一个 Obsidian、三个入口、一台常驻 Mac:我的 AI 个人工作流
把所有东西塞进一个 Obsidian 知识库,家里一台 Mac 24h 跑着,三个入口随时触达。我现在每天就是这么用 AI 的。
把所有东西塞进一个 Obsidian 知识库,家里一台 Mac 24h 跑着,三个入口随时触达。我现在每天就是这么用 AI 的。
这篇文章想讲的不是“我用了哪些工具”,而是一个更具体的问题:
怎么让 AI 长期站在我的全部数据上,并且在我需要的时候低摩擦地出现?
以前我用 AI 最大的挫败感不是模型不够聪明,而是它每次都像第一次认识我。它不知道我读过什么书,不知道我上周计划为什么没完成,不知道我之前为什么买某只股票,也不知道我过去几个月反复卡在什么地方。
所以我真正想解决的是三个问题:
数据散:笔记、灵感、任务、阅读记录、家庭资料分散在 N 个 App 和 SaaS 里,AI 看不到全貌
系统不活:知识库靠我手动整理,整理一次爽两天,过两周又乱
入口太重:只有坐到电脑前才想得起来用 AI,手机上、路上、通勤中触达成本太高
我现在的答案很简单:
一个本地 Obsidian vault 统一数据,一台常驻 Mac 统一执行环境,三个入口覆盖不同场景,再用 Skill 把外部工具接进来。
一个本地 Obsidian vault 统一数据,一台常驻 Mac 统一执行环境,三个入口覆盖不同场景,再用 Skill 把外部工具接进来。
先讲我原来卡在哪里,再讲这套系统怎么一层层解决。
我原来卡在哪里
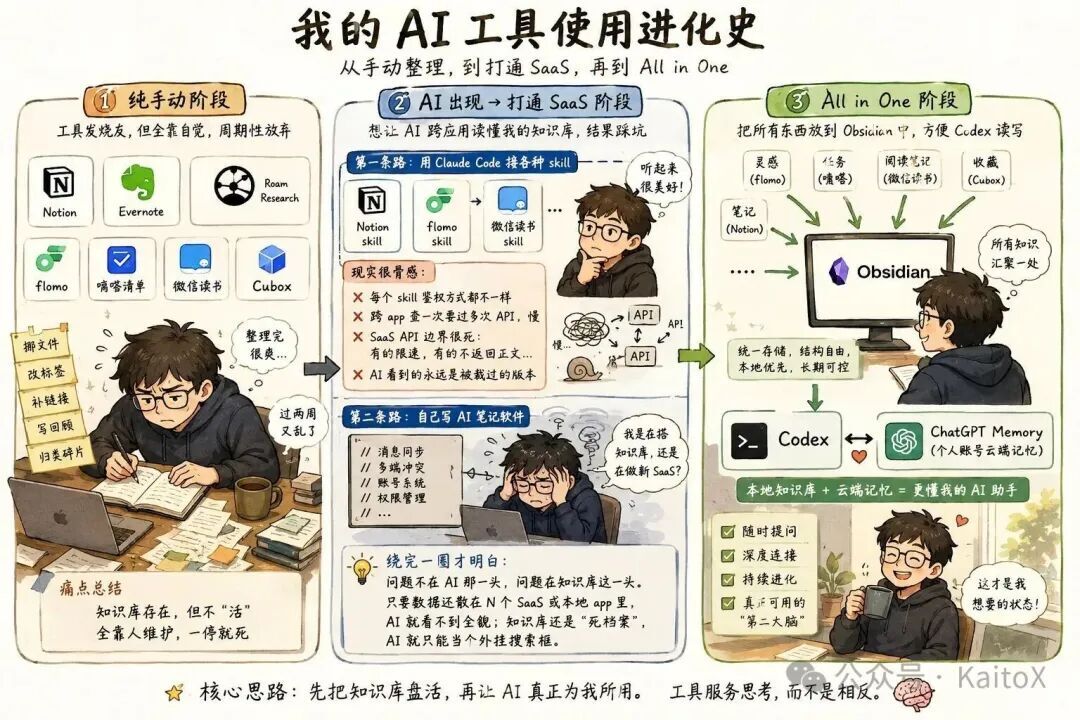
AI 出现之前:纯手工整理,周期性放弃
我是典型的工具发烧友。光笔记这一件事,我就先后折腾过 Notion、Evernote、Roam Research 一圈;灵感在 flomo,任务在嘀嗒,阅读笔记在微信读书,收藏在 Cubox。每个工具单独都挺好用。
但合起来就有个躲不掉的活:整理。
每隔一两周我都要逼自己坐下来花两三小时,挪文件、改标签、补链接、写月度回顾、把各个 App 里的碎片归类。整完那一刻很有成就感,过两周又乱。再过一个月就懒得动了。
这是 AI 出现之前的状态:知识库存在,但它不“活”。它靠人维护着,人一停它就死。
AI 出现之后:试着改进,但还是没解决
AI 工具铺开之后,我第一反应是:这玩意儿能不能帮我把知识库盘活?我试过两条路,都没成。
第一条:用 Claude Code 接各种 Skill,打通散在 SaaS 里的数据。
Notion Skill、flomo Skill、微信读书 Skill……一个个装上,想让 agent 能跨 App 读我的笔记和灵感。听起来很美,实际用下来全是坑:每个 Skill 鉴权方式都不一样;跨 App 查一次要过多次 API 来回,慢;更要命的是 SaaS 的 API 边界很死,有的一个 block 一次调用,有的限速,有的根本不返回正文。
最后 AI 拿到的永远是被 API 裁过的版本,看不到我数据的真实样子。维护一堆 Skill 的成本,反而比“先翻笔记复制粘贴”还高。
第二条:自己写一个 AI 笔记软件。
工程师本能上头,想从零做一个“AI 原生的知识库”。消息同步、多端冲突、账号系统、导入导出、移动端体验……搞着搞着就破防了:
我到底是在搭知识库,还是在做一个新 SaaS?
