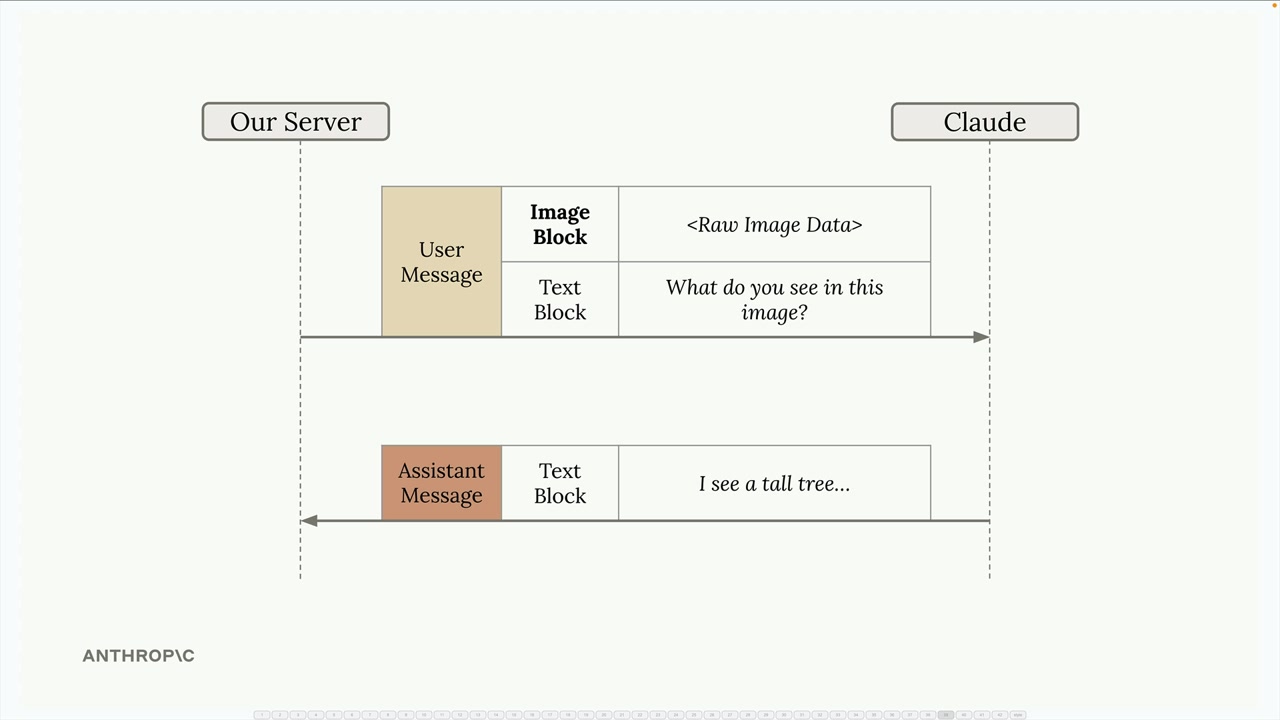
它的工作原理如下:
- 使用单独的 API 调用将你的文件(图片、PDF、文本等)上传到 Claude
- 接收一个包含唯一 file ID (文件 ID) 的 file metadata object (文件元数据对象)
- 在未来的消息中引用该文件 ID,而不是包含原始文件数据

当你想多次引用同一个文件,或者处理那些在每个请求中都包含会很麻烦的大文件时,这种方法特别有用。
Code Execution (代码执行) 工具
代码执行是一个 server-based tool (基于服务器的工具),不需要你提供实现。你只需在请求中包含一个预定义的工具模式,Claude 就可以选择性地在一个隔离的 Docker container (Docker 容器) 中执行 Python 代码。
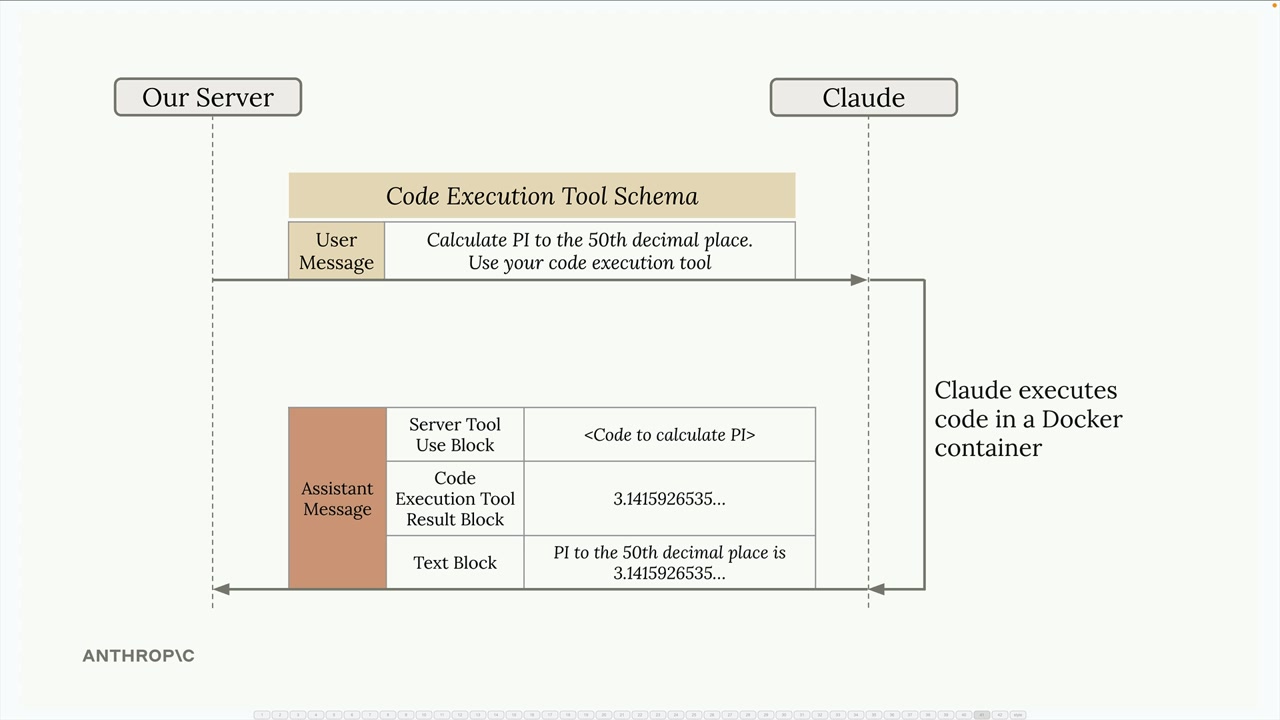
代码执行环境的主要特点:
- 在隔离的 Docker 容器中运行
- 无网络访问(不能进行外部 API 调用)
- Claude 可以在一次对话中多次执行代码
- 结果由 Claude 捕获并解释,用于最终的响应
结合 Files API 和代码执行
真正的威力来自于将这些功能结合使用。由于 Docker 容器没有网络访问权限,Files API 成为将数据传入和传出执行环境的主要方式。
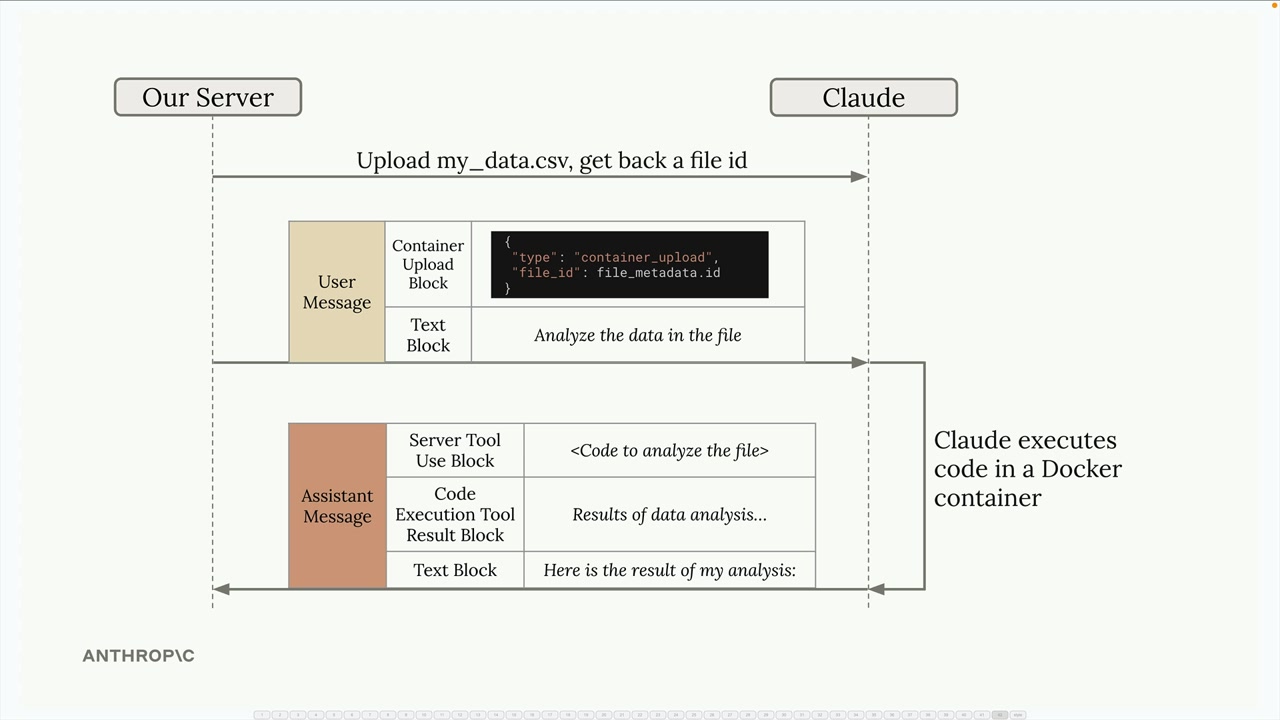
以下是一个典型的工作流程:
- 使用 Files API 上传你的数据文件(如 CSV)
- 在你的消息中包含一个带有文件 ID 的
container_upload块 - 要求 Claude 分析数据
- Claude 编写并执行代码来处理你的文件
- Claude 可以生成输出(如图表),供你下载
实践示例
让我们来看一个使用流媒体服务数据的真实示例。这个 CSV 文件包含用户信息,包括订阅等级、观看习惯,以及他们是否已经 churned (客户流失)(取消了订阅)。
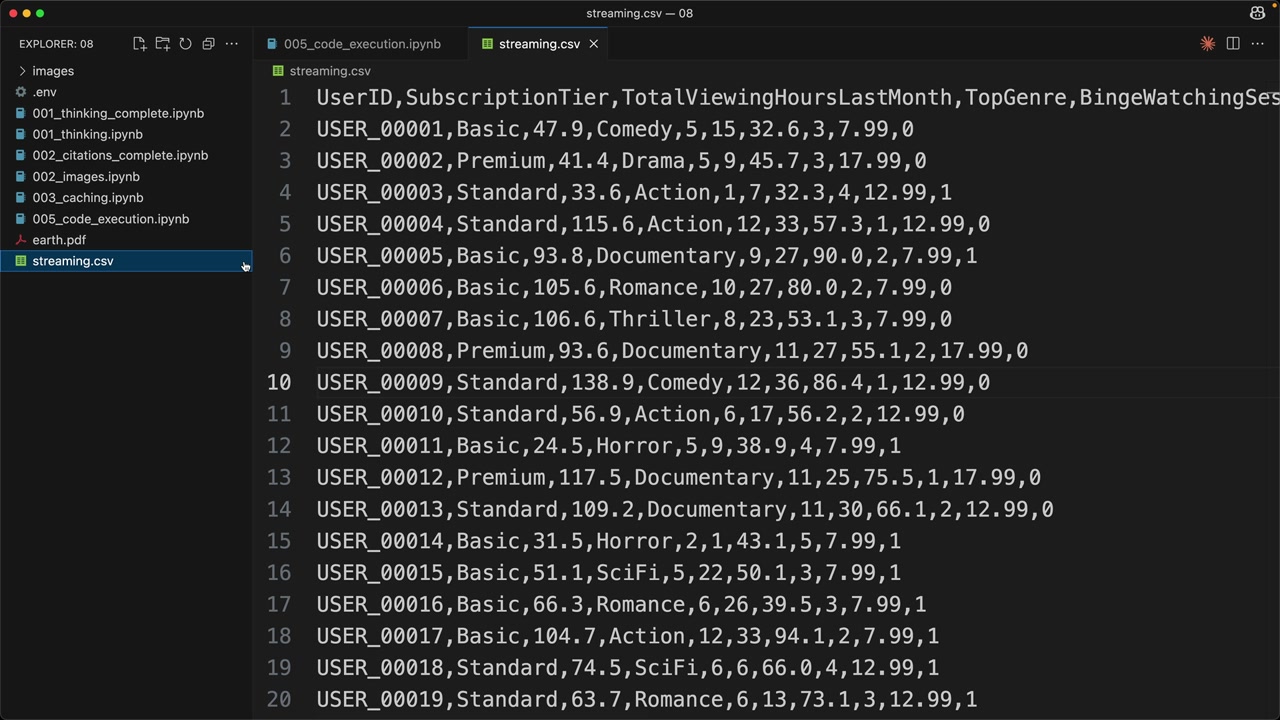
首先,使用一个辅助函数上传文件:
file_metadata = upload('streaming.csv')
然后创建一个消息,其中既包含上传的文件,也包含分析请求:
messages = []
add_user_message(
messages,
[
{
"type": "text",
"text": """Run a detailed analysis to determine major drivers of churn.
Your final output should include at least one detailed plot summarizing your findings."""
},
{"type": "container_upload", "file_id": file_metadata.id},
],
)
chat(
messages,
tools=[{"type": "code_execution_20250522", "name": "code_execution"}]
)
理解响应
当 Claude 使用代码执行时,响应包含多种类型的块:
- Text blocks (文本块) - Claude 的分析和解释
- Server tool use blocks (服务器工具使用块) - Claude 决定运行的实际代码
- Code execution tool result blocks (代码执行工具结果块) - 运行代码的输出
Claude 可能会在一次响应中多次执行代码,迭代地构建其分析。每个执行周期都包括代码及其结果。
下载生成的文件
最强大的功能之一是 Claude 能够生成文件(如图表或报告)并使其可供下载。当 Claude 创建一个可视化图表时,它会被存储在容器中,你可以使用 Files API 下载它。
在响应中查找类型为 code_execution_output 的块——这些块包含生成内容的 file ID (文件 ID):
download_file("file_id_from_response")
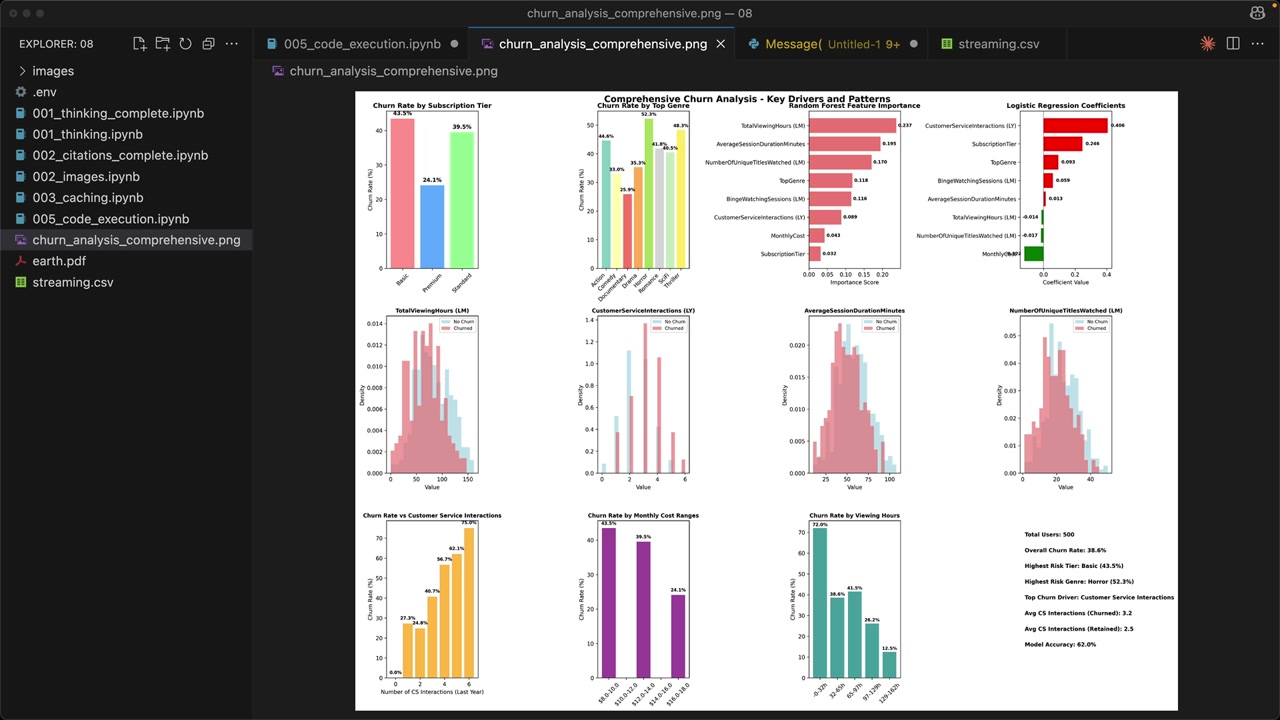
结果是一个带有专业可视化图表的全面分析,而要手动编码生成这些图表需要花费大量时间。
超越数据分析
虽然数据分析是一个天然的契合点,但 Files API 和代码执行的结合开启了许多可能性:
- 图像处理和操作
- 文档解析和转换
- 数学计算和建模
- 使用自定义格式生成报告
关键在于,你可以将复杂的计算任务委派给 Claude,同时通过 Files API 控制输入和输出。这创建了一个强大的工作流,Claude 在其中成为你的编码助手,能够实际执行和迭代解决方案。
视频文字稿
在本视频中,我们将探讨 Anthropic API 提供的两个功能。这两个功能看起来可能有些不同,有些独立,但事实证明,它们可以以非常有趣的方式结合在一起。那么,让我们开始吧。我们首先来了解一下 Files API 到底是什么。
在本课程的前面部分,我们讨论了如何将图片传递给 Claude,并要求 Claude 解释图片本身。我向你展示了我们如何包含一个 image block (图片块),其中可以包含以 base64 编码的原始图像数据。我们也看到了一个非常类似的过程被用于上传 PDF 文档。Files API 为整个系统带来了一点变化。
通过 Files API,我们可以提前发出一个单独的请求来上传特定的文档,无论是 PDF、图片、文本文件还是其他任何文件。所以我们可能会先向 Claude 发出一个初始请求来上传那个文件。然后我们会得到一个叫做文件元数据对象的东西。这个文件元数据对象包含一些不同的信息,但对我们来说最有趣或最重要的属性是文件 ID。
这个 ID 让我们可以在未来的某个时间点引用那个已上传的文件。所以,稍后在未来的某个时间点,用户可以提交一条消息,比如“你在这张图片里看到了什么”。在我们的图片块里,我们不需要包含图片本身的原始文件数据,而只需包含文件 ID。所以我们可以在那里放入文件 ID。
这会让 Claude 去寻找我们之前上传的那张图片。然后 Claude 会尽其所能地去解读这张图片。所以 Files API 允许我们提前上传一个文件,然后在稍后的请求中包含关于原始文件的一些数据给 Claude。所以你真的可以把这看作是我们向 Claude 提供图片或 PDF 的另一种方式。
现在我们了解了 Files API 背后的基本原理,即它允许我们提交一个文件,然后在未来的某个时间点引用它,我们将转换话题,讨论本视频的另一个重点,那就是代码执行。代码执行是一个基于服务器的工具。所以我们不必为这个工具提供实际的实现。我们所要做的就是提供一个预定义的工具模式。
在我们向 Claude 发出的初始请求中,我们将包含这个特别定义的工具模式,以及我们想要包含的任何用户提交的消息。然后在幕后,Claude 可以选择在一个隔离的 Docker 容器中执行一定量的 Python 代码。Claude 可以在这个容器中多次运行代码。Claude 从这些代码执行中打印出的任何内容都将被发送回 Claude,然后 Claude 可以解释结果并给我们写一个最终的答复。
这些 Docker 容器没有任何网络访问权限。这意味着 Claude 不能写出任何会发出网络请求或尝试访问任何外部 API 的代码。相反,为了将信息输入 Docker 容器并从中获取信息,我们依赖于将我们刚刚讨论的 Files API 与这个代码执行工具结合起来。让我来告诉你这是如何工作的。
让我们想象一下,我们有一个名为 maybemydata.csv 的 CSV 文件,它包含大量我们希望 Claude 分析的表格信息。我们不必经历一些非常复杂的代码设置,让 Claude 写出一些代码,然后我们自己手动执行,而是可以利用这个 Files API 和代码执行工具,让 Claude 自动分析文件并为我们生成一些结果。为此,我们将首先使用 Files API 上传我们的 CSV 文件。所以我们最初会在这里上传我们的 CSV 文件,里面有一些数据。
这会给我们返回一个文件 ID。然后我们将在对 Claude 的后续请求中包含那个文件 ID。所以我们将添加一个叫做 container upload block (容器上传块) 的东西。一个容器上传块只是意味着我们想要拿一个我们之前上传到 Claude 的文件,并以某种方式将它注入或放置到容器中。
所以我们将添加这个非常特别制作的块,其类型为 container_upload,文件 ID 属性为我们上传原始文件时得到的任何 ID。然后在一个单独的文本块中,我们会要求 Claude 做一些分析,可能像“分析这个文件中的数据”这样简单。然后在幕后,Claude 将会利用代码执行工具。Claude 将可以在 Docker 容器中访问那个上传的文件。
所以 Claude 可以写出一些代码来分析文件,处理结果,然后给我们一个关于该文件中所有数据的完整报告。现在让我们来看一个这个完整流程的例子。我准备了一个名为 005 code execution 的笔记本。我还创建了一个名为 streaming.csv 的独立 CSV 文件。
这里面是一堆来自一个视频流媒体服务的假数据。这个文件包含了关于特定用户的信息,他们所属的订阅等级,也就是他们拥有的访问级别,以及关于这个特定用户的大量统计数据。所以有他们观看的总小时数,热门类型,等等,然后在最后,最后一列叫做 churned (客户流失)。churned 是一个指示用户是否取消了他们的订阅的标志。
所以 0 意味着他们没有取消订阅,而 1 意味着他们已经取消了订阅。现在我可以写很多代码来分析这个文件中的数据,并找出这些不同特征与用户是否取消订阅之间是否存在某种关联。但与其我自己做所有这些,我可能会决定把整个任务交给 Claude。我可以先上传这个 stringing.csv 文件,然后要求 Claude 利用它的代码执行工具来分析这里面所有的数据。
让我来演示一下我们会怎么做。首先,回到笔记本里,我希望你看看辅助函数单元格。如果你向下滚动一点,你会注意到我添加了几个不同的函数。我添加了一个 upload 函数,它会根据给定的文件路径自动上传一个特定的文件。
我添加了一个 list_files 函数,它会列出我们上传到 Claude 的所有不同文件。我们也可以删除文件,下载文件,以及获取关于特定文件的信息。我们很快就会用到这些函数。所以我将折叠那个单元格,当然,也要确保我运行了它。
然后在下一个单元格中,我将尝试上传 streaming.csv 文件。所以我将立即运行那个单元格。我们会得到我们的文件元数据对象。在这里面,有我们的 ID。
这就是向 Claude 标识这个文件的唯一 ID。如果我们将来想在对话中包含它,我们会引用那个特定的 ID。然后在下一个单元格中,我有一个简短的提示,要求 Claude 进行详细分析,找出客户取消订阅的原因。我还要求 Claude 打印出一张总结其所有发现的图表。
在那之后,我有一个容器上传块,它将实际地把那个上传的文件包含在我们的请求中。所以现在我想运行这个单元格,请注意,每当你使用代码执行时,它有时实际上需要一些时间才能完成。我们得到的响应将包含大量的文本。在这个消息中,将包含 Claude 决定编写的所有代码,以及它得到的所有打印语句和输出,还有一些最终的分析。
Claude 可以决定在容器内多次运行代码,所以我们实际上可能会在这个消息中看到多个代码块和多个执行结果。现在为了帮助你理解消息中发生了什么,我把所有这些内容拿过来,并对它进行了一点更美观的格式化,这样我们就能理解发生了什么。所以这就是那条消息。我得到了我的内容列表,里面有各种不同的块。
第一个块是一个文本块,它将包含一些文本,只是 Claude 对初始问题的构架。然后 Claude 将提供一个服务器工具使用块。这将包含一些 Claude 想要在容器内运行的代码。然后这是我们的代码执行工具结果。
它将包含关于代码实际执行的一些信息。所以有来自标准输出、标准错误的数据,返回码以防需要任何错误处理,等等。然后看起来在这种情况下,Claude 决定在那之后运行更多的代码。所以它在这里做了一些进一步的分析,得到了一些更多的结果,然后又做了一些更多的分析,等等。
所以在这种情况下,Claude 连续运行了几次代码来进行彻底的分析。现在,你是否决定向你的用户展示所有这些内容完全取决于你和你正在开发的特定应用程序。如果你想,你可以建立一个非常漂亮的报告,也许像这样。我把我们刚才看到的所有信息拿过来,然后用 Claude 把它格式化得非常漂亮。
所以现在我可以看到最初的响应。这就是我们得到的最初文本块中的确切信息。然后这是我的代码执行工具。这是 Claude 决定运行的代码,以及执行它的输出。
我们可以看到这被重复了好几次。所以现在我在这里有更多的文本,另一个代码执行,等等。最后,我想向你展示代码执行最有趣的方面之一。你可能还记得,在我发出的这个提示中,我要求 Claude 包含一个详细的图表来总结它的发现。
Claude 在幕后确实在一个图像文件中生成了一个图表,并且它被存储在我们的 Docker 容器中。我们可以使用 Files API 来下载在 Docker 容器中生成的那个图表。让我来演示一下。首先,我将仔细看看我在这里格式化的消息。
如果我滚动浏览,我最终可能会看到一个带有额外嵌套 content 属性的文本块。在那个里面,我可能会看到一个 code_execution_output 类型。我的就在这里。如果你的响应中没有看到它,请尝试搜索 code_execution_output。
在那下面是一个文件 ID。所以我可以用这个文件 ID 来下载文件。我将复制它,回到我的笔记本,我将到最底部并添加一个新的单元格。好了。
我将调用 download_file,这是我们在这个视频开始时看到的预定义函数之一。我将粘贴我刚刚在响应中找到的文件 ID。我将运行这个。它会成功运行。
现在如果我看看我的笔记本所在的同一个目录,我会在那里找到一个 PNG 或 JPEG 文件。它们的名字是随机的。它不是真正随机的。它将是 Claude 决定命名的任何名字。
如果我然后打开那个文件,如果我然后打开那个文件,我会看到一堆 Claude 从那个 CSV 文件中提取的信息。所以这是一个很棒的可视化,告诉我所有我需要知道的事情。所以按观看小时数的流失率,按月费范围的流失率,等等,Claude 在这里做了一个非常彻底的分析,帮助我理解这个文件的内容。所以正如你所见,基于这个演示,将 Files API 和代码执行工具结合起来,让我们可以将相当复杂的任务委派给 Claude。
当然,你不仅限于做数据分析。你可以使用代码执行和 Files API 的组合来执行各种不同的任务。如何将其集成到你的应用程序中,这真的取决于你自己。
66. MCP 简介
类型:视频 | 时长:4:40 | 视频:09 - 001 - Introducing MCP.mp4
Model Context Protocol (MCP,模型上下文协议) 是一个通信层,它为 Claude 提供上下文和工具,而无需你编写大量繁琐的集成代码。可以把它看作是一种将工具定义和执行的负担从你的服务器转移到专门的 MCP 服务器的方式。
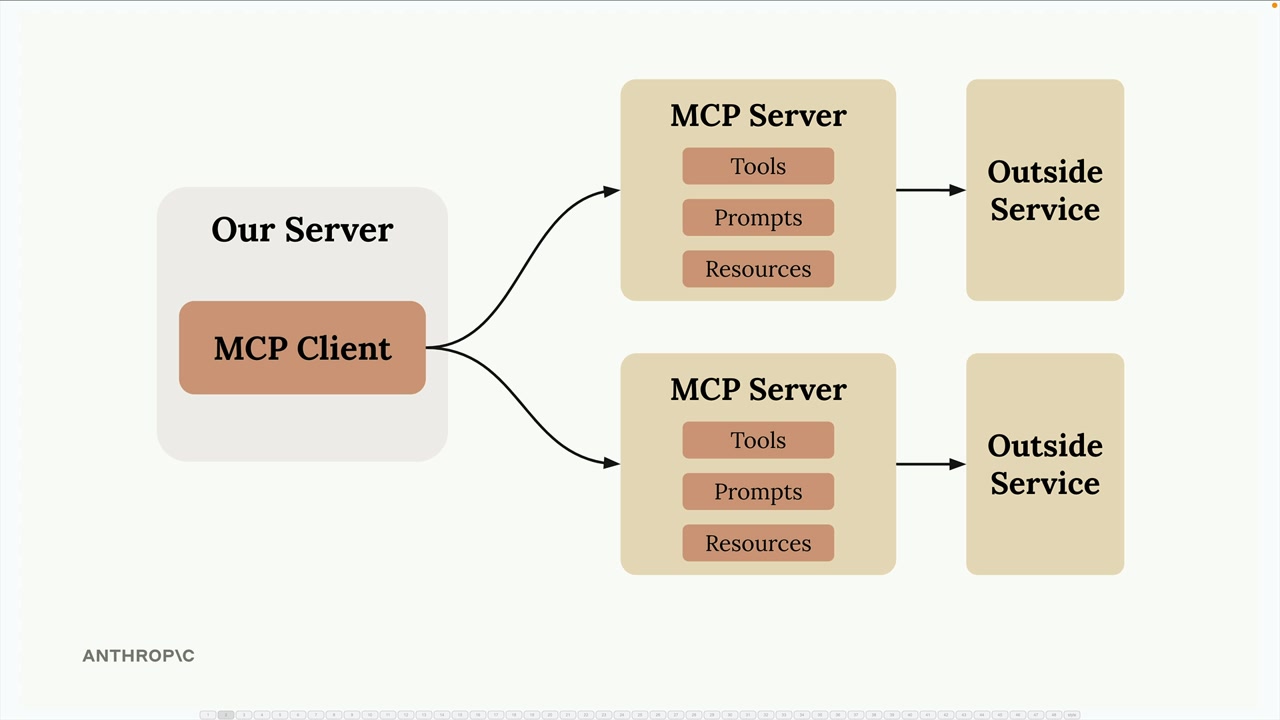
当你第一次接触 MCP 时,你会看到展示基本架构的图表:一个 MCP Client (MCP 客户端) 连接到包含工具、提示词和资源的 MCP Servers (MCP 服务器)。每个 MCP 服务器都充当某个外部服务的接口。
通过真实示例理解 MCP
假设你正在构建一个聊天界面,用户可以向 Claude 询问他们的 GitHub 数据。用户可能会问:“我所有仓库里有哪些开放的拉取请求?” 要回答这个问题,Claude 需要工具来访问 GitHub 的 API。
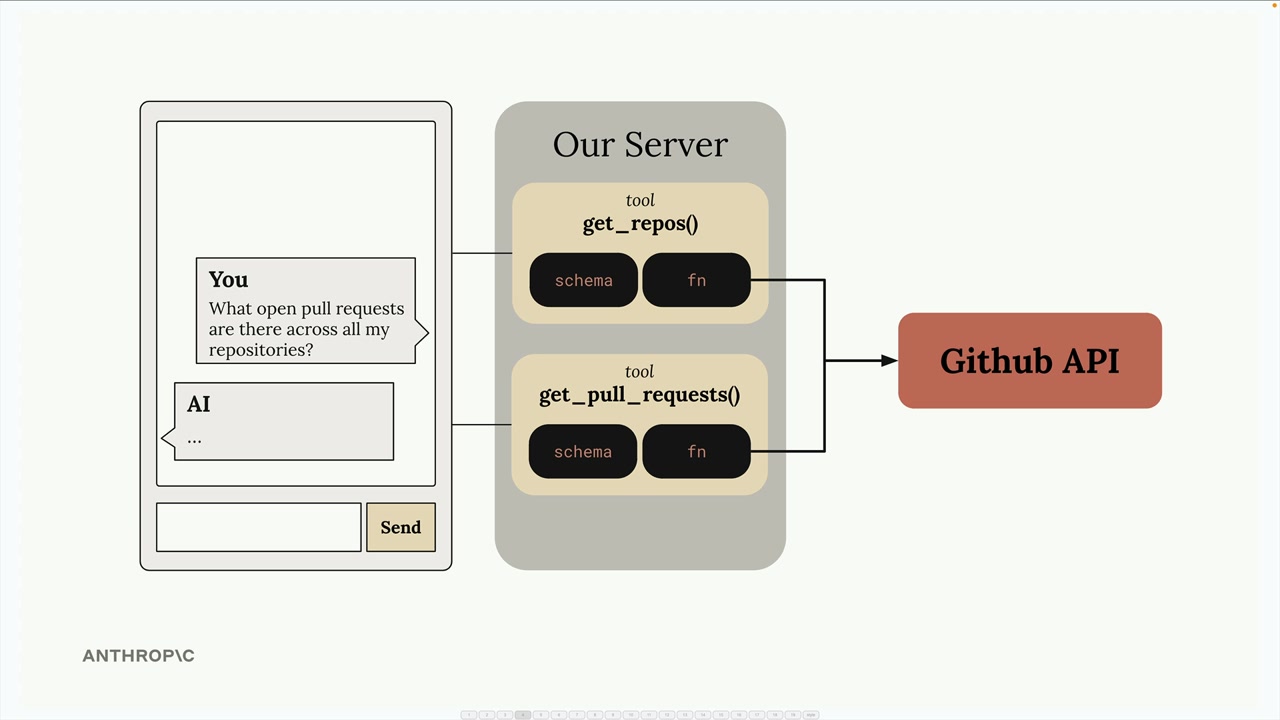
如果没有 MCP,你需要自己创建所有 GitHub 集成工具。这意味着要为你想支持的每一项 GitHub 功能编写模式和函数。
工具函数的问题
GitHub 功能极其丰富——仓库、拉取请求、问题、项目等等。要构建一个完整的 GitHub 聊天机器人,你需要编写数量惊人的工具:
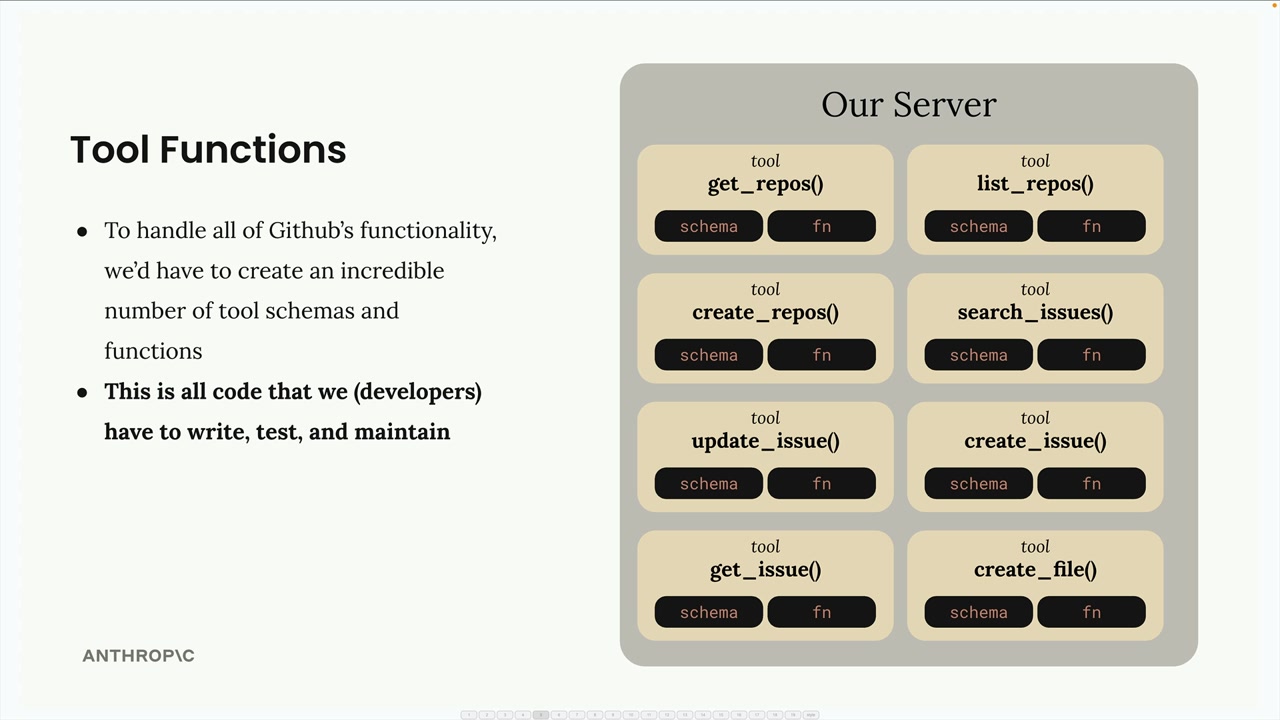
每个工具都需要一个模式定义和一个函数实现。这代表了作为开发者,你必须编写、测试和维护的大量代码。
MCP 如何解决这个问题
MCP 将工具定义和执行的负担从你的服务器转移到了 MCP 服务器。那些 GitHub 工具不再由你编写,而是在一个专用的 MCP 服务器内部编写和执行。
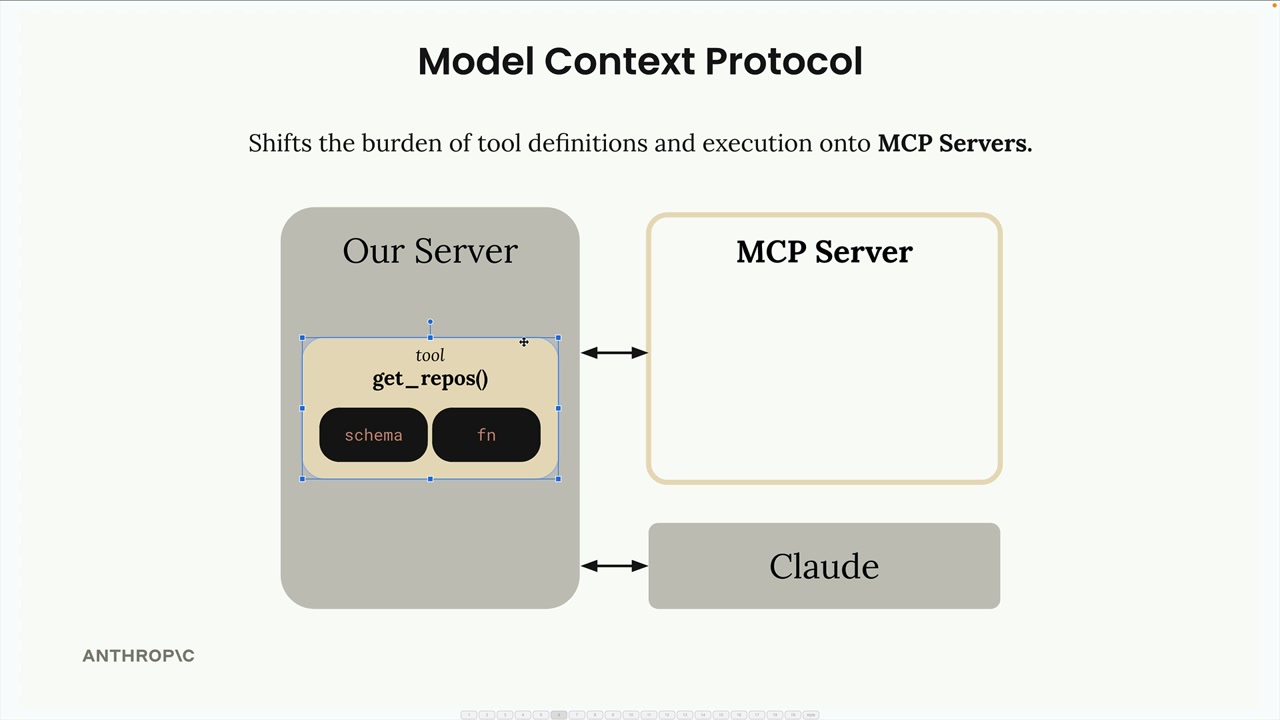
MCP 服务器充当 GitHub 功能的包装器,提供预构建的工具,你无需自己实现即可使用。
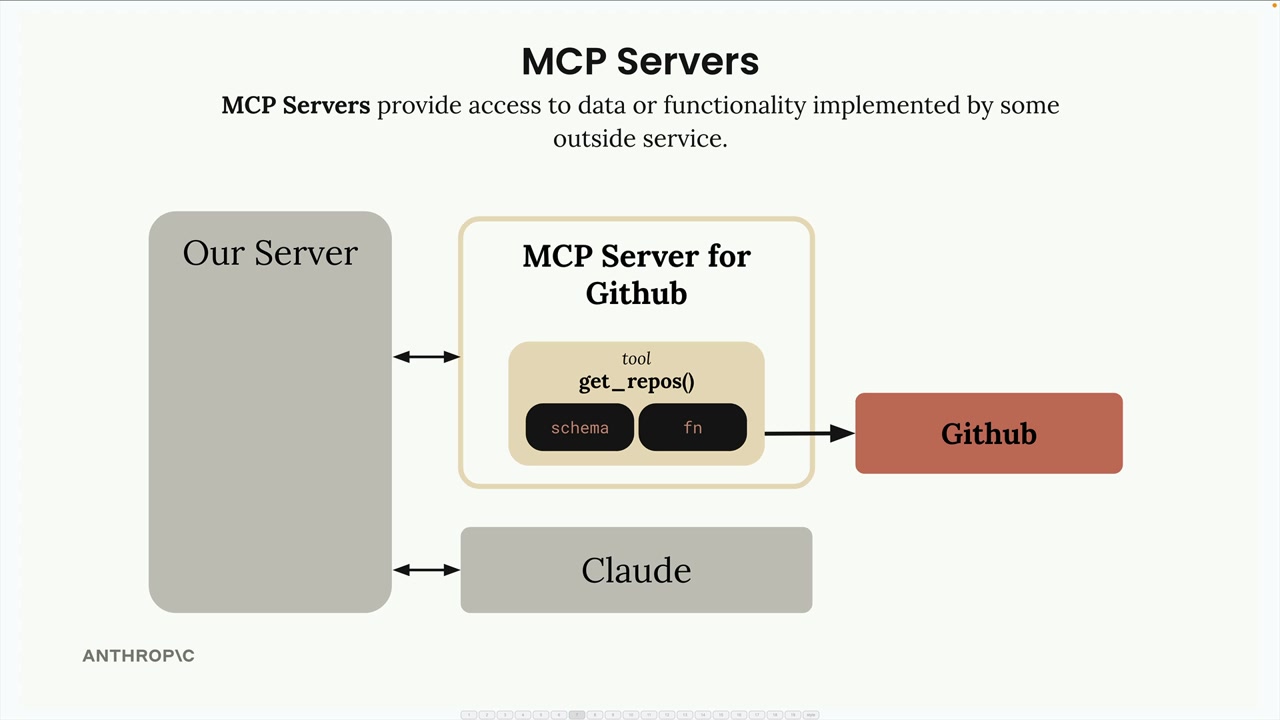
MCP 服务器提供对由外部服务实现的数据或功能的访问。它们将复杂的集成打包成可重用的组件,任何应用程序都可以连接。
关于 MCP 的常见问题

谁来编写 MCP 服务器?
任何人都可以创建 MCP 服务器实现。通常,服务提供商自己会制作他们自己的官方 MCP 实现。例如,AWS 可能会发布一个官方的 MCP 服务器,其中包含用于他们各种服务的工具。
MCP 与直接调用 API 有何不同?
MCP 服务器为你提供了已经定义好的工具模式和函数。如果你直接调用 API,你就需要自己负责编写那些工具定义。MCP 为你节省了那部分实现工作。
MCP 不就是 Tool Use (工具调用) 吗?
这是一个常见的误解。MCP 服务器和工具调用是互补但不同的概念。MCP 关注的是谁来做创建和维护工具的工作。使用 MCP,别人已经为你写好了工具函数和模式——它们被打包在 MCP 服务器内部。
关键的洞见是,MCP 服务器为你提供了已经定义好的工具模式和函数,从而消除了你自己构建和维护复杂集成的需要。
视频文字稿
在本模块中,我们将专注于模型上下文协议。MCP 是一个通信层,旨在为 Claude 提供上下文和工具,而无需你作为开发者编写大量繁琐的代码。当你第一次开始使用 MCP 时,你经常会看到像这样的图表。它展示了 MCP 的两个主要元素,即客户端和服务器。
服务器通常包含许多内部组件,名为工具、资源和提示词。这里有很多术语。所以为了帮助你理解所有这些,我们将想象我们正在构建一个小应用程序,并看看 MCP 是如何融入其中的。我们的示例应用程序将是另一个聊天界面。
它将允许用户与 Claude 就他们的 GitHub 数据进行聊天。所以如果用户问一个问题,比如我所有不同的仓库中有哪些开放的拉取请求,期望是 Claude 可能会利用一个工具来访问 GitHub,访问用户的帐户,并查看他们有哪些开放的拉取请求,也许是开放的仓库或其他任何东西。这里的要点是,我们可能会通过使用一组工具来实现这一点。现在,我想非常快速地提到一件事,那就是 GitHub 拥有巨大的功能。
有仓库、拉取请求、问题、项目以及大量其他东西。所以要拥有一个完整的 GitHub 聊天机器人,我们真的必须编写大量的工具。如果我们想构建那个示例应用程序,我们将不得不负责编写所有这些模式和所有这些函数。而这些都是你和我作为开发者必须编写、测试和维护的代码。
这对我们来说是很大的努力,很大的负担。让开发者维护一大堆集成的这个挑战,是模型上下文旨在解决的主要困难之一。MCP 将定义和运行工具的负担从你的服务器转移到另一个叫做 MCP 服务器的东西上。所以你和我将不再需要编写这个工具。
相反,它将在别处,在这个 MCP 服务器内部编写和执行。这些 MCP 服务器真的可以被看作是某个外部服务的接口。所以我可能有一个 GitHub MCP 服务器,它提供对特定由 GitHub 提供的数据和功能的访问,我们基本上是将围绕 GitHub 的大量功能包装起来,并以一组工具的形式放入这个 MCP 服务器中。所以到目前为止,我们对 MCP 服务器是什么有了一个非常基本的了解。
它让我们能够访问一组工具,这些工具暴露了与某个外部服务相关的功能。这样做的好处是,你和我不需要编写所有这些不同的工具模式和函数等等。现在我们有了这个基本的了解,我想谈谈一些很多人在初次了解 MCP 服务器时会有的非常常见的问题。所以,似乎总会出现三个常见问题。
第一个常见问题是,谁编写这些 MCP 服务器?答案是任何人。任何人都可以制作一个 MCP 服务器实现。但很多时候,你会发现服务提供商会制作他们自己的官方实现。
所以例如,AWS 可能会决定发布他们自己的官方 MCP 服务器实现,在其中,它可能会有各种各样不同的工具供你使用。第二个常见问题是,使用 MCP 服务器与直接调用服务的 API 有何不同?嗯,正如我们刚刚看到的,如果我们想直接调用一个 API,比如 GitHub,那么我们就必须自己编写这个工具。现在我们就可以直接调用 GitHub 了。
所以我们在这里得到了什么?嗯,真正改变的只是我们现在必须自己编写模式和函数实现。所以仅仅通过添加 MCP 服务器,我们就为自己节省了一点时间。最后一个常见问题更多的是你会看到人们对 MCP 提出的一个常见批评。
而这种批评最常来自那些不太了解 MCP 是什么的人。所以你经常会看到人们说 MCP 和工具使用是同一回事。嗯,正如我刚才向你阐述的,MCP 服务器和工具使用,它们是互补的。它们是不同的东西,但它们是互补的。
MCP 背后的想法是你不需要编写工具函数和工具模式。那是别人为你做的事情,并且被包装在这个 MCP 服务器内部。所以在某种程度上,是的,它们有点相似,因为我们在这两种情况下都在谈论工具使用,但 MCP 服务器真正谈论的是谁在做实际的工作。所以如果你看到这种批评,再次强调,这通常是因为人们不太了解 MCP 的全部内容。
67. MCP 客户端
类型:视频 | 时长:4:56 | 视频:09 - 002 - MCP Clients.mp4
MCP 客户端充当你服务器和 MCP 服务器之间的通信桥梁。可以把它看作是你访问 MCP 服务器提供的所有工具的接入点。当你需要使用外部工具或服务时,客户端会为你处理所有的消息传递和协议细节。
传输无关的通信
MCP 的一个关键优势是传输无关——这是一个花哨的说法,意思就是客户端和服务器可以使用不同的通信方法进行对话。最常见的设置是在同一台机器上运行 MCP 客户端和服务器,它们通过标准输入/输出进行通信。
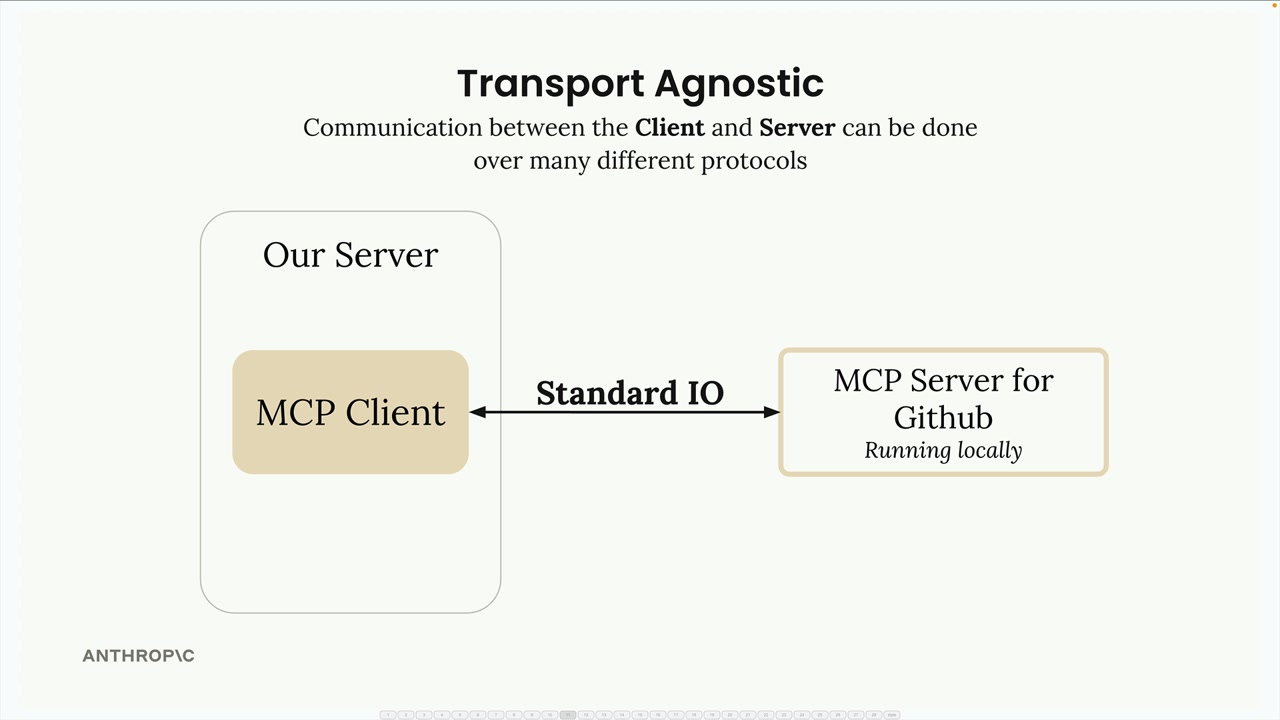
但你不仅限于这种方法。MCP 客户端和服务器也可以通过以下方式连接:
- HTTP
- WebSockets
- 各种其他网络协议
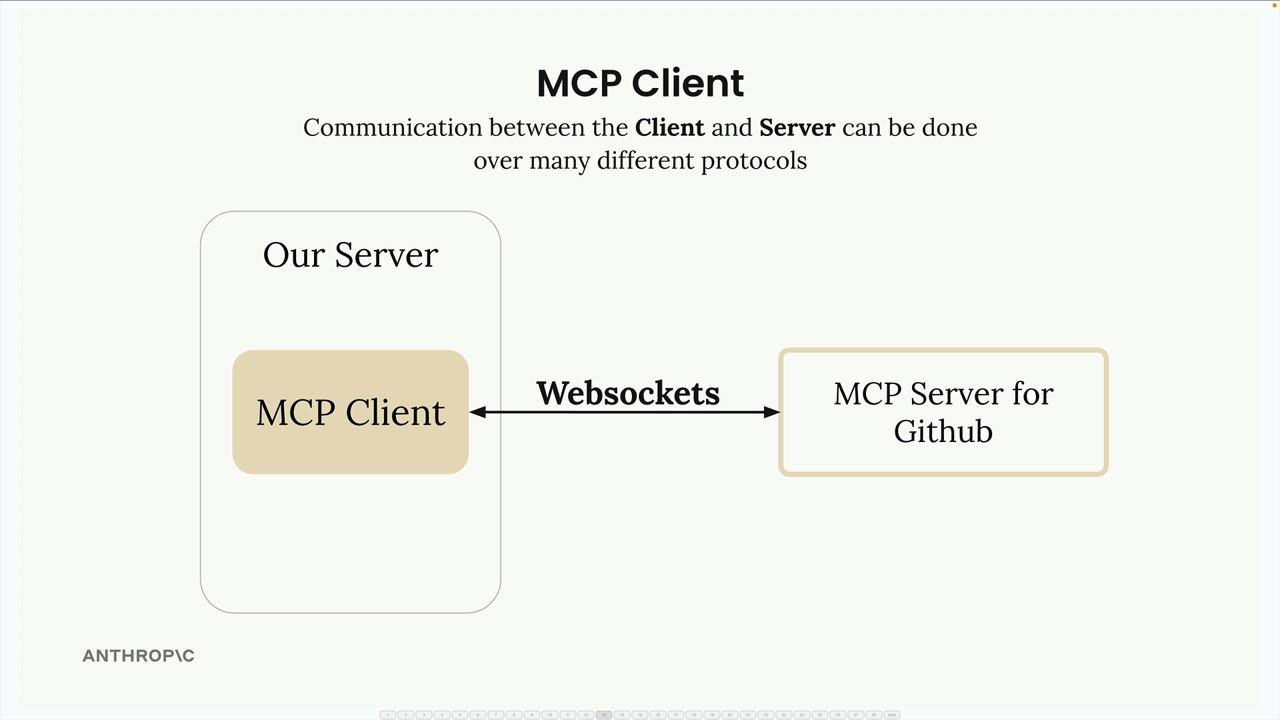
消息类型
连接后,客户端和服务器会交换 MCP 规范中定义的特定消息类型。你将主要使用的消息类型有:
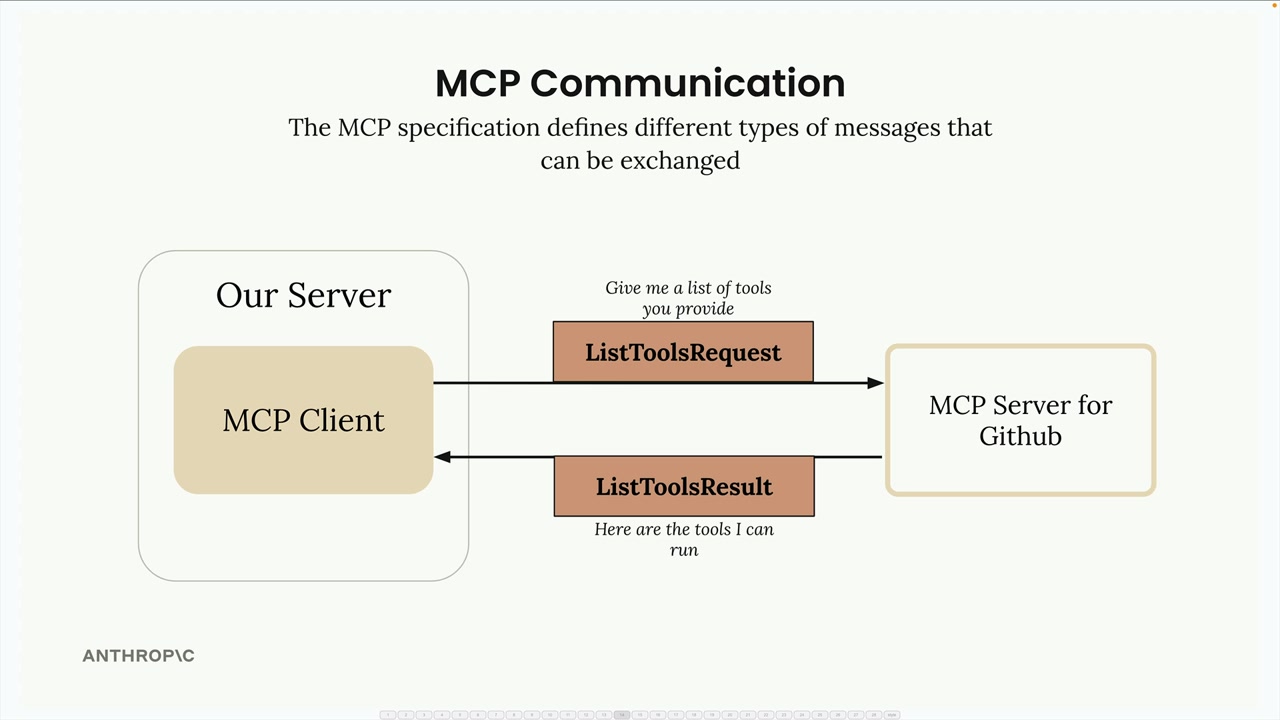
ListToolsRequest/ListToolsResult:客户端询问服务器“你提供哪些工具?”,并得到一个可用工具的列表。
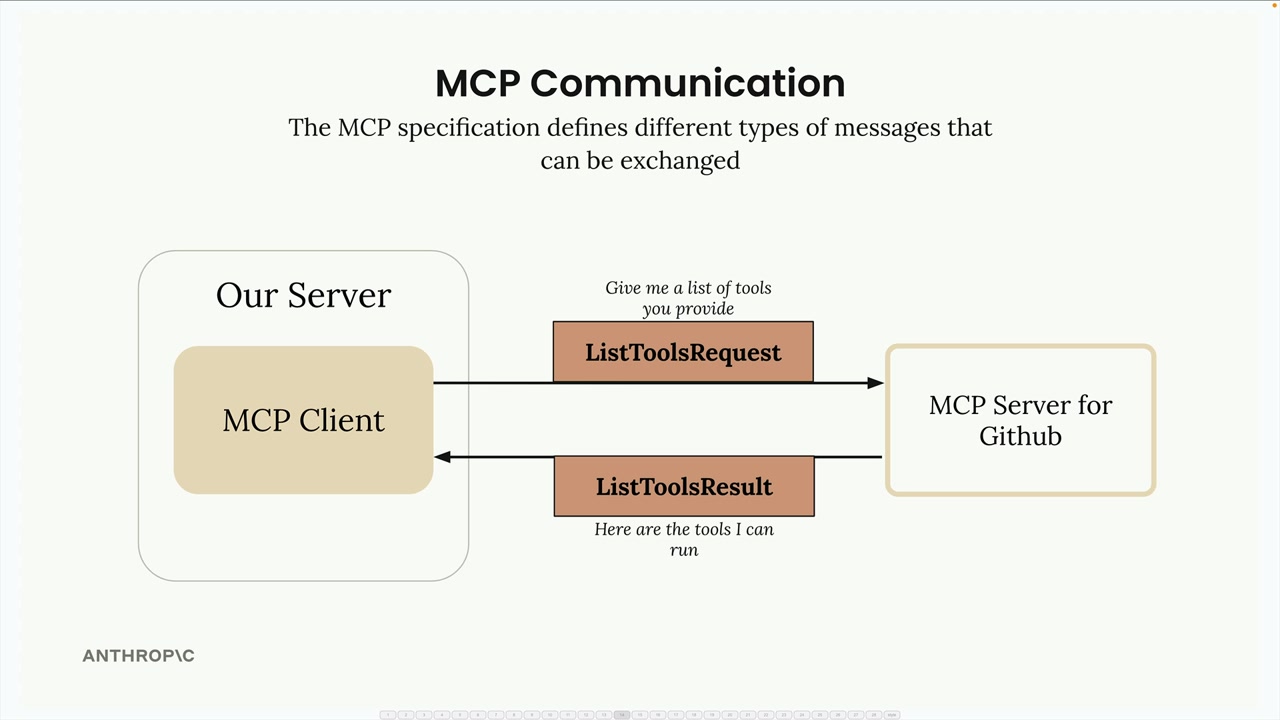
CallToolRequest/CallToolResult:客户端请求服务器用特定参数运行一个特定的工具,然后接收结果。
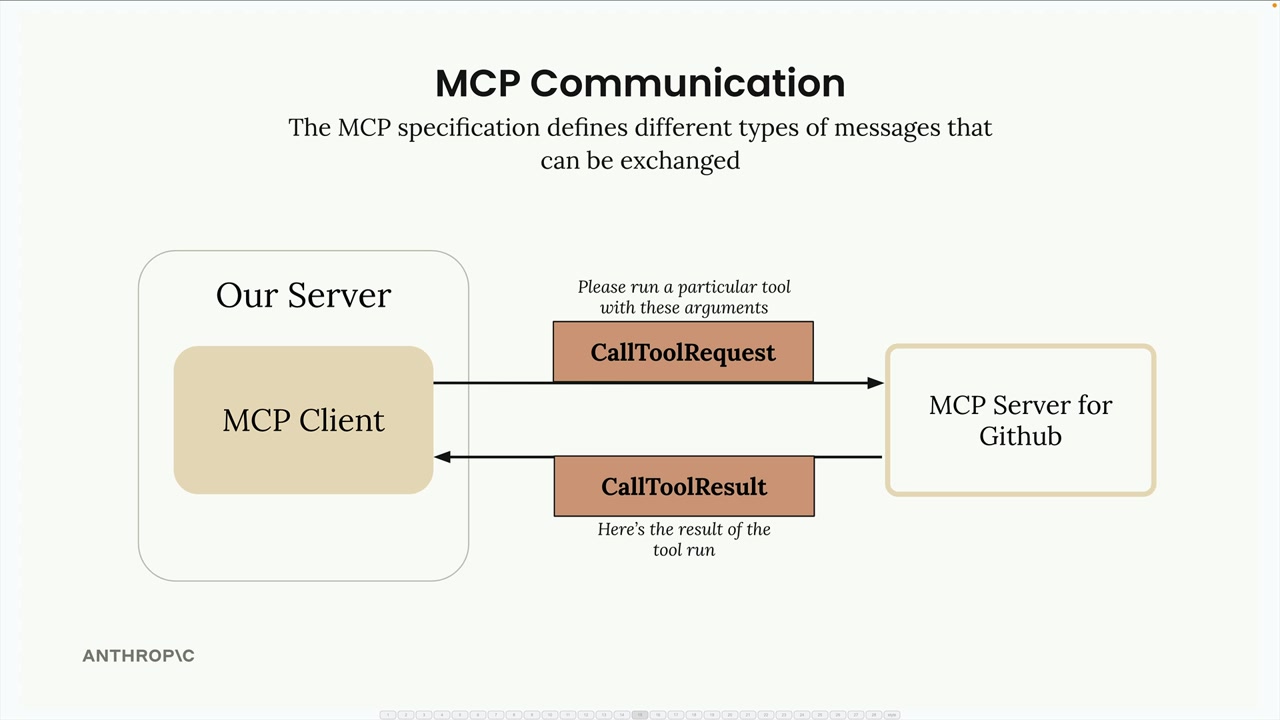
完整流程示例
以下是在真实场景中所有部分如何协同工作的。假设用户问“我有哪些仓库?”——这是完整的通信流程:

当用户向你的服务器提交查询时,流程开始。你的服务器意识到在发出请求之前,需要向 Claude 提供可用工具的列表。

你的服务器向 MCP 客户端请求工具,MCP 客户端向 MCP 服务器发送 ListToolsRequest 并接收到 ListToolsResult。
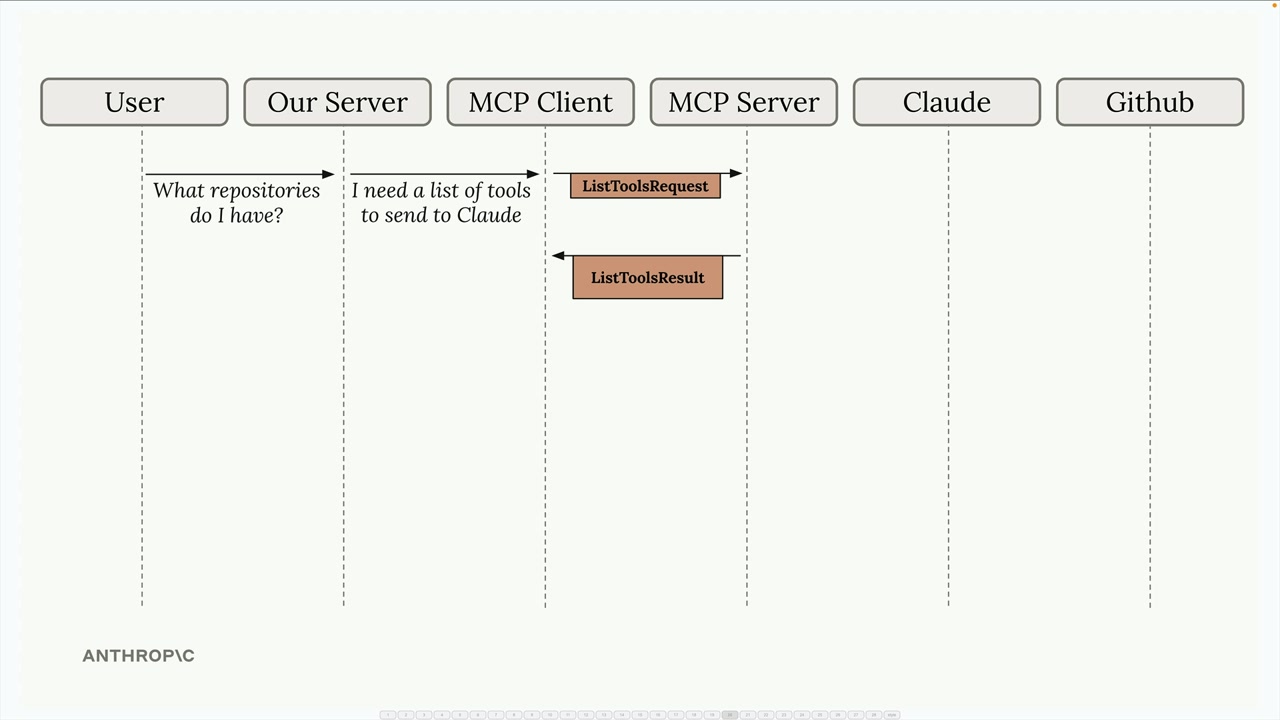
现在你的服务器拥有一切所需,可以向 Claude 发出初始请求——既有用户的问题,也有可用的工具。
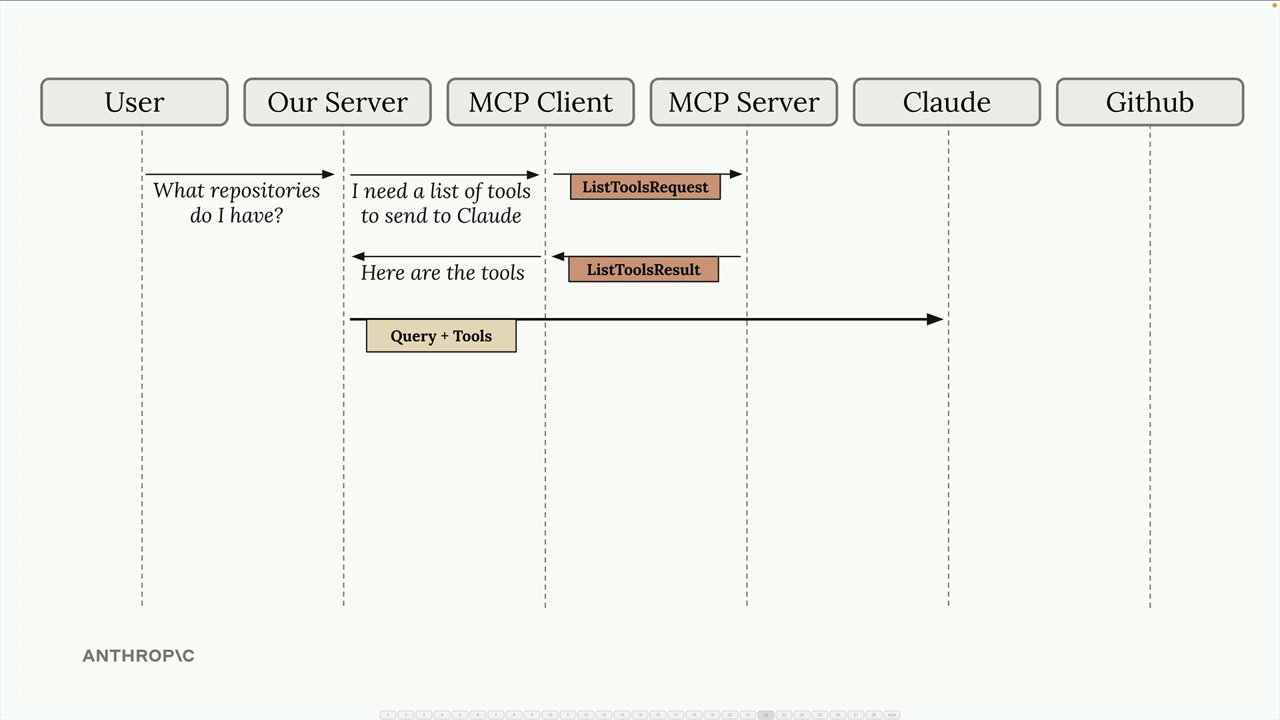
Claude 检查这些工具,并决定需要调用其中一个来回答问题。它以一个工具使用请求作为响应。
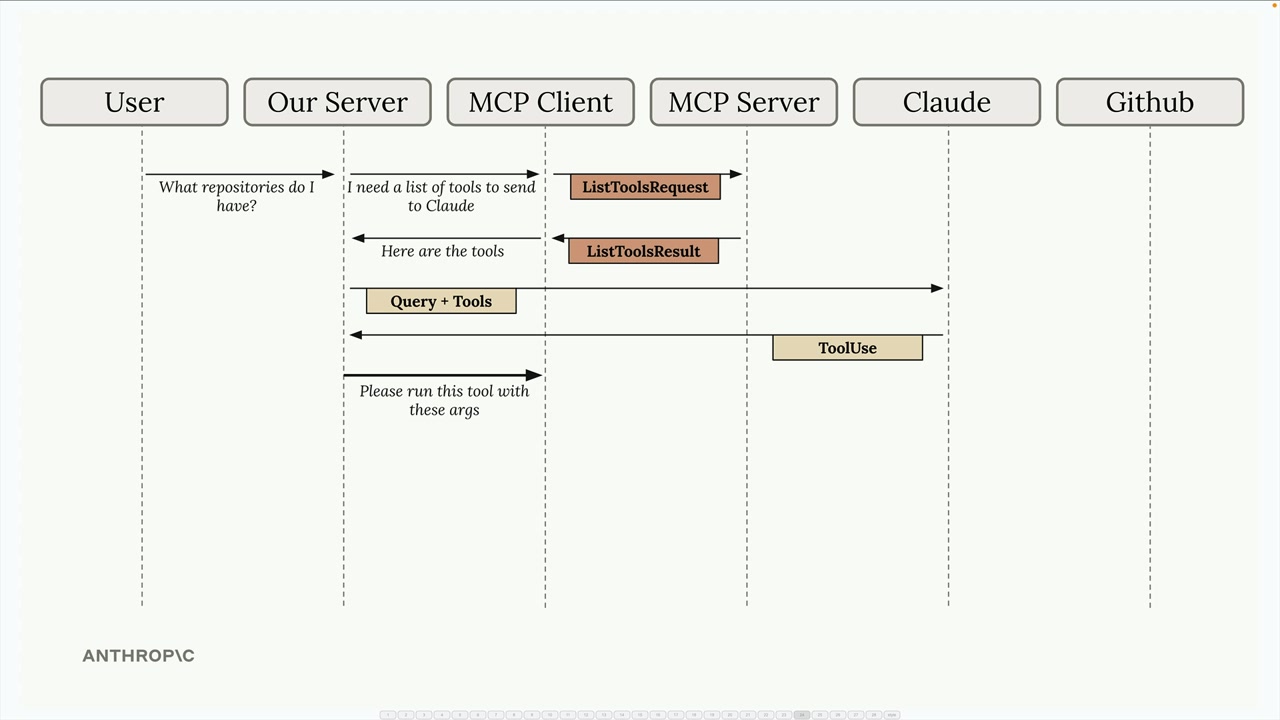
你的服务器请求 MCP 客户端执行 Claude 所请求的工具。MCP 客户端向 MCP 服务器发送 CallToolRequest,后者再向 GitHub 发出实际请求。
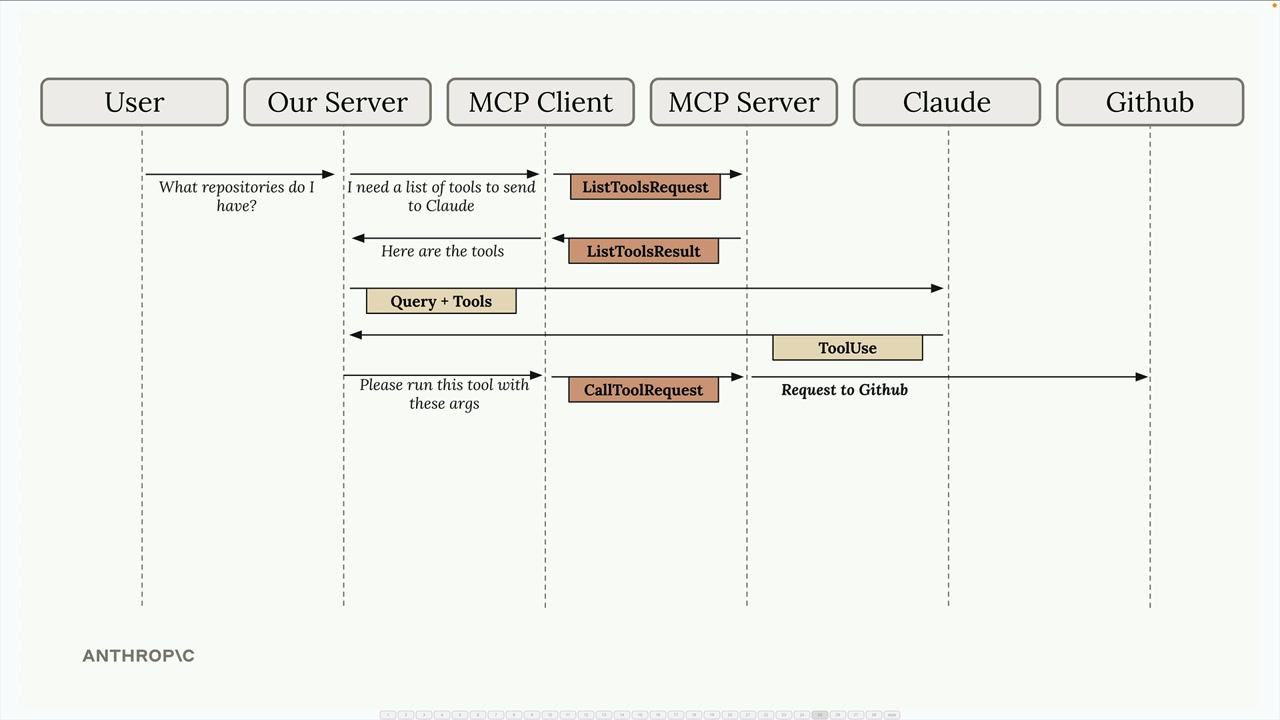
GitHub 返回仓库数据,这些数据作为 CallToolResult 流经 MCP 服务器,然后到 MCP 客户端,最后到你的服务器。
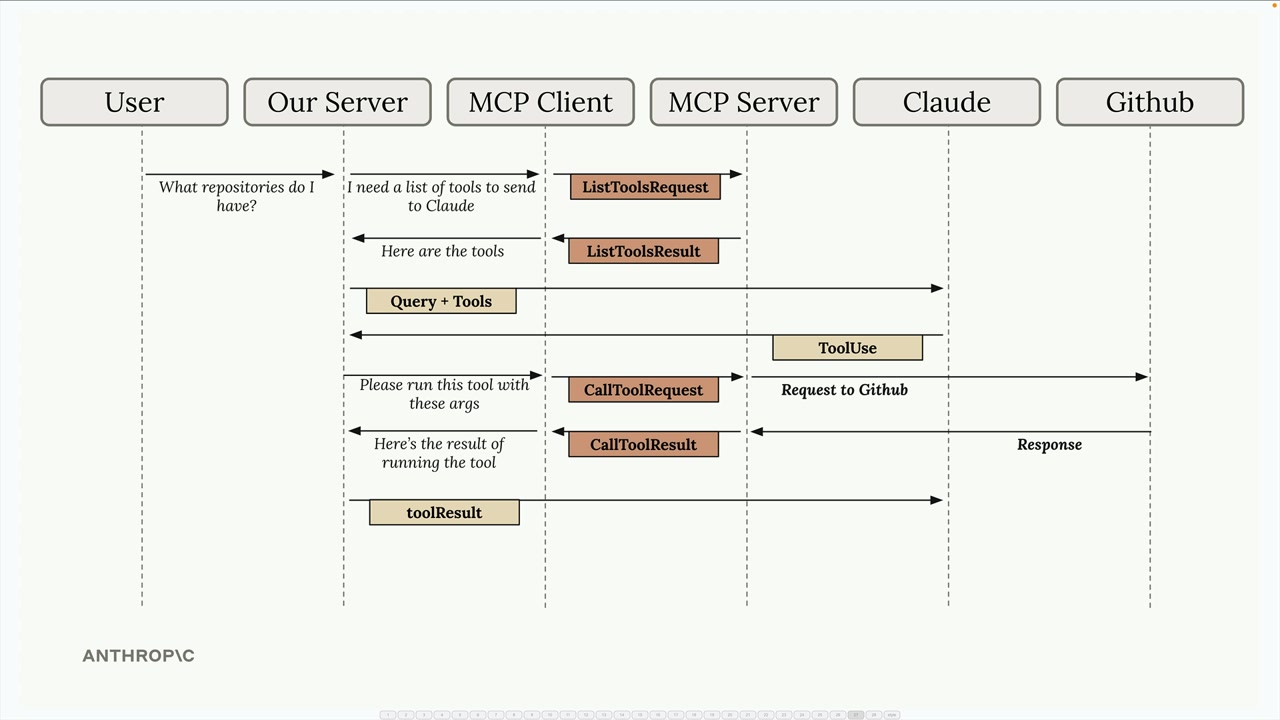
你的服务器在一条后续消息中将工具结果发回给 Claude。Claude 现在拥有了制定完整响应所需的所有信息。
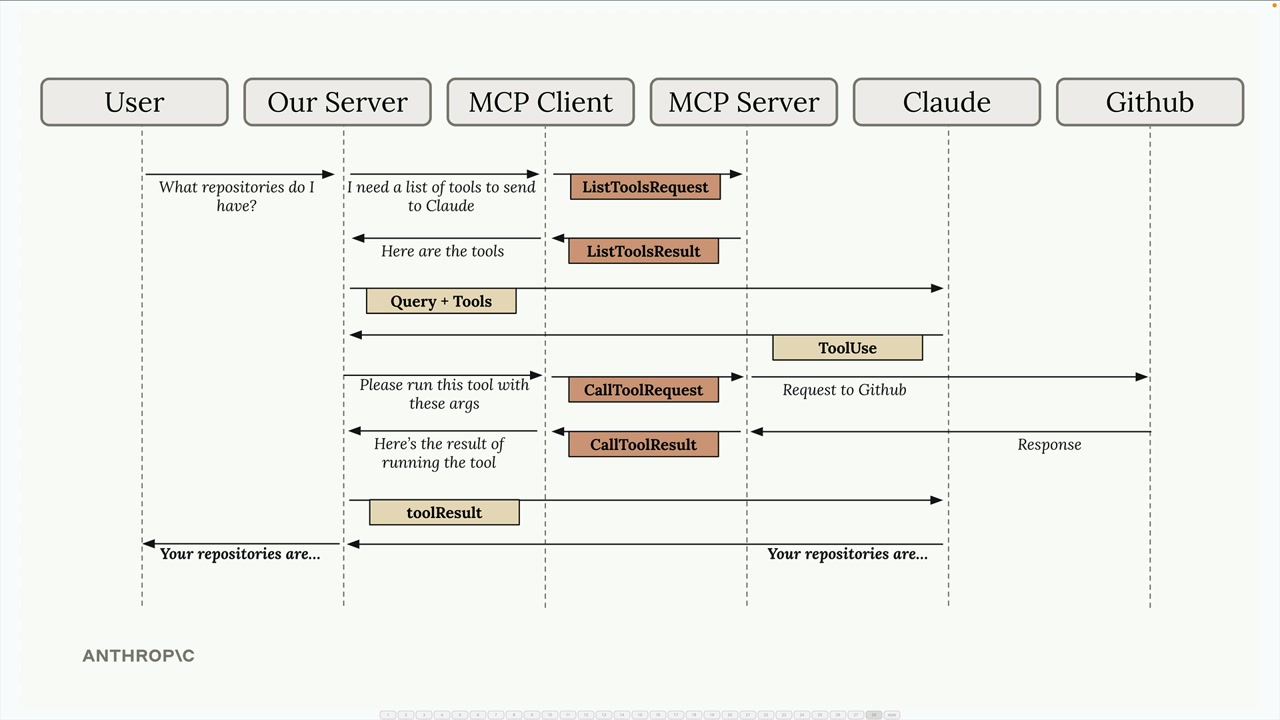
最后,Claude 以格式化的答案进行响应,你的服务器将其传回给用户。
是的,这个流程包含许多步骤,但每个组件都有明确的职责。MCP 客户端抽象掉了服务器通信的复杂性,让你能专注于构建你的应用程序逻辑。当我们实现自己的 MCP 客户端和服务器时,你会看到每个部分在实践中是如何组合在一起的。
视频文字稿
我们将要研究的模型上下文协议的下一部分是客户端。客户端的目的是在你的服务器和 MCP 服务器之间提供一种通信方式。这个客户端将是你访问该服务器实现的所有工具的入口点。现在,MCP 是传输无关的。
这是一个花哨的术语,只是说客户端和服务器可以通过各种不同的协议进行通信。目前,运行 MCP 服务器的一种非常常见的方式是在与 MCP 客户端相同的物理机器上。如果这两样东西在同一台机器上运行,那么它们可以通过标准输入输出进行通信。这就是我们稍后在本节中要设置的内容。
然而,我们还有其他方法可以连接 MCP 客户端和 MCP 服务器。它们也可以通过 HTTP 或 Web Sockets 或其他多种技术或方式连接。一旦客户端和服务器之间建立了连接,它们就通过交换消息进行通信。允许的确切消息都在 MCP 规范中定义。
我们即将关注的一些消息类型是 list tools request 和 list tools result。正如你所猜测的,list tools request 从客户端发送到服务器,并要求服务器列出它提供的所有不同工具。然后服务器会响应一个 list tools result 消息,其中包含它可以提供的所有不同工具的列表。我们将会看到的另外两种常见的消息类型是 call tool request 和 call tool result。
第一个将要求服务器用一些特定的参数运行一个工具,第二个将包含工具运行的结果。现在,在这一点上,我们有了服务器和客户端的概念。但我怀疑可能还不是很清楚所有这些东西是如何协同工作的。所以,在本视频的剩余部分,我们将做以下事情。
我们将通过一个涉及很多不同事物的示例调用来走一遍流程。所以这将是一个有点复杂的过程。但我们将想象用户或我们正在组建的服务器、一个 MCP 客户端、MCP 服务器、作为我们试图访问一些数据的提供者的 GitHub,以及 Claude 之间的通信。
所以,让我们开始吧。再次,我是 Stephen Grider,我们期望发生的第一件事是用户向我们的服务器提交某种查询或问题,比如“我有哪些仓库?”在这一点上,这将取决于我们的服务器是否向 Claude 发出请求。但在那个请求中,我们想要列出 Claude 可以访问的所有不同工具。
所以在我们的服务器向 Claude 发出请求之前,它首先会通过 MCP 客户端和服务器走一小段弯路。所以情况是这样的。服务器会意识到它需要看到一个工具列表,以便连同用户的查询一起发送给 Claude。所以它会要求 MCP 客户端获取一个工具列表。
MCP 客户端反过来会向服务器发送一个 list tools request,服务器会响应一个 list tools result。现在我们的 MCP 客户端有了一个工具列表,它会将那个工具列表返回给服务器。现在我们的服务器拥有了向 Claude 发出初始请求所需的一切。它既有来自用户的原始消息,也有一个要包含的工具列表。
所以我们的服务器可以用那个查询和那组工具向 Claude 发出请求。Claude 会看一看这些工具,然后意识到,你知道吗,为了回答用户最初的问题,我真的想调用一个工具。所以 Claude 会响应一些工具使用消息部分。在这一点上,我们的服务器会意识到 Claude 想要运行一个工具。
但我们的服务器不再真正负责执行任何工具。相反,我们的工具将由 MCP 服务器执行。所以为了运行 Claude 正在请求的工具,我们的服务器会要求 MCP 客户端用 Claude 提供的一些特定参数来运行一个工具。然而,MCP 客户端实际上并不运行工具。
它会向 MCP 服务器发送一个 call tool request。MCP 服务器会接收那个请求,并向 GitHub 发出一个后续请求。所以这就是我们实际上会获取属于这个特定用户的仓库列表的地方。GitHub 会用那个仓库列表进行响应。
然后 MCP 服务器会将那些数据包装在一个 call tool result 中,并将其发送回 MCP 客户端。然后 MCP 客户端反过来会将结果交给我们的服务器。现在我们的服务器有了仓库列表,它可以向 Claude 发出一个后续请求,在用户消息中包含工具结果部分。所以这个工具结果将包含 Claude 正在请求的仓库列表。
现在 Claude 拥有了制定最终响应所需的所有信息。所以它会写出一些文本,比如“你的仓库是”,然后将其发送回我们的服务器,我们的服务器会将其发送回我们的用户。好了,所以这个流程,是的,它相当复杂。我想向你展示这个的原因是,当我们开始实现我们自己的自定义 MCP 客户端和 MCP 服务器时,我们会看到所有这些不同的部分。
68. 项目设置
类型:视频 | 时长:3:09 | 视频:09 - 003 - Project Setup.mp4
我们将构建一个基于 CLI 的聊天机器人,以更好地理解 MCP 客户端和服务器如何协同工作。这个实践项目将让你获得 MCP 架构两端的实际经验。
我们要构建什么
我们的聊天机器人将允许用户通过 command-line interface (命令行界面) 与文档集合进行交互。该系统由两个主要部分组成:
- 一个处理用户交互的 MCP 客户端
- 一个管理文档操作的自定义 MCP 服务器
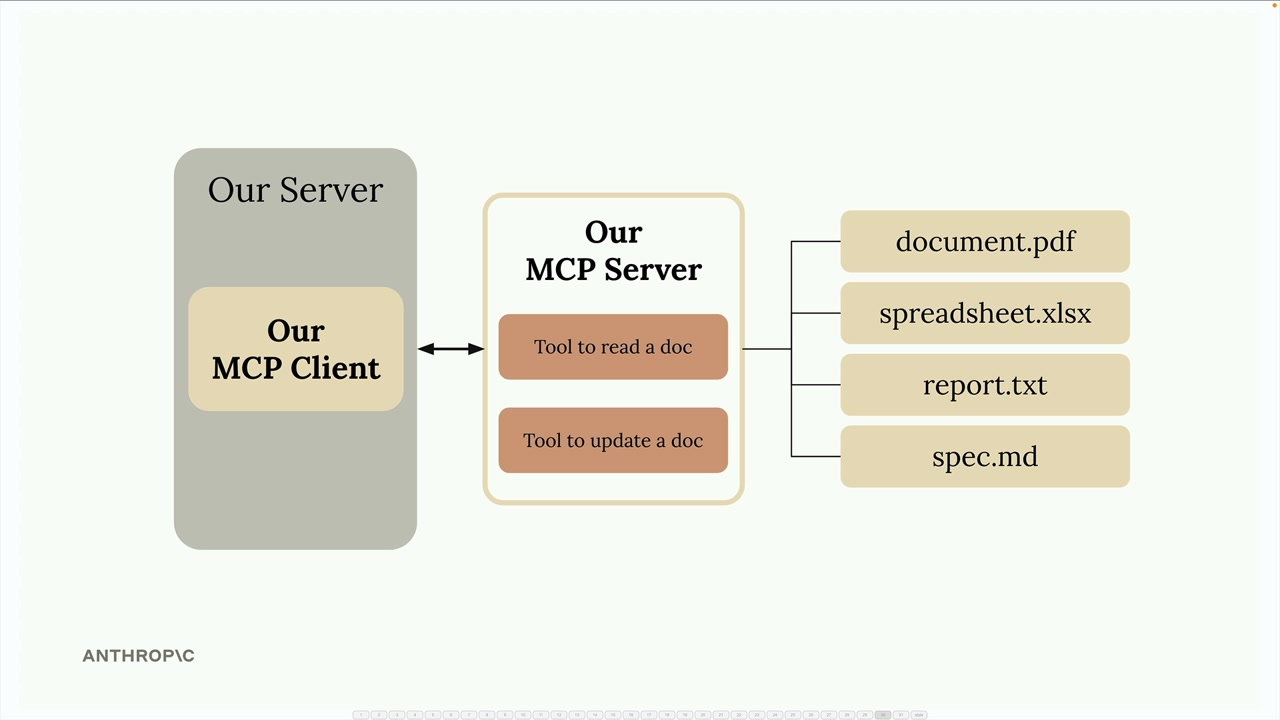
服务器将提供两个基本工具:一个用于读取文档内容,另一个用于更新它们。为简单起见,所有文档都将存储在内存中——不需要数据库。
重要的架构说明
在实际项目中,你通常只实现 MCP 客户端或 MCP 服务器,而不是两者都实现。你可能会创建:
- 一个 MCP 服务器,向其他开发者暴露你的服务
- 一个 MCP 客户端,连接到现有的 MCP 服务器
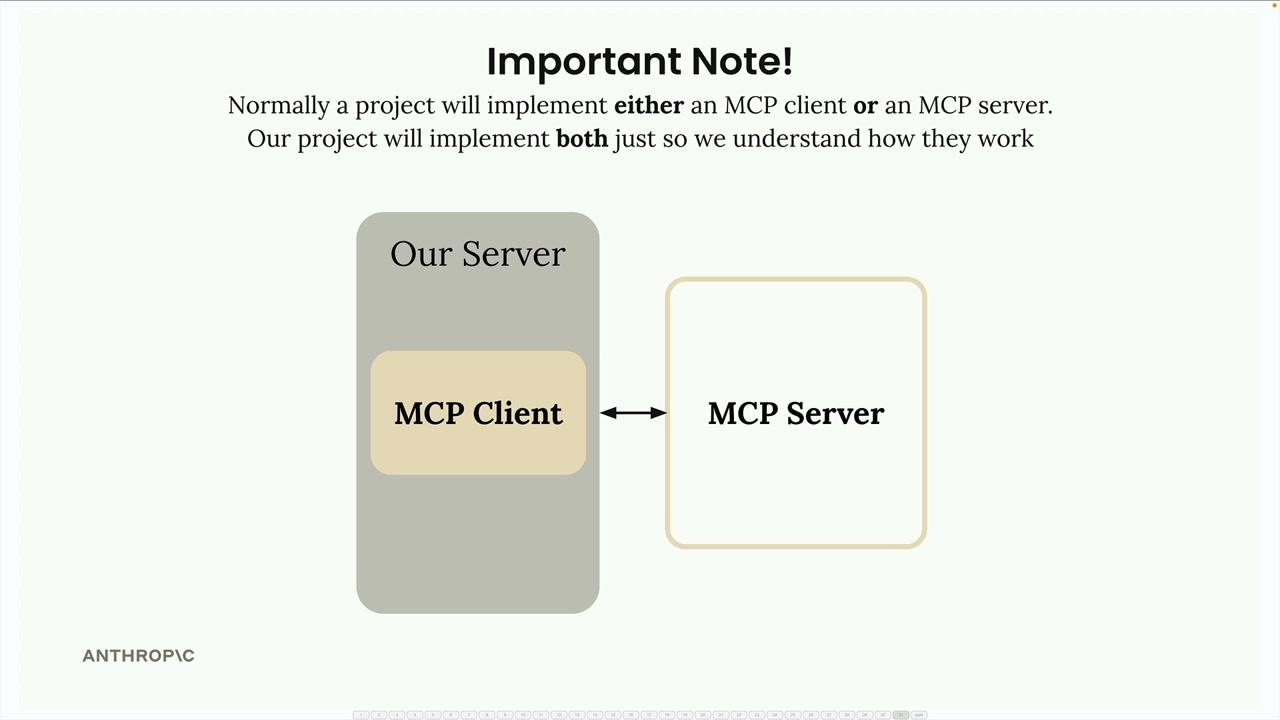
我们在这个项目中构建这两个组件纯粹是为了教学目的——为了理解它们如何通信和协同工作。
项目设置
下载本课附件中的 cli_project.zip 文件,并将其解压到你喜欢的开发目录。在项目文件夹中打开你的代码编辑器。
该项目包含一个全面的 README 文件,其中有设置说明。请遵循以下步骤:
- 将你的 Anthropic API 密钥添加到
.env文件中 - 使用 UV(推荐)或 pip 安装依赖项
- 运行启动应用程序以验证一切正常
运行应用程序
在终端中导航到你的项目目录。你会看到主要的项目文件,包括 main.py、mcp_client.py 和 mcp_server.py。
要启动应用程序,请使用以下命令之一:
# If using UV (recommended)
uv run main.py
# If using standard Python
python main.py
当应用程序成功启动时,你会看到一个聊天提示。通过问一个简单的问题来测试它,比如“1+1等于几?”——你应该会很快得到 Claude 的回应。
完成基本设置后,我们准备开始实现 MCP 功能,并探索客户端和服务器如何通过模型控制协议进行通信。
视频文字稿
为了更好地理解 MCP 的某些方面,我们将开始实现我们自己的基于 CLI 的聊天机器人。这将让我们更好地了解 Claude 和服务器实际上是如何协同工作的。在本视频中,我想做一些项目设置,并帮助你准确理解我们将要制作什么。这里我有很多关于我们将要构建的内容的项目描述。
我们会随着时间的推移逐一了解所有这些。现在,我只希望你有一个高层次的理解。正如我提到的,它将是一个基于 CLI 的聊天机器人。我们将允许用户处理一个文档集合。
这些将是假的文档。它们只会被存储在内存中。我们将构建一个小型的 MCP 客户端,它将连接到我们自己的自定义 MCP 服务器。目前,服务器内部将实现两个工具。
一个工具用于读取文档内容,另一个工具用于更新文档内容。再次强调,这些文档在右边这里。它们都是假的,所以它们将只被持久化在内存中。就是这样。
现在,在我们继续之前,有一个非常重要的说明,我真的希望你理解整个过程。那就是,在一个正常的项目中,我们通常会实现一个客户端或一个 MCP 服务器。所以在一个真实的项目中,我们可能只是编写一个 MCP 服务器,分发给全世界,让开发者可以访问我们建立的某个服务。或者,我们可能正在构建一个项目,我们只制作一个 MCP 客户端。
这里的意图是,我们将连接到一些由其他工程师已经实现的外部 MCP 服务器。所以在这个项目中,我们既制作客户端也制作服务器。我们只是在一个项目中这样做,这样你就能更好地理解这些东西实际上是如何协同工作的。好了,既然我们已经把这个免责声明说清楚了,让我们来做一些设置。
在本视频的附件中,你应该能找到一个名为 CLIproject.zip 的文件,里面是我们项目的一些启动代码。请确保你下载那个 zip 文件,解压它,然后在那个项目目录中打开你的代码编辑器。为了节省一点时间,我已经这样做了。所以我已经在那个小项目中打开了我的代码编辑器。
在这个项目中,我鼓励你看一下 readme.md 文件。在这里,我放了一些设置说明。它会引导你完成将你的 API 密钥放入这个项目的 .env 文件的过程。它还会引导你完成安装依赖项的过程,无论是否使用 uv。
完成所有这些设置后,你就可以立即运行这个启动项目了。为此,在你的终端中,确保你在你的项目目录内。我把我的项目命名为 MCP。在里面,我有我所有的不同项目文件和文件夹。
要运行这个项目,如果你正在使用 uv,我们将运行 uv run main.py。如果你没有使用 uv,那么就只是 python main.py。现在我正在使用 uv。所以我将执行 uv run main.py。
然后当我运行它时,我应该会看到一个聊天提示出现。如果我问“1+1等于几”,我应该会很快看到一个响应。我们的设置就到此为止。所以现在我们可以开始专注于为这个应用程序添加一些新功能了。
69. 使用 MCP 定义工具
类型:视频 | 时长:7:03 | 视频:09 - 004 - Defining Tools with MCP.mp4
当你使用官方的 Python SDK 时,构建一个 MCP 服务器会变得简单得多。SDK 通过装饰器和类型提示为你处理了所有复杂性,你无需手动为工具编写复杂的 JSON 模式。
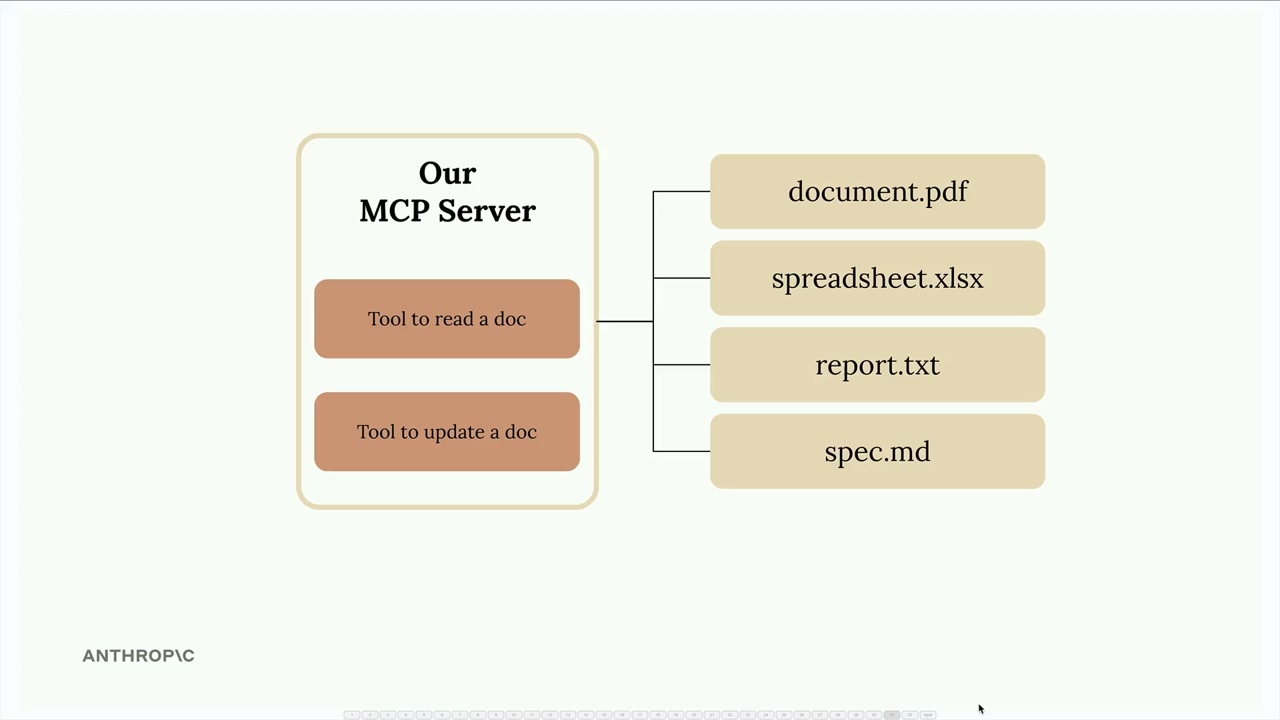
在这个例子中,我们正在创建一个 MCP 服务器,用于管理存储在内存中的文档。该服务器将提供两个基本工具:一个用于读取文档内容,另一个用于通过查找和替换操作来更新它们。
设置 MCP 服务器
Python MCP SDK 使服务器的创建变得异常简单。你只需一行代码就可以初始化一个完整的 MCP 服务器:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("DocumentMCP", log_level="ERROR")
对于这个实现,文档存储在一个简单的 Python 字典中,其中键是文档 ID,值包含文档内容:
docs = {
"deposition.md": "This deposition covers the testimony of Angela Smith, P.E.",
"report.pdf": "The report details the state of a 20m condenser tower.",
"financials.docx": "These financials outline the project's budget and expenditure",
"outlook.pdf": "This document presents the projected future performance of the",
"plan.md": "The plan outlines the steps for the project's implementation.",
"spec.txt": "These specifications define the technical requirements for the equipment"
}
使用装饰器定义工具
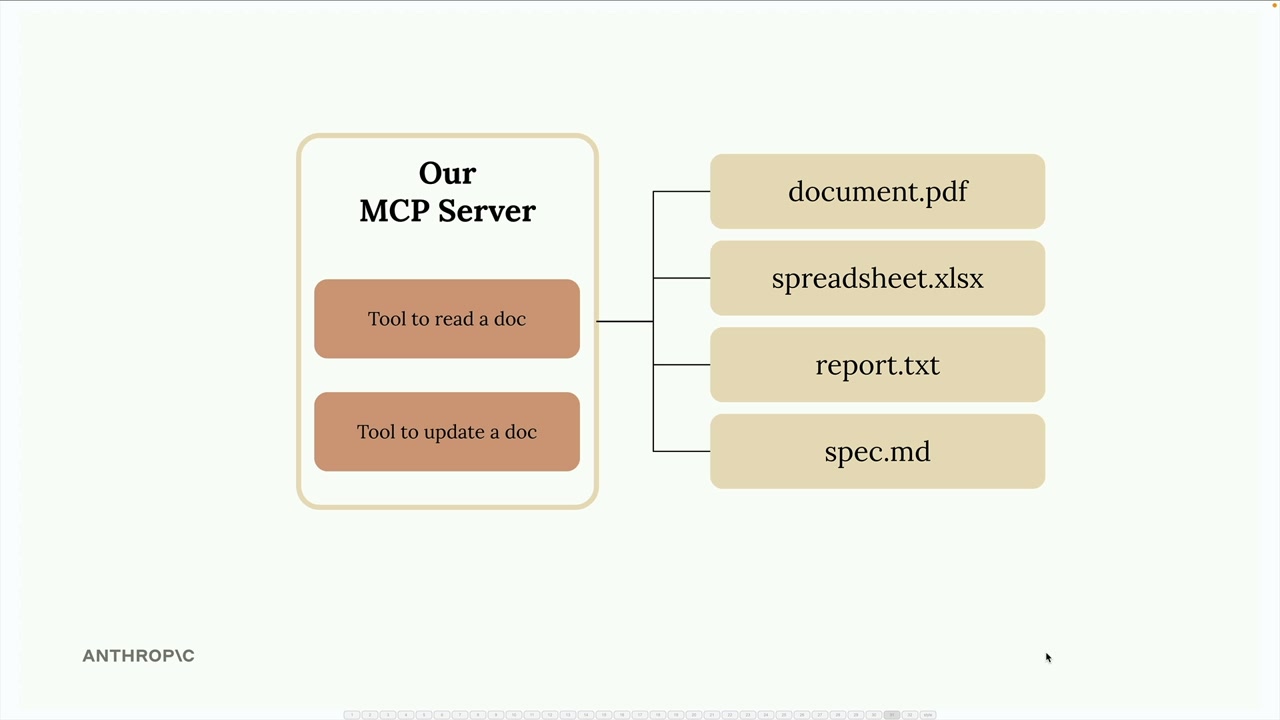
SDK 将工具创建从一个冗长的过程转变为干净易读的过程。你无需编写冗长的 JSON 模式,而是使用 Python 装饰器和类型提示。
创建文档读取工具
第一个工具允许 Claude 通过其 ID 读取任何文档。这是完整的实现:
@mcp.tool(
name="read_doc_contents",
description="Read the contents of a document and return it as a string."
)
def read_document(
doc_id: str = Field(description="Id of the document to read")
):
if doc_id not in docs:
raise ValueError(f"Doc with id {doc_id} not found")
return docs[doc_id]
@mcp.tool 装饰器会自动生成 Claude 所需的 JSON 模式。来自 Pydantic 的 Field 类提供了参数描述,帮助 Claude 理解每个参数期望什么。
构建文档编辑工具
第二个工具对文档执行简单的查找和替换操作:
@mcp.tool(
name="edit_document",
description="Edit a document by replacing a string in the documents content with a new string."
)
def edit_document(
doc_id: str = Field(description="Id of the document that will be edited"),
old_str: str = Field(description="The text to replace. Must match exactly, including whitespace."),
new_str: str = Field(description="The new text to insert in place of the old text.")
):
if doc_id not in docs:
raise ValueError(f"Doc with id {doc_id} not found")
docs[doc_id] = docs[doc_id].replace(old_str, new_str)
这个工具接受三个参数:文档 ID、要查找的文本和替换文本。为简单起见,该实现使用了 Python 内置的字符串 replace() 方法。
错误处理
这两个工具都包含了基本的错误处理,以管理 Claude 请求不存在的文档的情况。当提供无效的文档 ID 时,工具会引发一个带有描述性消息的 ValueError,Claude 可以理解并可能据此采取行动。
SDK 方法的主要优点
- 从 Python 类型提示自动生成 JSON schema
- 代码清晰、可读性强,易于维护
- 通过 Pydantic 内置参数验证
- 与手动编写 schema 相比,减少了样板代码
- 类型安全和 IDE 支持,提升开发体验
MCP Python SDK 将过去编写工具定义的复杂过程,转变为对 Python 开发者而言感觉自然的事情。你只需专注于业务逻辑,而 SDK 会处理协议的细节。
视频文字稿
让我们开始为我们的 CLI 聊天机器人创建一个 MCP 服务器。如你所见,CLI 本身已经可以工作,我们已经可以和 Claude 聊天,但目前还没有任何与 MCP 服务器相关联的附加功能。因此,我们现在要着手添加这个 MCP 服务器,它暂时会包含两个工具。一个工具用于读取文档,另一个用于更新文档内容。
服务器的实现将被放置在根项目目录下的 MCP server.py 文件中。在这里,我已经做了一些基础工作,建立了一个基本的 MCP 服务器。然后我定义了一个只存在于内存中的文档集合。最后,我整理了一些不同的待办事项。
这些就是你我将要在这个文件中完成的不同任务。目前,正如我刚才提到的,我们将只专注于前两项:编写两个工具。我们过去已经编写过工具,并且看到过,哦,那里有很多语法,有那些庞大的 JSON schema。
但我有好消息要告诉你。在这个项目中,我们正在使用官方的 MCP Python SDK。这就是我们在这里使用的 MCP 包。这个 MCP 包将为我们创建 MCP 服务器,只需一行代码,就像你看到的那样。
这个 SDK 也使得定义工具变得非常容易。要定义一个工具,我们所要做的就是写出你在右侧看到的代码。这将创建一个名为 add integers 的工具,附带此描述和两个需要传入的参数。一旦我们写出这样的工具定义,MCP 会在幕后为我们生成一个工具的 JSON schema,我们可以将其传递给 Claude。
所以,马上你就可以看到,做一些像定义工具这样的基本事情开始变得容易多了。现在,正如我所说的,我们的第一个任务是实现这两个不同的工具。所以,让我们立即回到我们的 MCP server.py 文件,我们将开始实现第一个工具:读取文档。所以,这里的唯一目标是接收某个文档的名称并返回其内容。
我们所有的文档都已放在这个 docs 字典里。键是文档的 ID 或本质上的名称,值是文档的内容。所以我们的工具非常简单。我们将接收这些字符串中的一个,在这个 docs 字典中查找相应的值,然后返回它。
这就是我们需要做的全部工作。为了实现这个,我将找到第一个待办事项,并在其正下方,通过写出 @mcp.tool 来定义一个新工具。我将给这个工具命名为 read_contents,描述为“读取文档内容并以字符串形式返回”。请记住,在理想情况下,我们会在这里写一个非常详尽的描述,以确保 Claude 非常清楚何时使用这个工具。
但现在,和往常一样,为了节省一点时间,也为了让你不必在这里输入大量文本,我将只留下一个非常简单的描述。然后我将定义我的实际工具函数。这是当我们决定运行这个工具时要运行的函数。我将把它命名为 read_document。
它将接收一个名为 doc_id 的参数,该参数是一个字符串。我将把它设置为一个带有描述“要读取的文档的 ID”的字段。然后我们需要确保在顶部导入这个 field 类。所以我将去到顶部并添加一个导入 from pydantic import field。
然后回到下面,在函数体内,我将放入我的实际实现。所以,我做的第一件事是确保处理 Claude 请求一个实际不存在的文档的情况。所以我会说 if doc_id not in docs。换句话说,如果提供的文档 ID 在这个字典中找不到对应的键,那么我将抛出一个 ValueError,带有一个 f-string “doc with id {doc_id} not found”。
ID 未找到。然后,如果我们通过了那个检查,我将继续并返回实际的文档。所以我将返回 docs[doc_id]。就是这样,定义一个工具就这么简单。
我们指定了工具的名称、描述、期望的参数、其类型以及该参数的描述。所有这些不同的装饰器和字段类型等等都将被这个 Python MCP SDK 整合在一起,并为我们生成一个 JSON schema。现在我们已经实现了第一个工具,我将删除那里的待办事项。然后我们将实现我们的另一个工具,即编辑文档的工具。
我们将重复完全相同的过程。我会说 MCP dot tool。我将给它一个名字 edit_document,描述为“通过将文档内容中的一个字符串替换为新字符串来编辑文档”。然后对于实现,我将调用这个函数 edit_doc。
或者为了保持一致,调用 edit_document。然后我们将接收几个不同的参数。首先是文档 ID,然后是要查找的旧字符串,然后是用来替换旧字符串的新字符串。所以让我们把这些都写出来。
我们将有一个 doc_id。它将是一个字符串,描述为“将被编辑的文档的 ID”。old_string 将是一个字符串,描述为“要替换的文本必须完全匹配,包括空格”。然后是我们的 new_string,即“要插入以替换旧文本的新文本”。
所以我们的文档编辑只是一个非常简单的查找和替换。就是这样。
再一次,在这里面,我要确保 Claude 请求的文档是真实存在的。所以如果 doc_id not in docs,就抛出 value_error 并附上 f-string “doc with id {doc_id} not found”。然后如果我们确实找到了正确的文档,我们将这样进行编辑。我们会写 docs [doc_id] = docs[doc_id].
replace(old_string, new_string)。就是这样。好了。就这样,我们非常、非常快地完成了两个工具的实现。
我不得不再次强调,用这个 MCP Python SDK 定义工具比手动编写 schema 定义要容易得多。既然我们已经完成了两个工具的开发,我将删除那里的待办事项。好的,这是一个不错的开始。我们已经搭建好了我们的 MCP 服务器,并在其中实现了两个工具。
70. 服务端检查器
类型:视频 | 时长:3:52 | 视频:09 - 005 - The Server Inspector.mp4
在构建 MCP 服务器时,你需要一种无需连接到完整应用程序即可测试功能的方法。Python MCP SDK 包含一个内置的、基于浏览器的检查器,让你能够实时调试和测试你的服务器。
启动检查器
首先,请确保你的 Python 环境已激活(具体命令请查看项目中的 README)。然后用以下命令运行检查器:
mcp dev mcp_server.py
这会在 6277 端口启动一个开发服务器,并给你一个本地 URL 以在浏览器中打开。检查器界面将会加载,显示 MCP Inspector 仪表盘。
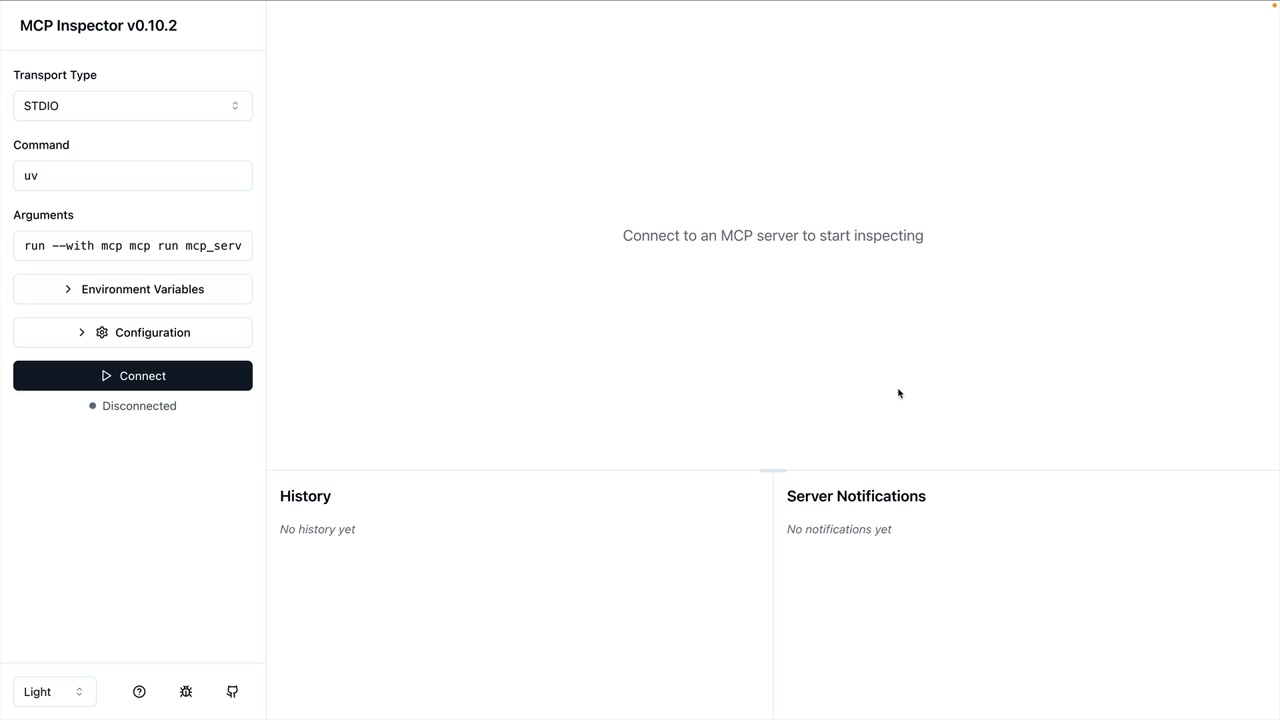
关于界面的重要说明
MCP 检查器正在积极开发中,所以你看到的界面可能与当前的截图有所不同。然而,用于测试工具、资源和提示的核心功能应该保持相似。
连接和测试工具
点击左侧的“Connect”按钮来启动你的 MCP 服务器。连接后,你会看到一个导航栏,其中包含 Resources、Prompts、Tools 和其他功能的部分。
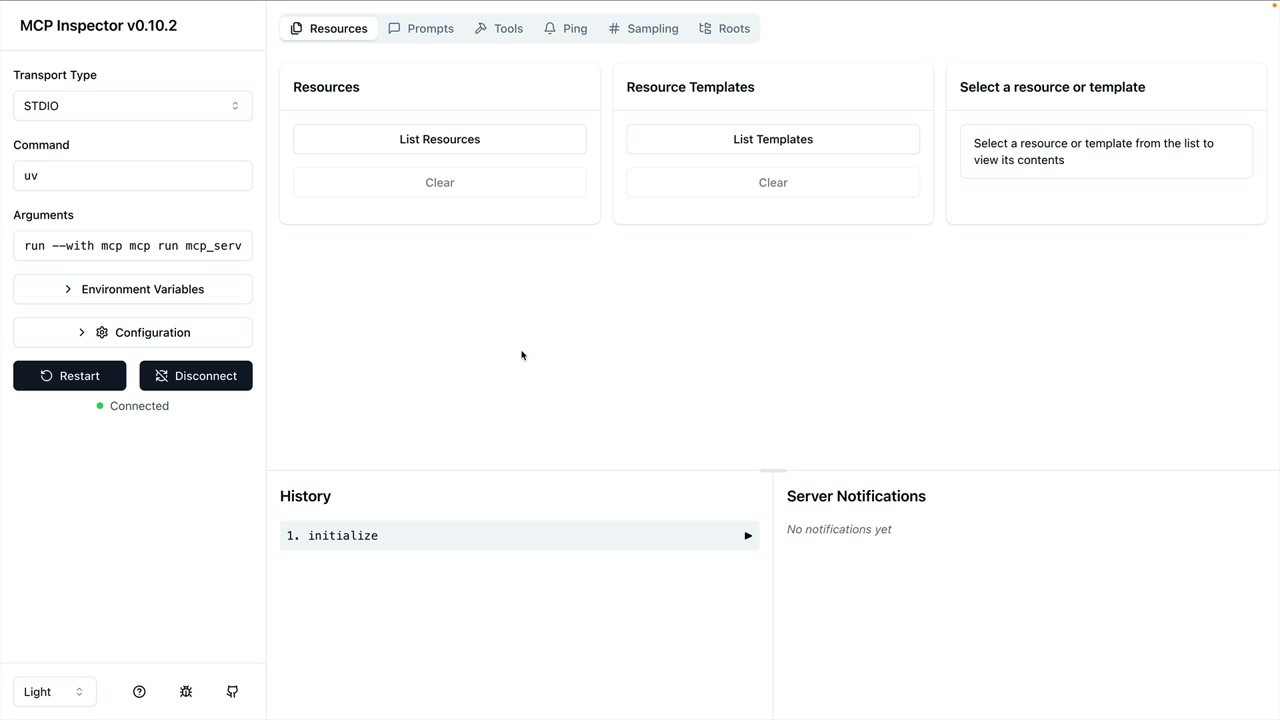
测试你的工具:
- 导航到 Tools 部分
- 点击 “List Tools” 查看所有可用工具
- 选择一个工具以打开其测试界面
- 填写所需的参数
- 点击 “Run Tool” 执行并查看结果
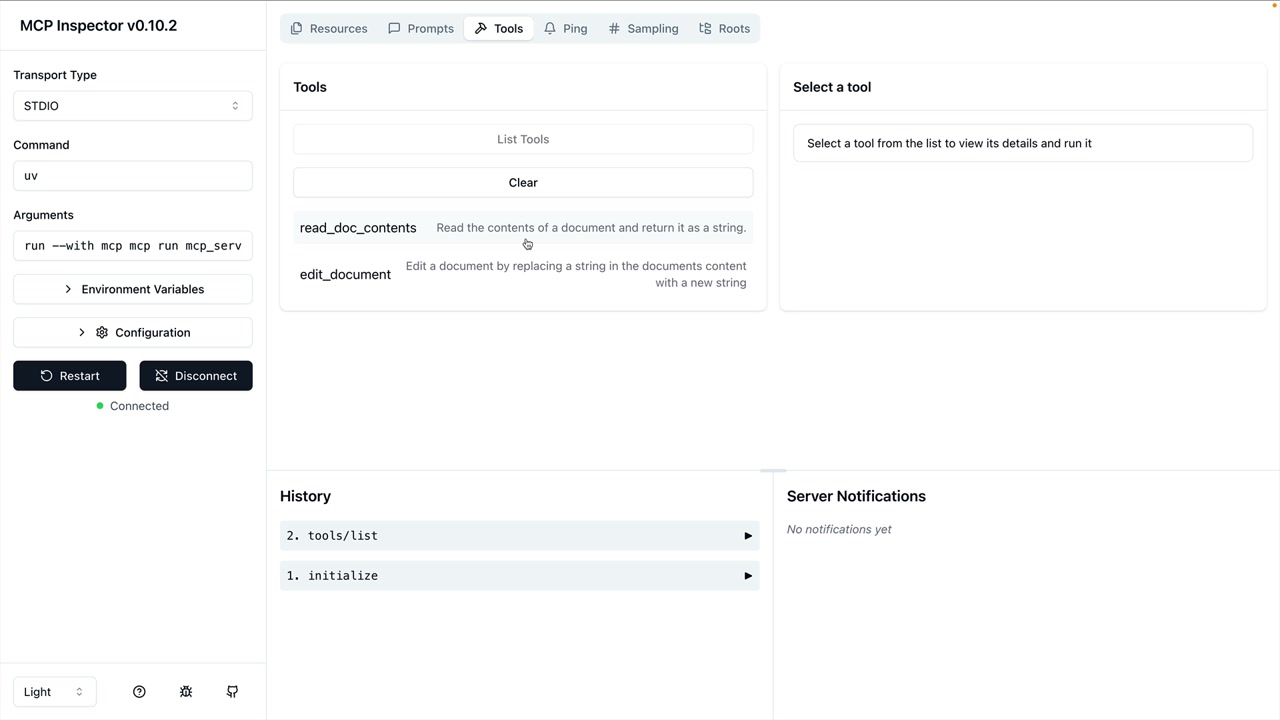
测试文档操作
例如,要测试一个文档读取工具,你需要输入一个文档 ID(如 “deposition.md”)并运行该工具。检查器会显示结果,包括任何返回的内容或成功消息。
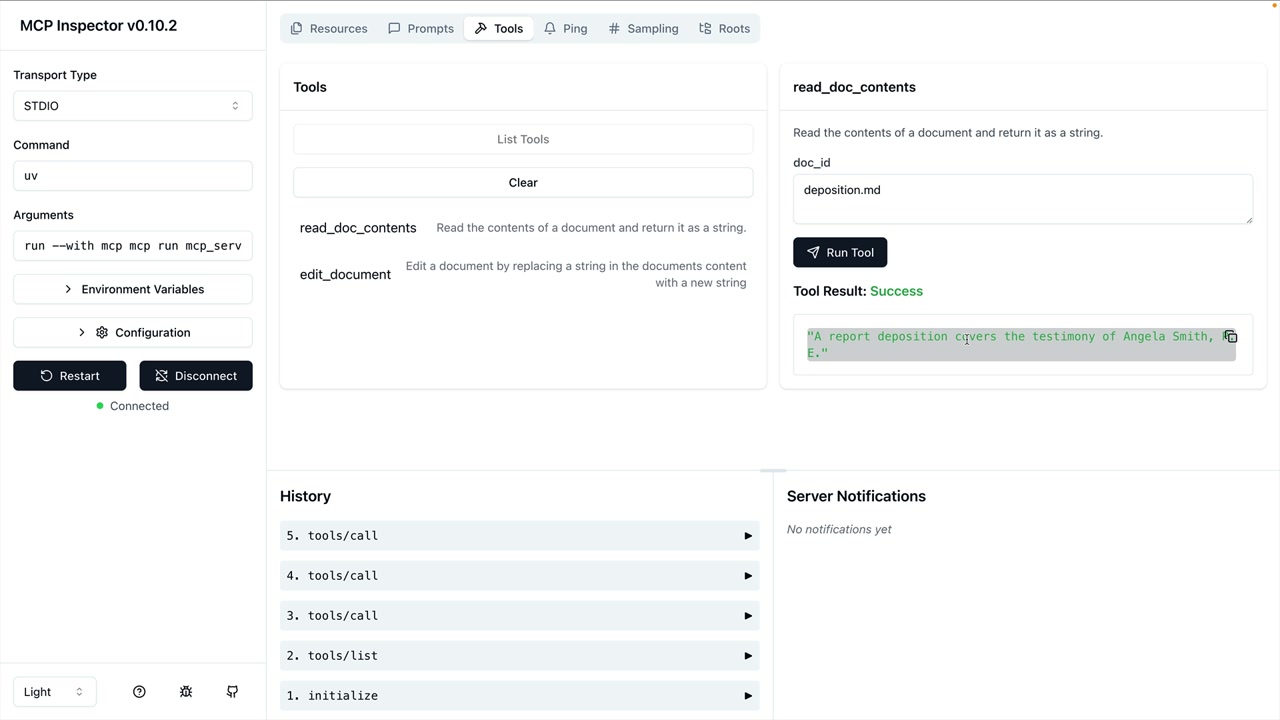
你可以链式操作来验证功能。例如,在通过替换文本编辑文档后,你可以立即再次运行读取工具,以确认更改已正确应用。
开发工作流
检查器创建了一个高效的开发循环:
- 对你的 MCP 服务器代码进行更改
- 通过检查器测试单个工具
- 无需完整的应用程序设置即可验证结果
- 独立调试问题
当你构建更复杂的 MCP 服务器时,这个工具变得至关重要。它消除了为了测试基本功能而将服务器连接到 Claude 或其他应用程序的需要,从而使开发更快、更专注。
视频文字稿
我们已经在 MCP 服务器中加入了一些功能,但我们不知道它是否能正常工作,所以如果我们能以某种方式测试一下,那就太好了。事实证明,通过使用这个 Python SDK,我们可以自动访问一个浏览器内的调试器,这样我们就可以确保这个服务器按预期工作。让我快速向你展示如何使用它。回到我的终端,我需要确保我的 Python 环境已经激活。
记住,ReadMe 文档详细说明了运行以确保环境已激活的确切命令。一旦你确定它已激活,我们将运行 MCP, Dev,然后是包含我们服务器的文件的名称。在这种情况下,它是 MCPServer.py。运行该命令后,我将被告知在端口 6277 上有一个服务器正在监听,并且我将获得一个实际访问它的直接地址。
我将在我的浏览器中打开那个地址。一旦你去了那里,你会看到类似这样的东西。这就是 MCP Inspector。现在,我想让你立刻明白一件重要的事情。
这个检查器正在积极开发中。所以到你观看这个视频的时候,你现在在屏幕上看到的内容可能与我展示的非常非常不同。尽管如此,它可能仍然具有一些非常相似的功能。在左侧,你会看到一个 Connect 按钮。
这将启动你的 MCP 服务器,也就是我们刚刚编辑的那个文件。我将点击 Connect,然后屏幕上会立刻出现一些不同的东西。我首先想让你注意上面的顶部菜单栏。它列出了资源、提示、工具和其他一些东西。
同样,在你观看此视频时,UI 可能会发生变化,所以如果你没有看到这个菜单栏,我们真正要找的只是某个 Tools 部分。一旦我点击 Tools,我将点击 List Tools,然后我会看到我们刚刚整合的工具的名称。如果我点击其中一个,右侧的面板就会改变。我可以使用这个面板来手动调用我的一个工具,以确保它按预期工作。
所以这就是我们如何在不实际将其连接到真实应用程序的情况下,对我们的 MCP 服务器进行实时开发。为了使用 Read.Contents 工具,我们所要做的就是输入一个文档 ID。如果我回到我的编辑器,然后转到 docs 字典这里,我可以复制其中一个文档 ID,所以我将取出 deposition.md。我将把它作为文档 ID 输入,然后点击运行工具。
然后我应该会看到“run tool of success”以及文档的内容。就是这样了。我可以验证它。所以这和我在那里看到的字符串完全一样。
我们可以用同样的方法来测试另一个工具。所以我将切换到编辑文档工具。现在我将输入我的文档 ID。我想替换的旧字符串,比如替换 deposition 这个词?
实际上,我有一个更容易打出的词。就这个吧。那会简单一点。所以我的旧字符串是 this。
请记住,这是区分大小写的,我将用 a report 来替换它。如果我运行该工具,我将收到一个成功信息。请记住,该工具实际上并不返回文档的内容。它只是编辑文档。
所以现在为了验证编辑是否正确完成,我可以回到 Read.Contents 工具,用相同的文档 ID 再次运行它,我应该看到 a report deposition,然后是等等等等。好了,如你所见,这个 MCP 检查器让我们能够非常容易地调试我们正在实现的 MCP 服务器,而无需实际将服务器连接到应用程序。当你开始构建自己的 MCP 服务器时,我预计你会经常使用这个检查器工具。我们在这个模块中可能还会更多地使用它,只是为了确保我们的服务器开发进展顺利。
71. 实现客户端
类型:视频 | 时长:7:26 | 视频:09 - 006 - Implementing a Client.mp4
既然我们的 MCP 服务器已经可以工作了,是时候构建客户端了。客户端是让我们的应用程序与 MCP 服务器通信并访问其功能的组件。
理解客户端架构
在大多数真实世界的项目中,你要么实现一个 MCP 客户端,要么实现一个 MCP 服务器——而不是两者都做。我们在这个项目中两者都构建,只是为了让你能看到它们是如何协同工作的。
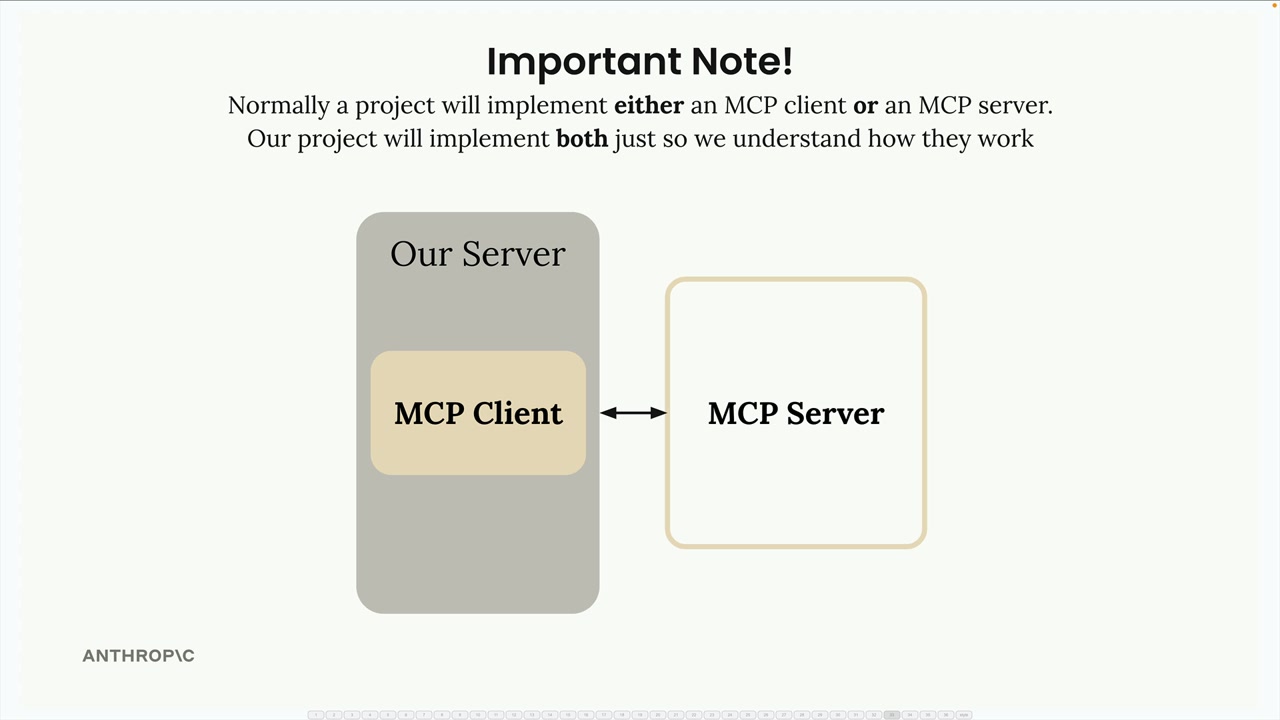
MCP 客户端由两个主要部分组成:
- MCP Client - 我们创建的一个自定义类,以简化会话的使用
- Client Session - 与服务器的实际连接(MCP Python SDK 的一部分)
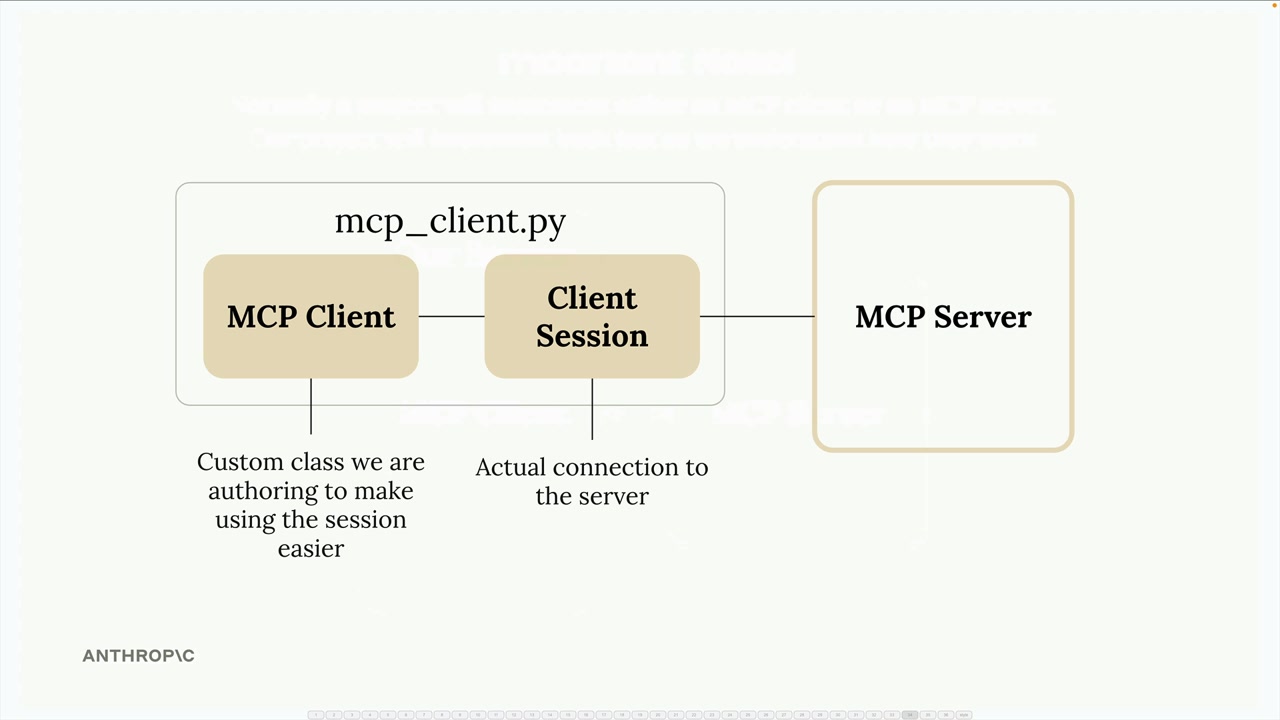
客户端会话在我们使用完毕后需要进行适当的资源清理。这就是为什么我们将其包装在自定义的 MCP Client 类中——为了自动处理所有这些清理工作。
客户端如何融入我们的应用程序
还记得我们的应用程序流程吗?我们的 CLI 代码需要与 MCP 服务器做两件主要的事情:
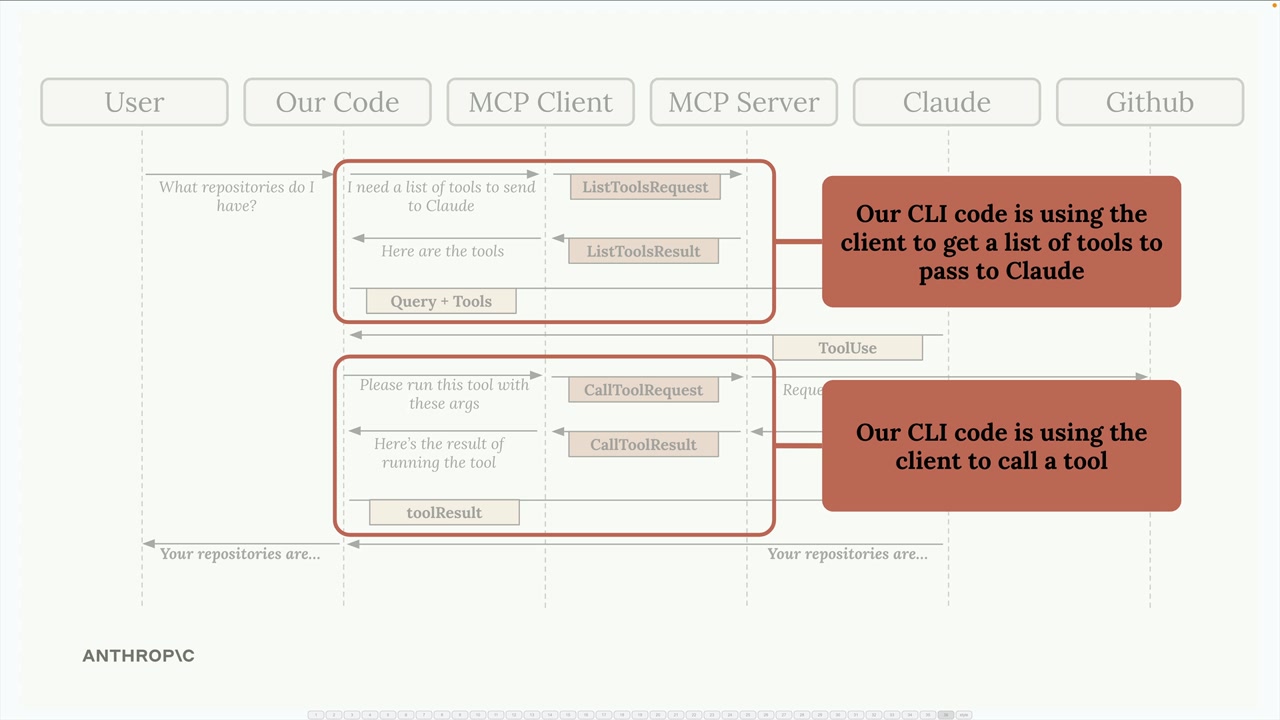
- 获取可用工具列表以发送给 Claude
- 当 Claude 请求时执行工具
MCP 客户端通过我们的应用程序代码可以使用的简单方法调用来提供这些功能。
实现核心方法
我们需要在客户端中实现两个关键方法:list_tools() 和 call_tool()。
List Tools 方法
此方法从服务器获取所有可用工具:
async def list_tools(self) -> list[types.Tool]:
result = await self.session().list_tools()
return result.tools
这很简单——我们访问我们的会话(与服务器的连接),调用内置的 list_tools() 函数,并从结果中返回工具。
Call Tool 方法
此方法在服务器上执行特定的工具:
async def call_tool(
self, tool_name: str, tool_input: dict
) -> types.CallToolResult | None:
return await self.session().call_tool(tool_name, tool_input)
我们将工具名称和输入参数(由 Claude 提供)传递给服务器并返回结果。
测试客户端
为了测试我们的实现,我们可以直接运行客户端。该文件包含一个测试工具,它会连接到我们的 MCP 服务器并调用我们的方法:
async with MCPClient(
command="uv", args=["run", "mcp_server.py"]
) as client:
result = await client.list_tools()
print(result)
当我们运行这个测试时,我们应该能看到我们的工具定义被打印出来,包括我们之前创建的 read_doc_contents 和 edit_document 工具。
整合所有部分
现在我们的客户端可以列出工具并调用它们,我们可以测试完整的流程。当我们运行主应用程序并向 Claude 询问有关文档的问题时:
- 我们的代码使用客户端获取可用工具
- 这些工具连同用户的问题一起发送给 Claude
- Claude 决定使用
read_doc_contents工具 - 我们的代码使用客户端执行该工具
- 结果被发送回 Claude,然后 Claude 回应用户
例如,询问“report.pdf 文档的内容是什么?”将触发 Claude 使用我们的文档读取工具,我们将得到关于我们在服务器中设置的 20m 冷凝塔文档的信息。
客户端充当了我们应用程序逻辑和 MCP 服务器之间的桥梁,使得访问服务器功能变得容易,而无需担心底层的连接细节。
视频文字稿
现在我们的服务器已经准备就绪,我们将稍微转换一下重点,开始开发我们的 MCP 客户端。客户端可以在根项目目录下的 MCP client.py 文件中找到。在我们在该文件中做任何事情之前,我只想给你一个非常快速的提醒。记住我之前告诉你的。
通常在一个典型的项目中,我们要么是使用一个客户端,要么是实现一个服务器。只是在我们正在进行的这个特定项目中,我们两者都在做。同样,只是为了让你能看到这个谜题的两面。现在,这个文件中的 MCP 客户端本身由一个单一的类组成。
你会注意到这里面有很多代码,而且它看起来不像我们刚才在服务器里写的一些代码那么漂亮。所以让我告诉你这个文件里到底发生了什么,以及它为什么这么大。好的,所以在这个文件里,我们正在创建 MCP client 类。这个类将包装一个叫做 client session 的东西。
client session 是与我们 MCP 服务器的实际连接。这个 client session 是 Anthropic Python SDK 的一部分。所以再次强调,这个 session 就是给我们提供与外部服务器连接的东西。session 本身需要一些资源清理。
换句话说,每当我们关闭程序或决定不再需要服务器时,我们都必须经历一个小的清理过程。而我已经将很多清理代码写在了 MCP client 类中。所以这确实是这个类存在的全部原因,只是为了让清理工作变得更容易一些。你可以在 Connect 函数中看到一些清理代码,再往下一点。
在 cleanup、async enter 和 async exit 函数中也能看到。因此,不直接使用这个 client session,而是将它包装在一个更大的类中来管理这些不同的资源事务,是一种非常常见的做法。接下来我想澄清的是,为什么这个客户端会存在。换句话说,这个客户端到底为我们做了什么?
嗯,还记得我们不久前看过的这个完整的流程吗?所以我们有我们的代码在这里。在某些时间点,我们需要,比如说,一个工具列表发送给 Claude。然后在那之后,我们还需要运行一个由 Claude 请求的工具。
为了联系我们的 MCP 服务器并获取这个工具列表或运行一个工具,我们就在使用 MCP 客户端。所以我们可以想象,这个客户端正在向我们代码库的其余部分暴露一些属于服务器的功能。所以,在我们代码库内部,具体来说是在这个项目的 core 目录中,已经有很多我整理好的代码正在使用这个类。所以还有一些其他的代码会调用你在这里看到的某些不同函数,比如 list tools、call tool、list prompts、get prompt 等等。
目前,在这个视频中,我们将专注于实现两个函数,list tools 和 call tool。正如你刚才在图表中看到的,这两个函数将在我们代码库的不同部分被使用,以获取一个工具列表提供给 Claude,然后最终在 Claude 请求调用工具时调用一个工具。实现这两个函数将非常简单直接。让我来告诉你我们将如何做。
我们将首先从 list tools 开始。我将删除里面的待办事项,并用 result is await self.session 替换它。我将像调用函数一样调用 list_tools。然后我将返回 result.tools。
就是这样。所以这将访问我们的会话,也就是我们与 MCP 服务器的实际连接。它将调用一个内置函数来获取该服务器实现的所有不同工具的定义或列表。我将得到 result,然后只返回 tools,就是这样。
然后我们可以在这里以非常相似的方式实现 call tool。所以这将是 return await self.session, call tool, tool_name, and tool_input。再次,获取对会话的访问,那是我们与服务器的连接,我将尝试调用一个非常具体的工具,即我们传入的工具名称,以及由 Claude 提供的输入参数或输入参数。现在,在这个时候,我想快速测试一下这两个函数。
为此,我们将转到这个文件的底部,我在那里为我们准备了一个非常小的测试工具。所以在这里,你会注意到我放了一个测试块,这样我们就可以直接运行这个 MCP client.py 文件。如果我们这样做,我们将与我们的 MCP 服务器建立连接,然后我们可以对它运行一些命令,看看我们得到了什么。请注意,在你的代码版本中,有一条关于更改这里的命令和参数的注释,以防你没有使用 UV。
所以如果你没有使用 UV,请务看一下那条注释。在这个 with 代码块内部,我将添加一些测试代码。所以我会说 result is await_client list tools。然后我将打印出我们得到的结果。
所以这应该会启动我们 MCP 服务器的一个副本,然后尝试获取它定义的所有不同工具的列表,然后只打印出结果。为了测试这个,我将切换回我的终端并执行 uv run, MCP_client.py。和往常一样,如果你没有使用 UV,你只需执行 python MCP client.py。好的,我运行它,这就是我们的工具定义列表。
我可以在这里看到,我有 read.contents 工具,这是我们不久前整合的,还有我们的 edit document 工具。每一个都有一个描述和一个输入 schema。所以这是我们的工具定义,最终将传递给 Claude。在继续之前,还有一件事我想测试。
记住,我们刚刚实现了那个允许我们列出一些工具并把它们传递给 Claude 的函数,以及那个允许我们调用由 MCP 服务器实现的工具并将结果也传递给 Claude 的函数。我已经实现了在这个项目的其他地方调用 list tools 和 call tool 的代码。所以现在我们已经添加了这个功能,现在我们已经定义了这些工具以及调用特定工具的能力,我们现在可以再次运行我们的 CLI 并尝试让 Claude 使用这些工具。换句话D,我们可以要求 Claude 检查某个特定文档的内容,甚至编辑一个文档。
让我来告诉你我们该怎么做。在我的 MCP 服务器里,我只想提醒你,有一个 ID 为 report.pdf 的文档,它有一些关于 20 米冷凝塔之类的纹理。我将回到我的终端,用 uv run main.py 运行我的项目。然后我将问 Claude report.pdf 文档的内容是什么。
请确保你在这里输入的是 report.pdf。当我们运行这个命令时,我们会连同请求一起发送我们的工具列表。Claude 会决定使用读取文档的工具。然后它会获取文档的内容。
然后我们会看到,是的,Claude 能够获取该文档的内容。我们被告知该报告是关于一个 20 米冷凝塔的内容。好了,到此为止,我们已经为我们的客户端添加了一些功能。记住,客户端是让我们能够访问在 MCP 服务器内部实现的一些功能的组件。
在目前这个阶段,我们已经能够列出由服务器创建的一些工具,并执行一个由服务器实现的工具。
72. 定义资源
类型:视频 | 时长:9:45 | 视频:09 - 007 - Defining Resources.mp4
MCP 服务器中的资源(Resources)允许你向客户端暴露数据,类似于典型 HTTP 服务器中的 GET 请求处理程序。它们非常适用于你需要获取信息而不是执行操作的场景。
通过一个例子理解资源
假设你想构建一个文档提及功能,用户可以输入 @document_name 来引用文件。这需要两个操作:
- 获取所有可用文档的列表(用于自动完成)
- 获取特定文档的内容(当被提及时)

