一个数据包是怎么从网卡到你的程序的?Linux 网络收包全链路图解
作者:小康,C/C++ 编程博主关键词:Linux 网络子系统、网卡、DMA、中断、软中断、协议栈、socket、recv、epoll前言写网络程序的时候,你调用recv()拿到数据,感觉理所当然。但有没有想过:对端发过来的那个数据包,是怎么一步步从网线上的电信号,变成你程序里buf数组里的那些字节的?中间经过了多少层?CPU 什么时候被通知?内核做了哪些事?epoll是怎么感知到"有数据来了"的?这条链路搞懂了,很多之前死记硬背的东西会突然全部串起来——为什么高并发要用 epoll、为什么零拷贝能提升性能、为什么网卡多队列能提升吞吐……背后都是同一套机制。这篇就把这条链路从头到尾走一遍。一、先看全局:数据包经过哪几层?收一个数据包,Linux 内核大概要经过这几个阶段:网卡收包 → DMA 写内存 → 硬件中断 → 软中断 → 协议栈处理 → 数据放入 socket 缓冲区 → 唤醒进程每个阶段各有分工,不是一个函数从头跑到尾。来看全局图: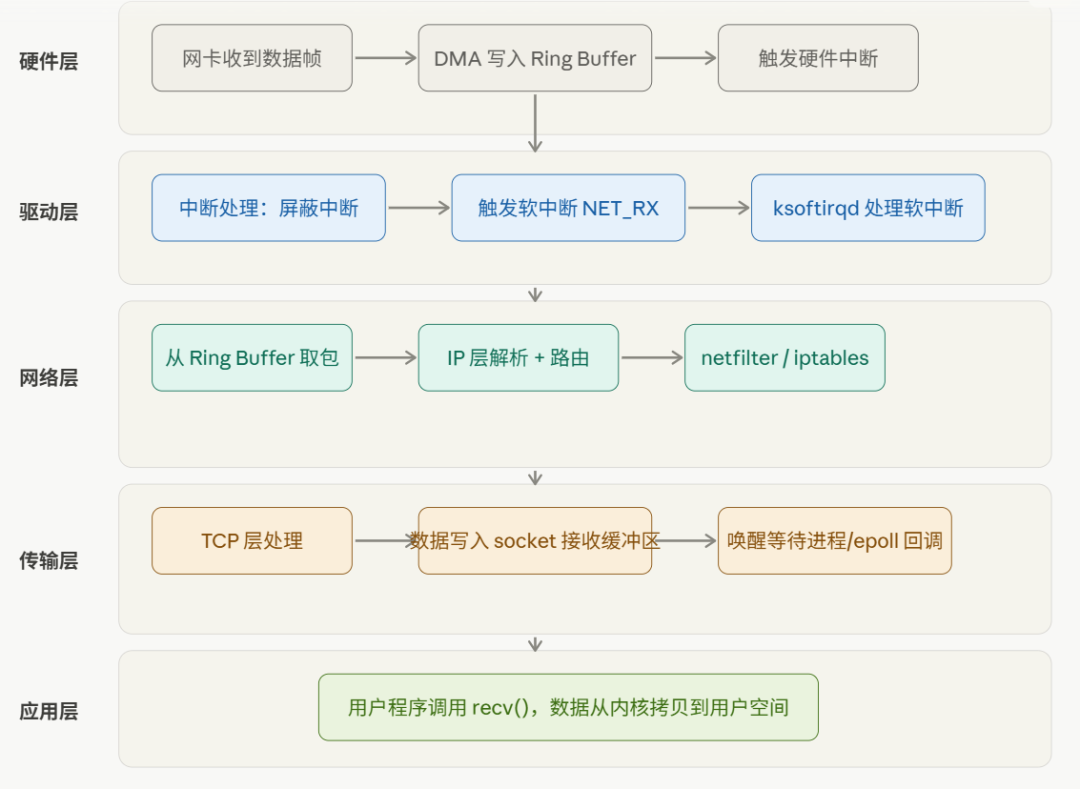 五个阶段,从下往上,我们逐层展开。二、第一步:网卡收包 + DMA 写内存数据包到达网卡的那一刻,CPU 其实什么都不知道,也没有参与任何操作。网卡自己完成了第一步:把数据帧从网线上接收下来,通过DMA(直接内存访问)直接写入内核预先分配好的一块内存区域——Ring Buffer(环形缓冲区)。整个过程 CPU 零参与,网卡是自己干的。Ring Buffer 是什么?Ring Buffer 是驱动程序在内核内存里分配的一个环形队列,里面预先放了一批sk_buff(socket buffer)结构体,每个槽位指向一块内存。网卡收到数据帧后,通过 DMA 把数据写到其中一个槽位指向的内存,然后把这个槽位标记为"已用"。Ring Buffer(环形队列):┌──────┬──────┬──────┬──────┬──────┬──────┐│ 空闲 │ 空闲 │ 已用 │ 已用 │ 已用 │ 空闲 │└──────┴──────┴──────┴──────┴──────┴──────┘↑ ↑待处理包 网卡下一个写这里Ring Buffer 满了会怎样?新来的包直接丢弃,这就是网卡层的丢包——用ethtool -S eth0 | grep drop可以看到。DMA 写完之后,网卡做一件事:向 CPU 发送一个硬件中断信号,告诉它"有新包来了,你来处理吧"。三、第二步:硬件中断 → 软中断CPU 收到网卡的中断信号,立刻暂停当前正在执行的任务,跳转到中断处理函数(ISR,Interrupt Service Routine)。但这里有个设计原则:中断处理函数要尽可能快,不能做太多事。原因很简单:中断处理期间,同一 CPU 上的其他中断都被屏蔽了。