绕完一圈我才想明白一件事:问题不在 AI 那一头,问题在知识库这一头。只要数据还散在 N 个 SaaS 后台里、分在多个本地 App 里,AI 接哪个都看不到全貌;只要知识库还是“死档案”,AI 就只能当个外挂搜索框。
所以我换了个方向。先不折腾更复杂的 AI,先把所有东西归到一个本地知识库里,再让 AI 站上来。
我的解法:先统一数据,再统一入口
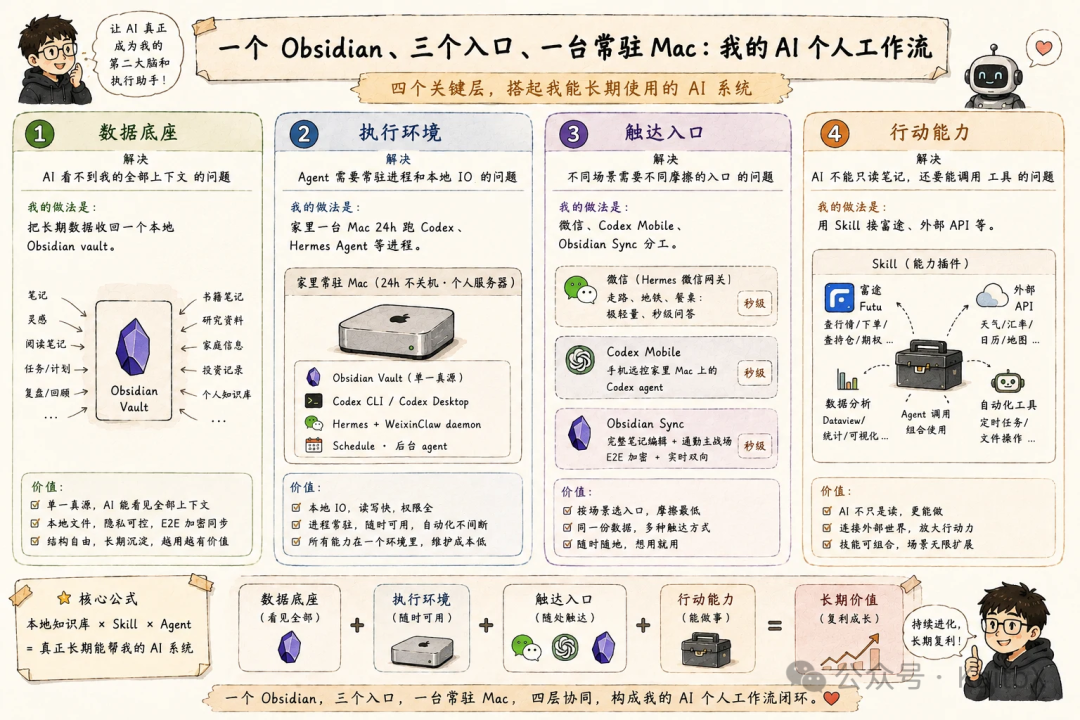 现在这套工作流可以拆成四层:层级解决的问题我的做法数据底座AI 看不到我的全部上下文把长期数据收回一个本地 Obsidian vault执行环境Agent 需要常驻进程和本地 IO家里一台 Mac 24h 跑 Codex、Hermes Agent 等进程触达入口不同场景需要不同摩擦的入口微信、Codex Mobile、Obsidian Sync 分工行动能力AI 不能只读笔记,还要能调用工具用 Skill 接富途、外部 API 等这四层的顺序很重要。如果没有统一数据,入口再多也只是多个聊天框;如果没有常驻执行环境,agent 只能在你打开电脑时工作;如果没有低摩擦入口,系统搭得再好也会被忘掉;如果没有 Skill,AI 最多是个会翻笔记的问答机器人。我真正解决的是这条链路:让 AI 读得到我,跑得起来,找得到我,也能替我做事。第一层:一个本地 Obsidian vault,解决数据全貌第一步不是上 agent,而是把数据先收回来。简单说,我把所有“过去会散在 N 个 App 里”的东西分成四类塞进 Obsidian:知识沉淀:工作 / 学习笔记、Wiki 实体流水记录:每日计划 + 反馈、灵感、即刻归档、日记等创作产出:文章草稿、视频脚本生活资料:读过的书 / 电影 / 去过的地方、签证 / 保险 / 账单等家庭杂事唯一的例外是少数结构化非常强且自带专业体验的东西,比如富途的实盘账户。这些不强行迁,但“我的判断 / 我的笔记”那一层全部回到 Obsidian。这里的重点不是 Obsidian 本身,而是数据所有权和数据形态。.md文件躺在本地磁盘上,agent 可以直接 grep、直接读、直接改;图片、PDF、HTML 归档也都在同一个文件系统里。AI 终于不是隔着 SaaS API 看一个被裁剪过的世界,而是站在我的真实资料库上工作。具体怎么组织目录、frontmatter 怎么写、Wiki 实体长什么样,是另一个话题,后面会专门写一篇。这里先记住一件事:Obsidian 在这套系统里的角色,不是漂亮的笔记软件,而是 AI 的本地数据底座。第二层:一台常驻 Mac,解决执行环境数据统一之后,下一个问题是:agent 在哪里跑?很多人听到“all in one 本地”会担心一件事:那我离家怎么办?我的答案是:让算力和数据都留在家里,外面的设备只做窗口。
现在这套工作流可以拆成四层:层级解决的问题我的做法数据底座AI 看不到我的全部上下文把长期数据收回一个本地 Obsidian vault执行环境Agent 需要常驻进程和本地 IO家里一台 Mac 24h 跑 Codex、Hermes Agent 等进程触达入口不同场景需要不同摩擦的入口微信、Codex Mobile、Obsidian Sync 分工行动能力AI 不能只读笔记,还要能调用工具用 Skill 接富途、外部 API 等这四层的顺序很重要。如果没有统一数据,入口再多也只是多个聊天框;如果没有常驻执行环境,agent 只能在你打开电脑时工作;如果没有低摩擦入口,系统搭得再好也会被忘掉;如果没有 Skill,AI 最多是个会翻笔记的问答机器人。我真正解决的是这条链路:让 AI 读得到我,跑得起来,找得到我,也能替我做事。第一层:一个本地 Obsidian vault,解决数据全貌第一步不是上 agent,而是把数据先收回来。简单说,我把所有“过去会散在 N 个 App 里”的东西分成四类塞进 Obsidian:知识沉淀:工作 / 学习笔记、Wiki 实体流水记录:每日计划 + 反馈、灵感、即刻归档、日记等创作产出:文章草稿、视频脚本生活资料:读过的书 / 电影 / 去过的地方、签证 / 保险 / 账单等家庭杂事唯一的例外是少数结构化非常强且自带专业体验的东西,比如富途的实盘账户。这些不强行迁,但“我的判断 / 我的笔记”那一层全部回到 Obsidian。这里的重点不是 Obsidian 本身,而是数据所有权和数据形态。.md文件躺在本地磁盘上,agent 可以直接 grep、直接读、直接改;图片、PDF、HTML 归档也都在同一个文件系统里。AI 终于不是隔着 SaaS API 看一个被裁剪过的世界,而是站在我的真实资料库上工作。具体怎么组织目录、frontmatter 怎么写、Wiki 实体长什么样,是另一个话题,后面会专门写一篇。这里先记住一件事:Obsidian 在这套系统里的角色,不是漂亮的笔记软件,而是 AI 的本地数据底座。第二层:一台常驻 Mac,解决执行环境数据统一之后,下一个问题是:agent 在哪里跑?很多人听到“all in one 本地”会担心一件事:那我离家怎么办?我的答案是:让算力和数据都留在家里,外面的设备只做窗口。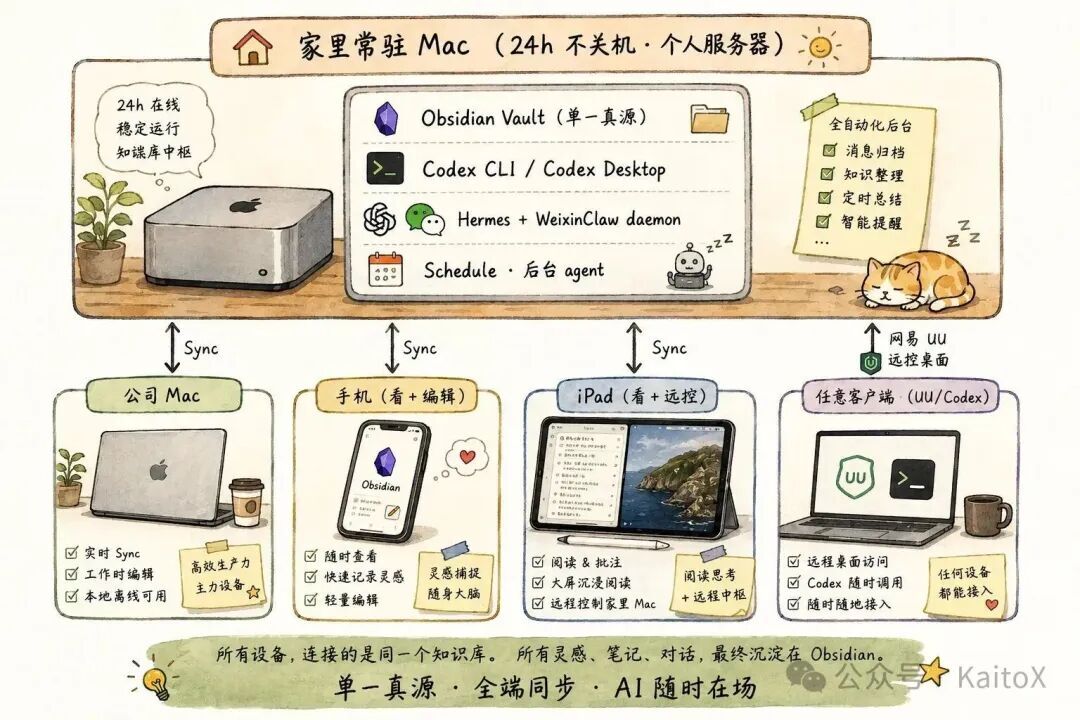 为什么是一台常驻 MacAgent 不是聊天框,它需要常驻进程:定时跑的 schedule,比如每日推送、周复盘Hermes Agent 的微信网关长轮询接消息偶尔跑的长任务,比如生成周复盘、批处理笔记但“为什么必须在家、不能放云”还有一个更关键的原因:家里那台 Mac 在我的局域网里,能直接挂载 NAS。我的 NAS 上存着照片库、视频原片、扫描的家庭文件、电子书、影视收藏,几个 T 的数据。Obsidian vault 只放轻量的“我的判断 / 我的笔记”,重的原始素材都在 NAS 上。Agent 跑在家里 Mac 上,等于站在 vault + NAS 这两份数据之上。想找一张旧照片、想从 NAS 里某本书抽段原文做引用、想把视频原片喂给视觉模型,全是本地 IO。云服务器解决不了这件事。NAS 不可能开公网,公网 NAS 也是反模式。你只能把数据传上云,而那就违反了“all in one 本地”的整个前提。所以我用的方案很朴素:一台老 MacBook 接着电源、合盖不睡眠,24 小时跑 Codex 和 Hermes Agent。重活全在它身上,外面所有设备只负责三件事:看触发轻编辑UU 远程是桌面级兜底除了后面会讲的三个日常入口,我还保留了一个兜底方案:网易 UU 远程。它不算我日常工作流里的“主入口”,更像是完整桌面远控。