拆解 AI Agent 内部:一个 300 行的 ReAct 循环
原文:What's actually inside an AI agent: a 300~ LoC ReAct loop — 作者构建了 Simple-ReAct-Agent,用极简实现看穿 Agent 的本质。
核心洞察:Agent 就是 ReAct 循环
作者想穿过 AI Agent 的炒作,弄清楚当一个应用开始运行 Agent 时,到底发生了什么变化。于是用伪代码先画了草图,读了奠定当前生产 Agent 的几篇论文,再跟主流 Agent 对话补齐细节,最终落到下图:
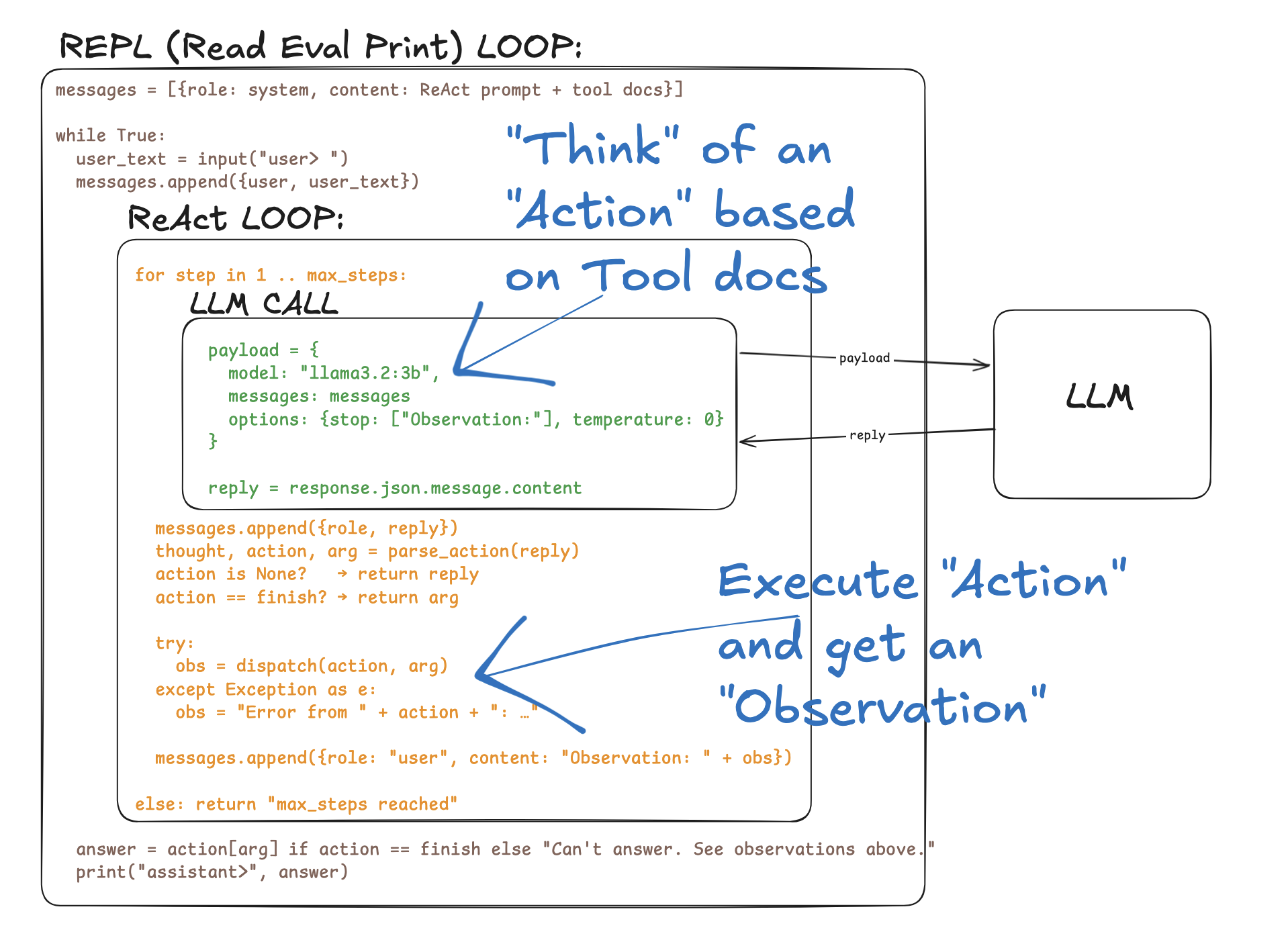
这个循环非常简单——也因此有些脆弱。跑小本地模型时会答错,而且只要其中一步出错,整条链就会被污染。
Action 可以是任何东西 — 这才是真正危险的地方
作者最想强调的一点:Action 可以是任意函数调用。一旦你不再把它当 Demo 看待,事情就变得非常危险:
- 如果你接了
shell.exec,等于把rm -rf的能力交给了模型 - 生产环境中已经出现过的真实事故:git commit 里夹带 secrets、
