意图识别实现方案横纵分析报告
研究时间:2026-05-14 | 所属领域:智能客服技术 | 研究对象类型:技术方案
一句话定义
意图识别(Intent Classification)是智能客服系统的入口层技术,通过分类算法将用户输入映射到预定义的意图类别,决定后续的路由和响应策略,是整个客服体验准确率的第一道门槛。
二、纵向分析:从规则到智能的演进
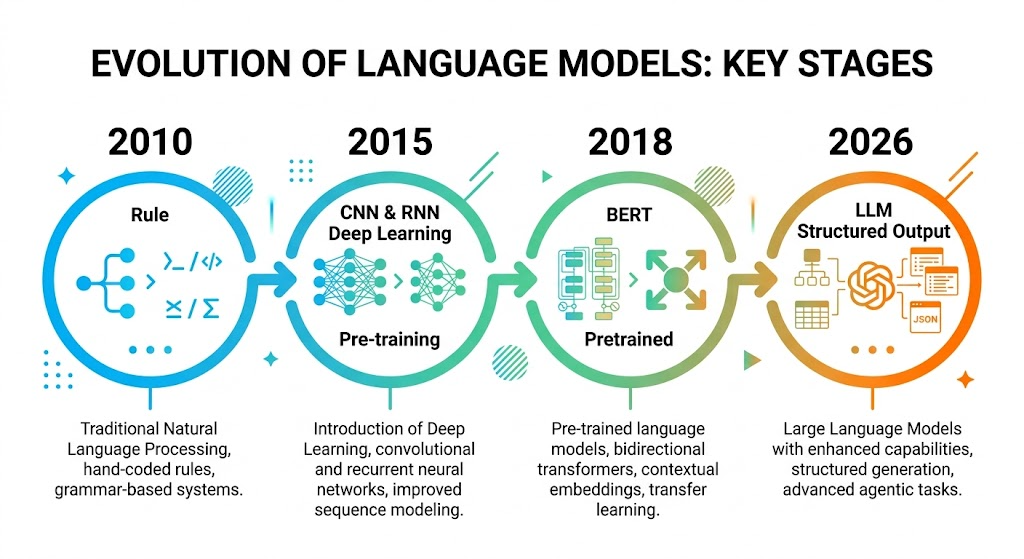
2.1 起源:基于规则的时期(2010年前)
意图识别的最早实践可以追溯到基于规则的对话系统年代。当时的解决方案主要依赖:
- 关键词匹配:提取用户消息中的关键词,与预定义的意图关键词库进行匹配
- 正则表达式:通过正则模式识别特定格式的查询
- 决策树:基于人工编写的决策规则进行意图判断
这种方案的优点是可控性强、可解释,缺点是需要大量人工维护规则库,无法处理口语化表达和变体表达。
2.2 深度学习时代:CNN与RNN(2015-2018年)
随着深度学习的兴起,意图识别进入神经网络时代:
- CNN卷积神经网络:利用卷积层提取局部特征,适合短文本分类
- RNN循环神经网络:特别是LSTM和GRU,能够处理序列信息,捕捉上下文
- TextCNN:将CNN应用于文本分类,在意图识别任务上取得不错效果
这一时期的核心问题是标注数据成本高,模型泛化能力有限。
2.3 BERT革命:预训练语言模型(2018-2022年)
2018年BERT的发布标志着NLP领域的范式转变,意图识别也随之进入BERT时代:
2018-2019年:BERT微调
- BERT(Bidirectional Encoder Representations from Transformers)通过预训练+微调范式,在多项NLP任务取得SOTA
- 意图识别任务上,BERT微调方案成为主流,只需少量标注数据即可达到高精度
- 代表工作:BERT-IR(2021)、IntentBERT(2021)
2020-2022年:专门优化
- BERT-Cap(2020):结合胶囊网络和focal loss,解决数据不均衡问题
- CONVBERT(2020):针对对话场景优化的BERT变体
- TOD-BERT(2020):任务导向对话专用预训练模型
- Joint Pre-training(2021):利用目标域无标注数据继续预训练
这一时期的特点是:效果显著提升,但依赖大量标注数据和GPU资源,部署成本较高。
2.4 LLM时代:Few-shot与结构化输出(2023-2026年)
ChatGPT引发的LLM浪潮彻底改变了意图识别的实现方式:
2023年:Few-shot LLM分类
- 不再需要微调,给出意图定义和少量示例即可分类
- 快速迭代,一个下午就能搭建生产级分类器
2024-2025年:结构化输出
- 使用LLM的结构化输出功能(Function Calling、JSON Mode)
- 输出被约束到严格的枚举值,解决解析问题
- 获得真实概率,可设置置信度阈值
2025年:多方案融合
- LLM-based Classifier:高质量、推理能力、实体抽取
- Embedding-based Classifier:确定性、低延迟、可控成本
- 小模型优先:用小模型(如GPT-4o-mini、Haiku 4.5)做分类,旗舰模型做下游回答
三、横向分析:三大实现方案对比
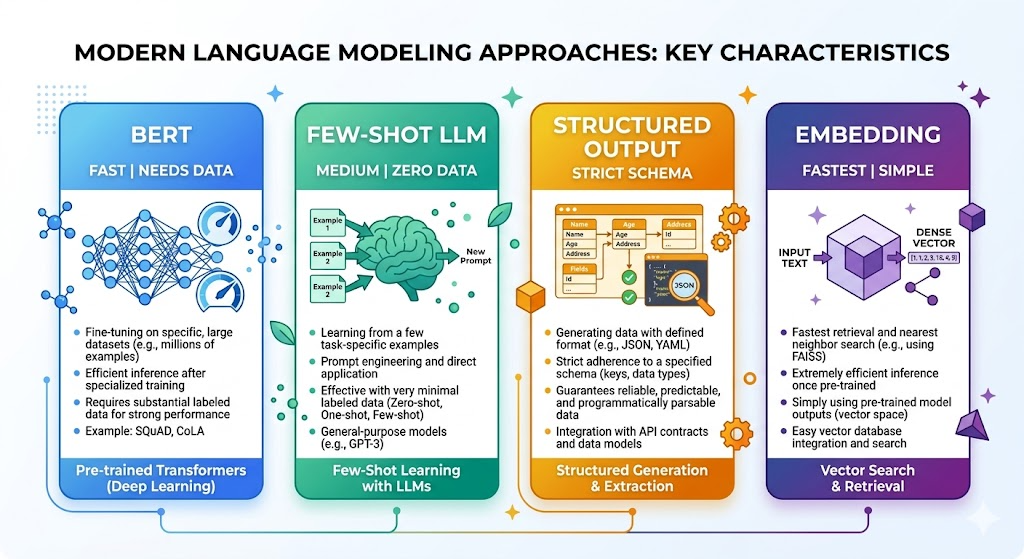
3.1 方案一:Encoder Fine-tune(BERT微调)
架构:
User Input → BERT Encoder → Classification Head → Intent Label
代表产品:
- Rasa LLM Intent Classifier
- 各类基于BERT的意图识别服务
核心优势:
- 高QPS(>50/s)下延迟低(<10ms)
- 推理成本可控,适合大规模场景
- 已有大量标注数据时可复用
核心劣势:
- 需要大量标注数据(通常1000+条/类)