需要跑一个完整的活时,我会用它:iPad 在路上想到一个研究方向,拉起 UU 连家里 Mac,调起 Codex,直接跑一个 deep research,结果自动写进 vault公司 Mac 上 vibe coding 卡住了,UU 连家里 Mac,用家里那个权限 / 配置 / Skill 都齐全的环境跑网易 UU 的好处是手机、iPad、Mac 客户端都有,免内网穿透,免端口转发。代价是有点延迟、画质有损,但对“我只想跑个 agent”这种活完全够用。iPad 的独立角色很多人把 iPad 当“手机的大号”,但在这套拓扑里,它有完全独立的角色。设备最适合什么手机秒级问答,微信里问一句 agent 回一句,红绿灯之间能完成的交互iPad长时段沉浸式消费,通勤路上读 30 分钟笔记、沙发上标注一篇长文、偶尔拉 UU 远控家里跑长任务公司 Mac正经写代码、写文章家里 Mac跑 agent、当服务器iPad 那种“屏幕够大、能竖着拿、续航长、能开 UU”的组合,让它成了我离开家时知识库的主显示器,尤其是周末在咖啡馆、出差路上、家里沙发上。把 iPad 加进来之后,我的“长时段使用知识库”体验,不再绑死在公司或家里的电脑前。身体在哪不重要。数据和算力始终在家里那台 Mac 上等我,外面的设备只是窗口。第三层:三个入口,解决触达摩擦执行环境固定在家里之后,下一个问题是:人在不同场景下,用什么方式触达知识库?
为什么是一台常驻 MacAgent 不是聊天框,它需要常驻进程:定时跑的 schedule,比如每日推送、周复盘Hermes Agent 的微信网关长轮询接消息偶尔跑的长任务,比如生成周复盘、批处理笔记但“为什么必须在家、不能放云”还有一个更关键的原因:家里那台 Mac 在我的局域网里,能直接挂载 NAS。我的 NAS 上存着照片库、视频原片、扫描的家庭文件、电子书、影视收藏,几个 T 的数据。Obsidian vault 只放轻量的“我的判断 / 我的笔记”,重的原始素材都在 NAS 上。Agent 跑在家里 Mac 上,等于站在 vault + NAS 这两份数据之上。想找一张旧照片、想从 NAS 里某本书抽段原文做引用、想把视频原片喂给视觉模型,全是本地 IO。云服务器解决不了这件事。NAS 不可能开公网,公网 NAS 也是反模式。你只能把数据传上云,而那就违反了“all in one 本地”的整个前提。所以我用的方案很朴素:一台老 MacBook 接着电源、合盖不睡眠,24 小时跑 Codex 和 Hermes Agent。重活全在它身上,外面所有设备只负责三件事:看触发轻编辑UU 远程是桌面级兜底除了后面会讲的三个日常入口,我还保留了一个兜底方案:网易 UU 远程。它不算我日常工作流里的“主入口”,更像是完整桌面远控。需要跑一个完整的活时,我会用它:iPad 在路上想到一个研究方向,拉起 UU 连家里 Mac,调起 Codex,直接跑一个 deep research,结果自动写进 vault公司 Mac 上 vibe coding 卡住了,UU 连家里 Mac,用家里那个权限 / 配置 / Skill 都齐全的环境跑网易 UU 的好处是手机、iPad、Mac 客户端都有,免内网穿透,免端口转发。代价是有点延迟、画质有损,但对“我只想跑个 agent”这种活完全够用。iPad 的独立角色很多人把 iPad 当“手机的大号”,但在这套拓扑里,它有完全独立的角色。设备最适合什么手机秒级问答,微信里问一句 agent 回一句,红绿灯之间能完成的交互iPad长时段沉浸式消费,通勤路上读 30 分钟笔记、沙发上标注一篇长文、偶尔拉 UU 远控家里跑长任务公司 Mac正经写代码、写文章家里 Mac跑 agent、当服务器iPad 那种“屏幕够大、能竖着拿、续航长、能开 UU”的组合,让它成了我离开家时知识库的主显示器,尤其是周末在咖啡馆、出差路上、家里沙发上。把 iPad 加进来之后,我的“长时段使用知识库”体验,不再绑死在公司或家里的电脑前。身体在哪不重要。数据和算力始终在家里那台 Mac 上等我,外面的设备只是窗口。第三层:三个入口,解决触达摩擦执行环境固定在家里之后,下一个问题是:人在不同场景下,用什么方式触达知识库?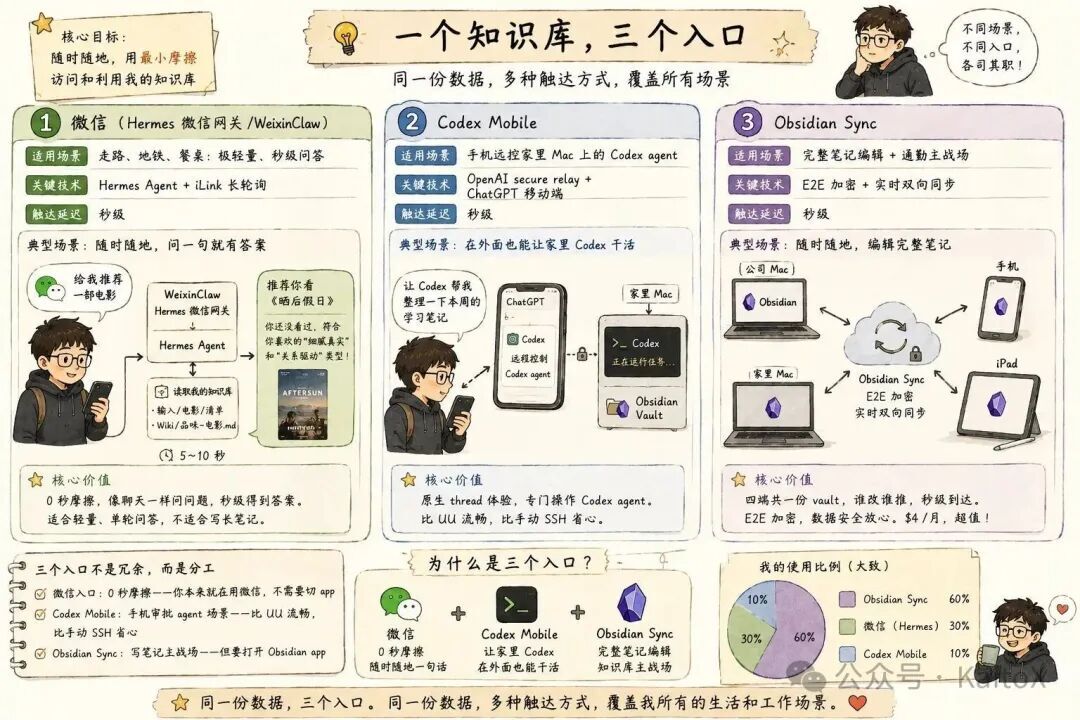 答案是三个入口,各自解决一种摩擦。入口适用场景关键技术微信(Hermes 微信网关 / WeixinClaw)走路、地铁、餐桌:极轻量、秒级问答Hermes Agent + iLink 长轮询Codex Mobile手机远控家里 Mac 上的 Codex agentOpenAI secure relay + ChatGPT 移动端Obsidian Sync完整笔记编辑 + 通勤主战场E2E 加密 + 实时双向入口 1:微信,解决秒级问答解决的核心问题:手机上随时随地能“对着我自己说一句话”,让 agent 接住、回去翻知识库、回我。我用的是 Hermes Agent。它是 Nous Research 出的一个 self-improving AI agent,内置了一组消息网关(Telegram / Discord / Signal / 微信等),让你能在任何 IM 平台里跟它说话。微信这一路,社区里习惯叫WeixinClaw,走的是 Tencent iLink Bot API:本地起一个hermes gateway进程,发起getupdates长轮询请求(35s timeout),消息来了就回包。它不需要公网 endpoint,不需要 webhook,不需要服务器。它就跑在我家里 Mac 上,跟 daemon 一样常驻。实际体验:周末晚上想找部片看,发条微信给“自己”:“给我推荐一部电影”Hermes 微信网关接消息,调 agentAgent 翻我 vault 里输入/电影/下看过的清单、想看清单,对照Wiki/品味-电影.md里我的偏好它推一部我没看过、和我口味匹配的,附上一句为什么整个过程 5-10 秒,和正常跟人聊天一模一样。关键不在“AI 能推电影”。豆瓣、小红书都能。关键在于它推的是“我没看过 + 符合我口味”的,因为它读得到我的清单和我的品味笔记。微信适合的就是这种秒级、轻量、单轮问答。它不适合写长笔记,但特别适合让 AI 在生活缝隙里出现。入口 2:Codex Mobile,解决手机远控 agent解决的核心问题:在外面也能让家里 Codex 接着干活,而不只是“看”。Codex Mobile 是 OpenAI 在 ChatGPT 移动端集成的 Codex 远程控制。通过 OpenAI 的 secure relay,它可以直连家里 Mac 上跑的 Codex,手机扫码授权一次后就能跨设备操作 thread,不暴露公网,也不需要 SSH。