如果中断处理函数跑太久,其他中断(键盘、磁盘……)全都在等,系统响应变差。所以网卡的中断处理函数只做两件事:告诉网卡"我收到通知了,你先别再发中断了"(屏蔽网卡中断)触发一个软中断(softirq):NET_RX_SOFTIRQ,然后立刻返回真正的收包处理,交给软中断去做。软中断由内核线程ksoftirqd处理,它在中断处理函数返回后,异步执行收包的主要逻辑:从 Ring Buffer 里取出数据包,往上送给协议栈。这个设计叫上半部/下半部(Top Half / Bottom Half):
五个阶段,从下往上,我们逐层展开。二、第一步:网卡收包 + DMA 写内存数据包到达网卡的那一刻,CPU 其实什么都不知道,也没有参与任何操作。网卡自己完成了第一步:把数据帧从网线上接收下来,通过DMA(直接内存访问)直接写入内核预先分配好的一块内存区域——Ring Buffer(环形缓冲区)。整个过程 CPU 零参与,网卡是自己干的。Ring Buffer 是什么?Ring Buffer 是驱动程序在内核内存里分配的一个环形队列,里面预先放了一批sk_buff(socket buffer)结构体,每个槽位指向一块内存。网卡收到数据帧后,通过 DMA 把数据写到其中一个槽位指向的内存,然后把这个槽位标记为"已用"。Ring Buffer(环形队列):┌──────┬──────┬──────┬──────┬──────┬──────┐│ 空闲 │ 空闲 │ 已用 │ 已用 │ 已用 │ 空闲 │└──────┴──────┴──────┴──────┴──────┴──────┘↑ ↑待处理包 网卡下一个写这里Ring Buffer 满了会怎样?新来的包直接丢弃,这就是网卡层的丢包——用ethtool -S eth0 | grep drop可以看到。DMA 写完之后,网卡做一件事:向 CPU 发送一个硬件中断信号,告诉它"有新包来了,你来处理吧"。三、第二步:硬件中断 → 软中断CPU 收到网卡的中断信号,立刻暂停当前正在执行的任务,跳转到中断处理函数(ISR,Interrupt Service Routine)。但这里有个设计原则:中断处理函数要尽可能快,不能做太多事。原因很简单:中断处理期间,同一 CPU 上的其他中断都被屏蔽了。如果中断处理函数跑太久,其他中断(键盘、磁盘……)全都在等,系统响应变差。所以网卡的中断处理函数只做两件事:告诉网卡"我收到通知了,你先别再发中断了"(屏蔽网卡中断)触发一个软中断(softirq):NET_RX_SOFTIRQ,然后立刻返回真正的收包处理,交给软中断去做。软中断由内核线程ksoftirqd处理,它在中断处理函数返回后,异步执行收包的主要逻辑:从 Ring Buffer 里取出数据包,往上送给协议栈。