当用户输入 @ 时,你需要显示可用的文档。当他们提交带有提及的消息时,你会自动将该文档的内容注入到发送给 Claude 的提示中。
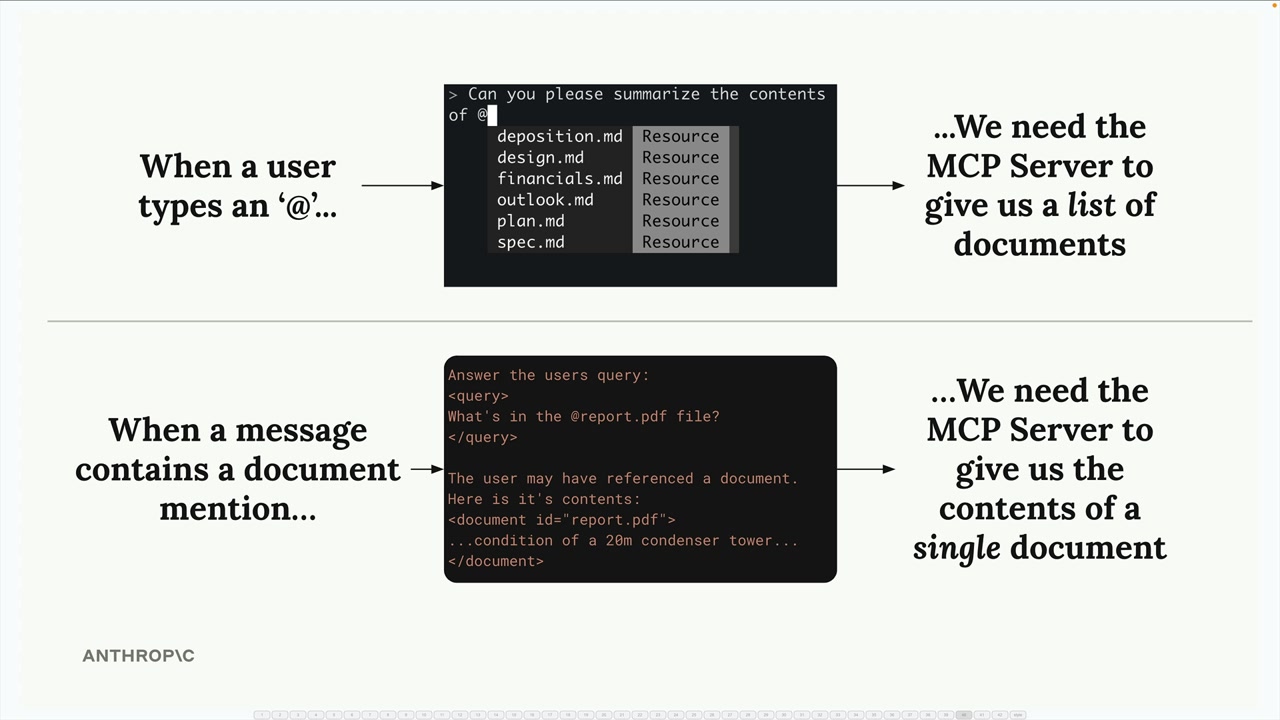
资源如何工作
资源遵循请求-响应模式。你的客户端发送一个带有 URI 的 ReadResourceRequest(读取资源请求),MCP 服务器则用数据响应。URI (统一资源标识符) 就像你要访问的资源的地址。

资源类型
资源有两种类型:

- 直接资源 (Direct Resources): 静态 URI,不会改变,如
docs://documents - 模板化资源 (Templated Resources): 带有参数的 URI,如
docs://documents/{doc_id}
对于模板化资源,Python SDK 会自动从 URI 中解析参数,并将它们作为关键字参数传递给你的函数。
实现资源
资源使用 @mcp.resource() 装饰器定义。以下是如何创建这两种类型:
直接资源(列出文档)
@mcp.resource(
"docs://documents",
mime_type="application/json"
)
def list_docs() -> list[str]:
return list(docs.keys())
模板化资源(获取文档)
@mcp.resource(
"docs://documents/{doc_id}",
mime_type="text/plain"
)
def fetch_doc(doc_id: str) -> str:
if doc_id not in docs:
raise ValueError(f"Doc with id {doc_id} not found")
return docs[doc_id]
MIME 类型
资源可以返回任何类型的数据——字符串、JSON、二进制等。mime_type 参数向客户端提示你返回的是哪种数据:
application/json- 结构化 JSON 数据text/plain- 纯文本内容- 任何其他适用于不同数据格式的有效 MIME 类型
MCP Python SDK 会自动序列化你的返回值。你不需要手动将其转换为 JSON 字符串。
测试资源
你可以使用 MCP Inspector 测试你的资源。通过以下命令运行你的服务器:
uv run mcp dev mcp_server.py
然后在浏览器中连接到检查器。你会看到:
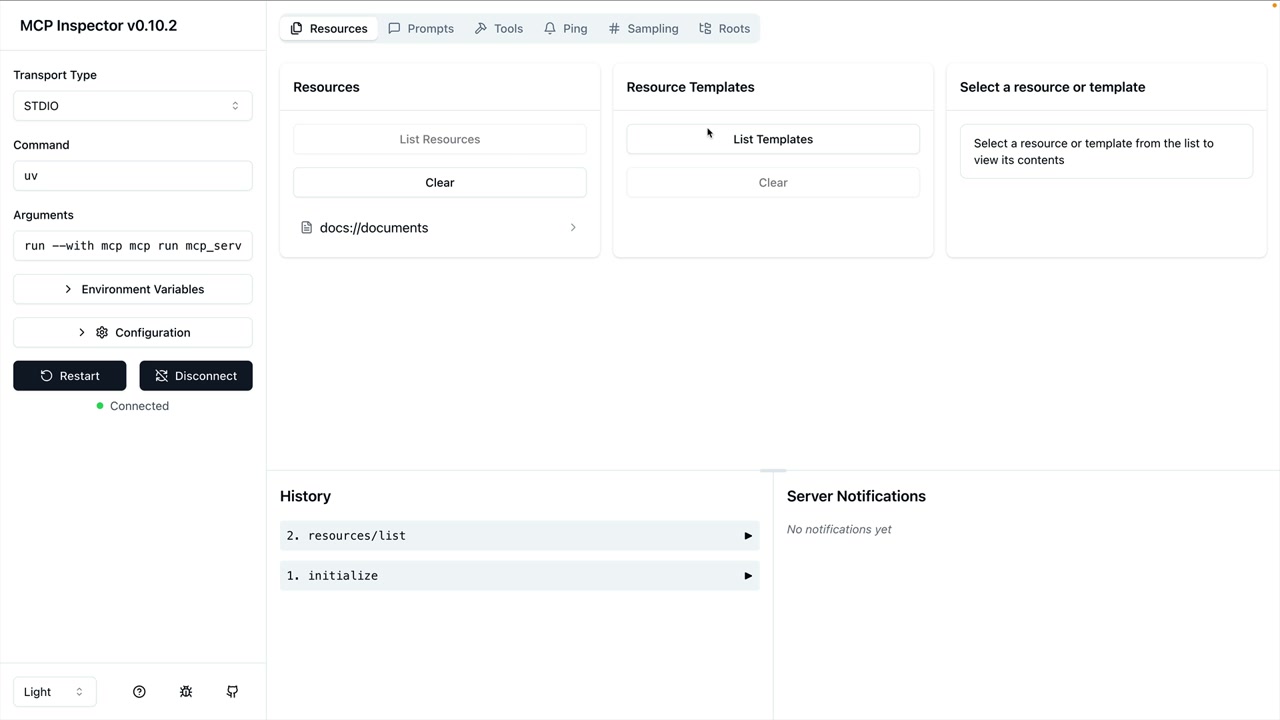
- Resources: 列出你的直接/静态资源
- Resource Templates: 显示接受参数的模板化资源
点击任何资源来测试它,并查看你的客户端将收到的确切响应结构。
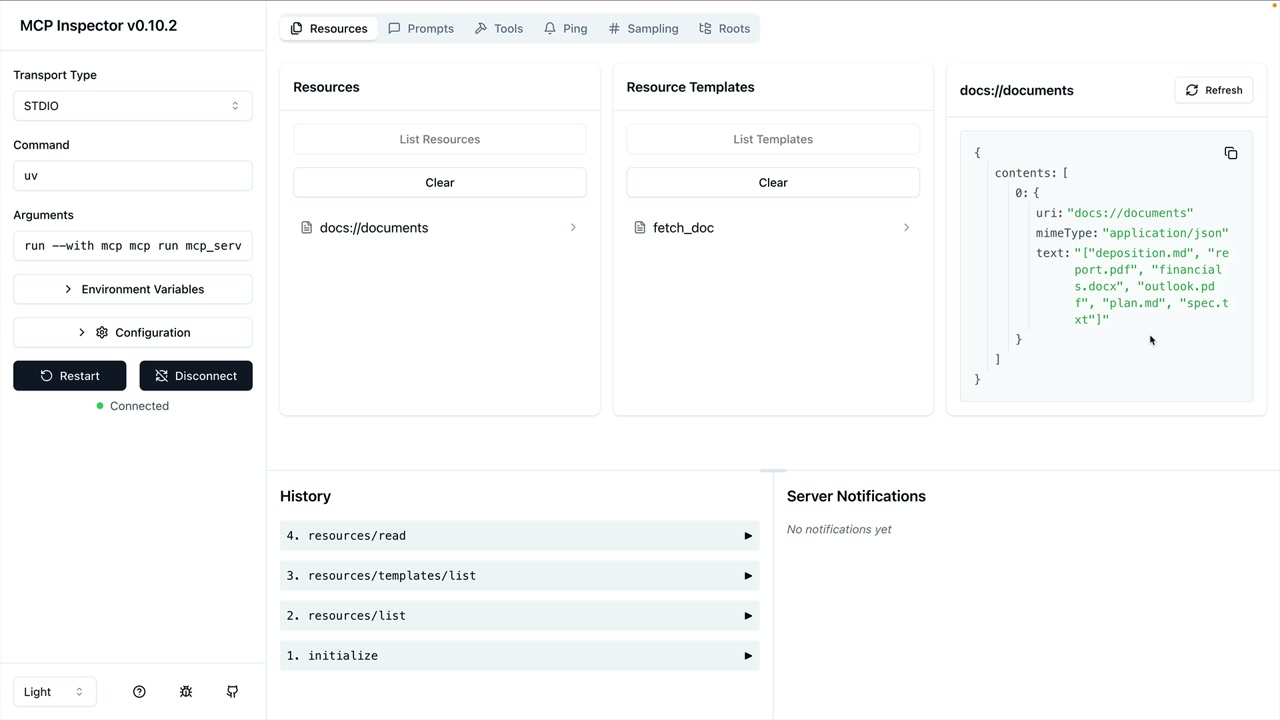
关键点
- 资源暴露数据,工具执行操作
- 对静态数据使用直接资源,对参数化查询使用模板化资源
- MIME 类型帮助客户端理解响应格式
- SDK 自动处理序列化
- 模板化 URI 中的参数名成为函数参数
资源提供了一种清晰的方式来向 MCP 客户端提供数据,从而实现了诸如文档提及、文件浏览或任何你需要从服务器获取信息的场景。
视频文字稿
在本视频中,我们将继续探讨 MCP 服务器中的下一个主要特性——资源。为了帮助你理解资源,我们将在项目中实现另一个功能。以下是我们要添加的内容。我希望允许用户通过输入 at 符号(@)后跟文档名称来提及一个文档。
当他们这样做时,我希望自动获取该文档的内容,并将其插入到我们发送给 Claude 的提示中。所以总的来说,这个功能有两个方面。当用户在消息中输入 at 符号时,我们将自动显示一个包含所有可以提及的文档的列表,在一个小小的自动完成窗口中。然后,当用户提交一条包含提及的消息时,我们将自动获取该文档的内容,并将其插入到我们发送给 Claude 的提示中。
举个例子,如果一个用户说“@report.pdf 文件里有什么内容”,我希望构建一个像这样的提示并发送给 Claude。所以,提示中会有用户的查询,然后我们还会告诉 Claude,用户可能引用了某个文档,这里是该文档的内容。所以这里的做法或想法是,我们不必依赖 Claude 使用某个工具来找出 report.pdf 文件里的内容。相反,用户可以直接预先提及文件,我们会自动提前插入一些上下文。
现在,我想澄清一点,我们实际上在讨论两个不同的功能。第一个功能是,当用户输入 at 符号时,我们确实需要 MCVP 服务器给我们一个所有用户可能提及的文档的列表。然后第二个方面是,当用户提交一条包含提及的消息时,我们需要 MCP 服务器给我们单个文档的内容。为了从我们的 MCP 服务器中获取这些信息,我们将使用资源。
资源允许我们的 MCP 服务器向客户端暴露一些数据。我们通常为每个不同的读取操作定义一个资源。所以在我们的例子中,我们需要获取一个文档列表并读取单个文档的内容。因此,我们可能会创建两个独立的资源。
一个资源将负责只返回一个文档名称列表,以便我们可以将它们放入自动完成列表中,然后我们可能会创建另一个资源,它将根据文档 ID 暴露单个文档的内容。当我们定义这些资源时,它们将通过我们的 MCP 客户端被访问。所以我们最终将构建的整个流程是,当用户输入类似“在应用程序中有什么”这样的内容,然后大概他们会在那里输入一些东西,一旦他们输入那个应用程序字符,我们需要显示一个文档名称列表以放入自动完成。所以我们的代码将联系 MCP 客户端,而客户端又将向 MCP 服务器发送一个读取资源请求。
在该读取资源请求中,我们将包含一个叫做 URI 的东西。这本质上是我们想要读取的资源的地址。这个 URI 是在我们最初创建资源时定义的。所以 URI 就是那个。
当我们发送这个读取资源请求时,MCP 服务器会查看我们放入其中的确切 URI,然后运行我们放在那里的函数。获取结果并将其在一个读取资源结果消息中发送回给我们。然后我们可以获取其中的数据并在我们的自动完成中显示它,或者用它做任何我们需要做的事情。资源有两种不同类型,直接资源和模板化资源。
你有时也会看到直接资源被称为静态资源。直接资源只有一个静态 URI,所以它总是完全一样的东西,比如 docs, colon slash slash documents。模板化资源在其 URI 中会有一个或多个参数。举个例子,我们可能有 documents slash,然后这里有一个通配符。
所以我们可以输入任何我们想要的文档 ID。当我们请求这个资源时,URI 中的那个文档 ID 会被 Python MCP SDK 自动解析,并作为关键字参数提供给我们的函数。关键字参数的名称将与你在这里输入的字符串完全相同。所以这里的 Doc ID 就会是那里的 Doc ID。
你可能已经猜到了,每当我们想在用户从我们的 MCP 服务器请求的内容中提供更多的选择、多样性或定制性时,我们都会使用模板化资源。实现资源非常直接。那么,让我们回到我们的编辑器,我们马上要在服务器中添加一些资源。好的,回到我的编辑器里,我将找到 MCP server.py 文件。
然后我将向下滚动一点,找到一些关于编写一个返回所有文档 ID 的资源和编写一个返回特定文档内容的资源的注释。现在,对于这里的第一个,我在注释中写了“文档 ID”。请记住,对我们来说,我们的文档 ID 本质上就是文档的名称。所以对我们来说,我们真的只是返回这些 ID。
它们将起到名称的作用。这意味着我们可以直接把它们放到那个自动完成元素中。好了,为了创建我们的资源,我将删除那个待办事项。然后我将添加一个 MCP.resource。
第一个参数将是访问这个东西的 URI。再次强调,这有点像一个路由处理器。所以我将使用 docs, colon slash slash documents,并且我还将添加一个 application slash JSON 的 MIME 类型。一个资源可以返回任何类型的数据,所以它可以是纯文本,可以是 JSON,可以是二进制数据,任何东西。
由我们来给我们的客户端一个提示,告诉它我们返回的是什么样的数据。为此,我们将定义这个 MIME 类型。application slash JSON 的 MIME 类型是对我们的客户端的一个提示,它最终会请求这个资源,告诉它我们将发送回一个包含结构化 JSON 数据的字符串。因此,由我们的客户端来反序列化这些数据,或者说把它转换成一个可用的数据结构。
在那个装饰器下面,我将写出我的 list_docs 函数,它将返回一个字符串列表。然后在其中,我将返回 list(docs.keys())。所以只是从那个字典中取出所有的键,把它们转换成一个列表,然后返回它。现在,你会注意到我们并没有返回一个明确的 JSON。
换句话说,我们实际上并没有返回一个字符串。MCP Python SDK 会自动将我们返回的任何内容转换为字符串。好了,让我们来处理我们的第二个资源。所以我将删除那条注释,然后用 MCP resource, docs, colon slash slash documents 替换它。
这次我想要一个模板化的资源,因为我在这里放了一个通配符。然后我的 mind type 这次,为了有点变化,我将返回纯文本,因为它将只是文档的内容。我不会把它包装在任何结构中。现在,我想让你知道,在一个真实的应用中,比如读取一个文档,我可能会返回一个完整的文档记录。
也就是一个包含 ID、内容、作者名、作者 ID 等等信息的字典。但仅仅为了举例,我将只返回文档的文本,向你展示我们通常如何返回纯文本。所以在这种情况下,我的 MIME 类型将是 text plane,然后我将创建 fetch doc。我将接收一个字符串类型的 doc ID,并返回一个字符串。
再次强调,你在这里输入的任何单词,都会在你的函数中显示为一个关键字参数。如果我们在这里添加一些额外的参数,比如 doc type 之类的,它就会像这样显示为一个额外的关键字参数。然后在这里面,我首先要确保这个人请求的 ID 确实存在。所以如果 doc ID not in docs,我将引发一个 ValueError,并附上一个 F 字符串,内容是“Doc with ID not found”。
然后如果我们通过了那个检查,我将返回 docs[doc ID]。就是这样。现在让我们再次在我们的 MCP Inspector 中测试这些东西。记住,在我们的终端,我们可以运行命令 UVRun, MCPDev, MCPServer.py。
这将启动一个端口为 6277 的 web 服务器,或者默认是 6274。所以我要确保我在浏览器中打开它。好了。我点击连接。
然后我找到资源。然后我应该能够列出所有可用的资源。现在,当我列出资源时,这将是特定的静态或直接资源。所以我只会看到 docs/documents。
然后我可以单独列出我所有的不同资源模板。所以我将看到我有一个 FetchDoc 的资源模板。我可以先尝试运行这里的 slash documents。我们看看会得到什么。
所以这就是实际的消息,从我们 MCP 服务器返回的确切结构。你会注意到它有一个 text 属性,里面是我们将要返回的所有数据,序列化为 JSON 字符串。所以再次强调,这将取决于我们在我们的 CLI 应用程序中,去获取这个文本并将其从这个 JSON 字符串反序列化为一个可用的字符串列表。然后我们也可以测试 fetch doc。
所以我点击它。我必须输入一个 doc ID。所以我要输入它。我想读取 report.pdf 文件。
我将读取资源。现在我应该能看到那个特定文档的内容了。你会注意到这次,我又得到了一个 text plain。所以这提示我这是纯文本。我不应该尝试以任何方式从 JSON 中反序列化它。
73. 访问资源
类型:视频 | 时长:4:38 | 视频:09 - 008 - Accessing Resources.mp4
MCP 中的资源允许你的服务器公开可以被直接包含在提示中的数据,而不是需要通过工具调用来访问信息。这为向像 Claude 这样的 AI 模型提供上下文创造了一种更高效的方式。
理解资源请求
当你在 MCP 服务器上定义了资源后,你的客户端需要一种方法来请求和使用它们。客户端充当你的应用程序和 MCP 服务器之间的桥梁,自动处理通信和数据解析。
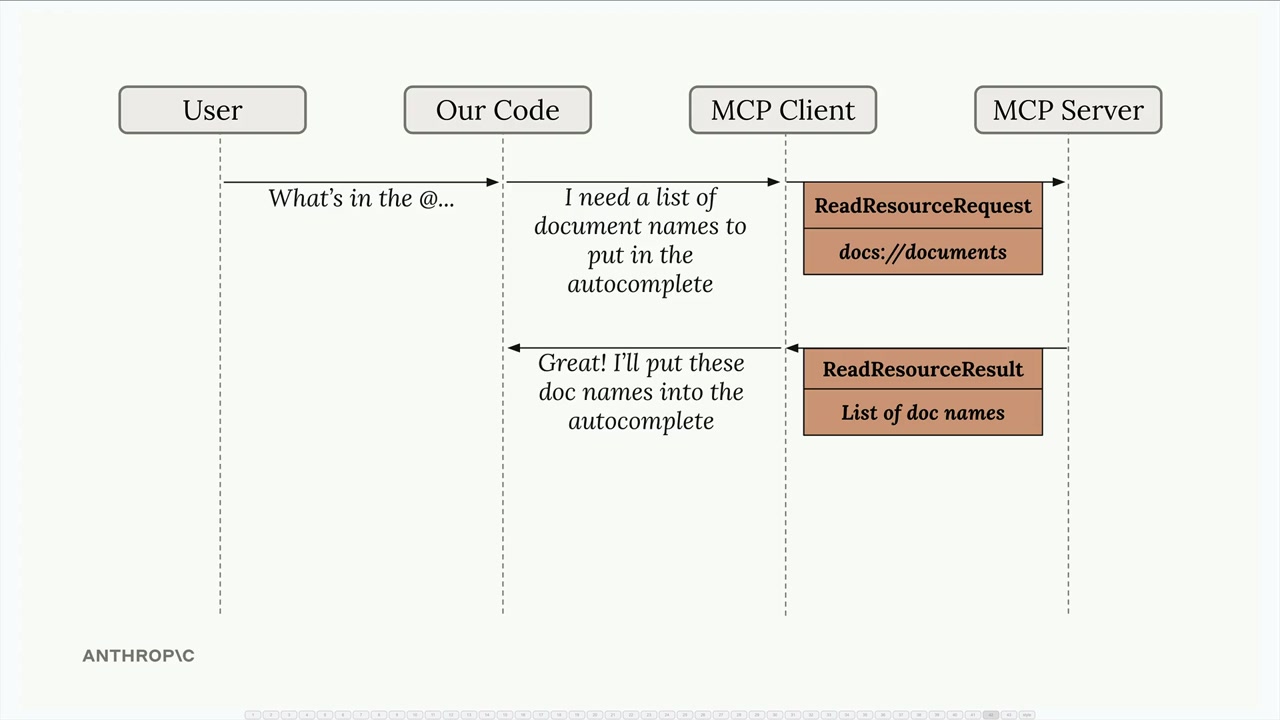
流程很简单:当用户想要引用一个文档时(比如输入“@report.pdf”),你的应用程序使用 MCP 客户端从服务器获取该资源,并将其内容直接包含在发送给 Claude 的提示中。
实现资源读取
核心功能需要在你的 MCP 客户端中有一个 read_resource 函数。这个函数接受一个 uri 参数,用于标识要获取哪个资源:
async def read_resource(self, uri: str) -> Any:
result = await self.session().read_resource(AnyUrl(uri))
resource = result.contents[0]
来自 MCP 服务器的响应包含一个 contents 列表。你通常只需要第一个元素,它包含了实际的资源数据以及像 MIME 类型这样的元数据。
处理不同的内容类型
资源可以返回不同类型的内容,所以你的客户端需要适当地解析它们。MIME 类型告诉你如何处理数据:
if isinstance(resource, types.TextResourceContents):
if resource.mimeType == "application/json":
return json.loads(resource.text)
return resource.text
这种方法确保了 JSON 资源被正确地解析成 Python 对象,而纯文本资源则作为字符串返回。MIME 类型是你决定正确解析策略的提示。
所需的导入
为了让这个功能正常工作,你需要在你的 MCP 客户端中进行这些导入:
import json
from pydantic import AnyUrl
json 模块处理 JSON 响应的解析,而 AnyUrl 确保 uri 参数的类型处理正确。
测试资源访问
实现后,你可以通过你的 CLI 应用程序测试该功能。当你输入类似“@report.pdf 文档里有什么?”这样的内容时,系统应该:
- 在自动完成列表中显示可用资源
- 允许你选择一个资源
- 自动获取资源内容
- 将该内容包含在给 Claude 的提示中
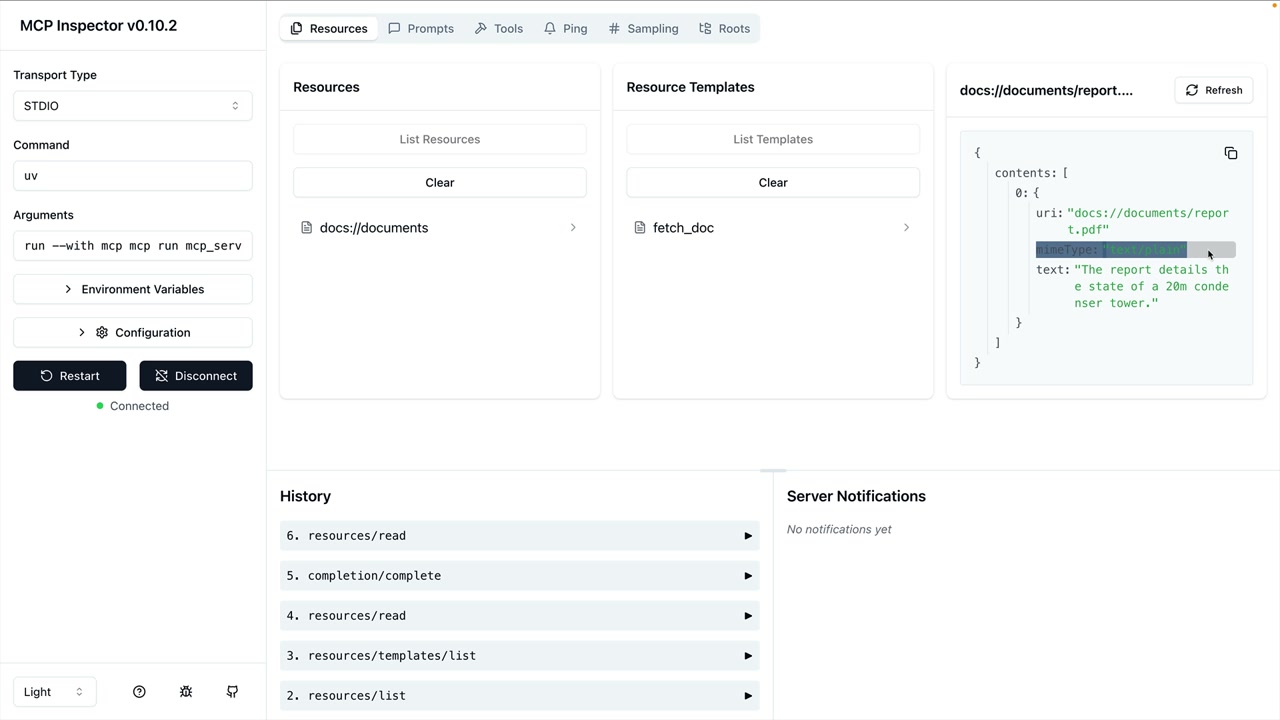
关键优势在于,Claude 直接在提示中接收到文档内容,无需通过工具调用来访问信息。这使得交互更快、更高效。
与你的应用程序集成
请记住,你编写的 MCP 客户端代码会被你应用程序的其他部分使用。read_resource 函数成为一个构建块,其他组件可以调用它来获取文档内容、列出可用资源或将资源数据集成到提示中。
这种关注点分离使你的代码保持清晰:MCP 客户端处理与服务器的通信,而你的应用程序逻辑则专注于如何有效地使用这些数据。
视频文字稿
我们已经在 MCP 服务器中定义了两个独立的资源。所以现在我们的客户端需要有能力请求这些资源。为此,我们将在 MCP 客户端中添加一个函数。请记住,这个 MCP 客户端将包含一些我们正在整合的功能,这些功能将被我们应用程序的其余部分使用。
而且我已经把那部分代码整理好了。所以在这个项目的其他地方,某个东西会尝试使用我们即将添加到 MCP 客户端的这个函数。为了开始,我将再次打开 MCP 客户端文件。我将向下滚动并找到这里的 read resource。
我们在这里的目标是通过向我们的 MCP 服务器发出请求来读取一个特定的资源,然后根据其 mime 类型解析返回的内容,最后只返回我们得到的任何数据。你会注意到它的一个参数是 URI。这将是我们想要从服务器获取的资源的 URI。为了发出请求,为了让我们的所有类型都正确,我们将在文件顶部添加两个导入。
我将为 JSON 模块添加一个导入。然后从 PyDientTik,我将导入 AnyURL。然后我将回到下面。到我们的 read resource 函数。
我将清除注释和返回语句。然后我将从调用 await. self. session 得到一个结果。
我想读取资源。然后再次强调,这真的只是为了让类型能够正常工作。我们将放入一个带有输入 URI 的 AnyURL。然后我将从那个结果中获取。
response 或者不好意思,是 result.contents 的第零个元素。我想在这里明确说明我们为什么添加这个。就在刚才,在我们的检查器里,我们看到了我们得到的响应。所以这基本上就是那个 result 变量。
Result 有一个 contents 列表。里面会有一个元素列表。我们真正关心的只有第一个。所以我想获取第一个字典。
我想访问 type 属性和 mime type。我特别需要 MIME type,因为它能帮助我理解我们收到了什么样的数据。如果是 JSON,那么我需要确保我将文本解析为 JSON 并返回那个结果。让我来告诉你我们将如何做。
我将添加一个 if isinstance(resource.contents[0], ResourceTypeText) 并且 resource.mime_type == "application/json": # 这是我们的提示。如果服务器告诉我们它返回的是一些 JSON,我们需要确保我们将文本内容解析为 JSON。所以我将在那种情况下返回 json.loads(resource.text)。然后,如果我们没有进入那个 if 语句并提前返回,我只想返回 resource.text。
所以在这种情况下,我们会以纯文本的形式返回文本,或者不解析任何东西。所以这实际上就是我们获取单个文档内容的情况。好了,应该就是这样了。我们已经完成了我们的 read resource。
现在,我想再次提醒你,我知道我已经说过好几次了,但我只想提醒你,因为我觉得可能有点不清楚。我们在 MCP 客户端中编写的代码正在被这个代码库的其他几个地方使用。所以在这个代码库的其他地方,我们将调用我们刚刚整合的函数来获取文档名称列表,然后最终获取文档内容以放入提示中。所以到目前为止,一切应该都能正常工作,因为剩下的工作已经为我们完成了。
有鉴于此,让我们回到我们的终端,我们将再次测试我们的 CLI 应用程序,看看这个提及功能是否有效。好的,回到这里,我将执行 uvicorn main:app --reload,现在我应该可以说出类似“what's in the at”这样的话,然后,我看到了我的资源列表,我可以用箭头键来滚动浏览。一旦我选定了一个我喜欢的资源,我只需按空格键,我们就会插入那个资源。那么,“report.pdf”文档里有什么呢?
现在,我可以告诉你这里一切都按预期工作。换句话说,这个文档的内容正被发送到 Claude 的提示中。所以如果我提交这个,我应该会立即得到一个响应,它会告诉我报告 PDF 里面有什么。所以这一次,Claude 不必使用工具来读取文档的内容。
好了,这就是资源。再次强调,我们利用资源从我们的 MCP 服务器中暴露一些信息。
74. 定义提示
类型:视频 | 时长:7:44 | 视频:09 - 009 - Defining Prompts.mp4
MCP 服务器中的提示 (Prompts) 允许你定义预构建的、高质量的指令,客户端可以使用这些指令,而无需从头开始编写自己的提示。可以把它们看作是精心制作的模板,能比用户自己想出的提示带来更好的结果。
为什么使用提示?
假设你希望 Claude 将文档重新格式化为 markdown。用户可以直接输入“将 report.pdf 转换为 markdown”,这也能行。但如果使用一个经过充分测试、包含关于格式、结构和输出要求的具体指令的提示,他们可能会得到好得多的结果。
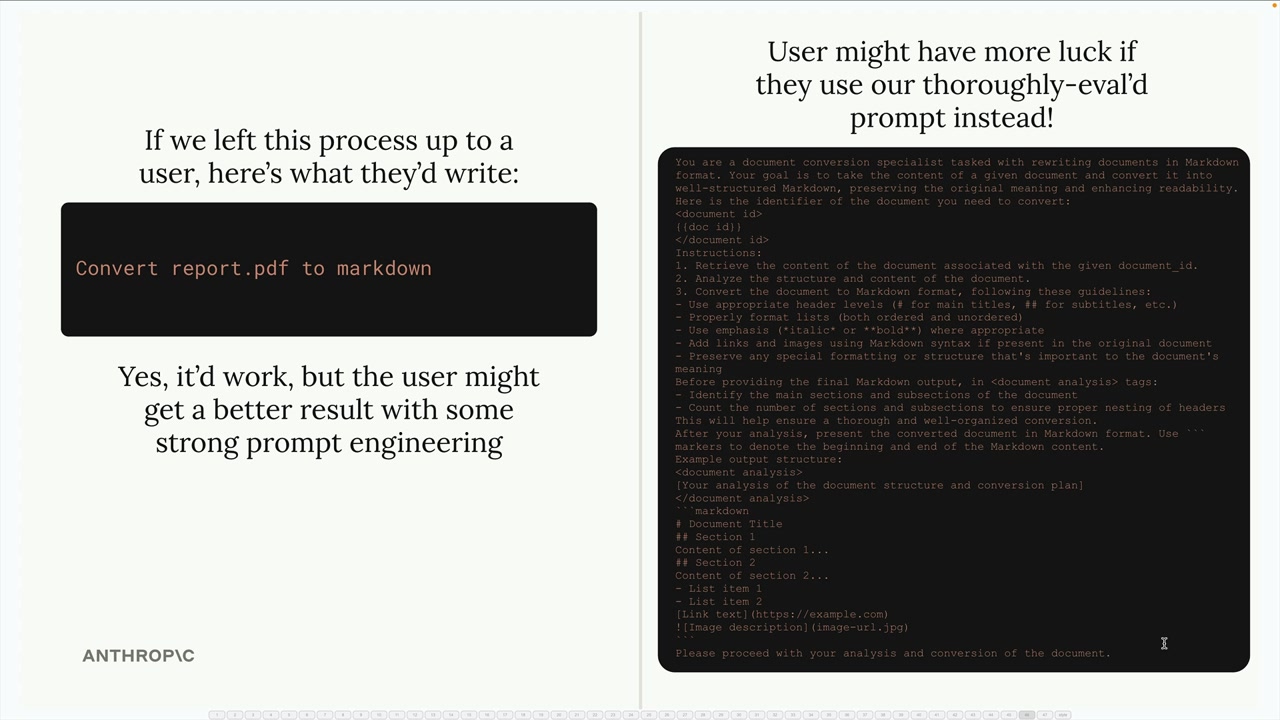
关键的洞见是,虽然用户可以自己完成这些任务,但当使用由 MCP 服务器作者精心开发和测试的提示时,他们将获得更一致、更高质量的结果。
提示如何工作
提示定义了一组用户和助手消息,客户端可以直接使用。当客户端请求一个提示时,你的服务器会返回一个可以直接发送给 Claude 的消息列表。

基本结构如下:
- 使用
@mcp.prompt()装饰器定义提示 -为每个提示添加名称和描述 -返回构成完整提示的消息列表 -这些提示应该是高质量、经过充分测试且与你的 MCP 服务器的目的相关的
构建格式化命令
以下是如何实现一个文档格式化提示。首先,你需要导入基本消息类型:
from mcp.server.fastmcp import base
然后定义你的提示函数:
@mcp.prompt(
name="format",
description="Rewrites the contents of the document in Markdown format."
)
def format_document(
doc_id: str = Field(description="Id of the document to format")
) -> list[base.Message]:
prompt = f"""
Your goal is to reformat a document to be written with markdown syntax.
The id of the document you need to reformat is:
{doc_id}
Add in headers, bullet points, tables, etc as necessary. Feel free to add in extra formatting.
Use the 'edit_document' tool to edit the document. After the document has been reformatted...
"""
return [
base.UserMessage(prompt)
]
测试你的提示
你可以使用 MCP Inspector 测试提示。导航到 Prompts 部分,选择你的提示,并提供任何必需的参数。检查器将向你显示将发送给 Claude 的生成消息。
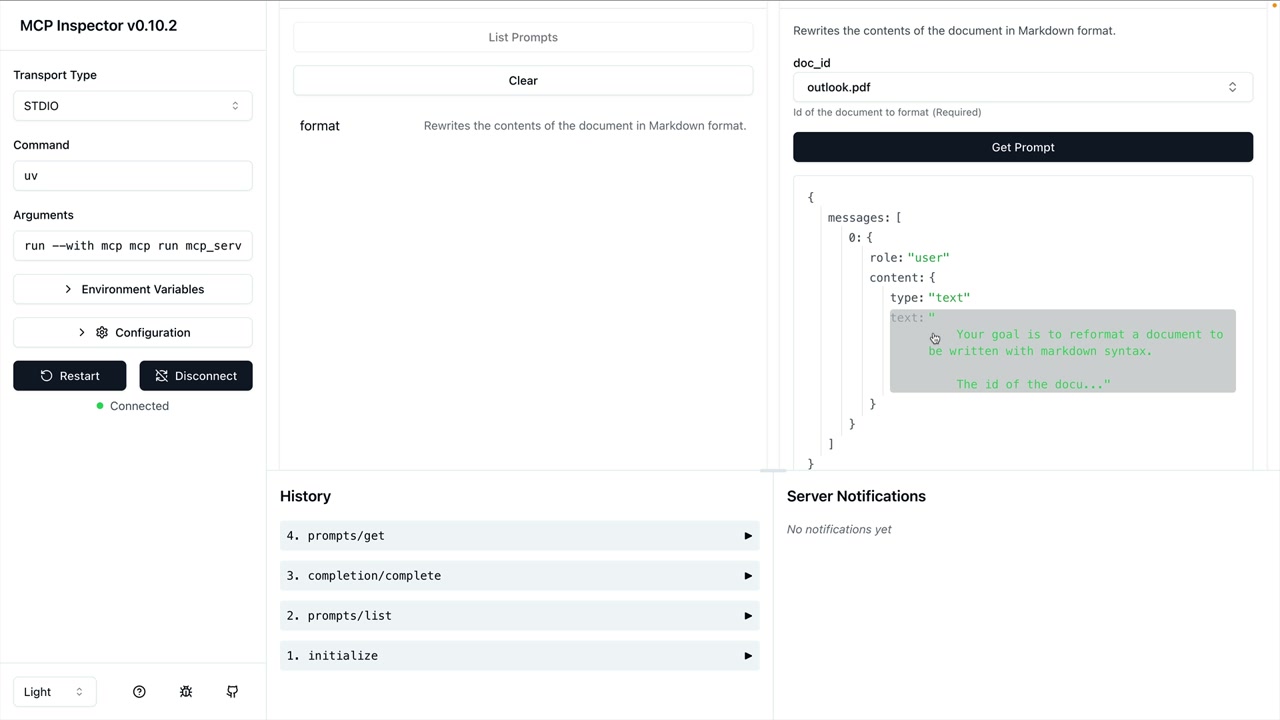
这使你可以在真实应用程序中使用之前,验证你的提示是否正确地插入了变量并产生了预期的消息结构。
最佳实践
在为您的 MCP server 创建 prompts (提示) 时:
- 专注于您的 server 的核心任务
- 编写详细、具体的指令,而不是模糊的请求
- 使用不同的输入彻底测试您的 prompts
- 提供清晰的描述,以便用户理解每个 prompt 的作用
- 考虑 prompt 如何与您的 server 的 tools (工具) 和 resources (资源) 协同工作
请记住,prompts 旨在提供用户无法轻易获得的价值——它们应该代表您在 MCP server 所覆盖领域内的专业知识。
视频文字稿
我们在 MCP server 中要关注的最后一个主要重点是 prompts。就像我们刚才处理 resources 一样,我们将再次在项目中实现一个小功能。我们将利用这个功能来理解 prompts 的全部内容。让我告诉您我们将在程序中添加的功能。
我们将添加对 slash commands (斜杠命令) 的支持。例如,我想要一个 format 命令。我这里有一些关于它如何工作的截图。当用户输入斜杠时,我们将列出我们应用程序支持的一些命令。
目前,我们只有一个名为 format 的命令。所以如果我只输入斜杠,我应该会看到一个小小的自动完成提示,唯一的选项应该是 format。如果我选择了 Format,系统应该会提示我在后面添加一个文档 ID。比如我们的某个文档名,像 report.pdf 之类的。
然后,当用户运行这个命令时,目标是让 Claude 使用 Markdown 语法重新格式化这个文档。换句话说,就是提取我们目前每个文档里没有任何特殊格式的纯字符串。记住,在我们的 MCP server 中,当前的文档内容只是纯文本。我们想把这个输入给 Claude,并让 Claude 用 Markdown 语法重写它。
所以我期望看到类似这样的输出,内容是“我将帮助您重新格式化文档”。然后 Claude 将使用一个工具来读取文档内容。最后,在最终的响应中,我希望看到该文档的内容被重写为 Markdown 语法。现在,关于这个功能,我想指出一些有趣的地方。
这个功能真正的核心,真正的目标,是允许用户将文档重新格式化为 Markdown 语法。而这个操作实际上并不需要你我,作为开发者,去编写任何代码来实现。这是什么意思呢?嗯,用户已经可以启动我们的 CLI 并说出类似“用 markdown 语法重新格式化 report.pdf 文件”这样的话。
用户已经可以做到这一点了。完全没问题。Claude 会做得相当不错。它会提取我们文档的内容并将其重新格式化为 markdown。
正如您在这里看到的,它完美地完成了工作。那么,我们做这个功能到底是为了什么呢?嗯,这里的思路是,如果我们完全放手让用户自己手动输入类似“把这个转换成 Markdown”的指令,他们可能会得到一个还算可以的结果,但如果他们有一个为这种特定场景(将文档转换为 Markdown)量身定制的、非常强大的 prompt,他们可能会得到好得多的结果。所以,如果我们作为 MCP server 的作者,能够坐下来,编写、测试、评估并完成整个流程,来打造一个真正周全、出色的 prompt,就像您在右边看到的这个一样,那么用户可能会更满意。
所以,再次重申,是的,用户可以自己执行整个工作流程,但如果他们改用这个精心设计的 prompt,我认为他们会得到更好的结果。这就是 MCP server 中 prompts 功能的真正目标。这里的想法是,我们可以预先在我们的 server 中定义一组 prompts,这些 prompts 是为我们的 server 所擅长的任何领域量身定制的。在我们的案例中,我们的 server 专注于管理文档、读取文档、编辑文档等等。
所以我们可能会决定添加一组高质量的 prompts,这些 prompts 经过了评估和测试,我们知道它们在各种不同场景下都能良好工作。然后我们可以将这些 prompts 开放给任何客户端应用程序使用,比如我们现在正在开发的这个 CLI 应用。现在,我想指出一点,我们可以开发这个 prompt 并直接将其放入我们的 CLI 代码库中。这完全可行。
我们当然可以这样做。但同样,这里的想法是,您的 MCP server 可能专注于某个特定任务,并可能开放一些 prompts,人们可以直接使用,而无需担心预先开发它们。为了在我们的 MCP server 中定义一个 prompt,我们将编写一些与我们已经创建的 tools 和 resources 非常相似的语法。我们将使用 prompt 装饰器。
我们会给 prompt 添加一个名称,并可选地添加一个描述。然后,当客户端请求这个 prompt 时,我们会返回一个消息列表。这些是实际的用户和助手消息。所以我们可以直接将这些消息发送给 Claude。
好的,那么让我们回到我们的 server,尝试创建一个我们自己的 prompt。就像您在这里看到的,它将是关于提取文档内容并以某种方式用 Markdown 格式重写它。好的,回到我的编辑器里,我将找到我的 MCP server 文件。我会向下滚动到关于用 Markdown 格式重写文档的注释。
我将删除那个待办事项,然后添加一个 MCP prompt,名称为 format,描述为“用 Markdown 格式重写文档内容”。然后我将添加一个实际的实现。所以是 format_document,我可以接收一个 doc_id 作为参数,然后我们也可以在这里添加一个字段描述,就像我们之前对工具所做的那样。所以我可以可选地添加一个字段,描述为“要格式化的文档的 ID”。
我还会添加一个 string 的类型注解。只是为了确保这一点也非常清楚。从这个函数中,我们将返回一个消息列表。我要确保立即在顶部为此 base 导入。
所以在现有的 MCP server 导入下方,我将添加 from mcp_server.fast_mcp.prompts import base。然后回到下面。在这里,我们将定义我们那个经过充分测试和评估的 prompt。我预先写好了一个 prompt。
我会把它粘贴进来。所以这个 prompt 只是要求 Claude 接收一个文档 ID。我们隐含地要求 Claude 使用 redocument 工具获取该文档 ID 的内容。然后在获取该文档后,直接用 Markdown 语法重写它。
最后,在重写之后,还要编辑该文档,以在我们的 server 中保存这些更新。现在,在定义了这个 prompt 之后,我们将返回一个消息列表。所以在下面,我将返回一个列表,其中包含 base.user_message,然后我会将我们刚刚写好的 prompt 传入其中,就像这样。现在我将保存这个文件,然后让我们启动 MCP 开发检查器,并从那个界面测试这个 prompt。
所以在我的终端,我将再次运行同样的命令,然后在我的浏览器中导航到那个地址。我将确保连接到我的服务器。然后我将找到 prompts 部分。我将列出所有可用的 prompts。
此时,我们只有一个 prompt,就是 format。所以我点击 format,然后我必须在这里输入一个文档 ID。这次,也许我们会输入一个文档 ID,比如 outlook.pdf。所以我输入那个。
然后点击 get prompt。然后这里是我们的消息列表。这些是预先组合好的。我这里有一个消息部分。
所以是一个文本部分,里面有我们完整的 prompt。我们可以看到文档 ID 已经被插入其中了。现在我们有了这些消息,我们可以把它们发送给 Claude。希望我们会得到一些适当的响应。
所以,再次强调,这些我们在 MCP server 中可能实现的 prompts 背后的整个理念是,我们定义的 prompts 将是经过充分测试、充分评估、真正专注于某一特定用例的。
75. 客户端中的 Prompts
类型:视频 | 时长:3:01 | 视频:09 - 010 - Prompts in the Client.mp4
MCP 中的 Prompts 定义了一组可供客户端使用的用户和 assistant (助手) 消息。这些 prompts 应该是高质量、经过充分测试,并与 MCP server 的整体目标相关的。

实现 List Prompts
第一步是在您的 MCP 客户端中实现 list_prompts 方法。此方法从服务器检索所有可用的 prompts:
async def list_prompts(self) -> list[types.Prompt]:
result = await self.session().list_prompts()
return result.prompts
这个简单的实现调用了 session 的 list_prompts 方法,并从结果中返回 prompts 数组。
获取单个 Prompt
get_prompt 方法检索一个特定的 prompt,并将参数插入其中。当您请求一个 prompt 时,您提供的参数会作为关键字参数传递给 prompt 函数:
async def get_prompt(self, prompt_name, args: dict[str, str]):
result = await self.session().get_prompt(prompt_name, args)
return result.messages
该方法从结果中返回 messages,这些消息构成了一个可以直接输入给 Claude 的对话。
Prompt 参数如何工作
当您在服务器端定义一个 prompt 函数时,它可以接受参数。例如,一个文档格式化 prompt 可能期望一个 doc_id 参数:
def format_document(doc_id: str):
# The doc_id gets interpolated into the prompt
当客户端调用 get_prompt 时,arguments 字典应包含预期的键。MCP server 会将这些作为关键字参数传递给 prompt 函数,从而允许将动态内容插入到 prompt 模板中。
在 CLI 中测试 Prompts
实现后,您可以通过命令行界面测试 prompts。当您键入一个正斜杠时,可用的 prompts 会作为命令出现。选择一个 prompt 可能会提示您从可用选项(如文档 ID)中进行选择,然后完整的 prompt 会被发送给 Claude。
工作流程如下:
- 用户选择一个 prompt(如 "format")
- 系统提示输入必需的参数(如要格式化的文档)
- 带有插入值的 prompt 被发送给 Claude
- Claude 随后可以使用工具来获取额外数据并完成任务
Prompt 最佳实践
在为您的 MCP server 创建 prompts 时:
- 使其与您的 server 的目标相关
- 在部署前进行彻底测试
- 使用清晰、具体的指令
- 设计它们以便与您可用的工具良好配合
- 考虑用户需要提供哪些参数
Prompts 弥合了预定义功能和动态用户需求之间的差距,为 Claude 执行复杂任务提供了结构化的起点,同时通过参数化保持了灵活性。
视频文字稿
我们最后的要任务是在 MCP 客户端中实现一些功能,允许我们列出 MCP server 中定义的所有 prompts,并获取一个插入了某些变量的特定 prompt。所以,让我们先实现 list_prompts。我将删除注释并替换为 result = await self.session.list_prompts(),然后我将返回 result.prompts。基本上就是这样。
然后是 get_prompt。需要明确的是,当我们获取一个单独的 prompt 时,我们会得到一些参数。这些参数最终会出现在我们的 prompt 函数中。例如,在 format_document 中,我们期望接收一个文档 ID。
在这个 args 字典中,期望会有一个 document_id 键。这个键将被传入到相应的函数中。然后我们会将该值插入到 prompt 本身。所以在 get_prompt 函数中,我将从 self.session.get_prompt() 获取一个结果。
我将传入 prompt 的名称。这是我想要检索的 prompt 的名称。然后我将传入参数。然后我将返回 result.messages。
所以这些是返回的消息。它们构成了某种我们希望直接输入给 Claude 的对话。就是这样。这就是我们在客户端需要做的全部工作。
所以现在我们可以在 CLI 本身中测试这个功能了。我将切换回来,再次运行项目。现在如果我在这里输入一个斜杠,我会看到我可以访问这个 format 命令。现在 format 实际上只是我们将要调用的 prompt 的名称。
所以如果我选择它然后按空格,系统会要求我选择一个文档,我选择 plan.md。我按回车。然后我们将整个 prompt,实际上只是那条用户消息,直接输入给 Claude。所以 Claude 现在收到了将文档重新格式化为 Markdown 语法的指令。
它也得到了我们想要重新格式化的文档的 ID。所以它需要做的第一件事是去获取那个文档的内容。它会通过使用 get_document 工具来做到这一点。然后最后,Claude 会用这个文档的 markdown 版本来回应。
所以这里是包含大量 markdown 语法的文档。好了,既然这看起来没问题,让我们快速回顾一下 prompts,确保我们理解了它们的全部内容。我们首先编写并评估一个与我们 MCP server 目标相关的 prompt。在我们的案例中,我们正在制作一个文档服务器。
所以有一些关于用不同风格重写文档的功能,我认为是合理的。一旦我们把 prompt 组合好,我们就会在 MCP server 中定义一个 prompt。然后我们的客户端可以在任何时候请求那个 prompt。当我们请求 prompt 时,我们会传入一些参数,这些参数会作为关键字参数提供给这个 prompting 函数。
然后我们的函数可以在 prompt 本身中使用这些关键字参数。
76. MCP 回顾
类型:视频 | 时长:4:12 | 视频:09 - 011 - MCP Review.mp4
视频文字稿
我们已经完成了我们的项目,但在继续之前,我想快速回顾一下我们学到的三个服务器原语 (server primitives)。也就是 tools (工具)、resources (资源) 和 prompts (提示)。我想特别强调一下它们各自的有趣之处。也就是说,一个应用的哪个部分真正负责运行它们?
换句话说,在一个典型的应用程序中,到底是谁在运行这些东西,谁又从中受益?嗯,我们会说 tools 是 model controlled (模型控制) 的。这意味着只有 Claude 负责决定何时运行某个工具。Resources 是 app controlled (应用控制) 的。
换句话说,您应用中运行的某些代码将决定它需要由 resource 提供的某些数据。将由您的应用代码决定执行一个 resource 并以某种方式使用返回的数据,也许是通过在 UI 中使用这些数据或类似的方式。在我们的案例中,我们获取一个 resource,然后在 UI 中使用该数据来提供一个自动完成选项列表。我们还获取一个 resource 来增强一个 prompt。
这两件事都是由你我编写的与应用程序相关的代码来完成的。最后,prompts 实际上是 user-controlled (用户控制) 的。所以用户决定一个 prompt 何时运行。用户可能会通过点击某个 UI 元素(如按钮或菜单选项)来启动一个 prompt 的调用,或者他们可能会使用我们所做的斜杠命令。
我强调每个部分由谁控制的原因是想让您对它们的用途有所了解。所以,如果您需要为 Claude 增加能力,您可能需要考虑在您的 MCP server 中实现一些 tools,或者通过您的 MCP 客户端使用某个服务器的 tools。如果您想为您的应用获取一些数据以在 UI 中显示内容或类似目的,那么您可能想使用一个 resource。而如果您想实现某种预定义的工作流,您可能需要考虑使用 prompts。
您可以在 Claude 的官方界面 claude.ai 上看到所有这些想法的例子。所以,这是它目前的样子。您会注意到主聊天输入框下面有一些按钮。如果我点击其中一个,然后点击这些例子中的一个,您会看到我立即进入了一个聊天。
这是一个用户控制的操作。作为用户,我决定启动这个特定的工作流,而且我正在使用一个可能已经预先写好并经过优化的 prompt。所以,要实现那里的按钮列表,我们可能需要在 MCP server 中创建一系列不同的 prompts。同样地,如果我回去,也许点击这个小标签,加号按钮,您会注意到我有一个“从 Google Drive 添加”的按钮。
现在,我不会点击它,因为它会显示我的一些内部文件。但如果我点击那个按钮,我会看到一些我可以添加到这个聊天中作为上下文的文档。知道在那个列表中实际渲染哪些文档,然后当我点击其中一个时,自动将其内容注入到这个聊天的上下文中,这完全是与应用程序相关的代码。所以完全是应用程序需要知道在这里渲染的文档列表。
而且,这再次是专门与 UI 相关的元素。所以,要实现从 Google Drive 列出文档的功能,我可能会考虑在 MCP server 中实现一个 resource。最后,如果我向这个聊天输入一条消息,比如,“3的平方是多少?”用 JavaScript 计算值然后发送,我显然期望 Claude 以某种方式执行一些 JavaScript 代码,这很可能是通过使用一个 tool 来完成的。在这种情况下,使用 tool 的决定是 100% 由模型控制的。
是模型决定使用某个 JavaScript tool execution。要在 MCP server 中实现这样的功能,我们很可能需要,你猜对了,提供一个 tool。所以,总的来说,这就是我们三个不同的服务器原语。每个原语实际上都旨在由您整个应用程序的不同部分使用。
所以我们有 tools,通常服务于您的模型;resources,通常服务于您的应用;以及 prompts,通常服务于您的用户。再次强调,这些是高层次的指导方针。我之所以提到它们,只是为了让您在根据您要构建的内容来决定何时使用这些原语时,能有一个大致的感觉。
78. Anthropic 应用
类型:视频 | 时长:0:43 | 视频:10 - 001 - Anthropic Apps.mp4
在本模块中,我们将探讨由 Anthropic 构建的两个强大应用:Claude Code 和 Computer Use。它们不仅本身是实用的工具,更是 AI agents (AI 代理) 的绝佳范例。通过理解它们的工作原理,您将为日后构建自己的 agents 打下坚实的基础。
我们的计划
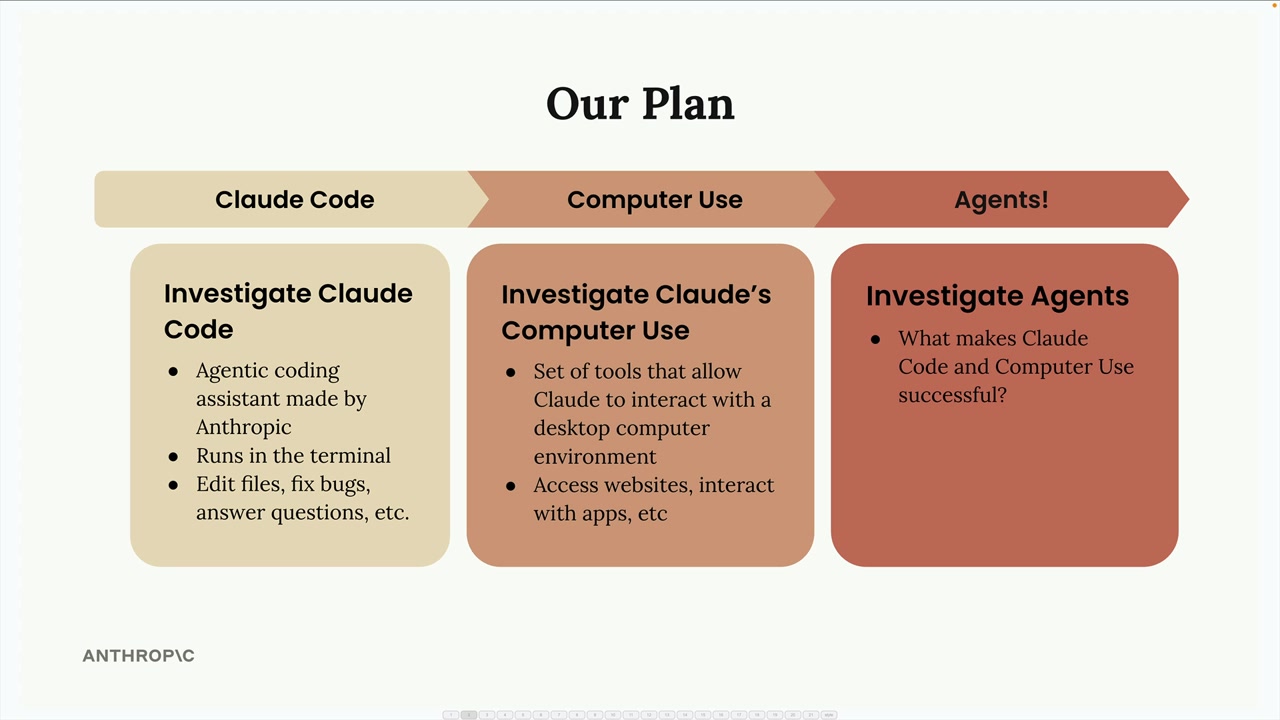
我们将循序渐进,逐步加深您的理解:
- Claude Code - 从这个在您终端中运行的代理式编码助手开始
- Computer Use - 探索这套让 Claude 与桌面应用程序交互的工具
- Agents - 理解是什么让这些应用作为 agents 获得成功
Claude Code
Claude Code 是一个基于终端的编码助手,可以帮助您完成各种编程任务。您可以把它想象成 Claude 就驻留在您的命令行中,随时准备:
- 编辑文件和修复错误
- 回答编码问题
- 协助开发工作流程
我们将带您走过完整的设置过程,然后在一个小型示例项目上使用 Claude Code,这样您就能确切地看到它在实践中是如何运作的。
Computer Use
Computer Use 将 Claude 的能力提升到了一个新高度。它是一系列工具的集合,允许 Claude 与完整的桌面计算机环境进行交互。这意味着 Claude 可以:
- 访问网站和浏览互联网
- 与桌面应用程序交互
- 执行需要视觉界面导航的任务
这极大地扩展了与纯文本交互相比的可能性。
为什么这些对 Agents 很重要
Claude Code 和 Computer Use 都是理解 agents 的绝佳案例研究。它们展示了使 agents 高效的关键原则:
- Tool integration and usage (工具集成与使用)
- Multi-step task execution (多步任务执行)
- Environmental interaction (环境交互)
- Autonomous problem-solving (自主解决问题)
通过研究这些真实世界的实现,您将深入了解是什么让 Claude Code 和 Computer Use 如此成功,这将为您自己的 agent 开发工作提供启示。
让我们在下一节开始 Claude Code 的设置过程。
视频文字稿
在本模块中,我们将看两个由 Anthropic 构建和部署的应用程序。它们是 Claude Code 和 Computer Use。Claude Code 是一个基于终端的编码助手。我将帮助您完成设置过程,然后我们将在一个非常小的示例项目上使用 Claude Code,以确切了解它的工作原理。
之后,我们将看一下 Computer Use。Computer Use 是一套工具,极大地扩展了 Claude 的能力。Claude Code 和 Computer Use 本身都非常有用,但我们讨论它们还有另一个原因。您看,Claude Code 和 Computer Use 是 agents (代理) 的完美例子。
一旦我们了解了它们的工作原理,我们就能更好地准备理解什么是 agents 以及如何构建一个有效的 agent。那么,让我们在下一个视频中开始 Claude Code 的设置过程。
79. Claude Code 设置
类型:视频 | 时长:1:33 | 视频:10 - 002 - Claude Code Setup.mp4
Claude Code 是一个基于终端的编码助手,直接在您的命令行中运行。您可以把它想象成 Claude 就驻留在您的终端里,随时帮助您处理任何正在进行的编码任务。
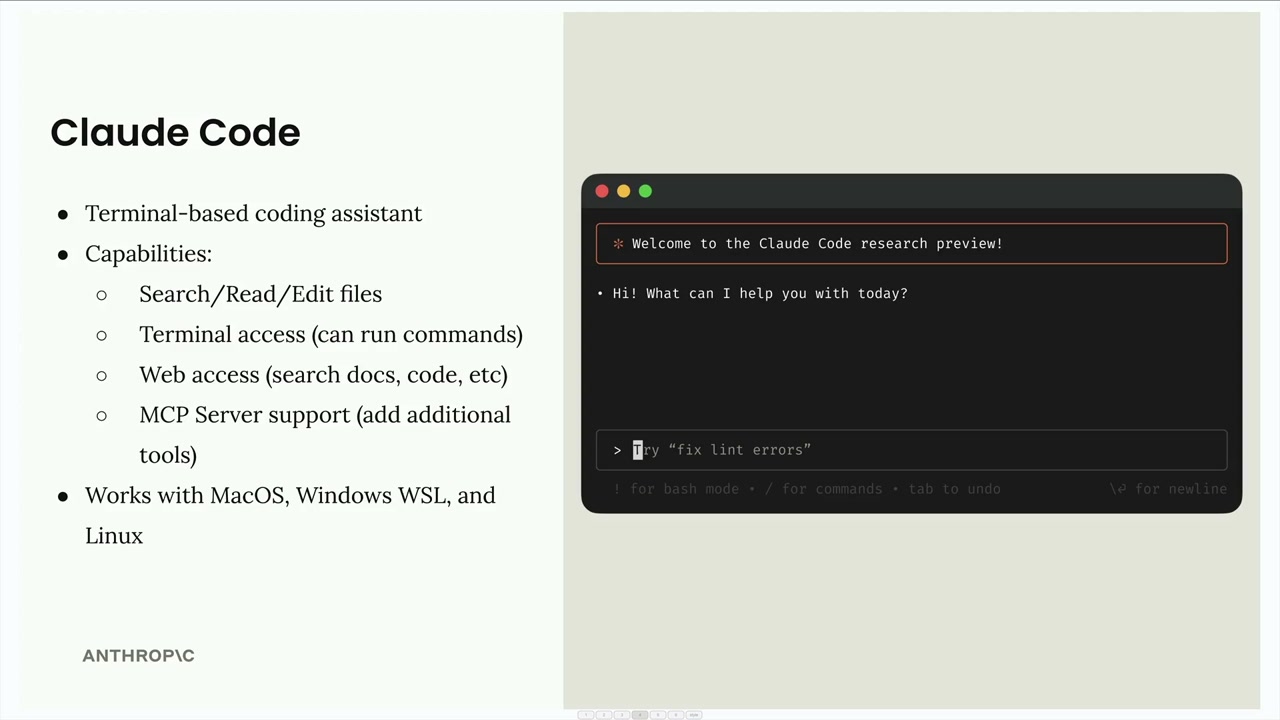
Claude Code 能做什么
Claude Code 配备了一套全面的工具来帮助您的开发工作流程:
- 文件操作 - 在您的项目中搜索、读取和编辑文件
- 终端访问 - 直接从对话中运行命令
- 网络访问 - 搜索文档、获取代码示例等
- MCP Server 支持 - 通过连接 MCP 服务器来添加额外的工具
MCP 集成尤其强大,因为它意味着您可以通过添加用于数据库、API 或您使用的任何其他服务的专用工具来扩展 Claude Code 的能力。
Claude Code 可在 MacOS、Windows WSL 和 Linux 上运行,因此无论您的开发环境如何,都可以使用它。
安装
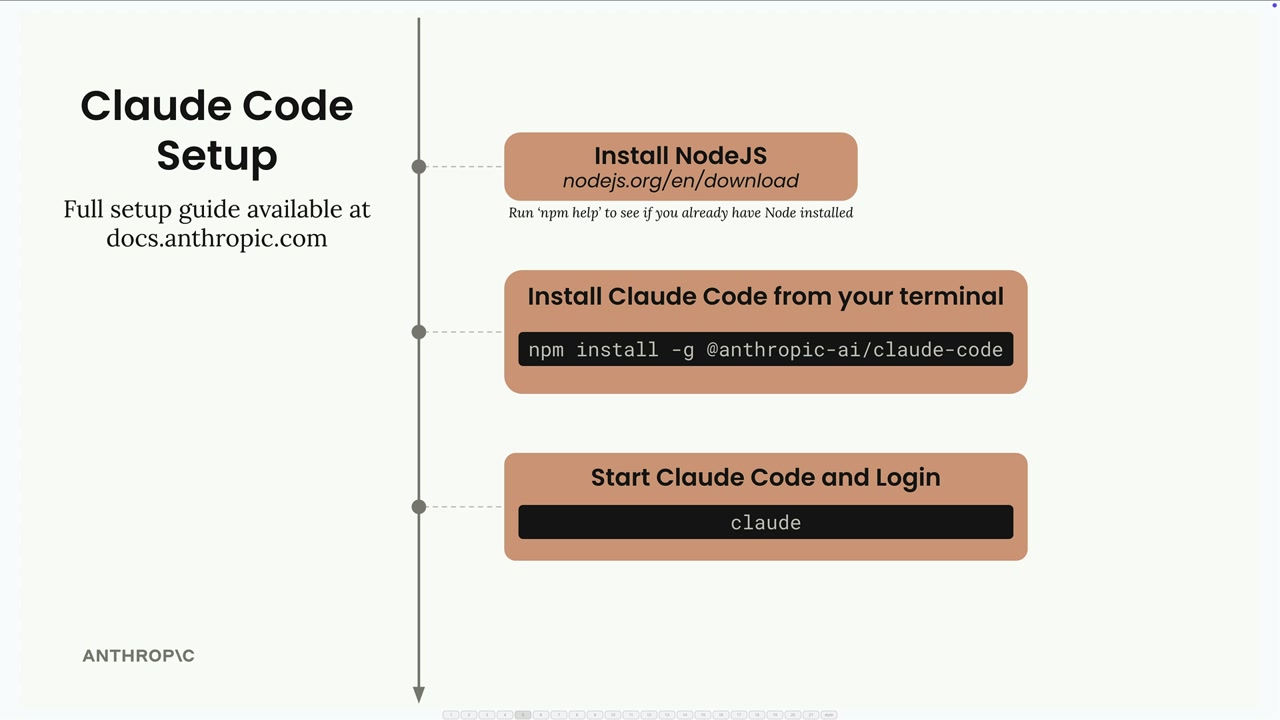
设置 Claude Code 只需三个步骤:
- 从 nodejs.org/en/download 安装 Node.js(通过在终端运行
npm help来检查是否已安装) - 使用命令
npm install -g @anthropic-ai/claude-code安装 Claude Code - 通过在终端中运行
claude来启动并登录
当您第一次运行 claude 命令时,它会提示您登录您的 Anthropic 账户。如果您需要更详细的说明,完整的设置指南可在 docs.anthropic.com 上找到。
设置完成后,您就可以直接在终端中使用 Claude,随时准备帮助您处理任何编码项目或任务。
视频文字稿
让我们来看看 Claude Code。我们将进行一些设置,学习它的工作原理,并看一些高级用例。Claude Code 是一个基于终端的编码助手。这是一个在您终端中运行的程序,可以帮助处理各种与代码相关的任务。
为了帮助您完成编码项目,Claude Code 可以访问许多不同的工具。它有许多基础工具,比如搜索、读取和编辑文件的能力。但它也有许多高级工具,比如网页抓取和终端访问。最后,Claude Code 可以作为一个 MCP 客户端。
您知道这意味着什么。这意味着它可以消费由 MCP 服务器提供的工具。所以我们可以通过添加一些额外的 MCP 服务器来轻松扩展 Claude Code 的能力。现在让我们进行一些设置,在您的机器上安装 Claude Code。
设置很简单。我们首先要安装一个 Node.js 的副本。您的机器上可能已经安装了 Node,要确定是否安装了,请打开您的终端并执行命令 NPM help。如果您看到有结果返回,那意味着您可能已经安装了 Node。
一旦您安装了 Node,您将执行一个 NPM install 命令来安装 Claude Code 本身。安装完成后,在您的终端运行 Claude 命令。这将提示您登录您的 Anthropic 账户。完整的设置指南可以在官方 Anthropic 文档 docs.anthropic.com 上找到。
现在我将让您自己完成这个设置过程,同样,只需这三个步骤。一旦您完成,我们将一起看一个小项目,看看 Claude Code 到底能为我们做什么。
80. Claude Code 实战
类型:视频 | 时长:10:29 | 视频:10 - 003 - Claude Code in Action.mp4
Claude Code 不仅仅是一个编写代码的工具——它被设计用来在软件项目的每个阶段与您并肩工作。您可以把它看作是您团队中的另一位工程师,能够处理从初始设置到部署和支持的所有事务。

/init 命令
当您开始在一个项目上使用 Claude Code 时,您首先要做的是运行 /init 命令。这会告诉 Claude 扫描您的整个代码库,以理解您项目的结构、依赖关系、编码风格和架构。
Claude 会将它学到的一切总结在一个名为 CLAUDE.md 的特殊文件中。这个文件会自动作为上下文包含在所有未来的对话中,所以 Claude 会记住关于您项目的重要细节。
您可以为不同的范围设置多个 CLAUDE.md 文件:
- Project (项目) - 在所有参与该项目的工程师之间共享
- Local (本地) - 您个人的笔记,不会被检入 git
- User (用户) - 在您所有的项目中通用
在运行 /init 时,您可以为您希望 Claude 关注的领域添加特殊指令。生成的文件将包括构建命令、编码指南以及 Claude 应遵循的项目特定模式。
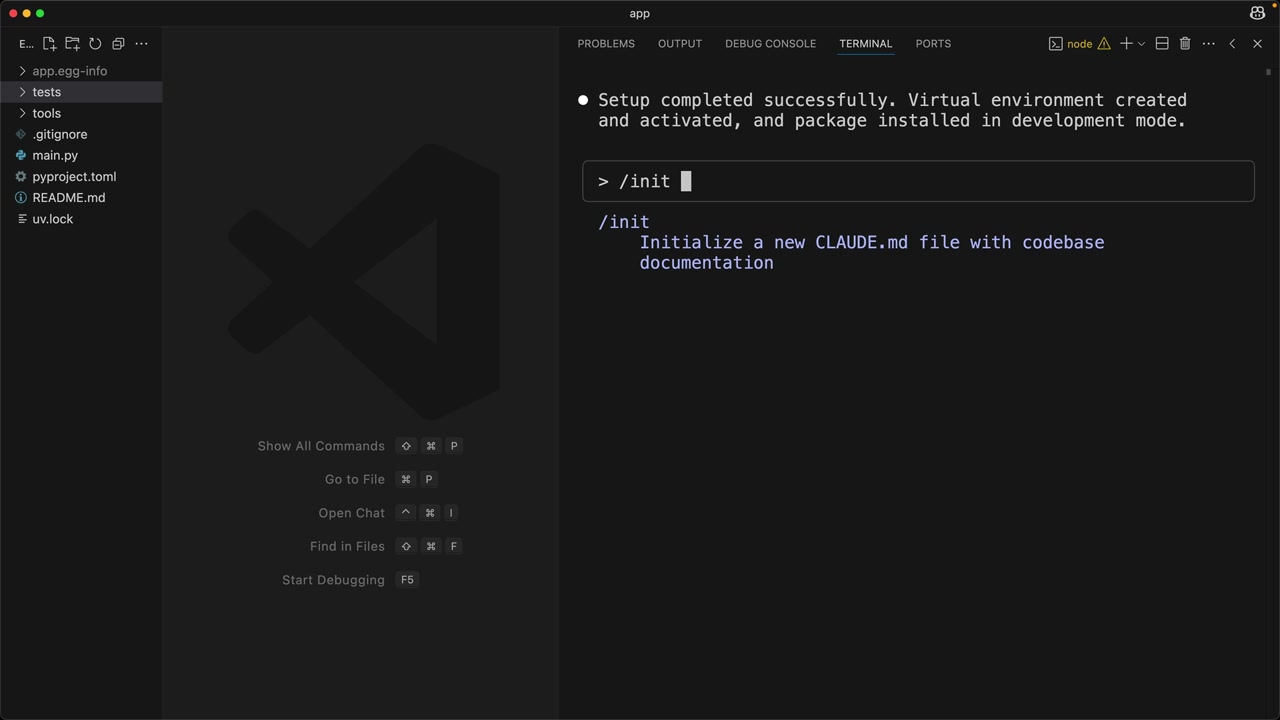
您还可以使用 # 命令快速向您的 CLAUDE.md 文件添加笔记。例如,输入 # Always use descriptive variable names 将提示您将此指南添加到您的项目、本地或用户内存中。
常用工作流程
当您将 Claude 视为一个效能倍增器时,它的效果最好。您提供的上下文和结构越多,您得到的结果就越好。以下是最有效的工作流程:

步骤 1:向 Claude 提供上下文
在要求 Claude 构建某样东西之前,先在您的代码库中找出与您想创建的功能相关的文件。首先要求 Claude 读取并分析这些文件。这为 Claude 提供了您的编码模式和它可以借鉴的现有功能的示例。
步骤 2:让 Claude 规划解决方案
不要直接跳到实现,而是要求 Claude 仔细思考问题并制定一个计划。明确告诉 Claude 先不要写任何代码——只专注于方法和所需的步骤。
步骤 3:要求 Claude 实现解决方案
一旦您有了一个可靠的计划,就要求 Claude 来实现它。Claude 将根据您们一起完成的上下文和规划工作来编写代码。
测试驱动开发工作流程
为了获得更好的结果,您可以使用 Test-Driven Development (测试驱动开发) 的方法:
- 向 Claude 提供上下文 - 和之前一样,向 Claude 展示相关文件
- 让 Claude 思考测试用例 - 让 Claude 集思广益,思考哪些测试可以验证您的新功能
- 让 Claude 实现这些测试 - 选择最相关的测试,并让 Claude 编写它们
- 让 Claude 编写能通过测试的代码 - Claude 将迭代实现,直到所有测试都通过
这种方法通常能产生更健壮的代码,因为 Claude 有明确的成功标准可以为之努力。
实践示例
这些工作流程在实践中是这样的。假设您想向一个现有项目添加一个文档转换工具:
// First, ask Claude to read relevant files
> Read the math.py and document.py files
// Then ask for planning (not implementation)
> Plan to implement document_path_to_markdown tool:
1. Create a function that:
- Takes a file path parameter
- Validates the file exists
- Determines file type from extension
- Reads binary data from file
- Leverages existing binary_document_to_markdown function
- Returns markdown string
2. Add appropriate documentation
3. Register the tool with MCP server
4. Add tests
// Finally, ask for implementation
> Implement the plan
然后,Claude 将创建该函数,更新必要的文件,编写测试,甚至运行测试套件以验证一切正常。
其他命令
Claude Code 包括几个有用的命令:
/clear- 清除对话历史并重置上下文/init- 扫描代码库并创建CLAUDE.md文档#- 向您的CLAUDE.md文件添加笔记
Claude 还可以处理日常的开发任务,如暂存和提交更改到 git、运行测试和管理依赖项。您不必在编辑器和终端之间切换,可以让 Claude 处理这些任务,而您则专注于更宏观的层面。
成功使用 Claude Code 的关键在于记住,它被设计成一个合作伙伴,而不仅仅是一个代码生成器。您提供的上下文和结构越多,Claude 就能越有效地帮助您构建和维护您的项目。
视频文字稿
为了让您亲身体验 Claude Code,我创建了一个小项目供我们一起实践。您应该可以在本讲座附带的 zip 文件中找到这个项目的源代码。我鼓励您下载这个 zip 文件,解压其内容,然后在这个新项目目录中启动您的代码编辑器。我已经在我的编辑器中打开了这个项目。
当您打开项目后,您可能会想浏览项目内容,或许还会按照 ReadMe 文件中的说明进行一些设置。但在您开始之前,我希望您了解关于 Claude Code 的一件重要事情。Claude Code 不仅仅是一个为您编写代码的工具。当然,它绝对能做到,但这并不是 Claude Code 的全部。
相反,您应该将 Claude Code 视为与您并肩工作的另一位工程师。您在常规项目中通常会经历的每一项任务,都可以完全委托给 Claude。这包括从最初的项目设置到新功能设计,再到部署和支持。在整个项目过程中,我们将在各个步骤中大量利用 Claude 来辅助我们。
我们将使用 Claude 来为我们设置项目,规划新功能,编写测试和代码,然后稍后在一个稍有不同的项目上,我将向您展示我们如何使用 Claude Code 自动发现并修复生产环境中的错误。那么,让我们开始吧。回到我的编辑器,我将打开我的终端,然后通过执行 Claude 在其中启动 Claude Code。一旦打开,我将向 Claude 发出我的第一个指令。
我将要求它读取 ReadMe 文件的内容,并执行其中列出的任何设置说明。我将要求 Claude 读取 ReadMe 文件的内容,并执行其中列出的设置说明。Claude 随后会使用各种不同的工具来读取该文件,然后执行一系列不同的命令。它会创建一个新的虚拟环境,激活该环境,并安装一些依赖。
完成后,我们将运行一个命令,帮助 Claude 更好地理解我们的项目。我们将通过运行 init 命令来做到这一点。这是我们将在 Claude Code 内部执行的一个命令。当您执行此命令时,Claude 会自动扫描您的代码库,以了解您项目的整体架构、编码风格等。
完成后,Claude 会将其所有发现写入一个名为 Claude.MD 的特殊文件。将来我们再次运行 Claude 时,这个文件将自动作为上下文包含进来。顺便说一下,有三个不同的 Claude 文件,分别是 Project、Local 和 User。我们稍后会看到对它们的引用。
到时我们再讨论它们各自的用途。每当您运行这个 init 命令时,您实际上还可以添加一些特殊指令,让 Claude 关注某些领域。那么,我们现在就来试试看,看看为我们的项目生成了什么。我将运行 init 命令,同时会传入一些特殊指令。
我将要求 Claude 包含一些关于定义 MCP 工具的详细说明。一旦完成,我将查看新生成的 Claude.MD 文件。这是 Claude 对我们代码库的总结。在顶部,它会列出一些它将来可能需要运行的重要命令。
我们会看到一些关于我们在这个项目中使用的编码风格的列表。然后,正如我特别要求的,它还包括了一些关于定义 MCP 工具的信息。正如我刚才提到的,这个文件将在我们未来向 Claude 发出的任何后续请求中作为上下文包含进来。现在,项目会随着时间变化。
我们可能会改变我们的编码风格或添加一些额外的命令。如果发生这种情况,我们可以非常轻松地手动编辑这个文件,或者我们可以选择重新运行 init 命令。如果您重新运行此命令,Claude 将更新 Claude.MD 文件的内容。最后,作为一个非常小的快捷方式,我们可以输入一个井号,然后输入我们希望追加到该文件内容中的特定说明。
所以我们可以用这个作为工具,向 Claude 提供非常具体的小指令,这些指令将包含在所有后续请求中。所以对我来说,我可能会在这里添加一个指令,比如“始终为函数参数应用适当的类型”。如果我运行它,系统会问我希望在哪里添加这个小说明。这就是我们看到 Project、Local 和 User 内存出现的地方。
在我的情况下,这是一个我希望与所有参与此项目的人共享的说明,所以我将把它添加到 Project 内存中。添加后,我可以检查我的 Claude.md 文件的内容,在代码风格下或者在最底部,我可能会看到我刚刚添加的任何说明。此时,我们向项目中添加了一个新文件,而这个项目是由 Git 管理的。所以通常情况下,我们会打开终端,将我们刚刚创建的这个新文件暂存到 Git 中,然后提交这些更改。
我们可以手动完成所有这些操作,但如果我们直接让 Claude 为我们做,会快得多。所以我将要求 Claude 暂存并提交所有更改。Claude 随后会查看我们对代码库所做的所有不同更改,编写一条描述性的提交信息,并提交这些文件。接下来,我想向您展示一些在编写代码时提高 Claude 效率的技巧。
我们将在这个项目中添加一个新功能。提醒一下,这个项目是一个非常小、非常简单的 MCP 服务器。我们将要求 Claude 向服务器添加一个新工具,该工具将读取 Word 文档或 PDF 文件,并将其内容转换为 Markdown。现在,我们当然可以直接向 Claude 输入指令,比如“制作一个 Word 文档+PDF 文件到 Markdown 的转换工具”。
但在这样做之前,我希望您知道,通过多花一点心思,我们可以显著提高 Claude 的效率。让我来展示如何做到。把 Claude Code 看作是一个效能倍增器。如果您在指导 Claude 的方式上多花一点心思,您将得到显著更好的结果。
我将向您展示两种不同的工作流程,两种不同的指导 Claude 完成任务的方式。这两种工作流程都需要您付出一些努力,但它们能让 Claude 解决更复杂的问题。在第一个工作流程中,我们将经历三个不同的步骤。首先,我们将确定我们代码库中与我们正在努力开发的功能相关的某些区域。
然后,我们将要求 Claude 专门阅读和分析这些文件。其次,我们将告诉 Claude 我们想要构建的功能,并要求它规划一个解决方案。也就是它实际会执行的步骤,以实现您试图解决的任何功能或问题。最后,在 Claude 完成规划步骤后,我们将要求 Claude 实际实现这些解决方案。
让我向您展示,对于我们添加新的文档转换工具这个特定功能,我们该如何操作。首先,我将浏览我的代码库,找出一些相关文件。您会注意到有一个 Tools 目录,里面有一个 Math.py 文件。这是一个已经完成的工具示例。
所以这个文件可能与我们试图构建的功能相关,因为它能让 Claude 更好地了解如何编写一个工具。其次,我们可能会要求 Claude 查看 document.py 文件,其中包含一个非常有用的函数,binary_document_to_markdown。这个函数会接收一些二进制数据并将其转换为 markdown。所以我们可以告诉 Claude 查看这些文件,Claude 会更好地了解如何编写工具,以及如何实际进行转换。
所以我将向 Claude 添加一些指令,让它只读取这些文件的内容。接下来,我将要求 Claude 规划一个名为 Document Path to Markdown 的新工具的实现,该工具将接收一个 PDF 或 Word 文档的路径,读取文件,将内容转换为 Markdown,并返回结果。我还将明确告诉 Claude 只规划功能,暂时不要编写任何代码。作为回应,Claude 会给我们一个相当详细的计划,其中会包含几个实施整个项目所需的步骤。
最后,我将要求 Claude 实现这个计划。它首先会更新 document.py 文件,这绝对是正确的。然后它会更新 main.py 文件,这也很好。最后,它会为这个新工具编写一个测试。
然后它会运行测试套件,并确保测试确实通过。您会注意到,在摘要消息中,Claude 还告诉我它为不存在或不支持的文件类型添加了一些错误处理,这绝对是适当的,尽管这并不是我在描述此功能时明确要求的内容。我想向您展示另一种我们可以要求 Claude 实现此功能的方式。在展示这个替代方案之前,我将让 Claude 通过储藏这些更改来移除它刚刚编写的所有代码。
现在,我又回到了一个干净的状态,没有任何与刚刚实现的新功能相关的东西。我们要探索的第二种技术是测试驱动开发工作流程。同样,这需要您预先付出更多的努力,但它能极大地提高 Claude 的效率。在这个工作流程中,我们将再次要求 Claude 查看一些相关的上下文。
然后,在编写任何代码之前,我们将要求 Claude 思考一些它可以为我们的功能编写的不同测试。接下来,我们将选择最相关的测试,并要求 Claude 实现它们。最后,在我们有了一些可用的测试之后,我们将要求 Claude 编写一个解决方案,并编写代码直到测试实际通过。让我向您展示,对于完全相同的功能,这种方法会是什么样子,即我们正在构建一个工具,它将从我们的硬盘上读取一个文档,并将其内容转换为 Markdown。
首先,我将运行 /clear 命令。这将清除我与 Claude 的对话历史,基本上是重置其上下文。在这种情况下,我这样做只是为了不让它抄袭之前的解决方案。然后我将再次要求 Claude 读取那两个相关文件。
然后我将添加一些非常明确的指令,让它思考一些可以用来评估我们想要构建的新功能的测试。同样,我将明确要求它暂时不要编写任何代码。我收到的建议非常可靠。现在,我不太想担心测试 6、7 和 8,因为那些比我们现在做的要专业一些。
所以我将要求 Claude 只实现测试一到五。现在我们将进入最后一步,我们将要求 Claude 编写一些代码来使这些测试通过。非常好,所有测试都通过了。现在,在我们继续之前,我只想再提醒您一次,Claude Code 真的是一个效能倍增器。
您可以给出非常简单的指令,Claude 会尽力而为。但您可以通过在您这边多花一点心思来显著提高 Claude 的效率。
81. 使用 MCP servers 进行功能增强
类型:视频 | 时长:2:30 | 视频:10 - 004 - Enhancements with MCP Servers.mp4
Claude Code 内置了一个 MCP 客户端,这意味着您可以连接 MCP 服务器来极大地扩展 Claude 的能力。这为定制您的开发工作流程开启了一些非常强大的可能性。
MCP 如何扩展 Claude
Model Context Protocol (模型上下文协议) 允许 Claude Code 通过 MCP 服务器连接到外部服务和工具。您不再局限于 Claude 的内置功能,而是可以通过连接提供特定工具、资源或集成的服务器来添加自定义功能。
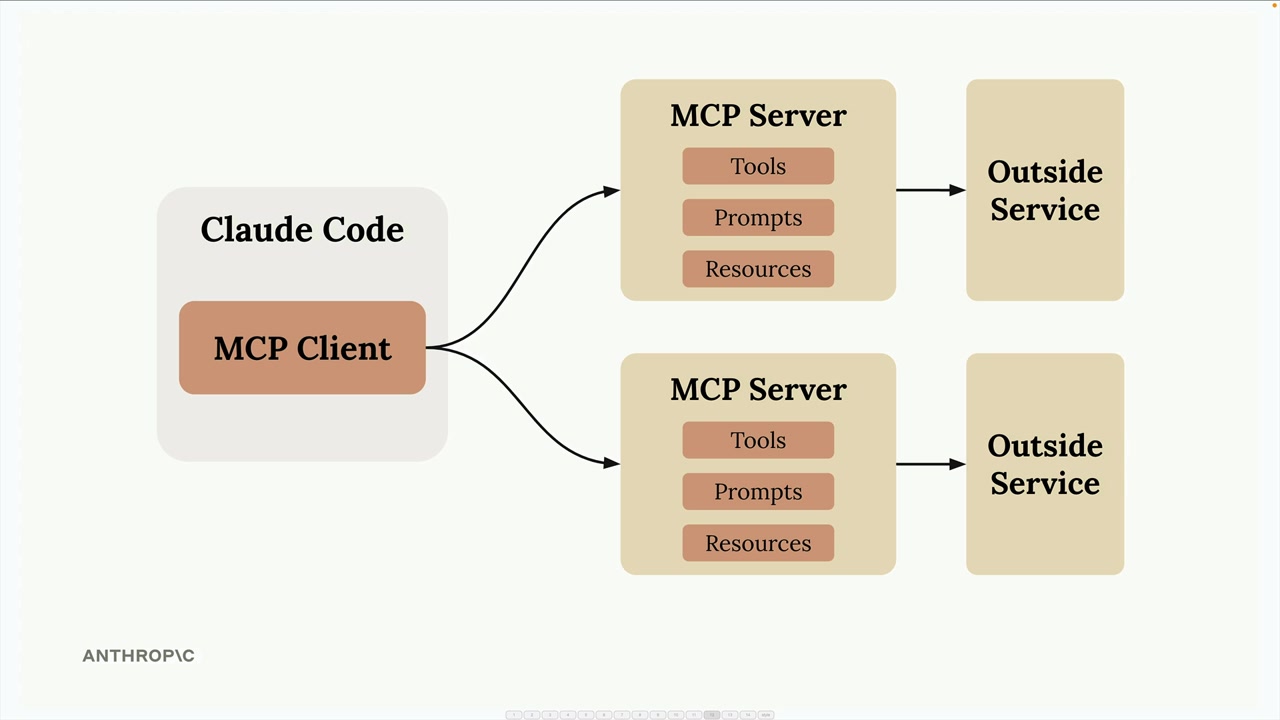
每个 MCP 服务器可以通过三个主要组件向 Claude 暴露不同类型的功能:Tools (用于执行操作)、Prompts (用于模板) 和 Resources (用于访问数据)。
设置 MCP 服务器
向 Claude Code 添加 MCP 服务器非常直接。您可以使用命令行来注册您的服务器:
claude mcp add [server-name] [command-to-start-server]
例如,如果您有一个文档处理服务器,启动命令是 uv run main.py,您将运行:
claude mcp add documents uv run main.py
注册后,Claude Code 在启动时会自动连接到您的服务器。
示例:文档处理
一个实际的例子是创建一个让 Claude 读取 PDF 和 Word 文档的工具。通过构建一个带有 "document_path_to_markdown" 工具的 MCP 服务器,您可以要求 Claude 将文档内容转换为 markdown 格式。
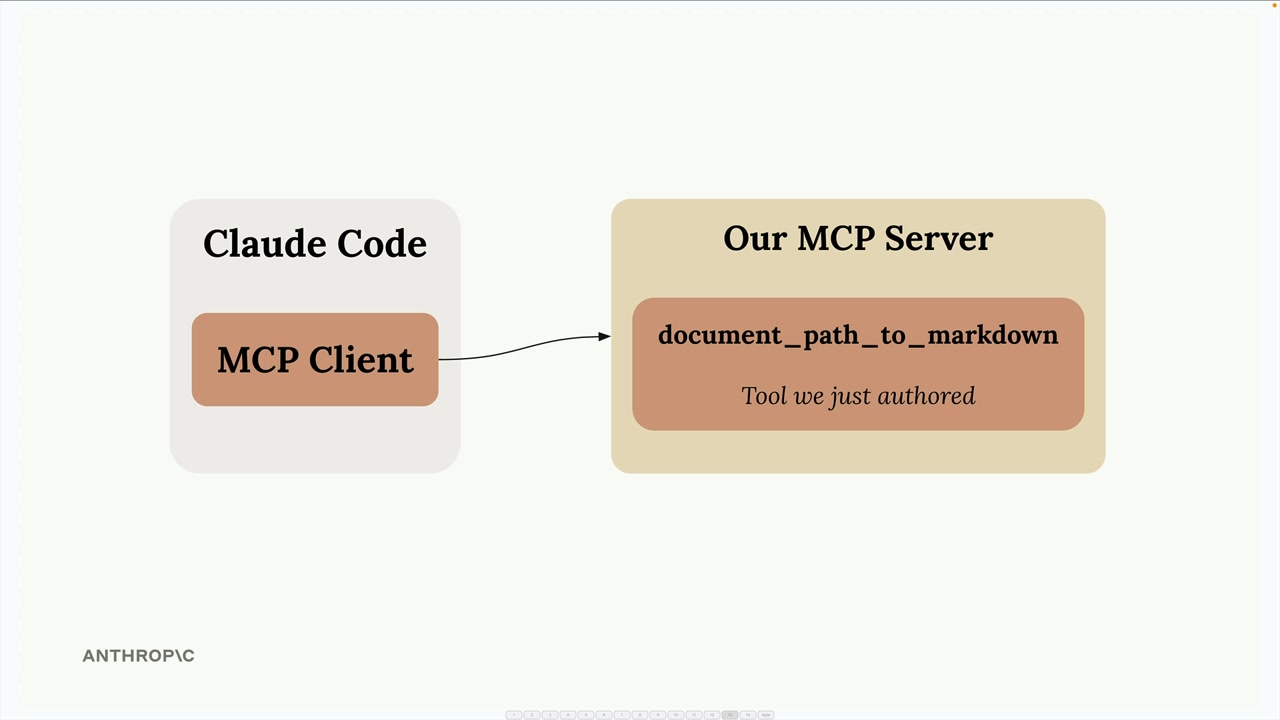
当您要求 Claude "Convert the tests/fixtures/mcp_docs.docx file to markdown" 时,它会自动使用您的自定义工具来读取文档并返回转换后的内容。
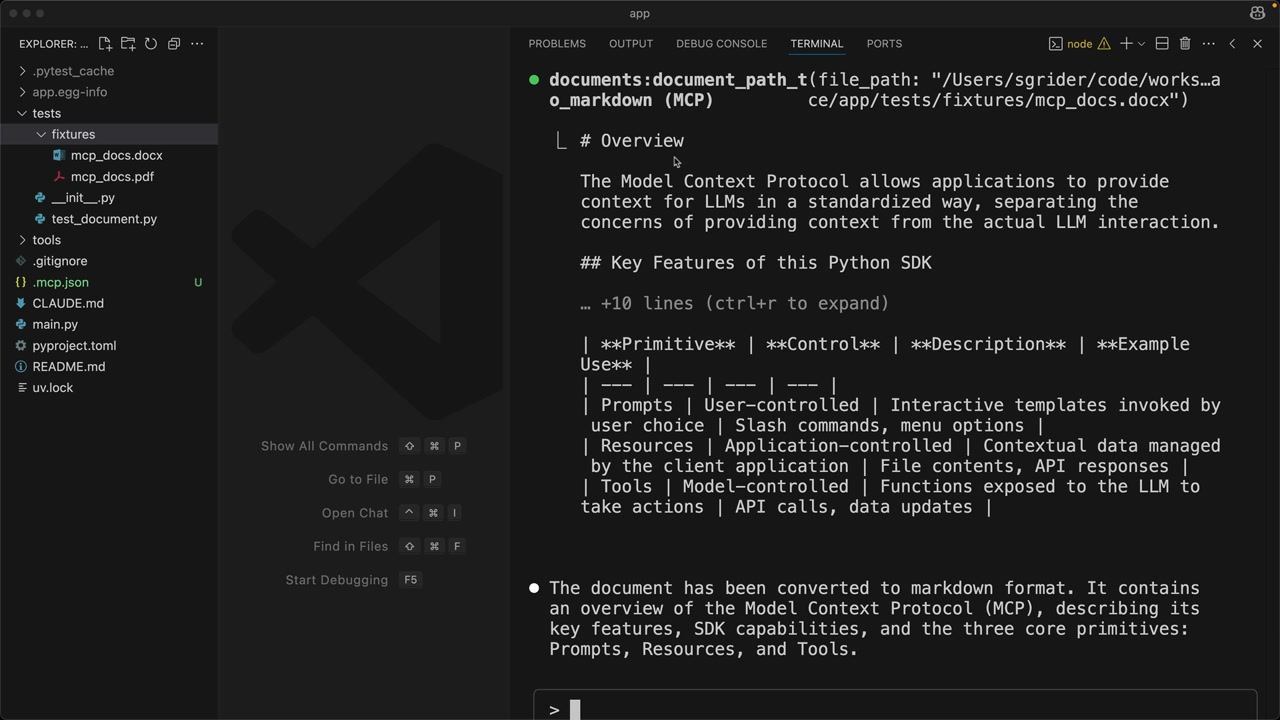
流行的 MCP 集成
MCP 生态系统包括许多常见开发工具和服务的服务器:
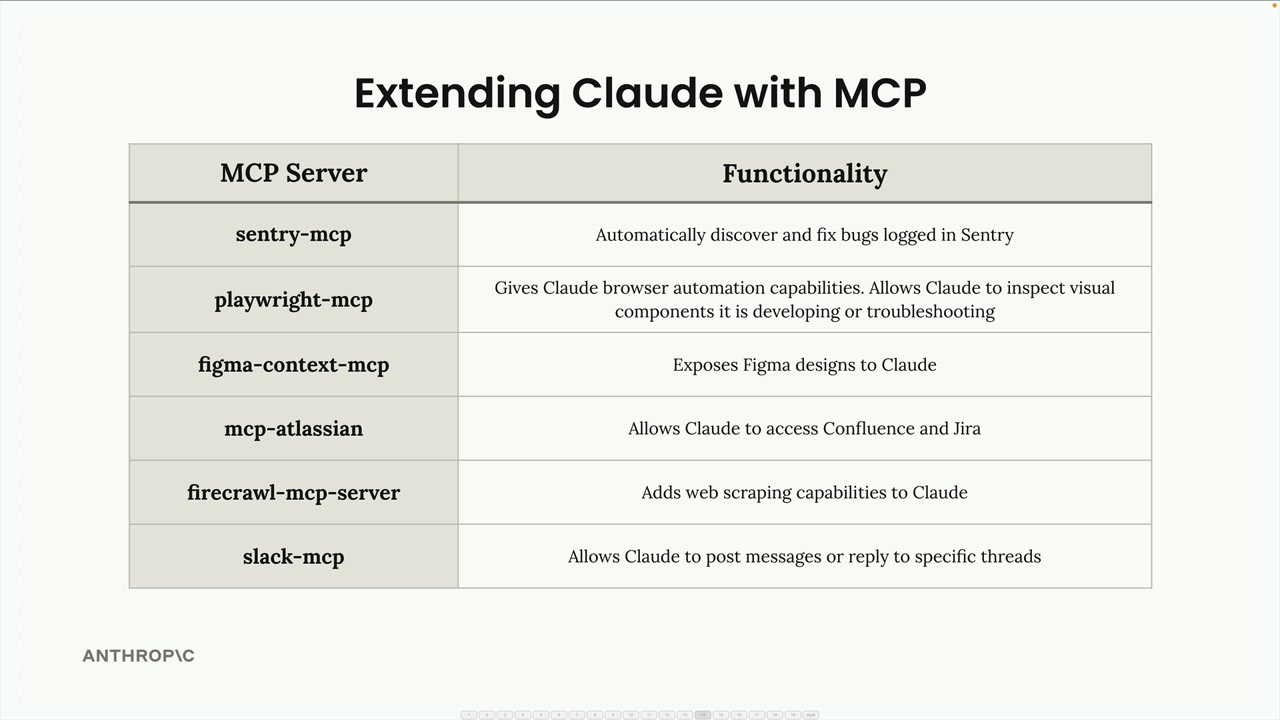
- sentry-mcp - 自动发现并修复 Sentry 中记录的错误
- playwright-mcp - 为 Claude 提供浏览器自动化能力,用于测试和故障排除
- figma-context-mcp - 向 Claude 暴露 Figma 设计
- mcp-atlassian - 允许 Claude 访问 Confluence 和 Jira
- firecrawl-mcp-server - 为 Claude 添加网页抓取能力
- slack-mcp - 允许 Claude 发送消息或回复特定帖子
构建您的开发工作流程
真正的威力来自于组合多个与您特定开发流程相匹配的 MCP 服务器。您可以设置:
- 一个 Sentry 服务器来获取生产环境的错误详情
- 一个 Jira 服务器来读取工单需求
- 一个 Slack 服务器在工作完成时通知您的团队
- 用于您内部工具和 API 的自定义服务器
这创造了一个开发环境,Claude 可以在其中与您已经使用的所有工具和服务无缝协作,使其成为一个更强大、更适合您特定工作流程的编码助手。
视频文字稿
在这个视频中,我想向您展示 Claude Code 最有趣的方面之一。Claude Code 内嵌了一个 MCP 客户端。这意味着我们可以将 MCP 服务器连接到 Claude Code,从而极大地扩展其功能。为了演示这一点,我们将把 Claude Code 连接到我们一直在开发的 MCP 服务器上。
我们刚刚编写了一个名为 Document Path to Markdown 的工具。我们现在可以将这个工具暴露给 Claude Code,使其能够读取 PDF 和 Word 文档的内容。所以我们正在动态地扩展 Claude Code 的能力。让我来向您展示如何设置。
回到我的终端,我将用 Control-C 结束我正在运行的会话。然后我将通过执行 Claude, MCP, add 向 Claude Code 添加一个 MCP 服务器,然后我们要输入我们 MCP 服务器的名称。现在这个名称可以是您想要的任何东西。在我们的案例中,我们正在创建一个与文档相关的服务器,所以我将把我们的服务器命名为 documents。
最后,我们将输入我们用来启动服务器的命令,对我们来说是 uvrun main.py。所以是 uvrun main.py。就是这样。我将执行它,然后用 Claude 重新启动 Claude Code。
现在我们可以利用我们刚刚创建的那个工具,在我们的测试目录中真正地测试它。在 fixtures 文件夹里有两个演示文件,一个 Word 文档和一个 PDF 文档。两者都包含一些关于 MCP 本身的少量文档。所以我现在将要求 Claude 将其中任一文件的内容转换为 Markdown。
我期望 Claude 会使用我们刚才编写的那个工具。如果我们向上滚动一点,果然成功了。所以这实际上就是那个文件的内容。这种消费 MCP 服务器的能力为 Claude Code 增加了令人难以置信的灵活性,并真正为一些非常有趣的开发机会打开了大门。
例如,您可能会决定添加一系列与您特定开发流程相关的 MCP 服务器。例如,如果您使用 Sentry 进行生产监控,您可以添加一个 Sentry MCP 服务器,让 Claude 获取生产中发生的错误的详细信息。如果您使用 JIRA,您可以添加一个 MCP 服务器,让 Claude 查看特定工单的内容。如果您是 Slack 用户,您可以添加 Slack,以便在 Claude 完成某个特定问题的工作时向您发送消息。
这些只是您可以添加到 Claude Code 中的可能增强功能的一小部分。所以绝对值得您花时间思考如何增强您特定的开发工作流程。
82. 并行化运行 Claude Code
类型:视频 | 时长:8:12 | 视频:10 - 005 - Parallelizing Claude Code.mp4
并行运行多个 Claude Code 实例是您可以实现的最大生产力提升之一。由于 Claude 是轻量级的,您可以轻松地启动多个副本,为每个副本分配不同的任务,让它们同时工作。这实际上为您提供了一个虚拟软件工程师团队来处理您的项目。
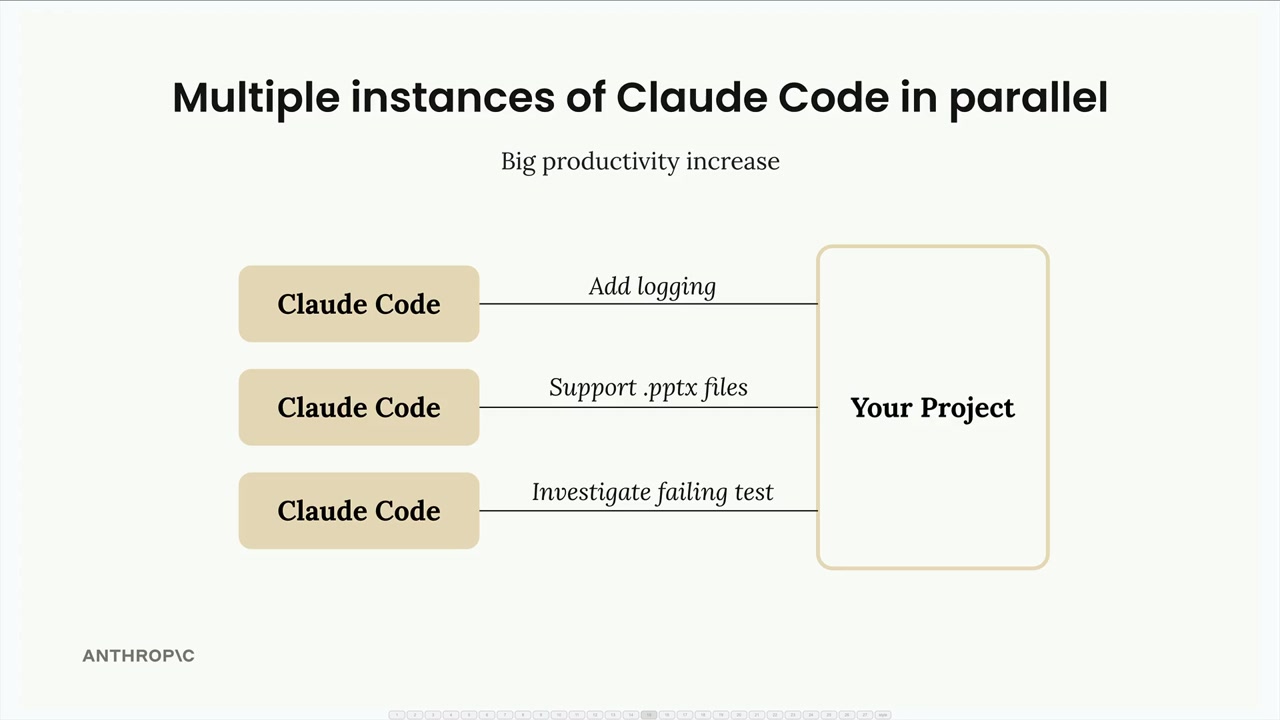
核心挑战
并行实例的主要问题是文件冲突。当两个 Claude 实例试图同时修改同一个文件时,它们可能会写入相互冲突或无效的代码,因为它们不知道对方的更改。
解决方案很简单:为每个实例提供其自己的独立工作空间。每个 Claude 实例使用其自己的项目副本进行工作,在隔离的环境中进行更改,然后将这些更改合并回您的主项目。
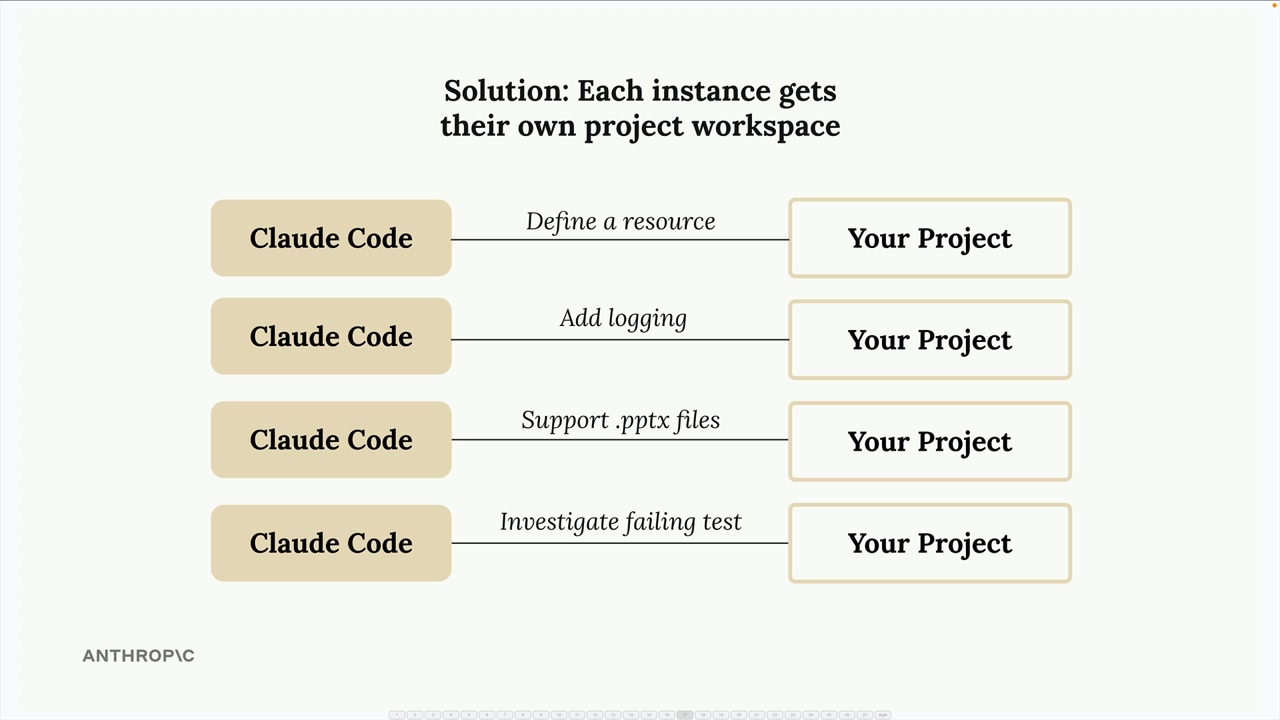
Git Worktrees
Git worktrees (Git 工作区树) 是此工作流程的完美工具。如果您的项目使用 Git(应该如此),您可以立即使用 worktrees。它们就像是 Git 分支系统的扩展,可以在独立的目录中创建您项目的完整副本。
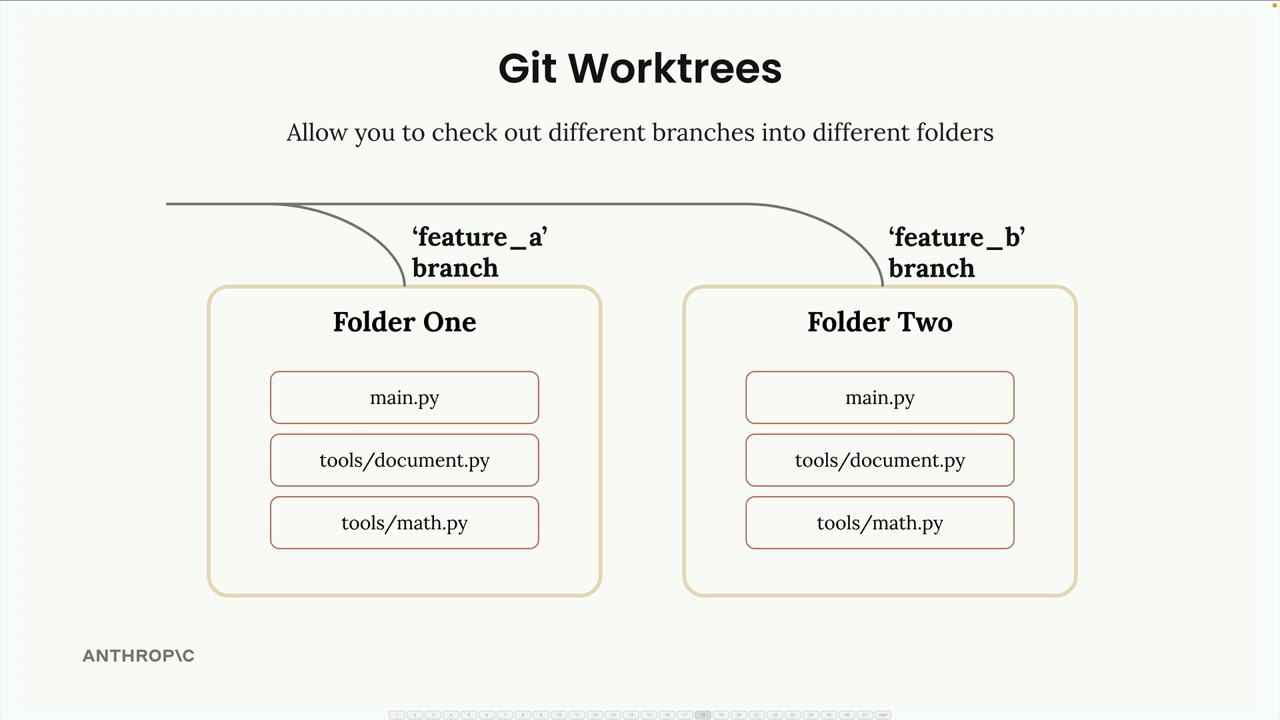
每个 worktree 对应一个独立的分支。您可以拥有:
- 一个文件夹中的功能 A 分支
- 另一个文件夹中的功能 B 分支
- 每个文件夹都包含您代码库的完整副本
- 每个文件夹中运行着独立的 Claude Code 实例
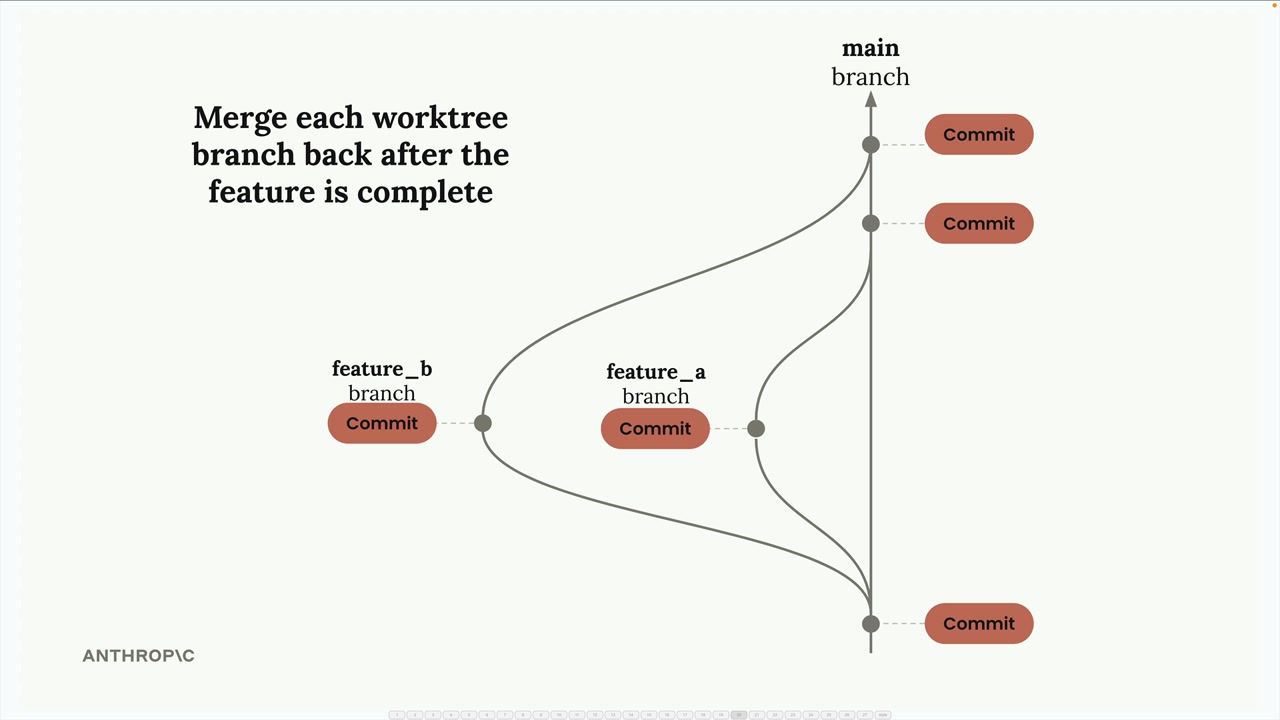
当每个 Claude 实例完成其工作时,您提交更改并将它们合并回主分支,就像任何正常的 Git 工作流程一样。