我用它最多的场景:地铁里突然想起昨晚那个 agent 跑完了没,打开 ChatGPT 看 thread,审批 commit,改 prompt 让它重跑在外面想到一段 prompt 没说清楚,掏手机重新调整、重新启动临时想让家里 agent 跑个新任务,手机直接下指令它和 UU 远程的分工很清楚:UU 是万能桌面,什么都能干,但有延迟;Codex Mobile 是原生 thread 体验,只适合操作 Codex agent,但更轻。入口 3:Obsidian Sync,解决笔记主战场解决的核心问题:所有设备共享同一份 vault,不需要任何手动同步。Obsidian Sync 没什么花招,它就是把.md文件实时同步到所有设备。但它做对了一件事:E2E 加密。这点对我很重要。我的 vault 里有身份信息、家庭资料、签证 checklist、投资笔记。这些放云端必须 E2E 加密。Sync 是 Obsidian 官方做的,四端共一份 vault,秒级到达,端到端加密。$4/月是我账单里性价比最高的一项。三个入口不是冗余,是分工很多人会问:既然 Sync 已经能同步到所有设备,为什么还要微信入口和 Codex Mobile?因为触达的摩擦不一样:微信入口:0 秒摩擦,你本来就在用微信,不需要切 AppCodex Mobile:手机审批 agent 场景,比 UU 流畅,比手动 SSH 省心Obsidian Sync:写笔记主战场,但要打开 Obsidian App我每天的使用比例大概是Sync 60% + 微信 30% + Codex Mobile 10%。三个加起来才覆盖了“在家 / 在公司 / 在地铁 / 在咖啡馆 / 在被窝里”的全部场景。同一份数据,三个入口。同一份数据,多种触达方式。第四层:Skill,解决行动能力
答案是三个入口,各自解决一种摩擦。入口适用场景关键技术微信(Hermes 微信网关 / WeixinClaw)走路、地铁、餐桌:极轻量、秒级问答Hermes Agent + iLink 长轮询Codex Mobile手机远控家里 Mac 上的 Codex agentOpenAI secure relay + ChatGPT 移动端Obsidian Sync完整笔记编辑 + 通勤主战场E2E 加密 + 实时双向入口 1:微信,解决秒级问答解决的核心问题:手机上随时随地能“对着我自己说一句话”,让 agent 接住、回去翻知识库、回我。我用的是 Hermes Agent。它是 Nous Research 出的一个 self-improving AI agent,内置了一组消息网关(Telegram / Discord / Signal / 微信等),让你能在任何 IM 平台里跟它说话。微信这一路,社区里习惯叫WeixinClaw,走的是 Tencent iLink Bot API:本地起一个hermes gateway进程,发起getupdates长轮询请求(35s timeout),消息来了就回包。它不需要公网 endpoint,不需要 webhook,不需要服务器。它就跑在我家里 Mac 上,跟 daemon 一样常驻。实际体验:周末晚上想找部片看,发条微信给“自己”:“给我推荐一部电影”Hermes 微信网关接消息,调 agentAgent 翻我 vault 里输入/电影/下看过的清单、想看清单,对照Wiki/品味-电影.md里我的偏好它推一部我没看过、和我口味匹配的,附上一句为什么整个过程 5-10 秒,和正常跟人聊天一模一样。关键不在“AI 能推电影”。豆瓣、小红书都能。关键在于它推的是“我没看过 + 符合我口味”的,因为它读得到我的清单和我的品味笔记。微信适合的就是这种秒级、轻量、单轮问答。它不适合写长笔记,但特别适合让 AI 在生活缝隙里出现。入口 2:Codex Mobile,解决手机远控 agent解决的核心问题:在外面也能让家里 Codex 接着干活,而不只是“看”。Codex Mobile 是 OpenAI 在 ChatGPT 移动端集成的 Codex 远程控制。通过 OpenAI 的 secure relay,它可以直连家里 Mac 上跑的 Codex,手机扫码授权一次后就能跨设备操作 thread,不暴露公网,也不需要 SSH。我用它最多的场景:地铁里突然想起昨晚那个 agent 跑完了没,打开 ChatGPT 看 thread,审批 commit,改 prompt 让它重跑在外面想到一段 prompt 没说清楚,掏手机重新调整、重新启动临时想让家里 agent 跑个新任务,手机直接下指令它和 UU 远程的分工很清楚:UU 是万能桌面,什么都能干,但有延迟;Codex Mobile 是原生 thread 体验,只适合操作 Codex agent,但更轻。入口 3:Obsidian Sync,解决笔记主战场解决的核心问题:所有设备共享同一份 vault,不需要任何手动同步。Obsidian Sync 没什么花招,它就是把.md文件实时同步到所有设备。但它做对了一件事:E2E 加密。这点对我很重要。我的 vault 里有身份信息、家庭资料、签证 checklist、投资笔记。这些放云端必须 E2E 加密。Sync 是 Obsidian 官方做的,四端共一份 vault,秒级到达,端到端加密。$4/月是我账单里性价比最高的一项。三个入口不是冗余,是分工很多人会问:既然 Sync 已经能同步到所有设备,为什么还要微信入口和 Codex Mobile?因为触达的摩擦不一样:微信入口:0 秒摩擦,你本来就在用微信,不需要切 AppCodex Mobile:手机审批 agent 场景,比 UU 流畅,比手动 SSH 省心Obsidian Sync:写笔记主战场,但要打开 Obsidian App我每天的使用比例大概是Sync 60% + 微信 30% + Codex Mobile 10%。三个加起来才覆盖了“在家 / 在公司 / 在地铁 / 在咖啡馆 / 在被窝里”的全部场景。同一份数据,三个入口。同一份数据,多种触达方式。第四层:Skill,解决行动能力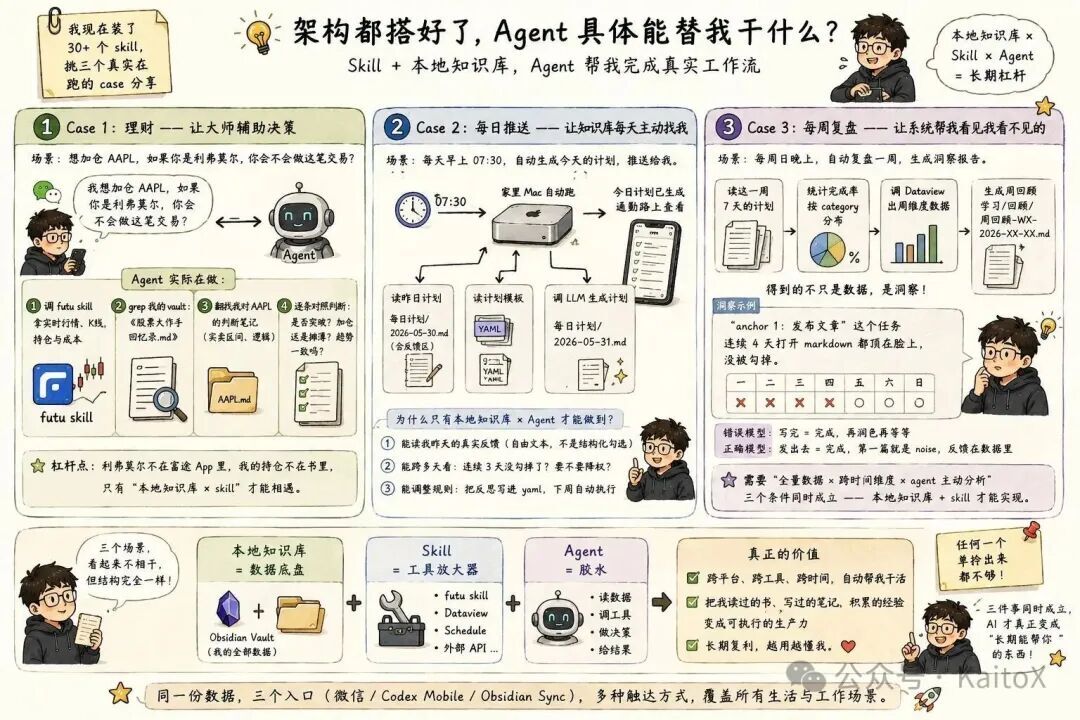 前面解决的是“AI 能不能读到我、能不能跑起来、我能不能随时触达它”。但 agent 具体能替我干什么,还要看 Skill。Skill 是给 agent 装上的能力插件:查股票、定时跑、调外部 API、操作浏览器、生成图片、发社交平台……我现在装了 30+ 个 Skill。下面挑三个真实在跑的 case 讲一下。Case 1:理财,让读过的书参与真实决策以我常用的 futu skill为例。它是富途 OpenAPI 的封装,能查实时行情、K 线、期权链、下单、撤单、查持仓。这种 Skill 单独装一个并不稀奇,富途自己的 App 就能干这些。真正的杠杆来自futu skill × 我的 vault。我的 vault 里有输入/书/股票大作手回忆录.md,里面手抄过利弗莫尔的几条核心交易准则:顺势、不摊薄亏损、突破才加仓、关键点位等等。