source.zip被推到 npm registry、Agent 跑进不应该访问的 shell
Action 就是一根电线,你接什么它就通什么。接 shell → 能删文件。接 API → 能改生产数据。接数据库 → 能 drop table。
上下文窗口是沉默的成本
循环还暴露了另一个问题:每一步都会把整个历史重新发送给模型。保持上下文紧凑,或者为每一次迭代付钱。
其他实现的典型样子:
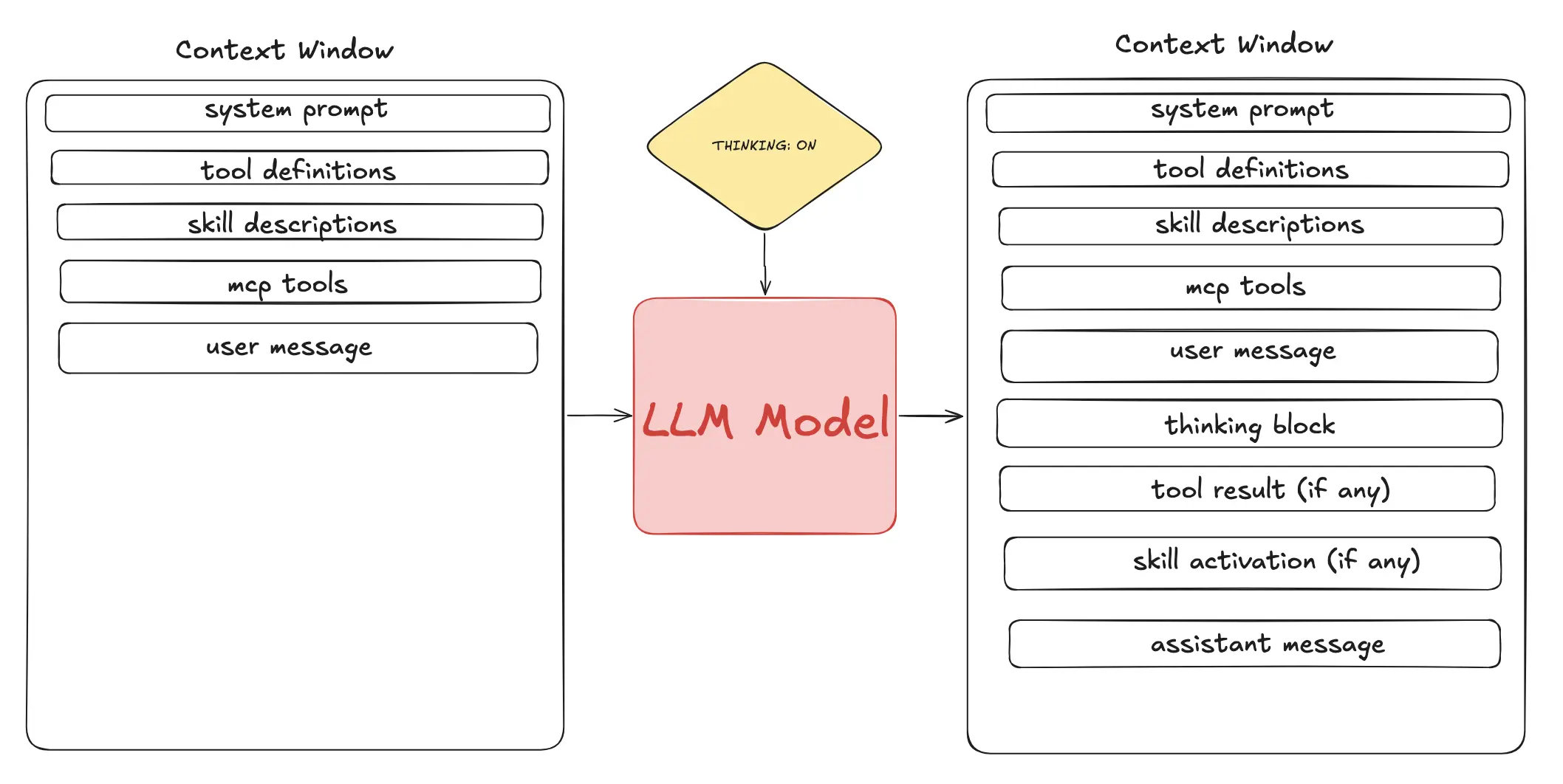
即使有各种 workaround — prompt caching、/compaction、summaries——说实话,让用户花更少 token 本就不符合 provider 的利益。他们就是靠这个赚钱。
我们应该做什么
作为软件工程师,应该认真对待上下文管理,并开始为自己的领域构建定制 Agent。Action 可以是:
- 内部 API 调用
- 告警生成
- 数据库查询
- 网页搜索
- 内部流程执行
核心观点是:一旦你自己写过这个循环,每个"AI 助手"就不再是黑盒了。 你会开始问对的问题:
- 我的上下文里有什么?
- 我的工具能碰到什么?
- 当模型出错时会发生什么?
- Prompt 的质量有多重要?(提示:非常重要)