自动化 Worktree 创建
您可以让 Claude 处理整个过程,而不是手动创建 worktrees。这是一个创建 worktree 并设置工作空间的 prompt:
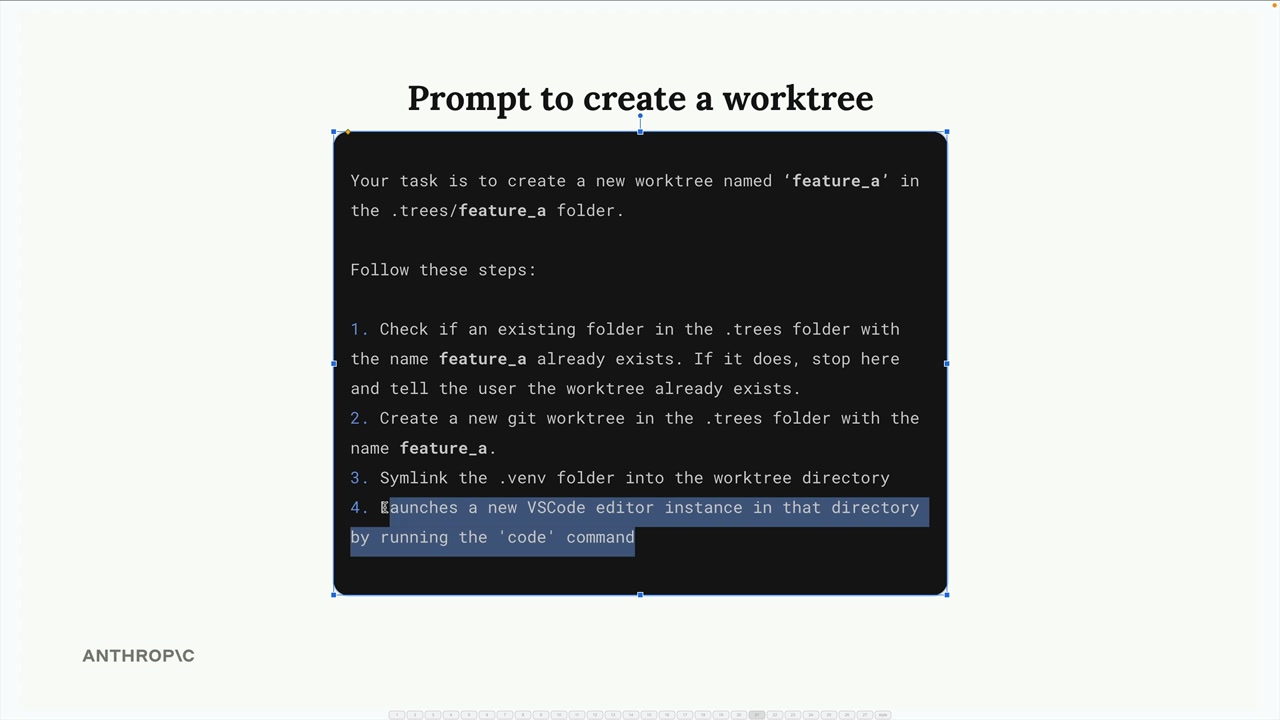
这个 prompt 告诉 Claude:
- 检查 worktree 是否已存在
- 在
.trees文件夹中创建一个新的 Git worktree - 对
.venv文件夹创建符号链接 (symlink)(因为虚拟环境不受 Git 跟踪) - 在该目录中启动一个新的 VSCode 实例
自定义斜杠命令
重复输入长长的 prompts 会很乏味。Claude Code 支持自动化此过程的自定义命令。

要创建自定义命令:
- 在
.claude/commands中添加一个.md文件 - 将您的 prompt 放在文件中
- 使用
$ARGUMENTS作为动态值的占位符 - 使用
/project:filename argument运行
例如,/project:create_worktree feature_b 将创建一个名为 "feature_b" 的 worktree。
并行开发工作流程
一个典型的并行开发会话是这样的:
- 为不同功能创建多个 worktrees
- 在每个工作空间中启动 Claude Code
- 为每个实例分配不同的任务
- 让它们并行工作
- 每个任务完成时提交更改
- 将所有分支合并回主分支

自动化合并
您还可以使用另一个自定义命令来自动化合并过程。创建一个合并 prompt,该 prompt 会:
- 切换到 worktree 目录
- 检查最新的提交
- 切换回根目录
- 合并 worktree 分支
- 自动处理任何合并冲突
- 根据对更改的理解来解决冲突
Claude 甚至可以智能地处理合并冲突,理解来自不同分支的更改上下文并适当地解决它们。
扩展你的开发
这种方法可以扩展到你能有效管理的任意数量的并行实例。你唯一的限制是:
- 你的机器资源
- 你协调多项任务的能力
- 潜在合并冲突的复杂性
生产力的提升是巨大的——你不再是按顺序开发功能,而是可以同时开发多个功能,从而显著减少复杂项目的开发时间。
视频文字稿
在这段视频中,我们将探讨 Claude Code 带来的最大生产力提升之一。因为 Claude 是一个轻量级进程,你可以轻松地运行它的多个副本。每个实例都可以被分配一个任务,然后这些独立的实例将并行工作。这项技术让单个开发者能够指挥他们自己的虚拟软件工程师团队。
因此,在接下来的视频中,我想向你展示在真实项目中实施此工作流的一些具体细节。首先要解决的一大挑战是,两个 Claude 实例可能想在差不多同一时间处理同一个文件。它们最终可能会写出相互冲突的代码,甚至是无效的代码,因为它们没有意识到有其他进程正在修改同一个文件。为了解决这个问题,我们可以确保每个实例都有自己独立的工作区。
每个实例都可以在自己项目副本上工作,进行更改,然后最终将这些更改合并回你的主项目工作区。实现这一点的一个常用方法是使用 Git worktree。Git worktree 是 Git 的一个功能,所以如果你的项目已经由 Git 管理,你就可以立即使用 worktree。Worktree 就像是 Git 内置分支功能的扩展。
一个 worktree 允许你在开发机器上的一个新目录里创建项目的完整副本。每个 worktree 对应一个单独的分支。所以,如果我们左边有功能 A,右边有功能分支 B,我们可以轻松创建两个独立的文件夹,每个文件夹都包含我们代码库的完整副本。然后,我们可以为每个 worktree 运行单独的 Claude Code 实例。
它们各自将在自己独立的环境中工作,完全隔离。一旦每个 Claude Code 副本完成某个功能,我们就可以为每个 worktree 提交工作,然后将它们合并回我们的主分支,就像我们合并一个普通分支一样。现在,这听起来可能是一个非常复杂且难以管理的工作流。但请记住,你可以将大量工作委托给 Claude Code,包括围绕 Git 的任务。
所以我们实际上可以让 Claude Code 自己来管理这整个工作流。让我来告诉你怎么做。首先,我们可以写一个 prompt,让 Claude 为我们创建 worktree。我们可能还会让它在新建的 worktree 文件夹中打开我们的代码编辑器。
这就是我这个 prompt 里的要求。我要求 Claude 在 trees/feature_a 目录下创建一个新的 worktree。然后,我将要求它 Simlink(符号链接)一些依赖项,因为这些依赖项不受 Git 跟踪,所以它们不会被自动复制到 WorkTree 目录中。然后我会让 Claude 也在那个新的子目录中打开我的代码编辑器。
现在让我演示一下这一切是如何运作的。所以,我将拿这个确切的 prompt,在 Claude code 中运行它。Claude 接下来会创建 worktree,创建虚拟环境的 Simlink(符号链接),然后在这个新的子项目文件夹中打开一个新的代码编辑器实例。
在我原来的编辑器窗口中,我会看到多了一个新的 trees 目录。里面有一个 feature a 文件夹。在那个 feature a 文件夹里,是我的项目的完整副本。而这个副本已经在这个新的编辑器窗口中被自动打开了。
所以在这个新的编辑器窗口里,我可以启动 Claude Code 并让它完成一些任务,比如添加一些新功能或编写测试,或者做任何我需要做的事情。现在这个 Claude Code 实例是在完全隔离的环境中运行的。不过,在让 Claude Code 在这里做任何事情之前,我想指出,记住这个 prompt 真的很长。而且每次我们想创建一个新的 worktree 时,到处复制粘贴会非常繁琐。
所以我们很快会讨论一个题外话,一个 Claude Code 的小功能,它使得创建和合并这些独立的 worktree 变得非常容易。所以我们可以通过利用 Claude Code 的另一个功能来自动化整个 prompt。即对自定义命令的支持。你可以通过在你项目的一个特殊目录里创建一个 markdown 文件来向 Claude Code 添加自定义斜杠命令。
这个特殊目录是 .claude/commands。在该目录下的一个文件里,我们会写下我们的整个 prompt,然后我们就可以随时轻松地运行这个自定义 prompt。让我来告诉你如何使用这个功能来轻松创建一个新的 worktree。所以在我的原始编辑器窗口中,我将创建一个名为 .claude 的新文件夹,在里面我再创建一个名为 commands 的文件夹,然后在里面我将创建一个文件,比如叫 createworktree.md。
然后,在里面,我将粘贴我们刚才看到的那个 prop。现在,这个 prompt 有一个硬编码的功能名称或硬编码的分支 feature_underscore_a。我并不总是想要完全一样的字符串。所以我将用一个特殊的字符串替换它。
即 dollar sign arguments(美元符号参数),全部大写。这允许我们在实际运行这个自定义命令时注入一些额外的参数。所以现在如果我保存这个文件并快速重启 Claude Code,我就可以运行 /project:create worktree。它被特别命名为 create work tree,因为这是我在那个 commands 目录中创建的文件的名称。
然后我将输入一个空格,然后是这个新 worktree 的名称。这次我将把它命名为 feature_underscore_B。所以现在 feature_B 将被用来替换我放置 dollar sign capital arguments(美元符号大写参数)的任何地方。所以现在如果我运行这个,我应该很快就会看到一个新的 worktree 被创建。
不久之后,我就有了我的新代码编辑器实例。所以现在这个是在 worktree feature_underscore_B 中打开的。我可以看到那个额外的 worktree 已经创建在 trees 目录里了。既然我们已经看到了如何创建多个不同的 worktree,我想在这里给你一个完整的演示。
我将创建四个独立的 worktree。每一个都旨在完成一些不同的任务。所以我将有四个 Claude Code 实例在运行。第一个将围绕文档添加一些测试。
第二个将添加一些日志记录。第三个将添加两个新工具,第四个将添加一个减法工具。我将并行运行所有这些任务,然后我将把它们所有的更改合并回我的主分支。所以对于第一步,我将创建四个独立的 worktree。
我现在有四个独立的编辑器实例,每个我想实现的功能都有一个。我将在每个实例中启动 Claude Code,并给它们各自一些关于要添加功能的指示。当 worktree 完成后,我将要求 Claude 提交该代码。然后当它们都完成后,是时候将所有这些来自不同分支的更改合并回我的主分支了。
我们不必手动操作。相反,我们可以让 Claude 帮我们做。所以我整理了另一个 prompt,我将把它作为项目中的一个额外的自定义命令连接起来。这个 prompt 要求 Claude 进入我们其中一个不同的功能 worktree。
查看最近的一次提交,只是为了了解做了什么,然后尝试将这些更改合并回主分支。我将把这个 prompt 作为另一个自定义 prompt 添加到我的项目中。所以在 Claude commands 内部,我将创建一个新文件。我将这个命名为 mergeworktree。
粘贴进去。然后我将重启 Claude Code。接着我将运行 mergeworktree 命令。我首先会要求它合并刚刚创建的 document test 分支。
然后我可以为所有其他 worktree 重复这个过程。当我合并 Subtract(减法)功能时,会有一个合并冲突,但 Claude 会自动为我解决这个冲突。当所有东西都合并好后,我就可以让 Claude 清理掉所有这些已经创建的不同 worktree。就是这样。
所以我现在通过使用 Git worktree,完全并行地实现了四个独立的功能。这显然是一个巨大的生产力提升。而且它能扩展到我作为一名工程师,在同一时间里感觉自己能管理的任意多个不同实例。
83. 自动化调试
类型:视频 | 时长:4:24 | 视频:10 - 006 - Automated Debugging.mp4
Claude Code 的能力远不止在你的编辑器中编写代码。它可以监控你已部署的应用程序,检测生产环境中的错误,甚至自动修复它们。这创造了一个强大的工作流,其中 Claude 充当你的自动化调试助手,捕捉那些只在生产环境中出现的问题。
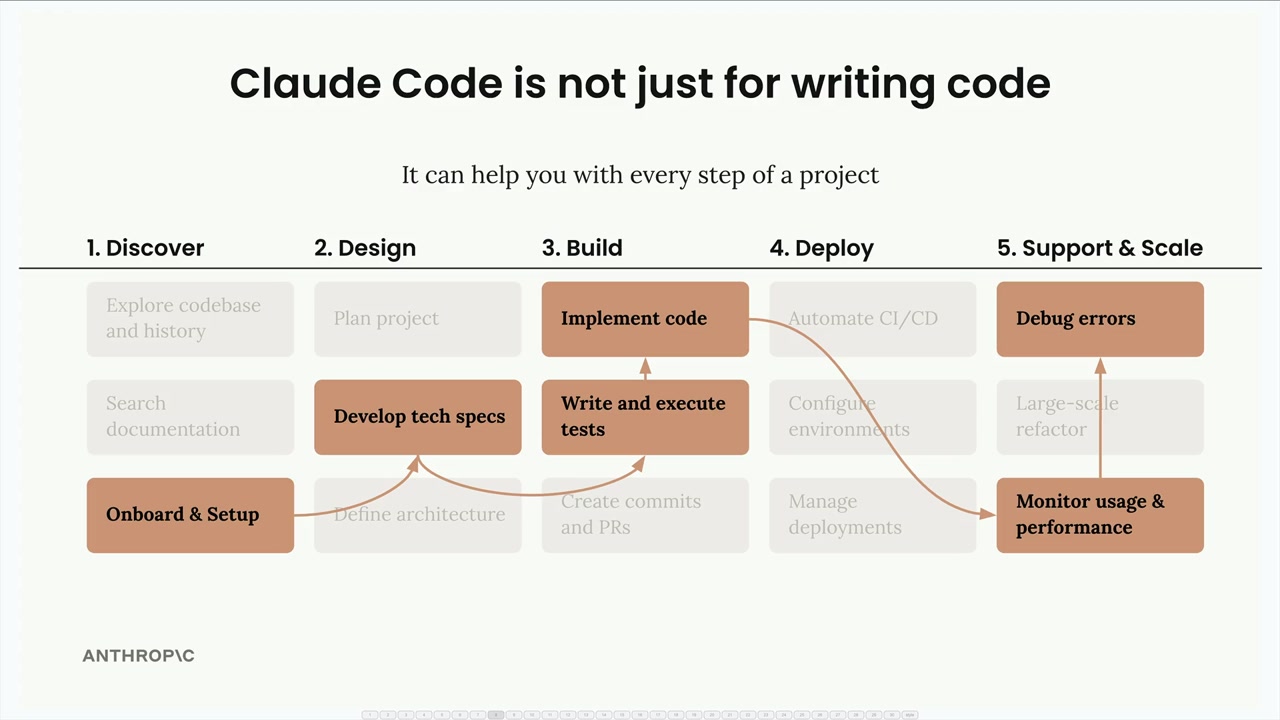
生产环境问题
这是一个常见场景:你的应用程序在开发环境中完美运行,但在生产环境中却出现问题。你可能有一个聊天机器人,在本地能正确回答简单问题,但部署到 AWS Amplify 后,在生成电子表格等工件时失败。请求看起来成功了,但结果是空的或不完整的。
传统上,你需要深入研究 CloudWatch 日志,寻找错误消息,并手动调试本地环境和生产环境之间的差异。这个过程非常耗时,并且需要你从开发工作切换到运维故障排除。
自动化错误检测与修复
与其手动调试,你可以设置 Claude 来自动处理整个工作流。以下是该系统的工作原理:
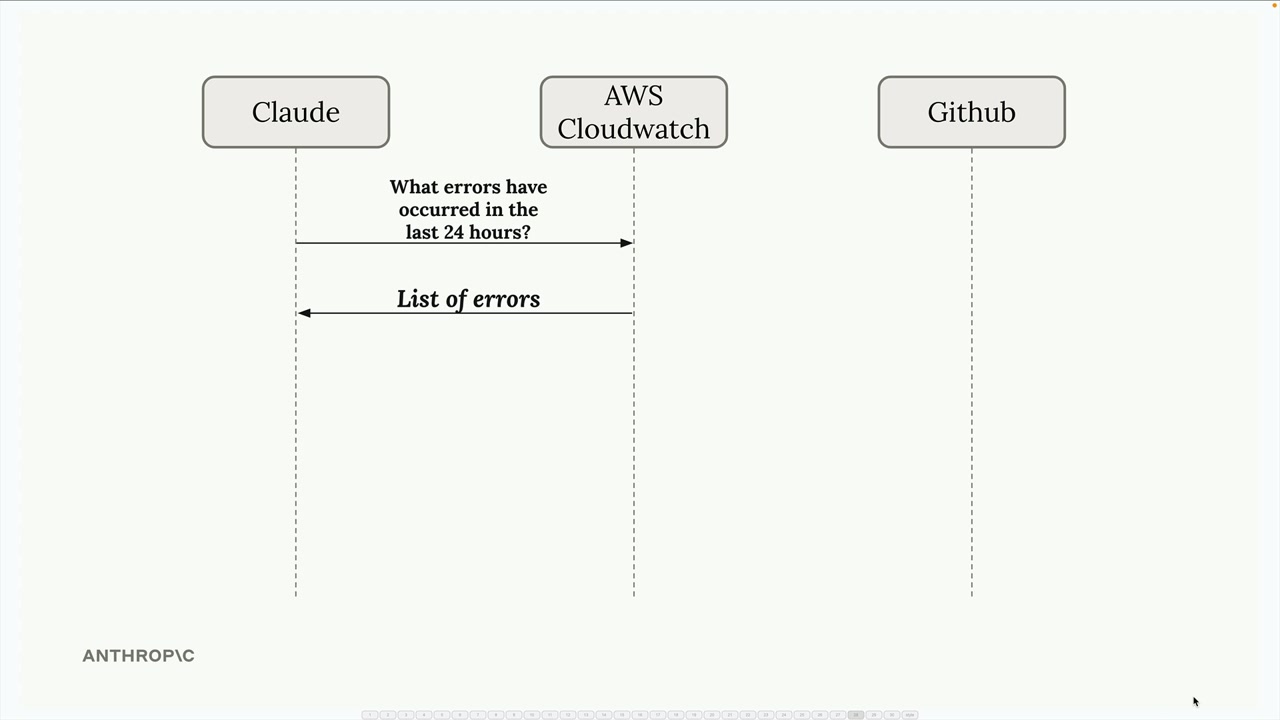
自动化工作流遵循以下步骤:
- 一个 GitHub Action(GitHub 动作)每天运行(通常在清晨)
- Claude 查询 CloudWatch 中过去 24 小时的错误
- 它对错误进行筛选和去重,以适应上下文限制
- Claude 分析每个错误并尝试修复它
- 修复后的代码被提交,并自动打开一个 pull request(拉取请求)
设置工作流
GitHub Action 需要几个组件才能有效工作:
repository checkout(仓库检出)和依赖安装- Claude Code 的设置和配置
- 安装 AWS CLI 以访问 CloudWatch
- 错误筛选逻辑以管理上下文窗口限制
- 自动提交和创建 pull request
当 Claude 在你的日志中发现错误时,它不仅仅是识别它们——它能理解上下文。例如,如果你有一个只影响生产环境的无效模型标识符(比如 us.anthropic.claude-3-5-sonnet-20241021-v2:0 而不是正确的 us.anthropic.claude-3-5-sonnet-20240624-v1:0),Claude 可以识别这种模式并应用适当的修复。
实际效果
当自动化系统成功运行时,你会看到包含以下内容的 pull request:
- 用通俗语言写的清晰错误描述
root cause analysis(根本原因分析)- 实施的具体修复
- 更新了正确模型标识符或配置的代码
这个 pull request 变成了一个可审查的工件,你可以清楚地看到 Claude 发现了什么以及它是如何修复问题的。这让你在保持代码审查实践的同时,对更改充满信心。
自定义你的调试工作流
这种自动化调试方法非常灵活。你可以根据你的具体需求进行调整:
- 调整错误检测频率
- 自定义优先处理哪些类型的错误
- 为你的应用程序添加特定的调试指令
- 与 CloudWatch 之外的不同日志系统集成
- 为关键问题设置通知
关键在于 Claude Code 能够理解你的应用程序上下文,智能地分析生产环境错误,并提出考虑到环境特定差异的修复方案。这将调试从一个被动的、手动的过程转变为一个主动的、自动化的系统,确保你的应用程序平稳运行。
视频文字稿
Cloud Code 不仅仅是帮助你在编辑器里编写代码。在你部署应用程序后,它还能帮助你监控错误,并在错误出现时协助修复。因此,在本视频中,我将引导你了解一个示例工作流,我们将观察一个在生产环境中出现错误的生产应用。我们将看看如何利用 Cloud Code 自动发现并修复这些错误。
首先,让我给你看一个我做的小示例应用。这是一个非常简单的聊天机器人,目前在我自己的电脑上本地运行。你可以看到证据,我目前在 localhost 3000。
如果我在这里问任何问题,比如“一加一等于几”,没问题。我很快就会得到答案。这个聊天应用还能制作简单的工件。例如,它可以显示一个内置的电子表格。
我将要求它用一些假数据制作一个电子表格。看起来一切都按预期 100% 正常工作。请记住,这个应用程序目前在我的本地开发环境中运行。但因为现在测试时一切正常,我可能会决定将它部署到生产环境。
我已经提前做好了。我已经把这个完全相同的应用部署到了 AWS Amplify。所以这是完全相同应用的生产版本,它现在托管在 Amplify 上。我将重复我刚才给你看的完全相同的测试。
我首先会问“一加一等于几”。然后我会紧接着提出和刚才在本地应用中一样的请求。也就是用一些假数据制作一个电子表格。我们会看到请求发出去了。
但不幸的是,电子表格本身是完全空的。实际上没有生成任何数据。所以现在很明显,这个生产环境中的某些东西没有按预期工作。开发环境中的一切都正常。
完全相同的操作序列在开发环境中完全没问题,但特别是在生产环境中,我遇到了这个错误。要找出问题所在,我可以查看我的 CloudWatch 日志。我已经打开了那些日志,并且已经搜索过并找到了这个错误的根源。所以我这里有一条错误信息。
它说提供的模型标识符无效。然后这里还包含了很多调试信息。所以我作为一名工程师,可以拿着这条我在日志中费力找到的错误信息,做一些本地调试,试图找出为什么这在生产环境中失败,但在本地却没有。或者,我可以把这整个任务委托给 Claude。
让我给你演示一下。在我的这个项目的 GitHub 仓库里,我创建了一个 GitHub Action,它每天都会在清晨自动运行。屏幕上现在是我今天早些时候一次示例运行的结果。我稍后会给你看一些这个 GitHub Action 的日志。
但首先,让我给你看一张图,它会帮助你理解里面发生了什么。好的,所以每当这个 GitHub Action 运行时,它会检出我的仓库,安装一些依赖,然后安装并设置 Cloud Code。接着我还会安装一个 AWS CLI,这让我可以访问并从 CloudWatch 获取一些日志。然后我把一些指令传递给 Claude。
我让它访问 CloudWatch 并找出过去 24 小时内发生的所有错误。我还在里面加入了一些逻辑来移除重复的错误,并减少错误的总数,以便 Claude 的上下文窗口能够处理。一旦 Claude 有了错误列表,它就会遍历它们并尝试修复每一个。然后,一旦 Claude 希望已经成功修复了这些错误,它就会提交这些更改并自动打开一个 pull request,我可以在那里查看它的工作。
所以在这种情况下,就像我们刚才看到的,我在我们的生产环境中遇到了一个错误。我在日志中看到了那个错误。如果我现在去我的 pull request 列表这里,我会说 Claude 自动运行了,它自动发现了问题,应用了修复,然后创建了一个 pull request。所以现在我可以非常轻松地审查这个 pull request。
整个问题都用简单的语言向我解释清楚了,在这种情况下,这只是我自己的一个拼写错误。我意外地输入了一个无效的模型 ID,这个 ID 只在生产环境中使用。所以 Claude 注意到了这一点。它找到了正确的模型 ID 并换上了正确的,然后提交了更改。
所以现在我可以非常轻松地审查更改并合并 pull request。这只是你可能用来自动监控和修复生产环境中应用的一个示例工作流。记住,Cloud Code 非常灵活,你可以创建像这样的自定义工作流来帮助你自己的调试工作。
84. 计算机使用
类型:视频 | 时长:3:05 | 视频:10 - 007 - Computer Use.mp4
Computer Use(计算机使用)是一项强大的功能,它能让 Claude 直接与桌面环境交互,从本质上赋予了 AI 像人类一样控制计算机的能力。这项能力为自动化、测试和工作流辅助开辟了全新的可能性。
计算机使用能做什么
Claude 不再仅仅是生成代码或提供建议,它实际上可以浏览网站、点击按钮、填写表单,并与应用程序进行实时交互。这使得它在以下任务中非常有用:
- Web 应用程序的自动化
QA testing(质量保证测试) - 数据录入和表单填写
- 网站导航和信息收集
UI testing(用户界面测试)和验证- 重复性的桌面任务
真实世界示例:自动化 QA 测试
这里有一个实际的例子,展示了 Computer Use 的强大功能。想象一下,你构建了一个带有自动完成功能的 React 组件——用户可以输入 @ 来提及文件或资源。乍一看,一切似乎都运行良好,但可能存在一些你尚未发现的边缘情况。
与其手动测试所有可能的交互,你可以将这项工作委托给 Claude。你只需提供如下指令:
你的目标是对托管在 https://test-mentioner.vercel.app/ 上的一个 React 组件进行 QA 测试
测试流程:
1. 打开一个新的浏览器标签页
2. 导航到 https://test-mentioner.vercel.app/
3. 逐一执行以下测试用例
4. 完成所有测试后,撰写一份简明报告
测试用例:
1. 输入 'Did you read @' 应该显示自动完成选项
2. 输入 'Did you read @' 然后按回车键应该添加 '@document.pdf'
3. 添加 '@document.pdf' 后,按退格键应该在文本正下方显示自动完成选项,而不是在页面的其他地方
实践中的工作原理
Computer Use 在一个受控环境中运行——通常是一个带有浏览器的 Docker 容器,它与你的主系统完全隔离。你通过一个聊天界面与 Claude 互动,给它下达指令,然后观察它如何导航和与应用程序交互。
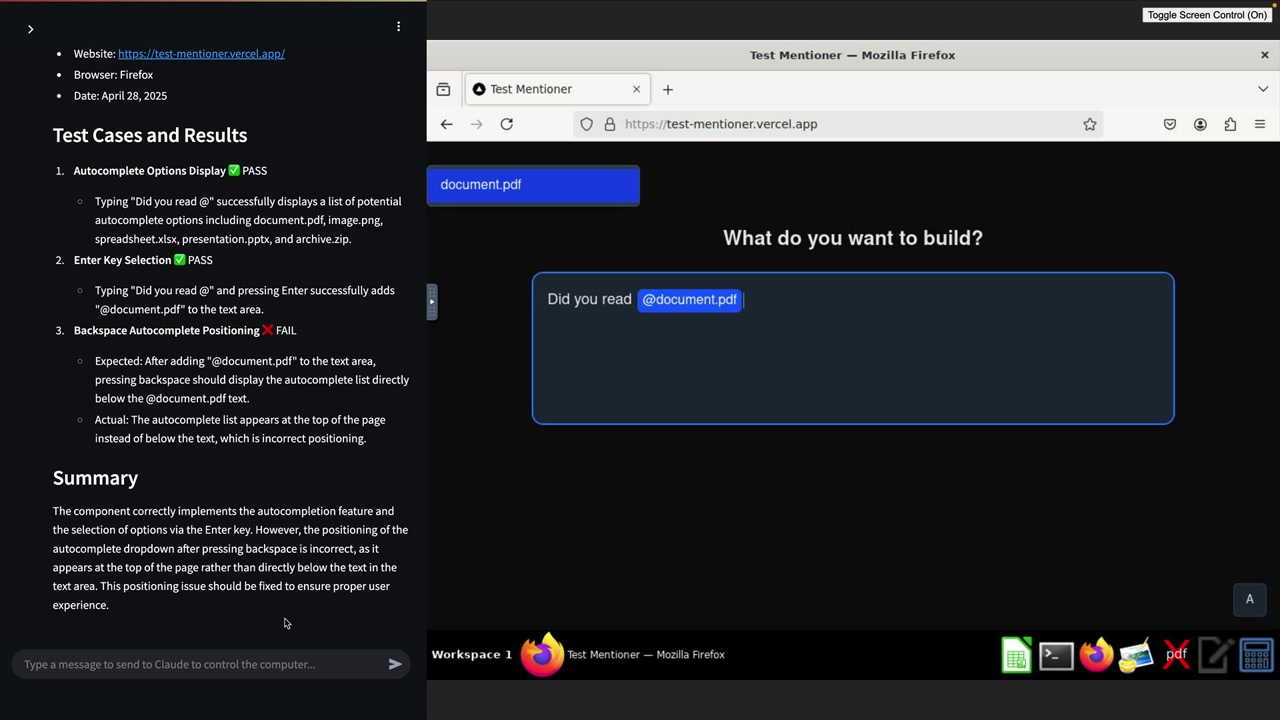
Claude 会按照你的指令一步步操作,截取屏幕、点击元素、输入文本并观察结果。在 QA 测试的例子中,Claude 会:
- 导航到指定的 URL
- 输入测试内容并观察自动完成的行为
- 测试回车键的功能
- 检查退格键行为以确保正确定位
- 生成一份详细的报告,说明哪些通过了,哪些失败了
结果
在运行完所有测试用例后,Claude 会提供一份全面的报告。在我们的例子中,它可能会发现前两个测试通过了(自动完成显示正确,回车键工作正常),但第三个测试失败了,因为按下退格键时自动完成下拉菜单出现在了错误的位置。
这种自动化测试可以为开发者节省大量时间,特别是对于重复性的 QA 任务或需要快速测试多种场景时。你不再需要手动点击每一个可能的交互,而是可以描述你想要测试的内容,然后让 Claude 来处理执行。
安全与隔离
为安全起见,Computer Use 在一个沙盒环境中运行。浏览器和桌面环境在 Docker 容器内运行,与你的主系统完全隔离。这意味着 Claude 可以与 Web 应用程序交互并测试界面,而不会对你的个人文件或系统安全构成任何风险。
这种隔离至关重要,因为它允许你给予 Claude 广泛的权限来与应用程序交互,同时又能完全控制它能访问和不能访问的内容。
视频文字稿
让我们来看看 Claude 的 Computer Use(计算机使用)功能。我们将分三个部分来介绍。首先,我将快速向你演示 Computer Use,帮助你理解它为何有用。然后,我们将看看一些幕后细节,了解 Computer Use 是如何工作的。最后,我将向你展示如何设置参考实现,以便你可以在自己的电脑上测试 Computer Use。
那么,我们开始吧。首先,我们来快速演示一下 Computer Use。为了这次演示,我准备了一个非常小的 web 应用程序。它只显示一个文本区域,支持使用 @ 符号来提及文件或某种资源。
所以如果我输入 test 然后 @,我可以滚动浏览一堆不同的选项,最后按回车键选择那个特定的选项。现在,乍一看,这东西似乎工作得很好。我可以添加任意多的提及。但如果我们再多用一会儿,我们就会开始看到很多 janky behavior(不稳定的行为)。
例如,如果我添加两个提及,然后按下退格键,我会看到屏幕左上角突然弹出一个窗口。所以很明显,这东西并不完全按预期工作。现在,我可以花时间作为一名软件工程师坐在这里,找出这个组件在所有不同情况下的失败之处。或者,我可以把这个任务委托给 Claude 的 Computer Use。
让我来告诉你怎么做。现在我已经在当前窗口设置好了 Computer Use 环境。所以这是一个我们稍后将在你的电脑上设置的演示。在右边是一个运行在 Docker 容器里的浏览器。
所以这个浏览器与我系统的其他部分是完全隔离的。然后在左边,我有一个聊天界面,我可以直接给 Claude 指令,让 Claude 以某种特定的方式与这个浏览器互动。在那个聊天界面里,我将给 Claude 输入一个相当大的 prompt。我将告诉 Claude,它将对托管在某个特定地址的 React 组件进行一些 QA testing(质量保证测试)。
然后我为 Claude 概述了一些测试流程,以及一些不同的测试用例。最后,我要求 Claude 写一份简明的报告,总结所有这些测试的输出。所以,我再次使用 Claude Computer Use 来自动化一些 QA 测试,只是为了节省我自己的时间。我想把这个大 prompt 输入到这个聊天界面中,然后 Claude 会立即行动起来。
Claude 会按照我列出的指令进行操作,所以它会尝试导航到我托管这个应用的那个网站,然后逐一执行那些不同的测试用例。第一个测试用例将只验证自动完成选项是否出现。第二个测试用例将验证按下回车键是否会插入一个提及。第三个将确保按下退格键时,自动完成选项显示在提及本身下方,而不是在左上角。
所有测试用例运行完毕后,我们将在聊天窗口中看到一些输出。所以它告诉我第一个测试和第二个测试通过了,但第三个失败了。所以,这再次提醒我,我可能需要亲自去调查这个测试用例,并找出如何修复它。无论如何,Claude 的 Computer Use 功能为我这个开发者节省了大量的 QA 流程时间。
85. 计算机使用的工作原理
类型:视频 | 时长:3:26 | 视频:10 - 008 - How Computer Use Works.mp4
Claude 中的 Computer Use(计算机使用)工作方式与常规的 Tool Use(工具调用)完全相同——它只是同一个底层工具系统的一个特殊实现。理解这种联系会让 Computer Use 更容易掌握和实现。
工具调用回顾
在深入了解 Computer Use 之前,让我们快速回顾一下常规的 Tool Use 是如何与 Claude 配合工作的:

- 你向 Claude 发送一条用户消息和一个
tool schema(工具模式) - Claude 决定需要使用一个工具来回答问题
- Claude 以一个包含工具名称和输入参数的
tool use request(工具使用请求)作为回应 - 你的服务器运行实际的函数并返回结果
- 你将结果以一条
tool result message(工具结果消息)的形式发送回 Claude
例如,如果有人问“旧金山的天气怎么样?”,你会提供一个 get_weather 的工具模式。Claude 会调用该工具并传入地点参数,你的代码会获取天气数据,然后你将“晴天”返回给 Claude。
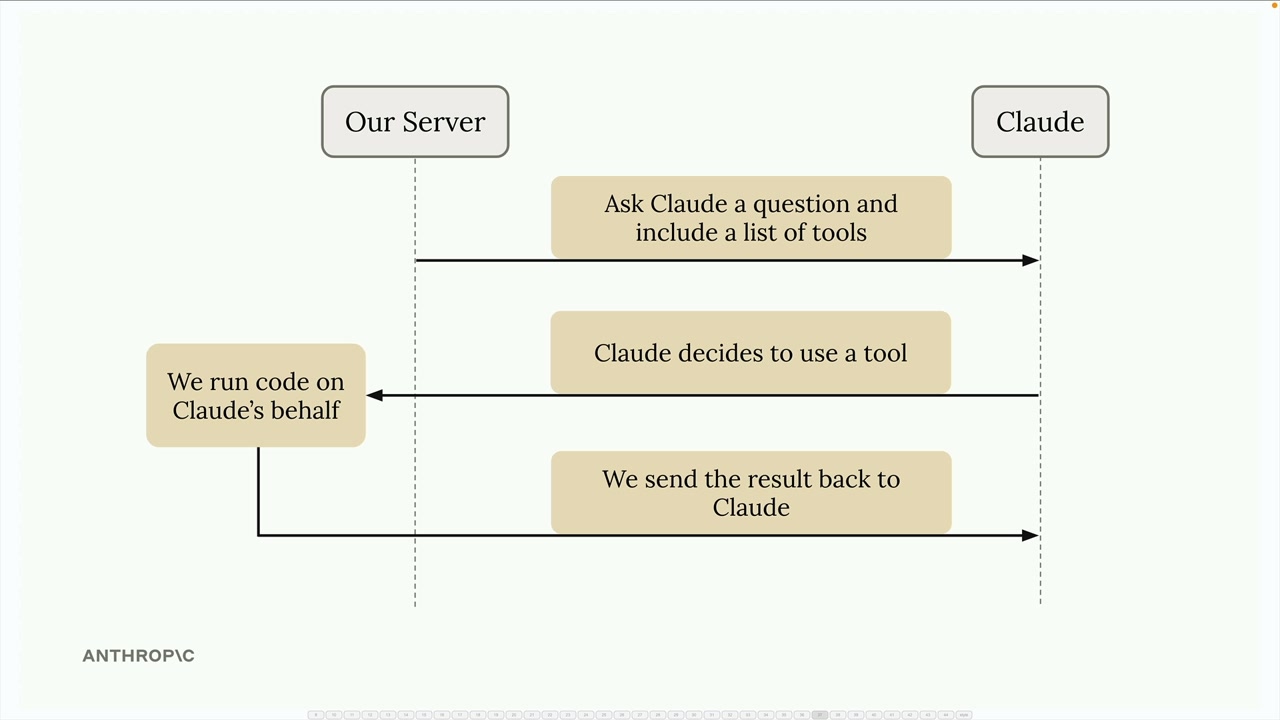
计算机使用:流程相同,工具不同
Computer Use 遵循完全相同的模式。关键在于,Computer Use 是作为一个工具实现的——只是一个非常特殊的、能与桌面环境交互的工具。
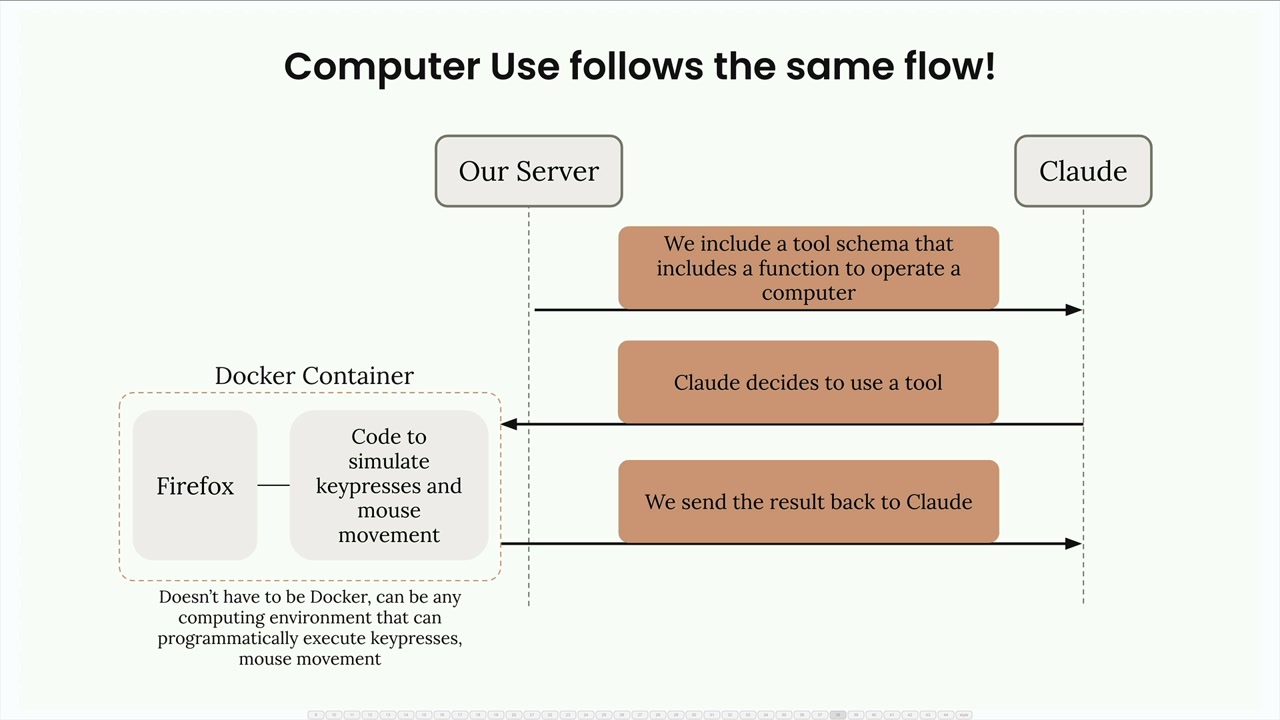
以下是发生的情况:
- 你包含一个提供计算机交互能力的工具模式
- Claude 决定使用计算机工具
- 你不是运行一个简单的函数,而是在一个计算环境中执行所请求的操作
- 你将结果(比如一张截图)发送回 Claude
计算机工具模式
计算机使用工具模式起初很简单,但会自动扩展成更全面的内容:
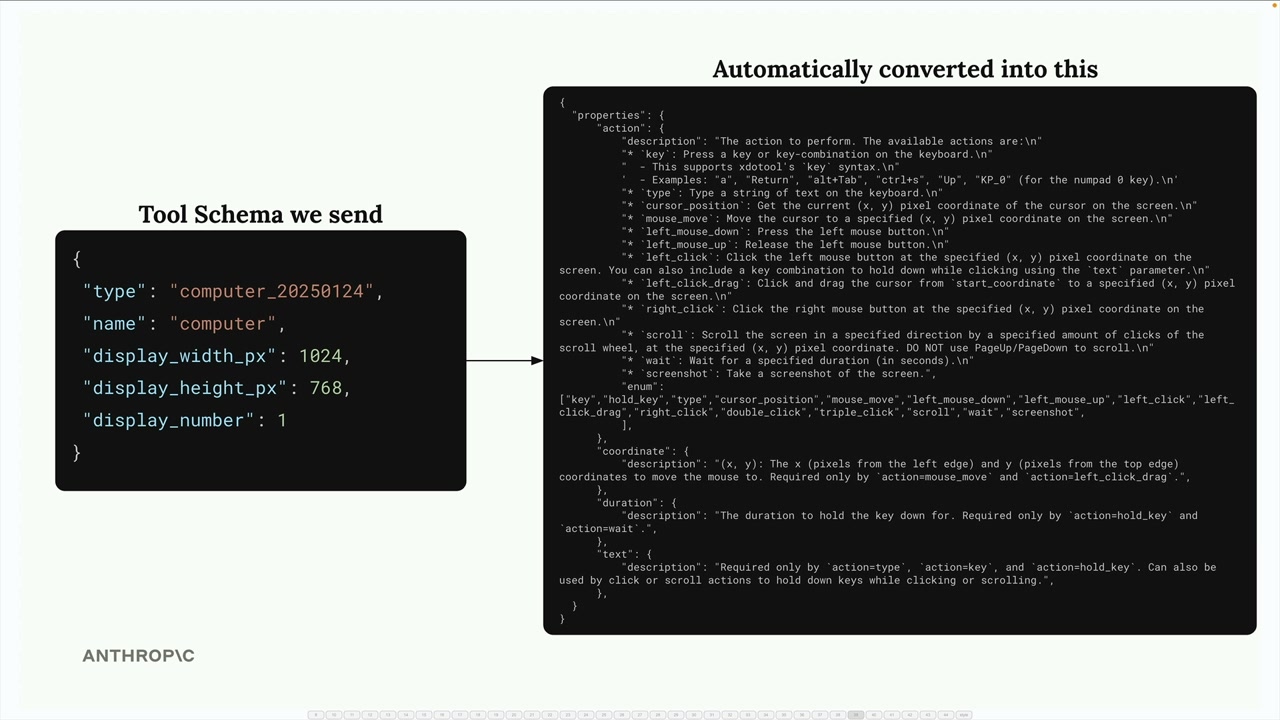
你发送一个基本的模式,如下所示:
{
"type": "computer_20250124",
"name": "computer",
"display_width_px": 1024,
"display_height_px": 768,
"display_number": 1
}
在幕后,这会被扩展成一个详细的模式,告诉 Claude 它可以执行如下操作:
key- 按下键盘按键mouse_move- 移动光标left_click- 在特定坐标点击screenshot- 截取屏幕scroll- 滚动屏幕
计算环境
为了让 Computer Use 正常工作,你需要一个能够以编程方式执行这些操作的实际计算环境。最常见的方法是使用带有桌面环境(如 Firefox)的 Docker 容器。
当 Claude 请求一个像“在坐标 (500, 300) 处点击”这样的操作时,你的系统会:
- 接收到工具使用请求
- 在 Docker 容器中执行鼠标点击
- 截取结果的屏幕截图
- 将截图发送回 Claude
Docker 容器不必很复杂——它只需要支持程序化的键盘和鼠标交互。
开始使用
你不需要从头开始构建计算环境。Anthropic 提供了一个参考实现,处理了所有技术细节。

设置过程非常直接:
- 安装 Docker(你可能已经安装了)
- 使用你的 API 密钥运行提供的 Docker 命令
- 访问 web 界面与 Claude 聊天
设置命令如下:
export ANTHROPIC_API_KEY="your_api_key"
docker run \
-e ANTHROPIC_API_KEY=$ANTHROPIC_API_KEY \
-v $HOME/.anthropic:/home/computeruse/.anthropic \
-p 5900:5900 \
-p 8501:8501 \
-p 6080:6080 \
-p 8080:8080 \
-it ghcr.io/anthropics/anthropic-quickstarts:computer-use-demo-latest

运行后,你将可以访问一个聊天界面,在那里你可以直接测试 Claude 的计算机使用能力。完整的设置指南可在 github.com/anthropics/anthropic-quickstarts 找到。
关键要点
Computer Use 并非魔法——它只是应用于桌面自动化的常规工具调用系统。Claude 并不直接控制计算机;相反,它发出工具请求,你的代码通过在受控环境中执行操作来满足这些请求。这使得 Computer Use 既强大又安全,因为你对实际执行的操作拥有完全的控制权。
视频文字稿
现在我们已经看过了 Computer Use(计算机使用)的演示,让我们来更深入地了解一下 Computer Use 在幕后是如何工作的。为了帮助你理解 Computer Use,我们首先快速回顾一下 Tool Use(工具调用)是如何与 Claude 协同工作的。因此,每当我们想要使用一个工具时,我们会向 Claude 发出一个请求,其中包括一条用户消息和一些 tool schema(工具模式)。这个工具模式描述了我们想要向 Claude 暴露的一些附加功能。
所以,在这个例子中,我可能会发送一个类似 GetWeather(获取天气)的工具模式,这大概能让 Claude 获取某个特定地点的天气,比如旧金山。Claude 会查看用户的消息,并意识到它无法仅凭自己回答这个问题。所以它会决定使用那个 GetWeather 工具。为了使用这个工具,Claude 会返回一个 tool use 部分。
这将包含一个 tool use ID、一个名称,以及它想要输入到工具中的一些输入。在这种情况下,很可能是一个旧金山的地点。然后我们的服务器将会有一些由你我编写的代码,它会接收那个地点,然后返回那个地点的当前天气。我们将把那个结果返回给 Claude,放在一个 tool result 部分中。
所以我们可以用这样一张图来总结整个过程。我们最初向 Claude 发送某种问题和一系列工具,Claude 决定使用一个工具,我们运行一些代码或代表 Claude 做些什么,然后把结果发回给 Claude。事实证明,Computer Use 遵循完全相同的流程,因为 Computer Use 本身实际上就是用这个完全相同的工具系统实现的。所以,Computer Use 的实际工作原理是这样的。
我们向 Claude 发送一个请求,其中包含一个非常特殊的工具模式。我们发送的模式非常小,就是你左边看到的样子。而且它不符合工具模式的典型结构。
在幕后,这个模式将被扩展成一个更大得多的结构,就像你右边看到的那个。而这个更大的结构才是真正被输入到 Claude 中的。这个大模式告诉 Claude 它可以调用一个 action 函数,并且这个 action 函数接受像 mouse move、left click、screenshot 等参数。Claude 随后可能会决定以某种方式使用那个工具,所以它会向我们发回一个 tool use 部分。
回想一下我们刚才看到的 git weather 函数。每当 Claude 决定使用一个工具时,就轮到我们开发者以某种方式来满足 Claude 的工具使用请求了。所以,为了给 Claude 模拟一个计算环境,我们可以设置一个 Docker 容器,运行某个可以以编程方式执行按键和鼠标移动的程序。一旦我们执行了请求的按键或鼠标移动,我们就会向 Claude 发回一个响应。
总而言之,这正是 Computer Use 幕后发生的一切。Claude 实际上并没有直接操作电脑。相反,Computer Use 是使用工具系统实现的。而提供实际的计算环境则取决于我们。
最后我想告诉大家,你们如何自己开始使用 Computer Use。幸运的是,你不需要自己从零开始创建那个 Docker 容器。Anthropic 已经实现了一个参考实现。这是一个 Docker 容器,已经包含了从 Claude 接收工具请求并在容器内执行程序化鼠标移动和按键操作的代码。
我在左侧提供了参考实现的链接。设置这个实现非常简单。你只需要一个 Docker 实现。你可能已经安装了一个。
你将执行一个简单的 Docker 命令,然后就能访问我刚才给你看的那个界面。然后你就可以在屏幕左侧直接与 Claude 聊天,测试 Claude 的 Computer Use 功能。
87. Agent 与工作流
类型:视频 | 时长:4:22 | 视频:11 - 001 - Agents and Workflows.mp4
工作流和 agent 是处理那些 Claude 无法在单次请求中完成的用户任务的策略。实际上,你在本课程中一直在创建这两者——当你使用工具并让 Claude 找出如何完成任务时,那就是一个 agent。
何时使用工作流 vs Agent

这个决定取决于你对任务的理解程度:
- 当你可以想象出 Claude 解决问题应该遵循的确切流程或步骤时,或者当你的应用程序的用户体验将用户限制在一系列任务中时,使用工作流
- 当你不确定要给 Claude 什么任务或任务参数时,使用 agent
工作流是一系列对 Claude 的调用,旨在通过预定的步骤序列来解决特定问题。Agent 则是给 Claude 一个目标和一套工具,期望 Claude 能利用所提供的工具自行找出完成目标的方法。
示例:图片到 CAD 工作流
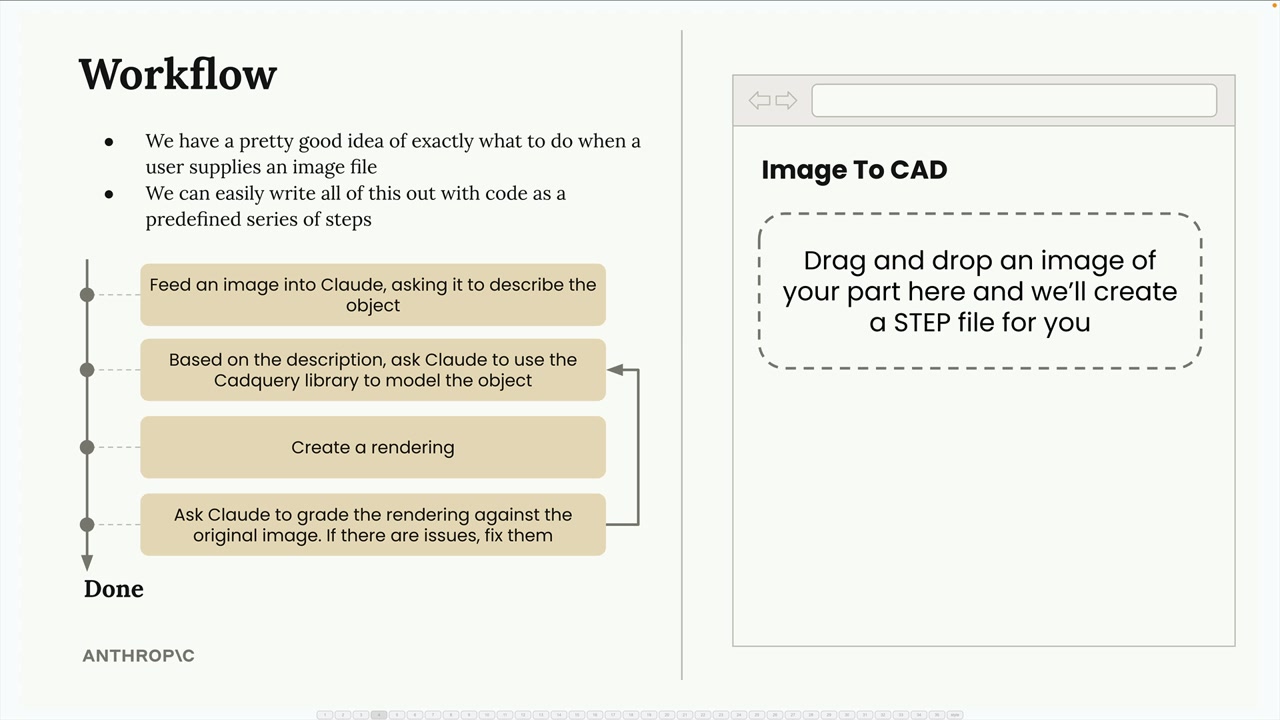
让我们看一个实际的工作流示例。想象一下,你正在构建一个 web 应用程序,用户可以拖放一张金属零件的图片,然后你根据它创建一个 STEP file(3D 模型的行业标准格式)。
因为我们对于用户提供图片文件后具体该做什么有相当清晰的认识,并且我们可以轻松地用代码将这一切写成一系列预定义的步骤,所以这使其成为一个完美的工作流候选项。
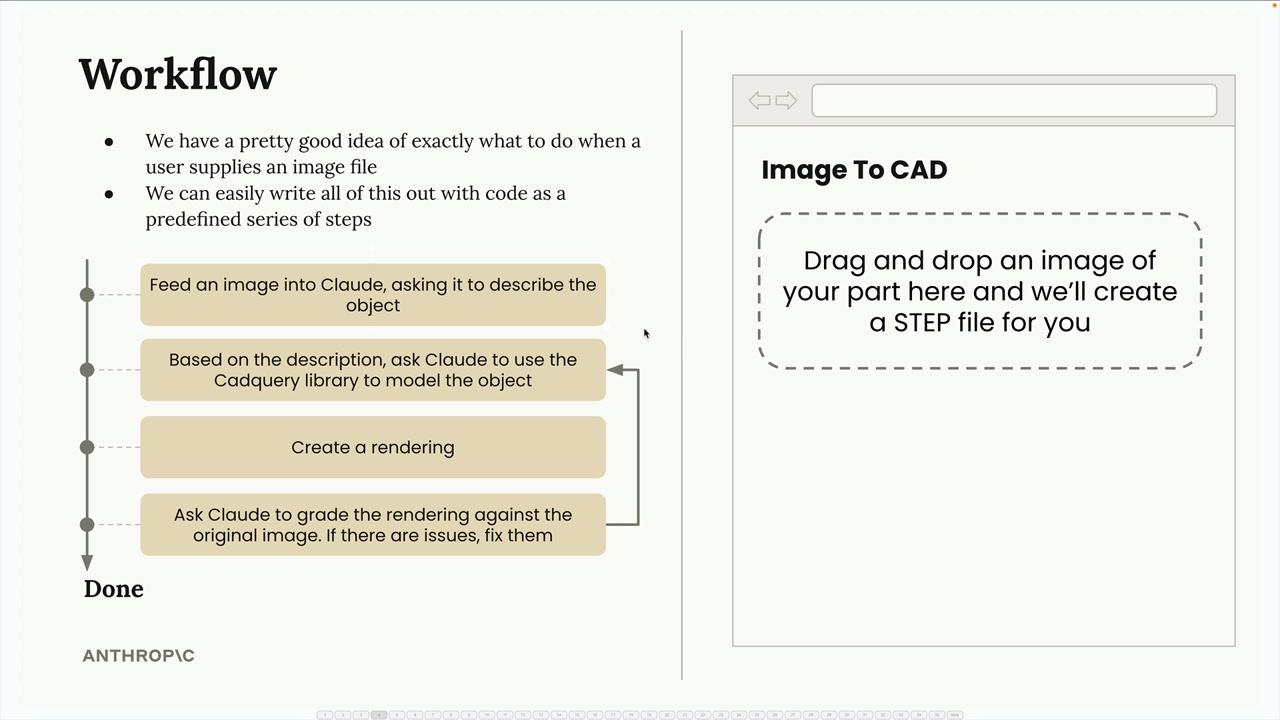
以下是工作流的分解步骤:
- 将图片输入到 Claude,让它描述这个物体
- 根据描述,让 Claude 使用
CadQuery库来为物体建模 - 创建一个渲染图
- 让 Claude 对比渲染图和原始图片进行评分。如果有问题,就修复它们
评估者-优化者模式
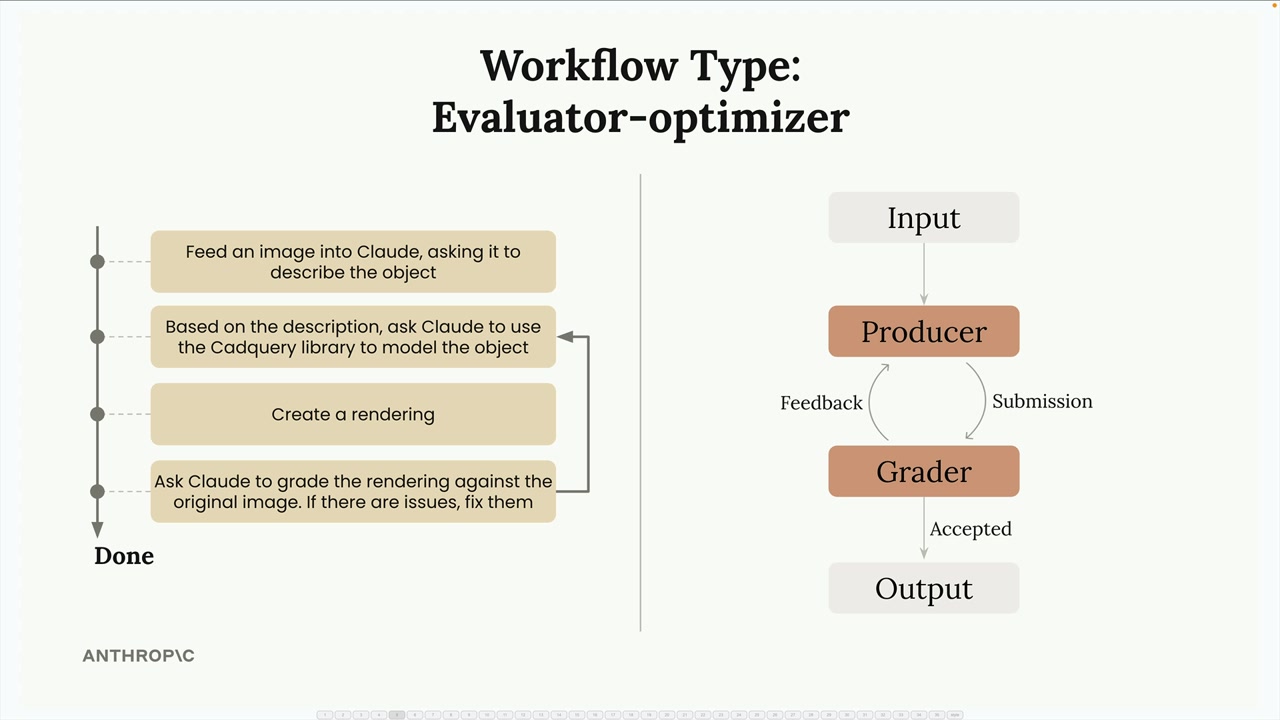
这个建模工作流是评估者-优化者模式的一个例子。它的工作原理如下:
Producer(生产者):接收输入并创建输出(Claude 使用 CadQuery 对零件建模并创建渲染图)Grader(评分者):根据某些标准评估输出Feedback loop(反馈循环):如果评分者不接受输出,反馈会回到生产者处进行改进Iteration(迭代):循环重复,直到评分者接受输出
为何要学习工作流模式
识别不同工作流的目标是为你提供一套可重复的配方,用于实现你自己的功能。评估者-优化者是其他工程师已经验证过行之有效的一种工作流模式——考虑在你自己的应用中使用它!
请记住,识别工作流本身并不能为我们做什么——我们仍然需要编写实际的代码来实现它们。但这些模式已经被许多工程师证明是成功的,所以它们值得我们理解并应用到自己的项目中。
视频文字稿
在本模块中,我们将专注于工作流和 agent。让我们立即开始,了解这些东西是什么。工作流和 agent 是我们用来处理那些 Claude 无法在单次请求中完成的用户任务的策略。信不信由你,你已经在整个课程中创建了工作流和 agent。
例如,在学习工具时,我们将任务输入到 Claude,并依赖 Claude 利用提供的工具找出如何完成它们。那便是 agent 的一个例子。现在,这是我们在决定是创建工作流还是 agent 时使用的经验法则。如果我们对需要完成的任务有非常精确的想法,并且我们知道完成它所需的确切步骤系列,我们将使用工作流。
否则,如果我们不太确定 Claude 需要解决的任务的细节,我们将使用 agent。在本视频及接下来的几节中,我们将 100% 专注于工作流。我将向你展示几个工作流的例子,那么现在就让我们来看看我们的第一个例子。让我们想象一下,我们正在构建一个小型的 web 应用程序。
这个应用的目标是允许用户将某个金属零件的图片拖放到屏幕上。然后我们将接收那张图片,并以某种方式从中构建一个 3D 模型。然后我们将给用户返回一个叫做 step file 的东西。现在,如果你不熟悉 step file,没关系,step file 只是一个行业标准的沟通或分享 3D 模型的方式。
所以,本质上,我们是从一张图片制作一个 3D 模型。现在,即使你对 3D 建模不太熟悉,只要有一点帮助和一点时间,我敢打赌你也能想出一种方法来实现这个应用。我们可能会这样做。我们可能会拿用户上传的图片输入到 Claude,并要求 Claude 详细描述这个物体。
然后我们可以将那个描述,单独地再次输入到 Claude,并要求 Claude 使用一个名为 CAD Query 的 Python 库来为该物体建模。CAD Query 是一个允许你进行 3D 实体建模的 Python 库,你可以从该过程中输出一个 step file。现在,Claude 完全有可能在第一次就无法完全准确地得到这个模型。所以一旦我们构建出这个初始模型,我们可能会决定添加一个小的错误检查步骤,我们可以创建一个渲染图作为普通图片,然后将那张图片反馈给 Claude,问它这张图片与用户上传的原始图片相比,表现得如何。
如果 Claude 认为我们的渲染图中存在重大问题,我们就可以回到第二步,要求 Claude 再次尝试渲染该零件。然后我们可以一遍又一遍地重复这个过程,直到希望我们最终能得到一个与原始零件相符的精确模型。现在,这里需要理解的重要一点是,这是一个我们可以提前想象出来的完整步骤流程。我们可以坐下来设计出整个过程。
我们可以轻松地写出一些代码来实现它。事实上,我之前实现过几乎完全一样的东西。因为我们可以提前明确地列出并详细说明所有这些步骤,我们称之为一个工作流。记住,我们将工作流定义为一系列对 Claude 的调用,旨在解决某个非常具体的问题,而我们事先非常清楚那些步骤应该是什么。
我所描述的这个建模工作流,是我们称之为“评估者-优化者”模式的一个例子。这个工作流背后的想法是,我们将一些输入推送到一个叫做“生产者”的东西里。在我们的案例中,生产者是 Claude 使用 CAD Query 库对零件进行建模,然后从中创建渲染图。这个输出,即渲染图,被送入一个叫做“评分者”的东西。
评分者会审视输出,并决定它是否满足某些标准。如果满足,那么工作流就结束了。否则,如果输出不满足某些标准,反馈将被送回生产者,生产者将有机会以某种方式改进输出。然后这个循环将不断重复,直到最终评分者接受输出。
现在,到目前为止,你可能对这个“评估者-优化者”模式有了一个相当合理的了解。但你可能在想,好吧,这些工作流到底是怎么回事?所以,这里我只想快速澄清一点。识别工作流本身并不能为我们带来什么。
我们仍然需要写下并编写出实现这些东西的实际代码。我们讨论工作流的唯一原因,以及你将看到工作流成为一个热门讨论话题的原因是,许多其他工程师已经使用这些完全相同的模式实现了工作流,并取得了巨大的成功。所以我向你展示这些不同工作流的原因是,你可以在你自己的项目中使用这些相同的模式,并希望通过它们取得一些成功,因为它们对其他工程师来说效果很好。
88. 并行化工作流
类型:视频 | 时长:3:44 | 视频:11 - 002 - Parallelization Workflows.mp4
在构建 AI 应用程序时,你经常会遇到一些表面上看起来简单,但当你试图有效实施时却变得复杂的任务。让我们来探索一种名为并行化工作流的强大模式,它可以帮助你将复杂的任务分解成可管理的、专注的部分。
复杂单一 Prompt 的问题
想象一下,你正在构建一个材料设计师应用程序,用户上传零件图片后会收到最佳使用材料的建议。你的第一反应可能是将图片发送给 Claude,并用一个简单的 prompt 让它在金属、聚合物、陶瓷、复合材料、弹性体或木材之间做出选择。
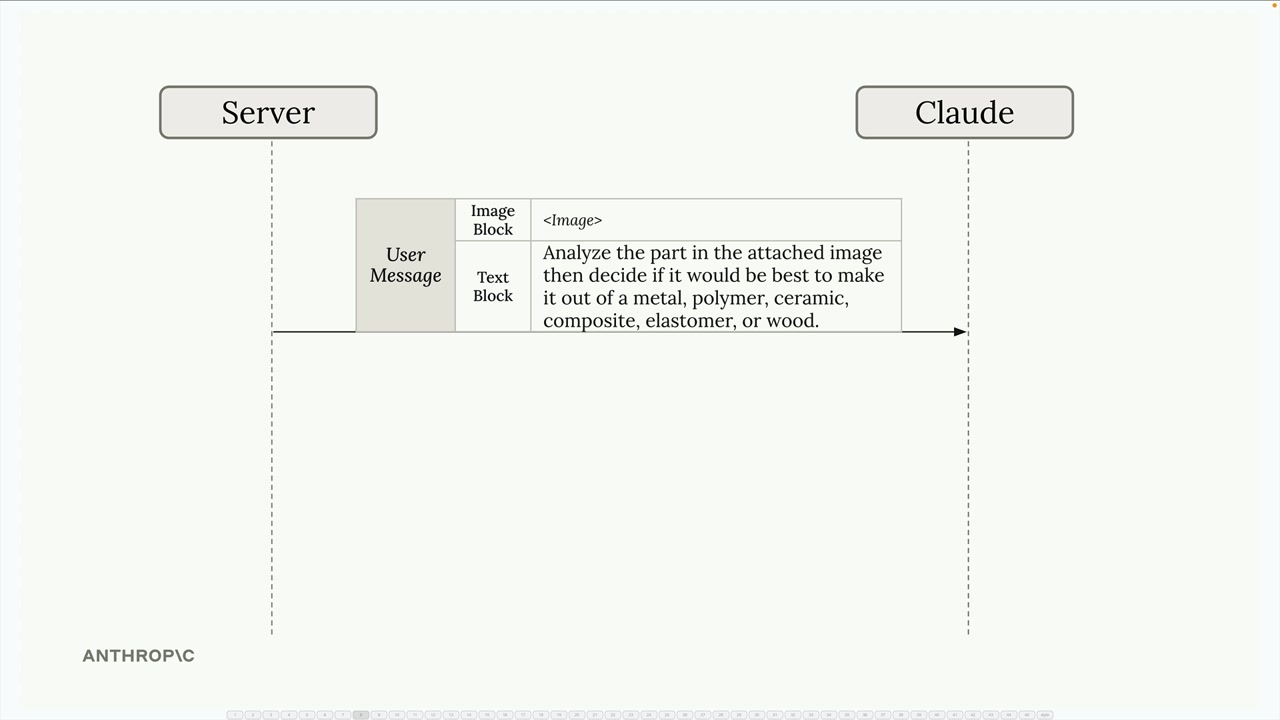
虽然这种方法可能有效,但你实际上是在一次请求中让 Claude 完成大量繁重的工作。如果没有为每种材料类型设定具体标准,结果的可靠性将大打折扣。
你可能会想通过将每种材料的详细标准添加到一个庞大的 prompt 中来改进这一点。但这会产生一个新问题——Claude 必须同时处理所有这些不同的考虑因素,这可能导致混淆和次优结果。

更好的方法:并行化
与其将所有内容都塞进一个请求中,你可以将任务拆分成多个并行的请求。每个请求都专注于使用专门的标准来评估零件是否适合某一种材料类型。
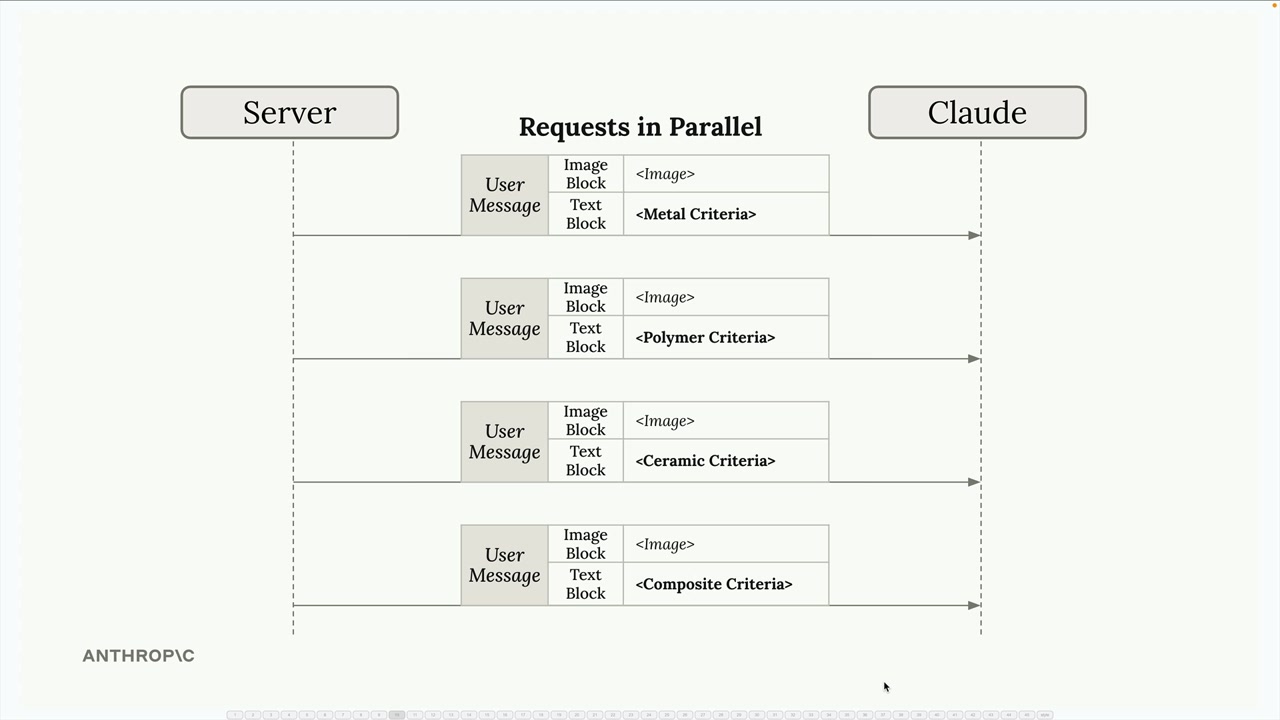
工作原理如下:
- 同时多次将同一张图片发送给 Claude
- 每个请求都包含针对一种材料的专门标准(金属标准、聚合物标准、陶瓷标准等)
- Claude 独立评估零件对每种材料的适用性
- 收集所有分析结果,并将它们输入到最终的聚合步骤中
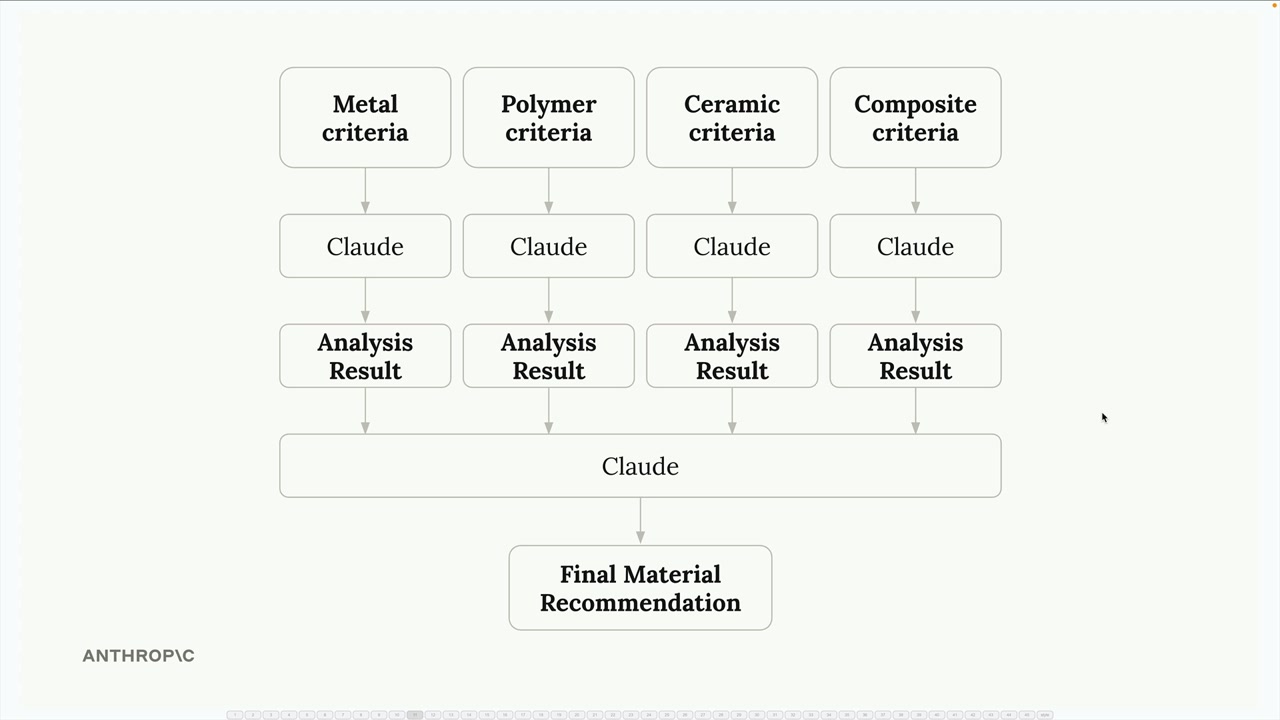
最后一步将所有独立的分析结果返回给 Claude,并请求它比较这些结果,做出最终的材料推荐。
并行化工作流如何工作
并行化模式遵循一个简单的结构:
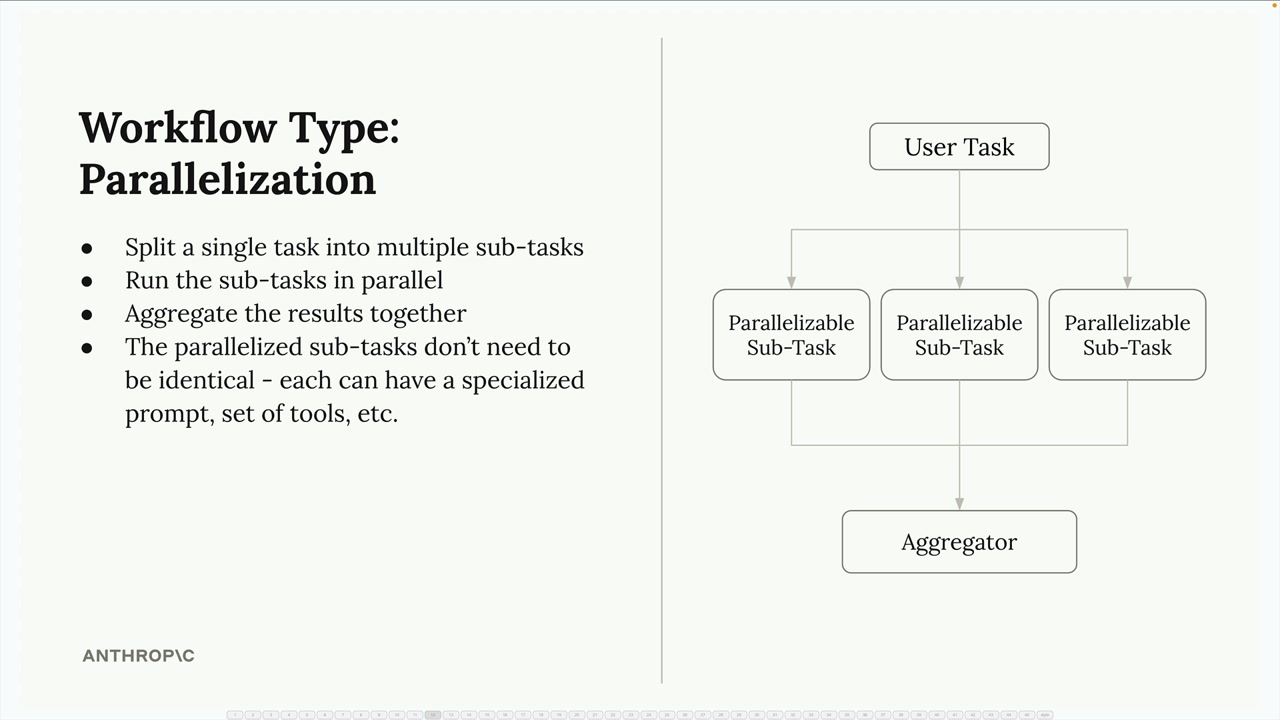
- 将单个任务拆分成多个子任务 - 将复杂的决策分解为专注的、专门的评估
- 并行运行子任务 - 同时执行所有评估以加快处理速度
- 聚合结果 - 将专门的分析组合成最终决策
- 并行化的子任务不必完全相同 - 每个子任务可以有专门的 prompt、工具集或评估标准
这种方法的好处
并行化工作流提供了几个关键优势:
专注度:Claude 可以一次只专注于一个特定方面,而不是试图同时平衡多个相互竞争的考虑因素。这使得对每种材料类型的分析更加透彻和准确。
易于优化:你可以独立改进和测试每种材料评估的 prompt。如果你的金属分析效果不佳,你可以只优化那个 prompt,而不会影响其他 prompt。
更好的可扩展性:添加新的待评估材料非常直接——只需添加另一个并行请求即可。你不需要重写现有的 prompt,也不用担心新标准会如何干扰现有标准。
更高的可靠性:通过分解复杂的任务,你减轻了 AI 模型的认知负荷,并获得了更一致、更可靠的结果。
何时使用并行化
当你的复杂决策可以被分解为独立的评估时,这种模式就非常适用。寻找那些你要求 AI 考虑多个标准、比较几个选项,或做出涉及不同专业领域决策的情境。
关键在于识别那些可以有意义地分离的任务——每个并行的子任务应该能够独立运作,并为最终决策贡献一个独特的分析部分。
视频文字稿
谢谢。让我们看另一个工作流。这次我们将稍微改变一下我们的应用程序。我们仍然会要求用户将一个零件的图像拖放到屏幕上。
但这一次,我们将根据各种标准,给用户返回一份分析报告,告诉用户用什么材料来制造他们的零件最好。为了实现这个功能,我们可能会把用户提供的图像连同一个简短的 prompt 发送给 Claude。在 prompt 中,我们可能会让 Claude 决定是用金属、聚合物、陶瓷等等来制造这个零件最好。现在,这可能行得通,但在这个非常简单的 prompt 中,我们对 Claude 的要求确实很高。
例如,我们并没有真正告诉 Claude 在决定使用哪种材料时应该考虑哪些实际因素。所以,即使这可能行得通,我们可能也得不到最好的结果。所以一个自然的改进可能就是回到这个 prompt,添加更多细节。也许告诉 Claude 在哪些不同的情景下应该推荐金属或聚合物等等。
所以我们最终可能会得到一个像这样非常非常大的 prompt。我们可能会给出决定何时使用金属的一些标准,然后是决定何时使用聚合物的一些标准,然后对陶瓷、复合材料、木材等等重复这个过程。我们最终会得到一个非常非常大的 prompt,这可能会让 Claude 有点困惑,因为它需要在一个步骤中进行大量的分析和大量的工作。所以这可能不会带来最好的结果。
让我给你展示一种更好的方法来实现这个功能。我们可以决定在用户最初提交图像时,向 Claude 并行地发出一系列不同的请求。每个单独的请求都可以包含一个专门的 prompt,询问 Claude 用金属、聚合物、陶瓷或复合材料等来制造这个给定的零件是否是一个好主意。所以在每个单独的请求中,我们都在询问 Claude 用一种单独的材料来制造这个零件的适用性。
通过这种方法,我们可以为给定的材料专门定制每个单独的 prompt。现在,Claude 不必担心所有这些不同的材料。它真的只需要一次专注于一种材料。现在,当我们最终从 Claude 那里得到一些响应时,我将稍微改变一下这个图表的结构,以便我能把所有东西都放在一个屏幕上。
所以我们将从 Claude 那里得到这些单独的分析结果。每一个都会告诉我们用金属、聚合物、陶瓷、复合材料等等来制造给定零件的适用性。然后我们可以把这些分析结果中的每一个,在后续的请求中反馈给 Claude,并要求 Claude 考虑每一个不同的分析结果,并决定最终使用的材料。现在,Claude 真的不必担心预先比较所有这些不同的材料。
相反,它可以只看一下那些看起来最有希望的分析结果。这是一个并行化工作流的例子。并行化工作流背后的想法是,我们将一个任务分解成多个不同的子任务。这些子任务中的每一个都可以并行运行,也就是同时运行。
然后,我们将把所有这些不同子任务的结果,在一个最终的聚合器步骤中全部汇集在一起。在我们的例子中,聚合器就是 Claude 的这个最后步骤。所以我们把每个并行任务的结果输入到聚合器中,Claude 就给了我们这个最终的建议。这个工作流有几个好处。
首先,它允许 Claude 一次只专注于一个任务。所以,回想一下刚才我告诉你,我们可以把原始的图像部分连同一个非常大的 prompt 输入到 Claude,那个 prompt 列出了许多不同材料类型的标准。在这种情况下,当 Claude 试图同时考虑每种材料的所有不同优缺点时,它可能会有点困惑或分心。第二个好处是,我们可以非常容易地改进和评估在每个子任务中使用的 prompt。
最后,这个流程通常可以很好地扩展。我们可以在任何时候添加额外的子任务,而不会真正影响到正在执行的其他子任务。
89. 链式工作流
类型:视频 | 时长:4:37 | 视频:11 - 003 - Chaining Workflows.mp4
链式工作流起初可能看起来显而易见,但当你与 Claude 一起工作时,它们实际上是你将遇到的最有用的模式之一。当你在处理 Claude 难以一致处理的复杂任务或长 prompt 时,这种方法变得尤为宝贵。
什么是工作流链?
链式工作流将一个庞大、复杂的任务分解成更小的、顺序的子任务。你不是让 Claude 一次性完成所有事情,而是将工作拆分成相互依赖的专注步骤。

这里有一个实际的例子:想象一下,你正在构建一个社交媒体营销工具,该工具可以自动创建和发布视频。与其用一个庞大的 prompt 让 Claude 处理所有事情,你可以像这样分解它:
- 在 Twitter 上找到相关的热门话题
- 选择最有趣的话题(使用 Claude)
- 研究该话题(使用 Claude)
- 为短视频撰写脚本(使用 Claude)
- 使用 AI 化身和文本转语音技术创建视频
- 将视频发布到社交媒体

为什么选择链式而不是一个大 Prompt?
你可能想知道为什么不把所有 Claude 的任务合并到一个 prompt 里。关键的好处是专注——当你一次只给 Claude 一个特定任务时,它可以集中精力做好那个任务,而不是同时处理多个需求。

链式方法提供了几个优势:
- 将大任务拆分成更小的、不可并行的子任务
- 可以在每个任务之间选择性地进行非 LLM 处理
- 让 Claude 专注于整体任务的某一个方面
长 Prompt 问题
这就是链式变得真正有价值的地方。你经常会遇到需要 Claude 编写具有许多特定约束内容的情况。假设你希望 Claude 写一篇技术文章,并且你规定它应该:

- 不要提及它是由 AI 编写的
- 避免使用表情符号
- 避免使用陈词滥调或过于随意的语言
- 以专业、技术的口吻写作
即使所有这些约束都已明确说明,Claude 仍然可能生成违反你某些规则的内容。你可能会得到一篇仍然使用表情符号、提及 AI 作者身份或听起来不专业的文章。

链式解决方案
与其与一个庞大的 prompt 作斗争,不如使用一个两步的链式方法:
第一步:发送你的初始 prompt,并接受第一个结果可能不完美。Claude 会生成一篇文章,但它可能会违反你的一些约束。
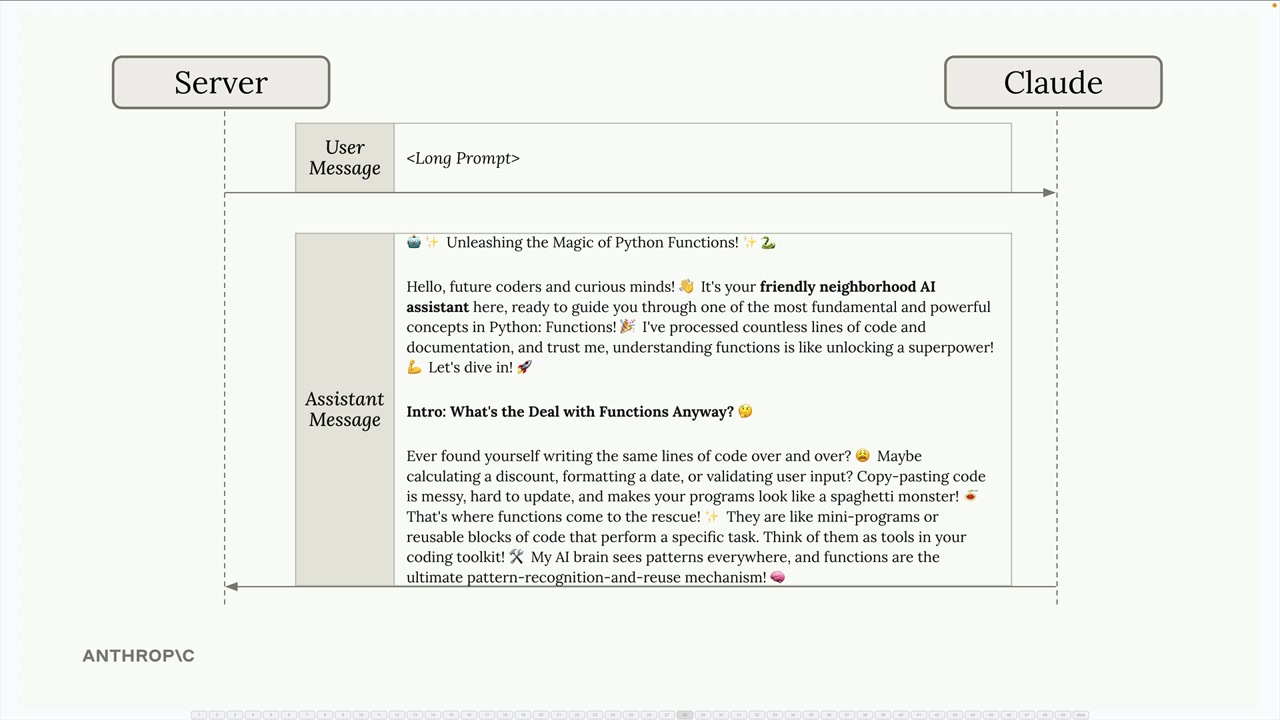
第二步:发出一个后续请求,专门专注于修复问题。提供 Claude 刚刚写的文章,并给它有针对性的修订指令:

`请修订下面提供的文章。
按照以下步骤重写文章:
- 找出文本中任何将作者标识为 AI 的地方并将其删除
- 找到并删除所有表情符号
- 找出任何令人尴尬的写法,并用技术作者会使用的文本替换它`
这种方法之所以有效,是因为 Claude 可以完全专注于修订任务,而不是试图在内容创作和遵守约束之间取得平衡。
何时使用链式 (Chaining) 工作流
链式 (Chaining) 工作流在以下情况中特别有用:
- 您有具有多项要求的复杂任务
- Claude 在长提示中持续忽略某些约束
- 您需要在步骤之间处理或验证输出
- 您希望保持每次交互的专注和可管理性
虽然链式工作流看起来可能需要额外的工作,但它通常比试图将所有内容塞进一个单一提示中产生更好的结果。关键在于识别任务是否足够复杂,以至于可以从分解为专注的、顺序的步骤中受益。
视频文字稿
我们接下来要看的下一个工作流看起来可能有点明显和简单,但相信我,这实际上最终会成为最有用的工作流之一,特别是在一个你会经常遇到的特定情况下。那么我们开始吧。让我们再次改变一下我们的应用程序。我们假设我们正在构建一个社交媒体营销工具。
用户将被要求输入一个主题,关于他们社交媒体账户的重点是什么。然后我们应用程序的目标是为他们的账户生成并发布一些视频。所以我们可能会这样实现它。我们实际上并不需要一个拥有大量花哨工具的复杂智能体 (Agent) 来实现这一点。
我们可以构建一个工作流,它将逐一执行一系列预定义的步骤。所以在第一步,我们可能会采纳用户在表单中输入的任何主题,并在 Twitter 上搜索热门话题。然后我们可以将话题列表全部输入给 Claude,并要求 Claude 选择最有趣的话题。接着,我们可以向 Claude 发出后续请求,要求对该话题进行一些网络研究。
研究完成后,我们可以要求 Claude 为一个短视频编写剧本。一旦我们有了剧本,我们就可以使用一个 AI 化身和一些文本转语音程序来创建一个真实的视频,并最终将该视频发布到社交媒体上。这是一个链式工作流的例子。在链式工作流中,我们把一个大的任务,最初是生成一些视频并发布到社交媒体,分解成一系列独立的步骤。
在我们的例子中,子任务是我们发送给 Claude 的单个调用。我们本可以尝试在对 Claude 的单次调用中完成所有这三个任务。所以我们本可以将一堆主题输入给 Claude,要求它选择最有趣的主题,研究该主题,并在一个提示中编写剧本。但通过将其分解为三个独立的调用,我们让 Claude 每次只专注于一个独立的任务。
现在,就像我说的,这可能看起来像是一个简单而明显的工作流,也许甚至不值得讨论,因为你过去可能已经实现过类似的东西。但我特别指出这个工作流有一个非常特殊的原因,因为它实际上最终成为理解如何在使用相当长的提示时,从 Claude 那里持续获得高质量输出的最重要的工作流之一。所以让我带你了解一个小场景。你以前可能没有遇到过这种情况,但我几乎可以保证你在某个时候会遇到。
让我们想象一下,你正在使用 Claude 来撰写一篇关于某个主题的文章。你最初可能只是向 Claude 发送一个非常简单的提示,要求它写一篇文章,然后你可能会得到一些结果,虽然可能还行,但其中可能有些方面你并不喜欢。所以你最初可能会发现 Claude 可能会提到它是一个 AI 在撰写文章,这你可能不想要。它可能会过度使用表情符号,这你可能也不想要。
而且它可能到处使用一些陈词滥调的语言,这你同样可能不想要。因此,随着时间的推移,当你开始完善这个提示时,你可能最终会建立一个长长的清单,告诉 Claude 完全不要做这些事。但不可避免地,无论你重复这些项目多少次,Claude 最终可能还是会给你一个似乎总是使用表情符号、提到它是由 AI 编写的、并且总体上有一种令人不适、不专业语气的回应。
而且无论你重复多少次这些约束或 Claude 不应该做的事情,Claude 可能仍然会坚持写出这样的文章。所以为了解决这个问题,你可以使用一个非常简单的提示链式工作流。你可以这样做。你可能会输入那个最初包含所有这些约束的长提示,然后就接受你会得到一篇不完全符合你要求的初步文章。Claude 可能会不可避免地决定违反你列出的一些不同约束。
为了解决这些问题,你可以向 Claude 发出后续请求,提供 Claude 刚刚写好的文章。在文章下面,你可以要求 Claude 以某种特定的方式重写文章。所以你可以说,找到任何作者自称是 AI 的地方并删除该提法,找到并删除所有表情符号,然后用专业技术作家的风格重写文本。通过使用这种链式工作流并将任务分解为多个步骤,你可以让 Claude 更专注于呈现给它的每个独立任务。
所以,即使它最初可能没有完全满足你在长提示中提出的所有要求,后续的提示也让 Claude 能够只专注于你真正关心的限制,并有望以你真正想要的风格重写文章。所以再次强调,即使提示链式看起来是显而易见和简单的事情,但当你有一个包含许多约束的任务,而 Claude 似乎并不总是如你所期望的那样遵守这些约束时,这确实会成为你将经常使用的东西。
90. 路由 (Routing) 工作流
类型:视频 | 时长:3:17 | 视频:11 - 004 - Routing Workflows.mp4
路由 (Routing) 工作流解决 AI 应用中一个常见的问题:不同类型的用户请求需要不同的处理方法。您不必使用一刀切的提示,而是可以将传入的请求分类,并将它们路由到专门的处理流水线。
通用提示词的问题
考虑一个社交媒体营销工具,它根据用户主题生成视频脚本。用户可能会输入“编程”或“冲浪”作为他们的主题,但这两种主题应该产生截然不同类型的内容:
编程主题需要包含清晰解释和定义的教育性内容。冲浪主题则更适合以娱乐为中心、强调刺激和视觉吸引力的脚本。单一的通用提示无法有效处理这两种情况。
设置内容类别
第一步是定义您的应用程序可能需要生成的不同类型的内容。您可以将请求分为以下几种类型:
- 娱乐 - 充满活力、与文化相关、使用潮流语言的内容
- 教育 - 清晰、引人入胜的解释,配以相关的例子
- 喜剧 - 尖锐、出人意料的内容,具有巧妙的观察和时机把握
- 个人Vlog - 真实、亲密的内容,采用对话式的故事叙述
- 评论 - 果断、基于经验的内容,突出优点和缺点
- 故事叙述 - 使用生动的细节和情感联系的沉浸式内容
每个类别都有其专门的提示模板。例如,教育性提示可能会要求 Claude “开发一个清晰、引人入胜的脚本,将复杂信息转化为易于理解的见解,使用相关的例子和发人深省的问题。”
路由在实践中如何工作
路由过程分两步进行:
- 分类 - 将用户的主题发送给 Claude,并请求将其归入您预定义的类型之一
- 专门处理 - 使用分类结果选择合适的提示模板并生成内容

例如,如果用户输入“Python 函数”作为他们的主题,您首先会要求 Claude 对其进行分类:
将视频主题归入所列类别之一:
<topic>Python 函数</topic>
<categories>
- 教育
- 娱乐
- 喜剧
- 个人Vlog
- 评论
- 故事叙述
</categories>
Claude 回应“教育”,因此您接着使用教育性提示模板来生成实际的脚本内容。

路由工作流架构
路由工作流遵循以下模式:
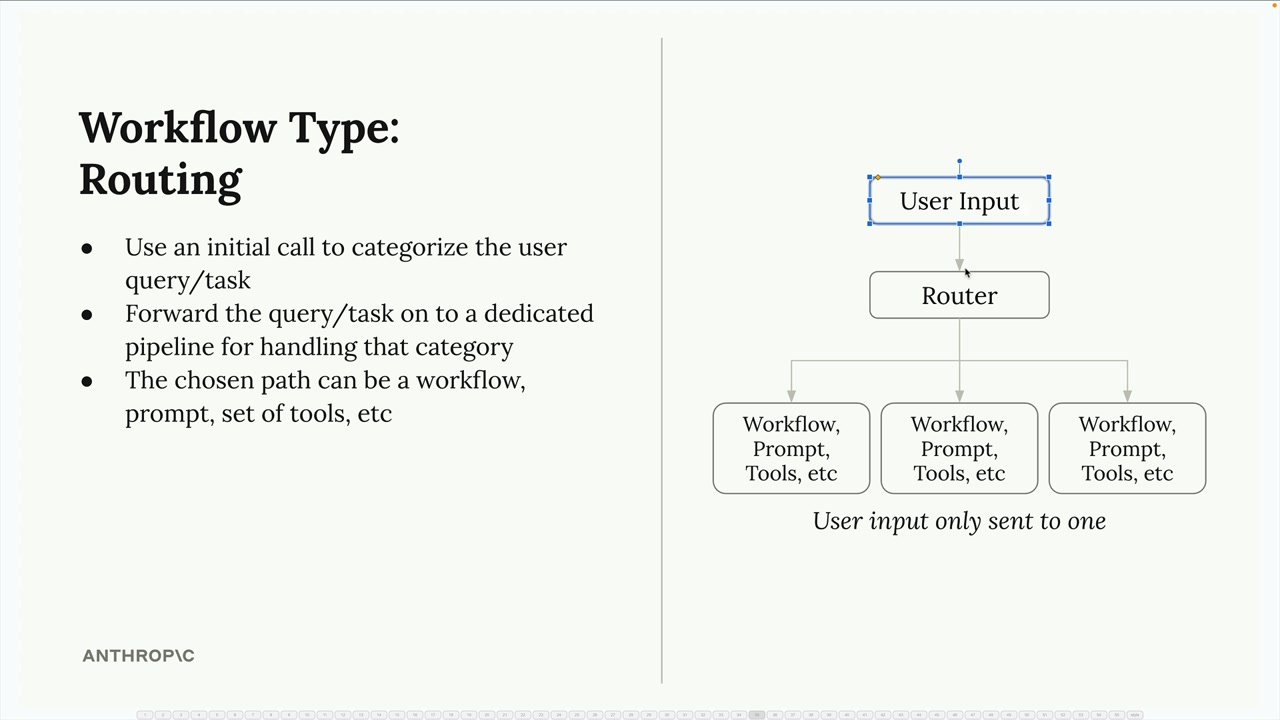
- 用户输入首先进入一个路由器组件
- 路由器通过初次 Claude 调用对请求进行分类
- 根据类别,输入被转发到一个特定的处理流水线
- 每个流水线可以有其自己的工作流、提示或为该类别优化的工具
关键的洞见是,用户输入只进入一个专门的流水线,而不是所有流水线。这使得每个流水线都能针对其特定用例进行高度优化。
何时使用路由
路由工作流在以下情况中效果良好:
- 您的应用程序处理需要不同方法的多种请求类型
- 您可以清晰地定义能覆盖您用例的类别
- 分类步骤可以由 Claude 可靠地处理
- 专门处理带来的性能优势超过了路由步骤的开销
这种模式对于客户服务机器人、内容生成工具以及任何“正确”响应在很大程度上取决于理解所提请求类型的应用尤其有价值。
视频文字稿
我们的下一个工作流将向我们展示一种改进这个社交媒体营销工具的方法。所以我们再次想象,一个用户将输入一个主题,然后我们将以某种方式制作一些视频,并发布到用户的社交媒体账户上。现在,关于脚本生成过程,我真的希望你思考一些事情。换句话说,就是这些不同视频中实际使用的语气和语言。
给定两个不同的主题,比如左边的编程和右边的冲浪,我们真的期望得到性质截然不同的视频脚本。所以在左边,对于编程,我们希望得到大量的信息,仔细解释定义,并且总体上可能是一个旨在具有教育性质的视频。如果用户输入冲浪作为主题,我们可能希望得到一个非常不同的视频脚本。可能是一些教育性质少得多,并且没有关于冲浪是什么的长篇定义或类似内容的东西。
所以让我向你展示一个我们可以使用的工作流,以确保给定主题将产生一个非常适合该主题性质的视频脚本。首先,我们会坐下来思考用户可能要求我们创建的所有不同可能的视频类型。所以我们可能会决定,用户将提供给我们的主题将适合六种不同类型中的一种。娱乐、教育、喜剧等等。
所以在我们之前的例子中,编程可能是教育性的,冲浪可能是娱乐性的。然后对于每一种不同的类型,我们可能会写出一个脚本生成提示。所以如果有人要求一个我们归类为教育性质的主题,我们会要求 Claude 使用这里的这个提示来写一个脚本。这个提示要求 Claude 制作一个清晰、引人入胜的脚本,其中包含一些有趣的例子和有趣的问题等等。
如果用户给我们一个冲浪的主题,我们可能会将其归类为娱乐。那么我们就会使用这里的这个提示,将主题设为冲浪,然后将整个提示输入到 Claude 中,并要求 Claude 写一个关于冲浪的脚本,可能包含一些潮流语言和引人入胜的开头等等。所以让我向你展示整个流程在实践中会是什么样子。我们最初会向 Claude 发送一个只包含用户输入的主题的请求,比如 Python 函数,并要求 Claude 将这个主题归类到我们刚刚提出的不同类别之一。
在这种情况下,Python 函数可能与教育类别最密切相关。所以然后我们会采纳 Claude 的这个回应,并发出一个后续请求,要求 Claude 写一个脚本,其中包含一些关于 Python 函数的清晰、引人入胜的信息,并有发人深省的例子。然后我们大概会得到一个具有这些不同品质和适合教育视频语气的脚本。这是一个路由工作流的例子。
在路由工作流中,我们将采纳用户的原始输入,并将其输入到一个路由步骤中。这个路由步骤很可能本身就是对 Claude 的一次调用,要求 Claude 以某种方式对用户输入或任务进行分类。然后,根据 Claude 的回答,我们将用户的输入转发到某个非常特定的后续处理流水线。所以可能是这里的这一个,或这里的这一个,或这里的这一个,等等。
但可能只是这三个中的一个。这些不同的路由选项中的每一个都可能在其中实现了不同的工作流,或者一个为处理用户所要求的确切任务而定制的提示或一套定制的工具。
91. 智能体 (Agent) 与工具
类型:视频 | 时长:5:02 | 视频:11 - 005 - Agents and Tools.mp4
智能体 (Agent) 代表了从我们一直使用的结构化工作流的转变。虽然工作流在您确切知道完成任务所需步骤时非常完美,但当您不确定这些步骤应该是什么时,智能体便大放异彩。您不是定义一个刚性的序列,而是给 Claude 一个目标和一套工具,然后让它自己想出如何组合这些工具来实现目标。
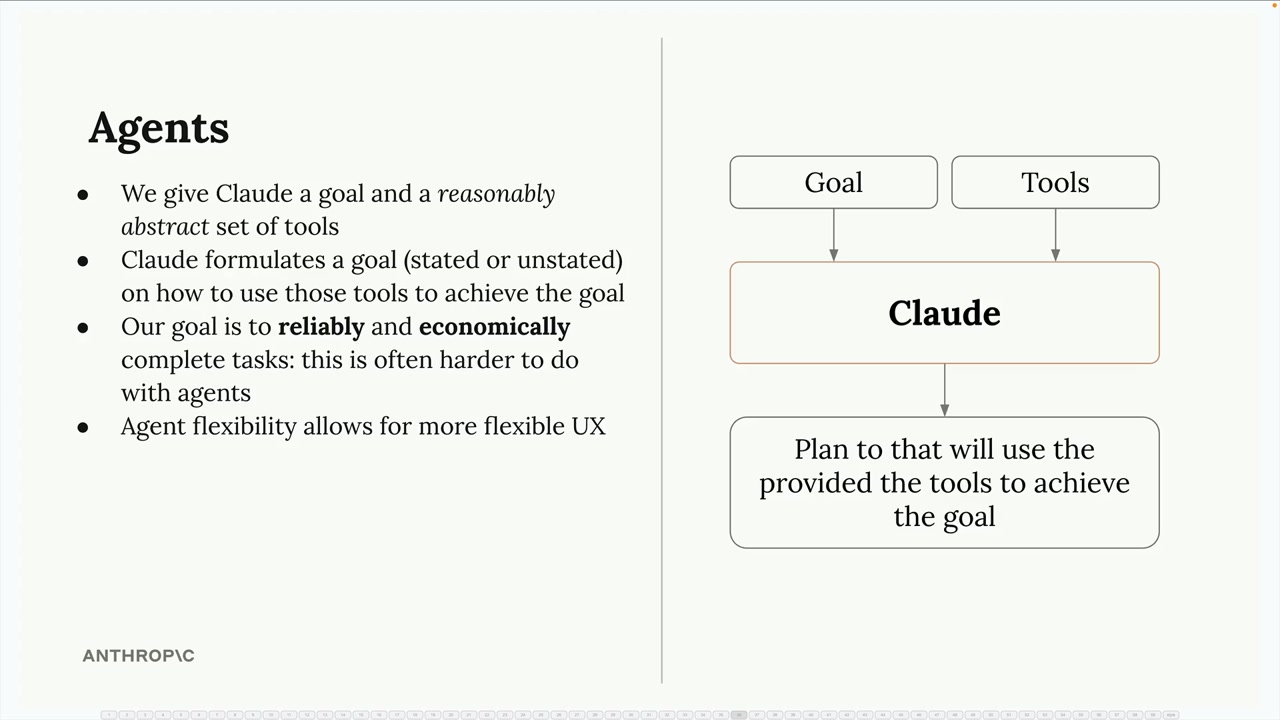
这种灵活性使得智能体在构建需要处理各种不可预测任务的应用程序时很有吸引力。您可以一次性创建一个智能体,确保它工作得相当好,然后部署它来解决广泛的问题。然而,这种灵活性也带来了我们稍后将探讨的在可靠性和成本方面的权衡。
工具如何成就智能体
智能体的真正力量在于它们能够以意想不到的方式组合简单的工具。考虑一套基本的日期时间工具:

- get_current_datetime - 获取当前日期和时间
- add_duration_to_datetime - 向给定日期添加时间
- set_reminder - 为特定时间创建提醒
这些工具单独看起来很简单,但 Claude 可以将它们串联起来处理出人意料的复杂请求:
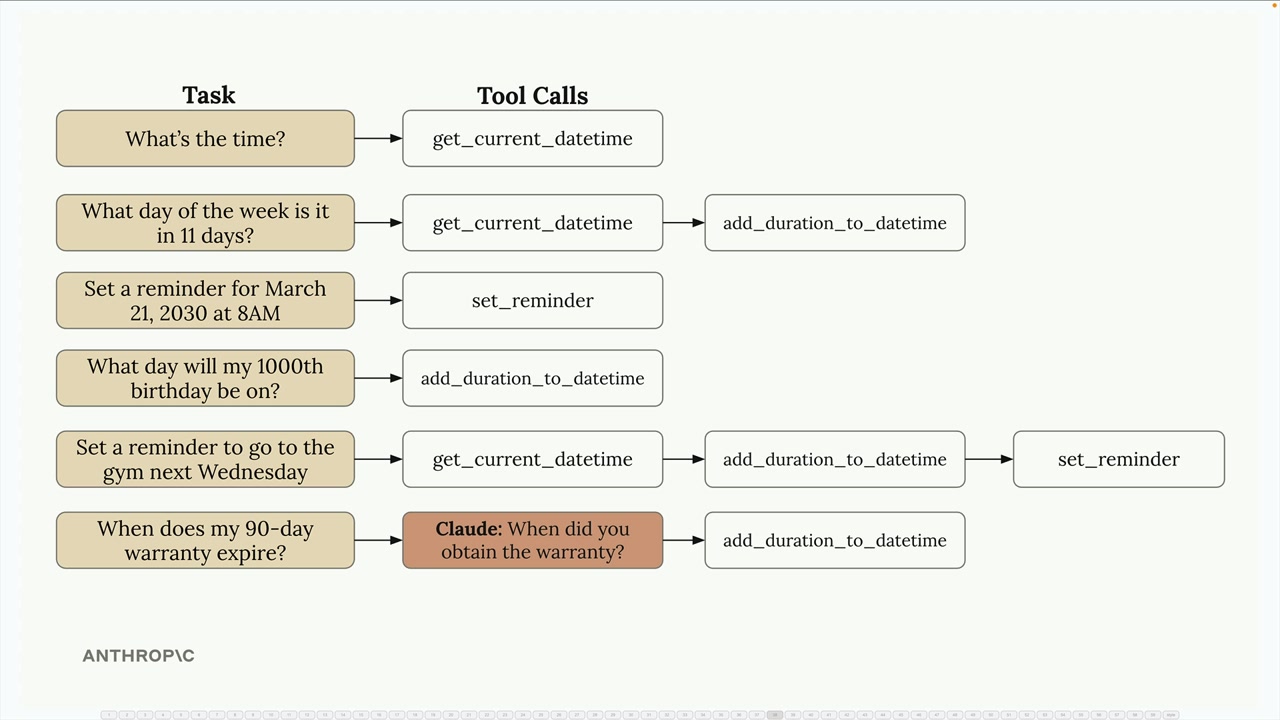
对于“现在几点了?”,Claude 只需调用 get_current_datetime。但对于“11 天后是星期几?”,它会先调用 get_current_datetime,然后再调用 add_duration_to_datetime。对于设置下周三的健身提醒,它可能会依次使用所有这三个工具。
Claude 甚至能识别出何时需要更多信息。如果您问“我的 90 天保修期何时到期?”,它知道在计算到期日期之前,需要先询问您购买该物品的时间。
工具应当是抽象的
构建高效智能体的关键洞见是提供相当抽象的工具,而不是高度专门化的工具。Claude Code 完美地展示了这一原则。

Claude Code 可以访问通用的、灵活的工具,例如:
- bash - 运行任何命令
- read - 读取任何文件
- write - 创建任何文件
- edit - 修改文件
- glob - 查找文件
- grep - 搜索文件内容
值得注意的是,它没有像“重构代码”或“安装依赖”这样的专门工具。相反,Claude 会自己想出如何使用这些基础工具来完成这些复杂的任务。这种抽象性使其能够处理开发者从未明确计划过的无数编程场景。
最佳实践:可组合的工具
在设计智能体时,提供 Claude 可以创造性组合的工具。例如,一个社交媒体视频智能体可能包括:

- bash - 访问 FFMPEG 进行视频处理
- generate_image - 根据提示创建图像
- text_to_speech - 将文本转换为音频
- post_media - 将内容上传到社交平台
这个工具集既能实现简单的工作流(创建并发布视频),也能提供更具互动性的体验,例如智能体可能先生成一张样本图片,获得用户批准,然后继续进行视频创作。