这个设计叫上半部/下半部(Top Half / Bottom Half):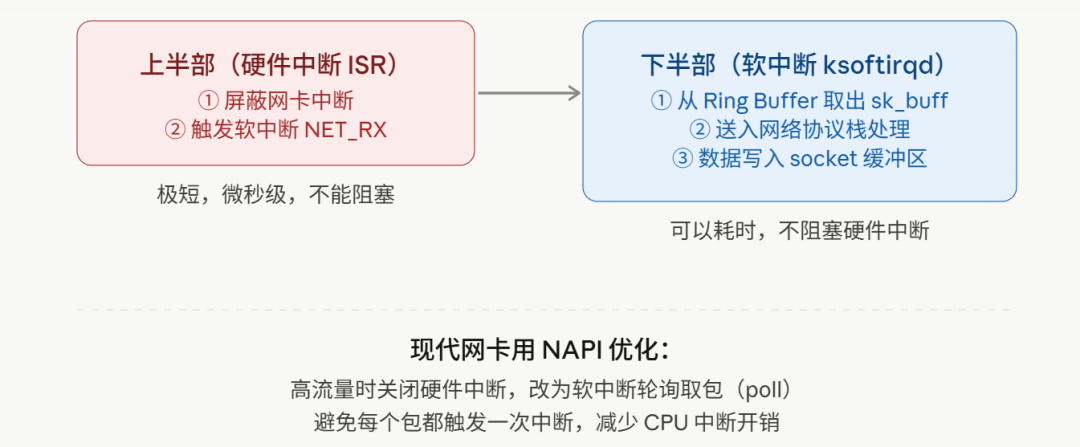 现代网卡驱动几乎都用NAPI(New API)机制:高流量时主动关闭硬件中断,改用软中断轮询批量取包,避免每个包都打断 CPU 一次。高并发场景下这个优化非常重要——否则几十万 pps 的流量,CPU 光处理中断就耗尽了。四、第三步:协议栈处理软中断拿到sk_buff之后,开始往协议栈里送。这里是内核网络子系统最复杂的部分,但逻辑很清晰——就是一层一层剥包头。链路层(L2):检查以太网帧头,确认目标 MAC 是自己的,剥掉帧头,把sk_buff往上送。网络层(L3):IP 层拿到数据包,做三件事:检查 IP 头,确认目标 IP 是本机过 netfilter 钩子(iptables规则在这里生效)根据协议字段(TCP=6,UDP=17)决定送给哪个传输层处理传输层(L4):TCP 层是最重的一步:校验序号、确认号,处理乱序重传把数据放入对应 socket 的接收缓冲区(sk->sk_receive_queue)如果有进程在等这个 socket 的数据,唤醒它这三层的关系画出来是这样:
现代网卡驱动几乎都用NAPI(New API)机制:高流量时主动关闭硬件中断,改用软中断轮询批量取包,避免每个包都打断 CPU 一次。高并发场景下这个优化非常重要——否则几十万 pps 的流量,CPU 光处理中断就耗尽了。四、第三步:协议栈处理软中断拿到sk_buff之后,开始往协议栈里送。这里是内核网络子系统最复杂的部分,但逻辑很清晰——就是一层一层剥包头。链路层(L2):检查以太网帧头,确认目标 MAC 是自己的,剥掉帧头,把sk_buff往上送。网络层(L3):IP 层拿到数据包,做三件事:检查 IP 头,确认目标 IP 是本机过 netfilter 钩子(iptables规则在这里生效)根据协议字段(TCP=6,UDP=17)决定送给哪个传输层处理传输层(L4):TCP 层是最重的一步:校验序号、确认号,处理乱序重传把数据放入对应 socket 的接收缓冲区(sk->sk_receive_queue)如果有进程在等这个 socket 的数据,唤醒它这三层的关系画出来是这样: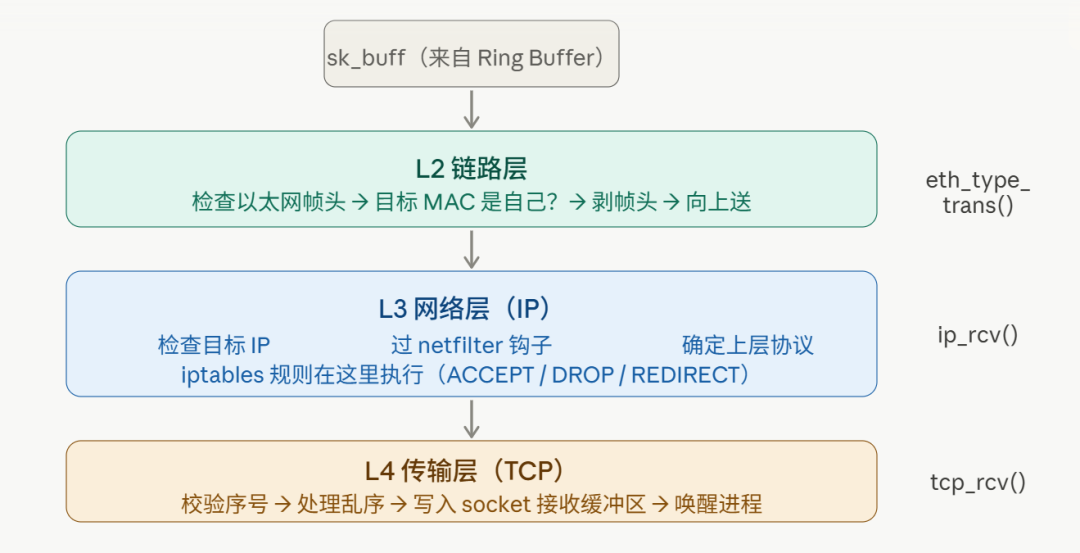 五、第四步:数据进入 socket 缓冲区,epoll 怎么感知?TCP 层把数据放入 socket 接收缓冲区之后,接下来发生了什么?取决于应用层怎么等待数据:情况一:进程阻塞在recv()进程调用recv()时如果没有数据,会被挂起,加入这个 socket 的等待队列。TCP 层写完数据之后,直接唤醒等待队列里的进程,进程从recv()返回,拿到数据。情况二:进程用 epoll 监听epoll_ctl把 fd 注册到 epoll 时,内核在 socket 的等待队列里挂了一个回调函数。TCP 层写完数据、执行唤醒逻辑时,会触发这个回调——把这个 socket 加入 epoll 的就绪链表,然后epoll_wait返回,告诉应用层"这个 fd 有数据了"。这就是 epoll 感知数据到来的底层机制——不是轮询,是靠 TCP 层的回调驱动的。