- 训练和部署成本高
- 模型更新需要重新训练
适用场景:
- 高并发、低延迟要求的生产环境
- 已有成熟标注数据的成熟产品
3.2 方案二:Few-shot LLM
架构:
User Input + Intent Definitions + Examples → LLM → Intent Label
核心优势:
- 无需标注数据,定义+示例即可工作
- 快速上线,一下午就能完成
- 支持复杂语义理解
核心劣势:
- 延迟较高(通常200-500ms)
- 推理成本按token计费
- 输出一致性不如结构化输出
适用场景:
- 快速验证PMF
- 意图 taxonomy 还在探索阶段
3.3 方案三:Structured Output LLM(2026默认方案)
架构:
User Input + Intent Schema → LLM with Structured Output → Structured Intent + Confidence
核心优势:
- 输出严格约束到枚举值,解析零成本
- 获得真实概率,支持置信度阈值
- 工程成本最低
- 无需标注数据
核心劣势:
- 延迟和成本仍高于传统模型
- 需要支持结构化输出的模型
适用场景:
- 2026年绝大多数场景的起点
- 需要快速上线、没有标注数据的团队
3.4 方案四:Embedding-based Classifier
架构:
User Input → Embedding Model → Vector Similarity → Intent Label
代表产品:
- MCP Agent的Embedding Classifier
- 各类向量检索服务
核心优势:
- 延迟极低
- 成本可控
- 确定性输出
核心劣势:
- 无法处理复杂语义
- 需要定义示例向量
适用场景:
- 对延迟敏感的场景
- 作为LLM Classifier的补充
3.5 横向对比矩阵
| 维度 | BERT Fine-tune | Few-shot LLM | Structured Output | Embedding-based |
|---|---|---|---|---|
| 延迟 | <10ms | 200-500ms | 200-500ms | <50ms |
| 标注数据 | 1000+/类 | 0 | 0 | 0 |
| 部署成本 | 高 | 中 | 中 | 低 |
| 语义理解 | 强 | 强 | 强 | 弱 |
| 置信度输出 | 原生概率 | 需要解析 | 原生概率 | 相似度 |
| 2026推荐度 | 特定场景 | 过渡方案 | 首选 | 补充方案 |
四、横纵交汇洞察
4.1 历史演进揭示的规律
回顾意图识别技术的发展历程,几个规律清晰可见:
成本结构的根本转变:从"数据成本为主"到"推理成本为主"。BERT时代需要大量标注数据(数据成本)和GPU训练资源(训练成本);LLM时代无需标注数据,但推理成本成为主要支出。
准确性vs速度的动态平衡:早期方案(规则)速度快但准确性差;BERT方案准确性高但延迟大;2026年的最佳实践是"小模型分类+大模型回答",在延迟和准确性之间取得平衡。
从单一方案到混合架构:没有任何单一方案能解决所有问题。生产级系统通常采用:Embedding做快速筛选 → LLM做精细分类 → 置信度阈值控制转人工。
4.2 各方案的历史根源
BERT微调方案的今天:它起源于学术研究对预训练模型的探索,核心优势是延迟和成本可控。但它的前提——大量标注数据——在很多新场景下不成立。这解释了为什么它在"已有成熟数据"的场景仍是首选,但在"新产品探索"场景被LLM方案取代。
LLM方案的本质:它不是"更准确的分类器",而是"通用的语义理解器"。它的优势不是分类准确率(实际上可能略低于调优好的BERT),而是"零数据启动"和"理解复杂表达"的能力。这解释了为什么它成为2026年的默认起点。
混合架构的必然性:没有任何方案是完美的。延迟敏感的用Embedding,准确率优先的用LLM,追求极致成本的用小模型。这种分层是技术演进的自然结果。
4.3 未来推演

最可能的剧本(60%概率):