智能体可以根据用户的反馈和偏好调整其方法,这对于刚性的工作流来说是很难实现的。这种灵活性正是智能体在构建动态、用户响应式应用方面的强大之处。
视频文字稿
现在我们已经看过了几种不同的工作流,我们将转向并开始讨论智能体。如果你回想一下工作流,特别是我们实际使用它们的时候,就最容易理解智能体了。当我们知道完成给定任务所需的确切步骤时,工作流最有效。而另一方面,当我们不完全清楚需要哪些步骤时,智能体则更有效。
所以在这些情况下,我们给 Claude 一个任务和一套工具。然后我们依赖 Claude 来制定一个计划,使用给定的工具来完成任务。智能体的这种灵活性使它们在构建应用时非常有吸引力。我们的思路是,你可以制作一个智能体,确保它工作得相当好,然后这个智能体就可以解决各种不同的任务。
然而,这种方法有一些主要的缺点,我们稍后会讨论。智能体的一个关键方面是它们能够以不同组合方式使用工具。所以为了帮助你理解这一点,我想让你回想一下我们之前在本课程中讨论过的一个例子,在那里我们组合了三种不同的工具。我们创建了像 Get Current Date Time(获取当前日期时间)、Add duration to Date Time(向日期时间添加时长)和 Set Reminder(设置提醒)这样的工具。
这些工具中的每一个本质上都相当简单,但是 Claude 能够以不同、甚至有点出人意料的方式将它们组合起来,以完成我们可能没有提前计划好的各种不同任务。让我给你看一些例子。所以在这张图的左边,我列出了一些我们可以连同那三种不同工具一起输入给 Claude 的示例任务。然后在右边部分是 Claude 可能为完成给定任务而进行的一系列不同工具调用。
所以举个例子,如果我们问 Claude 现在是什么时间,很简单,Claude 只需单独调用 get current date time 工具就能回答问题。如果我们问 Claude 11 天后是星期几,它可以先调用 get current date time,然后再调用 add duration to date time。如果我们让 Claude 说,设置一个下周三去健身房的提醒,Claude 可以先找出当前是星期几,然后给它加上一个时长,最后为那个特定的日子设置一个提醒。最后,Claude 还能判断出何时需要一些额外信息才能成功调用一个工具。
所以如果一个用户问,我的 90 天保修期什么时候到期?那么,并不能保证用户就是今天获得的保修。所以 Claude 可能会先向用户询问一些额外信息,特别是他们实际获得保修的时间。一旦用户提供了这些信息,Claude 就可以调用 add duration to date time 并计算出保修期何时到期。
这些都是 Claude 如何能够将一套工具以有趣的方式组合起来以解决给定任务的例子。这将引导我们进入关于智能体的第一个重要课程或理解。那就是我们提供给智能体的工具集需要是相当抽象的。为了帮助你理解我所说的抽象的真正含义,一个很好的例子是回顾一下 Claude code 以及提供给它的一些工具。
Claude Code 获得了一套非常小的抽象工具。当我说抽象时,我指的是通用的或目的上有点模糊的。它们在任何方面都不是高度专业化的。所以 Claude Code 可以访问像 Bash 这样的工具来运行命令,web fetch 来获取 URL,write 来创建文件,等等。
Claude Code 能够以非常惊人的方式,通过组合这些不同的工具来修改和向现有代码库添加功能。Claude Code 无法访问那些只能在一种特定场景下完成一个非常具体任务的高度专业化工具。所以举个例子,在这张图的右侧,这些都是 Claude Code 明确没有的工具。所以没有一个 refactor 工具可以神奇地重构文件。
相反,Claude Code 应该想出如何利用左侧的工具来重构某些东西。同样,也没有 install dependencies 工具。相反,Claude Code 需要读取文件来理解项目配置,然后运行 bash 工具来执行适当的命令来安装依赖。我们可以从中得到的教训是,每当我们创建一个智能体时,我们都希望确保我们提供的是相当抽象的工具,Claude 能够以某种方式想出如何将它们组合在一起以实现某个目标。
所以举个例子,如果我们回到我们构建某种社交媒体视频创作智能体的例子,我们可能会提供给它不同的工具。一个可能是 Bash,这将让它能够访问 FFmpeg。这是一个常用的命令行工具,你可以用它来根据一些输入的图像、视频、文本或音频等来生成视频。我们可能还会给它一个 generate image 工具、一个 text to speech 工具,只是为了增强视频生成过程,然后最后是一个 post media 工具,这样它就可以将生成的内容,无论是什么,发布到社交媒体账户上。
Claude 可以以相当出人意料的方式使用这套工具。所以举个例子,它将能够实现你在左侧看到的流程,用户可能会与我们的智能体聊天,并要求它创建并发布一个关于 Python 编程的视频。但这套工具也可能允许与用户进行更动态的互动。例如,在右侧,用户可能会要求一个视频,但首先要求智能体生成一个用于视频的样本封面图片。
然后我们的智能体可以首先生成一个图片,展示给用户,获得用户的批准,然后进入视频生成过程。
92. 环境检查 (Environment Inspection)
类型:视频 | 时长:3:05 | 视频:11 - 006 - Environment Inspection.mp4
在构建 AI 智能体时,一个至关重要的概念常常被忽视:环境检查 (Environment Inspection)。Claude 是在盲目操作的——它需要能够观察并理解其行动的结果才能有效工作。
环境检查为何重要
想想 Claude 是如何与计算机交互的。每当 Claude 执行一个动作,比如输入文本或点击按钮,它都会立即收到一张截图来了解发生了什么。这不仅仅是一个锦上添花的功能——它是必不可少的。
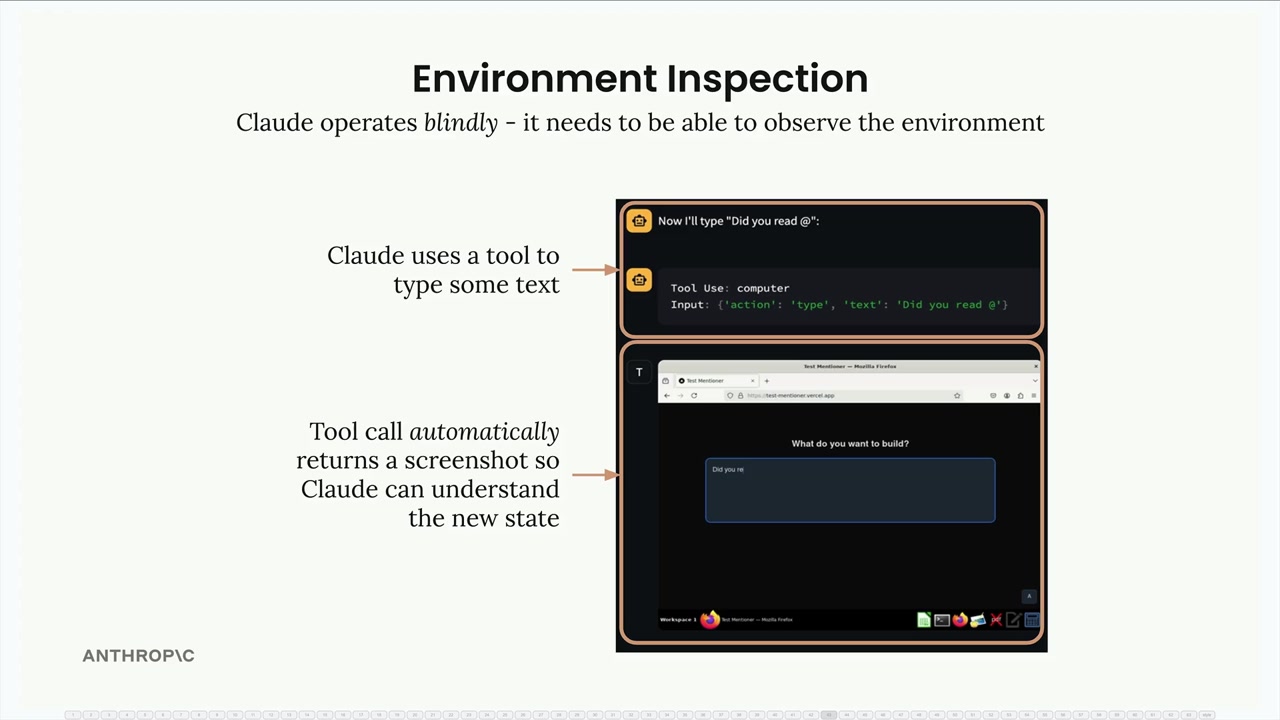
从 Claude 的角度来看,点击一个按钮可能会导航到一个新页面、打开一个菜单或触发任何数量的变化。如果无法看到结果,Claude 就无法理解其行动是否成功,或者环境的新状态是怎样的。
写入前先读取
同样的原则也适用于文件操作。在 Claude 能够修改任何文件之前,它需要了解当前的内容。这可能看起来很明显,但这是您在构建智能体时应该始终遵循的模式。
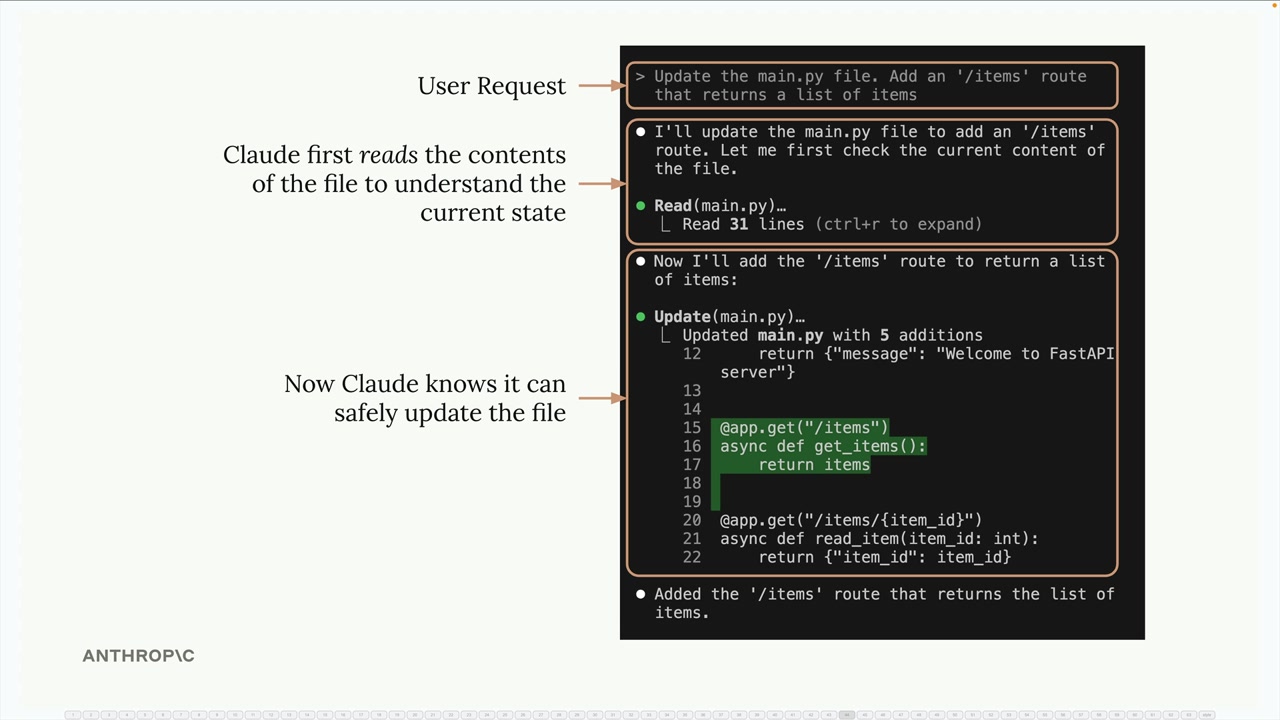
在上面的例子中,当被要求向一个 Python 文件添加新路由时,Claude 首先读取现有代码以了解当前结构。只有这样,它才能安全地进行所请求的更改,而不会破坏现有功能。
用于环境检查的系统提示词
您可以通过系统提示词来引导 Claude 检查其环境。对于像视频生成这样的复杂任务,这一点变得尤其重要。
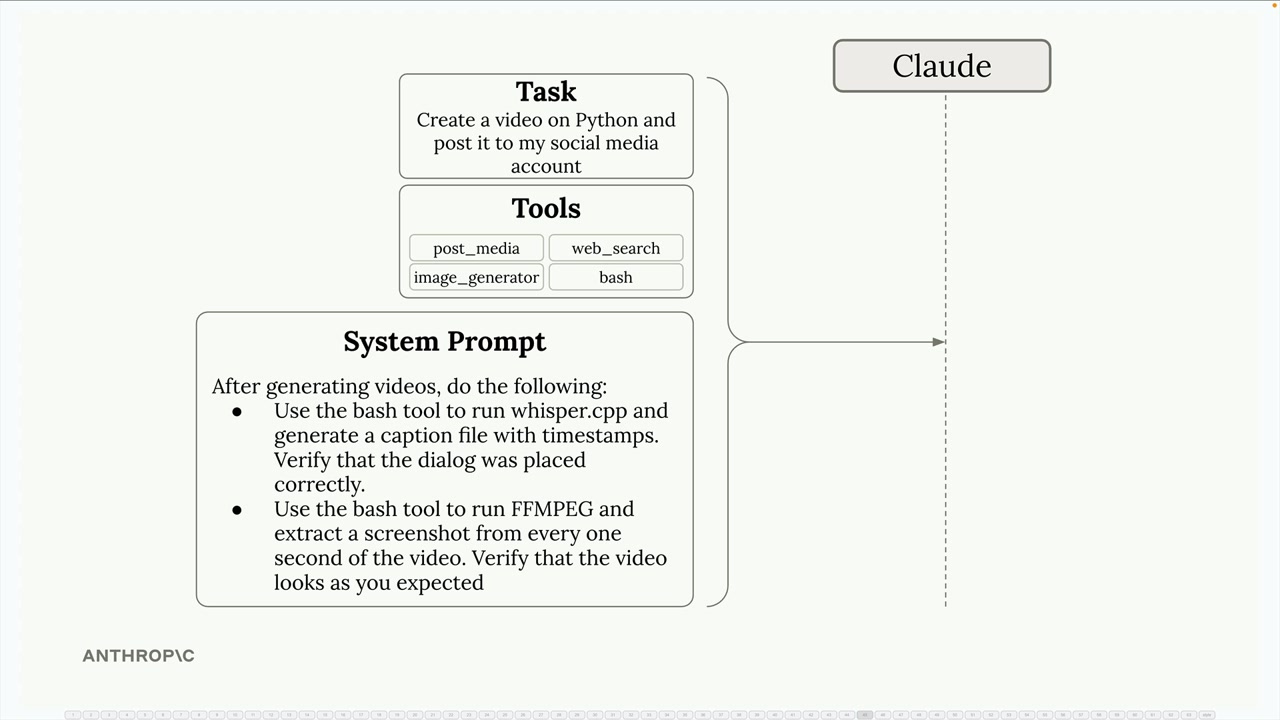
考虑一个需要执行以下操作的视频创作智能体:
- 使用 FFmpeg 等工具生成视频内容
- 验证音频对话是否放置正确
- 检查视觉元素是否按预期出现
您可能会在系统提示中包含如下指令:
- 使用 bash 工具运行 whisper.cpp 并生成带有时间戳的字幕文件,以验证对话放置位置
- 使用 FFmpeg 从视频中定期提取截图,以直观地检查输出
- 将生成的内容与原始需求进行比较
环境检查的好处
当 Claude 能够检查其环境时,有几个方面会得到改善:
- 更好的进度跟踪 - Claude 可以评估它离完成任务还有多近
- 错误处理 - 可以检测和纠正意外结果
- 质量保证 - 可以在认为任务完成之前验证输出
- 适应性行为 - Claude 可以根据观察到的情况调整其方法
实践中的实现
在设计您自己的智能体时,总要问:“Claude 将如何知道这个动作是否成功?”无论您是在处理文件、API 还是用户界面,都要提供工具和指令,让 Claude 能够观察其行动的结果。
这可能意味着:
- 在修改前读取文件内容
- 在 UI 交互后截取屏幕截图
- 检查 API 响应中是否包含预期数据
- 根据需求验证生成的内容
环境检查将 Claude 从一个盲目执行命令的执行者转变为一个能够真正理解并适应其工作环境的智能体。
视频文字稿
我们接下来要讨论的关于智能体的下一个想法是环境检查。当我们之前看计算机使用时,你可能还记得一些有趣的事情。在左侧记录的每一个动作之后,比如打字或移动鼠标,我们似乎总能立即看到一张截图,这正是我在这张图中向你展示的。Claude,试图输入一些文本,我们看到这记录在上面的第一个面板中,然后紧接着,我们看到一张截图立即出现。
我希望你从 Claude 的角度来看待计算机的使用。Claude 试图在某个地方打字或点击,页面大概会发生变化,但 Claude 并不真正理解是如何变化的。点击一个按钮可能会导航到一个新页面,或者可能会打开一个菜单。为了理解它所采取的任何行动的结果,Claude 需要一张截图来了解它所处的新状态或环境。
这个同样的想法适用于我们组装的任何智能体。在采取行动之后,有时在采取行动之前,Claude 真的需要一种方法来评估行动的结果,这往往超出了工具返回的范围。通过帮助 Claude 理解其环境,它可以更好地衡量完成任务的进度,也能更好地处理意外结果或错误。当我们在使用 Claude code 时,可以看到一个非常相似的想法。
所以在这张截图中,在最顶部,我要求 Claude 更新 main.py 文件。现在,我给 Claude 的任务,即添加一个额外的路由,其实很简单。但在我们以任何方式修改该文件之前,这似乎非常明显。嗯,Claude 需要先了解文件里当前的代码是什么。
所以 Claude 需要某种方式来读取文件的内容。现在,我知道这似乎很明显,但我鼓励你在构建自己的智能体时,随时思考这个关于在写入文件之前先读取文件的想法。这个想法甚至适用于我们的社交媒体视频智能体。所以每当我们向 Claude 发出请求时,我们可能会给它一个任务,比如创建一个关于 Python 的视频并发布到我的社交媒体账户上,同时附上我们的工具列表。
然后我们可能会在系统提示中提供一些特殊说明,帮助 Claude 理解在生成视频后如何检查其环境。就我个人而言,如果我依赖 Claude 使用 FFimPig 来生成视频,我有点预料到它有时可能会在对话放置上犯错。具体来说,就是当它使用一些文本转语音功能生成的音频片段播放时。为了帮助 Claude 在制作这些视频时更好地了解完成任务的进度,我可能会给它一些指令,让它使用 BASH 工具,特别是运行一个名为 Whisper CPP 的程序。
这是一个我们可以用来从视频中自动生成字幕文件的程序。这些字幕文件里有时间戳,所以 Claude 可以使用这个程序来确保对话放置正确。我们可能还会建议 Claude 使用 bash 工具运行 ffimpeg,它有能力从视频中提取截图。我们可能会告诉 Claude 每秒或每 10 秒提取一张截图,并查看这些截图,以确保视频看起来符合它的预期。
这让 Claude 能够检查其行动的结果,即它创建的实际视频,并确保它正在按要求完成任务。
93. 工作流 vs 智能体
类型:视频 | 时长:2:00 | 视频:11 - 007 - Workflows vs Agents.mp4
在构建由 AI 驱动的应用程序时,您通常需要在这两种不同的架构方法之间做出选择:工作流和智能体。每种方法都有其独特的优势和权衡,使其适用于不同的场景。
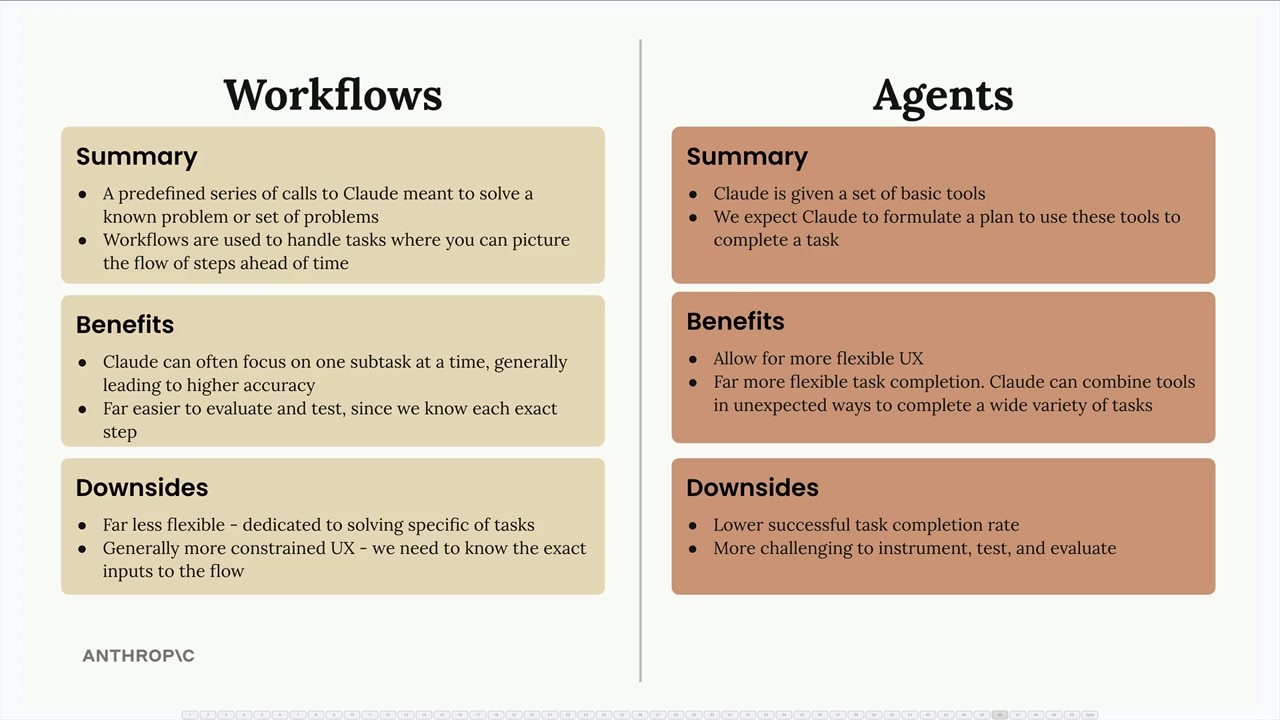
什么是工作流?
工作流是为解决一个已知问题或一组问题而设计的一系列预定义的对 Claude 的调用。当您可以预先构想出步骤流程时——基本上是当您知道完成任务所需的确切顺序时——您会使用工作流。
可以把工作流看作是把一个大任务分解成许多更小、更具体的子任务。每一步都专注于一个单一的领域,这使得 Claude 能够更精确地工作。
什么是智能体?
对于智能体,Claude 会得到一套基础工具,并被期望制定一个计划来使用这些工具完成任务。与工作流不同,您不确切知道将提供什么任务,因此系统需要更具适应性。
智能体可以通过以意想不到的方式组合工具,创造性地找出如何处理各种各样的挑战。
工作流的优势
- Claude 可以一次专注于一个子任务,通常能带来更高的准确性
- 由于您知道每个确切的步骤,因此更容易评估和测试
- 执行更可预测和可靠
- 更适合解决具体的、定义明确的问题
智能体的优势
- 允许更灵活的用户体验
- 任务完成方式更灵活——Claude 可以以意想不到的方式组合工具来完成各种任务
- 可以处理开发过程中未预料到的新情况
- 需要时可以向用户请求额外输入
工作流的劣势
- 灵活性差得多——专用于解决特定类型的任务
- 用户体验通常更受限制——您需要知道流程的确切输入
- 需要更多的前期规划和设计工作
智能体的劣势
- 与工作流相比,任务成功完成率较低
- 由于您通常不知道智能体将执行什么系列步骤,因此更难进行检测、测试和评估
- 行为更不可预测
何时使用哪种方法
作为工程师,您的首要目标是可靠地解决问题。用户可能不关心您构建了一个花哨的智能体——他们想要的是一个能持续工作的产品。
一般的建议是,在可能的情况下,始终专注于实施工作流,只有在真正需要时才求助于智能体。工作流提供了大多数生产应用所需的可靠性和可预测性,而智能体则为无法预先确定确切需求的场景提供了灵活性。
当您有定义明确的流程时,考虑使用工作流;当您需要处理需要创造性解决问题的不可预测、多样的用户请求时,考虑使用智能体。
视频文字稿
让我们通过比较和对比工作流和智能体的一些不同方面来总结。首先,回想一下,工作流是预先定义的一系列对 Claude 的调用。当我们对完成一项任务所需的确切步骤有很好的了解时,我们通常会使用工作流。而对于智能体,我们并不确切知道将提供什么任务,所以我们转而提供一套坚实的基础工具,并期望 Claude 将这些工具组合起来完成给定的任务。
您可能已经注意到,工作流的一个共同主题是我们把一个大任务分解成许多更小的任务。这些更小的任务中的每一个都更具体,使 Claude 能够一次专注于一个领域。这种增强的专注度通常会导致与智能体相比,完成任务的准确性更高。因为我们知道工作流执行的确切步骤,所以它们也更容易测试和评估。
对于智能体,我们不受限于一系列一成不变的步骤。相反,Claude 可以创造性地想出如何应对各种各样的挑战。伴随这种灵活性,我们在用户体验方面也获得了灵活性。工作流期望接收一套非常特定的输入,而智能体可以根据从用户那里收到的查询创建自己的输入,并且当需要时,智能体还可以向用户请求更多输入。
智能体的缺点是,与工作流相比,它们的任务成功完成率通常较低,因为我们把如此多的工作委托给了 Claude。此外,它们也更难测试和评估,因为我们通常不清楚智能体将执行什么系列步骤来完成给定的任务。归根结底,智能体确实很有趣,但请记住,作为一名工程师,您的首要目标是可靠地解决问题。用户可能不关心您制作了一个花哨的智能体。
他们真正想要的只是一个能 100% 工作的产品。因此,考虑到这一点,一般的建议是尽可能地专注于实施工作流,只有在真正需要时才求助于智能体。
96. 课程总结
类型:视频 | 时长:3:12 | 视频:12 - 001 - Course Wrap Up.mp4
视频文字稿
如果你完成了这门课程,你已经付出了巨大的努力,我向你表示祝贺。在我们结束之前,我想非常迅速地回顾一下我们讨论过的一些主要主题,并给你一些建议,供你将来研究的后续主题。首先,快速回顾一下我们已经涵盖的内容。我们在这门课程开始时讨论了 Anthropic 提供的不同模型。
记住,我们有 Haiku 用于快速、较小的请求,还有 Sonnet 用于更高的智能。然后我们花了很多时间讨论如何通过 API 访问 Claude 以及我们可以输入给 Claude 的不同参数,以调整其响应。例如,我们讨论了温度和停止序列、消息预填充。所有这些都是我们可以用来引导 Claude 朝特定方向发展、控制其创造力,并确保我们获得预期数据格式或输出的参数。
然后我们花了相当多的时间讨论提示词评估 (Prompt evaluations)。我怎么强调都不过分。提示词评估是迄今为止你在自己的项目中实施的最重要的实践。你可能坐下来自己运行一个提示 10 次,然后觉得一切都好,但一旦你将它部署到生产环境中,你的用户可能得不到你希望他们得到的结果。
确保你正在编写有效提示的唯一方法就是对它们进行评估。记住,提示评估不必很困难。你不必使用一个花哨的框架或做任何复杂的设置。你可以使用 Claude 来自己生成一个提示评估框架。
这大概就是你在这门课程中所看到的。我们使用的提示评估框架,其中很多代码都是由 Claude 直接编写的。然后我们花了一些时间讨论提示词工程 (Prompt engineering)。记住,有几种技巧需要你牢记。
其中最主要的就是简单明了地直接告诉 Claude 你对它的期望。之后,我们花了很多精力在工具调用 (Tool Use) 上,这可能是课程中比较复杂的部分之一。工具调用极其重要,因为它极大地扩展了 Claude 的能力。然后我们花了一些时间研究了 Anthropic 直接发布的两个重要应用,Claude code 和 Computer use。
我希望你喜欢亲身体验 Claude Code。就我个人而言,我用它来帮助我编写代码和项目。我实际上不怎么使用花哨的编辑器内助手。我真的就像你在那些视频中看到的那样,在终端运行 Claude Code。
最后,我们花了相当多的时间讨论工作流和智能体。现在,请记住,智能体确实很有趣。这是一个非常令人兴奋的话题,但通过使用工作流,你通常会得到更好的结果和更高的准确性。由于时间关系,我们无法在这门课程中涵盖所有主题。
有一些重要的项目,我建议你跟进并自己做一些研究。其中最主要的是很多关于智能体的主题。理解如何让智能体通过智能体编排 (Agent orchestration) 协同工作,理解如何评估和监控智能体的性能,以及 RAG (Retrieval-Augmented Generation) 的一个变体,即智能体 RAG (Agentic RAG),都是我建议你花时间自己研究的主题。我还建议你看一些关于 RAG 评估和工具评估的不同技术。
工具评估类似于提示评估。我们希望确保我们的工具描述正在以我们真正期望的方式帮助 Claude。好了,就到这里。就像我说的,我希望你喜欢这门课程,并感谢你花时间学习这些内容。
第 9 课:Claude 与 Google Vertex AI
在 Google Cloud 平台上使用 Claude 课程链接:Claude 与 Google Vertex AI | 共 93 节课
Claude 模型概览
Claude 模型分为 3 个系列,针对不同优先级进行了优化。
Opus = 智能程度最高的模型。适用于需要深度推理和规划的复杂多步任务。可以独立工作数小时。支持 reasoning capability (推理能力)。其权衡是成本更高和中等延迟。
Sonnet = 平衡型模型。在智能、速度和成本效益方面表现良好。具有强大的编码能力,能精确编辑代码而不破坏功能。文本生成速度快。是大多数用例的最佳选择。
Haiku = 速度最快的模型。为速度和成本效益而优化。不具备推理能力。最适合实时用户交互和高吞吐量处理。
选择框架:智能优先 → Opus。速度优先 → Haiku。需要平衡 → Sonnet。
关键洞察:团队通常在同一应用中使用多个模型。Haiku 用于用户交互,Sonnet 用于业务逻辑,Opus 用于复杂推理任务。
所有模型都共享核心能力 = 文本生成、编码、图像分析。
访问 API
API Access Flow (API 访问流程) = 从用户输入到响应显示的 5 步流程。
第 1 步:客户端将用户文本发送到开发者的服务器(绝不直接从客户端访问 Vertex,凭证必须保密)。
第 2 步:服务器使用 SDK(Python/TypeScript/Go/Ruby)向 Vertex AI 发出请求。必需参数:模型名称、messages list (消息列表)、max_tokens (最大令牌数) 限制。
第 3 步:Claude 文本生成过程 = 4 个阶段:
- Tokenization (分词) = 输入被分解为 token (令牌)(单词/部分/符号)。
- Embedding (嵌入) = 令牌被转换为表示所有可能含义的数字列表。
- Contextualization (语境化) = 根据相邻令牌调整嵌入,以确定精确含义。
- Generation (生成) = 输出层产生词汇概率,模型根据概率和随机性进行选择,添加所选词汇,重复此过程。
第 4 步:当达到 max_tokens 或模型生成 end-of-sequence token (序列结束令牌) 时,生成停止。
第 5 步:API 返回包含生成文本、使用量计数和 stop reason (停止原因) 的响应。服务器将其转发给客户端进行显示。
关键组件:
- Token (令牌) = 文本块(单词/部分/符号)。
- Embedding (嵌入) = 令牌含义的数值表示。
- Contextualization (语境化) = 使用周围上下文进行意义细化。
- Max tokens (最大令牌数) = 生成长度的限制。
- Stop reason (停止原因) = 生成结束的原因。
- Usage (使用量) = 输入/输出的令牌计数。
安全性:始终通过服务器路由 API 调用,切勿在客户端应用程序中暴露 credentials (凭证)。
发出请求
向 Vertex AI Claude 发出请求
设置步骤:
- 安装 anthropic SDK:
%pip install "anthropic[vertex]" - 导入并创建客户端:
from anthropic import vertex然后使用region="global"和project_id进行实例化。 - 定义模型版本变量以供重用。
client.messages.create() 的必需参数:
- model = 特定的 Claude 模型版本字符串。
- max_tokens = 响应长度的安全限制(不是目标,只是最大值)。
- messages = 消息字典列表。
消息类型:
- 用户消息 =
{role: "user", content: "text written by humans"} - 助手消息 =
{role: "assistant", content: "text generated by Claude"}
响应访问: 原始响应包含元数据。使用以下方式提取生成的文本:message.content[0].text
关键概念: Messages = 用户与 Claude 之间的对话交流。 Max tokens = 防止过度生成的安全机制。 Project ID = 来自 Google Cloud 控制台的唯一标识符。
多轮对话
Multi-Turn Conversations (多轮对话) = 在与 Claude 的多次交流中保持上下文。
关键限制:Anthropic API 不存储任何消息。每个请求都是 stateless (无状态的) - 没有先前交流的记忆。
问题:在没有上下文的情况下发送后续请求会产生不相关的响应,因为 Claude 没有先前对话的记忆。
解决方案要求:
- 在你的代码中手动维护消息列表。
- 每次请求都发送整个 conversation history (对话历史)。
实现模式:
- 创建一个空的消息列表。
- 将用户消息添加到列表中。
- 发送给 Claude,获取响应。
- 将助手响应添加到列表中。
- 添加下一条用户消息到列表中。
- 将整个更新后的列表发送给 Claude。
- 重复。
必要的辅助函数:
add_user_message(messages, text)= 将用户消息附加到对话历史中。add_assistant_message(messages, text)= 将助手响应附加到对话历史中。chat(messages)= 将消息列表发送到 Claude API 并返回响应。
消息结构 = 包含 "role" (user/assistant) 和 "content" 字段的字典列表。
上下文保持 = 在每个 API 调用中包含完整的对话历史,使 Claude 能够理解引用并保持连贯的对话流程。
系统提示
System Prompts (系统提示) = 指导 Claude 在特定用例中调整其语气、风格和行为的指令。
目的 = 控制 Claude 如何响应,而不仅仅是响应什么。例如:让 Claude 扮演一个耐心的数学导师,提供提示而不是直接给出答案。
实现 = 将系统提示作为纯字符串通过 system keyword argument (关键字参数) 传递给 create 函数。
结构 = 第一行通常为 Claude 分配一个 role (角色)(“你是一个耐心的数学导师”),后面跟着具体的行为指令。
关键原则 = 系统提示引导 Claude 的方法——导师提供指导并提出引导性问题,而不是直接解决问题。
技术考虑 = system 参数不能为 None,必须在提示存在时才条件性地包含在 API 调用中。
最佳实践 = 使系统提示可配置,而不是硬编码,以便在不同用例中重用。
结果 = 将直接的问答互动转变为根据特定角色和情境量身定制的、有指导的互动体验。
温度 (Temperature)
Temperature (温度) = 控制 Claude 文本生成中随机性的参数,为一个 0-1 之间的十进制数值。
文本生成过程 = 分词 → 概率分配 → 基于概率选择令牌。
Temperature 的影响:
- Temperature 0 = deterministic output (确定性输出),总是选择概率最高的令牌。
- 更高的 Temperature = 增加选择较低概率令牌的机会,产生更有创意/意想不到的输出。
使用指南:
- 低 Temperature(接近 0)= 数据提取、事实性任务、一致的输出。
- 高 Temperature(接近 1)= 创意写作、头脑风暴、笑话、市场营销。
实现 = 在模型调用函数中添加 temperature 参数,默认为 1.0 以保持创造性。
关键洞察 = 更高的温度会增加变化的可能性,但不能保证一定有变化,可能需要多次尝试才能看到创造性的差异。
响应流 (Response Streaming)
Response Streaming (响应流) = 一种在 AI 长时间生成响应期间为用户提供即时反馈的技术,而不是让他们看 10-30 秒的加载动画。
工作原理:服务器将用户消息发送给 Claude → Claude 立即发送初始响应(无文本内容,仅为确认)→ Claude 发送包含文本块的事件流 → 服务器接收事件并将文本块发送到前端 → 用户看到文本逐块渐进式地出现。
事件类型:message_start、content_block_start、content_block_delta(包含实际文本)、content_block_stop、message_delta、message_stop。
实现:
- 基本流式处理:
client.messages.create(model, max_tokens, messages, stream=True)返回一个事件的 iterator (迭代器)。 - 专注于文本的流式处理:
client.messages.stream()与 context manager (上下文管理器) 结合使用,通过stream.text_stream提供更清晰的文本内容访问方式。 - 最终消息组装:
stream.get_final_message()将所有块收集成一个完整的消息,用于数据库存储。
关键好处:用户看到即时的渐进式响应,而不是等待完整生成,从而改善了聊天界面中的用户体验。
控制模型输出
模型输出控制 = 除了修改提示之外的两种主要技术:pre-filling assistant messages (预填充助手消息) 和 stop sequences (停止序列)。
预填充助手消息 = 在消息列表末尾手动添加助手消息,以引导响应方向。Claude 将预填充的内容视为已创作并从该点继续。例如:添加“咖啡更好,因为”会迫使 Claude 为咖啡的偏好辩护。响应会从预填充文本的末尾继续,而不是完全替换。
实现:在消息列表中的用户消息之后,添加一个包含部分内容的助手消息。Claude 会将其视为自己之前的响应,并在此基础上构建。
停止序列 = 当特定字符串出现时,强制 Claude 停止生成。提供一个字符串列表,当生成这些字符串时会立即终止响应。生成的停止序列文本不包含在最终输出中。
实现:在 API 调用中添加 stop_sequences 参数,并附上一个触发字符串列表。一旦遇到任何列出的序列,生成将立即停止。
用例:预填充控制响应的方向/立场。停止序列通过在特定点终止来控制响应的长度/格式。
结构化数据
结构化数据生成 = 结合停止序列和助手消息预填充,以获得没有注释的原始输出。
问题:在生成结构化数据(JSON、Python、列表)时,Claude 自然会添加页眉/页脚/解释。用户通常只想要原始内容,以便于复制/粘贴。
解决方案模式:
- 用开始 delimiter (分隔符)(例如,
\``json`)预填充助手消息。 - 将停止序列设置为匹配的结束分隔符(例如,
\```)。 - Claude 假定它已经写了开头部分,只生成内容,并在结束分隔符处停止。
结果:获得没有任何额外注释的原始结构化数据。
示例流程:
- 用户:“以 JSON 格式生成事件桥接规则”
- 助手预填充:
\``json` - 停止序列:
\``` - 输出:仅为分隔符之间的 JSON 内容。
关键好处:
- 消除不需要的 markdown 格式。
- 移除解释性文本。
- 实现直接的复制/粘贴功能。
- 适用于任何结构化数据类型(JSON、代码、列表)。
实现:text.strip() 或 JSON.loads() 可以清理剩余的换行符/格式。
用例:任何需要精确结构化输出而无需 Claude 自然提供的帮助性注释的场景。
提示评估
Prompt Engineering (提示工程) = 编写/编辑提示以帮助 Claude 理解请求和期望响应格式的技术。
Prompt Evaluation (提示评估) = 使用客观指标自动测试提示以衡量其有效性。
编写提示后的三条路径:
- 测试一两次,部署到生产环境(陷阱)。
- 使用自定义输入进行测试,针对边界情况进行微调(陷阱)。
- 通过 evaluation pipeline (评估流水线) 进行客观评分(推荐)。
选项 1 和 2 是常见的陷阱——工程师在生产使用前没有充分测试提示。
最佳实践 = 使用评估流水线获得客观的性能分数,然后在部署前根据结果迭代优化提示。
在学习序列中,评估先于工程——首先衡量有效性,然后学习改进技术。
典型的评估工作流
典型的 Eval Workflow (评估工作流) = 一个用于提示优化的 5 步迭代过程。
第 1 步:初始提示草稿 = 编写带有输入变量的基本提示(例如:“请回答用户的问题 [user_input]”)。
第 2 步:评估数据集 = 创建一个测试输入集合(最少 3 个示例,实际应用中会用数百/数千个)。可以手工制作或由 AI 生成。
第 3 步:提示执行 = 将每个数据集输入填充到 prompt template (提示模板) 中以创建完整的提示,然后发送给 Claude 获取响应。
第 4 步:评分 = 使用 grader system (评分系统) 对每个问答对进行评分(通常为 1-10 分)。对所有分数取平均值,得到整体的提示性能指标。
第 5 步:迭代 = 根据结果修改提示,重复整个过程,比较分数以确定更好的版本。
关键原则:
- 行业内没有标准化的方法论。
- 有多种实现选项(开源包、付费解决方案、自定义构建)。
- 可以在 Jupyter notebook 中从简单开始,然后扩展。
- 客观评分使得数据驱动的提示改进成为可能。
- 过程重复进行,直到达到满意的性能。
该工作流通过可衡量的性能比较,而不是主观评估,实现了系统性的提示优化。
生成测试数据集
自定义提示评估工作流 = 构建一个系统来评估 AWS 代码生成提示。
目标 = 通过输出三种格式之一:Python、JSON 配置或原始正则表达式,帮助用户编写特定于 AWS 的代码。
提示结构 = "Please provide a solution to the following task: [user task]",不带任何额外的解释/页眉/页脚。
Test Dataset (测试数据集) = 一个 JSON 对象数组,其中每个对象都有一个 "task" 属性,描述所需的 AWS 任务。
数据集生成方法 = 手动组装或使用 Claude Haiku(推荐使用更快的模型)自动生成。
实现过程:
- 创建一个
generate_dataset()函数,其中包含一个大的提示,要求 Claude 生成测试用例。 - 使用预填充技术,助手消息以
\``json` 开头。 - 将停止序列设置为
\``` 以确保输出干净的 JSON。 - 使用
JSON.loads()解析响应。 - 使用
JSON.dump()将数据集保存到文件中,以供后续评估使用。
数据集结构 = [{task: "description"}, {task: "description"}, ...]
关键技术 = 预填充 + 停止序列,用于从 LLM 响应中可靠地解析 JSON。
下一步 = 使用保存的数据集文件来评估提示在所有测试用例中的性能。
运行评估
测试用例 = 从生成的数据集中取出的单个记录,与提示合并后输入给 Claude。
run_prompt 函数 = 接收一个测试用例,将其与提示(简单的“请解决以下任务” + 测试用例)合并,发送给 Claude,并返回输出。目前缺少格式化指令,因此返回的输出很冗长。
run_test_case 函数 = 接收单个用例,调用 run_prompt,对结果进行评分(目前硬编码为 10 分),并返回一个包含输出/测试用例/分数的字典。
run_eval 函数 = 加载数据集,遍历每个测试用例并调用 run_test_case,将所有结果组装成一个列表。
评估流水线工作流 = 数据集 → 与提示合并 → 发送给 Claude → 对结果评分 → 收集输出。
当前局限性 = 没有实现评分逻辑(硬编码分数),提示中没有输出格式化指令,执行时间相对较慢(使用 Haiku 模型为 31 秒)。
结果格式 = 一个对象数组,其中每个对象包含 Claude 的输出、原始测试用例以及每个测试用例的分数。
下一步 = 实现实际的评分器以取代硬编码的评分系统。
基于模型的评分
Model Based Grading (基于模型的评分) = 使用 AI 模型通过提供客观评分信号来评估其他 AI 模型的输出。
三种评分器类型:
- Code graders (代码评分器) = 程序化检查(长度、语法、可读性、单词存在性)。
- Model graders (模型评分器) = 额外的 API 调用来评估质量、指令遵循度、完整性。
- Human graders (人工评分器) = 手动评估(灵活但耗时)。
关键要求:
- 所有评分器必须返回客观信号(通常是 1-10 分)。
- 预先定义评估标准。
- 对于模型评分器:使用详细的提示,要求提供优点/缺点/推理,以避免得到中间分数(模型在没有推理要求的情况下默认给 6 分左右)。
实现模式:
- 创建一个接收测试用例和模型输出的评分函数。
- 使用带有角色定义和明确评估指令的结构化提示。
- 提取包含分数/推理的 JSON 响应。
- 计算所有测试用例的平均分,作为最终指标。
常见评估标准 = 格式合规性、语法验证、任务完成准确性。
模型评分器为评估主观质量提供了高度灵活性,而代码评分器则处理客观的验证检查。
基于代码的评分
基于代码的评分 = 一个用于验证模型输出仅包含有效代码(Python/JSON/RegEx)而无解释的系统。
核心组件:
validate_json()= 尝试解析 JSON,如果有效则返回 10,如果出错则返回 0。validate_python()= 尝试进行 AST (抽象语法树) 解析,如果有效则返回 10,如果出错则返回 0。validate_regex()= 尝试编译正则表达式,如果有效则返回 10,如果出错则返回 0。grade_syntax()= 一个调度函数,根据测试用例的格式调用相应的验证器。
实现步骤:
- 添加尝试解析/编译的验证器函数。
- 更新数据集,包含一个 "format" 键,指定预期的输出类型(JSON/Python/RegEx)。
- 更新提示模板,明确要求只输出代码,不带注释。
- 使用带有代码块和停止序列的预填充助手消息。
- 通过取平均值将语法分数与模型分数合并。
数据集格式 = 必须包含 format 字段,以指明每个测试用例预期的代码类型。
提示工程 = 使用 \``code` 作为预填充的助手消息,因为事先不知道确切的格式。
分数计算 = (model_score + syntax_score) / 2
关键洞察 = 通过 try/catch 解析来验证语法,而不是复杂的基于规则的验证。
提示工程 (Prompt Engineering)
Prompt Engineering (提示工程) = 改进提示以从语言模型获得更可靠、更高质量输出的技术。
目标:根据身高、体重、身体目标和饮食限制,为运动员生成一日三餐的膳食计划。
过程:
- 编写初始提示(糟糕的初稿)。
- 评估提示性能。
- 迭代应用提示工程技术。
- 每次改进后重新评估。
- 监控性能改进。
初始提示示例:“这个人应该吃什么?” + 基本的参数插值(身高、体重、目标、限制)。
评估设置使用 Prompt Evaluator 类,其并发性可配置(开始时设置较低,如 3,如果遇到速率限制则降至 1)。可以指定额外的标准,如卡路里总和、宏量营养素分解、具体的食物/份量/时间等输出要求。
预期模式:初始分数很差,通过系统性地应用技术来改进。输出评估会创建一个 HTML 报告,显示测试用例结果、分数和推理。
关键洞察:从简单开始,衡量性能,然后逐步应用工程技术,同时持续评估改进效果。
清晰直接
清晰直接 = 一种通过关注提示第一行来提高提示有效性的技术。
第一行的重要性 = 提示中最关键的部分,为 AI 响应奠定基础。
结构 = 使用动词 + 简单直接的语言 + 清晰的任务描述。
动词 = write (编写)、generate (生成)、create (创建)、identify (识别)、analyze (分析) - 明确告诉 AI 要做什么。
任务说明 = 包括有关预期输出格式和内容要求的详细信息。
示例:
- "Write three paragraphs about how solar panels work" (编写三段关于太阳能电池板工作原理的文字) = 动词 + 输出格式 + 主题。
- "Identify three countries that use geothermal energy and for each include generation stats" (识别三个使用地热能的国家,并为每个国家附上发电统计数据) = 动词 + 数量 + 具体要求。
实现 = 用直接的命令替换模糊的开头,这些命令既指定了动作又指定了预期的交付成果。
结果 = 提示性能显著提高(示例显示评分从 2.32 提高到 3.92)。
具体化
具体化 = 添加指导方针或步骤来引导模型输出朝特定方向发展。
两种类型的指导方针:
- A 型:控制输出属性(长度、结构、特质)。
- B 型:为模型提供要遵循的步骤(强制考虑特定元素,提高推理质量)。
两种类型通常在专业的提示中结合使用。
何时使用:
- A 型:几乎总是使用 - 列出期望的输出特质。
- B 型:对于需要超越模型自然范围、更广泛地考虑观点/数据的复杂问题。
改进示例:添加指导方针后,评估分数从 3.92 提高到 7.86,表明对输出质量有显著影响。
使用 XML 标签构建结构
用于提示结构的 XML 标签 = 一种使用自定义 XML 风格标签来组织和澄清提示中不同内容部分的技术。
目的 = 当大量文本被插入提示时,帮助语言模型区分不同类型的插值内容。
实现 = 用描述性标签(如 <sales_records> 或 <athlete_info>)包裹内容部分,而不是直接堆砌原始文本。
标签命名 = 使用具体、描述性的名称(sales_records > records > data)来提供关于内容性质的上下文。
用例 = 分离代码和文档、标记运动员信息、组织销售数据,以及任何在单个提示中有多种内容类型的场景。
好处 = 减少关于文本用途的歧义,提高模型对提示结构的理解,尤其能提升简单模型的质量。
最佳实践 = 即使对于较短的内容部分,XML 标签也可以阐明该内容代表外部输入或特定的信息类别。
提供示例
one-shot/multi-shot prompting (单样本/多样本提示) = 在提示中提供示例以引导模型行为。单样本 = 单个示例,多样本 = 多个示例。
实现 = 将示例包裹在 XML 标签中,并包含示例输入和理想输出部分。这种结构清晰地将示例内容与主提示分离开来。
corner cases (边界情况) = 使用多样本提示来处理边缘情况,如讽刺检测。添加上下文解释为什么特定场景需要特别注意。
复杂输出 = 示例对于演示复杂的 JSON 结构或格式要求尤其有效。
与提示评估集成 = 从评估结果中提取高分测试用例作为示例。包括对输出为何理想的推理说明,以强化期望的行为模式。
有效性 = 通过提供具体的行为模板和输出格式指导,持续提高模型性能。
工具调用简介
Tool use (工具调用) = 一种允许 Claude 访问其训练数据之外的外部信息的机制。
核心限制:Claude 只知道来自训练数据的信息,缺乏实时/当前信息。
工具调用流程:
- 向 Claude 发送初始请求 + 访问 external data (外部数据) 的指令。
- Claude 判断是否需要外部数据,并请求特定信息。
- 服务器运行代码从外部源获取所请求的数据。
- 向 Claude 发送包含检索到数据的后续请求。
- Claude 使用原始提示 + 外部数据生成最终响应。
天气示例:
- 用户询问旧金山当前天气。
- 无工具:Claude 回答“无法访问当前天气数据”。
- 有工具:Claude 请求天气数据 → 服务器调用天气 API → Claude 接收数据 → 提供当前天气响应。
关键概念:工具使 Claude 能够通过结构化的数据检索过程,用实时的外部信息来增强其响应。
项目概览
项目目标 = 在 Jupyter notebook 中通过工具教 Claude 设置基于时间的提醒。
目标交互 = 用户说“为下周四的医生预约设置提醒” → Claude 回答“我会在那个时间点提醒您”。
识别出三个核心问题:
- Claude 缺乏精确的当前时间知识(知道日期,但不知道确切时间)。
- Claude 有时在基于时间的计算上会失败(例如,“从 1973 年 1 月 13 日起的 379 天”)。
- Claude 没有实际设置提醒的机制(理解概念但无法执行)。
解决方案方法 = 三个专用工具:
- 获取当前日期时间工具(日期 + 时间)。
- 向日期时间添加时长工具(处理时间计算)。
- 提醒设置工具(执行实际的提醒创建)。
实现 = 每次实现一个工具,最终将多个工具组合以实现完整功能。
工具函数
Tool Functions (工具函数) = 当 Claude 需要额外信息来帮助用户时自动执行的 Python 函数。
关键组件:
- 工具函数 = 一个普通的 Python 函数,用于检索特定数据(例如,当前日期时间、天气)。
- 当 Claude 判断需要额外信息来回答用户查询时执行。
最佳实践:
- 使用描述性的函数/参数名称。
- 验证输入,并对无效数据抛出错误。
- 包含有意义的错误消息,以帮助 Claude 纠正错误。
错误处理的好处:
- 当工具调用失败时,Claude 能看到确切的错误消息。
- 能根据错误反馈,用修正后的参数重试工具调用。
- 示例:“location cannot be empty” (位置不能为空) 帮助 Claude 使用有效位置重试。
实现模式:
def get_current_datetime(date_format="%Y%m%d %H:%M:%S"):
if not date_format:
raise ValueError("date format cannot be empty")
return datetime.now().strftime(date_format)
工具函数应专注于单一职责(获取日期时间、天气等),并进行适当的输入验证和清晰的错误消息传递,以便 Claude 的重试逻辑能够工作。
工具模式 (Tool Schemas)
Tool Schemas (工具模式) = 描述语言模型可用的工具函数的 JSON 配置对象。
JSON Schema = 一种数据验证规范(并非特定于语言模型),用于验证 JSON 数据。语言模型社区采用它来进行工具调用,因为它广为人知且方便。
工具模式结构:
name: 工具函数的名称。description: 3-4 句话解释工具的作用、何时使用以及返回的数据。input_schema: 描述函数参数的实际 JSON schema(每个参数的类型、描述)。
最佳实践:为工具和单个参数都使用 3-4 句话的描述,以帮助 Claude 理解其目的和用法。
模式生成技巧:让 Claude 为你的函数编写 JSON schema,并附上 Anthropic 工具使用的文档以获取最佳实践。这样可以产生高质量的模式。
命名约定:function_name + function_name_schema 以便于跟踪。
类型安全:将模式包裹在从 anthropic.types 导入的 ToolParam 中,以防止实现过程中的类型错误。
处理消息块
第 3 步:使用工具模式调用 Claude
API 请求结构 = 包含带有 JSON 模式列表的 tools 参数,以告知 Claude 可用的工具。
多块消息响应
消息内容类型 = Text blocks (文本块)(用于用户显示)+ Tool use blocks (工具调用块)(用于函数调用)。
工具调用块内容 = 函数名称 + 用于执行的输入参数。
关键的消息历史管理
对话持久性 = 需要手动跟踪 - Claude 不存储任何历史记录。
多块处理 = 在追加到消息历史时,必须保留整个内容列表,包括所有块(文本 + 工具调用)。
实现 = messages.append({"role": "assistant", "content": response.content})
需要更新辅助函数
当前限制 = add_user_message 和 add_assistant_message 仅支持单个文本块。
需要修复 = 更新辅助函数以处理每条消息中的多个内容块。
发送工具结果
第 4 步:执行 Claude 请求的工具函数。使用 response.content[1].input 从工具调用块中提取参数,然后使用 **kwargs 语法调用函数,将字典转换为关键字参数。
第 5 步:向 Claude 发送一个后续请求,其中包含完整的对话历史记录,外加一个包含工具结果块的新用户消息。
工具结果块结构:
tool_use_id= 匹配原始工具调用块中的 ID(当调用多个工具时,使 Claude 能够将请求与结果匹配)。content= 转换为字符串的工具函数输出。is_error= false(默认值,如果工具执行失败则设置为 true)。
工具使用 ID 系统:当 Claude 进行多次工具调用时,每次调用都会获得一个唯一的 ID。工具结果必须引用匹配的 ID,以便 Claude 能够关联哪个结果属于哪个请求。
完整流程:原始用户消息 → 带有工具调用块的助手消息 → 执行工具函数 → 带有工具结果块的用户消息 → 使用工具输出的最终助手响应。
一旦引入工具,所有请求中都必须包含工具模式,即使在后续调用中也是如此。
使用工具进行多轮对话
使用工具进行多轮对话 = 一个允许 AI 在单次对话中进行多次顺序工具调用的系统。
问题:用户提交的查询需要多个工具才能完成。例如:“从今天起 103 天后是哪一天?”需要 get_current_datetime 工具,然后是 add_duration_to_datetime 工具。
流程:
- Claude 请求第一个工具 (
get_current_datetime)。 - 系统执行工具并返回结果。
- Claude 请求第二个工具 (
add_duration_to_datetime)。 - 系统执行工具并返回结果。
- Claude 提供最终答案。
实现模式:
run_conversation函数接收初始消息列表。- While 循环:调用 Claude,检查响应。
- 如果响应包含
tool_use块:执行工具,将结果添加到对话中,继续循环。 - 如果响应不包含
tool_use:向用户返回最终答案。
所需重构:
- 更新
add_user_message/add_assistant_message辅助函数以处理多个消息块(文本 +tool_use块)。 - 修改
chat函数以接受工具模式列表,并返回整个消息而不仅仅是文本。 - 添加
text_from_message辅助函数以从多块消息中提取文本。 - 实现支持顺序工具调用的对话循环。
关键概念:不可预测的工具链需要灵活的对话管理,假设每次查询都可能进行多次工具调用。
实现多轮
多轮 = 一个循环,持续调用 Claude 直到它停止请求工具,这由 stop_reason 字段指示。
Stop Reason = Claude 响应中的一个字段,指示文本生成停止的原因。值为 "tool_use" 意味着 Claude 想要调用一个工具。
Run Conversation 函数 = 主循环,它:
- 用消息和可用工具调用 Claude。
- 将助手响应添加到消息历史中。
- 检查
stop_reason- 如果不是 "tool_use",则跳出循环。 - 如果是
tool_use,则调用run_tools函数。 - 将工具结果作为用户消息添加。
- 重复此过程,直到 Claude 给出最终响应。
Run Tools 函数 = 处理来自单个消息的多个工具调用:
- 从
message.content中仅筛选出tool_use块。 - 遍历每个工具请求。
- 使用工具请求的名称/输入运行相应的工具函数。
- 创建
tool_result块,包含:type="tool_result"、tool_use_id=original_id、content=JSON_encoded_output、is_error=false/true。 - 返回所有工具结果块的列表。
Run Tool 函数 = 一个辅助函数,使用 if 语句将工具名称映射到实际的工具函数。这使得可以轻松扩展到多个工具。
错误处理 = 在工具执行周围使用 try/catch,当工具失败时设置 is_error=true 并在 content 中包含错误消息。
消息流 = 用户消息 → 带有 tool_use 的助手响应 → 作为用户消息的工具结果 → 助手响应(重复直到没有 tool_use) → 最终响应。
多块消息 = 单个 Claude 消息可以包含多个块(文本 + 多个 tool_use 块)。代码必须能处理并分别提取和处理所有 tool_use 块。
使用多个工具
在实现工具模式和函数后,向 Claude 添加多个工具需要更新两个关键函数。
过程:
- 将工具模式添加到
RunConversation函数的tools列表中。 - 使用 if/elif 语句将相应的函数调用添加到
RunTool函数中。 - 当 Claude 请求时,工具函数会执行并返回结果。
示例实现:
RunTool检查tool_name,并使用**tool_input调用相应的函数。- 模式:
if tool_name == "ToolName": return ToolFunction(**tool_input)
多工具使用: Claude 可以按顺序链接多个工具(例如,AddDurationToDateTime → SetReminder)。每个工具调用都会在对话历史中创建单独的 tool_use 和 tool_result 对的消息块。
关键模式: 一旦建立了初始框架,添加新工具就变成了:添加模式 + 添加函数 + 更新 RunTool 的 switch 语句。这个过程变得标准化且可扩展。
批量工具
Batch Tool (批量工具) = 一种变通方法,使 Claude 能在单个助手消息中并行调用多个工具。
问题:Claude 理论上可以在一个响应中发送多个工具使用块,但在实践中很少这样做。它倾向于发送带有单个工具使用的、独立的、顺序的助手消息,这会产生不必要的请求轮次。
解决方案:实现一个作为抽象层的批量工具。Claude 调用批量工具,而不是直接调用单个工具。
批量工具模式:接受一个 "invocations" 参数,这是一个对象列表,每个对象代表要调用的另一个工具(工具名称 + 参数)。
实现:
- 将批量工具添加到可用工具列表中。
- 当 Claude 调用批量工具时,提取
invocations列表。 - 遍历每个调用,解析 JSON 参数,并为每个调用
run_tool()。 - 将合并后的结果作为单个工具结果返回。
结果:Claude 使用批量工具来并行化多个工具调用,而不是进行独立的顺序调用。这将请求轮次从 N+1 减少到 2(初始请求 + 批量响应)。
关键洞察:这种方法通过提供一个 Claude 更可能使用的高级抽象,来“欺骗” Claude 进行并行执行,而不是使用原生的多工具使用块。
用于结构化数据的工具
用于结构化数据的工具:
一种使用工具从 Claude 中提取结构化 JSON 的替代方法,而不是使用消息预填充/停止序列。这种方法更可靠,但设置更复杂。
核心概念:为工具创建一个 JSON 模式规范,其中输入与期望的输出结构相匹配。Claude 调用该工具时,会提供包含提取数据的结构化参数。
工作流程:
- 编写一个提示,要求 Claude 分析数据并调用提供的工具。
- 提供一个定义工具输入的 JSON 模式(与期望的输出结构相匹配)。
- Claude 以一个包含结构化参数的
tool_use块作为响应。 - 从工具参数中提取 JSON - 不需要
tool_result响应。
关键要求:使用 tool_choice 参数强制 Claude 调用特定的工具,例如 tool_choice = {"type": "tool", "name": "tool_name"}。
设置步骤:
- 定义一个模式,其工具输入与期望的 JSON 结构相匹配。
- 更新
chat函数以接受tool_choice参数。 - 将
tool_choice传递给client.messages.create()。 - 通过
response.content[0].input访问结构化数据。
优点 = 更可靠的结构化输出。 缺点 = 设置比基于提示的方法更复杂。
两种技术都很有用,具体取决于场景的复杂性要求。
文本编辑器工具
Text Editor Tool (文本编辑器工具) = Claude 内置的用于文件/文本操作的工具,具有广泛的文本编辑器功能(打开/读取文件、编辑范围、添加/替换文本、创建文件、撤销)。
只有 JSON 模式是内置于 Claude 中的,实现部分并未内置。开发者必须编写工具函数的实现来处理 Claude 的文本编辑器请求。
需要根据模型版本提供模式存根:
- Claude 3.7:特定的日期格式
- Claude 3.5:不同的日期格式 这个小模式会在 Claude 中自动扩展为完整的模式。
能力 = 复制代码编辑器的功能(文件操作、重构、创建测试文件)。用例 = 适用于无法访问功能齐全的代码编辑器但需要以编程方式操作文件的场景。
需要一个实现类,其中包含 view(文件/目录内容)、string_replace、create_file 等方法。
网络搜索工具
Web Search Tool (网络搜索工具) = Claude 内置的工具,用于在网络上搜索以查找最新/专业的信息。
关键实现:
- 需要最简化的模式:
type="web_search_20250305", name="web_search", max_uses=5 - 无需自定义实现 - Claude 会处理搜索的执行。
max_uses= 总搜索次数的限制(单次搜索可能返回多个结果)。
响应结构:
- 文本块 = Claude 的框架性说明/答案。
- 服务器工具使用块 = 搜索查询输入。
- 网络搜索工具结果块 = 带有标题/URL 的搜索结果。
- Citations (引用) 块 = 支持 Claude 陈述的文本。
模式配置:
allowed_domains= 将搜索限制在特定域名(例如,"NIH.gov"用于医疗内容)。- 通过限制于权威来源来提高结果质量。
UI 渲染最佳实践:
- 将文本块显示为纯文本。
- 分别高亮显示网络搜索结果块和引用。
- 显示来源域名、标题、URL 和引用的文本以保证透明度。
- 帮助用户理解信息来源。
用例 = 时事、专业知识、使用可信来源进行事实核查。
检索增强生成 (RAG) 简介
RAG (Retrieval Augmented Generation, 检索增强生成) = 一种使用 LLM 查询大型文档的技术。
问题:如何从大型文档(100-1000页)中提取特定信息以供 LLM 处理。
选项 1(直接方法):将整个文档文本输入到提示中。
- 局限性:Token limits (令牌限制),长提示效果下降,成本更高,处理更慢。
选项 2(RAG 方法):
- 第 1 步:将文档分解成小块。
- 第 2 步:为用户问题找到最相关的块,仅将这些块包含在提示中。
RAG 优势:LLM 专注于相关内容,可扩展到大型/多个文档,更小的提示意味着更快/更便宜的处理。
RAG 劣势:需要复杂的前期处理,需要搜索机制来检索块,必须定义“相关性”,不能保证块包含完整的上下文,可能有多种 chunking strategies (分块策略)(等分 vs. 基于标题)。
关键挑战:为特定用例确定最佳的分块策略和搜索机制。
RAG 以简单性换取了可扩展性和效率,但需要仔细的实现评估。
文本分块策略
Text Chunking (文本分块) = 将源文档分割成更小的文本段以用于 RAG 流水线的过程。
核心问题:文本如何分块会显著影响 RAG 的质量。糟糕的分块会导致检索到错误的上下文(例如,由于词语重叠,为软件工程问题检索到关于“bugs”的医学文本)。
三种主要策略:
Size-based Chunking (基于大小的分块) = 将文档分割成等长的字符串。
- 优点:最容易实现,在生产环境中最常见。
- 缺点:会在句子中间切断词语,缺乏上下文。
- 解决方案:overlap strategy (重叠策略) = 包含相邻块的字符以保留上下文。
- 权衡:会产生文本重复,但能提高块的意义完整性。
Structure-based Chunking (基于结构的分块) = 基于文档结构(标题、段落、章节)进行分割。
- 对格式化文档(markdown、有清晰章节)效果很好。
- 局限:需要结构化输入,对纯文本/PDF 无效。
- 实现依赖于文档格式的保证。
Semantic-based Chunking (基于语义的分块) = 使用 NLP (Natural Language Processing, 自然语言处理) 将相关的句子/章节分组。
- 最先进的技术。
- 将连续的相关内容分组。
- 实现复杂,此处不详细介绍。
关键参数:
- 块大小 = 每个文本段的长度。
- 重叠 = 相邻块之间共享的字符数。
- 分隔标准 = 定义块边界的依据。
策略选择取决于:
- 文档结构的保证。
- 输入格式的一致性。
- 用例要求。
默认建议:按字符分块 = 尽管结果可能不是最优,但在各种文档类型中最为可靠。
文本嵌入 (Text Embeddings)
Text Embeddings (文本嵌入) = 文本中意义的数值表示,由 embedding model (嵌入模型) 生成。
嵌入模型 = 接收文本输入,输出一长串数字(值范围为 -1 到 +1)。
每个数字 = 代表输入文本某种质量/特征的分数(实际质量未知,但可以理解为幸福感、主题相关性等语义特征)。
Semantic Search (语义搜索) = 使用文本嵌入通过比较数值表示而不是精确的词语匹配来查找相关内容。
RAG 流水线过程 = 提取文本块 → 用户提交查询 → 使用嵌入找到相关的块 → 作为上下文添加到提示中。
Google 的 text-embedding-005 = Vertex AI 上可用的一个特定嵌入模型,用于生成文本嵌入。
关键限制 = 我们不知道嵌入中的每个数字实际代表什么,但可以将它们概念化为语义质量分数。
实现 = 使用 Google GenAI SDK,创建客户端,将文本通过模型以获得嵌入 vector (向量)。
用例 = 通过比较数值表示而不是关键字匹配,来查找与用户问题相关的文本块。
完整的 RAG 流程
RAG Pipeline (RAG 流水线) = 从文档处理到通过嵌入和向量搜索进行查询响应的完整流程。
第 1 步:文本分块 = 将源文档分割成独立的文本片段进行处理。
第 2 步:生成嵌入 = 使用嵌入模型将文本块转换为数值向量。嵌入是数值表示,其中每个维度都捕捉了语义含义。
第 3 步:Normalization (归一化) = 将嵌入向量缩放到单位长度(大小 = 1.0),通常由嵌入 API 自动处理。
第 4 步:Vector Database (向量数据库) 存储 = 将归一化的嵌入存储在专门为数值向量操作优化的数据库中。
第 5 步:查询处理 = 用户提交问题,使用与源文档相同的模型进行嵌入。
第 6 步:Similarity Search (相似度搜索) = 向量数据库找到与查询嵌入最相似的已存储嵌入。
Cosine Similarity (余弦相似度) = 衡量向量之间相似度的指标,计算为它们之间夹角的余弦值。返回值在 -1 到 1 之间,其中 1 = 非常相似,-1 = 非常不同。
Cosine Distance (余弦距离) = 1 减去余弦相似度。接近 0 的值 = 高相似度,较大的值 = 较低的相似度。
第 7 步:响应生成 = 在提示中将用户查询与检索到的最相关的文本块结合起来,发送给 LLM 以获得最终响应。
关键点:预处理(第 1-4 步)是提前进行的。当用户提交查询时,实时处理仅涉及第 5-7 步。
实现 RAG 流程
RAG 流程实现 = 使用向量数据库进行文档检索的完整工作流。
5 个核心步骤:
- 文本分块 = 使用
chunk_by_section函数将文档分割成章节。 - 生成嵌入 = 使用
generate_embedding为每个文本块创建嵌入。 - 向量存储填充 = 创建一个向量索引实例,遍历块-嵌入对,并通过
store.add_vector插入,其中包含嵌入和带有原始文本的元数据字典。 - 查询处理 = 使用相同的
generate_embedding函数为用户问题生成嵌入。 - 相似度搜索 = 使用
store.search(user_embedding, num_results)找到最相关的块,返回包含余弦距离的文档。
关键技术点:
- 向量数据库存储嵌入和原始文本元数据(仅有嵌入对开发者无用)。
- 余弦距离衡量相似度(值越低越相似)。
- 返回多个块以提供全面的上下文。
- 实现使用
VectorIndex类作为示例向量数据库。
查询示例:“软件工程部门去年做了什么?” 返回了第 2 节(距离 0.71)和方法论部分(距离 0.72)作为最佳匹配。
局限性:当前实现在某些场景下工作不佳,需要进一步改进。
BM25 词法搜索
BM25 = Best Match 25,一种在 RAG 流水线中使用的 lexical search (词法搜索) 算法,用于补充语义搜索的基于文本的搜索。
仅使用语义搜索的问题:尽管性能良好,但可能返回不相关的结果。例如:搜索 “incident 2023 Q4 011” 返回了正确的第 10 节,但也返回了不相关的第 3 节(财务分析),该节从未提及该事件。
解决方案:Hybrid search (混合搜索),将语义搜索(嵌入 + 向量数据库)与词法搜索(BM25)并行运行,然后合并结果以获得更好的平衡。
BM25 算法步骤:
- Tokenize (分词) 用户查询 = 通过移除标点符号和按空格分割,将查询分解为单个词项。
- 计算 term frequency (词频) = 计算每个词项在所有文本块中出现的频率。
- 分配重要性权重 = 罕见词项获得更高的重要性,常见词项(如“a”)获得较低的重要性。
- 对块进行排名 = 优先考虑更频繁包含较高权重词项的块。
关键优势:BM25 优先考虑包含罕见、特定词项(如 “incident 2023”)的块,而不是通用的常见词,从而为精确词项匹配带来更相关的结果。
实现:语义和词法搜索系统都使用相似的 API(add_document、search 函数),这使得混合搜索的集成变得容易。
下一步:合并两种搜索系统,以获得语义理解和精确词项匹配的综合优势。
多索引 RAG 流水线
Multi-Index RAG Pipeline (多索引 RAG 流水线) = 一个结合了语义搜索(向量索引)和词法搜索(BM25 索引)以提高检索准确性的系统。
核心架构:
- 向量索引 + BM25 索引 = 两者都具有相同的 API(
add_document、search方法)。 Retriever类 = 一个包装器,将查询转发给两个索引并合并结果。- 统一接口 = 使得可以轻松添加新的搜索方法。
Reciprocal Rank Fusion (倒数排序融合) = 一种用于合并不同搜索方法结果的技术:
- 公式:分数 = Σ (1 / (1 + 排名)),对每个搜索方法求和。
- 过程:收集所有结果 → 记录每个方法中的排名 → 应用公式 → 按最高分排序。
- 示例:如果一个文档在向量搜索中排名第一,在 BM25 中排名第二,它将获得比排名第二和第三的文档更高的综合分数。
好处:
- 比单一方法搜索的相关性更高。
- 模块化设计允许添加新的搜索索引。
- 在所有组件中保持一致的 API。
关键结果:混合方法产生的搜索结果优于单独的语义或词法搜索,特别是对于需要概念理解和关键字匹配的复杂查询。
结果重排序
Reranking (重排序) = 一种后处理技术,通过使用 LLM 根据相关性重新排序搜索结果来提高检索准确性。
过程:在混合检索(向量 + BM25)之后,将排名靠前的结果传递给 Claude,并附上一个提示,要求按与用户查询的相关性对文档进行排序。Claude 返回一个重新排序的列表,其中最相关的文档排在最前面。
实现细节:为了效率,使用 document IDs (文档 ID) 而不是全文 - 为块分配随机 ID,并要求 Claude 返回排序后的 ID 而不是全部内容。在提示中使用 XML 格式化文档,并使用预填充和停止序列来获取 JSON 响应。
权衡:提高了搜索准确性,但由于 LLM 调用而增加了延迟。当需要语义理解时尤其有效(例如:“engineering team” 查询正确地将软件工程部分优先于网络安全部分)。
提示结构:用户问题 + 候选文档 + 指示按相关性降序返回 N 个最相关的文档。
上下文检索
Contextual Retrieval (上下文检索) = 一种 RAG 改进技术,在进行向量存储之前为文本块添加文档上下文。
问题:文档分块会从原始源中移除上下文,从而降低检索准确性。
解决方案:在预处理步骤中使用 LLM 为每个块生成上下文信息。
过程:
- 获取单个块 + 原始源文档。
- 将它们发送给 LLM (Claude),并附上一个提示,要求将该块置于更大的文档上下文中。
- LLM 生成简短的上下文描述。
- 将生成的上下文 + 原始块 = 上下文化的块。
- 将上下文化的块存储在向量/BM25 索引中。
大型文档处理:当源文档太大无法放入单个提示时,使用选择性上下文:
- 包含开头几块(1-3块)以获取文档摘要/摘要。
- 包含目标块之前的几个块以获取局部上下文。
- 跳过提供较少相关上下文的中间块。
实现:add_context() 函数接收块 + 源文本,通过 LLM 生成上下文,并将上下文与原始块连接起来。
好处:在单个块内保持文档关系和交叉引用,提高了对于具有相互关联章节的复杂文档的检索准确性。
扩展思考
Extended Thinking (扩展思考) = Claude 的一项功能,允许在生成最终响应前进行推理。
关键机制:
- 在聊天 UI 中显示一个独立的思考过程。
- 用户需要为在思考阶段生成的 token 付费。
- 提高了复杂任务的准确性,但增加了成本和延迟。
何时启用:
- 首先使用提示评估。
- 仅当在提示优化后准确性仍不足时才启用。
技术实现:
- 响应包含一个 thinking block (思考块) 和一个文本块。
- 思考块包含一个 cryptographic signature (加密签名) 以防止篡改。
- 当在对话中重用时,Claude 会验证思考文本未被修改。
- 最小思考预算 = 1024 个 token。
max_tokens必须超过thinking_budget(建议有显著的缓冲)。
特殊情况:
- 当思考文本被安全系统标记时,会出现经过编辑的思考块。
- 编辑过的内容以加密形式提供,以保留上下文。
- 有一个测试字符串可用于强制生成编辑过的思考块以进行测试。
代码要求:
- 添加
thinking参数(默认为false)。 - 添加
thinking_budget参数(最小为 1024)。 - 在 API 参数中包含一个
thinking对象,其type="enabled"和budget_tokens值。 - 确保
max_tokens>>thinking_budget以便有足够的空间生成响应。
图像支持
Claude Vision Capabilities (Claude 视觉能力) = 能够为每个请求向 Claude 发送多达 100 张图像,用于分析、比较、计数和其他视觉任务。
技术要求 = 存在图像大小/尺寸限制,图像根据像素尺寸(高 x 宽)消耗 token,成本通过特定公式计算。
图像集成 = 在用户消息中使用图像块,其中包含原始的 base64 图像数据或在线图像的 URL。每条消息允许多个图像块。
关键成功因素 = 为获得准确结果,复杂的提示技术至关重要。简单的提示通常会失败。
图像提示技术 = 提供分析步骤、指导方针、单样本/多样本示例。用具体的顺序指令构建提示,而不是基本请求。
示例增强方法 =
- 逐步分析(识别物体,有条不紊地计数,用不同策略验证计数,比较结果)。
- 单样本提示(展示一个带有正确答案的示例图像,然后呈现目标图像)。
消息结构 = 在单个用户消息中交替使用图像部分和文本部分,以提供示例和指令。
实际应用示例 = 使用卫星图像进行野火风险评估,评估树木密度、紧急通道、屋顶悬挑,并分配数值风险分数。
关键启示 = 图像准确性完全取决于提示工程的质量,而不仅仅是图像的清晰度。
PDF 支持
Claude PDF 支持 = 能够直接读取和处理 PDF 文件内容。
实现 = 与图像处理代码几乎相同,关键变化在于:
- 文件类型:
"document"而不是"image"。 - 媒体类型:
"application/pdf"而不是"image/png"。 - 变量命名:
file_bytes而不是image_bytes。
PDF 功能 = 提取文本、图像、图表、表格和其他文档元素。
使用模式 = 附加 PDF 文件,用新的类型/媒体类型修改现有的图像处理代码,然后附上文本提示发送给 Claude。
关键好处 = 一个单一的工具即可实现全面的 PDF 内容提取和分析。
引用 (Citations)
Citations (引用) = Claude 的一项功能,允许 AI 在生成响应时引用特定的源文档。
引用目的 = 告知用户 AI 的响应来自实际来源,而不仅仅是 AI 的记忆/训练数据。
引用类型:
- 引用页面位置 = 对于 PDF 文档,包括引用的文本 + 文档索引 + 文档标题 + 起始/结束页码。
- 引用字符位置 = 对于纯文本,包括文本块内的字符位置。
实现 = 在 API 请求中添加 citations 字段并设置为 enabled:true,同时提供源文档。
响应结构 = Content 变成一个文本块列表,其中一些包含带有位置数据的 citations 数组。
用户界面好处 = 可以构建弹出窗口/覆盖层,向用户精确显示每个 AI 声明由哪个源文本支持。
支持格式 = PDF 文档和纯文本源。
核心价值 = 用户可以通过检查原始源材料来验证 AI 的解释,从而确保透明度和准确性。
提示缓存
Prompt caching (提示缓存) = 一项通过重用先前请求的计算工作来加速 Claude 响应并降低文本生成成本的功能。
正常请求过程:用户发送消息 → Claude 对输入进行大量内部计算 → 生成输出 → 丢弃所有计算工作 → 准备下一个请求。
问题:当后续请求包含先前见过的消息时,Claude 必须重做它已经执行过并丢弃的相同计算。
解决方案:提示缓存将计算工作存储在临时数据存储中,而不是丢弃它。当后续请求中出现完全相同的输入时,Claude 会重用缓存的计算,而不是重新计算。
好处:响应时间更快,由于避免了对重复内容的冗余处理,成本更低。
关键要求:输入文本必须与先前缓存的内容完全相同,才能发生重用。
提示缓存规则
Prompt Caching (提示缓存) = 一个系统,Claude 保存初始请求的处理工作,以便在后续包含相同内容的请求中重用。
缓存时长 = 5 分钟临时存储。
激活 = 需要在消息块中手动设置 cache breakpoint (缓存断点),默认不启用。
文本块格式 = 必须使用长格式 {type: "text", text: "content", cache_control: {...}} 而不是速记字符串赋值来添加缓存控制。
缓存范围 = 所有内容都会被缓存,直到(并包括)断点处,断点之后的内容不被缓存。
内容一致性规则 = 后续请求在断点之前的内容必须完全相同,否则缓存将失效。
断点位置 = 文本块、图像块、工具使用、工具结果、工具模式、系统提示。
处理顺序 = 工具 → 系统提示 → 消息(在后台连接在一起)。
多重断点 = 总共最多允许 4 个断点,以实现精细的缓存控制。
最小缓存长度 = 内容需要至少 1024 个 token 才能被缓存。
用例 = 跨请求的重复内容、稳定的系统提示、不变的工具模式。
提示缓存实战
提示缓存实现:
缓存断点 = 单个请求中可以有多个缓存点(工具 + 系统提示 + 消息)。
工具模式缓存:
- 仅在最后一个工具模式中添加
cache_control字段。 - 最佳实践 = 先复制工具列表,克隆最后一个工具,然后添加
cache_control type="ephemeral"。 - 防止意外修改原始的工具模式。
系统提示缓存:
- 将系统字符串转换为一个列表,其中包含一个带有
cache_control type="ephemeral"的文本块。 - 格式:
[{"type": "text", "text": system_content, "cache_control": {"type": "ephemeral"}}]
缓存顺序 = 工具 → 系统提示 → 消息。
使用模式:
cache_creation_input_tokens= 写入缓存的 token 数(首次使用)。cache_read_input_tokens= 从缓存中读取的 token 数(后续相同请求)。- 对缓存内容的任何更改都会使缓存失效,并强制创建新的缓存。
Token 计数示例:
- 基本消息:约 14 个 token。
- 工具模式:约 1.7K 个 token。
- 系统提示:约 6.3K 个 token。
缓存失效 = 对工具/系统提示的任何修改都会创建一个全新的缓存断点。
用例 = 跨请求的相同内容(相同的工具、系统提示、消息序列)。
MCP 简介
MCP (Model Context Protocol, 模型上下文协议) = 一个通信层,为 Claude 提供上下文和工具,而无需开发者编写繁琐的代码。
MCP 架构 = client-server 模型,其中服务器包含工具、资源和提示。
解决的主要问题 = 将定义和运行工具的负担从开发者的服务器转移到 MCP 服务器。开发者无需自己编写工具模式和函数,MCP 服务器会处理这些。
MCP 服务器 = 一个到外部服务(如 GitHub)的接口,将功能封装成预构建的工具。消除了开发者编写/维护工具实现的需求。
谁创建 MCP 服务器 = 任何人都可以,但通常服务提供商会提供官方实现(例如,AWS 发布他们自己的 MCP 服务器)。
MCP vs 直接 API 调用 = MCP 通过提供预构建的工具模式和函数实现来节省开发时间,而不是要求自定义编写。
MCP vs 工具使用 = 互补概念,不完全相同。MCP 关注的是谁来做这项工作(预构建 vs 自定义),而两者都涉及工具的使用。常见的误解源于不理解 MCP 的委托方面。
关键好处 = 减轻了开发者为具有广泛功能的复杂服务创建/维护集成的负担。
MCP 客户端
MCP Client (MCP 客户端) = 你的服务器和 MCP 服务器之间的通信接口,提供对服务器工具的访问。
传输无关 = 客户端/服务器可以通过多种协议通信(stdin/stdout、HTTP、WebSockets 等)。
通信方法 = 遵循 MCP 规范的消息交换。
关键消息类型:
list tools request= 客户端向服务器请求可用工具。list tools result= 服务器响应工具列表。call tool request= 客户端请求服务器运行特定工具并附带参数。call tool result= 服务器返回工具执行结果。
典型流程:
- 用户查询你的服务器。
- 服务器向 MCP 客户端请求工具列表。
- MCP 客户端向 MCP 服务器发送
list tools请求。 - MCP 服务器响应可用工具。
- 服务器将用户查询 + 工具发送给 Claude。
- Claude 请求执行工具。
- 服务器请求 MCP 客户端运行工具。
- MCP 客户端向 MCP 服务器发送
call tool请求。 - MCP 服务器执行工具(例如,GitHub API 调用)。
- 结果沿链路返回:MCP 服务器 → MCP 客户端 → 你的服务器 → Claude → 用户。
MCP 客户端角色 = 一个中介,在你的服务器和 MCP 服务器之间进行转换,它不直接执行工具。
项目设置
项目设置 = 一个基于 CLI (Command-Line Interface, 命令行界面) 的聊天机器人实现,用于理解 MCP 客户端-服务器交互。
组件 = MCP 客户端 + 自定义 MCP 服务器,位于单个项目中。 文档 = 仅存储在内存中的伪文档。 服务器工具 = 读取文档内容,更新文档内容。
重要提示 = 通常项目只实现客户端或服务器,而不是两者都实现。本项目为了学习目的同时实现了两者。
设置步骤:
- 下载 CLI project.zip 启动代码。
- 解压并在代码编辑器中打开。
- 查看 readme.md 中的设置说明。
- 在 .env 文件中添加 API 密钥。
- 安装依赖项(使用或不使用 UV)。
- 运行项目:
uv run main.py或python main.py。 - 验证聊天提示出现并能响应查询。
项目结构 = 所有文件都在项目目录中,准备好添加新功能。
使用 MCP 定义工具
MCP 服务器实现 = 使用 Python SDK 通过一行代码创建服务器(mcp 包)。
工具定义语法 = 使用 @mcp.tool decorator (装饰器),并附带名称、描述和类型化参数,而不是手动编写 JSON 模式。
Python MCP SDK 的好处 = 从装饰器和字段类型自动生成 JSON 模式,消除了手动编写模式的工作。
创建的示例工具 = read_doc_contents(接收 doc_id 字符串,从内存中的 docs 字典返回文档内容)和 edit_document(接收 doc_id、old_string、new_string 用于查找/替换操作)。
工具结构 = 装饰器指定元数据,函数实现逻辑,来自 pydantic 的 Field() 添加参数描述。
错误处理 = 检查 doc_id 是否存在于 docs 字典中,如果未找到则引发 ValueError。
文档存储 = 内存中的字典,以文档 ID 为键,内容为值。
实现模式 = @mcp.tool 装饰器 → 函数定义 → 带有 Field 描述的类型化参数 → 验证逻辑 → 核心功能。
服务器检查器
MCP Inspector (MCP 检查器) = 一个浏览器内的调试器,用于在不连接到应用程序的情况下测试 MCP 服务器。
访问:在激活了 Python 环境的终端中运行 mcp dev [server-file.py] → 生成一个本地服务器 URL → 在浏览器中打开。
主要功能:
- Connect 按钮 = 启动 MCP 服务器。
- 顶部菜单栏 = 显示资源、提示、工具部分。
- 工具部分 = 列出服务器上可用的工具。
- 右侧面板 = 手动工具调用界面。
测试工作流程:
- 点击 Connect 启动服务器。
- 导航到 Tools → List Tools。
- 选择要测试的特定工具。
- 在右侧面板中输入所需参数。
- 点击 Run Tool 执行并验证输出。
工具测试示例:
read_doc_contents工具:输入文档 ID → 返回文档内容。edit_document工具:输入文档 ID + 旧字符串 + 新字符串 → 修改文档。- 通过重新运行读取工具来验证编辑。
目的 = 在实现阶段对 MCP 服务器进行实时开发和调试。UI 可能会随着工具的积极开发而改变,但核心功能保持相似。
实现客户端
MCP 客户端实现:
MCP 客户端 = 一个围绕客户端会话的包装类,用于资源管理和清理。 客户端会话 = 从 Python SDK 到 MCP 服务器的实际连接,需要资源清理。 客户端目的 = 向代码库暴露服务器功能,将服务器工具连接到应用程序代码。
关键函数:
list_tools()=await self.session.list_tools(),返回result.tools。call_tool()=await self.session.call_tool(tool_name, tool_input),使用 Claude 提供的参数执行特定工具。
实现模式: 客户端包装会话 → 管理连接生命周期 → 暴露服务器工具 → 实现 Claude 集成。
测试:直接执行文件会测试连接和工具列表功能。
使用流程:应用程序调用 client.list_tools() → 发送给 Claude → Claude 请求执行工具 → client.call_tool() → 将结果返回给 Claude。
资源管理:客户端通过 async context managers (异步上下文管理器)(connect、cleanup、async enter/exit 函数)处理会话清理。
定义资源
MCP Resources (MCP 资源) = MCP 服务器向客户端公开数据以供读取操作的机制。
资源类型:
- 直接/静态资源 = 固定的 URI (Uniform Resource Identifier, 统一资源标识符),地址始终相同(例如,
docs://documents)。 - 模板化资源 = 带通配符的参数化 URI(例如,
documents/{doc_id})。
资源流程:
- 客户端向 MCP 服务器发送带有 URI 的读取资源请求。
- 服务器将 URI 与定义的资源函数匹配。
- 服务器执行函数并通过读取资源结果返回数据。
实现:
- 使用带有 URI 和 MIME type 的
@mcp.resource装饰器。 - MIME type = 关于数据格式的提示(
application/json、text/plain等)。 - 模板化资源的参数成为函数的关键字参数。
- MCP SDK 自动将返回值序列化为字符串。
用例示例:
- 资源 1:返回文档名称列表用于自动完成。
- 资源 2:按 ID 返回特定文档内容。
- 实现
@提及功能,用户引用的文档会自动插入到提示中。
关键点:
- 每个不同的读取操作对应一个资源。
- 资源公开数据,不修改数据。
- 客户端负责反序列化返回的数据。
- 模板化资源实现了动态内容选择。
访问资源
MCP 资源访问实现:
资源获取 = MCP 客户端函数通过 URI 从 MCP 服务器读取资源,根据 MIME type 解析内容,并返回数据。
关键导入 = json 模块,以及用于类型处理的 pydantic 中的 AnyURL。
函数流程 = await self.session.read_resource(AnyURL(uri)) → 从 results.contents[0] 中提取第一个内容 → 检查 MIME type → 相应地解析。
内容解析逻辑 = 如果资源是 TextResourceContents 并且 mime_type == "application/json" → 返回 json.loads(resource.text),否则作为纯文本返回 resource.text。
响应结构 = result.contents 列表,包含带有 type 和 mime_type 属性的资源对象。
集成 = read_resource 函数被其他应用程序组件调用,以获取用于提示的文档内容。
测试工作流程 = CLI 显示资源列表 → 用户使用方向键/空格键选择 → 资源内容直接发送到 Claude 的提示中,无需工具调用。
核心概念 = 资源向客户端公开服务器信息,实现了直接内容访问,而不是基于工具的检索。
定义提示
MCP Prompts (MCP 提示) = 由 MCP 服务器为专门任务提供的、预定义且经过测试的提示。
目的 = 允许服务器作者创建高质量、特定领域的提示,而不是让用户手动编写通用提示。
实现:
- 使用带有名称和描述的
@prompt装饰器。 - 函数接收参数(如文档 ID)。
- 返回一个消息列表(用户/助手格式)。
- 导入:
from mcp.server.fastmcp.prompts import BaseMessage。
示例结构:
@prompt(name="format", description="rewrites document in markdown")
def format_document(doc_id: str) -> list[BaseMessage]:
return [BaseMessage.user(prompt_text)]
关键好处 = 服务器作者可以为其领域(文档管理等)创建专门的、经过测试的提示,客户端可以通过斜杠命令或直接调用来使用。
流程 = 客户端请求提示 → 服务器返回消息列表 → 客户端发送给 LLM → LLM 使用可用工具执行。
测试 = 在部署前使用 MCP 开发检查器测试提示。
客户端中的提示
MCP 客户端实现中的提示
客户端侧的提示函数:
list_prompts()=await self.session.list_prompts(),返回result.props。get_prompt()=await self.session.get_prompt(prompt_name, arguments),返回result.messages。
提示工作流:
- 在 MCP 服务器中定义带变量(例如,
document_id)的提示。 - 客户端使用提示名称和参数字典调用
get_prompt。 - 参数作为关键字参数插入到提示函数中。
- 返回的消息直接输入给 Claude。
使用示例: 格式化命令 → 选择文档 → 带有文档 ID 的提示传递给 Claude → Claude 使用工具获取文档 → 以请求的样式重新格式化。
关键概念: 提示 = 服务器定义的模板,客户端可以用运行时参数调用,从而实现带有变量替换的动态提示生成。
MCP 回顾
MCP 服务器 Primitives (原语) = 三个具有不同控制模式和用途的核心组件。
工具 = 模型控制的动作。Claude 根据对话需求决定何时执行。目的:为 AI 模型添加能力(例如,用于计算的 JavaScript 执行)。实现:在 MCP 服务器中定义工具供模型使用。
资源 = 应用控制的数据访问。应用程序代码决定何时获取和使用数据。目的:为 UI 元素或提示增强提供数据(例如,自动完成选项、文档列表、Google Drive 集成)。实现:获取资源以填充应用界面。
提示 = 用户控制的工作流。用户通过 UI 按钮、菜单选项或斜杠命令触发。目的:实现预定义的工作流和优化的对话启动器。实现:为常见的用户操作创建提示模板。
控制模式总结:
- 工具服务于模型。
- 资源服务于应用。
- 提示服务于用户。
使用指南:需要 AI 能力 → 实现工具。需要应用数据 → 使用资源。需要用户工作流 → 创建提示。
代理与工作流
Workflows (工作流) 和 Agents (代理) = 处理无法由 Claude 在单次请求中完成的用户任务的策略。
决策规则:当您预先知道确切的任务步骤时,使用工作流。当任务细节不确定时,使用代理。
工作流 = 针对特定问题的一系列对 Claude 的调用,其中所有步骤都是预先确定且可规划的。
代理 = 让 Claude 利用提供的工具自行找出如何完成任务(如此前课程模块中的工具示例)。
工作流示例:图像到 3D 模型转换器
- 第 1 步:Claude 详细描述上传的金属零件图像。
- 第 2 步:Claude 使用 CADQuery Python 库根据描述创建 3D 模型。
- 第 3 步:生成模型的图像渲染。
- 第 4 步:Claude 将渲染图与原始图像进行比较。
- 第 5 步:如果不准确,返回第 2 步并提供反馈;如果准确,则输出 STEP 文件。
这遵循了 evaluator-optimizer pattern (评估器-优化器模式):
- Producer (生产者) = 创建输出(Claude + CADQuery 建模)。
- Evaluator (评估器) = 判断输出质量(Claude 比较图像)。
- 循环继续,直到评估器接受输出。
关键点:工作流只是其他工程师成功使用过的成熟模式。您仍然必须自己编写实际的实现代码。
并行化工作流
Parallelization Workflows (并行化工作流) = 将一个复杂任务分解为多个并行的子任务,然后聚合结果。
核心模式:
- 将复杂的分析分解为专门的并行请求。
- 每个子任务专注于一个特定方面。
- Aggregator (聚合器) 步骤将所有结果组合成最终输出。
示例实现:
- 原始方法:一个大的提示,要求 Claude 分析图像并推荐最佳材料(金属/聚合物/陶瓷等)。
- 并行化方法:多个同时进行的独立请求,每个请求评估图像对一种材料类型的适用性。
- 最后一步:将所有独立的分析反馈给 Claude 以获得最终推荐。
主要优点:
- 专注 = 每个请求处理单个任务,而不是同时处理多个考量。
- 优化 = 可以独立改进/评估每个专门的提示。
- 可扩展性 = 易于添加新的子任务而不影响现有的。
结构:输入 → 多个并行子任务 → 聚合器 → 最终输出。
最适用于需要同时评估多个独立标准或选项的复杂决策场景。
链式工作流
Chaining Workflows (链式工作流) = 将大型任务分解为顺序的、不同的步骤,而不是单个复杂的提示。
关键结构:一个主任务 → 多个顺序子任务 → 每个步骤的输出作为下一个步骤的输入。
示例工作流:用户输入主题 → Twitter 趋势搜索 → Claude 选择最佳主题 → Claude 研究主题 → Claude 编写脚本 → AI 创建视频 → 发布到社交媒体。
主要好处 = 允许 AI 一次专注于一个任务,而不是同时处理多个要求。
关键用例:当 AI 在包含许多约束的大型提示中,尽管有重复的指令,仍持续违反某些要求时。
解决方案模式:
- 发送包含所有约束的初始复杂提示。
- 接受违反某些约束的不完美输出。
- 发送后续提示,要求 AI 修复先前输出中的特定违规行为。
- AI 专注于修正任务。
为何有效 = AI 在处理专注的修正任务时表现更好,而不是在单个提示中管理众多同时存在的约束。
最有用的时候 = 当 AI 在复杂的提示中,尽管有明确的指令,仍持续忽略某些约束时。
路由工作流
Routing Workflows (路由工作流) = 一种工作流模式,它对用户输入进行分类,以确定适当的处理流水线。
过程:
- 用户提供输入/主题。
- 路由步骤 = AI 调用,将输入分类到预定义的流派/类别中。
- 根据类别,输入被转发到专门的处理流水线。
- 每个流水线都有针对该类别类型定制的提示/工具。
示例:社交媒体视频脚本生成
- 编程主题 → 教育类别 → 教育脚本提示(清晰的解释、定义、示例)。
- 冲浪主题 → 娱乐类别 → 娱乐脚本提示(潮流语言、引人入胜的开场)。
关键组件:
- 用于分类的预定义类别/流派。
- 针对预期输出风格量身定制的特定类别提示。
- 单个路由决策决定整个下游处理。
- 每个路由可以有不同的、为该任务类型专门化的工作流/工具。
目的 = 确保输出与输入类型相匹配的性质/风格,而不是采用一刀切的方法。
代理与工具
Agents (代理) = 使用工具来完成任务的 AI 系统,当确切步骤未知时使用;与需要精确预定步骤的工作流不同。
关键区别:工作流 = 已知的步骤序列,代理 = 灵活的工具组合,用于未知的步骤序列。
代理的优势:能够使用同一套工具灵活地解决各种任务。Claude 使用可用工具动态创建计划。
Tool abstraction principle (工具抽象原则):代理需要抽象/通用的工具,而不是高度专业化的工具。例如:Claude 代码使用 bash、web fetch、file write(抽象的)而不是特定的重构或安装工具。
工具组合示例:有了 get_current_datetime、add_duration、set_reminder 工具,Claude 可以处理“现在几点了”(单个工具)或“提醒我下周三去健身房”(多个工具 + 规划)。
动态交互能力:代理可以在需要时请求额外的用户信息,例如询问保修购买日期以计算到期时间。
最佳实践:提供一小组可以创造性地组合的抽象工具,而不是许多专门的单一用途工具。
实际示例:一个带有 bash/FFmpeg、generate_image、text_to_speech、post_media 工具的社交媒体视频代理,既可以实现简单的“创建视频”,也可以实现复杂的“先生成样本封面以供批准”的工作流。
环境检查
Environment Inspection (环境检查) = 代理在采取行动之后(或之前)检查其环境状态,以了解结果和进展。
核心概念:代理需要工具返回值之外的反馈来理解行动的后果和当前状态。
计算机使用示例:Claude 在每次操作(打字、点击)后都会截屏,因为它无法预测操作将如何改变环境。点击按钮可能会导航到新页面或打开菜单——截屏揭示了新的状态。
代码编辑示例:在修改文件之前,代理必须读取当前文件内容以了解现有状态。
社交媒体视频代理应用:
- 通过
bash工具使用 Whisper CPP 生成带时间戳的字幕,验证音频位置。 - 使用 FFmpeg 按间隔提取视频截图,验证视觉输出。
- 检查生成的视频以确保任务完成质量。
好处:通过环境状态感知,实现更好的进度跟踪、错误处理和意外结果管理。
工作流 vs. 代理
工作流 = 用于具有已知步骤序列的任务的一系列预定义的对 Claude 的调用。代理 = 使用 Claude 创造性地组合的基本工具的灵活系统,用于未知任务。
主要区别:
任务方法:工作流将大任务分解为更小的、具体的子任务以进行集中执行。代理通过创造性的工具组合来应对各种挑战。
准确性:由于步骤集中且具体,工作流能实现更高的准确性。由于委托了复杂性,代理的成功完成率较低。
测试:工作流由于步骤序列已知,更容易测试/评估。代理由于执行路径不可预测,更难测试。
灵活性:工作流需要特定的输入和固定的序列。代理能适应各种用户查询,可以请求额外输入,用户体验灵活。
可靠性:工作流对于一致的任务完成更可靠。代理更具实验性,但可靠性较低。
建议:尽可能优先使用工作流以实现可靠的问题解决。仅在确实需要灵活性时才使用代理。用户想要 100% 可用的产品,而不是花哨但不可靠的代理。
第 10 课:Claude Code 实战
Claude Code 编程助手完整实战教程 课程链接:Claude Code 实战 | 共 21 节课
第1部分:What is Claude Code?
1. Introduction (介绍)
类型:视频 | 时长:0:38 | 视频:001 - Introduction.mp4
视频文字稿
大家好,欢迎来到本课程。我是 Stephen Grider,Anthropic 的技术人员。在本课程中,我们将带您快速掌握 Claude Code。在深入技术细节之前,我想快速概述一下我们将要学习的内容。
本课程分为四个部分。首先,我们将花一些时间确切地了解什么是编码助手(coding assistant)。然后,我们将深入了解 Claude Code 本身,并理解它在众多编码助手中脱颖而出的原因。在此之后,我们将通过在一个典型项目上使用 Claude Code 来获得一些实践经验。
最后,我们将总结如何让您在自己的项目中最大限度地利用 Claude Code。
2. What is a coding assistant? (什么是编码助手?)
类型:视频 | 时长:5:53 | 视频:002 - What is a Coding Assistant?.mp4
编码助手(coding assistant)不仅仅是一个编写代码的工具,它是一个复杂的系统,利用语言模型(language model)来处理复杂的编程任务。了解这些助手在幕后的工作原理,将帮助您更好地理解是什么造就了一个真正强大的编码伙伴。
How Coding Assistants Work (编码助手的工作原理)
当你给编码助手一个任务时,比如根据错误信息修复一个 Bug,它会遵循一个类似于人类开发者解决问题的过程:
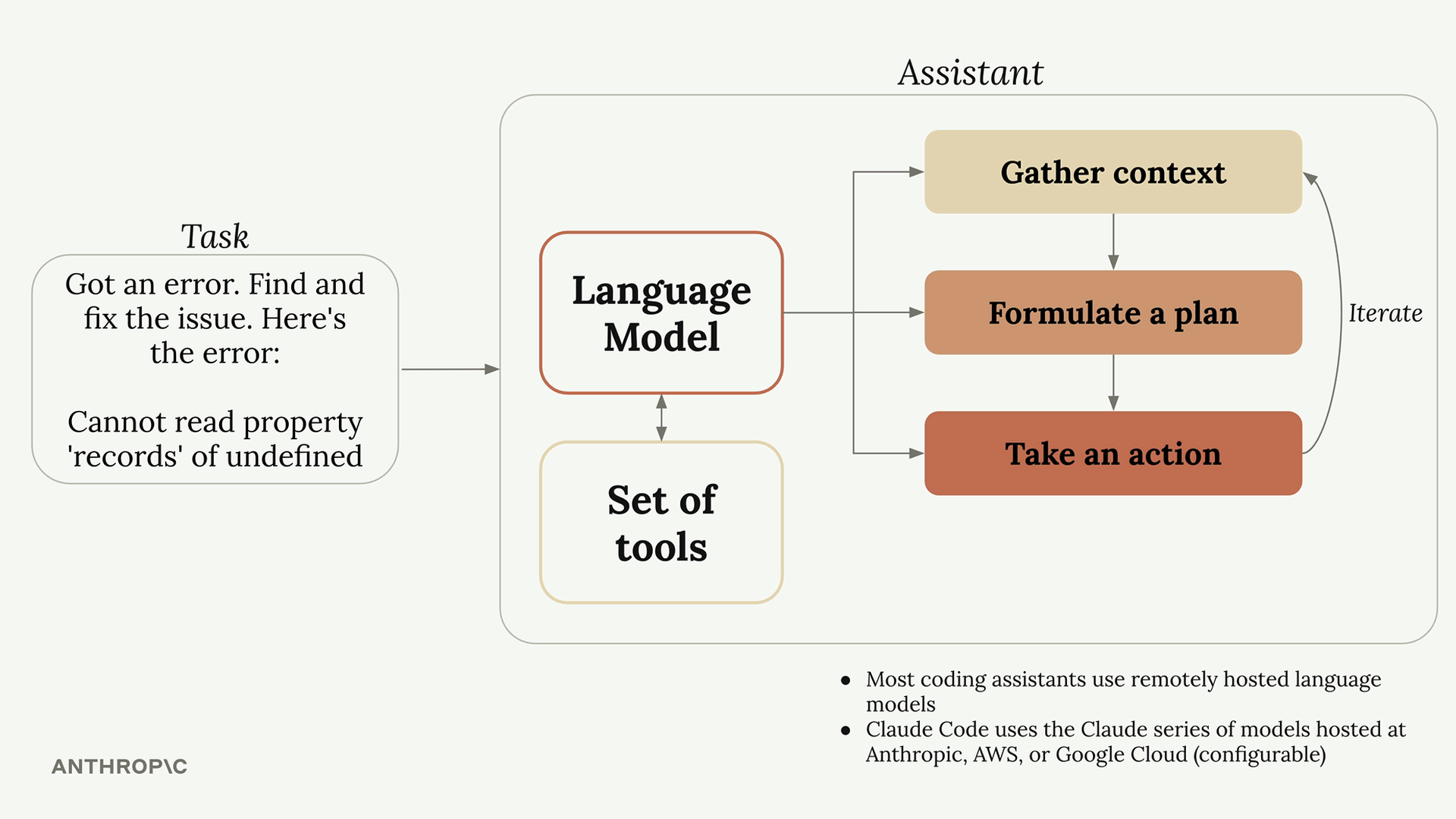
- Gather context (收集上下文) - 理解错误所指的内容、代码库中受影响的部分以及哪些文件是相关的。
- Formulate a plan (制定计划) - 决定如何解决问题,例如修改代码并运行测试以验证修复。
- Take action (采取行动) - 实际通过更新文件和运行命令来实施解决方案。
这里的关键在于,第一步和最后一步需要助手与外部世界进行交互——读取文件、获取文档、运行命令或编辑代码。
The Tool Use Challenge (工具调用面临的挑战)
这就是有趣的地方。语言模型(language model)本身只能处理文本并返回文本——它们实际上无法读取文件或运行命令。如果你让一个独立的语言模型读取文件,它会告诉你它不具备这种能力。
那么编码助手是如何解决这个问题的呢?它们使用了一个巧妙的系统,称为“Tool Use(工具调用)”。
How Tool Use Works (工具调用的工作原理)
当你向编码助手发送请求时,它会自动在你的消息中添加指令,教语言模型如何请求操作。例如,它可能会添加类似“如果你想读取文件,请回应‘ReadFile: 文件名’”的文本。
以下是完整的流程:
- 你问:“main.go 文件里写了什么代码?”
- 编码助手在你的请求中添加 Tool instructions(工具指令)。
- 语言模型回应:“ReadFile: main.go”。
- 编码助手读取实际文件,并将其内容发回给模型。
- 语言模型根据文件内容提供最终答案。
这个系统使得语言模型能够有效地“读取文件”、“编写代码”和“运行命令”,尽管它们实际上只是生成格式精良的文本回应。
Why Claude's Tool Use Matters (为什么 Claude 的工具调用能力很重要)
并非所有语言模型都同样擅长使用工具。Claude 系列模型(Opus, Sonnet, 和 Haiku)在理解工具功能并有效使用它们来完成复杂任务方面尤其强大。
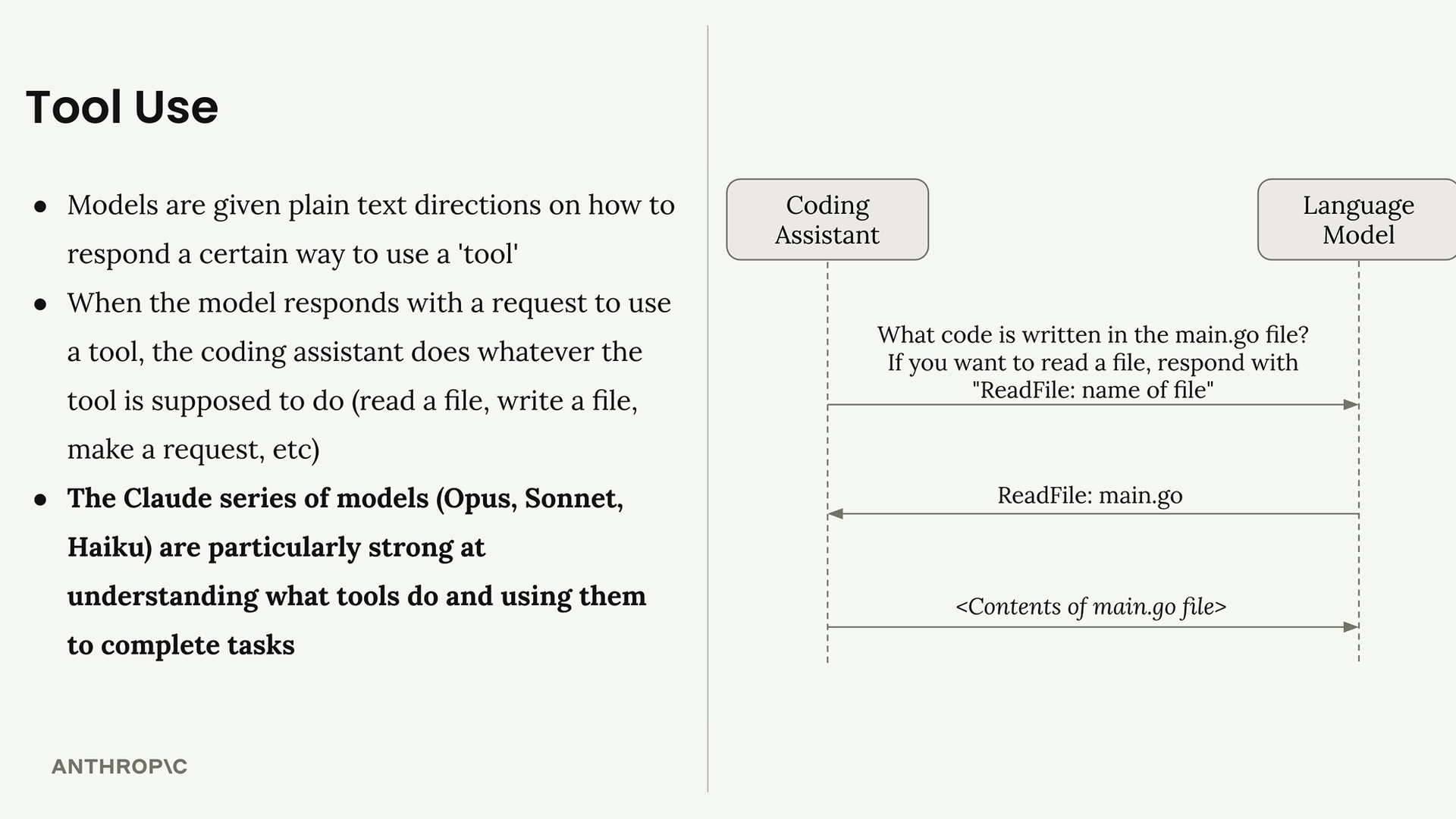
这种在 Tool Use(工具调用)方面的优势为 Claude Code 带来了几个关键好处:
Benefits of Strong Tool Use (强大工具调用的好处)
- Tackles harder tasks (应对更困难的任务) - Claude 可以结合不同的工具来处理复杂工作,并且会使用它以前未见过的工具。
- Extensible platform (可扩展平台) - 您可以轻松地为 Claude Code 添加新工具,并且 Claude 会随着您的工作流程演变而适应使用它们。
- Better security (更好的安全性) - Claude Code 可以在无需索引的情况下浏览代码库,这通常意味着无需将整个代码库发送到外部服务器。
Key Takeaways (主要收获)
理解编码助手归结为几个关键点:
- 编码助手使用语言模型(language model)来完成不同的任务。
- 语言模型需要 Tool(工具)来处理大多数实际编程任务。
- 并非所有语言模型都以相同的技能水平使用 Tool(工具)。
- Claude 强大的 Tool Use(工具调用)能力使 Claude Code 具有更好的安全性、可定制性和长久性。
这种 Tool Use(工具调用)能力将简单的文本生成模型转变为强大的编码助手,能够读取您的文件、理解您的代码库并对您的项目进行有意义的更改。
视频文字稿
在本视频中,我们将更好地理解什么是编码助手。是的,编码助手是一个编写代码的工具,但我希望您更深入地了解其幕后发生的事情。您看,通过理解编码助手真正做什么以及它如何工作,您将更好地欣赏一个真正出色的助手如何补充您的团队。这里有一种您可以想象编码助手正在做的事情。
助手首先会收到一个任务。在这种情况下,助手可能需要根据某种错误消息修复一个 Bug。这个任务会在内部传递给一个语言模型(language model),该模型需要找出如何解决问题。现在,不同的语言模型会根据任务的复杂性以非常不同的风格解决问题。
但在许多情况下,它们的工作方式与人类非常相似。它可能首先需要通过理解错误指的是什么、代码库中哪个区域正在抛出错误以及哪些文件似乎相关来收集上下文(gather context)。一旦收集到这些信息,它就需要制定一个计划(formulate a plan),说明如何实际完成任务。在这种情况下,它可能会决定修改一些代码,然后运行或编写测试来验证问题是否确实已修复。
最后,它将采取行动(take an action)。在这种情况下,这可能意味着更新文件和运行测试。现在,我想为您提供有关整个过程的更多信息。特别是,我想让您注意到这里的第一个和最后一个步骤需要编码助手实际做一些事情。
换句话说,要实际从外部世界收集信息或以某种方式影响外部世界。例如,为了收集上下文,助手可能需要读取文件或在线获取一些文档。而为了采取行动,助手可能需要实际运行命令或编辑文件。现在,让语言模型实际完成这些事情比听起来要棘手一些。
让我帮助您理解为什么会这样。让我们想象一下,我们正在直接与一个语言模型交互,所以它没有在任何编码助手或类似工具中运行。然后让我们想象一下,我们直接询问这个语言模型 main.go 文件里写了什么代码。在任何编码助手或类似工具的上下文之外运行的语言模型本身不具备读取文件、编写命令或任何类似操作的能力。
语言模型接收文本等内容,并返回文本。仅此而已。这就是它们能力的全部范围。所有语言模型都是如此。
因此,如果你向一个纯粹的语言模型发送一些文本,要求它读取文件,它很可能会回应说它不具备读取任何文件的能力。所以让我向您展示编码助手和许多其他工具是如何实际让语言模型“引用”读取文件的。所以这就是发生的情况。每当你向编码助手发送请求时,编码助手会在幕后自动向你的请求中添加大量文本。
在这种特殊情况下,我们可以想象编码助手将添加一些文本,其中写着,如果你,语言模型,想读取文件,请回应这个格式非常仔细的消息。例如,可能类似“read file, 冒号,然后是要读取的文件名”。因此,在这种情况下,语言模型很可能会意识到,为了回答我们的问题,它需要通过读取该文件来回应。所以它可能会回应“read file colon main.go”。
现在,编码助手将负责接收这条格式非常仔细的消息,并意识到语言模型希望通过读取文件来采取某种行动。因此,编码助手将负责实际读取文件,并将该文件的内容发回给语言模型。现在,语言模型已经收到该文件的实际内容,它可以编写一个最终响应,并将其发回给我们。其中它可能会说,我读取了这个文件,它包含一些代码,或其他任何文件中的内容。
这种向语言模型提供额外的小指令,要求它以格式良好或仔细格式化的方式回应的整个系统,被称为 Tool Use(工具调用)。因此,工具被用来赋予模型额外的能力。模型负责以非常特定的方式回应。然后,像我们的编码助手这样的东西将负责实际执行承诺的一切。
所以实际读取文件,编写文件,或任何其他东西。再次强调,这是目前所有语言模型的工作方式。它们都遵循 Tool Use(工具调用)的理念。现在,这里是理解的关键部分。
Claude 系列模型,即 Opus、Sonnet 和 Haiku,在理解工具的作用、何时调用它们以及实际有效使用它们来完成复杂任务方面尤其强大,并且能够以非常有趣的组合来完成更高级或更复杂的任务。Claude 强大的 Tool Use(工具调用)能力是 Claude Code 作为编码助手的绝对核心优势。原因如下。首先,正如我刚才提到的,凭借更好的 Tool Use(工具调用),Claude 可以处理更复杂的任务。
其次,Claude Code 本身是可扩展的,因此向 Claude 添加新工具非常容易。Claude 也会乐意使用这些工具。这对于持续相关性尤其重要,考虑到我们现在所看到的开发领域发生的快速变化。换句话说,Claude Code 是一个在未来几年会与您一同变化的助手。
最后,通过改进 Tool Use(工具调用),您通常会获得更好的安全性,因为 Claude 可以有效地搜索您的代码库以找到相关代码,而无需依赖索引,而索引通常依赖于将您的整个代码库发送到外部服务器。让我们快速回顾一下本视频中关于编码助手究竟是什么所学到的知识。因此请记住,编码助手在内部使用语言模型(language model)来完成不同的任务。这些语言模型需要知道如何使用 Tool(工具)来处理它们所收到的绝大多数任务。
工具被用于读取文件、编写文件、运行命令,以及基本上所有不只涉及生成文本的事情。并非所有语言模型都以相同的水平使用 Tool(工具),这对其编码助手的整体效率有很大影响。
3. Claude Code in action (Claude Code 实战)
类型:视频 | 时长:8:25 | 视频:003 - Claude Code in Action.mp4
Claude Code 附带了一套全面的内置 Tool(工具),用于处理常见的开发任务,如读取文件、编写代码、运行命令和管理目录。但 Claude Code 真正强大的地方在于它如何智能地组合这些 Tool(工具)来解决复杂的、多步骤的问题。
视频文字稿
刚才,我做了一些相当大的声明,说 Claude 是一个 Tool Use(工具调用)专家。而且 Claude Code 很容易扩展。自然,你可能会有点怀疑,所以我想给你几个快速的演示。这张表格是 Claude Code 中可用的默认 Tool(工具)。
它拥有你所期望的所有能力,比如读取文件、编写文件、运行命令等等。我将向你展示使用 Claude Code 完成的几个任务。在每种情况下,它都会以相当智能的方式使用这套 Tool(工具)。在至少一个任务中,我甚至会给 Claude 一套额外的 Tool(工具)来使用。
这个过程不仅能让你很好地了解 Claude Code 开箱即用的功能,希望你也能看到如何轻松地扩展 Claude Code 的功能。这是我给 Claude Code 的第一个任务。我将要求它在 chalk 库中查找并优化性能问题。如果你不熟悉它,chalk 是一个 JavaScript 包。
这是它的文档。这是一个非常小的库,只有一个非常简单的目的。它所做的就是用漂亮的颜色打印文本,就像你在这个示例截图中所看到的那样。所以你可以给文本设置颜色或背景以及格式化,所有这些。
现在,这听起来可能是一个非常简单和愚蠢的包,但关键是。事实证明,它实际上是整个 JavaScript 生态系统中下载量排名第五的包。特别是上周,它有 4.29 亿次下载。所以这个包被广泛使用。
简而言之,如果我能找到任何方法来优化这个包中的任何东西,那么努力大概是值得的。所以我会要求 Claude 运行基准测试,找出性能最差的案例,使用一些分析工具找出这些案例运行缓慢的原因,然后修复它们。然后我们会看到 Claude 将使用各种不同的 Tool(工具)智能地解决这个问题。它将形成一个 2D 列表来跟踪其进度,执行命令以运行基准测试,编写一个文件以更好地聚焦于一个特定案例,使用 CPU 分析器来了解该案例运行缓慢的原因,然后实施一些改进。
最后,我们将在围绕这个库的某个特定操作中获得 3.9 倍的吞吐量改进。这是 Claude 如何将不同的 Tool Call(工具调用)串联起来完成一个相当复杂的任务的另一个例子。我将给它一个 CSV 文件中的数据集。这里面的所有数据都包含视频流媒体平台不同用户的信息。
我将要求它进行一般性分析,也许找出平台上用户流失的一些原因。我希望所有这些分析都在 Jupyter Notebook 中完成。这是我的数据集。然后我将要求 Claude 运行分析,让我们看看它的表现如何。
这是一个有效 Tool Use(工具调用)非常重要的绝佳例子。你看,Claude 仅仅在 Notebook 中编写代码是不够的。Claude 还可以执行不同单元格中的代码,并查看这些执行的结果。这意味着 Claude 可以在 Notebook 中初步查看数据,然后自定义后续的每个单元格,以深入研究某些特定细节。
接下来,我想向您展示一个任务示例,其中我通过向 Claude Code 授予访问一组新 Tool(工具)的权限来扩展其功能。我构建了一个小型应用程序,它会根据屏幕左侧输入的一些描述生成 UI 组件。生成的组件会显示在右侧。现在,该应用程序可以非常轻松地生成美观的组件,但左侧的聊天界面和顶部的标题看起来不那么好。
因此,我将使用 Claude Code 来改进样式。如果我只是要求它修复聊天界面和标题中的样式,它可能会做得很好。但请记住,我的目标是向您展示向 Claude Code 添加额外功能是多么容易。因此,除了此样式任务之外,我还将授予 Claude Code 访问由 Playwright MCP 服务器提供的一组新 Tool(工具)的权限,稍后我将详细介绍它。
这些 Tool(工具)允许 Claude 直接打开和控制浏览器。因此,这就是该过程的实际情况。我将要求 Claude 改进我的应用程序的样式并使用浏览器来完成此操作。然后,它将在屏幕右侧打开一个浏览器。
导航到我的应用程序,它将截屏以查看当前样式,然后更新样式。我们甚至可以要求 Claude 在完成时再截取一次页面截图,并多次迭代设计,以获得一个真正出色的设计。不久之后,我们就会得到一些看起来相当合理的东西。我还有最后一组演示想给您看。
还记得我刚才提到的吗?Claude 如此擅长利用 Tool(工具)的能力,将使 Claude Code 在未来能够与您和您的团队共同成长。让我立即向您展示一个示例。Claude 与 GitHub 有着非常紧密的集成。
您可以设置 Claude Code 在 GitHub Actions 中运行,它将根据某些事件自动执行,例如创建拉取请求或在问题中直接被提及。当 Claude Code 在 GitHub 上运行时,它不仅可以查看和运行您的代码,还可以访问一组新的 Tool(工具)来与 GitHub 交互,例如创建评论或创建提交或拉取请求等。您可以使用此集成来自动审查拉取请求。让我向您展示一个示例。让我首先为您设置一个小的场景。
让我们想象一下,我们正在 AWS 上构建一些基础设施,并且我们所有的基础设施都在一组 terraform 文件中找到,这些文件已提交并存储在 GitHub 上。因为我们所有的基础设施都在 terraform 文件中定义,所以 Claude Code 对信息如何在我们的基础设施中流动有一个非常好的理解。让我们想象一下,在 SAP 中,我有一个 DynamoDB 表。如果你不熟悉它们,它有点像一个普通的数据库表。
在里面,我存储了一些关于用户的不同信息,包括可能已查看的计划和注册日期。出于某种原因,我们希望与一些内部营销团队以及一些外部营销团队分享这些已查看的计划和注册日期信息。因此,一些其他公司可以访问我们在此存储桶中写入的数据。因此,我们始终了解随着时间的推移写入该存储桶的信息内容非常重要。
夜间,我们可能会有一个 Lambda 函数,提取已添加到该表中的所有不同用户,然后仅提取已查看的计划和注册日期,并将其存储在 S3 存储桶中,以便这两个营销团队可以访问该信息。现在让我们想象一下几个月后,内部营销团队要求我们也在这个 S3 存储桶中存储电子邮件。因此,我们可能会进入 Lambda 函数,并仅添加一行代码,获取用户的电子邮件并将其存储在存储桶中。由于这已经是几个月后的事情,我们可能已经完全忘记了这个 S3 存储桶是与外部营销合作伙伴共享的。
所以现在,我们正在将个人身份信息放入这个存储桶中,而这个存储桶可以被一家独立的公司访问。这是一个大忌。绝对是我们不想做的事情。但与此同时,这是一个确实会发生的错误,如果我们不清楚这个 S3 存储桶究竟发生了什么,就很难捕捉到。
好吧,事实证明,Claude Code 可以在拉取请求中非常轻松地捕捉到这种情况,特别是因为我们所有的基础设施都在这些 terraform 文件中定义。所以这是一个快速示例。我构建了刚才在图中向您展示的项目。我创建了一个拉取请求,以在 Lambda 函数中添加用户的电子邮件。
因此,我更改的唯一一行代码就是那里。我说,对于每个用户,我希望获取他们的电子邮件并将其添加到存储桶中。现在,Claude 对我的基础设施有一个很好的了解。因此,它能够在自动化审查中,也就是我们现在看到的,查看我在这个拉取请求中所做的所有更改。它能够准确地找出我的基础设施是如何工作的,并且能够识别出我正在向合作伙伴暴露一些 PII。因此,它在这里列出了数据流,即发生的精确步骤。并详细说明了这个存储桶是如何与外部合作伙伴共享的。
在开发过程中而不是在部署此更改之后捕获此类问题,是使用 Claude Code 在 GitHub 上的集成所带来的巨大好处。我将在稍后详细介绍,并向您展示如何设置这样一个流程。我想我们现在对 Claude Code 的能力有了一个很好的了解,这要归功于它出色的 Tool Use(工具调用)能力。请记住,您真的应该将 Claude Code 视为一个灵活的助手,它可以根据您的团队需求进行定制、成长和改变。
第2部分:Getting hands on (动手实践)
4. Claude Code setup (Claude Code 设置)
此课时为环境配置/安装指南,请访问在线课程平台按步骤操作。
5. Project setup (项目设置)
此课时为环境配置/安装指南,请访问在线课程平台按步骤操作。
6. Adding context (添加上下文)
类型:视频 | 时长:5:14 | 视频:004 - Adding Context.mp4
在与 Claude 合作进行编码项目时,上下文管理(context management)至关重要。你的项目可能包含数十甚至数百个文件,但 Claude 只需要正确的信息才能有效地帮助你。过多的无关上下文实际上会降低 Claude 的性能,因此学会引导它关注相关文件和文档至关重要。
The /init Command (/init 命令)
首次在新项目中使用 Claude 时,请运行 /init 命令。这会告诉 Claude 分析整个代码库并理解:
- 项目的目的和架构
- 重要命令和关键文件
- 编码模式和结构
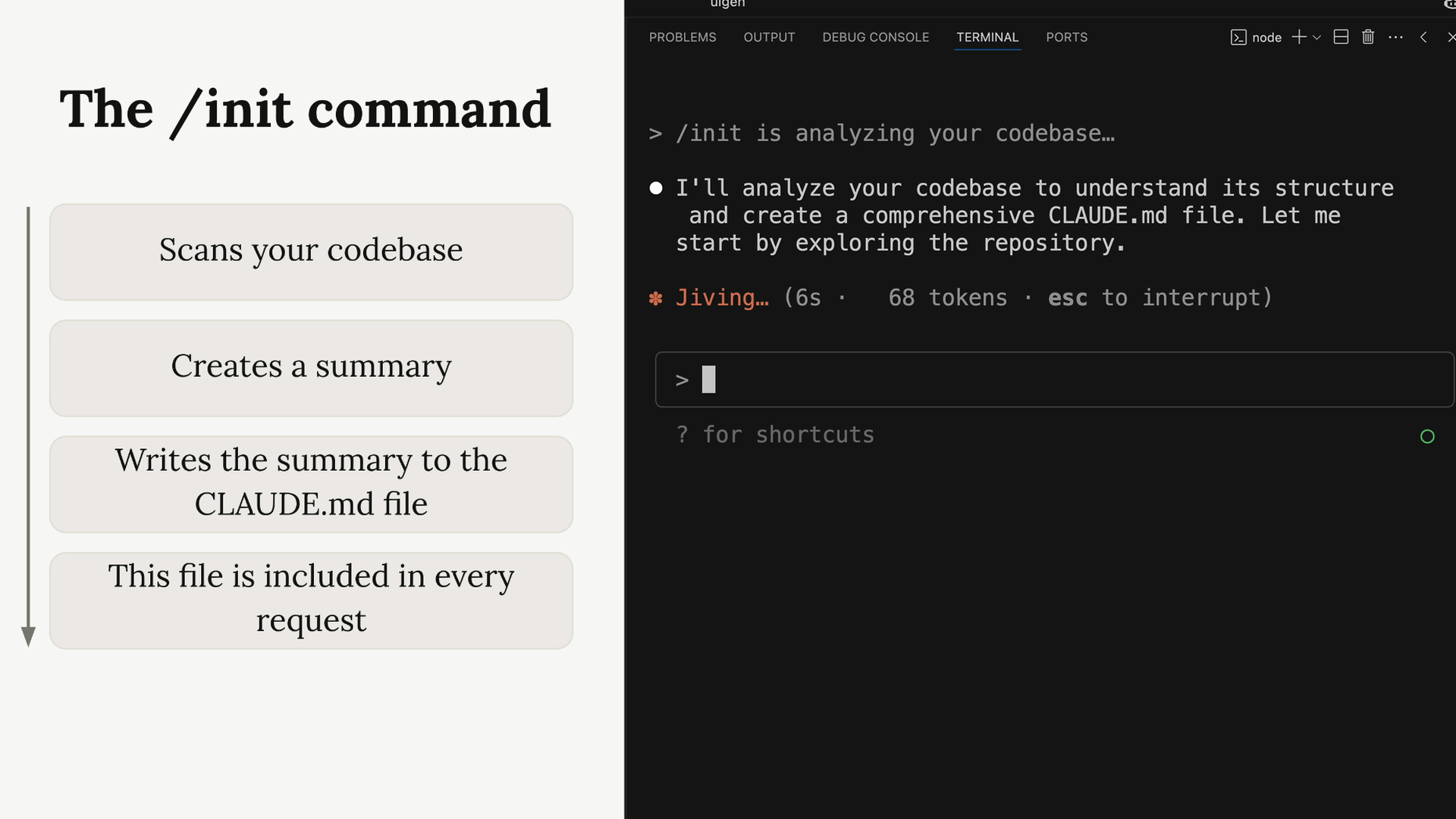
分析代码后,Claude 会创建一份摘要并将其写入 CLAUDE.md 文件。当 Claude 请求创建此文件时,您可以按 Enter 键批准每次写入操作,或按 Shift+Tab 键让 Claude 在整个会话中自由写入文件。
The CLAUDE.md File (CLAUDE.md 文件)
CLAUDE.md 文件有两个主要用途:
- 引导 Claude 了解您的代码库,指出重要命令、架构和编码风格
- 允许您向 Claude 提供特定或自定义指令
此文件包含在您向 Claude 发出的每个请求中,因此它就像您项目的持久化系统提示(persistent system prompt)一样。
CLAUDE.md File Locations (CLAUDE.md 文件位置)
Claude 识别三个常见位置的三个不同 CLAUDE.md 文件:
- CLAUDE.md - 通过
/init生成,提交到版本控制(source control),与其他工程师共享。 - CLAUDE.local.md - 不与其他工程师共享,包含个人指令和对 Claude 的定制。
- ~/.claude/CLAUDE.md - 用于您机器上的所有项目,包含您希望 Claude 在所有项目上遵循的指令。
Adding Custom Instructions (添加自定义指令)
您可以通过向 CLAUDE.md 文件添加指令来定制 Claude 的行为。例如,如果 Claude 在代码中添加了过多的注释,您可以通过更新文件来解决此问题。
使用 # 命令进入“memory mode(记忆模式)”——这允许您智能地编辑 CLAUDE.md 文件。只需输入类似以下内容:
# Use comments sparingly. Only comment complex code.
Claude 将自动将此指令合并到您的 CLAUDE.md 文件中。
File Mentions with '@' (使用“@”提及文件)
当您需要 Claude 查看特定文件时,请使用 @ 符号,后跟文件路径。这会自动将该文件内容包含在您向 Claude 发出的请求中。
例如,如果您想询问您的认证系统,并且您知道相关文件,您可以输入:
How does the auth system work? @auth
Claude 将向您显示一个 auth 相关的可选文件列表,然后将所选文件包含在您的对话中。
Referencing Files in CLAUDE.md (在 CLAUDE.md 中引用文件)
您还可以在 CLAUDE.md 文件中直接使用相同的 @ 语法提及文件。这对于与项目许多方面都相关的文件特别有用。
例如,如果您的数据库 schema 文件定义了数据结构,您可以将其添加到 CLAUDE.md:
The database schema is defined in the @prisma/schema.prisma file. Reference it anytime you need to understand the structure of data stored in the database.
当您以这种方式提及文件时,其内容会自动包含在每个请求中,因此 Claude 可以立即回答有关您的数据结构的问题,而无需每次都搜索和读取 schema 文件。
视频文字稿
我的代码编辑器在这个小项目中打开了,我将使用 NPM run dev 启动开发服务器。运行后,我将能够在浏览器中导航到 localhost 3000 并看到应用程序正在运行。所以它就在这里。我们将使用 Claude 在这个项目上做一些工作。
但首先,我希望你理解一些关于使用 Claude 的非常关键的事情。具体来说,我希望你通过本课程对上下文管理(context management)有一个深刻的理解。你看,在你的典型项目中,可能存在数十甚至数百个文件,每个文件都包含大量信息。每当我们向 Claude 提问或给它一个任务时,Claude 都需要一定量的理想信息。
恰好足以帮助它理解如何回答你的问题或完成你的任务。一旦我们开始添加不相关的额外信息,Claude 的效率就会开始下降。因此,引导 Claude 关注项目中相关的文件或文档对我们来说非常重要。Claude Code 当然可以在没有任何指导的情况下工作,但如果你提供一点指导,你将获得最好的结果。
所以在这个视频的其余部分,我将给你一些关于如何为 Claude 提供最佳上下文的技巧。首先,在我的编辑器中,我打开了终端,我将通过运行 Claude 命令来启动 Claude Code。每当你第一次在项目中运行 Claude Code 时,我强烈建议运行 slash init 命令。这会让 Claude 深入研究你的整个代码库。
它会找出项目的目的、通用架构、相关命令、关键文件等等。搜索完成后,它会总结其发现并将其放入一个名为 Claude.md 的文件中。当 Claude 尝试创建此文件时,它会请求权限。你可以按 Enter 键接受,或者如果你不想每次文件写入请求都授予权限,你也可以按 Shift Tab,这将允许 Claude Code 在你的项目中自由写入文件。
我鼓励您打开生成的 Claude.md 文件并查看其内容。正如我所提到的,此文件的内容包含在我们向 Claude 发出的每个请求中。此文件实际上有两个不同的用途。首先,它帮助 Claude 更好地理解您的代码库,以便它可以更快地找到相关的代码。
其次,它作为您可以向 Claude 提供一些通用指导的位置。您要知道,Claude Code 会使用多个 Claude.md 文件。有一个项目级别(project level)、一个本地级别(local level)和一个机器级别(machine level)。项目级别是我们通过运行 slash init 命令刚刚生成的。
我们通常会将此文件提交到版本控制(source control),例如 Git。我们将与您的其他工程师共享此文件,并且只包含一些我们希望传递给 Claude 的项目特定指令。此外,我们还可以选择创建一个 Claude.local.md 文件。此文件不会被提交,并且通常不会与任何其他工程师共享。
在此文件中,您可能会放置一些您希望 Claude 仅为您遵循的个人指令。最后,您可以在您的机器上拥有一个全局的 Claude.md 文件。此文件将包含您希望 Claude 在您本地运行的所有项目上遵循的指令或应用于所有项目。现在,我一直提到给 Claude 特殊或自定义指令。
所以让我向您展示一个例子。让我们想象一下 Claude 在它编写的代码中使用了太多注释。我们可以通过更新我们的 Claude.md 文件来解决这个问题。我们可以手动修改文件,或者有一个小技巧是在 Claude Code 中我们可以输入一个井号(pound sign)。
这会让我们进入记忆模式(memory mode)。这允许我们智能地编辑我们的 Claude.md 文件。所以我们可以提出一个请求,比如,不要经常写注释。然后我将指定我希望将此指令添加到项目 Claude.md 文件中,然后 Claude 将智能地将此指令合并到该文件中。
如果我然后打开文件并进行搜索,我会发现,是的,它确实添加了该新指令。既然我们已经创建了 Claude.md 文件,我想让您更好地理解如何将特定上下文(specific context)引入对话。让我们假设我们想更好地理解这个项目中的身份验证系统是如何工作的。我们可以直接询问 Claude 关于它的信息,在这种情况下,我们会搜索我们的代码库并找到与身份验证系统相关的文件。
这当然会奏效,但这需要一定的时间。另外,如果我们已经知道一些与身份验证系统相关的文件,我们可以使用 @ 字符提及它们。当我们提及一个文件时,它会自动包含在我们发送给 Claude 的请求中。这是一种引导 Claude 朝特定方向前进的绝佳技术。
你也可以使用相同的语法在 Claude.md 中提及文件。让我给你看一个非常有用的例子。在这个项目的 Prisma 文件夹中,有一个名为 schema.prisma 的文件。这个文件包含了这个项目中用于存储信息的 SQLite 数据库中所有不同表格和记录类型的完整定义。
因为这些信息对这个项目的许多方面都非常重要且相关,我可能会决定在我的 Claude.md 文件中提及这个文件。让我告诉你我该怎么做。首先,我将输入一个井号(pound)进入记忆模式。然后我将提及那个 schema 文件,并具体告诉 Claude,任何时候需要理解数据库中存储的数据结构时,都要引用那个文件。
更新完成后,我将查看 Claude.md 文件,并验证备注是否已添加。当你像这样提及一个文件时,它的内容会自动包含在你的请求中。所以如果我问用户有什么属性,Claude 可以立即回答,而无需读取 schema 文件。
7. Making changes (进行更改)
类型:视频 | 时长:4:04 | 视频:005 - Making Changes.mp4
在您的开发环境中与 Claude 合作时,您经常需要对现有项目进行更改。本指南涵盖了有效实施更改的实用技术,包括使用截图进行视觉沟通以及利用 Claude 的高级推理能力。
Using Screenshots for Precise Communication (使用截图进行精确沟通)
与 Claude 沟通最有效的方式之一是通过截图。当您想要修改界面的特定部分时,截取屏幕截图可以帮助 Claude 准确理解您所指的内容。
要将截图粘贴到 Claude 中,请使用 Ctrl+V(在 macOS 上不是 Cmd+V)。此键盘快捷键专门用于将截图粘贴到聊天界面中。粘贴图像后,您可以要求 Claude 对应用程序的该区域进行特定更改。
Planning Mode (计划模式)
对于需要对代码库进行广泛研究的更复杂任务,您可以启用 Planning Mode(计划模式)。此功能使 Claude 在实施更改之前对项目进行彻底探索。
通过按 Shift + Tab 两次(如果您已经自动接受编辑,则按一次)启用 Planning Mode(计划模式)。在此模式下,Claude 将:
- 读取项目中更多文件
- 创建详细的实施计划
- 准确显示它打算做什么
- 在继续之前等待您的批准
这使您有机会审查计划,并在 Claude 遗漏重要内容或未考虑特定场景时,重新引导它。
Thinking Modes (思考模式)
Claude 通过“thinking(思考)”模式提供不同级别的推理。这些模式允许 Claude 在提供解决方案之前花费更多时间思考复杂问题。
可用的 Thinking Modes(思考模式)包括:
- "Think" (思考) - 基本推理
- "Think more" (深入思考) - 扩展推理
- "Think a lot" (大量思考) - 全面推理
- "Think longer" (长时间思考) - 延长推理时间
- "Ultrathink" (超强思考) - 最大推理能力
每种模式都会逐渐为 Claude 提供更多的令牌(token)来处理,从而能够对具有挑战性的问题进行更深入的分析。
When to Use Planning vs Thinking (何时使用计划模式与思考模式)
这两个功能处理不同类型的复杂性:
Planning Mode(计划模式)最适合:
- 需要对代码库有广泛理解的任务
- 多步骤实现
- 影响多个文件或组件的更改
Thinking Mode(思考模式)最适合:
- 复杂的逻辑问题
- 调试疑难问题
- 算法挑战
您可以将这两种模式结合起来,以处理既需要广度又需要深度的任务。请记住,这两种功能都会消耗额外的令牌(token),因此使用它们会产生成本考虑。
视频文字稿
让我们尝试对这个项目进行一些更改。在此过程中,我将向您展示一些关于 Claude Code 的有用功能。我首先想做的是将左侧的占位符文本移动到此面板的中心。为了帮助 Claude 准确理解我想要移动的内容,我将截取该区域的屏幕截图,然后使用 Ctrl V 将其粘贴到 Claude Code 中。
请注意,是 Ctrl-V,而不是您在 macOS 上可能习惯的 Command-V。Ctrl-V 专门用于粘贴屏幕截图。然后我可以要求 Claude 将该占位符居中。经过一番搜索,Claude 成功地进行了样式更新。
然后回到浏览器中,是的,看起来很棒。让我向您展示我希望在此应用程序中更改的下一件事。我将要求一个卡片组件,该组件显示标题和一些描述。卡片已生成,没有任何问题,但有一个尴尬的地方。
在聊天界面的左侧,有一个字符串替换编辑器。那个小面板旨在向用户表明正在创建一个文件。但现在它正在使用一个非常技术性的术语“String Replace Editor”来表示正在后台使用的工具。我希望向用户显示一些更友好的文本,并告诉用户正在创建一个文件以及文件的名称。
当然,我们还应该处理这种情况,例如聊天机器人正在编辑文件或删除文件等。为了引导 Claude 的注意力,我将再次截取屏幕截图,以便它准确理解我在说什么。然后,回到这里,我将粘贴该图像并要求 Claude 将该特定文本替换为一些更友好的消息。现在,这是一个有点棘手的任务,Claude 需要在这个项目中进行大量研究才能完成。
每当你给 Claude 一个更困难的任务时,有两种方法可以轻松提高 Claude 的智能。第一种方法是启用计划模式(Plan mode)。计划模式通过按 Shift-Tab 两次启用,或者如果你已经自动接受文件编辑,则只需按一次。在计划模式下,Claude 将对你的项目内容进行更多的研究,阅读更多的文件,并制定一个详细的计划来完成你的任务。
完成计划后,Claude 会告诉你它具体想怎么做来完成你的任务。届时,你可以选择接受这个计划,Claude 就会实施它,或者你可以以某种方式重定向 Claude,也许它遗漏了一些文件,或者没有考虑到某种情况。我们可以提高 Claude 智能的第二种方法是启用 Thinking Mode(思考模式)。这会开启 Claude 的扩展思考功能,让它能够更深入地思考某个特定任务。
要启用思考功能,有几个不同的触发短语。每个短语都会逐步为 Claude 提供更大的令牌预算来思考。鉴于这是一项棘手的任务,我可能会要求 Claude 对如何最好地实现它进行“超强思考”(ultra-think)。最后要理解的是,计划和思考可以一起使用。
因此,除了这种超强思考之外,我还将开启计划模式。现在我将运行它,看看 Claude 如何实现这个功能。你可能想知道什么时候应该使用计划,什么时候应该使用思考。把这两者想象成处理广度优先深度。
当你有一个任务需要对代码库有广泛的理解,并且需要查看不同的区域时,规划模式很有用。当处理需要几个步骤才能完成的任务时,它也很有用。另一方面,当你在专注于一个特别棘手的逻辑或排除一个困难的 Bug 时,思考模式很有用。你可能有的第二个问题是,是否应该一直启用思考和规划。
当然可以,但请记住,规划和思考会消耗额外的令牌,因此使用它们会产生相关的成本。经过几分钟的工作,这个功能似乎已经完成了。所以我要回到我的编辑器中进行测试。所以很快,我们可以看到我们这里得到了一些比以前更好的状态信息。
用户现在被告知正在创建一个文件。如果我发送一个后续请求,也许是更改标题。希望现在在后续操作中,我们会看到一些关于编辑该文件的信息。所以我们看到了。
现在我们正在编辑 app.jsx 文件。嗯,我想说 Claude 肯定成功地实现了这个功能。既然我们已经对这个项目进行了一些更改,我们可能应该提交我们的更改。Claude Code 是一个可靠的 Git 助手。
我们可以要求它暂存并提交我们的更改,它将为我们编写一个描述性的提交消息。
9. Controlling context (控制上下文)
类型:视频 | 时长:3:37 | 视频:006 - Controlling Context.mp4
在使用 Claude 处理复杂任务时,您通常需要引导对话以使其保持专注和高效。有几种技术可用于控制对话流程并帮助 Claude 保持在正确的轨道上。
Interrupting Claude with Escape (使用 Escape 键中断 Claude)
有时 Claude 会开始走错方向或试图一次处理太多任务。您可以按下 Escape 键来停止 Claude 的响应,从而重新引导对话。
当您希望 Claude 专注于一个特定任务而不是同时处理多个任务时,这尤其有用。例如,如果您要求 Claude 为多个函数编写测试,而它开始为所有这些函数创建全面的计划,您可以中断并要求它一次只专注于一个函数。
Combining Escape with Memories (结合 Escape 键与记忆)
Escape 技术最强大的应用之一是修复重复性错误。当 Claude 在不同对话中重复犯相同的错误时,您可以:
- 按下
Escape键停止当前响应 - 使用
#快捷方式添加关于正确方法的 memory(记忆) - 使用更正后的信息继续对话
这可以防止 Claude 在未来关于您项目的对话中犯相同的错误。
Rewinding Conversations (回溯对话)
在长时间的对话中,您可能会积累变得不相关或分散注意力的上下文。例如,如果 Claude 遇到错误并花费时间调试它,那么来回的讨论可能对下一个任务没有用。
您可以按两次 Escape 键来回溯对话。这会显示您发送的所有消息,允许您跳回到较早的时间点并从那里继续。此技术有助于您:
- 维护有价值的上下文(例如 Claude 对您的代码库的理解)
- 删除分散注意力或不相关的对话历史
- 让 Claude 专注于当前任务
Context Management Commands (上下文管理命令)
Claude 提供了几个命令来帮助有效地管理对话上下文:
/compact (/compact 命令)
/compact 命令会总结您的整个对话历史,同时保留 Claude 所学到的关键信息。这在以下情况下是理想选择:
- Claude 已经获得了关于您项目的宝贵知识
- 您想继续处理相关任务
- 对话变得冗长但包含重要上下文
当 Claude 对当前任务了解很多,并且您希望在它转向下一个相关任务时保留这些知识时,请使用 compact。
/clear (/clear 命令)
/clear 命令会完全清除对话历史记录,让您重新开始。这在以下情况下最有用:
- 您正在切换到一个完全不同且不相关的任务
- 当前对话上下文可能会让 Claude 对新任务感到困惑
- 您想在没有任何先前上下文的情况下重新开始
When to Use These Techniques (何时使用这些技术)
这些对话控制技术在以下情况下特别有价值:
- 上下文可能变得混乱的长时间对话
- 先前上下文可能分散注意力的任务转换
- Claude 反复犯相同错误的情况
- 您需要专注于特定组件的复杂项目
通过战略性地使用 escape、双击 escape、/compact 和 /clear,您可以让 Claude 在整个开发工作流程中保持专注和高效。这些不仅仅是便利功能——它们是维护有效 AI 辅助开发会话的必备工具。
视频文字稿
在本视频中,我想向您展示几种控制和引导对话流程的不同技术。这里有一个基本的例子。我将要求 Claude 为身份验证文件中编写的一些函数编写测试。Claude 很快就制定了一个编写多个不同测试的计划。
然而,我知道测试这个文件有点困难,我希望 Claude 一次只测试一件事。要中断 Claude,我可以按 Escape 键。这将阻止 Claude 继续执行,让我可以建议一条不同的路径。将 Escape 键与记忆结合使用是一种非常强大的方法,可以修复 Claude 重复犯的错误。
这是一个例子。我将再次要求 Claude 为同一个文件编写测试。这一次,它将尝试读取一个实际上不存在的测试配置文件。现在,这是一个我以前见过 Claude 在这个项目上犯的错误。
因此,为了阻止这个错误再次发生,我将非常迅速地按下 Escape 键。然后我将使用井号(pound shortcut)添加一个关于这个测试配置文件正确名称的记忆。现在,我可能不必再看到这个错误了。其中一些对话控制快捷方式看起来只是为了方便。
但如果使用得当,它们确实可以提高 Claude 的工作效率,并使其保持专注。所以让我向您展示一个更实际的例子。在 auth.ts 文件中,有四个不同的函数。我希望 Claude 为它们中的每一个编写测试,一次一个,首先从一个名为 create session 的函数开始。
Claude 肯定会尝试编写测试,但在运行它们时,它遇到了一个错误,并花了一些时间调试它。事实证明,我忘记安装了一个包。最终,测试完成并正常工作,是时候开始下一组测试了。但问题是。
现在我的对话历史中有很多关于那个损坏包的来回讨论。现在,这堆上下文与编写下一组测试完全不相关。理想情况下,我们应该能够回到过去,回到我们发送的上一条消息,然后将其更新为“为 git session 编写测试”。这样做的好处是,我们保留了上下文,其中 Claude 已经查看了 auth.ts 文件的内容。
而且当我们提到 git session 时,它已经知道我们在说什么。而且因为我们删除了所有那些只是关于调试的额外消息,所以我们这里不会有那么多干扰。所以,Claude 真的可以专注于任务。要回到对话历史中,请按两次 Escape 键。
这将显示您设置的所有不同消息,因此您可以回溯到以前的时间点并跳过一些中间对话。Claude 现在将开始处理下一组测试。这一次,Claude 保持了高度专注,但不幸的是,它遇到了许多问题。它最终解决了这些问题并使测试通过。
现在,Claude 已经独自工作了几分钟,并且对如何编写此文件的测试有了一个很好的了解。同时,再一次,我们在这个对话历史中有大量的上下文。当需要为下一个函数编写测试时,我想使用一个名为 compact 的命令。compact 命令将获取当前对话中的所有消息并进行总结。
当 Claude 对当前任务了解很多,并且您希望在它转向下一个任务时保留这些知识时,compact 命令非常有用。最后一个需要注意的上下文相关命令是 Clear 命令。Clear 命令将清除整个对话历史记录,让您从头开始。Clear 命令最有用的是当您即将开始一个与当前任务完全不不同的任务时。
我建议您经常使用这些快捷方式,特别是当您在任务之间切换时,或者当您与 Claude 进行长时间对话时。在本课程的其余部分,我们将多次使用它们,以确保 Claude 保持专注并专注于任务。
10. Custom commands (自定义命令)
类型:视频 | 时长:1:44 | 视频:007 - Custom Commands.mp4
Claude Code 附带了可以通过输入斜杠访问的内置命令,但您也可以创建自己的 Custom Commands(自定义命令)来自动化您经常运行的重复性任务。
Creating Custom Commands (创建自定义命令)
要创建自定义命令,您需要在项目中设置特定的文件夹结构:
- 找到项目目录中的
.claude文件夹 - 在其中创建一个名为
commands的新目录 - 创建一个带有您所需命令名称的新的 Markdown 文件(例如
audit.md)
文件名将成为您的命令名称——因此 audit.md 会创建 /audit 命令。
Example: Audit Command (示例:Audit 命令)
这是一个自定义命令的实际示例,该命令用于审核项目依赖项是否存在漏洞:
此 audit 命令执行三项操作:
- 运行
npm audit查找易受攻击的已安装包 - 运行
npm audit fix应用更新 - 运行测试以验证更新没有破坏任何东西
创建命令文件后,您必须重新启动 Claude Code,它才能识别新命令。
Commands with Arguments (带参数的命令)
自定义命令可以使用 $ARGUMENTS 占位符接受参数。这使它们更具灵活性和可重用性。
例如,write_tests.md 命令可能包含:
Write comprehensive tests for: $ARGUMENTS
Testing conventions:
* Use Vitests with React Testing Library
* Place test files in a __tests__ directory in the same folder as the source file
* Name test files as [filename].test.ts(x)
* Use @/ prefix for imports
Coverage:
* Test happy paths
* Test edge cases
* Test error states
然后,您可以将此命令与文件路径一起运行:
/write_tests the use-auth.ts file in the hooks directory
参数不一定是文件路径——它们可以是您想要传递的任何字符串,以向 Claude 提供任务的上下文和方向。
Key Benefits (主要好处)
- Automation (自动化) - 将重复性工作流程转变为单个命令
- Consistency (一致性) - 确保每次都遵循相同的步骤
- Context (上下文) - 为 Claude 提供您项目的特定指令和约定
- Flexibility (灵活性) - 使用参数使命令适用于不同的输入
自定义命令对于项目特定的工作流程特别有用,例如运行测试套件、部署代码或根据团队约定生成样板(boilerplate)。
视频文字稿
当你运行 Claude Code 时,你可以输入一个斜杠并看到 Claude Code 默认内置的一系列命令。除了这些默认命令之外,你还可以轻松添加自己的自定义命令。自定义命令对于自动化你经常运行的重复性任务很有用。让我向你展示如何创建一个。
在我的项目目录中,我将找到 .Claude 文件夹。在里面,我将创建一个名为 commands 的新目录。然后在里面,我将创建一个名为 audit.md 的新文件。我们创建的文件的名称,在这个例子中是 audit,将是我们最终运行的命令的名称。
这个命令的目标是审计项目中安装的所有不同依赖项,如果有任何漏洞就更新它们,然后运行测试以确保没有任何东西被破坏。创建命令文件后,你需要重新启动 Claude Code。不要忘记重新启动它。当你重新打开 Claude Code 时,输入 slash audit。
这将显示你刚刚创建的命令。然后你可以运行它,在这种情况下,它会完全按照我们要求 Claude 做的事情。它将运行一个命令,查看是否有任何易受攻击的包,必要时修复它们,然后运行测试。命令也可以接收参数。
让我向你展示一个例子。我将创建另一个名为 write test 的命令。每当我运行此命令时,我希望为项目中的某个特定文件创建一些测试。在命令文本中,我将放入一个美元符号加 arguments 的占位符。
每当我运行该命令时,如果我传入一个文件的路径,该路径将插入到美元符号 arguments 的位置。所以现在我可以再次重新启动 Claude Code,然后执行 write test 命令。现在,需要明确的是,我们传入的参数不一定是文件路径。它可以是我们想要传入的任何字符串。
所以我可能会随意请求为某个特定文件夹中的文件进行测试,给 Claude 一点方向,告诉它在哪里查找。
11. MCP servers with Claude Code (使用 Claude Code 的 MCP 服务器)
类型:视频 | 时长:2:53 | 视频:008 - Extending Claude Code with MCP Servers.mp4
您可以通过添加 MCP (Model Context Protocol) 服务器来扩展 Claude Code 的功能。这些服务器可以在远程或本地计算机上运行,并为 Claude 提供其通常不具备的新 Tool(工具)和能力。
最受欢迎的 MCP 服务器之一是 Playwright,它赋予 Claude 控制网络浏览器(web browser)的能力。这为网络开发工作流程带来了强大的可能性。
Installing the Playwright MCP Server (安装 Playwright MCP 服务器)
要将 Playwright 服务器添加到 Claude Code,请在您的终端(而不是在 Claude Code 内部)运行此命令:
claude mcp add playwright npx @playwright/mcp@latest
此命令执行两项操作:
- 将 MCP 服务器命名为 "playwright"
- 提供在本地计算机上启动服务器的命令
Managing Permissions (管理权限)
首次使用 MCP 服务器工具时,Claude 每次都会请求权限。如果您厌倦了这些权限提示,可以通过编辑设置来预先批准服务器。
打开 .claude/settings.local.json 文件,并将服务器添加到 allow 数组中:
{
"permissions": {
"allow": ["mcp__playwright"],
"deny": []
}
}
请注意 mcp__playwright 中的双下划线。这允许 Claude 在不每次请求权限的情况下使用 Playwright 工具。
Practical Example: Improving Component Generation (实际示例:改进组件生成)
以下是 Playwright MCP 服务器如何改进您的开发工作流程的实际示例。您无需手动测试和调整提示,而是可以让 Claude:
- 打开浏览器并导航到您的应用程序
- 生成一个测试组件
- 分析视觉样式和代码质量
- 根据观察结果更新生成提示
- 使用改进的提示测试新组件
例如,您可以要求 Claude:
"Navigate to localhost:3000, generate a basic component, review the styling, and update the generation prompt at @src/lib/prompts/generation.tsx to produce better components going forward." (“导航到 localhost:3000,生成一个基本组件,审查样式,并更新 @src/lib/prompts/generation.tsx 中的生成提示,以便将来生成更好的组件。”)
Claude 将使用浏览器 Tool(工具)与您的应用程序交互,检查生成的输出,然后修改您的提示文件以鼓励更原始和富有创意的设计。
Results and Benefits (结果与好处)
在实践中,这种方法可以带来显著更好的结果。Claude 可能不再生成通用的紫色到蓝色渐变和标准 Tailwind 模式,而是更新提示以鼓励:
- 温暖的日落渐变(橙色到粉色到紫色)
- 海洋深色主题(青色到翠绿色到青色)
- 不对称设计和重叠元素
- 创意间距和非常规布局
主要优点是 Claude 可以看到实际的视觉输出,而不仅仅是代码,这使其能够对样式改进做出更明智的决策。
Exploring Other MCP Servers (探索其他 MCP 服务器)
Playwright 只是 MCP 服务器可能实现的一个示例。生态系统包括用于以下方面的服务器:
- 数据库交互
- API 测试和监控
- 文件系统操作
- 云服务集成
- 开发工具自动化
考虑探索符合您特定开发需求的 MCP 服务器。它们可以将 Claude 从一个代码助手转变为一个全面的开发伙伴,可以与您的整个工具链交互。
视频文字稿
您可以通过使用 MCP 服务器向 Claude Code 添加新的 Tool(工具)和功能。这些 MCP 服务器既可以在远程运行,也可以在您的机器上本地运行。一个非常受欢迎的 MCP 服务器名为 Playwright,它赋予 Claude Code 控制浏览器的能力。让我向您展示如何将其添加到 Claude Code,然后我们将使用它来进一步开发我们的应用程序。
要在您的终端中安装服务器,而不是在 Claude Code 内部,我们将执行 Claude MCP Add。然后给这个 MCP 服务器起一个名字,我将把它命名为 Playwright。然后在这个名字之后,我们将添加一个命令,它将在您的机器上本地启动服务器。然后我们可以启动 Claude Code,并要求它打开浏览器并导航到我们在 localhost 3000 上的应用程序。
在浏览器打开之前,您可能会注意到您需要授予该工具运行权限。如果您厌倦了所有这些权限弹出窗口,您可以打开 Claude 目录,在 settings.local.json 中。然后在允许(allow)数组中,您可以添加一个字符串 mcp_underscore_underscore,请注意这里有两个下划线,playwright。这允许 Claude Code 以任何方式使用这个 MCP 服务器及其内部的工具,而无需您每次都提供权限。
如果我重新启动 Claude Code,然后再次要求它打开浏览器,它将这样做,而无需我提供权限。你可以使用 Playwright MCP 服务器的方式有很多。让我给你看一个对我们现在正在做的项目非常适用的例子。回到我的编辑器中,我将找到 SRC, Lib, prompts, generation.tsx 文件。
这是用于实际生成您在我们的应用程序中请求的组件的提示。因此,我希望允许 Claude Code 使用浏览器,自行生成一个组件,然后根据生成的组件自行调整这个提示。希望最终我们能从我们的应用程序中生成出更好看的组件。所以让我向您展示我们该怎么做。
回到 Claude Code 中,我将要求它导航到 localos3000。尝试生成一个组件,查看生成的源代码并评估样式,然后更新 generation.tsx 文件中的提示,希望最终我们的生成组件能有更好的样式。所以让我们看看它表现如何。Claude 会首先打开浏览器。
它将尝试生成一个组件。从 Claude 的一些评论来看,它似乎不太满意。你可能会注意到,它抱怨了在类似应用程序中非常常见的一种样式,即紫色到蓝色的渐变。Claude 随后会更新我们的提示,然后尝试生成一个新组件。
老实说,这实际上比我预期的结果要好得多。这张推荐卡片看起来真的很棒。仅凭这些结果,你就可以立即感觉到 MCP 服务器确实为许多有趣的用例打开了大门。我强烈建议你研究一些 MCP 服务器,它们可能会帮助 Claude 开发你个人正在做的任何类型的项目。
12. Github integration (GitHub 集成)
类型:视频 | 时长:3:40 | 视频:009 - Github Integration.mp4
Claude Code 提供了官方的 GitHub integration(集成),允许 Claude 在 GitHub Actions 中运行。此集成提供了两种主要工作流程:issue 和 pull request 的提及支持,以及自动 pull request 审查。
Setting Up the Integration (设置集成)
要开始使用,请在 Claude 中运行 /install-github-app。此命令会引导您完成设置过程:
- 在 GitHub 上安装 Claude Code 应用程序
- 添加您的 API 密钥
- 自动生成包含 workflow 文件的 pull request
生成的 pull request 会向您的存储库添加两个 GitHub Actions。合并后,您将在 .github/workflows 目录中拥有 workflow 文件。
Default GitHub Actions (默认 GitHub Actions)
此集成提供了两种主要工作流程:
Mention Action (提及操作)
您可以使用 @claude 在任何 issue 或 pull request 中提及 Claude。当被提及后,Claude 将:
- 分析请求并创建任务计划
- 拥有完整代码库访问权限执行任务
- 直接在 issue 或 PR 中回复结果
Pull Request Action (Pull Request 操作)
每当您创建 pull request 时,Claude 会自动:
- 审查提议的更改
- 分析修改的影响
- 在 pull request 上发布详细报告
Customizing the Workflows (自定义工作流程)
合并初始 pull request 后,您可以自定义 workflow 文件以适应您的项目需求。以下是增强提及工作流程的方法:
Adding Project Setup (添加项目设置)
在 Claude 运行之前,您可以添加步骤来准备您的环境:
- name: Project Setup
run: |
npm run setup
npm run dev:daemon
Custom Instructions (自定义指令)
向 Claude 提供有关您的项目设置的上下文:
custom_instructions: |
The project is already set up with all dependencies installed.
The server is already running at localhost:3000. Logs from it
are being written to logs.txt. If needed, you can query the
db with the 'sqlite3' cli. If needed, use the mcp__playwright
set of tools to launch a browser and interact with the app.
MCP Server Configuration (MCP 服务器配置)
您可以配置 MCP 服务器以赋予 Claude 额外功能:
mcp_config: |
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest",
"--allowed-origins",
"localhost:3000;cdn.tailwindcss.com;esm.sh"
]
}
}
}
Tool Permissions (工具权限)
在 GitHub Actions 中运行 Claude 时,您必须明确列出所有允许的 Tool(工具)。这在使用 MCP 服务器时尤其重要。
allowed_tools: "Bash(npm:*),Bash(sqlite3:*),mcp__playwright__browser_snapshot,mcp__playwright__browser_click,..."
与本地开发不同,GitHub Actions 中没有权限捷径。来自每个 MCP 服务器的每个 Tool(工具)都必须单独列出。
Best Practices (最佳实践)
设置 Claude 的 GitHub integration(集成)时:
- 从默认工作流程开始,并逐步定制
- 使用 Custom Instructions(自定义指令)提供项目特定上下文
- 使用 MCP 服务器时,明确 Tool Permissions(工具权限)
- 在处理复杂任务之前,使用简单任务测试您的工作流程
- 配置额外步骤时,考虑项目的具体需求
GitHub integration(集成)将 Claude 从一个开发助手转变为一个自动化团队成员,可以在您的 GitHub 工作流程中直接处理任务、审查代码并提供见解。
视频文字稿
Claude Code 有一个官方的 GitHub integration(集成),允许 Claude Code 在 GitHub Actions 中运行。您可以通过运行斜杠安装 GitHub 应用来设置此集成。这将引导您完成几个步骤。首先,您需要在 GitHub 上安装 Claude Code 应用。
接下来,您需要添加一个 API 密钥。然后,一个 pull request 将自动生成。此 pull request 添加了两个不同的 GitHub Actions。第一个操作添加了提及支持(mentioning support)。
因此,您可以从 issue 或 pull request 中提及 Claude,使用 @Claude 并给 Claude 一些任务来运行。第二个操作添加了对审查 pull request 的支持。因此,无论何时您创建 pull request,Claude Code 都会自动运行并审查提议的更改。这两个操作都可以自定义,您还可以添加额外的操作以根据其他类型的事件触发。
让我向您展示如何自定义提及功能。首先,我们已将这两个 action config 文件合并到 GitHub 上的存储库中。因此,我需要将这些更改拉取到我的本地计算机上。然后,在新创建的 GitHub workflows 目录中,我将看到这两个 action config 文件。
一个添加了对 pull request 审查的支持,另一个添加了对处理提及的支持。现在,这就是我希望如何自定义提及功能。每当我在 issue 或 pull request 中提及 Claude 时,我希望它能够运行项目并使用 Playwright MCP 服务器在 Web 浏览器中访问应用程序,所有这些都在 GitHub Action 中完成。为了实现这一点,我首先会在 Claude Code 在此工作流程中运行之前添加一个步骤。
我将运行 setup 命令,然后启动开发服务器。然后我将更新 Claude Code 配置。我将添加一些自定义指令。这些指令直接传递给 Claude,它们允许我们提供一些额外的指示或上下文。
在这种情况下,我将告诉 Claude 开发服务器已经运行,并且如果需要,我可以使用 Playwright MCP 服务器在浏览器中访问应用程序。然后我将添加一些配置来设置 Playwright MCP 服务器本身。这里还有一件事需要注意。当您在操作中运行 Claude Code 时,我们必须明确列出我们希望授予 Claude Code 的所有权限。
这有一个棘手之处。如果您正在使用 MCP 服务器,您必须单独列出您希望允许的每个 MCP 服务器中的每个工具。不像我们之前看到的权限快捷方式。不幸的是,Playwright MCP 服务器有许多不同的工具,因此它们都需要单独列出。
完成此配置更新后,我将确保提交这些更改并推送它们。现在是时候测试这个更新后的工作流程了。我将给 Claude 一个小任务。在我们的实际应用程序中,请看上面这两个按钮。
现在它们工作正常。我可以在预览面板和代码面板之间切换,没有任何问题。但我将假装它们没有按预期工作。我将截取该按钮的屏幕截图。
我将创建一个 issue。我将粘贴屏幕截图。然后我将提及 Claude,使用 @Claude 并要求它验证这两个按钮是否按预期工作。然后我将创建 issue 并等待。
现在,操作实际启动并等待 Claude 响应可能需要一两分钟。请记住,正如我们刚刚在操作中看到的那样,我们现在正在设置整个应用程序并启动它运行,然后 Claude Code 才开始运行。但最终,Claude 会响应。它通常会创建一份步骤清单来完成给定的任务。
在这种情况下,它将尝试访问应用程序,手动测试按钮,并修复它发现的任何问题。Claude 会注意到按钮实际上工作正常,因此它会提前终止并附上记录其发现的消息。现在,这只是一个关于如何使用 Claude Code 的 GitHub 集成的小例子。我建议你花一些时间思考如何为你的特定项目量身定制它。
第3部分:Hooks and the SDK (钩子和 SDK)
13. Introducing hooks (钩子介绍)
类型:视频 | 时长:3:37 | 视频:010 - Introducing Hooks.mp4
Hooks(钩子)允许您在 Claude 尝试运行 Tool(工具)之前或之后运行命令。它们对于实现自动化工作流程(automated workflows)非常有用,例如在文件编辑后运行代码格式化程序、文件更改时执行测试或阻止对特定文件的访问。
How Hooks Work (钩子的工作原理)
要理解 Hooks(钩子),我们首先回顾一下与 Claude Code 交互时的正常流程。当你向 Claude 提问时,你的查询会与 Tool definitions(工具定义)一起发送到 Claude 模型。Claude 可能会通过提供格式化的响应来决定使用 Tool(工具),然后 Claude Code 执行该 Tool(工具)并返回结果。
Hooks(钩子)会插入到这个过程中,允许您在 Tool execution(工具执行)发生之前或之后执行代码。
Hooks(钩子)有两种类型:
- PreToolUse hooks (预工具使用钩子) - 在 Tool(工具)被调用之前运行。
- PostToolUse hooks (后工具使用钩子) - 在 Tool(工具)被调用之后运行。
Hook Configuration (钩子配置)
Hooks(钩子)在 Claude settings 文件中定义。您可以将它们添加到:
- Global (全局) -
~/.claude/settings.json(影响所有项目) - Project (项目) -
.claude/settings.json(与团队共享) - Project (not committed) (项目(未提交)) -
.claude/settings.local.json(个人设置)
您可以在这些文件中手动编写 Hooks(钩子),或者在 Claude Code 内部使用 /hooks 命令。