五、第四步:数据进入 socket 缓冲区,epoll 怎么感知?TCP 层把数据放入 socket 接收缓冲区之后,接下来发生了什么?取决于应用层怎么等待数据:情况一:进程阻塞在recv()进程调用recv()时如果没有数据,会被挂起,加入这个 socket 的等待队列。TCP 层写完数据之后,直接唤醒等待队列里的进程,进程从recv()返回,拿到数据。情况二:进程用 epoll 监听epoll_ctl把 fd 注册到 epoll 时,内核在 socket 的等待队列里挂了一个回调函数。TCP 层写完数据、执行唤醒逻辑时,会触发这个回调——把这个 socket 加入 epoll 的就绪链表,然后epoll_wait返回,告诉应用层"这个 fd 有数据了"。这就是 epoll 感知数据到来的底层机制——不是轮询,是靠 TCP 层的回调驱动的。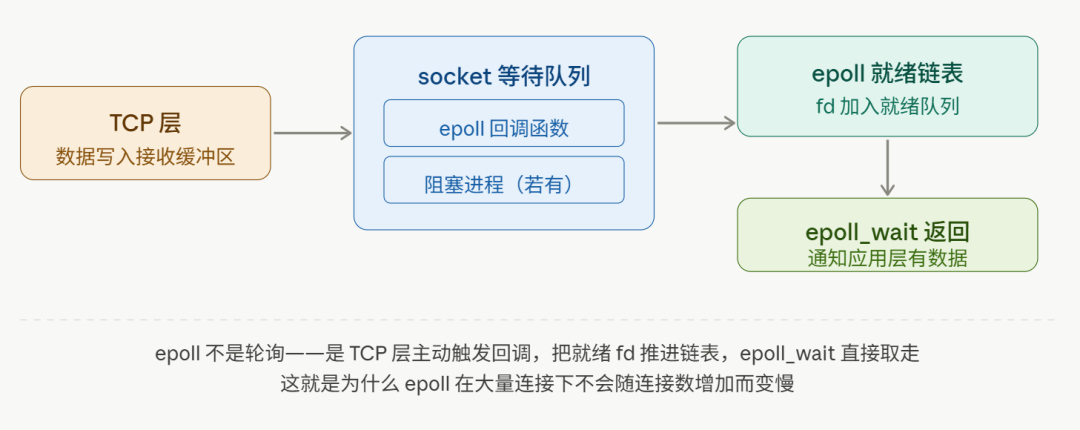 六、第五步:recv() 把数据从内核拷到用户空间epoll_wait返回之后,应用程序调用recv(),这才是最后一步。charbuf[4096];intn = recv(fd, buf,sizeof(buf),0);recv()是一个系统调用,进入内核后做的事情很简单:把 socket 接收缓冲区里的数据,从内核空间拷贝到用户空间的buf里,然后返回拷贝的字节数。这里有个关键点:这是整条链路唯一一次数据拷贝到用户空间的时机。从网卡 DMA 写入 Ring Buffer,到协议栈处理,再到 socket 缓冲区,数据全程在内核空间流转,没有一次拷贝到用户空间。只有recv()这一刻,才做了那一次拷贝。这也是为什么零拷贝(sendfile、mmap)能提升性能——它们绕过了这次用户空间的拷贝。七、把整条链路串起来看到这里整条链路就完整了,总结一下每个阶段的关键点:阶段谁在做关键动作耗时量级网卡收帧网卡硬件DMA 写 Ring Buffer硬件级触发中断网卡 → CPU硬件中断通知 CPU微秒软中断处理ksoftirqd从 Ring Buffer 取包微秒协议栈内核(L2/L3/L4)剥包头、TCP 校验、写缓冲区微秒到毫秒唤醒/回调TCP 层唤醒进程或触发 epoll 回调微秒recv()用户进程内核拷贝到用户空间微秒八、几个衍生问题,顺便一起搞懂Q:为什么高并发推荐多队列网卡?默认情况下,一个网卡只有一个中断,只能绑定到一个 CPU 核心处理。多队列网卡(RSS)有多个硬件接收队列,每个队列绑定不同 CPU 核,多个核并行处理网络包,吞吐量随核数线性提升。Q:软中断ksoftirqd占用 CPU 过高怎么办?top里看到si(软中断)很高,说明收包压力大。