里面还有过去几个月我对每个标的的判断笔记、家庭资产配置表。所以我在微信问:“我想加仓 AAPL,如果你是利弗莫尔,你会不会做这笔交易?”Agent 实际上在做:调 futu skill 拿 AAPL 实时报价、K 线、我的持仓和成本grepvault 里股票大作手回忆录.md,把利弗莫尔那几条准则当作判断框架翻出我之前对 AAPL 的判断笔记,比如买卖区间、当时的逻辑给我一个逐条对照的判断:现在的价位是不是“关键点位的突破”?我的成本和当前价之间是不是在“加仓而非摊薄”?趋势方向和我之前判断的逻辑一致吗?这不是“AI 看盘”,也不是 Bloomberg 终端。这是让我读过的书反过来参与我的真实决策。利弗莫尔不在富途 App 里。我的持仓不在《股票大作手回忆录》里。这两件事只能在“本地知识库 × Skill”的组合里相遇。Case 2:每日推送,让知识库每天主动找我第二个 case 是我现在每天都在用的:每日推送。早上 07:30,家里 Mac 自动跑(Codex Desktop 定时任务):读昨日每日计划/2026-05-30.md,包括我手写的反馈区读学习/计划模板.yaml,也就是计划生成规则调 LLM 生成今天的每日计划/2026-05-31.md我通勤路上掏出手机,今天该干啥已经在那里了。这件事看起来简单,但有几个细节只有“本地知识库 × agent”才能做到:Agent 能读昨天的真实反馈,不是结构化勾选,而是我顺手写的“今天累、砍英语”这种自由文本Agent 能跨多天看,比如“这件事是不是连续 3 天没勾掉了?要不要降权?”Agent 能调整规则,周日复盘后,我把一条反思(“anchor 任务周一晚不发出去判定失败”)写进 yaml,下周自动执行这套督学系统有兴趣的话我可以在后续文章中分享一下Case 3:每周复盘,让系统帮我看见我看不见的第三个 case 是周日的自动复盘。每周日晚上,agent 自动跑:读这一周 7 天的每日计划/文件统计完成率、按 category 分布调 Dataview 出周维度的数据生成学习/回顾/周回顾-WX-2026-XX-XX.md我得到的不只是数据,是洞察。比如最近一周复盘,agent 给我指出了一件事:“anchor 1:发布文章”这个任务连续 4 天打开 markdown 都顶在脸上,但一直没被勾掉。我自己当时是没意识到的。每天看到那一行只觉得“嗯还没发,再润色一下”。直到 agent 把数据拉出来对比,我才看清自己卡在哪里。错误模型:写完 = 完成,再润色再等等正确模型:发出去 = 完成,第一篇就是 noise,反馈在数据里这种洞察光靠人看是看不到的。它需要三个条件同时成立:全量数据跨时间维度agent 主动分析本地知识库 + Skill,是唯一同时满足这三件事的组合。这三个 case 共同说明的一件事理财 / 督学 / 复盘,三个场景看起来完全不相干。但它们都有同一个结构:本地知识库 = 数据底盘Skill = 工具放大器Agent = 把两者拼起来的胶水任何一个单拎出来都不够。futu skill 单独装一个,是个查行情工具;本地知识库单独存着,就是堆死档案;agent 单独跑,也只是聊天机器人。只有三件事同时成立,AI 才真正变成“长期能帮你”的东西。收尾回头看,整套工作流的骨架其实就一句话:一份本地知识库 + 一台常驻 Mac + 三个入口 + N 个 Skill。我用了一个月。它不复杂,不贵,不需要把核心数据搬到云上,搭起来 1-2 天,跑起来不需要我特别维护。但它给我的真正改变,不是“我变得更高效”。那种话每个工具都能讲。真正的改变是:我第一次相信“AI 能持续帮我”这件事。以前我装一个新 AI 工具,兴奋三天,第四天就忘了打开它。因为它和我前面的数据、前面的判断、前面的生活是断的。它每次都从零开始认识我。现在不一样。无论我问 AI 什么,它都站在我全部的数据上:我的笔记、我的反馈、我的历史决策、我连续几个月的轨迹。它不是一个“很厉害的助手”,它是一个真正长出“对我的理解”的东西。这件事的杠杆,不在“用更新的模型”。真正的杠杆,是让 AI 够得着你的全部数据。而要做到这一点,你不需要等下一代模型,不需要等更聪明的 agent。你今天就能开始的,就一件事:把你散在 N 个工具里的东西,收回一个本地知识库。你的数据现在在 AI 够得着的地方吗?这套系统我还在持续迭代:督学系统怎么搭、Obsidian 目录和 frontmatter 怎么组织、Hermes 微信网关怎么跑、每个 Skill 的踩坑细节,后面都会陆续拆开写。如果这篇对你有用,或者你也在折腾「让 AI 站在自己全部数据上」这件事,欢迎扫码进群,一起交流踩坑、互相抄作业:也特别想听听你的反馈:这套工作流里哪一层最戳你?你自己卡在哪一步?还想看我把哪个部分单独拆开写?评论区或者群里告诉我,会直接影响我下一篇写什么。群二维码会定期更新,如果过期了,可以在公众号后台回复「进群」获取最新入口。
前面解决的是“AI 能不能读到我、能不能跑起来、我能不能随时触达它”。但 agent 具体能替我干什么,还要看 Skill。Skill 是给 agent 装上的能力插件:查股票、定时跑、调外部 API、操作浏览器、生成图片、发社交平台……我现在装了 30+ 个 Skill。下面挑三个真实在跑的 case 讲一下。Case 1:理财,让读过的书参与真实决策以我常用的 futu skill为例。它是富途 OpenAPI 的封装,能查实时行情、K 线、期权链、下单、撤单、查持仓。这种 Skill 单独装一个并不稀奇,富途自己的 App 就能干这些。真正的杠杆来自futu skill × 我的 vault。我的 vault 里有输入/书/股票大作手回忆录.md,里面手抄过利弗莫尔的几条核心交易准则:顺势、不摊薄亏损、突破才加仓、关键点位等等。里面还有过去几个月我对每个标的的判断笔记、家庭资产配置表。所以我在微信问:“我想加仓 AAPL,如果你是利弗莫尔,你会不会做这笔交易?”Agent 实际上在做:调 futu skill 拿 AAPL 实时报价、K 线、我的持仓和成本grepvault 里股票大作手回忆录.md,把利弗莫尔那几条准则当作判断框架翻出我之前对 AAPL 的判断笔记,比如买卖区间、当时的逻辑给我一个逐条对照的判断:现在的价位是不是“关键点位的突破”?我的成本和当前价之间是不是在“加仓而非摊薄”?趋势方向和我之前判断的逻辑一致吗?这不是“AI 看盘”,也不是 Bloomberg 终端。这是让我读过的书反过来参与我的真实决策。利弗莫尔不在富途 App 里。我的持仓不在《股票大作手回忆录》里。这两件事只能在“本地知识库 × Skill”的组合里相遇。Case 2:每日推送,让知识库每天主动找我第二个 case 是我现在每天都在用的:每日推送。