- 小模型分类成为标配(如Qwen2-0.5B、GPT-4o-nano)
- 结构化输出成为LLM分类的标准接口
- 置信度体系完善,自动转人工阈值智能化
最危险的剧本(20%概率):
- 长上下文窗口突破,模型"一次性理解"整个对话历史
- 意图识别被端到端的对话模型"吸收",不再作为独立模块
最乐观的剧本(20%概率):
- 多模态意图识别(结合语音、图像、表情)
- 主动式意图预测(用户还没说,就能预测)
- 跨语言零样本迁移成为常态
4.4 给智能客服建设的建议
回到智能客服场景,意图识别方案如何选择?
短期(1-3个月):
- 如果是新产品、没有标注数据:直接用Structured Output LLM
- 如果已有标注数据:用BERT微调作为基线,LLM方案作为对比
中期(3-6个月):
- 建立置信度体系,设定自动转人工阈值
- 引入Embedding Classifier处理高频简单查询,降低LLM调用成本
长期(6个月以上):
- 根据业务量选择合适的模型规格(小模型→大模型)
- 建立持续优化机制:根据用户反馈迭代意图定义
五、信息来源
- Respan: Intent Classification With LLMs (2026 Guide). https://www.respan.ai/articles/intent-classification-with-llms
- Orq.ai: Build an Intent Classification Chatbot. https://docs.orq.ai/docs/tutorials/intent-classification
- MCP Agent: Intent Classifier Pattern. https://docs.mcp-agent.com/mcp-agent-sdk/effective-patterns/intent-classifier
- Vellum: A Beginner's Guide to LLM Intent Classification for Chatbots. https://www.vellum.ai/blog/how-to-build-intent-detection-for-your-chatbot
- Rasa: Using LLMs for Intent Classification. https://rasa.com/docs/rasa/next/llms/llm-intent/
- FlowX: Intent Classification and Routing. https://docs.flowx.ai/5.1/ai-platform/patterns/intent-classification-routing
- IntentBERT (2021): Few-shot Intent Classification with BERT. https://aclanthology.org/2021.findings-emnlp.96.pdf
- BERT-Cap (2020): User Intent Classification with Capsule Network. https://pdfs.semanticscholar.org/65f7/aad10a9e2a42f9183abb4ddad8ad1045e87a.pdf
- BERT-IR (2021): Pretrained NLP Model for Intent Recognition. https://www.atlantis-press.com/journals/hcis/125963694/view
方法论说明
本报告采用横纵分析法(Horizontal-Vertical Analysis)进行深度研究。该方法由数字生命卡兹克(Khazix)提出,融合了语言学中的历时-共时分析(Saussure)、社会科学中的纵向-横截面研究设计、商学院案例研究法、以及竞争战略分析的核心思想。核心原则:纵向追时间深度,横向追同期广度,最终交汇出判断。