可以:开启 NAPI 批量取包减少中断次数;配置多队列网卡 + RSS 把中断分散到多个核;或者用 DPDK 直接把网卡控制权交给用户态,完全绕过内核协议栈。Q:recv()返回 0 代表什么?对端调用了close()或shutdown(),TCP 四次挥手完成,连接正常关闭。recv()返回 0 是正常的 EOF,不是出错——应该关闭 fd,不要继续recv()。Q:socket 接收缓冲区满了会怎样?TCP 层写不进去,会在 ACK 里把接收窗口(rwnd)设为 0,通知对端暂停发送——这就是 TCP 的流量控制机制。对端收到零窗口通知后停发,等你的应用层recv()消费掉缓冲区数据、窗口重新打开,才继续发。九、用一段代码把这条链路对上// 服务端:epoll 驱动的收包骨架intepfd = epoll_create1(0);// 把 listenfd 和 connfd 都注册到 epoll// 内核在 socket 等待队列挂上 epoll 回调structepoll_eventev= {.events = EPOLLIN, .data.fd = connfd};epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, &ev);structepoll_eventevents[64];while(1) {// 阻塞等待,直到某个 socket 的 TCP 层触发了回调// 把 fd 推入就绪链表,epoll_wait 才返回intn = epoll_wait(epfd, events,64,-1);for(inti =0; i < n; i++) {charbuf[4096];// 这里才真正把数据从内核拷到用户空间intlen = recv(events[i].data.fd, buf,sizeof(buf),0);// ...处理 buf}}对照这段代码,整条链路就清楚了:epoll_ctl注册 → 网卡收包 → DMA → 软中断 → 协议栈 → TCP 层触发回调 →epoll_wait返回 →recv()拷贝数据。写在最后一个数据包从网线到你的buf,穿越了硬件、驱动、内核协议栈三个世界,每一层各司其职:网卡和 DMA 负责把数据搬进内存,CPU 不参与硬中断只做最少的事,把主要工作交给软中断协议栈一层层剥包头,TCP 层把数据放到正确的 socket 缓冲区epoll 靠回调感知就绪,不是轮询recv()是唯一一次把数据拷到用户空间的时机理解了这条链路,之前很多"知其然不知其所以然"的问题就有了答案:epoll 为什么快、零拷贝优化的是哪一步、多队列网卡解决的是哪个瓶颈……都是同一套机制的不同侧面。这篇是内核网络子系统的主干,后续的 TCP 握手、拥塞控制、Reactor 模式,都建立在这条链路上。觉得有收获,点赞、推荐、转发给有需要的朋友 🙏 你的支持是我持续更新的动力!