早上 07:30,家里 Mac 自动跑(Codex Desktop 定时任务):读昨日每日计划/2026-05-30.md,包括我手写的反馈区读学习/计划模板.yaml,也就是计划生成规则调 LLM 生成今天的每日计划/2026-05-31.md我通勤路上掏出手机,今天该干啥已经在那里了。这件事看起来简单,但有几个细节只有“本地知识库 × agent”才能做到:Agent 能读昨天的真实反馈,不是结构化勾选,而是我顺手写的“今天累、砍英语”这种自由文本Agent 能跨多天看,比如“这件事是不是连续 3 天没勾掉了?要不要降权?”Agent 能调整规则,周日复盘后,我把一条反思(“anchor 任务周一晚不发出去判定失败”)写进 yaml,下周自动执行这套督学系统有兴趣的话我可以在后续文章中分享一下Case 3:每周复盘,让系统帮我看见我看不见的第三个 case 是周日的自动复盘。每周日晚上,agent 自动跑:读这一周 7 天的每日计划/文件统计完成率、按 category 分布调 Dataview 出周维度的数据生成学习/回顾/周回顾-WX-2026-XX-XX.md我得到的不只是数据,是洞察。比如最近一周复盘,agent 给我指出了一件事:“anchor 1:发布文章”这个任务连续 4 天打开 markdown 都顶在脸上,但一直没被勾掉。我自己当时是没意识到的。每天看到那一行只觉得“嗯还没发,再润色一下”。直到 agent 把数据拉出来对比,我才看清自己卡在哪里。错误模型:写完 = 完成,再润色再等等正确模型:发出去 = 完成,第一篇就是 noise,反馈在数据里这种洞察光靠人看是看不到的。它需要三个条件同时成立:全量数据跨时间维度agent 主动分析本地知识库 + Skill,是唯一同时满足这三件事的组合。这三个 case 共同说明的一件事理财 / 督学 / 复盘,三个场景看起来完全不相干。但它们都有同一个结构:本地知识库 = 数据底盘Skill = 工具放大器Agent = 把两者拼起来的胶水任何一个单拎出来都不够。futu skill 单独装一个,是个查行情工具;本地知识库单独存着,就是堆死档案;agent 单独跑,也只是聊天机器人。只有三件事同时成立,AI 才真正变成“长期能帮你”的东西。收尾回头看,整套工作流的骨架其实就一句话:一份本地知识库 + 一台常驻 Mac + 三个入口 + N 个 Skill。我用了一个月。它不复杂,不贵,不需要把核心数据搬到云上,搭起来 1-2 天,跑起来不需要我特别维护。但它给我的真正改变,不是“我变得更高效”。那种话每个工具都能讲。真正的改变是:我第一次相信“AI 能持续帮我”这件事。以前我装一个新 AI 工具,兴奋三天,第四天就忘了打开它。因为它和我前面的数据、前面的判断、前面的生活是断的。它每次都从零开始认识我。现在不一样。无论我问 AI 什么,它都站在我全部的数据上:我的笔记、我的反馈、我的历史决策、我连续几个月的轨迹。它不是一个“很厉害的助手”,它是一个真正长出“对我的理解”的东西。这件事的杠杆,不在“用更新的模型”。真正的杠杆,是让 AI 够得着你的全部数据。而要做到这一点,你不需要等下一代模型,不需要等更聪明的 agent。你今天就能开始的,就一件事:把你散在 N 个工具里的东西,收回一个本地知识库。你的数据现在在 AI 够得着的地方吗?这套系统我还在持续迭代:督学系统怎么搭、Obsidian 目录和 frontmatter 怎么组织、Hermes 微信网关怎么跑、每个 Skill 的踩坑细节,后面都会陆续拆开写。如果这篇对你有用,或者你也在折腾「让 AI 站在自己全部数据上」这件事,欢迎扫码进群,一起交流踩坑、互相抄作业:也特别想听听你的反馈:这套工作流里哪一层最戳你?你自己卡在哪一步?还想看我把哪个部分单独拆开写?评论区或者群里告诉我,会直接影响我下一篇写什么。群二维码会定期更新,如果过期了,可以在公众号后台回复「进群」获取最新入口。
现在这套工作流可以拆成四层:
层级解决的问题我的做法数据底座AI 看不到我的全部上下文把长期数据收回一个本地 Obsidian vault执行环境Agent 需要常驻进程和本地 IO家里一台 Mac 24h 跑 Codex、Hermes Agent 等进程触达入口不同场景需要不同摩擦的入口微信、Codex Mobile、Obsidian Sync 分工行动能力AI 不能只读笔记,还要能调用工具用 Skill 接富途、外部 API 等
层级
解决的问题
我的做法
数据底座
AI 看不到我的全部上下文
把长期数据收回一个本地 Obsidian vault
执行环境
Agent 需要常驻进程和本地 IO
家里一台 Mac 24h 跑 Codex、Hermes Agent 等进程
触达入口
不同场景需要不同摩擦的入口
微信、Codex Mobile、Obsidian Sync 分工
行动能力
AI 不能只读笔记,还要能调用工具
用 Skill 接富途、外部 API 等
这四层的顺序很重要。
如果没有统一数据,入口再多也只是多个聊天框;如果没有常驻执行环境,agent 只能在你打开电脑时工作;如果没有低摩擦入口,系统搭得再好也会被忘掉;如果没有 Skill,AI 最多是个会翻笔记的问答机器人。
我真正解决的是这条链路:
让 AI 读得到我,跑得起来,找得到我,也能替我做事。
让 AI 读得到我,跑得起来,找得到我,也能替我做事。
第一层:一个本地 Obsidian vault,解决数据全貌
第一步不是上 agent,而是把数据先收回来。
简单说,我把所有“过去会散在 N 个 App 里”的东西分成四类塞进 Obsidian:
知识沉淀:工作 / 学习笔记、Wiki 实体
流水记录:每日计划 + 反馈、灵感、即刻归档、日记等
创作产出:文章草稿、视频脚本
生活资料:读过的书 / 电影 / 去过的地方、签证 / 保险 / 账单等家庭杂事
唯一的例外是少数结构化非常强且自带专业体验的东西,比如富途的实盘账户。这些不强行迁,但“我的判断 / 我的笔记”那一层全部回到 Obsidian。
这里的重点不是 Obsidian 本身,而是数据所有权和数据形态。
.md文件躺在本地磁盘上,agent 可以直接 grep、直接读、直接改;图片、PDF、HTML 归档也都在同一个文件系统里。AI 终于不是隔着 SaaS API 看一个被裁剪过的世界,而是站在我的真实资料库上工作。
具体怎么组织目录、frontmatter 怎么写、Wiki 实体长什么样,是另一个话题,后面会专门写一篇。这里先记住一件事:
Obsidian 在这套系统里的角色,不是漂亮的笔记软件,而是 AI 的本地数据底座。
Obsidian 在这套系统里的角色,不是漂亮的笔记软件,而是 AI 的本地数据底座。
第二层:一台常驻 Mac,解决执行环境
数据统一之后,下一个问题是:agent 在哪里跑?
