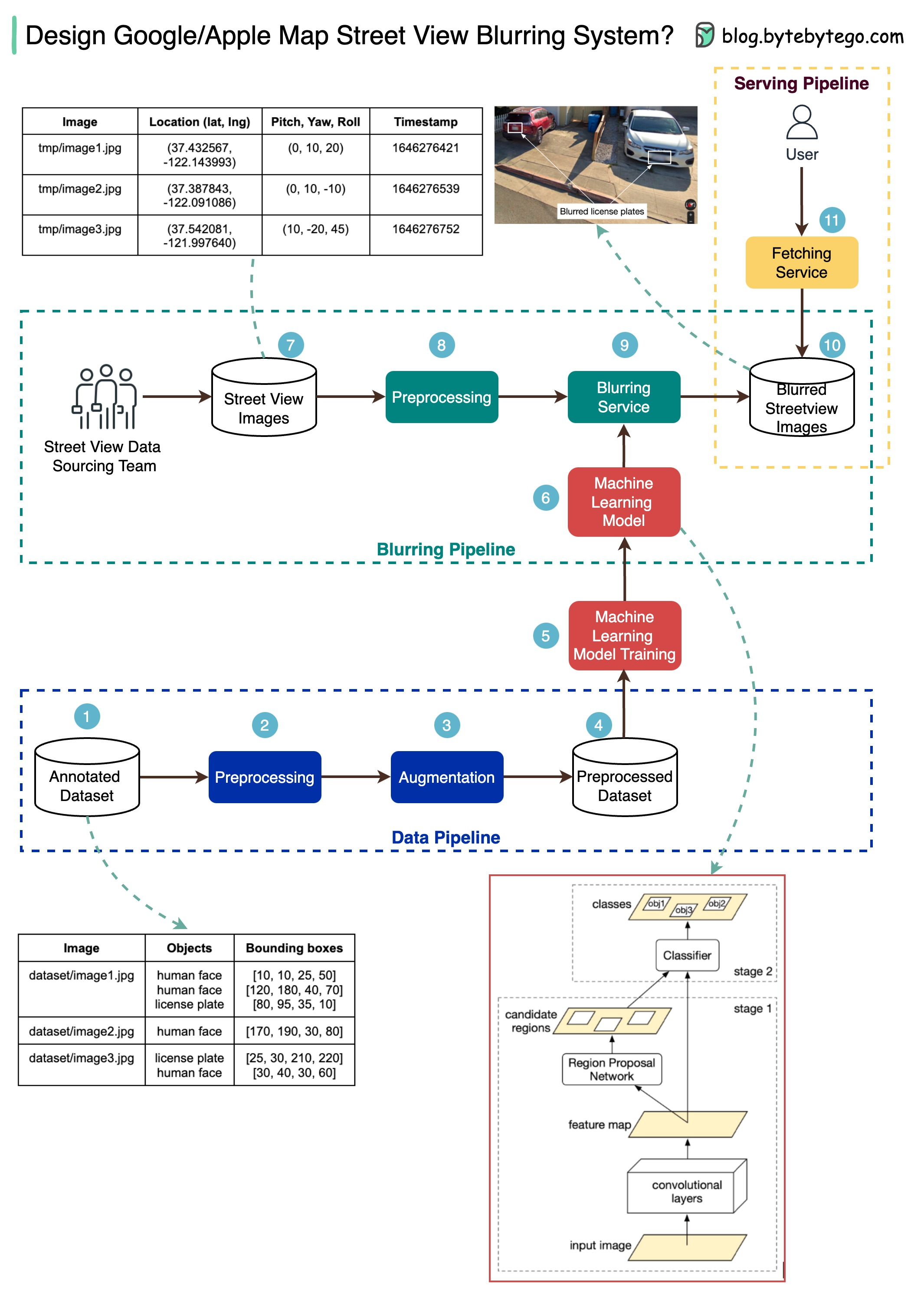
The diagram below presents a possible solution that might work in an interview setting.
The high-level architecture is broken down into three stages:
- Data pipeline - prepare the training data set
- Blurring pipeline - extract and classify objects and blur relevant objects, for example, license plates and faces.
- Serving pipeline - serve blurred street view images to users.
Data Pipeline
Step 1: We get the annotated dataset for training. The objects are marked in bounding boxes.
Steps 2-4: The dataset goes through preprocessing and augmentation to be normalized and scaled.
Steps 5-6: The annotated dataset is then used to train the machine learning model, which is a 2-stage network.
Blurring Pipeline
Steps 7-10: The street view images go through preprocessing, and object boundaries are detected in the images. Then sensitive objects are blurred, and the images are stored in an object store.
Serving Pipeline
Step 11: The blurred images can now be retrieved by users.