六、第五步:recv() 把数据从内核拷到用户空间epoll_wait返回之后,应用程序调用recv(),这才是最后一步。charbuf[4096];intn = recv(fd, buf,sizeof(buf),0);recv()是一个系统调用,进入内核后做的事情很简单:把 socket 接收缓冲区里的数据,从内核空间拷贝到用户空间的buf里,然后返回拷贝的字节数。这里有个关键点:这是整条链路唯一一次数据拷贝到用户空间的时机。从网卡 DMA 写入 Ring Buffer,到协议栈处理,再到 socket 缓冲区,数据全程在内核空间流转,没有一次拷贝到用户空间。只有recv()这一刻,才做了那一次拷贝。这也是为什么零拷贝(sendfile、mmap)能提升性能——它们绕过了这次用户空间的拷贝。七、把整条链路串起来看到这里整条链路就完整了,总结一下每个阶段的关键点:阶段谁在做关键动作耗时量级网卡收帧网卡硬件DMA 写 Ring Buffer硬件级触发中断网卡 → CPU硬件中断通知 CPU微秒软中断处理ksoftirqd从 Ring Buffer 取包微秒协议栈内核(L2/L3/L4)剥包头、TCP 校验、写缓冲区微秒到毫秒唤醒/回调TCP 层唤醒进程或触发 epoll 回调微秒recv()用户进程内核拷贝到用户空间微秒八、几个衍生问题,顺便一起搞懂Q:为什么高并发推荐多队列网卡?默认情况下,一个网卡只有一个中断,只能绑定到一个 CPU 核心处理。多队列网卡(RSS)有多个硬件接收队列,每个队列绑定不同 CPU 核,多个核并行处理网络包,吞吐量随核数线性提升。Q:软中断ksoftirqd占用 CPU 过高怎么办?top里看到si(软中断)很高,说明收包压力大。可以:开启 NAPI 批量取包减少中断次数;配置多队列网卡 + RSS 把中断分散到多个核;或者用 DPDK 直接把网卡控制权交给用户态,完全绕过内核协议栈。Q:recv()返回 0 代表什么?对端调用了close()或shutdown(),TCP 四次挥手完成,连接正常关闭。recv()返回 0 是正常的 EOF,不是出错——应该关闭 fd,不要继续recv()。Q:socket 接收缓冲区满了会怎样?TCP 层写不进去,会在 ACK 里把接收窗口(rwnd)设为 0,通知对端暂停发送——这就是 TCP 的流量控制机制。对端收到零窗口通知后停发,等你的应用层recv()消费掉缓冲区数据、窗口重新打开,才继续发。九、用一段代码把这条链路对上// 服务端:epoll 驱动的收包骨架intepfd = epoll_create1(0);// 把 listenfd 和 connfd 都注册到 epoll// 内核在 socket 等待队列挂上 epoll 回调structepoll_eventev= {.events = EPOLLIN, .data.fd = connfd};epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, &ev);structepoll_eventevents[64];while(1) {// 阻塞等待,直到某个 socket 的 TCP 层触发了回调// 把 fd 推入就绪链表,epoll_wait 才返回intn = epoll_wait(epfd, events,64,-1);for(inti =0; i < n; i++) {charbuf[4096];// 这里才真正把数据从内核拷到用户空间intlen = recv(events[i].data.fd, buf,sizeof(buf),0);// ...处理 buf}}对照这段代码,整条链路就清楚了:epoll_ctl注册 → 网卡收包 → DMA → 软中断 → 协议栈 → TCP 层触发回调 →epoll_wait返回 →recv()拷贝数据。写在最后一个数据包从网线到你的buf,穿越了硬件、驱动、内核协议栈三个世界,每一层各司其职:网卡和 DMA 负责把数据搬进内存,CPU 不参与硬中断只做最少的事,把主要工作交给软中断协议栈一层层剥包头,TCP 层把数据放到正确的 socket 缓冲区epoll 靠回调感知就绪,不是轮询recv()是唯一一次把数据拷到用户空间的时机理解了这条链路,之前很多"知其然不知其所以然"的问题就有了答案:epoll 为什么快、零拷贝优化的是哪一步、多队列网卡解决的是哪个瓶颈……都是同一套机制的不同侧面。这篇是内核网络子系统的主干,后续的 TCP 握手、拥塞控制、Reactor 模式,都建立在这条链路上。觉得有收获,点赞、推荐、转发给有需要的朋友 🙏 你的支持是我持续更新的动力!
作者:小康,C/C++ 编程博主
关键词:Linux 网络子系统、网卡、DMA、中断、软中断、协议栈、socket、recv、epoll
前言
写网络程序的时候,你调用recv()拿到数据,感觉理所当然。
但有没有想过:对端发过来的那个数据包,是怎么一步步从网线上的电信号,变成你程序里buf数组里的那些字节的?