配置结构包含两个主要部分:

PreToolUse Hooks (预工具使用钩子)
PreToolUse Hooks(钩子)在 Tool(工具)执行之前运行。它们包含一个 matcher(匹配器),指定要定位的 Tool types(工具类型):
"PreToolUse": [
{
"matcher": "Read",
"hooks": [
{
"type": "command",
"command": "node /home/hooks/read_hook.ts"
}
]
}
]
在执行“Read”工具之前,此配置会运行指定的命令。您的命令会收到 Claude 想要进行的 Tool Call(工具调用)的详细信息,您可以:
- 允许操作正常进行
- 阻止 Tool Call(工具调用)并向 Claude 发送错误消息
PostToolUse Hooks (后工具使用钩子)
PostToolUse Hooks(钩子)在 Tool(工具)执行后运行。这是一个在写入、编辑或多重编辑操作后触发的示例:
"PostToolUse": [
{
"matcher": "Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": "node /home/hooks/edit_hook.ts"
}
]
}
]
由于 Tool Call(工具调用)已经发生,PostToolUse Hooks(钩子)无法阻止操作。但是,它们可以:
- 运行后续操作(例如,格式化刚刚编辑的文件)
- 向 Claude 提供关于 Tool Use(工具使用)的额外反馈
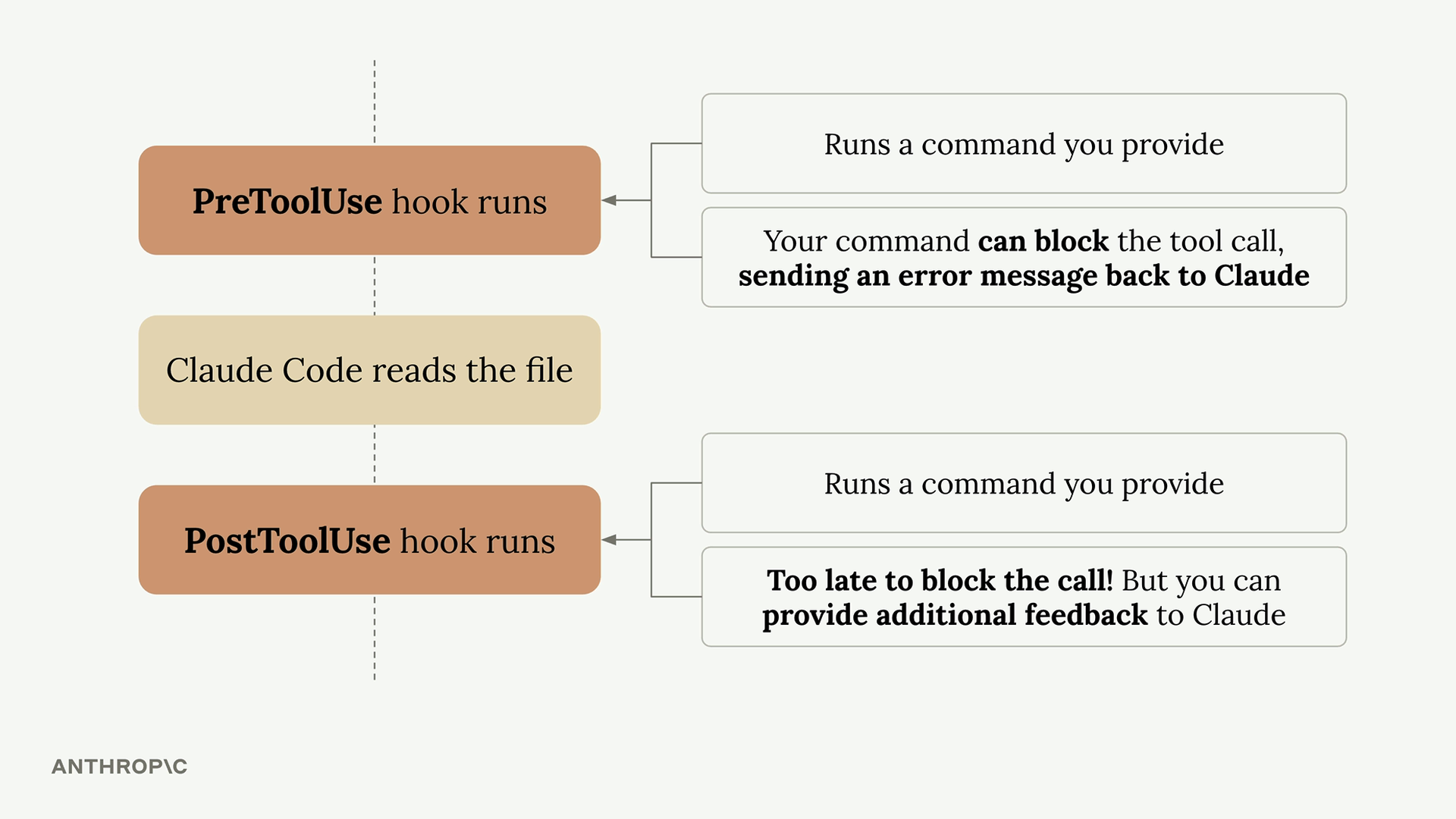
Practical Applications (实际应用)
以下是一些使用 Hooks(钩子)的常见方式:
- Code formatting (代码格式化) - Claude 编辑文件后自动格式化文件
- Testing (测试) - 文件更改时自动运行测试
- Access control (访问控制) - 阻止 Claude 读取或编辑特定文件
- Code quality (代码质量) - 运行 linter 或 type checker 并向 Claude 提供反馈
- Logging (日志记录) - 跟踪 Claude 访问或修改了哪些文件
- Validation (验证) - 检查命名约定或编码标准
关键的见解是,Hooks(钩子)允许您通过将自己的 Tool(工具)和流程集成到工作流程中来扩展 Claude Code 的功能。PreToolUse Hooks(钩子)让您控制 Claude 可以做什么,而 PostToolUse Hooks(钩子)让您增强 Claude 已做的事情。
视频文字稿
在本视频中,我们将了解 Hooks(钩子)。它们允许您在 Claude 尝试运行 Tool(工具)之前或之后运行命令。Hooks(钩子)可以用于实现非常有趣和非常有用的功能。例如,在 Claude 决定编写文件后,您可以自动对创建的文件运行代码格式化程序,或者在文件编辑后运行测试,或者阻止 Claude 读取特定文件。
可能性无穷无尽,我准备了几个很好的例子来向您展示如何在您的特定项目中使用 Hooks(钩子)。然而,首先,让我帮助您确切地理解 Hooks(钩子)是如何工作的。提醒一下,当您向 Claude Code 询问某些内容时,您的查询会与一些 Tool definitions(工具定义)一起发送到 Claude 模型。Claude 模型可能会通过提供精心格式化的响应来决定运行一个 Tool(工具)。
此时,Claude Code 负责运行请求的 Tool(工具),也许在这种情况下是读取文件,然后响应该 Tool Call(工具调用)的结果。现在,Hooks(钩子)使我们能够在 Tool execution(工具执行)之前或之后执行代码。在 Tool(工具)之前运行的 Hooks(钩子)被称为 PreToolUse hooks,因为它们在 Tool(工具)之前运行。在 Tool(工具)之后运行的 Hooks(钩子)被称为 PostToolUse hooks,原因相同。
要定义 Hooks(钩子),我们将配置添加到 Claude 设置文件中。请记住,有几个不同的设置文件,一个用于您机器上所有项目的全局使用,一个用于您的特定项目并与其他工程师共享,以及一个仅用于您在特定项目中的文件。您可以手动在这些文件中添加 Hooks(钩子),或者通过在 Claude Code 本身内部使用内置的 /hooks 命令。配置本身看起来就像您在屏幕右侧看到的那样。
让我带您了解这个示例文件,以便您更好地了解正在发生的事情。因此,首先,请注意此文件中包含两个不同的部分。一个部分列出了在 Tool Use(工具使用)之前应执行的所有命令。请记住,这些被称为 PreToolUse hooks。
另一个部分列出了在 Tool Use(工具使用)之后应执行的所有不同命令。同样,这些是 PostToolUse hooks。在每个部分中,我们都提供了一个匹配器(matcher)。这表示我们正在寻找哪种 Tool Use Types(工具使用类型)。
所以在这个例子中,我想找到 read 工具的使用。每当 Claude Code 尝试读取文件时,我希望运行您那里列出的命令。同样,在 PostToolUse 部分中,在使用了 write、edit 或 multi-edit 工具之后,我想运行一个不同的命令。现在,这是重要的部分。
这就是 Hooks(钩子)真正想要做的事情。您看到的那些命令将获得 Claude 想要运行的 Tool Call(工具调用)的详细信息。对于 PreToolUse hook,您可以检查 Claude 想要做什么。如果出于任何原因您不希望允许它,您可以阻止 Tool Use(工具使用)操作并向 Claude 发送错误消息。
在 PostToolUse hook 的情况下,Tool Call(工具调用)已经发生,所以阻止它已经太晚了。但是您可以根据 Tool Call(工具调用)执行一些后续操作,例如格式化刚刚编辑的文件。您还可以向 Claude 提供有关该 Tool Use(工具使用)的一些消息。例如,您可能会决定运行一个单独的程序来检查编辑的代码质量,或者进行类型检查,然后将该反馈提供给 Claude。
Claude 可能会接受该反馈并更新它刚刚写入的文件。如果您仍然对 Hooks(钩子)或它们的用途感到困惑,那完全没问题。理解 Hooks(钩子)可能真的很有挑战性。所以让我们稍后回来,在一个示例项目上使用 Hooks(钩子)来了解所有这些步骤是如何协同工作的。
14. Defining hooks (定义钩子)
类型:视频 | 时长:3:44 | 视频:011 - Defining Hooks.mp4
Claude Code 中的 Hooks(钩子)允许您在 Tool Call(工具调用)执行之前或之后进行拦截和控制。这使您可以对 Claude 在您的开发环境中可以做什么和不能做什么进行细粒度控制。
Building a Hook (构建一个钩子)
创建 Hook(钩子)涉及四个主要步骤:
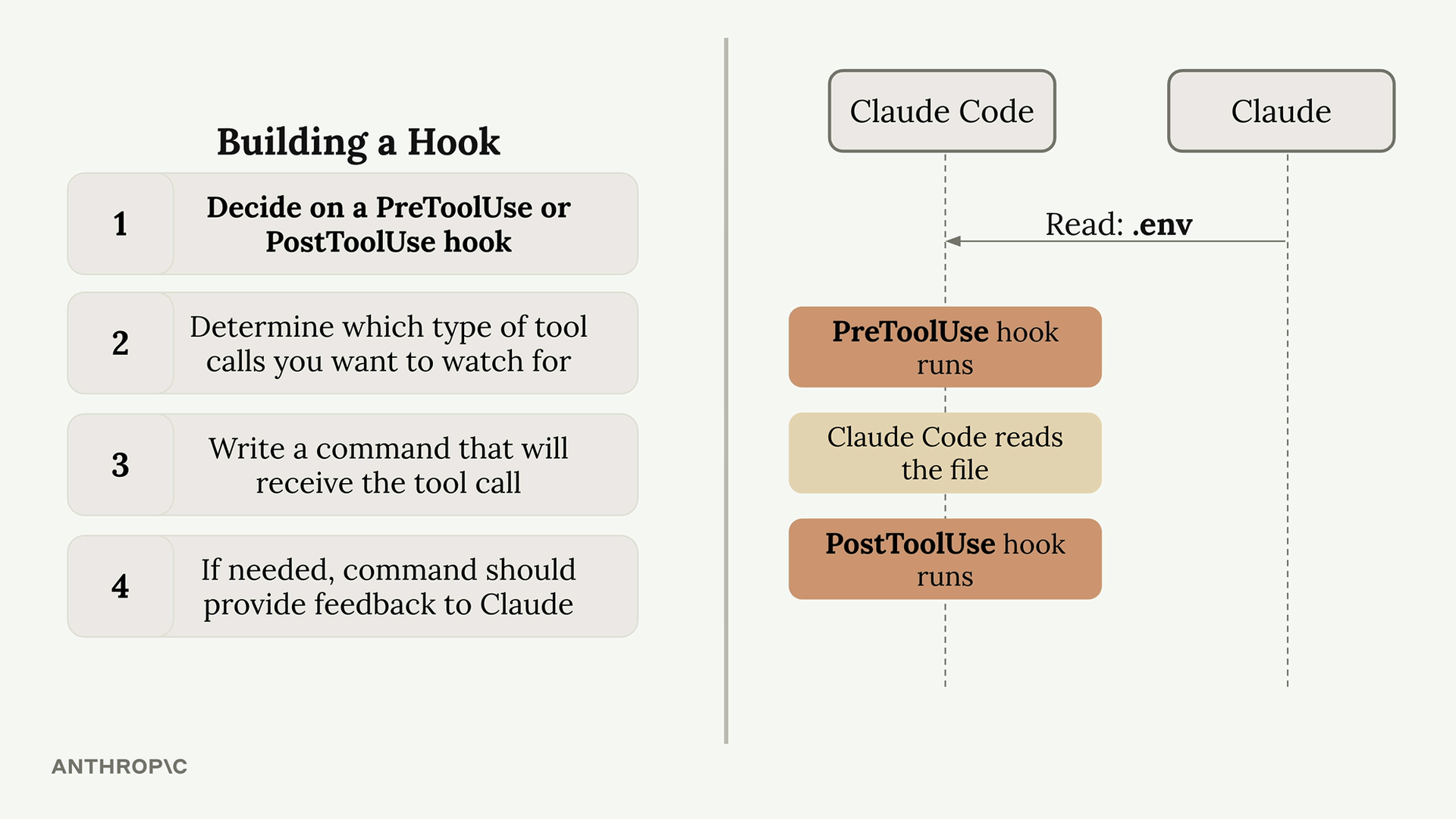
- Decide on a PreToolUse or PostToolUse hook (决定是 PreToolUse 还是 PostToolUse 钩子) -
PreToolUse钩子可以阻止 Tool Call(工具调用)的执行,而PostToolUse钩子在 Tool(工具)已使用后运行。 - Determine which type of tool calls you want to watch for (确定您要监视哪种类型的工具调用) - 您需要准确指定哪些工具应该触发您的 Hook(钩子)。
- Write a command that will receive the tool call (编写一个将接收工具调用的命令) - 此命令通过标准输入(standard input)以 JSON 格式接收有关拟议 Tool Call(工具调用)的数据。
- If needed, command should provide feedback to Claude (如果需要,命令应向 Claude 提供反馈) - 您的命令的 exit code(退出代码)会告诉 Claude 是否允许或阻止该操作。
Available Tools (可用工具)
Claude Code 提供了几个内置 Tool(工具),您可以使用 Hooks(钩子)进行监控:

要确切了解您当前设置中可用的 Tool(工具),您可以直接向 Claude 询问列表。这尤其有用,因为当您添加 Custom MCP servers(自定义 MCP 服务器)时,可用工具可能会发生变化。
Tool Call Data Structure (工具调用数据结构)
当您的 Hook command(钩子命令)执行时,Claude 会通过标准输入(standard input)发送 JSON 数据,其中包含有关拟议 Tool Call(工具调用)的详细信息:
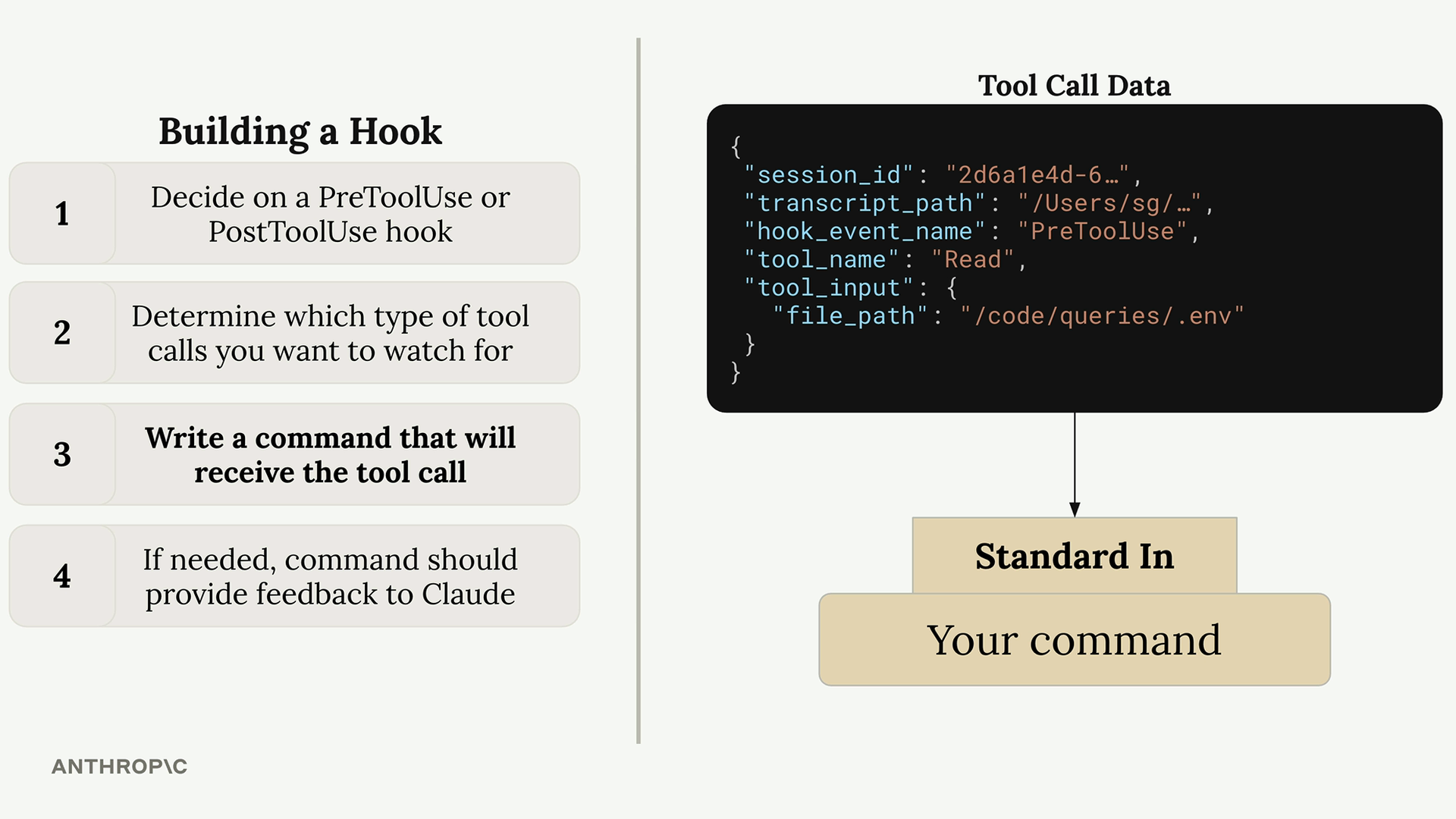
{
"session_id": "2d6a1e4d-6...",
"transcript_path": "/Users/sg/...",
"hook_event_name": "PreToolUse",
"tool_name": "Read",
"tool_input": {
"file_path": "/code/queries/.env"
}
}
您的命令会从标准输入读取此 JSON,解析它,然后根据 Tool Name(工具名称)和 Input Parameters(输入参数)决定是允许还是阻止该操作。
Exit Codes and Control Flow (退出代码和控制流)
您的 Hook command(钩子命令)通过 Exit Codes(退出代码)与 Claude 进行通信:
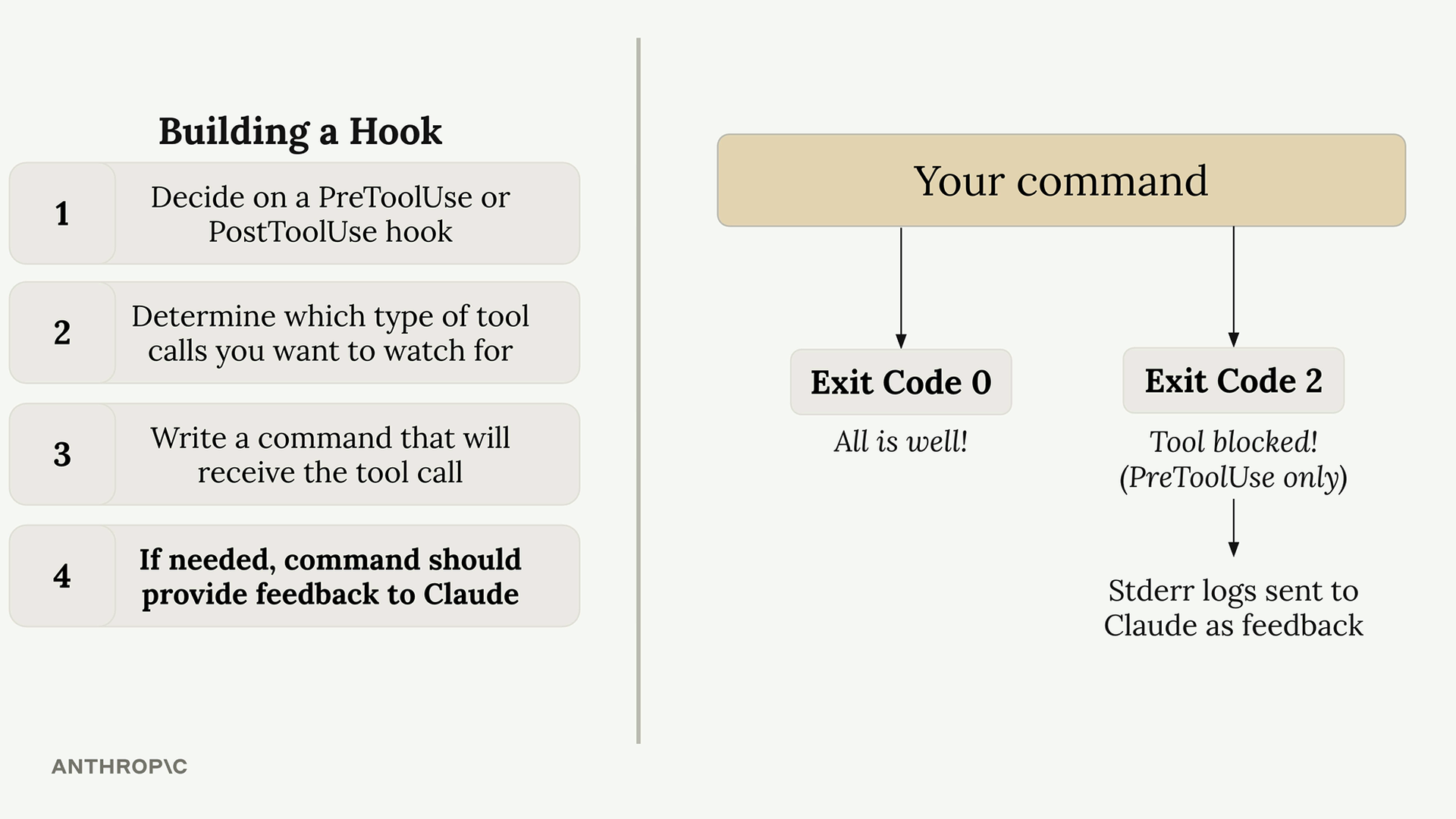
- Exit Code 0 - 一切正常,允许 Tool Call(工具调用)继续。
- Exit Code 2 - 阻止 Tool Call(工具调用)(仅限
PreToolUse钩子)。
当您在 PreToolUse 钩子中以代码 2 退出时,您写入标准错误(standard error)的任何错误消息都将作为反馈发送给 Claude,解释操作被阻止的原因。
Example Use Case (示例用例)
一个常见的用例是阻止 Claude 读取敏感文件,例如 .env 文件。由于 Read 和 Grep 这两个 Tool(工具)都可以访问文件内容,因此您需要监视这两种工具类型,并检查它们是否正在尝试访问受限文件路径。
这种方法使您可以完全控制 Claude 的文件系统访问,同时提供关于为什么某些操作受到限制的清晰反馈。
视频文字稿
为了更好地理解 Hooks(钩子)的工作原理,我们将研究一个新的示例项目。随本讲座附带的文件名为 Query.zip。我鼓励您下载此项目并在其中打开您的代码编辑器。打开编辑器后,在终端中运行 NPM Run Setup。
这将安装一些依赖项并准备好一些 Hooks(钩子)以供使用。为了更好地理解 Hooks(钩子),我们将在本项目中创建我们自己的 Hook(钩子)。所以这是我希望我们的 Hook(钩子)做的事情。在项目根目录中有一个名为 .env 的文件。
此文件包含一些敏感信息。出于谨慎考虑,我希望完全阻止 Claude 直接读取此文件。让我向您展示几张图表,以帮助您理解我们将如何构建此 Hook(钩子)。第一步是决定我们是否需要 PreToolUse 或 PostToolUse 钩子。
在这种情况下,我们希望阻止 Claude 读取特定文件。如果我们创建一个 PostToolUse 块,那么我们将在 Claude 已经读取文件之后执行我们的 Hook(钩子)或运行我们的命令。因此,在这种情况下,我们肯定需要一个 PreToolUse hook 来确保我们可以阻止读取操作的发生。我们需要做的下一件事是准确决定我们要监视哪种类型的 Tool Call(工具调用)。
我在此图表的右侧列出了所有当前不同的 Tool Name(工具名称)。现在,记住 Claude Code 中包含的所有不同 Tool Name(工具名称)可能非常具有挑战性,特别是当您可以通过使用 MCP 服务器添加自己的 Custom Tool(自定义工具)时。所以让我向您展示一个您可以在这里使用的小技巧。如果我回到并打开 Claude Code,我可以直接向 Claude 询问它目前有权访问的所有不同 Tool Name(工具名称)的列表。
在所有这些不同的 Tool(工具)中,有两种可以非常轻松地读取文件内容。首先是 read 工具,然后很容易被忽略,但这个也可以读取文件内容,即 grep 工具。grep 可以搜索文件内容。所以我们确实需要监视 read 工具和 grep 工具的 Tool Call(工具调用)。
接下来,我们需要编写一个命令,它将接收有关 Claude 想要进行的 Tool Call(工具调用)的一些信息。这就是那部分的工作原理。我们将编写一个命令,Claude 将自动执行它。然后,在那个进程的标准输入(standard in)上,Claude 将以 JSON 格式提供一些 Tool Call Data(工具调用数据)。
我在右上角有一个 Tool Call Data(工具调用数据)的示例。所以它将是一个大的 JSON 对象,其中包含一些关于 Tool Name(工具名称)和该工具的输入的信息。在这种情况下,Tool Name(工具名称)是 read,所以 Claude 正在尝试调用 read 工具,它可能正在尝试专门读取指向那个 .env 文件的文件路径。再次强调,这就是我们希望阻止读取操作的文件。
因此,在我们的程序或命令中,我们需要通过标准输入(standard in)接收此信息,解析该 JSON,然后读取 Tool Name(工具名称)、Tool Input Arguments(工具输入参数)等,并决定我们希望如何处理此 Tool Call(工具调用)。然后进行第四步。在第四步中,在我们的命令收到拟议的 Tool Call Data(工具调用数据)后,我们将退出。我们的 Exit Code(退出代码)将向 Claude Code 提供信号。
Exit Code 0 意味着一切正常,我们希望允许此 Tool Call(工具调用)发生。然而,Exit Code 2 是向 Claude Code 发出的信号,表示我们希望阻止此 Tool Call(工具调用)。这专门适用于 PreToolUse hooks。因为请记住,只有在 PreToolUse hook 中,我们才能实际阻止 Tool Call(工具调用)。
如果我们以代码 2 退出,那么我们在该时间段内在命令中生成的任何标准错误(standard air logs)也将作为反馈发送给 Claude。因此,我们既可以拒绝 Tool Call(工具调用),又可以同时向 Claude 给出理由。所以这就是整个过程。我再次知道这里发生了很多事情。
因此,让我们完成将此 Hook(钩子)所需的一切连接起来的整个过程,以了解所有这些步骤如何协同工作。
15. Implementing a hook (实现钩子)
类型:视频 | 时长:4:14 | 视频:012 - Implementing a Hook.mp4
让我们构建一个 Custom hook(自定义钩子),以防止 Claude 读取敏感文件(如 .env)。这是一个实际示例,展示了 Hooks(钩子)如何在开发会话期间保护您的环境变量和其他机密数据。
Setting Up the Hook Configuration (设置钩子配置)
首先,我们需要在设置文件中配置我们的 Hook(钩子)。打开您的 .claude/settings.local.json 文件并找到 hooks 部分。我们将创建一个 PreToolUse 钩子,因为我们希望在 Tool Call(工具调用)执行之前拦截它们。
配置需要两个关键部分:
- Matcher (匹配器) - 指定要监视哪些工具
- Command (命令) - 当这些工具被调用时运行的脚本
对于匹配器,我们希望捕获可能访问 .env 文件的 read 和 grep 操作:
"matcher": "Read|Grep"
管道符号(|)充当 OR 运算符,因此这将在任一工具上触发。对于命令,我们将指向一个 Node.js 脚本:
"command": "node ./hooks/read_hook.js"
Understanding Tool Call Data (理解工具调用数据)
当 Claude 尝试使用 Tool(工具)时,您的 Hook(钩子)会通过标准输入(standard input)以 JSON 格式接收有关该调用的详细信息。此数据包括:
- Session ID(会话 ID)和 Transcript path(脚本路径)
- Hook event name(钩子事件名称)(在我们的例子中是
PreToolUse) - Tool name(工具名称)(Read、Grep 等)
- Tool input parameters(工具输入参数),包括文件路径
您的 Hook Script(钩子脚本)会处理此数据,然后可以通过退出特定代码来允许操作继续或阻止它。
Implementing the Hook Script (实现钩子脚本)
Hook Script(钩子脚本)需要从标准输入(standard input)读取 Tool Call Data(工具调用数据),并检查 Claude 是否正在尝试访问 .env 文件。核心逻辑如下:
async function main() {
const chunks = [];
for await (const chunk of process.stdin) {
chunks.push(chunk);
}
const toolArgs = JSON.parse(Buffer.concat(chunks).toString());
// Extract the file path Claude is trying to read
const readPath =
toolArgs.tool_input?.file_path || toolArgs.tool_input?.path || "";
// Check if Claude is trying to read the .env file
if (readPath.includes('.env')) {
console.error("You cannot read the .env file");
process.exit(2);
}
}
脚本检查文件路径中是否包含 .env,如果找到则阻止操作。当您以代码 2 退出时,Claude 会收到错误消息并理解操作被 Hook(钩子)阻止。
Testing Your Hook (测试您的钩子)
保存配置和 Hook Script(钩子脚本)后,重新启动 Claude Code 以使更改生效。然后通过要求 Claude 读取您的 .env 文件来测试它。
当 Claude 尝试读取操作时,您的 Hook(钩子)将拦截它并返回错误消息。Claude 将识别出操作被阻止,并向您解释原因,通常会提及读取 Hook(钩子)阻止了对文件的访问。
相同的保护也适用于 grep 操作——如果 Claude 尝试在 .env 文件中搜索,Hook(钩子)也会阻止该操作。
Key Benefits (主要好处)
这种方法提供了几个优点:
- Proactive protection (主动保护) - 在读取敏感数据之前阻止访问
- Transparent operation (透明操作) - Claude 理解操作失败的原因
- Flexible matching (灵活匹配) - 适用于多种工具(read、grep 等)
- Clear feedback (清晰反馈) - 提供有意义的错误消息
虽然此特定示例侧重于 .env 文件,但相同的模式可以保护您项目中的任何敏感文件或目录。您可以扩展逻辑以检查多个文件模式,或根据您的安全要求实施更复杂的访问控制。
视频文字稿
让我们一起完成自定义 Hook(钩子)。请记住,这里的整个目标是阻止 Claude 读取 .env 文件的内容。在上一视频中,我们讨论了我们需要设置的许多不同配置选项,因此在此视频中,我们将主要关注实现。首先,在 .Claude 目录中,我将打开 settings.local.json 文件。
请记住,在这里面,我们有一个 PreToolUse hooks 和 PostToolUse hooks 列表。正如我们刚才讨论的,我们希望创建一个 PreToolUse hook,以便我们可以阻止 Claude 读取该特定文件的内容。我已经为我们添加了一个小配置部分,只是为了节省一些打字时间。我们只需要填写匹配器(matcher)和命令(command)。
首先是匹配器。匹配器将是我们想要监视的工具。正如我们讨论的,我们想要监视对 read 和 grep 工具的调用。我将用管道符号分隔这两个工具名称。
所以它不是字母 L 或大写字母 I。它是键盘上返回键上方的一个符号。然后,接下来,我们需要提供一个命令,用于在 Claude 尝试调用这两个工具时运行。我们可以在这里放入任何您想要的命令,所以它可以是一个 CLI,也可以是对 shell 脚本的调用,绝对任何东西。为了遵循我在此文件其余部分中已建立的模式,我将调用一个 Node.js 脚本,我已提前将其放置在本项目的 hooks 目录中。
所以,在 hooks 目录中,我为我们准备了一个 read_hook.js 文件。这就是我希望在 Claude 尝试调用这两个工具之一时运行的文件。所以要调用它,我将把这里的 true(这只是一个占位符)替换为 node ./hooks/read_hook.js。我将保存此文件,这就是我们在此文件中需要做的所有事情。接下来,我们需要实际实现该命令,该命令将在 Claude 尝试调用 read 或 grep 工具时运行。
所以这将是 read_hook.js 文件。在这个文件的顶部,我有一些代码将从标准输入(standard in)读取数据并将其解析为 JSON。所以这里的 toolArgs 对象,将是我在这张图表中向您展示的那个大的 JSON 对象。所以它将具有 session ID、tool name、tool input 等属性。所以我们真正需要做的就是查看该文件路径,并决定它是否正在尝试读取 .env 文件。
如果是,那么我们希望确保我们退出我们的程序或这里的命令,退出代码为 2。并且希望还能向 Claude 记录一些信息,说抱歉,但您无法读取该文件。所以您会注意到,在这里,我有一些代码将读取该文件路径。您还会注意到,这里有一个查看 toolInput.path 的回退。
我稍后会告诉您为什么会添加它。所以现在让我们实现待办事项语句。我们将说如果 readPath 包含 .env,那意味着 Claude 肯定正在尝试读取 .env 文件。如果是这种情况,那么我希望确保我们阻止该操作并向 Claude 提供一些日志反馈。
所以我首先会添加一个 console.error,特别是一个 console.error,因为我们希望记录到标准错误(standard error)。请记住,这就是我们向 Claude 提供一些反馈的方式。我会说一些类似“您无法读取 .env 文件”的话。然后我会执行 process.exit(2)。所以现在为了测试这一点,我将保存文件。
我将打开 Claude Code。如果您已经打开了它,请确保重新启动 Claude Code。您必须重新启动它才能使您的 hooks 的任何更改生效。我将要求 Claude 读取 .env 文件。
它可能会尝试读取它,但当它尝试读取时,我们会返回一个错误,说“你无法读取 .env 文件”。Claude 希望能够识别出,抱歉,你实际上无法读取这个文件。事实上,它甚至能够识别出它被一个读取钩子阻止了。现在,我们的钩子也应该适用于 grep 操作。所以如果我要求 Claude 尝试 grep 工具,这应该也希望能被禁止。
所以让我们看看它表现如何。是的,同样,它现在被禁止了。所以这就是我们已经完成的一个有效 Hook(钩子)。现在,这个 Hook(钩子)并不是特别有用,我稍后将向您展示一个更有用的 Hook(钩子)。
16. Gotchas around hooks (钩子陷阱)
此课时内容请访问在线课程平台查看完整内容。
17. Useful hooks! (有用的钩子!)
类型:视频 | 时长:11:33 | 视频:013 - Useful Hooks!.mp4
Claude Code Hooks(钩子)可以帮助解决 AI 辅助开发中常见的弱点,尤其是在大型项目上。这些 Hooks(钩子)在 Claude 对您的代码进行更改时自动运行,提供即时反馈并防止常见问题。
TypeScript Type Checking Hook (TypeScript 类型检查钩子)
最有用的 Hooks(钩子)之一解决了一个根本性问题:当 Claude 修改函数签名(function signature)时,它通常不会更新整个项目中调用该函数的所有位置。
例如,如果您要求 Claude 在 schema.ts 中的函数中添加一个 verbose 参数,它将成功更新函数定义,但会错过 main.ts 中的调用点(call site)。这会产生 Claude 无法立即捕获的类型错误。
解决方案是一个 post-tool-use hook,它在每次文件编辑后运行 TypeScript 编译器:
- 运行
tsc --noEmit检查类型错误 - 捕获发现的任何错误
- 立即将错误反馈给 Claude
- 提示 Claude 修复其他文件中的问题
此 Hook(钩子)适用于任何可以通过运行 Type Checker(类型检查器)进行类型检查的语言。对于 untyped languages(无类型语言),您可以使用自动化测试而不是 Type Checker(类型检查器)来实现类似的功能。
Query Duplication Prevention Hook (查询重复预防钩子)
在大型项目中,由于有许多数据库查询,Claude 有时会创建重复的功能,而不是重用现有代码。当您给 Claude 复杂的、多步骤的任务(其中数据库操作只是一个组成部分)时,这尤其成问题。
考虑一个项目结构,其中包含多个查询文件,每个文件都包含许多 SQL 函数。当您要求 Claude“创建一个 Slack 集成,用于警报超过 3 天未处理的订单”时,它可能会编写一个新查询,而不是使用现有的 getPendingOrders() 函数。

Query Duplication Hook(查询重复钩子)通过实施审查流程来解决此问题:

它的工作原理如下:
- 当 Claude 修改
./queries目录中的文件时触发 - 以编程方式启动另一个 Claude Code 实例
- 要求第二个实例审查更改并检查是否存在类似的现有查询
- 如果发现重复项,则向原始 Claude 实例提供反馈
- 提示 Claude 删除重复项并使用现有功能
Implementation Considerations (实现注意事项)
这两个 Hooks(钩子)都使用 pre-tool-use 或 post-tool-use hook 系统。TypeScript 钩子相对轻量且运行迅速。查询重复钩子需要更多资源,因为它为每次审查启动一个单独的 Claude 实例。
对于查询 Hook(钩子),请考虑以下权衡:
- Benefits (好处):代码库更清晰,重复更少
- Costs (成本):每次查询目录编辑都会增加时间和 API 使用量
- Recommendation (建议):仅监视关键目录以最大程度地减少开销
这些 Hooks(钩子)使用 Claude 的 TypeScript SDK 以编程方式与 AI 交互。这允许您创建复杂的 workflow(工作流),其中一个 Claude 实例可以审查并提供对另一个实例工作的反馈。
Extending These Concepts (扩展这些概念)
这些 Hooks(钩子)演示了您可以应用于自己项目的更广泛原则:
- 使用编译器/linter 输出提供即时反馈
- 使用独立的 AI 实例实现代码审查流程
- 专注于对一致性最重要的有价值目录的监控
- 平衡自动化收益与性能成本
关键在于识别开发工作流程中的具体痛点,并创建有针对性的 Hooks(钩子)来自动解决这些问题。
视频文字稿
在本视频中,我想向您展示一些您可能希望在自己的项目中使用非常有用的 Hooks(钩子)。这些 Hooks(钩子)旨在解决 Claude Code 中一些常见的弱点。为了帮助您理解第一个 Hook(钩子)的工作原理,让我快速向您演示 Claude Code 有时会遇到的一个问题,尤其是在大型项目上。所以在 SRC 目录中,我将找到 schema.ts。
在里面,只有一个名为 create schema 的函数。这个函数是从 main.ts 文件中调用的,具体在这里。现在,我将回到 schema.ts 文件中,并更新函数定义。我将声明,如果您想调用此函数,则还必须传入一个 verbose 参数,其类型必须为 Boolean。
现在,一旦我添加此更改,如果我返回到 main.ts 文件,我将收到一个类型错误,因为我刚刚更新了此函数的定义,但我实际上并未为 verbose 添加值。因此,这里的错误明确指出,没有为 verbose 提供参数。现在,我将非常快速地撤消该更改。我将关闭 main.ts 文件。
然后我将打开 Claude Code,并要求它进行完全相同的更改。现在,如果我运行它,Claude Code 绝对不会有任何问题进行此编辑。但它会更新此文件,然后不幸的是,在进行该更改后,新 verbose 就在那里。不幸的是,Claude 不会遍历项目并尝试查找该函数实际被调用的位置,并尝试更新任何不同的调用站点。
因此,如果我现在打开 main.ts,我们会看到,事实上,我们这里确实有一个错误。不幸的是,Claude 并没有真正捕获到这一点。所以我想向您展示的第一个 Hook(钩子)将非常轻松地解决这个问题。如果您不熟悉 TypeScript,而且如果您不熟悉,那也没关系。
如果我关闭 Claude Code 并运行命令 TSC-dash-noemit,它将对我的整个项目进行类型检查。在这个类型检查中,我们可以看到错误在这里非常明显。所以它抱怨我们从 main.ts 文件中调用 create schema。所以我的 Hook(钩子)的想法非常简单。
我认为,任何时候我们编辑 TypeScript 文件时,我们都应该运行 TypeScript 类型检查器,看看是否有任何明显的错误。如果有,我们应该尝试通过 post-tool-use hook 立即将这些错误反馈给 Claude。希望这会给 Claude 一个信号,告诉它它刚刚引入了一个类型错误,它可能需要在我们项目中的其他地方修复它。现在,我已经为我们准备好了这个 Hook(钩子),幸运的是,只是为了节省一些时间,在 hooks、TSC.js 文件中。
所以在这个文件中,我有一堆逻辑,用于运行 TypeScript 类型检查器,捕获发现的任何错误,并将它们反馈给 Claude。目前,我禁用了这个 Hook(钩子),只是为了向您演示您刚才看到的内容。因此,我通过在那里添加 process exit 0 来禁用它。我将删除它。
现在这个 Hook(钩子)应该工作正常了。所以如果我现在回到 schema.ts 文件,删除那个冗余的 flag,重新启动 Claude Code,然后再次要求它进行相同的更改。它会进行更改。然后希望这次,它会立即从 TypeScript 类型检查器那里得到反馈,说,嘿,你刚刚在项目的其他地方引入了一个错误。
希望 Claude 会去修复它。所以我们可以在这里看到,这就是所做的编辑。我们从我们一起编写的 Hook(钩子)中得到了一些编辑操作反馈。所以它在我们的一个不同文件中发现了一个问题。
Claude 现在说,好的,我明白了。我引入了一个错误。我需要修复 main.ts 中 create schema 的调用。然后它进行的下一次更新将尝试进入该文件并更新该函数调用以添加缺少的那一个参数。
所以这是一个你可能想要在自己的个人项目上尝试实现的 Hook(钩子)。现在,即使这个 Hook(钩子)是专门为 TypeScript 实现的,它仍然适用于任何其他类型的语言,只要你可以非常容易地运行类型检查器。即使你使用的是无类型语言(untyped language),你甚至可以使用测试而不是运行类型检查器来实现相同的功能。所以每次进行编辑时,你都可以运行测试以确保编辑是正确的。
现在,我想向您展示的下一个 Hook(钩子)解释起来有点挑战性,但一旦您理解了其背后的想法,我认为您肯定会发现下一个 Hook(钩子)真的很有帮助,尤其是在大型项目中。为了帮助您理解这个 Hook(钩子),我想向您介绍一下这个项目的背景。在 SRC 查询目录中,有许多不同的文件。每个不同的文件都包含许多用不同函数编写的 SQL 查询。
特别是在 orderqueries.ts 文件中,我想指出其中有一个名为 git pending orders 的函数。此查询遍历一个包含一些电子商务相关数据的数据库。理论上,它将找到所有已创建且处于待处理状态的不同订单。所以请记住这个函数一会。
好的,所以我会快速向您展示几张图表,以帮助您理解大型项目中开始出现的一个常见问题。所以在这张图中,我的左侧列出了不同的查询文件,正如我们所看到的,每个不同的查询文件都包含许多不同的查询。特别是 order queries 文件中有一个 git pending orders 函数。所以我们已经准备好了一个查询,它将尝试查找一些不同的待处理订单。
现在,如果我向 Claude 提问并要求它更新 main.ts 文件以打印出所有已待处理超过三天的订单,在一个完美的世界中,Claude 会找到 order queries.ts 文件。它会找到那个现有查询,并会使用它而不是编写一个新的查询。这就是我们想要的。我们将看到,如果我们现在使用 Claude 并要求它完全做到这一点,我们将得到我们想要的结果。
所以我要在 main.ts 文件中要求 Claude 打印出已待处理的订单。为了肯定 Claude 的功劳,它将查看存在的不同查询文件。它将找到 order queries 文件。然后,在其中,它将识别出已经有一个名为 get pending orders 的查询。
它将尝试使用该函数,而不是创建新的查询。我们不想要新的查询。我们希望 Claude 使用现有函数。因此,当我们给 Claude 一个非常集中和直接的任务时,它能够理解,是的,我可能不应该编写新的查询。它至少应该查看一些已经存在的查询。这当然是好的。现在我要给 Claude 一个小小的难题。
我故意让这个任务变得更难一些。首先,我将运行斜杠清除(slash clear)以清除我们获得的所有上下文。然后,我希望您查看 task.md 文件。在这个文件中,我编写了一个提示,仍然要求 Claude 查找已待处理一段时间的订单,但我也将其包装在某个更大的项目中。我要求 Claude 编写一个 Slack 集成,每天向特定频道发送消息,其中包含所有已待处理太久的订单。
所以在这个场景中,我们仍然想找到待处理太久的订单,但现在我把它包装在这个更大的任务中。如果我接受这个任务,然后将其输入到 Claude 中,再次,在执行了那个斜杠清除操作之后,我们会发现这次不幸的是,它不会保持那么专注,最终它会尝试编写一个全新的 Git pending orders 查询,这再次不是我们想要的,因为这会导致我们的项目中出现重复代码。如果我让它运行一段时间,我最终会看到,是的,它确实创建了一个全新的查询,名为 Git orders pending too long。所以这是一个例子,说明 Claude 有点失焦,决定编写一个全新的查询,而不是重用现有查询。
再次,我们这里有一些重复的代码,这可能不是我们想要的。此外,它不仅创建了新的查询,还创建了一个全新的文件,这可能也不是我们想要的。我们可能希望将这个与订单相关的查询添加到 order queries 文件中。既然我们理解了这里的问题,让我向您展示我们如何通过使用 Hook(钩子)来潜在地修复它。
好的,所以每当 Claude 尝试写入、编辑或使用 multi-edit 工具修改 queries 目录中的某些内容时,我将运行以下 Hook(钩子)。首先,在这个 Hook(钩子)中,我将以编程方式启动一个新的独立的 Claude Code 副本。我将要求这个新副本查看刚刚进行的更改,并查看 queries 目录中一些现有代码,看看是否已经存在类似的查询。然后,如果存在现有查询,我将获取该反馈并将其发送回原始的 Claude 副本,我将要求 Claude 也许决定修复这种情况。
所以删除添加的查询并使用已经存在的查询。所以这将使我们能够确保 queries 文件夹通常保持干净,并且其中没有一堆重复的代码。所以让我向您展示这将如何实际工作。首先,我将翻回这里。
我将删除刚刚创建的全新 order alerts.queries.ts 文件和 slack.ts 文件。然后我将在 hooks 目录中找到 query hook 文件。所以我已经为我们准备好了这个 Hook(钩子)。现在它目前被禁用,因为我在顶部有一个 process.exit。
所以让我们快速浏览一下这个 Hook(钩子)。首先,我将告诉它它只审查对 SRC queries 目录的更改。然后,稍低一点,我将检查并查看刚刚进行的更改是否是在 queries 目录中进行的。之后,我有一个很长的提示,要求 Claude 对刚刚进行的更改进行审查。然后之后就是我以编程方式启动 Claude Code 的地方。
具体来说,就是这里的这些行。这正在使用 Claude Code TypeScript SDK。我稍后可以给你更多信息。目前,只需了解这里本质上与我们在终端使用 Claude Code 相同。一旦 Claude Code 运行,我从中得到响应,我检查并查看 Claude 是否决定,是的,更改看起来没问题,或者我们可能有一个重复的查询。如果确实有,那么我们将以退出代码 2 提前退出,这将把这个反馈传回给 Claude,并希望告诉它它需要进行更改。
所以现在我有了这个额外的 Hook(钩子),并通过删除顶部的 process exit zero 来启用它,我将再次重新启动 Claude Code,然后再次运行相同的查询。希望这次它最初可能会放入那个重复的查询,但然后我们的 Hook(钩子)将运行,并希望告诉它,嘿,我们不想要那个重复的代码。您应该使用一些已经存在的查询来实现此功能。现在,Claude Code 将再次尝试创建一个全新的、完全独立的查询文件,而不是使用旧的、已经存在的查询。
然而,当它试图创建该文件时,我们的 Hook(钩子)将运行。它将启动 Claude Code 的那个单独的副本,该副本将进行一些研究,并发现确实存在一个可以重用的现有查询。它将提供一些建议,并说,嘿,您可能可以更新这个现有的查询,以完全满足您的目的。我们将看到 Claude(我们正在与之交互的主要实例)的一些反馈,说,啊,是的,存在这个现有查询。
让我们修改那个现有查询,而不是尝试编写一个新的查询。现在这个 Hook(钩子)的缺点是,每次我想编辑 queries 目录中的内容时,它都会花费额外的时间和费用来运行。但优点是,我的 queries 目录中重复的代码会少得多。所以这实际上取决于您的一系列权衡,您是否希望在自己的项目中实现类似这样的功能。
如果您这样做,我至少建议您做我在 query hook 中向您展示的内容。所以就是这个,并且只监视您项目中少数几个非常重要的文件夹,以尽量减少所做的额外工作量。
18. Another useful hook (另一个有用的钩子)
此课时内容请访问在线课程平台查看完整内容。
19. The Claude Code SDK (Claude Code SDK)
类型:视频 | 时长:2:46 | 视频:014 - The Claude Code SDK.mp4
Claude Code SDK 允许您在自己的应用程序和脚本中以编程方式运行 Claude Code。它适用于 TypeScript、Python 和 CLI,为您提供与在终端使用的 Claude Code 相同的功能,但已集成到更大的工作流程中。

SDK 运行与您已经熟悉的 Claude Code 完全相同的代码。它有权访问所有相同的 Tool(工具),并将使用它们来完成您交给它的任何任务。这使其在自动化和集成场景中特别强大。
Key Features (主要特点)
- 以编程方式运行 Claude Code
- 与终端版本相同的 Claude Code 功能
- 继承同一目录中 Claude Code 实例的所有设置
- 默认只读权限
- 作为更大管道或工具的一部分最有用
Basic Usage (基本用法)
这是一个简单的 TypeScript 示例,要求 Claude 分析代码以查找重复查询:
import { query } from "@anthropic-ai/claude-code";
const prompt = "Look for duplicate queries in the ./src/queries dir";
for await (const message of query({
prompt,
})) {
console.log(JSON.stringify(message, null, 2));
}
当您运行此代码时,您将看到本地 Claude Code 与 Claude 语言模型之间的原始对话,消息逐条显示。最后一条消息包含 Claude 的完整响应。
Permissions and Tools (权限和工具)
默认情况下,SDK 只有只读权限。它可以读取文件、搜索目录和执行 grep 操作,但不能写入、编辑或创建文件。
要启用写入权限,您可以将 allowedTools 选项添加到查询中:
for await (const message of query({
prompt,
options: {
allowedTools: ["Edit"]
}
})) {
console.log(JSON.stringify(message, null, 2));
}
或者,您可以在 .claude 目录中的设置文件中配置权限,以实现项目范围的访问。
Practical Applications (实际应用)
Claude Code SDK 在集成到更大的开发工作流程中时表现出色。考虑将其用于:
- 自动审查代码更改的 Git hooks(钩子)
- 分析和优化代码的构建脚本
- 代码维护任务的辅助命令
- 自动化文档生成
- CI/CD 管道中的代码质量检查
SDK 本质上允许您将 AI 驱动的智能添加到开发过程中任何有价值的编程访问部分。
视频文字稿
刚才我们查看查询审查钩子时,我们简要了解了 Claude Code SDK。SDK 允许您以编程方式使用 Claude Code。您可以通过 CLI、TypeScript 库或 Python 库使用 SDK。这与您在终端使用的 Claude Code 完全相同。
它拥有所有相同的工具,并将使用它们来完成给定的任务。SDK 作为更大管道或工具的一部分最有用,正如我们刚才在那个钩子中看到的那样。您可以轻松地将 Claude Code 作为更大过程的一部分,为某些给定工作流程添加大量智能。我想通过将其添加到我们现有项目中,向您快速演示一下 TypeScript SDK。
回到我的编辑器中,我将找到根项目目录中的 SDK.ts 文件。在里面,我写了一些代码,以便我们开始使用 SDK。我将更新顶部的提示,并要求 Claude 在 SRC 查询目录中查找重复的查询。然后我将保存此文件,并打开终端执行 NPM Run SDK 来运行它。
现在,这不是一个内置命令,您要知道,但在后台,它只是将此文件作为普通的 TypeScript 文件执行。我只是为我们创建了这个小快捷方式,以便更容易地运行 TypeScript 文件。当我们运行它时,我们会看到本地 Claude Code 和 Claude Language model 之间的原始对话,消息逐条显示。最终,我们会回到命令行。
打印出的最后一条消息将包含 Claude 的最终响应。现在关于 SDK 有一个小小的陷阱。那就是默认情况下,它只有读取能力。换句话说,它只能读取文件、目录、执行 grep 操作等等。
它没有能力写入、编辑或创建文件等。要授予写入权限,您可以手动在此处的查询调用中添加写入权限,或者,您可以将一些权限设置添加到您的 .Claude 目录中的设置文件中。让我向您展示我们如何允许 SDK 在此项目中使用编辑工具。我将找到这里的 prompt 参数。
在它后面,我将添加 options,放入一个对象,allow tools,它将是一个数组,我将放入 edit。我将更新顶部的提示,并要求它向 package.json 文件添加描述。现在我将保存并再次运行 npmrunsdk。然后一旦完成,我可以打开 package.json 文件,我将看到它确实添加了描述。
所以现在它肯定有能力编辑文件。正如我之前提到的,Claude Code SDK 作为其他工具的一部分最有用。所以我鼓励您考虑在您自己的项目中的帮助命令、脚本或最值得注意的是 hooks 中使用它的机会。
第4部分:Wrapping up (总结)
21. Summary and next steps (总结与后续步骤)
类型:视频 | 时长:0:53 | 视频:010 - Wrap Up.mp4
视频文字稿
我希望您喜欢这次 Claude Code 的概述。在我们结束之前,我想给您一些关于下一步该怎么做的建议。首先,请记住 Claude Code 正在不断变化并积极开发中。所以请关注 Claude Code 的主页。
我那里有它的地址。并留意新功能和新技术的出现。其次,我真的建议您进行实验。有许多不同的方法可以定制 Claude Code,并真正使其适应您的特定用例。
尝试编写一些自定义命令,或者在您的 Claude MD 文件中添加额外的指令。此外,还可以尝试一些不同的 MCP 服务器,除了我们在此课程中介绍的那些。最后,自动化。查看 GitHub 集成,并思考一些您经常做的不同常见任务,并思考如何根据 GitHub 存储库中发生的事件,自动将这些任务委托给 Claude。
再次,我希望您喜欢这门课程,并享受使用 Claude Code 的时光。
第 11 课:Claude 与 Amazon Bedrock
在 AWS Bedrock 上使用 Claude 课程链接:Claude 与 Amazon Bedrock | 共 83 节课
第1部分:课程介绍 (Course introduction)
1. 课程介绍 (Introduction to the course)
此课时为课程介绍/总结页面,请访问在线平台查看。
2. Claude 模型概览 (Overview of Claude Models)
类型:视频 | 时长:3:56 | 视频:02 - 001 - Overview of Claude Models.mp4
Claude 提供三个不同的模型家族,每个家族都针对不同的优先级进行了优化。所有三个模型都共享 Claude 的核心能力——它们可以处理文本生成、编码、图像分析和其他任务。关键区别在于它们如何在智能性、速度和成本之间取得平衡。
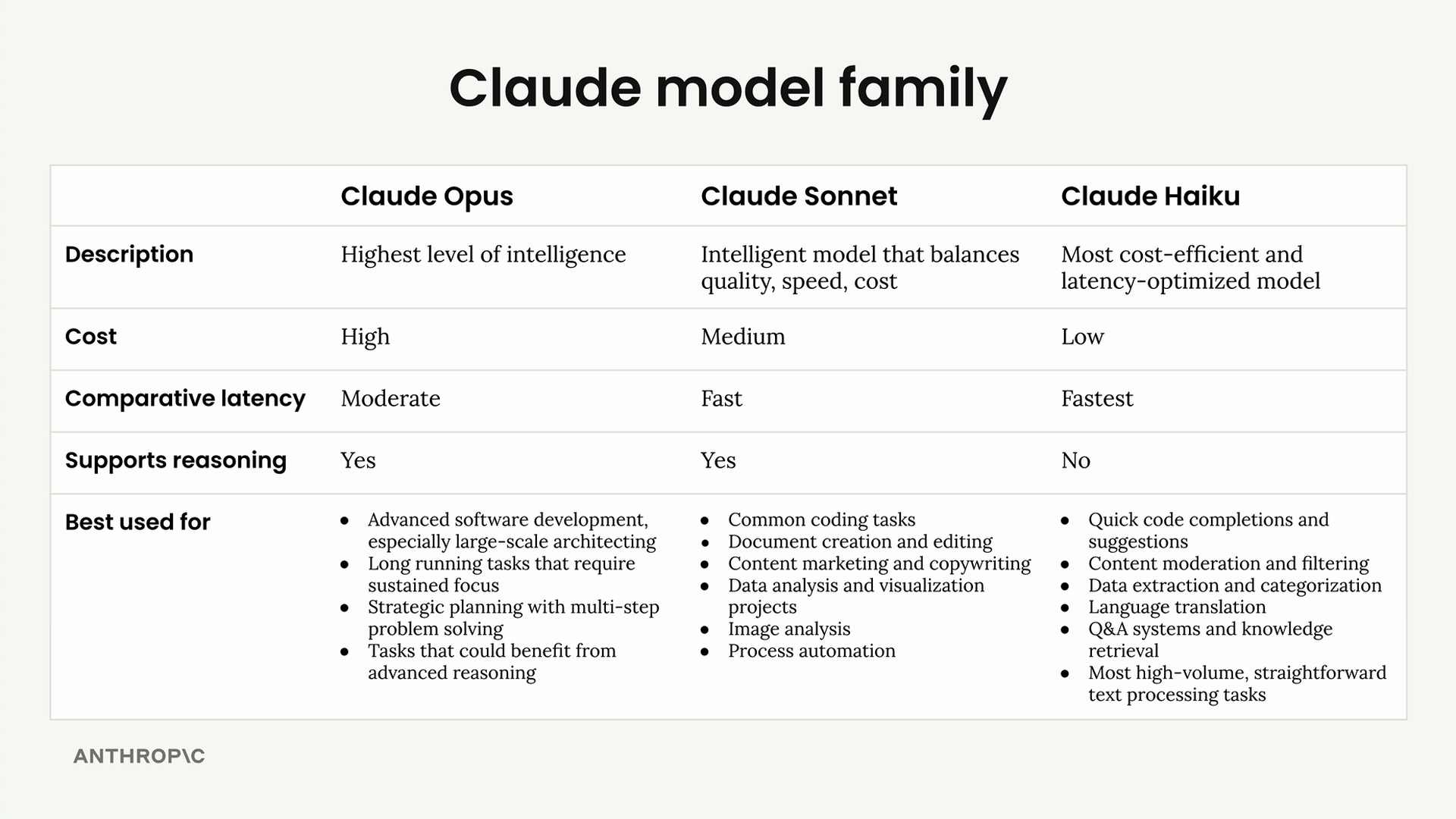
Claude Opus
Opus 提供了 Claude 最高水平的智能。它专为需要复杂推理和规划能力的复杂场景而设计。
Opus 擅长在长时间内独立完成复杂项目。它可以管理多步骤流程,并在无需大量人工干预的情况下应对不同的需求。该模型支持推理,这意味着它可以为简单任务提供快速响应,也可以花时间思考更复杂的问题。
其权衡是适中的延迟和更高的成本。您需要为这种额外的智能支付更高的费用并等待更长时间。
Claude Sonnet
Sonnet 位于 Claude 产品线中的最佳位置,提供了智能性、速度和成本的平衡组合,适用于大多数实际应用。
Sonnet 尤其有价值的是其强大的编码能力与快速文本生成相结合。许多开发人员赞赏它能够对复杂代码库进行精确编辑,而不会破坏现有功能。
Claude Haiku
Haiku 是 Claude 最快的模型,专门为响应时间至关重要的应用而构建。它针对速度和成本效率进行了优化,而不是追求最大智能。
一个重要的限制:Haiku 不支持 Opus 和 Sonnet 提供的推理能力。这使其非常适合需要实时交互的面向用户应用程序,但不太适合复杂的解决问题任务。
选择合适的模型
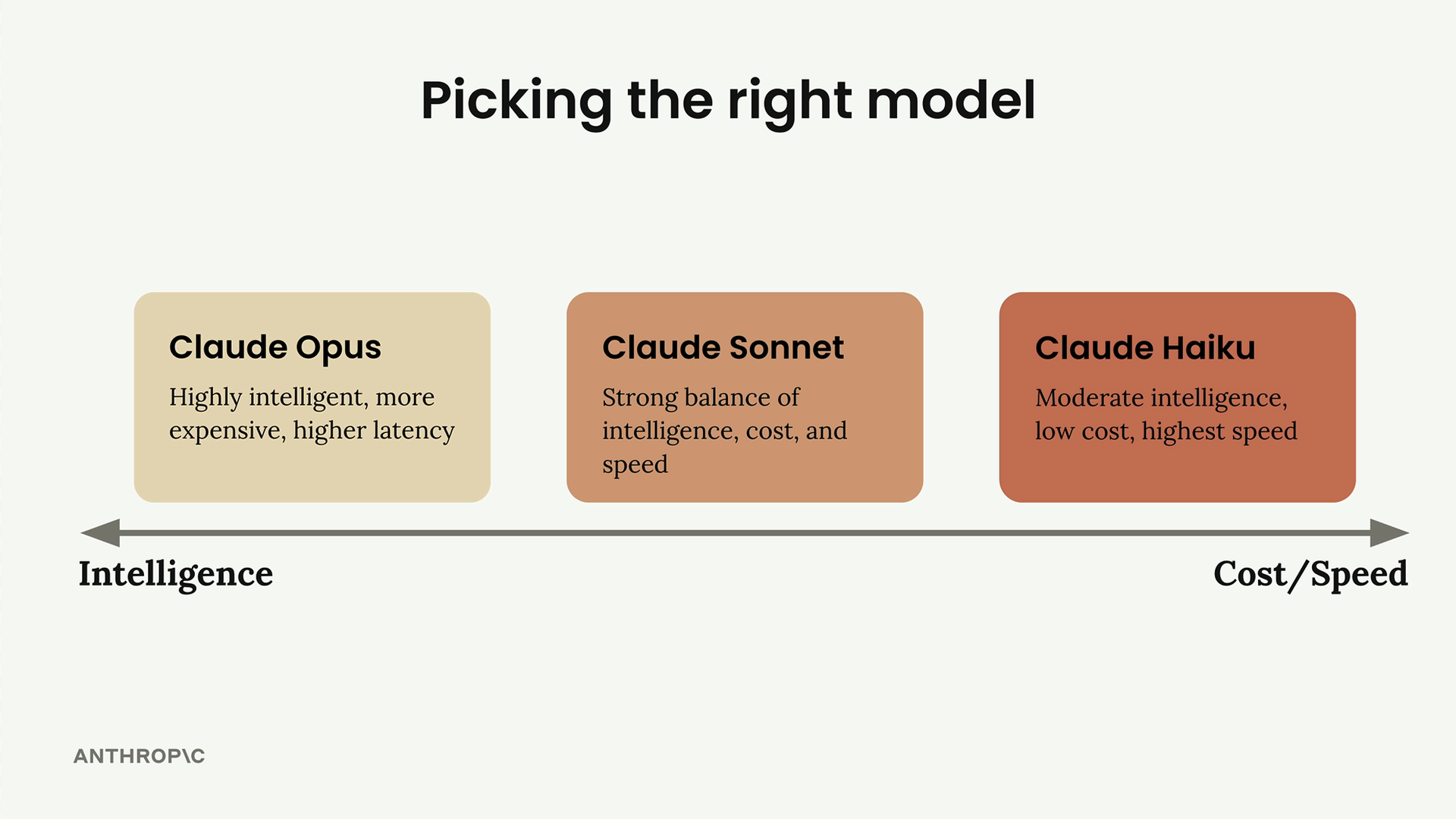
模型选择归结为理解智能与成本/速度之间的权衡。以下是决定方法:
- 选择 Opus,当智能是您的首要任务时。如果您有需要强大推理能力的复杂任务,您将选择质量而非速度和成本。
- 选择 Haiku,当速度最重要时。适用于需要最快响应的实时用户交互或高吞吐量处理。
- 选择 Sonnet,当您需要平衡时。大多数应用程序都受益于 Sonnet 的智能、速度和合理成本的结合。
使用多个模型
许多团队不会只使用一个模型。相反,他们会在同一个应用程序的不同部分使用不同的模型:
- Haiku 用于对速度至关重要的面向用户交互
- Sonnet 用于主要业务逻辑
- Opus 用于需要更深层推理的复杂任务
这种方法使您能够针对应用程序的特定需求优化每个部分,同时管理总体成本和性能。
视频文字稿
本视频中,我们将探讨 Claude 的三个模型家族,并了解哪一个最适合您的特定用例。为了帮助您理解这些模型的区别,我将为您讲解每个模型的关键特征,然后展示一个简单的框架来选择合适的模型。在我们深入细节之前,请允许我澄清一点。这三个模型都共享 Claude 的核心能力,因此它们都能处理文本生成、编码、图像分析以及许多其他任务。
它们之间的真正区别在于其优化方向。一个侧重于智能性,一个侧重于速度和成本效率,而另一个则是在智能性和速度之间取得更好的平衡。第一个是 Opus。Opus 是 Claude 最强大的模型。
当我说强大时,我的意思是它能提供您从 Claude 获得最高水平的智能。实际上,这意味着 Opus 专为那些具有复杂需求、需要高水平智能和规划才能完成的场景而设计。它可以在长时间内独立处理复杂的项目,就像一个可能运行数小时的任务,模型需要自行管理多步骤流程并处理大量不同的需求,而无需过多的人工干预。Opus 支持我们所说的推理(reasoning),这意味着它可以为简单任务提供快速响应,也可以花时间思考更复杂的任务。
缺点是 Opus 具有适中的延迟和更高的成本,这正是您需要权衡的地方。虽然您获得了极高的智能,但每次请求也需要花费更多的时间和成本。接下来是 Sonnet。Sonnet 在 Claude 的产品线中处于一个“甜点”位置。
它在智能性、速度和成本之间取得了良好的平衡,这使得它对于大多数实际用例都非常有用。Sonnet 的强大之处在于其卓越的编码能力以及快速的文本生成。许多开发者喜欢它能够对复杂代码库进行精确编辑,这意味着它可以在不破坏现有功能的情况下对项目进行更改。最后,我们有 Haiku。
Haiku 是 Claude 最快的模型,它专为响应时间至关重要的应用程序而设计。关于 Haiku,需要注意的一点是,它不支持 Opus 和 Sonnet 提供的推理能力。相反,Haiku 针对速度和成本效率进行了优化。这使得 Haiku 成为需要实时交互的面向用户应用程序的绝佳选择。
现在,我们来讨论如何为您的特定应用程序选择这三个模型中的哪一个。模型选择的关键在于理解这些不同模型之间的权衡。一方面,您拥有极高的智能性;另一方面,您需要权衡成本和速度。Opus 倾向于智能性。
它非常智能、更昂贵,并且具有更高的延迟。Haiku 倾向于成本和速度。它具有适中的智能性、低成本和最快的速度。而 Sonnet 则处于中间,在这些不同品质之间取得了良好的平衡。
那么,您该如何决定使用哪种模型呢?您确实需要确定对您的特定用例来说,什么是最重要的。如果智能性是您的首要任务,这意味着您有一个需要强大推理能力的复杂任务,那么您可能希望使用 Opus。您是在选择质量而非速度和成本。
如果速度是您的优先考虑,这意味着您有实时用户交互,或者您有高吞吐量的处理需求,需要尽快获得响应,那么您应该选择 Haiku。如果您需要在智能性、速度和成本之间取得平衡,这通常是大多数应用程序的情况,那么 Sonnet 可能是您的最佳选择。这里需要注意一点,许多团队不会只选择一个模型并坚持使用。相反,您可能会在同一个应用程序的不同部分使用多个不同的模型。
您可能会将 Haiku 用于对速度至关重要的面向用户交互,将 Sonnet 用于主要业务逻辑,而将 Opus 用于需要更深层推理的真正复杂任务。这涵盖了 Claude 的三个模型家族以及如何选择它们。顺便说一句,我们在此课程中通常会使用 Claude Sonnet,因为它在这三个不同品质之间提供了非常出色的平衡。
第2部分:使用 API (Working with the API)
3. 访问 API (Accessing the API)
类型:视频 | 时长:2:31 | 视频:001 - Accessing the API.mp4
在使用 AI 模型构建应用程序时,您需要了解从用户输入到 AI 生成响应的数据流。让我们来看看 AWS Bedrock 的工作原理,并了解典型聊天应用程序幕后发生的事情。
聊天应用程序的工作原理
想象您正在构建一个带有简单聊天界面的 Web 应用程序。用户输入“定义量子计算”并点击发送。实际发生的情况是:
用户看到一个简洁的界面,但幕后有一个完整的系统在工作以生成该响应。
请求流程 (The Request Flow)
当用户提交文本时,消息会经历以下过程:
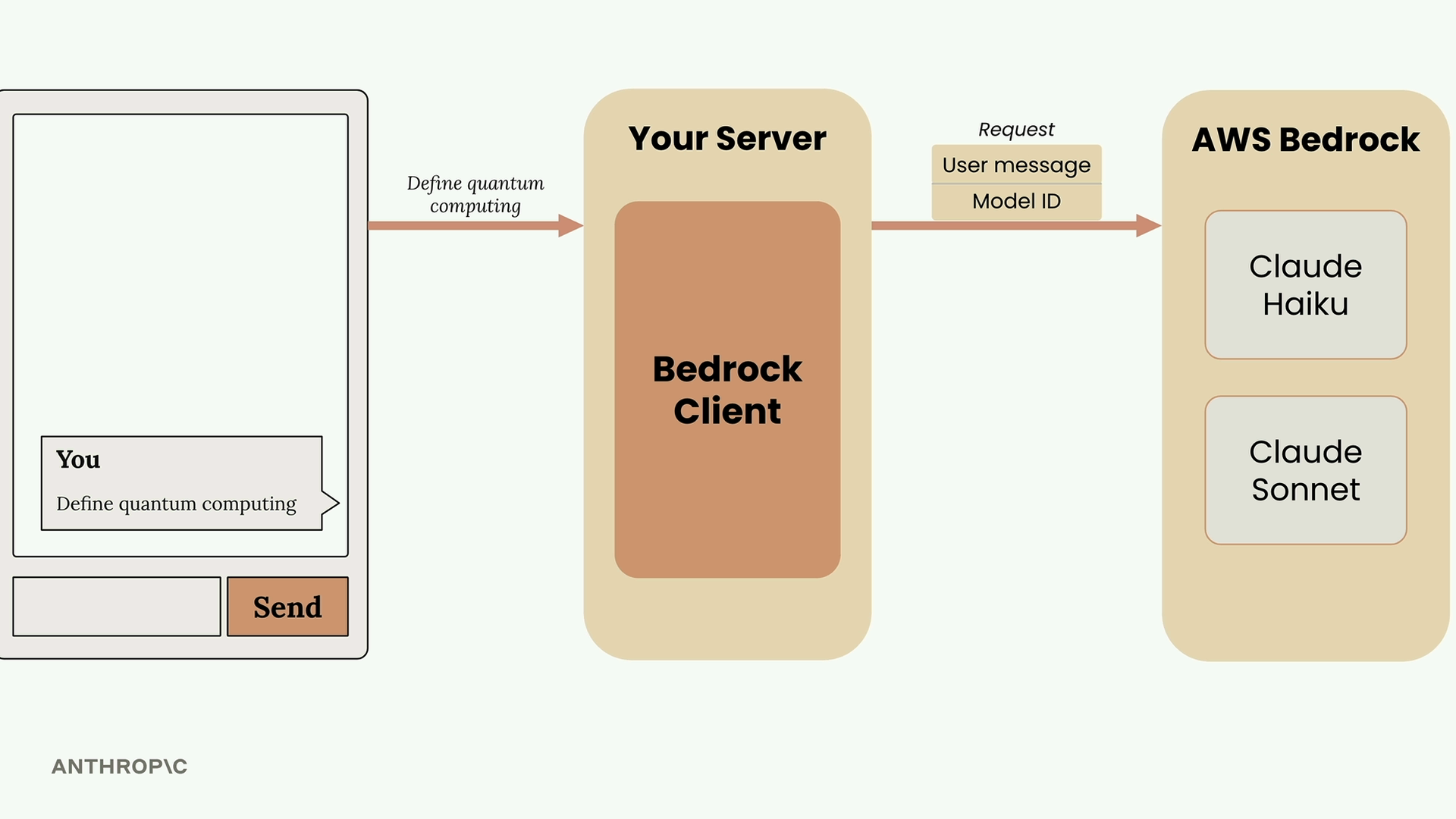
- 用户通过您的 Web 界面提交他们的消息
- 您的服务器接收包含该文本的请求
- 您的服务器使用 Bedrock 客户端向 AWS Bedrock 发送请求
- 请求包含用户消息 (user message) 和模型 ID (model ID)(例如 Claude Haiku 或 Claude Sonnet)
- 所选模型处理请求并生成文本
- AWS Bedrock 发送回包含生成响应的助理消息 (assistant message)
- 您的服务器将此响应转发回用户的浏览器
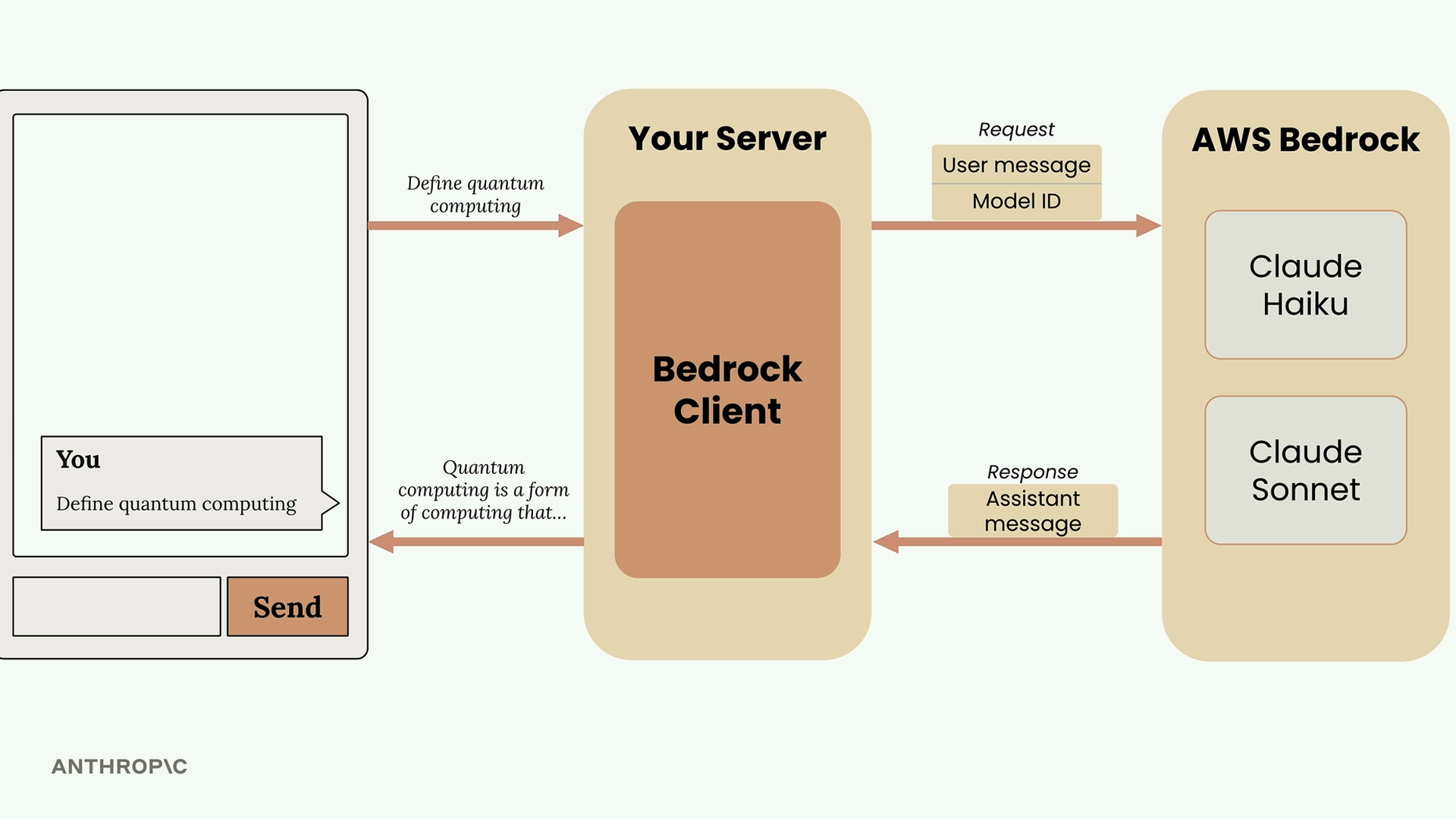
视频文字稿
在本模块中,我们将了解如何通过 AWS Bedrock 访问 Claude 模型并使用它们生成一定量的文本。首先,我想通过一个小示例应用程序——一个直接、标准的聊天机器人应用程序来引导您。因此,让我们想象您正在制作一个 Web 应用程序,并且想要向用户展示一个聊天界面,用户可以在其中输入一些消息,然后点击发送。每当他们这样做时,他们的期望是某个响应会神奇地出现。
但是,让我们研究一下幕后发生的事情,以真正实现这一点。每当用户提交一些文本时,包含该文本的请求将发送到您的服务器。您的服务器将使用 Bedrock 客户端向 AWS Bedrock 服务发送请求,Anthropic 模型实际上托管在该服务中。发送到 Bedrock 服务的此请求将包含一个称为用户消息(user message)的内容,其中包含用户提交的文本,以及一个模型 ID(model ID),它指定我们要运行哪个模型。
所选模型将运行,它将生成一些文本,并通过一个称为助理消息(assistant message)的内容发送回您的服务器。然后,您的服务器可以获取生成的文本并将其发送回浏览器,在那里可以在屏幕上呈现给用户查看。现在,在本课程的这一部分中,我们将完全专注于 Bedrock 客户端与 Bedrock 服务之间的通信层。我们将研究如何发出 API 请求,如何访问生成的文本,并在此过程中发现一些常见的设计模式。
在我们继续之前,我想澄清一个常见的混淆点,特别是 Bedrock API 和 Anthropic API 之间的区别。首先,一个非常快速的回顾。在本课程早些时候,我们讨论了 Claude Sonnet 和 Claude Haiku 模型。这些模型负责生成一定量文本的实际计算工作。
Claude 系列模型目前通过两种不同的服务托管:AWS Bedrock 和官方 Anthropic API。如果您正在学习本课程,您将使用 AWS Bedrock 服务的 Claude 系列模型。现在,您需要注意的重点是。这些确实是不同的服务。
它们通过不同的 SDK 访问。它们有不同的文档来源。因此,每当您查阅文档或试图理解如何使用模型时,请务必确保您正在查看专门针对 AWS Bedrock 的资源。现在我们已经消除了这个混淆点,让我们在下一个视频中继续向 Bedrock 发出我们的第一个请求。
4. 发送请求 (Making a request)
类型:视频 | 时长:7:34 | 视频:05 - 002 - Making a Request.mp4
向 AWS Bedrock 发出您的第一个 API 请求需要三个基本组件:一个用于连接服务的 Bedrock Runtime Client(Bedrock 运行时客户端)、一个用于指定要运行哪个模型的 Model ID(模型 ID),以及一个包含要输入到模型的文本的 User Message(用户消息)。
设置 Bedrock 客户端 (Setting Up the Bedrock Client)
首先使用 boto3 创建一个客户端来连接 Bedrock 运行时服务:
import boto3
client = boto3.client("bedrock-runtime", region_name="us-west-2")
理解模型 ID 和区域可用性 (Understanding Model IDs and Regional Availability)
这里情况变得有些棘手。并非每个模型都在每个 AWS 区域中可用。如果您尝试运行一个在您选择的区域中不存在的模型,您将收到一条神秘的错误消息,称该模型不存在。
例如,如果 Claude Sonnet 在 us-west-2 可用,但您从 us-east-1 发出请求,您的请求将失败。
使用推理配置文件 (Using Inference Profiles)
推理配置文件 (Inference profiles) 通过自动将您的请求路由到实际托管您所选模型的区域来解决区域可用性问题。
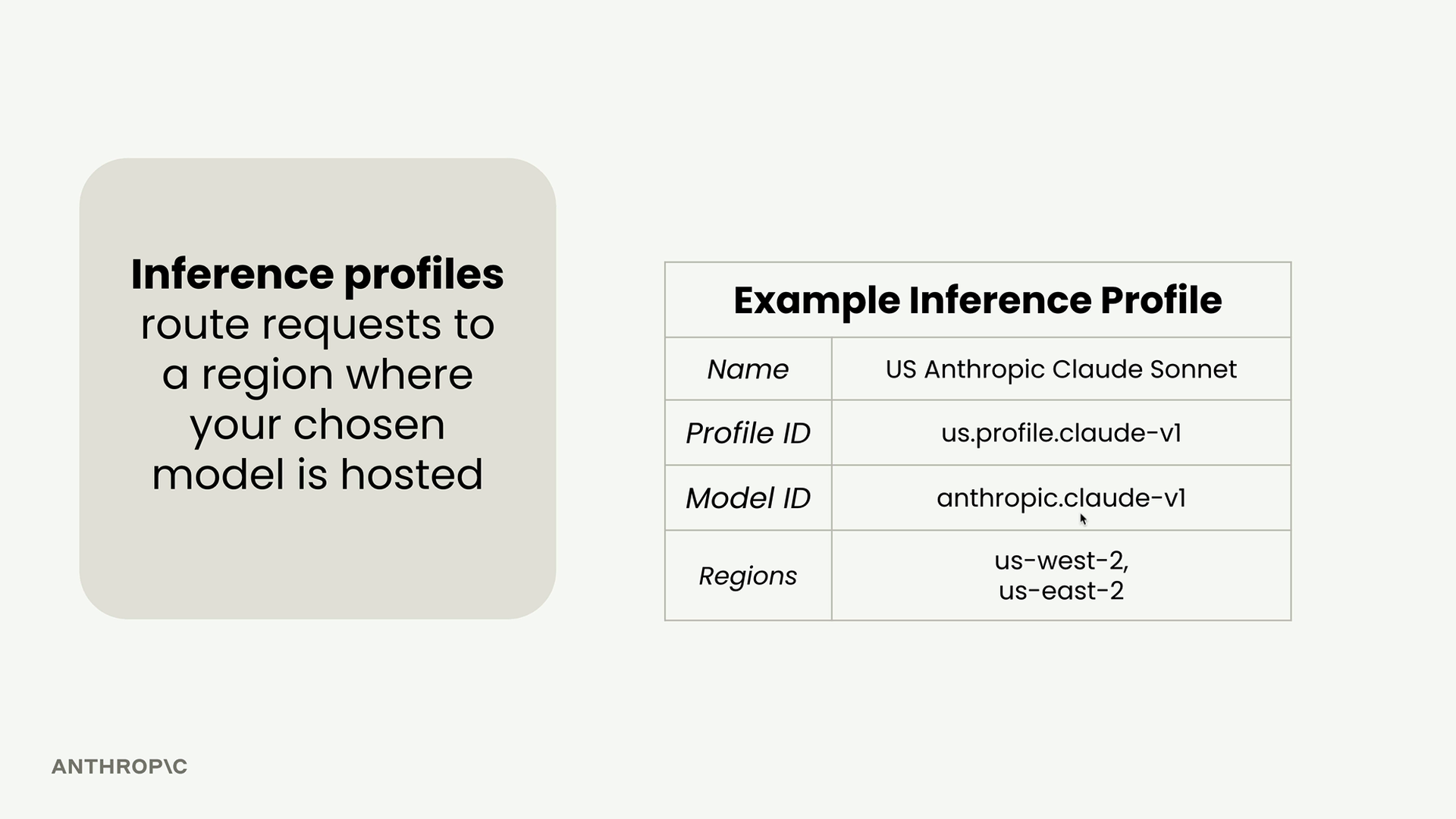
您无需跟踪哪些模型在哪些区域,可以使用一个推理配置文件,该配置文件知道模型在 us-west-2 和 us-east-2 等多个区域中可用。
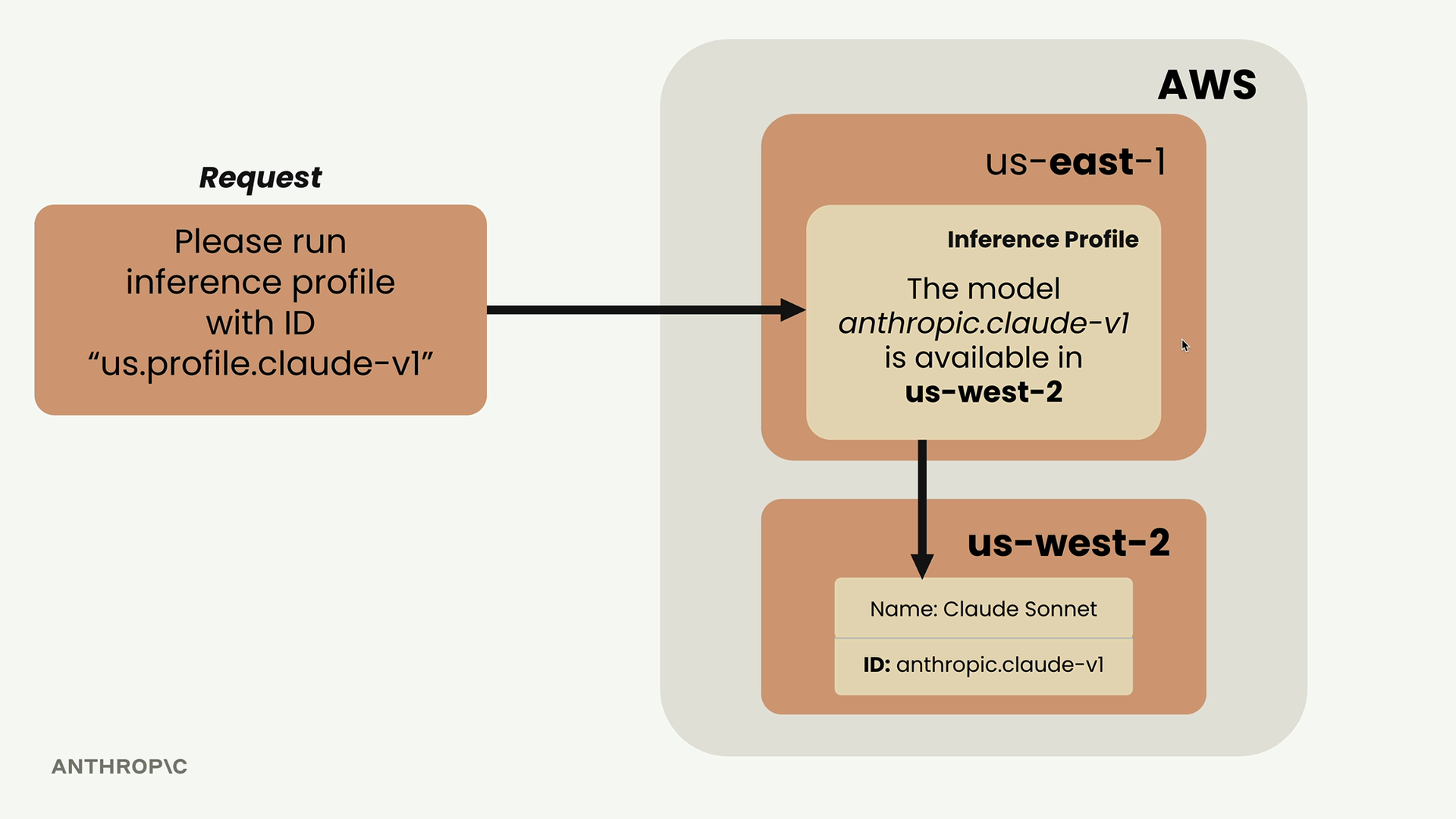
当您使用推理配置文件发出请求时,AWS 会自动将其路由到您的模型存在的正确区域,即使您是从不同区域连接的。
要查找推理配置文件 ID,请转到 AWS Bedrock 控制台,并在“跨区域推理”(Cross-region inference) 下查找,而不是使用主模型目录页面中的模型 ID。
复制您所选模型的推理配置文件 ID。
创建用户消息 (Creating User Messages)
用户消息 (User messages) 具有特定的结构,乍一看可能显得过于复杂,但这样做有充分的理由:
user_message = {
"role": "user",
"content": [
{"text": "What's 1+1?"}
]
}
内容 (content) 是一个列表,因为单个消息可以包含不同类型的内容——文本、图像或其他媒体类型。这种结构允许您发送多模态请求。

发送请求 (Making the Request)
现在您可以使用 converse 方法进行 API 调用:
response = client.converse(
modelId=model_id,
messages=[user_message]
)
响应 (response) 包含大量元数据,但要仅获取生成的文本,您需要通过响应结构进行导航:
response["output"]["message"]["content"][0]["text"]
理解消息类型 (Understanding Message Types)
您将主要使用两种消息类型:
- 用户消息 (User messages) – 您希望输入到模型中的内容(role: "user")
- 助理消息 (Assistant messages) – 模型生成的内容(role: "assistant")
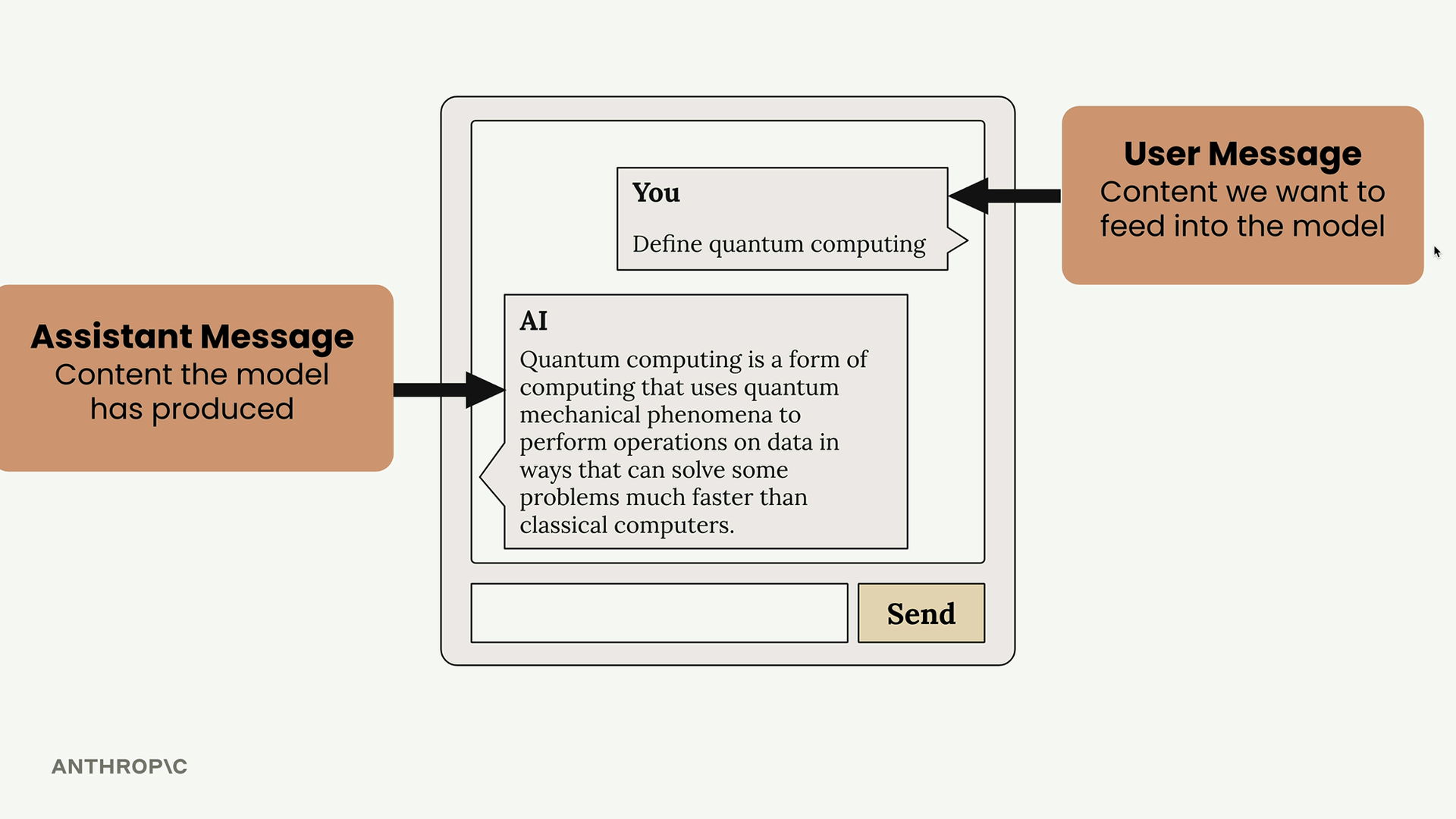
两种消息类型都遵循相同的结构,包含 role 和 content 列表。这种一致性使得通过交替用户消息和助理消息来构建对话变得容易。
您从 Bedrock 收到的助理消息与您的用户消息格式完全相同,只是 role 不同。这种标准化结构使得将多个请求链接起来进行更长时间的对话变得简单直接。
视频文字稿
让我们动手写一些代码。在本视频中,我们将重点介绍向 AWS Bedrock 发出我们的第一个 API 请求。我们将运行一个模型并生成少量文本。现在您会注意到,我已经创建了一个 Python 笔记本。
我鼓励您在此处暂停视频,并创建自己的笔记本,以便您可以跟着我一起编写代码,从而获得发出这些 API 请求的一些经验。为了发出我们的第一个请求,我们需要三样东西。首先,我们需要一个客户端来实际访问 Bedrock。我们将使用 Bodo3 Python 模块创建这个客户端。
其次,我们需要一个模型 ID (Model ID)。这将是托管在 Bedrock 中的确切模型的 ID,我们希望运行该模型。最后,我们还需要一个称为用户消息(User Message)的东西。这将是一个经过特殊格式化的对象,其中包含我们希望输入到模型中的文本。
回到我的笔记本中,让我向您展示我们将如何创建该客户端、获取模型 ID 并创建用户消息。首先,我将使用 Bodo3 模块创建一个客户端。我将专门连接到 Bedrock 运行时并指定一个区域名称。在我的案例中,我将使用 US West 2。
接下来,我们需要指定我们的模型 ID,它将是一个字符串。不幸的是,模型 ID 实际上会比乍看起来要复杂一些。所以让我向您展示几个图表,帮助您理解发生了什么。现在,作为提醒,每当我们向 Bedrock 发出请求时,都需要包含我们希望运行的实际模型的 ID。
我们将把该请求发送到非常特定的区域。在我的案例中,我输入了 US-S2。但这里有一个非常大的陷阱,文档中没有非常清楚地说明,但您非常需要注意。事实证明,并非每个模型都托管在每个区域中。
因此,例如,US East 1 是 AWS 中的另一个区域。而 US East 1 可能实际上并未运行我希望执行的确切模型。因此,如果我将此请求发送到 US East 1,我可能最终会收到一条错误消息,指出该模型根本不可用。要解决该错误,我可以尝试找出哪个区域实际托管了我正在寻找的模型。
或者,我也可以尝试跟踪哪个模型托管在哪个区域。但是,有一种更简单的方法可以使用称为推理配置文件(Inference Profile)的东西来解决此问题。推理配置文件用于将请求路由到实际托管您所选模型的不同区域。因此,举例来说,我们可能有一个推理配置文件,指出此特定模型保证托管在 U.S.
West 2 和 U.S. East 2 中。以下是推理配置文件在幕后所做的事情。我们仍然会向 AWS 中托管的某个特定区域发出请求。
但是,我们不会指定特定的模型 ID,而是指定推理配置文件的 ID。然后,当我们发送该请求时,AWS 会自动将我们的请求重新路由到模型保证托管在其中的另一个区域。因此,我之所以提到这里的模型 ID 有点难以理解,是因为它在所有地方都被称为模型 ID。但实际上,我们通常并不会真正输入模型 ID。
相反,我们提供推理配置文件的 ID,以便我们获得自动请求路由。让我非常快速地向您展示一个 Bedrock 控制台中的示例,以便推理配置文件这个概念非常清晰。因此,在我的 Bedrock 控制台中,我已进入左侧的模型目录。然后,我将查看 Claude 系列模型之一。
然后在此页面上,如果我向下滚动一点,我会在这里看到,是的,我有一个模型 ID。但同样,此模型 ID 可能不是我们实际希望添加到请求中的内容。相反,我们可能希望使用的是左侧的“跨区域推理”(Cross-region inference)。如果我点击它,我将找到我正在寻找的模型。
我们来了。然后在此页面上,我将找到我的推理配置文件 ID (Inference Profile ID)。而这个推理配置文件 ID 正是我们想要的,因为它将自动将我们的请求路由到模型保证托管在其中的某个区域。因此,我将获取该推理配置文件 ID,复制它,然后将其放回我的笔记本中并将其分配给模型 ID。
在发出请求之前,我们需要创建的最后一件事是我们的用户消息 (User Message)。请记住,这是一个经过特殊格式化的对象,其中包含我们希望输入到模型中的文本。我将在下面创建一个名为 user_message 的变量。它将是一个 Python 字典,其 role 为 user,content 将是一个列表,其中包含另一个嵌套字典,其中包含一些文本。
文本值将是我希望输入到模型中的内容。因此,在我的案例中,我将询问模型:“1+1 是多少?”现在,我将在稍后向您详细介绍用户消息的结构。但目前,我们只关注发出请求,以确保我们能够实际生成一些文本。
为了发出我们的实际请求,我将向下滚动一点,并添加对 client.converse 的调用。我们将输入我们的 modelId,请注意这里的关键字参数是 modelId,其中 I 是大写的。我还会添加 messages。这将是我们的消息列表。
在这种情况下,我们只有一个。它将是我们刚刚创建的用户消息。然后我将确保我运行两个单元格。然后我将在其下方添加一个新单元格并打印出 response。
此响应中包含大量信息,但要仅获取生成的文本,您需要导航响应结构:
response["output"]["message"]["content"][0]["text"]
因此,这将查看输出属性,查看其中的消息,查看其中的内容,查看此列表中的第一个元素,然后获取我们的文本,这就是我们生成的文本实际所在的位置。因此,如果我现在再次运行此单元格,我将只看到生成的文本“1 + 1 = 2”。现在,我将非常快速地对此行进行更改。我将删除内容,删除文本中的零查找,然后再次运行该单元格。
现在我将得到一个字典,它有一个 role 为 assistant 和一些分配给它的 content。如果您查看此字典,它可能会看起来有点熟悉。它看起来与我们刚才创建的结构非常相似,特别是这里的用户消息。因此,让我帮助您理解这些消息是什么以及它们对我们有什么作用。
消息包含我们希望输入到模型中的文本,它们还包含最终由模型生成的文本。有两种不同类型的消息:用户消息 (user messages) 和助理消息 (assistant messages)。因此,用户消息将始终包含我们希望输入到模型中的文本。而助理消息将包含模型本身生成的文本。
这两种不同消息类型的结构总是非常相似的。它们之间唯一的最大区别是,用户消息的 role 始终是 user,而助理消息的 role 始终是 assistant。两种消息类型都将始终具有一个 content 属性,我们将其称为列表。您可能会有点好奇为什么那里会有一个列表,为什么它不仅仅是一个简单的文本属性,告诉我们我们输入到模型中的内容或我们得到的结果。
content 属性是一个列表,因为最终我们将看到单个消息可以包含许多不同的部分。例如,我们可能向模型发送一条消息,其中包含图像和一些文本。我们会将图像和文本编码为内容项列表中的单独部分。我们现在还不会担心包含多个内容部分的消息。
我只是提到它以帮助您理解为什么会有那个额外的语法。好的,现在我们已经成功发出了第一个请求。让我们稍后再回来,更详细地讨论。
5. 多轮对话 (Multi-Turn conversations)
类型:视频 | 时长:9:05 | 视频:05 - 003 - Multi-Turn Conversations.mp4
我们目前编写的代码模拟了与 Claude 的一次非常简单的交流。但当您想继续对话时会发生什么?当您在问完“1+1 是多少?”之后,又问了一个后续问题,比如“再加 3 呢?”,您可能会期望 Claude 明白您是在问将 3 加到前一个结果 2 上。
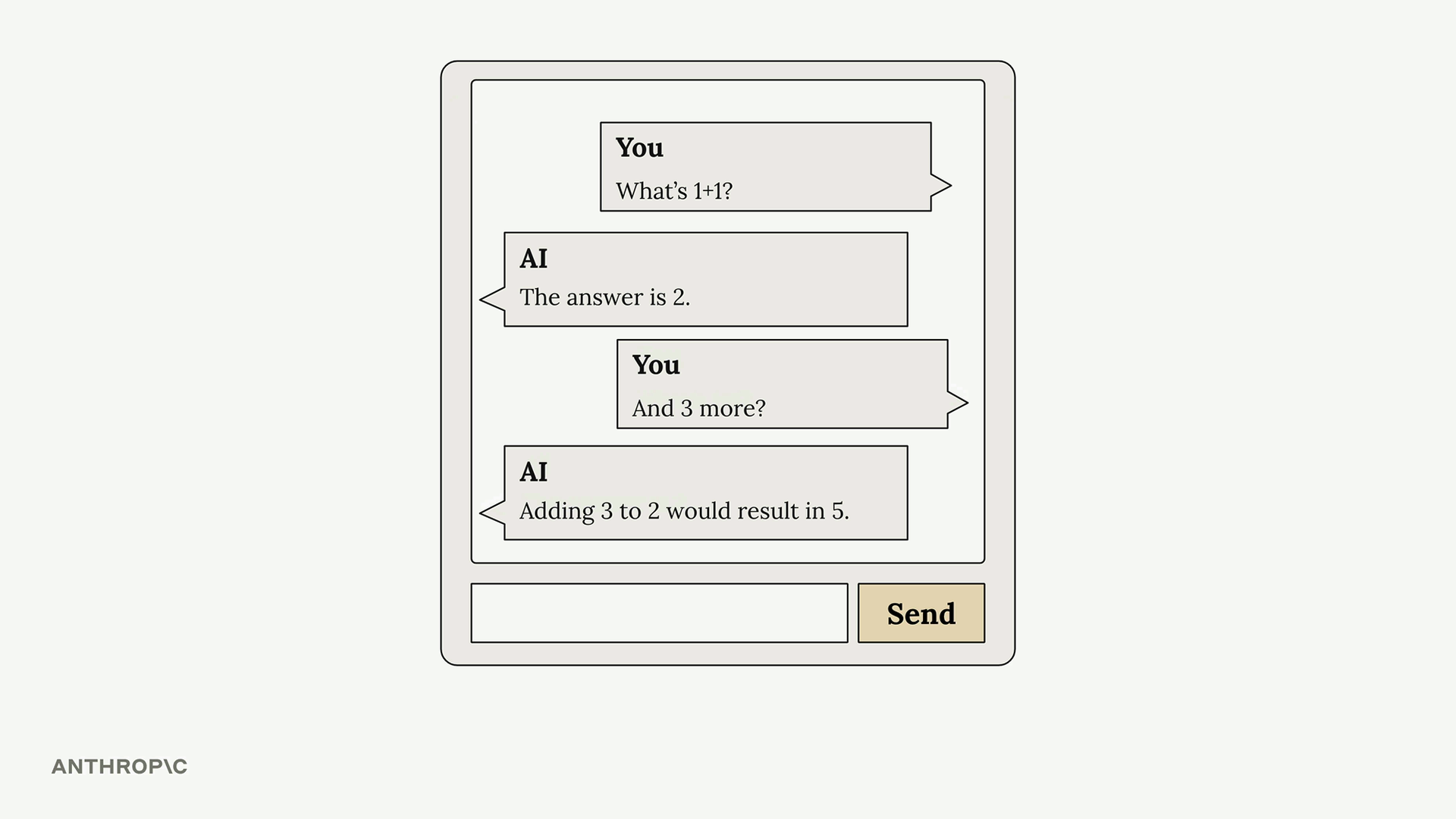
然而,您需要了解有关 Bedrock API 和 Claude 本身的关键信息。
不存储消息 (No Message Storage)
Bedrock 和 Claude 不会存储任何消息。您发送的任何消息都不会被存储,您收到的任何响应也不会被存储。每次 API 调用都是完全独立的。