很多人听到“all in one 本地”会担心一件事:那我离家怎么办?
我的答案是:让算力和数据都留在家里,外面的设备只做窗口。
为什么是一台常驻 Mac
Agent 不是聊天框,它需要常驻进程:
定时跑的 schedule,比如每日推送、周复盘
Hermes Agent 的微信网关长轮询接消息
偶尔跑的长任务,比如生成周复盘、批处理笔记
但“为什么必须在家、不能放云”还有一个更关键的原因:家里那台 Mac 在我的局域网里,能直接挂载 NAS。
我的 NAS 上存着照片库、视频原片、扫描的家庭文件、电子书、影视收藏,几个 T 的数据。Obsidian vault 只放轻量的“我的判断 / 我的笔记”,重的原始素材都在 NAS 上。
Agent 跑在家里 Mac 上,等于站在 vault + NAS 这两份数据之上。想找一张旧照片、想从 NAS 里某本书抽段原文做引用、想把视频原片喂给视觉模型,全是本地 IO。
云服务器解决不了这件事。NAS 不可能开公网,公网 NAS 也是反模式。你只能把数据传上云,而那就违反了“all in one 本地”的整个前提。
所以我用的方案很朴素:一台老 MacBook 接着电源、合盖不睡眠,24 小时跑 Codex 和 Hermes Agent。重活全在它身上,外面所有设备只负责三件事:
看
触发
轻编辑
UU 远程是桌面级兜底
除了后面会讲的三个日常入口,我还保留了一个兜底方案:网易 UU 远程。
它不算我日常工作流里的“主入口”,更像是完整桌面远控。需要跑一个完整的活时,我会用它:
iPad 在路上想到一个研究方向,拉起 UU 连家里 Mac,调起 Codex,直接跑一个 deep research,结果自动写进 vault
公司 Mac 上 vibe coding 卡住了,UU 连家里 Mac,用家里那个权限 / 配置 / Skill 都齐全的环境跑
网易 UU 的好处是手机、iPad、Mac 客户端都有,免内网穿透,免端口转发。代价是有点延迟、画质有损,但对“我只想跑个 agent”这种活完全够用。
iPad 的独立角色
很多人把 iPad 当“手机的大号”,但在这套拓扑里,它有完全独立的角色。
设备最适合什么手机秒级问答,微信里问一句 agent 回一句,红绿灯之间能完成的交互iPad长时段沉浸式消费,通勤路上读 30 分钟笔记、沙发上标注一篇长文、偶尔拉 UU 远控家里跑长任务公司 Mac正经写代码、写文章家里 Mac跑 agent、当服务器
设备
最适合什么
手机
,微信里问一句 agent 回一句,红绿灯之间能完成的交互
,通勤路上读 30 分钟笔记、沙发上标注一篇长文、偶尔拉 UU 远控家里跑长任务
公司 Mac
正经写代码、写文章
家里 Mac
跑 agent、当服务器
iPad 那种“屏幕够大、能竖着拿、续航长、能开 UU”的组合,让它成了我离开家时知识库的主显示器,尤其是周末在咖啡馆、出差路上、家里沙发上。
把 iPad 加进来之后,我的“长时段使用知识库”体验,不再绑死在公司或家里的电脑前。
身体在哪不重要。数据和算力始终在家里那台 Mac 上等我,外面的设备只是窗口。
身体在哪不重要。数据和算力始终在家里那台 Mac 上等我,外面的设备只是窗口。
第三层:三个入口,解决触达摩擦
执行环境固定在家里之后,下一个问题是:人在不同场景下,用什么方式触达知识库?
答案是三个入口,各自解决一种摩擦。
入口适用场景关键技术微信(Hermes 微信网关 / WeixinClaw)走路、地铁、餐桌:极轻量、秒级问答Hermes Agent + iLink 长轮询Codex Mobile手机远控家里 Mac 上的 Codex agentOpenAI secure relay + ChatGPT 移动端Obsidian Sync完整笔记编辑 + 通勤主战场E2E 加密 + 实时双向
入口
适用场景
关键技术
走路、地铁、餐桌:极轻量、秒级问答
Hermes Agent + iLink 长轮询
手机远控家里 Mac 上的 Codex agent
OpenAI secure relay + ChatGPT 移动端
完整笔记编辑 + 通勤主战场
E2E 加密 + 实时双向
入口 1:微信,解决秒级问答
解决的核心问题:手机上随时随地能“对着我自己说一句话”,让 agent 接住、回去翻知识库、回我。
解决的核心问题:手机上随时随地能“对着我自己说一句话”,让 agent 接住、回去翻知识库、回我。
我用的是 Hermes Agent。它是 Nous Research 出的一个 self-improving AI agent,内置了一组消息网关(Telegram / Discord / Signal / 微信等),让你能在任何 IM 平台里跟它说话。
微信这一路,社区里习惯叫WeixinClaw,走的是 Tencent iLink Bot API:本地起一个hermes gateway进程,发起getupdates长轮询请求(35s timeout),消息来了就回包。
它不需要公网 endpoint,不需要 webhook,不需要服务器。它就跑在我家里 Mac 上,跟 daemon 一样常驻。
实际体验:
周末晚上想找部片看,发条微信给“自己”:“给我推荐一部电影”
Hermes 微信网关接消息,调 agent
Agent 翻我 vault 里输入/电影/下看过的清单、想看清单,对照Wiki/品味-电影.md里我的偏好
它推一部我没看过、和我口味匹配的,附上一句为什么
整个过程 5-10 秒,和正常跟人聊天一模一样。
关键不在“AI 能推电影”。豆瓣、小红书都能。关键在于它推的是“我没看过 + 符合我口味”的,因为它读得到我的清单和我的品味笔记。
微信适合的就是这种秒级、轻量、单轮问答。它不适合写长笔记,但特别适合让 AI 在生活缝隙里出现。
入口 2:Codex Mobile,解决手机远控 agent
解决的核心问题:在外面也能让家里 Codex 接着干活,而不只是“看”。
解决的核心问题:在外面也能让家里 Codex 接着干活,而不只是“看”。
Codex Mobile 是 OpenAI 在 ChatGPT 移动端集成的 Codex 远程控制。通过 OpenAI 的 secure relay,它可以直连家里 Mac 上跑的 Codex,手机扫码授权一次后就能跨设备操作 thread,不暴露公网,也不需要 SSH。
我用它最多的场景:
地铁里突然想起昨晚那个 agent 跑完了没,打开 ChatGPT 看 thread,审批 commit,改 prompt 让它重跑
在外面想到一段 prompt 没说清楚,掏手机重新调整、重新启动
临时想让家里 agent 跑个新任务,手机直接下指令
它和 UU 远程的分工很清楚:UU 是万能桌面,什么都能干,但有延迟;Codex Mobile 是原生 thread 体验,只适合操作 Codex agent,但更轻。
入口 3:Obsidian Sync,解决笔记主战场
解决的核心问题:所有设备共享同一份 vault,不需要任何手动同步。
解决的核心问题:所有设备共享同一份 vault,不需要任何手动同步。
Obsidian Sync 没什么花招,它就是把.md文件实时同步到所有设备。但它做对了一件事:E2E 加密。
这点对我很重要。我的 vault 里有身份信息、家庭资料、签证 checklist、投资笔记。这些放云端必须 E2E 加密。Sync 是 Obsidian 官方做的,四端共一份 vault,秒级到达,端到端加密。$4/月是我账单里性价比最高的一项。
三个入口不是冗余,是分工
很多人会问:既然 Sync 已经能同步到所有设备,为什么还要微信入口和 Codex Mobile?