中间经过了多少层?CPU 什么时候被通知?内核做了哪些事?epoll是怎么感知到"有数据来了"的?
这条链路搞懂了,很多之前死记硬背的东西会突然全部串起来——为什么高并发要用 epoll、为什么零拷贝能提升性能、为什么网卡多队列能提升吞吐……背后都是同一套机制。
这篇就把这条链路从头到尾走一遍。
一、先看全局:数据包经过哪几层?
收一个数据包,Linux 内核大概要经过这几个阶段:
网卡收包 → DMA 写内存 → 硬件中断 → 软中断 → 协议栈处理 → 数据放入 socket 缓冲区 → 唤醒进程
每个阶段各有分工,不是一个函数从头跑到尾。来看全局图:
五个阶段,从下往上,我们逐层展开。
二、第一步:网卡收包 + DMA 写内存
数据包到达网卡的那一刻,CPU 其实什么都不知道,也没有参与任何操作。
网卡自己完成了第一步:把数据帧从网线上接收下来,通过DMA(直接内存访问)直接写入内核预先分配好的一块内存区域——Ring Buffer(环形缓冲区)。
整个过程 CPU 零参与,网卡是自己干的。
Ring Buffer 是什么?
Ring Buffer 是驱动程序在内核内存里分配的一个环形队列,里面预先放了一批sk_buff(socket buffer)结构体,每个槽位指向一块内存。网卡收到数据帧后,通过 DMA 把数据写到其中一个槽位指向的内存,然后把这个槽位标记为"已用"。
Ring Buffer 满了会怎样?新来的包直接丢弃,这就是网卡层的丢包——用ethtool -S eth0 | grep drop可以看到。
DMA 写完之后,网卡做一件事:向 CPU 发送一个硬件中断信号,告诉它"有新包来了,你来处理吧"。
三、第二步:硬件中断 → 软中断
CPU 收到网卡的中断信号,立刻暂停当前正在执行的任务,跳转到中断处理函数(ISR,Interrupt Service Routine)。
但这里有个设计原则:中断处理函数要尽可能快,不能做太多事。
原因很简单:中断处理期间,同一 CPU 上的其他中断都被屏蔽了。如果中断处理函数跑太久,其他中断(键盘、磁盘……)全都在等,系统响应变差。
所以网卡的中断处理函数只做两件事:
告诉网卡"我收到通知了,你先别再发中断了"(屏蔽网卡中断)
触发一个软中断(softirq):NET_RX_SOFTIRQ,然后立刻返回
真正的收包处理,交给软中断去做。
软中断由内核线程ksoftirqd处理,它在中断处理函数返回后,异步执行收包的主要逻辑:从 Ring Buffer 里取出数据包,往上送给协议栈。
这个设计叫上半部/下半部(Top Half / Bottom Half):
现代网卡驱动几乎都用NAPI(New API)机制:高流量时主动关闭硬件中断,改用软中断轮询批量取包,避免每个包都打断 CPU 一次。高并发场景下这个优化非常重要——否则几十万 pps 的流量,CPU 光处理中断就耗尽了。
四、第三步:协议栈处理
软中断拿到sk_buff之后,开始往协议栈里送。这里是内核网络子系统最复杂的部分,但逻辑很清晰——就是一层一层剥包头。
链路层(L2):检查以太网帧头,确认目标 MAC 是自己的,剥掉帧头,把sk_buff往上送。
网络层(L3):IP 层拿到数据包,做三件事:
检查 IP 头,确认目标 IP 是本机
过 netfilter 钩子(iptables规则在这里生效)
根据协议字段(TCP=6,UDP=17)决定送给哪个传输层处理
传输层(L4):TCP 层是最重的一步:
校验序号、确认号,处理乱序重传
把数据放入对应 socket 的接收缓冲区(sk->sk_receive_queue)
如果有进程在等这个 socket 的数据,唤醒它
这三层的关系画出来是这样:
五、第四步:数据进入 socket 缓冲区,epoll 怎么感知?
TCP 层把数据放入 socket 接收缓冲区之后,接下来发生了什么?