要进行保持上下文的多次消息对话,您需要:
- 在代码中手动维护所有消息的列表
- 在每个后续请求中提供完整的消息列表
为什么上下文很重要 (Why Context Matters)
让我们看看在没有正确上下文的情况下会发生什么。如果您只发送“再加 3 呢?”作为独立消息,Claude 不知道您指的是什么。它会尽力回应,但答案没有意义,因为它缺乏您之前对话的上下文。
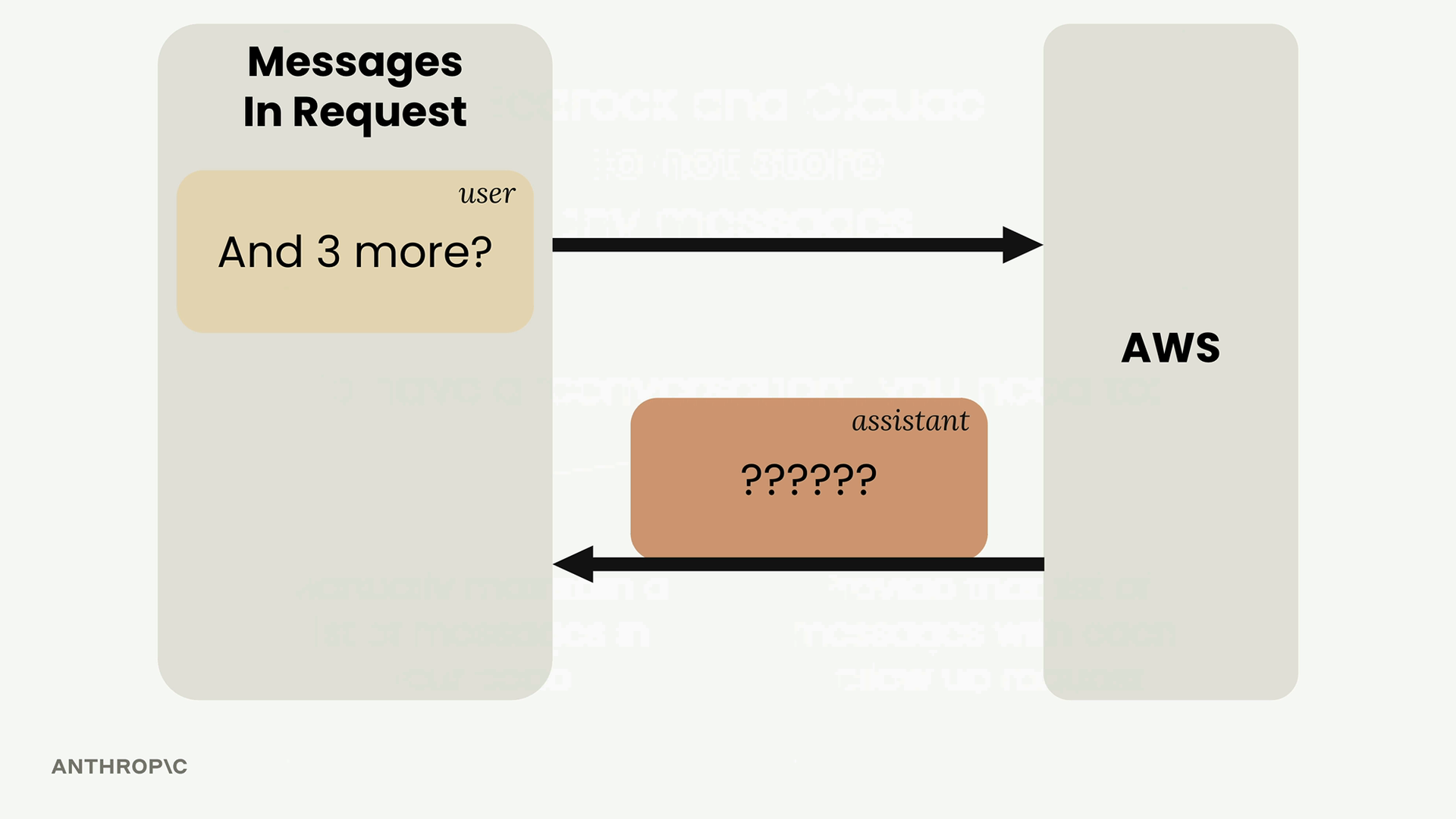
当您只发送后续问题时,Claude 只会看到那条孤立的消息,并尝试在不知道之前“1+1 是多少?”交流的情况下进行回应。
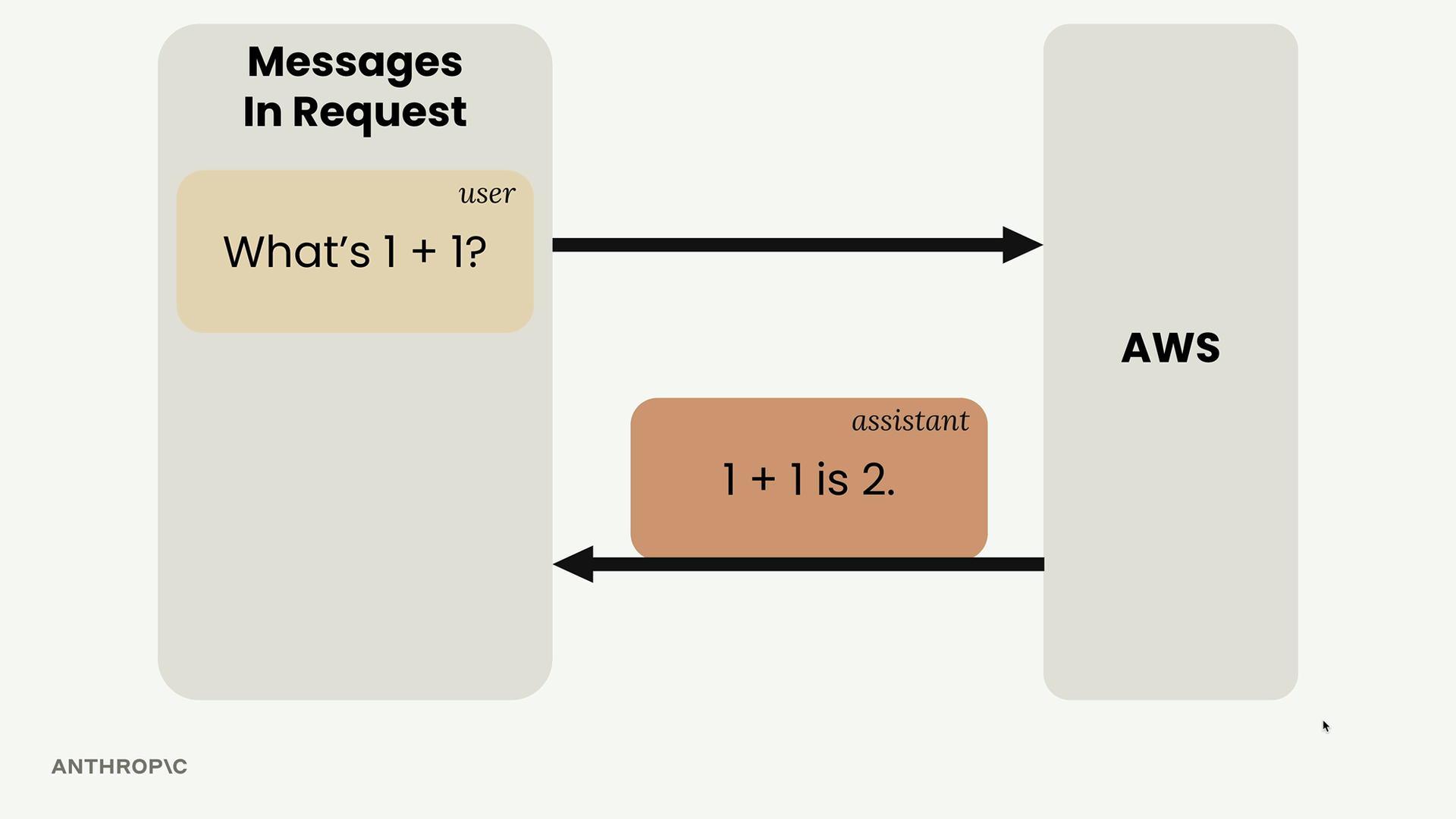
构建对话上下文 (Building Conversation Context)
为了保持上下文,您需要在每个请求中包含完整的对话历史记录。其工作原理如下:
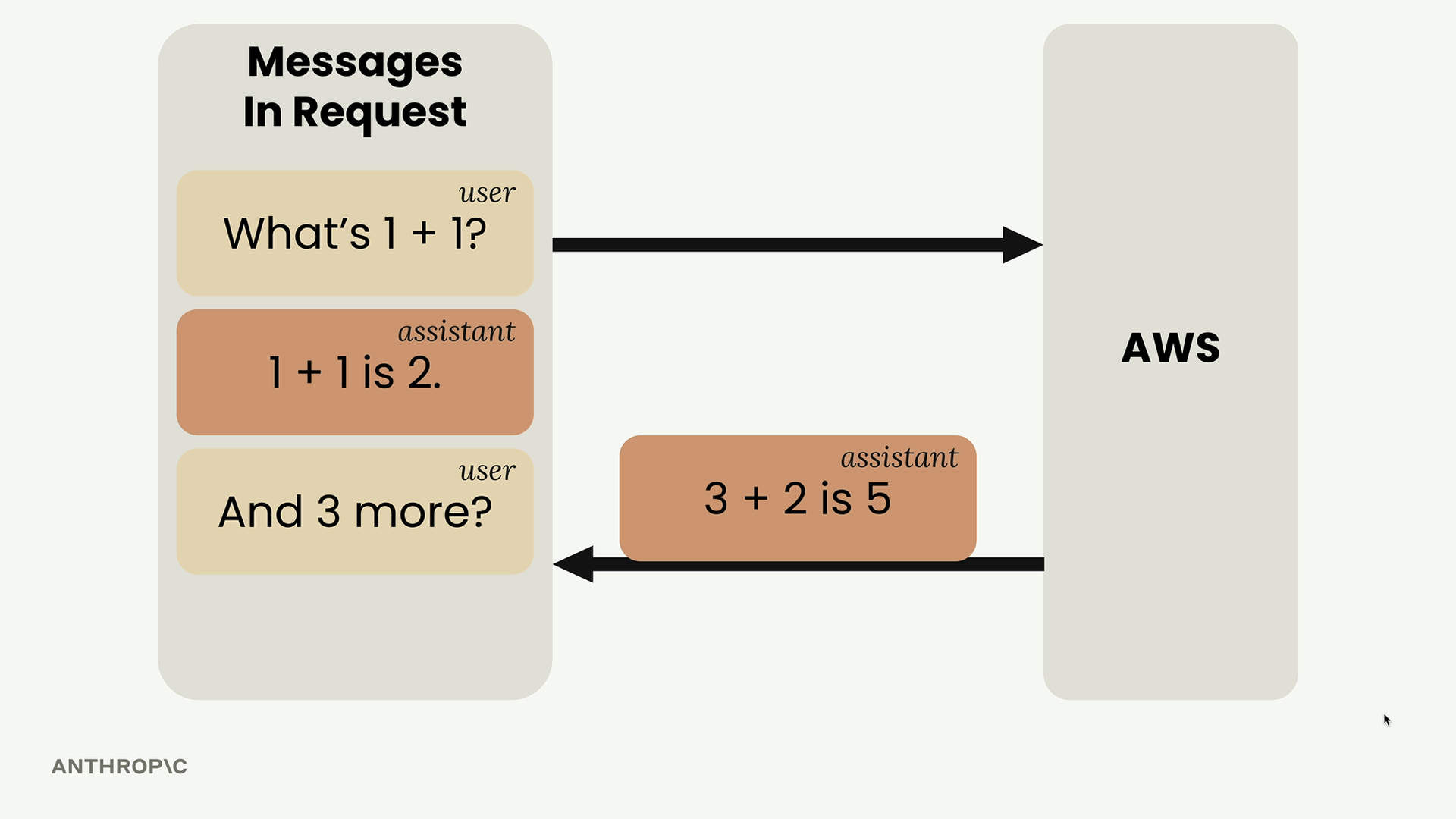
您的消息列表应包含所有先前的交流——包括用户消息和助理响应。当您发送此完整上下文时,Claude 可以理解“再加 3 呢?”指的是将 3 加到前一个结果 2 上。
消息管理辅助函数 (Helper Functions for Message Management)
为了使对话管理更容易,您可以创建辅助函数:
def add_user_message(messages, text):
user_message = {
"role": "user",
"content": [
{"text": text}
]
}
messages.append(user_message)
def add_assistant_message(messages, text):
assistant_message = {
"role": "assistant",
"content": [
{"text": text}
]
}
messages.append(assistant_message)
def chat(messages):
response = client.converse(
modelId=model_id,
messages=messages
)
return response["output"]["message"]["content"][0]["text"]
实现多轮对话 (Implementing Multi-Turn Conversations)
以下是逐步构建对话的方法:
# Make a starting list of messages
messages = []
# Add in the initial user question of "What's 1+1?"
add_user_message(messages, "What's 1+1?")
# Pass the list of messages into chat to get an answer
answer = chat(messages)
# Take the answer and add it as an assistant message into our list
add_assistant_message(messages, answer)
# Add in the user's followup question
add_user_message(messages, "And 3 more added to that?")
# Call chat again with the list of messages to get a final answer
answer = chat(messages)
print(answer)
这种方法确保 Claude 拥有完整的上下文,并能做出适当的响应:“从 1+1 = 2 的结果开始,如果我们再加 3,我们得到:2 + 3 = 5”
消息角色交替 (Message Role Alternation)
在构建消息列表时,请务必确保消息角色正确交替:
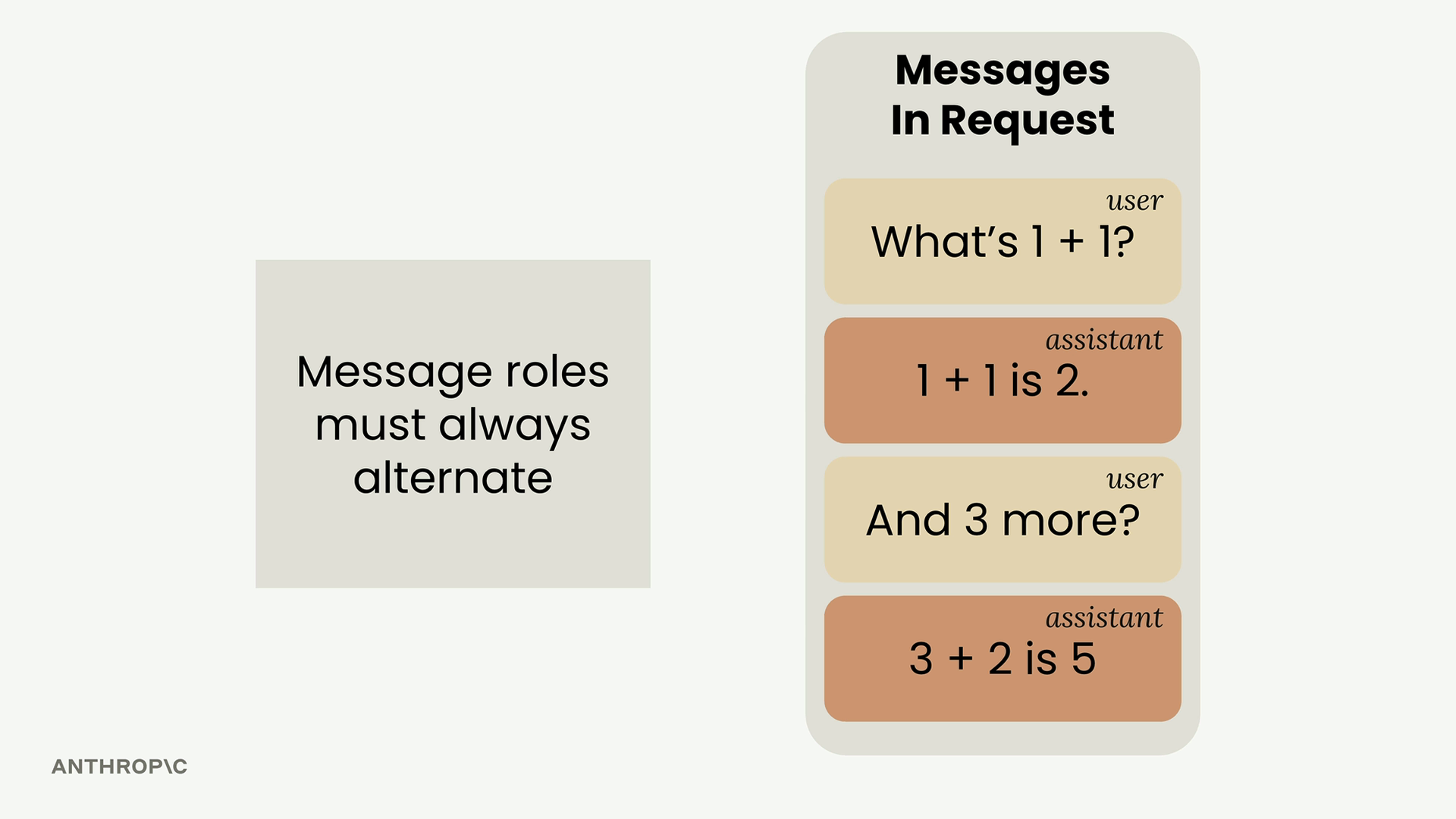
您的对话应遵循以下模式:用户 (user) → 助理 (assistant) → 用户 (user) → 助理 (assistant)。绝不能连续出现两条用户消息或两条助理消息。API 要求这种交替模式,它反映了自然的对话流程。
虽然这种手动消息管理乍一看可能显得繁琐,但您很快就会习惯。这种模式是构建任何需要维护与 Claude 对话上下文的应用程序的基础。
视频文字稿
我们目前编写的代码模拟了与我们模型的一次非常简单的交流。我们可以通过这样的聊天框来可视化这次对话。因此,我们发送了一个请求,询问“1 加 1 是多少?”我们得到了一个非常简单的回复。
比如答案是 2。自然,我们可能想在某个时候继续这个对话。所以我们可能想发送一个后续问题,比如“再加 3 呢?”然后我们期望得到一个回复,说“2 再加 3 会得到 5”。
要进行这种多消息对话,您需要了解 Bedrock API 和 Claude 本身的一个非常关键的问题。那就是 Betterock 和 Claude 不会存储任何消息。您发送的任何消息都不会以任何方式存储,您收到的任何回复也不会以任何方式存储。因此,如果您希望进行某种对话,其中有多个消息能够保持上下文或流程,那么您需要做两件事。
您需要在代码中手动维护您正在交换的所有消息的列表。其次,您需要确保在您发出的每个后续请求中都提供该完整的消息列表。因此,让我们详细了解整个概念,以便您真正清楚发生了什么。我想做的第一件事是运行一些示例代码。
所以我仍然有我们上一个视频中编写的代码,我们在其中询问了 1 加 1 是多少,我们得到了 1 加 1 是 2。现在我将粘贴一些我提前编写的额外代码片段。因此,在这个我刚刚粘贴的额外代码片段中,我正在向 Bedrock 发出另一个调用,这次我提供了一条消息,仅仅是“再加 3 呢?”这有点模拟了我刚才向您展示的屏幕截图。
现在,如果我运行此单元格,我最终将得到一个完全没有意义的回复。所以让我向您展示一个图表,以确保清楚我们为什么会得到这个非常奇怪的文本。好的。因此,在左侧,我有我包含在发送到 Bedrock 的请求中的消息。
我最初只发送了一条“1 加 1 是多少”的消息。我们发送了它,我们得到了助理消息“1 加 1 是 2”,这正是我们所期望的。然后,当我执行您刚才看到的代码(那个额外的代码片段)时,我发送了一个请求,其中只包含一条消息,上面写着“再加 3 呢?”现在,当我们发送这个“再加 3 呢?”时,Claude 会尽力给您一个回复。
在我们的案例中,我们实际得到的回复没有多大意义,但它正在尽力而为,因为它只知道我们说了“再加 3 呢?”。所以为了解决这个问题,我们将这样做。正如我刚才提到的,我们将在代码中手动维护这些消息的列表,并确保在每次后续请求中都提供该列表。因此,作为我们接下来将要做什么的演示,每当我们想进行多轮对话时,我们仍然会发送这条原始用户消息。
我们将收到助理回复,然后我们将把该助理消息包含在我们的消息列表中。所以我们将其移到左侧。然后,每当我们想要继续对话时,我们将在列表末尾添加另一条用户消息,我们询问“再加 3 呢?”现在,当我们获取完整的消息列表并发出请求时,Claude 将拥有对话的完整上下文。
它会看到所有三条消息,当我们说“再加 3 呢?”时,它会确切地知道我们在说什么。因此,我们希望得到一个回复,比如 3 加 2 是 5。让我们回到我们的笔记本,尝试模拟这种多轮对话。好的,回到这里,我将非常快速地删除我粘贴的那个小代码片段。
然后在这个较早的代码单元格中,我将编写三个辅助函数。这些辅助函数只会使我们更容易维护整个对话的上下文并维护消息列表。因此,在用户消息的上方,我将定义一个 add_user_message 函数。我将假设我将使用消息列表和一些文本来调用此函数。
我将像这样缩进用户消息。我将用我们将传入的文本参数替换这里的“1 加 1 是多少”。然后在我们定义用户消息之后,我将把它添加到消息列表中。接下来,我将完全复制这个函数。
我将它粘贴到这里。我将其重命名为 add_assistant_message,将此变量的名称更改为 assistant_message,将角色更改为 assistant,最后将这里的 messages.append 更新为 assistant_message。所以现在我们有了两个辅助函数,它们可以非常轻松地为我们创建消息类型,无论是用户消息还是助理消息,并将其追加到现有消息列表中。
然后还有一个辅助函数。在这里,我将使我们更容易调用模型、获取回复,然后获取我们关心的实际文本。所以我还将在这里定义一个名为 chat 的函数。它将接收一个消息列表。
我将缩进 response。我将像这样传入消息列表。然后我将从这个函数返回 response、output、message。您还记得要输入的所有内容吗?
然后是 content。对了。然后我们得到零和文本。所以现在有了这三个函数,我们可以非常轻松地模拟一次完整的对话。
让我向您展示我们将如何做到这一点。在这里的这个单元格中,我将粘贴一些我提前编写的注释,只是为了引导自己并确保我正确地进行了整个对话。所以这是我的注释列表。我们将为我添加的每个注释放入一行代码。
但别担心,每行代码都非常简短和简单。首先,我将创建一个初始的消息列表。所以最初,我没有任何通信。然后我将添加初始的用户问题,也就是最初的用户消息“1 加 1 是多少?”。
为此,我将调用 add_user_message,传入消息列表,然后第二个参数将是我希望在此消息中包含的实际文本。所以在这个例子中,它将是“1 加 1 是多少?”然后紧接着,我将非常快速地打印出消息,以确保我们走在正确的轨道上。所以我将运行它。
看起来,是的,我们正确地添加了我们的用户消息。所以我有了 user 角色,content 是一个列表,里面有一个 Python 字典。所以我将继续下一步。我将把消息列表传递给我们创建的 chat 函数,以获取答案。
所以当我们调用那个 chat 函数时,它会联系 Bedrock 并调用我们的 API。所以我们会说 answer 是 chat 并传入消息列表。然后再次,为了确保我走在正确的轨道上,我将打印出 answer。我将运行它。
短暂暂停后,我看到了,是的,我们正确地得到了它。我们得到了答案“1 加 1 等于 2”。所以现在我们得到了这个答案作为一个纯字符串。我们需要获取它并将其作为助理消息添加到我们的列表中。
同样,我们将使用我们刚刚制作的辅助函数来完成此操作。所以我们将调用 add_assistant_message,传入我们的列表和我们刚刚得到的答案。然后再次,打印出消息,以确保我们正确地执行此操作。所以现在我们将看到,是的,我们确实正在构建我们的对话。
我们正在构建我们的消息列表。我们首先是用户,然后是助理。我们得到了“1 加 1 是多少”,然后是我们得到的答案。所以现在我们可以回答用户的额外问题,也就是 add_user_message。
我们会说,“再加 3 呢?”我们不会再检查消息了。让我们再次调用我们的 API,并传入完整的消息列表,以获取后续答案。我将打印出最终答案,让我们看看结果如何。
果然,从 1+1=2 的结果开始,我们再加 3,最终得到 5。所以现在很清楚,通过在后续请求中包含所有以前的消息,我们正在维护此对话的上下文。现在,这最初可能看起来有点繁琐,甚至这里的代码可能看起来有点令人困惑。如果令人困惑,我不会责怪您。
别担心,您会很快习惯这种事情。我只想再提一下消息列表,就像我们在这里组装的列表。也就是说,每当我们向 API 发送消息列表时,我们都需要确保每条消息的角色都正确交替。换句话说,我们应该始终是用户 (user),然后是助理 (assistant),然后是用户 (user),然后是助理 (assistant)。
我们绝不应该连续发送两条用户消息,也不应该连续发送两条助理消息,或者任何类似的情况。所以我们总是要确保我们正在改变或交替这些角色。
6. 聊天机器人练习 (Chat bot exercise)
类型:视频 | 时长:5:13 | 视频:05 - 004 - Chat Bot Exercise.mp4
视频文字稿
让我们快速做个练习,以确保到目前为止一切都理解了。本次练习的目标是使用我们刚才组合的三个辅助函数来制作一个非常简单的聊天机器人。现在您可以阅读我列出的您可能需要实现的各个步骤,但要理解这个练习,最简单的方法可能是我直接向您演示我希望您尝试构建什么。所以这就是我们的目标。
在一个 Jupyter Notebook 中,我们将制作一个像我这里这样的单个单元格。我的解决方案在这里,但我已经将其折叠起来,以便您看不到。现在,如果我运行这个单元格,我希望提示我的用户输入一些内容。所以对我来说,它出现在这里顶部。
然后我将输入一些我想要发送给模型的字符串。在我的案例中,我将输入“编写一个一句话的产品描述”。现在,如果我按下回车键,我将等待一秒钟,然后我应该会在这里看到一个回复。现在我应该会再次在这里看到我的输入,我应该能够输入一个后续消息,该消息仍然会将这些以前的消息作为上下文。
所以我应该能够说“让它更短一些”,然后看到一个回复,这会清楚地表明我们仍然在谈论产品描述,因为我们包含了那些以前的消息,我确实做到了。然后我应该能够尽可能长时间地重复这个过程。所以我可能会说“让它提及一种颜色”,然后我就可以一直继续下去。现在您应该仍然能够完成这个练习,即使您在 VS Code 之外运行 Jupyter Notebook。
所以,作为一个快速演示,如果我切换过去,我也有一个在浏览器 Notebook 中运行的。所以如果我运行那个单元格,我可以在这里输入我的提示。所以是一个一句话的产品描述,我仍然应该以完全相同的方式看到输出。现在这个练习有点棘手,因为它需要一些基本的 Python 知识。
如果你对 Python 不太熟悉,那也没关系。我将在这里给你一个关于你将要编写的代码的一般结构的快速提示,以使其工作。所以作为提示,我将在这里放入一些注释和一两个代码片段。我们开始了。
这有点像是我们的起点。所以,以防你需要在第一时间创建初始列表消息,我们可以通过 while true 来永远运行我们的聊天机器人。然后为了获取用户输入,我们可以调用内置的 input 函数。然后我为你需要完成的其他步骤放入了一些注释,我相信你可以根据我们在上一个视频中讨论的关于添加用户消息、调用聊天以及依赖助理消息的代码来找出这些步骤。
所以我鼓励你尝试一下这个练习。所以现在暂停视频,然后去试一试。好了,你已经取消暂停了,我们马上就来解决。所以我将从我刚才给你的代码片段开始。
我们只需填写几行代码。我们已经有了初始的消息列表。我们这里有一个 while true 来永远运行它。我们已经收集了一些用户输入作为文本。
现在我们所要做的就是为每个注释填写一些不同的任务。对于第一个,我们将获取用户刚刚输入的任何文本,并将其添加到我们的消息列表中。为此,我们可以使用我们刚才组合的函数,也就是 add_user_message 函数。所以我会调用 add_user_message。
我将传入要添加到的消息列表,然后是用户刚刚输入的任何内容。然后我们将获取该消息列表并将其发送到我们的 API,并保存我们收到的任何文本。所以我会说我们正在生成的文本将是 chat 和消息。所以这里的 text,就是我们收到的回复。
这就是生成的文本。所以我们现在将使用 add_assistant_message 将生成的文本添加到我们的消息列表中。我们可能也应该打印出来。好的,现在,根据您是在 VS Code 中运行笔记本还是不在,这里可能还需要做一件事。
如果您在 VS Code 中运行,您将需要打印出用户输入。所以我要在这里打印出用户输入。我会在它前面放一个小小的脱字符号和一个空格,让它看起来像一个漂亮的提示。只有在 VS Code 中才需要这样做。
如果您不在 VS Code 中,如果您在浏览器中运行 Jupyter 笔记本,您将自动看到用户输入打印出来。所以再次强调,只有在 VS Code 中才需要。我也许还想在打印文本时添加一些漂亮的格式。但这完全是可选的。
让我们运行一下,确保它确实有效。所以我将运行它,然后就像我们之前看到的那样,我在这里得到了一个漂亮的提示,我将要求提供一个一句话的产品描述。然后我应该看到我的,是的,我们做到了。非常好。
这是我的回应。在这个对话中,随着时间的推移添加更多的消息。所以我可以说缩短它,添加一种颜色等等。非常好。
现在,如果您在本次练习中遇到任何困难,请不要担心。这是我们第一次练习 AI,第一次接触这些内容。所以我们将在整个课程中进行更多练习,有更多机会确保您对所发生的一切充满信心。
7. 系统提示词 (System prompts)
类型:视频 | 时长:7:20 | 视频:05 - 005 - System Prompts.mp4
在为特定用例构建 AI 聊天机器人时,您需要一种方法来控制 AI 的响应方式。系统提示词 (System prompts) 是将通用 AI 转变为遵循特定准则并保持主题专业的助手。

用户级指令的问题 (The Problem with User-Level Instructions)
您可能认为解决方案是将所有要求都包含在用户消息 (user message) 本身中。例如,在每次对话中告诉 AI“提及 AWS 服务”和“不要提及竞争对手”。这种方法存在严重的局限性:
- 您需要预测所有可能的问题和边缘情况
- 指令列表变得笨重且重复
- 用户看到所有内部指令,使对话混乱
- 要求会根据提出的具体问题而改变

系统提示词:一种更好的方法 (System Prompts: A Better Approach)
系统提示词 (System prompts) 通过赋予 Claude 一个角色来解决这个问题。您不是列出具体的“应该做什么”和“不应该做什么”,而是告诉 Claude 扮演特定类型的专业人士。然后 AI 会像那个人一样自然地回应。

系统提示词提供了几个关键优势:
- Claude 获得关于如何一致响应的指导
- AI 采用指定角色的思维模式和约束
- 响应自动保持专注和符合品牌调性
- 您无需预测所有可能的情况
实现系统提示词 (Implementing System Prompts)
要将系统提示词添加到您的 Claude 对话中,您可以将其作为参数传递给 converse 函数:
system_prompt = """
You are an AWS cloud support specialist. Your job is to answer user queries related
to cloud hosting services on AWS.
"""
response = client.converse(
modelId=model_id,
messages=messages,
system=[{"text": system_prompt}]
)
系统提示词作为一个列表传递,其中包含一个带有“text”键的字典。这告诉 Claude 在看到任何用户消息之前应该扮演什么角色。
构建灵活的聊天函数 (Building a Flexible Chat Function)
这是一个可重用的聊天函数,可以优雅地处理系统提示词:
def chat(messages, system=None):
params = {"modelId": model_id, "messages": messages}
if system:
params["system"] = [{"text": system}]
response = client.converse(**params)
return response["output"]["message"]["content"][0]["text"]
这种方法允许您选择性地包含系统提示词。当不提供系统提示词时,Claude 会以其默认状态响应。当您包含一个时,Claude 会扮演该特定角色。
系统提示词实战 (System Prompts in Action)
当您使用和不使用系统提示词测试相同的问题时,差异会立即显现。在没有系统提示词的情况下询问“我如何托管 Postgres 数据库?”,您将获得一个涵盖多个云提供商和自托管选项的全面答案。
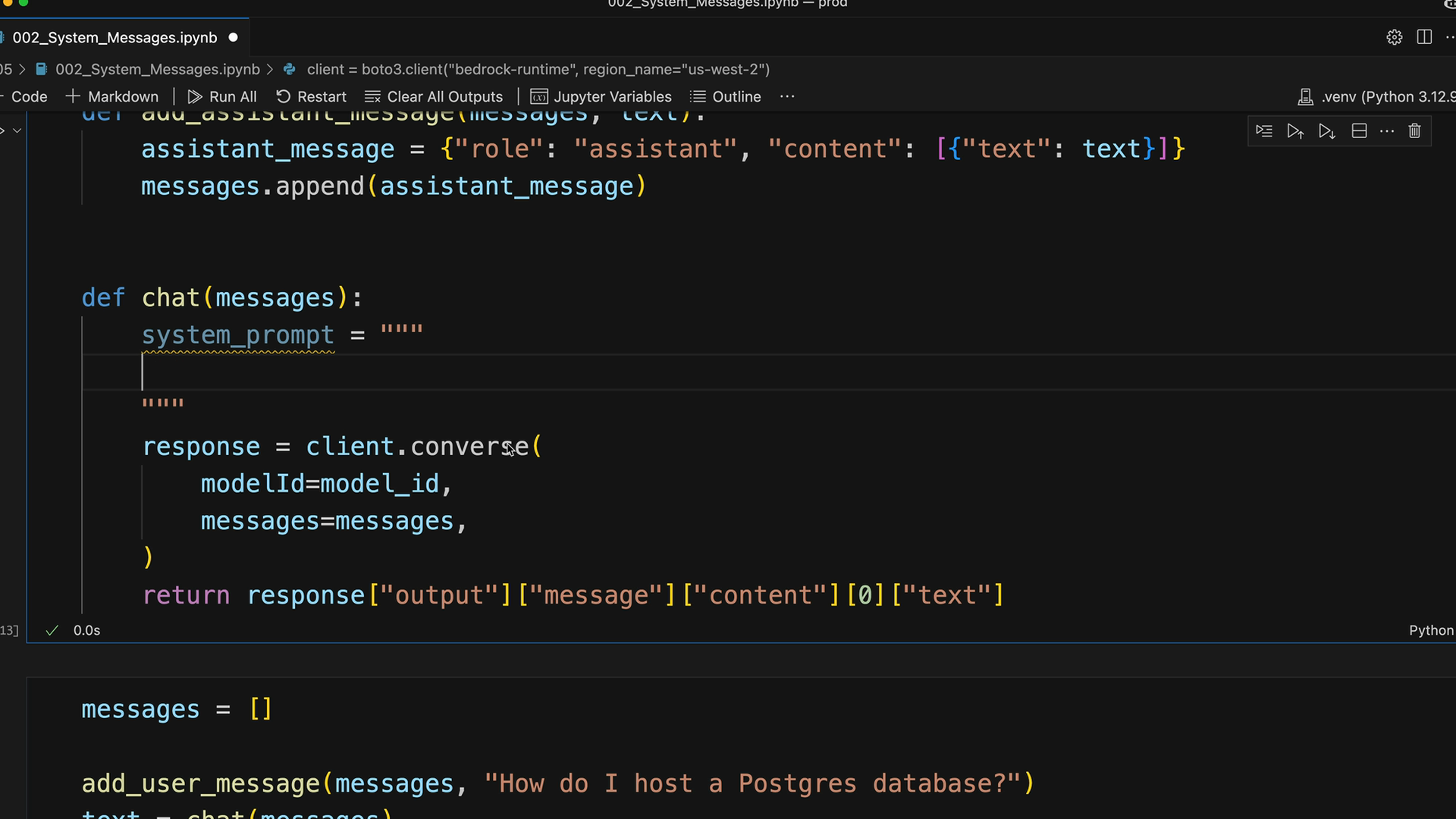
使用 AWS 支持专家系统提示词,响应将专门关注 RDS、Aurora 和基于 EC2 部署等 AWS 解决方案。没有提及竞争对手,并且答案包含 AWS 特定的设置步骤。
更令人印象深刻的是系统提示词如何处理离题问题。使用 AWS 专家提示词询问面包食谱,Claude 会礼貌地拒绝,同时保持角色不变:
重要的技术细节 (Important Technical Details)
在使用系统提示词时,请记住以下要求:
- 系统提示词不能为空字符串——它们必须至少包含一个字符
system参数期望一个带有“text”键的字典列表- 系统提示词在对话中的任何用户消息之前进行处理
- 您可以在对话之间更新系统提示词,但不能在对话中途更新
系统提示词使您能够强大地控制 AI 行为,而无需复杂的规则系统。通过为 Claude 分配特定的专业角色,您可以获得一致、适当的响应,这些响应自然遵循该角色的约束和专业知识。
视频文字稿
在本模块早些时候,我们讨论了如何制作一个基于网络的聊天界面。现在,我想再次回顾那个示例,但稍微做些改变。我想象一下我们如何将那个示例变成一种 AWS 支持专家聊天机器人。所以,也许用户会问一个问题,比如“我如何托管 Postgres 数据库?”那么我们得到的答案应该满足一些要求。
例如,我们得到的并展示给用户的回复应该直接回答用户的问题,并列出在 AWS 上托管 Postgres 的几种不同方式。它甚至可能希望引导用户完成一些初始步骤。最后,它可能还想提及用户可能感兴趣的一些相关 AWS 服务。现在,正如我们希望回复包含一些内容一样,我们的回复也绝对不应该包含某些类型的内容。
例如,我们不希望看到任何提及如何使用竞争对手解决方案托管 Postgres 的答案。我们也不希望看到任何与云服务无关的问题的答案。因此,如果用户询问“我如何修理我的汽车?”,我们可能希望我们的聊天机器人非常礼貌地拒绝回答该问题。现在,我们将探讨两种可能的方法来实现这样的聊天机器人。
这样用户可以提出问题,然后获得符合特定要求的答案。第一种选择,也许不是最好的选择,但我们还是要看一下,我们可以编写一条用户消息,列出所有这些不同的要求。因此,在用户消息中,我们可以说,“确保您提及如何在 AWS 上托管事物。”我们还可以说,“不要提及如何在 AWS 之外托管服务。”而且不要回答与 AWS 没有任何关系的问题。现在,使用第一种选择会非常繁琐,因为我们必须想出一个非常全面的“应该做”和“不应该做”的列表,以解决用户可能提出的每个不同问题。
所以,这可能不是最好的解决方案。也许我们有更好的方法来处理这个问题。考虑到这一点,让我向您展示第二种选择,这将是解决这个问题的更好方法。在第二种选择中,我们将向 converse 函数调用提供一个系统提示词 (System prompt)。
系统提示词将为 Claude 提供关于如何精确响应的指导。它通过为 Claude 分配一个角色来做到这一点。我所说的角色是指我们将本质上告诉 Claude 假装它有一个真实的职业。所以,在这个例子中,我们的系统提示词可能会说,“你是一名 AWS 云支持专家。”这将迫使 Claude 假装它是一名真实的云支持专家。
它将尝试以真实支持专家会回应的方式进行回应。因此,推测起来,真实专家绝不会尝试用竞争对手的解决方案来回答,并且可能会非常礼貌地拒绝回答与云服务无关的问题。通过仅仅分配这个系统提示词,Claude 将尝试做同样的事情。它将尝试以真实支持专家会回应的方式进行回应。
现在,掌握系统提示词的最佳方法是编写一些代码。所以让我们回到 Jupyter Notebooks,获得一些使用系统提示词的经验。回到这里,我已经创建了一个新的 Notebook,但它与我们之前拥有的代码几乎相同。所以我仍然在创建一个客户端,一个模型 ID,然后定义这三个辅助函数。
我还在这里组建了另一个单元格,我只是问了一个非常简单的问题:如何托管 Postgres 数据库?现在,此时此刻,我没有任何系统消息。因此,如果我运行它,我将期望看到一个回复,它有点像一个通用 Claude 答案。它将像 Claude 通常那样回复,给出一个非常全面的答案。
而且它不会满足我们聊天机器人的一些主要要求。也就是说,如果我查看这里的响应,它可能会提及一些竞争对手,这不是我们真正想要的。所以我们可以通过添加系统消息来解决这个问题。现在,我只是硬编码一个系统消息。
然后我将向您展示如何在之后使这个聊天函数更具可重用性。所以首先,在 chat 函数中,我将在这里添加一个系统提示词。为了节省一些时间,我将复制、粘贴一个系统提示词。它与您刚才在图表中看到的相同。
所以它只是说你是一个云支持专家,你只需要回答与云托管相关的问题。然后要将其传递给 converse 调用,我们将在这里添加一个 system 关键字。它将是一个列表,其中包含一个带有该系统提示词文本的字典,如下所示。所以现在我将重新运行该单元格以重新定义 chat 函数。
然后我将尝试在这里重新运行我的对话,我们将看到响应如何更新。希望它会响应一些 AWS 特定的 Postgres 解决方案,而不会提及任何竞争对手。事实证明,这正是我们在这里看到的。我们将看到不同的托管解决方案、一些自托管选项,以及一些初始设置。
然后,值得注意的是,它不会提及任何竞争对手或类似的东西。同样,我们也可以尝试将我们的查询更新为与云托管完全无关的内容。现在,这并非总是有效,但通常有效。所以我会尝试问一些类似“给我一个面包食谱”的问题。
我们会看到现在我们得到了什么样的回应。因此,自然地,如果没有系统提示词,我们期望得到一个实际的食谱。但是有了系统提示词,我们得到了非常礼貌的拒绝。它说,好的,我明白您的意思,但我真正擅长的是 AWS 云支持。
所以如果您有任何相关问题,我可以帮助您。但除此之外,我可能无法回答您关于面包的问题。让我们回到那个聊天函数。正如我提到的,我希望重构这个东西,并使其更容易传入系统提示词,而不是像现在这样总是硬编码。
请注意,如果我们在这里传入这个 system 关键字,我们必须传入一个至少包含一个字符的系统提示词。所以如果我们尝试传入一个空字符串,像这样,然后我运行这个单元格和下一个单元格,我最终会得到一个很大的错误消息。它会告诉我我提供了一个长度为零的系统提示词,并且它必须至少包含一个字符。因此,为了重构这个东西,并使其更容易指定系统提示词,我将在这里复制粘贴一些代码,以节省我们一些时间。
我将替换聊天函数,如下所示。所以现在我将默认接收一个系统提示。它将是 None。然后我提前创建了 params 对象。
然后,如果传入了系统提示词,我将其添加到 system 关键字中,并将所有这些参数传递给 converse 函数。所以现在,作为如何使用这个更新后的 chat 函数的快速演示,我将重新运行那个单元格。我将向下滚动。现在当我调用 chat 时,我可以传入一个 system,内容是“你是一名 AWS 支持专家”。
当然,我们可以对此进行充实。但目前,让我们尝试一下,并确保我们仍然得到一些适当的输出。也就是说,对于“给我一个面包食谱”这个问题,它不应该给出任何好的输出。看起来,是的,我们确实得到了很好的输出。
8. 系统提示词练习 (System prompt exercise)
类型:视频 | 时长:2:47 | 视频:05 - 006 - System Prompt Exercise.mp4
视频文字稿
让我们快速尝试一个关于系统提示词的练习。所以在这个练习中,我希望你编写一些像你在这里看到的代码。我创建了一个消息列表,并添加了一条用户消息,内容是“编写一个检查字符串中是否存在重复字符的函数”。然后我从中获取了一些文本并打印出来。
现在,使用这个起始提示词,我最终得到了很多输出。所以这是我个人得到的结果。你可以看到这里有一些前言。
我有点解释了解决方案,代码中有很多注释。最后,还有一些关于所编写代码的结束语。现在,对于一个相当简单的函数来说,这是很多响应。所以我希望以某种方式获得一个更简洁的答案。
我们可以获得更简洁答案的一种方法是调整用户消息并添加大量不同的要求。因此,例如,在用户消息中,我们可以说,不要添加任何注释之类的东西,只用代码响应,等等。或者,另一种更好的方法是添加一个非常简短的系统提示词,为 Claude 分配一个角色。因此,在这个练习中,我希望你获取你在这里看到的代码,然后只在 chat 函数中添加一个系统提示词,看看你是否能得到一个没有标题文本或页脚,没有注释之类的结果,除了一个通用的函数注释,就像这里这个,那完全没问题。
但除此之外,我真的只想要代码,没有别的。所以我鼓励你现在暂停这个视频,然后尝试一下这个练习。否则,如果你想继续观看,我将立即给出解决方案。所以这就是你解决这个问题的方法。
现在我将为我们的 chat 函数调用添加一个系统提示词。在这种情况下,我将放入一个系统提示词,非常简单,一个角色,暗示 Claude 应该编写一些非常简洁的代码。所以我将放入一个系统提示词:“你是一个编写非常简洁代码的 Python 工程师。”这可能足以删除所有那些额外的注释。
所以我要运行它,我们看看结果如何。是的,我想这可能就是我们想要的。所以它会检查字符串中是否有重复字符。
那个漂亮的函数注释就在那里。但除此之外,我们没有得到任何解释性前言或页脚,也没有任何额外的注释。所以我会说,添加系统提示词比尝试大量调整我们的提示词或特别是用户消息并添加所有那些额外的要求要容易得多。所以我们说这是一个非常好的解决方案。
现在,再次强调,如果你在本次练习中遇到任何困难,请不要担心。我们将在整个课程中继续进行大量练习。
9. 温度参数 (Temperature)
类型:视频 | 时长:7:55 | 视频:05 - 007 - Temperature.mp4
温度 (Temperature) 是一个强大的参数,它控制 Claude 响应的创造性或确定性。了解如何有效地使用它,可以显著改善您的 AI 应用程序。
Claude 如何生成文本 (How Claude Generates Text)
在深入了解温度之前,了解 Claude 的文本生成过程会很有帮助。当您向 Claude 发送“你觉得呢?”之类的提示词时,它会经历三个阶段:
- 分词 (Tokenization):将您的输入分解成更小的块
- 预测 (Prediction):计算可能的下一个词元 (token) 的概率
- 采样 (Sampling):根据这些概率选择一个词元

在上图中,您可以看到 Claude 如何为潜在的下一个词元分配不同的概率。“about”一词有 30% 的机会,“would”有 20% 的机会,依此类推。这个过程会为每个词元重复,直到响应完成。
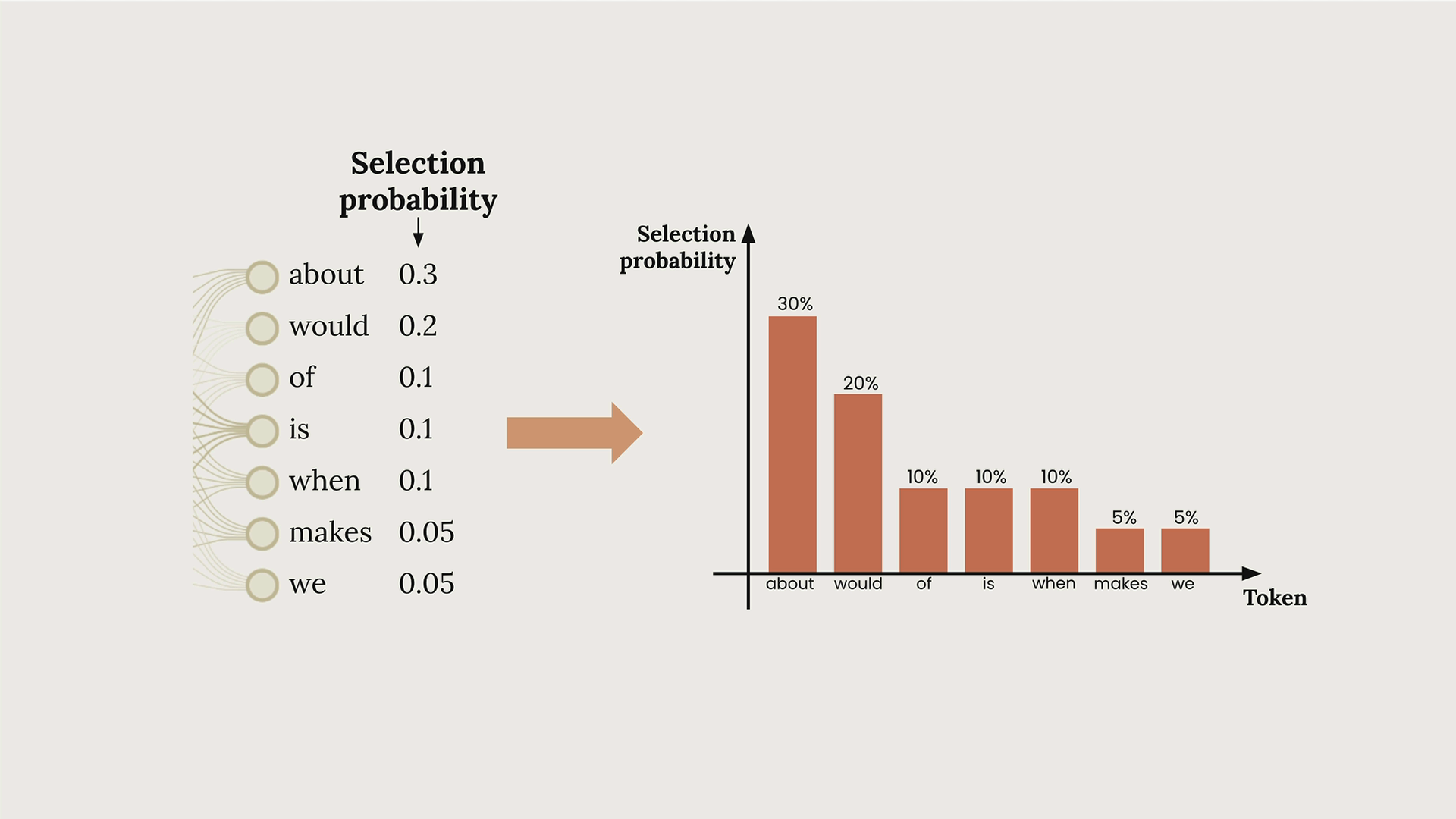
温度参数的作用 (What Temperature Does)
温度 (Temperature) 是一个介于 0 和 1 之间的十进制值,它直接影响这些词元选择概率。将其视为一个创造性拨盘:
- 低温度(接近 0):使概率最高的词元更有可能被选择
- 高温度(接近 1):更均匀地分布所有可能词元的概率
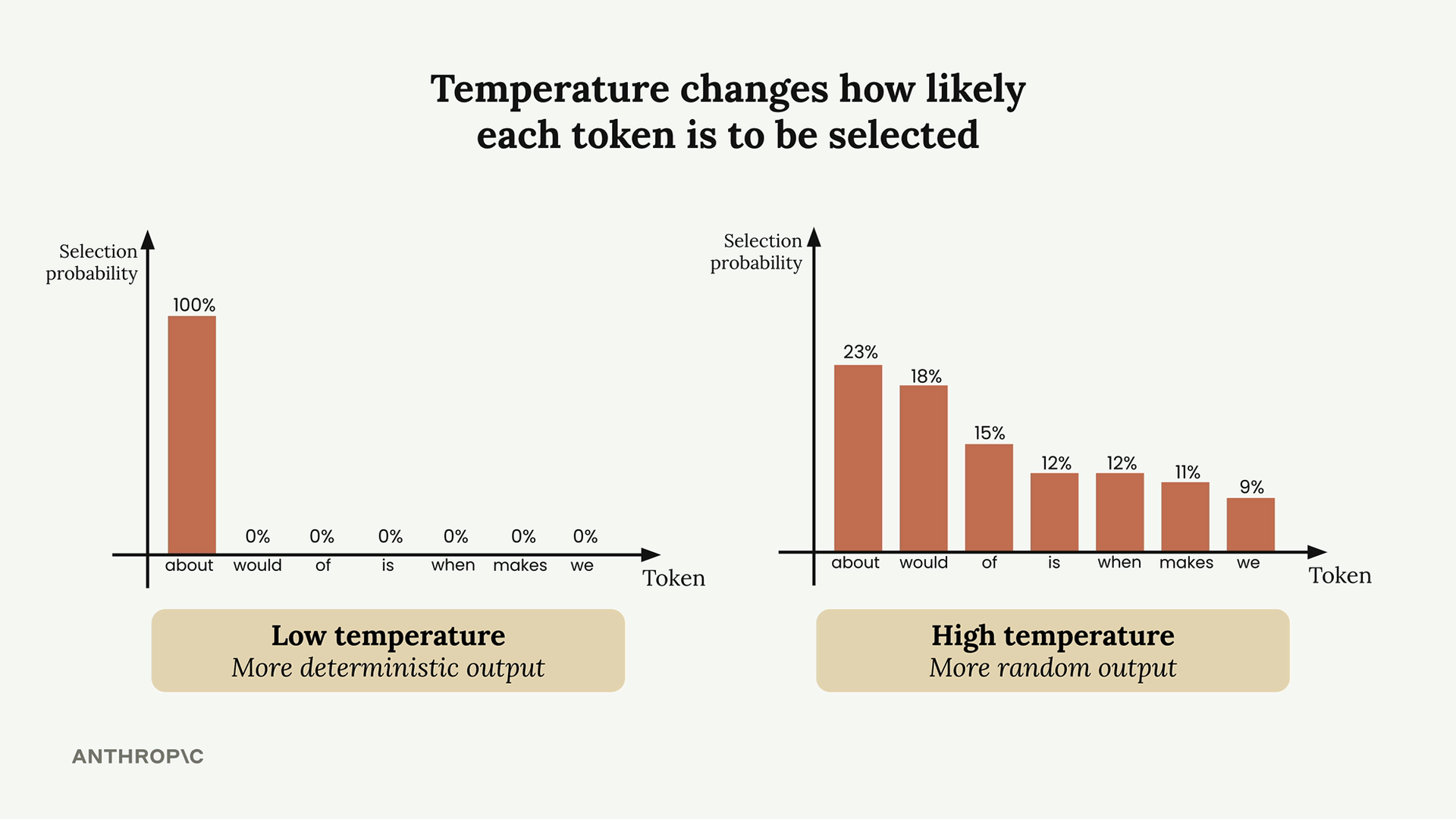
在温度为 0 时,Claude 变得确定性——它将始终选择最可能的词元。在温度为 1 时,低概率词元被选中的机会更大,从而产生更具创造性和多样性的输出。
温度范围和用例 (Temperature Ranges and Use Cases)
不同的任务需要不同的温度设置:
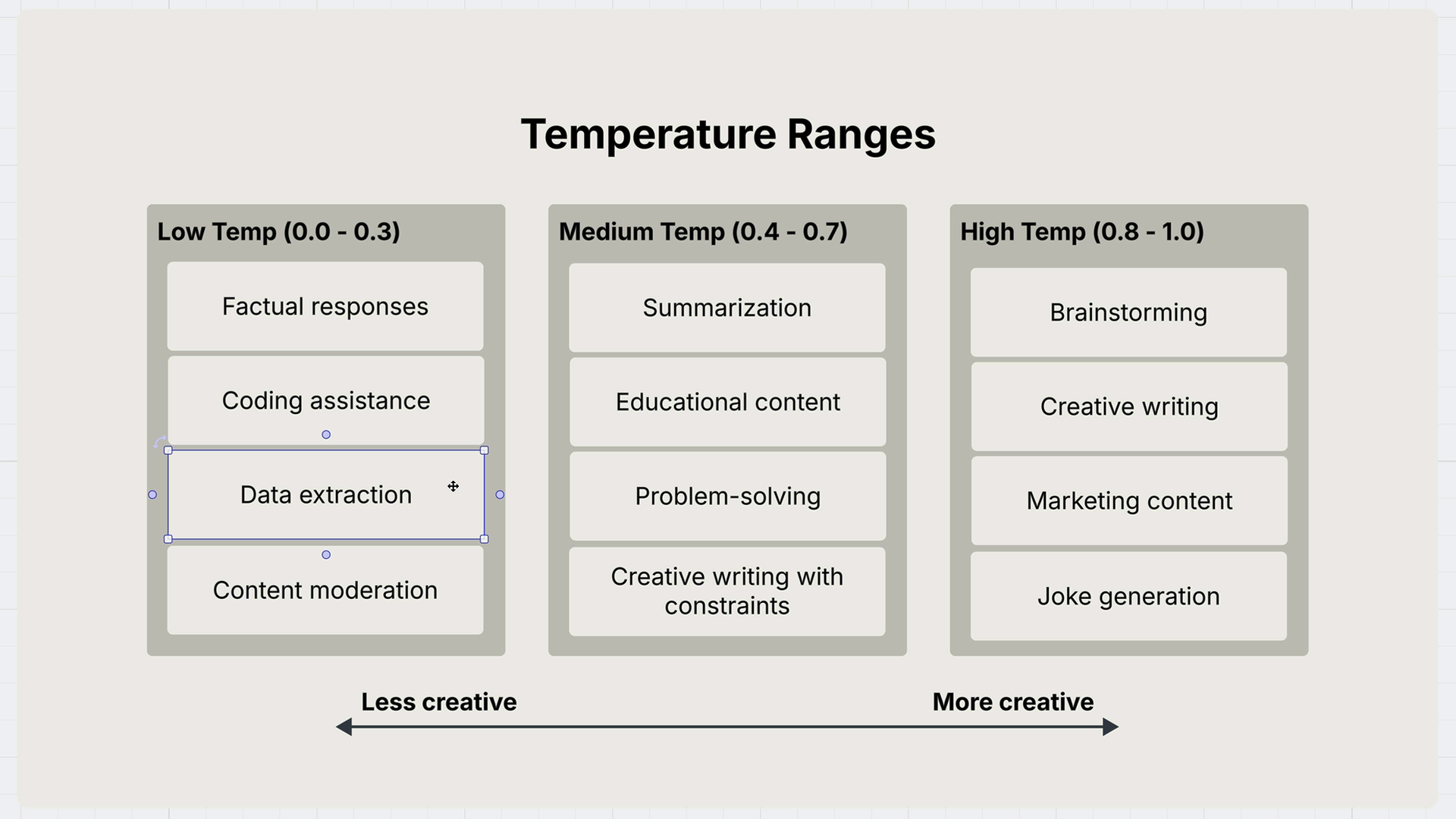
低温度 (Low Temperature) (0.0 - 0.3)
- 事实性回答
- 编码辅助
- 数据提取
- 内容审核
中等温度 (Medium Temperature) (0.4 - 0.7)
- 摘要
- 教育内容
- 解决问题
- 有约束的创意写作
高温度 (High Temperature) (0.8 - 1.0)
- 头脑风暴
- 创意写作
- 营销内容
- 笑话生成
在代码中设置温度 (Setting Temperature in Code)
默认情况下,Claude 的温度设置为 1.0,这意味着最大的创造性。您可以通过将温度添加到推理配置 (inference configuration) 中来覆盖此设置:
def chat(messages, system=None, temperature=1.0):
params = {
"modelId": model_id,
"messages": messages,
"inferenceConfig": {"temperature": temperature}
}
if system:
params["system"] = [{"text": system}]
response = client.converse(**params)
return response["output"]["message"]["content"][0]["text"]
温度参数实战 (Temperature in Practice)
这是一个使用电影创意生成的实际示例。当温度设置为默认值 (1.0) 时,您可能会得到富有创意的回复,例如:
“一位隐居的折纸大师发现她精巧的纸质作品在夜间活了过来,带领她踏上了一段奇幻旅程,从一个威胁要展开他们存在的神秘影子生物手中拯救他们的微型世界。”
但是,当您将相同提示词的温度设置为 0.0 时,您将始终得到更可预测的响应:
“一位时间旅行的考古学家必须阻止一位科技亿万富翁窃取古代文物,该亿万富翁正在利用这些文物建造一个利用其被遗忘力量的末日装置。”
多次运行低温度版本将产生非常相似的响应,通常带有重复的主题,例如“时间旅行历史学家”或“时间旅行考古学家”。
主要收获 (Key Takeaways)
温度 (Temperature) 让您可以直接控制 Claude 的创造力水平。当您需要一致、事实性响应时,请使用较低的温度;当您想要创意、多样化的输出时,请使用较高的温度。默认温度 1.0 使创造力最大化,因此对于需要精确和一致性的任务,请考虑降低它。
视频文字稿
在本课程早些时候,我们简要地谈到了 Claude 实际上是如何生成文本的。请记住,我们将一些文本输入到 Claude 中,例如“你觉得呢?”Claude 然后将对这段文本进行分词(tokenize),或者将其分解成更小的块。Claude 然后将进入预测阶段,在此阶段,它会决定接下来可能出现的单词,并为每个选项分配一个概率。最后,在采样阶段,会根据这些概率实际选择一个词元(token)。
因此,在我屏幕上的这张图中,给定“你觉得呢?”的输入,可能的下一个词元可能是 about、would、of 等等,您在这里右侧看到的所有内容。每个词元都被分配一个概率,然后,在这种情况下,Claude 可能会选择 about 作为最佳的下一个词元。因此,我们最终会得到一个短语“你觉得关于什么?”然后重复整个过程以完成句子或完成整个消息。现在为了确保事情真的清楚,我在这里显示的数字是概率,每个词元被选中的百分比机会。
为了使这些概率更清晰,我将在本视频的其余部分以图表形式显示它们。所以仍然是相同的概率,只是以一种我们更容易理解的格式。您还会注意到,我有点将它们从左到右排序了。这里没有实际的内部排序。
我只是将它们从大到小排序,以使这个图表更容易理解。所以现在我们已经回顾了 Claude 如何生成文本,我想向您展示一种我们可以直接影响这些概率并控制 Claude 实际决定选择哪个词元的方法。所以我们可以使用一个称为“温度”(temperature)的参数来控制这些概率。温度是一个介于 0 和 1 之间的十进制值,我们在进行模型调用时提供它,也就是每当我们调用 converse 函数时。温度将影响概率的精确分布。
这有点难以理解,所以您可以查看我在这里的图表,或者,我制作了一个使用 Claude 本身的快速演示,以便让您更好地了解正在发生的事情。所以让我向您展示那个演示。好的,这就是我们刚才在图表中看到的相同图表。每当我们提供一个温度值接近 0 时,您会看到我这里有一个温度,最高概率的事件更有可能发生。
所以我们的最高概率是 about,它会一直增加到 100%。所以在温度为 0 时,我们开始得到我们所说的确定性输出,我们总是选择具有最高初始概率的词元。然后,当我们开始增加温度时,它会增加我们选择具有较低初始概率的词元的几率。所以我们从选择 we 作为下一个词元的 0% 几率,一直增加到 9%。
这就是温度背后的理论,但这在现实世界中到底意味着什么呢?嗯,我们会根据我们尝试完成的实际任务来开始使用不同的温度值。这些是一些示例范围和可能适合每个样本范围的任务。对于像数据提取这样的任务,我们真的不希望有很多随机性或创造性。
如果我们给 Claude 大块文本并要求它提取非常特定的信息片段,那里根本不需要真正的创造性。我们只希望 Claude 查看我们提供的确切文本并提取最相关的信息。然后,在较高温度方面,我们会变得更具创造性,并且会看到使用较不常见的词元。您可能希望在进行任何需要真正创造力重点的任务时使用较高温度,例如头脑风暴、写作、可能进行一些非常有创意的营销,或者像笑话这样的任务,其中很多笑话确实取决于以不总是完全预期的方式使用单词。
现在我们对温度有了大致了解,让我们来看看如何使用 Bedrock API 来玩转它。所以我想向您展示的第一件事是在 Bedrock 文档或特别是 Bedrock 用户指南中。在这里,在左侧,我已导航到 Anthropic Claude 模型,并且正在查看一些关于 Claude Sonnet 的文档。如果我在此页面上搜索“temperature”,然后向下滚动一点,我最终会在这里找到温度,这是一个参数的描述,您会看到默认情况下,温度设置为 1。
这意味着默认情况下,每当我们通过 Bedrock 访问 Claude 时,我们通常会得到一些非常有创意的回复,这可能好也可能不好。所以我们可能希望控制这个温度值,有时为了确保我们得到更确定性的输出,例如数据提取任务,然后也许我们可以根据我们是否需要更具创造性的任务(例如,为电影编写剧本)来调整温度。所以现在回到 Jupyter 中,我有了上一个视频中一直在使用的相同笔记本。我在这里添加了一个新单元格,我在其中创建了一个新的消息列表。
我添加了一条用户消息,我在其中要求 Claude 用一句话生成一个电影创意。然后我调用 chat,得到一些文本并打印出来。在运行它之前,让我们更新我们的 chat 函数。因此它将接收一个可选的温度参数,我们将通过 converse 调用传递它。
所以我们可以稍微调整一下我们模型的创造力。我将回到这里的 chat 函数。我将添加一个额外的温度参数,我将匹配模型本身的默认温度值,即 1.0。然后我将通过这个 params 字典传递它。
所以我将为此添加一个新键 inferenceConfig。请注意,这是一个词 inference。它不是 interface。所以请确保拼写正确。
然后我将设置传入的温度值。就是这样。所以现在如果我重新运行那个单元格以重新定义 chat,我将回到我在这里添加的用于生成电影创意的单元格。请记住,现在我们有一个默认温度为 1,我暂时保持不变。
如果我运行一次,我应该会得到一个至少有点创意的电影创意。如果我仔细阅读,一位隐居的折纸大师,这是一个非常有创意的电影创意,您立刻就能看出来,我再运行一次。我们肯定会得到另一个非常有创意的电影创意。好的,这个看起来也合理,再来一个。
是的,相当有创意。现在我要把温度加到零。理论上,我们应该会得到一些电影创意,这些创意可能没那么有创意。所以如果我运行它,我会看到一个时间旅行的考古学家。
现在,您和我很难仅仅运行这个提示几次就决定它是否具有创造性。但是让我们再运行一两次,我想您会很快注意到一个主题。请注意,这是一个时间旅行的考古学家。
所以如果我自己再运行一次,我可能会在这里看到另一个关于,是的,我们来了,一个时间旅行的与历史相关的东西。我再来一次。我可能又会看到,一个时间旅行的历史学家。所以您可以立刻开始看到,我们开始得到的回复的创造性会稍微低一些,并且它们往往与我们输入这个相同的初始提示“用一句话生成一个电影创意”时得到的所有其他回复非常相似。
好了,这就是温度。现在请记住,这里有一些通用指南。每当我们执行需要较少创造性或我们希望获得非常确定性输出的任务时,我们都会使用较低的温度。然后,每当我们执行需要更多创造性的任务时,我们就会开始考虑稍微提高一下创造力。
10. 流式输出 (Streaming)
类型:视频 | 时长:9:05 | 视频:05 - 008 - Streaming.mp4
在用 AI 模型构建聊天界面时,用户希望立即看到响应,而不是等待 10-30 秒才能得到完整的响应。converse_stream 函数通过流式传输生成文本来解决这个问题,从而创造了更好的用户体验。
流式输出的工作原理 (How Streaming Works)
流式传输 (Streaming) 不会等待整个响应生成完毕,而是在文本可用时立即发送文本片段。以下是流程变化:
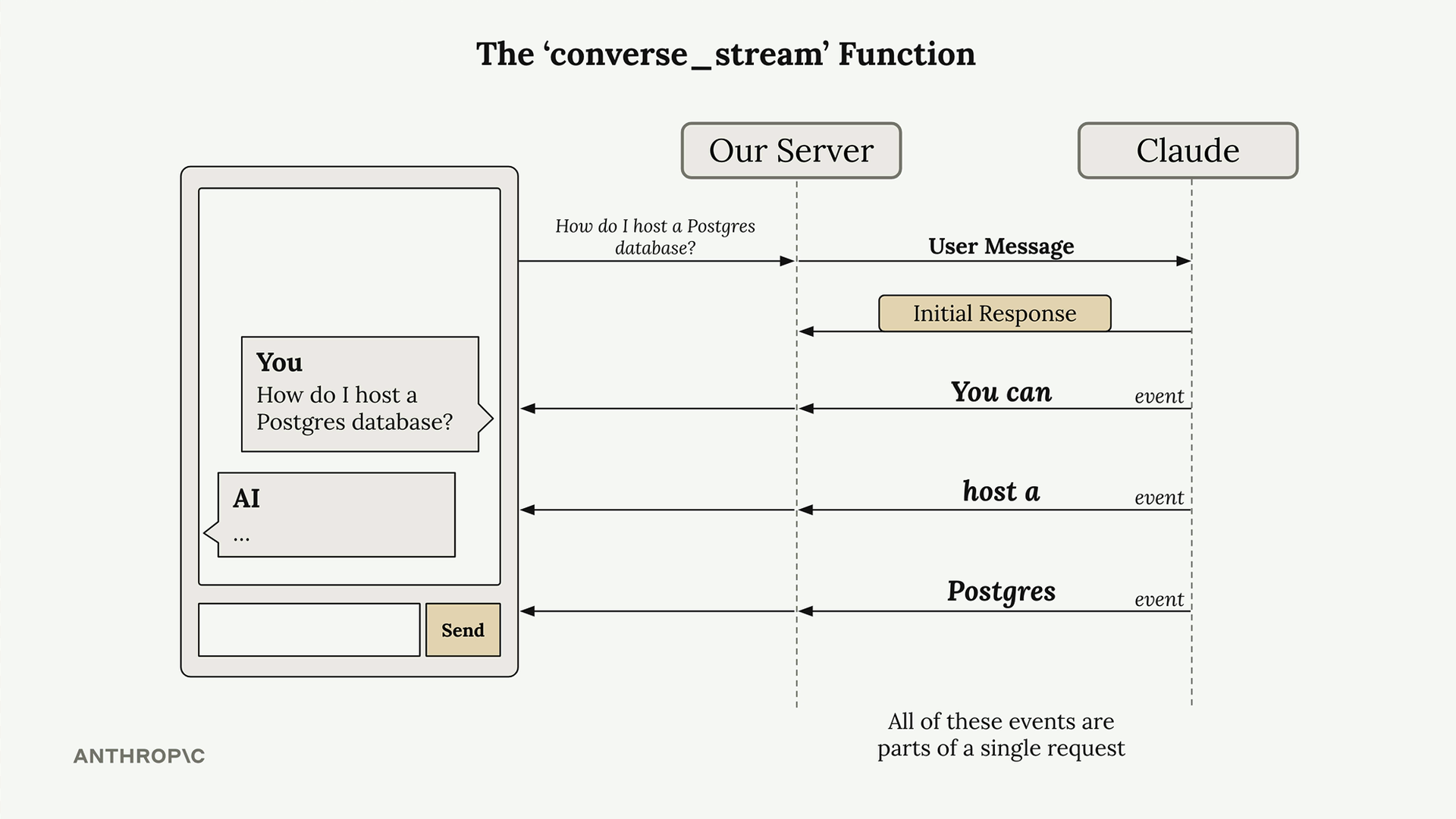
当您调用 converse_stream 时,您会立即获得一个包含流对象 (stream object) 的初始响应。此流是一个生成器,它在模型生成文本时产生事件 (event)。每个事件都包含整体响应的一小部分。
基本实现 (Basic Implementation)
以下是如何在代码中使用 converse_stream:
messages = []
add_user_message(messages, "Write a 1 sentence description of a fake database")
response = client.converse_stream(messages=messages, modelId=model_id)
for event in response["stream"]:
print(event)
这将打印出所有不同的事件,因为它们会陆续到达。您将看到响应以块的形式出现,而不是一次性全部出现。
理解流事件 (Understanding Stream Events)
流会产生几种类型的事件,每种事件都有不同的用途:
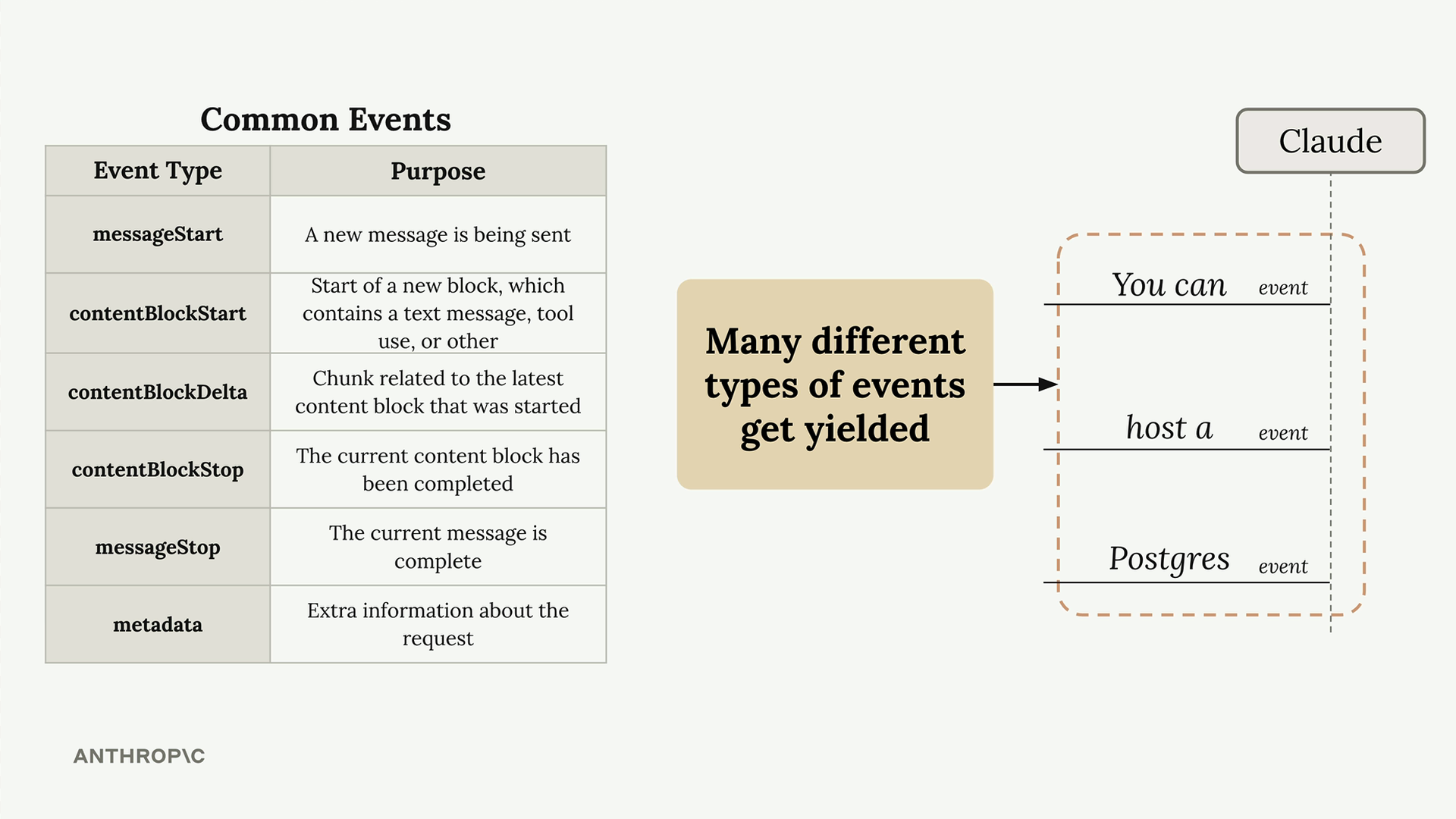
对于基本的文本生成,您只需要关注 contentBlockDelta 事件。这些事件包含您想要显示给用户的实际生成的文本块。
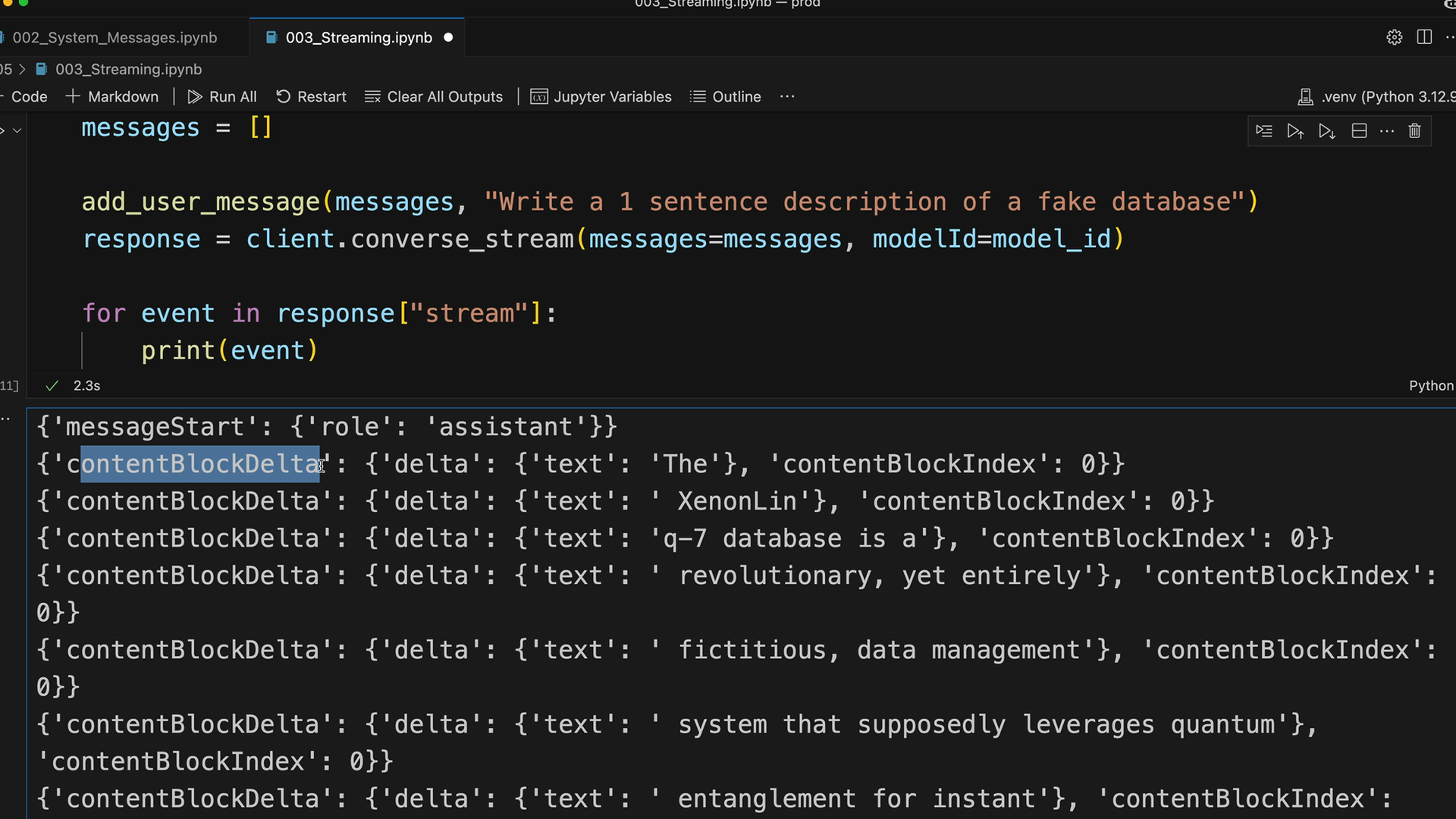
事件总是以可预测的顺序到达:messageStart、多个包含文本的 contentBlockDelta 事件、然后是 contentBlockStop、messageStop,最后是 metadata。
提取文本 (Extracting the Text)
要从每个块中仅获取生成的文本,请过滤 contentBlockDelta 事件并提取文本:
text = ""
for event in response["stream"]:
if "contentBlockDelta" in event:
chunk = event["contentBlockDelta"]["delta"]["text"]
print(chunk, end="")
text += chunk
print("\n\nTotal Message:\n" + text)
end="" 参数消除了 Python 的 print 函数自动添加的换行符,使流式文本显示更自然。
实际应用 (Practical Applications)
在实际应用中,您通常不会打印每个块,而是:
- 通过 WebSockets 或 Server-Sent Events 将每个块发送到您的前端
- 更新 UI 以实时显示不断增长的响应
- 在流式传输完成后存储完整的消息
- 处理流式传输过程中可能发生的任何错误
这种流式传输方法将用户体验从“提交并等待”转变为“提交并观看响应出现”,使您的 AI 驱动应用程序感觉更具响应性和吸引力。
视频文字稿
我想再次回顾我们最初的聊天界面示例。请记住,我们有一个运行在网站或移动应用程序上的聊天界面。用户将提交一个问题,或者他们会将文本输入到我们的服务器中,将其放入用户消息中,然后发送到 Bedrock,Bedrock 将向我们返回一个助理消息,我们将从中提取一些文本,然后可能会将其发送到浏览器,在那里实际生成的文本可以显示给用户。现在,所有这些都将奏效,但它有一个很大的缺点。
那就是发送带有用户消息的初始请求和收到响应之间的时间有时会非常长,这取决于正在生成的响应的长度。因此,它可能需要三秒钟,但也可能需要 30 秒。大多数用户的期望是,每当他们输入某种初始消息时,例如“我如何托管 Postgres 数据库”,他们都希望立即在屏幕上看到一些内容正在生成。但他们不想等 30 秒。
因此,为了实现这种即时反馈,我们可以使用一个函数,它有点像 converse,只是工作方式略有不同。那就是 converse_stream 函数。converse_stream 允许我们流式传输响应。它会流式传输模型正在生成的文本。
让我向您展示几个图表,以确保清楚其工作原理。所以再次,我们将有一个用户向我们的服务器提交初始问题。然后我们将向 Bedrock 发送请求,这次使用 converse_stream 函数。然后我们收到的响应在性质上会有些不同。
立即,我们就会收到一个初始响应。这个初始响应中实际上不会有任何生成的文本。它实际上只是 Bedrock 的一条消息,说:“嘿,我们收到了您的请求,我们现在正在生成一些文本。”然后我们将开始接收事件流。我们将更详细地讨论这些事件到底是什么。
但现在,只需了解它们包含我们要最终发送回用户的生成响应片段即可。我们将收到许多不同的事件。我们收到的数量取决于我们正在生成多少文本。每个事件都将包含正在生成的总体消息的一小部分。
所以也许第一个事件的文本是“你可以”,然后下一个是“托管一个”,然后下一个是“Postgres”。理论上,我们可能在那之后还有一些额外的事件来真正充实消息。当我们收到每个事件时,我们会获取生成的文本,将其发送到浏览器,然后希望我们的浏览器或移动应用程序会在屏幕上显示生成消息的那一部分。然后我们会为每个额外的事件重复此过程。所以我们会获取文本,将其发送到浏览器,并在屏幕上显示出来。
最终,我们将流式传输每个块,因此用户可以尽快开始阅读响应。现在,我想花很多时间讨论这些事件的精确性质,因为这确实是理解 converse_stream 工作原理的挑战部分。但首先,让我们编写一些代码,以便动手操作 Converse Stream 并真正理解它。所以回到笔记本中,我再次有了一组初始消息,它们最初是空的。
我添加了一条消息,只是说,写一个关于虚假数据库的一句话描述。现在我将通过调用 clientConverseStream 来获取响应。我将传入我的消息列表。当然,我仍然需要传入我的模型 ID。
请记住,我们的 modelId 关键字实际上是 model 大写 ID,但我们之前指定的 modelId 是 model_id。现在我将打印出当前的响应。当我运行这个单元格时,您会注意到我只需大约一秒钟即可获得初始响应。所以再次,这是我们在图中看到的初始响应。
它就是这里。在这个初始响应中,实际上没有任何生成的文本。相反,我们会在其中添加一个新的 stream 键。stream 是一个事件流对象。
本质上,它是一个生成器,我们可以对其进行迭代。并且该生成器发出的或产生的每个值都将是这些不同事件对象之一。所以让我们在这里稍微更新一下代码。我将其更改为 for event in response。
请记住,该内容特别位于响应对象中的 stream 键处。然后我将打印出该事件。然后我将再次运行它。让我们看看最终会得到什么。
所以现在我们开始看到一系列不同的事件被打印出来。尽管有点难以看清,但您可能会注意到,当您运行该单元格时,您首先看到一两个打印输出,例如第一个事件打印。然后您会看到其他事件开始逐渐出现,每个事件之间都有很小的延迟。所以让我向您展示一个图表,它可以帮助您理解这些事件到底是什么。
所以再次,每当我们向 bedrock 发出请求时,我们将收到一系列不同的事件。该生成器将产生几种不同类型的事件。当我们运行该单元格时,我们可以看到这些事件都被打印出来。所以我们可能会看到类型为 message start 的事件。
然后我们可能会看到类型为 content block start 和 content block delta 等事件。如果我回到 Jupyter 中,我将在这里看到这些事件。所以这是 message start。然后我有一些 content block deltas。
如果我向下滚动,我最终会收到 message stop 和 metadata 事件。现在,这些不同的事件在我们的响应上下文中具有不同的含义。目前,我们真正关注的唯一事件是 content block delta。每个 content block delta 事件都包含模型生成的一小段文本。
这就是我们最终可能想要显示给用户或以某种方式利用的实际文本。所以如果我再次查看这里的日志,我会看到每个 content block delta 内部都嵌套了一个 delta,然后是一个 text。这就是我关心的实际文本。所以对我来说,我最终会得到一个生成的文本,内容是“Xenonlin Q7 数据库是一个革命性的,但完全是blah blah,你看,等等等等”。
您总是会看到这些不同的事件以相同的顺序列出。所以我们总是会先看到 message start 事件。然后我们会看到一些 content block delta 事件,然后是 content block stop,message stop 和 metadata。现在,当我们开始研究模型的一些更高级功能时,我们最终可能会看到多个 content block start 和 stop。
但目前,当我们只生成文本时,我们只会收到一组 content block deltas 和一个 content block stop。我们甚至实际上不会看到 content block start,尽管那是一个事件。所以那是一个事件,但如果我们只生成文本,我们实际上不会看到它。它只有在我们开始使用工具时才会变得相关,我们稍后会介绍。
所以再次,目前,当我们只关心文本时,我们真正关心的唯一事件是 content block delta。考虑到这一点,让我们更新代码中的 for 循环。我希望收集所有不同的 content block delta 事件。每当我们得到一个这样的事件时,我希望尝试打印出该事件中的文本。
所以我们将这样做。我将更新 for 循环的内容,然后我会说 if "contentBlockDelta" in event。所以,我只是检查这个事件字典中是否存在该字符串。然后我希望获取块文本,我将其命名为 chunk,它将是 event["contentBlockDelta"]["delta"]["text"]。
然后我只会打印出那个块。每当我们使用 Python 的 print 函数打印一个块时,它都会自动在打印语句的末尾添加一个新行。因此,这样读取起来会有点困难。所以我可能会建议添加 end 关键字。
11. 控制模型输出 (Controlling model output)
类型:视频 | 时长:6:44 | 视频:05 - 009 - Controlling Model Output.mp4
除了精心制作更好的提示词之外,还有两种强大的技术可以控制 Claude 的输出:预填充助理消息 (prefilled assistant messages) 和停止序列 (stop sequences)。这些方法使您能够精确控制 Claude 如何响应以及何时停止生成文本。
预填充助理消息 (Prefilled Assistant Messages)
消息预填充 (Message prefilling) 让您可以提供 Claude 响应的开头,这会极大地影响其答案的方向。您无需让 Claude 决定如何开始其响应,而是为其提供一个特定的开头,以引导对话。
其工作原理如下:您使用用户的问题构建正常的消息列表,但随后在末尾添加一条包含您想要的响应开头的助理消息。当 Claude 处理此消息时,它会看到助理消息并认为“我已开始响应此问题,所以我应该从我离开的地方继续。”
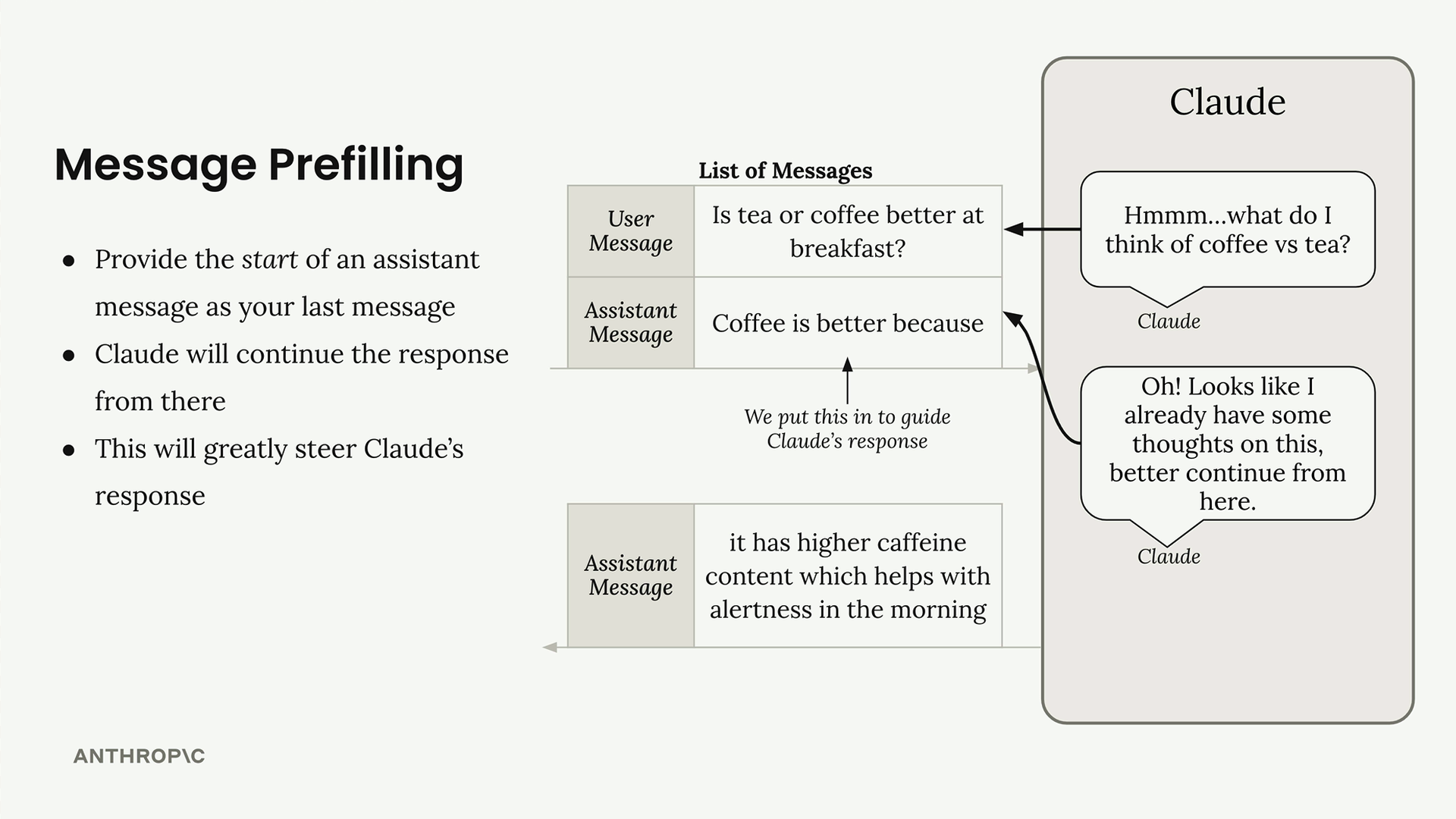
例如,如果您问“早餐是茶还是咖啡更好?”并预填充“咖啡更好,因为”,Claude 将从该点继续并构建一个支持咖啡的响应。关键的见解是 Claude 将从您预填充文本结束的地方继续——它不会重复您已写过的内容。
让我们在实践中看看:
messages = []
add_user_message(messages, "Is coffee or tea better for breakfast?")
add_assistant_message(messages, "Coffee is better because")
chat(messages)
这会返回类似“它含有更多咖啡因”的内容。请注意,Claude 直接从您预填充的文本继续,因此您需要将两部分结合起来才能获得完整的响应:“咖啡更好,因为它含有更多咖啡因。”
您可以通过更改预填充文本来引导 Claude 朝任何方向发展:
- “茶更好,因为”——倾向于茶
- “它们相同,因为”——创建中立响应
停止序列 (Stop Sequences)
停止序列 (Stop sequences) 会强制 Claude 在生成特定文本时立即结束其响应。这在您希望在特定点截断输出或阻止 Claude 继续超出某个标记时很有用。