因为触达的摩擦不一样:
微信入口:0 秒摩擦,你本来就在用微信,不需要切 App
Codex Mobile:手机审批 agent 场景,比 UU 流畅,比手动 SSH 省心
Obsidian Sync:写笔记主战场,但要打开 Obsidian App
我每天的使用比例大概是Sync 60% + 微信 30% + Codex Mobile 10%。三个加起来才覆盖了“在家 / 在公司 / 在地铁 / 在咖啡馆 / 在被窝里”的全部场景。
同一份数据,三个入口。同一份数据,多种触达方式。
同一份数据,三个入口。同一份数据,多种触达方式。
第四层:Skill,解决行动能力
前面解决的是“AI 能不能读到我、能不能跑起来、我能不能随时触达它”。但 agent 具体能替我干什么,还要看 Skill。
Skill 是给 agent 装上的能力插件:查股票、定时跑、调外部 API、操作浏览器、生成图片、发社交平台……我现在装了 30+ 个 Skill。下面挑三个真实在跑的 case 讲一下。
Case 1:理财,让读过的书参与真实决策
以我常用的 futu skill为例。它是富途 OpenAPI 的封装,能查实时行情、K 线、期权链、下单、撤单、查持仓。
这种 Skill 单独装一个并不稀奇,富途自己的 App 就能干这些。真正的杠杆来自futu skill × 我的 vault。
我的 vault 里有输入/书/股票大作手回忆录.md,里面手抄过利弗莫尔的几条核心交易准则:顺势、不摊薄亏损、突破才加仓、关键点位等等。里面还有过去几个月我对每个标的的判断笔记、家庭资产配置表。
所以我在微信问:“我想加仓 AAPL,如果你是利弗莫尔,你会不会做这笔交易?”
Agent 实际上在做:
调 futu skill 拿 AAPL 实时报价、K 线、我的持仓和成本
grepvault 里股票大作手回忆录.md,把利弗莫尔那几条准则当作判断框架
翻出我之前对 AAPL 的判断笔记,比如买卖区间、当时的逻辑
给我一个逐条对照的判断:现在的价位是不是“关键点位的突破”?我的成本和当前价之间是不是在“加仓而非摊薄”?趋势方向和我之前判断的逻辑一致吗?
这不是“AI 看盘”,也不是 Bloomberg 终端。这是让我读过的书反过来参与我的真实决策。
利弗莫尔不在富途 App 里。我的持仓不在《股票大作手回忆录》里。这两件事只能在“本地知识库 × Skill”的组合里相遇。
Case 2:每日推送,让知识库每天主动找我
第二个 case 是我现在每天都在用的:每日推送。
早上 07:30,家里 Mac 自动跑(Codex Desktop 定时任务):
读昨日每日计划/2026-05-30.md,包括我手写的反馈区
读学习/计划模板.yaml,也就是计划生成规则
调 LLM 生成今天的每日计划/2026-05-31.md
我通勤路上掏出手机,今天该干啥已经在那里了。
这件事看起来简单,但有几个细节只有“本地知识库 × agent”才能做到:
Agent 能读昨天的真实反馈,不是结构化勾选,而是我顺手写的“今天累、砍英语”这种自由文本
Agent 能跨多天看,比如“这件事是不是连续 3 天没勾掉了?要不要降权?”
Agent 能调整规则,周日复盘后,我把一条反思(“anchor 任务周一晚不发出去判定失败”)写进 yaml,下周自动执行
这套督学系统有兴趣的话我可以在后续文章中分享一下
Case 3:每周复盘,让系统帮我看见我看不见的
第三个 case 是周日的自动复盘。
每周日晚上,agent 自动跑:
读这一周 7 天的每日计划/文件
统计完成率、按 category 分布
调 Dataview 出周维度的数据
生成学习/回顾/周回顾-WX-2026-XX-XX.md
我得到的不只是数据,是洞察。
比如最近一周复盘,agent 给我指出了一件事:“anchor 1:发布文章”这个任务连续 4 天打开 markdown 都顶在脸上,但一直没被勾掉。
我自己当时是没意识到的。每天看到那一行只觉得“嗯还没发,再润色一下”。直到 agent 把数据拉出来对比,我才看清自己卡在哪里。
错误模型:写完 = 完成,再润色再等等正确模型:发出去 = 完成,第一篇就是 noise,反馈在数据里
错误模型:写完 = 完成,再润色再等等正确模型:发出去 = 完成,第一篇就是 noise,反馈在数据里
这种洞察光靠人看是看不到的。它需要三个条件同时成立:
全量数据
跨时间维度
agent 主动分析
本地知识库 + Skill,是唯一同时满足这三件事的组合。
这三个 case 共同说明的一件事
理财 / 督学 / 复盘,三个场景看起来完全不相干。但它们都有同一个结构:
本地知识库 = 数据底盘Skill = 工具放大器Agent = 把两者拼起来的胶水
本地知识库 = 数据底盘Skill = 工具放大器Agent = 把两者拼起来的胶水
任何一个单拎出来都不够。futu skill 单独装一个,是个查行情工具;本地知识库单独存着,就是堆死档案;agent 单独跑,也只是聊天机器人。
只有三件事同时成立,AI 才真正变成“长期能帮你”的东西。
收尾
回头看,整套工作流的骨架其实就一句话:
一份本地知识库 + 一台常驻 Mac + 三个入口 + N 个 Skill。
一份本地知识库 + 一台常驻 Mac + 三个入口 + N 个 Skill。
我用了一个月。它不复杂,不贵,不需要把核心数据搬到云上,搭起来 1-2 天,跑起来不需要我特别维护。
但它给我的真正改变,不是“我变得更高效”。那种话每个工具都能讲。
真正的改变是:我第一次相信“AI 能持续帮我”这件事。
以前我装一个新 AI 工具,兴奋三天,第四天就忘了打开它。因为它和我前面的数据、前面的判断、前面的生活是断的。它每次都从零开始认识我。
现在不一样。无论我问 AI 什么,它都站在我全部的数据上:我的笔记、我的反馈、我的历史决策、我连续几个月的轨迹。它不是一个“很厉害的助手”,它是一个真正长出“对我的理解”的东西。
这件事的杠杆,不在“用更新的模型”。
真正的杠杆,是让 AI 够得着你的全部数据。
真正的杠杆,是让 AI 够得着你的全部数据。
而要做到这一点,你不需要等下一代模型,不需要等更聪明的 agent。你今天就能开始的,就一件事:
把你散在 N 个工具里的东西,收回一个本地知识库。
你的数据现在在 AI 够得着的地方吗?
这套系统我还在持续迭代:督学系统怎么搭、Obsidian 目录和 frontmatter 怎么组织、Hermes 微信网关怎么跑、每个 Skill 的踩坑细节,后面都会陆续拆开写。
如果你这篇对你有用,欢迎交流踩坑、互相抄作业。