取决于应用层怎么等待数据:
情况一:进程阻塞在recv()
进程调用recv()时如果没有数据,会被挂起,加入这个 socket 的等待队列。TCP 层写完数据之后,直接唤醒等待队列里的进程,进程从recv()返回,拿到数据。
情况二:进程用 epoll 监听
epoll_ctl把 fd 注册到 epoll 时,内核在 socket 的等待队列里挂了一个回调函数。TCP 层写完数据、执行唤醒逻辑时,会触发这个回调——把这个 socket 加入 epoll 的就绪链表,然后epoll_wait返回,告诉应用层"这个 fd 有数据了"。
这就是 epoll 感知数据到来的底层机制——不是轮询,是靠 TCP 层的回调驱动的。
六、第五步:recv() 把数据从内核拷到用户空间
epoll_wait返回之后,应用程序调用recv(),这才是最后一步。
recv()是一个系统调用,进入内核后做的事情很简单:把 socket 接收缓冲区里的数据,从内核空间拷贝到用户空间的buf里,然后返回拷贝的字节数。
这里有个关键点:这是整条链路唯一一次数据拷贝到用户空间的时机。
从网卡 DMA 写入 Ring Buffer,到协议栈处理,再到 socket 缓冲区,数据全程在内核空间流转,没有一次拷贝到用户空间。只有recv()这一刻,才做了那一次拷贝。
这也是为什么零拷贝(sendfile、mmap)能提升性能——它们绕过了这次用户空间的拷贝。
七、把整条链路串起来看
到这里整条链路就完整了,总结一下每个阶段的关键点:
阶段谁在做关键动作耗时量级网卡收帧网卡硬件DMA 写 Ring Buffer硬件级触发中断网卡 → CPU硬件中断通知 CPU微秒软中断处理ksoftirqd从 Ring Buffer 取包微秒协议栈内核(L2/L3/L4)剥包头、TCP 校验、写缓冲区微秒到毫秒唤醒/回调TCP 层唤醒进程或触发 epoll 回调微秒recv()用户进程内核拷贝到用户空间微秒
阶段
谁在做
关键动作
耗时量级
网卡收帧
网卡硬件
DMA 写 Ring Buffer
硬件级
触发中断
网卡 → CPU
硬件中断通知 CPU
微秒
软中断处理
ksoftirqd
从 Ring Buffer 取包
微秒
协议栈
内核(L2/L3/L4)
剥包头、TCP 校验、写缓冲区
微秒到毫秒
唤醒/回调
TCP 层
唤醒进程或触发 epoll 回调
微秒
recv()
用户进程
内核拷贝到用户空间
微秒
八、几个衍生问题,顺便一起搞懂
Q:为什么高并发推荐多队列网卡?
默认情况下,一个网卡只有一个中断,只能绑定到一个 CPU 核心处理。多队列网卡(RSS)有多个硬件接收队列,每个队列绑定不同 CPU 核,多个核并行处理网络包,吞吐量随核数线性提升。
Q:软中断ksoftirqd占用 CPU 过高怎么办?
top里看到si(软中断)很高,说明收包压力大。可以:开启 NAPI 批量取包减少中断次数;配置多队列网卡 + RSS 把中断分散到多个核;或者用 DPDK 直接把网卡控制权交给用户态,完全绕过内核协议栈。
Q:recv()返回 0 代表什么?
对端调用了close()或shutdown(),TCP 四次挥手完成,连接正常关闭。recv()返回 0 是正常的 EOF,不是出错——应该关闭 fd,不要继续recv()。
Q:socket 接收缓冲区满了会怎样?
TCP 层写不进去,会在 ACK 里把接收窗口(rwnd)设为 0,通知对端暂停发送——这就是 TCP 的流量控制机制。对端收到零窗口通知后停发,等你的应用层recv()消费掉缓冲区数据、窗口重新打开,才继续发。
九、用一段代码把这条链路对上
对照这段代码,整条链路就清楚了:
epoll_ctl注册 → 网卡收包 → DMA → 软中断 → 协议栈 → TCP 层触发回调 →epoll_wait返回 →recv()拷贝数据。
写在最后
一个数据包从网线到你的buf,穿越了硬件、驱动、内核协议栈三个世界,每一层各司其职:
网卡和 DMA 负责把数据搬进内存,CPU 不参与
硬中断只做最少的事,把主要工作交给软中断
协议栈一层层剥包头,TCP 层把数据放到正确的 socket 缓冲区
epoll 靠回调感知就绪,不是轮询
recv()是唯一一次把数据拷到用户空间的时机
理解了这条链路,之前很多"知其然不知其所以然"的问题就有了答案:epoll 为什么快、零拷贝优化的是哪一步、多队列网卡解决的是哪个瓶颈……都是同一套机制的不同侧面。
这篇是内核网络子系统的主干,后续的 TCP 握手、拥塞控制、Reactor 模式,都建立在这条链路上。