这个概念很简单:您提供一个字符串列表,一旦 Claude 生成其中任何一个字符串,它就会停止并返回迄今为止生成的所有内容。停止序列本身不包含在响应中。
要使用停止序列,您需要修改 chat 函数以接受它们作为参数:
def chat(messages, system=None, temperature=1.0, stop_sequences=[]):
params = {
"modelId": model_id,
"messages": messages,
"inferenceConfig": {
"temperature": temperature,
"stopSequences": stop_sequences
},
}
这是一个实际示例:
messages = []
add_user_message(messages, "Count from 1 to 10")
chat(messages, stop_sequences=["5"])
这会返回“1, 2, 3, 4,”,并在包含“5”之前停止。您可以指定多个停止序列,Claude 将在它首先遇到的任何一个停止:
chat(messages, stop_sequences=["5", "3, 4"])
停止序列特别适用于:
- 控制响应的长度
- 在结构化输出的自然断点处停止
- 防止 Claude 继续超出特定标记或分隔符
这两种技术都使您能够对 Claude 的行为进行细粒度控制,从而以仅凭简单提示无法实现的方式塑造响应。
视频文字稿
除了改变我们发送给 Claude 的提示词之外,还有另外两种方法可以强烈影响我们从它那里获得的输出。因此,在本视频中,我们将讨论两种技术。一种是预填充助理消息 (pre-filling assistant messages),另一种是停止序列 (stop sequences)。让我们首先看看预填充助理消息。
好的,假设我们向 Claude 发送了一个非常难以回答的问题,比如早餐是茶还是咖啡更好。我完全不知道 Claude 会给我什么样的回复。事实上,让我们快速转到 Jupyter 笔记本,看看我们首先得到了什么样的回复。所以回到这里,我创建了一个新的笔记本,但它仍然包含我们之前所有的相同代码,所以我仍然在创建一个客户端,分配我的模型 ID,然后定义这三个辅助函数。
在下一个单元格中,我将创建一个消息列表。我将添加一条用户消息:“早餐是咖啡还是茶更好?”然后让我们看看我们得到了什么。因此,在短暂暂停之后,我们可能会得到一个相当长的消息,因为我认为 Claude 在这个话题上有很多输入,但您会立即看到它并没有真正采取立场。
因此,在某些情况下,我们可能希望以某种方式强烈影响 Claude,我们希望以某种特定方式引导其输出或响应。因此,我们实现这一点的一种方法是预填充助理响应。通过消息预填充,我们仍然会组装一个消息列表。我们将在其中放入我们的用户提示,但会有一个额外的细微差别。
您和我会手动在末尾添加一条助理消息,并且您和我会编写该助理消息中的内容。然后我们将其发送到 Bedrock。然后,在 Claude 中,我们可以想象幕后发生的事情。我们可以想象 Claude 会看到第一条消息,然后自言自语道:“好的,用户想知道我对咖啡和茶的看法。”然后它会查看第二条消息,这是一条助理消息。
因为它是一条助理消息,Claude 会自言自语道:“哦,看来我对此情况已经有一些想法了。”所以我会继续我的最终回复。我将使用它作为开头发送回去。所以 Claude 本质上会将其用作回复的开头。因为 Claude 看到这句话:“咖啡更好,因为”,这会非常强烈地引导它支持咖啡在早餐时更好。
因此,Claude 很有可能会给我们返回一条最终助理消息,内容是“它含有更多的咖啡因”,这意味着在谈论咖啡。现在,这里需要区分的一个非常重要的事情是,每当我们在这里放入这条最终助理消息时,Claude 会假设这是一种已经编写好的内容,并且它会从句子的末尾继续其回复。所以您会期望 Claude 给您一个完整的回复,例如“咖啡更好,因为它含有更多的咖啡因”,但事实并非如此。它会从您预填充的任何内容的末尾继续回复。
换句话说,这并不是一个完整的句子。如果你想使用它,你可能需要回去将这里的文本和那里的文本缝合在一起。好的。当你解释它时,有时很难理解,但实际上,一旦你看到一两个演示,它就真的很容易了。
所以我们再写一些代码,看看这到底是如何工作的。回到这里,消息预填充,超级简单。我们所要做的就是说“添加助理消息”,然后我们会说“咖啡更好,因为”,现在当我们发送这个时,Claude 希望会给我们一些比以前更能支持咖啡的东西。所以之前,它有点摇摆不定。
它说,“哦,是的,茶或咖啡都可以,”但现在有了消息预填充,我们已经非常强烈地引导它偏爱咖啡。当然,我们也可以说,“茶更好,因为,”好的,这可行。然后,当然,我们也可以给它一个中立的立场。我们可以说,“它们相同,因为,”然后我们得到一个不偏爱任何一方的更中立的回复。
再说一遍,我想让您注意到,当我们使用这种消息预填充时,我们得到的是一个部分响应。所以它只是说,“两种饮料都没有任何营养。”所以就像我之前在图表中提到的,当你使用这种技术时,你需要将你的预填充响应和实际响应的结尾结合起来。现在我们已经看到了消息预填充,让我们来看看本视频的另一个主题,即停止序列 (stop sequences)。停止序列将强制 Claude 在生成特定文本后立即停止响应。
所以我们假设我们提供了一个从 1 数到 10 的提示词。自然地,我们期望会得到 1、2、3、4、5,一直到 10。我们可以通过提供一个值为“5”的停止序列来提前停止生成。然后,在内部,每当 Claude 生成字符串“5”时,它将立即停止响应,并将已经生成的内容发送给我们。
再举一个例子。停止序列是作为额外参数提供给我们的 converse 函数的。所以我将向上滚动一点,找到我们在这里定义 chat 的地方,因为那是我们实际调用 converse 的地方。我将为 chat 函数本身添加一个额外的可选关键字参数。
我将它命名为 stop_sequences,并将其默认值设置为空列表。然后,在 inferenceConfig 字典中,我将像这样传递 stop_sequences。然后我将确保我重新运行该单元格。现在让我们测试一下。
我将转到我的笔记本的最底部,创建一个新单元格。我将复制所有内容,以节省一些打字时间。我将删除预填充的消息,然后更新用户消息,使其内容为“从 1 数到 10”。如果我按原样运行它,我期望会得到完整的列表,也就是 1 到 10。
因此,如果我们想截断响应或在某个点停止它,我们现在可以将一个 stop_sequences 关键字参数添加到我们的 chat 函数中。那将是一个列表。在其中,我们将放入我们可能希望停止的所有不同字符。它们不必是单个字符。
它们可以是完整的单词。所以我可能会说,每当你打印出字符五时就停止。如果我现在运行这个,我们只会看到一、二、三、四。你会注意到它不包含字符五。
所以 5 被完全移除了。我们可以放入任意数量的停止序列。所以我也可以放入,比如说,三、四,像这样。只要它看到这些序列中的任何一个,响应就会停止。
12. 结构化数据 (Structured data)
类型:视频 | 时长:6:01 | 视频:05 - 010 - Structured Data.mp4
当您需要 Claude 生成结构化数据,如 JSON、Python 代码或项目符号列表时,您会经常遇到一个常见问题:Claude 乐于助人,但会在您的内容周围添加解释性文本、标题或 Markdown 格式。当您只需要原始数据时,这种额外的评论会破坏用户体验。
考虑构建一个生成 AWS EventBridge 规则的 Web 应用程序。用户输入描述,点击生成,并期望看到他们可以立即复制和使用的清晰 JSON。如果 Claude 返回的 JSON 被 Markdown 代码块包裹并带有解释性文本,用户就无法简单地复制整个响应——他们必须手动选择 JSON 部分。
默认响应的问题 (The Problem with Default Responses)
默认情况下,Claude 倾向于按以下方式格式化结构化输出:
# EventBridge Rule
```json
{
"source": ["aws.ec2"],
"detail-type": ["EC2 Instance State-change Notification"],
"detail": {"state": ["running"]}
}
This rule captures EC2 instance state changes when instances start running or stop.
虽然这对于文档来说很好,但当您需要仅用于编程用途的 JSON 时,就会出现问题。
## 解决方案:预填充助理消息 + 停止序列 (The Solution: Assistant Message Prefilling + Stop Sequences)
您可以将预填充助理消息 (assistant message prefilling) 与停止序列 (stop sequences) 结合使用,以获得您想要的确切内容。其工作原理如下:
messages = [] add_user_message(messages, "Generate a very short event bridge rule as json") add_assistant_message(messages, "```json")
text = chat(messages, stop_sequences=["```"])
这种技术的工作原理是:
- 使用开头的 Markdown 分隔符预填充助理消息
- 设置停止序列以在 Claude 尝试关闭代码块时停止生成
- 仅捕获这些分隔符之间的内容
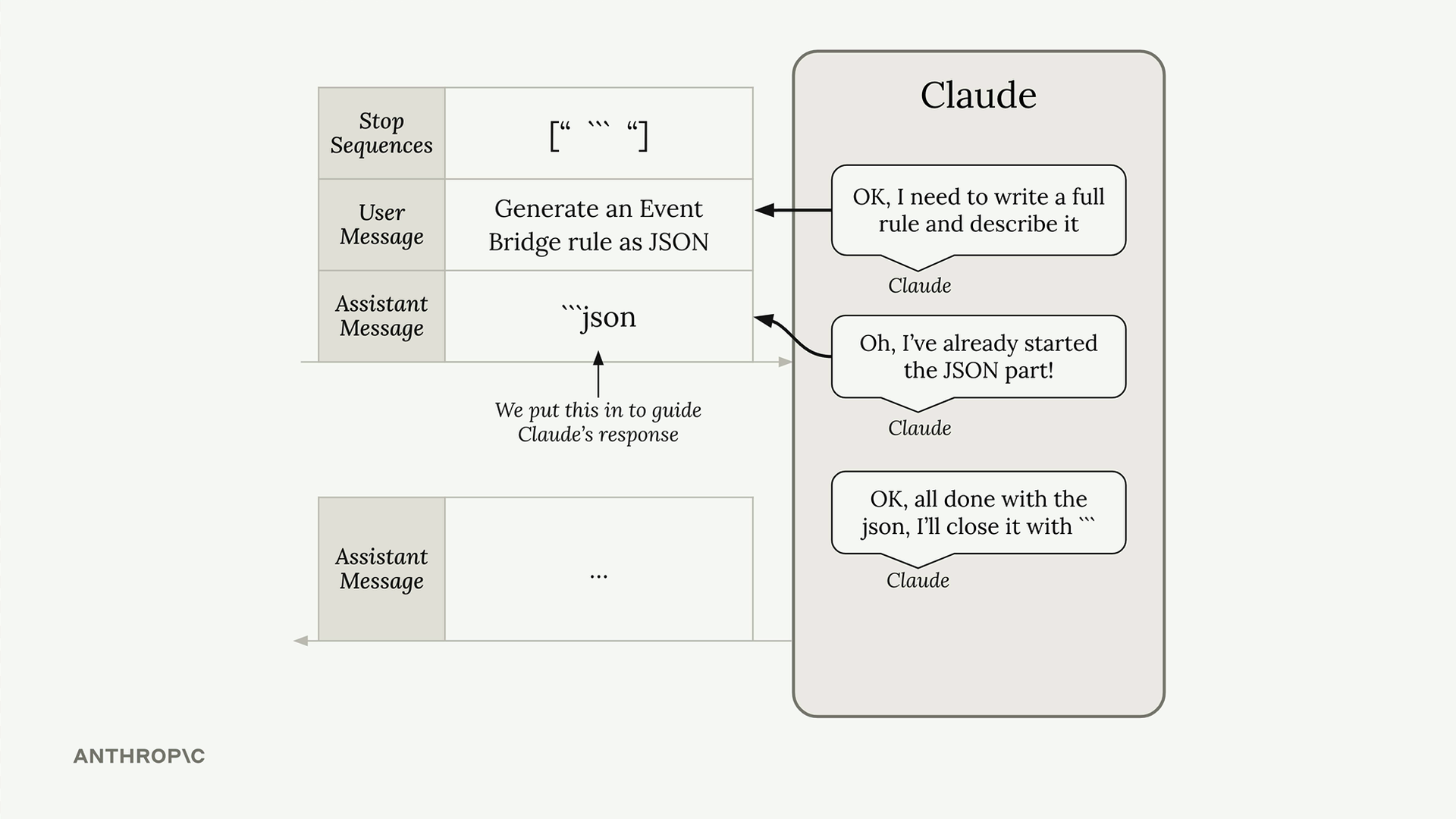
## 幕后工作原理 (How It Works Behind the Scenes)
当 Claude 收到您的请求时,它会看到预填充的助理消息,并认为它已经开始编写 JSON 代码块。Claude 会直接生成实际的 JSON 内容,而不是添加自己的标题和开头分隔符。
当 Claude 完成 JSON 并自然地想要用 ``` 关闭 Markdown 代码块时,停止序列会立即停止生成并返回响应。您将只获得 JSON 内容,没有任何额外的格式。
## 处理结果 (Processing the Results)
返回的文本可能包含一些换行符,但您可以轻松清理:
import json
Parse as JSON to validate and format
parsed_data = json.loads(text.strip())
Or just strip whitespace for other data types
clean_text = text.strip()
## 超越 JSON (Beyond JSON)
这种技术不仅限于 JSON 生成。您可以将其用于任何结构化数据,您只希望获得内容,而不需要 Claude 自然倾向于添加的解释性文本:
- Python 代码片段
- 项目符号列表
- CSV 数据
- 配置文件
- 任何需要清晰、可复制输出的格式
关键在于确定 Claude 会自然地在您的内容类型周围使用哪些分隔符,然后预填充开头分隔符并在结尾分隔符处停止。这使您能够精确控制输出格式,同时利用 Claude 的自然格式化本能。
---
### 13. 结构化数据练习 (Structured data exercise)
> 此课时为互动演练/练习,请访问在线课程平台进行实操。
### 15. 提示词评估 (Prompt evaluation)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 16. 典型评估工作流 (A typical eval workflow)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 17. 生成测试数据集 (Generating test datasets)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 18. 运行评估 (Running the eval)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 19. 基于模型的评分 (Model based grading)
> 类型:视频 | 时长:10:01 | 视频:06 - 005 - Model Based Grading.mp4
在构建提示词评估工作流时,评分器 (graders) 提供有关输出质量的客观信号。评分器接收模型输出并返回某种可衡量的反馈——通常是 1-10 之间的数字,其中 10 表示高质量,1 表示低质量。
## 评分器类型 (Types of Graders)
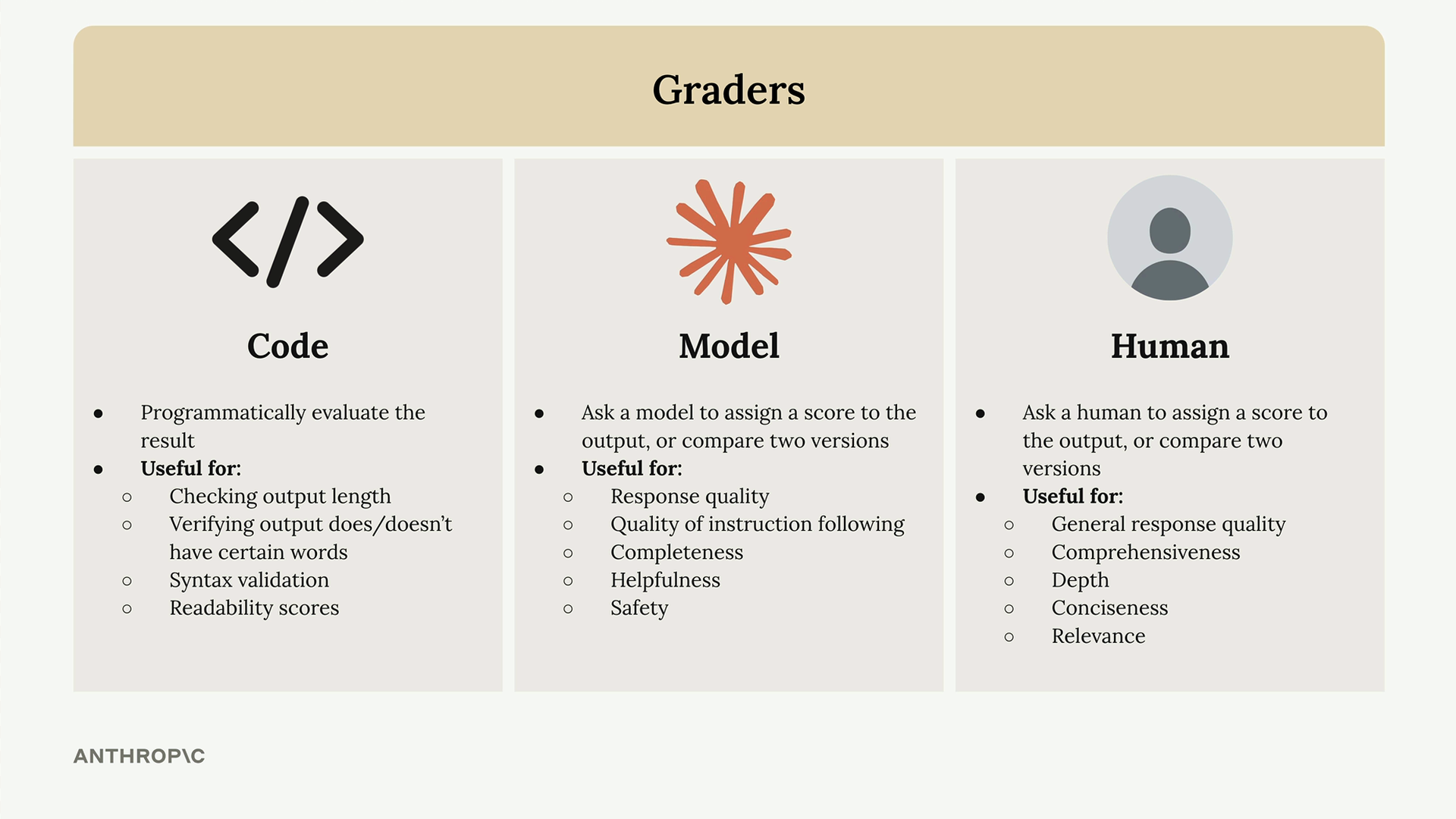
评估模型输出主要有三种方法:
- **代码评分器 (Code graders)** – 使用自定义逻辑以编程方式评估输出
- **模型评分器 (Model graders)** – 使用另一个 AI 模型评估质量
- **人工评分器 (Human graders)** – 由人工手动审查和评分输出
### 代码评分器 (Code Graders)
代码评分器允许您实现任何可以想象的编程检查。常见用途包括:
- 检查输出长度
- 验证输出是否包含/不包含某些单词
- JSON、Python 或正则表达式的语法验证
- 可读性分数
唯一的要求是您的代码在运行时返回某种可衡量的信号。
### 模型评分器 (Model Graders)
模型评分器发出额外的 API 请求来评估原始输出。这种方法为评估以下内容提供了极大的灵活性:
- 响应质量
- 指令遵循质量
- 完整性
- 有用性
- 安全性
### 人工评分器 (Human Graders)
人工评分器提供了最大的灵活性,但耗时且繁琐。它们对于评估以下方面很有用:
- 整体响应质量
- 全面性
- 深度
- 简洁性
- 相关性
## 定义评估标准 (Defining Evaluation Criteria)

在实施任何评分器之前,您需要明确的评估标准。对于代码生成提示词,您可能关注:
- **格式 (Format)** – 应该只返回 Python、JSON 或 Regex,不带解释
- **有效语法 (Valid Syntax)** – 生成的代码应该具有有效语法
- **任务遵循 (Task Following)** – 响应应该通过准确的代码直接解决用户的任务
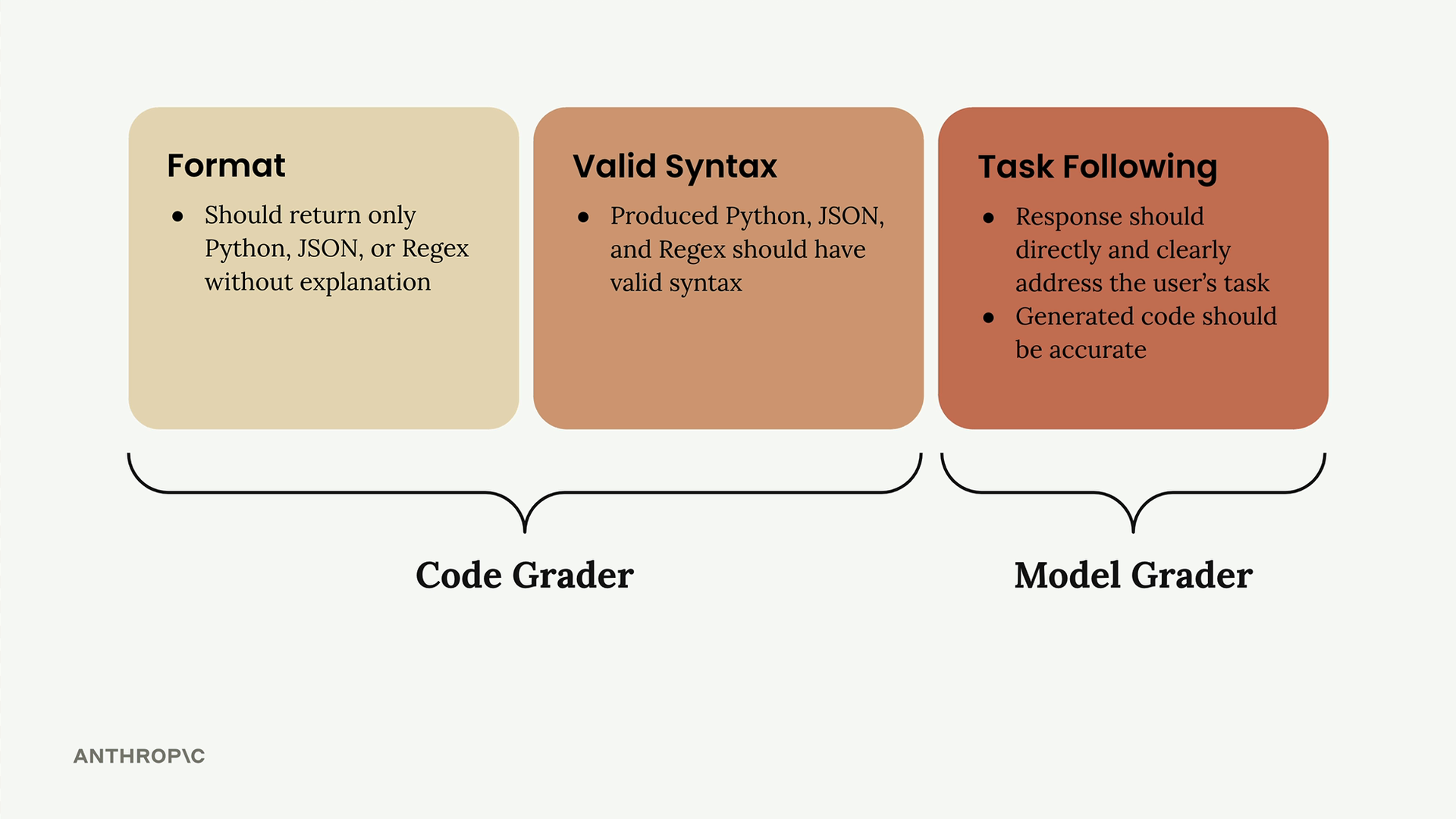
前两个标准非常适合代码评分器,而任务遵循由于其灵活性更适合模型评分器。
## 实现模型评分器 (Implementing a Model Grader)
以下是构建模型评分器函数的方法:
def grade_by_model(test_case, output): # Create evaluation prompt eval_prompt = """ You are an expert code reviewer. Evaluate this AI-generated solution.
Task: {task}
Solution: {solution}
Provide your evaluation as a structured JSON object with:
- "strengths": An array of 1-3 key strengths
- "weaknesses": An array of 1-3 key areas for improvement
- "reasoning": A concise explanation of your assessment
- "score": A number between 1-10
"""
messages = []
add_user_message(messages, eval_prompt)
add_assistant_message(messages, "```json")
eval_text = chat(messages, stop_sequences=["```"])
return json.loads(eval_text)
关键的见解是除了分数之外,还要询问优点、缺点和推理。如果没有这个上下文,模型往往会默认给出 6 左右的中间分数。
## 集成评分器 (Integrating the Grader)
更新您的测试用例函数以使用模型评分器:
def run_test_case(test_case): output = run_prompt(test_case)
# Get model evaluation
model_grade = grade_by_model(test_case, output)
score = model_grade["score"]
reasoning = model_grade["reasoning"]
return {
"output": output,
"test_case": test_case,
"score": score,
"reasoning": reasoning
}
## 计算平均分数 (Calculating Average Scores)
为了获得总体性能指标,计算所有测试用例的平均分数:
from statistics import mean
def run_eval(dataset): results = []
for test_case in dataset:
result = run_test_case(test_case)
results.append(result)
average_score = mean([result["score"] for result in results])
print(f"Average score: {average_score}")
return results
这为您提供了一个具体、客观的指标来跟踪提示词随时间的性能。虽然模型评分器可能有些不一致,但它们为系统地衡量和改进您的提示词提供了起点。
#### 视频文字稿
接下来,我们需要实现我们的代码评分器 (Code Grader)。所以我们的代码评分器将接收模型的一些输出,并确保我们只得到纯粹的 Python、JSON 或正则表达式,没有任何解释。此外,我们还应该确保我们得到的任何类型的代码都具有有效的语法。您可能会好奇,我们如何验证 Python 的语法呢?
嗯,我们使用一个小技巧。我们将定义三个辅助函数。一个称为 `validate JSON`,另一个称为 `validate Python`,还有一个称为 `validate RegEx`。然后,在每个函数内部,我们将获取模型的所有输出,并尝试将其解析为 JSON,或者尝试将其解析为 Python 抽象语法树(AST),或者尝试将其编译为正则表达式。
然后对于其中每一个,如果我们成功解析或加载或进行其他操作,我们将返回满分 10 分。否则,如果在解析操作期间出现错误,我们将假定我们完全未能通过语法检查并返回 0 分。这里还需要注意一件事。为了知道要运行这些不同的验证器或这些类型的评分函数中的哪一个,我们的测试用例数据集需要包含我们期望为每个输出返回的格式。
换句话说,回到我们的数据集这里,至少对我来说,在我们的第一个任务中,我期望得到一个 Python 函数,然后是 JSON,然后是 RegEx。所以我们需要更新我们的数据集,使其包含一个像 `format` 这样的键,它会说,嘿,这个输出应该是 Python,这个应该是 JSON,这个是 RegEx。当然,我可以直接手动编辑这个文件,但相反,我们将更新生成我们数据集的提示词,以便我们最终可以生成非常大的数据集用于测试目的。
现在总的来说,要完成所有这些工作,我们需要经历几个不同的步骤。因此,为了帮助您理解代码方面的内容并保持一切一致,我整理了一个快速核对清单,我们将逐一完成。所以我们的第一项,添加函数来验证 JSON、Python 和正则表达式。为此,我将回到我的笔记本。
我将找到 `run test case` 单元格。我将在它上方添加一个新单元格。然后,在其中,我将添加您刚才在图表中看到的三个函数。为了再次节省一些时间,我将它们粘贴在这里。
您总是可以从这个笔记本的最终版本中复制完成的代码。所以在单元格的顶部,我导入了这两个辅助模块。然后我有了我们刚才看到的三个不同的验证器函数。然后在底部,我有一个通用的函数来找出要使用这些不同的验证器中的哪一个。
所以这里我有了 `grades syntax`。它将查看测试用例。它将特别查看格式。所以我们需要确保我们的测试用例具有我刚才提到的那个 `format` 属性。
然后根据此情况,我们将调用相应的格式函数。好的,这是第一步。所以第二步,我们需要更新我们的数据集以确保我们包含那个 `format` 键。为此,我们将向上滚动一点,找到我们的数据集。
它就在这里。所以生成数据集。我将添加到示例输出中。在任务上,我将在末尾添加一个逗号,然后我将添加一个 `format` 键。
在这里面,我们只需说 JSON 或 Python。或者正则表达式。就这些。所以现在如果我重新运行那个单元格并重新运行它下面的单元格,那实际上会生成数据集。
好了,我们完成了。现在我将回到我的数据集文件。我会看到,是的,我确实在那里得到了格式。看起来它与任务完美匹配。
所以第一个任务是创建 JSON 配置。得到 JSON,写 Python,得到 Python,然后写一个正则表达式,我得到了 regex。好的,接下来是第三步。现在,我们将更新我们的草稿提示模板,只是为了确保我们只需要 JSON、Python 或正则表达式,而不需要其他任何内容。
因为现在我们的草稿提示只说:“是的,尝试解决任务。”所以不可避免地,我们将得到一些非 JSON 或非 Python 的内容,并且我们总是会未能通过实际的验证检查。所以我们将在这里为我们的提示提供一点帮助,给它一些我们知道它需要的工作。所以对于第三步,我们将回到我们的 `run prompt`,也就是我们的草稿提示所在的位置,我将稍微更新一下提示。我将添加一些注释,并要求它只用 Python、JSON 或纯正则表达式响应。
并且不要添加任何注释、评论或解释。接下来,我将确保我们只获取我们真正关心的原始内容。为此,我们将再次使用预填充助理消息 (pre-filled Assistant message) 和停止序列 (stop sequence)。所以我会在这里添加一个助理消息。
在我的助理消息中,在这种情况下,我将输入三个反引号,然后通常,正如我们之前看到的,我们可能会在这里输入类似 JSON、Bash 或 Python 的内容。但在这种特殊情况下,我们事先并不知道我们期望返回的确切格式。我们不知道是会返回 Python、JSON 还是正则表达式。所以这里有一个小小的作弊码,一个变通方法,我们只需输入 `code`,然后那个预填充的助理消息就会告诉 Claude,嘿,你将在这里面放入一些代码,而无需我们明确说明这将是 Python、JSON 或正则表达式。
然后我将像这样添加结束停止序列,并加上反引号。最后,我们需要实际合并模型评分器和代码评分器的分数。为此,我将再次向下滚动,然后我们将找到我们的 `run test case` 函数。所以这就是我们运行模型评分器的地方。
就在它下面,我将组合代码评分器的语法评分器,无论您想怎么称呼它。所以我会说我的语法分数是 `grade syntax`。我们需要传入输出和我们的测试用例。然后最后,我们将语法分数与模型分数合并。
我将首先将这里的 `score` 重命名为 `model_score` 以便清楚。我将取这两个分数的平均值。所以我会说 `score` 将是 `model_score` 加 `syntax_score` 除以二。就是这样。
所以这就是添加一点代码评分所需要做的一切。所以最后一件事是测试这一切。为此,我们将在这里向下滚动一点。所以紧挨着 `run_eval` 函数的是我们实际调用 `run_eval` 并计算我们的总体平均分数的地方。
所以我将重新运行它,请记住它通常需要相当多的时间才能完成。短暂暂停后,我得到了 8.166 的最终分数。那么现在的问题是,这好吗?嗯,真正的答案是,我们不知道。
我们知道的唯一方法是,如果我们现在尝试以某种方式更改我们的提示,并希望获得更好的分数。所以让我们在下一个视频中尝试一个练习,我们将尝试稍微更改我们的提示,并希望提高我们的分数。
---
### 21. 提示词评估练习 (Exercise on prompt evals)
> 类型:视频 | 时长:4:44 | 视频:06 - 007 - Exercise on Prompt Evals.mp4
#### 视频文字稿
让我们来做一个练习,以改进我们的提示词评估工作流。所以这是我将交给您的任务。我想通过提供更多上下文来稍微改进我们的模型评分器 (model grader),让它知道一个好的解决方案应该是什么样子。现在,乍一看这可能有点挑战性,但实际上您只需要通过两个步骤即可添加此额外上下文。
所以第一步,我鼓励您回到我们生成数据集的提示词,并在该提示词中尝试要求其为每个测试用例包含一些解决方案标准。因此,理想情况下,我们的测试用例输出现在应该有一个额外的解决方案标准键,它可能看起来像您在这里看到的。所以它可能会说一些关于好的解决方案应该是什么样子。也许您会说,好的解决方案将包括这个特征、这个特征和这个特征。
一旦我们有了这个额外的解决方案标准,我们就可以将其插入到我们的 `grade by model` 提示词中。所以您可能会找到该提示词中我们放入解决方案以进行评估的现有区域,然后紧接着,您可能会添加新生成的解决方案标准。这就是让我们的模型评分器更好地了解一个好的解决方案应该是什么样子所需要的一切。像往常一样,我鼓励您现在暂停视频,然后尝试一下这个练习。
否则,我们现在就来解决。所以解决方案实际上就是这两个独立的步骤。应该非常直接地开始。回到我的笔记本中,我将找到我们的 `generate_data_set` 函数。
在其中,我将找到我们输入的大提示词。然后当我们要求每个不同的测试用例时,我会说,除了任务和输出格式之外,我还希望获得一些解决方案标准,然后我将在这里放入一个字符串,只是为了给我们的模型一个指示,说明这个键实际上应该是什么。所以我会要求提供一些评估解决方案的关键标准。差不多就是这样。
所以我将重新运行单元格。我将转到下面的单元格并重新生成数据集。好的,只需几秒钟。它应该完成了。
我们来了。所以现在我们应该有一个更新的 `data_set.JSON` 文件。我将打开该文件,现在我应该会在这里看到一些更新的任务,仍然带有格式,但现在我也获得了一些解决方案标准。所以解决方案标准,我们可以回顾一下。
当然,您的会和我的不同,但它会再次给出一些关于好的解决方案应该是什么样子的想法。接下来是第二步,我们将找到我们的 `grade by model` 函数,特别是其中的提示词。然后我们将包含这个新生成的解决方案标准,再次告诉模型评分器,一个好的解决方案是什么样的。为此,我将回到笔记本。
我将向下滚动并找到那个 `grade by model` 函数。它就在这里。所以我会找到提示词。我们已经放入了原始任务,生成的输出。
然后在那之后,我将给模型写一些说明,并说,这里有一些您应该用来评估解决方案的标准。所以,您应该用来评估解决方案的标准。我将添加一些标签。我很快就会告诉您为什么我们添加这些标签,因为我们开始讨论提示工程。
然后我将从测试用例中插入我们的解决方案标准。那个键就在那里,记住,我们的测试用例实际上是这些对象,这些对象中的每一个都单独存在,所以我们知道,因为我们在这里这个文件中看到了它,那个字典中有一个 `solution_criteria` 的键。所以我们正在获取那句话并将其放在这里。好的,现在是时候运行单元格了。
我们现在将重新运行我们的管道,看看一切如何运作。所以我会向下滚动到 `run_eval` 函数。然后紧接着就是我们实际执行所有内容的地方。所以我将运行它,然后我们就会得到更新后的分数。
现在我想快速打印出结果。只是为了看看这会如何影响实际输出。所以我们会再次打印出 JSON `dumps results`,缩进为两个空格。所以现在我们可以看到模型输出的结果。
所以这是实际的生成输出。这是我们的测试用例。所以我们可以查看任务和解决方案标准。在这种情况下,分数是 9。
现在,希望我们由模型评分器生成的推理部分会比以前更加充实,因为我们包含了解决方案标准。
---
### 23. 提示词工程 (Prompt engineering)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 24. 清晰直接 (Being clear and direct)
> 类型:视频 | 时长:2:05 | 视频:07 - 002 - Being Clear and Direct.mp4
提示词的第一行是您整个请求中最重要的部分。这是您为后续所有内容奠定基础的地方,做好这一点可以显著改善您的结果。
## 清晰直接 (Being Clear and Direct)
在撰写那关键的第一行时,您需要关注两个关键原则:清晰 (clarity) 和直接 (directness)。这意味着使用简单明了的语言,不留任何歧义,明确您希望 Claude 做什么。

## 清晰沟通 (Clear Communication)
“清晰”意味着:
- 使用任何人都易于理解的简单语言
- 明确表达您想要什么,不要拐弯抹角
- 以直截了当的陈述来引导 Claude 的任务
不要写“我想了解人们放在屋顶上利用太阳的那些东西——那些太阳能电池板,我想它们是这样叫的”这样模糊的话,而是直接写:“写三段关于太阳能电池板工作原理的文章。”
## 直接指令 (Direct Instructions)
“直接”侧重于您构建请求的方式:
- 使用指令,而不是问题
- 以直接的动作动词开头,例如“Write(编写)”、“Create(创建)”或“Generate(生成)”
不要问“我在读关于可再生能源的文章,地热能听起来很棒。哪些国家使用它?”尝试改为:“列出使用地热能的三个国家。包括每个国家的发电统计数据。”
## 付诸实践 (Putting It Into Practice)
让我们看看这项技术在实践中。从一个只是简单地问“这个人应该吃什么?”的弱提示词开始,我们可以应用我们清晰直接的方法。
改进后的版本变为:为符合其饮食限制的运动员生成一份一日三餐计划。
此修订立即告诉 Claude:
- 要采取什么行动(生成)
- 要创建什么(膳食计划)
- 关键约束(一天,为运动员,考虑限制)
## 结果很重要 (Results Matter)
这个简单的改变可以对输出质量产生显著影响。在我们的示例中,评估分数从 2.32 跳到 3.92——仅通过重构第一行就实现了 substantial 的改进。
关键 takeaway (takeaway) 是,当您将 Claude 视为需要明确指导的能干助理时,它会做出最佳响应,而不是一个必须猜测您想要什么的人。以直接的动作动词强力开头,明确任务,您会立即看到更好的结果。
#### 视频文字稿
起始分数是 2.32,我们肯定只能往上走。考虑到这一点,让我们来看看我们将用来改进提示词的第一个提示词工程技术。好的,我们将讨论清晰直接的概念。这两条规则实际上是关于您提示词的第一行。
提示词的第一行往往是最重要的。在第一行中,您需要使用简单直接的语言,并用一种动作动词,精确地告诉 Claude 它的任务是什么。例如,我们可能希望提示词的第一行是“写三段关于太阳能电池板工作原理的文章”。这告诉 Claude 它将有一个任务,需要编写或生成或创建一些东西。
它还澄清了一些关于预期输出的信息以及该输出应该包含什么。因此,我们真正在第一行设置了一个动作并提供了一个任务。另一个很好的例子是列出使用地热能的三个国家,并为每个国家提供发电统计数据。同样,我们告诉 Claude 做某事或立即给它一个任务,以及一些关于预期输出的信息。
让我们把这种在提示词第一行清晰直接的理念付诸实践,看看我们能否用它来改进我们目前正在处理的提示词的结果。使用我们刚刚学到的规则,我可能会将这一行更新为“为符合其饮食限制的运动员生成一份一日三餐计划”。所以再次,我通过在开头使用一个动作动词来保持直接,然后用非常简单的语言,我为 Claude 提供了一个直接的任务来完成。现在,让我们重新运行这个单元格以获取我们更新后的提示词,然后重新运行评估本身,看看这是否会改善我们的分数。
我敢打赌,正如您所猜测的,是的,我们可能会比以前做得好一点。所以我想我以前是 2.32。现在我达到了 3.92,这无疑是一个进步,但仍然不是很好。所以让我们继续下一个视频,看看我们的下一个提示工程主题,以便稍微改进我们的提示。
---
### 25. 具体明确 (Being specific)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 26. 使用 XML 标签构建结构 (Structure with XML tags)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 27. 提供示例 (Providing examples)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 28. 提示词练习 (Exercise on prompting)
> 此课时为互动演练/练习,请访问在线课程平台进行实操。
### 30. 工具调用介绍 (Introducing tool use)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 31. 工具函数 (Tool functions)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 32. 工具的 JSON Schema (JSON Schema for tools)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 33. 处理工具调用响应 (Handling tool use responses)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 34. 运行工具函数 (Running tool functions)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 35. 发送工具结果 (Sending tool results)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 36. 带工具的多轮对话 (Multi-Turn conversations with tools)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 37. 添加多个工具 (Adding multiple tools)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 38. 批量工具调用 (Batch tool use)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 39. 带工具的结构化数据 (Structured data with tools)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 40. 灵活的工具提取 (Flexible tool extraction)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 41. 文本编辑器工具 (The text editor tool)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 43. 检索增强生成介绍 (Introducing Retrieval Augmented Generation)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 44. 文本分块策略 (Text chunking strategies)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 45. 文本嵌入 (Text embeddings)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 46. 完整的 RAG 流程 (The full RAG flow)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 47. 实现 RAG 流程 (Implementing the RAG flow)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 48. BM25 词法搜索 (BM25 lexical search)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 49. 多搜索 RAG 流水线 (A multi-search RAG pipeline)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 50. 结果重排序 (Reranking results)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 51. 上下文检索 (Contextual retrieval)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 53. 扩展思考 (Extended thinking)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 54. 图像支持 (Image support)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 55. PDF 支持 (PDF support)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 56. 引用 (Citations)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 57. 提示词缓存 (Prompt caching)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 58. 提示词缓存规则 (Rules of prompt caching)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 59. 提示词缓存实战 (Prompt caching in action)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 61. MCP 介绍 (Introducing MCP)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 62. MCP 客户端 (MCP clients)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 63. 项目设置 (Project setup)
> 此课时为环境配置/安装指南,请访问在线课程平台按步骤操作。
### 64. 使用 MCP 定义工具 (Defining tools with MCP)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 65. 服务器检查器 (The server inspector)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 66. 实现客户端 (Implementing a client)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 67. 定义资源 (Defining resources)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 68. 访问资源 (Accessing resources)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 69. 定义提示词 (Defining prompts)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 70. 客户端中的提示词 (Prompts in the client)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 71. MCP 回顾 (MCP review)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 73. 代理概览 (Agents overview)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 74. Claude Code 设置 (Claude Code setup)
> 此课时为环境配置/安装指南,请访问在线课程平台按步骤操作。
### 75. Claude Code 实战 (Claude Code in action)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 76. 使用 MCP 服务器增强 (Enhancements with MCP servers)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 77. Claude Code 并行化 (Parallelizing Claude Code)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 78. 自动化调试 (Automated debugging)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 79. 计算机使用 (Computer Use)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 80. 计算机使用原理 (How Computer Use works)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 81. 代理的品质 (Qualities of agents)
> 本节内容与「使用 Anthropic API 构建应用」课程的对应章节基本一致,区别在于使用 Amazon Bedrock 平台调用 Claude。请参考本文档第 8 课的对应章节获取详细教程内容,或访问在线课程查看 Bedrock 特定示例代码。
### 83. 课程总结 (Course wrap up)
> 此课时为课程介绍/总结页面,请访问在线平台查看。
---
# 第 12 课:模型上下文协议(MCP)入门
> MCP 开发完整教程
> 课程链接:[模型上下文协议(MCP)入门](https://anthropic.skilljar.com/introduction-to-model-context-protocol) | 共 14 节课
---
## 第1部分:简介
### 1. 课程欢迎辞
> 此课时为课程介绍/总结页面,请访问在线平台查看。
### 2. MCP 简介
> 类型:视频 | 时长:4:40 | 视频:09 - 001 - Introducing MCP.mp4
模型上下文协议 (MCP) 是一个通信层,它能为 Claude 提供上下文和工具,而无需您编写大量繁琐的集成代码。您可以把它看作是一种将工具定义和执行的负担从您的服务器转移到专门的 MCP 服务器的方式。
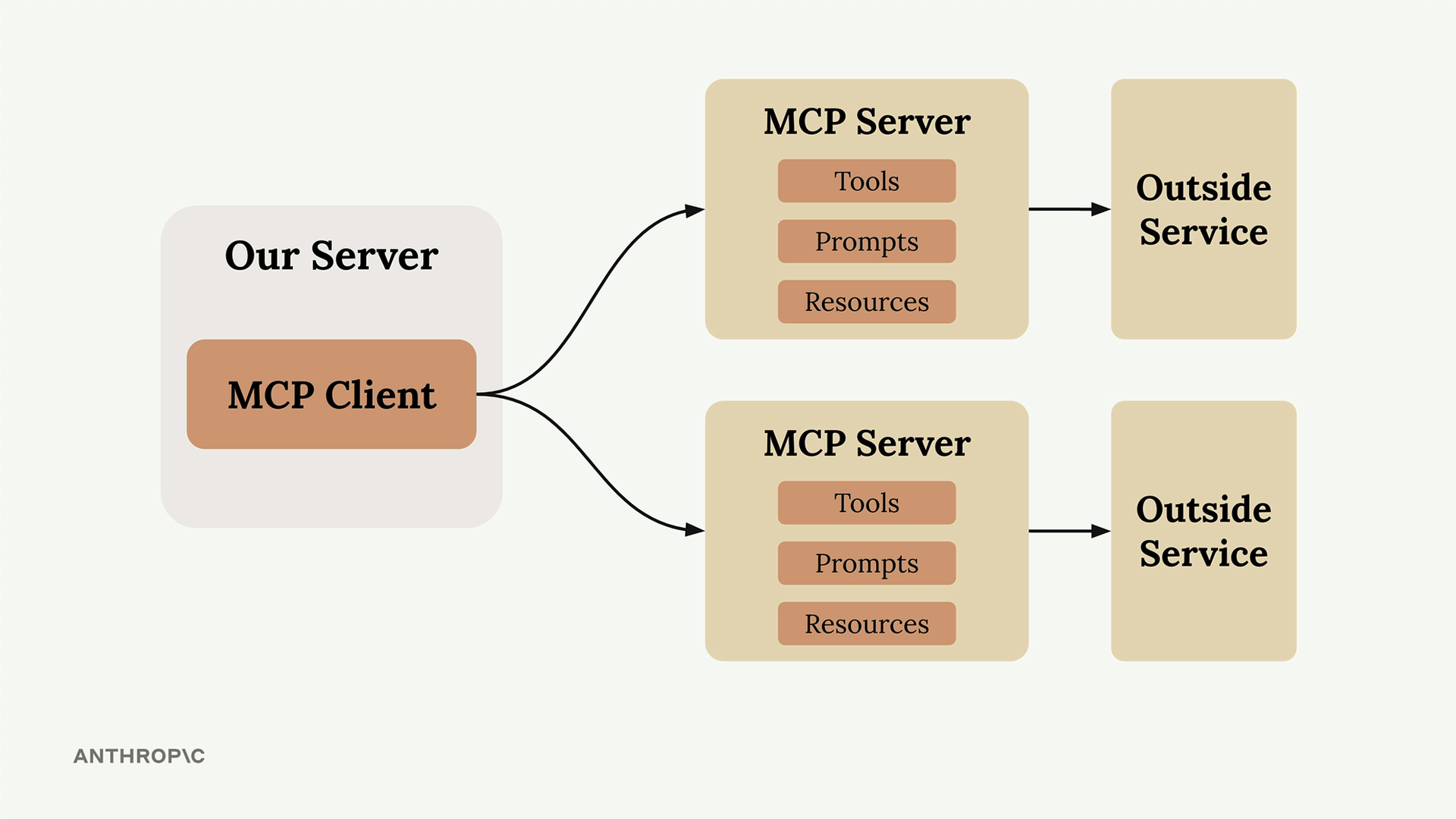
初次接触 MCP 时,您会看到展示其基本架构的图表:一个 MCP Client (MCP 客户端)(您的服务器)连接到包含工具、提示和资源的 MCP Servers (MCP 服务器)。每个 MCP Server 都充当某个外部服务的接口。
## MCP 解决的问题
假设您正在构建一个聊天界面,用户可以向 Claude 询问他们的 GitHub 数据。用户可能会问:“我所有仓库里有哪些开放的拉取请求?”为了处理这个问题,Claude 需要工具来访问 GitHub 的 API。

GitHub 功能非常庞大——仓库、拉取请求、问题、项目等等。如果没有 MCP,您需要创建数量惊人的工具模式和函数来处理 GitHub 的所有功能。
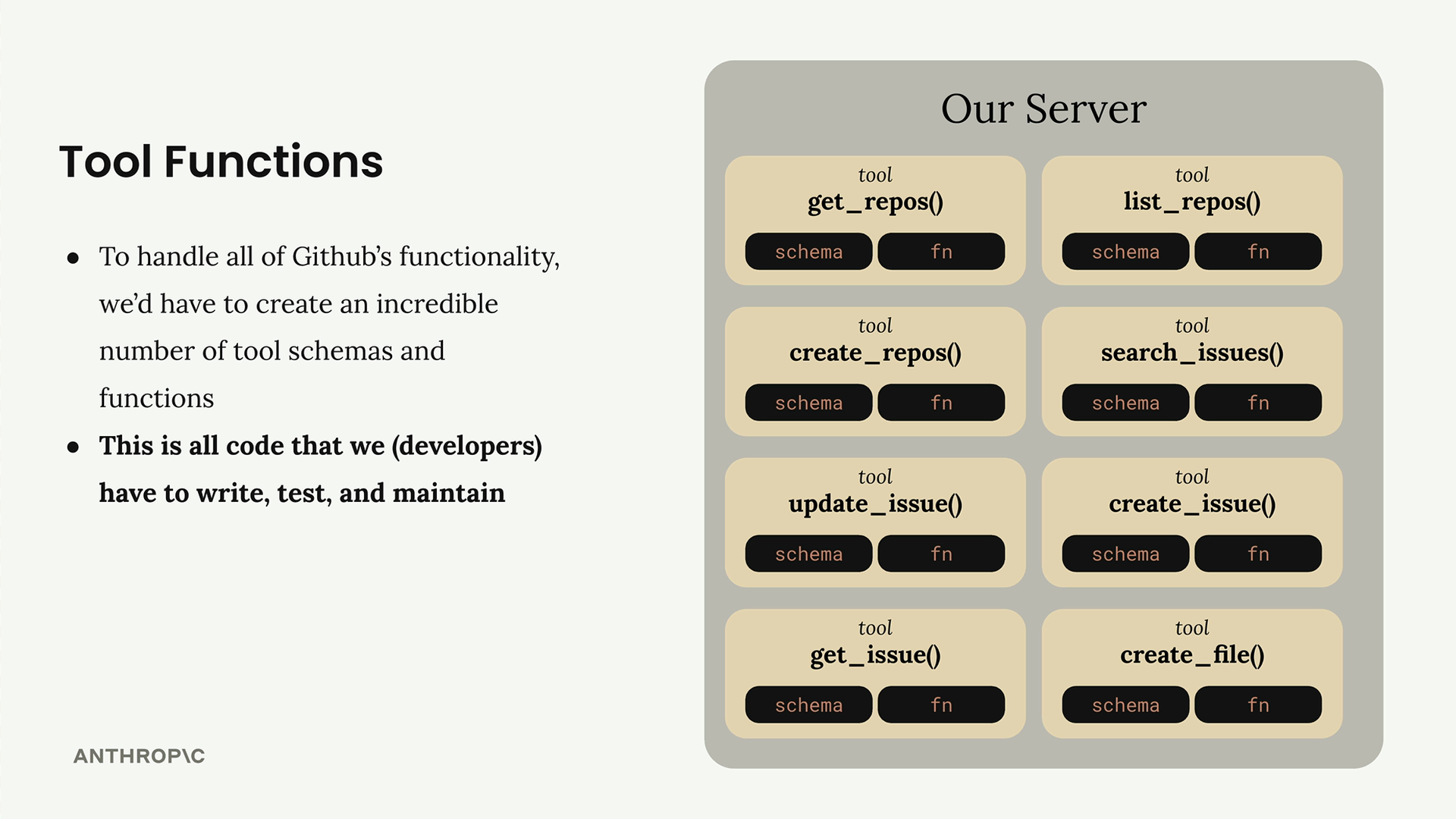
这意味着您需要自己编写、测试和维护所有这些集成代码。这会耗费大量精力,并带来持续的维护负担。
## MCP 的工作原理
MCP 通过将工具定义和执行从您的服务器转移到专用的 MCP 服务器来减轻这种负担。您无需再为 GitHub 编写所有工具,而是由一个针对 GitHub 的 MCP Server 来处理。
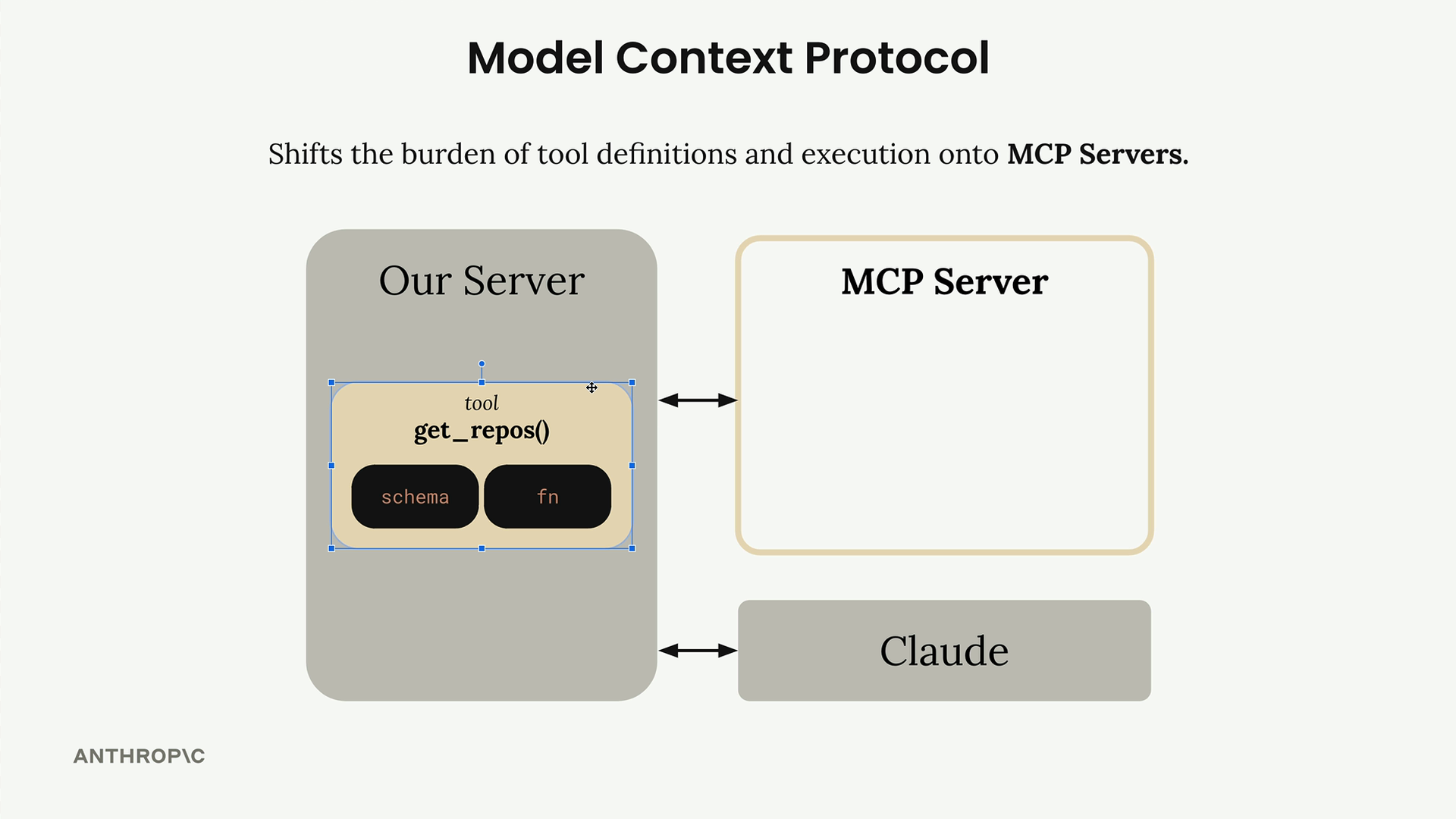
MCP Server 封装了大量围绕 GitHub 的功能,并将其作为一套标准化的工具暴露出来。您的应用程序连接到这个 MCP 服务器,而不是从头开始实现所有东西。
## MCP 服务器详解
MCP 服务器提供对外部服务实现的数据或功能的访问。它们充当专门的接口,以标准化的方式暴露工具、提示和资源。
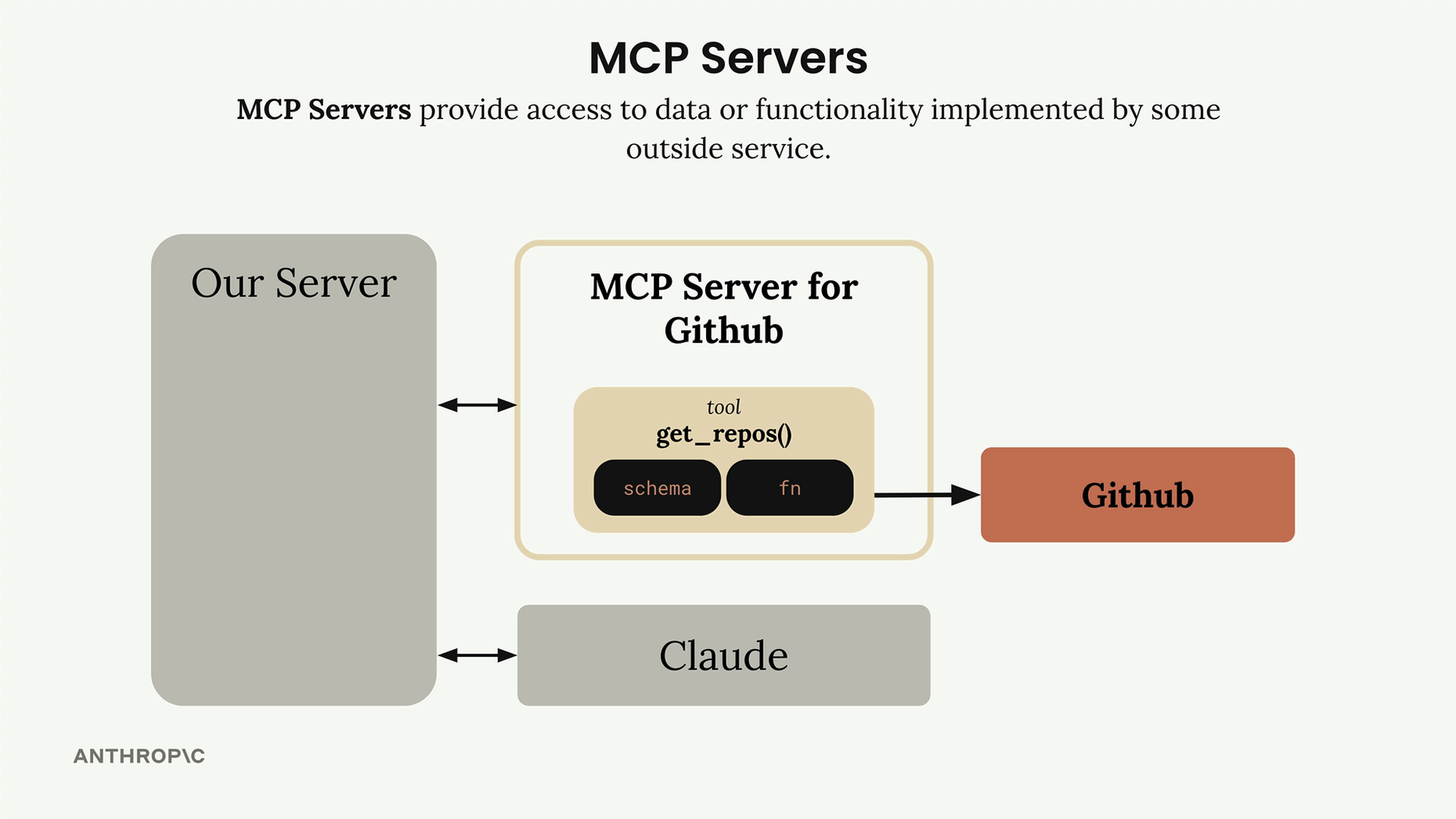
在我们的 GitHub 示例中,针对 GitHub 的 MCP Server 包含 `get_repos()` 等工具,并直接连接到 GitHub 的 API。您的服务器与 MCP 服务器通信,后者处理所有 GitHub 特定的实现细节。
## 常见问题
### 谁来编写 MCP 服务器?
任何人都可以创建 MCP 服务器实现。通常,服务提供商自己会制作其官方的 MCP 实现。例如,AWS 可能会发布一个官方的 MCP 服务器,其中包含用于其各种服务的工具。
### 这与直接调用 API 有何不同?
MCP 服务器为您提供了已经定义好的工具模式和函数。如果您想直接调用 API,则需要自己编写这些工具定义。MCP 为您节省了这部分实现工作。
### MCP 不就是工具使用(Tool Use)吗?
这是一个常见的误解。MCP 服务器和 `Tool Use (工具使用)` 是互补但不同的概念。MCP 服务器为您提供已经定义好的工具模式和函数,而工具使用是关于 Claude 如何实际调用这些工具。关键区别在于谁来完成工作——使用 MCP,别人已经为您实现了工具。
好处是显而易见的:您无需自己维护一套复杂的集成,而是可以利用 MCP 服务器来处理连接到外部服务的繁重工作。
#### 视频文字稿
> 在本模块中,我们将重点关注模型上下文协议。MCP 是一个通信层,旨在为 Claude 提供上下文和工具,而无需您作为开发者编写大量繁琐的代码。初次接触 MCP 时,您会经常看到像这样的图表。它展示了 MCP 的两个主要元素,即客户端和服务器。
>
> 服务器通常包含许多内部组件,名为工具、资源和提示。这里有很多术语。因此,为了帮助您理解这一切,我们将想象我们正在构建一个小应用程序,并看看 MCP 如何融入其中。我们的示例应用程序将是另一个聊天界面。
>
> 它将允许用户与 Claude 就其 GitHub 数据进行聊天。因此,如果用户问一个问题,比如“我所有不同的仓库中有哪些开放的拉取请求?”,期望是 Claude 可能会利用一个工具来访问 GitHub,访问用户的帐户,并查看他们有哪些开放的拉取请求,或许还有开放的仓库或其他任何东西。这里的要点是,我们可能会通过使用一组工具来实现这一点。现在,我想非常快地提一下,GitHub 拥有巨大的功能。
>
> 有仓库、拉取请求、问题、项目以及大量其他东西。因此,要拥有一个完整的 GitHub 聊天机器人,我们真的必须编写大量的工具。如果我们想构建那个示例应用程序,我们就得负责编写所有这些模式和所有这些函数。这都是作为开发者的你我必须编写、测试和维护的代码。
>
> 这需要大量的努力,给我们带来了很大的负担。让开发者维护一个大型集成集的挑战是模型上下文协议旨在解决的主要困难之一。MCP 将定义和运行工具的负担从您的服务器转移到所谓的 MCP 服务器。所以你我不再需要编写这个工具了。
>
> 相反,它将在别处,在这个 MCP 服务器内部被编写和执行。这些 MCP 服务器真的可以被认为是某个外部服务的接口。所以我可能有一个 GitHub MCP 服务器,它提供对由特定 GitHub 提供的数据和功能的访问,我们基本上将大量围绕 GitHub 的功能包装起来,并以一组工具的形式放入这个 MCP 服务器中。所以在这一点上,我们对 MCP 服务器是什么有了非常基本的了解。
>
> 它为我们提供了一组工具的访问权限,这些工具暴露了与某个外部服务相关的功能。这里的好处是,你我不需要编写所有这些不同的工具模式和函数等等。既然我们有了这个基本的了解,我想谈谈一些很多人在初次学习 MCP 服务器时会有的非常常见的问题。所以,似乎总会出现三个常见问题。
>
> 第一个常见问题是,谁编写这些 MCP 服务器?答案是任何人。任何人都可以制作一个 MCP 服务器实现。但你经常会发现服务提供商会制作他们自己的官方实现。
>
> 所以举个例子,AWS 可能会决定发布他们自己的官方 MCP 服务器实现,并且在其中,可能会有各种各样不同的工具供你使用。第二个常见问题是,使用 MCP 服务器与直接调用服务 API 有什么不同?嗯,正如我们刚刚看到的,如果我们想直接调用一个 API,比如 GitHub,那么我们就必须自己编写这个工具。现在我们就可以直接调用 GitHub 了。
>
> 那我们得到了什么呢?嗯,所有真正改变的是我们现在必须自己编写模式和函数实现。所以仅仅通过添加 MCP 服务器,我们就为自己节省了一点时间。最后一个常见问题更多的是一个常见的批评,你会看到人们对 MCP 有这种批评。
>
> 而这种批评最常来自于那些不太了解 MCP 到底是什么的人。所以你经常会看到人们说 MCP 和工具使用是同一回事。嗯,正如我刚才向你阐述的,MCP 服务器和工具使用,它们是互补的。它们是不同的东西,但它们是互补的。
>
> MCP 背后的理念是,您不必编写工具函数和工具模式。那是别人为您完成的,并且被包装在这个 MCP 服务器中。所以在某种程度上,是的,它们有点相似,因为我们在这两种情况下都在谈论工具使用,但 MCP 服务器真正关注的是谁在做实际工作。所以如果你看到这种批评,同样,通常是因为人们不太了解 MCP 的全部内容。
---
### 3. MCP 客户端
> 类型:视频 | 时长:4:56 | 视频:09 - 002 - MCP Clients.mp4
MCP 客户端充当您的服务器和 MCP 服务器之间的通信桥梁。它是您访问 MCP 服务器提供的所有工具的入口点,负责处理消息交换和协议细节,这样您的应用程序就无需操心这些了。
## 传输无关的通信
MCP 的一个关键优势是传输无关性(transport agnostic)——这是一个花哨的说法,意思是客户端和服务器可以根据您的设置通过不同的协议进行通信。
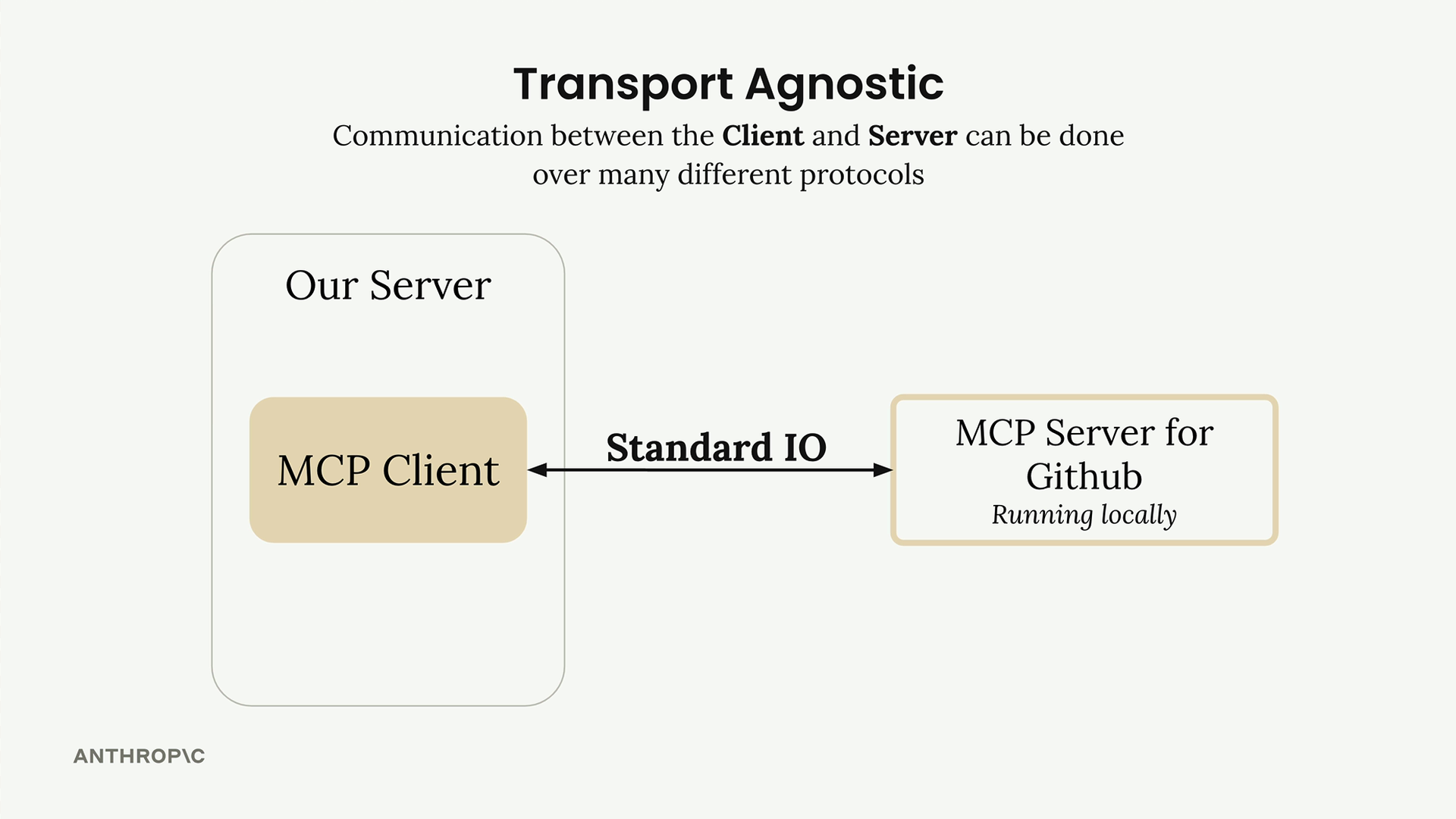
最常见的设置是在同一台机器上运行 MCP 客户端和服务器,通过`standard input/output (标准输入/输出)`进行通信。但您也可以通过以下方式连接它们:
- HTTP
- WebSockets
- 其他各种网络协议
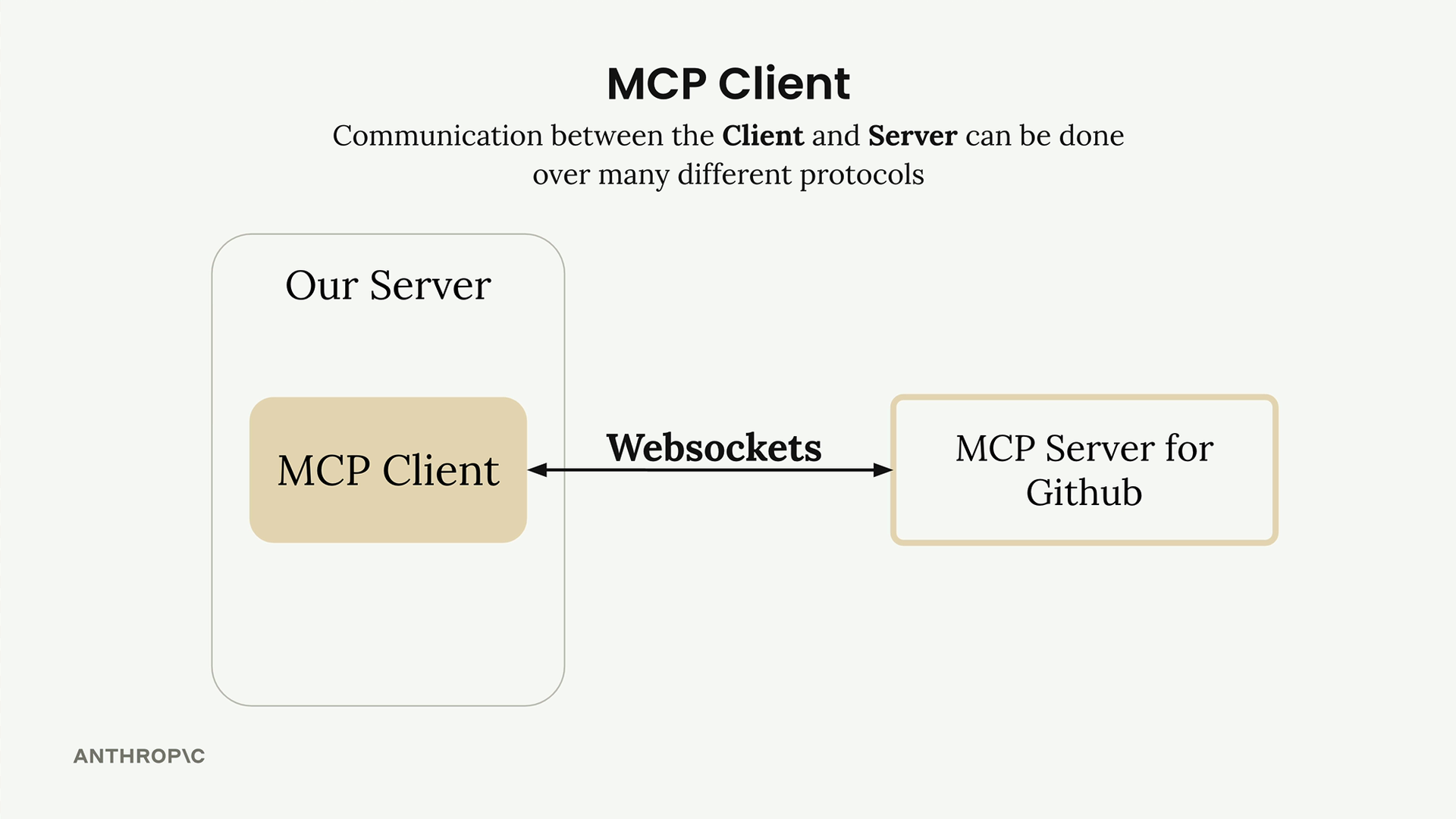
## MCP 消息类型
连接后,客户端和服务器会交换 MCP 规范中定义的特定消息类型。您将主要使用的类型包括:
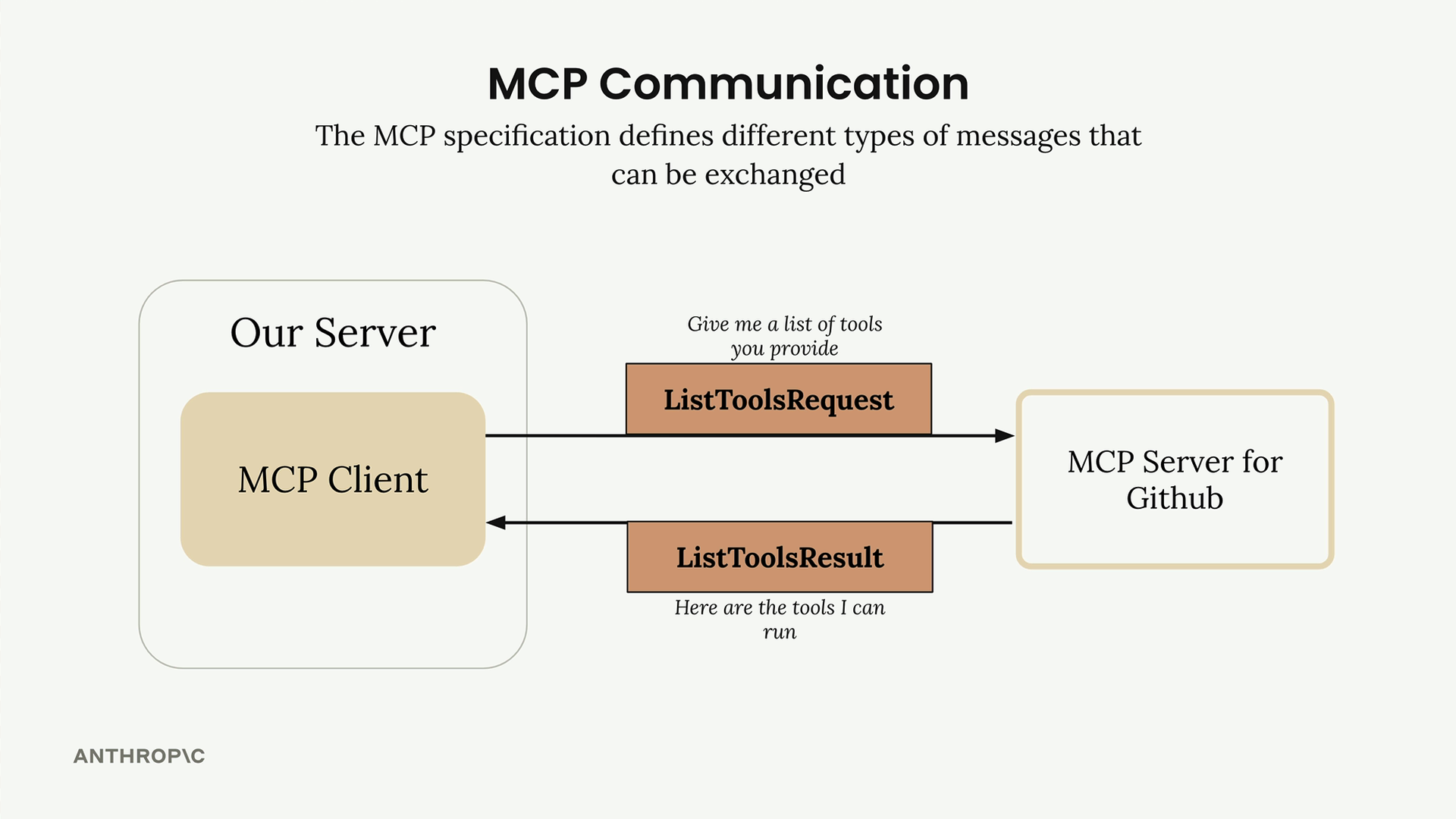
ListToolsRequest/ListToolsResult:客户端询问服务器“您提供哪些工具?”,并得到一个可用工具的列表。
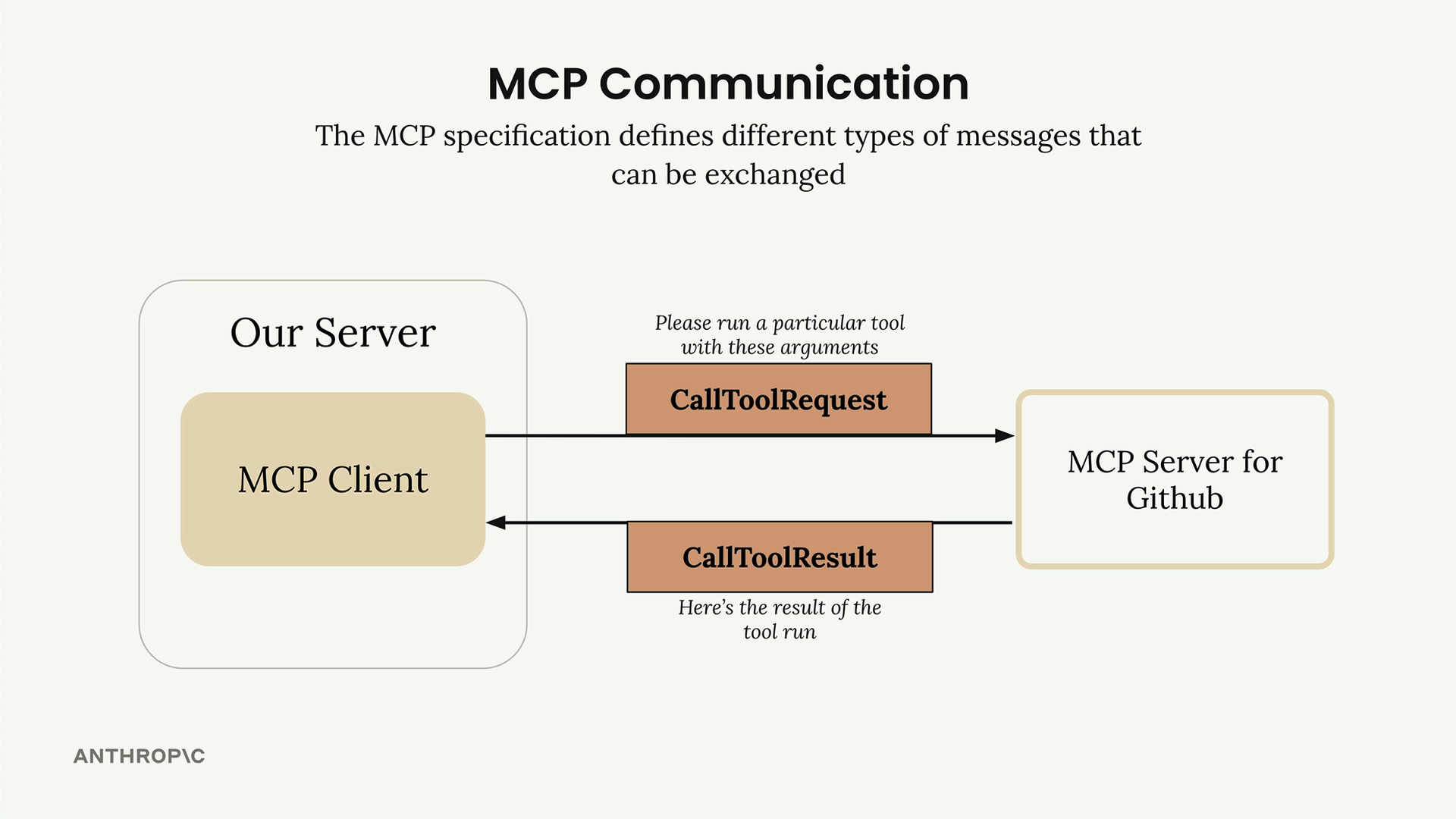
CallToolRequest/CallToolResult:客户端要求服务器使用给定的参数运行特定工具,然后接收结果。
## 它们如何协同工作
以下是一个完整的示例,展示了用户查询如何流经整个系统——从您的服务器,通过 MCP 客户端,到像 GitHub 这样的外部服务,再返回给 Claude。
假设用户问:“我有哪些仓库?”以下是逐步流程:
1. **用户查询:** 用户向您的服务器提交他们的问题
2. **工具发现:** 您的服务器需要知道有哪些可用的工具可以发送给 Claude
3. **列出工具交换:** 您的服务器向 MCP 客户端请求可用工具
4. **MCP 通信:** MCP 客户端向 MCP 服务器发送 `ListToolsRequest` 并接收 `ListToolsResult`
5. **Claude 请求:** 您的服务器将用户的查询以及可用的工具发送给 Claude
6. **工具使用决策:** Claude 决定需要调用一个工具来回答问题
7. **工具执行请求:** 您的服务器要求 MCP 客户端运行 Claude 指定的工具
8. **外部 API 调用:** MCP 客户端向 MCP 服务器发送 `CallToolRequest`,后者进行实际的 GitHub API 调用
9. **结果返回:** GitHub 以仓库数据响应,这些数据通过 MCP 服务器作为 `CallToolResult` 返回
10. **工具结果到 Claude:** 您的服务器将工具结果发送回 Claude
11. **最终响应:** Claude 使用仓库数据形成最终答案
12. **用户得到答案:** 您的服务器将 Claude 的响应传递回用户
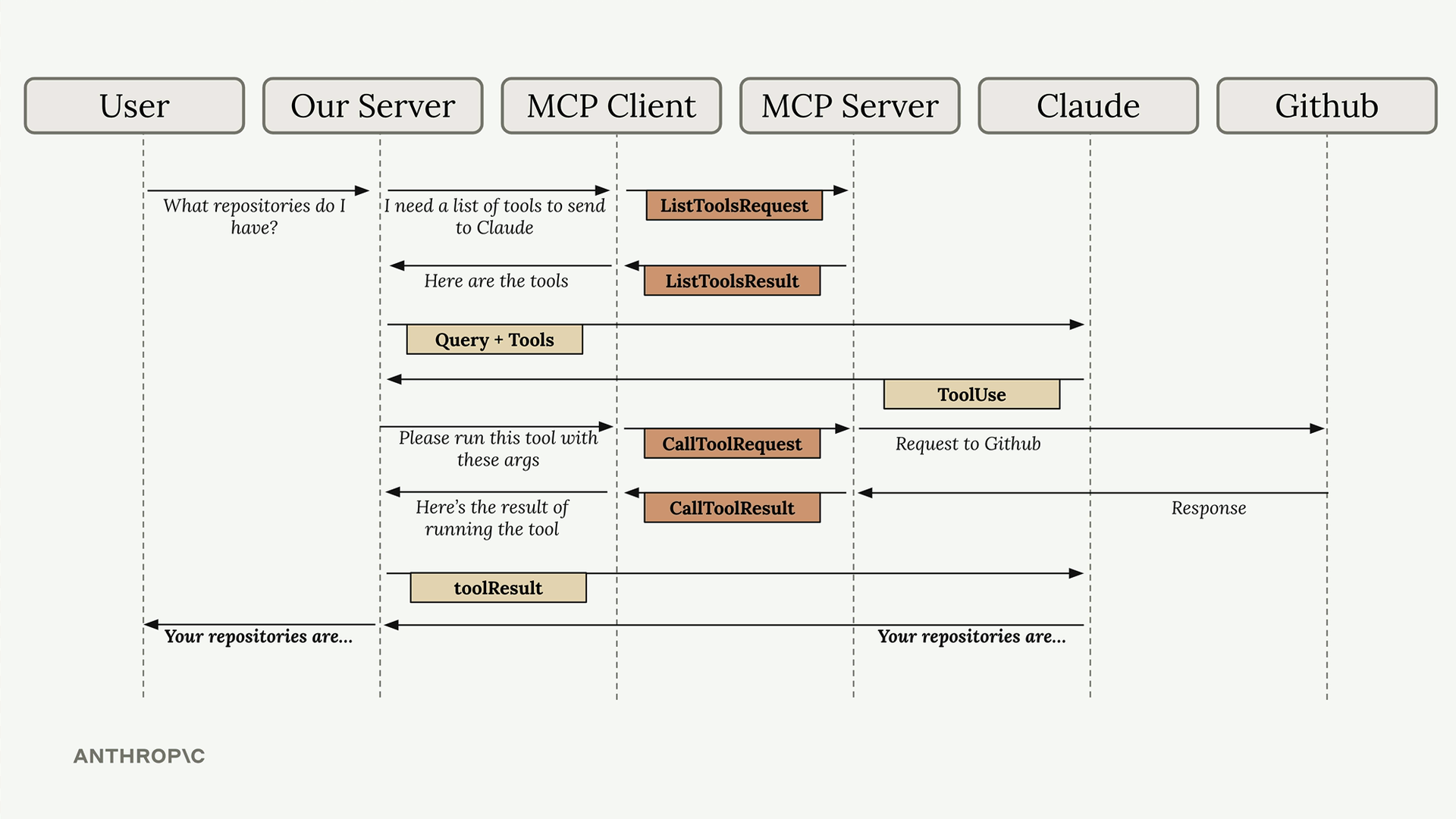
是的,这个流程涉及许多步骤,但每个组件都有明确的职责。MCP 客户端抽象了服务器通信的复杂性,让您能够专注于应用程序逻辑,同时仍然可以访问强大的外部工具和数据源。
理解这个流程至关重要,因为在接下来的部分中,当您构建自己的 MCP 客户端和服务器时,您会看到所有这些部分。
#### 视频文字稿
> 我们要研究的模型上下文协议的下一部分是客户端。客户端的目的是在您的服务器和 MCP 服务器之间提供一种通信方式。这个客户端将是您访问该服务器实现的所有工具的入口点。现在 MCP 是传输无关的。
>
> 这是一个花哨的术语,只是说客户端和服务器可以通过各种不同的协议进行通信。目前运行 MCP 服务器的一种非常常见的方式是在与 MCP 客户端相同的物理机器上。如果这两样东西在同一台机器上运行,那么它们可以通过标准输入输出进行通信。这就是我们稍后将在本节中设置的内容。
>
> 然而,我们还有其他方式可以连接 MCP 客户端和 MCP 服务器。所以它们也可以通过 HTTP 或 Web Sockets 或任何其他多种技术连接。一旦客户端和服务器之间建立了连接,它们通过交换消息进行通信。所有允许的消息都在 MCP 规范中定义。
>
> 我们将关注的一些消息类型是 `list tools request` 和 `list tools result`。正如你所猜测的,`list tools request` 从客户端发送到服务器,并要求服务器列出它提供的所有不同工具。服务器然后会响应一个 `list tools result` 消息,其中包含它能提供的所有不同工具的列表。我们将会看到的另外两种常见的消息类型是 `call tool request` 和 `call tool result`。
>
> 第一个会要求服务器用特定的参数运行一个工具,第二个会包含工具运行的结果。现在,在这个时间点,我们有了服务器和客户端的概念。但我怀疑可能还不是很清楚所有这些东西到底是怎么一起工作的。所以在这段视频的剩余部分,我们要做的是,我们将通过一个涉及很多不同事物的调用示例来讲解。
>
> 所以这将是一个有点复杂的过程。但我们将想象一下用户或我们正在组建的服务器之间的通信。一个 MCP 客户端,MCP 服务器,GitHub 作为我们试图访问一些数据的提供者,还有 Claude。
>
> 那么我们开始吧。再次,Stephen Grider,我们期望发生的第一件事是用户向我们的服务器提交某种查询或问题,比如“我有哪些仓库?”。此时,就该由我们的服务器向 Claude 发出请求了。但在这个请求中,我们想列出 Claude 可以访问的所有不同工具。
>
> 所以在我们的服务器向 Claude 发出请求之前,它首先会通过 MCP 客户端和服务器走一小段弯路。所以事情是这样的。服务器会意识到它需要一个工具列表来连同用户的查询一起发送给 Claude。所以它会要求 MCP 客户端获取一个工具列表。
>
> MCP 客户端反过来会向服务器发送一个 `list tools request`,服务器会响应一个 `list tools result`。现在我们的 MCP 客户端有了一个工具列表,它会把这个工具列表交还给服务器。现在我们的服务器拥有了向 Claude 发出初始请求所需的一切。它既有用户的原始消息,也有一个要包含的工具列表。
>
> 所以我们的服务器可以用那个查询和那套工具向 Claude 发出请求。Claude 会看一看这些工具然后意识到,你知道吗,为了回答用户最初的那个问题,我真的想调用一个工具。所以 Claude 会响应一个工具使用消息部分。此时,我们的服务器会意识到 Claude 想要运行一个工具。
>
> 但我们的服务器不再真正负责执行任何工具。相反,我们的工具将由 MCP 服务器执行。所以为了运行 Claude 请求的工具,我们的服务器会要求 MCP 客户端用 Claude 提供的某些特定参数来运行一个工具。然而,MCP 客户端并不实际运行工具。
>
> 它将向 MCP 服务器发送一个 `call tool request`。MCP 服务器将接收该请求并向 GitHub 发出一个后续请求。所以这里就是我们实际获取属于这个特定用户的仓库列表的地方。GitHub 会用那个仓库列表进行响应。
>
> 然后 MCP 服务器会将这些数据包装在一个 `call tool result` 中,并将其发送回 MCP 客户端。然后 MCP 客户端反过来会将结果交给我们的服务器。现在我们的服务器有了仓库列表,它可以向 Claude 发出一个带有用户消息中工具结果部分的后续请求。所以这个工具结果将包括 Claude 请求的仓库列表。
>
> 现在 Claude 拥有了形成最终响应所需的所有信息。所以它会写出一些类似“你的仓库是”之类的文本,然后把它发回我们的服务器,我们的服务器再把它发回给我们的用户。好了,所以这个流程,是的,相当复杂。我想给你们看这个的原因是,当你们和我稍后开始实现我们自己的自定义 MCP 客户端和 MCP 服务器时,我们将会看到所有这些不同的部分。
---
## 第2部分:MCP 服务器实践
### 4. 项目设置
> 类型:视频 | 时长:3:09 | 视频:09 - 003 - Project Setup.mp4
#### 视频文字稿
> 为了更好地理解 MCP 的某些方面,我们将开始实现我们自己的基于 `CLI (命令行界面)` 的聊天机器人。这将让我们更好地了解客户端和服务器实际上是如何协同工作的。在这段视频中,我想做一些项目设置,并帮助您准确理解我们将要制作什么。我在这里有很多关于我们将要构建的内容的产品描述。
>
> 我们将逐步完成所有这些。现在,我只希望您有一个高层次的理解。正如我所提到的,它将是一个基于 CLI 的聊天机器人。我们将允许用户处理一个文档集合。
>
> 这些将是假的文档。它们只会被存储在内存中。我们将构建一个小型的 MCP 客户端,它将连接到我们自己定制的 MCP 服务器。目前,服务器将实现两个工具。
>
> 一个工具用于读取文档内容,另一个工具用于更新文档内容。再次强调,这些文档就在右边。它们都是假的,所以它们将只持久化在内存中。就是这样。
>
> 现在,在我们继续之前,有一个非常重要的说明,我真的希望您在整个过程中理解。那就是,在一个正常的项目中,通常我们要么实现一个客户端,要么实现一个 MCP 服务器。所以在真实的项目中,我们可能只是在编写一个 MCP 服务器,分发给全世界,让开发者能够访问我们构建的某个服务。或者,我们可能在构建一个只制作 MCP 客户端的项目。
>
> 这里的意图是,我们将连接到一些外部的 MCP 服务器,这些服务器已经由其他一些工程师实现了。所以在这个项目中,我们既制作客户端又制作服务器。我们只是在一个项目中这样做,这样您就能更好地理解这些东西实际上是如何协同工作的。好了,既然我们已经把这个免责声明说清楚了,让我们来进行一些设置。
>
> 附在这段视频后面的,您应该会找到一个名为 `CLIproject.zip` 的文件,里面是我们项目的一些起始代码。请确保您下载那个 zip 文件,解压它,然后在您的代码编辑器中打开那个项目目录。为了节省一点时间,我已经这样做了。所以我已经在那个小项目中打开了我的代码编辑器。
>
> 在这个项目中,我鼓励您看一下 `readme.md` 文件。在里面,我放了一些设置说明。所以它会引导您完成将您的 API key 放入这个项目内的 `.emv` 文件的过程。它还会引导您完成安装依赖项的过程,无论是否使用 uv。
>
> 一旦您完成了所有这些设置,您就可以立即运行起始项目了。为此,在您的终端中,确保您在您的项目目录内。我把我的项目叫做 MCP。在里面,我有我所有的不同项目文件和文件夹。
>
> 要运行项目,如果您使用 uv,我们将运行 `uv run main.py`。如果您不使用 uv,那么就是 `python main.py`。现在我正在使用 uv。所以我将执行 `uv run main.py`。
>
> 然后当我运行它时,我应该会看到一个聊天提示符出现。如果我问一加一等于几,我应该会很快看到一个响应。我们的设置就到此为止。所以现在我们可以开始专注于为这个应用程序添加一些新功能了。
---
### 5. 使用 MCP 定义工具
> 类型:视频 | 时长:7:03 | 视频:09 - 004 - Defining Tools with MCP.mp4
当您使用官方的 Python `SDK (软件开发工具包)` 时,构建 MCP 服务器会变得简单得多。您可以使用`decorators (装饰器)`来定义工具,让 SDK 处理繁重的工作,而无需手动编写复杂的 `JSON schemas (JSON 模式)`。
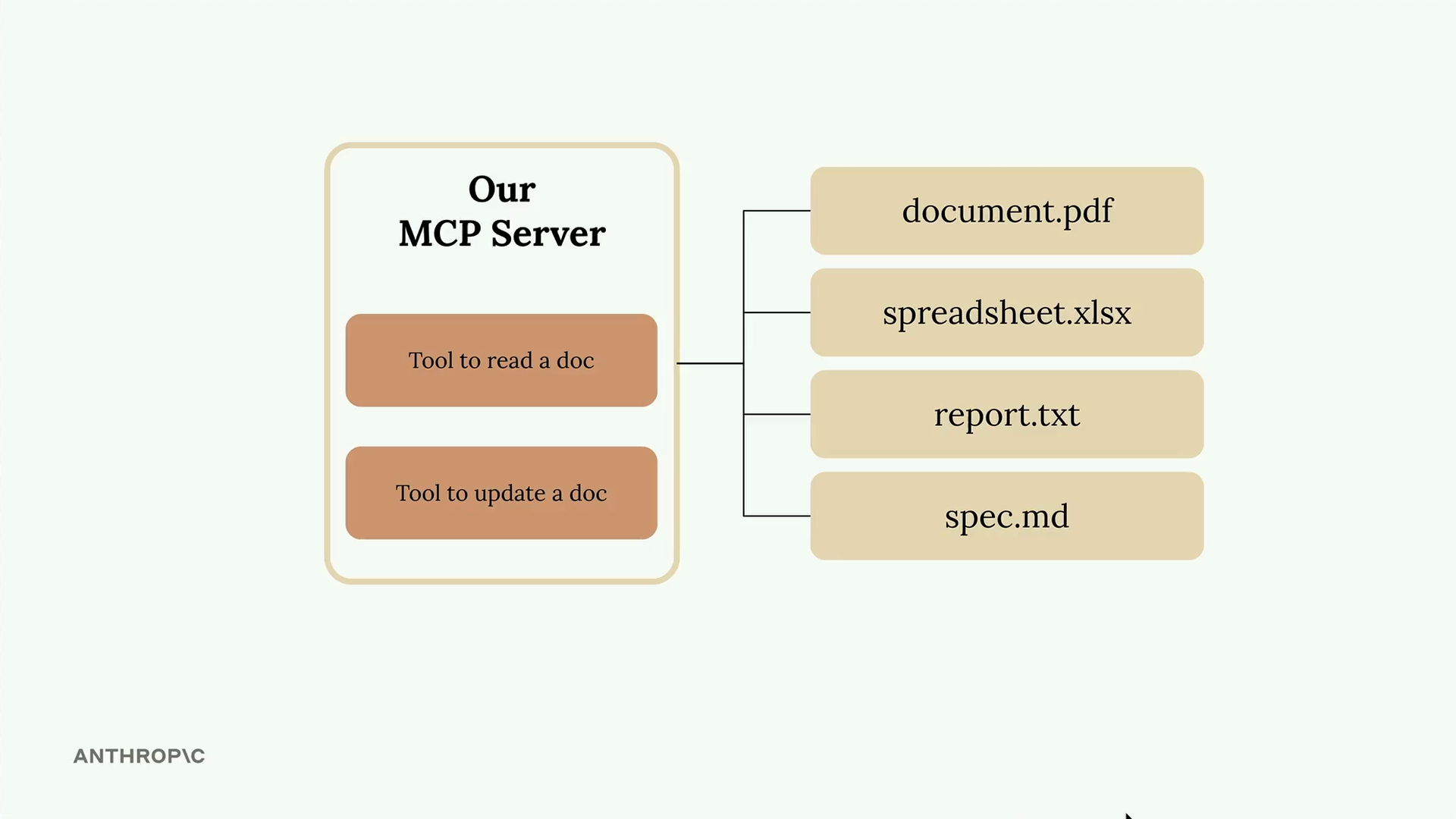
在此示例中,我们正在创建一个文档管理服务器,它有两个核心工具:一个用于读取文档,另一个用于更新文档。所有文档都作为简单的字典存在于内存中,其中键是文档 ID,值是内容。
## 设置 MCP 服务器
Python MCP SDK 使服务器创建变得直截了当。您只需一行代码即可初始化服务器:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("DocumentMCP", log_level="ERROR")
您的文档可以存储在简单的字典结构中:
docs = { "deposition.md": "This deposition covers the testimony of Angela Smith, P.E.", "report.pdf": "The report details the state of a 20m condenser tower.", "financials.docx": "These financials outline the project's budget and expenditures", "outlook.pdf": "This document presents the projected future performance of the system", "plan.md": "The plan outlines the steps for the project's implementation.", "spec.txt": "These specifications define the technical requirements for the equipment" }
## 使用装饰器定义工具
SDK 使用装饰器来定义工具。您可以使用 Python 的 `type hints (类型提示)` 和字段描述,而无需手动编写 JSON 模式。SDK 会自动生成 Claude 能理解的正确模式。
## 创建文档读取器工具
第一个工具通过 ID 读取文档内容。以下是完整实现:
@mcp.tool( name="read_doc_contents", description="Read the contents of a document and return it as a string." ) def read_document( doc_id: str = Field(description="Id of the document to read") ): if doc_id not in docs: raise ValueError(f"Doc with id {doc_id} not found")
return docs[doc_id]
装饰器指定了工具名称和描述,而函数参数定义了必需的参数。来自 Pydantic 的 `Field` 类提供了参数描述,帮助 Claude 理解每个参数的预期值。
## 构建文档编辑器工具
第二个工具对文档执行简单的查找和替换操作:
@mcp.tool( name="edit_document", description="Edit a document by replacing a string in the documents content with a new string." ) def edit_document( doc_id: str = Field(description="Id of the document that will be edited"), old_str: str = Field(description="The text to replace. Must match exactly, including whitespace."), new_str: str = Field(description="The new text to insert in place of the old text.") ): if doc_id not in docs: raise ValueError(f"Doc with id {doc_id} not found")
docs[doc_id] = docs[doc_id].replace(old_str, new_str)
此工具接受三个参数:文档 ID、要查找的文本和替换文本。该实现包括对缺失文档的错误处理,并执行直接的字符串替换。
## SDK 方法的主要优势
- 无需手动编写 JSON 模式
- 类型提示提供自动验证
- 清晰的参数描述帮助 Claude 理解工具用法
- 错误处理与 Python 异常自然集成
- 工具通过装饰器自动注册
MCP Python SDK 将工具创建从复杂的模式编写工作转变为简单的 Python 函数定义。这种方法使得构建和维护 MCP 服务器变得更加容易,同时确保 Claude 接收到格式正确的工具规范。
#### 视频文字稿
> 让我们开始为我们的 CLI 聊天机器人制作一个 MCP 服务器。正如你所看到的,CLI 本身已经可以工作,我们已经可以和 Claude 聊天,但是还没有任何与 MCP 服务器相关的附加功能。所以我们将要着手添加这个 MCP 服务器,它目前将有两个工具。它会有一个工具来读取文档,另一个工具来更新文档的内容。
>
> 服务器的实现将放在根项目目录下的 MCP server.py 文件中。在这里面,我已经做了一些工作来建立一个基本的 MCP 服务器。然后我定义了一个只存在于内存中的文档集合。最后,我整理了一些待办事项。
>
> 这些是你我将在这个文件中完成的不同任务。目前,正如我刚才提到的,我们将只处理前两项,即编写两个工具。现在我们过去已经编写过工具,我们看到,哦,那里有很多语法。有那些大的 JSON 模式。
>
> 但我在这里有好消息要告诉你。在这个项目中,我们正在使用官方的 MCP Python SDK。所以这就是我们在这里使用的 MCP 包。这个 MCP 包将为我们创建我们的 MCP 服务器,只需一行代码,就像你在这里看到的那样。
>
> 这个 SDK 也使得定义工具变得非常容易。要定义一个工具,我们所要做的就是写出你在这里右边看到的内容。这将创建一个名为 add integers 的工具,带有这个描述和两个需要传入的参数。一旦我们写出这样的工具定义,在幕后,Anthropic 将为我们生成一个工具 JSON 模式,我们可以拿来传递给 Claude。
>
> 所以马上,你可以看到,做一些像定义工具这样的基本事情开始变得容易多了。现在,正如我提到的,我们的第一个任务将是实现这两个不同的工具。所以让我们立即回到我们的 MCP server.py 文件,我们将开始实现第一个工具,读取文档。所以唯一的目标是接收某个文档的名称并返回其内容。
>
> 我们所有的文档都已经放在这个 `docs` 字典里了。键是文档的 ID 或本质上的名称,值是文档的内容。所以我们的工具非常简单。我们将接收这些字符串中的一个,在这个 `docs` 字典里查找相应的值,然后返回它。
>
> 这就是我们需要做的全部。所以为了实现这个,我会找到第一个待办事项,然后在它下面,我会通过写出 `@mcp.tool` 来定义一个新工具。我会给这个工具一个名字 `read_contents` 和一个描述 `读取文档内容并以字符串形式返回`。请记住,在理想世界中,我们会在这里放入一个非常详尽的描述,以确保对 Claude 来说,什么时候使用这个工具非常清楚。
>
> 但现在,和往常一样,为了节省一点时间,让你不必在这里输入大量文本,我只会留下一个非常简单的描述。然后我会定义我的实际工具函数。所以这是我们决定运行这个工具时要运行的函数。我会叫它 `read_document`。
>
> 它将接收一个名为 `doc_id` 的参数,该参数是一个字符串。我将把它设置为一个 `Field`,描述为“要读取的文档的 ID”。然后我们需要确保我们在顶部导入这个 `Field` 类。所以我将去到顶部并添加一个 `from pydantic import field` 的导入。
>
> 然后回到这里,在函数体内,我将放入我的实际实现。所以我首先要做的是确保我处理了 Claude 请求一个实际上不存在的文档的情况。所以我会说 `if doc_id not in docs`。换句话说,如果提供的文档 ID 在这个字典中没有作为键找到,那么我将引发一个 `ValueError`,带有一个 f-string "未找到 id 为 {doc_id} 的文档"。
>
> ID 未找到。然后如果我们通过了那个检查,我将继续返回实际的文档。所以我将返回 `docs[doc_id]`。就是这样,定义一个工具就这么简单。所以我们指定了工具的名称,它的描述,它期望的参数,它的类型,以及该参数的描述。
>
> 所有这些不同的装饰器和字段类型等等都将被这个 Python MCP SDK 整合在一起,它将为我们生成一个 JSON 模式。现在我们已经实现了这个第一个工具,我将删除那里的待办事项。然后我们将实现我们的另一个工具,那个编辑文档的工具。所以我们将重复完全相同的过程。
>
> 我会说 MCP dot tool。我会给它一个名字 `edit_document`,描述为“通过用新字符串替换文档内容中的一个字符串来编辑文档”。然后对于实现,我会调用这个函数 `edit_doc`。或者为了保持一致,调用 `edit_document`。
>
> 然后我们将接收几个不同的参数。首先是文档 ID,然后是要查找的旧字符串,然后是用来替换旧字符串的新字符串。所以让我们把这些都写出来。我们将有一个 `doc_id`。
>
> 这将是一个字符串,描述为“将被编辑的文档的 ID”。`old_string` 将是一个字符串,描述为“要替换的文本,必须完全匹配,包括空格”。然后是我们的 `new_string`。
>
> “要插入以代替旧文本的新文本。”所以我们的文档编辑只是一个非常简单的查找和替换。就是这样。再一次,在这里面,我要确保 Claude 请求的文档是实际存在的。
>
> 所以 `if doc_id not in docs`,引发一个 `ValueError`,带有一个 f-string “未找到 id 为 {doc_id} 的文档”。然后如果我们确实找到了正确的文档,我们将这样进行编辑。我们会说 `docs [doc_id] = docs[doc_id].replace(old_string, new_string)`,用 `new_string` 替换 `old_string`。就是这样。好了。
>
> 就这样,我们非常非常快地完成了两个工具的实现。我再说一遍,用这个 MCP Python SDK 定义工具比手动写出模式定义要容易得多。既然两个工具都完成了,我就把那里的 Tudu 删掉。好的,这是一个好的开始。
>
> 我们已经组建了我们的 MCP 服务器,并在其中实现了两个工具。
---
### 6. 服务器检查器
> 类型:视频 | 时长:3:52 | 视频:09 - 005 - The Server Inspector.mp4
在构建 MCP 服务器时,您需要一种方法来测试其功能,而无需连接到完整的应用程序。Python MCP SDK 包含一个内置的基于浏览器的`inspector (检查器)`,让您可以实时调试和测试您的服务器。
## 启动检查器
首先,确保您的 Python 环境已激活(请查看您项目的 README 文件以获取确切的命令)。然后使用以下命令运行检查器:
mcp dev mcp_server.py
这将启动一个`development server (开发服务器)`并为您提供一个本地 URL,通常类似于 http://127.0.0.1:6274。在浏览器中打开此 URL 以访问 MCP 检查器。
## 使用检查器界面
检查器界面正在积极开发中,因此在您使用时它可能会有所不同。然而,核心功能保持一致。请寻找以下关键元素:
- **Connect**:一个启动您的 MCP 服务器的按钮
- **Resources**:用于工具、提示和其他功能的导航标签
- 一个工具列表和测试面板
首先单击“Connect”按钮来初始化您的服务器。您会看到连接状态从“Disconnected”变为“Connected”。
## 测试您的工具
导航到“Tools”部分,然后单击“List Tools”以查看服务器上所有可用的工具。当您选择一个工具时,右侧面板会显示其详细信息和输入字段。
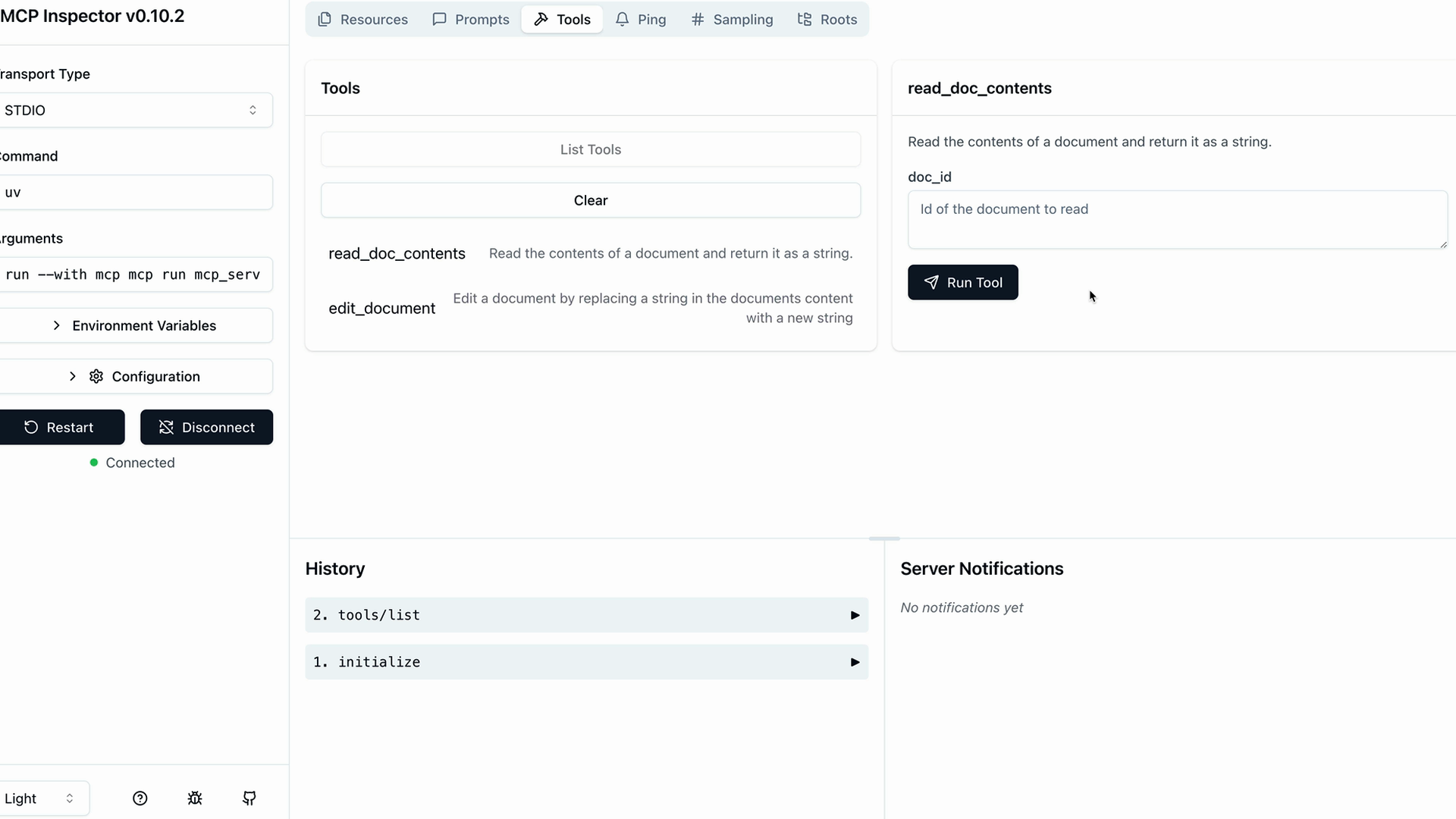
例如,要测试一个文档读取工具:
1. 选择 `read_doc_contents` 工具
2. 输入一个文档 ID(如 "deposition.md")
3. 单击 "Run Tool"
4. 检查结果是否成功以及是否为预期输出
检查器会显示成功状态和实际返回的数据,使得验证您的工具是否正常工作变得容易。
## 测试工具交互
您可以按顺序测试多个工具,以验证复杂的工作流程。例如,在使用编辑工具修改文档后,立即测试读取工具以确认更改已正确应用。
检查器在工具调用之间保持您的服务器状态,因此编辑会持久存在,您可以验证 MCP 服务器的完整功能。
## 开发工作流程
MCP 检查器成为您开发过程中必不可少的一部分。您无需编写单独的测试脚本或连接到完整的应用程序,而是可以:
- 快速迭代工具实现
- 测试边缘情况和错误条件
- 验证工具交互和状态管理
- 实时调试问题
这种即时反馈循环使 MCP 服务器开发效率更高,并有助于在开发过程的早期发现问题。
#### 视频文字稿
> 我们已经在我们的 MCP 服务器中加入了一些功能,但我们不知道它是否能用,所以如果我们能以某种方式测试一下,那将是非常棒的。事实证明,通过使用这个 Python SDK,我们可以自动访问一个浏览器内的调试器,这样我们就能确保这个服务器按预期工作。让我快速向你展示如何使用它。回到我的终端,我想要确保我的 Python 环境已经激活。
>
> 记住,ReadMe 文档详细说明了运行以确保你已激活该环境的确切命令。一旦你确定它已激活,我们将运行 MCP, Dev, 然后是包含我们服务器的文件的名称。在这种情况下,它是 MCPServer.py。一旦我运行它,我就会被告知我有一个在端口 6277 上监听的服务器,并且我会得到一个直接的地址来实际访问它。
>
> 我将在我的浏览器中打开那个地址。一旦你去了那里,你会看到类似这样的东西。这就是 MCP 检查器。现在马上,我希望你理解一件重要的事情。
>
> 这个检查器正在积极开发中。所以当你观看这个视频的时候,你现在屏幕上看到的东西可能和我展示的非常非常不同。尽管如此,它可能仍然会有一些非常相似的功能。在左手边,你会看到一个连接按钮。
>
> 这将启动你的 MCP 服务器,也就是我们刚才编辑的那个文件。我将点击连接,然后马上,我们会看到屏幕上出现几样不同的东西。我首先希望你注意顶部的菜单栏。它列出了资源、提示、工具和其他一些东西。
>
> 再次强调,UI 可能会在你观看这个视频时发生变化,所以如果你没有看到这个菜单栏,我们真正寻找的只是某个工具部分。一旦我点击工具,我将点击列出工具,我将看到我们刚才组合的工具的名称。如果我点击其中一个,右边的面板就会改变。
>
> 我可以使用这边的面板来手动调用我的一个工具,以确保它按预期工作。所以这就是我们如何在不实际将其连接到真实应用程序的情况下对我们的 MCP 服务器进行一些实时开发。为了使用 Read.Contents 工具,我们所要做的就是输入一个文档 ID。如果我回到我的编辑器,然后去到 `docs` 字典那里,我可以复制其中一个文档 ID,所以我将拿出 `deposition.md`。
>
> 我会把它作为文档 ID 输入,然后点击运行工具。然后我应该会看到运行工具成功,并带有文档的内容。就是这样。我可以验证它。所以完全相同的字符串就是我在这里看到的。
>
> 我们可以用同样的技术来测试另一个工具。所以我将切换到编辑文档工具。现在我将输入我的文档 ID。我想替换的旧字符串,如何替换 deposition 这个词?
>
> 实际上,我有一个更容易打的词。就这个怎么样?那会容易一点。所以我的旧字符串是这个。
>
> 记住,那将是区分大小写的,我将用 a report 替换它。如果我运行工具,我将得到一个成功。记住,那个工具实际上不返回文档的内容。它只是编辑文档。
>
> 所以现在为了验证编辑是否正确完成,我可以回到 redock contents 工具,用相同的文档 ID 再次运行那个工具,我应该会看到 a report deposition,然后是 blah,blah,blah。好了,正如你所看到的,这个 MCP 检查器让我们能够非常容易地调试我们正在实现的 MCP 服务器,而无需实际将服务器连接到应用程序。当你开始构建自己的 MCP 服务器时,我预计你会经常使用这个检查器工具。我们可能会在这个模块中更多地使用它,只是为了确保我们的服务器开发进展顺利。
---
### 8. 实现客户端
> 类型:视频 | 时长:7:26 | 视频:09 - 006 - Implementing a Client.mp4
既然我们的 MCP 服务器已经可以工作了,现在是时候构建客户端了。客户端允许我们的应用程序代码与 MCP 服务器通信并访问其功能。
## 理解客户端架构
在大多数真实世界的项目中,您要么实现一个 MCP 客户端,要么实现一个 MCP 服务器——而不是两者都做。我们在这个项目中构建两者只是为了让您能看到它们是如何协同工作的。
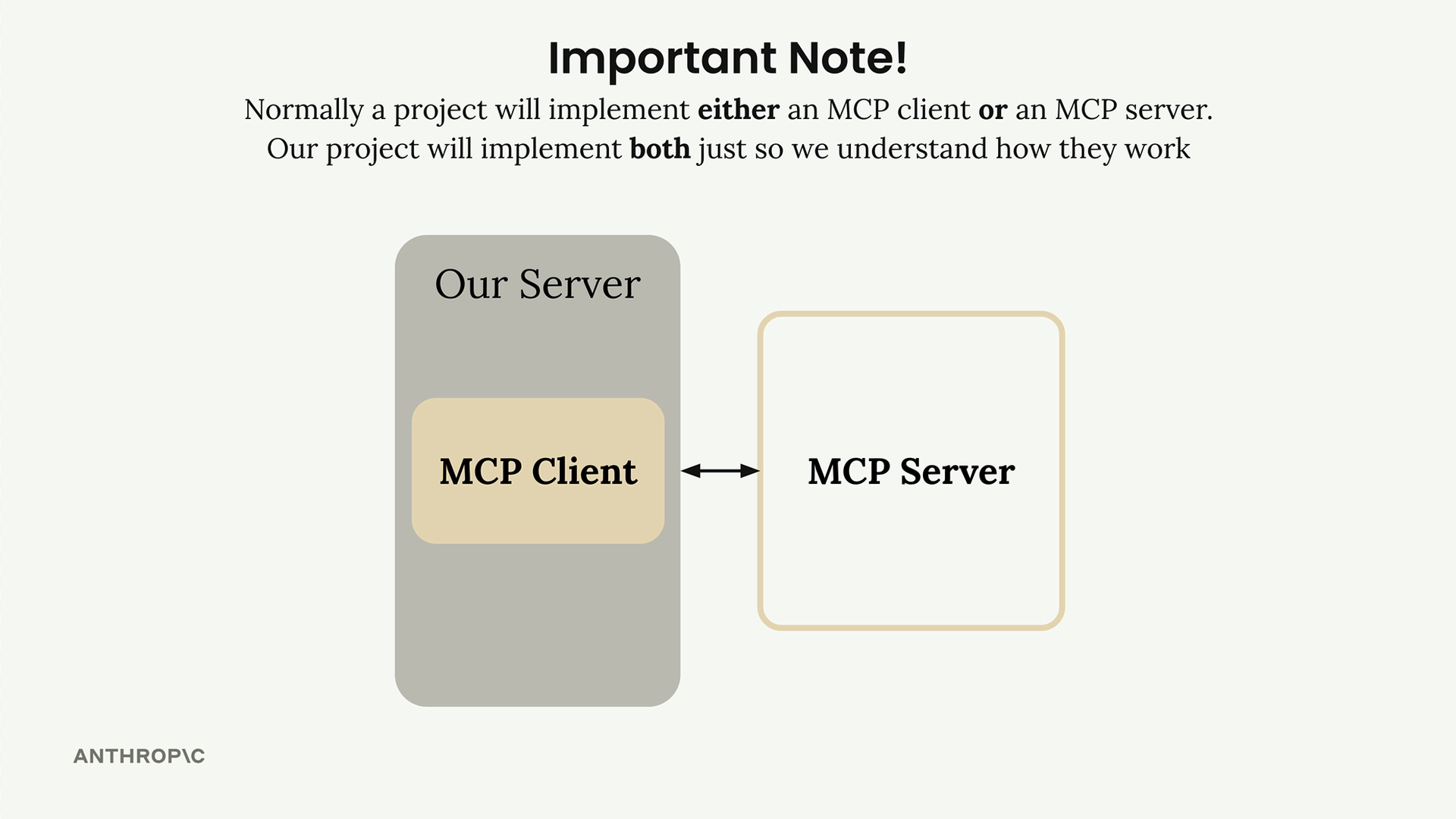
MCP 客户端由两个主要组件构成:
- **MCP Client** - 我们创建的一个自定义类,以简化会话的使用
- **Client Session** - 到服务器的实际连接(MCP Python SDK 的一部分)
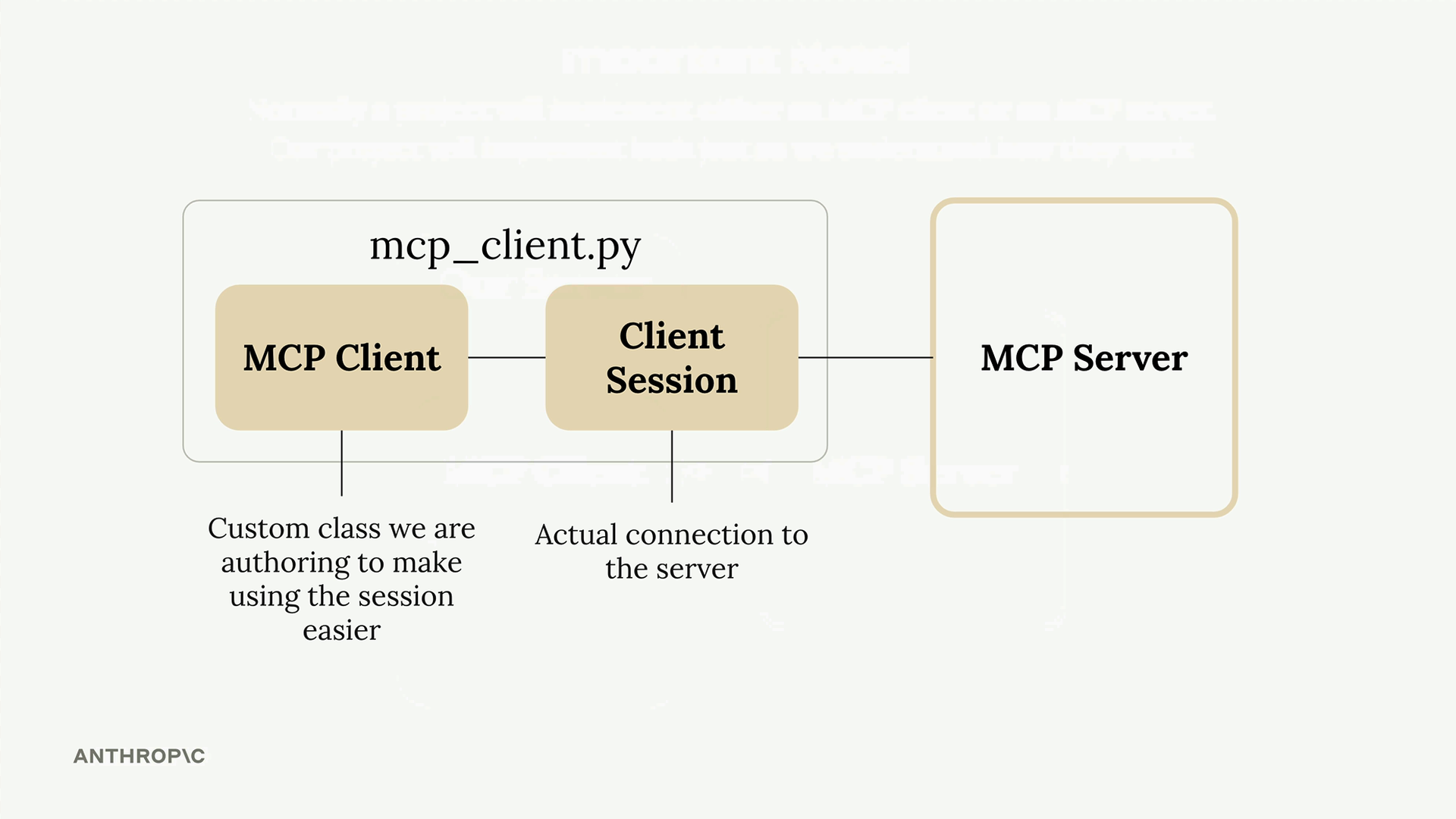
客户端会话需要仔细的`resource cleanup (资源清理)`——当完成时,我们需要正确地清理连接。这就是为什么我们将其包装在我们自己的类中,该类会自动处理所有清理工作。
## 客户端如何融入我们的应用程序
还记得我们的应用程序流程图吗?客户端使我们的代码能够在两个关键点与 MCP 服务器交互:
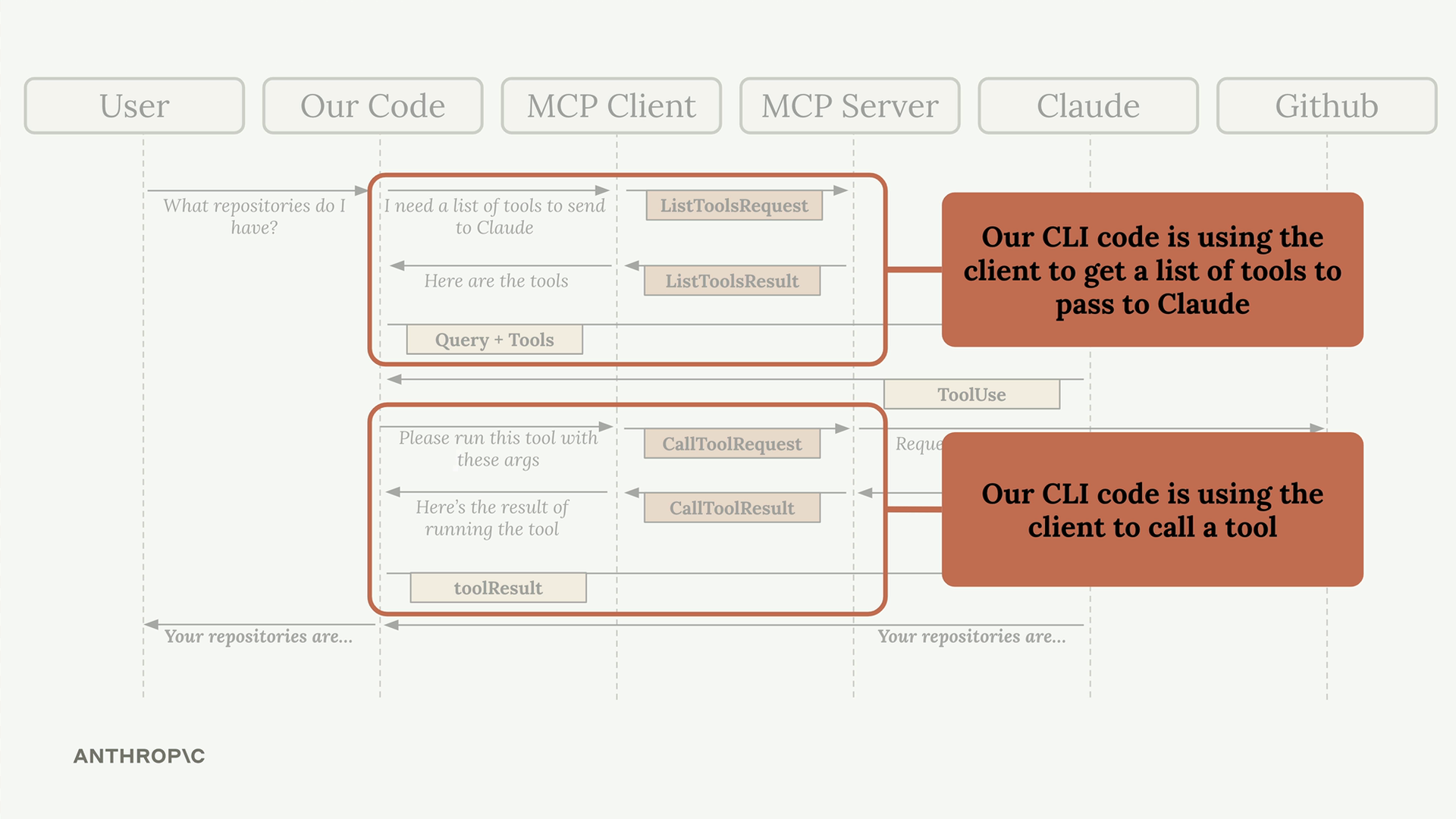
我们的 CLI 代码使用客户端来:
- 获取可用工具列表以发送给 Claude
- 在 Claude 请求时执行工具
## 实现核心客户端函数
我们需要实现两个基本函数:`list_tools()` 和 `call_tool()`。
### List Tools 函数
此函数从 MCP 服务器获取所有可用的工具:
async def list_tools(self) -> list[types.Tool]: result = await self.session().list_tools() return result.tools
这很简单——我们访问我们的会话(到服务器的连接),调用内置的 `list_tools()` 方法,并从结果中返回工具。
### Call Tool 函数
此函数在服务器上执行特定的工具:
async def call_tool( self, tool_name: str, tool_input: dict ) -> types.CallToolResult | None: return await self.session().call_tool(tool_name, tool_input)
我们将工具名称和输入参数(由 Claude 提供)传递给服务器并返回结果。
## 测试客户端
客户端文件底部包含一个简单的测试工具。您可以直接运行它来验证一切正常:
uv run mcp_client.py
这将连接到您的 MCP 服务器并打印出可用的工具。您应该能看到显示您的工具定义的输出,包括描述和输入模式。
## 整合所有部分
一旦客户端函数实现完毕,您可以通过运行主应用程序来测试整个流程:
uv run main.py
尝试提问:“`report.pdf` 文档的内容是什么?”
幕后发生的事情如下:
1. 您的应用程序使用客户端获取可用工具
2. 这些工具与您的问题一起发送给 Claude
3. Claude 决定使用 `read_doc_contents` 工具
4. 您的应用程序使用客户端执行该工具
5. 结果返回给 Claude,然后它会响应您
客户端充当您的应用程序逻辑和 MCP 服务器功能之间的桥梁,使得将强大的工具集成到您的 AI 工作流程中变得容易。
#### 视频文字稿
> 现在我们的服务器已经准备好了,我们将稍微转换一下思路,开始处理我们的 MCP 客户端。客户端可以在根项目目录下的 `MCP client.py` 文件中找到。在我们在这个文件中做任何事情之前,我只想给您一个非常快的提醒。记住我之前告诉过您的。
>
> 通常在一个典型的项目中,我们要么使用一个客户端,要么实现一个服务器。只有在这个我们正在进行的特定项目中,我们才两者都做。再说一次,只是为了让您能看到这个谜题的两面。现在 MCP 客户端本身在这个文件中由一个单独的类组成。
>
> 您会注意到这里面有很多代码,它看起来不像我们刚才在服务器里写的一些代码那么漂亮。所以让我告诉您这个文件里到底发生了什么,以及它为什么这么大。好的,所以在这个文件里,我们正在制作 MCP 客户端类。这个类将包装一个叫做客户端会话的东西。
>
> 客户端会话是到我们的 MCP 服务器的实际连接。这个客户端会话是 MCP Python SDK 的一部分。再说一次,这个会话就是给我们这个到外部服务器连接的东西。会话本身需要一些资源清理。
>
> 换句话说,每当我们关闭我们的程序或者决定我们不再需要服务器时,我们都必须经过一个小小的清理过程。而我已经把很多清理代码写在了 MCP 客户端类里面。所以这就是为什么这个类存在的真正原因,只是为了让清理工作更容易一些。您可以在 Connect 函数和下面一点的
>
> `cleanup`、`async enter` 和 `async exit` 函数中看到一些清理代码。所以,不直接使用这个客户端会话,而是将其包装在一个更大的类中,由这个类来管理这些不同的资源,这是非常常见的做法。接下来我想澄清的是,这个客户端到底为什么存在。换句话说,这个客户端到底为我们做了什么?
>
> 嗯,还记得我们不久前看过的那个完整的流程图吗?所以我们的代码在这里。在某些时候,我们需要,比如说,一个工具列表来发送给 Claude。然后在那之后,我们还需要运行一个由 Claude 请求的工具。
>
> 为了联系我们的 MCP 服务器并获取这个工具列表或运行一个工具,我们就在这里使用 MCP 客户端。所以我们可以想象这个客户端正在向我们代码库的其他部分暴露属于服务器的某些功能。所以在这个项目的代码库内部,特别是在核心目录内部,我已经放了很多代码,这些代码正在使用这个类。所以还有一些其他的代码会调用
>
> 你在这里面看到的一些不同的函数,比如 `list tools`、`call tool`、`list prompts`、`get prompt` 等等。目前,在这段视频中,我们将专注于实现两个函数,`list tools` 和 `call tool`。所以正如你刚才在图表中看到的,我们刚才看的,这两个函数将在我们代码库的不同部分被用来获取一个工具列表以提供给 Claude,然后最终在 Claude 请求调用工具时调用一个工具。实现这两个函数将非常简单直接。所以让我告诉你我们将如何做。
>
> 我们将首先从 `list tools` 开始。我将移除里面的 `to do`,并用 `result is awaitself.session` 替换它。我将像一个函数一样调用 `list_tools`。然后我将返回 `result dot tools`。
>
> 就这样。所以这将获得对我们 `session` 的访问,也就是我们到 MCP 服务器的实际连接。它将调用一个内置函数来获取该服务器实现的所有不同工具的定义或列表。我将得到 `result`,然后只返回 `tools`,就这样。
>
> 然后我们可以在这里以非常相似的方式实现 `call tool`。所以这将是 `return a waitself.session`, `call tool`, `tool name`, and `tool input`。再一次,获取对 `session` 的访问,也就是我们到服务器的连接,我将尝试调用一个非常具体的工具,我们传入的工具名称,以及 Claude 提供的输入参数或输入参数。现在,此时此刻,我想非常快地测试一下这两个函数。
>
> 为此,我们将到这个文件的底部,我在那里为我们准备了一个非常小的测试工具。所以在这里,你会注意到我准备了这个测试块,所以我们可以直接运行这个 `MCP client.py` 文件。如果我们这样做,我们将与我们的 MCP 服务器建立连接,然后我们可以对它运行一些命令,看看我们得到了什么。请注意,在你的代码版本中,有一个关于更改这里的 `command` 和 `args` 的注释,以防你没有使用 Uvicorn。
>
> 所以如果你不使用 Uvicorn,请确保你看一下那个注释。在这个 `with` 块中,我将添加一点测试代码。所以我将说 `result is await _client list tools`。然后我将只打印出我们得到的结果。
>
> 所以这应该会启动我们 MCP 服务器的一个副本,然后尝试获取它定义的所有不同工具的列表,然后只打印出结果。为了测试这个,我将切换回我的终端并执行一个 `uvicorn run, MCP_client.py`。和往常一样,如果你不使用 uvicorn,你只需执行一个 `Python MCP client.py`。好的,我运行它,这就是我们的工具定义列表。
>
> 所以我可以在这里看到我有 `read.contents` 工具,这是我们不久前组合的,还有我们的 `edit document` 工具。每一个都有一个描述和一个输入模式。所以这是我们的工具定义,最终将传递给 Claude。在我们继续之前,还有一件事我想测试。
>
> 记住,我们刚刚实现了那个允许我们列出一些工具并把它们传递给 Claude 的函数,以及那个允许我们调用一个由 MCP 服务器实现的工具然后把结果也传递给 Claude 的函数。我已经实现了将调用 `list tools` 和 `call tool` 的代码,在这个项目的其他地方。所以既然我们已经添加了这个功能,既然我们已经定义了这些工具和调用特定工具的能力,我们现在可以再次运行我们的 CLI,并尝试让 Claude 使用这些工具。
>
> 换句话说,我们可以要求 Claude 检查某个特定文档的内容,甚至编辑一个文档。所以让我告诉你我们该怎么做。在我的 MCP 服务器中,我只想提醒你,有一个 ID 为 `report.pdf` 的文档,它有一些关于一个 20 米冷凝塔之类的纹理。我将回到我的终端,我将用一个 `uvicorn run main.py` 来运行我的项目。
>
> 然后我将问 Claude `report.pdf` 文档的内容是什么。请确保你在这里准确地输入 `report.pdf`。当我们运行这个时,我们将连同请求一起发送我们的工具列表。Claude 将决定使用 `read document` 工具。它将获取文档的内容。
>
> 然后我们会看到,是的,Claude 能够获取该文档的内容。我们被告知该报告是关于一个 20 米高的冷凝塔的一些事情。好了,到此为止,我们已经为我们的客户端添加了一些功能。记住,客户端是让我们能够访问在 MCP 服务器内部实现的某些功能的东西。
>
> 到目前为止,我们已经能够列出一些由服务器创建的工具,并执行一个由服务器实现的工具。
---
### 9. 定义资源
> 类型:视频 | 时长:9:45 | 视频:09 - 007 - Defining Resources.mp4
MCP 服务器中的`Resources (资源)`允许您向客户端暴露数据,类似于典型 HTTP 服务器中的 `GET request handlers (GET 请求处理器)`。它们非常适合需要获取信息而不是执行操作的场景。
## 通过示例理解资源
假设您想构建一个文档提及功能,用户可以输入 `@document_name` 来引用文件。这需要两个操作:
- 获取所有可用文档的列表(用于自动完成)
- 获取特定文档的内容(当被提及时)

当用户提及一个文档时,您的系统会自动将文档内容注入到发送给 Claude 的提示中,从而无需 Claude 使用工具来获取信息。

## 资源的工作原理
资源遵循请求-响应模式。当您的客户端需要数据时,它会发送一个带有 `URI (统一资源标识符)` 的 `ReadResourceRequest`,以标识它想要的资源。MCP 服务器处理此请求并在 `ReadResourceResult` 中返回数据。
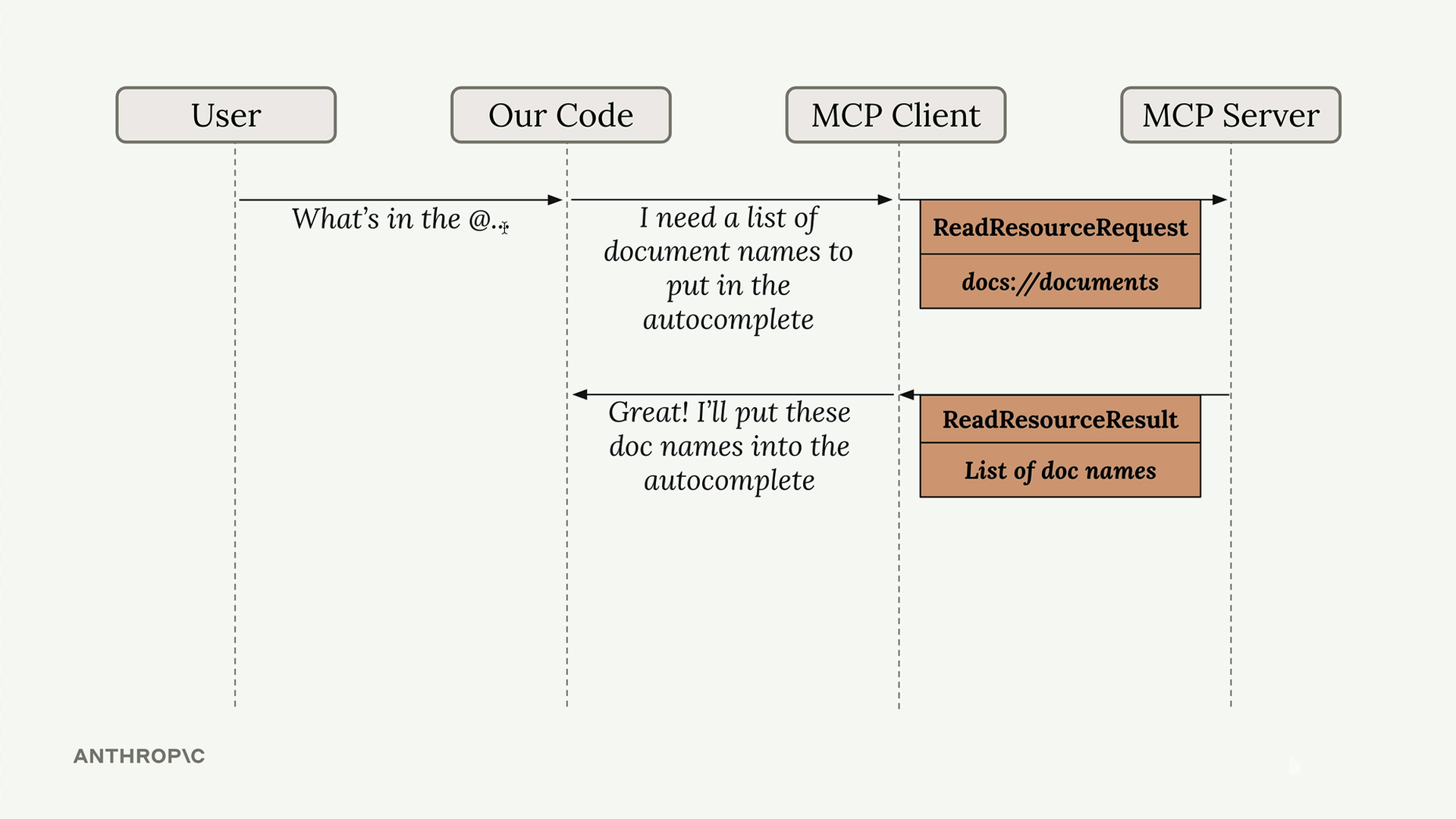
流程如下:您的代码向 MCP 客户端请求一个资源,客户端将请求转发给 MCP 服务器。服务器处理 URI,运行适当的函数,并返回结果。
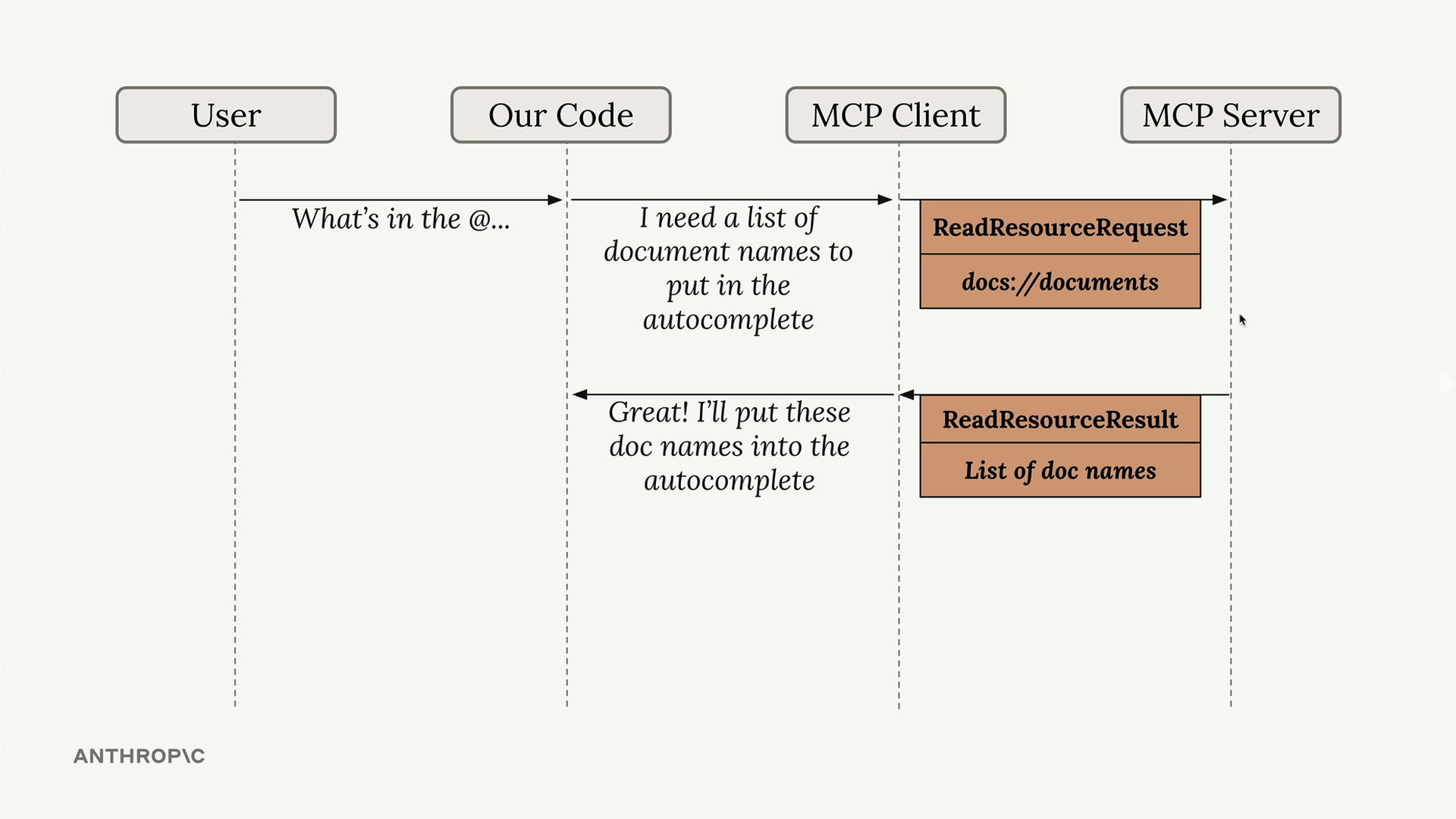
## 资源类型
资源有两种类型:
### 直接资源
直接资源具有永不改变的静态 URI。它们非常适合不需要参数的操作。
@mcp.resource( "docs://documents", mime_type="application/json" ) def list_docs() -> list[str]: return list(docs.keys())
### 模板化资源
模板化资源在其 URI 中包含参数。Python SDK 会自动解析这些参数,并将它们作为关键字参数传递给您的函数。
@mcp.resource( "docs://documents/{doc_id}", mime_type="text/plain" ) def fetch_doc(doc_id: str) -> str: if doc_id not in docs: raise ValueError(f"Doc with id {doc_id} not found") return docs[doc_id]

## 实现细节
资源可以返回任何类型的数据——字符串、JSON、二进制数据等。使用 `mime_type` 参数向客户端提示您要返回的数据类型:
- `"application/json"` 用于结构化数据
- `"text/plain"` 用于纯文本
- `"application/pdf"` 用于二进制文件
MCP Python SDK 会自动序列化您的返回值。您无需手动将对象转换为 JSON 字符串——只需返回数据结构,让 SDK 处理序列化。
## 测试你的资源
你可以使用 MCP Inspector 来测试资源。通过以下命令启动你的服务器:
uv run mcp dev mcp_server.py
然后在浏览器中连接到 inspector。你会看到两个部分:
- **Resources (资源)** - 列出你的直接/静态资源
- **Resource Templates (资源模板)** - 列出你的模板化资源
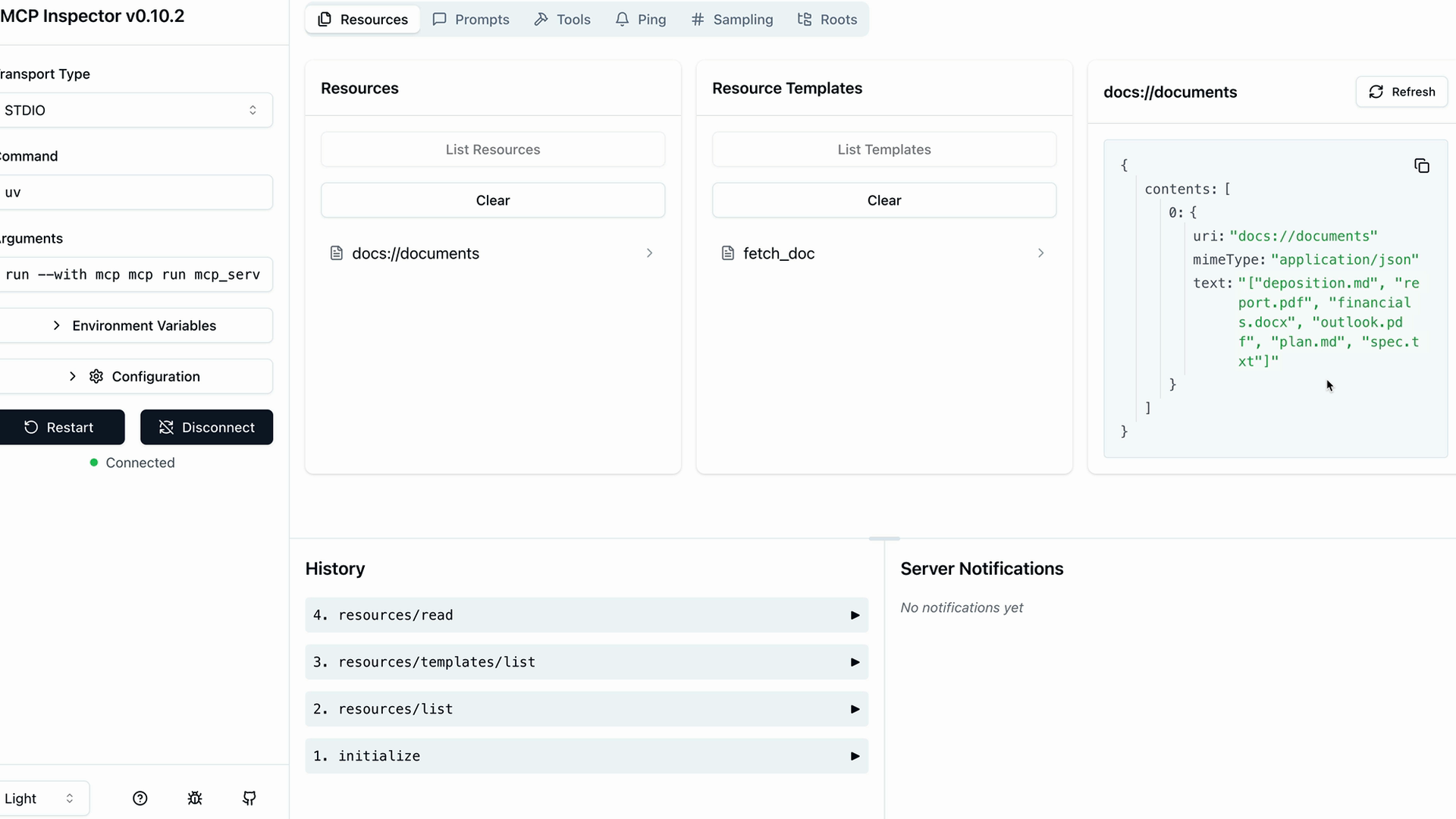
点击任何资源进行测试。对于模板化资源,你需要为参数提供值。Inspector 会向你显示客户端将收到的确切响应结构,包括 MIME type (MIME 类型) 和序列化后的数据。
资源提供了一种简洁的方式来从你的 MCP 服务器暴露只读数据,使客户端可以轻松获取信息,而无需涉及工具调用的复杂性。
#### 视频文字稿
> 在本视频中,我们将继续探讨 MCP 服务器的下一个主要功能——资源 (Resources)。为了帮助你理解资源,我们将在项目中实现另一个功能。我们将添加以下内容:我希望允许用户通过输入 @ 符号后跟文档名称来提及一个文档。
>
> 每当用户这样做时,我希望自动获取该文档的内容,并将其插入我们发送给 Claude 的提示 (Prompt) 中。总的来说,这个功能有两个方面。当用户在消息中输入 @ 符号时,我们将自动在一个小的自动完成窗口中显示所有他们可以提及的不同文档的列表。然后,当用户提交一条包含提及的消息时,我们将自动获取该文档的内容,并将其插入我们发送给 Claude 的提示中。
>
> 例如,如果用户说“@report.pdf 文件里有什么内容”,我希望构建一个如下的提示并发送给 Claude。所以我们会将用户的查询放在里面,然后我们还会告诉 Claude,用户可能引用了某个文档,这里是该文档的内容。所以这里的思路是,我们不必依赖 Claude 去使用某个工具来找出 report.pdf 文件里有什么。相反,用户可以预先提及该文件,我们会自动提前插入一些上下文。
>
> 现在,我想澄清一点,我们实际上在讨论两个不同的功能。第一个功能是,当用户输入 @ 符号时,我们确实需要 MCP 服务器给我们一个所有用户可能提及的文档的列表。第二个方面是,当用户提交一条包含提及的消息时,我们需要 MCP 服务器给我们单个文档的内容。为了从我们的 MCP 服务器获取这些信息,我们将使用资源。
>
> 资源允许我们的 MCP 服务器向客户端暴露一些数据。我们通常为每个不同的读取操作定义一个资源。所以在我们的例子中,我们需要获取文档列表和读取单个文档的内容。因此,我们可能最终会创建两个独立的资源。
>
> 一个资源将负责返回文档名称列表,以便我们可以将它们放入自动完成列表中。然后,我们可能会创建另一个资源,它将根据文档 ID 暴露单个文档的内容。当我们定义这些资源时,它们将通过我们的 MCP 客户端进行访问。所以我们最终要构建的整个流程是,当用户输入“@...”之类的内容时,一旦他们输入 @ 字符,我们就需要显示一个文档名称列表以供自动完成。所以我们的代码会联系 MCP 客户端,后者会向 MCP 服务器发送一个读取资源请求 (Read Resource Request)。
>
> 在那个读取资源请求中,我们将包含一个叫做 URI 的东西。这本质上是我们想要读取的资源的地址。这个 URI 是在我们最初构建资源时定义的。所以 URI 就是那个东西。
>
> 当我们发送这个读取资源请求时,MCP 服务器会查看我们放入其中的确切 URI,然后运行我们之前编写的函数。获取结果并将其在一个读取资源结果消息 (Read Resource Result Message) 中返回给我们。然后我们可以获取其中的数据,并将其显示在我们的自动完成窗口中,或者做任何我们需要做的事情。资源有两种不同类型:直接资源 (direct) 和模板化资源 (templated)。
>
> 你有时也会看到直接资源被称为静态资源 (static resources)。直接资源只有一个静态的 URI,所以它总是完全一样的东西,比如 `docs:://documents`。模板化资源则在其 URI 中包含一个或多个参数。例如,我们可能有 `documents/`,然后在这里有一个通配符。
>
> 所以我们可以放入任何我们想要的文档 ID。当我们请求这个资源时,URI 中的那个文档 ID 将被 Python MCP SDK 自动解析,并作为关键字参数提供给我们的函数。该关键字参数的名称将与你在此处输入的字符串完全相同。所以这里的 `doc_id` 就会是那里的 `doc_id`。
>
> 你可能已经猜到了,我们会在任何时候想要在别人从我们的 MCP 服务器请求的内容中允许更多选择、多样性或定制时,使用模板化资源。实现资源非常直接。那么,让我们回到我们的编辑器,立即为我们的服务器添加一些资源。好了,回到我的编辑器里,我将找到 `MCP_server.py` 文件。
>
> 然后我将向下滚动一点,找到关于编写一个资源以返回所有文档 ID 和编写一个资源以返回特定文档内容的注释。对于第一个,我写了注释“文档 ID”。请记住,对我们来说,文档 ID 本质上就是文档的名称。所以对我们来说,我们实际上只是返回这些 ID。
>
> 它们将起到名称的作用。这意味着我们可以直接将它们放入那个自动完成元素中。好了,为了创建我们的资源,我将删除那个待办事项,然后我会添加一个 `@mcp.resource`。
>
> 第一个参数将是访问这个东西的 URI。同样,它有点等同于一个路由处理器。所以我将使用 `docs:://documents`,并且我还会添加一个 `application/json` 的 MIME 类型。资源可以返回任何类型的数据,所以它可以是纯文本、JSON、二进制数据,任何东西。
>
> 这取决于我们给客户端一个提示,告诉它我们返回的是什么样的数据。为此,我们将定义这个 MIME 类型。`application/json` 的 MIME 类型是对我们客户端的一个提示,它最终会请求这个资源,告诉它我们将返回一个包含结构化 JSON 数据的字符串。因此,我们的客户端将负责反序列化该数据,或者说将其转换成可用的数据结构。
>
> 在那个装饰器下面,我将写出我的函数 `list_docs`,它将返回一个字符串列表。然后在其中,我将返回 `list(docs.keys())`。所以只需从那个字典中取出所有的键并将其转换为一个列表,然后返回它。现在,你会注意到我们这里返回的不是独立的 JSON。
>
- 换句话说,我们实际上并没有返回一个字符串。MCP Python SDK 会自动将我们返回的任何内容转换为字符串。好了,让我们来处理我们的第二个资源。所以我将删除那条注释,然后用 `@mcp.resource('docs:://documents/{doc_id}')` 替换它。
>
> 这次我想要一个模板化的资源,因为我在这里放入了这个通配符。然后这次我的 MIME 类型,为了增加一点多样性,我将返回纯文本,因为它将只是文档的内容。我不会将它包装在任何类型的结构中。现在,只是想让你知道,在一个真实的应用中,像读取文档这样的操作,我可能会返回整个文档记录。
>
> 也就是某种包含 ID、内容、作者名、作者 ID 等的字典。但仅为了举例,我将只返回文档的文本,向你展示我们通常如何返回纯文本。所以在这种情况下,我的 MIME 类型将是 `text/plain`,然后我将创建 `fetch_doc`。我将接收一个 `doc_id`,它是一个字符串,我将返回一个字符串。
>
> 再一次,你在这里输入的任何单词,都会作为关键字参数出现在你的函数中。如果我在这里加入一些额外的参数,比如 `doc_type` 之类的,它就会作为额外的关键字参数出现,像这样。然后在这里面,我首先要确保这个人请求的 ID 确实存在。所以如果 `doc_id` 不在 `docs` 中,我将抛出一个 `ValueError`,并附带一个 f-string,内容是“未找到 ID 为...的文档”。
>
> 然后如果我们通过了那个检查,我将返回 `docs[doc_id]`。就这样。现在让我们再次在我们的 MCP Inspector 中测试这些东西。记住,在我们的终端,我们可以运行 `uvicorn mcptest.mcpserver:app --reload` 命令。
>
> 这将会在端口 6277 或者默认的 6274 启动一个 web 服务器。所以我要确保在我的浏览器中打开它。好了。我点击连接。
>
> 然后我找到资源。然后我应该能够列出所有可用的资源。现在当我列出资源时,这将是特指静态或直接资源。所以我只会看到 `docs/documents`。
>
> 然后我可以分开列出所有不同的资源模板。所以我看到我有一个 `fetch_doc` 的资源模板。我可以先尝试运行这里的 `slash documents`。我们看看会得到什么。
>
> 这就是实际的消息,从我们 MCP 服务器返回的确切结构。你会注意到它有一个 `text` 属性,里面是我们返回的所有数据,序列化为 JSON 字符串。所以再次强调,这将取决于我们在 CLI 应用程序中,去获取这个文本并将其从这个 JSON 字符串反序列化为一个可用的字符串列表。然后我们也可以测试 `fetch_doc`。
>
> 所以我点击它。我必须输入一个文档 ID。所以我将输入,我想读取 `report.pdf` 文件。
>
> 我会读取资源。现在我应该能看到那个特定文档的内容了。你会注意到这次,我又得到了一个 `text/plain`。
>
> 所以这提示我这是纯文本。我不应该尝试以任何方式从 JSON 中反序列化它。
---
### 10. 访问资源
> 类型:视频 | 时长:4:38 | 视频:09 - 008 - Accessing Resources.mp4
MCP 中的资源允许你的服务器暴露可以直接包含在提示中的信息,而不是需要通过工具调用来访问数据。这创建了一种更高效的方式来为 AI 模型提供上下文。
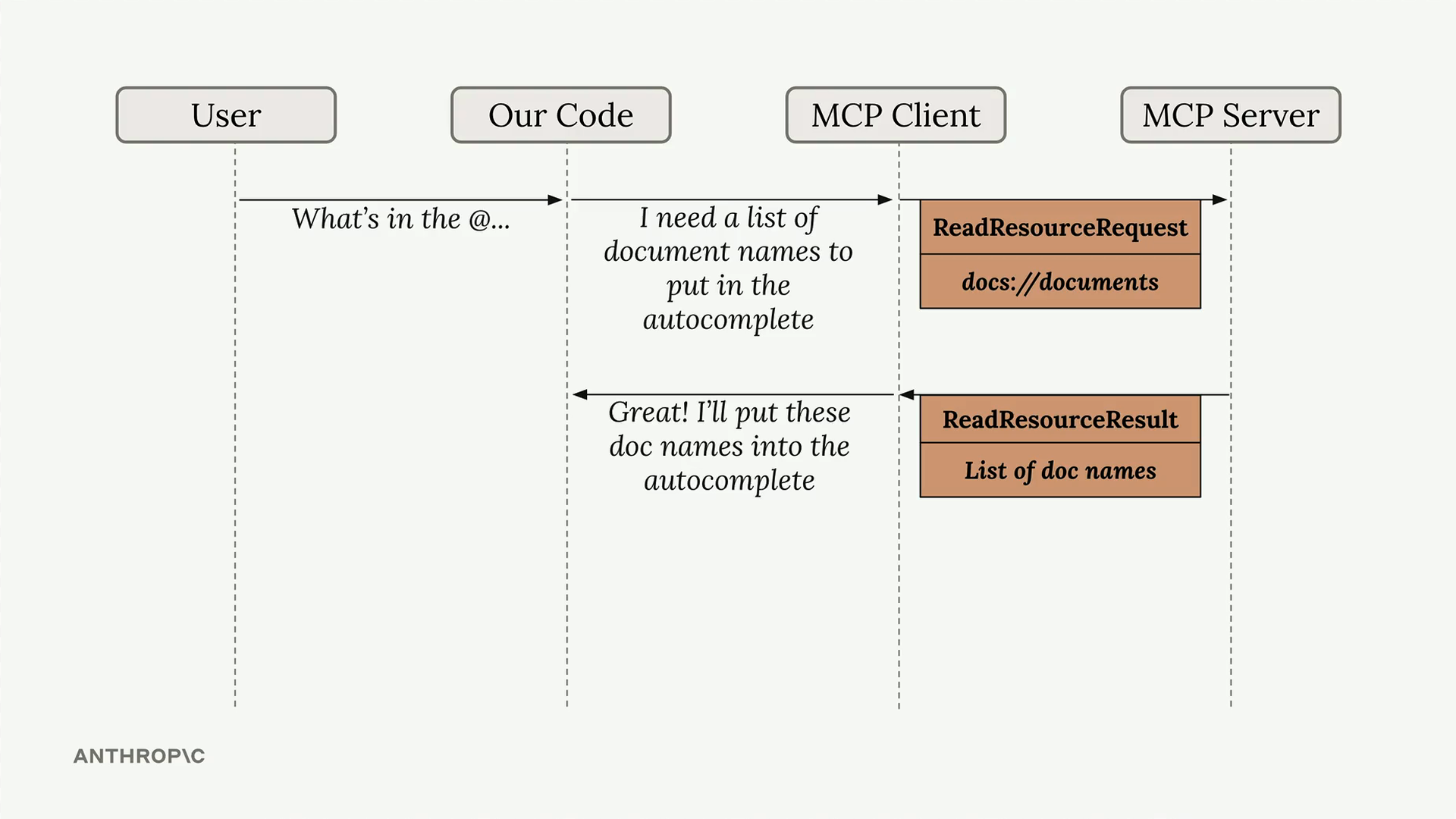
上图展示了资源的工作原理:当用户输入类似“What's in the @...”时,我们的代码会将其识别为资源请求,向 MCP 服务器发送一个 `ReadResourceRequest` (读取资源请求),并取回一个带有实际内容的 `ReadResourceResult` (读取资源结果)。
## 实现资源读取
要在你的 MCP 客户端中启用资源访问,你需要实现一个 `read_resource` 函数。首先,添加必要的导入:
import json from pydantic import AnyUrl
核心函数向 MCP 服务器发出请求,并根据其 MIME 类型处理响应:
async def read_resource(self, uri: str) -> Any: result = await self.session().read_resource(AnyUrl(uri)) resource = result.contents[0]
if isinstance(resource, types.TextResourceContents):
if resource.mimeType == "application/json":
return json.loads(resource.text)
return resource.text
## 理解响应结构
当你请求一个资源时,服务器会返回一个带 `contents` 列表的结果。我们访问第一个元素,因为通常我们一次只需要一个资源。响应包括:
- 实际内容(文本或数据)
- 一个告诉我们如何解析内容的 MIME 类型
- 关于资源的其他元数据
## 内容类型处理
该函数检查 MIME 类型以确定如何处理内容:
- 如果是 `application/json`,则将文本解析为 JSON 并返回解析后的对象
- 否则,返回原始文本内容
这种方法可以无缝处理结构化数据(如 JSON)和纯文本文档。
## 测试资源访问
实现后,你可以通过你的 CLI 应用程序测试资源功能。当你输入“@”后跟资源名称时,系统将:
1. 在自动完成列表中显示可用资源
2. 让你使用箭头键和空格键选择一个资源
3. 将资源内容直接包含在你的提示中
4. 将所有内容发送给 AI 模型,无需额外的工具调用
与让 AI 模型进行单独的工具调用来访问文档内容相比,这创建了更流畅的用户体验。资源内容成为初始上下文的一部分,从而可以对数据进行即时响应。
#### 视频文字稿
> 我们已经在 MCP 服务器中定义了两个独立的资源。所以现在我们的客户端需要有能力请求这些资源。为此,我们将在 MCP 客户端中添加一个函数。请记住,这个 MCP 客户端将包含一些我们正在构建的功能,这些功能将被我们应用程序的其余部分使用。
>
> 我已经完成了那部分代码。所以在本项目的其他地方,会有东西尝试使用我们即将添加到 MCP 客户端的这个函数。首先,我将再次打开 MCP 客户端文件。我会向下滚动并找到 `read_resource` 这里。
>
> 所以我们在这里的目标是通过向我们的 MCP 服务器发出请求来读取特定资源,然后根据其 MIME 类型解析返回的内容,并返回我们得到的任何数据。你会注意到它的一个参数是 URI。这将是我们想从服务器获取的资源的 URI。为了发出请求,为了让我们的类型都能很好地工作,我们将在文件顶部添加两个导入。
>
> 我将为 JSON 模块添加一个导入。并从 PyDantic 导入 `AnyUrl`。然后我将回到我们的 `read_resource` 函数。我将清除注释和返回语句。
>
> 然后我将从调用 `await self.session().read_resource()` 中获得一个结果。再次强调,这真的只是为了让类型能够正常工作。我们将放入一个带有输入 URI 的 `AnyUrl`。然后我将从该结果的 `result.contents[0]` 中提取。我想在这里明确说明我们为什么添加这个。
>
> 就在刚才,在我们的 Inspector 中,我们看到了我们得到的响应。这基本上就是那个 `result` 变量。`Result` 有一个 `contents` 列表。里面会有一个元素列表。
>
> 我们真正关心的只有第一个。所以我想要第一个字典。我想访问 `type` 属性和 `mime type`。我特别想要 MIME 类型,因为它会帮助我理解我们得到的是什么样的数据。
>
> 如果是 JSON,那么我需要确保将文本解析为 JSON 并返回该结果。让我向你展示我们将如何做到这一点。我将添加一个 `if isinstance(resource, types.TextResourceContents)`。在其中,如果 `resource.mime_type` 等于 `application/json`。
>
> 所以这是我们的使用提示。如果服务器告诉我们它返回了一些 JSON,我们需要确保将文本内容解析为 JSON。所以我将在这种情况下返回 `json.loads(resource.text)`。然后,如果我们没有进入那个 if 语句并提前返回,我只想返回 `resource.text`。
>
> 所以在这种情况下,我们将以纯文本的形式返回文本,或者不解析任何东西。这实际上就是我们获取单个文档内容的情况。好了,应该就是这样了。我们已经完成了 `read_resource` 的编写。
>
> 现在我想再次提醒你,我知道我已经说过好几次了,但我还是想提醒你,因为我觉得可能有点不清楚。我们在 MCP 客户端中编写的代码正被这个代码库中的其他几个地方使用。所以在这个代码库的其他地方,我们将调用我们刚刚编写的那个函数,以获取文档名称列表,并最终获取文档内容以放入提示中。所以在这一点上,一切基本上都应该可以工作了,因为其余的工作已经为我们完成了。
>
> 考虑到这一点,让我们回到我们的终端,再次测试我们的 CLI 应用程序,看看这个提及功能是否有效。好的,回到这里,我将执行 `uvrun main.py`,现在我应该可以说出类似“what's in the at”这样的话,然后瞧,我看到了我的资源列表,我可以使用箭头键滚动浏览。一旦我找到了我喜欢的资源,我只需按空格键,它就会插入那个资源。那么,report.pdf 文档里有什么呢?现在,我可以告诉你,这里的一切都按预期工作。
>
> 换句话说,这个文档的内容正被发送到 Claude 的提示中。所以如果我提交这个,我应该会看到一个即时响应,它会告诉我报告 PDF 里面有什么。所以这次,Claude 不必使用工具来读取文档的内容。好了,这就是资源。
>
> 再次强调,我们利用资源从我们的 MCP 服务器中暴露一些信息。
---
### 11. 定义提示
> 类型:视频 | 时长:7:44 | 视频:09 - 009 - Defining Prompts.mp4
MCP 服务器中的提示 (Prompts) 让你能够定义预先构建的、高质量的指令,客户端可以使用这些指令,而无需从头开始编写自己的提示。可以把它们看作是精心制作的模板,能比用户自己临时想出的提示带来更好的结果。
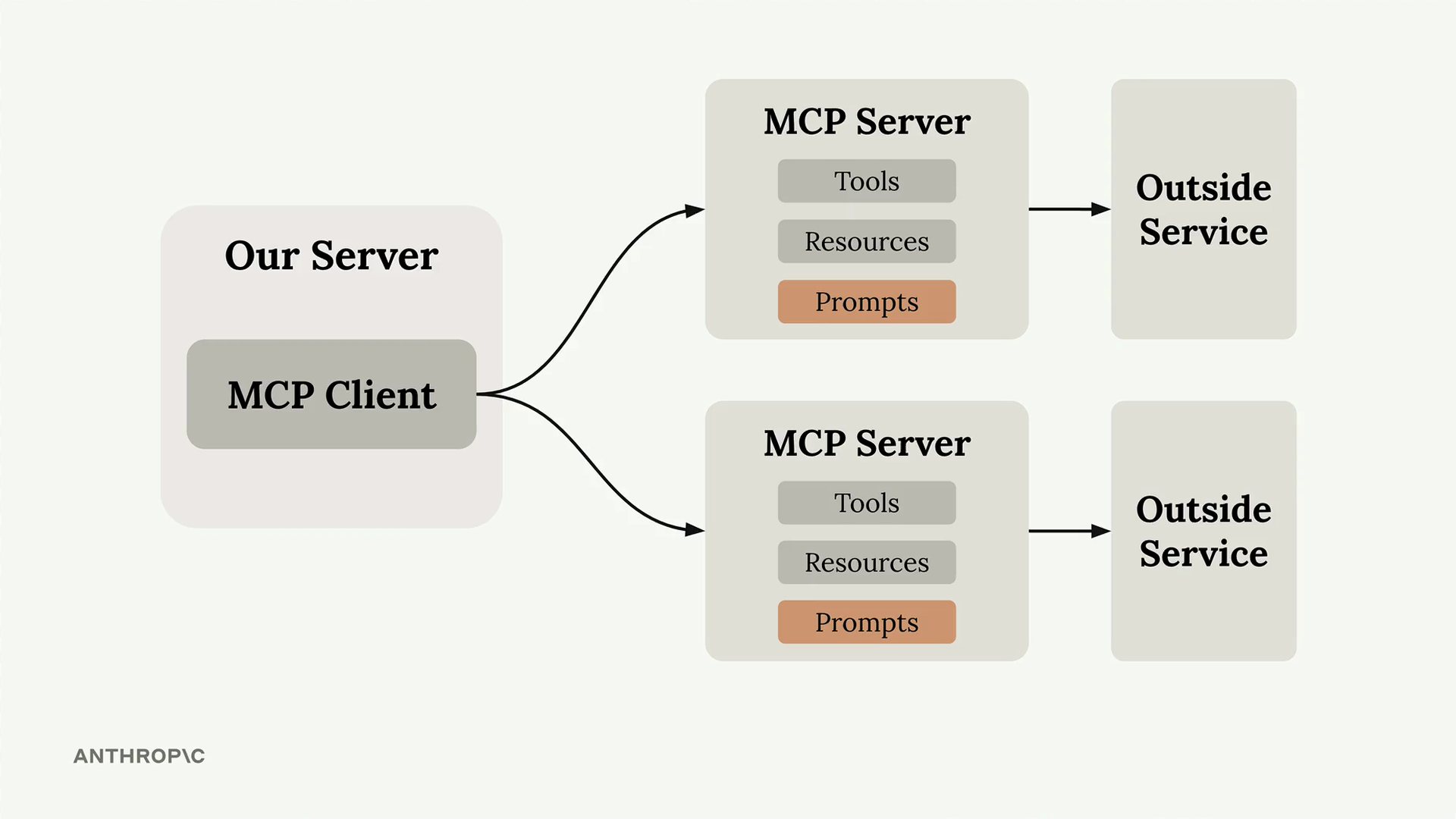
## 为什么使用提示?
这里的关键洞察是:用户已经可以直接要求 Claude 做大多数任务。例如,用户可以输入“用 markdown 格式重新排版 report.pdf”并得到不错的结果。但如果你提供一个经过充分测试、专门为处理边界情况和遵循最佳实践而设计的提示,他们会得到好得多的结果。
作为 MCP 服务器的作者,你可以花时间精心设计、测试和评估在不同场景下都能稳定工作的提示。用户无需自己成为提示工程专家就能从这些专业知识中受益。

## 构建一个格式化命令
让我们实现一个实际的例子:一个将文档转换为 markdown 的 `format` 命令。用户将输入 `/format doc_id`,然后得到一个专业格式化的 markdown版本的文档。
工作流程如下:
- 用户输入 `/` 查看可用命令
- 他们选择 `format` 并指定一个文档 ID
- Claude 使用你预先构建的提示来读取并重新格式化文档
- 结果是带有正确标题、列表和格式的干净的 markdown
## 定义提示
提示使用与工具和资源类似的装饰器模式:
@mcp.prompt( name="format", description="Rewrites the contents of the document in Markdown format." ) def format_document( doc_id: str = Field(description="Id of the document to format") ) -> list[base.Message]: prompt = f""" Your goal is to reformat a document to be written with markdown syntax.
The id of the document you need to reformat is: <document_id> {doc_id} </document_id>
Add in headers, bullet points, tables, etc as necessary. Feel free to add in structure. Use the 'edit_document' tool to edit the document. After the document has been reformatted... """
return [
base.UserMessage(prompt)
]
该函数返回一个消息列表,这些消息将直接发送给 Claude。你可以包含多个用户和助手消息来创建更复杂的对话流。
## 测试你的提示
在部署之前,使用 MCP Inspector 测试你的提示:
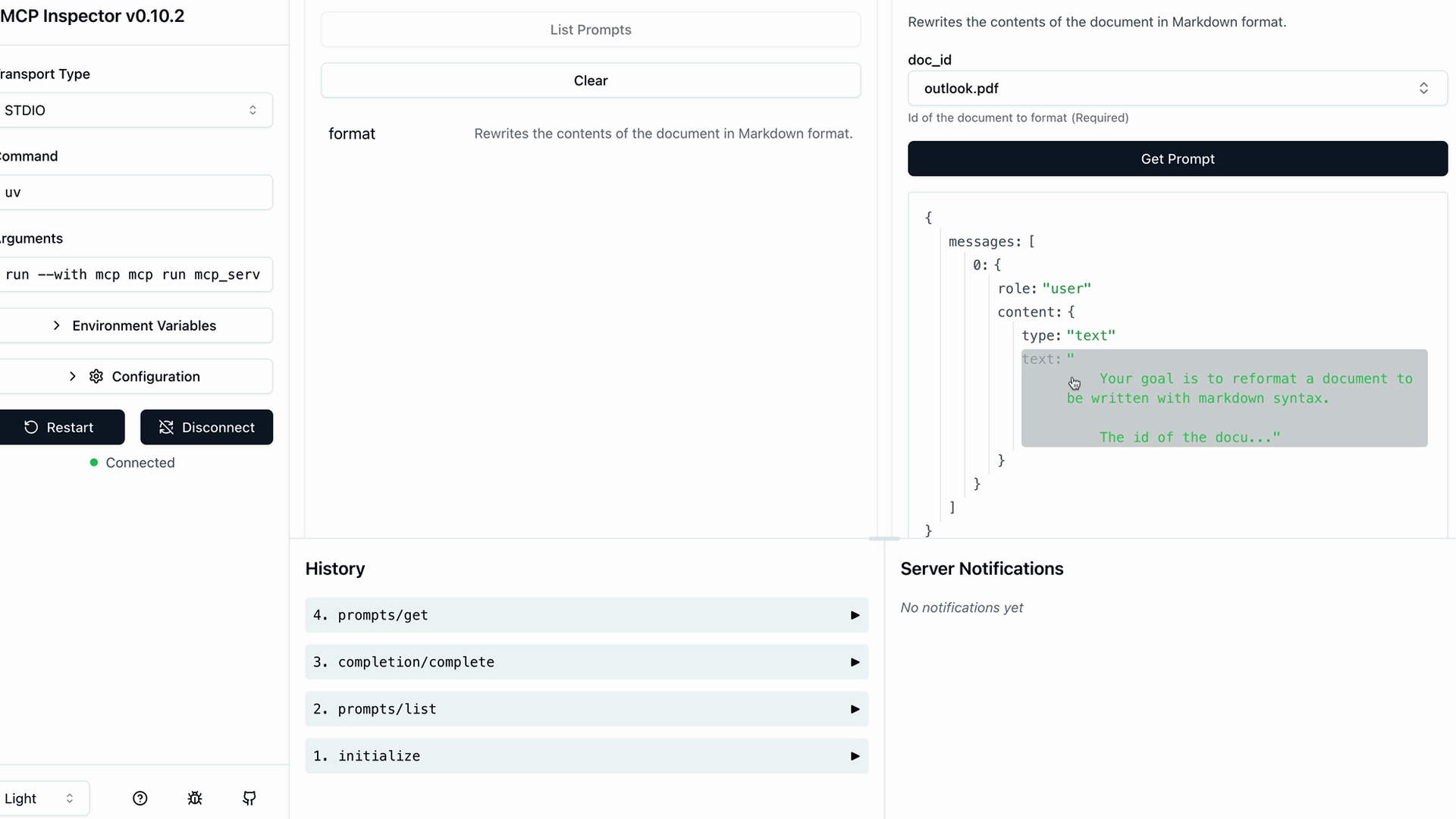
Inspector 会准确地向你显示将发送给 Claude 的消息,包括变量是如何插入到你的提示模板中的。这使你可以在用户开始依赖它之前验证提示看起来是否正确。
## 关键优势
- **一致性** - 用户每次都能得到可靠的结果
- **专业性** - 你可以将领域知识编码到提示中
- **可重用性** - 多个客户端应用程序可以使用相同的提示
- **可维护性** - 在一个地方更新提示以改进所有客户端
当提示针对你的 MCP 服务器的领域进行专门化时,它们的效果最好。一个文档管理服务器可能有用于格式化、摘要或分析文档的提示。一个数据分析服务器可能有用于生成报告或可视化的提示。
目标是提供经过精心设计和测试的提示,以至于用户更喜欢使用它们,而不是从头开始编写自己的指令。
#### 视频文字稿
> 我们在 MCP 服务器中的最后一个主要关注点将是提示(prompts)。再一次,就像我们处理资源时一样,我们将在我们的项目中实现一个小功能。我们将利用这个功能来理解提示到底是什么,就像我们刚才处理资源一样。让我告诉你我们将在程序中添加的功能。
>
> 我们将添加对斜杠命令的支持。例如,我想要一个格式化命令。我这里有一些关于它如何工作的截图。当用户输入斜杠时,我们将列出一些我们的应用程序支持的命令。
>
> 目前,我们只有一个名为 `format` 的命令。所以如果我只输入斜杠,我应该会看到一个小的自动完成窗口,唯一的选项应该是 `format`。如果我选择了 `format`,我应该会被提示在后面添加一个文档 ID。比如我们的一个文档名,像 `report.pdf` 或者其他什么。
>
> 然后当用户运行这个命令时,目标是让 Claude 使用 Markdown 语法重新格式化这个文档。换句话说,就是取我们现在每个文档里的没有任何特殊格式的纯字符串。记住,在我们的 MCP 服务器里,我们当前的文档内容只是纯文本。我们想把这个输入给 Claude,并以某种方式让 Claude 用 Markdown 语法重写它。
>
> 所以我期望看到像这样的输出,一些东西说,我会帮你重新格式化文档。Claude 然后会使用一个工具来读取文档的内容。最后,在最终的响应中,我希望看到那个文档的内容在这里以 Markdown 语法重写。现在,关于这个功能,我想指出的一个有趣之处。
>
> 这个功能真正的核心,真正的目标,是允许用户将文档重新格式化为 Markdown 语法。而这个操作实际上并不需要我们开发者编写任何代码来实现。我这是什么意思呢?嗯,用户已经可以启动我们的 CLI 并说出类似“用 markdown 语法重新格式化 report.pedia 文件”这样的话。
>
> 用户已经可以做到这一点了。完全没有问题。而且 Claude 会做得相当不错。它会获取我们文档的内容并将其重新格式化为 Markdown。
>
> 正如你在这里看到的,它完美地完成了工作。那么我们用这个功能到底在做什么呢?嗯,这里的思路是,如果我们完全放手让用户自己去做,让他们手动输入像“把这个转换成 Markdown”这样的指令,他们可能会得到一个还不错的结果,但如果他们有一个专门为将文档转换为 Markdown 这种特定场景量身定制的、非常强大的提示,他们可能会得到好得多的结果。所以,如果作为 MCP 服务器的作者,我们坐下来,编写、测试、评估,并走完评估我们那些非常详尽、出色的提示(就像你右边看到的那个)的整个过程,用户可能会更满意。
>
> 所以,再说一遍,是的,用户可以自己完成这整个工作流程,但如果他们改用这边这个花哨的提示,嗯,我想他们会得到更好的结果。这就是 MCP 服务器中提示功能的真正目标。这里的想法是,我们可以提前在我们的服务器中定义一套提示,这些提示是为我们的服务器真正擅长做的事情量身定制的。在我们的例子中,我们的服务器是关于管理文档、阅读文档、编辑文档等等。
>
> 所以我们可能会决定添加一套非常高质量的提示,这些提示经过了评估和测试,我们知道它们在各种不同场景下都能工作。然后我们可以将这些提示暴露出来,供任何客户端应用程序使用,比如我们现在正在构建的这个 CLI 应用。现在,我想指出一点,我们可以开发这个提示并直接把它放到我们的 CLI 代码库中。这完全是可能的。
>
> 我们可以这样做,显然。但再次强调,这里的想法是,你的 MCP 服务器可能专注于某个特定任务,它可能会暴露一些提示,人们可以直接来使用,而无需担心提前开发它们。为了在我们的 MCP 服务器中定义一个提示,我们将编写一些与我们已经完成的工具和资源非常相似的语法。
>
> 我们将使用 `prompt` 装饰器。我们将为提示添加一个名称,并可选择地添加描述。然后,当客户端请求这个提示时,我们将返回一个消息列表。这些是实际的用户和助手消息。所以我们可以将这些消息直接发送给 Claude。
>
> 好了,让我们转到我们的服务器,我们将尝试构建我们自己的提示。就像你在这里看到的,它将完全是关于获取文档内容并以某种方式用 Markdown 格式重写它。好的,回到我的编辑器里,我将找到我的 MCP 服务器文件。我将向下滚动到关于用 Markdown 格式重写文档的注释。
>
> 我会删除那个待办事项,然后我会添加一个 `@mcp.prompt`,名称为 `format`,描述为“用 Markdown 格式重写文档内容”。然后我将添加一个实际的实现。所以 `format_document`,我可以接收一个 `doc_id` 作为参数,然后我们也可以在这里添加一个字段描述,就像我们之前对工具所做的那样。所以我可以选择性地添加一个字段,描述为“要格式化的文档的 ID”。
>
> 我还将添加一个 `string` 的类型注解。只是为了确保那也很清楚。从这个函数中,我们将返回一个消息列表。我将确保立即在顶部添加对这个 `base` 的导入。
>
> 所以在现有的 MCP 服务器导入下面,我将添加 `from mcptest_mcp_prompts import base`。然后回到下面。在这里面,我们将定义我们经过充分测试、充分评估的提示。我提前写好了一个提示。
>
> 我会把它粘贴进来,像这样。所以这个提示只是要求 Claude 接收一个文档 ID。我们隐含地要求 Claude 使用 `redocument` 工具获取文档 ID 的内容。然后在获取该文档后,直接用 Markdown 语法重写它。
>
> 最后,在重写之后,还要编辑文档,以将这些更新保存在我们的服务器中。现在,在定义了这个提示之后,我们将返回一个消息列表。所以在下面,我将返回一个列表,其中包含 `base.user_message`,我将把我们刚刚写出的提示输入进去,像这样。现在我将保存这个文件,然后让我们启动我们的 MCP 开发检查器,并从那个界面测试这个提示。
>
> 所以在我的终端,我将再次运行相同的命令,然后在我的浏览器中导航到那个地址。我将确保连接到我的服务器。然后我找到提示部分。我将列出所有对我们可用的不同提示。
>
> 在这一点上,我们只有一个提示,就是 `format`。所以我点击 `format`,然后我必须在这里输入一个文档 ID。让我们,这次,也许我们会输入一个文档 ID,比如 `outlook.pdf`。所以我把它输入进去。
>
> 然后获取提示。然后这是我们的消息列表。这些都是提前准备好的。我这里有一个消息部分。
>
> 也就是一个带有我们完整提示的文本部分。我们可以看到文档 ID 已经被插入进去了。现在我们有了这些消息,我们可以把它们发送给 Claude。希望我们能得到一些适当的响应。
>
> 所以再次强调,这些我们在 MCP 服务器中可能实现的提示背后的整个思想是,我们定义的提示将是经过充分测试、充分评估的,并且真正专注于某个特定的用例。
---
### 12. 在客户端中使用提示
> 类型:视频 | 时长:3:01 | 视频:09 - 010 - Prompts in the Client.mp4
构建 MCP 客户端的最后一步是实现提示功能。这使我们能够列出服务器上所有可用的提示,并检索填充了变量的特定提示。
## 实现列出提示
`list_prompts` 方法很简单。它调用会话的 `list_prompts` 函数并返回提示:
async def list_prompts(self) -> list[types.Prompt]: result = await self.session().list_prompts() return result.prompts
## 获取单个提示
`get_prompt` 方法更有趣,因为它处理变量插值。当你请求一个提示时,你提供的参数会作为关键字参数传递给提示函数:
async def get_prompt(self, prompt_name, args: dict[str, str]): result = await self.session().get_prompt(prompt_name, args) return result.messages
例如,如果你的服务器有一个需要 `doc_id` 参数的 `format_document` 提示,那么参数字典将包含 `{"doc_id": "plan.md"}`。这个值会被插入到提示模板中。
## 测试运行中的提示
实现后,你可以通过 CLI 测试提示。当你输入斜杠 (/) 时,可用的提示会作为命令出现。选择像 "format" 这样的提示会提示你从可用的文档中选择。
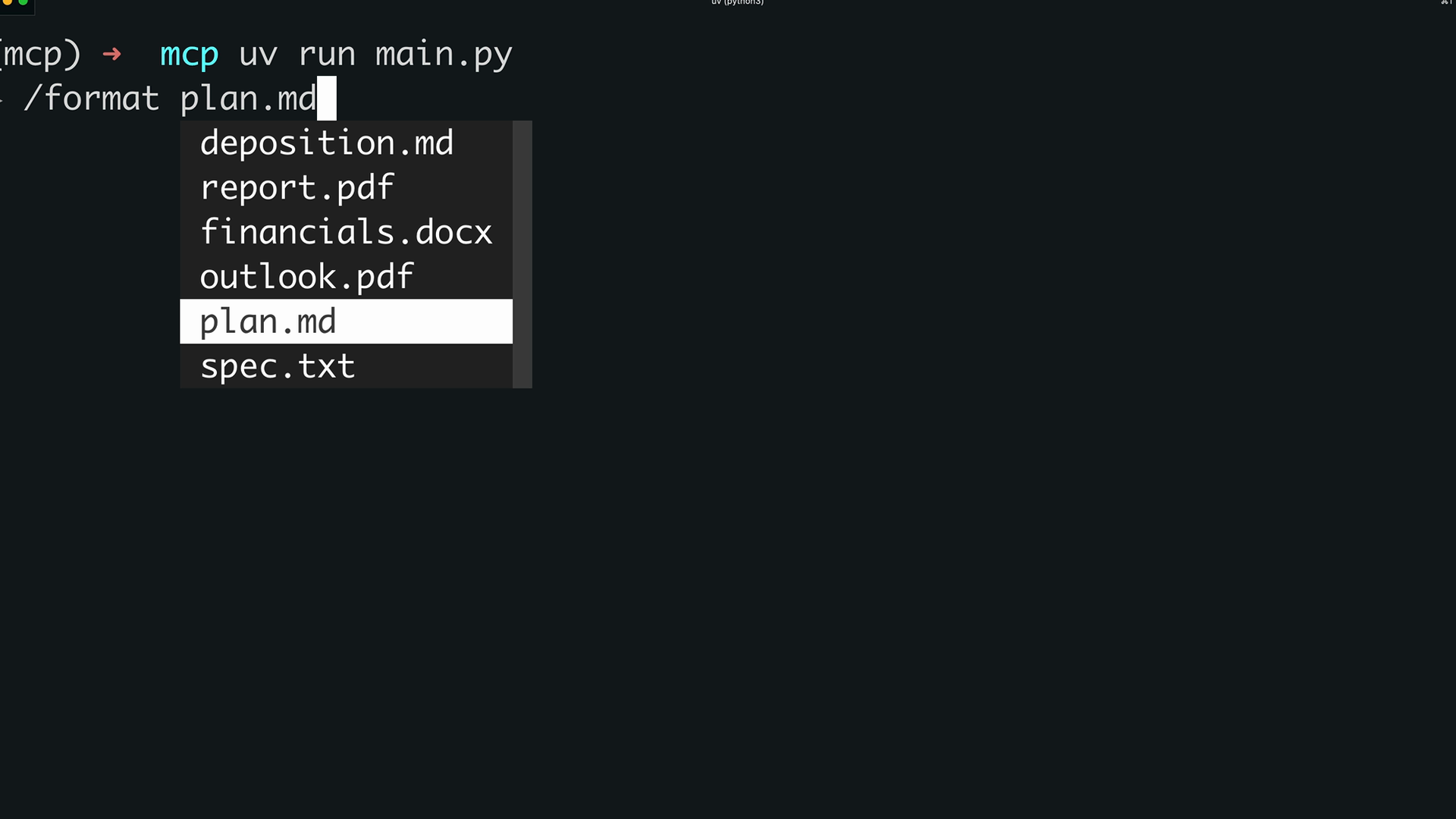
选择一个文档后,系统会将完整的提示发送给 Claude。AI 会收到格式化指令和文档 ID,然后使用可用的工具来获取和处理内容。
## 提示的工作原理

提示定义了一组用户和助手消息,供客户端使用。它们应该是高质量、经过充分测试并与你的 MCP 服务器的用途相关的。工作流程是:
- 编写并评估与你的服务器功能相关的提示
- 使用 `@mcp.prompt` 装饰器在你的 MCP 服务器中定义提示
- 客户端可以随时请求该提示
- 客户端提供的参数成为你提示函数中的关键字参数
- 该函数返回为 AI 模型准备好的格式化消息
这个系统创建了可重用的、参数化的提示,这些提示在保持一致性的同时允许通过变量进行定制。这对于复杂的工作流特别有用,在这些工作流中,你希望确保 AI 每次都能收到结构正确的指令。
#### 视频文字稿
> 我们最后的主要任务是在我们的 MCP 客户端中实现一些功能,让我们能够列出 MCP 服务器中定义的所有不同提示,并获取一个插入了一些变量的特定提示。所以让我们首先实现 `list_prompts`。我将删除注释并用 `result = await self.session().list_prompts()` 替换它,然后我将返回 `result.prompts`。基本上就是这样。
>
> 然后是 `get_prompt`。需要明确的是,当我们获取单个提示时,我们会得到一些参数。这些参数最终会出现在我们的提示函数中。例如,在 `format_document` 中,我们期望接收一个文档 ID。
>
> 在这个 `args` 字典中,期望会有一个 `document ID` 键。它将被传递到这边相应的函数中。然后我们将在提示本身中得到那个值的插值。所以在 `get_prompt` 函数中,我将从 `self.session().get_prompt()` 中得到一个结果。
>
> 我将传入 `prompt_name`。这是我想要检索的提示的名称。然后我将传入参数。然后我将返回 `result.messages`。
>
> 所以这些是返回的消息。它们构成了某种我们想要直接输入给 Claude 的对话。就这样。这就是我们为客户端需要做的所有事情。
>
> 所以现在我们可以在 CLI 本身中测试这个。我将切换回去,再次运行项目。现在如果我在这里输入一个斜杠,我会看到我可以访问这个 `format` 命令。现在 `format` 实际上只是我们将要调用的提示的名称。
>
> 所以如果我选择它,然后按空格键,我就会被要求选择一个文档,比如 `plan.md`。我按回车。然后我们把整个提示,实际上只是那个单一的用户消息,直接输入给 Claude。所以 Claude 现在有了用 Markdown 语法重新格式化文档的指令。
>
> 它也得到了我们想要重新格式化的文档的 ID。所以它需要做的第一件事是去获取那个文档的内容。它会通过使用 `get_document` 工具来做到这一点。然后最后,Claude 会用这个文档的 Markdown 版本来回应。
>
> 所以这是带有大量 Markdown 语法的文档。好了,既然这看起来工作得很好,让我们快速回顾一下提示,并确保我们理解它们到底是什么。我们从编写和评估一个与我们 MCP 服务器的目的相关的提示开始。在我们的例子中,我们正在制作一个文档服务器。
>
> 所以有一些关于用不同风格重写文档的功能或东西,我认为这有点道理。一旦我们把提示组合好了,我们就在 MCP 服务器中定义一个提示。然后我们的客户端可以在任何时候请求那个提示。当我们请求提示时,我们会输入一些参数,这些参数将作为关键字参数提供给这个提示函数。
>
> 然后我们的函数可以在提示本身中使用那些关键字参数。
---
## 第4部分:评估与总结
### 14. MCP 回顾
> 类型:视频 | 时长:4:12 | 视频:09 - 011 - MCP Review.mp4
既然我们已经构建了我们的 MCP 服务器,让我们回顾一下三个核心的服务器原语 (primitives),并理解何时使用每一个。关键的洞察是,每个原语都由你的应用程序栈的不同部分控制。
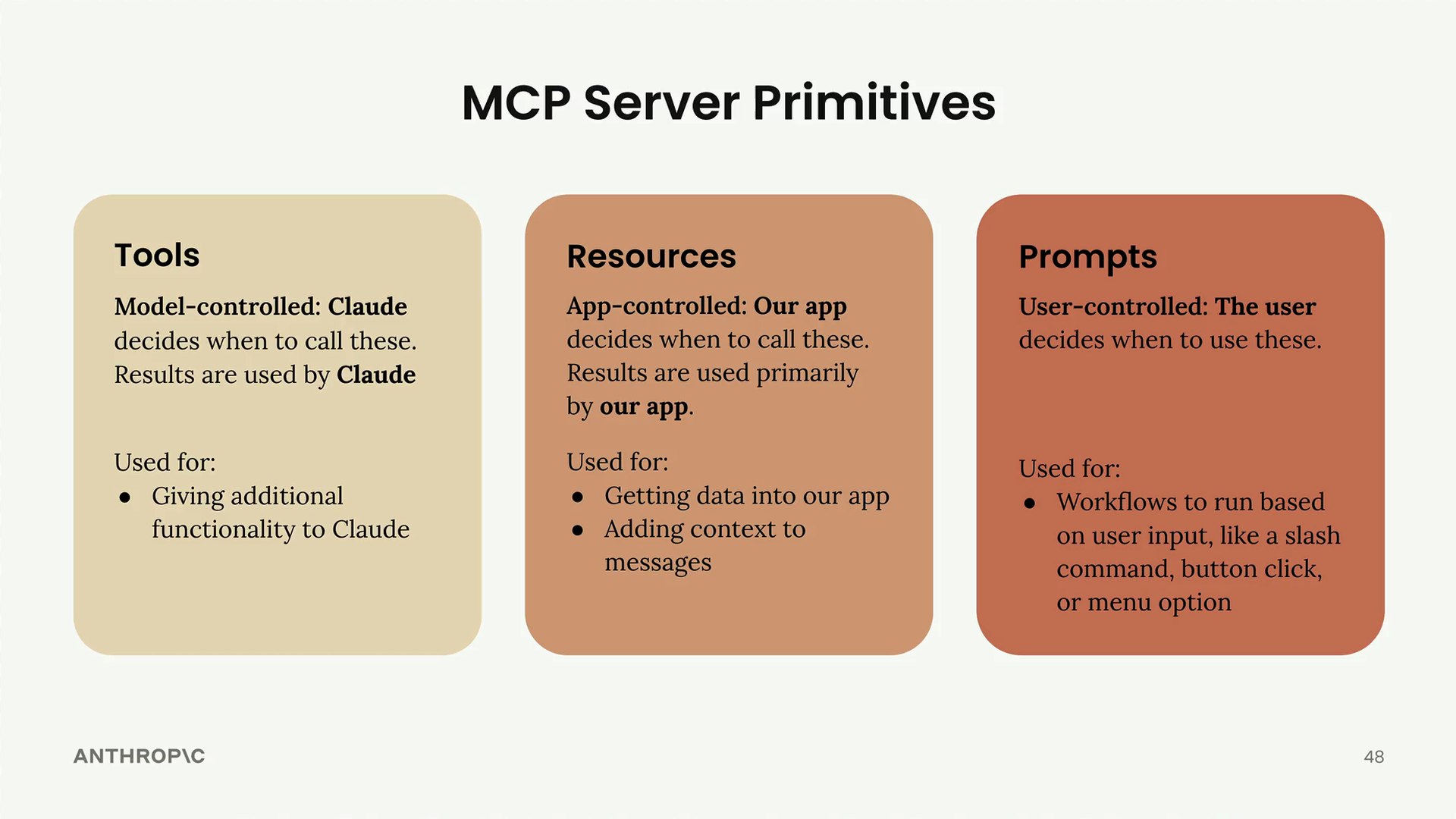
## 工具:模型控制
工具 (Tools) 完全由 Claude 控制。AI 模型决定何时调用这些函数,其结果直接被 Claude 用于完成任务。
当你需要赋予 Claude 能够自主使用的额外能力时,工具是完美的选择。当你让 Claude“用 JavaScript 计算 3 的平方根”时,是 Claude 决定使用一个 JavaScript 执行工具来运行计算。
## 资源:应用控制
资源 (Resources) 由你的应用程序代码控制。你的应用决定何时获取资源数据以及如何使用它——通常用于 UI 元素或为对话添加上下文。
在我们的项目中,我们通过两种方式使用了资源:
- 获取数据以填充 UI 中的自动完成选项
- 检索内容以增强带有额外上下文的提示
可以想想 Claude 界面中的“从 Google Drive 添加”功能——是应用程序代码决定显示哪些文档,并处理将其内容注入到聊天上下文中的过程。
## 提示:用户控制
提示 (Prompts) 由用户操作触发。用户通过 UI 交互(如按钮点击、菜单选择或斜杠命令)来决定何时运行这些预定义的工作流。
当需要实现用户可以按需触发的工作流时,提示是理想的选择。在 Claude 的界面中,聊天输入框下方的那些工作流按钮就是提示的例子——用户只需单击一下即可启动的预定义、优化的工作流。
## 选择正确的原语
这是一个快速决策指南:
- **需要给 Claude 新的能力?** 使用工具
- **需要将数据获取到你的应用中用于 UI 或上下文?** 使用资源
- **想要为用户创建预定义的工作流?** 使用提示
你可以在 Claude 的官方界面中看到所有这三种原语的实际应用。工作流按钮演示了提示,Google Drive 集成展示了资源的应用,而当 Claude 执行代码或进行计算时,它在幕后使用的就是工具。
这些是帮助你为特定用例选择正确原语的高级指导方针。每个原语服务于你应用程序栈的不同部分——工具服务于模型,资源服务于你的应用,而提示服务于你的用户。
#### 视频文字稿
> 我们的项目已经全部完成了,但在我们继续之前,我想快速回顾一下我们学到的三个服务器原语:工具 (tools)、资源 (resources) 和提示 (prompts)。特别地,我想强调一下它们各自的有趣之处。也就是说,一个应用的哪个部分真正负责运行每一个?
>
> 换句话说,在一个典型的应用程序中,谁真正运行这些东西,谁又从中受益?嗯,我们会说工具是模型控制的 (model controlled)。这意味着 Claude 独自负责决定何时运行一个给定的工具。资源是应用控制的 (app controlled)。
>
> 换句话说,你应用中运行的某些代码会决定它需要由资源提供的一些数据。将由你应用的代码来决定执行一个资源并以某种方式使用返回的数据,也许是通过在 UI 中使用这些数据或类似的方式。在我们的案例中,我们获取一个资源,然后在 UI 中使用这些数据来提供一个自动完成选项列表。我们还获取一个资源来增强一个提示。
>
> 这两件事实际上都是由你我编写的应用程序相关代码来完成的。最后,提示实际上是用户控制的 (user-controlled)。所以用户决定一个提示何时运行。用户可能会通过点击某个 UI 元素(如按钮或菜单选项)来启动一个提示的调用,或者他们可能会使用斜杠命令,就像我们做的那样。
>
> 我之所以强调每种东西由什么控制,是为了让你对它们的用途有所了解。所以,如果你需要为 Claude 添加功能,你可能需要考虑在你的 MCP 服务器中实现一些工具,或者通过你的 MCP 客户端使用某个服务器的工具。如果你想把一些数据弄到你的应用里,用于在 UI 中显示内容或类似目的,那么你可能想使用资源。而如果你想实现某种预定义的工作流,你可能需要考虑提示。
>
> 现在你可以在 `claude.ai` 的官方 Claude 界面中看到所有这些想法的例子。所以这是我目前看到的样子。你会注意到主聊天输入框下面有一些按钮。如果我点击其中一个,然后再点击这些例子中的一个,你会看到我立即进入了一个聊天。
>
> 所以这是一个用户控制的操作。我,作为用户,决定开始这个特定的工作流,并且我正在使用一个可能已经提前写好并且可能已经以某种方式优化过的提示。所以要实现那里的按钮列表,我们可能需要在 MCP 服务器中构建一系列不同的提示。同样地,如果我回去,也许点击这个小标签,加号按钮,你会注意到我有一个从 Google Drive 添加的按钮。
>
> 现在,我不会点击它,因为它会显示我的一些内部文件。但如果我点击那个按钮,我会看到一些我可以作为上下文添加到这个聊天中的文件。知道在那个列表中实际渲染哪些文件,然后当我点击其中一个时,自动将其内容注入到这个聊天的上下文中,这些都与应用程序代码相关。所以完全是应用程序需要知道要在这里渲染的文档列表。
>
> 而且,这再次是专门与 UI 相关的元素。所以要实现从 Google Drive 列出文档的功能,我可能会考虑在 MCP 服务器中实现一个资源。然后,最后,如果我向这个聊天输入一条消息,比如,“3的平方根是多少,用 JavaScript 计算值”并发送出去,我显然期望 Claude 以某种方式执行一些 JavaScript 代码,这很可能是通过使用一个工具来完成的。在这种情况下,使用工具的决定是 100% 由模型控制的。
>
> 是模型决定使用某个 JavaScript 工具来执行。要在 MCP 服务器中实现这样的功能,我们很可能需要,你猜对了,提供一个工具。所以总的来说,这就是我们的三个不同的服务器原语。每一个都真正旨在被你整个应用程序的不同部分使用。
>
> 所以我们有工具,通常服务于你的模型;资源,通常服务于你的应用;以及提示,将服务于你的用户。再次强调,这些都是高层次的指导方针。我之所以提到它们,只是为了让你对何时应该使用这些原语有所感觉,这取决于你正在尝试构建什么。
---
# 第 13 课:MCP 高级主题
> 模型上下文协议进阶开发
> 课程链接:[MCP 高级主题](https://anthropic.skilljar.com/model-context-protocol-advanced-topics) | 共 15 节课
---
## 第1部分:Introduction
### 1. Let's get started!
> 此课时为课程介绍/总结页面,请访问在线平台查看。
### 2. Sampling
> 类型:视频 | 时长:5:17 | 视频:002 - Sampling.mp4
Sampling(采样)允许服务器通过连接的 MCP 客户端访问像 Claude 这样的语言模型。服务器不是直接调用 Claude,而是请求客户端代其调用。这将文本生成的责任和成本从服务器转移到了客户端。
## Sampling 解决的问题
假设你有一个 MCP 服务器,它带有一个从 Wikipedia 获取信息的研究工具。在收集完所有数据后,你需要将其汇总成一份连贯的报告。你有两个选择:
选项 1:让 MCP 服务器直接访问 Claude。服务器需要自己的 API 密钥,处理身份验证,管理成本,并实现所有 Claude 集成代码。这虽然可行,但增加了显著的复杂性。
选项 2:使用 sampling。服务器生成一个提示,然后向客户端请求“你能为我调用 Claude 吗?”。客户端已经与 Claude 建立了连接,它会进行调用并返回结果。
## Sampling 的工作原理
流程很简单:
- 服务器完成其工作(如获取 Wikipedia 文章)
- 服务器创建一个请求文本生成的提示
- 服务器向客户端发送一个 sampling 请求
- 客户端使用提供的提示调用 Claude
- 客户端将生成的文本返回给服务器
- 服务器在其响应中使用生成的文本
## Sampling 的好处
- **降低服务器复杂性:** 服务器无需直接与语言模型集成
- **转移成本负担:** 客户端支付 token 使用费,而不是服务器
- **无需 API 密钥:** 服务器不需要 Claude 的凭据
- **非常适合公共服务器:** 你不希望公共服务器为每个用户承担 AI 成本
## 实现
设置 sampling 需要在客户端和服务器两端编写代码:
### 服务器端
在你的工具函数中,使用 `create_message` 函数请求文本生成:
@mcp.tool() async def summarize(text_to_summarize: str, ctx: Context): prompt = f""" Please summarize the following text: {text_to_summarize} """
result = await ctx.session.create_message(
messages=[
SamplingMessage(
role="user",
content=TextContent(
type="text",
text=prompt
)
)
],
max_tokens=4000,
system_prompt="You are a helpful research assistant",
)
if result.content.type == "text":
return result.content.text
else:
raise ValueError("Sampling failed")
### 客户端
创建一个 `sampling callback (采样回调)` 来处理服务器的请求:
async def sampling_callback( context: RequestContext, params: CreateMessageRequestParams ): # Call Claude using the Anthropic SDK text = await chat(params.messages)
return CreateMessageResult(
role="assistant",
model=model,
content=TextContent(type="text", text=text),
)
然后在初始化客户端会话时传递这个回调:
async with ClientSession( read, write, sampling_callback=sampling_callback ) as session: await session.initialize()
## 何时使用 Sampling
在构建可公开访问的 MCP 服务器时,Sampling 最有价值。你不希望随机用户无限制地使用你的资源并产生费用。通过使用 sampling,每个客户端在受益于你服务器功能的同时,支付自己的 AI 使用费用。
这项技术实质上将 AI 集成的复杂性从你的服务器转移到了客户端,而客户端通常已经具备了必要的连接和凭据。
#### 视频文字稿
Sampling(采样)允许服务器通过连接的 MCP 客户端访问像 Claude 这样的语言模型。为了帮助你理解这是什么意思以及 sampling 的全部内容,我想向你展示一个快速的演示应用程序。就是这个。这是一个由 Claude 驱动的聊天应用程序,所以我可以问它一加一等于几,然后我会得到一个回答。
这个聊天应用程序也连接到一个实现了名为“研究工具”的单一 MCP 服务器。我可以用这个工具请 Claude 写一份关于考古学的报告。当我这样做时,Claude 会决定使用那个研究工具,表示它将进行一些研究,综合所有结果,然后向我呈现一份报告。既然你已经看到了这个研究工具的运行,我想向你展示这个应用程序背后发生了什么,以及这个研究工具实际上是如何工作的。
好的,所以这里是整个过程的高层次概述。首先,在左上角,我有一个 Next.js 应用程序,它实际上是在浏览器中渲染一些内容,并且它内部集成了一个 MCP 客户端。某个时候,一个用户会要求我们研究一个主题,比如考古学。我们会将这个查询发送给 Claude,Claude 会决定运行它预先被提供的研究工具。
我们 Next.js 应用程序上的 MCP 客户端会将其转换为一个工具调用请求,并发送到 MCP 服务器。然后在 MCP 服务器上,研究工具会运行。它会向 Wikipedia 发出多个请求,试图找到一些关于考古学的文章以及一些相关内容等等。一旦研究工具从 Wikipedia 获取了一些页面,我们需要将所有这些内容综合成一份最终报告,以便显示给用户。
我们有不止一种方法可以做到这一点。让我给你展示两种不同的选择。在第一种选择中,我们可以让 MCP 服务器直接联系 Claude 或其他类似的 LLM,并要求它总结从 Wikipedia 搜索中找到的所有结果。所以在这种情况下,我们会让我们的 MCP 服务器直接访问一个语言模型。
这绝对是可行的。这绝对是我们能做的事情。然而,这会给我们的 MCP 服务器增加很多复杂性。我们必须编写一些代码,让 MCP 服务器能够向 Claude 发出请求,获取响应,提取生成的文本等等。
我们还必须确保 MCP 服务器拥有访问 Claude 或我们使用的任何其他语言模型的 API 密钥。所以,再次强调,选项一是可行的,但它增加了相当多的复杂性。所以我们来看选项二。在选项二中,我们将让我们的 MCP 服务器使用一种被称为 sampling(采样)的技术。
通过 sampling,我们将让我们的 MCP 服务器请求客户端代其运行一个提示。简而言之,MCP 服务器会编写一个提示,将其发送给 MCP 客户端,然后说,嘿,你能帮我把这个输入到 Claude 吗?我们构建的 MCP 客户端会接收那个提示并将其发送给 Claude。它会得到一个响应,然后将文本生成的结果发送回 MCP 服务器,服务器可以用生成的文本做任何它想做的事情。
这种方法将复杂性转移到了 MCP 客户端。在这种情况下,这还算可以。因为如你所见,我们的 MCP 客户端或者说那个 Next.js 应用程序已经与 Claude 有了现有的连接。它已经在向 Claude 发出请求了。
所以,仅仅代表 MCP 服务器多运行一个请求,并不会增加太多工作量。另一个明显的好处是,MCP 服务器完全不需要 API 密钥来访问 Claude。如果这是一个可公开访问的 MCP 服务器,现在它就不用担心为使用该服务器的其他人生成的 token 支付费用了。所以这项技术被称为 sampling。
它允许一个 MCP 服务器请求客户端运行 Claude 或任何其他语言模型来生成一些文本。你可以把 sampling 看作是将调用 Claude 的责任从服务器转移到客户端。在你构建一个可公开访问的 MCP 服务器时,Sampling 是最有用的。你不想有一个对任何人开放的公开可用的 MCP 服务器,让任何人都可以来生成一些文本。
对于你的公开可访问服务器,你会希望使用 sampling,并将生成文本的责任从你的服务器转移到任何连接到它的客户端。使用 sampling 需要在服务器和客户端两边都进行一些设置。首先,在服务器上,在一个工具函数内部,你会调用 Create Message 函数。然后你会传入一个你希望最终交给 Claude 的消息列表。
这个消息列表将被格式化成一个请求,发送给客户端。然后在客户端,你必须编写更多的代码,特别是一种叫做 sampling callback(采样回调)的东西。在这个代码片段的右上角,我有一个 sampling callback 的例子。你的 sampling callback 将会收到从服务器发送来的消息。
然后在这个回调函数内部,由你来决定如何调用 Claude 或你正在使用的任何其他语言模型,生成一些文本,然后返回一个 create message result。好了,这就是 sampling。如你所见,它并不是特别复杂。它实际上只是这个概念或想法,即把生成一些文本的负担从服务器转移回客户端。
再说一次,这是你在构建一个可公开访问的 MCP 服务器时,肯定会想要研究的技术。
---
### 3. Sampling walkthrough
> 此课时为互动演练/练习,请访问在线课程平台进行实操。
### 4. Log and progress notifications
> 类型:视频 | 时长:2:41 | 视频:003 - Log and Progress Notitications.mp4
日志和进度通知实现起来很简单,但在使用 MCP 服务器时,它们能极大地改善用户体验。它们帮助用户了解在长时间运行的操作中发生了什么,而不是让他们疑惑是否出了问题。
当 Claude 调用一个需要时间来完成的工具时——比如研究一个主题或处理数据——用户通常在操作完成前什么也看不到。这可能令人沮丧,因为他们不知道工具是在工作还是已经卡住了。
启用了日志和进度通知后,用户可以获得实时反馈,确切地显示幕后发生的事情。他们可以在操作运行时看到进度条、状态消息和详细日志。
## 工作原理
在 Python MCP `SDK (软件开发工具包)` 中,日志和进度通知通过自动提供给你工具函数的 Context 参数来工作。这个上下文对象提供了在执行期间与客户端通信的方法。
@mcp.tool( name="research", description="Research a given topic" ) async def research( topic: str = Field(description="Topic to research"), *, context: Context ): await context.info("About to do research...") await context.report_progress(20, 100) sources = await do_research(topic)
await context.info("Writing report...")
await context.report_progress(70, 100)
results = await generate_report(sources)
return results
你会用到的关键方法是:
- `context.info()` - 向客户端发送日志消息
- `context.report_progress()` - 用当前值和总值更新进度
## 客户端实现
在客户端,你需要设置 `callback (回调)` 函数来处理这些通知。服务器发出这些消息,但由你的客户端应用程序决定如何向用户呈现它们。
async def logging_callback(params: LoggingMessageNotificationParams): print(params.data)
async def print_progress_callback( progress: float, total: float | None, message: str | None ): if total is not None: percentage = (progress / total) * 100 print(f"Progress: {progress}/{total} ({percentage:.1f}%)") else: print(f"Progress: {progress}")
async def run(): async with stdio_client(server_params) as (read, write): async with ClientSession( read, write, logging_callback=logging_callback ) as session: await session.initialize()
await session.call_tool(
name="add",
arguments={"a": 1, "b": 3},
progress_callback=print_progress_callback,
)
你在创建客户端会话时提供日志回调,在进行单个工具调用时提供进度回调。这使你能够灵活地适当地处理不同类型的通知。
## 呈现选项
你如何呈现这些通知取决于你的应用程序类型:
- **CLI 应用程序** - 只需将消息和进度打印到终端
- **Web 应用程序** - 使用 WebSockets、服务器发送事件或轮询将更新推送到浏览器
- **桌面应用程序** - 更新你 UI 中的进度条和状态显示
请记住,实现这些通知完全是可选的。你可以选择完全忽略它们,只显示某些类型,或者以任何对你的应用程序有意义的方式呈现它们。它们纯粹是用户体验增强功能,以帮助用户了解在长时间运行的操作期间发生了什么。
#### 视频文字稿
接下来是日志和进度通知。这些通知设置起来非常简单,并且能极大地改善你 MCP 服务器的用户体验。那么,让我再次给你做一个快速演示。你可能还记得我刚才给你展示的那个研究应用的例子。
如果我让 Claude 生成一份关于考古学的报告,它会通过我们刚才讨论的 MCP 服务器进行一次工具调用。它会特别调用那个研究函数。现在,这个研究函数需要一段时间才能完成。在它运行的时候,用户实际上得不到任何反馈。
所以就用户而言,这个工具调用可能实际上已经失败了,可能只是处于卡顿状态之类的。所以,如果我们能让用户更深入地了解幕后发生了什么,那就太好了。要做到这一点,我们可以使用日志和通知。让我给你看看,如果我打开日志和通知,同样的查询会是什么样子,我刚才刷新页面时就已经打开了。
所以我将再次发出同样的查询,现在我将得到同样的研究工具调用,但现在我将得到一个进度条和一些日志语句。进度和日志条不是假数据。这些是在工具调用内部,在研究工具内部发出的日志和进度语句。所以让我给你看一些代码,帮助你理解这是如何工作的。
要在我们服务器上的一个工具函数内部开始使用日志和进度通知,我们会收到 `context` 参数,它会自动作为我们工具函数的最后一个参数被包含进来。在那个 `context` 对象上,有各种不同的方法,允许我们记录信息或向客户端报告这个工具运行的进度。所以我们有像 `info` 和 `report_progress` 这样的方法。每当你调用这些函数时,一条消息就会自动发送回客户端。
为了在客户端使用日志语句和进度更新,我们会写一些与刚才看到的关于 sampling 类似的代码。所以我们会组合一个回调函数。当它从服务器收到日志语句时,它会被调用。我们还会制作一个单独的回调,它将从服务器接收进度更新。
然后我们会将日志回调传递给我们的客户端会话,将进度回调传递给 `call_tool` 函数。在这些回调函数内部,由你来决定如何向你的用户报告这些日志语句和进度。如果你在制作一个 CLI 应用程序,你可以直接将它们打印在终端上。如果你在制作一个 web 应用,你就需要想出更聪明的解决方案来将这些信息传递到浏览器。
当然,你也不必实际包含任何这些日志语句或进度语句。如果你不想,你完全可以不向用户展示它们。这些只是用户体验的增强。再次强调,只是为了让你的用户更好地了解正在发生什么。
---
### 5. Notifications walkthrough
> 此课时为互动演练/练习,请访问在线课程平台进行实操。
### 6. Roots
> 类型:视频 | 时长:7:55 | 视频:004 - Roots.mp4
Roots (根目录) 是一种授权 MCP 服务器访问你本地机器上特定文件和文件夹的方法。你可以把它看作一个权限系统,它会说“嘿,MCP 服务器,你可以访问这些文件”——但它们的功能远不止于此。
## Roots 解决的问题
如果没有 roots,你会遇到一个常见问题。想象一下,你有一个 MCP 服务器,上面有一个视频转换工具,它接受一个文件路径,并将 MP4 格式转换为 MOV 格式。
当用户要求 Claude “将 biking.mp4 转换为 mov 格式”时,Claude 会只用文件名来调用这个工具。但问题是——Claude 无法搜索你的整个文件系统来找到该文件的实际位置。
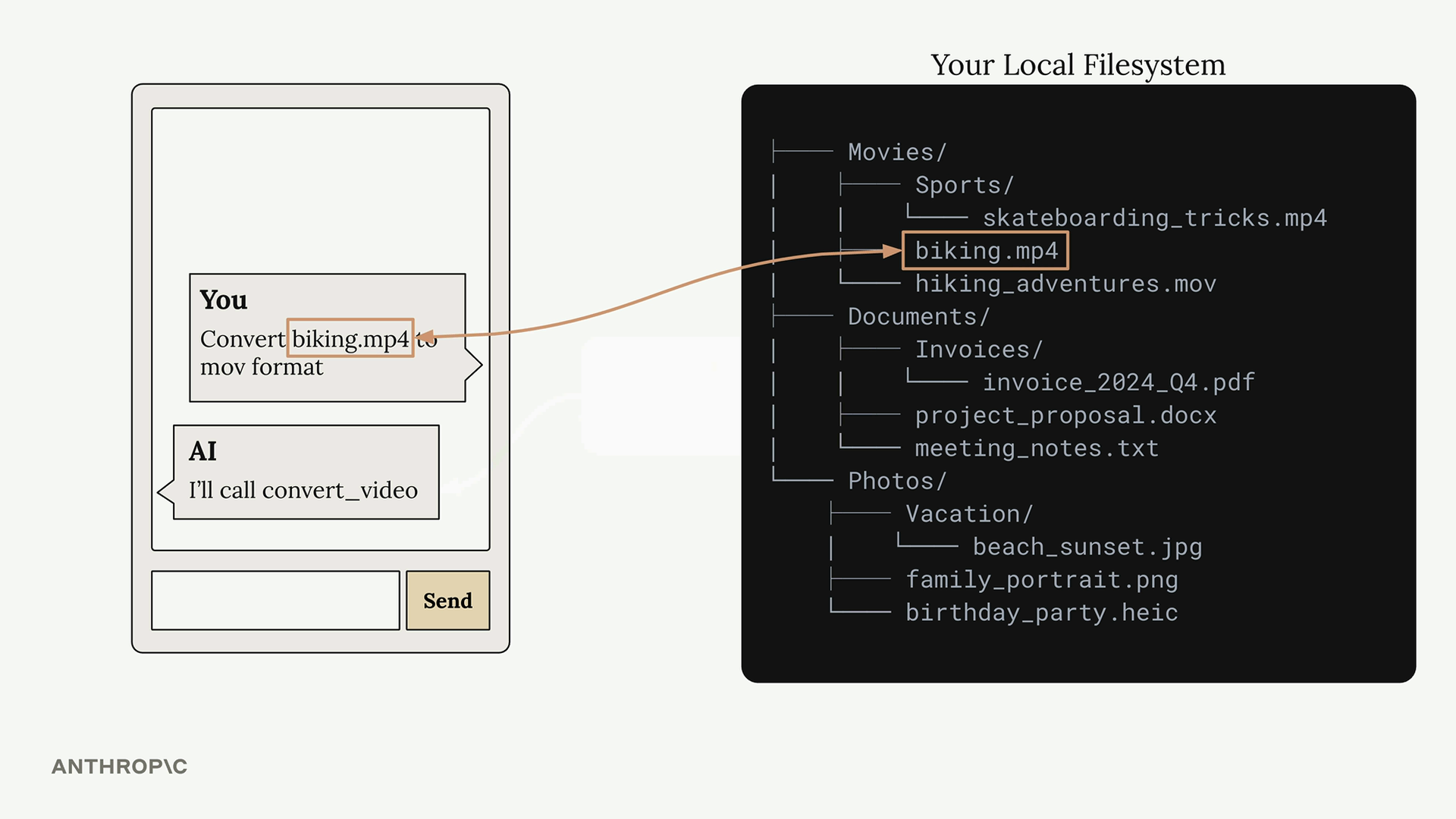
你的文件系统可能很复杂,文件散布在不同的目录中。用户知道 biking.mp4 文件在他们的 Movies 文件夹里,但 Claude 没有这个上下文信息。
你可以通过要求用户总是提供完整路径来解决这个问题,但这并不友好。没人愿意每次都输入完整的文件路径。
## Roots 的实际应用
以下是使用 roots 后工作流程的变化:
1. 用户请求转换一个视频文件
2. Claude 调用 `list_roots` 来查看它可以访问哪些目录
3. Claude 在可访问的目录上调用 `read_dir` 来查找文件
4. 找到文件后,Claude 使用完整路径调用转换工具
这一切都是自动发生的——用户仍然可以只说“转换 biking.mp4”,而无需提供完整路径。
## 安全与边界
Roots 还通过限制访问来提供安全性。如果你只授予对 Desktop 文件夹的访问权限,MCP 服务器就无法访问像 Documents 或 Downloads 等其他位置的文件。
当 Claude 尝试访问批准的 roots 之外的文件时,它会收到一个错误,并可以通知用户该文件在当前服务器配置下无法访问。
## 实现细节
MCP SDK 不会自动强制执行 root 限制——你需要自己实现这一点。一个典型的模式是创建一个像 `is_path_allowed()` 这样的辅助函数,它会:
- 接受一个请求的文件路径
- 获取批准的 roots 列表
- 检查请求的路径是否在这些 roots 之一的范围内
- 返回 true/false 作为访问权限
然后,在任何访问文件或目录的工具中,在执行实际文件操作之前调用这个函数。
## 主要优点
- **用户友好** - 用户无需提供完整的文件路径
- **聚焦搜索** - Claude 只在批准的目录中查找,使文件发现更快
- **安全性** - 防止意外访问批准区域外的敏感文件
- **灵活性** - 你可以通过工具提供 roots,或直接将它们注入到提示中
Roots 通过为 Claude 提供查找文件所需的上下文,同时保持对其可访问内容的明确界限,使 MCP 服务器既更强大又更安全。
#### 视频文字稿
我们的下一个主题是 root 系统。Roots(根目录)允许用户授予服务器访问某些特定文件和文件夹的权限。你可以把 roots 看作是一种编码化的方式,用来表示,嘿,MCP 服务器,你可以访问这些文件。但 roots 的作用不仅仅是授予权限。
让我通过一个快速的例子来帮助你理解它们是如何工作的。在这个例子中,我首先会向你展示一个如果没有 Roots 会遇到的常见问题。一旦我们理解了这个问题,我们再来看看 Roots 是如何解决这个问题的。所以在这个例子中,我们将有一个非常简单的 MCP 服务器,它只有一个叫做 `Convert Video` 的工具。
这个工具会接收用户本地机器上的一个视频文件路径,然后将该视频文件转换成其他文件类型,比如从 MP4 转换成 MOV。现在让我们想象一下用户会如何实际使用这个功能。用户可能会在某个 CLI 应用程序或类似的东西里输入,请求 Claude 将一个 biking.mp4 视频文件转换成 MOV 格式。Claude 随后会查看这个 MCP 服务器提供的工具列表,发现 `convert video` 工具可用。
所以 Claude 可能会决定,太好了。我要调用那个工具,并且我会传入一个路径 `Viking.mp4`。因为这正是用户要求的。用户要求转换一个名为 `Viking.mp4` 的视频文件。
这是我可能会期望从那个工具得到的响应。我可能会期望看到一个错误返回,说类似“没有找到 Viking.mp4 文件”。那么我为什么会期望看到那个错误呢?嗯,记住,用户的文件系统可能非常复杂。
他们可能有各种各样的文件和文件夹,到处都是大量的不同文档。所以用户可能知道 `Viking.mp4` 文件在这个 movies 目录里,但 Claude 并没有真正的方法知道这一点。所以如果一个用户只是请求 `Viking.mp4`,Claude 并没有能力搜索用户的文件系统并找出那个特定文档究竟在哪里。
现在,我们可以解决这个问题的一个方法是,要求用户总是传入一个视频文件的完整路径。所以我们可能会说,你知道吗,如果你想使用这个工具,你必须传入一个完全合格的路径,比如 `movies/Viking.mp4`。现在,这可能行得通,但并不是特别方便。
用户并不真的想坐在那里,为他们试图访问的每一个文件都输入完整的路径。他们可能真的只想输入类似“转换这个视频”,然后只输入它的名字,转换成其他格式。所以现在我们明白了问题所在,让我来告诉你我们如何利用 roots 的概念来解决它。
所以我们将通过在我们的 MCP 服务器中添加一些额外的工具来解决这个问题。我们仍然会有同样的 `convert video` 工具,但我们还会添加一个 `read directory` 工具。我敢打赌你能猜到它是做什么的。它只是列出某个特定目录下的所有文件和文件夹。
然后我们将拥有的第三个工具叫做 `List Roots`。它会返回一个 roots 列表。我们的 root 是一个文件或文件夹,用户已经预先授予了读取权限。换句话说,当他们第一次启动这个 MCP 服务器时,他们可能会作为命令行参数传入一个服务器被允许读取的文件和文件夹列表。
除此之外,我们还会在我们的其他工具中加入一个小小的要求。我们会在我们的 `read directory` 工具和 `convert video` 工具中添加一些代码。我们会确保无论何时它们试图访问某个目录或某个视频文件时,它们只能访问包含在这些不同 roots 之一内的文件和文件夹。
为了帮助你理解这三个不同的工具是如何协同工作的,我制作了一个非常小的示例应用程序。所以让我马上给你一个快速演示。要运行这个程序,我执行 `uvrunmay.py`。然后这个程序被设置为接受一列额外的命令行参数。
所以如果我愿意,我可以输入 `desktop`,像这样。这将被设置为 MCP 服务器内部的一个 root。所以我基本上是在说,我希望服务器能够访问桌面文件夹以及其中的所有文件。然后在右边的这里,你可以看到我的桌面目录,里面有一个叫做 `Viking.mp4` 的文件。
所以现在我要运行这个,然后我会让 Claude 把 `Viking.mp4` 文件转换成一个 MOV 文件。现在我要运行它,我们会看到一些工具调用被打印出来。首先,Claude 会通过调用 `List Roots` 工具来查看它能访问的所有不同的文件和文件夹。然后它会看到只有一个目录可以访问,就是桌面文件夹,因为这是我在这个程序中唯一授予访问权限的。
然后它会尝试读取那个目录,然后它会发现里面的 `Viking.mp4` 文件。所以在那个时候,它现在拥有了实际成功运行 `convert video` 工具所需的一切。所以它可以用我桌面文件夹的完全合格路径,`Viking.mp4`,来运行那个工具。现在记住,roots 的目的是限制 MCP 服务器可以访问哪些文件和文件夹。
所以除了那个桌面文件夹,我这里还有一个文档文件夹。在那个目录里面,有一个 `swimming.mp4` 文件。所以现在我要让 Claude 把 `swimming.mp4` 文件也转换成 MOV 文件。这一次,我将提供 MP4 文件的完整路径。
所以现在理论上,Claude 不需要查看 roots 列表。它可以直接调用 `convert video` 工具,因为它已经有了它想要转换的特定文件的完全合格路径。所以我可以运行这个,我们来看看会发生什么。所以它会立即尝试调用 `convert video`,但它会提前返回,因为 Claude 会说,抱歉,但我在运行那个工具时遇到了一个错误。
它没能找到那个特定的文件。Claude 随后会尝试查看可用的 roots。读取唯一可用的 root,在这种情况下,是桌面。然后 Claude 会意识到,嘿,看起来我根本无法访问那个文件。
我唯一能访问的目录是桌面。如果你想让我转换那个游泳文件,嗯,我就是访问不了。所以试着给我访问权限,或者移动文件,或者其他什么。现在,基于那个演示,你可能会注意到 roots 实际上有两个截然不同的目的。
一方面,它们允许用户授予对特定文件和文件夹的访问权限。但另一方面,它们的另一个非常好的好处是,它们允许 Claude 只关注你文件系统的特定区域。所以正如我们所见,我们不必为某个我们可能希望 Claude 访问的特定目录或文件输入完全合格的路径。相反,Claude 可以自主决定查看可用的 roots,然后在这些 roots 中搜索以找到某个特定的文件。
我在这里还没有完全提到,但对你理解非常关键的一件事是,roots 的概念有点松散。并且围绕它们的实现并不多。换句话说,在任何 Anthropic SDK 中,都没有任何东西会自动限制对特定文件和文件夹的访问。相反,这取决于你在你的 Anthropic 服务器中确保,无论何时一个工具试图访问一个文件或文件夹时,它都被列出或包含在这些不同的 roots 之一中。
你可能会通过实现一个像你在这里右上角看到的函数来做到这一点,比如 `is path allowed`。在那个函数内部,它接收一个请求的路径,然后它会从客户端获取一个 roots 列表,然后看看工具想要使用的路径是否包含在那些 routes 之一中。如果是,太好了,我们允许访问。否则,不,我们根本不允许访问。
现在,我想提到的最后一件事是,我展示了实现一个像 `list roots` 这样的工具,并允许 Claude 在任何时候调用那个工具。这并不是严格要求的。你也可以只获取 roots 列表,然后手动将它们全部扔到一个提示中。所以你不必制作那个工具。
这只是我发现的一个有助于让 Claude 在它决定需要找出它能访问哪些文件和文件夹时查看 roots 列表的模式。
---
### 7. Roots walkthrough
> 此课时为互动演练/练习,请访问在线课程平台进行实操。
### 9. JSON message types
> 类型:视频 | 时长:6:45 | 视频:005 - JSON Message Types.mp4
MCP (Model Context Protocol) 使用 JSON 消息来处理客户端和服务器之间的通信。理解这些消息类型对于使用 MCP 至关重要,尤其是在处理不同的 `transport (传输)` 方法(如 streamable HTTP transport)时。
## 消息格式
所有的 MCP 通信都通过 JSON 消息进行。每种消息类型都有特定的用途——无论是调用工具、列出可用资源,还是发送关于系统事件的通知。

这是一个典型的例子:当 Claude 需要调用一个由 MCP 服务器提供的工具时,客户端会发送一个“Call Tool Request”消息。服务器处理这个请求,运行工具,然后用一个包含输出的“Call Tool Result”消息来响应。

## MCP 规范
完整的消息类型列表在 GitHub 上的官方 MCP 规范仓库中定义。这个规范独立于各种 SDK 仓库(如 Python 或 TypeScript SDKs),并作为 MCP 应如何工作的权威来源。
消息类型是用 TypeScript 编写的,这只是为了方便——不是因为它们作为 TypeScript 代码执行,而是因为 TypeScript 提供了一种清晰的方式来描述数据结构和类型。
## 消息类别
MCP 消息分为两大类:

### 请求-结果消息
这些消息总是成对出现。你发送一个请求,并期望得到一个结果:
- **Call Tool Request** → Call Tool Result
- **List Prompts Request → List Prompts Result**
- **Read Resource Request → Read Resource Result**
- **Initialize Request → Initialize Result**
### 通知消息
这些是单向消息,用于通知事件,但不需要响应:
- **Progress Notification** - 关于长时间运行操作的更新
- **Logging Message Notification** - 系统日志消息
- **Tool List Changed Notification** - 当可用工具改变时
- **Resource Updated Notification** - 当资源被修改时
## 客户端与服务器消息
MCP 规范按消息发送方来组织消息:
客户端消息包括客户端发送给服务器的请求(如工具调用)和客户端可能发送的通知。
服务器消息包括服务器发送给客户端的请求和服务器广播的通知。
## 这为什么重要
在处理不同的传输方法时,理解服务器可以向客户端发送消息这一点尤为重要。一些传输方式,比如 streamable HTTP transport,对哪些类型的消息可以在哪个方向流动有限制。
关键的洞见是,MCP 被设计为一个双向协议——客户端和服务器都可以发起通信。当你需要为你的特定用例选择正确的传输方法时,这一点变得至关重要。
#### 视频文字稿
我们已经讨论了几个主题,在继续之前,我只想给你一个小小的提醒。你看,接下来的两三个视频将重点关注 MCP 消息和标准 IO 传输。这些视频可能看起来有点枯燥和无聊,但我们讨论这些主题有一个非常重要的原因。本课程的一个主要目标是帮助你理解 streamable HTTP transport,它允许客户端连接到远程托管的 MCP 服务器。
问题在于,在某些情况下,当 MCP 服务器使用 HTTP 传输时,它的功能会受到很大的限制。理解这些限制可能相当具有挑战性,但如果你对 MCP 消息和标准 IO 传输有扎实的基础,理解起来就会容易得多。所以这就是为什么我们要花些时间在头两个主题上。考虑到所有这些,让我们来看看 MCP 用来通信的格式,特别是消息格式。
客户端和服务器使用 JSON 进行通信。我们将这些 JSON 片段称为消息。在 MCP 规范中定义了许多不同类型的消息,每一种都为不同的目的而设计。那么让我马上给你看一个例子。
举个例子,如果一个连接到 MCP 客户端的语言模型决定调用一个由 MCP 服务器提供的工具,客户端会向服务器发送一条消息。这种类型的消息被命名为 `call tool request`。在这个图的顶部,我有一个 `call tool request` 的例子。MCP 服务器随后会运行该工具,然后将工具运行的结果放入另一种名为 `call tool result` 的消息类型中。
在这个图的底部,我也有一个例子。现在,正如我所提到的,MCP 规范定义了所有不同消息类型的完整列表。你可以在 GitHub 上托管的 MCP 规范仓库中找到完整的列表,我们稍后会看一看。但首先,要明确一下我们将要看的这个仓库,这个规范仓库与所有不同的 SDK 仓库是分开的,比如 Python 或 TypeScript MCP SDKs。
这个规范仓库有一些不同的文档,描述了 MCP 规范是如何工作的。所以在这个仓库中,完整的消息类型列表写在一个 TypeScript 文件里。再次明确一下,这个 TypeScript 文件从未被任何东西执行过。它不包含在任何不同的 SDK 中。
这些类型只是用 TypeScript 写的,因为 TypeScript 是一种非常方便的语言,用于描述类型化数据。所以我想向你展示这个 schema 文件,它列出了所有不同的消息类型,只是因为从中可以得到一些非常有趣的见解。所以我要导航到你屏幕顶部的这个地址。然后在这个仓库里,你会在某个路径下找到一个叫做 `schema.ts` 的文件。
`schema.ts` 文件包含了所有可用的不同消息类型。所以在这个文件里,我可以搜索 `call tool request`。就在这里。这是一个 `call tool request` 的例子。
所以一个 `call tool request` 必须有一个 `tool/call` 的方法,然后一个参数对象,其中包含我们想调用的工具的名称和一些要传入的参数。你可能注意到,在我刚才给你看的图表中,回到这里,还有一个 `JSON RPC` 和一个 `ID`。那些实际上是在 schema 文件中的一个单独对象上定义的,叫做 `JSON RPC request`。所以如果我查一下,我会看到,好的,这里是 `JSON RPC request`,它也必须有一个 `ID`。
现在,在整个文件中,我真正想让你关注的是在最底部定义的一些不同的类型。所以我要滚动到底部,非常非常底部的文件。然后我再向上滚动一点,我会找到一个写着 `server messages` 的注释,和一个写着 `client messages` 的注释。你会注意到在这两个部分内部,有一些名称相似的类型。
所以在客户端消息中,有 `client request`、`client notification` 和 `client result`。然后在服务器部分,有 `server request`、`server notification` 和 `server result`。所以让我给你看一个图表。它可以帮助你理解这个文件中的这些不同类型,特别是客户端和服务器部分,到底告诉了我们什么。
好的,我们开始。所以在这个类型文件中,我们可以把所有这些不同类型的消息分成两到三个不同的类别。首先,在这个图表的左侧,是请求-结果消息。这些消息类型总是成对出现。
它们的名字总是 `something-something-request`,然后配对的消息类型是 `something-something-result`。举个例子,我们有 `call-tool-request`,它与 `call-tool-result` 配对。我们有 `initialized request`,它与 `initialized result` 配对。所有这些不同的消息类型,我敢打赌你能猜到它们是做什么的。
它们描述了我们发送给客户端或服务器的消息,以及我们期望在响应中得到的消息类型。所以如果我发送了一个 `call to request`,我期望得到一个 `call tool result`。我们要处理的另一种消息是通知消息。这些更像是事件。
它们告诉客户端或服务器刚刚发生了什么,但它们并不真的需要响应。所以我们有像 `progress notification`、`logging message notification`、`tool change notification` 等等类型。现在,回到我们刚才看的类型文件,你可能已经注意到我们有 `server messages` 和 `client messages` 的标题。这些注释以及每一个里面的类型,旨在表明这些类型的消息是由客户端还是服务器发送的。
例如,这个 `client request` 类型描述了所有预期从客户端发送的不同类型的请求。同样地,这里的这些都是预期从服务器发送的请求。对于服务器通知也是一样,这些都是由服务器发出的通知。而这些都是由客户端发出的通知。
所以我们可以用一个像这样的图表来总结一切。现在这并没有显示每种类型的消息。我只是想表明,有一些请求是打算从 MCP 客户端发出的,我这里有例子。有一些结果是打算从服务器发出的。
有一些结果是打算从客户端发送的。有一些请求是打算从服务器发送的,等等。好了,所以这里是我希望你理解的关键点。这个视频的重点,当我们开始讨论可流式 HTTP 传输时,这将变得非常重要。
这里要理解的关键点是,有很多不同的消息是打算从服务器发送到客户端的。所以这里的服务器请求类型和服务器通知类型。这些都是将从服务器发送到客户端的消息。我知道现在这可能看起来完全无关紧要,为什么知道这个很重要呢?
再说一次,当我们开始看可流式 HTTP 传输时,这将变得非常重要。所以暂时记住这一点。
---
### 10. The STDIO transport
> 类型:视频 | 时长:9:28 | 视频:006 - The Stdio Transport.mp4
MCP 客户端和服务器通过交换我们称之为消息的 JSON 对象进行通信。现在,JSON 通常可以通过多种不同的方式在客户端和服务器之间传输。例如,我们可以发出 HTTP 请求。我们可以使用 WebSockets。
我们甚至可以在明信片上写下一些 JSON,然后寄给别人,让他们手动将那个 JSON 输入到服务器中。所以实际上有非常多的方式来发送和接收 JSON。在 MCP 规范中,我们用来在客户端和服务器之间实际移动 JSON 的东西被称为 transport (传输)。当你最初开发 MCP 服务器或客户端时,一个非常常用的传输是 `stdio transport (stdio 传输)`。
这个传输的想法是,我们的客户端将启动一个服务器作为一个独立的 `subprocess (子进程)`。通过这样做,客户端就有了对那个进程的句柄,客户端可以通过将消息写入服务器的 `standard in (标准输入)` 通道来向服务器发送消息。并且它可以通过观察服务器的 `standard out (标准输出)` 通道来接收消息。
关于 `stdio` 传输,有一点非常好,那就是客户端或服务器之间的通信可以非常容易地在任何一方发起。换句话说,在任何时候,客户端都可以通过写入标准输入来与服务器通信或向服务器发送消息。而服务器可以通过写入标准输出来与客户端通信。但 `stdio` 传输也有一个很大的缺点,那就是我们只能在客户端和服务器在同一台物理机器上运行时才能使用这个传输。
为了帮助你更好地理解 `stdio` 传输,让我给你做一个快速演示。我制作了一个非常小的 MCP 服务器。我在这里顶部有一些打印语句,只是为了帮助你理解正在发生什么。但除了那些打印语句,这个服务器并没有太多内容。
我正在创建一个服务器,我定义了一个单一的工具,然后用 `stdio` 传输启动服务器。现在我可以创建一个客户端,使用 `stdio` 传输连接到这个服务器,但我也可以直接从我的终端连接到服务器,而无需创建任何独立的客户端。让我给你看看我的意思。如果我在这里运行 `UVRunServer.py`,它会启动那个服务器。
现在那个服务器将会监听标准输入,并将任何传出的消息写入标准输出。嗯,在我的终端里,以防你不知道,每当我运行一个程序,如果我在这里下面输入任何东西,我就是在向这个正在运行的程序的标准输入写入。所以我实际上可以在这里下面粘贴 JSON 消息,执行它们,它们将被作为服务器的输入接收。所以让我给你一个快速演示。
我要快速重启服务器。然后我要复制这里的第一个示例消息。我要把它粘贴到这里。当我按回车键时,它几乎会立即发生。
我会立即得到一个响应。所以我用一条消息写入了标准输入。我在标准输出上看到了一个输出消息。然后我将发送另一条消息。
开始了。这一次,我将不会看到任何响应。最后,我将在这里下面运行最后一条消息。
当我运行这个时,我会立即得到一个响应,然后是另一个响应,再然后是另一个响应。总共三个对象。这是一个,这是两个,这是三个。所以让我给你看几个图表,帮助你理解当我粘贴这些不同消息时,我到底在做什么。
好的,回到这里。在左手边,我标记为我的 MCP 客户端,但实际上只是我在终端粘贴消息。通过粘贴那些消息,我正在向 MCP 服务器的标准输入写入。服务器随后会处理这些给定的消息,然后可能会通过简单地将其打印到标准输出来发送一个结果,我直接在我的终端上看到。
我发送的第一条消息是一种叫做 `initialize request` 的东西。让我给你一点背景知识。每当一个客户端第一次连接到服务器时,MCP 规范规定我们必须来回发送一个由三个不同消息组成的序列。第一条消息必须总是 `initialize request`。
再说一次,这就是我最初粘贴进来的东西。那就是 `initialize request`。因为我发送了一个请求类型的消息,我期望得到一个结果。而这正是发生的事情。
我得到了一个叫做 `initialized result` 的东西。那就是那段文本。然后 NCP 规范还说,在交换了这些初始消息之后,我们必须从客户端向服务器发送一个 `initialized notification`。提醒一下,通知不需要响应。
所以我确实发送了那个 `initialized notification`。正如我们注意到的,我们没有得到任何即时响应。再说一次,这只是因为通知不需要响应。一旦我们交换了这三条消息,我们与 MCP 服务器的连接就被认为是初始化了。
从那时起,我们就可以运行 `call tool` 请求或运行提示列表请求,或者我们想做的任何其他事情。所以在我的例子中,如你所见,我发送了一个 `call tool` 请求。那是最后一个。我试图用参数 5 和 3 来调用 `add` 工具。
我编写 `add` 工具的方式是,它被设置为发送回几个不同的日志,然后最终是一个 `called tool result`。所以如果我查看日志,我实际上把它从你在那个图表中看到的样子改了。首先,我收到了一个消息通知。这是一个来自那里的登录语句。
那是我的登录语句。然后我得到了一个进度语句。所以那是那里的进度更新。那些都是从服务器发送到客户端的通知。
最后,我得到了我的 `call tool` 响应,里面是加上 3 加 5 的计算结果,我看到是 8。所以现在我们已经看到了 `stdio` 传输的一个例子,有一些关于这个特定传输的非常关键的想法,我想指出来,这些想法在我们开始看可流式 HTTP 传输时将非常相关或非常重要。首先,我刚才给你看了一个图表。我给你看这个图表是为了帮助你理解,有一些消息类型是打算从客户端发送到服务器的,还有一些类型是打算从服务器发送到客户端的。
我真正想让你从这个图表中理解的另一件事是,在某些情况下,特别是在左上角的这些消息中,我们可以想象客户端正在与服务器发起通信。换句话说,客户端在说,我正在发出一个请求,我期望得到一个响应。同样,在某些情况下,MCP 服务器正在发送初始请求,并期望得到一个响应。这就像是 `create message` 请求,这是用来启动采样的。
所以服务器需要向客户端发送这个请求,并期望得到某种结果。现在用稍微更清晰的术语来说,我真正想用它来表示的是。实际上,对于像 `stdio` 传输这样的不同传输,我们有四种不同的情况需要处理。我们需要能够处理从客户端到服务器的初始请求或某种初始请求,并且传输需要能够处理从服务器到客户端的响应。
此外,服务器需要能够向客户端发送初始请求,同样,客户端也需要能够响应。所以我想遍历所有这四种不同的情况,并思考我们将如何用 `stdio` 传输来实现它们。所以首先是从客户端到服务器的初始请求。所以这种情况会是任何时候客户端想要向服务器发送一些东西,比如一个调用请求或类似的东西。
要用 `stdio` 传输来实现这一点,我们所要做的就是写入标准输入。MCP 服务器会接收那条消息,处理它,然后希望形成一个响应。一旦它有了响应,它会通过向标准输出写入一条消息来响应。现在第三种情况是,我们有一个要从客户端发送到服务器的初始请求。
所以这会是服务器可能想做一些采样,而这需要服务器向客户端发送某种初始消息。每当服务器需要向客户端发送初始请求时,它所要做的就是写入标准输出。然后同样地,要响应,客户端所要做的就是写入标准输入。好了,我知道这几分钟的视频和我刚才讲的一系列图表可能有点令人困惑。
你可能在想,这关于初始请求和响应等等到底是什么?嗯,重点是。所有这些的重点是帮助你理解,`stdio` 传输真的非常棒,因为在任何时候,客户端或服务器都可以发起通信。任何一方都可以在任何时候发送一个请求,并期望得到一个响应。
这里是关键。对于可流式 HTTP 传输来说,情况并非如此。在某些情况下,可流式 HTTP 传输不允许这种情况。在某些情况下,服务器无法向客户端发送一些初始请求。
这就是关于可流式 HTTP 传输难以理解的地方。所以现在我们在这里暂停一下。回来后,我们将开始看 HTTP 传输。
我们会看到这个特定的场景,并理解,是的,关于这个,有一些棘手的事情,你在开发自己的 MCP 服务器时肯定需要理解。
---
### 11. The StreamableHTTP transport
> 类型:视频 | 时长:6:26 | 视频:007 - The StreamableHTTP Transport.mp4
`streamable HTTP transport (可流式HTTP传输)` 使 MCP 客户端能够通过 HTTP 连接到远程托管的服务器。与要求客户端和服务器在同一台机器上的 `standard I/O transport (标准I/O传输)`不同,这种传输为任何人都可以访问的公共 MCP 服务器开辟了可能性。
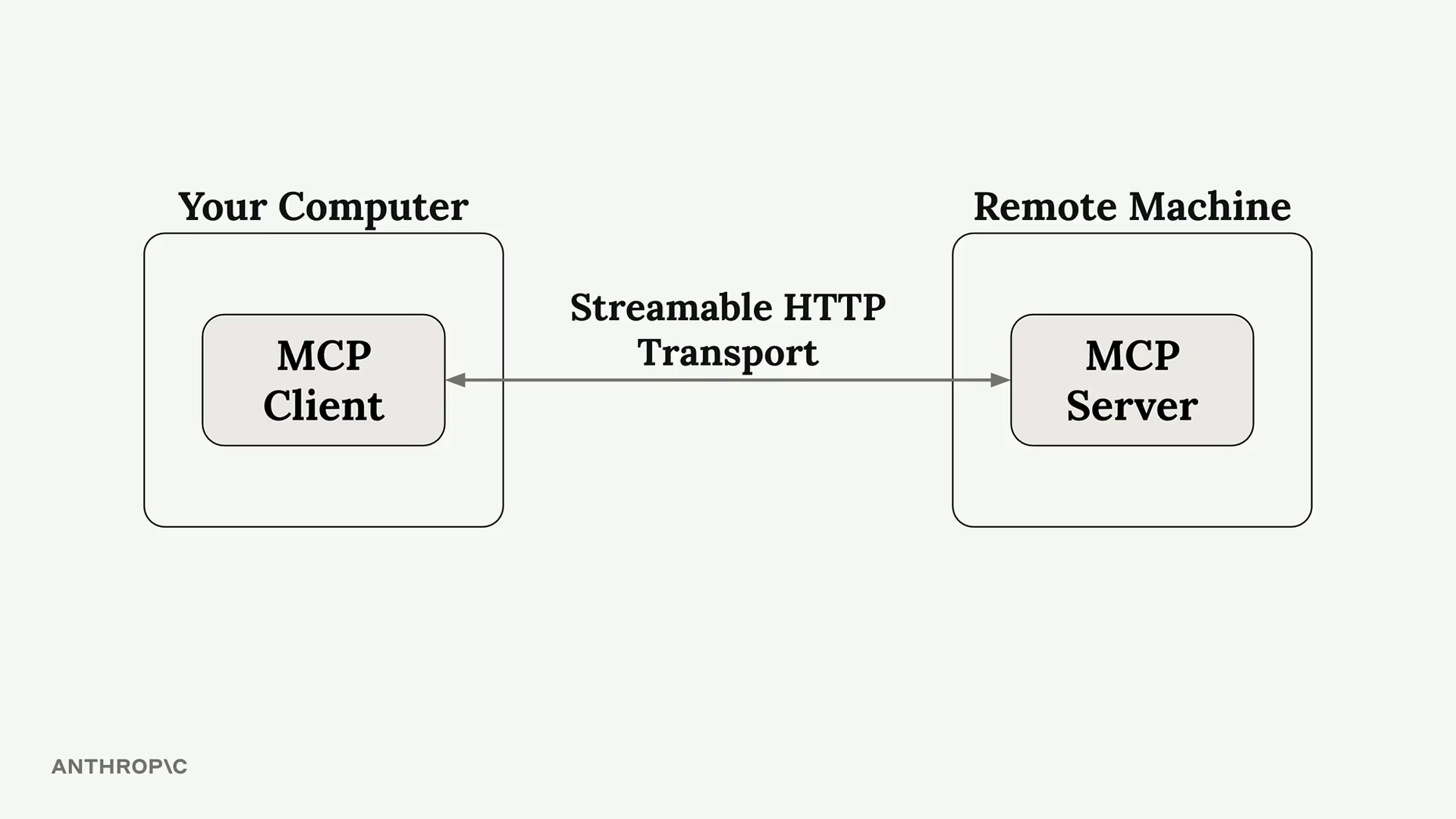
然而,有一个重要的警告:某些配置设置会严重限制你的 MCP 服务器的功能。如果你的应用程序在本地使用标准 I/O 传输时工作得很好,但在部署了 HTTP 传输后就出问题了,这很可能就是罪魁祸首。
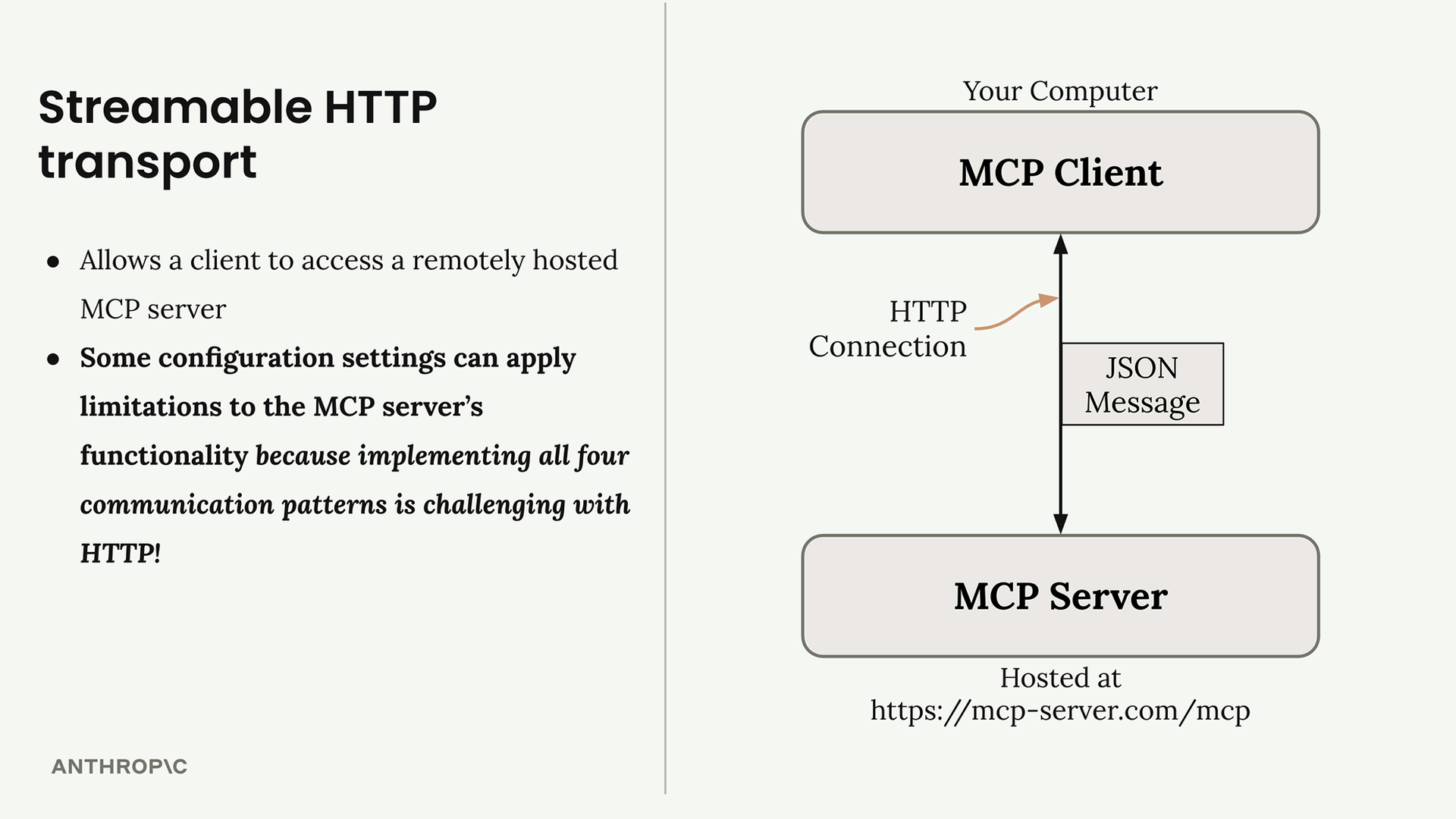
## 重要的配置设置
两个关键设置控制着可流式 HTTP 传输的行为:
- `stateless_http` - 控制连接状态管理
- `json_response` - 控制响应格式处理
默认情况下,这两个设置都是 false,但某些部署场景可能会迫使你将它们设置为 true。启用后,这些设置可能会破坏核心功能,如进度通知、日志记录和服务器发起的请求。
## HTTP 通信的挑战
要理解为什么存在这些限制,我们需要回顾一下 HTTP 通信的工作原理。在标准 HTTP 中:
- 客户端可以轻松地向服务器发起请求(服务器有一个已知的 URL)
- 服务器可以轻松地响应这些请求
- 服务器无法轻易地向客户端发起请求(客户端没有已知的 URL)
- 从客户端返回服务器的响应模式变得有问题
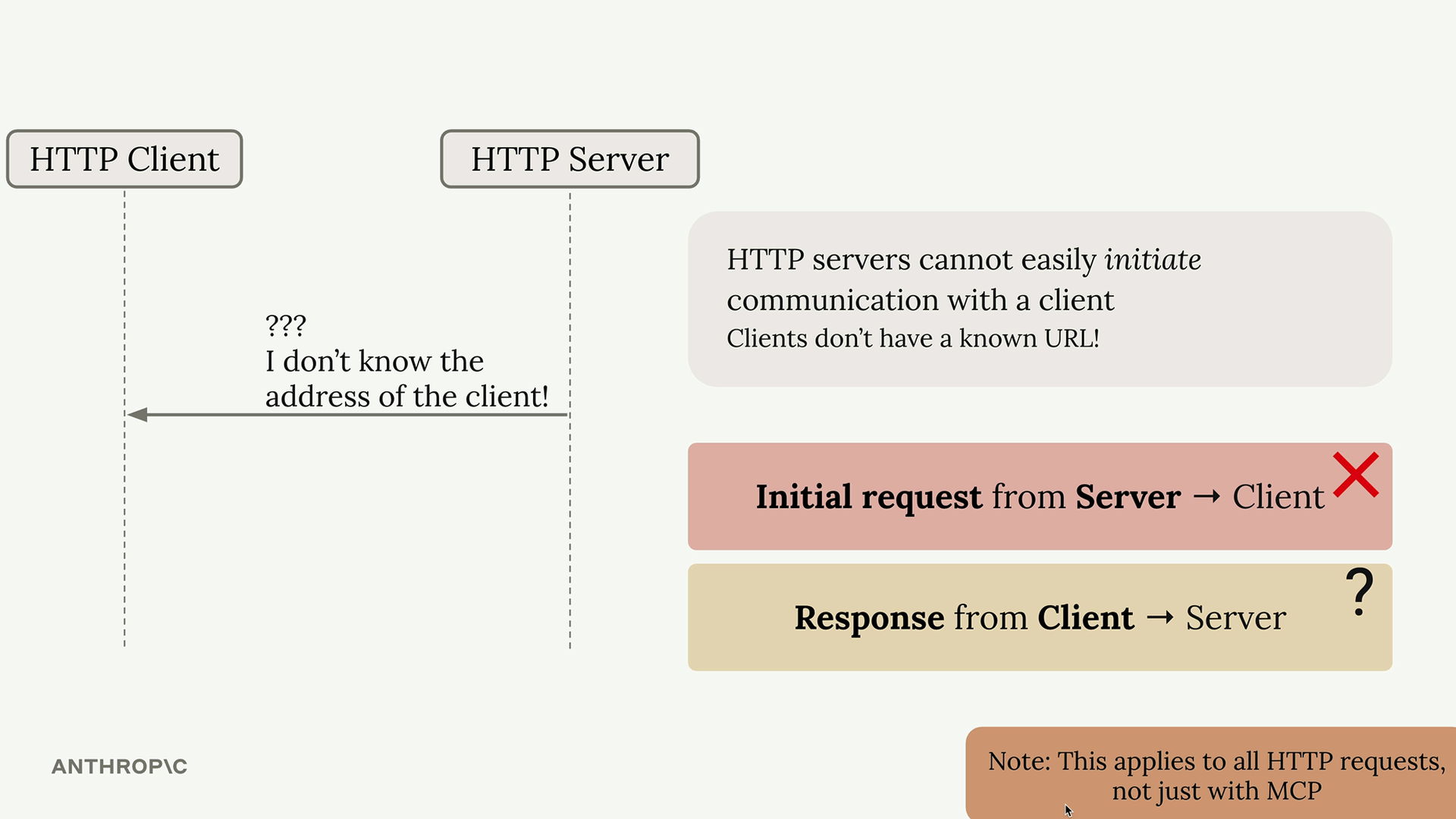
## 受影响的 MCP 消息类型
这种 HTTP 限制影响了特定的 MCP 通信模式。以下消息类型在使用普通 HTTP 时变得难以实现:
- **服务器发起的请求:** Create Message 请求, List Roots 请求
- **通知:** Progress 通知, Logging 通知, Initialized 通知, Cancelled 通知
这些正是当你启用限制性 HTTP 设置时会中断的功能。进度条消失,日志记录停止工作,服务器发起的采样请求失败。
## 可流式 HTTP 解决方案
可流式 HTTP 传输确实提供了一种巧妙的解决方案来解决 HTTP 的局限性,但它也带来了权衡。当你被迫使用 `stateless_http=True` 或 `json_response=True` 时,你实际上是在告诉传输在 HTTP 的约束内运行,而不是绕过它们。

理解这些局限性有助于你做出明智的决策:
- 针对不同的部署场景使用哪种传输方式
- 如何设计你的 MCP 服务器以优雅地处理 HTTP 限制
- 何时为了远程托管的优势而接受功能上的削减
关键在于了解这些限制的存在,并相应地规划你的 MCP 服务器架构。如果你的应用程序严重依赖服务器发起的请求或实时通知,你可能需要重新考虑你的传输选择或实现替代的通信模式。
#### 视频文字稿
现在来讨论 Streamable HTTP transport (流式 HTTP 传输)。这种传输方式允许我们在客户端和服务器之间通过 HTTP 连接发送消息。它的优点在于它真正实现了远程托管的 MCP 服务器。相比之下,对于 Standard IO transport (标准输入输出传输),我们总是必须在同一台机器上运行客户端和服务器。
有了流式 HTTP 传输,我们就可以远程托管我们的服务器。所以我们的远程服务器可能托管在 MCPServer.com 或类似的域名上。这确实为 MCP 服务器带来了更广泛的可能性,因为你可以创建一个任何人都可以连接的公共服务器。然而,正如我在前几个视频中提到的,你可能需要对这种传输方式应用一些设置,这些设置会限制你的 MCP 服务器的功能,特别是限制你可以从服务器发送回客户端的消息类型。
所以这是我希望你注意到的一个大问题。当你使用这种特定的传输方式时,有些设置会限制服务器的功能。因此,如果你在本地机器上开发应用程序,使用标准输入输出传输一切正常,然后部署并开始使用 HTTP 传输时发现事情不那么顺利,那么你就需要回过头来看这个视频,以理解到底发生了什么。首先,我想快速演示一下我之前在本课程中给你展示过的一个应用程序。
你可能还记得这个维基百科研究助手。它使用一个 Next.js 应用程序连接到一个实现了研究工具的 MCP 服务器。这个服务器正在使用流式 HTTP 传输,所以我可以用这个应用程序向你展示几个流式 HTTP 传输不按预期工作的场景。首先,我将在这里发送一个请求,就要求一份关于考古学的报告,只是为了让你回想一下这个应用程序的样子。
通常,当我发送这样的查询时,我会在这里看到一个 call tool request (工具调用请求),然后会有一个漂亮的进度条,我会得到状态更新,最终,如果我稍等片刻,我将得到完整的响应。现在,在 MCP 服务器的源代码这边,你会注意到我注释掉了两个设置:Stateless HTTP (无状态 HTTP) 和 JSON response (JSON 响应)。默认情况下,这些设置都设为 false,但在某些情况下,你非常需要启用它们或将它们设置为 true,稍后我会更详细地说明这些情况。
将这些设置更改为 true 会影响你的 MCP 服务器的功能,在某些情况下,甚至可能会破坏你客户端的工作方式。那么,让我马上给你看一个例子。我想将 `stateless HTTP` 改为 true。我将保存文件。
然后我将重新加载页面并再次运行完全相同的查询。现在你在这里不会看到很大的差异,但你会立刻注意到一些事情。你会注意到现在我没有进度条了。所以日志语句上方完全没有进度条。
此外,如果我让它在这里放一会儿,我会加快视频速度,我们会看到最终请求完全失败,而没有生成任何文本。现在我将刷新页面,将 `JSON response` 设置为 true,保存文件,然后再次运行完全相同的查询。现在我们会看到,当这两个设置都设为 true 时,我们得到了一些更令人惊讶的结果。现在我看不到任何进度条,也得不到任何日志语句,请相信我,如果我们让它就这么放着,请求会再次失败。
所以,我们马上就能看到这两个看似无害的设置,对我们的 MCP 服务器有很大的影响。因此,本视频的其余部分旨在帮助你理解这些设置的含义,我们为什么可能将它们设置为 true,以及这里到底发生了什么。首先,我想快速提醒你我在上一个视频中展示过的一张图。我曾重点强调,标准输入输出传输能够从客户端向服务器发起请求,然后获得响应。
同样,服务器也可以在任何时候向客户端发起请求,并获得响应。所以请暂时记住这一点,我来给你快速回顾一下 HTTP 通信。这是关于 HTTP 的一些基础知识,这适用于所有 HTTP 通信,不仅仅是与 MCP 相关的东西。提醒一下,如果我们有一个客户端和一台服务器,客户端可以在任何时候非常容易地向服务器发出请求。
例如,在右侧,客户端可以向服务器发出一个 POST 请求,并期望得到某种响应。这种设置没有任何问题。所以将这个转换到 MCP 的世界里,这意味着如果我们想从客户端向服务器发出初始请求,没问题,可以工作。如果我们想从服务器向客户端获得响应,也完全没问题,可以正常工作。
然而,如果我们考虑相反的场景,如果服务器想向客户端发起一个请求,这在 HTTP 请求中就不那么容易了。在一个非常基础的层面上,服务器不知道客户端的地址,而且客户端甚至可能不是公开可访问的。因此,在传统的 HTTP 中,服务器向客户端发起请求是非常有挑战性的。这意味着在我们的 MCP 世界里,服务器真的很难向下发送那个初始请求,这也意味着很难想象你如何能期望从客户端得到返回给服务器的响应。
所以,如果我们看我们刚才看过的这张图,我曾告诉你有些请求是从服务器发往客户端的,这意味着在这个 HTTP 世界里,有些消息类型用普通的 HTTP 请求来实现是相当困难的。具体来说,sampling request (采样请求)、listing routes (列出路由)、progress notifications (进度通知) 和 logging notifications (日志通知),以及我没有在这张图上显示的其他一些消息类型,在 HTTP 世界里实现起来更困难。果然,这和你刚才在这个演示中看到的情况差不多。一旦我开始将这些属性从 false 切换到 true,你就会看到应用程序的不同部分开始出问题,并且不像预期的那样工作。
到底哪里出问题了?没错。进度通知坏了,日志记录坏了,采样,或者说 `create message` 请求也坏了。采样被用来撰写研究报告。
不过我有个好消息。尽管在纯 HTTP 世界中从服务器向客户端发出请求很有挑战性,但流式 HTTP 传输确实有一个巧妙的解决方案。但你需要注意一些注意事项。让我们稍后看看这种传输方式实际上是如何工作的,以及那些注意事项具体是什么。
---
### 12. 深入了解 StreamableHTTP
> 类型:视频 | 时长:10:28 | 视频:008 - StreamableHTTP in Depth.mp4
StreamableHTTP 是 MCP 针对一个基本问题的解决方案:一些 MCP 功能需要服务器向客户端发出请求,但 HTTP 使这变得具有挑战性。让我们探讨 StreamableHTTP 是如何绕过这个限制的,以及在什么情况下你可能需要打破这个变通方法。
## 核心问题
一些 MCP 功能,如采样、通知和日志记录,依赖于服务器向客户端发起请求。然而,HTTP 是为客户端向服务器发出请求而设计的,而不是反过来。StreamableHTTP 通过使用 Server-Sent Events (SSE, 服务器发送事件) 这一巧妙的变通方法解决了这个问题。
## StreamableHTTP 的工作原理
这个神奇的过程通过一个多步骤的过程,在客户端和服务器之间建立持久连接。
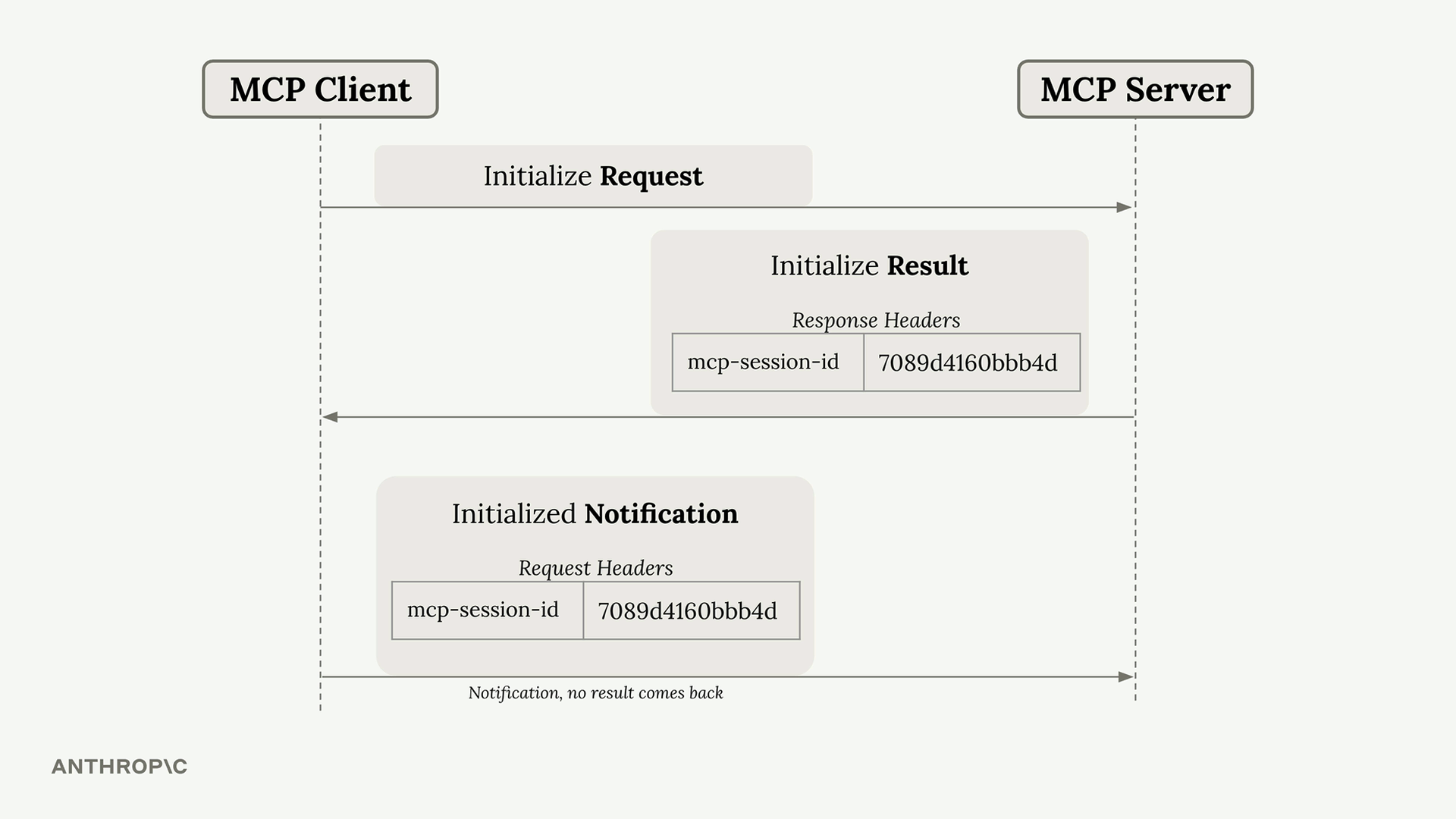
### 初始连接设置
该过程像任何 MCP 连接一样开始:
- 客户端向服务器发送一个 `Initialize Request`
- 服务器用一个包含特殊 `mcp-session-id` 头部的 `Initialize Result` 进行响应
- 客户端用会话 ID 发送一个 `Initialized Notification`
这个会话 ID 至关重要——它唯一地标识了客户端,并且必须包含在所有未来的请求中。
### SSE 变通方法
初始化后,客户端可以发出一个 GET 请求来建立一个服务器发送事件连接。这将创建一个长连接的 HTTP 响应,服务器可以随时用它来向客户端流式传输消息。
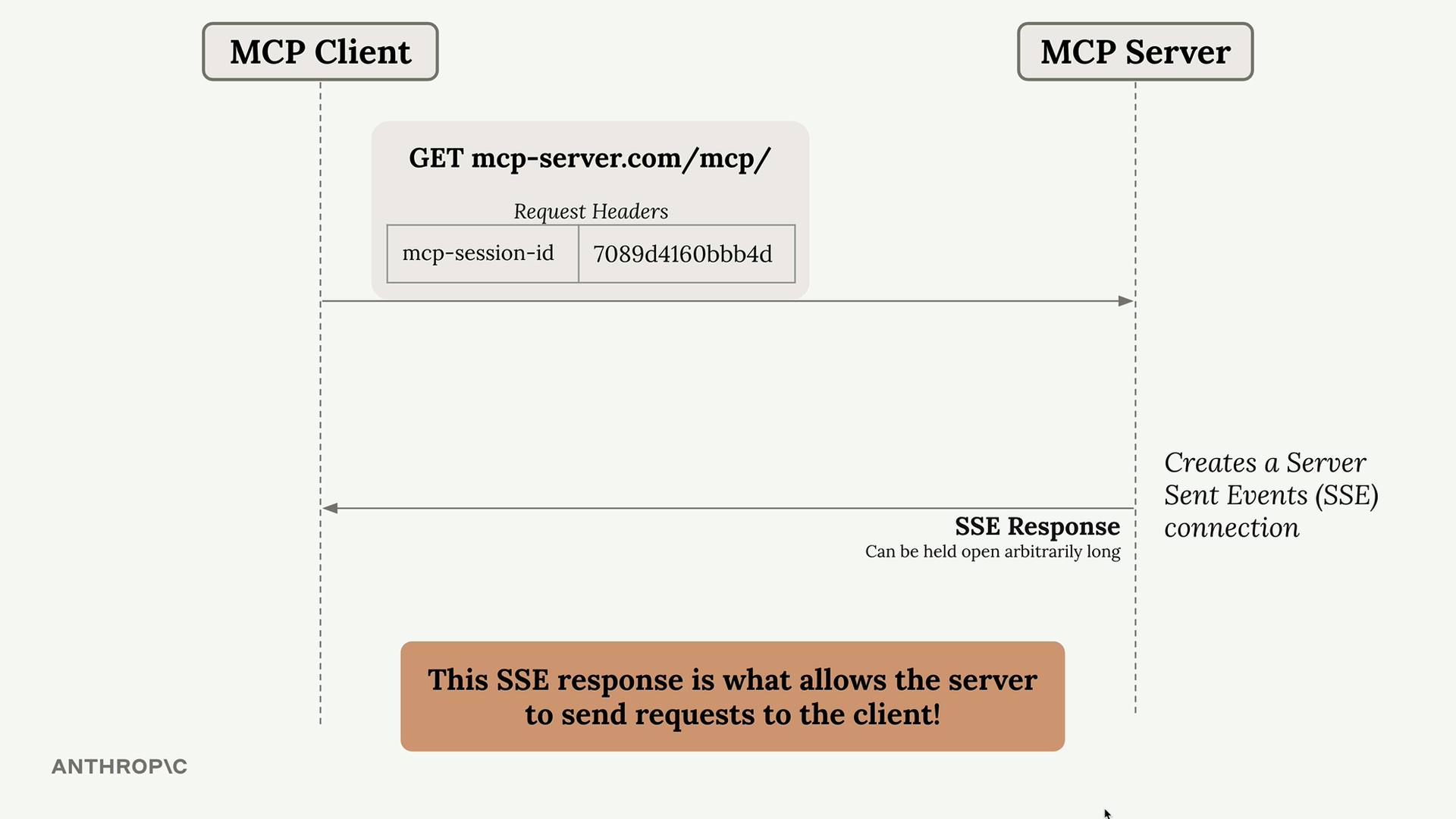
这个 SSE 连接是实现服务器到客户端通信的关键。服务器现在可以通过这个持久通道发送请求、通知和其他消息。
## Tool Calls 和双重 SSE 连接
当客户端进行 tool call (工具调用) 时,情况变得更加复杂。系统会创建两个独立的 SSE 连接:
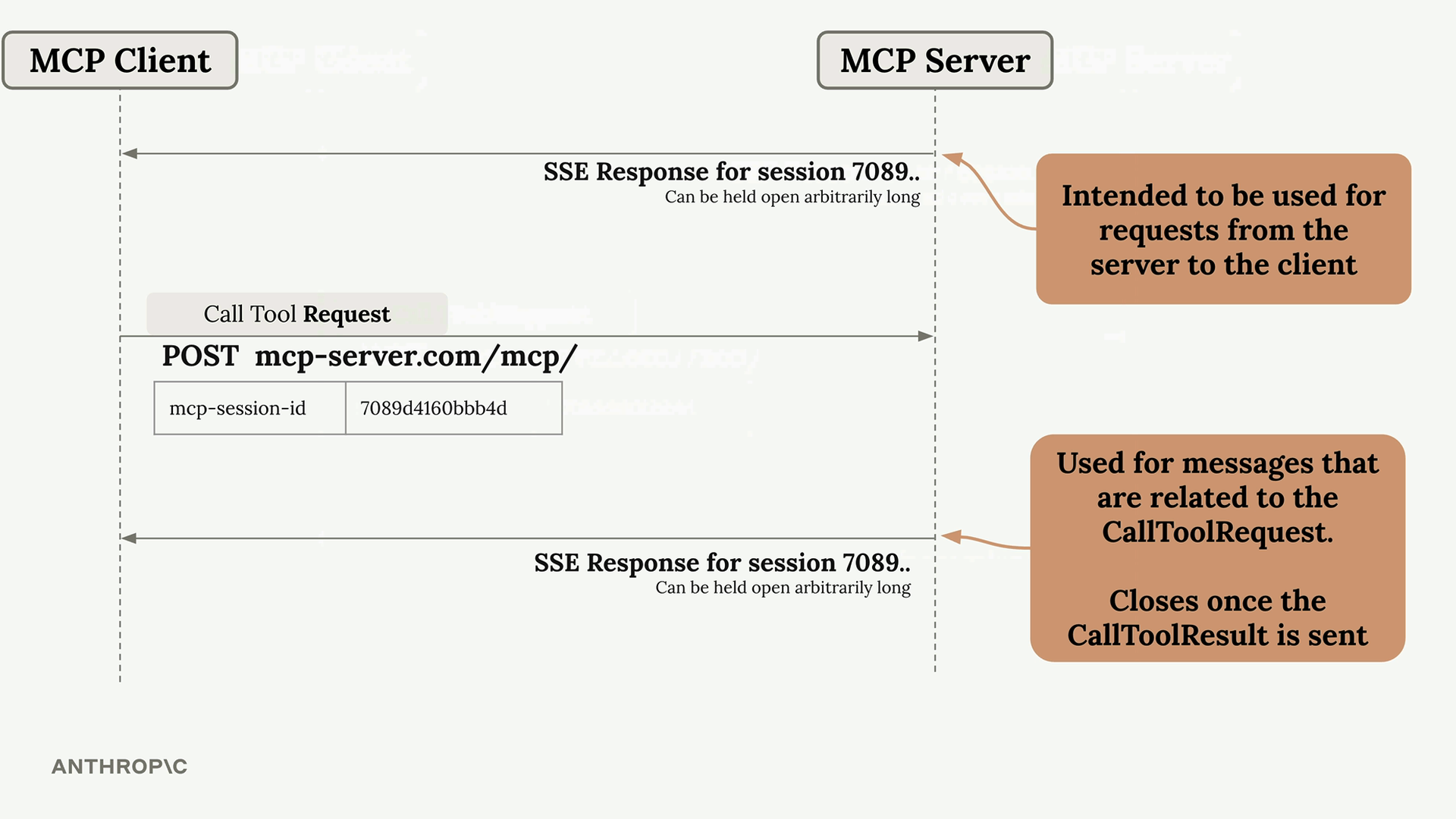
- **主 SSE 连接:** 用于服务器发起的请求,并无限期保持打开状态
- **特定于工具的 SSE 连接:** 为每个工具调用创建,并在工具结果发送后自动关闭
### 消息路由
不同类型的消息通过不同的连接进行路由:
- **进度通知:** 通过主 SSE 连接发送
- **日志消息和工具结果:** 通过特定于工具的 SSE 连接发送
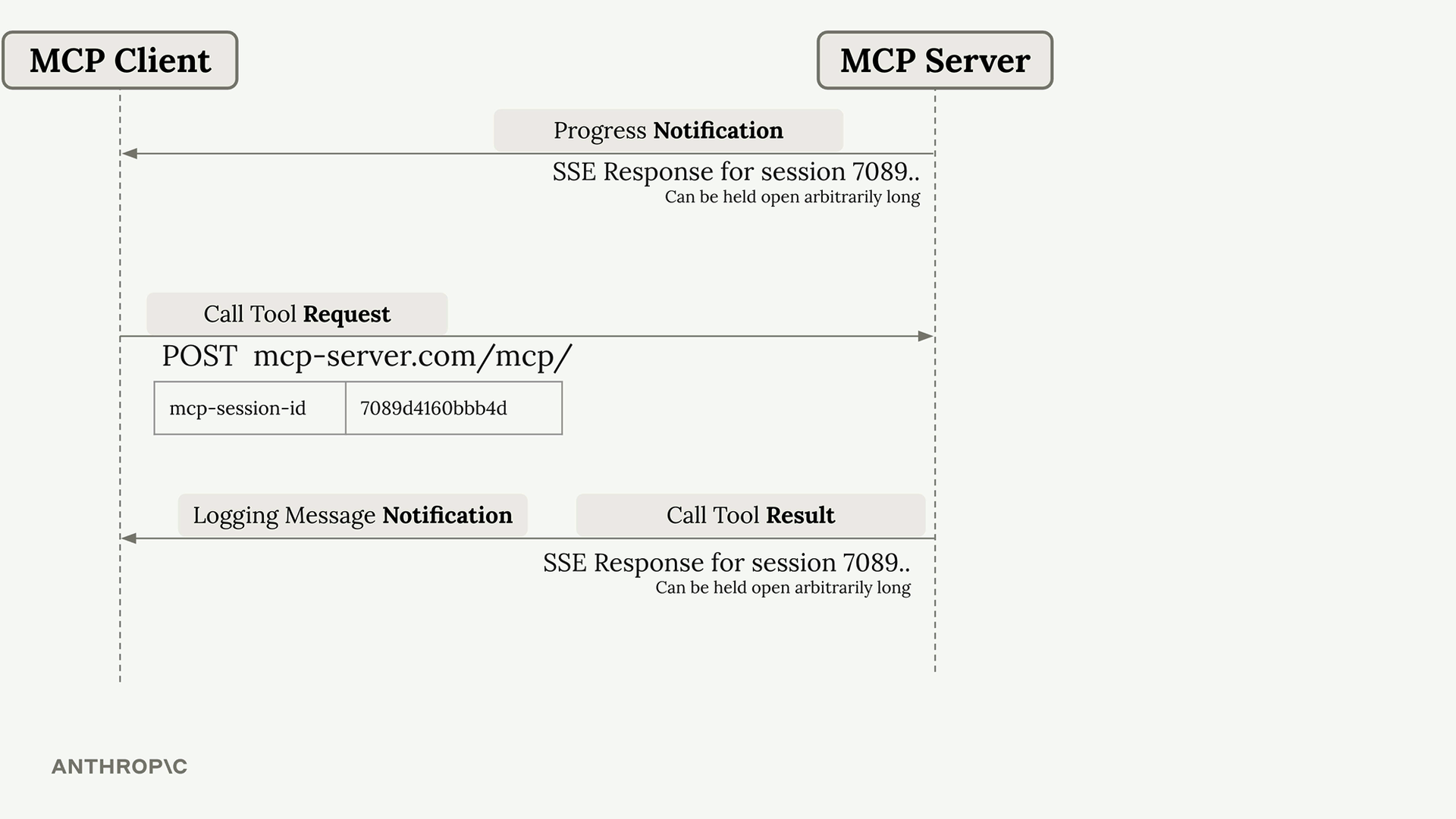
## 破坏变通方法的配置标志
StreamableHTTP 包含两个重要的配置选项:
- `stateless_http`
- `json_response`
将这些设置为 `True` 会破坏 SSE 的变通机制。在某些情况下,你可能希望启用这些标志,但这样做会限制依赖于服务器到客户端通信的完整 MCP 功能。
## 关键要点
StreamableHTTP 比其他 MCP 传输更复杂,因为它必须绕过 HTTP 的限制。基于 SSE 的变通方法实现了通过 HTTP 的完整 MCP 功能,但理解双连接模型对于调试和优化至关重要。
当使用 StreamableHTTP 构建 MCP 应用程序时,请记住,初始化后的所有请求都需要会话 ID,并且系统会自动管理多个 SSE 连接来处理不同类型的服务器到客户端通信。
#### 视频文字稿
让我们快速回顾一下前几个视频的内容,确保我们达成共识。首先我们了解到,一些 MCP 功能,即采样、通知和日志记录等,依赖于服务器向客户端发出请求。此后不久,我们又了解到,当我们普遍使用 HTTP 时,让服务器向客户端发出请求是相当困难的。所以这前两点有些矛盾。
它们是相互冲突的。我们需要服务器构建并向客户端发出请求以获得完整功能,但同时,在使用 HTTP 时这很难做到。现在,正如我所提到的,Streamable HTTP 有一个变通方法来解决这个问题。我将在这个视频中向你展示这个变通方法到底是什么,以及这种传输方式通常是如何工作的。
所以我们终于要搞清楚到底发生了什么。最后,请记住,在某些情况下,我们会将这两个标志设置为 true,我们会讨论为什么我们会这样做。当你这样做时,会破坏这个变通方法。这也就是为什么 Streamable HTTP 作为一种传输方式有点难以理解的原因,因为我们有这个关于 HTTP 的限制。
我们有变通方法,但在某些情况下,我们不想使用那个变通方法,这就是为什么这是一个棘手的话题。好了,闲话少说,让我们开始吧。让我们来了解一下这种传输方式实际上是如何工作的。我将首先向你展示几个不同的图表,以帮助你理解幕后的过程。
我还会给你看一个简短的演示,你将看到所有这些请求的实际发出过程,以及整个系统在一个非常小的演示应用程序中如何协同工作。那么,我们开始吧。首先,我希望你回忆一下当客户端最初连接到服务器时会发生什么。根据 MCP 规范,客户端必须向服务器发送一个初始化请求,服务器回复一个结果,然后客户端必须用初始化通知发出一个后续请求。
到那时,服务器就认为客户端已连接,一切就绪。现在,一旦我们开始使用 HTTP 传输,这个流程会发生微小的变化。因此,一旦你开始使用这种传输方式,从服务器发送回的初始化结果将在 HTTP 响应中包含一个头部。这个头部就是 MCP 会话 ID。
这是一个随机的数字和字母字符串,被分配给我们的客户端,作为我们与服务器连接的标识符。一旦我们收到那个头部,我们必须在向服务器发出的所有后续请求中包含它。这允许服务器识别我们的客户端。现在,在我们完成这个初始化并获得那个会话 ID 之后,神奇的部分开始了。
这就是允许服务器向客户端发出请求的重要变通方法。一旦我们完成初始化,客户端可以选择性地(不是必须这样做)向 MCP 服务器发出一个 GET 请求,并在请求中包含那个会话 ID。我们得到的响应非常特殊。它是一个 SSE 响应。
SSE 是 Server-Sent Events (服务器发送事件) 的缩写。这是一种可以保持打开任意时间的响应。一旦这个响应与我们的客户端建立起来,服务器就可以向我们的客户端流式传输小块信息,基本上是单个消息。所以一旦这个连接建立起来,现在,在这一点上,这是真正关键的部分。
这现在允许服务器在任何时候向下发送消息到客户端。这个连接可以被用来,本质上,允许服务器向客户端发出请求。所以这就是诀窍。这就是 HTTP 传输使用的变通方法。
它利用了这个长连接的 SSE 响应,并将它想要发送给客户端的消息流式传输下来。那么,现在让我们更进一步,走一遍当客户端可能想要调用一个工具时会发生什么,因为复杂性还没完。你还需要理解另一个关键部分。现在在这张图的顶部,我有我们刚刚创建的那个 SSE 响应。
记住,那个响应,那个打开的连接,它有一个会话 ID 与之绑定。所以 MCP 服务器确切地知道那个连接器,那个连接属于哪个客户端。那么稍后在某个未来的时间点,当那个响应仍在运行时,我们的客户端可能会决定向服务器发出一个 call tool (调用工具) 请求。当它发出这个请求时,它会将会话 ID 作为头部包含进去。
然后 MCP 服务器会打开第二个 SSE 响应。所以现在,在这一点上,我们有两个独立的 SSE 响应。顶部的第一个,旨在用于从服务器到客户端的请求。第二个全新的 SSE 响应旨在用于与此 call tool 请求相关的消息。
重要的是,这是关键部分,这个第二个 SSE 响应,在 call tool 结果消息发送后会立即自动关闭。所以底部的响应,在我们得到结果后会很快自动关闭,而上面的响应则意在保持打开任意长的时间。然后,记住,我们这里的最终目标实际上是调用一个工具。所以也许我们调用了我们见过很多次的 add tool (加法工具)。
我给你展示过几次的那个实现,它里面有一些日志消息和一些进度通知。最终,它返回一个结果,也就是我们的 call tool 结果。现在这里有另一个有点棘手的部分。从技术上讲,日志消息和进度通知都与 call tool 请求紧密相关。
所以你可能会认为这两个首要消息都应该在底部的响应中被发送回来,因为它们都与这个 call tool 请求真正相关。嗯,这并不完全是目前许多 SDK 的工作方式。进度通知最终被认为是与传入的 call tool 请求分开的。所以进度通知实际上是在第一个 SSE 响应中发送的。
所以那是那个意在长时间保持打开以允许服务器向客户端发出请求的响应。然后日志消息和实际的 call tool 结果在对发出的 POST 请求或 GET tool 请求的响应中被发送回来。所以这就是整个流程。现在为了确保这一切都清晰明了,我想带你走一遍一个非常快速的演示,你可以用一种非常直观的方式看到所有这些不同的请求被发出。
所以我准备了一个小演示。首先,我再次准备了一个简单的 MCP 服务器,带有一个简单的 add tool。add tool 将记录一些信息,等待两秒钟,发出一个进度报告,然后返回一个结果。我用这个在浏览器中运行的客户端连接到这个 MCP 服务器。
这个客户端将允许我们向服务器发出一些不同的请求,然后显示我们得到的具体响应。现在,总的来说,这个客户端将经历你在屏幕上看到的流程。我知道这里有很多东西,但本质上,我们首先要经历整个初始化过程,用顶部的这些东西。然后我们将形成 GET SSE 连接,这允许服务器向客户端发送请求。
然后我们将做一个 call tool 请求,这将形成第二个 SSE 连接,负责处理与这个特定 call tool 请求相关的消息。那么让我们运行它,看看会发生什么。首先,我将发出初始化请求。所以我将发送它。
这将给我我的会话 ID,它在任何未来的请求中唯一地标识我的客户端到服务器。记住,会话 ID 仅在你使用流式 HTTP 传输时提供。它完全不用于标准 IO 传输。你会注意到它以 EAA 开头。
这个头部被自动获取并应用于所有未来的请求。所以如果我向下滚动到下一个请求,你会注意到 MCP 会话 ID 已经自动应用了正确的会话 ID,这个 ID 是我从上面的请求中得到的。所以现在我们已经发送了初始化请求,就是那个,我们的第二个请求是初始化通知。所以我将发送它。
好的,现在在这一点上,我们已经处理了这里的头三个框。所以现在我们将向服务器发出我们的 GET 请求。这个 GET 请求将保持打开很长时间。这就是允许服务器在任何它希望的时候向我们的客户端发送请求的原因。
它将用于诸如采样或任何类型的服务器发起的请求。要发出那个请求,我将使用右下角的这个小框。所以我将点击 Start GET SSE。这个请求也将包含那个会话 ID。
现在我已经形成了那个连接。所以现在理论上,在任何时候,服务器都可以向我的客户端发送一条消息,用于采样、日志记录或进度通知等等。如果我收到任何这些消息,它们应该出现在这个框内。所以现在是最后一步。
我将调用 Add 函数。我再次在其中包含了正确的会话 ID。现在,提醒你一下,当我点击这个时,理论上,我们希望能看到日志语句、进度语句和最终的 call to a result 都出现在这个框里,这代表了响应的那部分。但实际上,仅仅因为 Python 的 MCP SDK 的设置方式,进度通知实际上将作为这个上面的响应的一部分被发送。
所以我们应该在这里看到一个日志语句和一个 call tool 结果。我们应该在右下角的那个框里看到进度语句。那么让我们运行它,看看会发生什么。好的,我将运行它。
然后经过一小段延迟,因为记住里面有两秒的暂停,我们然后会得到我们的结果。所以果然,在右下角,我得到了一个 notification/progress。所以那是进度语句。我完成了 80% out of 100%。
所以那是在那个响应通道中发送的。然后对我的 call tool 请求的实际响应有一个以 notification/message 形式的日志语句。然后在那之后,我得到了 call tool 请求的实际结果。所以这是我的 call tool 结果,那两个数字相加的答案是八。
然后记住,一旦我们得到那个 call tool 结果,这个连接就会自动关闭。所以我看到那里,是的,连接已关闭,我再也无法沿着我们得到的这个 SSE 响应接收任何消息了。好吧,就是这样。这就是整个流程。
所以现在你明白了流式 HTTP 传输幕后发生了什么。但我们还没完。记住,我多次说过,在某些情况下,你会想要将这些标志设置为 true,它会破坏这个流程的某些部分。所以这是我们需要理解的最后一件事。
我们为什么会把它们设置为 true?因为这可能是你在某个时候想要做的事情,它到底会破坏什么?所以这是我们真正需要弄清楚的最后一件事。
---
### 13. 状态与 StreamableHTTP 传输
> 类型:视频 | 时长:6:29 | 视频:009 - Stateless HTTP.mp4
MCP 服务器中的 `stateless_http` 和 `json_response` 标志控制着你服务器行为的基本方面。理解何时以及为何使用它们至关重要,特别是如果你计划扩展服务器或在生产环境中部署它。
## 何时需要无状态 HTTP
想象你构建了一个广受欢迎的 MCP 服务器。最初,可能只有几个客户端连接到一个单一的服务器实例:
随着服务器的增长,你可能会有成千上万的客户端尝试连接。运行一个单一的服务器实例将无法扩展以处理所有这些流量:
典型的解决方案是水平扩展——在 load balancer (负载均衡器) 后面运行多个服务器实例:
但这里事情变得复杂了。记住,MCP 客户端需要两个独立的连接:
- 一个 GET SSE 连接,用于接收服务器到客户端的请求
- POST 请求,用于调用工具和接收响应
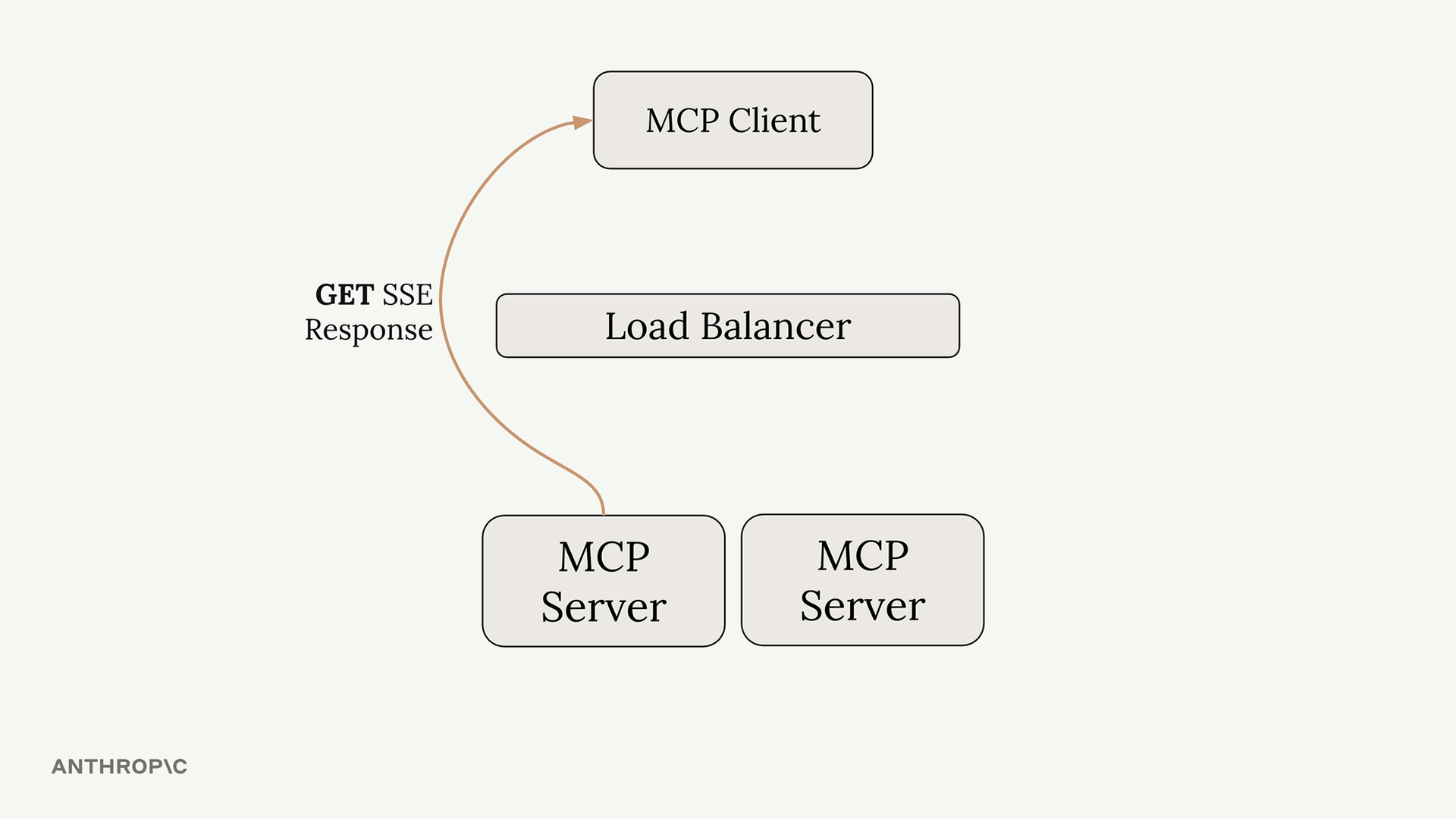
使用负载均衡器,这些请求可能会被路由到不同的服务器实例。如果你的工具需要使用 Claude(通过采样),处理 POST 请求的服务器将需要与处理 GET SSE 连接的服务器进行协调。这在服务器之间产生了一个复杂的协调问题。
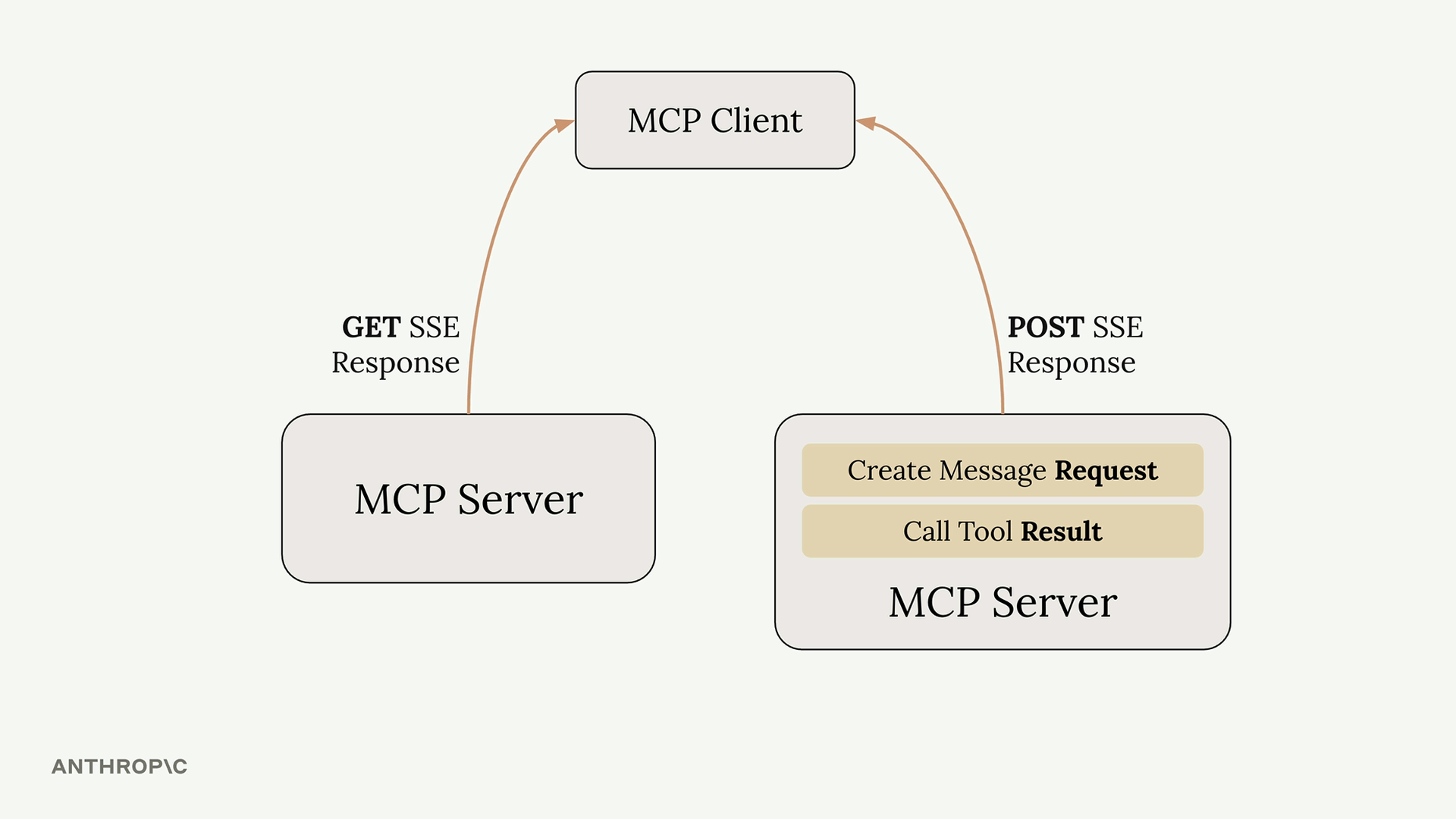
## 无状态 HTTP 如何解决这个问题
设置 `stateless_http=True` 消除了这个协调问题,但带来了显著的权衡:
当启用无状态 HTTP 时:
- **客户端不会得到会话 ID** - 服务器无法跟踪单个客户端
- **没有服务器到客户端的请求** - GET SSE 通道变得不可用
- **没有采样** - 无法使用 Claude 或其他 AI 模型
- **没有进度报告** - 无法在长时间操作期间发送进度更新
- **没有订阅** - 无法通知客户端关于资源的更新
然而,有一个好处:不再需要客户端初始化。客户端可以直接发出请求,无需初始握手过程。
## 理解 JSON 响应
`json_response=True` 标志更简单——它只是禁用了 POST 请求响应的流式传输。你不会在工具执行时获得多个 SSE 消息,而是只得到作为纯 JSON 的最终结果。
禁用流式传输后:
- 没有中间进度消息
- 执行期间没有日志语句
- 只有最终的工具结果
## 何时使用这些标志
在以下情况下使用无状态 HTTP:
- 你需要使用负载均衡器进行水平扩展
- 你不需要服务器到客户端的通信
- 你的工具不需要 AI 模型采样
- 你希望最小化连接开销
在以下情况下使用 JSON 响应:
- 你不需要流式响应
- 你更喜欢更简单、非流式的 HTTP 响应
- 你正在与期望纯 JSON 的系统集成
## 开发与生产
如果你在本地使用标准 I/O 传输进行开发,但计划使用 HTTP 传输进行部署,请使用与生产环境中相同的传输方式进行测试。有状态和无状态模式之间的行为差异可能很大,最好在开发期间而不是部署后发现任何问题。
这些标志从根本上改变了你的 MCP 服务器的运作方式,因此请根据你的具体扩展和功能需求来选择它们。
#### 视频文字稿
我们需要做的最后一件事是理解 stateless (无状态) 和 JSON response 标志的含义。它们如何影响我们的服务器,以及我们何时会将它们设置为 true?我首先想带你了解一个我们可能希望将这些标志设置为 true 的场景,因为它真正解释了这些标志为何存在以及它们如何影响我们的服务器。让我们想象一下,你我构建了一个 MCP 服务器,并将其公开发布在网上,任何人都可以连接到它。
所以,也许我们用自己的客户端连接到它,然后其他一些人用他们自己的客户端也连接到它。随着时间的推移,我们的服务器可能会变得非常非常受欢迎,除了我们最初连接的三个客户端之外,可能还有许许多多其他人也连接到它。在某个时刻,在一台机器上运行我们服务器的单个实例可能无法扩展以应对传入的流量。因此,我们解决这个问题的一种方法是通过一些水平扩展。
通过水平扩展,我们可能会运行我们服务器的多个副本,然后通过一个 load balancer (负载均衡器) 来控制对它们的访问。因此,任何传入的请求都会被随机路由到这些不同的服务器之一。这将使我们能够扩展以满足更高的流量需求。让我们想一想,如果在这里放一个负载均衡器会发生什么,特别是要记住这样一个事实,即我们希望从任何给定的客户端到我们的 MCP 服务器有两个独立的连接。
首先,我们希望那个运行中的 get 请求始终在运行,以便我们可以接收从服务器到客户端的请求。我们的客户端还需要发出 post 请求,然后接收一个包含若干消息的 SSE 响应。所以,让我们只考虑一个客户端连接到可能两个不同的服务器。这个客户端会发出一个初始请求,建立那个初始的 Git SSC 响应管道。
所以,我们然后可以想象,我们有这个响应待处理或持续不断地运行到客户端。再次记住,这一切都是为了让服务器能够重新向下发送请求到客户端。然后,也许在未来的某个时间点,客户端决定运行一个工具。所以它可能会使用 post 请求发出一个 call tool (调用工具) 请求。
也许这个请求被路由到第二个 MCP 服务器。第二个服务器然后会通过建立自己独立的 SSC 响应来回应。现在,在这一点上,为了清晰起见,我不会显示负载均衡器。当工具在该服务器内运行时,让我们暂时想象一下,它需要使用 Claude,它可能会尝试通过创建一个 create message (创建消息) 请求来使用 Claude。
记住,这代表了一次使用采样的尝试。现在,采样请求总是需要通过 Git SSE 响应。但那个连接是由一个完全独立的服务器建立的。所以,我们需要找出某种方法,将这个请求从这里发送到另一个服务器,让这个服务器通过这个 Git SSC 响应向下发送请求,让 MCP 客户端运行 Claude,生成一些文本,将其发送回这个服务器,然后以某种方式将生成的文本再传回这个服务器。
正如你马上就能看出的,协调这一切将非常非常有挑战性。现在,这绝对是可以做到的,但它代表了大量的困难和大量的额外配置和基础设施。所以,如果我们正在构建一个我们期望水平扩展的 MCP 服务器,并且我们不想经历所有这些额外的协调和基础设施设置,我们可能会决定将那个 stateless HTTP 标志设置为 true。将此标志设置为 true 有一个直接但非常重要的效果。
这意味着客户端不会得到一个会话 ID,这意味着服务器永远无法跟踪一个客户端。马上,这就会产生一些非常大的后续效应。没有会话 ID,MCP 服务器就无法再利用 Git SSC 响应通道向客户端发送请求。要理解为什么那个响应通道不能再使用了,我建议你想象一个没有任何账户 ID 的银行。
所以,一个银行可能会收到钱,但它不会真正知道是谁给了他们钱,也不会真正知道该给谁钱,因为它不知道谁该得到什么。这里没有识别令牌的情况也是一样的。现在,没有那个 Git SSC 响应通道,这意味着因为我们的服务器不能在客户端上发送任何请求,我们也无法使用像采样或进度日志记录或围绕资源变化等事物的订阅等功能。然而,这也有一个好处。
在无状态模式下,你不再需要进行客户端初始化。所以,这意味着回到这个应用程序中,记住每当我们连接到服务器时,我们都必须发出那个初始化请求,然后是后续的初始化通知。当你在无-状态模式下时,你不需要发出那两个请求,这无疑减少了你的服务器接收的流量。所以,这里有一个相当不错的权衡。
现在,我们一直在讨论的另一个标志是 JSON 响应。每当你将 JSON 响应设置为 true 时,这只意味着你向下发送给客户端的 post 请求将不会启用流式传输。我可以给你一个非常简单易懂的演示,让你看看那是什么样子。所以,在这里,让我快速提醒你一下这个应用程序通常是如何工作的。
我将发送初始化请求,初始化通知,然后当我调用 add tool (加法工具) 函数时,我将打开那个 SSC 连接,我将首先得到一条消息,然后是 call tool 结果。现在,我将非常快速地将 JSON 响应标志翻转为 true。再次,这意味着我得到的所有响应都将只是作为纯 JSON 的最终结果。根本没有流式传输。
所以,现在我将再次经历同样的过程。我将运行初始化,我将运行通知,现在这次当我调用 add 函数时,我将不会得到那些关于某些日志记录或其他任何东西的中间消息。相反,我将得到最终的工具调用结果,没有别的。所以,现在如果我运行这个,我们会看到我没有将响应流式传输回来。
相反,我正在等待直到工具调用完成,我只得到结果,绝对没有其他任何东西。根本没有日志语句。所以你可以马上看到这两个标志对你的服务器行为有巨大的影响。但是,根据你尝试开发和部署应用程序的方式,将这些标志设置为 true 可能完全合适。
好了,通过大量的耐心和许多不同的图表,我想我们终于对流式 HTTP 传输的工作原理有了一个合理的了解。所以,请记住这两个标志以及它们究竟如何影响你的服务器。如果你正在本地机器上使用标准 IO 作为传输方式开发你的服务器,当你部署到生产环境时,如果你打算使用流式 HTTP 传输,请记住你的服务器可能会表现得有点不同。所以,在你开发服务器时,我建议你使用你计划在生产中使用的传输方式,因为这将在以后为你省去很多麻烦。
---
## 第4部分:Assessment and next steps
### 15. Wrapping up
> 此课时为课程介绍/总结页面,请访问在线平台查看。
---